
Federated Learning for IoT Intrusion Detection


Abstract
:1. Introduction
- We propose a method for the detection of attacks in IoT network environments based on a FL framework that uses FedAvg as the aggregation function. The distributed framework is composed of four clients, sharing a shallow ANN, and a server acting as the aggregator. The primary objective is the evaluation of FL as an approach to the detection and classification of attacks in an IoT network environments.
- We evaluate the framework on two open-source datasets, namely ToN_IoT and CICIDS2017, on both binary and multiclass classification. Our method offers a high level of accuracy with a low False Positive (FP) rate in both types of classification for both datasets.
- We compare results from our experiments against a centralized approach based on the same model, showing that performance of our FL framework is comparable to its centralized counterpart.
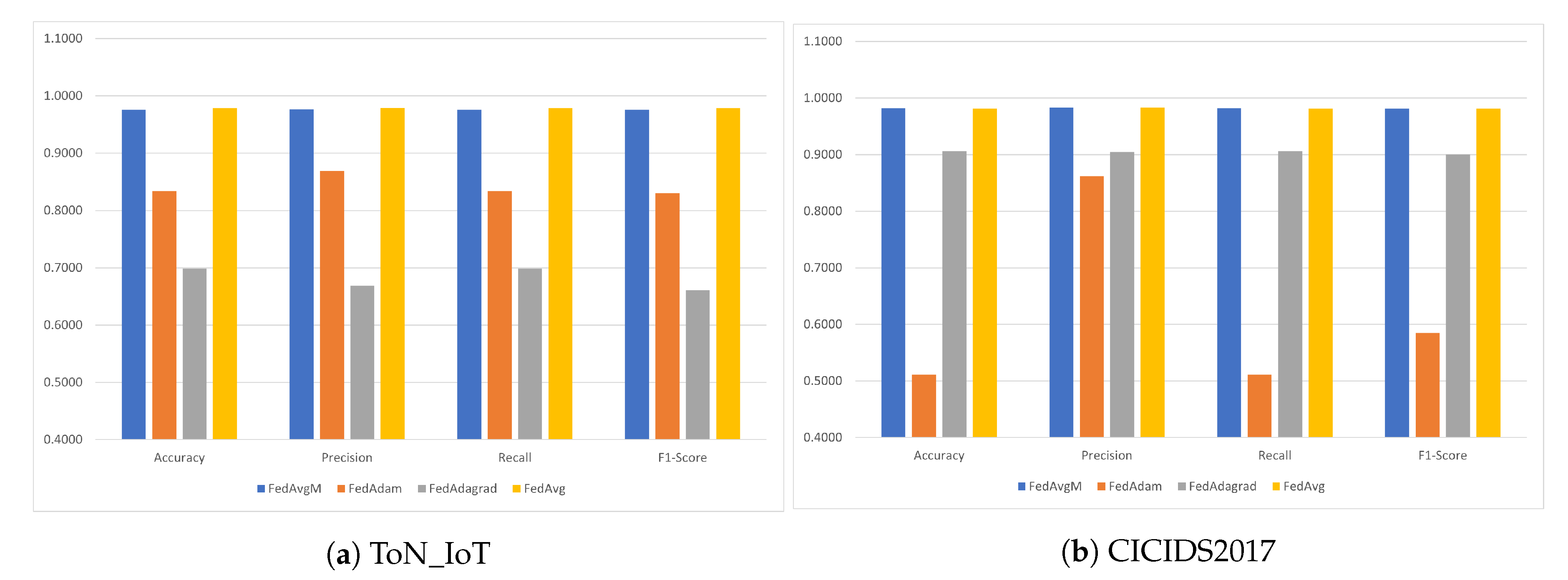
- In this scenario, we evaluate three alternative aggregation methods, namely FedAvgM, FedAdam and FedAdagrad, and compare their performances against FedAvg.
2. Literature Review
- Non-IID—Data stored locally in a device is not a representation of the entire population distribution.
- Unbalanced—Local data has a large variation in size. In other words, some devices will train on larger datasets compared to others.
- Massively Distributed—Large number of clients.
- Limited Communication—Communication amongst clients is not guaranteed as some may be offline. Training may be completed with a smaller number of devices or asynchronously.
2.1. Federated Learning in IoT Intrusion Detection
2.2. Averaging Algorithms
| Algorithm 1: The FedAvg Algorithm. The K clients are indexed by k; B is the local minibatch size, E is the number of local epochs and is the learning rate |
| 1: Server executes: |
| 2: initialize |
| 3: for each round do |
| 4: max |
| 5: |
| 6: for each client in parallel do |
| 7: |
| 8: end for |
| 9: |
| 10: end for |
| 11: ClientUpdate//run on client k |
| 12: |
