
Enhancement of Partially Coherent Diffractive Images Using Generative Adversarial Network


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Proposed Approach
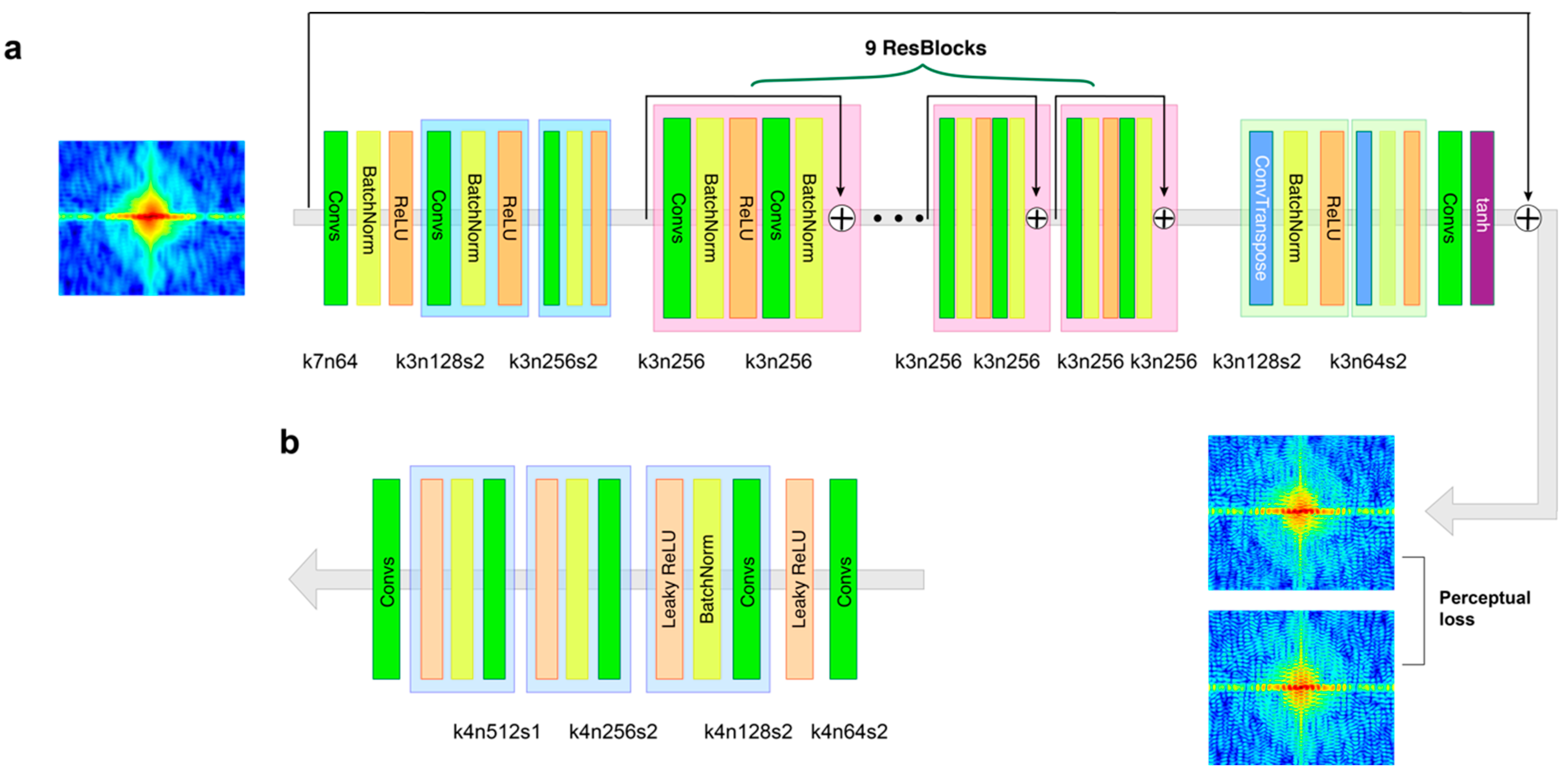
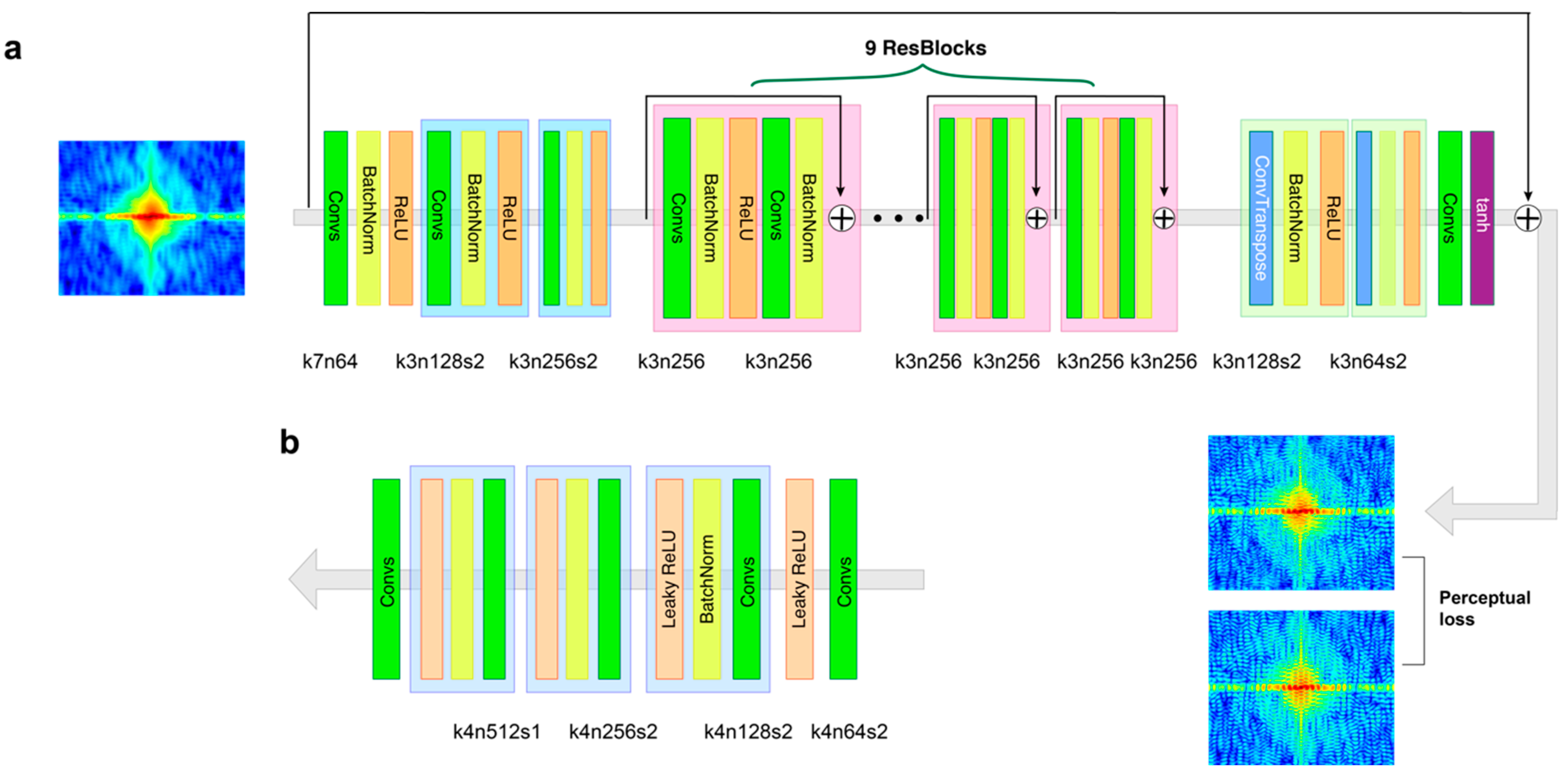
2.1. Conditional GAN
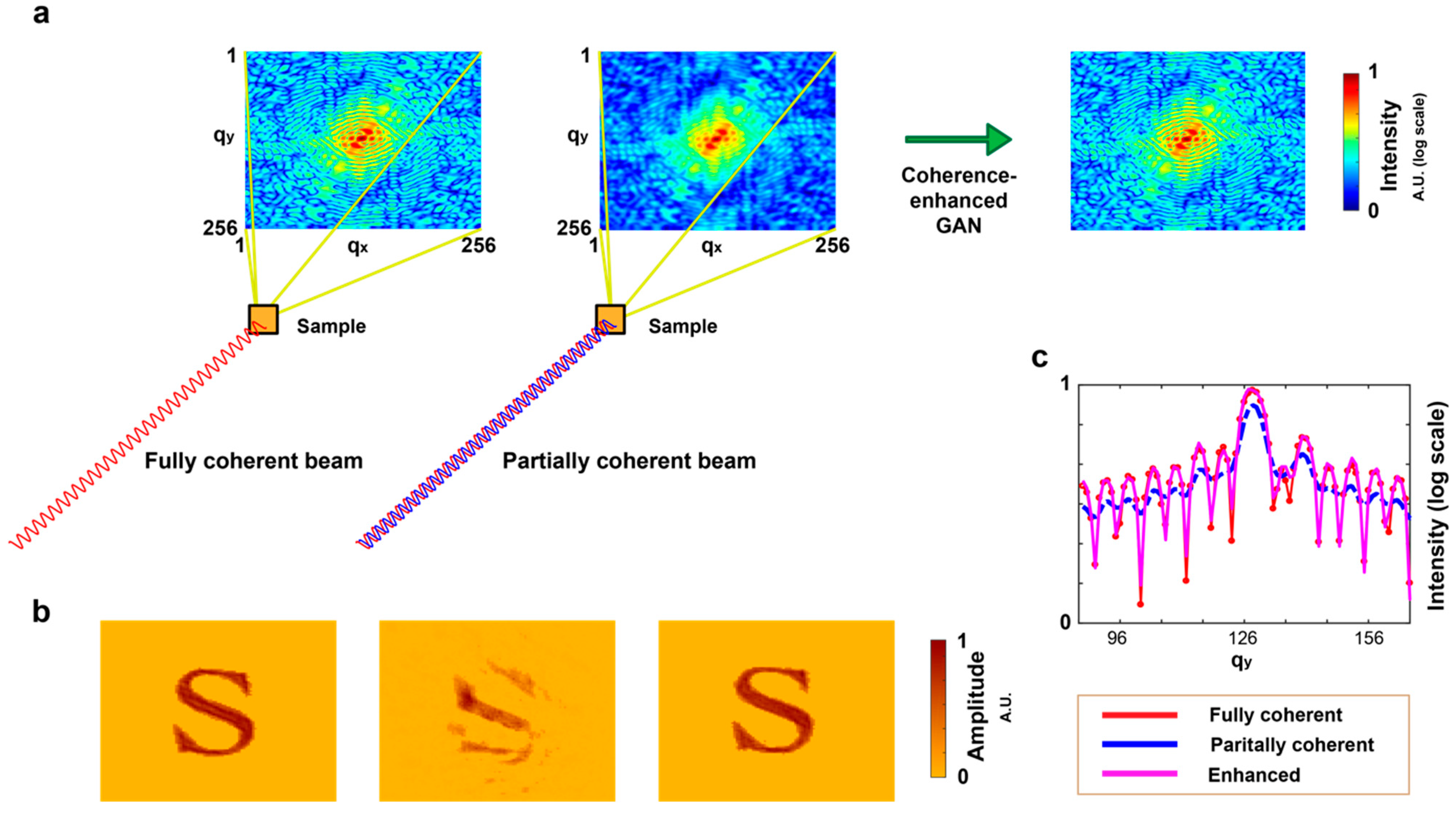
2.2. Coherence-Enhanced GAN
2.3. Loss Functions
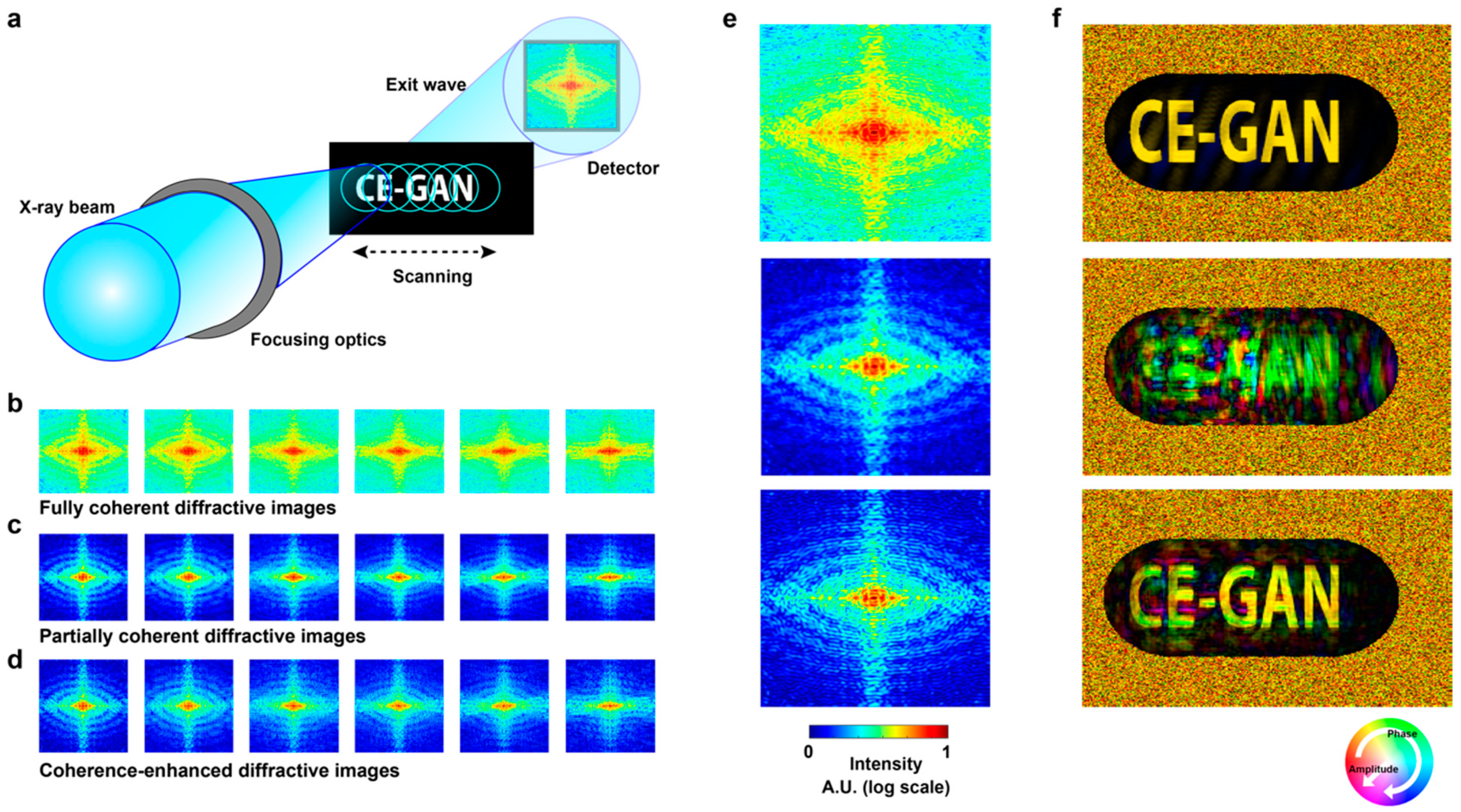
3. Image Synthesis for Computational Experiments
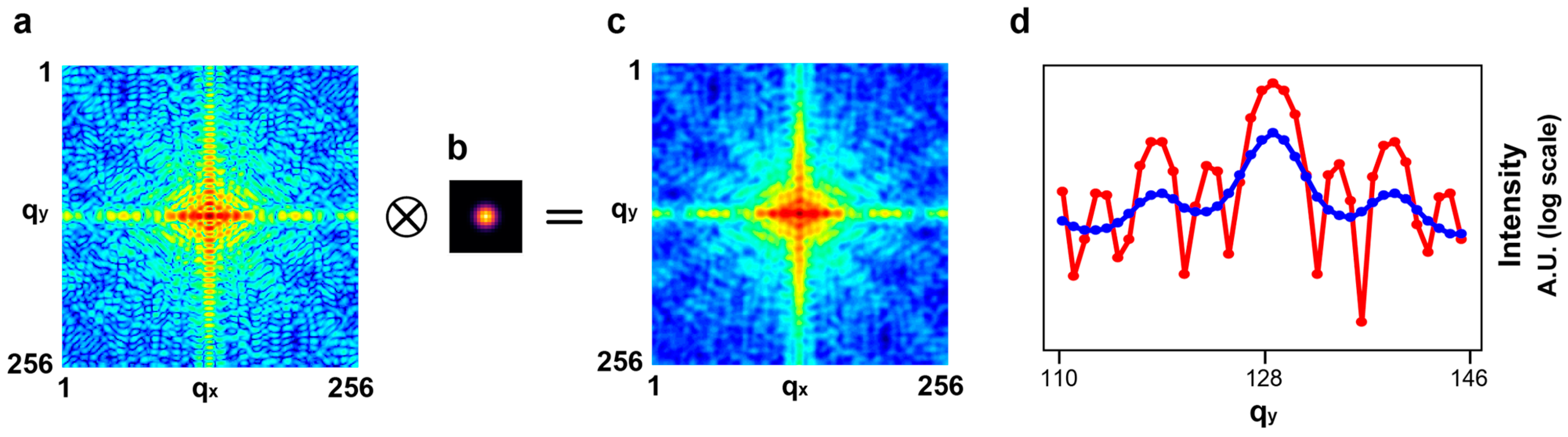
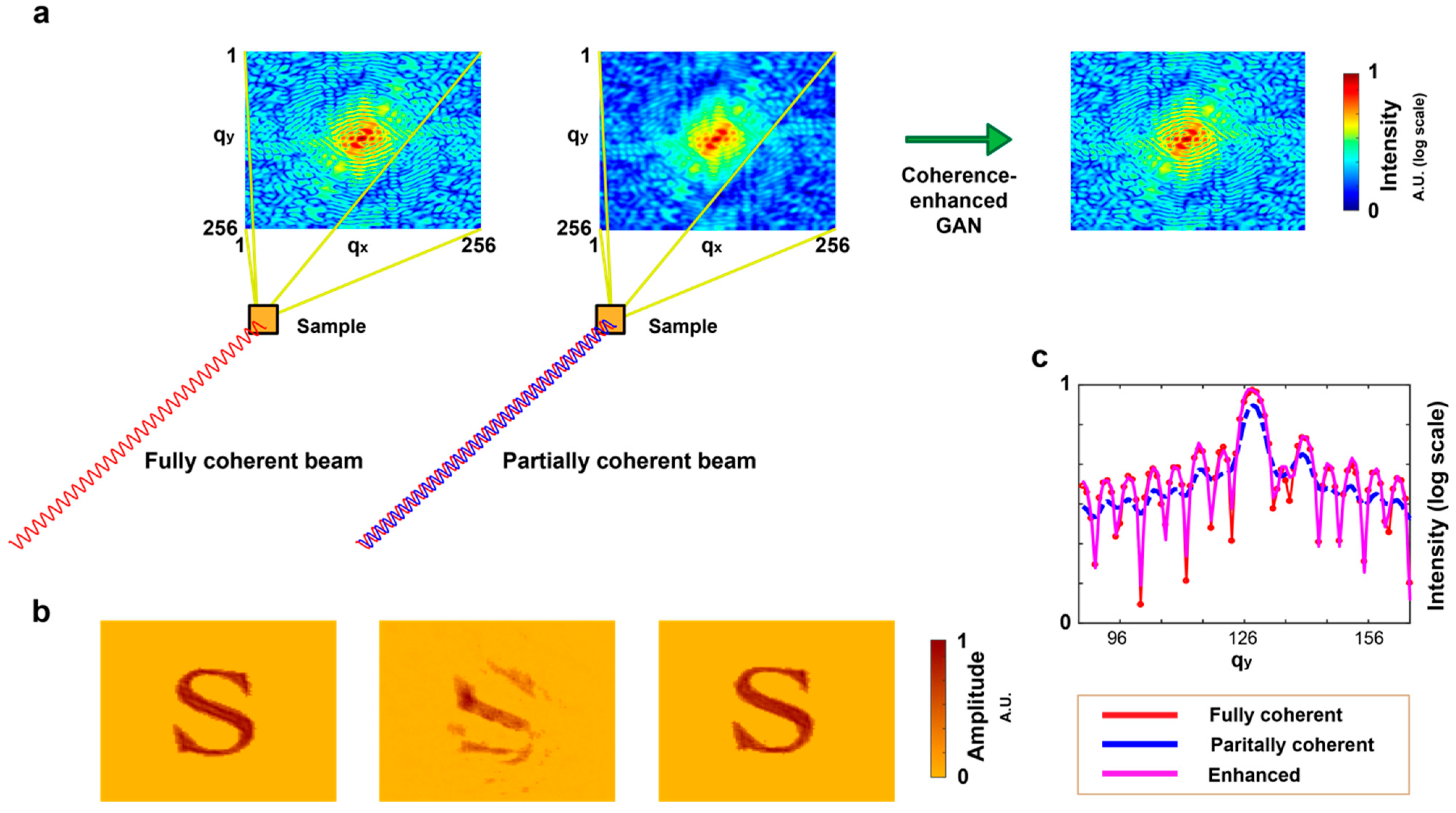
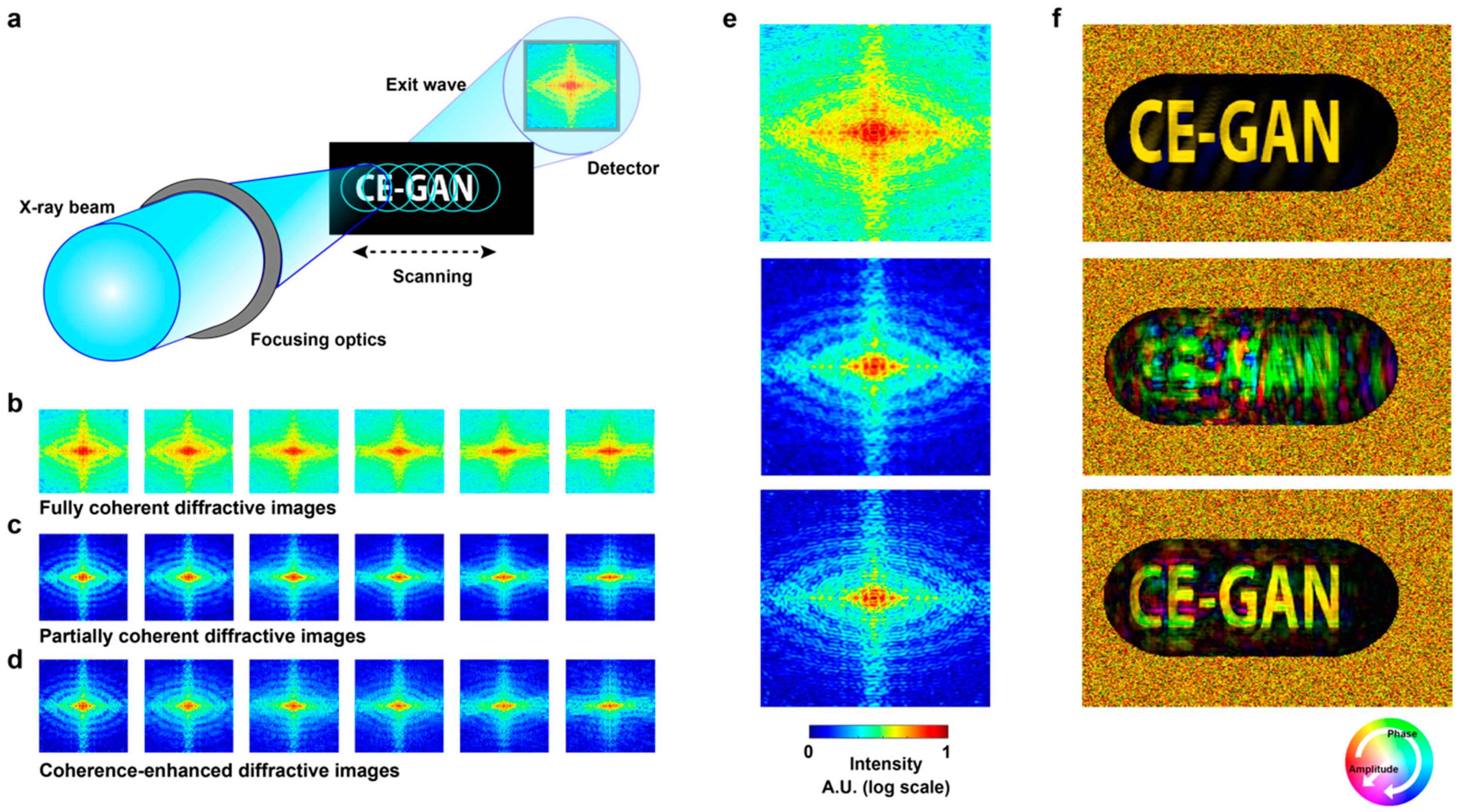
3.1. Synthesis of Partially Coherent Diffractive Images
3.2. Degree of Coherence
4. Model Validation and Discussion
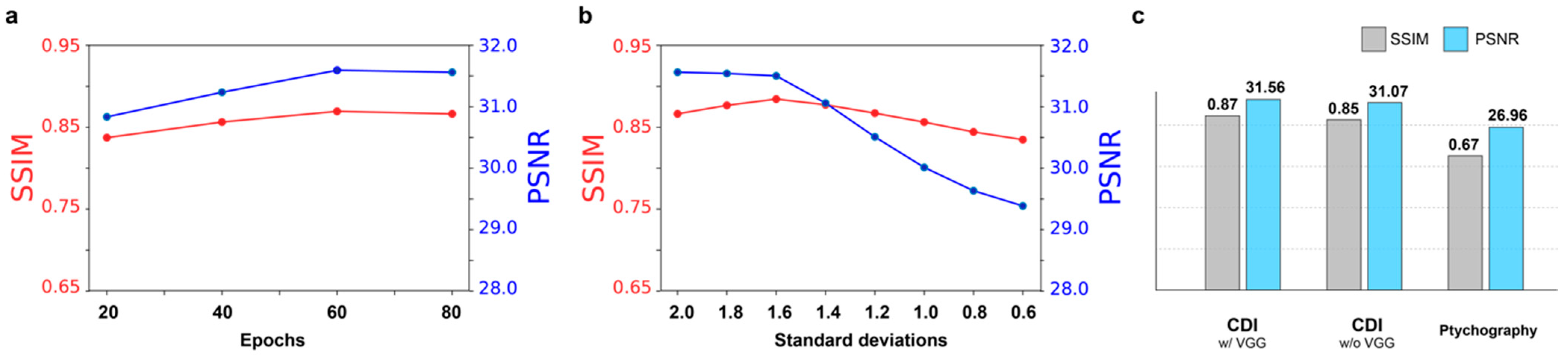
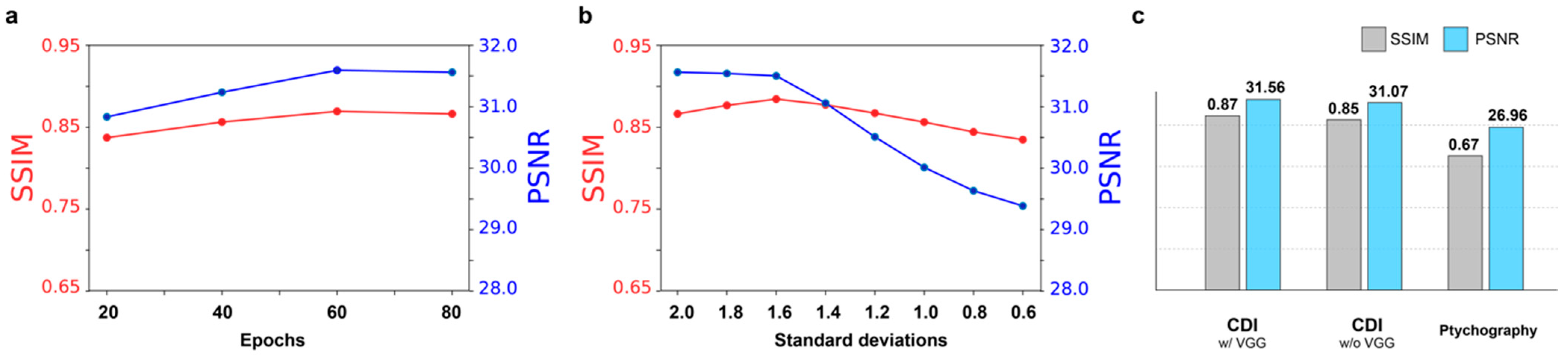
4.1. Model Details and Parameters
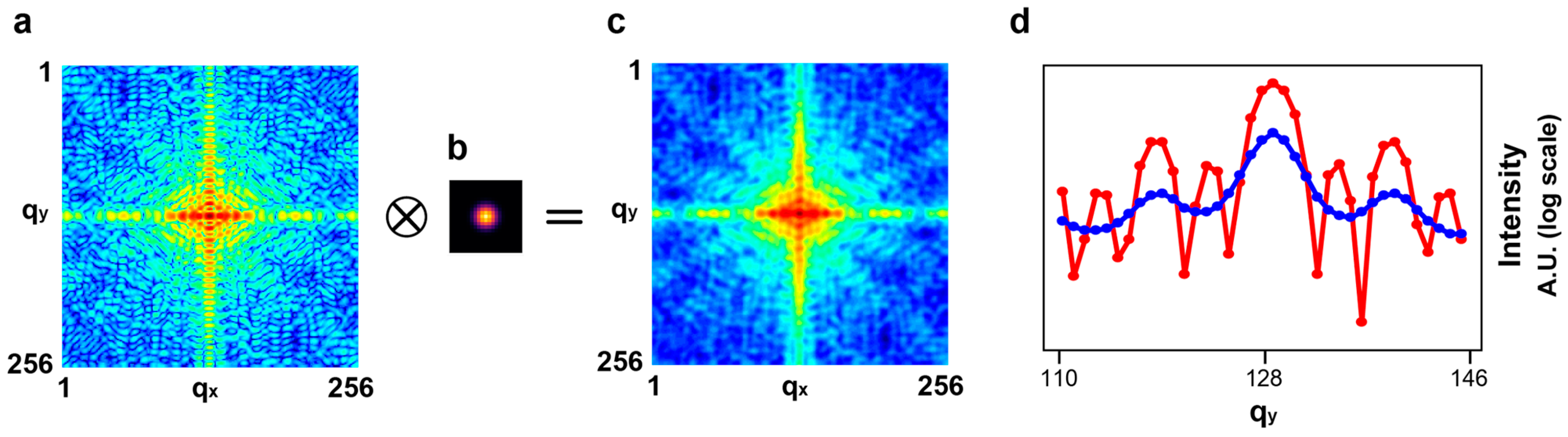
4.2. Comparison of Performance
4.3. Performance of Coherent Diffractive Imaging
4.4. Performance of Ptychography
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miao, J.; Charalambous, P.; Kirz, J.; Sayre, D. Extending the methodology of X-ray crystallography to allow imaging of micrometre-sized non-crystalline specimens. Nature 1999, 400, 342–344. [Google Scholar] [CrossRef]
