1. Introduction
Currently, artificial intelligence (AI) has been adopted in robot vacuum cleaners to improve their performance and efficiency in smart building systems. For example, AI algorithms can create room maps and plan the most efficient cleaning path to navigate and avoid obstacles. Another exciting feature is object recognition and classification. AI algorithms can recognize different indoor objects, such as toys, furniture, or charging cables, and adjust the cleaning path accordingly. The use of AI techniques helps to ensure that robot vacuum cleaners clean all room areas and avoid becoming stuck or damaging anything. To date, several AI models have been proposed for indoor object classification to identify cleanable litter and non-cleanable hazardous obstacles. However, these studies mainly focus on the high accuracy in object classification, while ignoring the fact that robot vacuum cleaners require lightweight AI models due to their limited computational and memory resources. As an example of edge computing devices, robot vacuum cleaners typically have limited hardware resources (CPU, memory and power) compared to other computing devices such as desktop computers or servers. Rather than relying on the cloud-based computing resource, robot vacuum cleaners involve processing data and running AI models on the device itself [
1,
2]. This means that they cannot handle large and complex AI models that require high computational power, making lightweight models a better fit. Additionally, robot vacuum cleaners need to process data in real-time to recognize objects in video streams from built-in cameras. Lightweight AI models are often faster and more efficient than larger models, making them better suited for real-time object classification applications. In addition, robot vacuum cleaners are designed for mass production, which means they need to be cost-effective. Therefore, lightweight AI models help to reduce the cost of robot vacuum cleaners by using less powerful and low-cost hardware components, thereby, overcoming the limitations of computational resources and implementation costs.
Generally, there are several potential techniques to reduce the complexity of AI models, including weight quantization [
3,
4,
5,
6,
7], network pruning [
8,
9,
10,
11,
12], transfer learning [
13,
14], the input image resizing [
15,
16], well-designed model architecture [
17], and so on. In deep AI models, weights are typically represented as 32-bit floating-point numbers, which require a large amount of memory. Weight quantization allows us to represent weights using fewer bits, reducing the memory requirements. For example, converting a 32-bit floating-point weight to an 8-bit integer weight reduces the memory size by a factor of 4. The researchers have presented post-training weight quantization, which involves quantizing the weights of a pre-trained model after it has been trained [
2,
18], so there is no need for retraining, making it convenient to use. In contrast, the researchers [
3,
6,
7,
19] present quantization-aware training, which involves quantizing the weights of AI models during training, taking into account the quantization constraints during the optimization process. Training-aware quantization can result in more accurate quantization and reduced accuracy loss, since it allows the model to adapt and learn to perform effectively with quantized weights and activations. During quantization-aware training, additional techniques can be applied to improve the performance of the quantized model. For example, techniques like precision scaling, where different layers are assigned different bit precisions, can be employed to optimize the model’s accuracy and efficiency further. Furthermore, post-training quantization often requires an additional calibration step to determine optimal quantization parameters for each layer. This calibration process can be time-consuming. In contrast, quantization-aware training avoids the need for post-training calibration by incorporating the quantization process directly into the training phase. Both post-training quantization and quantization-aware training typically use linear quantization, while the weight distribution of well-trained neural network models is often non-linear.
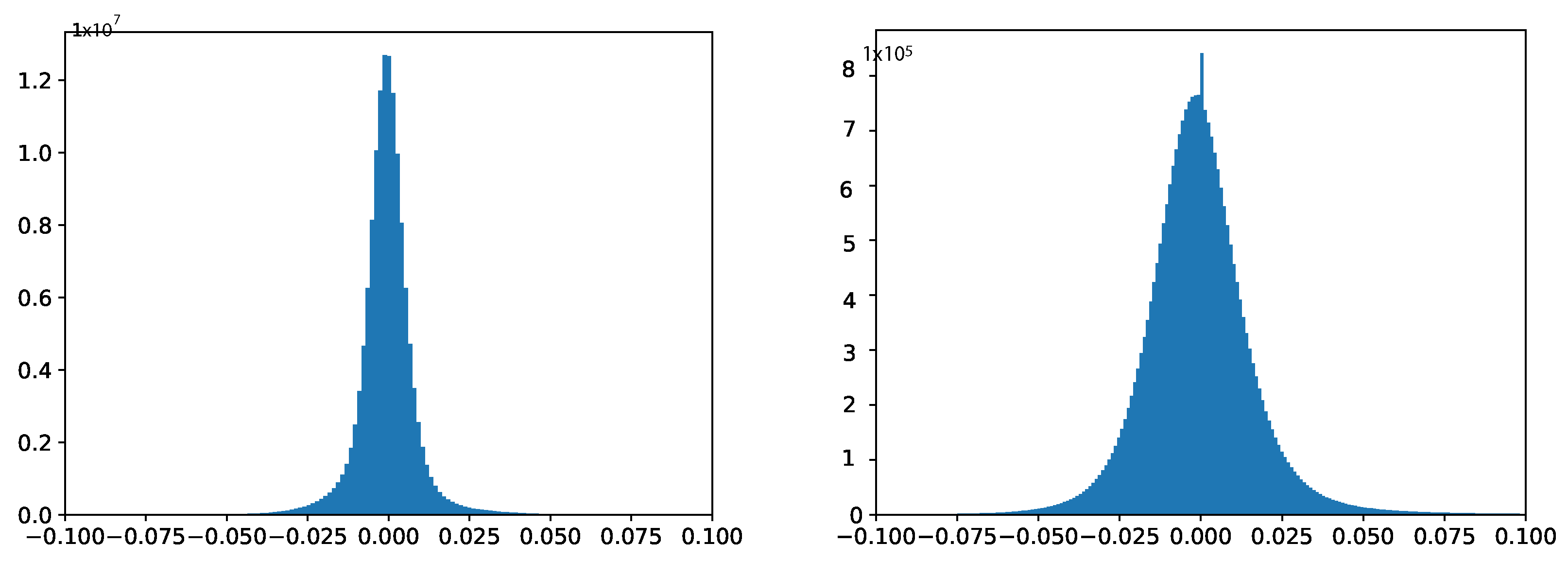
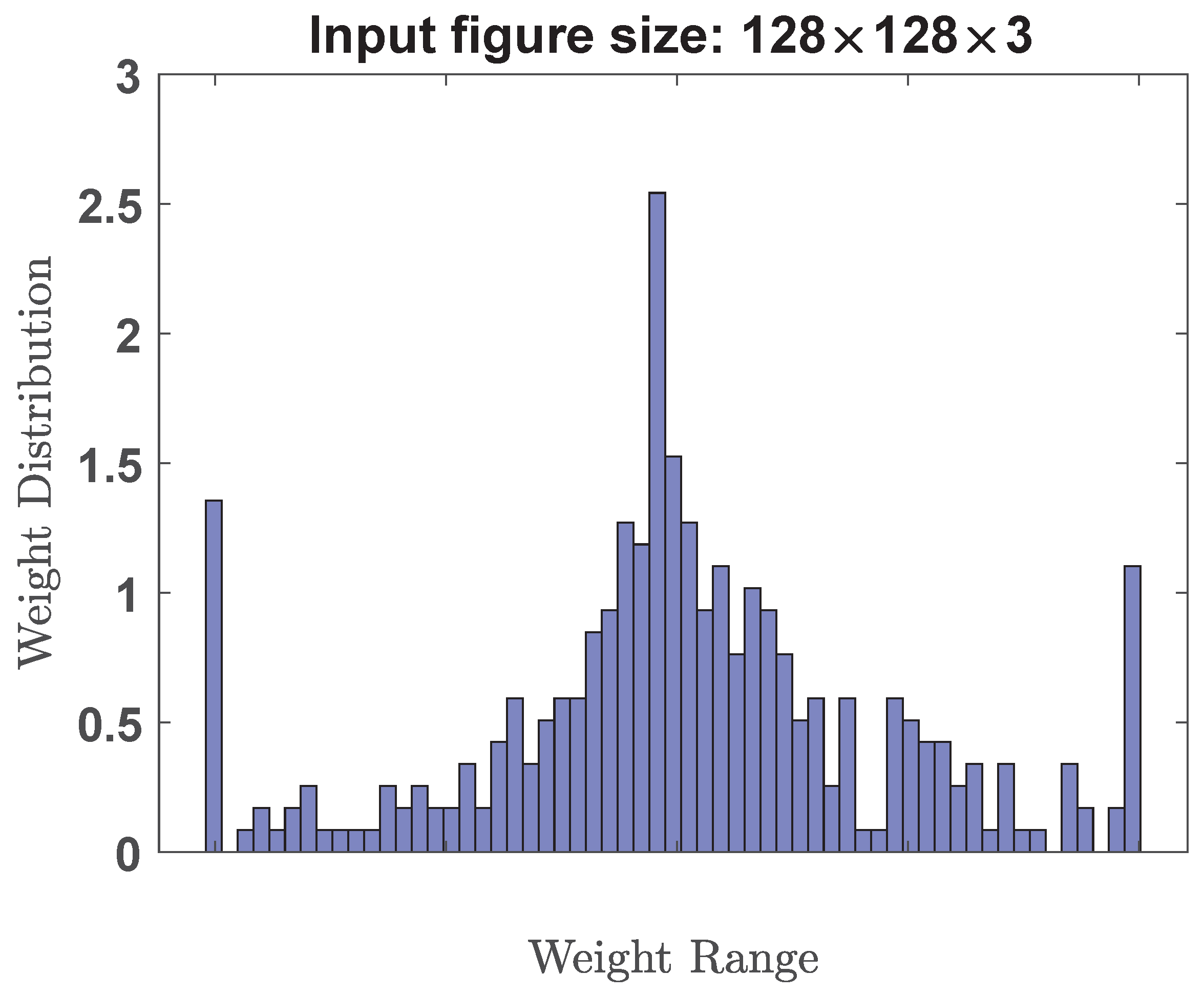
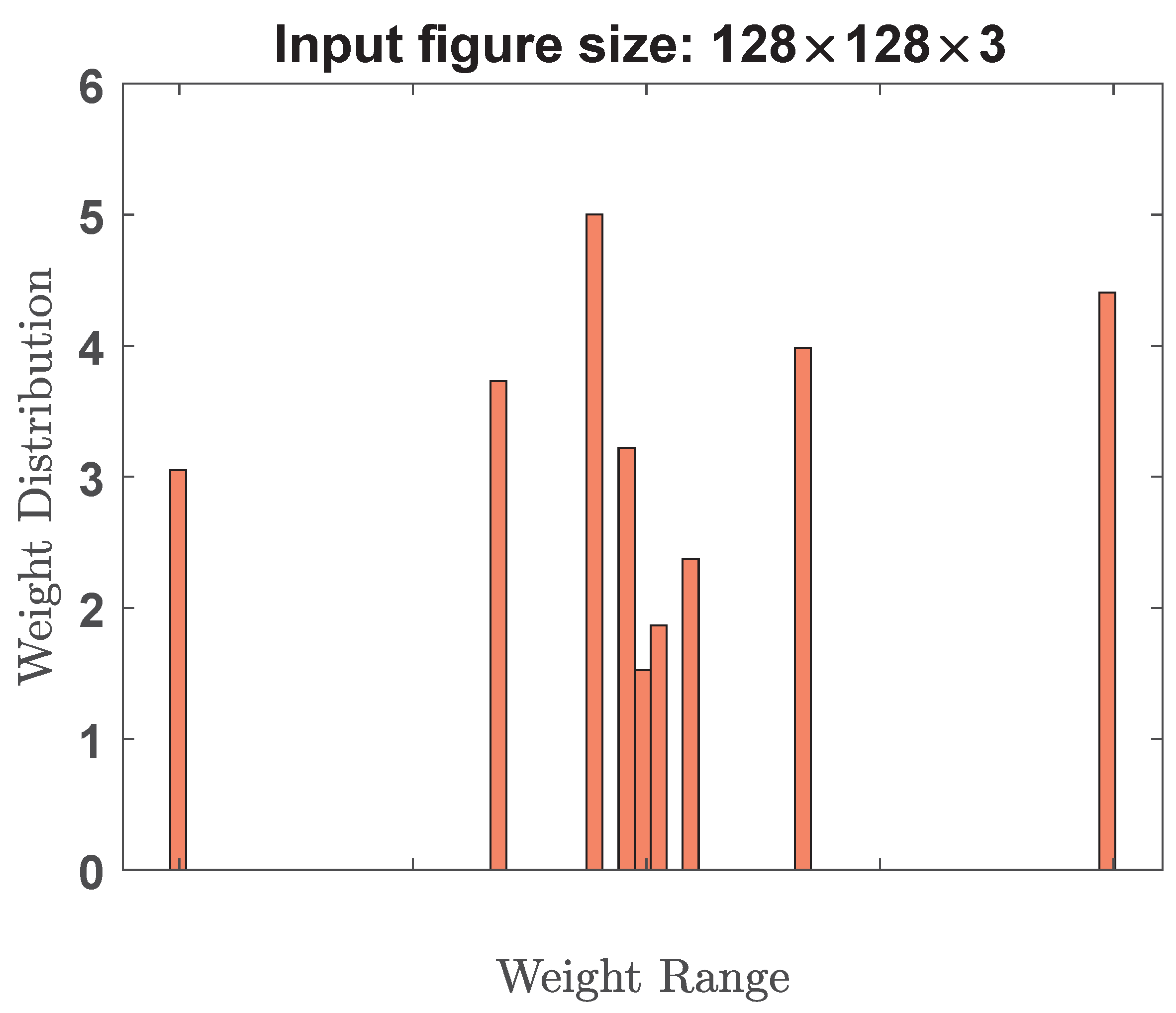
