Abstract
Robust object detection in autonomous driving is challenged by inherent limitations of conventional frame-based cameras, such as motion blur and limited dynamic range. In contrast, event-based cameras, which operate asynchronously and capture rapid changes with high temporal resolution and expansive dynamic range, offer a promising augmentation. While the previous research on event-based object detection has predominantly focused on algorithmic enhancements via advanced preprocessing and network optimizations to improve detection accuracy, the practical engineering and integration challenges of deploying these sensors in real-world systems remain underexplored. To address this gap, our study investigates the integration of event-based cameras as a complementary sensor modality in autonomous driving. We adapted a conventional frame-based detection model (YOLOv8) for event-based inputs by training it on the GEN1 dataset, achieving a mean average precision (mAP) of 70.1%, a significant improvement over previous benchmarks. Additionally, we developed a real-time object detection pipeline optimized for event-based data, integrating it into the CARLA simulation environment and ROS for system prototyping. The model was further refined using transfer learning to better adapt to simulation conditions, and the complete pipeline was validated across diverse simulated scenarios to address practical challenges. These results underscore the feasibility of incorporating event cameras into existing perception systems, paving the way for their broader deployment in autonomous vehicle applications.
1. Introduction
Autonomous driving systems have gained significant attention in recent years, promising a transformative shift in transportation with the potential to improve safety and efficiency [1]. At the core of these systems are sensors such as cameras, radar, LiDAR, and ultrasound, which collectively enable vehicles to perceive and navigate their environments [2]. Among these, vision cameras play a critical role in detecting and interpreting real-world driving scenarios, which is essential to prevent potential traffic accidents and enable intelligent decision making. Object detection, in particular, is a cornerstone of perception systems, enabling vehicles to identify and track obstacles, pedestrians, and other critical entities in dynamic environments [3].
Despite their widespread application, conventional frame-based vision systems face several inherent challenges when deployed in real-world driving scenarios. First, they are highly susceptible to extreme variations in illumination, including overexposure in bright sunlight and reduced visibility in low-light conditions. Second, high-speed motion often introduces motion blur in captured frames, compromising the effectiveness of subsequent object detection algorithms. Additionally, frame-based cameras must navigate a fundamental trade-off between latency and bandwidth: increasing frame rates reduces perceptual latency but imposes greater bandwidth requirements, while lower frame rates conserve bandwidth but fail to capture critical scene dynamics [4,5]. These limitations significantly hinder their reliability in fast-paced and complex driving scenarios.
To address these challenges, event-based vision systems have emerged as a promising augmentation. Unlike frame-based cameras, event cameras operate asynchronously, detecting changes in brightness at individual pixels with microsecond-level precision [6]. This unique mechanism allows event cameras to excel under high-dynamic-range conditions, effectively capturing motion without suffering from motion blur or latency issues. Moreover, their ability to process only relevant changes in the scene reduces data redundancy and leads to significant energy savings compared to conventional cameras. These advantages make event cameras particularly well-suited for autonomous driving tasks, where high-speed and high-accuracy detection are essential.
While recent research has explored object detection with event cameras using CNNs, SNNs, and neuromorphic methods [7,8], the majority of studies focus on improving accuracy through advanced preprocessing techniques and network optimizations. However, practical integration and engineering challenges for real-world autonomous driving systems remain underexplored. To bridge this gap, this study investigates the practical integration of event cameras into autonomous driving systems, focusing on their potential as a complementary sensor modality similar to radar and LiDAR. Specifically, we aim to develop a robust framework for event-based object detection that can be seamlessly integrated into existing perception systems, thereby supporting the further development of detection algorithms and enabling extensions to downstream applications such as end-to-end control systems.
The contribution of this paper is summarized as follows: (1) Proposed Framework for Event-Based Detection: We introduce a training framework to adapt frame-based object detection models, such as YOLOv8, for event-based data. Leveraging transfer learning, we fine-tuned pre-trained models using small event image datasets, achieving competitive performance. (2) Real-Time Detection Pipeline: We developed a real-time event-based object detection pipeline for autonomous driving. This pipeline was implemented in CARLA and integrated with a robot operating system (ROS), demonstrating its feasibility and real-time capabilities for research and prototyping. (3) Robust Validation in Simulated Scenarios: We designed diverse test scenarios in the CARLA simulator to validate the framework and pipeline. These scenarios replicated real-world challenges, such as dynamic environments, variable lighting, and dense traffic, demonstrating robustness and reliability.
2. Related Work
2.1. Event-Camera and Neuromorphic Vision
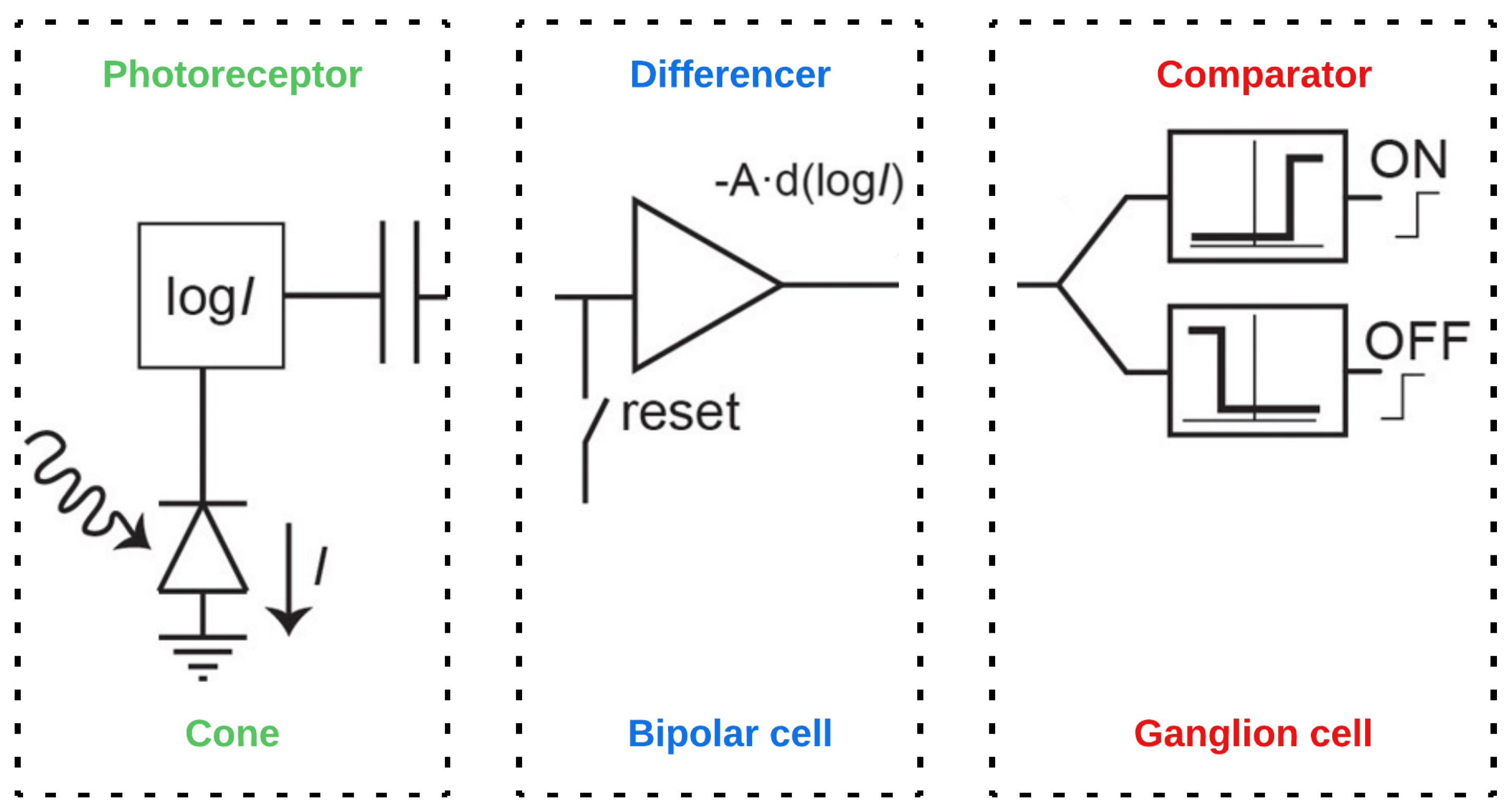
Event cameras, or dynamic vision sensors (DVS), operate on a principle that emulates the biological retina, capturing changes in light intensity rather than continuously recording images at fixed intervals. Each pixel in an event camera independently detects luminance changes and generates an event only when these changes exceed a predefined threshold [6]. This mechanism allows for high-speed data output with low latency, as the camera focuses solely on significant alterations in the scene rather than redundant static information. The output from each pixel is characterized by a tuple (x, y, p, t), where (x, y) represents the spatial coordinates of the pixel, p indicates the polarity of the change (positive or negative), and t denotes the timestamp of the event. The event data structure is inherently time-related and provides a collection of discrete points that convey rich spatial and temporal information. This facilitates efficient processing of dynamic scenes, as the asynchronous nature of event generation allows for capturing rapid movements with high temporal resolution and a wide dynamic range. By focusing on changes in luminance rather than absolute brightness values, event cameras can effectively reduce data redundancy and computational complexity, making them particularly advantageous for applications requiring real-time processing [7]. The working principle of a DVS is depicted in Figure 1 below:
Figure 1.