| 13: for each local epoch i from 1 to E do |
| 14: for batch do |
| 15: |
| 16: end for |
| 17: end for |
| 18: Return w to Server |
| Algorithm 2: The FedAdam and FedAdagrad Algorithms |
| 1: Input: optional for FedAdam |
| 2: for do |
| 3: Sample a subset of clients |
| 4: |
| 5: for each client in parallel do |
| 6: for do |
| 7: for do |
| 8: |
| 9: end for |
| 10: end for |
| 11: |
| 12: end for |
| 13: |
| 14: |
| 15: |
| 16: |
| 17: |
| 18: end for |
| Algorithm 3: The FedAvgM Algorithm. The K clients are indexed by k; B is the local minibatch size, E is the number of local epochs and is the learning rate |
| 1: Server executes: |
| 2: initialize |
| 3: for each round do |
| 4: max |
| 5: |
| 6: for each client in parallel do |
| 7: |
| 8: end for |
| 9: |
| 10: end for |
| 11: Client Update//run on client k |
| 12: |
| 13: for each local epoch i from 1 to E do |
| 14: for batch do |
| 15: |
| 16: |
| 17: end for |
| 18: end for |
| 19: Return w to Server |
2.3. Federated Learning Frameworks
3. Proposed Model
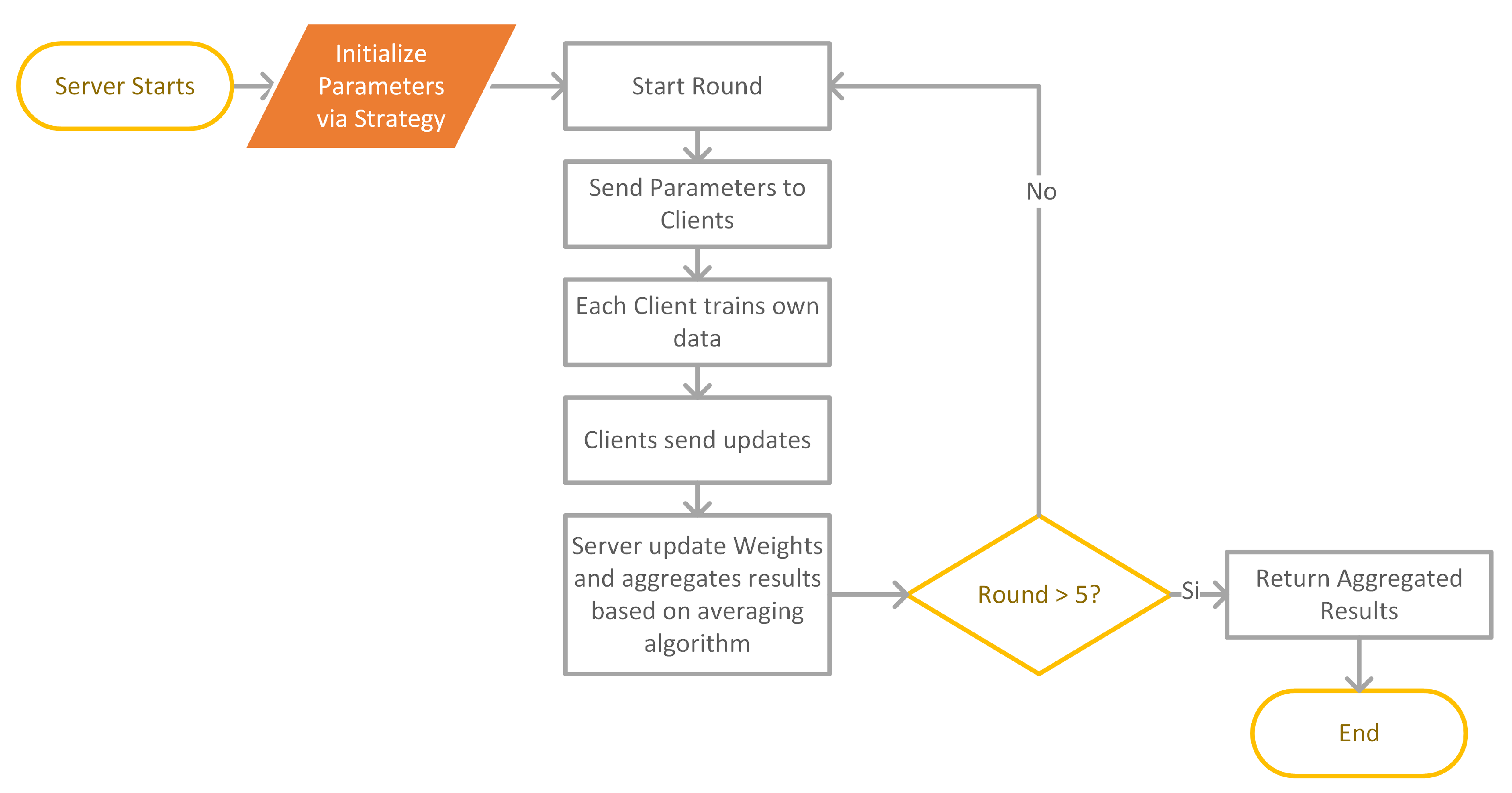
3.1. Overall Architecture
- -
- The server starts and accepts connections from a number of clients based on a specific scenario.
- -
- The server sends initial parameters of the global model to clients.
- -
- Each client completes training on their local data, calculates their local parameters and sends an update to the server.
- -
- The server updates parameters for the global model and aggregates results.
| Algorithm 4: High-level pseudocodes for the FL algorithm. are the clients; S is the server, is the local client’s data and R is the aggregated results |
| 1: Server S starts: |
| 2: initialize parameters: p |
| 3: Clients: |
| 4: Client’s Data: |
| 5: for each round do |
| 6: |
| 7: for each Client in parallel do |
| 8: Classify |
| 9: |
| 10: end for |
| 11: |
| 12: |
| 13: end for |
| 14: Return R |
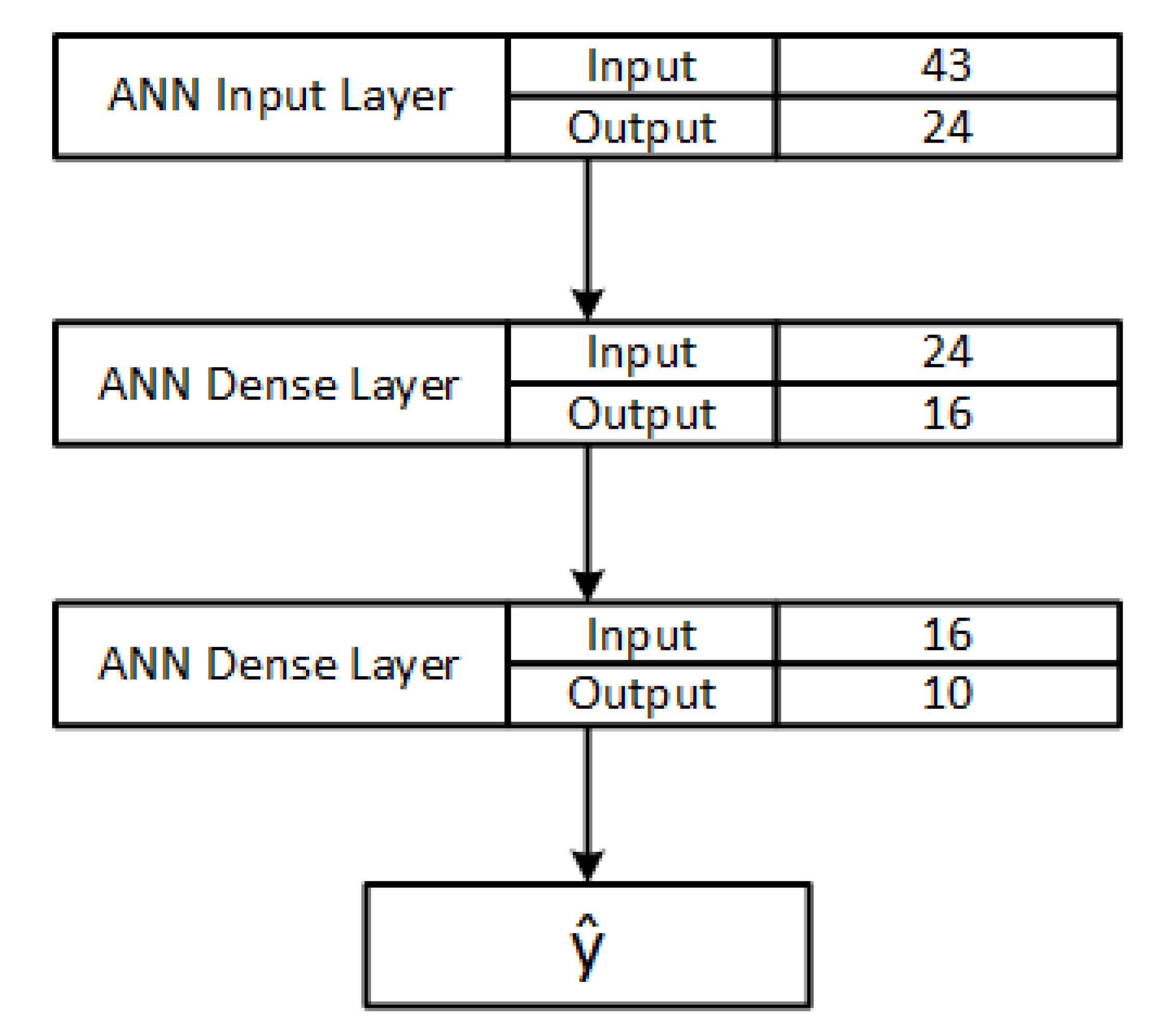
3.2. Shared Model
3.3. Comparison of Averaging Algorithms
4. Datasets, Pre-Processing and Performance Metrics
4.1. Datasets
