
The Complexity of Medical Device Regulations Has Increased, as Assessed through Data-Driven Techniques



Abstract
:1. Introduction
Medical Device Regulations
2. Background
2.1. Complexity of Regulations
2.2. Complexity of Text
2.2.1. Common Readability Metrics
2.2.2. Complexity and Response Time
2.2.3. Research Aims
3. Materials and Methods
3.1. Linguistic Complexity of Regulatory Documentation
3.2. Data
3.3. Data Processing and Analysis
4. Results
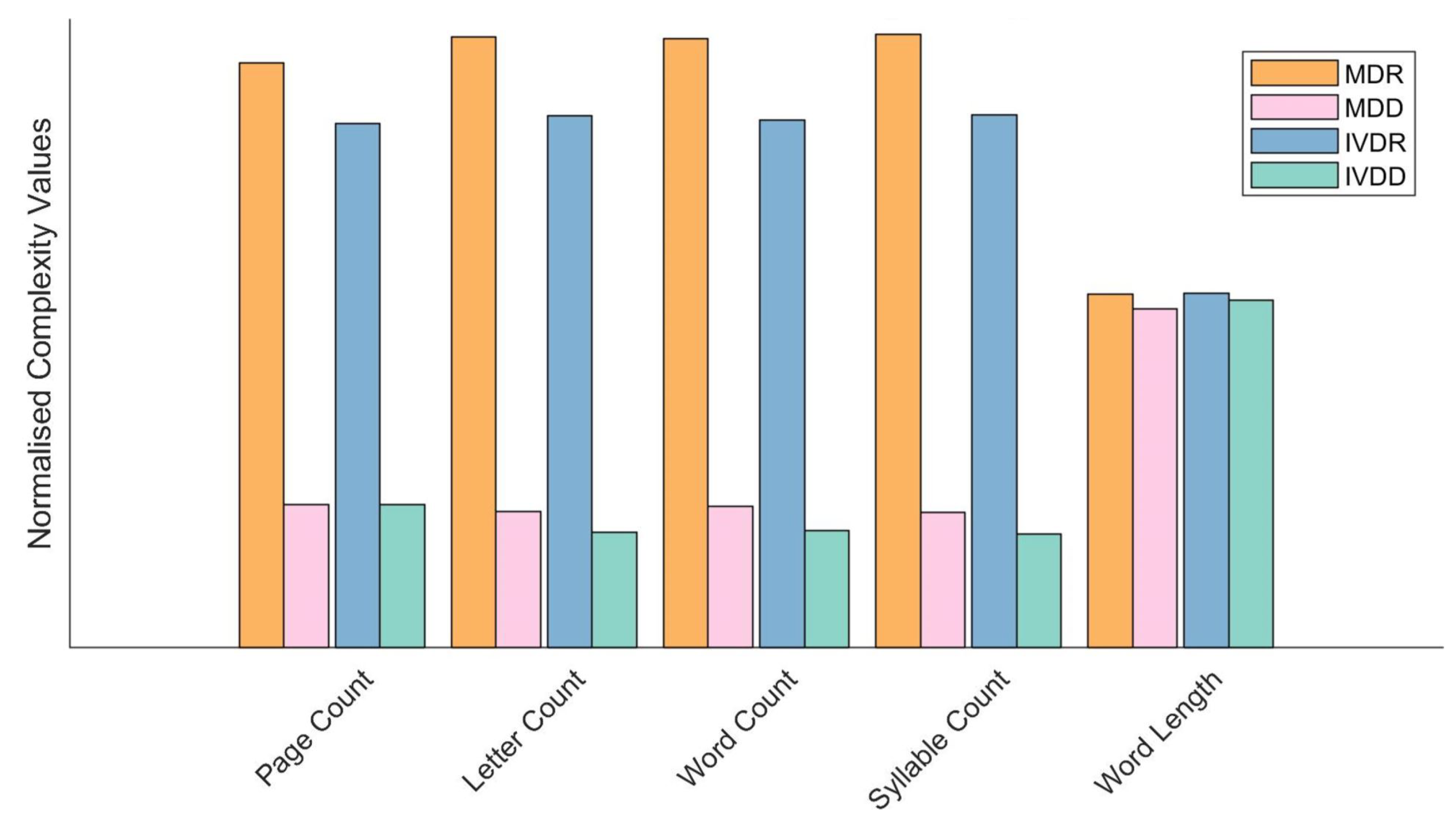
