
Reinforcement Learning Your Way: Agent Characterization through Policy Regularization


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background and Related Work
2.1. Agent Characterization
- Probabilistic argumentation [9] in which a human expert creates an ‘argumentation graph’ with a set of arguments and sub-arguments; sub-arguments attack or support main arguments which attack or support discrete actions. Sub-arguments are labelled as ‘ON’ or ‘OFF’ depending on the state observation for each time-step. Main arguments are labelled as ‘IN’, ‘OUT’, or ‘UNDECIDED’ in the following RL setting: states are the union of the argumentation graph and the learned policy, actions are the probabilistic ‘attitudes’ towards given arguments, and rewards are based on whether an argument attacks or supports an action. The learned ‘attitudes’ towards certain arguments are used to characterize agents’ behaviour.
- Structural causal modelling (SCM) [10] learns causal relationships between states and actions through ‘action influence graphs’ that trace all possible paths from a given initial state to a set of terminal states, via all possible actions in each intermediate state. The learned policy then identifies a causal chain as the single path in the action influence graph that connects the initial state to the relevant terminal state. The explanation is the vector of rewards along the causal chain. Counter-explanations are a set of comparative reward vectors along chains originating from counter-actions in the initial state. Characterizations are made based on causal and counterfactual reasons for agents’ choice of action.
- Introspection (interesting elements) [15] is a statistical post hoc analysis of the policy. It considers elements such as the frequency of visits to states, the estimated values of states and state-action pairs, state-transition probabilities, how much of the state space is visited, etc. Interesting statistical properties from this analysis are used to characterize the policy.