4.1.1. ToN_IoT Dataset
4.1.2. CICIDS2017 Dataset
4.2. Data Pre-Processing
4.3. Performance Metrics
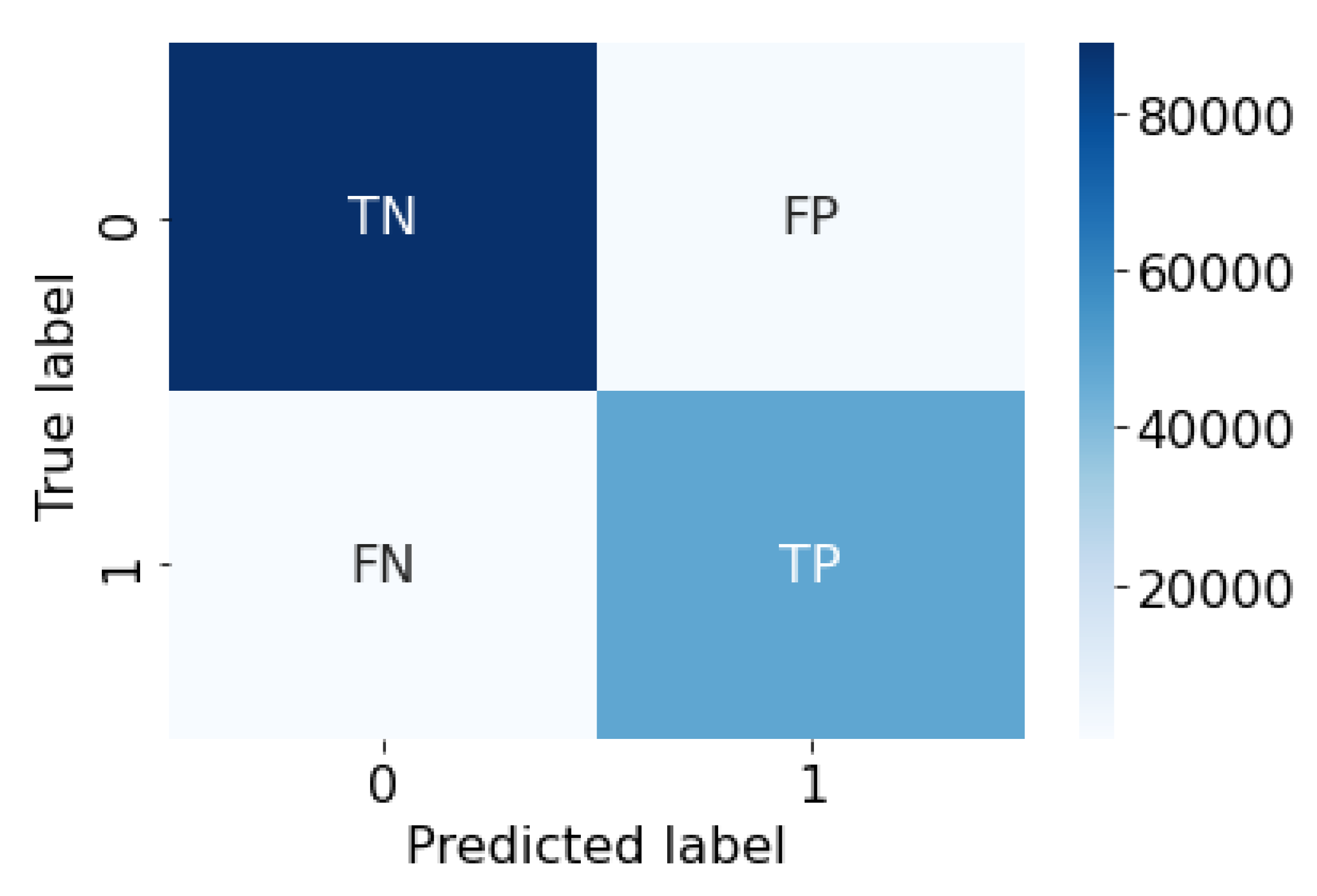
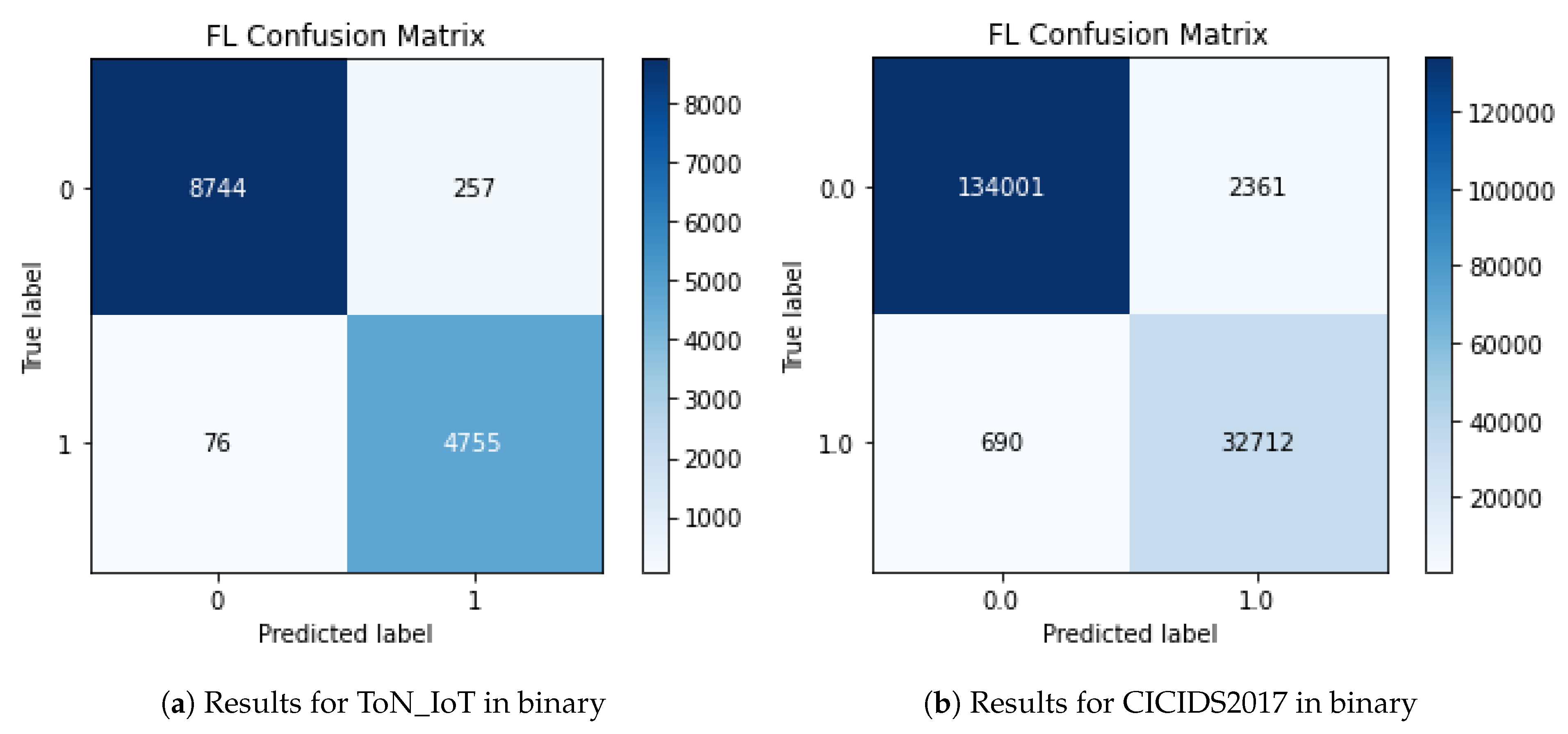
- Detect anomalies or attacks correctly—i.e., True Positives (TP);
- Detect normal traffic correctly—i.e., True Negatives (TN);
- Confuse normal traffic as anomalous—i.e., False Positives (FP);
- Confuse anomalous traffic as normal—i.e., False Negatives (FN).
- Accuracy—This is the ratio of correctly classified instances among the total number as shown in Equation (2).
- Precision—This provides the rate of elements that have been classified as positive and that are actually positive. It is obtained by dividing correctly classified anomalies (TP) by the total number of positive instances (FP + TP) as shown in Equation (3).
- Recall—Also defined as sensitivity or true positive rate (TPR), it is obtained from the correctly classified attacks (TP) divided by the total number of attacks (TP) + (FN) and measures the model’s ability to identify all positive instances (i.e., attacks) in the data. Recall is calculated by Equation (4).
- F1-score—This uses both precision and recall to calculate their harmonic mean as shown in Equation (5). The higher the score the better the model.
5. Results and Discussion
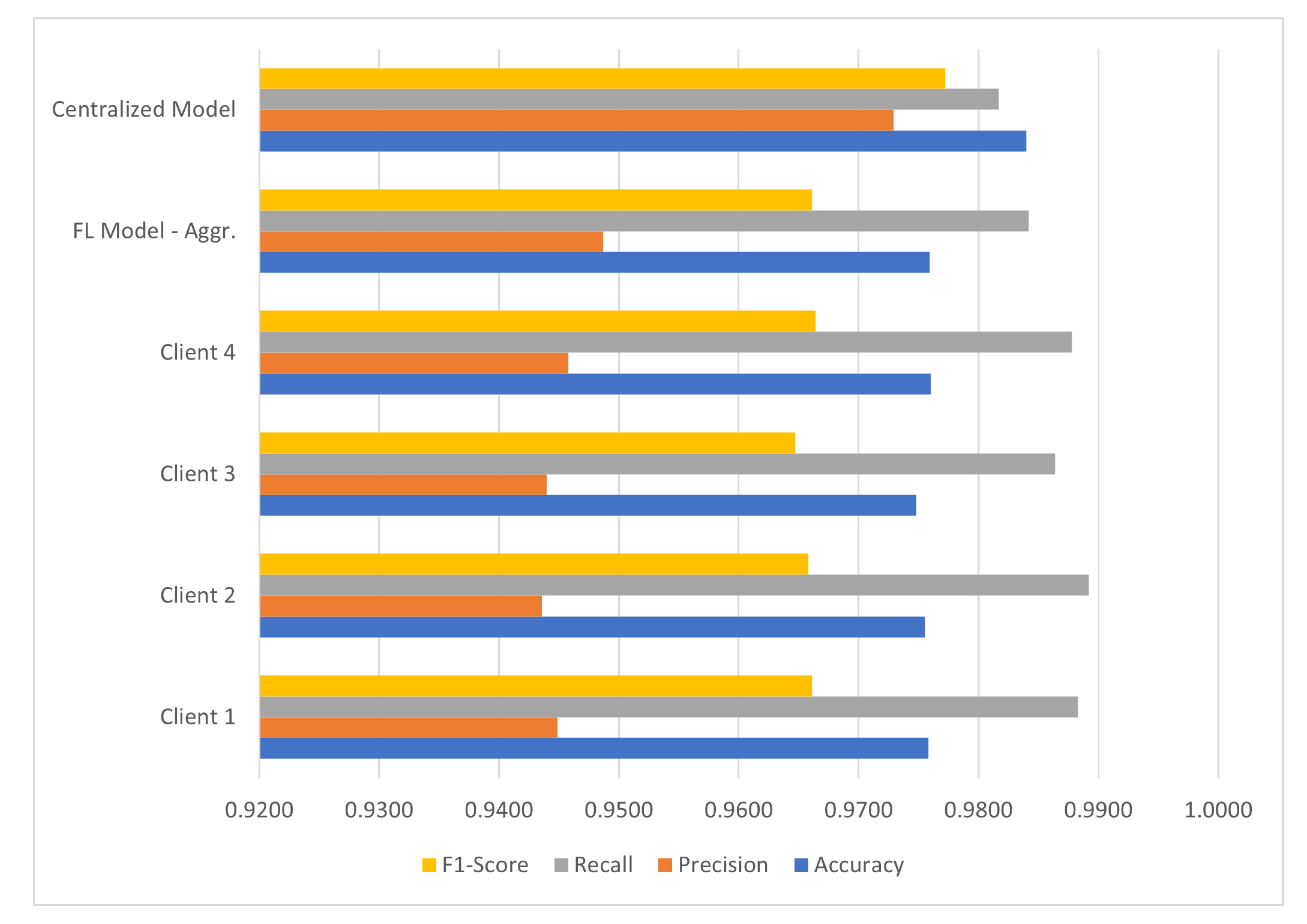
5.1. Binary Classification
5.2. Multiclass Classification
5.3. Confusion Matrices
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Laghari, A.A.; Wu, K.; Laghari, R.A.; Ali, M.; Khan, A.A. A Review and State of Art of Internet of Things (IoT). Arch. Comput. Methods Eng. 2022, 29, 1395–1413. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Rieger, P.; Miettinen, M.; Sadeghi, A.R. Poisoning Attacks on Federated Learning-based IoT Intrusion Detection System. In Proceedings of the Workshop on Decentralized IoT Systems and Security (DISS) 2020, San Diego, CA, USA, 23–26 February 2020; Internet Society: Reston, VA, USA, 2021; Volume 8. [Google Scholar] [CrossRef]