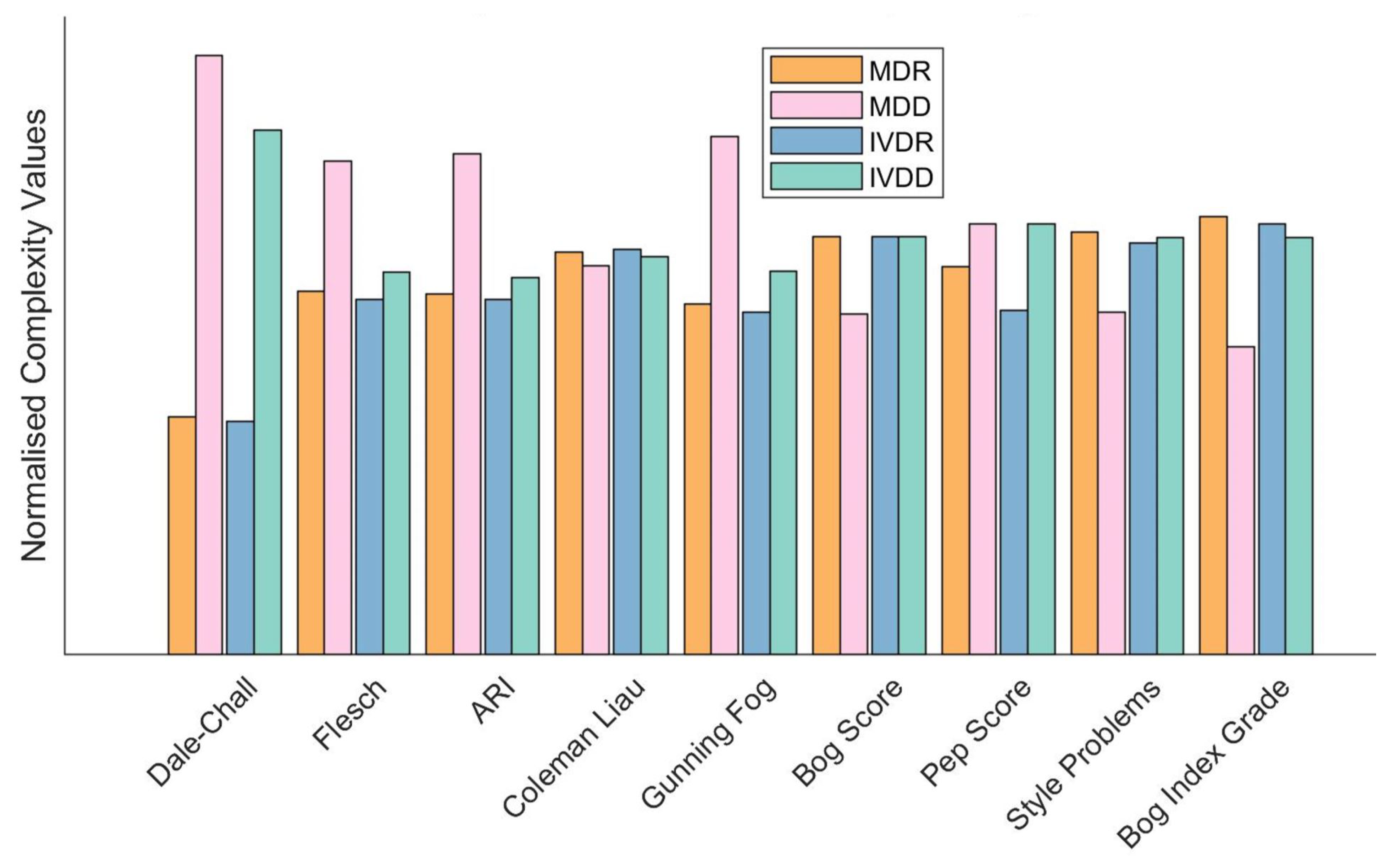
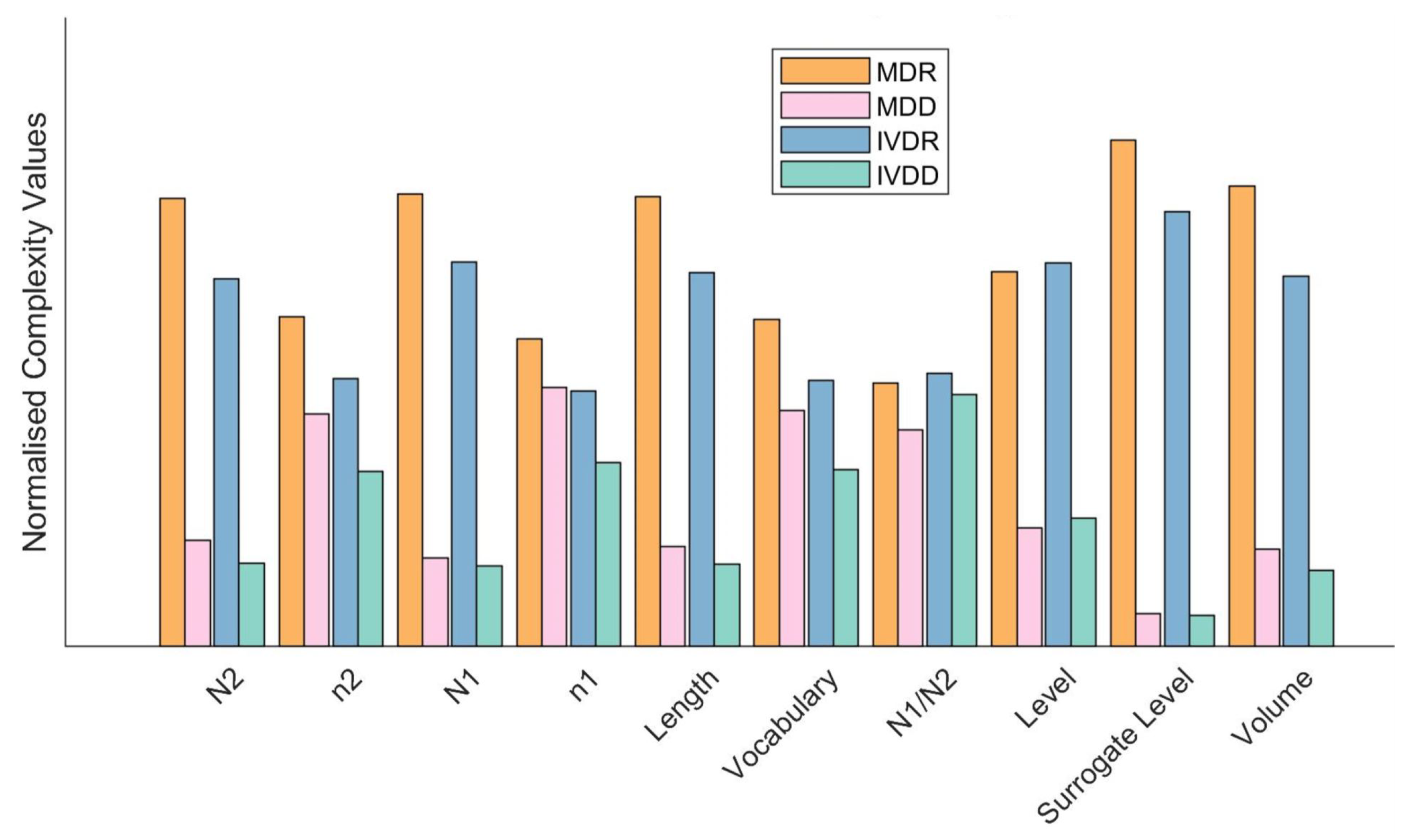
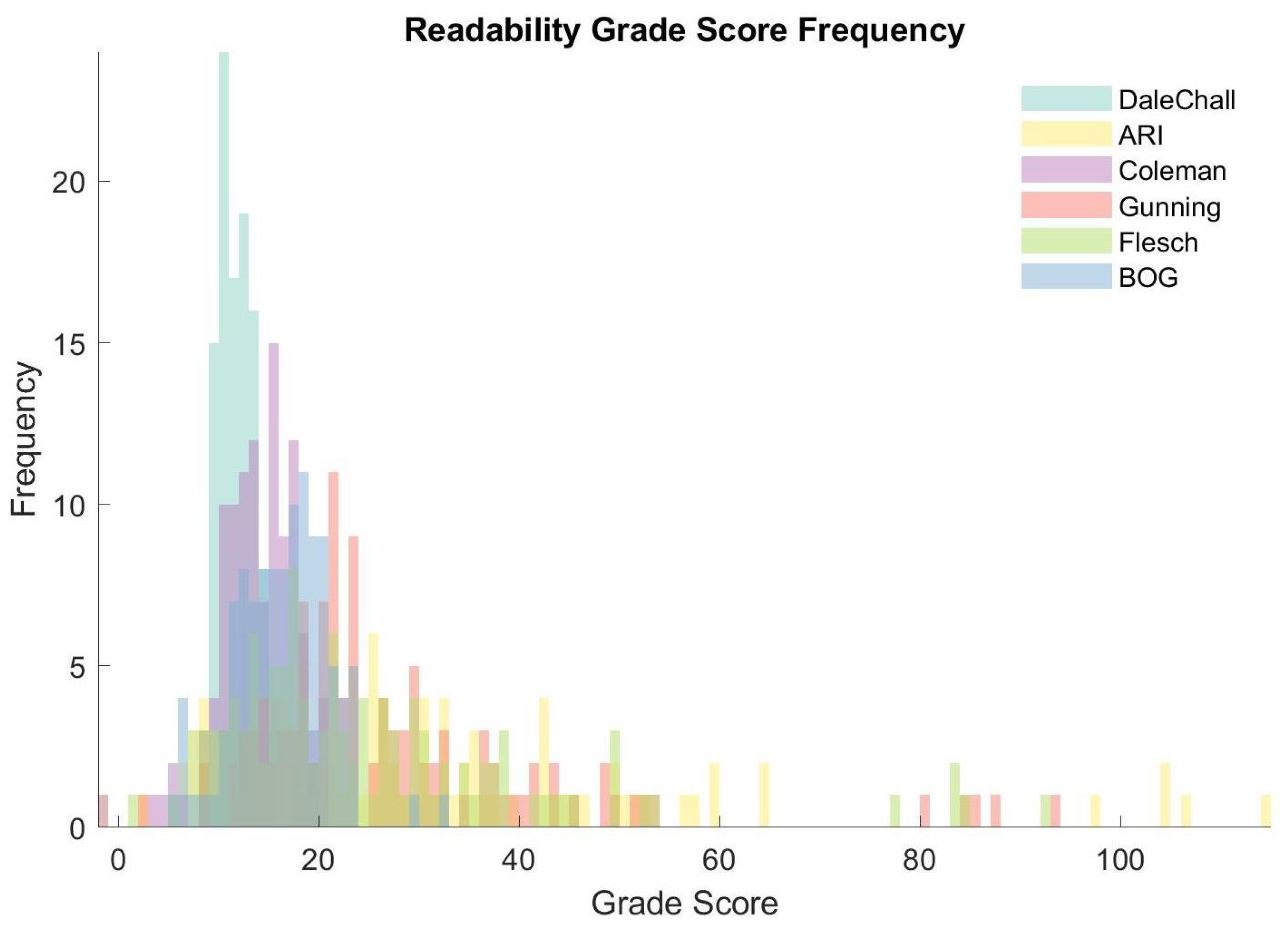
4.1. Linguistic Complexity of Regulatory Documentation
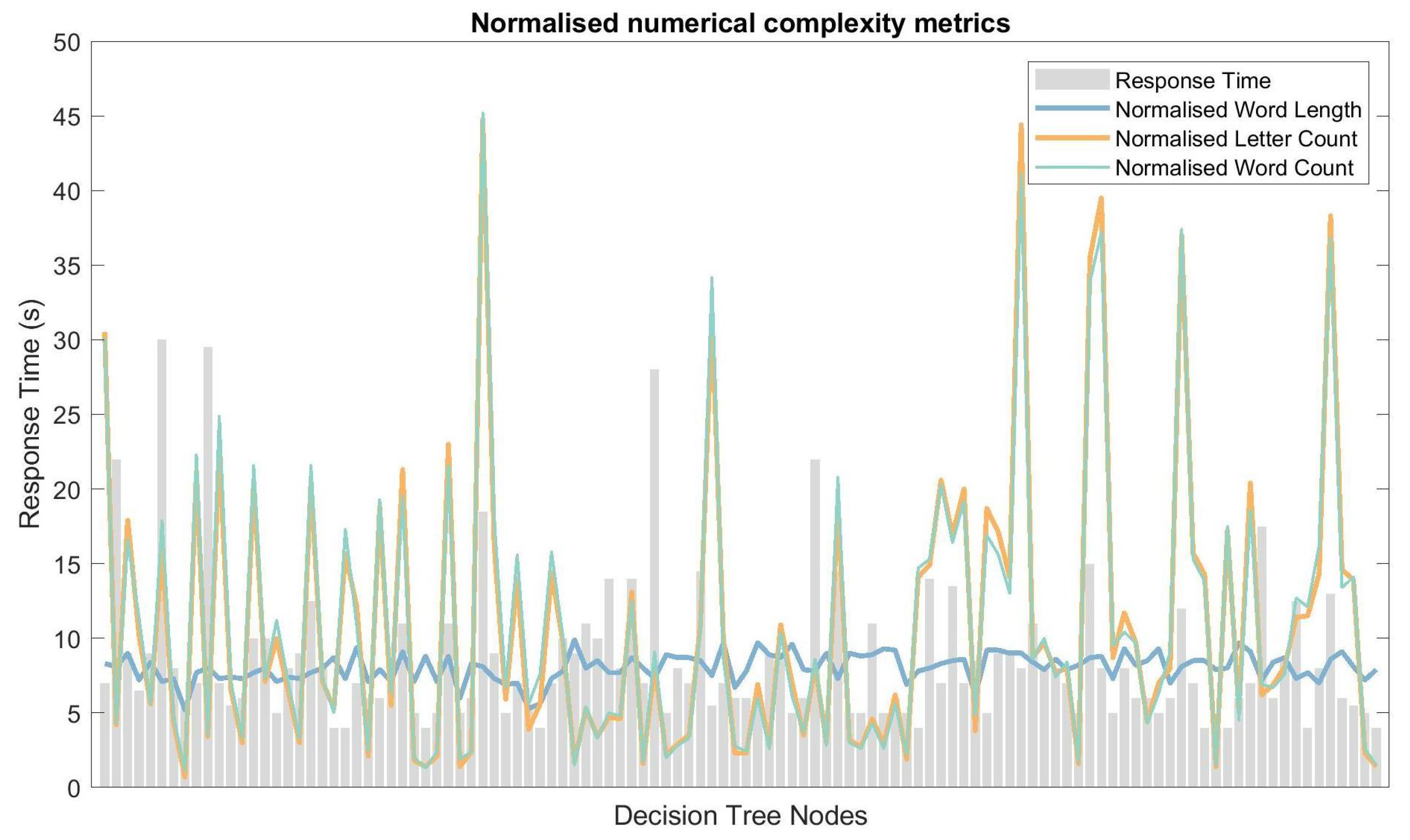