2.2. Multi-Agent Reinforcement Learning and Policy Regularization
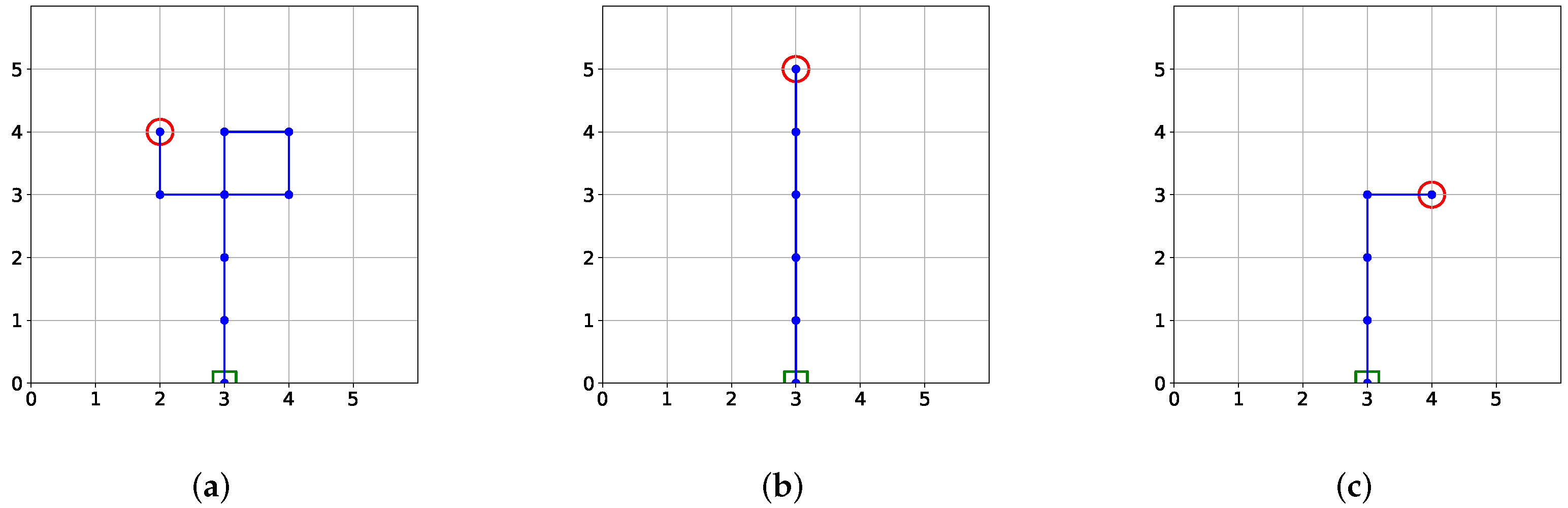
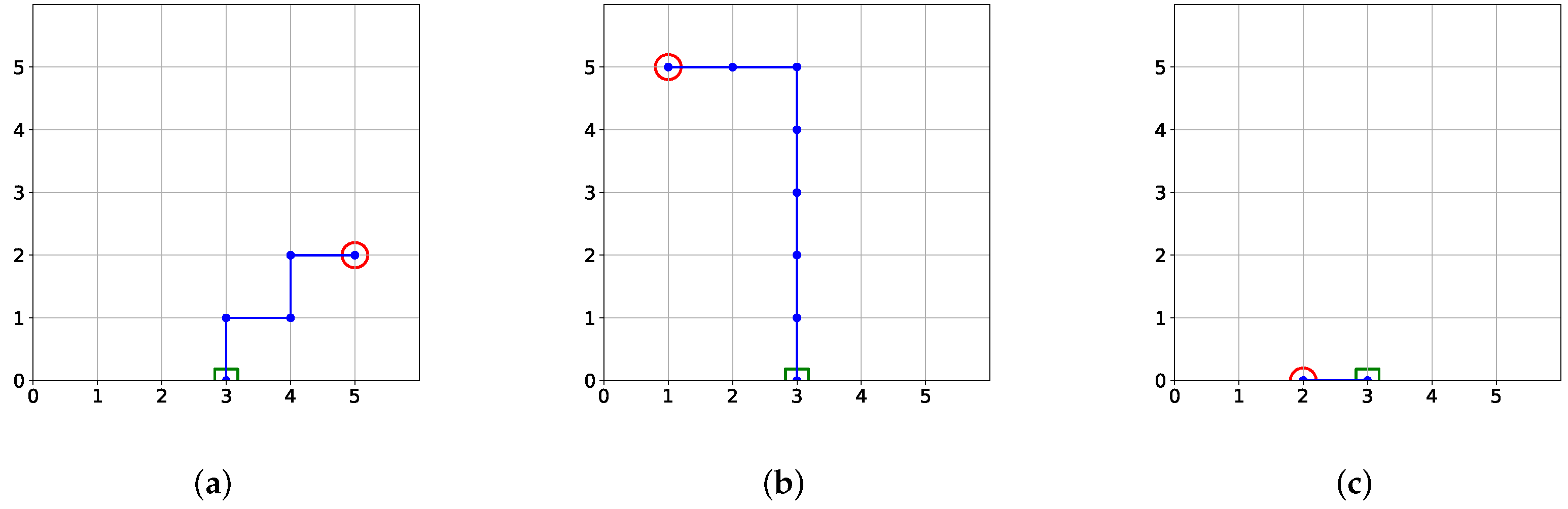
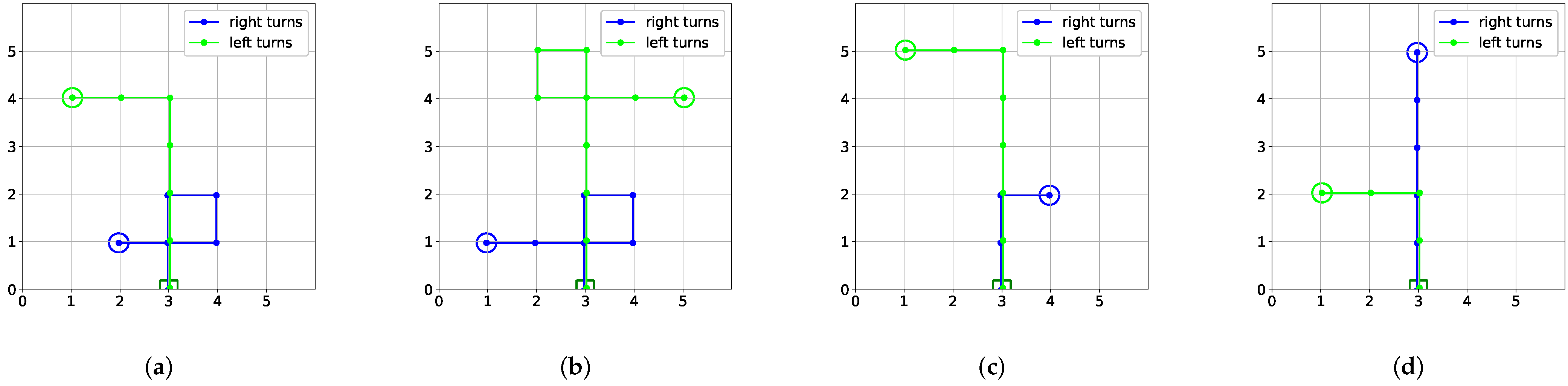
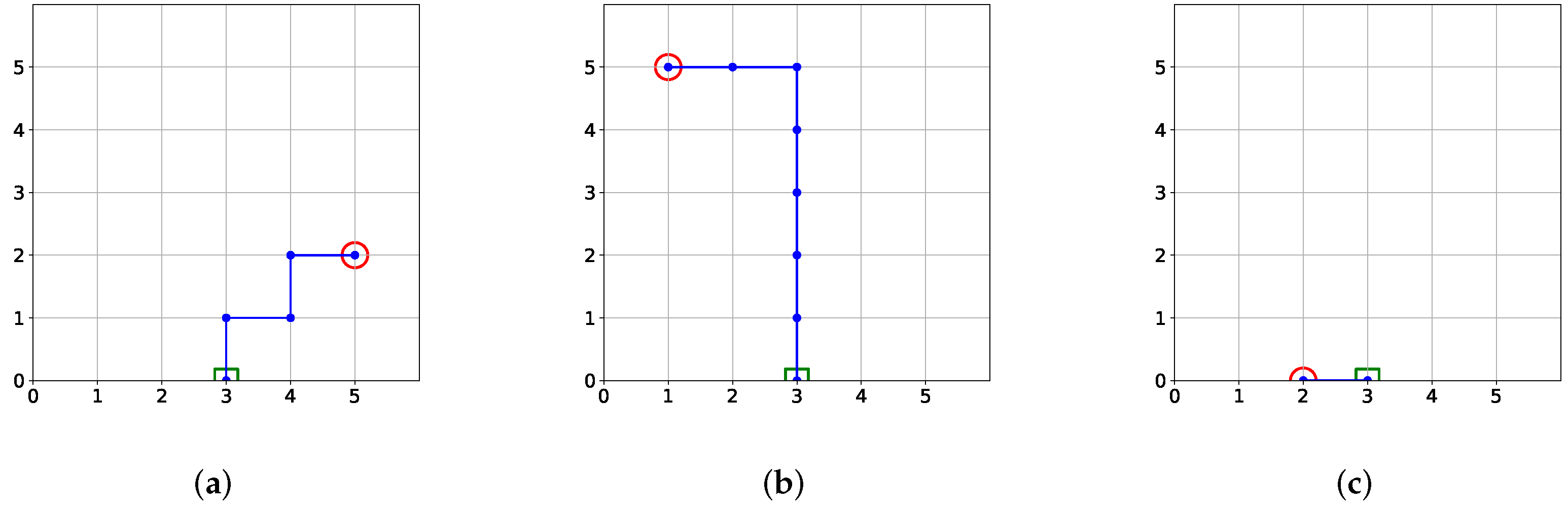
3. Methodology
Action Regularization
| Algorithm 1 Action-regularized MADDPG algorithm. |
|
4. Experiments
4.1. Empirical Setup
4.2. Results
5. Conclusions and Direction for Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Heuillet, A.; Couthouis, F.; Díaz-Rodríguez, N. Explainability in deep reinforcement learning. Knowl. Based Syst. 2021, 214, 1–24. [Google Scholar] [CrossRef]
- García, J.; Fernández, F. A Comprehensive Survey on Safe Reinforcement Learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Wells, L.; Bednarz, T. Explainable AI and Reinforcement Learning: A Systematic Review of Current Approaches and Trends. Front. Artif. Intell. 2021, 4, 1–48. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.; Singal, G.; Garg, D. Deep Reinforcement Learning Techniques in Diversified Domains: A Survey. Arch. Comput. Methods Eng. 2021, 28, 4715–4754. [Google Scholar] [CrossRef]
- Haarnoja, T.; Tang, H.; Abbeel, P.; Levine, S. Reinforcement Learning with Deep Energy-Based Policies. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Galashov, A.; Jayakumar, S.; Hasenclever, L.; Tirumala, D.; Schwarz, J.; Desjardins, G.; Czarnecki, W.M.; Teh, Y.W.; Pascanu, R.; Heess, N. Information asymmetry in KL-regularized RL. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Lu, J.; Dissanayake, S.; Castillo, N.; Williams, K. Safety Evaluation of Right Turns Followed by U-Turns as an Alternative to Direct Left Turns—Conflict Analysis; Technical Report, CUTR Research Reports 213; University of South Florida, Scholar Commons: Tampa, FL, USA, 2001. [Google Scholar]
