
Distinguishing Malicious Drones Using Vision Transformer


Abstract
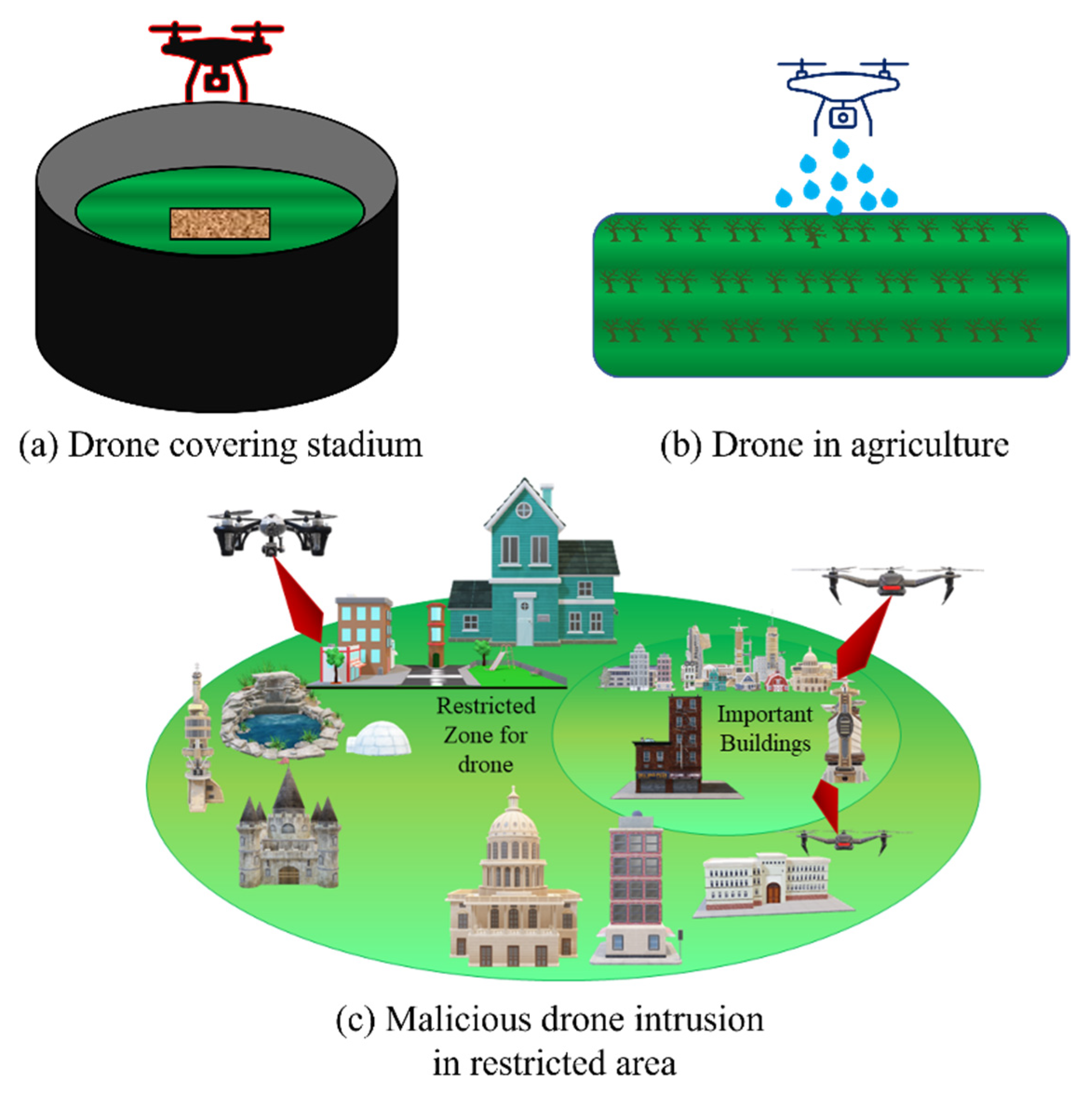
:1. Introduction
2. Proposed Methodology
2.1. Handcrafted Descriptors
2.2. D-CNN Models
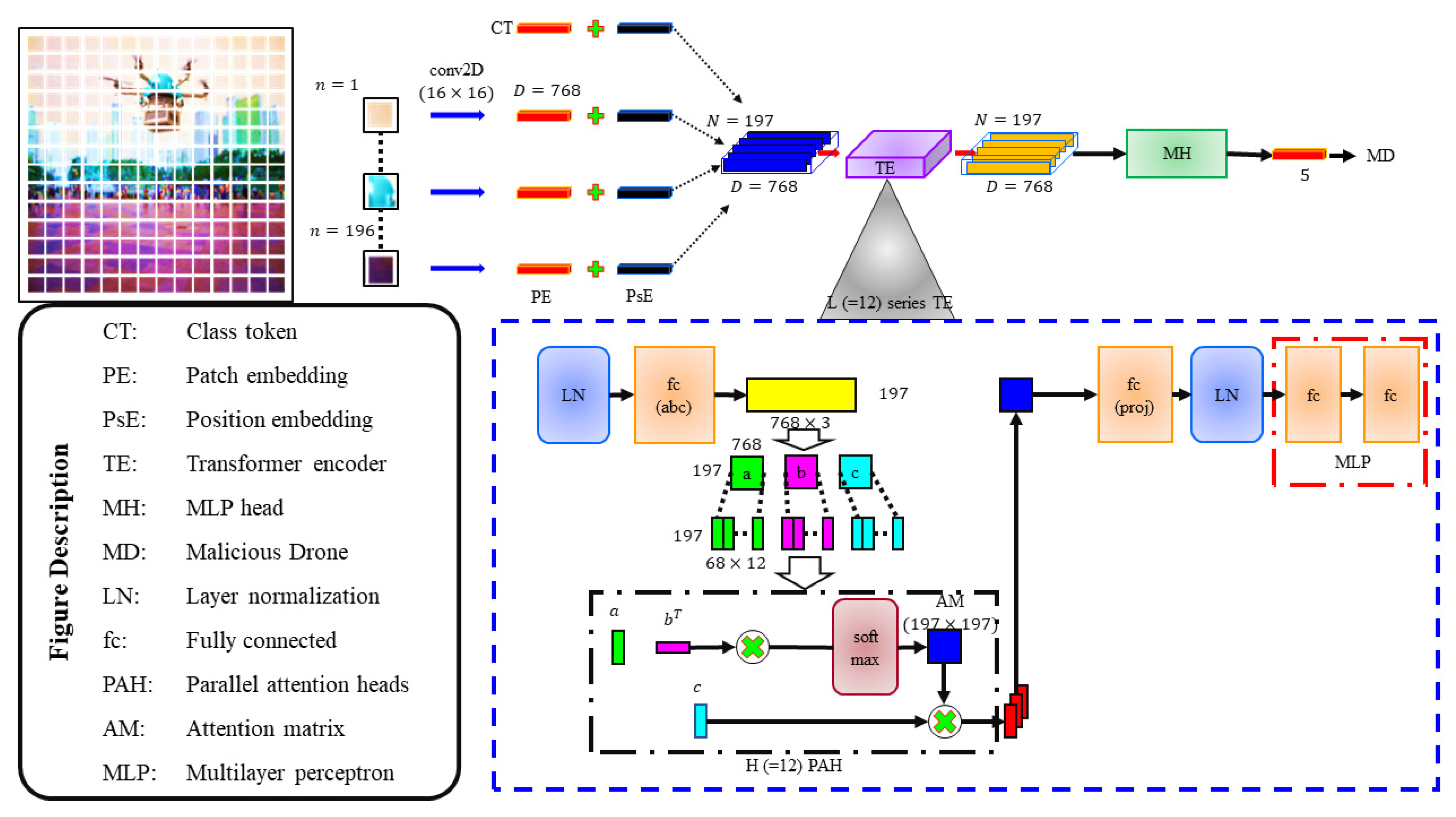
2.3. ViT-Based Classification
2.4. Dataset
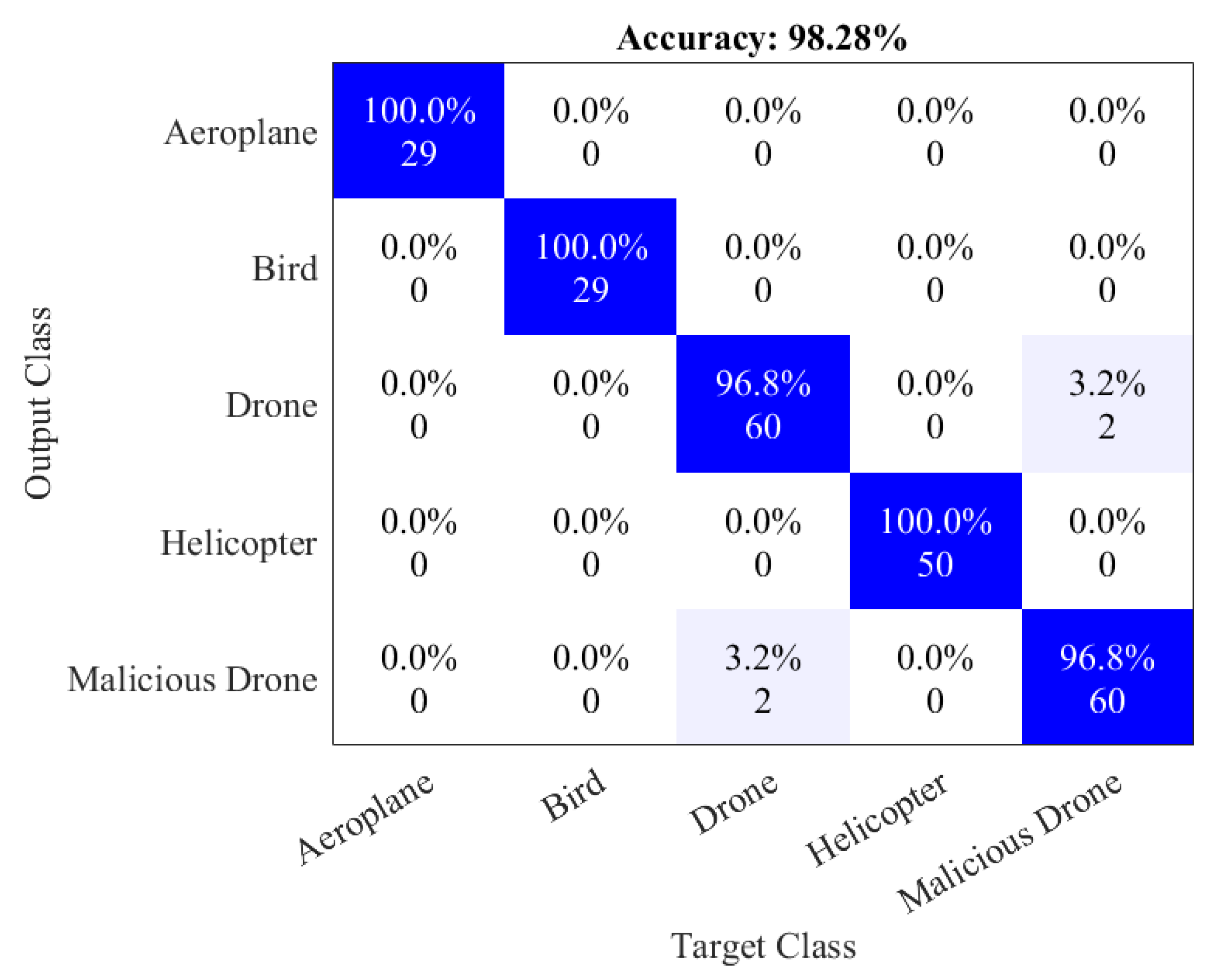
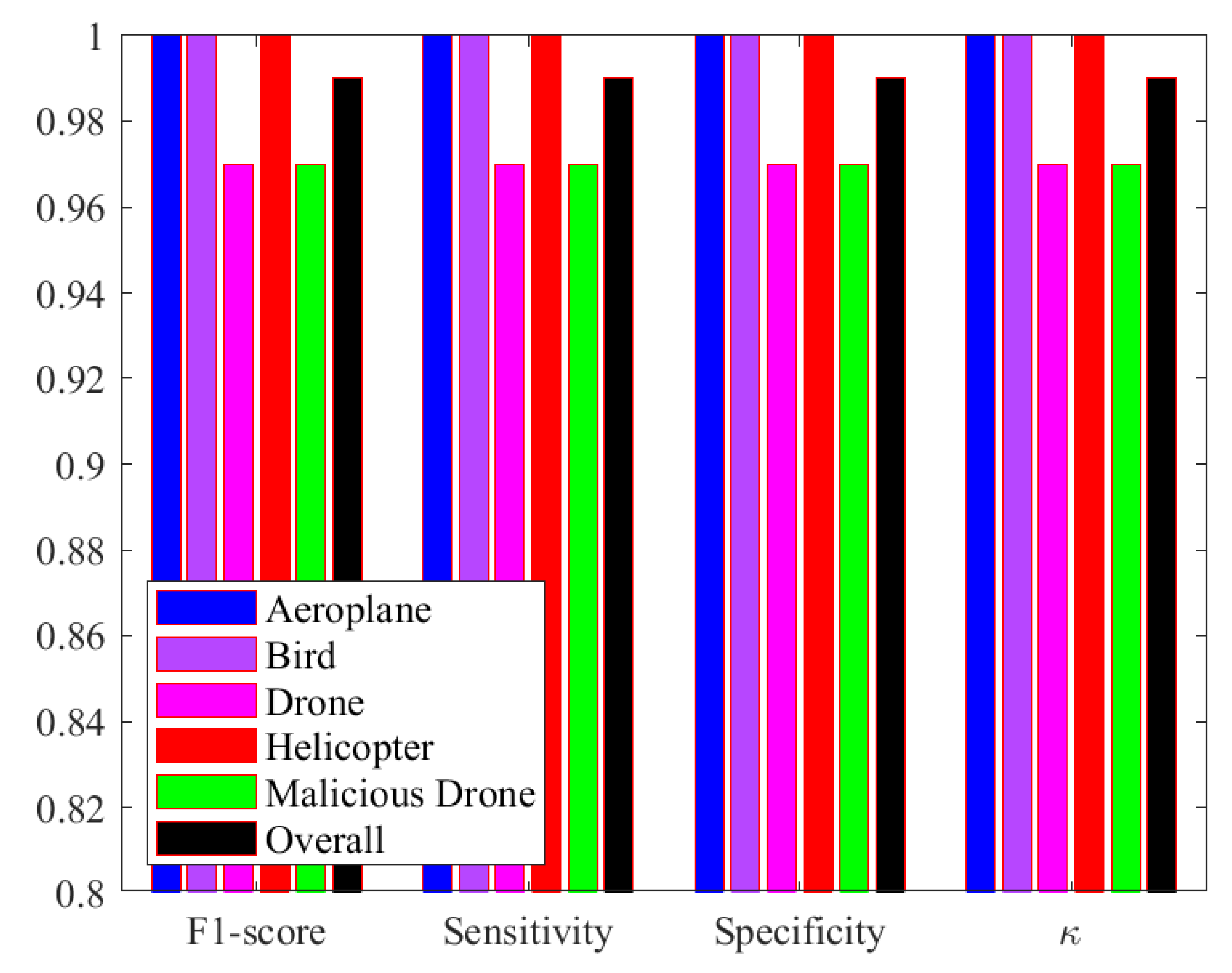
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ayamga, M.; Tekinerdogan, B.; Kassahun, A. Exploring the Challenges Posed by Regulations for the Use of Drones in Agriculture in the African Context. Land 2021, 10, 164. [Google Scholar] [CrossRef]
- Cancela, J.J.; González, X.P.; Vilanova, M.; Mirás-Avalos, J.M. Water Management Using Drones and Satellites in Agriculture. Water 2019, 11, 874. [Google Scholar] [CrossRef] [Green Version]
- Hwang, J.; Kim, I.; Gulzar, M.A. Understanding the Eco-Friendly Role of Drone Food Delivery Services: Deepening the Theory of Planned Behavior. Sustainability 2020, 12, 1440. [Google Scholar] [CrossRef] [Green Version]
- Dal Sasso, S.F.; Pizarro, A.; Manfreda, S. Recent Advancements and Perspectives in UAS-Based Image Velocimetry. Drones 2021, 5, 81. [Google Scholar] [CrossRef]
- Amponis, G.; Lagkas, T.; Zevgara, M.; Katsikas, G.; Xirofotos, T.; Moscholios, I.; Sarigiannidis, P. Drones in B5G/6G Networks as Flying Base Stations. Drones 2022, 6, 39. [Google Scholar] [CrossRef]
- Verdiesen, I.; Aler Tubella, A.; Dignum, V. Integrating Comprehensive Human Oversight in Drone Deployment: A Conceptual Framework Applied to the Case of Military Surveillance Drones. Information 2021, 12, 385. [Google Scholar] [CrossRef]
- Jamil, S.; Fawad; Rahman, M.; Ullah, A.; Badnava, S.; Forsat, M.; Mirjavadi, S.S. Malicious UAV Detection Using Integrated Audio and Visual Features for Public Safety Applications. Sensors 2020, 20, 3923. [Google Scholar] [CrossRef] [PubMed]