Working principle of a Dynamic Vision Sensor [9].
2.2. Object Detection with Event Cameras
The unique working principle of event cameras, such as their asynchronous operation, high temporal resolution, and sparse data output, make object detection fundamentally different from traditional frame-based approaches. Unlike conventional cameras that capture dense, synchronous frames, event cameras generate sparse event streams that encode changes in light intensity at the pixel level. This asynchronous and sparse nature requires specialized methods to process and interpret event data effectively, particularly for real-time object detection in dynamic environments. Research on object detection with event cameras can be broadly divided into three major directions.
Dense neural networks (DNNs). The most common and practical approach to object detection with event cameras involves adapting dense neural networks (DNNs), particularly convolutional neural networks (CNNs), to process event data. To make event data compatible with DNNs, researchers often preprocess the sparse event streams into dense representations, such as event frames [10,11] or voxel grids [12]. The early work in this area relied on single event representations generated from short temporal windows. This limited the ability to detect slowly moving objects, as relevant information outside the window was excluded. Recent advancements have addressed this issue by incorporating recurrent neural network (RNN) layers [13,14,15], which improve detection performance by capturing temporal dependencies over longer periods. However, this approach sacrifices the spatio-temporal richness of event data, leading to increased memory and computational overhead. Despite this limitation, CNN-based methods remain popular due to their simplicity, robustness, and compatibility with existing deep learning frameworks.
Graph neural networks (GNNs). One research direction focuses on using graph neural networks (GNNs) to model event data as a spatio-temporal graph [16]. In this approach, each event is treated as a node, and edges are established between events that are close in both space and time. GNNs excel at capturing the relationships between events, making them well-suited for processing the interconnected nature of event streams. However, designing GNN architectures that can propagate information over large spatio-temporal distances remains a challenge, particularly for slowly moving objects. Additionally, aggressive sub-sampling of events is often required to maintain low-latency inference, which can lead to the loss of crucial information [15]. GNN-based methods face critical failure modes in scenarios with high event rates, such as fast camera motion or scenes with numerous moving objects. The computational complexity of GNNs scales poorly with the number of events, leading to prohibitive processing times and memory requirements in real-world applications. These methods also struggle with generalization across different event camera models due to their sensitivity to event distribution patterns. Furthermore, the graph construction process often introduces hyperparameters that require careful tuning for each specific scenario, limiting the practical utility of GNN approaches in dynamic or unpredictable environments.
Spiking neural networks (SNNs). Another promising field of research explores spiking neural networks (SNNs) [17,18], which are biologically inspired and process information using discrete spikes. SNNs are particularly well-suited for event data due to their asynchronous and sparse processing nature. However, the non-differentiable spike generation mechanism poses significant challenges for training and optimization. While some workarounds, such as propagating features without thresholds [19], have been proposed, they often result in the loss of the sparse-processing property in deeper layers. Additionally, although neuromorphic hardware like IBM’s TrueNorth and Intel’s Loihi have been developed to support SNNs, these specialized processors are not yet widely available. As a result, SNNs remain in the early stages of development, and their performance in object detection tasks lags behind traditional DNNs. SNN-based detection methods exhibit substantial limitations in practice. They frequently fail when presented with objects of varying scales or when scene illumination changes rapidly. The inherent difficulty in training deep SNNs leads to models with insufficient representational capacity for complex detection tasks. When implemented on general-purpose hardware rather than specialized neuromorphic processors, SNNs lose their theoretical efficiency advantages and often perform significantly worse than both CNN and GNN alternatives. Current SNN architectures also demonstrate poor robustness against noise in event streams, which is common in real-world sensing environments, resulting in unreliable detection under suboptimal conditions.
In this work, we focus on CNN-based methods for event-based object detection, building on the strengths of dense neural networks while addressing the challenges of processing sparse event data. CNNs are widely used in traditional frame-based object detection due to their ability to extract hierarchical features from dense, grid-like data. By preprocessing event streams into dense representations, we enable the use of well-established CNN architectures like YOLO [20] for event-based object detection. This approach provides a practical and efficient solution for real-time applications, particularly in autonomous driving scenarios where low latency and high accuracy are critical. While acknowledging the limitations of CNN-based approaches described above, our work aims to develop mitigation strategies that preserve more of the temporal information during the event-to-frame conversion process. We also recognize that no single approach currently provides a complete solution for all event-based detection scenarios, and a comprehensive understanding of each method’s failure modes is essential for advancing the field.
2.3. Automotive Application with Event Detection
The recent research has explored various methodologies for leveraging event-based detection in autonomous driving. Advanced frameworks such as the recurrent event-camera detector(RED) [14] and recurrent vision transformer (RVT) [15] demonstrate the effectiveness of using event streams to model sequential data. RED introduces a recurrent architecture with temporal consistency loss, enabling high accuracy by directly training on raw events without reconstructing intensity images, outperforming feed-forward methods. RVT achieves state-of-the-art performance with fast inference and efficient design, leveraging multi-stage processing for low-latency, high-accuracy event detection. Another noteworthy approach is the joint detection framework (JDF) [5], which combines event-based and frame-based perception. By fusing these two modalities within a convolutional neural network (CNN) and incorporating spiking neural networks to generate visual attention maps, JDF achieves effective synchronization of event and frame data streams. This hybrid method highlights the benefits of integrating event-based vision with traditional image-based systems in automotive applications.
Pedestrian detection, in particular, is an essential safety-critical task in autonomous driving. A mixed-frame/event driven detector [21] leverages a dynamic and active pixel sensor (DAVIS) to detect pedestrians in a traffic monitoring scenario by combining conventional grayscale frames and asynchronous event data. Using YOLO-based models and a confidence map fusion method, the approach achieves higher accuracy, faster frame rates, and lower latency compared to conventional cameras. Recently, another hybrid event- and frame-based object detector [22] that combines the high temporal resolution and efficiency of event cameras with the rich information of standard RGB cameras. The method achieves low-latency, high-rate object detection, matching the performance of a 5000-fps camera with the bandwidth of a 45-fps camera, paving the way for efficient, robust perception in advanced driver assistance systems.
However, all the aforementioned works primarily focus on evaluating the performance of event-based detection methods using pre-recorded event data. While these detection algorithms provide valuable benchmarks for accuracy and robustness, they do not address the practical challenges of integrating event-based perception into real-time autonomous driving systems. This absence of system-level evaluation limits the applicability of such approaches in dynamic, real-world driving scenarios.
To fully realize the potential of event cameras in vehicular applications, it is essential to move beyond algorithmic benchmarking and develop complete, deployable pipelines that account for both real-time constraints and system integration challenges.
However, all the aforementioned works primarily focus on evaluating the performance of event-based detection methods using pre-recorded event data. While these detection algorithms provide valuable benchmarks, they do not address the challenges of integrating event-based detection into real-time autonomous driving systems. This lack of system-level integration limits the practical applicability of event-based approaches in dynamic, real-world driving scenarios to fully realize the potential of the application of event camera in vehicle applications.
2.4. Automotive Event Dataset
The rapid evolution of event-driven object detection has led to the development of several specialized datasets tailored for autonomous applications. Unlike traditional image-based object detection, which relies on individual frames, event-based detection captures continuous semantic information over time, resembling video analysis. Recent datasets have been designed to exploit the rich spatio-temporal data generated by event cameras, often involving the collection of continuous scene data. While some efforts have been made to convert existing image datasets into event formats, this approach typically sacrifices the inherent continuity that characterizes event data [7]. Most publicly available datasets focus on autonomous driving scenarios, where the low latency and high dynamic range of event cameras present a compelling alternative to conventional visual sensors.
These datasets can be categorized into two main types: pure event data and multi-modal datasets that include both event and traditional camera data. For instance, the Gen1 dataset [23] is notable for being the first large-scale object detection dataset derived directly from event cameras. It comprises recordings captured in real-world driving scenarios using event cameras mounted on a vehicle. The recordings were collected with a high degree of environmental diversity to ensure generalization across typical daily driving tasks. Following on that, the 1Mpx dataset [14] utilized a higher-resolution event camera and more label classes. Others like the DDD17 dataset [24] utilize advanced sensors such as a dynamic and active-pixel vision sensor (DAVIS) to record both RGB and event data simultaneously. Multi-modal datasets enhance the robustness of object detection by integrating semantic information from different modalities, addressing limitations faced by event cameras in low-motion or low-light conditions. The DSEC dataset [25] further exemplifies this approach by combining high-resolution traditional camera data with event data in real-time driving scenarios, thus providing a comprehensive resource for researchers aiming to advance event-based detection techniques in autonomous systems.