Figure 1 plots the weight distribution curves of two typical deep neural networks (VGG-19 and ResNet-50), respectively. It is observed that these weight distributions are centered around zero. This means that most weights have positive and negative values, with a mean close to zero. In addition, the weight distribution in deep neural networks is often assumed to follow a normal or Gaussian distribution. This assumption is supported by the central limit theorem, which states that the sum of many independent and identically distributed random variables tends to follow a Gaussian distribution. Therefore, as the number of layers and weights increases in a deep neural network, the weight distribution tends to approach a Gaussian distribution. Traditional uniform quantization is insensitive to weight distribution characteristics because they treat all weights equally, without considering the specific distribution characteristics of weight values. Therefore, these traditional uniform quantization methods that do not match the actual weight distribution will inevitably limit the performance of the model.
Network pruning reduces the size of AI models by removing unnecessary weights, neurons, or connections. Since weights that are close to zero are usually considered to be redundant or unnecessary, removing them can result in slight performance degradation and a significant reduction in the size of AI models. However, pruning cannot reduce computational cost unless customized hardware accelerators are used. This is because network pruning often leads to irregular sparsity patterns where certain connections or weights are removed while others are preserved. This irregular sparsity poses challenges for hardware architectures, such as CPUs or micro-controllers, which are designed for dense matrix operations. These architectures may not efficiently utilize the sparsity in the pruned network and still perform computations on the unused connections, resulting in limited computational savings. Since customized hardware accelerators are not affordable in cost-effective robot vacuum cleaners, network pruning is not a suitable approach for reducing memory requirements in this context.
Transfer learning is another popular technique in deep learning for object classification tasks, where a pre-trained AI model is used as a starting point for a new classification task. The pre-trained model has already been trained on a large dataset, typically using millions of images, and has learned to recognize a wide range of features that can be useful for many other tasks. Transfer learning consists of four steps: choosing a pre-trained model, freezing the pre-trained layers, replacing the classification layers, and fine-tuning the model. Despite the benefits of transfer learning, it involves a very high training cost. Robot vacuums often have limited computational resources and memory compared to larger computing systems used in training deep neural networks. This can restrict the complexity and size of the transferred model that can be deployed on the robot vacuum cleaner. The limited hardware capabilities may hinder the performance and scalability of the transferred model, affecting its ability to handle complex object recognition tasks.
Because the training image size affects the size of AI models, input image resizing has significant impacts on the performance of AI models [
14,
15]. Larger training images generally contain more details and information about the objects or scenes they represent. This additional information can help the model learn more discriminative features and improve its ability to distinguish between different classes. Consequently, using larger training images can potentially lead to better model performance. However, if the training images are too large, the AI model may not fit into the memory of robot vacuum cleaners, which can slow down the training or inference process due to high memory usage or computational cost per training iteration. On the other hand, if the input images are too small, the AI model may not be able to capture the important visual features of the image, which can result in lower accuracy and generalization performance. Therefore, the architecture and size of AI models should be appropriately chosen to be compatible with the input image size. It has been reported that the performance of well-designed model architecture [
17] can rival that of much larger models. However, the effectiveness of such architectures heavily relies on the experience of designers. In many cases, the availability of experienced model design experts is limited, especially when dealing with diverse applications. It is important to strike a balance between training image size, computational resources, and the specific requirements of the task at hand.
