

From Data to Decisions: Leveraging Retrieval-Augmented Generation to Balance Citation Bias in Burn Management Literature

 ,
,  , and
, and 
Abstract
1. Introduction
1.1. Background
1.2. Research Objectives
- If citation metrics impact the accuracy of responses using RAG in burn management.
- If the readability of RAG-generated responses is influenced by citation metrics.
- If the use of highly cited papers affects RAG’s response time compared with less-cited sources.
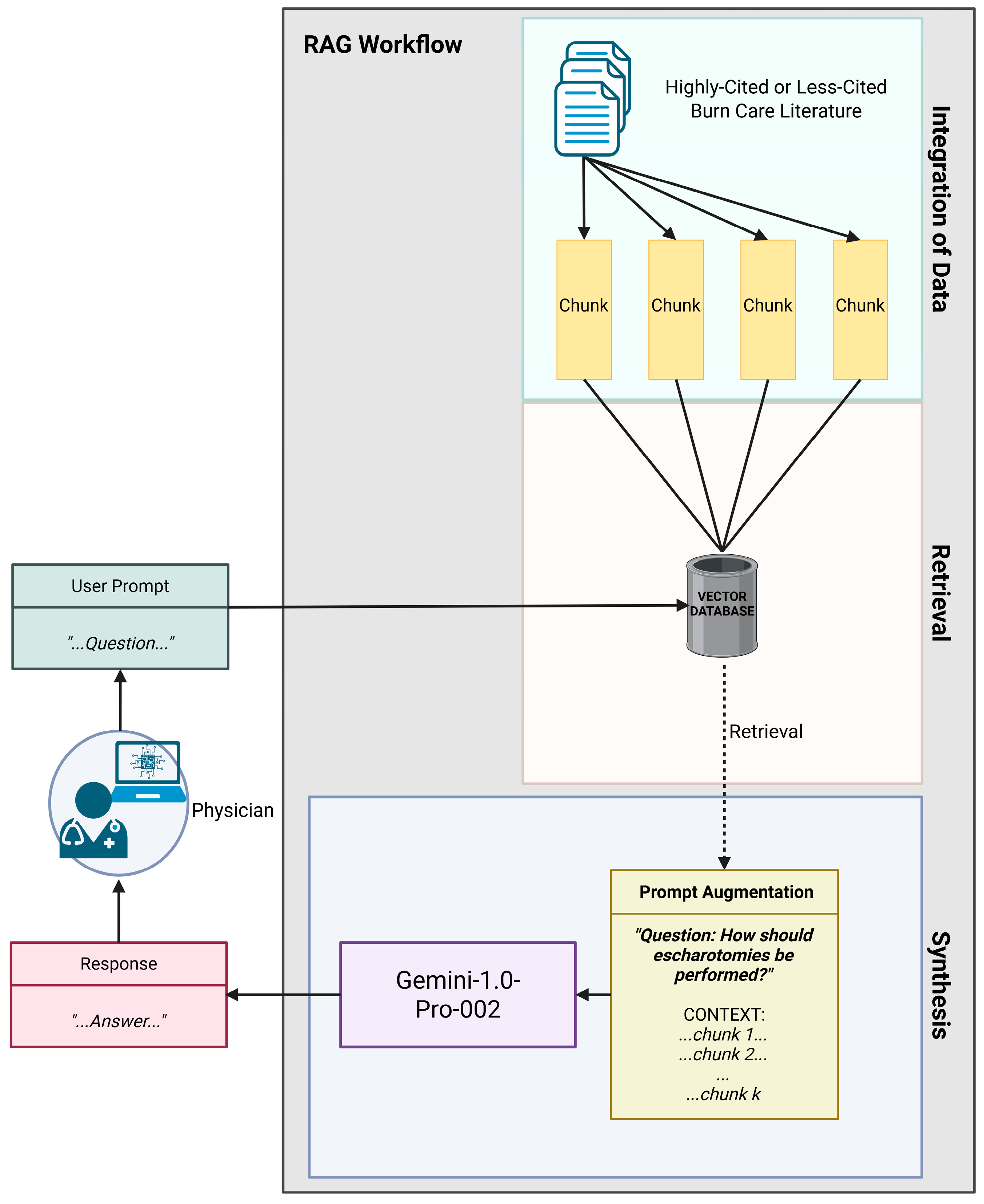
2. Materials and Methods
2.1. Source Material Selection
2.2. Question Development
2.3. Response Generation
2.4. Accuracy Assessment
2.5. Readability Evaluation
2.6. Response Time Assessment
2.7. Statistical Analysis
3. Results
3.1. Accuracy Results
3.2. Readability Results
3.3. Response Time Results
4. Discussion
4.1. Summary of Key Findings
4.2. Interpretation of Results
4.3. Strengths and Limitations
4.4. Implications and Future Directions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RAG | Retrieval-augmented generation |
| LLM | Large language model |
References
- American Burn Association. Burn Incidence Fact Sheet. 2024. Available online: https://ameriburn.org/resources/burn-incidence-fact-sheet (accessed on 14 December 2024).