- Robinson, I.; Harder, R. Coherent X-ray Diffraction Imaging of Strain at the Nanoscale. Nat. Mater. 2009, 8, 291–298. [Google Scholar] [CrossRef] [PubMed]
- Williams, G.J.; Pfeifer, M.A.; Vartanyants, I.A.; Robinson, I.K. Three-Dimensional Imaging of Microstructure in Au Nanocrystals. Phys. Rev. Lett. 2003, 90, 175501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.W.; Manna, S.; Dietze, S.; Ulvestad, A.; Harder, R.; Fohtung, E.; Fullerton, E.; Shpyrko, O. Curvature-induced and thermal strain in polyhedral gold nanocrystals. Appl. Phys. Lett. 2014, 105, 173108. [Google Scholar] [CrossRef]
- Kim, J.W.; Ulvestad, A.; Manna, S.; Harder, R.; Fullerton, E.E.; Shpyrko, O.G. 3D Bragg coherent diffractive imaging of five-fold multiply twinned gold nanoparticle. Nanoscale 2017, 9, 13153–13158. [Google Scholar] [CrossRef]
- Seaberg, M.D.; Zhang, B.; Gardner, D.F.; Shanblatt, E.R.; Murnane, M.M.; Kapteyn, H.R.; Adams, D.E. Tabletop nanometer extreme ultraviolet imaging in an extended reflection mode using coherent Fresnel ptychography. Optica 2014, 1, 39–44. [Google Scholar] [CrossRef]
