


Safety of the Intended Functionality Validation for Automated Driving Systems by Using Perception Performance Insufficiencies Injection


Abstract
1. Introduction
1.1. Safety Validation
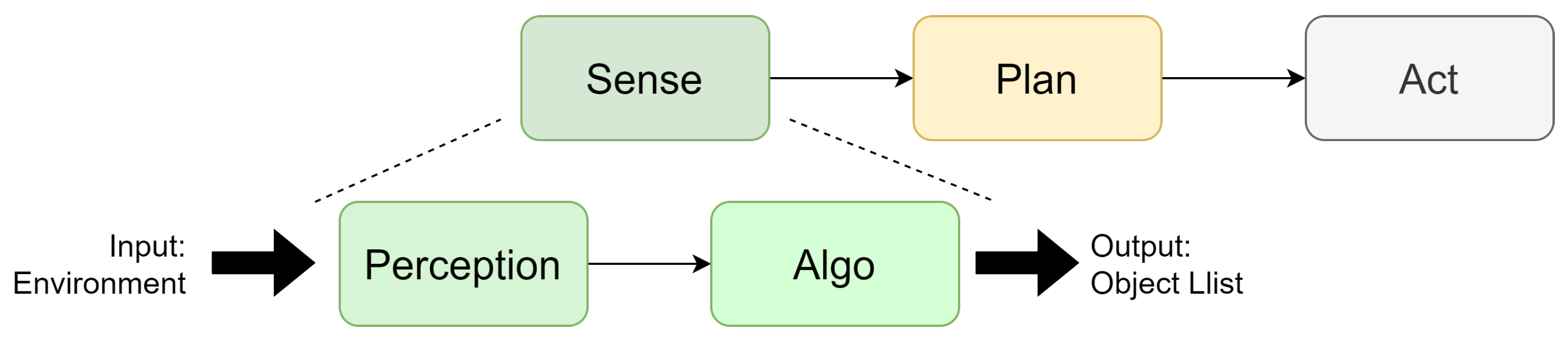
1.2. Sensor Models
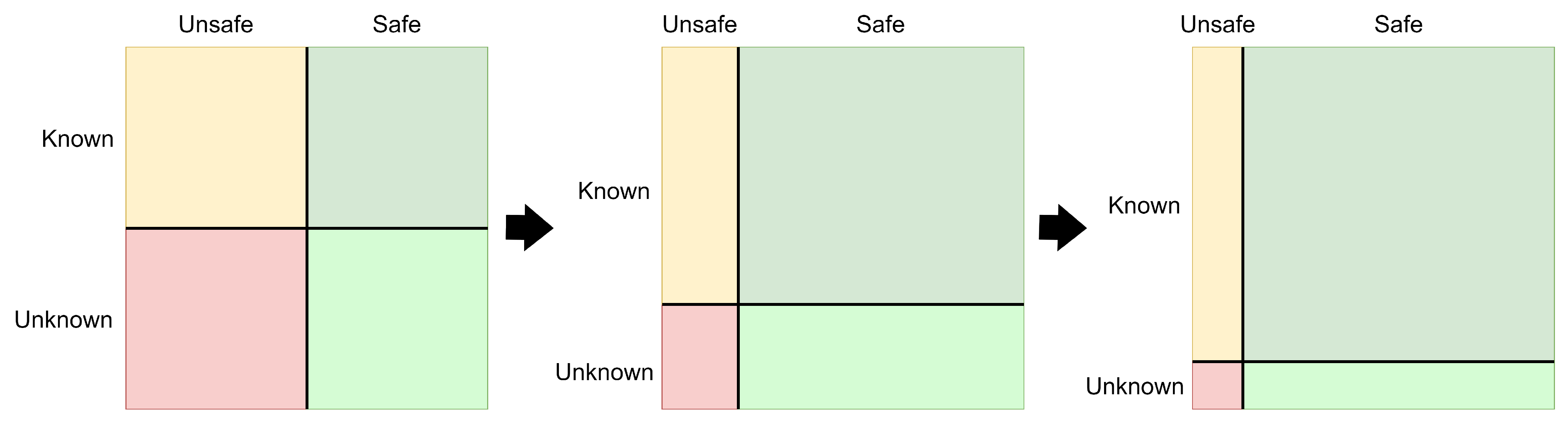
1.3. Risk Evaluation for Autonomous Vehicles
1.4. Structure of the Article
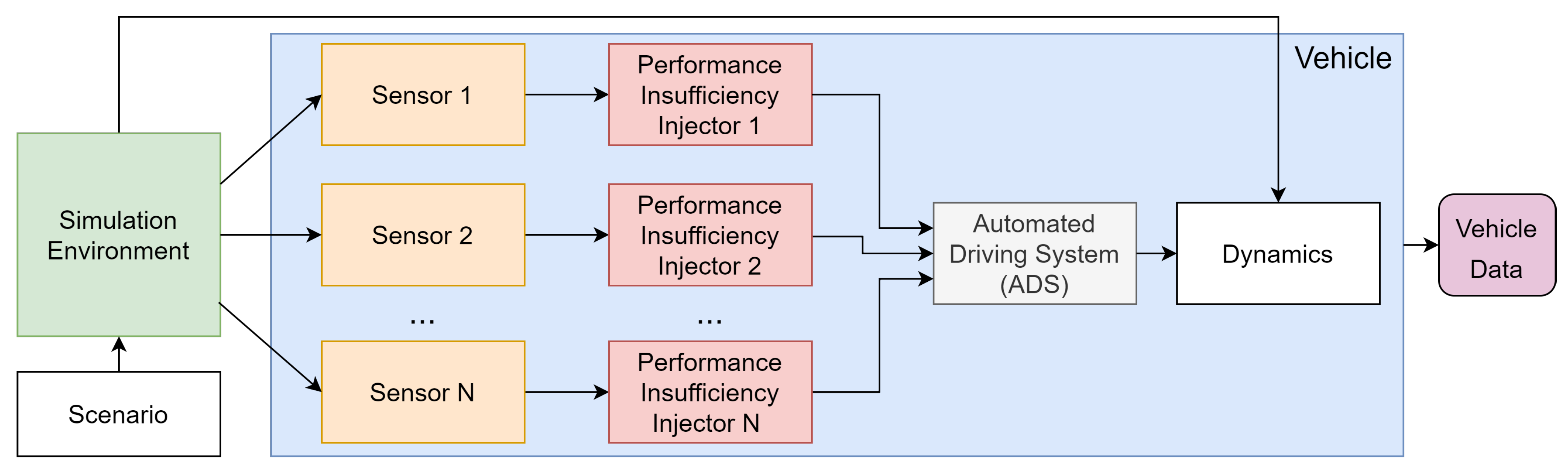
2. Perception Performance Insufficiencies Injection
- Generic Performance Insufficiency (GPI): This refers to a general performance insufficiency that is not related to any specific sensor technology but rather the impact on sensor perception. It is used as a general category for performance insufficiencies. Table 1 shows an excerpt of some identified performance insufficiencies, also describing their impact on the sensor.