- Kao, C.C.; Garner, W.L. Acute Burns. Plast. Reconstr. Surg. 2000, 105, 2482. [Google Scholar] [CrossRef] [PubMed]
- Johnson, C. Management of burns. Surgery 2018, 36, 435–440. [Google Scholar] [CrossRef]
- Al-Mousawi, A.M.; Mecott-Rivera, G.A.; Jeschke, M.G.; Herndon, D.N. Burn Teams and Burn Centers: The Importance of a Comprehensive Team Approach to Burn Care. Clin. Plast. Surg. 2009, 36, 547. [Google Scholar] [CrossRef] [PubMed]
- Munn, Z.; Kavanagh, S.; Lockwood, C.; Pearson, A.; Wood, F. The development of an evidence based resource for burns care. Burns 2013, 39, 577–582. [Google Scholar] [CrossRef]
- Knottnerus, J.A.; Tugwell, P. The evidence base of taming continuously proliferating evidence. J. Clin. Epidemiol. 2012, 65, 1241–1242. [Google Scholar] [CrossRef]
- León, S.A.; Fontelo, P.; Green, L.; Ackerman, M.; Liu, F. Evidence-based medicine among internal medicine residents in a community hospital program using smart phones. BMC Med. Inform. Decis. Mak. 2007, 7, 5. [Google Scholar] [CrossRef]
- Bartneck, C.; Lütge, C.; Wagner, A.; Welsh, S. What Is AI? In An Introduction to Ethics in Robotics and AI; Springer: Cham, Switzerland, 2020; pp. 5–16. [Google Scholar]
- Mohapatra, D.P.; Thiruvoth, F.M.; Tripathy, S.; Rajan, S.; Vathulya, M.; Lakshmi, P.; Singh, V.K.; Haq, A.U. Leveraging Large Language Models (LLM) for the Plastic Surgery Resident Training: Do They Have a Role? Indian J. Plast. Surg. 2023, 56, 413–420. [Google Scholar] [CrossRef]
- Gomez-Cabello, C.A.; Borna, S.; Pressman, S.M.; Haider, S.A.; Sehgal, A.; Leibovich, B.C.; Forte, A.J. Artificial Intelligence in Postoperative Care: Assessing Large Language Models for Patient Recommendations in Plastic Surgery. Healthcare 2024, 12, 1083. [Google Scholar] [CrossRef]
- Abdelhady, A.M.; Davis, C.R. Plastic Surgery and Artificial Intelligence: How ChatGPT Improved Operation Note Accuracy, Time, and Education. Mayo Clin. Proc. Digit. Health 2023, 1, 299–308. [Google Scholar] [CrossRef]
- Kaneda, Y.; Takita, M.; Hamaki, T.; Ozaki, A.; Tanimoto, T. ChatGPT’s Potential in Enhancing Physician Efficiency: A Japanese Case Study. Cureus 2023, 15, e48235. [Google Scholar] [CrossRef]
- Drazen, J.M.; Kohane, I.S.; Leong, T.-Y. Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N. Engl. J. Med. 2023, 388, 1233–1239. [Google Scholar]
- Bhayana, R.; Fawzy, A.; Deng, Y.; Bleakney, R.R.; Krishna, S. Retrieval-Augmented Generation for Large Language Models in Radiology: Another Leap Forward in Board Examination Performance. Radiology 2024, 313, e241489. [Google Scholar] [CrossRef]
- Shadish, W.R.; Tolliver, D.; Gray, M.; Gupta, S.K.S. Author Judgements about Works They Cite: Three Studies from Psychology Journals. Soc. Stud. Sci. 1995, 25, 477–498. [Google Scholar] [CrossRef]
- Eika, E.; Sandnes, F.E. Starstruck by journal prestige and citation counts? On students’ bias and perceptions of trustworthiness according to clues in publication references. Scientometrics 2022, 127, 6363–6390. [Google Scholar] [CrossRef] [PubMed]