- Anwar, M.Z.; Kaleem, Z.; Jamalipour, A. Machine Learning Inspired Sound-Based Amateur Drone Detection for Public Safety Applications. IEEE Trans. Veh. Technol. 2019, 68, 2526–2534. [Google Scholar] [CrossRef]
- Liu, H.; Wei, Z.; Chen, Y.; Pan, J.; Lin, L.; Ren, Y. Drone detection based on an audio-assisted camera array. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017; pp. 402–406. [Google Scholar]
- Dumitrescu, C.; Minea, M.; Costea, I.M.; Cosmin Chiva, I.; Semenescu, A. Development of an Acoustic System for UAV Detection. Sensors 2020, 20, 4870. [Google Scholar] [CrossRef]
- Digulescu, A.; Despina-Stoian, C.; Stănescu, D.; Popescu, F.; Enache, F.; Ioana, C.; Rădoi, E.; Rîncu, I.; Șerbănescu, A. New Approach of UAV Movement Detection and Characterization Using Advanced Signal Processing Methods Based on UWB Sensing. Sensors 2020, 20, 5904. [Google Scholar] [CrossRef] [PubMed]
- Singha, S.; Aydin, B. Automated Drone Detection Using YOLOv4. Drones 2021, 5, 95. [Google Scholar] [CrossRef]
- Al-Emadi, S.; Al-Ali, A.; Al-Ali, A. Audio-Based Drone Detection and Identification Using Deep Learning Techniques with Dataset Enhancement through Generative Adversarial Networks. Sensors 2021, 21, 4953. [Google Scholar] [CrossRef] [PubMed]
- Wojtanowski, J.; Zygmunt, M.; Drozd, T.; Jakubaszek, M.; Życzkowski, M.; Muzal, M. Distinguishing Drones from Birds in a UAV Searching Laser Scanner Based on Echo Depolarization Measurement. Sensors 2021, 21, 5597. [Google Scholar] [CrossRef]
- Coluccia, A.; Fascista, A.; Schumann, A.; Sommer, L.; Dimou, A.; Zarpalas, D.; Méndez, M.; de la Iglesia, D.; González, I.; Mercier, J.-P.; et al. Drone vs. Bird Detection: Deep Learning Algorithms and Results from a Grand Challenge. Sensors 2021, 21, 2824. [Google Scholar] [CrossRef] [PubMed]