- Riveret, R.; Gao, Y.; Governatori, G.; Rotolo, A.; Pitt, J.V.; Sartor, G. A probabilistic argumentation framework for reinforcement learning agents. Auton. Agents Multi-Agent Syst. 2019, 33, 216–274. [Google Scholar] [CrossRef]
- Madumal, P.; Miller, T.; Sonenberg, L.; Vetere, F. Explainable Reinforcement Learning Through a Causal Lens. arXiv 2019, arXiv:1905.10958v2. [Google Scholar] [CrossRef]
- van Seijen, H.; Fatemi, M.; Romoff, J.; Laroche, R.; Barnes, T.; Tsang, J. Hybrid Reward Architecture for Reinforcement Learning. arXiv 2017, arXiv:1706.04208. [Google Scholar]
- Juozapaitis, Z.; Koul, A.; Fern, A.; Erwig, M.; Doshi-Velez, F. Explainable Reinforcement Learning via Reward Decomposition. In Proceedings of the International Joint Conference on Artificial Intelligence. A Workshop on Explainable Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Beyret, B.; Shafti, A.; Faisal, A. Dot-to-dot: Explainable hierarchical reinforcement learning for robotic manipulation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 5014–5019. [Google Scholar]
- Marzari, L.; Pore, A.; Dall’Alba, D.; Aragon-Camarasa, G.; Farinelli, A.; Fiorini, P. Towards Hierarchical Task Decomposition using Deep Reinforcement Learning for Pick and Place Subtasks. arXiv 2021, arXiv:2102.04022. [Google Scholar]
- Sequeira, P.; Yeh, E.; Gervasio, M. Interestingness Elements for Explainable Reinforcement Learning through Introspection. IUI Work. 2019, 2327, 1–7. [Google Scholar]
- Littman, M.L. Markov Games as a Framework for Multi-Agent Reinforcement Learning. In Proceedings of the Eleventh International Conference on Machine Learning, New Brunswick, NJ, USA, 10–13 July 1994; pp. 157–163. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations (ICLR) (Poster), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ziebart, B.D. Modeling Purposeful Adaptive Behavior with the Principle of Maximum Causal Entropy. Ph.D. Thesis, Machine Learning Department, Carnegie Mellon University, Pittsburgh, PA, USA, 2010. [Google Scholar]