- Nicholas, D.; Jamali, H.R.; Watkinson, A.; Herman, E.; Tenopir, C.; Volentine, R.; Allard, S.; Levine, K. Do Younger Researchers Assess Trustworthiness Differently when Deciding what to Read and Cite and where to Publish? Int. J. Knowl. Content Dev. Technol. 2015, 5, 45–63. [Google Scholar] [CrossRef]
- Beel, J.; Gipp, B. Google Scholar’s ranking algorithm: The impact of citation counts (An empirical study). In Proceedings of the 2009 Third International Conference on Research Challenges in Information Science, Fez, Morocco, 22–24 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 22–24. [Google Scholar]
- Teplitskiy, M.; Duede, E.; Menietti, M.; Lakhani, K.R. Status drives how we cite: Evidence from thousands of authors. arXiv 2020, arXiv:2002.10033. [Google Scholar]
- Cubison, T.C.S.; Pape, S.A.; Parkhouse, N. Evidence for the link between healing time and the development of hypertrophic scars (HTS) in paediatric burns due to scald injury. Burns J. Int. Soc. Burn. Inj. 2006, 32, 992–999. [Google Scholar] [CrossRef]
- Orgill, D.P. Excision and skin grafting of thermal burns. N. Engl. J. Med. 2009, 360, 893–901. [Google Scholar] [CrossRef]
- Papini, R. Management of burn injuries of various depths. BMJ (Clin. Res. Ed.) 2004, 329, 158–160. [Google Scholar] [CrossRef]
- Zuo, K.J.; Medina, A.; Tredget, E.E. Important Developments in Burn Care. Plast. Reconstr. Surg. 2017, 139, 120–138. [Google Scholar] [CrossRef]
- Whitaker, I.S.; Prowse, S.; Potokar, T.S. A critical evaluation of the use of Biobrane as a biologic skin substitute: A versatile tool for the plastic and reconstructive surgeon. Ann. Plast. Surg. 2008, 60, 333–337. [Google Scholar] [CrossRef]
- Baumeister, S.; Köller, M.; Dragu, A.; Germann, G.; Sauerbier, M. Principles of microvascular reconstruction in burn and electrical burn injuries. Burns J. Int. Soc. Burn. Inj. 2005, 31, 92–98. [Google Scholar] [CrossRef] [PubMed]
- Iwuagwu, F.C.; Wilson, D.; Bailie, F. The use of skin grafts in postburn contracture release: A 10-year review. Plast. Reconstr. Surg. 1999, 103, 1198–1204. [Google Scholar] [CrossRef] [PubMed]
- Hettiaratchy, S.; Papini, R. Initial management of a major burn: II--assessment and resuscitation. BMJ (Clin. Res. Ed.) 2004, 329, 101–103. [Google Scholar] [CrossRef]
- Kurtzman, L.C.; Stern, P.J. Upper extremity burn contractures. Hand Clin. 1990, 6, 261–279. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.A.; Davidson, T.M. Scar management: Prevention and treatment strategies. Curr. Opin. Otolaryngol. Head Neck Surg. 2005, 13, 242–247. [Google Scholar] [CrossRef]
- Latenser, B.A.; Kowal-Vern, A.; Kimball, D.; Chakrin, A.; Dujovny, N. A Pilot Study Comparing Percutaneous Decompression With Decompressive Laparotomy for Acute Abdominal Compartment Syndrome in Thermal Injury. J. Burn. Care Rehabil. 2002, 23, 190–195. [Google Scholar] [CrossRef]