- Swinney, C.J.; Woods, J.C. The Effect of Real-World Interference on CNN Feature Extraction and Machine Learning Classification of Unmanned Aerial Systems. Aerospace 2021, 8, 179. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Patel, C.I.; Labana, D.; Pandya, S.; Modi, K.; Ghayvat, H.; Awais, M. Histogram of Oriented Gradient-Based Fusion of Features for Human Action Recognition in Action Video Sequences. Sensors 2020, 20, 7299. [Google Scholar] [CrossRef] [PubMed]
- Song, T.; Li, H.; Meng, F.; Wu, Q.; Cai, J. LETRIST: Locally encoded transform feature histogram for rotation-invariant texture classification. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1565–1579. [Google Scholar] [CrossRef]
- Yasmin, S.; Pathan, R.K.; Biswas, M.; Khandaker, M.U.; Faruque, M.R.I. Development of a Robust Multi-Scale Featured Local Binary Pattern for Improved Facial Expression Recognition. Sensors 2020, 20, 5391. [Google Scholar] [CrossRef] [PubMed]
- Fanizzi, A.; Basile, T.M.; Losurdo, L.; Bellotti, R.; Bottigli, U.; Campobasso, F.; Didonna, V.; Fausto, A.; Massafra, R.; Tagliafico, A.; et al. Ensemble Discrete Wavelet Transform and Gray-Level Co-Occurrence Matrix for Microcalcification Cluster Classification in Digital Mammography. Appl. Sci. 2019, 9, 5388. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Zong, Z.; Ogunbona, P.; Li, W. Object detection using non-redundant local binary patterns. In Proceedings of the 17th IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 4609–4612. [Google Scholar]
- Wu, X.; Sun, J. Joint-scale LBP: A new feature descriptor for texture classification. Vis. Comput. 2017, 33, 317–329. [Google Scholar] [CrossRef]
- Murala, S.; Maheshwari, R.P.; Balasubramanian, R. Local Tetra Patterns: A New Feature Descriptor for Content-Based Image Retrieval. IEEE Trans. Image Process. 2012, 21, 2874–2886. [Google Scholar] [CrossRef]