In this work, we investigate and develop a lightweight AI model with low bitwidth non-uniform quantization technique. The proposed design needs very little memory usage and computational resources for easy deployment on resource-constrained robot vacuum cleaners. Since the weight distribution of well-trained AI models (for example,
Figure 1) has been observed to exhibit a resemblance to a power-of-N function [
20], therefore, we propose to adopt a power-of-N quantization scheme. In this proposed scheme, weight values are discretized into a set of predefined levels that are distributed according to the power-of-N pattern. This proposed scheme ensures that the weight levels are distributed in a way that aligns with the underlying power-of-N trend, capturing the statistical characteristics of the weight distribution.
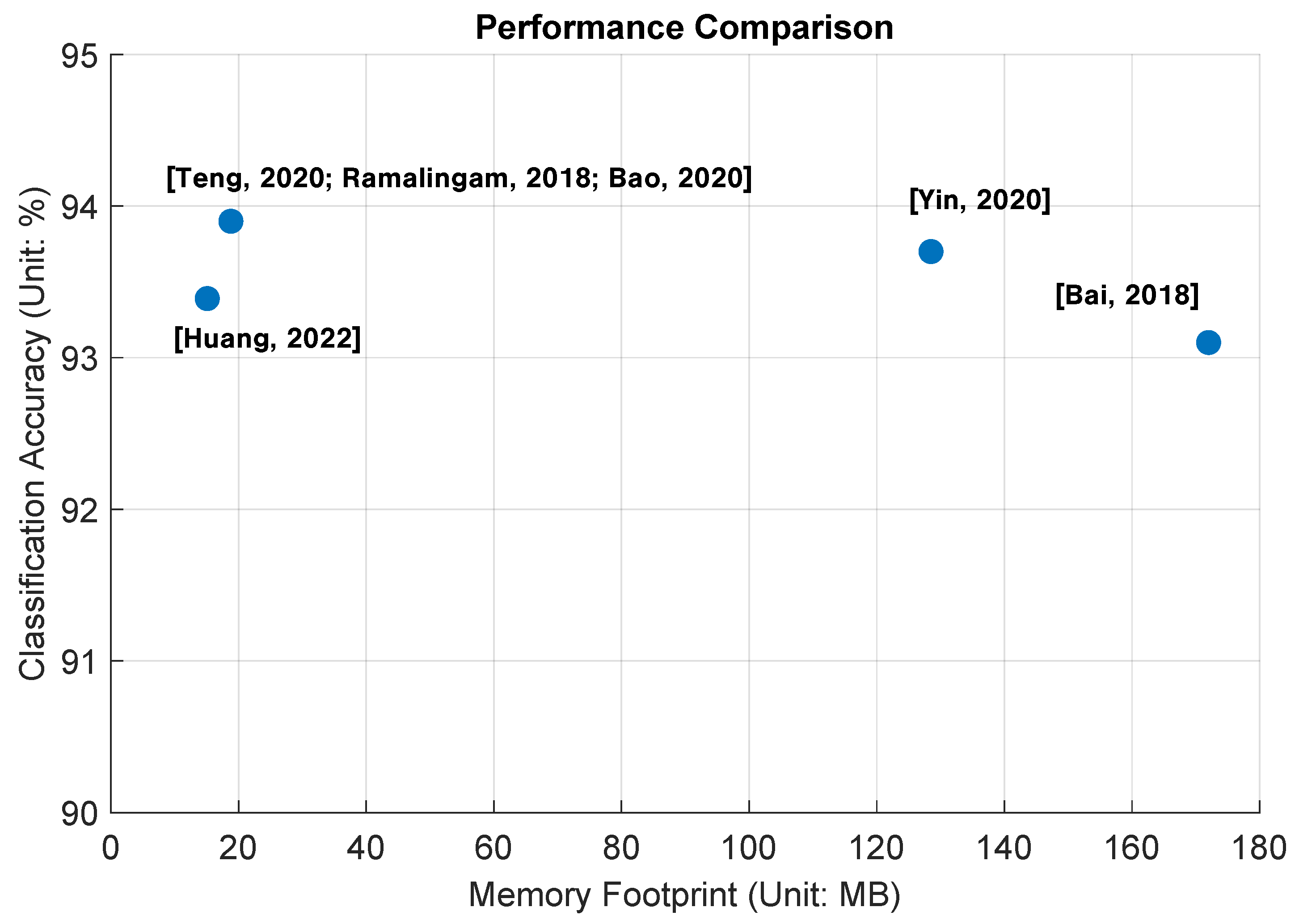
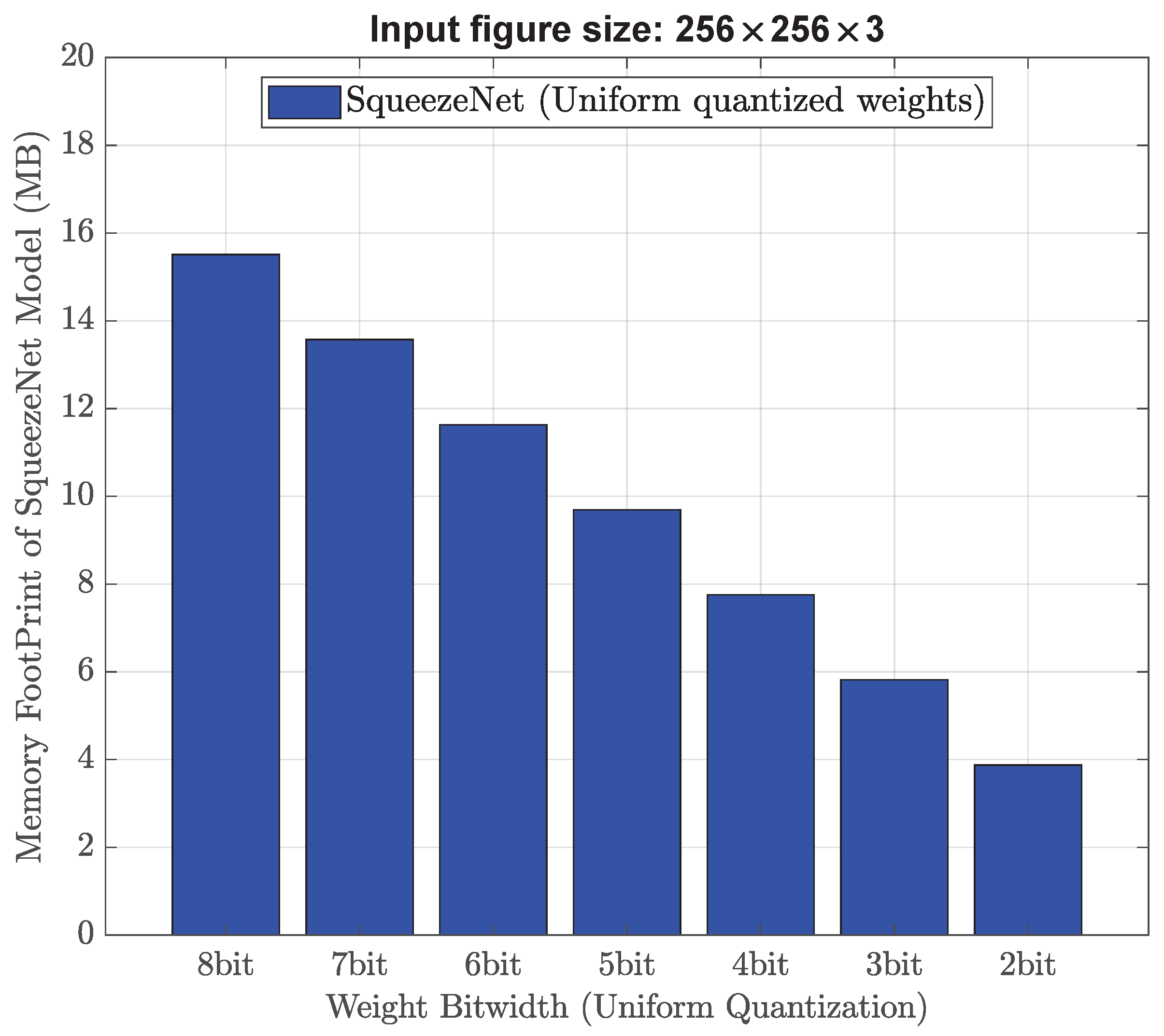
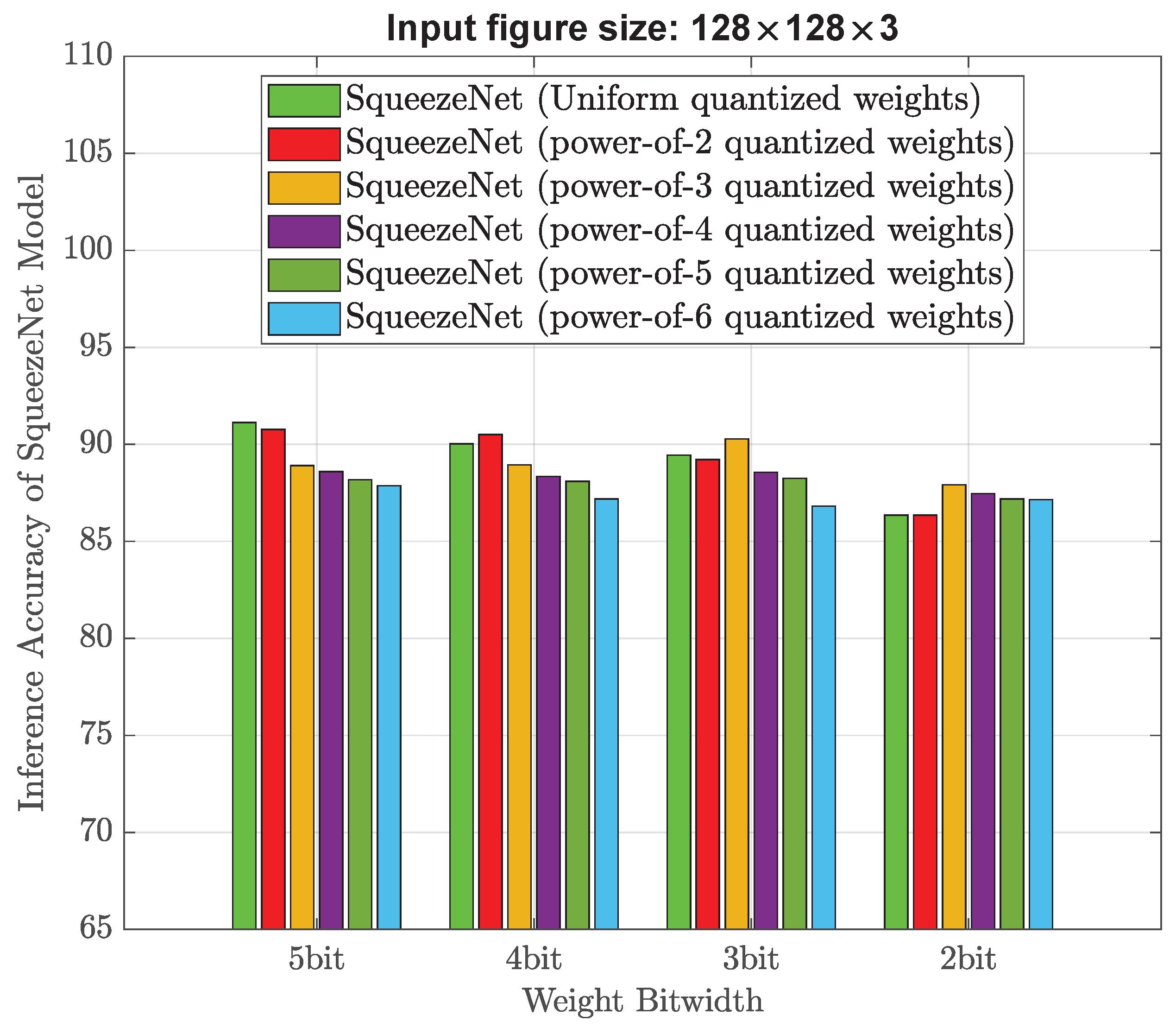
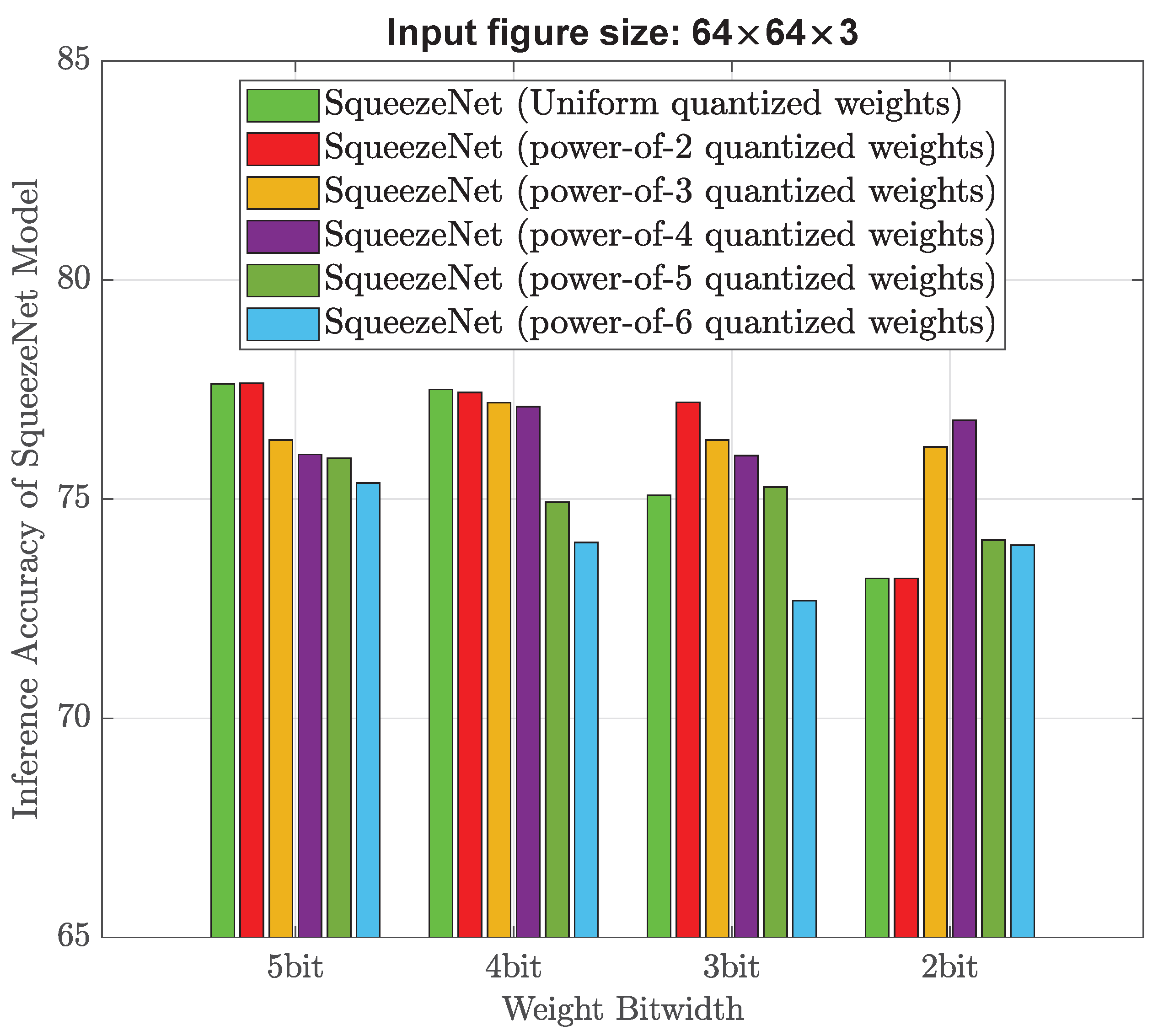
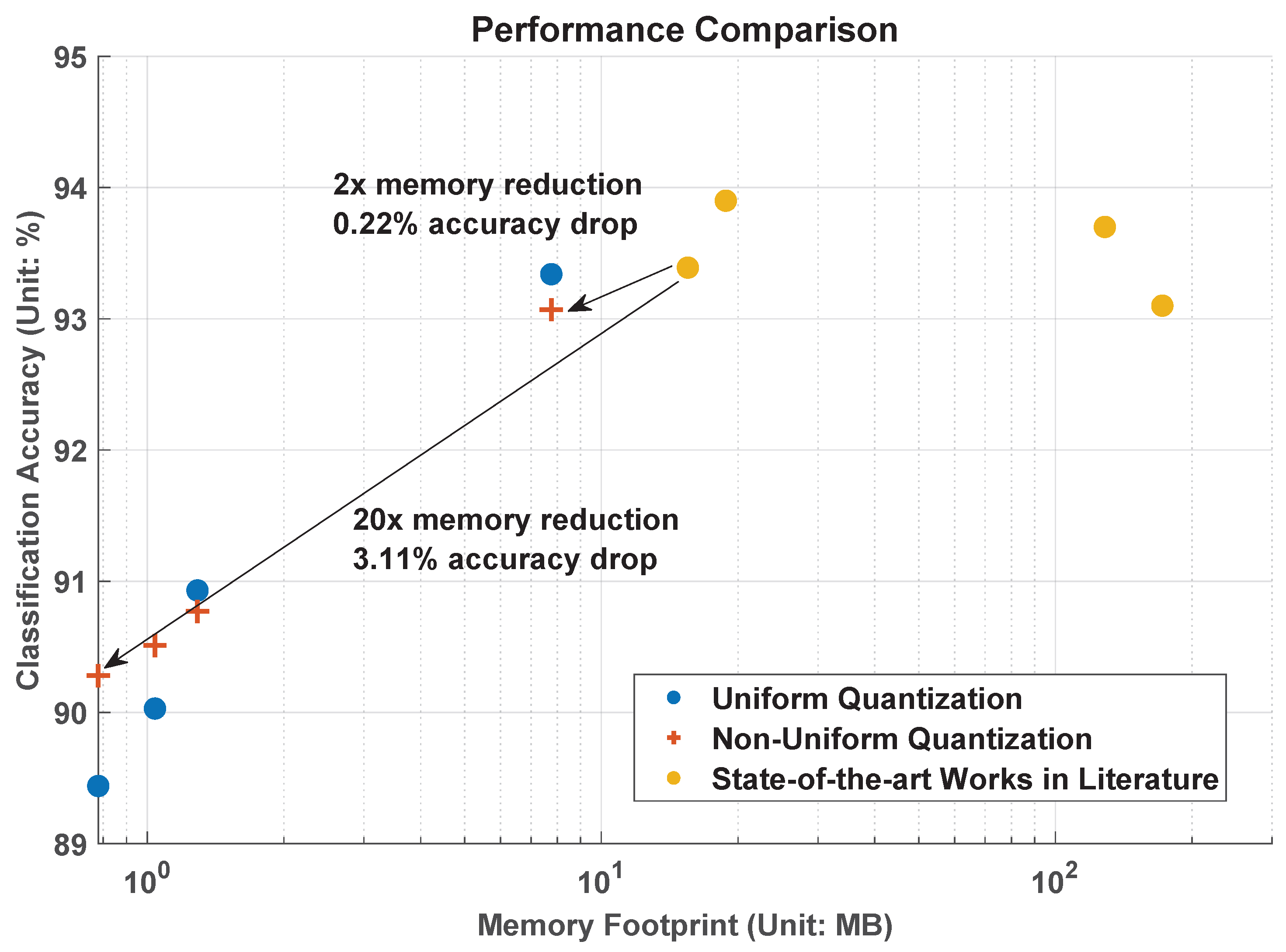
Experiments are first carried out using the same training image size (256 × 256 × 3) as that of the existing design [
4]. Compared with our recent design [
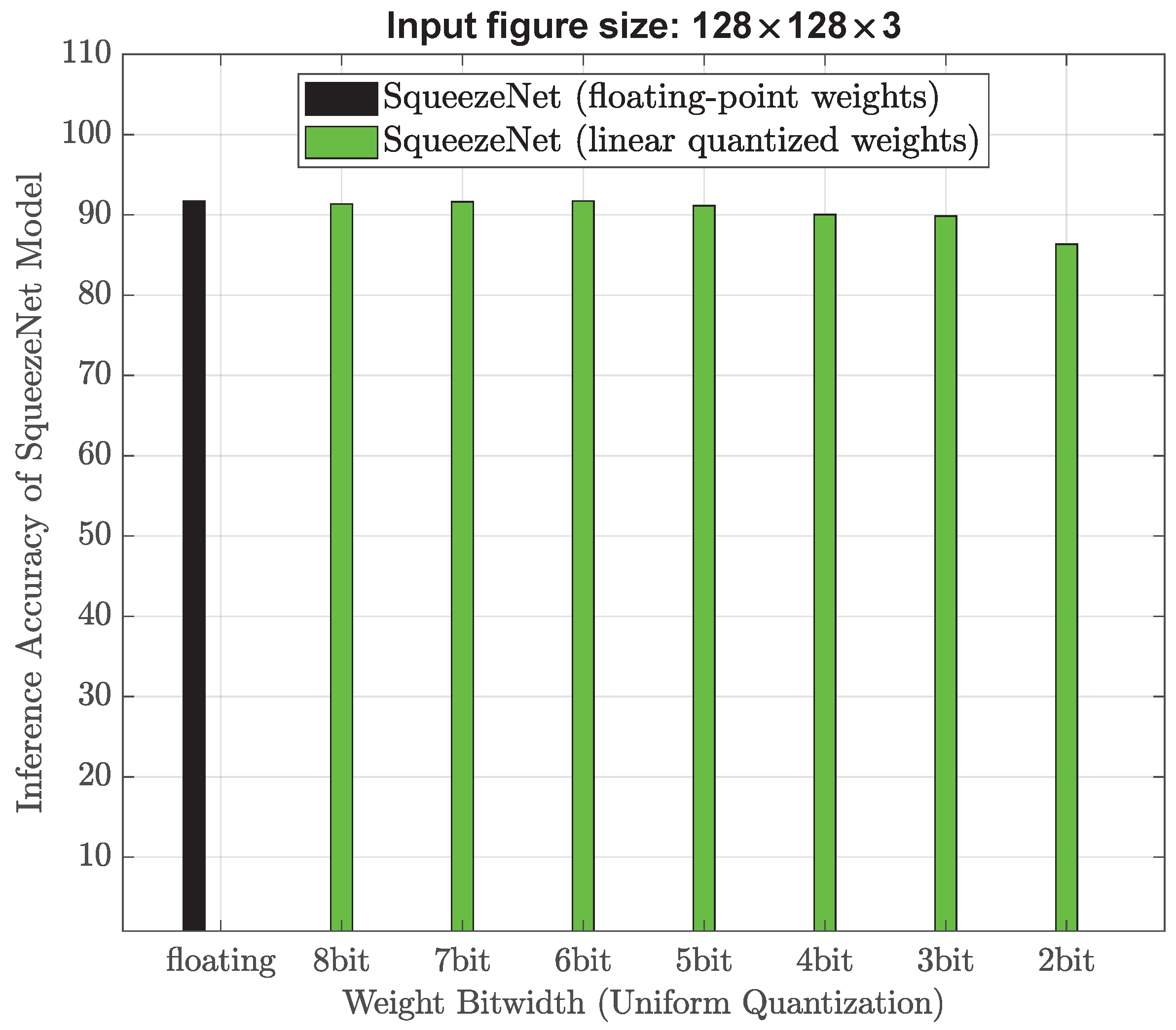
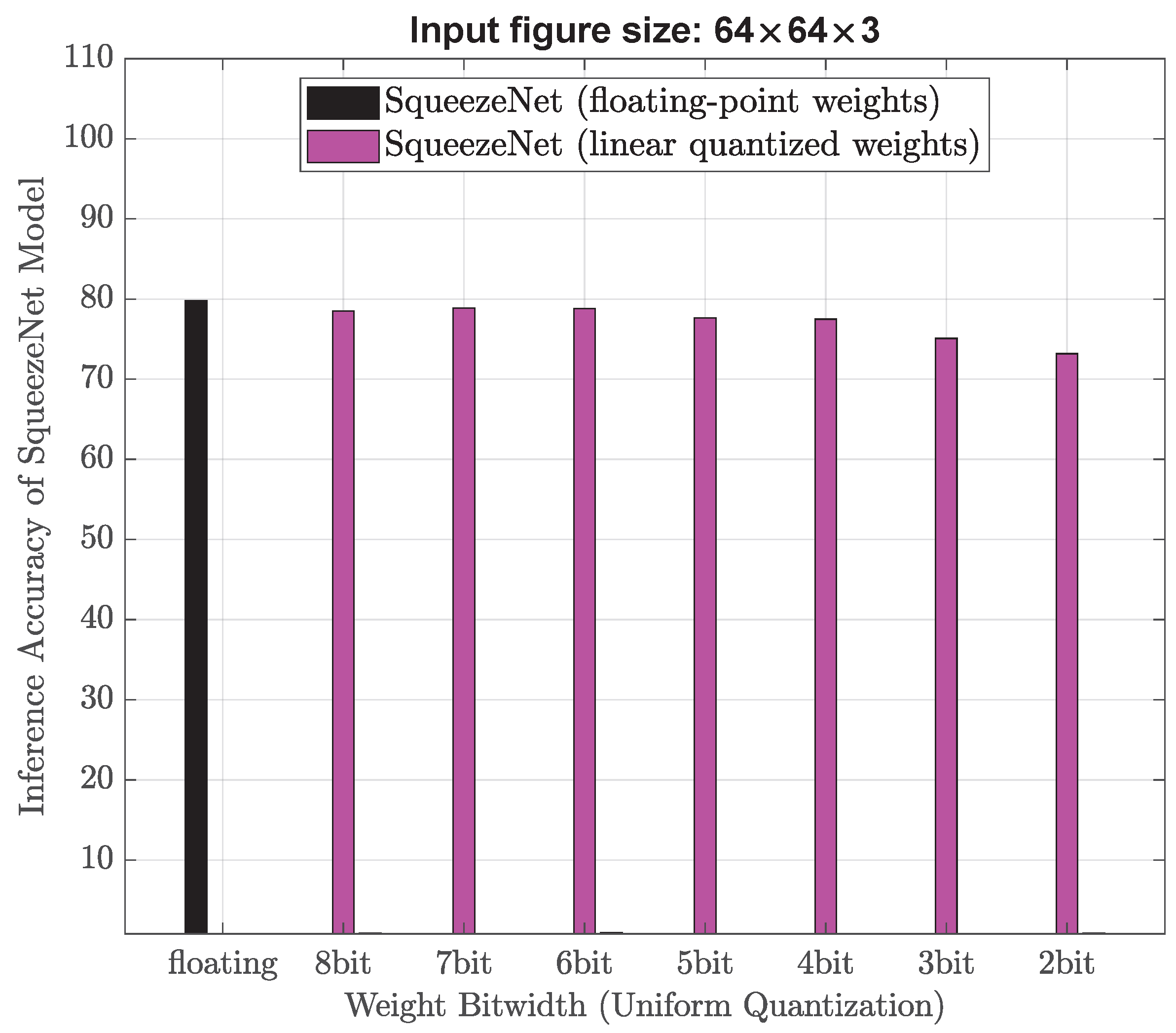
4] whose memory usage is 15.51 MB and accuracy result is 93.39%, our experimental results indicate that the high-performance uniform quantization model could achieve half the memory footprint (from 15.51 MB down to 7.76 MB) with a negligible accuracy