Measurement-Based Adaptation Protocol with Quantum Reinforcement Learning in a Rigetti Quantum Computer



Abstract
:1. Introduction
2. Results
2.1. Measurement-Based Adaptation Protocol with Quantum Reinforcement Learning
- The environment system (E) contains the reference state copies.
- The register (R) interacts with E and obtains information from it.
- The agent (A) is adapted by digital feedback depending on the outcome of the measurement of the register.
2.2. Experimental Setup: Rigetti Forest Cloud Quantum Computer
Python-Implemented Algorithm
- Reward and punishment ratios: and .
- Exploration range: .
- The unitary transformation matrices: .
- Partially-random unitary operator: .
- Initial values of the random angles: . Makes for the first iteration.
- Initial value of the iteration index: .
- Number of iterations: N.
- Step 1: While , go to Step 2.
- Step 2: If
- Step 3: First quantum algorithm.First, we define the agent, environment and register qubits as,and act upon the environment,Then, we haveWe apply the policyand measure the register qubit storing the result in .
- Step 4: Second quantum algorithm.Subsequently, we act with on the agent qubit in order to approach it to the environment state, :Afterwards, we measure this qubit and store the result in a classical register array. We repeat Step 4 a total of 8192 times to determine the state created after applying .
- In this last step, we apply the reward function,and increase the iteration index by one after it: . Go to Step 1.
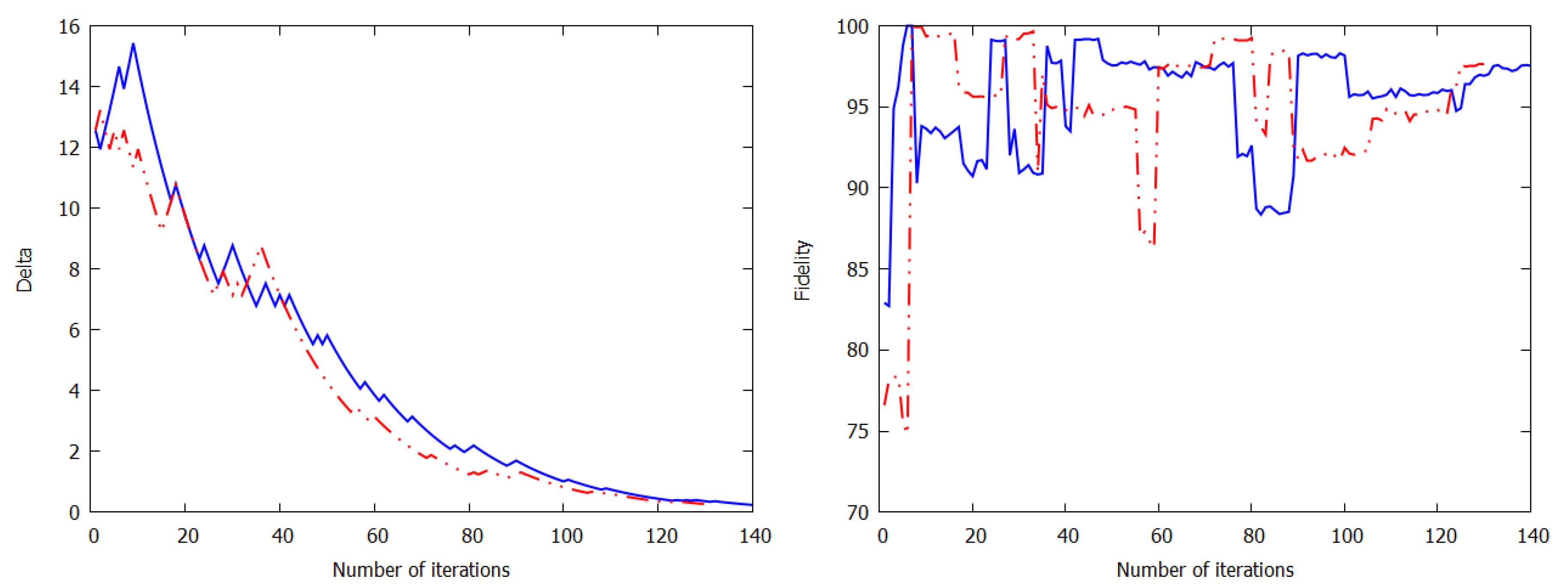
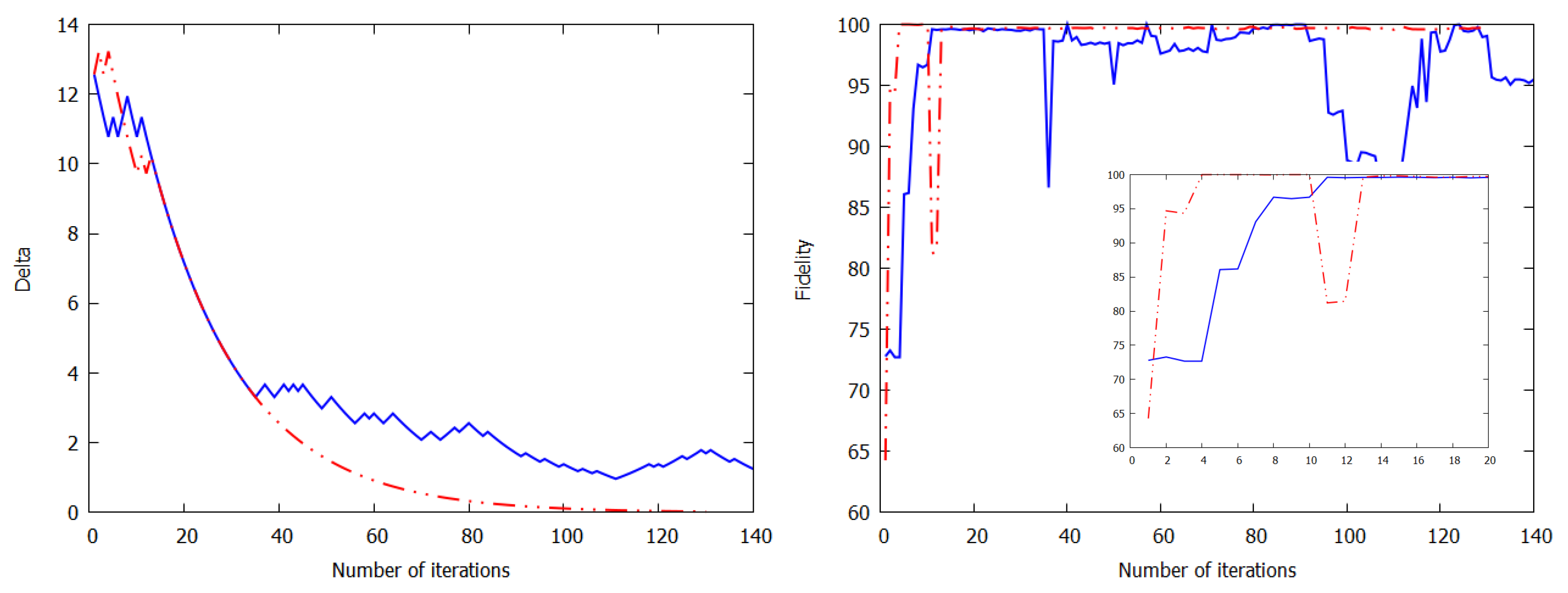
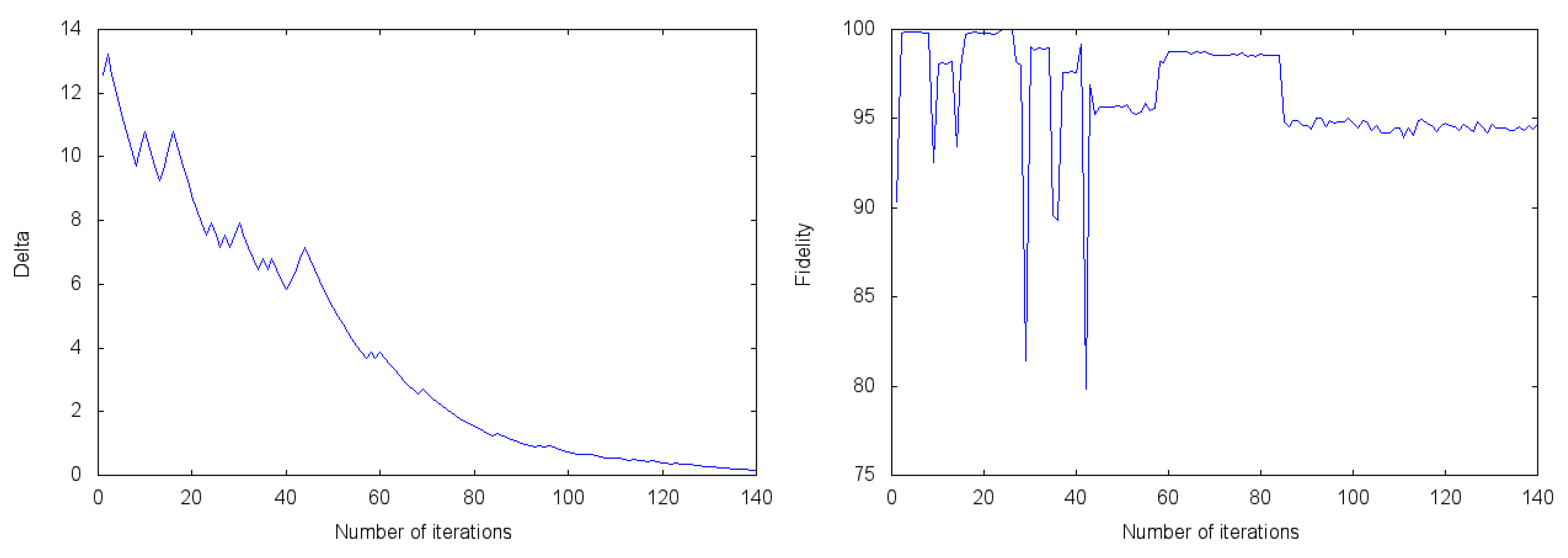
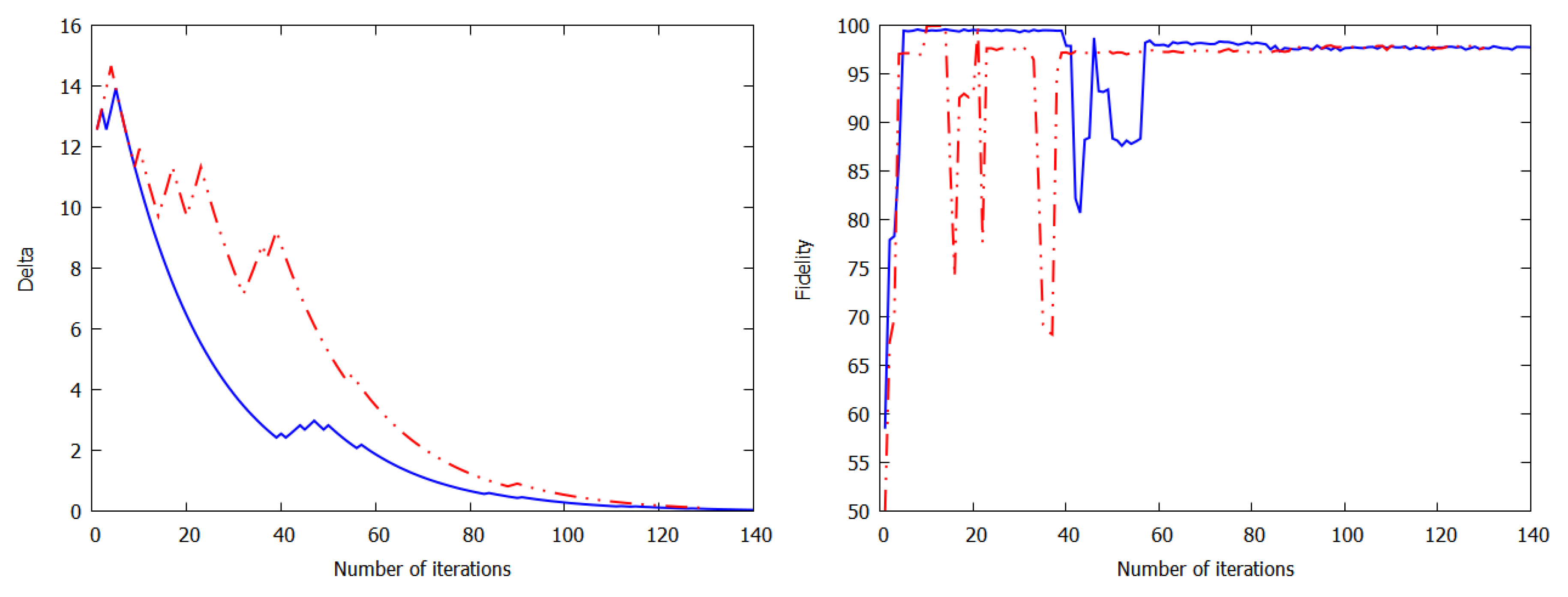
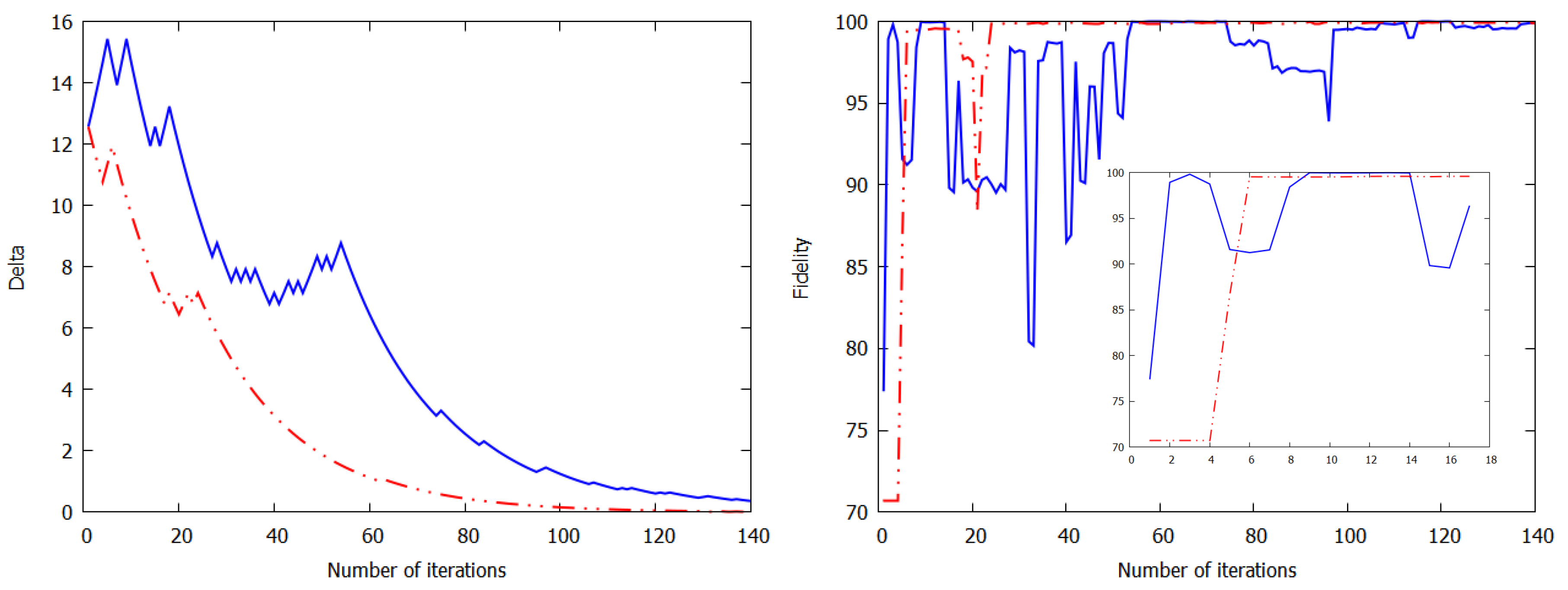
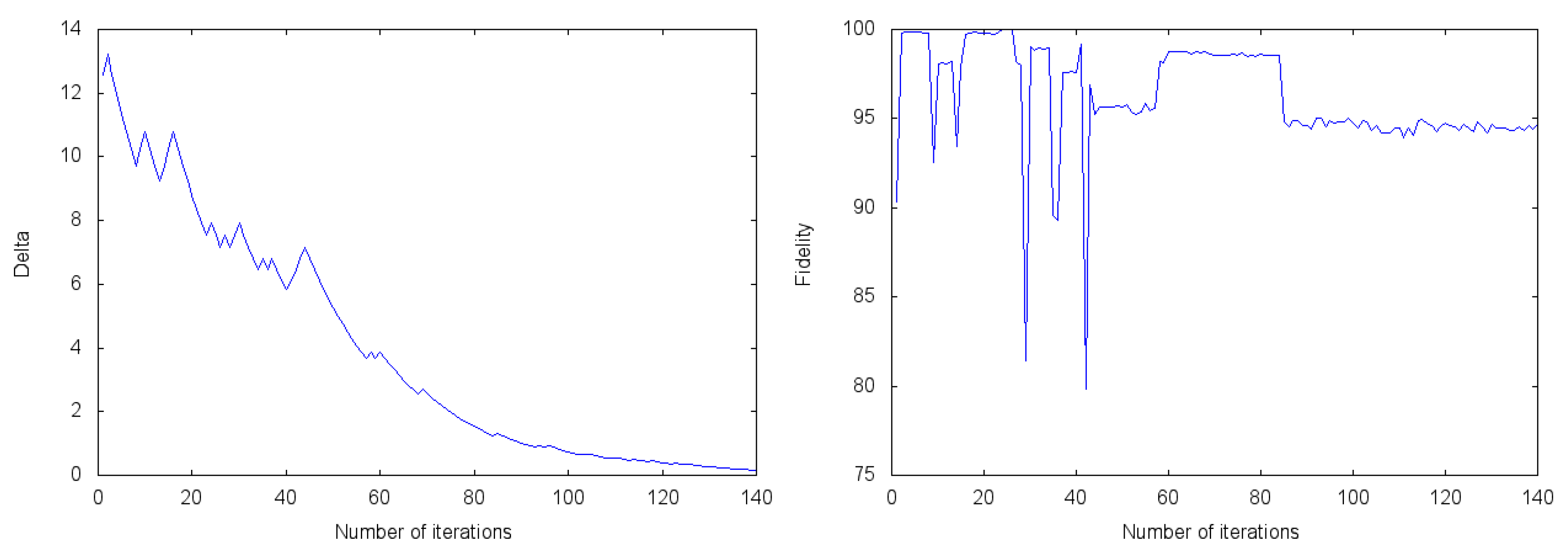
2.3. Experimental Results of Quantum Reinforcement Learning with the Rigetti Cloud Quantum Computer
3. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Albarrán-Arriagada, F.; Retamal, J.C.; Solano, E.; Lamata, L. Measurement-based adaptation protocol with quantum reinforcement learning. Phys. Rev. A 2018, 98, 042315. [Google Scholar] [CrossRef] [Green Version]
- Albarrán-Arriagada, F.; Retamal, J.C.; Solano, E.; Lamata, L. Reinforcement learning for semi-autonomous approximate quantum eigensolver. Mach. Learn. Sci. Technol. 2020, 1, 015002. [Google Scholar] [CrossRef]
- Harrow, A.W.; Hassidim, A.; Lloyd, S. Quantum algorithm for linear systems of equations. Phys. Rev. Lett. 2009, 103, 150502. [Google Scholar] [CrossRef] [PubMed]
- Wiebe, N.; Braun, D.; Lloyd, S. Quantum algorithm for data fitting. Phys. Rev. Lett. 2012, 109, 050505. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, S.; Mohseni, M.; Rebentrost, P. Quantum algorithms for supervised and unsupervised machine learning. arXiv 2013, arXiv:1307.0411. [Google Scholar]