- Rodenburg, J.M. Ptychography and related diffractive imaging methods. Adv. Imaging Electron Phys. 2008, 150, 87. [Google Scholar]
- Fienup, J.R.; Marron, J.C.; Schulz, T.J.; Seldin, J.H. Hubble space telescope characterized by using phase-retrieval algorithms. Appl. Opt. 1993, 32, 1747. [Google Scholar] [CrossRef] [Green Version]
- Miao, J.; Kirz, J.; Sayre, D. The oversampling phasing method. Acta Crystallogr. D 2000, 56, 1312. [Google Scholar] [CrossRef] [Green Version]
- Chapman, H.N.; Nugent, K.A. Coherent lensless X-ray imaging. Nat. Photon. 2010, 4, 833–839. [Google Scholar] [CrossRef]
- Pfeifer, M.A.; Williams, G.J.; Vartanyants, I.A.; Harder, R.; Robinson, I.K. Three-dimensional mapping of a deformation field inside a nanocrystal. Nature 2006, 442, 63–66. [Google Scholar] [CrossRef] [PubMed]
- Rodenburg, J.M.; Faulkner, H.M.L. A phase retrieval algorithm for shifting illumination. Appl. Phys. Lett. 2004, 85, 4795–4797. [Google Scholar] [CrossRef] [Green Version]
- Thibault, P.; Dierolf, M.; Bunk, O.; Menzel, A.; Pfeiffer, F. Probe retrieval in ptychographic coherent diffractive imaging. Ultramicroscopy 2009, 109, 338–343. [Google Scholar] [CrossRef] [PubMed]