drop of 0.05%. By ensuring a classification accuracy of over 90%, the minimum memory requirement for our model is determined to be 1.04 MB. This signifies a substantial reduction in memory, specifically a 15-fold decrease from the initial 15.51 MB down to 1.04 MB. Experimental results also show that when compared with the state-of-the-art AI models in the literature, the proposed non-uniform quantized AI model achieves a 1.6-fold decrease in memory usage from 15.51 MB down to 9.69 MB while maintaining the same accuracy of around 93.39%. In addition, the proposed strong non-uniform quantization AI model may minimize memory usage by 20 times (from 15.51 MB down to 0.78 MB) with an accuracy drop of 3.11% (the classification accuracy is still above 90%). These above results demonstrate that the proposed strong non-uniform weight quantization approach is advantageous in high-performance and low-memory applications. Next, experiments are also conducted using smaller training image sizes (128 × 128 × 3) and (64 × 64 × 3) to evaluate their impact on memory usage and object classification accuracy. Through the utilization of our proposed strong non-uniform quantization and downscaled input image size of (128 × 128 × 3), we have discovered that SqueezeNet can attain an accuracy level of 90.28% while utilizing only 0.78 MB of memory. Therefore, our proposed AI models may fit better into the available memory on robot vacuum cleaners, without worrying about performance degradation or even crashes. Note that