- Rebentrost, P.; Mohseni, M.; Lloyd, S. Quantum support vector machine for big data classification. Phys. Rev. Lett. 2014, 113, 130503. [Google Scholar] [CrossRef]
- Wiebe, N.; Kapoor, A.; Svore, K.M. Quantum algorithms for nearest-neighbor methods for supervised and unsupervised learning. Quantum Inf. Comput. 2015, 15, 316. [Google Scholar]
- Lloyd, S.; Mohseni, M.; Rebentrost, P. Quantum principal component analysis. Nat. Phys. 2014, 10, 631. [Google Scholar] [CrossRef] [Green Version]
- Lau, H.K.; Pooser, R.; Siopsis, G.; Weedbrook, C. Quantum machine learning over infinite dimensions. Phys. Rev. Lett. 2017, 118, 080501. [Google Scholar] [CrossRef] [Green Version]
- Schuld, M.; Sinayskiy, I.; Petruccione, F. An introduction to quantum machine learning. Contemp. Phys. 2015, 56, 172. [Google Scholar] [CrossRef] [Green Version]
- Adcock, J.; Allen, E.; Day, M.; Frick, S.; Hinchli, J.; Johnson, M.; Morley-Short, S.; Pallister, S.; Price, A.; Stanisic, S. Advances in quantum machine learning. arXiv 2015, arXiv:1512.02900. [Google Scholar]
- Dunjko, V.; Taylor, J.M.; Briegel, H.J. Quantum-enhanced machine learning. Phys. Rev. Lett. 2016, 117, 130501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dunjko, V.; Briegel, H.J. Machine learning & artificial intelligence in the quantum domain: A review of recent progress. Rep. Prog. Phys. 2018, 81, 074001. [Google Scholar] [PubMed] [Green Version]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195. [Google Scholar] [CrossRef]