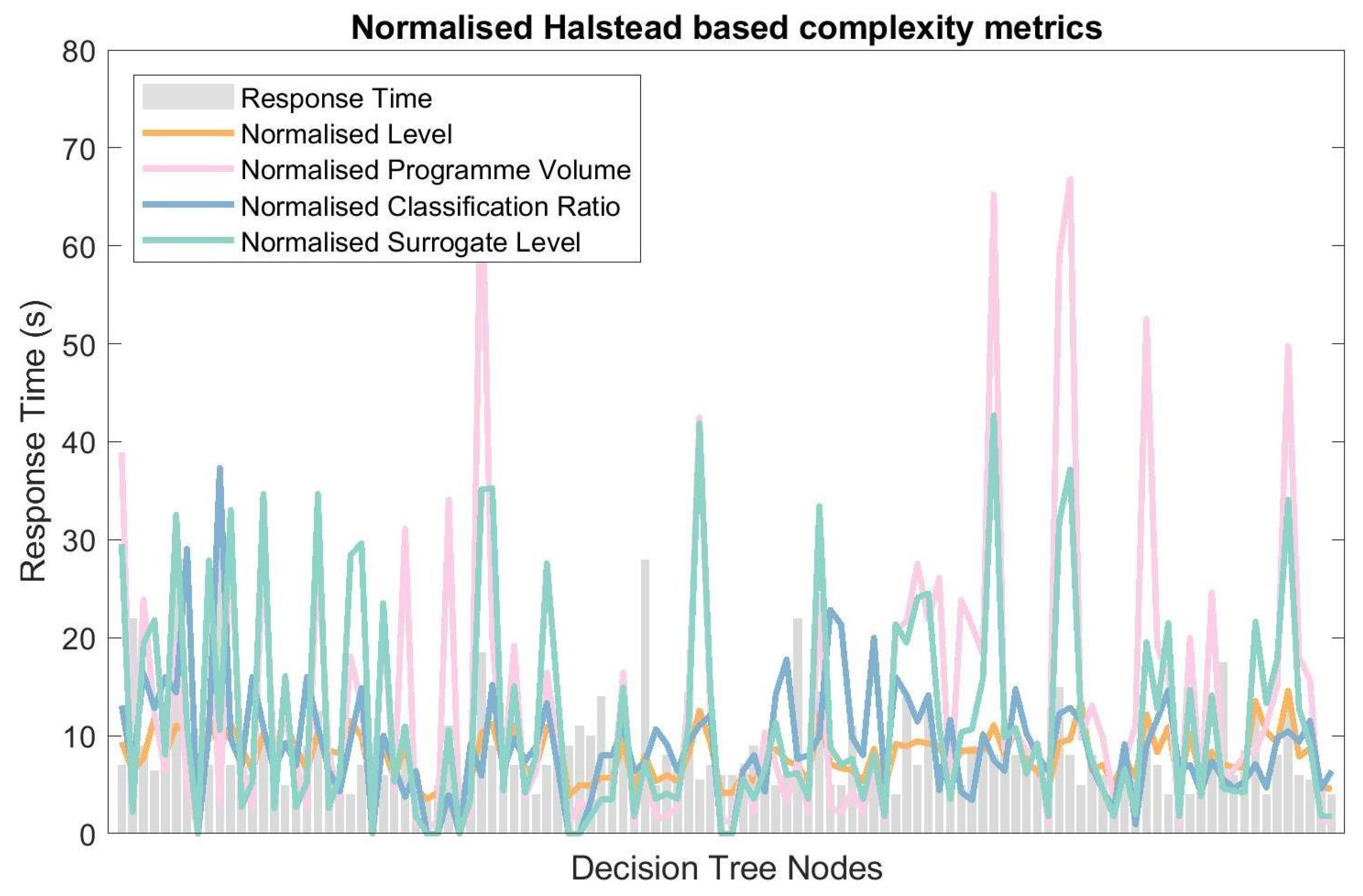
4.2. Response Time and Linguistic Complexity
5. Discussion
5.1. Linguistic Complexity of Regulatory Documentation
5.2. Response Time
5.3. Response Time and Linguistic Complexity
5.4. Considerations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- KPMG. The Changing Landscape of the Medical Devices Industry in the APAC Region. 2020. Available online: https://assets.kpmg/content/dam/kpmg/jp/pdf/2020/jp-medical-device-apac-en.pdf (accessed on 25 July 2021).