3. Methodology
Our research methodology encompassed two distinct phases. In the initial phase, we developed a comprehensive training framework that enables off-the-shelf conventional frame-based detectors to effectively process and analyze event-based datasets. Subsequently, we implemented and incorporated the trained model into an autonomous driving simulation environment. During this second phase, we performed model fine-tuning to optimize performance specifically for the simulated conditions and enhance environmental adaptation.
3.1. Deep Learning Model Training
3.1.1. Dataset
We chose the GEN1 dataset [23] for this work due to its strong relevance to autonomous driving applications and its status as a benchmark for event-based object detection. It was specifically designed for real-world traffic scenarios, capturing authentic and unaltered event streams from dynamic urban environments, which makes it highly suitable for evaluating the robustness of detection algorithms under practical conditions.
While newer datasets offer higher spatial resolution, GEN1’s lower resolution contributes to significantly reduced data volume and computational overhead—a key consideration for real-time inference in resource-constrained autonomous systems. This data efficiency allows us to focus on pipeline integration and latency evaluation without being dominated by the cost of processing high-resolution input.
Its widespread adoption in the field facilitates direct comparisons with prior works, providing a well-established baseline for demonstrating improvements. The GEN1 dataset comprises 39 h of event camera recordings at a resolution of 304 × 240, containing 228 k car and 28 k pedestrian bounding boxes annotated at 1, 2, or 4 Hz. Following the original evaluation criteria [14], bounding boxes with side lengths under 10 pixels or diagonals below 30 pixels are excluded. A sample of GEN1 data is visualized in Figure 2 below. Mean average precision (mAP) and inference time are the main metrics considered in this study.

Figure 2.
GEN1 event data visualization for (a) vehicles and (b) pedestrians.
3.1.2. Event-to-Frame Conversion
The GEN1 dataset consists of 60-s segments of continuous, asynchronous event streams. In contrast, most recent and successful deep learning algorithms are designed for traditional video input (i.e., frame-based and synchronous data), which aligns better with the architecture of conventional processors. To utilize conventional image-based deep learning techniques, asynchronous events need to be converted into synchronous frames. There has been a range of studies exploring different forms of event representations, with a comprehensive study [26] investigating their effectiveness in object detection. In this work, we chose the 2D histogram [11] for its compatibility with CNN architectures, as they provide a dense, grid-based representation that aligns well with spatial feature extraction in YOLO. By aggregating event data over a fixed time window, histograms preserve essential motion patterns and object contours while offering robustness against noise, unlike finer-grained representations such as time surfaces or event cubes. Moreover, histograms are computationally efficient compared to other approaches, making them well-suited for real-time autonomous driving applications.
In 2D histograms, events ek = (xk, yk, tk, pk) are accumulated over a fixed time interval T to generate pixel-wise histograms, capturing the relative motion between the event camera and the scene. To preserve polarity information, separate histograms are maintained for positive and negative events, defined as
where Equations (1) and (2) represent positive and negative events, respectively; is the Kronecker delta. These two histograms are stacked into a two-channel event image, preventing information loss due to polarity cancellation. This representation retains the spatiotemporal structure of event data while ensuring compatibility with CNN-based detectors like YOLO. In practice, histogram representation is extended through a temporal binning mechanism, where events are accumulated not only spatially but also across discrete time bins within a given interval. This results in a four-dimensional tensor H of shape (n, c, h, w), where n represents the number of time bins, c the polarity channels, and h,w the spatial dimensions. Each event, defined by its position (x, y), polarity p, and timestamp t, updates the corresponding bin as follows:
where is the time interval in microseconds. The resulting histograms are stacked to form a tensor input for the YOLO model, preserving temporal structure while leveraging the high temporal resolution and sparsity of event data. This approach enables the effective application of conventional deep learning frameworks designed for frame-based images to event-based detection.
3.1.3. YOLO Framework Modification
To adapt the YOLOv8 framework for event-based data, we modified key components of the architecture to handle the unique characteristics of event cameras. The dataset handling process was updated to support event histograms stored in hierarchical data format tensor, replacing traditional image formats. We also adjusted the label handling to align with the temporal nature of event data, ensuring that labels corresponded accurately to event frames. The input pipeline was refined to accommodate the two-channel format of event data, and data augmentation methods were adapted to suit this new input type. Finally, the visualization and prediction mechanisms were updated to correctly process and display event-based input. These modifications enable YOLOv8 to effectively handle event data, making it compatible with event-stream dataset.
3.2. Autonomous Driving System Integration in Simulation
3.2.1. CARLA Simulator and Carla–ROS-Bridge
Ensuring safety is a critical aspect of autonomous driving research. The CARLA 0.9.13. simulator [27] has been widely adopted as a high-fidelity testing platform that enables controlled and repeatable evaluation of vehicle perception and control systems. Recent work [28] further reinforces its value by demonstrating how CARLA can support large-scale, realistic safety validation scenarios that would be difficult or unsafe to conduct in the real world.
For our purposes, CARLA’s rich feature set—including customizable traffic scenarios, diverse weather and lighting conditions, and support for dynamic, high-speed interactions—makes it particularly well-suited for evaluating the robustness of event-based object detection frameworks under a wide range of challenging conditions.
To facilitate system integration and enable real-time data exchange between the simulator and external processing units, we leveraged the CARLA–ROS-bridge. ROS is a widely adopted middleware for robotics research, providing a modular and scalable architecture for sensor data collection, communication, and control. The CARLA–ROS-bridge integrates the CARLA simulator with ROS, enabling seamless interaction with ROS nodes for data collection, sensor simulation, and control tasks. This integration is particularly useful for real-time testing and validation of event-based object detection pipelines, as it supports easy synchronization of simulation data with real-world robotic software systems. By using CARLA in combination with ROS, we were able to develop and test a comprehensive, real-time event-based detection system, ensuring that our approach could handle the dynamic and complex nature of autonomous driving tasks.
3.2.2. CARLA DVS Modeling
The DVS camera in the CARLA environment is configured with a dynamic range of 140 dB, a temporal resolution in the order of microseconds, and a spatial resolution of 304 × 240 pixels. It generates a continuous stream of events, each represented as e = (x, y, t, p), where an event is triggered at pixel coordinates (x, y) and timestamp t when the change in logarithmic intensity L exceeds a predefined contrast threshold C, typically between 15% and 30%. This process is governed by the equation
where t − δt represents the timestamp of the last event at that pixel, and p denotes the polarity of the event. A positive polarity indicates an increase in brightness, while a negative polarity corresponds to a decrease. In this work, the threshold is set to C = 0.3. Events are visualized in plots, where positive events appear as blue dots and negative events as red dots, illustrating the dynamic response of the sensor to changes in brightness over time.
The current implementation of the DVS camera in CARLA operates using uniform temporal sampling between two consecutive synchronous simulation world ticks, which functions in a manner conceptually similar to our preprocessing method. This implies that the conversion of raw event data into event frames or tensors is automatically handled within the simulation. However, to accurately emulate the high temporal resolution of a real event camera on the order of microseconds, the sensor must operate at a significantly higher frequency than conventional frame-based cameras. Since the number of generated events is proportional to the motion dynamics of the scene, the event rate naturally increases with the speed of a vehicle. Consequently, the sensor’s operating frequency should be adjusted accordingly to maintain temporal fidelity.
In practice, a trade-off must be carefully considered between time resolution and computational efficiency, as excessively high sensor frequencies can lead to increased processing overhead, while lower frequencies may compromise the fidelity of event- based perception.
Despite its simplifications, CARLA’s DVS sensor provides a practical and configurable approximation of event-based vision. For the purposes of this study, focusing on system-level integration and real-time object detection, the current implementation offers sufficient fidelity to evaluate key performance trends and validate the robustness of our proposed pipeline under dynamic conditions.
3.2.3. Fine Tuning the Model Through Transfer Learning
Due to differences in data modality, as well as the inherent discrepancies between real-world and simulated environments, the model trained on the GEN1 dataset requires further adaptation to perform optimally within the CARLA simulation. To achieve this, the pre-trained model undergoes transfer learning using a dataset of approximately 4.6 k labeled event images generated within CARLA. This process refines the model’s parameters, enabling it to better capture the unique characteristics of simulated event data, which may differ in distribution, noise characteristics, and temporal dynamics from real-world event streams. This step ensures improved generalization and robustness within the simulation environment, allowing for more accurate event-based perception in the CARLA environment.