- Lamata, L. Quantum machine learning and quantum biomimetics: A perspective. arXiv 2020, arXiv:2004.12076. [Google Scholar]
- Biswas, R.; Jiang, Z.; Kechezhi, K.; Knysh, S.; Mandrà, S.; O’Gorman, B.; Perdomo-Ortiz, A.; Petukhov, A.; Realpe-Gómez, J.; Rieffel, E.; et al. A NASA perspective on quantum computing: Opportunities and challenges. Parallel Comput. 2017, 64, 81. [Google Scholar] [CrossRef] [Green Version]
- Perdomo-Ortiz, A.; Benedetti, M.; Realpe-Gómez, J.; Biswas, R. Opportunities and challenges for quantum-assisted machine learning in near-term quantum computers. Quantum Sci. Technol. 2018, 3, 030502. [Google Scholar] [CrossRef] [Green Version]
- Perdomo-Ortiz, A.; Feldman, A.; Ozaeta, A.; Isakov, S.V.; Zhu, Z.; O’Gorman, B.; Katzgraber, H.G.; Diedrich, A.; Neven, H.; de Kleer, J.; et al. Readiness of quantum optimization machines for industrial applications. Phys. Rev. Appl. 2019, 12, 014004. [Google Scholar] [CrossRef] [Green Version]
- Sasaki, M.; Carlini, A. Quantum learning and universal quantum matching machine. Phys. Rev. A 2002, 66, 022303. [Google Scholar] [CrossRef] [Green Version]
- Benedetti, M.; Realpe-Gómez, J.; Biswas, R.; Perdomo-Ortiz, A. Quantum-Assisted Learning of Hardware-Embedded Probabilistic Graphical Models. Phys. Rev. X 2017, 7, 041052. [Google Scholar] [CrossRef] [Green Version]