- Minhas, R.A.; Javed, A.; Irtaza, A.; Mahmood, M.T.; Joo, Y.B. Shot Classification of Field Sports Videos Using AlexNet Convolutional Neural Network. Appl. Sci. 2019, 9, 483. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Zhang, C.; Xu, Q.; Cheng, R.; Song, Y.; Yuan, X.; Sun, J. I3D-Shufflenet Based Human Action Recognition. Algorithms 2020, 13, 301. [Google Scholar] [CrossRef]
- Fulton, L.V.; Dolezel, D.; Harrop, J.; Yan, Y.; Fulton, C.P. Classification of Alzheimer’s Disease with and without Imagery Using Gradient Boosted Machines and ResNet-50. Brain Sci. 2019, 9, 212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, A.; Wang, M.; Jiang, K.; Cao, M.; Iwahori, Y. A Dual Neural Architecture Combined SqueezeNet with OctConv for LiDAR Data Classification. Sensors 2019, 19, 4927. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, W.; Liu, K. Confidence-Aware Object Detection Based on MobileNetv2 for Autonomous Driving. Sensors 2021, 21, 2380. [Google Scholar] [CrossRef]
- Sun, X.; Li, Z.; Zhu, T.; Ni, C. Four-Dimension Deep Learning Method for Flower Quality Grading with Depth Information. Electronics 2021, 10, 2353. [Google Scholar] [CrossRef]
- Lee, Y.; Nam, S. Performance Comparisons of AlexNet and GoogLeNet in Cell Growth Inhibition IC50 Prediction. Int. J. Mol. Sci. 2021, 22, 7721. [Google Scholar] [CrossRef] [PubMed]
- Jamil, S.; Rahman, M.; Haider, A. Bag of Features (BoF) Based Deep Learning Framework for Bleached Corals Detection. Big Data Cogn. Comput. 2021, 5, 53. [Google Scholar] [CrossRef]
- Ananda, A.; Ngan, K.H.; Karabağ, C.; Ter-Sarkisov, A.; Alonso, E.; Reyes-Aldasoro, C.C. Classification and Visualisation of Normal and Abnormal Radiographs; A Comparison between Eleven Convolutional Neural Network Architectures. Sensors 2021, 21, 5381. [Google Scholar] [CrossRef]
- Demertzis, K.; Tsiknas, K.; Takezis, D.; Skianis, C.; Iliadis, L. Darknet Traffic Big-Data Analysis and Network Management for Real-Time Automating of the Malicious Intent Detection Process by a Weight Agnostic Neural Networks Framework. Electronics 2021, 10, 781. [Google Scholar] [CrossRef]