3.2.4. Domain Gap Evaluation Between GEN1 Dataset and Carla Dataset
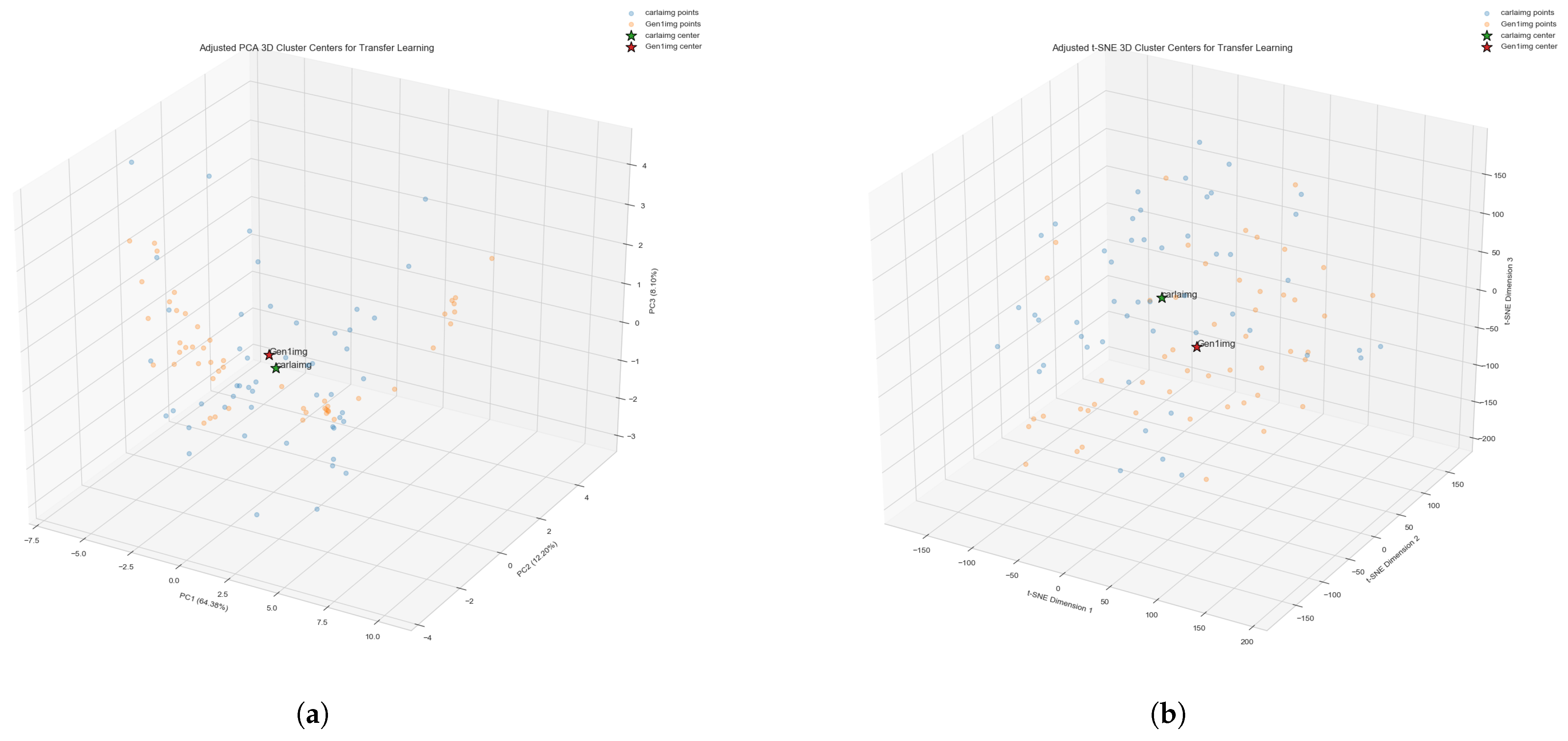
To systematically evaluate the “domain gap” between real event camera data and simulated data, we conducted a quantitative analysis of the feature space to provide objective evidence for our proposed transfer learning strategy, as shown in Table 1. We randomly sampled from real data captured by Gen1 event cameras and simulated data generated by the CARLA simulator, extracting a multi-dimensional feature set including GLCM texture features, LBP texture features, gradient features, edge features, region features, HOG features, and surface roughness features. Through principal component analysis (PCA), we precisely quantified the domain gap.

Table 1.
Summary of Image Features Used for Domain Gap Analysis.
Results from Figure 3 Table 2 show that in the standardized feature space, the distance between the cluster centers of the two domains is 7.3718, while the average distances of within-domain samples to their respective centers are 3.8798 (CARLA) and 4.4233 (Gen1). The standard deviations are 1.8789 (CARLA) and 2.1514 (Gen1), indicating relatively concentrated distributions within domains. These data clearly demonstrate that the inter-domain distance is significantly larger than the average intra-domain variation, quantitatively proving the existence of distinct feature distribution differences between the two domains. t-SNE analysis further confirmed this gap, with the distance between cluster centers reaching 34.8101 in t-SNE space.
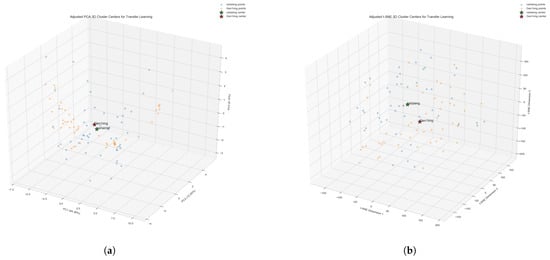
Figure 3.
Cluster Center Visualization. (a) PCA 3D Cluster Centers. (b) s-SNE 3D Cluster Centers.
Table 2.
Cluster Statistics for Gen1Img and CarlaImg Using PCA and t-SNE.
Despite this domain gap, our analysis also revealed similarities between the two domains. By comparing the feature distribution shapes and variance structures, we found they exhibit similar scatter patterns in the principal component space (standard deviation ratio approximately 1:1.14), indicating that these domains, despite their different center positions, share similar internal feature structures. This structural similarity provides the foundation for knowledge transfer, suggesting that with appropriate transfer learning methods, shared feature structures across domains can be leveraged while adapting to domain-specific differences. Based on this quantified analysis of domain gap and structural similarity, we confirmed the necessity and feasibility of our transfer learning strategy.
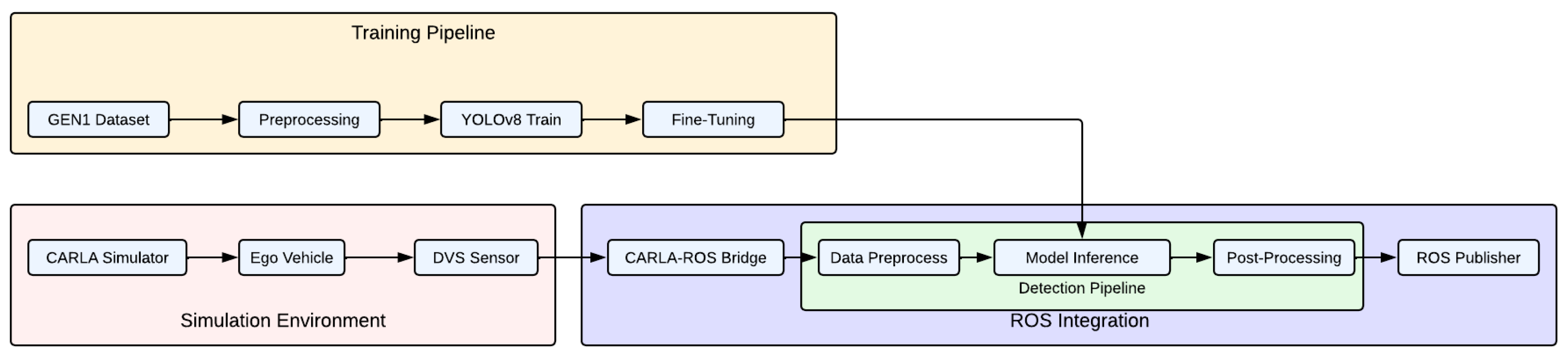
3.2.5. Overall System Pipeline
The overall system integration pipeline consists of three interconnected modules mentioned before: the training pipeline, the simulation environment, and ROS integration, as illustrated in Figure 4:
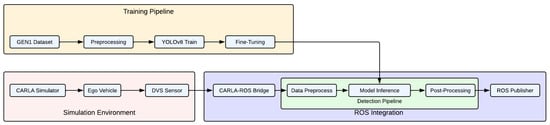
Figure 4.
Overall system pipeline.
The training pipeline prepares the event-based object detection model by first preprocessing the GEN1 dataset and training a YOLOv8 network. To adapt the model to the CARLA simulation environment, fine-tuning is performed using a dataset of labeled event images generated within CARLA. The simulation environment is built within the CARLA simulator, where an ego vehicle is equipped with a DVS to generate event data based on real-time interactions with the environment. This event stream is transmitted through the CARLA–ROS Bridge, facilitating integration with the ROS-based detection pipeline. The ROS integration module processes and utilizes the incoming event data. Within the detection pipeline, the preprocessed event frames are fed into the fine-tuned YOLOv8 model for object detection, after which post-processing refines the predictions. The final detection results are published via a ROS Publisher, making them accessible for downstream robotic perception and decision-making tasks.
3.2.6. Scenario Validation
To assess the effectiveness of the integrated event-based detection system, a set of test scenarios is designed to replicate real-world challenges in autonomous driving. Given computational constraints that limit high-speed motion testing, the advantage of microsecond-level temporal resolution of event cameras is not fully explored in this work. Thus the evaluation focuses on variations in environmental conditions and object layouts, including varying light conditions, varying traffic densities and occlusion. Evaluation is conducted primarily through qualitative analysis of detection outputs. Bounding box alignment, false positive and false negative occurrences, and consistency of detections over time serve as key indicators of model performance. These scenarios provide insights into the model’s robustness under different settings relevant to real-world deployment.