- Bahemia, I.A.; Muganza, A.; Moore, R.; Sahid, F.; Menezes, C. Microbiology and antibiotic resistance in severe burns patients: A 5 year review in an adult burns unit. Burn. J. Int. Soc. Burn. Inj. 2015, 41, 1536–1542. [Google Scholar] [CrossRef]
- Chua, A.W.C.; Khoo, Y.C.; Tan, B.K.; Tan, K.C.; Foo, C.L.; Chong, S.J. Skin tissue engineering advances in severe burns: Review and therapeutic applications. Burn. Trauma 2016, 4, 3. [Google Scholar] [CrossRef]
- Pallua, N.; Wolter, T.; Markowicz, M. Platelet-rich plasma in burns. Burn. J. Int. Soc. Burn. Inj. 2010, 36, 4–8. [Google Scholar] [CrossRef]
- Antia, N.H.; Buch, V.I. Chondrocutaneous advancement flap for the marginal defect of the ear. Plast. Reconstr. Surg. 1967, 39, 472–477. [Google Scholar] [CrossRef] [PubMed]
- Herndon, D.N.; Tompkins, R.G. Support of the metabolic response to burn injury. Lancet 2004, 363, 1895–1902. [Google Scholar] [CrossRef]
- Jeschke, M.G.; Pinto, R.; Kraft, R.; Nathens, A.B.; Finnerty, C.C.; Gamelli, R.L.; Gibran, N.S.; Klein, M.B.; Arnoldo, B.D.; Tompkins, R.G.; et al. Morbidity and survival probability in burn patients in modern burn care. Crit. Care Med. 2015, 43, 808–815. [Google Scholar] [CrossRef] [PubMed]
- Cuttle, L.; Kempf, M.; Liu, P.-Y.; Kravchuk, O.; Kimble, R.M. The optimal duration and delay of first aid treatment for deep partial thickness burn injuries. Burn. J. Int. Soc. Burn. Inj. 2010, 36, 673–679. [Google Scholar] [CrossRef]
- Schneider, J.C.; Holavanahalli, R.; Helm, P.; Goldstein, R.; Kowalske, K. Contractures in burn injury: Defining the problem. J. Burn. Care Res. 2006, 27, 508–514. [Google Scholar] [CrossRef] [PubMed]
- Magnotti, L.J.; Deitch, E.A. Burns, bacterial translocation, gut barrier function, and failure. J. Burn. Care Rehabil. 2005, 26, 383–391. [Google Scholar] [CrossRef]
- Greenhalgh, D.G. Burn resuscitation: The results of the ISBI/ABA survey. Burns J. Int. Soc. Burn. Inj. 2010, 36, 176–182. [Google Scholar] [CrossRef]
- ISBI Practice Guidelines Committee; Steering Subcommittee; Advisory Subcommittee. ISBI Practice Guidelines for Burn Care. Burns 2016, 42, 953–1021. [Google Scholar] [CrossRef]
- Ramundo, J.; Gray, M. Enzymatic wound debridement. J. Wound Ostomy Cont. Nurs. 2008, 35, 273–280. [Google Scholar] [CrossRef]
- Draaijers, L.J.; Tempelman, F.R.H.; Botman, Y.A.M.; Tuinebreijer, W.E.; Middelkoop, E.; Kreis, R.W.; van Zuijlen, P.P.M. The patient and observer scar assessment scale: A reliable and feasible tool for scar evaluation. Plast. Reconstr. Surg. 2004, 113, 1960–1965. [Google Scholar] [CrossRef]
- Anderson, R.R.; Donelan, M.B.; Hivnor, C.; Greeson, E.; Ross, E.V.; Shumaker, P.R.; Uebelhoer, N.S.; Waibel, J.S. Laser treatment of traumatic scars with an emphasis on ablative fractional laser resurfacing: Consensus report. JAMA Dermatol. 2014, 150, 187–193. [Google Scholar] [CrossRef] [PubMed]