- Chao, X.; Hu, X.; Feng, J.; Zhang, Z.; Wang, M.; He, D. Construction of Apple Leaf Diseases Identification Networks Based on Xception Fused by SE Module. Appl. Sci. 2021, 11, 4614. [Google Scholar] [CrossRef]
- Guo, Y.; Fu, Y.; Hao, F.; Zhang, X.; Wu, W.; Jin, X.; Bryant, C.R.; Senthilnath, J. Integrated phenology and climate in rice yields prediction using machine learning methods. Ecol. Indic. 2021, 120, 106935. [Google Scholar] [CrossRef]
- Joachims, T. 11 Making Large-Scale Support Vector Machine Learning Practical. In Advances in Kernel Methods: Support Vector Learning; The MIT Press: Cambridge, MA, USA, 1999; p. 169. [Google Scholar]
- Roshani, M.; Phan, G.T.T.; Ali, P.J.M.; Roshani, G.H.; Hanus, R.; Duong, T.; Corniani, E.; Nazemi, E.; Kalmoun, E.M. Evaluation of flow pattern recognition and void fraction measurement in two phase flow independent of oil pipeline’s scale layer thickness. Alex. Eng. J. 2021, 6, 1955–1966. [Google Scholar] [CrossRef]
- Sattari, M.A.; Roshani, G.H.; Hanus, R.; Nazemi, E. Applicability of time-domain feature extraction methods and artificial intelligence in two-phase flow meters based on gamma-ray absorption technique. Measurement 2021, 168, 108474. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Jamil, S.; Piran, M.J.; Rahman, M. Learning-Driven Lossy Image Compression; A Comprehensive Survey. arXiv 2022, arXiv:2201.09240. [Google Scholar]
- Roy, A.M.; Bhaduri, J. A Deep Learning Enabled Multi-Class Plant Disease Detection Model Based on Computer Vision. AI 2021, 2, 413–428. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. Real-time growth stage detection model for high degree of occultation using DenseNet-fused YOLOv4. Comput. Electron. Agric. 2022, 193, 106694. [Google Scholar] [CrossRef]