3.3. Use of Generative AI Tools
In this study, we used generative AI tools, specifically OpenAI’s ChatGPT-4 and Anthropic’s Claude 3.5 Sonnet, to assist with various aspects of the research process. These tools were employed in the following ways:
- Literature Review and Surveying—They were used to summarize research papers, extract key insights, and generate comparisons between different methodologies. The AI-generated summaries were manually verified against the original papers to ensure accuracy and relevance.
- Brainstorming and Concept Development—AI tools were used to generate and refine research questions, explore alternative methodologies, and identify potential challenges. While AI-generated suggestions were considered, the final research design was determined based on domain knowledge and the existing literature.
- Code Review and Optimization—AI tools were used to assist in debugging and optimizing Python scripts related to data preprocessing and model implementation. AI suggestions were manually reviewed, tested, and modified as necessary to align with research objectives.
All AI-generated content was critically evaluated to ensure originality, correctness, and compliance with ethical standards. No AI-generated text or code was directly used in the final manuscript or results without human validation.
4. Experiment and Results
4.1. Implement Details
In this work, the YOLOv8 model is trained using the Gen1 dataset with a set of training parameters designed to optimize detection performance. The model is trained for a total of 100 epochs, with an early stopping criterion set at 50 epochs to prevent overfitting. The batch size is dynamically adjusted based on the GPU memory capacity for each model configuration. Pre-trained weights are used to initialize the model, and data augmentation techniques, including flipping, scaling, and translation, are applied to enhance robustness. Augmentations such as mosaic, mixup, and albumentation were excluded, as they are not suitable for event histograms. The optimizer is set to “auto” with a learning rate of 0.02 and weight decay of 0.0005 to further mitigate overfitting. All training processes were conducted on an NVIDIA GeForce RTX 4090 GPU (NVIDIA, Santa Clara, CA, USA). Typically, the model converges to the optimal performance in less than 3 h, although the total training time is longer due to the early stopping patience setting.
To evaluate the model’s compatibility with automotive-grade embedded systems, inference times are measured across two GPU architectures within the CARLA simulation. While desktop-grade hardware does not fully replicate the power-to-performance profiles of onboard vehicular processors, these benchmarks establish a pragmatic performance range for real-world latency estimation. The NVIDIA GeForce RTX 4090 serves as a high-performance ceiling, representing the upper bound of achievable inference speeds. Meanwhile, we used the NVIDIA GeForce GTX 1660, a mid-range desktop GPU lacking dedicated tensor cores and mixed-precision optimizations, as a conservative baseline to approximate the computational constraints of embedded automotive processors. The inference time from the GTX 1660 is obtained real-time when the simulation is running to best mimic the real world scenario.
4.2. Results from GEN1 Dataset
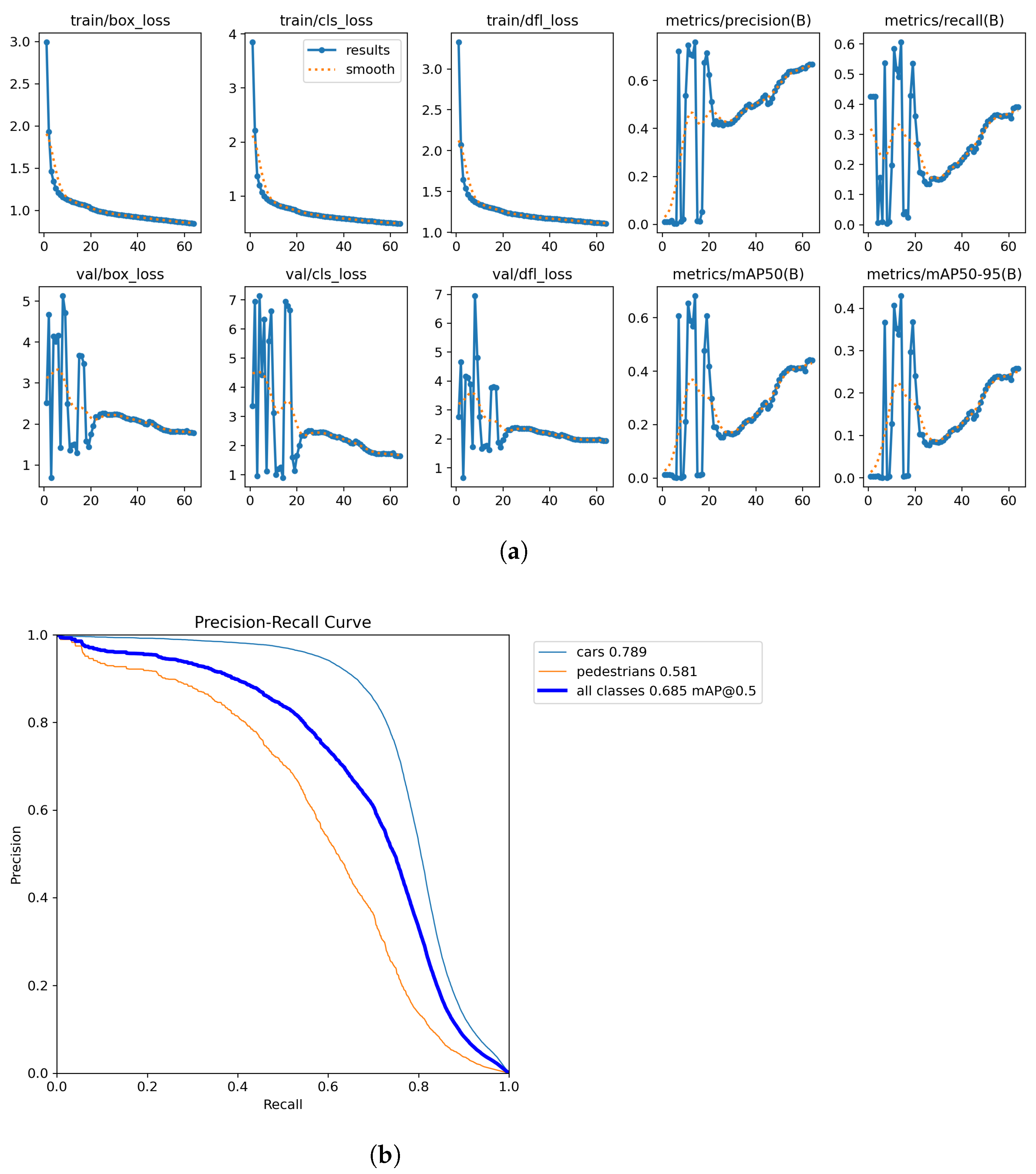
Figure 5a shows the YOLOv8 model training results without transfer learning show clear patterns across multiple metrics. The loss functions—box_loss, cls_loss, and dfl_loss—in both training and validation sets demonstrate a significant downward trend, particularly rapid during the first 10 epochs. However, validation loss curves exhibit noticeable fluctuations and peaks in the early stages (approximately 0–15 epochs), indicating initial training instability. Notably, precision, recall, and mAP metrics display high peak values early in training, but following oscillation adjustments, these metrics fail to return to their initial high levels. Figure 5b shows the precision–recall curves reveal performance variations across detection classes. The car category (blue line, mAP of 0.789) significantly outperforms the pedestrian category (orange line, mAP of 0.581), with an overall mAP@0.5 of 0.685 across all classes. The car category PR curve maintains high precision across elevated recall rates (approximately 0–0.7), declining gradually until recall exceeds 0.7, demonstrating reliable car detection. In contrast, the pedestrian category PR curve begins declining noticeably after recall exceeds 0.2, with a steeper drop in the mid-recall range (0.4–0.7), indicating more false positives and missed detections when identifying pedestrians. The overall PR curve (thick blue line) falls between these extremes, showing relatively stable performance below 0.7 recall, suggesting that even without transfer learning, the model achieves balanced performance in detecting these categories, though pedestrian detection remains the key performance bottleneck.
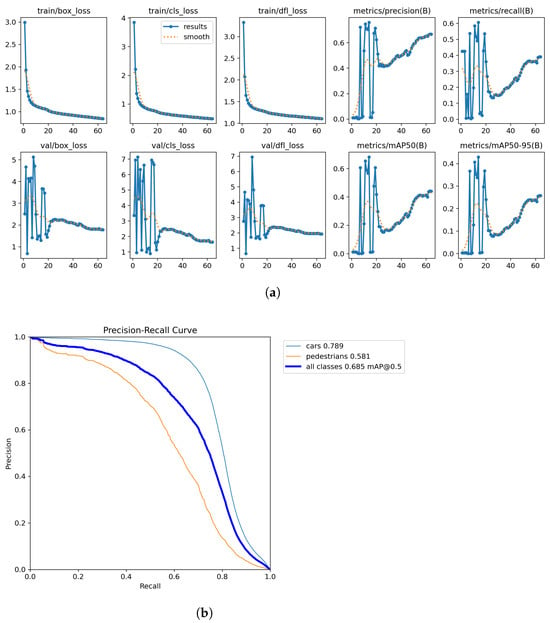
Figure 5.