- Halim, A.S.; Khoo, T.L.; Yussof, S.J.M. Biologic and synthetic skin substitutes: An overview. Indian J. Plast. Surg. 2010, 43, S23. [Google Scholar] [CrossRef]
- Bonate, P.L. Pathophysiology and pharmacokinetics following burn injury. Clin. Pharmacokinet. 1990, 18, 118–130. [Google Scholar] [CrossRef]
- Bizrah, M.; Yusuf, A.; Ahmad, S. An update on chemical eye burns. Eye 2019, 33, 1362–1377. [Google Scholar] [CrossRef] [PubMed]
- Akan, M.; Yildirim, S.; Misirlioğlu, A.; Ulusoy, G.; Aköz, T.; Avci, G. An alternative method to minimize pain in the split-thickness skin graft donor site. Plast. Reconstr. Surg. 2003, 111, 2243–2249. [Google Scholar] [CrossRef] [PubMed]
- Moncrief, J.A. Third degree burns of the dorsum of the hand. Am. J. Surg. 1958, 96, 535–544. [Google Scholar] [CrossRef]
- Fujita, K.; Mishima, Y.; Iwasawa, M.; Matsuo, K. The practical procedure of tumescent technique in burn surgery for excision of burn eschar. J. Burn. Care Res. 2008, 29, 924–926. [Google Scholar] [CrossRef] [PubMed]
- Pegg, S.P. Escharotomy in burns. Ann. Acad. Med. Singap. 1992, 21, 682–684. [Google Scholar]
- Moravvej, H.; Hormozi, A.K.; Hosseini, S.N.; Sorouri, R.; Mozafari, N.; Ghazisaidi, M.R.; Rad, M.M.; Moghimi, M.H.; Sadeghi, S.M.; Mirzadeh, H. Comparison of the Application of Allogeneic Fibroblast and Autologous Mesh Grafting With the Conventional Method in the Treatment of Third-Degree Burns. J. Burn. Care Res. 2016, 37, 90–95. [Google Scholar] [CrossRef]
- Fukui, M.; Hihara, M.; Takeji, K.; Matsuoka, Y.; Okamoto, M.; Fujita, M.; Kakudo, N. Potent Micrografting Using the Meek Technique for Knee Joint Wound Reconstruction. Eplasty 2023, 23, e14. [Google Scholar]
- Webber, C.E.; Glanges, E.; Crenshaw, C.A. Treatment of second degree burns: Nitrofurazone, povidone-iodine, and silver sulfadiazine. J. Am. Coll. Emerg. Physicians 1977, 6, 486–490. [Google Scholar] [CrossRef] [PubMed]
- Zukowski, M.; Lord, J.; Ash, K.; Shouse, B.; Getz, S.; Robb, G. The gracilis free flap revisited: A review of 25 cases of transfer to traumatic extremity wounds. Ann. Plast. Surg. 1998, 40, 141–144. [Google Scholar] [CrossRef]
- Shelley, O.P.; Van Niekerk, W.; Cuccia, G.; Watson, S.B. Dual benefit procedures: Combining aesthetic surgery with burn reconstruction. Burn. J. Int. Soc. Burn. Inj. 2006, 32, 1022–1027. [Google Scholar] [CrossRef]
- Tenenhaus, M.; Rennekampff, H.O. Burn surgery. Clin. Plast. Surg. 2007, 34, 697–715. [Google Scholar] [CrossRef]
- Germann, G. Hand Reconstruction After Burn Injury: Functional Results. Clin. Plast. Surg. 2017, 44, 833–844. [Google Scholar] [CrossRef] [PubMed]
- Obaidi, N.; Keenan, C.; Chan, R.K. Burn Scar Management and Reconstructive Surgery. Surg. Clin. N. Am. 2023, 103, 515–527. [Google Scholar] [CrossRef]
- La, H.; Brown, T.; Muller, M.J. Damage limitation in burn surgery. Injury 2004, 35, 697–707. [Google Scholar]
- Al-Byti, A.M.; Chakmakchy, S.A.; Waheeb, A.A.; Alazzawy, M.A. Study of Isolated Bacteria from Burn Wound of Patients Attended Plastic Surgery and Burns Unit. Indian J. Forensic Med. Toxicol. 2019, 13, 1462–1466. [Google Scholar] [CrossRef]