- Kagita, M.K.; Thilakarathne, N.; Gadekallu, T.R.; Maddikunta, P.K.R.; Singh, S. A Review on Cyber Crimes on the Internet of Things. In Signals and Communication Technology; Springer Science and Business Media GmbH: Berlin, Germany, 2021; pp. 83–98. [Google Scholar] [CrossRef]
- Kuzlu, M.; Fair, C.; Guler, O. Role of Artificial Intelligence in the Internet of Things (IoT) cybersecurity. Discov. Internet Things 2021, 1, 7. [Google Scholar] [CrossRef]
- Sengupta, S.; Basak, S.; Saikia, P.; Paul, S.; Tsalavoutis, V.; Atiah, F.; Ravi, V.; Peters, A. A review of deep learning with special emphasis on architectures, applications and recent trends. Knowl.-Based Syst. 2020, 194, 105596. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, Z.; Shahid Khan, A.; Wai Shiang, C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 2021, 32, e4150. [Google Scholar] [CrossRef]
- Tsimenidis, S.; Lagkas, T.; Rantos, K. Deep Learning in IoT Intrusion Detection. J. Netw. Syst. Manag. 2022, 30, 8. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 19. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Ferrari, P.; Sisinni, E.; Brandão, D.; Rocha, M. Evaluation of communication latency in industrial IoT applications. In Proceedings of the 2017 IEEE International Workshop on Measurement and Networking, M and N 2017—Proceedings, Naples, Italy, 27–29 September 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Schulz, P.; Matthe, M.; Klessig, H.; Simsek, M.; Fettweis, G.; Ansari, J.; Ashraf, S.A.; Almeroth, B.; Voigt, J.; Riedel, I.; et al. Latency Critical IoT Applications in 5G: Perspective on the Design of Radio Interface and Network Architecture. IEEE Commun. Mag. 2017, 55, 70–78. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, Ft. Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Campos, E.M.; Saura, P.F.; González-Vidal, A.; Hernández-Ramos, J.L.; Bernabé, J.B.; Baldini, G.; Skarmeta, A. Evaluating Federated Learning for intrusion detection in Internet of Things: Review and challenges. Comput. Netw. 2022, 203, 108661. [Google Scholar] [CrossRef]