- Xiong, G.; Moutanabbir, O.; Reiche, M.; Harder, R.; Robinson, I. Coherent X-ray diffraction imaging and characterization of strain in silicon-on-insulator nanostructures. Adv Mater. 2014, 26, 7747–7763. [Google Scholar] [CrossRef] [Green Version]
- Williams, G.J.; Quiney, H.M.; Peele, A.G.; Nugent, K.A. Coherent diffractive imaging and partial coherence. Phys. Rev. B 2007, 75, 104102. [Google Scholar] [CrossRef] [Green Version]
- Vartanyants, I.A.; Singer, A. Coherence properties of hard X-ray synchrotron sources and free-electron lasers. New J. Phys. 2010, 12, 035004. [Google Scholar] [CrossRef]
- Graves, W.S.; Bessuille, J.; Brown, P.; Carbajo, S.; Dolgashev, V.; Hong, K.-H.; Ihloff, E.; Khaykovich, B.; Lin, H.; Murari, K.; et al. Compact X-ray source based on burst-mode inverse Compton scattering at 100 kHz. Phys. Rev. ST Accel. Beams 2014, 17, 120701. [Google Scholar] [CrossRef]
- Whitehead, L.W.; Williams, G.J.; Quiney, H.M.; Vine, D.J.; Dilanian, R.A.; Flewett, S.; Nugent, K.A.; Peele, A.G.; Balaur, E.; McNulty, I. Diffractive imaging using partially coherent X-rays. Phys. Rev. Lett. 2009, 103, 243902. [Google Scholar] [CrossRef] [Green Version]