- Houschyar, K.S.; Tapking, C.; Nietzschmann, I.; Rein, S.; Weissenberg, K.; Chelliah, M.P.; Duscher, D.; Maan, Z.N.; Philipps, H.M.; Sheckter, C.C.; et al. Five Years Experience With Meek Grafting in the Management of Extensive Burns in an Adult Burn Center. Plastic Surg. 2019, 27, 44–48. [Google Scholar] [CrossRef]
- Gupta, S.; Goil, P.; Thakurani, S. Autologous Platelet Rich Plasma As A Preparative for Resurfacing Burn Wounds with Split Thickness Skin Grafts. World J. Plast. Surg. 2020, 9, 29. [Google Scholar]
- Bos, E.J.; Doerga, P.; Breugem, C.; van Zuijlen, P. The burned ear; possibilities and challenges in framework reconstruction and coverage. Burns 2016, 42, 1387–1395. [Google Scholar] [CrossRef] [PubMed]
- Lawton, G.; Dheansa, B. The management of major burns—A surgical perspective. Curr. Anaesth. Crit. Care 2008, 19, 275–281. [Google Scholar] [CrossRef]
- Romanowski, K.S.; Sen, S. Wound healing in older adults with severe burns: Clinical treatment considerations and challenges. Burn. Open Int. Open Access J. Burn. Inj. 2022, 6, 57. [Google Scholar] [CrossRef]
- Kim, E.; Drew, P.J. Management of burn injury. Surgery 2022, 40, 62–69. [Google Scholar]
- AlQahtani, S.M.; Alzahrani, M.M.; Carli, A.; Harvey, E.J. Burn Management in Orthopaedic Trauma: A Critical Analysis Review. JBJS Rev. 2014, 2, 01874474–201410000. [Google Scholar] [CrossRef] [PubMed]
- Ng, J.W.G.; Cairns, S.A.; O’Boyle, C.P. Management of the lower gastrointestinal system in burn: A comprehensive review. Burn. J. Int. Soc. Burn. Inj. 2016, 42, 728–737. [Google Scholar] [CrossRef]
- Kim, H.; Shin, S.; Han, D. Review of History of Basic Principles of Burn Wound Management. Medicina 2022, 58, 400. [Google Scholar] [CrossRef] [PubMed]
- Miroshnychenko, A.; Kim, K.; Rochwerg, B.; Voineskos, S. Comparison of early surgical intervention to delayed surgical intervention for treatment of thermal burns in adults: A systematic review and meta-analysis. Burns Open 2021, 5, 67–77. [Google Scholar] [CrossRef]
- Salehi, S.H.; Momeni, M.; Vahdani, M.; Moradi, M. Clinical Value of Debriding Enzymes as an Adjunct to Standard Early Surgical Excision in Human Burns: A Systematic Review. J. Burn. Care Res. 2020, 41, 1224–1230. [Google Scholar] [CrossRef]
- Johnson, S.P.; Chung, K.C. Outcomes Assessment After Hand Burns. Hand Clin. 2017, 33, 389. [Google Scholar] [CrossRef]
- Altemir, A.; Boixeda, P. Laser Treatment of Burn Scars. Actas Dermo-Sifiliogr. 2022, 113, 938–944. [Google Scholar] [CrossRef] [PubMed]
- Alissa Olga, L.; Rao, N.; Yan, L.; Pye, J.S.; Li, H.; Wang, B.; Li, J.J. Stem Cell-Based Tissue Engineering for the Treatment of Burn Wounds: A Systematic Review of Preclinical Studies. Stem Cell Rev. Rep. 2022, 18, 1926–1955. [Google Scholar]
- Herman, A.; Herman, A.P. Herbal Products for Treatment of Burn Wounds. J. Burn. Care Res. 2020, 41, 457–465. [Google Scholar] [CrossRef]