- Booij, T.M.; Chiscop, I.; Meeuwissen, E.; Moustafa, N.; Hartog, F.T. ToN_IoT: The Role of Heterogeneity and the Need for Standardization of Features and Attack Types in IoT Network Intrusion Data Sets. IEEE Internet Things J. 2022, 9, 485–496. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the ICISSP 2018—4th International Conference on Information Systems Security and Privacy, Funchal, Portugal, 22–24 January 2018; SciTePress: Setúbal, Portugal, 2018; Volume 2018, pp. 108–116. [Google Scholar] [CrossRef]
- Konečný, J.; McMahan, B.; Ramage, D. Federated Optimization:Distributed Optimization Beyond the Datacenter. arXiv 2015, arXiv:1511.03575. [Google Scholar]
- Sarhan, M.; Layeghy, S.; Moustafa, N.; Portmann, M. A Cyber Threat Intelligence Sharing Scheme based on Federated Learning for Network Intrusion Detection. J. Netw. Syst. Manag. 2023, 31, 3. [Google Scholar] [CrossRef]
- Zhao, R.; Yin, Y.; Shi, Y.; Xue, Z. Intelligent intrusion detection based on federated learning aided long short-term memory. Phys. Commun. 2020, 42, 101157. [Google Scholar] [CrossRef]
- Zhao, L.; Li, J.; Li, Q.; Li, F. A Federated Learning Framework for Detecting False Data Injection Attacks in Solar Farms. IEEE Trans. Power Electron. 2022, 37, 2496–2501. [Google Scholar] [CrossRef]
- Mothukuri, V.; Khare, P.; Parizi, R.M.; Pouriyeh, S.; Dehghantanha, A.; Srivastava, G. Federated-Learning-Based Anomaly Detection for IoT Security Attacks. IEEE Internet Things J. 2022, 9, 2545–2554. [Google Scholar] [CrossRef]
- Zhang, T.; He, C.; Ma, T.; Gao, L.; Ma, M.; Avestimehr, S. Federated Learning for Internet of Things: A Federated Learning Framework for On-device Anomaly Data Detection. arXiv 2021, arXiv:2106.07976. [Google Scholar]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Shabtai, A.; Breitenbacher, D.; Elovici, Y. N-BaIoT-Network-based detection of IoT botnet attacks using deep autoencoders. IEEE Pervasive Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef] [Green Version]
- ANT. The ANT Lab: Analysis of Network Traffic. 2017. Available online: https://ant.isi.edu/ (accessed on 16 May 2022).