- Insights, F.B. Medical Device Market Size, Share and Industry Analysis by Type. 2021. Available online: https://www.fortunebusinessinsights.com/industry-reports/medical-devices-market-100085 (accessed on 25 July 2021).
- Office for Life Science. UK Medical Technology Sector, Bioscience and Health Technology Sector Statistics. 2019. Available online: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/910441/Bioscience_and_Health_Technology_Statistics_2019_Infographic_-_Medical_Technology.pdf (accessed on 25 July 2021).
- Em Agency; AGENCY, E.M. Medical Devices. Available online: https://www.ema.europa.eu/en/human-regulatory/overview/medical-devices (accessed on 25 July 2021).
- World Health Organization. Medical Device Regulations: Global Overview And Guiding Principles. 2003. Available online: https://apps.who.int/iris/handle/10665/42744 (accessed on 25 July 2021).
- Medical Device Coordination Group. Regulation (EU) 2017/745: Clinical Evidence Needed for Medical Devices Previously CE Marked under Directives 93/42/EEC or 90/385/EEC. A Guide for Manufacturers and Notified Bodies. Available online: https://ec.europa.eu/docsroom/documents/40904 (accessed on 25 July 2021).
- World Health Organization. Guidance for Post-Market Surveillance and Market Surveillance of Medical Devices, Including IVD; World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Soliman, E.; Mogefors, D.; Bergmann, J.H. Problem-driven innovation models for emerging technologies. Health Technol. 2020, 10, 1195–1206. [Google Scholar] [CrossRef]
- Ceross, A.; Bergmann, J. Evaluating the Presence of Software-as-a-Medical-Device in the Australian Therapeutic Goods Register. Prosthesis 2021, 3, 221–228. [Google Scholar] [CrossRef]
- Martindale, V.; Menache, A. The PIP scandal: An analysis of the process of quality control that failed to safeguard women from the health risks. J. R. Soc. Med. 2013, 106, 173–177. [Google Scholar] [CrossRef] [Green Version]
- News, D.I. The Metal-on-Metal Hip Implants Scandal. Available online: https://www.druginjurynews.com/news/metal-metal-hip-implants-scandal/ (accessed on 25 July 2021).
- The European Parliament and the Council of the European Union. Regulation (EU) 2017/745 of the European Parliament and of the Council of 5 April 2017 on Medical Devices. 2017. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32017R0745 (accessed on 25 July 2021).
- Medical Device Regulation Revision. Available online: https://www.bsigroup.com/en-GB/medical-devices/our-services/MDR-Revision/ (accessed on 25 July 2021).
- The European Parliament and the Council of the European Union. Council Directive 93/42/EEC of 14 June 1993 Concerning Medical Devices. 1993. Available online: https://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=CONSLEG:1993L0042:20071011:en:PDF (accessed on 25 July 2021).
- The European Parliament and the Council of the European Union. Regulation (EU) 2017/746 of the European Parliament and of the Council of 5 April 2017 on In Vitro Diagnostic Medical Devices. 2017. Available online: https://eur-lex.europa.eu/eli/reg/2017/746/oj (accessed on 25 July 2021).
- In Vitro Diagnostic Regulation Revision. Available online: https://www.bsigroup.com/en-GB/medical-devices/our-services/IVDR-Revision/ (accessed on 25 July 2021).
- Directive 98/79/EC of the European Parliament and of the Council of 27 October 1998 on In Vitro Diagnostic Medical Devices. 1998. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:31998L0079 (accessed on 25 July 2021).
- Government, U. Guidance for Medical Devices: EU Regulations for MDR and IVDR (Northern Ireland). Available online: https://www.gov.uk/guidance/medical-devices-eu-regulations-for-mdr-and-ivdr (accessed on 25 July 2021).