existing studies in the literature only consider the parameter size of their AI models when calculating memory usage, ignoring the memory used for the forward and backward passes. The forward and backward passes in AI models require a significant amount of memory because they involve a large number of matrix operations. In the forward pass, the input data undergo multiplication with the weight matrices and subsequently pass through activation functions. The intermediate results of these operations are stored in memory to be used in the backward pass. The output of the forward pass is also stored in memory for later use. In the backward pass, the gradient of loss function concerning each weight is computed by carrying out a series of matrix operations in reverse order. The intermediate results of these operations are also stored in memory to be used in the weight updates. Therefore, the memory usage for forward and backward passes often exceed the parameter size itself. In our study, we adopt a practical approach to present the memory footprint by incorporating various factors such as input image size, parameter size, and the memory needed for both forward and backward passes. This enables a comprehensive understanding of the memory requirements involved in the process.
The rest of this paper is organized as follows.
Section 2 introduces related work on several state-of-the-art deep AI models, and traditional uniform weight quantization technique.
Section 3 describes the concepts of proposed low bitwidth strong non-uniform weight quantization and input image size adjustment.
Section 4 describes the dataset preparation, experimental setup, and various experimental results, and comprehensive comparison with the state-of-the-art works in the literature.
Section 5 concludes the paper and discusses future work.
3. Proposed AI Models with Non-Uniform Weight Quantization and Downsized Input
To deal with the memory limitation challenge, we propose to use non-uniform weight quantization and downsized input images.
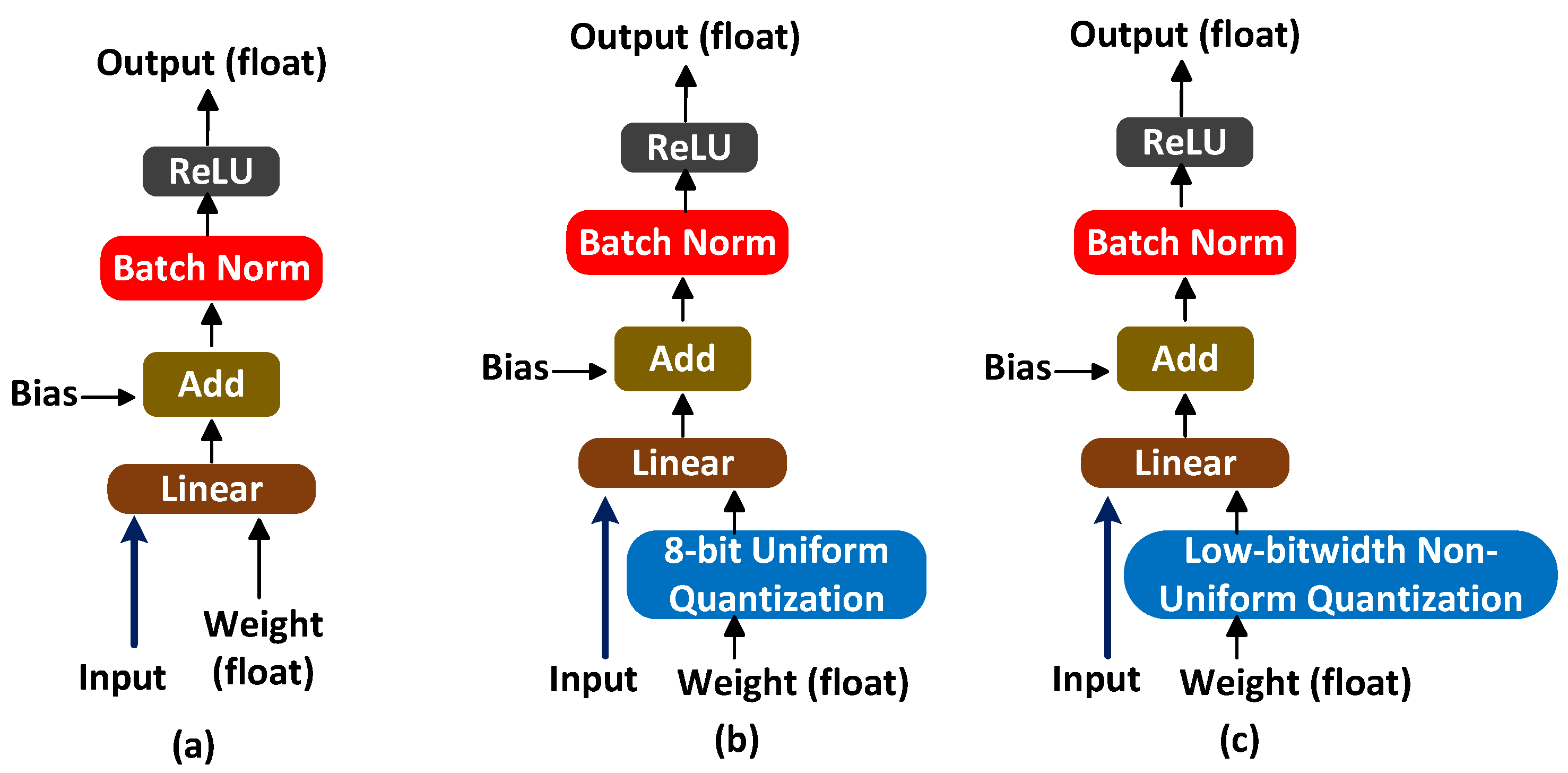
Figure 3a illustrates the conventional process of training an AI model (forward pass for one network layer) in [
21,
22,
23,
24,
25]. In this process, the input undergoes a linear operation with floating-point weight, followed by the addition of bias to the resulting output. Linear operation forms the basis of many fundamental computations in neural networks, such as matrix multiplications in fully connected layers or convolutions in convolutional layers. It helps in transforming the input data into a higher-dimensional space, enabling the network to learn complex patterns and make predictions. Next, information is subjected to batch normalization to normalize the values, and then it is passed through an activation function (for example, ReLU) to obtain the final output. Due to the utilization of floating-point weights, there is a significant demand for a large memory footprint (for example, 172 MB in [
21], 128.5 MB in [
22], 18.8 MB in [
23,
24,
25]).