- Chatterjee, S.; Hanawal, M.K. Federated Learning for Intrusion Detection in IoT Security: A Hybrid Ensemble Approach. Int. J. Internet Things-Cyber-Assur. 2022, 2, 62–86. [Google Scholar] [CrossRef]
- Saha, R.; Misra, S.; Deb, P.K. FogFL: Fog-Assisted Federated Learning for Resource-Constrained IoT Devices. IEEE Internet Things J. 2021, 8, 8456–8463. [Google Scholar] [CrossRef]
- Chen, Z.; Lv, N.; Liu, P.; Fang, Y.; Chen, K.; Pan, W. Intrusion Detection for Wireless Edge Networks Based on Federated Learning. IEEE Access 2020, 8, 217463–217472. [Google Scholar] [CrossRef]
- Zhang, J.; Luo, C.; Carpenter, M.; Min, G. Federated Learning for Distributed IIoT Intrusion Detection using Transfer Approaches. IEEE Trans. Ind. Inform. 2023, 19, 8159–8169. [Google Scholar] [CrossRef]
- Thonglek, K.; Takahashi, K.; Ichikawa, K.; Iida, H.; Nakasan, C. Federated Learning of Neural Network Models with Heterogeneous Structures. In Proceedings of the 19th IEEE International Conference on Machine Learning and Applications, ICMLA 2020, Miami, FL, USA, 14–17 December 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; Volume 12, pp. 735–740. [Google Scholar] [CrossRef]
- Qin, Q.; Poularakis, K.; Leung, K.K.; Tassiulas, L. Line-Speed and Scalable Intrusion Detection at the Network Edge via Federated Learning. In Proceedings of the IFIP Networking 2020 Conference and Workshops–-Networking 2020, Paris, France, 22–25 June 2020; pp. 352–360. [Google Scholar]
- Otoum, Y.; Nayak, A. AS-IDS: Anomaly and Signature Based IDS for the Internet of Things. J. Netw. Syst. Manag. 2021, 29, 23. [Google Scholar] [CrossRef]
- Man, D.; Zeng, F.; Yang, W.; Yu, M.; Lv, J.; Wang, Y. Intelligent Intrusion Detection Based on Federated Learning for Edge-Assisted Internet of Things. Secur. Commun. Netw. 2021, 2021, 9361348. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Conditional variational autoencoder for prediction and feature recovery applied to intrusion detection in iot. Sensors 2017, 17, 1967. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of FedAvg on Non-IID Data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Online, 13–18 July 2020; Volume PartF16814, pp. 5088–5099. [Google Scholar]
- Hsu, T.M.H.; Qi, H.; Brown, M. Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]
- Sun, T.; Li, D.; Wang, B. Decentralized Federated Averaging. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4289–4301. [Google Scholar] [CrossRef]
- Muhammad, K.; Wang, Q.; O’Reilly-Morgan, D.; Tragos, E.; Smyth, B.; Hurley, N.; Geraci, J.; Lawlor, A. FedFast: Going beyond Average for Faster Training of Federated Recommender Systems. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Online, 23–27 August 2020; Volume 20, pp. 1234–1242. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated Optimization in Heterogeneous Networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated Learning with Matched Averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Reddi, S.; Charles, Z.; Zaheer, M.; Garrett, Z.; Rush, K.; Konečný, J.; Kumar, S.; McMahan, H.B. Adaptive Federated Optimization. arXiv 2020, arXiv:2003.00295. [Google Scholar]