- Chowdhury, G.G. Natural language processing. Annu. Rev. Inf. Sci. Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef] [Green Version]
- Dale, E.; Chall, J.S. A formula for predicting readability: Instructions. Educ. Res. Bull. 1948, 27, 37–54. [Google Scholar]
- Chall, J.S.; Dale, E. Readability Revisited: The New Dale–Chall Readability Formula; Brookline Books: Cambridge, MA, USA, 1995. [Google Scholar]
- Frisson, S.; Pickering, M.J. The processing of familiar and novel senses of a word: Why reading Dickens is easy but reading Needham can be hard. Lang. Cogn. Process. 2007, 22, 595–613. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, X.L.; So, M.; Reder, L.M. Familiarity acts as a reduction in objective complexity. Mem. Cogn. 2020, 48, 1376–1387. [Google Scholar] [CrossRef] [PubMed]
- Benjamin, R.G. Reconstructing readability: Recent developments and recommendations in the analysis of text difficulty. Educ. Psychol. Rev. 2012, 24, 63–88. [Google Scholar] [CrossRef]
- Schuyler, M.R. A readability formula program for use on microcomputers. J. Read. 1982, 25, 560–591. [Google Scholar]
- Flesch, R. A new readability yardstick. J. Appl. Psychol. 1948, 32, 221. [Google Scholar] [CrossRef]
- Senter, R.; Smith, E.A. Automated Readability Index; Technical Report; Cincinnati University: Cincinnati, OH, USA, 1967. [Google Scholar]
- Thomas, G.; Hartley, R.D.; Kincaid, J.P. Test-retest and inter-analyst reliability of the automated readability index, Flesch reading ease score, and the fog count. J. Read. Behav. 1975, 7, 149–154. [Google Scholar] [CrossRef] [Green Version]
- Smith, E.A.; Kincaid, J.P. Derivation and validation of the automated readability index for use with technical materials. Hum. Factors 1970, 12, 457–564. [Google Scholar] [CrossRef]
- Coleman, M.; Liau, T.L. A computer readability formula designed for machine scoring. J. Appl. Psychol. 1975, 60, 283. [Google Scholar] [CrossRef]
- Zhou, S.; Jeong, H.; Green, P.A. How Consistent Are the Best-Known Readability Equations in Estimating the Readability of Design Standards? IEEE Trans. Prof. Commun. 2017, 60, 97–111. [Google Scholar] [CrossRef]
- Prabowo, R.; Thelwall, M. Sentiment analysis: A combined approach. J. Inf. 2009, 3, 143–157. [Google Scholar] [CrossRef]
- Gohil, S.; Vuik, S.; Darzi, A. Sentiment analysis of health care tweets: Review of the methods used. JMIR Public Health Surveill. 2018, 4, e5789. [Google Scholar] [CrossRef]
- Gai, P.; Kemp, M.H.; Sánchez Serrano, A.; Schnabel, I. Regulatory Complexity and the Quest for Robust Regulation. Number 8. Reports of the Advisory Scientific Committee. 2019. Available online: https://ideas.repec.org/p/srk/srkasc/20198.html (accessed on 25 July 2021).
- Colliard, J.E.; Georg, C.P. Measuring Regulatory Complexity. 2020. Available online: https://www.institutlouisbachelier.org/wp-content/uploads/2019/11/papier_jean-edouard-colliard.pdf (accessed on 25 July 2021).
- Spatt, C.S. Complexity of regulation. Harv. Bus. L. Rev. Online 2012, 3, 1. [Google Scholar]
- Gunning, R. The Technique of Clear Writing; McGraw-Hill: New York, NY, USA, 1952. [Google Scholar]
- Bothun, L.S.; Feeder, S.E.; Poland, G.A. Readability of Participant Informed Consent Forms and Informational Documents From Phase III COVID-19 Vaccine Clinical Trials in the United States. In Mayo Clinic Proceedings; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar] [CrossRef]
- Li, F. Annual report readability, current earnings, and earnings persistence. J. Account. Econ. 2008, 45, 221–247. [Google Scholar] [CrossRef]
- Miller, B.P. The effects of reporting complexity on small and large investor trading. Account. Rev. 2010, 85, 2107–2143. [Google Scholar] [CrossRef]
- Loughran, T.; McDonald, B. Measuring readability in financial disclosures. J. Financ. 2014, 69, 1643–1671. [Google Scholar] [CrossRef]
- Felsenfeld, C. The plain English movement. Can. Bus. LJ 1981, 6, 408. [Google Scholar]
- Securities and Exchange Commission. Plain English Disclosure. 1998. Available online: https://www.federalregister.gov/documents/1998/02/06/98-2889/plain-english-disclosure (accessed on 25 July 2021).
- DuBay, W.H.; The Principles of Readability. Impact Information. 2004. Available online: http://impact-information.com/impactinfo/readability02.pdf (accessed on 25 July 2021).