- Clark, J.N.; Huang, X.; Harder, R.; Robinson, I.K. High-resolution three-dimensional partially coherent diffraction imaging. Nat. Commun. 2012, 3, 993. [Google Scholar] [CrossRef]
- Clark, J.N.; Peele, A.G. Simultaneous sample and spatial coherence characterization using diffractive imaging. Appl. Phys. Lett. 2011, 99, 154103. [Google Scholar] [CrossRef] [Green Version]
- Parks, D.H.; Shi, X.; Kevan, S.D. Partially coherent X-ray diffractive imaging of complex objects. Phys. Rev. A 2014, 89, 063824. [Google Scholar] [CrossRef]
- Jiang, Y.; Xu, J.; Yang, B.; Xu, J.; Zhu, J. Image inpainting based on generative adversarial networks. IEEE Access 2020, 8, 22884–22892. [Google Scholar] [CrossRef]
- Wolterink, J.M.; Leiner, T.; Viergever, M.A.; Isgum, I. Generative adversarial networks for noise reduction in low-dose CT. IEEE Trans Med Imaging 2017, 36, 2536–2545. [Google Scholar] [CrossRef] [PubMed]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE CVPR, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE CVPR, Salt Lake City, UT, USA, 18–22 June2018; pp. 8183–8192. [Google Scholar]