- Nesterov, Y. A method for unconstrained convex minimization problem with the rate of convergence. Dokl. Akad. Nauk. SSSR 1983, 269, 543. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Su, W.; Chen, L.; Wu, M.; Zhou, M.; Liu, Z.; Cao, W. Nesterov accelerated gradient descent-based convolution neural network with dropout for facial expression recognition. In Proceedings of the 2017 Asian Control Conference, ASCC 2017, Gold Coast, QLD, Australia, 17–20 December 2017; IEEE: Piscataway, NJ, USA, 2018; pp. 1063–1068. [Google Scholar] [CrossRef]
- Google Inc. TensorFlow Federated. 2022. Available online: https://www.tensorflow.org/federated (accessed on 7 February 2022).
- Ziller, A.; Trask, A.; Lopardo, A.; Szymkow, B.; Wagner, B.; Bluemke, E.; Nounahon, J.M.; Passerat-Palmbach, J.; Prakash, K.; Rose, N.; et al. PySyft: A Library for Easy Federated Learning. In Studies in Computational Intelligence; Springer Science and Business Media GmbH: Berlin, Germany, 2021; Volume 965, pp. 111–139. [Google Scholar] [CrossRef]
- Ludwig, H.; Baracaldo, N.; Thomas, G.; Zhou, Y.; Anwar, A.; Rajamoni, S.; Ong, Y.; Radhakrishnan, J.; Verma, A.; Sinn, M.; et al. IBM Federated Learning: An Enterprise Framework White Paper V0.1. arXiv 2020, arXiv:2007.10987. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Fernandez-Marques, J.; Gao, Y.; Sani, L.; Li, K.H.; Parcollet, T.; de Gusmão, P.P.B.; et al. Flower: A Friendly Federated Learning Research Framework. arXiv 2020, arXiv:2007.14390. [Google Scholar]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Dataset | Shared Model | Aggregation Function | No. of Clients | FL Library |
|---|---|---|---|---|---|
| Sarhan et al. [17] | NF-UNSW-NB15 NF-BoT-IoT | LSTM DNN | FedAvg | - | - |
| Zhao et al. [19] | Proprietary | LSTM | - | 4 | Flower |
| Mothukuri et al. [20] | MODBUS Network Data | GRU Random Forest | FlAverage | - | Pysyft |
| Zhang et al. [27] | CICIDS2017 CICIDS2018 | Adaboost and RF | Weighed Voting FedAvg | 5 | - |
| Zhang et al. [21] | N-BaIoT USC LANDER IoT | Auto-Encoder | 9 | ||
| Chatterjee et al. [24] | NSL-KDD DS2OS Traffic Gas Pipeline Data Water Tank Data | MLP Stacking Ensemble | FedStacking | 4 | - |
| Saha et al. [25] | MNIST | MLP | FogFL | 6 | - |
| Zhao et al. [18] | SEA Dataset | LSTM | FedAvg | 4 | Tensorflow |
| Campos et al. [13] | ToN_IoT | Logistic Regression | FedAvg Fed+ | 10 | IBMFL |
| Chen et al. [26] | KDD CUP 99 CICIDS2017 WSN-DS | GRU-SVM | FedAGRU FedAvg | up to 50 | Pysyft |
| Hyperparameter | Value |
|---|---|
| Learning Rate | 0.01 |
| Epoch | 5 in first 3 rounds |
| 8 in last 2 rounds | |
| FL Rounds | 5 |
| Numerical ID | Traffic Type | No. of Samples |
|---|---|---|
| 0 | Backdoor | 20,000 |
| 1 | DDoS | 20,000 |
| 2 | DoS | 20,000 |
| 3 | Injection | 20,000 |
| 4 | MITM | 1043 |
| 5 | Normal | 300,000 |
| 6 | Password | 20,000 |
| 7 | Ransomware | 20,000 |
| 8 | Scanning | 20,000 |
| 9 | XSS | 20,000 |
| Numerical ID | Traffic Type | Number of Samples |
|---|---|---|
| 0 | Benign | 2,273,097 |
| 1 | Bot | 1966 |
| 2 | DDoS | 128,027 |
| 3 | DoS GoldenEye | 10,293 |
| 4 | DoS Hulk | 230,124 |
| 5 | DoS slowhttptest | 5499 |
| 6 | DoS slowloris | 5796 |
| 7 | FTP-Patator | 7938 |
| 8 | Heartbleed | 11 |
| 9 | Infiltrator | 36 |
| 10 | PortScan | 158,930 |
| 11 | SSH-Patator | 5897 |
| 12 | Web attacks—brute force | 1507 |
| 13 | Web attack—SQL Inj | 21 |
| 14 | Web attack XSS | 652 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| FL Model—Client 1 | 0.9758 | 0.9449 | 0.9883 | 0.9661 |