- Roy, A.M.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network. Neural Comput. Appl. 2022, 34, 3895–3921. [Google Scholar]
- Roy, A.M. An efficient multi-scale CNN model with intrinsic feature integration for motor imagery EEG subject classification in brain-machine interfaces. Biomed. Signal Process. Control 2022, 74, 103496. [Google Scholar] [CrossRef]
- Roy, A.M. A multi-scale fusion CNN model based on adaptive transfer learning for multi-class MI-classification in BCI system. BioRxiv 2022. [Google Scholar] [CrossRef]
- Jamil, S.; Rahman, M. A Novel Deep-Learning-Based Framework for the Classification of Cardiac Arrhythmia. J. Imaging 2022, 8, 70. [Google Scholar] [CrossRef]
- Jamil, S.; Rahman, M.; Tanveer, J.; Haider, A. Energy Efficiency and Throughput Maximization Using Millimeter Waves–Microwaves HetNets. Electronics 2022, 11, 474. [Google Scholar] [CrossRef]
- Too, J.; Abdullah, A.R.; Mohd Saad, N.; Tee, W. EMG Feature Selection and Classification Using a Pbest-Guide Binary Particle Swarm Optimization. Computation 2019, 7, 12. [Google Scholar] [CrossRef] [Green Version]
- Jamil, S.; Rahman, M.; Abbas, M.S.; Fawad. Resource Allocation Using Reconfigurable Intelligent Surface (RIS)-Assisted Wireless Networks in Industry 5.0 Scenario. Telecom 2022, 3, 163–173. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Trainable Parameters | 85.8 M |
| Model Parameters size | 171.605 MB |
| Learning rate | 2 × 10−5 |
| Optimizer | Adam |
| Mini Batch Size | 8 |
| Descriptor | Classifier | Accuracy |
|---|---|---|
| HOG | SVM (Linear Kernel) 1 | 76.70% |
| kNN 2 | 37.90% | |
| DT 3 | 58.60% | |
| NB 4 | 57.30% | |
| Ensemble | 78.90% | |
| MLP | 70.50% | |
| RBF | 75.60% | |
| GMDH | 74.50% | |
| LETRIST | SVM (Linear Kernel) 1 | 31.90% |
| kNN 2 | 39.70% | |
| DT 3 | 36.60% | |
| NB 4 | 43.50% | |
| Ensemble | 52.20% | |