- Tran, C.Q.; Peele, A.G.; Roberts, A.; Nugent, K.A.; Paterson, D.; McNulty, I. Synchrotron beam coherence: A spatially resolved measurement. Opt. Lett. 2005, 30, 204. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; p. 27. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; p. 30. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Ramakrishnan, S.; Pachori, S.; Gangopadhyay, S.; Raman, S. Deep generative filter for motion deblurring. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 2993–3000. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial network. arXiv 2016, arXiv:1611.07004. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with Markovian generative adversarial networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; Springer: Cham, Switzerland, 2016; pp. 702–716. [Google Scholar]
- Feng, H.; Guo, J.; Xu, H.; Ge, S.S. SharpGAN: Dynamic scene deblurring method for smart ship based on receptive field block and generative adversarial networks. Sensors 2021, 21, 3641. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the CVPR09, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Vartanyants, I.A.; Robinson, I.K. Partial coherence effects on the imaging of small crystals using coherent X-ray diffraction. J. Phys. Condens. Matter 2001, 13, 10593–10611. [Google Scholar] [CrossRef]
- Maddali, S.; Allain, M.; Cha, W.; Harder, R.; Park, J.-S.; Kenesei, R.; Almer, J.; Nashed, Y.; Hruszkewycz, S.O. Phase retrieval for Bragg coherent diffraction imaging at high X-ray energies. Phys. Rev. A 2019, 99, 053838. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Asokan, R. Alphabet Characters Fonts Dataset. Available online: https://www.kaggle.com/thomasqazwsxedc/alphabet-characters-fonts-dataset (accessed on 10 November 2021).
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fienup, J.R. Reconstruction of an object from the modulus of its Fourier transform. Opt. Lett. 1978, 3, 27–29. [Google Scholar] [CrossRef] [PubMed]
- Fienup, J.R. Reconstruction of a complex-valued object from the modulus of its Fourier transform using a support constraint. J. Opt. Soc. Am. A 1987, 4, 118–123. [Google Scholar] [CrossRef]
