Appendix A. Mathematica Notebook for Quantum-Inspired Classifications
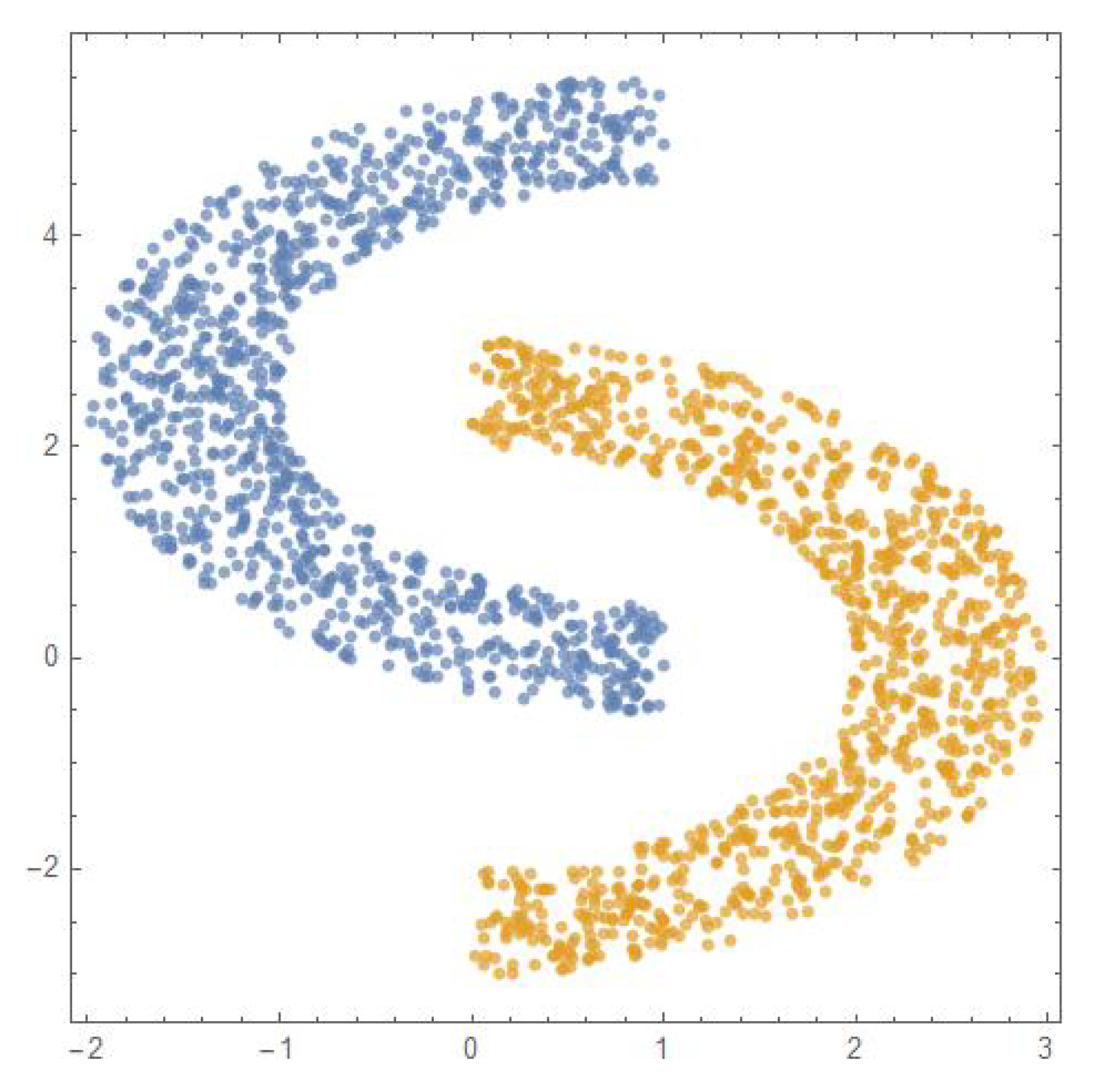
DBSCAN with a toy dataset
0.8455 is the Helstrom accuracy on the training set
0.8365 is the Helstrom accuracy on the test set
0.503 is the Helstrom accuracy on the training set