- Bonsall IV, S.B.; Leone, A.J.; Miller, B.P.; Rennekamp, K. A plain English measure of financial reporting readability. J. Account. Econ. 2017, 63, 329–357. [Google Scholar] [CrossRef]
- Nirmaldasan. StyleWriter’s Bog Index. Available online: https://strainindex.wordpress.com/2010/01/19/stylewriters-bog-index/m (accessed on 25 July 2021).
- Halstead, M.H. Elements of Software Science (Operating and Programming Systems Series); Elsevier Science Inc.: Amsterdam, The Netherlands, 1977. [Google Scholar]
- Flater, D.W. ’Software Science’ Revisited: Rationalizing Halstead’s System Using Dimensionless Units; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2018. [Google Scholar]
- Holbrook, A.; Cho, Y.I.; Johnson, T. The impact of question and respondent characteristics on comprehension and mapping difficulties. Int. J. Public Opin. Q. 2006, 70, 565–595. [Google Scholar] [CrossRef]
- Bergmann, J.H.; Hendricusdottir, R.; Lee, R. Regulatory Navigation: A Digital Tool to Understand Medical Device Classification Pathways. In Comprehensive Biotechnology, 3rd ed.; Moo-Young, M., Ed.; Pergamon: Oxford, UK, 2019; pp. 167–172. [Google Scholar] [CrossRef]
- Stahl, R.J. Using “Think-Time” and “Wait-Time” Skillfully in the Classroom. ERIC Digests. 1994. Available online: https://eric.ed.gov/?id=ED370885 (accessed on 25 July 2021).
- Natural Interaction Lab, University of Oxford. Oxford Global Guidance. 2021. Available online: https://www.oxfordglobalguidance.org (accessed on 25 July 2021).
- Lewis, M.L.; Frank, M.C. The length of words reflects their conceptual complexity. Cognition 2016, 153, 182–195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redish, J. Readability formulas have even more limitations than Klare discusses. ACM J. Comput. Doc. (JCD) 2000, 24, 132–137. [Google Scholar] [CrossRef]
- Hendricusdottir, R.; Hussain, A.; Milnthorpe, W.; Bergmann, J.H. Lack of Support in Medical Device Regulation within Academia. Prosthesis 2021, 3, 1–8. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Complexity Method | Equation |
|---|---|
| Dale–Chall Readability Formula [21] | |
| Flesch Kincaid Grade Level [25] | |
| Automated Readability Index Formula [28] | |
| Coleman Liau Index Formula (adapted from [31]) | |
| Gunning Fog Formula [31] |
| Complexity Metric | Pearson’s Correlation Coefficient (p-Value) |
|---|---|
| Letter Count | 0.204 (0.015) |
| Word Count | 0.214 (0.011) |
| Syllable Count | 0.202 (0.016) |
| Syllables per Word | −0.087 (0.180) |
| Letters per Word | −0.019 (0.421) |
| Dale–Chall | 0.003 (0.488) |
| ARI | 0.158 (0.048) |
| Coleman Liau | 0.055 (0.283) |
| Gunning Fog | 0.133 (0.081) |
| Flesch Grade | 0.149 (0.059) |
| Bog Index | 0.153 (0.054) |
| Complexity Metrics | Pearson’s Correlation Coefficient (p-Value) |
|---|---|
| Operator Count | 0.200 (0.017) |
| Operand Count | 0.193 (0.021) |
| Programme Length | 0.200 (0.020) |
| Vocabulary Size | 0.201 (0.020) |
| Classification Ratio | 0.228 (0.008) |
| Level | 0.209 (0.013) |
| Surrogate Level | 0.214 (0.011) |
| Programme Volume | 0.197 (0.019) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arnould, A.; Hendricusdottir, R.; Bergmann, J. The Complexity of Medical Device Regulations Has Increased, as Assessed through Data-Driven Techniques. Prosthesis 2021, 3, 314-330. https://doi.org/10.3390/prosthesis3040029
Arnould A, Hendricusdottir R, Bergmann J. The Complexity of Medical Device Regulations Has Increased, as Assessed through Data-Driven Techniques. Prosthesis. 2021; 3(4):314-330. https://doi.org/10.3390/prosthesis3040029
Chicago/Turabian StyleArnould, Arthur, Rita Hendricusdottir, and Jeroen Bergmann. 2021. "The Complexity of Medical Device Regulations Has Increased, as Assessed through Data-Driven Techniques" Prosthesis 3, no. 4: 314-330. https://doi.org/10.3390/prosthesis3040029
APA StyleArnould, A., Hendricusdottir, R., & Bergmann, J. (2021). The Complexity of Medical Device Regulations Has Increased, as Assessed through Data-Driven Techniques. Prosthesis, 3(4), 314-330. https://doi.org/10.3390/prosthesis3040029