- Marchesini, S.; He, H.; Chapman, H.N.; Hau-Riege, A.P.; Noy, A.; Howells, M.R.; Weierstall, U.; Spence, J.C.H. X-ray image reconstruction from a diffraction pattern alone. Phys. Rev. B 2003, 68, 140101. [Google Scholar] [CrossRef] [Green Version]
- Maiden, A.M.; Rodenburg, J.M. An improved ptychographical phase retrieval algorithm for diffractive imaging. Ultramicroscopy 2009, 109, 1256–1262. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.W.; Messerschmidt, M.; Graves, W.S. Enhancement of Partially Coherent Diffractive Images Using Generative Adversarial Network. AI 2022, 3, 274-284. https://doi.org/10.3390/ai3020017
Kim JW, Messerschmidt M, Graves WS. Enhancement of Partially Coherent Diffractive Images Using Generative Adversarial Network. AI. 2022; 3(2):274-284. https://doi.org/10.3390/ai3020017
Chicago/Turabian StyleKim, Jong Woo, Marc Messerschmidt, and William S. Graves. 2022. "Enhancement of Partially Coherent Diffractive Images Using Generative Adversarial Network" AI 3, no. 2: 274-284. https://doi.org/10.3390/ai3020017
APA StyleKim, J. W., Messerschmidt, M., & Graves, W. S. (2022). Enhancement of Partially Coherent Diffractive Images Using Generative Adversarial Network. AI, 3(2), 274-284. https://doi.org/10.3390/ai3020017