- Cheng, R.; Verma, A.; Orosz, G.; Chaudhuri, S.; Yue, Y.; Burdick, J.W. Control Regularization for Reduced Variance Reinforcement Learning. arXiv 2019, arXiv:1905.05380. [Google Scholar]
- Parisi, S.; Tangkaratt, V.; Peters, J.; Khan, M.E. TD-regularized actor-critic methods. Mach. Learn. 2019, 108, 1467–1501. [Google Scholar] [CrossRef] [Green Version]
- Miryoosefi, S.; Brantley, K.; Daume III, H.; Dudik, M.; Schapire, R.E. Reinforcement Learning with Convex Constraints. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 1–10. [Google Scholar]
- Chow, Y.; Ghavamzadeh, M.; Janson, L.; Pavone, M. Risk-Constrained Reinforcement Learning with Percentile Risk Criteria. J. Mach. Learn. Res. 2015, 18, 1–51. [Google Scholar]
- Maree, C.; Omlin, C.W. Clustering in Recurrent Neural Networks for Micro-Segmentation using Spending Personality (In Print). In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 4–7 December 2021; pp. 1–5. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maree, C.; Omlin, C. Reinforcement Learning Your Way: Agent Characterization through Policy Regularization. AI 2022, 3, 250-259. https://doi.org/10.3390/ai3020015
Maree C, Omlin C. Reinforcement Learning Your Way: Agent Characterization through Policy Regularization. AI. 2022; 3(2):250-259. https://doi.org/10.3390/ai3020015
Chicago/Turabian StyleMaree, Charl, and Christian Omlin. 2022. "Reinforcement Learning Your Way: Agent Characterization through Policy Regularization" AI 3, no. 2: 250-259. https://doi.org/10.3390/ai3020015
APA StyleMaree, C., & Omlin, C. (2022). Reinforcement Learning Your Way: Agent Characterization through Policy Regularization. AI, 3(2), 250-259. https://doi.org/10.3390/ai3020015