| MLP | 30.90% | |
| RBF | 32.30% | |
| GMDH | 30.40% | |
| LBP | SVM (Linear Kernel) 1 | 45.30% |
| kNN 2 | 38.40% | |
| DT 3 | 34.90% | |
| NB 4 | 39.70% | |
| Ensemble | 45.70% | |
| MLP | 39.10% | |
| RBF | 44.20% | |
| GMDH | 43.10% | |
| GLCM | SVM (Linear Kernel) 1 | 49.60% |
| kNN 2 | 36.60% | |
| DT 3 | 39.20% | |
| NB 4 | 34.50% | |
| Ensemble | 44.40% | |
| MLP | 43.40% | |
| RBF | 48.50% | |
| GMDH | 47.40% | |
| NRLBP | SVM (Linear Kernel) 1 | 28.00% |
| kNN 2 | 16.80% | |
| DT 3 | 30.60% | |
| Ensemble | 30.60% | |
| MLP | 22.00% | |
| RBF | 27.00% | |
| GMDH | 26.00% | |
| CJLBP | SVM (Linear Kernel) 1 | 36.20% |
| kNN 2 | 30.20% | |
| DT 3 | 38.40% | |
| NB 4 | 36.60% | |
| Ensemble | 50.90% | |
| MLP | 30.00% | |
| RBF | 35.10% | |
| GMDH | 34.00% | |
| LTrP | SVM (Linear Kernel) 1 | 29.70% |
| kNN 2 | 34.10% | |
| DT 3 | 37.90% | |
| NB 4 | 44.80% | |
| Ensemble | 47.80% | |
| MLP | 23.50% | |
| RBF | 28.60% | |
| GMDH | 27.50% |
| D-CNN Model | Classifier | Accuracy |
|---|---|---|
| AlexNet | SVM 1 | 88.80% |
| kNN 2 | 75.90% | |
| DT 3 | 59.50% | |
| NB 4 | 71.10% | |
| Ensemble | 83.30% | |
| MLP | 82.60% | |
| RBF | 87.70% | |
| GMDH | 86.60% | |
| ShuffleNet | SVM 1 | 86.20% |
| kNN 2 | 77.60% | |
| DT 3 | 63.80% | |
| NB 4 | 76.30% | |
| Ensemble | 86.20% | |
| MLP | 80.00% | |
| RBF | 85.10% | |
| GMDH | 84.00% | |
| ResNet-50 | SVM 1 | 89.20% |
| kNN 2 | 77.20% | |
| DT 3 | 73.70% | |
| NB 4 | 72.80% | |
| Ensemble | 86.60% | |
| MLP | 83.00% | |
| RBF | 88.10% | |
| GMDH | 87.00% | |
| SqueezeNet | SVM 1 | 61.60% |
| kNN 2 | 64.20% | |
| DT 3 | 66.40% | |
| NB 4 | 63.80% | |
| Ensemble | 82.80% | |
| MLP | 55.40% | |
| RBF | 60.50% | |
| GMDH | 59.40% | |
| MobileNet-v2 | SVM 1 | 91.80% |
| kNN 2 | 84.50% | |
| DT 3 | 62.90% | |
| NB 4 | 83.60% | |
| Ensemble | 85.30% | |
| MLP | 85.60% | |
| RBF | 90.70% | |
| GMDH | 89.60% | |