Quantitative Results for Medium model. (a) Training results. (b) PR Curve.
The results in Table 3 reveal a clear performance–complexity tradeoff across the three YOLOv8 variants (nano, small, and medium named by their parameter size, as indicated in Table 3) trained on the GEN1 dataset. The medium-sized model achieves the highest overall mAP of 70.1, surpassing the small (65.1 mAP) and nano (49.7 mAP) variants with gains of 5.0 and 20.4 points, respectively. This scaling trend is consistent across object categories: car detection improves from 56.6 mAP (nano) to 75.5 mAP (medium), while pedestrian detection rises from 42.8 mAP (nano) to 64.7 mAP (medium). The performance gap between car and pedestrian detection—evident in all models—reflects the inherent challenges of detecting smaller, more dynamic objects in event-based data. Notably, the medium model’s 25.8 M parameters yield diminishing returns compared to the small variant (11.2 M parameters), suggesting that model scaling alone cannot fully compensate for limitations in event representation or dataset diversity. These results underscore the importance of balancing model capacity with computational efficiency, particularly for resource-constrained autonomous systems.
Table 3.
Results across multiple model sizes trained with GEN1 dataset results across models.
Baseline Comparison. The results in Table 4 demonstrate that our modified YOLOv8 variants achieve state-of-the-art performance on the GEN1 dataset, surpassing prior methods significantly in mAP. Specifically, our medium-sized model attains 70.1 mAP, outperforming transformer-based ERGO-12 (50.4 mAP) and hybrid CNN-RNN architectures like RVT-B (47.2 mAP). Notably, these improvements are achieved without major architectural overhauls, highlighting the effectiveness of our training framework and event-to-frame conversion strategy. The performance gains stem from three key factors inherent to YOLOv8 and our framework design. First, the integration of polarity-separated 2D histograms with temporal binning translates asynchronous event streams into dense, spatiotemporally rich representations, balancing noise robustness with motion pattern preservation while maintaining compatibility with CNN architectures. Second, YOLOv8’s modernized backbone architecture, anchor-free detection head, and advanced feature fusion mechanisms inherently enhance feature discrimination and localization accuracy, enabling superior generalization to event-based data without structural modifications. Third is for the efficiency of pure CNN architectures. While transformer-based methods (ERGO-12) and hybrid models (RED, RVT-B) introduce inductive biases for temporal modeling, our results suggest that well-optimized CNNs can outperform such approaches in event-based detection. The temporal binning mechanism in our event representation implicitly encodes motion cues, reducing the need for explicit temporal modeling modules like RNNs. Together, these components demonstrate that systematic optimization of data representation and training strategies, rather than structural complexity, drives breakthroughs in event-based detection.
Table 4.
Comparison of various methods, their network structures, mAP, and inference time. * indicates runtime within the detection module only, while some other works did not specify whether frame conversion is included. Overall, our method remained the inference time advantage of frame-based CNN detection.
Direct Integration. While the trained models exhibit strong numerical performance on the benchmark dataset, their direct integration into the CARLA simulation environment revealed several limitations, as depicted in Figure 6 below:

Figure 6.
Direct integrating models in CARLA simulation. (a) Nano Model. (b) Small Model. (c) Medium Model.
The nano model frequently misclassified environmental event points (e.g., shadows, static objects) as vehicles, producing a high rate of false positives. This suggests insufficient model complexity to capture nuanced feature representations, leading to overgeneralization. Its limited capacity likely prevents it from distinguishing fine-grained correlations between sensor inputs and object semantics. However, even the more complex small and medium models struggle to reliably detect clearly visible vehicles in simple scenarios (e.g., unobstructed roads). We attribute this to a domain discrepancy between the training and testing data, as introduced in Section 3.2.3. The models fail to generalize to the simulation’s unique sensory representation, necessitating fine-tuning to align with the simulation environment.
4.3. Results After Transfer Learning
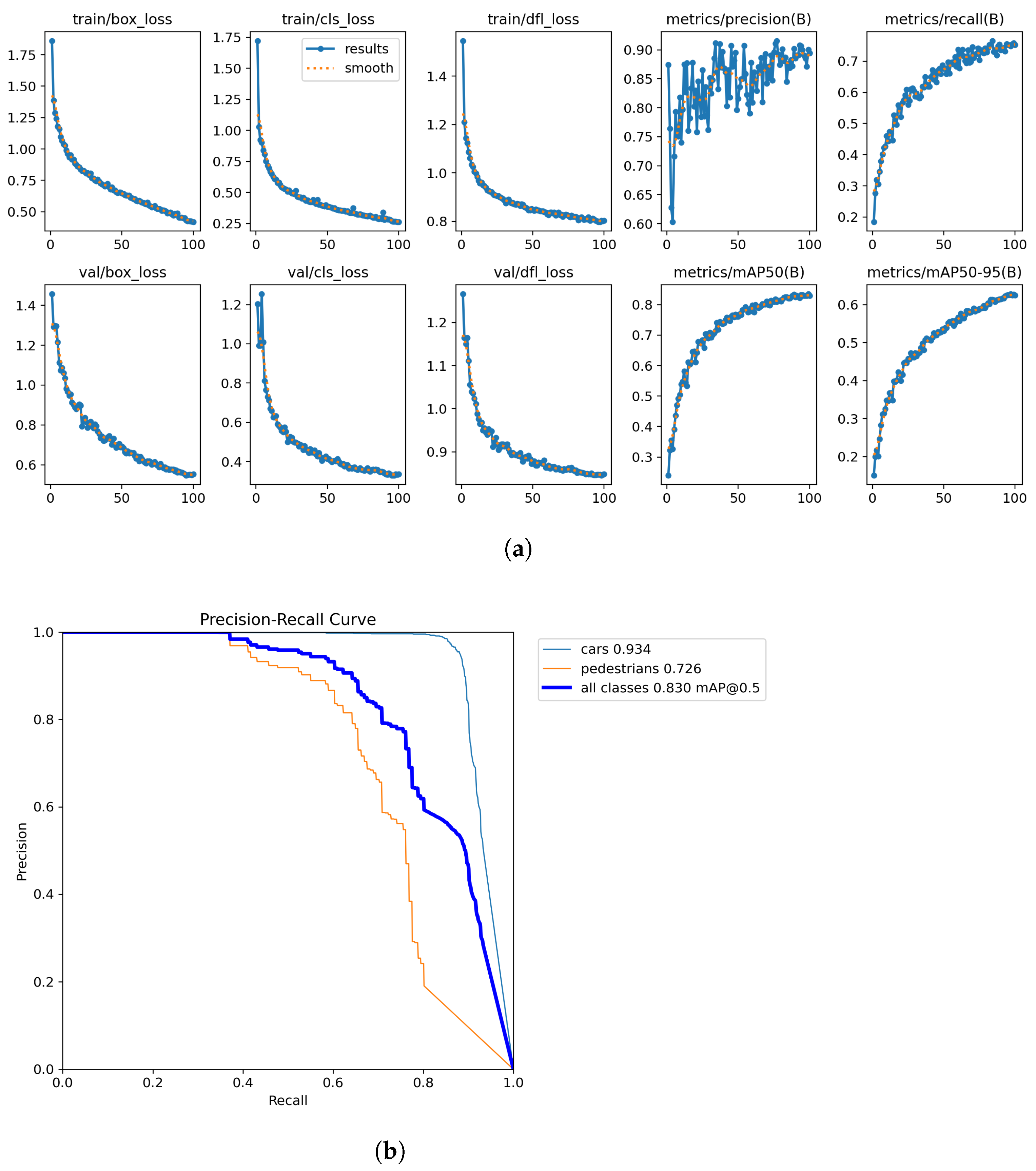
Figure 5a shows the YOLOv8 model training results without transfer learning, while Figure 7a demonstrates the significant improvements achieved through transfer learning. In contrast to the non-transfer learning approach, the transfer learning model exhibits remarkably stable training with minimal early fluctuations. Loss functions (box_loss, cls_loss, and dfl_loss) in both training and validation sets show consistently smooth decreasing curves without the pronounced oscillations seen in the non-transfer learning model. The performance metrics display steady improvement without the misleading early peaks observed in the non-transfer model. Most notably, the transfer learning approach achieves substantially higher final metrics, with precision values reaching approximately 0.9 compared to 0.65 in the non-transfer model and recall improving to around 0.7 versus 0.4 previously. Figure 7b further emphasizes the transfer learning advantages through improved PR curves across all categories. The car detection performance increases dramatically (mAP of 0.934 versus 0.789), showing near-perfect precision until much higher recall values (approximately 0.8). Similarly, pedestrian detection shows significant enhancement (mAP of 0.726 versus 0.581) with a more gradual precision decline across increasing recall values. The overall mAP@0.5 improves remarkably from 0.685 to 0.830, demonstrating transfer learning’s ability to leverage pre-learned features for more accurate and consistent object detection. The transfer learning approach not only eliminates the training instability of the non-transfer model but also achieves substantially higher performance across all metrics while requiring fewer training epochs to converge.