- Benedetti, M.; Realpe-Gómez, J.; Perdomo-Ortiz, A. Quantum-assisted helmholtz machines: A quantum-classical deep learning framework for industrial datasets in near-term devices. Quantum Sci. Technol. 2018, 3, 034007. [Google Scholar] [CrossRef] [Green Version]
- Aïmeur, E.; Brassard, G.; Gambs, S. Quantum speed-up for unsupervised learning. Mach. Learn. 2013, 90, 261. [Google Scholar] [CrossRef] [Green Version]
- Melnikov, A.A.; Nautrup, H.P.; Krenn, M.; Dunjko, V.; Tiersch, M.; Zeilinger, A.; Briegel, H.J. Active learning machine learns to create new quantum experiments. Proc. Natl. Acad. Sci. USA 2018, 115, 1221. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alvarez-Rodriguez, U.; Lamata, L.; Escandell-Montero, P.; Martín-Guerrero, J.D.; Solano, E. Supervised Quantum Learning without Measurements. Sci. Rep. 2017, 7, 13645. [Google Scholar] [CrossRef]
- Paparo, G.D.; Dunjko, V.; Makmal, A.; Martin-Delgado, M.A.; Briegel, H.J. Quantum Speedup for Active Learning Agents. Phys. Rev. X 2014, 4, 031002. [Google Scholar] [CrossRef]
- Lamata, L. Basic protocols in quantum reinforcement learning with superconducting circuits. Sci. Rep. 2017, 7, 1609. [Google Scholar] [CrossRef] [Green Version]