- Saccu, G.; Menchise, V.; Giordano, C.; Castelli, D.D.; Dastrù, W.; Pellicano, R.; Tolosano, E.; Van Pham, P.; Altruda, F.; Fagoonee, S. Regenerative Approaches and Future Trends for the Treatment of Corneal Burn Injuries. J. Clin. Med. 2021, 10, 317. [Google Scholar] [CrossRef] [PubMed]
- Kogan, S.; Halsey, J.; Agag, R.L. Biologics in Acute Burn Injury. Ann. Plast. Surg. 2019, 83, 26–33. [Google Scholar] [CrossRef]
- Gemini Team Google. Gemini: A Family of Highly Capable Multimodal Models. arXiv, 2023; arXiv:2312.11805.
- Genovese, A. Leveraging Retrieval-Augmented Generation (RAG)-Based Gemini for Burn Care Management Assistance. Created in BioRender. 2025. Available online: https://BioRender.com/e41o855 (accessed on 14 December 2024).
- Hutchinson, N.; Baird, G.L.; Garg, M. Examining the Reading Level of Internet Medical Information for Common Internal Medicine Diagnoses. Am. J. Med. 2016, 129, 637–639. [Google Scholar] [CrossRef]
- Haught, P.A.; Walls, R.T. Adult learners: New norms on the nelson-denny reading test for healthcare professionals. Read. Psychol. 2002, 23, 217–238. [Google Scholar] [CrossRef]
- Good Calculators. Flesch Kincaid Calculator. 2025. Available online: https://goodcalculators.com/flesch-kincaid-calculator/ (accessed on 3 January 2025).
- Lindgren, L. If Robert Merton said it, it must be true: A citation analysis in the field of performance measurement. Evaluation 2011, 17, 7–19. [Google Scholar] [CrossRef]
- Chen, J.; Lin, H.; Han, X.; Sun, L. Benchmarking Large Language Models in Retrieval-Augmented Generation. arXiv 2023, arXiv:2309.01431. [Google Scholar] [CrossRef]
- Borgeaud, S.; Mensch, A.; Hoffmann, J.; Cai, T.; Rutherford, E.; Millican, K.; van den Driessche, G.; Lespiau, J.-B.; Damoc, B.; Clark, A.; et al. Improving language models by retrieving from trillions of tokens. arXiv 2021, arXiv:2112.04426. [Google Scholar]
- Rejeleene, R.; Xu, X.; Talburt, J. Towards trustable language models: Investigating information quality of large language models. arXiv 2024, arXiv:2401.13086. [Google Scholar]
- Hu, M.; Wu, H.; Guan, Z.; Zhu, R.; Guo, D.; Qi, D.; Li, S. No Free Lunch: Retrieval-Augmented Generation Undermines Fairness in LLMs, Even for Vigilant Users. arXiv 2024, arXiv:2410.07589. [Google Scholar]
- Algaba, A.; Mazijn, C.; Holst, V.; Tori, F.; Wenmackers, S.; Ginis, V. Large language models reflect human citation patterns with a heightened citation bias. arXiv 2024, arXiv:2405.15739. [Google Scholar]
- Ante, L. The relationship between readability and scientific impact: Evidence from emerging technology discourses. J. Informetr. 2022, 16, 101252. [Google Scholar] [CrossRef]
- Hu, H.; Wang, D.; Deng, S. Analysis of the scientific literature’s abstract writing style and citations. Online Inf. Rev. 2021, 45, 1290–1305. [Google Scholar] [CrossRef]