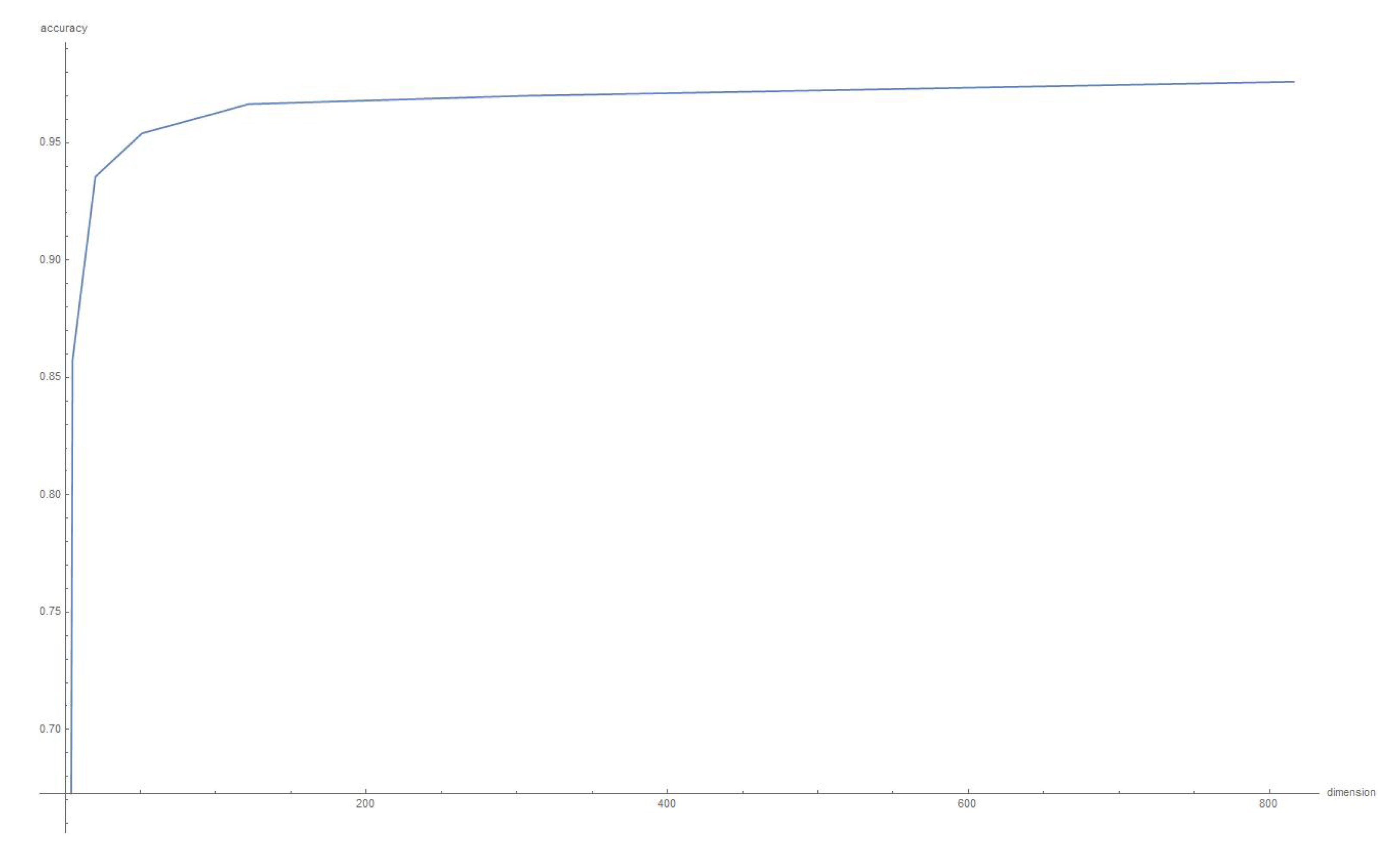
Heltrom classifier gives the best average success probability
but it does not work with the same centroid (such as 1/2 I).
0.73 is the Helstrom accuracy on the training set




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