- Cárdenas-López, F.A.; Lamata, L.; Retamal, J.C.; Solano, E. Multiqubit and multilevel quantum reinforcement learning with quantum technologies. PLoS ONE 2018, 13, e0200455. [Google Scholar] [CrossRef]
- Dong, D.; Chen, C.; Li, H.; Tarn, T.J. Quantum reinforcement learning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2008, 38, 1207–1220. [Google Scholar] [CrossRef] [Green Version]
- Crawford, D.; Levit, A.; Ghadermarzy, N.; Oberoi, J.S.; Ronagh, P. Reinforcement learning using quantum Boltzmann machines. Quant. Inf. Comput. 2018, 18, 51. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Prentice Hall: Upper Saddle River, NJ, USA, 1995. [Google Scholar]
- Ristè, D.; Silva, M.P.D.; Ryan, C.A.; Cross, A.W.; Córcoles, A.D.; Smolin, J.A.; Gambetta, J.M.; Chow, J.M.; Johnson, B.R. Demonstration of quantum advantage in machine learning. NPJ Quantum Inf. 2017, 3, 16. [Google Scholar] [CrossRef]
- Quantum Computing Powered by Light. Available online: https://www.xanadu.ai (accessed on 16 May 2020).
- The Quantum Cloud Service Built for Business. Available online: https://www.dwavesys.com/home (accessed on 16 May 2020).
- Quantum Computing. Available online: https://www.research.ibm.com/ibm-q/ (accessed on 16 May 2020).
- Think Quantum. Available online: https://www.rigetti.com (accessed on 16 May 2020).