| Inceptionv3 | SVM 1 | 90.90% |
| kNN 2 | 88.40% | |
| DT 3 | 70.70% | |
| NB 4 | 85.30% | |
| Ensemble | 88.40% | |
| MLP | 84.70% | |
| RBF | 89.80% | |
| GMDH | 88.70% | |
| GoogleNet | SVM 1 | 87.90% |
| kNN 2 | 82.30% | |
| DT 3 | 64.20% | |
| NB 4 | 84.50% | |
| Ensemble | 87.50% | |
| MLP | 83.70% | |
| RBF | 86.80% | |
| GMDH | 85.70% | |
| EfficientNetb0 | SVM 1 | 92.20% |
| kNN 2 | 84.50% | |
| DT 3 | 66.40% | |
| NB 4 | 86.20% | |
| Ensemble | 89.20% | |
| MLP | 86.00% | |
| RBF | 91.10% | |
| GMDH | 90.00% | |
| Inception-ResNet-v2 | SVM 1 | 91.80% |
| kNN 2 | 87.90% | |
| DT 3 | 72.00% | |
| NB 4 | 80.20% | |
| Ensemble | 89.70% | |
| MLP | 85.60% | |
| RBF | 90.70% | |
| GMDH | 89.60% | |
| DarkNet-53 | SVM 1 | 68.50% |
| kNN 2 | 62.50% | |
| DT 3 | 75.00% | |
| NB 4 | 74.60% | |
| Ensemble | 91.40% | |
| MLP | 62.30% | |
| RBF | 67.40% | |
| GMDH | 66.30% | |
| Xception | SVM 1 | 93.50% |
| kNN 2 | 87.90% | |
| DT 3 | 72.40% | |
| NB 4 | 87.50% | |
| Ensemble | 88.80% | |
| MLP | 87.30% | |
| RBF | 92.40% | |
| GMDH | 91.30% | |
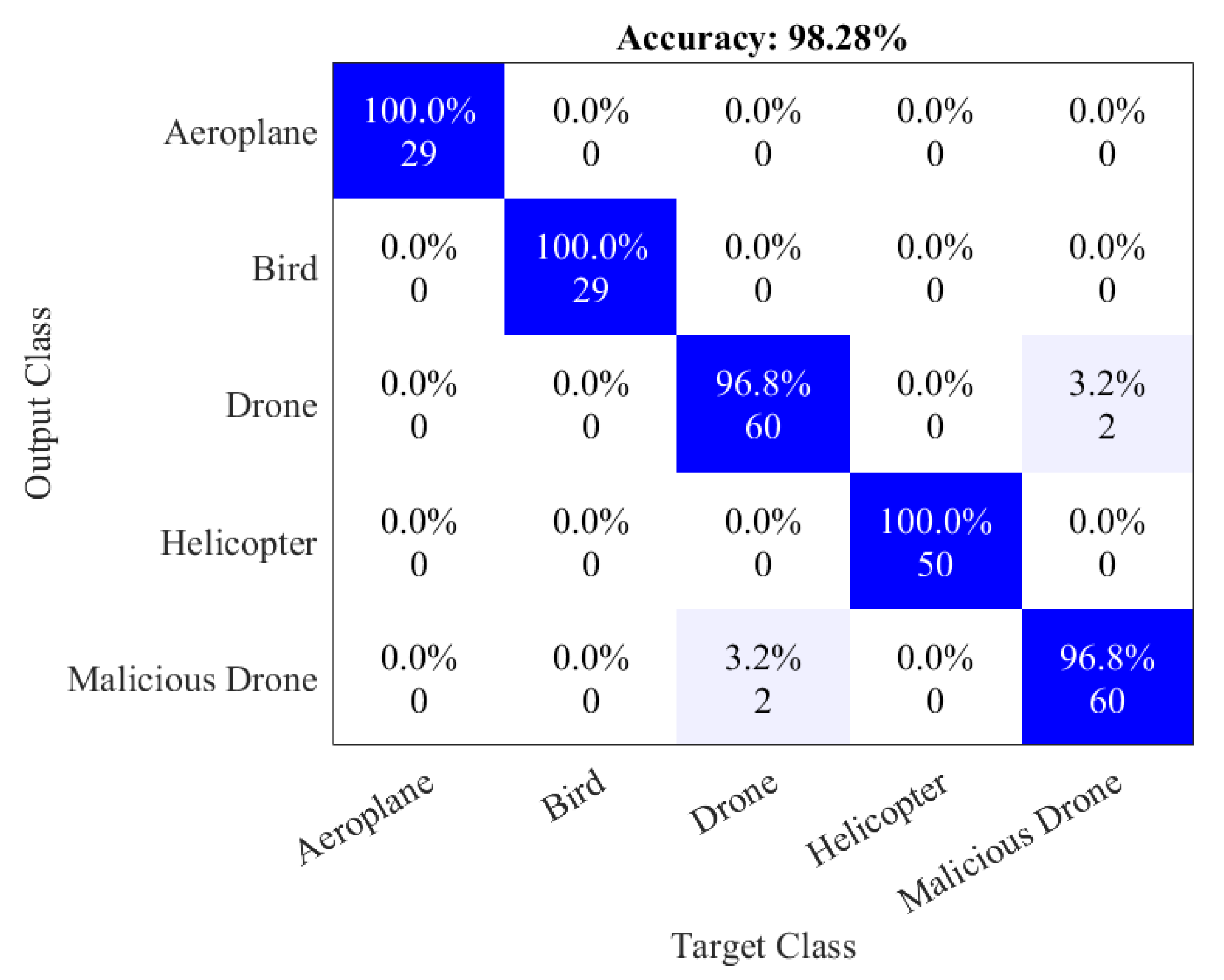
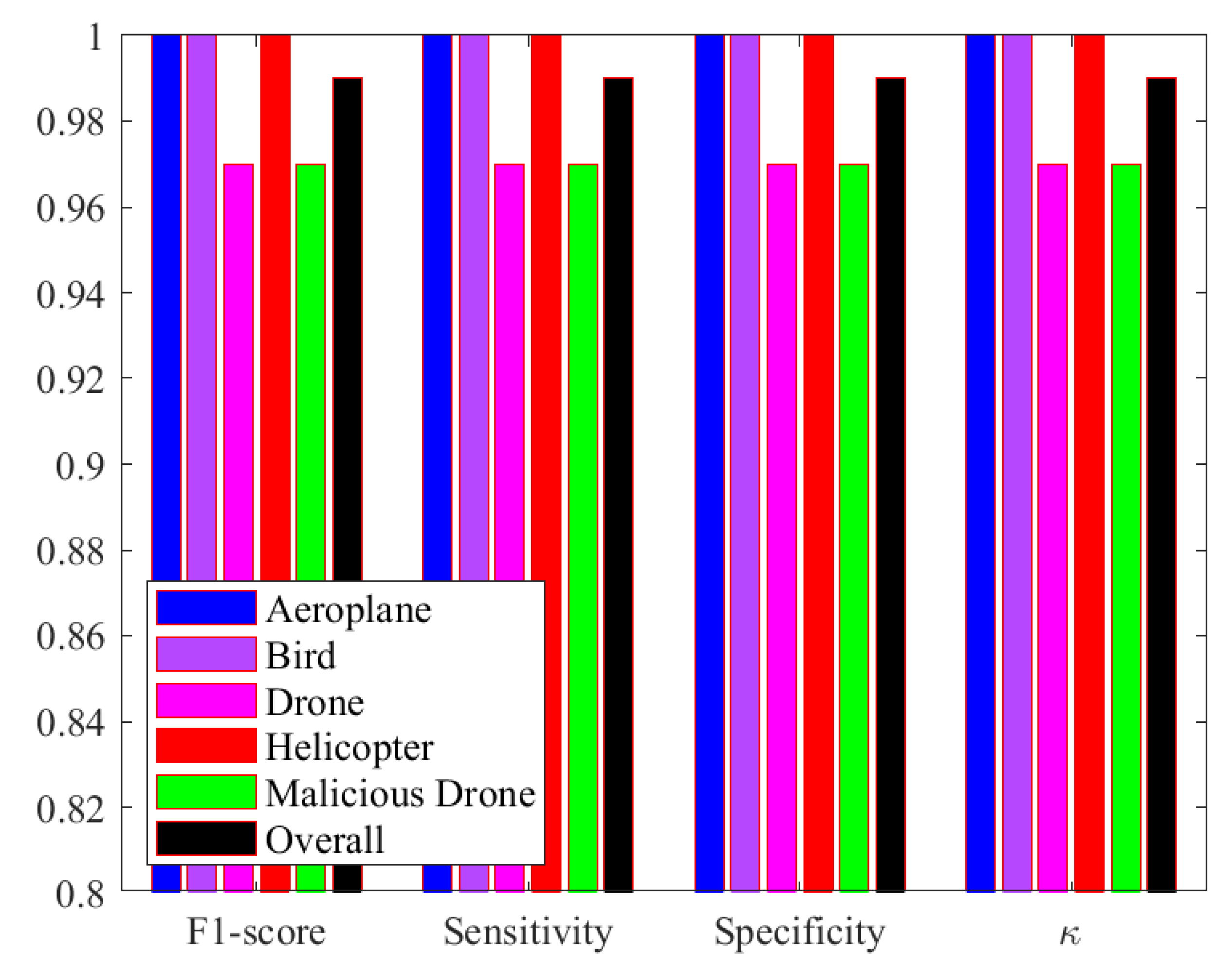
| Proposed | ViT classifier | 98.28% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamil, S.; Abbas, M.S.; Roy, A.M. Distinguishing Malicious Drones Using Vision Transformer. AI 2022, 3, 260-273. https://doi.org/10.3390/ai3020016
Jamil S, Abbas MS, Roy AM. Distinguishing Malicious Drones Using Vision Transformer. AI. 2022; 3(2):260-273. https://doi.org/10.3390/ai3020016
Chicago/Turabian StyleJamil, Sonain, Muhammad Sohail Abbas, and Arunabha M. Roy. 2022. "Distinguishing Malicious Drones Using Vision Transformer" AI 3, no. 2: 260-273. https://doi.org/10.3390/ai3020016
APA StyleJamil, S., Abbas, M. S., & Roy, A. M. (2022). Distinguishing Malicious Drones Using Vision Transformer. AI, 3(2), 260-273. https://doi.org/10.3390/ai3020016