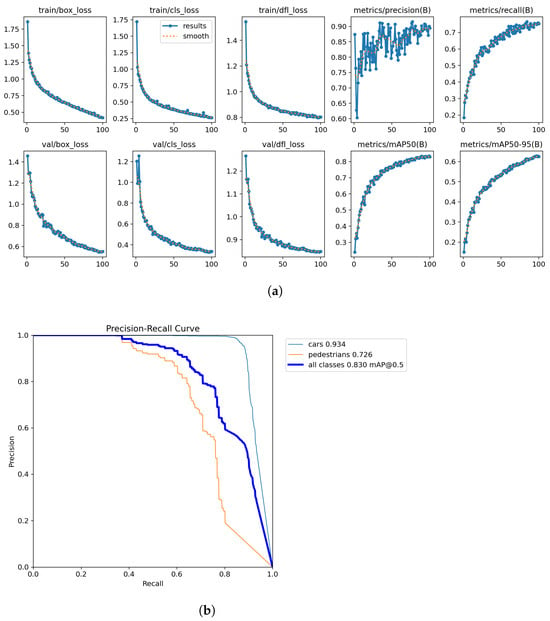
Figure 7.
Quantitative Results for Medium model after transfer learning. (a) Training results. (b) PR Curve.
Detection Accuracy. The post-fine-tuning results in Table 5 demonstrate the critical role of transfer learning in bridging the domain gap between real-world and simulated event-based data. After fine-tuning the pre-trained GEN1 models on 4.6 k CARLA-generated event images, the medium-sized YOLOv8 variant achieves 83.0 mAP overall, a 12.9-point improvement over its pre-fine-tuned performance (70.1 mAP). Notably, pedestrian detection accuracy rises to 72.6 mAP (from 64.7 mAP), while car detection reaches 93.4 mAP, underscoring the framework’s adaptability to simulated sensor noise and temporal dynamics. These gains highlight how targeted fine-tuning enables models to generalize across data modalities, mitigating distribution shifts caused by discrepancies in event generation mechanisms.
Table 5.
Comparison of models with mAP scores and inference times on RTX4090 and GTX 1660.
Latency. The RXT 4090 demonstrates sub-10 ms latencies for all models (nano: 2.1 ms; small: 3.5 ms; medium: 5.4 ms), representing the theoretical upper bound of achievable speeds. Conversely, the GTX 1660 provides a conservative baseline under real-time simulation loads, yielding latencies of 8.4 ms (nano), 15.9 ms (small), and 33.4 ms (medium). These results align more closely with the computational constraints of automotive-grade systems: while the nano and small models meet or approach real-time thresholds (30 ms) on the 1660, the medium model’s latency (33.4 ms) slightly exceeds this target despite remaining below the 50 ms critical threshold. This suggests that even models achieving moderate latencies on mid-tier hardware may require quantization, architectural pruning, or framework-specific acceleration to satisfy the stricter 20–30 ms requirements of deployed automotive processors.
4.4. Results Validation from Scenario
The efficacy of transfer learning is further validated through qualitative evaluations in dynamic CARLA scenarios, where the fine-tuned model was deployed in the ego-vehicle’s perception system across diverse driving environments. To best demonstrate the model’s capability, the medium model is selected as the optimal configuration for balancing inference speed and accuracy in resource-constrained onboard systems.
Figure 8 illustrates the model’s robustness across three distinct illumination conditions. In daytime scenarios (Figure 8a), the model effectively detects vehicles despite challenges such as shadows and specular highlights caused by direct sunlight. During sunset (Figure 8b), where angled glare and high-contrast silhouettes often obscure partial views, the model prioritizes temporal consistency in object edges to distinguish vehicles from glare-induced noise. In night conditions (Figure 8c), detection remains reliable under the effect of traffic lights and low signal-to-noise ratios. The model reliably provides detection for vehicles with high confidence and closely aligned bounding boxes.

Figure 8.
Detection results under varying light conditions. (a) Daytime. (b) Sunset. (c) Night.
Figure 9 illustrates a complex traffic junction scenario that demonstrates one of the fundamental limitations of event cameras: their dependency on detecting motion. As the ego vehicle approaches the junction, which contains both vehicles and pedestrians, this limitation becomes apparent. In Figure 9a, the model successfully detects the vehicle ahead while the ego vehicle is in motion. However, when both vehicles come to a complete stop, the stationary front vehicle becomes “invisible” to the event camera, with only distant moving objects remaining detectable, as shown in Figure 9b,c. A notable detection challenge appears in Figure 9b, where a pedestrian standing in close proximity to a vehicle creates overlapping event data. This spatial proximity results in the model misclassifying the combined event signature as a single vehicle detection. Figure 9c further illustrates this detection challenge: once the vehicle moves away, it is detected with high confidence, while the pedestrian remains undetected. This sequence of events highlights a significant limitation in the system’s pedestrian detection capabilities, particularly in scenarios with overlapping objects or when objects are in close proximity.

Figure 9.
Detection in traffic light scenario under direct sunlight. (a) Approaching. (b) Overlapping objects. (c) Separated objects.
Following on from the observation from the previous scenario, the next set of scenarios focuses on pedestrian detections.
The observed inconsistencies in pedestrian detection performance in Figure 10 stem from a confluence of sensor limitations, dataset constraints, and algorithmic challenges inherent to event-based perception systems. Event sensors, which encode data as asynchronous brightness changes, struggle to capture semantically rich features for pedestrians due to their sparse and motion-dependent output. In scenarios with uniform lighting and the slow-moving pedestrians as the sole moving object (Figure 10a), the limited event density reduces discriminative cues, leading to ambiguous detections (e.g., confidence scores as low as 0.56). Cluttered environments (Figure 10b,d) further compound this issue, as pedestrian motion patterns often blend with background noise, such as foliage or moving shadows, resulting in missing detections. Algorithmically, the reliance on motion cues rather than static appearance introduces challenges in distinguishing pedestrians from dynamic artifacts. Overlapping event clusters in crowded scenes (Figure 10d) and insufficient spatiotemporal resolution for slow-moving subjects hinder precise localization.

Figure 10.
Pedestrian detection results under various conditions. (a) Only pedestrian moving. (b) Pedestrians with surroundings. (c) True positive and false negative. (d) Multiple pedestrian detection.
These algorithmic limitations manifest visually in the event frame representations. By comparing Figure 10c,d, we observe that undetected pedestrians (false negatives) often appear differently within the event frame, corresponding to sparse or fragmented event clusters in the temporal bins. These artifacts arise from the fixed-duration temporal binning mechanism (20 Hz in this implementation), which aggregates asynchronous events into discrete frames. Prolonged bin intervals can merge intermittent pedestrian motion with background noise, creating ambiguous spatial patterns that resemble motion smearing. Additionally, dataset biases—such as insufficient number of pedestrian class labels, lack of representations under different scenes, and overfitting to isolated pedestrian examples (Figure 10b)—limit the model’s ability to generalize to real-world complexity. Addressing these issues requires adaptive binning strategies and diversified training data to better capture pedestrian dynamics across scenarios.
5. Conclusions
This study demonstrates the feasibility and challenges of integrating event-based vision into autonomous driving perception systems, using a framework that bridges real-world event data and simulation. By adapting YOLOv8 for event-based detection through polarity-separated 2D histograms and temporal binning, we achieved state-of-the-art performance on the GEN1 dataset while maintaining real-time inference speeds. Transfer learning proved to be critical for bridging the domain gap between real-world and simulated event data, boosting the mAP of the medium model by 12.9 points in CARLA scenarios. The results presented in this work demonstrate the robustness of event cameras and affirm their potential as a complementary sensing modality to traditional sensors in autonomous driving applications. The proposed learning strategy and system pipeline are designed to be modular and adaptable, enabling straightforward integration with higher-resolution datasets or those containing a broader range of object classes without requiring major changes to the architecture. This flexibility paves the way for further research and development in incorporating event-based vision into vehicle perception systems.
Limitation. However, key limitations remain. Pedestrian detection in cluttered environments and the detection of stationary objects under low-motion conditions highlight the inherent challenges of event-based vision, particularly its reliance on relative movement.
While our framework demonstrates low latency on high-performance hardware, the processing of raw event data into frame-like representations has been automatically handled by DVS camera model within CARLA, which simplifies many of the complexities encountered in real-world event camera systems. Specifically, the use of a fixed temporal binning strategy in our training pipeline does not fully exploit the asynchronous nature and high temporal resolution of event-based data, potentially limiting the detection performance, particularly in scenarios involving slow-moving or overlapping objects.To ensure real-time performance and system reliability in automotive-grade embedded platforms, further optimization will be required.
In practice, event-based systems require dedicated preprocessing pipelines to convert raw asynchronous event streams into frame-like representations (e.g., event histograms, time surfaces, voxel grids) for the majority of detection algorithms to work, each of which comes with trade-offs in latency, memory usage, and computational complexity. These conversion steps often require precise timestamp alignment, memory buffering, and noise filtering, all of which are bypassed in the current simulation framework for efficiency and reproducibility. Improvements in these areas are critical for bridging the sim-to-real gap and enabling robust deployment in safety-critical autonomous driving applications.