- Yu, S.; Albarrán-Arriagada, F.; Retamal, J.C.; Wang, Y.-T.; Liu, W.; Ke, Z.-J.; Meng, Y.; Li, Z.-P.; Tang, J.-S.; Solano, E.; et al. Reconstruction of a Photonic Qubit State with Quantum Reinforcement Learning. Adv. Quantum Technol. 2019, 2, 1800074. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.36 | 0.24 | 0.18 | 0.03 | 0.05 | 0.24 | 0.16 | |
|---|---|---|---|---|---|---|---|
| 99.89 | 99.72 | 99.53 | 99.20 | 97.72 | 97.53 | 94.72 | |
| Initial environment state |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olivares-Sánchez, J.; Casanova, J.; Solano, E.; Lamata, L. Measurement-Based Adaptation Protocol with Quantum Reinforcement Learning in a Rigetti Quantum Computer. Quantum Rep. 2020, 2, 293-304. https://doi.org/10.3390/quantum2020019
Olivares-Sánchez J, Casanova J, Solano E, Lamata L. Measurement-Based Adaptation Protocol with Quantum Reinforcement Learning in a Rigetti Quantum Computer. Quantum Reports. 2020; 2(2):293-304. https://doi.org/10.3390/quantum2020019
Chicago/Turabian StyleOlivares-Sánchez, Julio, Jorge Casanova, Enrique Solano, and Lucas Lamata. 2020. "Measurement-Based Adaptation Protocol with Quantum Reinforcement Learning in a Rigetti Quantum Computer" Quantum Reports 2, no. 2: 293-304. https://doi.org/10.3390/quantum2020019
APA StyleOlivares-Sánchez, J., Casanova, J., Solano, E., & Lamata, L. (2020). Measurement-Based Adaptation Protocol with Quantum Reinforcement Learning in a Rigetti Quantum Computer. Quantum Reports, 2(2), 293-304. https://doi.org/10.3390/quantum2020019