| FL Model—Client 2 | 0.9755 | 0.9436 | 0.9892 | 0.9658 |
| FL Model—Client 3 | 0.9748 | 0.9440 | 0.9864 | 0.9647 |
| FL Model—Client 4 | 0.9760 | 0.9458 | 0.9878 | 0.9664 |
| FL Model—Aggr. | 0.9759 | 0.9487 | 0.9842 | 0.9661 |
| Centralized Model | 0.9840 | 0.9729 | 0.9817 | 0.9772 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| FedAvgM | 0.9772 | 0.9512 | 0.9853 | 0.9679 |
| FedAdam | 0.8767 | 0.7580 | 0.9505 | 0.8434 |
| FedAdagrad | 0.8176 | 0.6635 | 0.9697 | 0.7879 |
| FedAvg | 0.9759 | 0.9487 | 0.9842 | 0.9661 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| FL Model—Client 1 | 0.9851 | 0.9481 | 0.9778 | 0.9627 |
| FL Model—Client 2 | 0.9841 | 0.9507 | 0.9694 | 0.9600 |
| FL Model—Client 3 | 0.9821 | 0.9292 | 0.9841 | 0.9559 |
| FL Model—Client 4 | 0.9821 | 0.9312 | 0.9816 | 0.9557 |
| FL Model—Aggr. | 0.9820 | 0.9326 | 0.9793 | 0.9554 |
| Centralized Model | 0.9840 | 0.9490 | 0.9720 | 0.9610 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| FedAvgM | 0.9814 | 0.9263 | 0.9839 | 0.9542 |
| FedAdam | 0.8085 | 0.5075 | 0.9104 | 0.6517 |
| FedAdagrad | 0.8986 | 0.7908 | 0.6589 | 0.7189 |
| FedAvg | 0.9820 | 0.9326 | 0.9793 | 0.9554 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
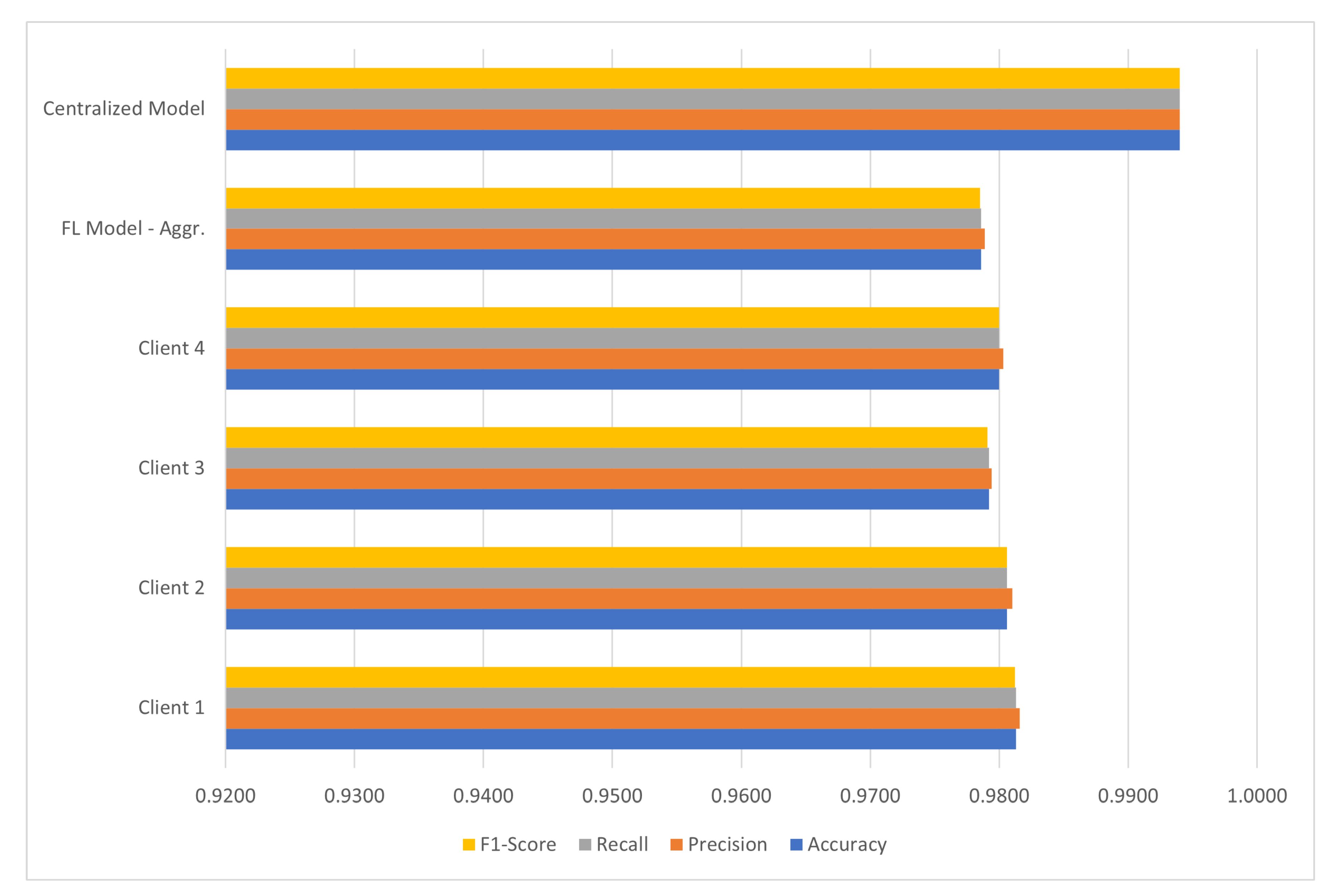
| FL Model—Client 1 | 0.9813 | 0.9816 | 0.9813 | 0.9812 |
| FL Model—Client 2 | 0.9806 | 0.9810 | 0.9806 | 0.9806 |
| FL Model—Client 3 | 0.9792 | 0.9794 | 0.9792 | 0.9791 |
| FL Model—Client 4 | 0.9800 | 0.9803 | 0.9800 | 0.9800 |
| FL Model—Aggr. | 0.9786 | 0.9789 | 0.9786 | 0.9785 |
| Centralized Model | 0.9940 | 0.9940 | 0.9940 | 0.9940 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| FedAvgM | 0.9757 | 0.9766 | 0.9757 | 0.9758 |
| FedAdam | 0.8340 | 0.8694 | 0.8340 | 0.8299 |
| FedAdagrad | 0.6983 | 0.6687 | 0.6983 | 0.6612 |
| FedAvg | 0.9786 | 0.9789 | 0.9786 | 0.9785 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
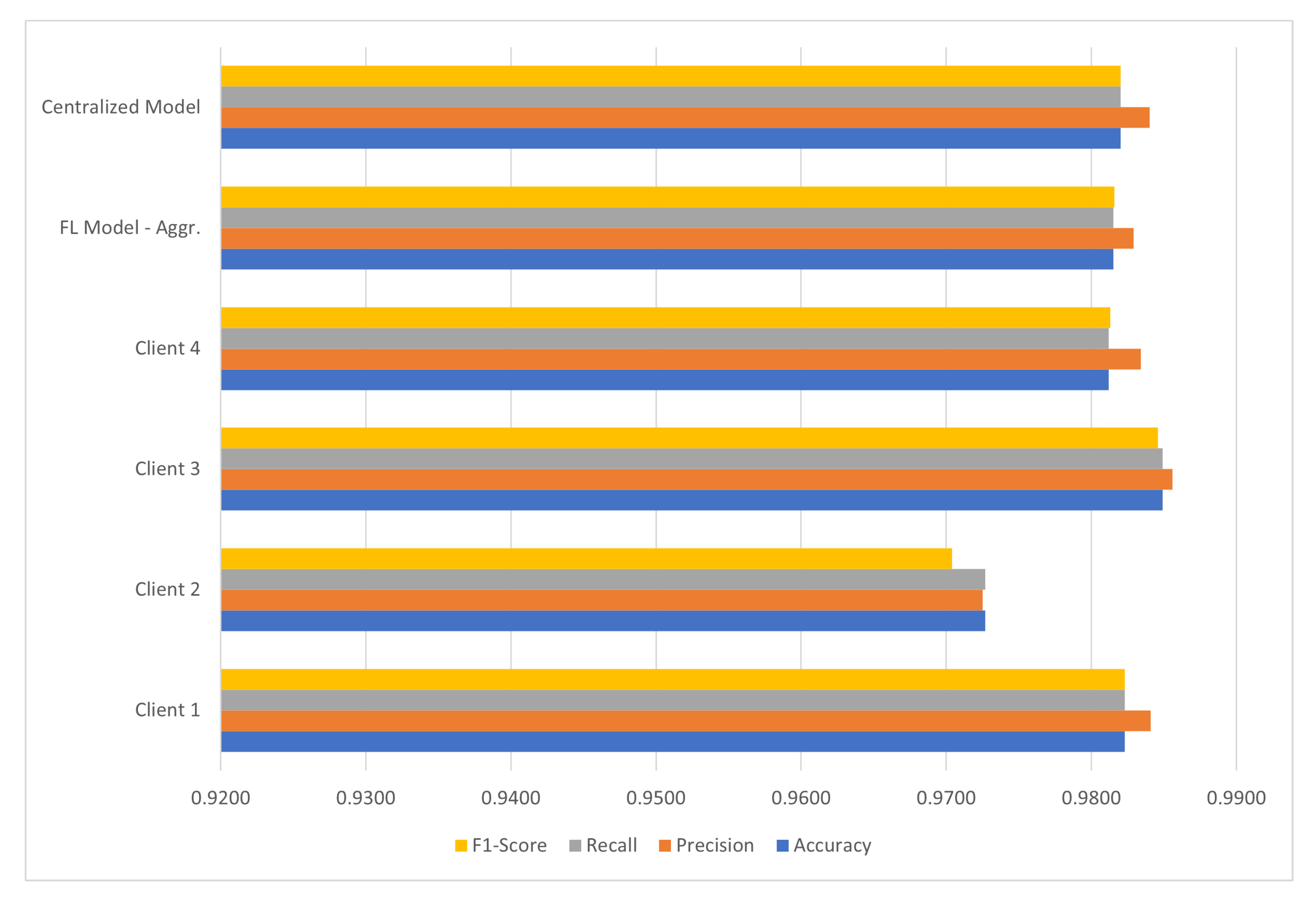
| FL Model—Client 1 | 0.9823 | 0.9841 | 0.9823 | 0.9823 |
| FL Model—Client 2 | 0.9727 | 0.9725 | 0.9727 | 0.9704 |
| FL Model—Client 3 | 0.9849 | 0.9856 | 0.9849 | 0.9846 |
| FL Model—Client 4 | 0.9812 | 0.9834 | 0.9812 | 0.9813 |
| FL Model—Aggr. | 0.9815 | 0.9829 | 0.9815 | 0.9816 |
| Centralized Model | 0.9820 | 0.9840 | 0.9820 | 0.9820 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| FedAvgM | 0.9817 | 0.9831 | 0.9817 | 0.9816 |
| FedAdam | 0.5111 | 0.8624 | 0.5111 | 0.5847 |
| FedAdagrad | 0.9065 | 0.9046 | 0.9065 | 0.9005 |
| FedAvg | 0.9815 | 0.9829 | 0.9815 | 0.9816 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lazzarini, R.; Tianfield, H.; Charissis, V. Federated Learning for IoT Intrusion Detection. AI 2023, 4, 509-530. https://doi.org/10.3390/ai4030028
Lazzarini R, Tianfield H, Charissis V. Federated Learning for IoT Intrusion Detection. AI. 2023; 4(3):509-530. https://doi.org/10.3390/ai4030028
Chicago/Turabian StyleLazzarini, Riccardo, Huaglory Tianfield, and Vassilis Charissis. 2023. "Federated Learning for IoT Intrusion Detection" AI 4, no. 3: 509-530. https://doi.org/10.3390/ai4030028
APA StyleLazzarini, R., Tianfield, H., & Charissis, V. (2023). Federated Learning for IoT Intrusion Detection. AI, 4(3), 509-530. https://doi.org/10.3390/ai4030028