Figure 3b illustrates the model training process in [
4], where weights undergo 8-bit uniform quantization. 8-bit quantization reduces the precision of weights to only 8 bits, resulting in a limited range of possible values. This reduction in precision helps in reducing memory requirements and computational complexity, but it may introduce some loss of accuracy compared to using floating-point weights. In order to further minimize the memory size, we propose to perform low-bitwidth non-uniform quantization, as depicted in
Figure 3c. The weights of a neural network are quantized to a reduced number of bits, typically much less than 8 bits, while using a non-uniform quantization scheme. This is particularly beneficial for deployment on resource-constrained devices or in scenarios where memory efficiency is critical.
3.1. Low-Bitwidth Strong Non-Uniform Weight Quantization
Compared to uniform weight quantization where the step sizes between quantization levels are constant, the quantization step size of non-uniform quantization varies and depends on the value being quantized. Non-uniform quantization allows for a better representation of data, especially in cases where the weight distribution is skewed. Please note that the effectiveness of the power-of-N quantization scheme may vary depending on the specific AI model, dataset, and application domain. Experiments are necessary to determine the optimal values of N and evaluate the impact on model accuracy, memory footprint, and computational efficiency. The choice of N plays a crucial role in determining the non-linearity and uniformity of the quantization levels. A larger N implies that the levels are spaced farther apart, resulting in a more significant distinction between adjacent quantization values. In other words, the probability of weight values falling into each quantization level is not evenly distributed. The introduction of nonlinearity and non-uniformity through a larger N value allows the power-of-N quantization scheme to better adapt to the specific distribution of weights in AI models. It can capture the fine-grained variations in weight values while allocating quantization levels in a way that reflects the underlying statistical properties of the well-trained model. However, it is essential to strike a balance when selecting the value of N. If N is chosen to be excessively large, it may result in an overly fine-grained quantization scheme. Therefore, careful consideration and experimentation are necessary to determine the optimal value of N based on the specific model, dataset, and weight bitwidth.
Table 1 shows how the number of weight elements vary with quantization bitwidth. In this work, the relationship between the bitwidth
b and the number of weight elements
e for weight quantization can be expressed as:
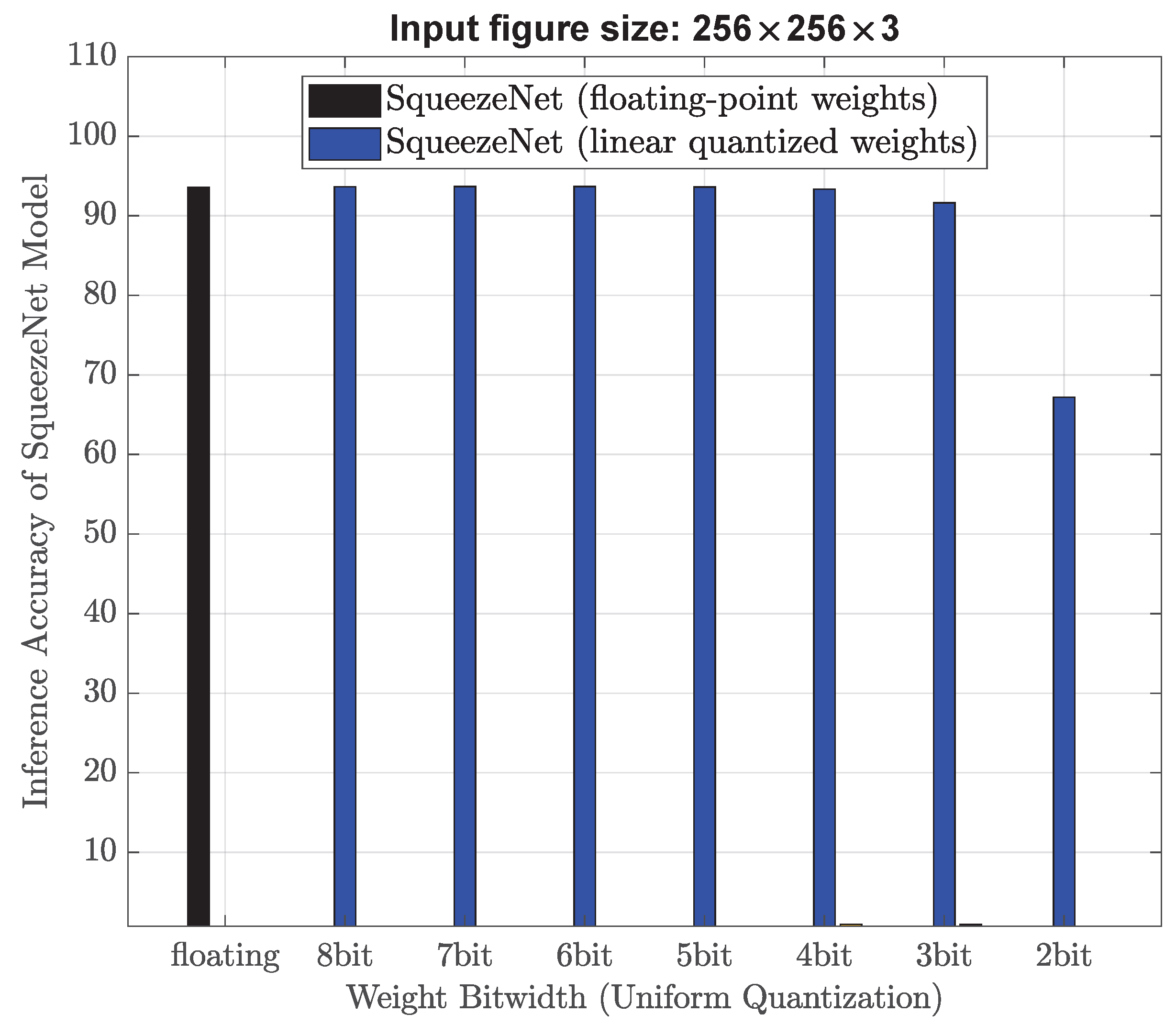
This equation shows that the number of weight elements e grows exponentially with increasing bitwidth b. For example, if b = 4, then the number of weight elements would be 15. If b = 5, then the number of weight elements would be 31. Therefore, reducing the bitwidth can significantly reduce the number of weight elements, which can lead to a smaller model size and faster inference on resource-constrained devices. However, reducing the bi-width too much (for example, b = 2 or 3) may result in a loss of accuracy or failed convergence. This is because very low-bit width neural networks have limited representation capacity. As a result, the quantized weights may struggle to capture the full richness of the original model with high precision.