- Rooein, D.; Curry, A.C.; Hovy, D. Know Your Audience: Do LLMs Adapt to Different Age and Education Levels? arXiv 2023, arXiv:2312.02065. [Google Scholar]
- Amin, K.S.; Mayes, L.C.; Khosla, P.; Doshi, R.H. Assessing the efficacy of large language models in health literacy: A comprehensive cross-sectional study. Yale J. Biol. Med. 2024, 97, 17. [Google Scholar] [CrossRef] [PubMed]
- Ellsworth, M.A.; Homan, J.M.; Cimino, J.J.; Peters, S.G.; Pickering, B. Herasevich A Survey from a Large Academic Medical Center. Appl. Clin. Inform. 2015, 06, 305–317. [Google Scholar]
- Thompson, J.T.; Wines, R.C.; Brewington, M.; Crotty, K.; Aikin, K.J.; Sullivan, H. Healthcare Providers’ Understanding of Data Displays of Clinical Trial Information: A Scoping Review of the Literature. J. Commun. Healthc. 2022, 16, 260. [Google Scholar] [CrossRef]
- Thompson, M.L. Characteristics of information resources preferred by primary care physicians. Bull. Med. Libr. Assoc. 1997, 85, 187–192. [Google Scholar]


{kind=link}
{kind=link}
| High-Citation Set (N = 30) | Low-Citation Set (N = 30) | p Value | |
|---|---|---|---|
| Accuracy | 0.49 | ||
| Mean (SD) | 4.6 (0.7) | 4.2 (1.4) | |
| Median (range) | 5.0 (3.0, 5.0) | 5.0 (1.0, 5.0) | |
| Response Time (seconds) | 0.39 | ||
| Mean (SD) | 2.8 (1.4) | 2.5 (1.3) | |
| Median (range) | 2.5 (0.9, 5.6) | 1.9 (0.9, 4.7) | |
| Flesch–Kincaid Grade Level | 0.29 | ||
| Mean (SD) | 9.9 (2.4) | 9.5 (2.7) | |
| Median (range) | 10.4 (5.0, 14.8) | 9.1 (5.0, 15.4) | |
| Flesch Reading Ease | 0.26 | ||
| Mean (SD) | 42.8 (16.2) | 46.5 (18.8) | |
| Median (range) | 41.7 (3.8, 72.3) | 50.4 (7.5, 72.5) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the European Burns Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Genovese, A.; Prabha, S.; Borna, S.; Gomez-Cabello, C.A.; Haider, S.A.; Trabilsy, M.; Tao, C.; Forte, A.J. From Data to Decisions: Leveraging Retrieval-Augmented Generation to Balance Citation Bias in Burn Management Literature. Eur. Burn J. 2025, 6, 28. https://doi.org/10.3390/ebj6020028
Genovese A, Prabha S, Borna S, Gomez-Cabello CA, Haider SA, Trabilsy M, Tao C, Forte AJ. From Data to Decisions: Leveraging Retrieval-Augmented Generation to Balance Citation Bias in Burn Management Literature. European Burn Journal. 2025; 6(2):28. https://doi.org/10.3390/ebj6020028
Chicago/Turabian StyleGenovese, Ariana, Srinivasagam Prabha, Sahar Borna, Cesar A. Gomez-Cabello, Syed Ali Haider, Maissa Trabilsy, Cui Tao, and Antonio Jorge Forte. 2025. "From Data to Decisions: Leveraging Retrieval-Augmented Generation to Balance Citation Bias in Burn Management Literature" European Burn Journal 6, no. 2: 28. https://doi.org/10.3390/ebj6020028
APA StyleGenovese, A., Prabha, S., Borna, S., Gomez-Cabello, C. A., Haider, S. A., Trabilsy, M., Tao, C., & Forte, A. J. (2025). From Data to Decisions: Leveraging Retrieval-Augmented Generation to Balance Citation Bias in Burn Management Literature. European Burn Journal, 6(2), 28. https://doi.org/10.3390/ebj6020028