Future work. To advance event-based perception systems, several critical pathways emerge. First, multimodal fusion strategies—such as integrating event data with sparse RGB frames or LiDAR inputs—could help mitigate hardware limitations in detecting static or slow-moving objects. By combining semantic information from RGB images with depth cues from LiDAR, the system can better resolve ambiguities when identifying and distinguishing overlapping objects, while still preserving the low-latency advantages of event-based sensing.
Building on this, exploiting the microsecond temporal resolution of event cameras through lightweight recurrent architectures (e.g., LSTMs) would reduce reliance on fixed temporal binning, enabling finer-grained motion modeling. Complementing these efforts, dataset diversification is essential to address current biases.
Addressing the earlier-mentioned issue of automatic event-to-frame conversion is crucial, as it represents a significant source of the sim-to-real gap. Another key direction for future work involves integrating a more realistic event-data preprocessing stack, such as custom voxel encoders or DVS-specific front-end processors, and benchmarking the end-to-end latency and resource consumption of the full pipeline in embedded or hardware-in-the-loop environments.
To fully realize the technology’s potential, the CARLA–ROS pipeline we proposed could be used as a testbed for further research in end-to-end control systems, where event-driven detection directly informs real-time maneuvers such as collision avoidance or adaptive cruise control.
Finally, deploying these systems in real-world settings demands hardware-aware optimizations, such as model quantization and pruning, to balance accuracy and latency on resource-constrained automotive processors. By systematically addressing these challenges, event-based vision can evolve from a supplementary tool to a foundational component of autonomous driving systems, enhancing both safety and operational efficiency.
Author Contributions
Writing—original draft preparation, J.F.; methodology, J.F. and P.Z.; conceptualization, J.F., P.Z., A.S., J.K., H.Z. and P.K.; investigation, J.F. and P.Z.; data curation, J.F., A.S., J.K., P.Z. and H.Z.; writing—review and editing, P.K. and H.Z.; resources, P.Z. and J.F.; formal analysis, J.F. and P.K.; supervision, P.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The Gen1 dataset used in this study is publicly available through https://prophesee-prod.euregion.site/2020/01/24/prophesee-gen1-automotive-detection-dataset/ (accessed on 17 December 2024). The custom dataset for fine-tuning the model is available on request from the corresponding author.
Acknowledgments
The authors acknowledge the use of OpenAI’s ChatGPT-4 and Anthropic’s Claude for assisting in literature review, brainstorming, and code review in this study. The authors have reviewed and edited the output and take full responsibility for the content of this publication. The authors would like to deeply thank the Faculty of Engineering, Rajamangala University of Technology Krungthep, and School of Automobile Engineering Foshan PolytechnicFoshan for providing the necessary facilities to conduct this research. In addition, we would like to express our sincere appreciation to the Department of Electrical, Computer, and Software Engineering, University of Auckland, and the Department of Chemical and Materials Engineering, University of Auckland for their invaluable support in technical data and the completion of related duties. Finally, the Research and Development Institute of Rajamangala University of Technology Krungthep, and Guangzhou Panyu Polytechnic, Guangzhou were instrumental in facilitating the successful completion of this work.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LiDAR | Light detection and ranging |
| CNN | Convolutional neural network |
| SNN | Spiking neural network |
| DNN | Dense neural network |
| GNN | Graph neural network |
| YOLO | You Only Look Once |
| ROS | Robot operating system |
| DVS | Dynamic vision sensor |
| DAVIS | Dynamic and active-pixel vision sensor |
References
- Sivaraman, S.; Trivedi, M.M. Looking at vehicles on the road: A survey of vision-based vehicle detection, tracking, and behavior analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1786. [Google Scholar] [CrossRef]
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; Jesus, L.; Berriel, R.; Paixão, T.; Mutz, F.; et al. Self-driving cars: A survey. arXiv 2019, arXiv:1901.04407. [Google Scholar] [CrossRef]
- Liu, F.; Lu, Z.; Lin, X. Vision-based environmental perception for autonomous driving. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2023, 239, 39–69. [Google Scholar] [CrossRef]
- Chen, G.; Cao, H.; Conradt, J.; Tang, H.; Rohrbein, F.; Knoll, A. Event-Based Neuromorphic Vision for Autonomous Driving: A Paradigm Shift for Bio-Inspired Visual Sensing and Perception. IEEE Signal Process. Mag. 2020, 37, 34–49. [Google Scholar] [CrossRef]
- Li, J.; Dong, S.; Yu, Z.; Tian, Y.; Huang, T. Event-Based Vision Enhanced: A Joint Detection Framework in Autonomous Driving. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1396–1401. [Google Scholar]
- Gallego, G.; Delbruck, T.; Orchard, G.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.J.; Conradt, J.; Daniilidis, K.; et al. Event-Based Vision: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 154–180. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Jiang, J. Deep Event-Based Object Detection in Autonomous Driving: A Survey. arXiv 2024, arXiv:2405.03995. [Google Scholar]
- Iaboni, C.; Abichandani, P. Event-Based Spiking Neural Networks for Object Detection: A Review of Datasets, Architectures, Learning Rules, and Implementation. arXiv 2024, arXiv:2411.17006. [Google Scholar] [CrossRef]
- Steffen, L.; Reichard, D.; Weinland, J.; Kaiser, J.; Roennau, A.; Dillmann, R. Neuromorphic Stereo Vision: A Survey of Bio-Inspired Sensors and Algorithms. Front. Neurorobot. 2019, 13, 28. [Google Scholar] [CrossRef] [PubMed]
- Iacono, M.; Weber, S.; Glover, A.; Bartolozzi, C. Towards event driven object detection with off-the-shelf deep learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Maqueda, A.I.; Loquercio, A.; Gallego, G.; Garcia, N.; Scaramuzza, D. Event-Based Vision Meets Deep Learning on Steering Prediction for Self-Driving Cars. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5419–5427. [Google Scholar]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. Unsupervised event-based learning of optical flow, depth, and egomotion. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Li, J.; Li, J.; Zhu, L.; Xiang, X.; Huang, T.; Tian, Y. Asynchronous spatio-temporal memory network for continuous event-based object detection. IEEE Trans. Image Process. 2022, 31, 2975–2987. [Google Scholar] [CrossRef] [PubMed]
- Perot, E.; de Tournemire, P.; Nitti, D.; Masci, J.; Sironi, A. Learning to detect objects with a 1 megapixel event camera. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Gehrig, M.; Scaramuzza, D. Recurrent Vision Transformers for Object Detection with Event Cameras. arXiv 2023, arXiv:2212.05598. [Google Scholar]
- Schaefer, S.; Gehrig, D.; Scaramuzza, D. AEGNN: Asynchronous Event-Based Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12361–12371. [Google Scholar]
- Cordone, L.; Miramond, B.; Thierion, P. Object detection with spiking neural networks on automotive event data. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022. [Google Scholar]
- Zhang, J.; Dong, B.; Zhang, H.; Ding, J.; Heide, F.; Yin, B.; Yang, X. Spiking transformers for event-based single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Messikommer, N.; Gehrig, D.; Loquercio, A.; Scaramuzza, D. Event-based asynchronous sparse convolutional networks. In Proceedings of the European Conference Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Ultralytics. YOLOv8: The Latest Version of YOLO by Ultralytics. GitHub Repository. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 12 November 2024).
- Jiang, Z.; Xia, P.; Huang, K.; Stechele, W.; Chen, G.; Bing, Z.; Knoll, A. Mixed Frame-/Event-Driven Fast Pedestrian Detection. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8332–8338. [Google Scholar]
- Gehrig, D.; Scaramuzza, D. Low-latency automotive vision with event cameras. Nature 2024, 629, 1034–1040. [Google Scholar] [CrossRef] [PubMed]
- de Tournemire, P.; Nitti, D.; Perot, E.; Migliore, D.; Sironi, A. A Large Scale Event-based Detection Dataset for Automotive. arXiv 2020, arXiv:2001.08499. [Google Scholar]
- Binas, J.; Neil, D.; Liu, S.-C.; Delbruck, T. DDD17: End-To-End DAVIS Driving Dataset. arXiv 2017, arXiv:1711.01458. [Google Scholar]
- Gehrig, M.; Aarents, W.; Gehrig, D.; Scaramuzza, D. DSEC: A stereo event camera dataset for driving scenarios. IEEE Robot. Autom. Lett. 2021, 6, 4947–4954. [Google Scholar] [CrossRef]
- Zubić, N.; Gehrig, D.; Gehrig, M.; Scaramuzza, D. From Chaos Comes Order: Ordering Event Representations for Object Recognition and Detection. arXiv 2023, arXiv:2304.13455. [Google Scholar]
- Dosovitskiy, A. CARLA: An Open Urban Driving Simulator. Proc. Conf. Robot Learn. 2017, 78, 1–16. [Google Scholar]
- Xu, Z.; Wang, X.; Wang, X.; Zheng, N. Safety validation for connected autonomous vehicles using large-scale testing tracks in high-fidelity simulation environment. Accid. Anal. Prev. 2025, 215, 108011. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).