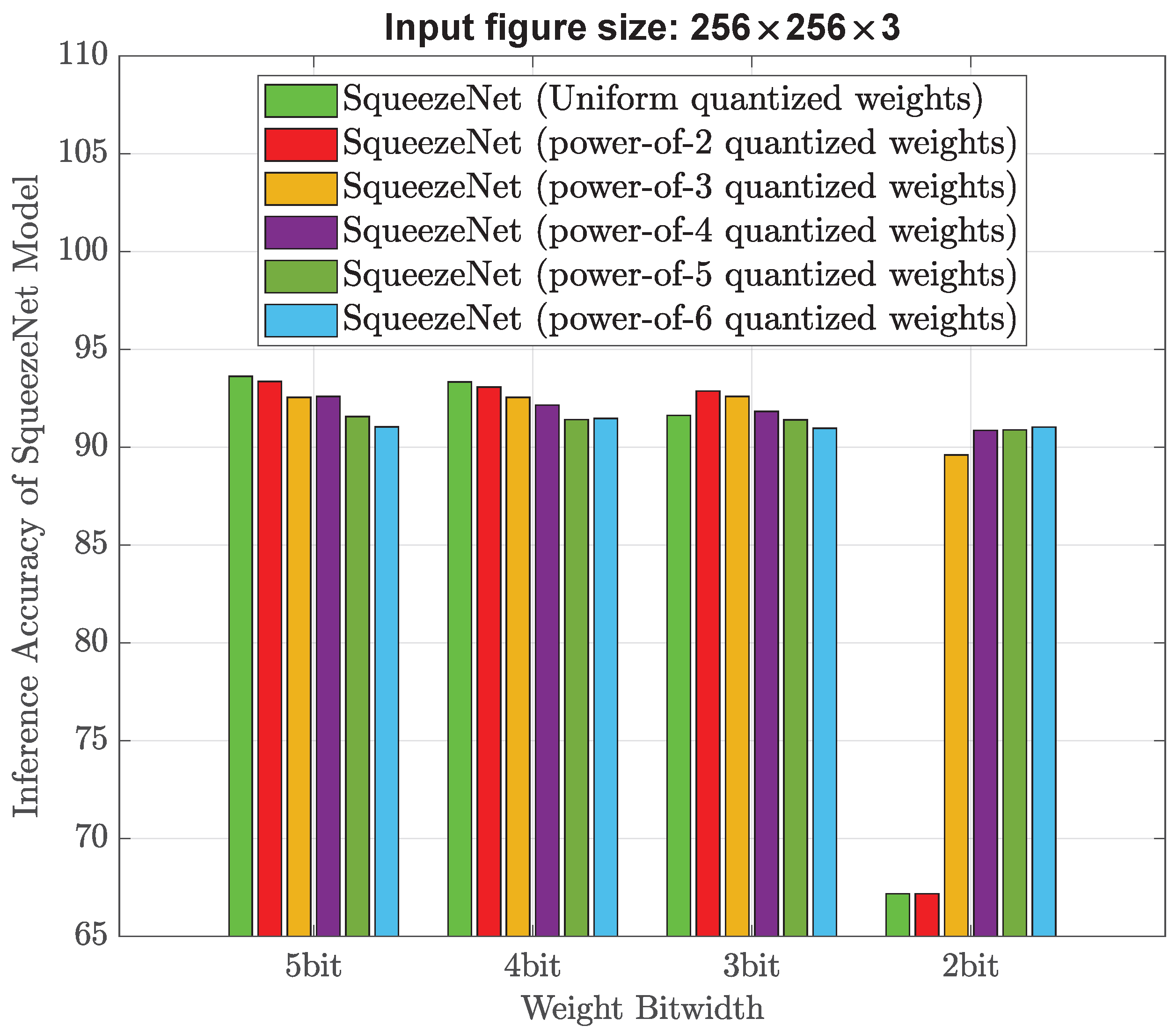
As shown in
Table 2, we adopt five different non-uniform quantization options: power-of-2 [
29,
30], power-of-3, power-of-4, power-of-5, and power-of-6. The idea of power-of-2 quantization is based on the fact that many processors or circuits can perform operations on binary numbers faster than on other number bases. By quantizing weights to power-of-2 values, the computations can be performed using simple shift and add operations, rather than using more complex multiplication and division operations. This leads to faster execution times and reduced memory requirements, which are critical for resource-constrained environments such as mobile and embedded systems. In [
29], power-of-2 quantization has demonstrated great advantages on 8-bit AI models in terms of power and hardware resources. According to [
31], in well-trained deep AI models, the weight values often follow a skewed distribution, with many values heavily clustering around zero and a few large values representing important weights. In other words, the majority of weights are concentrated around zero, while a small fraction of weights have much larger magnitudes. Being inspired by [
29] and the skewed weight distribution histograms, we think stronger non-uniform weight quantization (for example, power-of-4) is considered better than the existing power-of-2 quantization for low bitwidth (such as 4–5 bits), because it allows for a more efficient use of the available bits by allocating more bits to important weight values around zero and fewer bits to less important ones. Stronger non-uniform quantization can take advantage of this heavily skewed weight distribution to achieve higher accuracy with fewer bits.
Within the weight range of [−1, 1] across all layers, symmetric weight quantization is applied where the range of weights is divided symmetrically around zero. This means that both the positive and negative values are represented with the same number of elements. For example, in a 3-bit symmetric weight quantization, the range of weights would be divided into 6 intervals, with 3 intervals for positive values and 3 intervals for negative values. This symmetrical approach is preferred because it enables the use of signed arithmetic and leads to efficient hardware implementation and faster inference time.
3.2. Input Image Size Adjustment
The complexity of an AI model varies with the input image size. Typically, as the input image size increases, the number of parameters in the model also increases to handle the increased information. This is because larger images contain more fine-grained details that require a more complex model to capture and process. On the other hand, reducing the input image size can simplify the model by reducing the number of parameters and computations required, but it may also lead to a loss of information and reduced accuracy. It is important to balance the input image size with the model complexity to achieve optimal performance.
Downsizing input images for neural networks has both positive and negative impacts on their performance and computational efficiency. On the positive side, downsizing input images reduces the computational burden on the network, which makes training and inference faster and requires less memory. This is especially important when working with resource-limited devices. On the negative side, downsizing input images can lead to a loss of information and details, which can negatively impact the accuracy of the network. This is especially true for tasks that require high precision, such as object detection or image segmentation, where small details can be crucial. Additionally, if the downsizing factor is too large, the network may lose the ability to recognize certain objects or features, which can severely limit its usefulness.
Overall, the impact of downsizing input images on neural network performance depends on the specific task and the extent of the downsizing. It is important to carefully consider the trade-offs between computational efficiency and accuracy when deciding on an appropriate image size for a given neural network. In this work, the original input image size is 256 × 256 × 3, we downsize it to be 128 × 128 × 3, and 64 × 64 × 3, respectively.
Table 3 displays the number of trainable parameters and multiplier–adder operations for each model, respectively. It is apparent that decreasing the input image size significantly reduces the computational complexity of AI models.
Table 4 lists their breakdown of memory usage results when 8-bit quantization is employed. As we reduce the size of input images, we observe a significant decrease in the required memory usage. In the next section, we will run experiments to the corresponding object classification results.
5. Conclusions and Future Works
One of the key challenges in robot vacuum cleaners is to develop lightweight AI models that enable the robot vacuum to effectively navigate and clean environments while using limited computational resources and memory. Lightweight AI models are easier to deploy and update in resource-limited devices, as they require less storage space and bandwidth. In this work, we propose low-bitwidth strong non-uniform quantization and use input image downsizing techniques to address the above challenge. The proposed strong non-uniform weight quantization provides the flexibility to allocate bits based on the weight distribution. It enables data-driven bit allocation schemes that adaptively assign more bits to important weights and fewer bits to less important ones. This adaptability helps to maximize the classification accuracy while maintaining a low bitwidth. Experimental results show that the proposed AI model can achieve comparable classification accuracy around 93%, while also reducing the memory footprint by a factor of 2. By adjusting the training image size and using low bitwidth non-uniform quantization, it is feasible to build an AI model that fits with a memory budget of 0.78 MB (that is a 20-fold memory reduction) and retains classification accuracy above 90%. Therefore, our proposed AI models may fit better into the available memory on robot vacuum cleaners, without worrying about performance degradation or even crashes.
One area of future work is to investigate the impact of different quantization schemes on AI model performance. While strong non-uniform quantization has shown promising results, there may be other quantization schemes that could achieve even better performance or memory reduction. There may exist an optimal quantization technique for each individual network layer of AI models. It is interesting to explore how non-uniform quantization could be combined with other techniques, such as network pruning or knowledge distillation, to create even more efficient and accurate AI models.
Right now, we provide simulation results using PyTorch Platform on GPU machines for fast evaluation and assessment. The PyTorch Platform reports the memory usage information and object classification accuracy. This is a typical way for machine learning researchers to evaluate new quantization methods. Our proposed model can be applied to the real world (i.e., integration the trained AI model within a robotic vacuum cleaner) with the technical support of robotic vacuum manufacturers. Since it is a time-consuming process to negotiate and interact with interested robotic vacuum manufacturers, we have not implemented it in robotic vacuum cleaners now. We will continue to make efforts to apply our developed AI model to the real world.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}