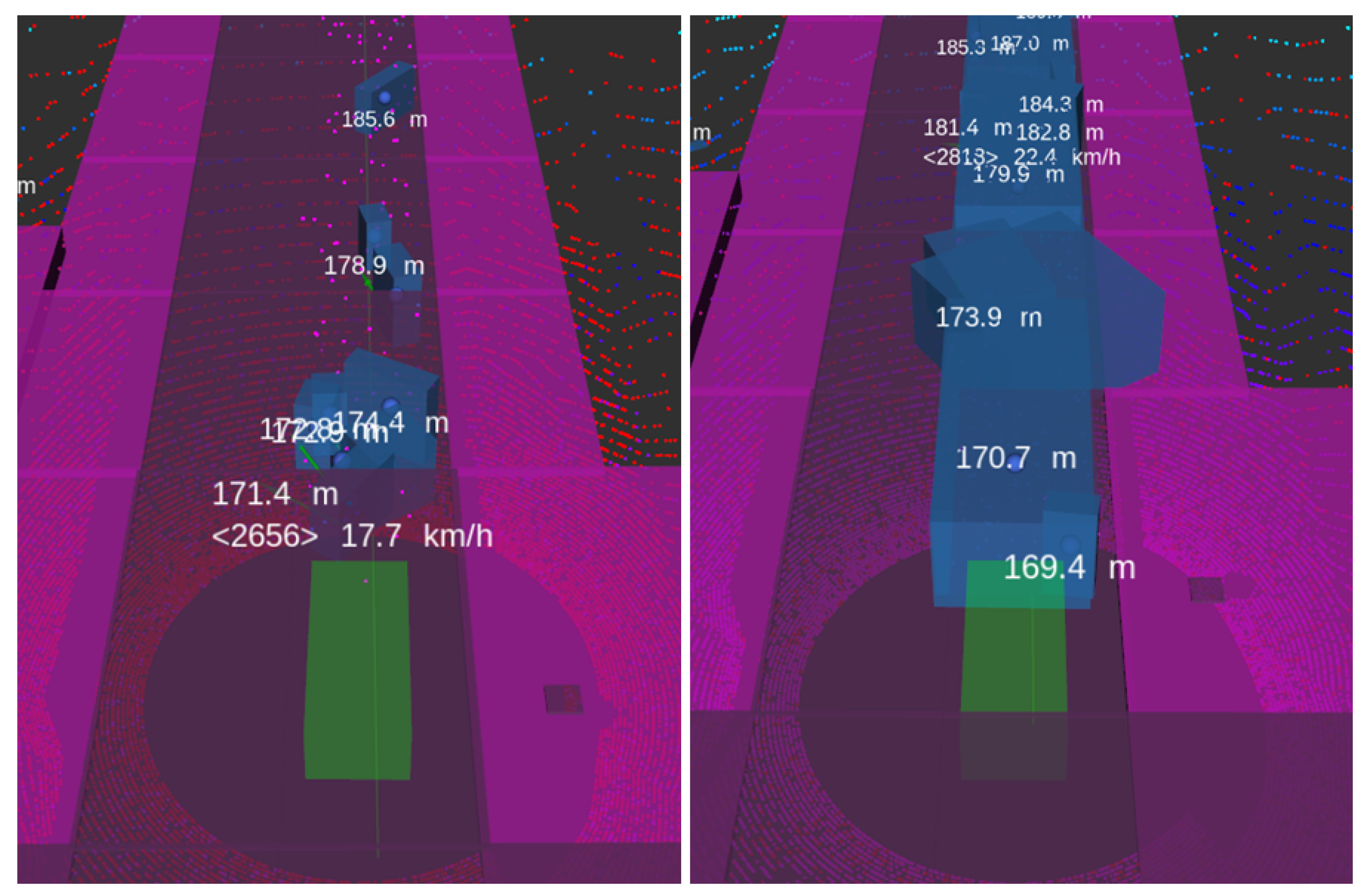
- Technology Performance Insufficiency (TPI): In these insufficiencies, the defined generic performance insufficiencies are modelled for a specific technology. For example, the reduction of field of view performance insufficiency from the GPI table could be defined for the lidar technology as cropping in the point cloud message provided by the lidar sensor function. Thus, if the visibility of the sensor is limited to a specified distance, the injector will remove the points farther than this distance. Table 2 shows an excerpt of the performance insufficiencies for the lidar technology and how they are modelled in the system.
- Triggering Condition Performance Insufficiency (TCPI): This is a performance insufficiency that was modelled for a specific triggering condition and technology, such as the lidar snowfall modelling from [36] or camera rain models from [38]. This category also includes the defined taxonomies from the standards (SAE [54], BSI [21], SOTIF [9], etc.) that could be set as triggering conditions in the validation process. For example, visibility in a heavy snow scenario is limited to 500 m according to the SAE [54]. Note that these performance insufficiencies are not system-independent; therefore, they have to be included in all available sensors simultaneously. In this context, if a triggering condition is validated for ADS, then this includes a radar, camera, and lidar sensor; all performance insufficiency injections for all sensors must be included at the same time and at the same fidelity level to avoid inaccurate results.
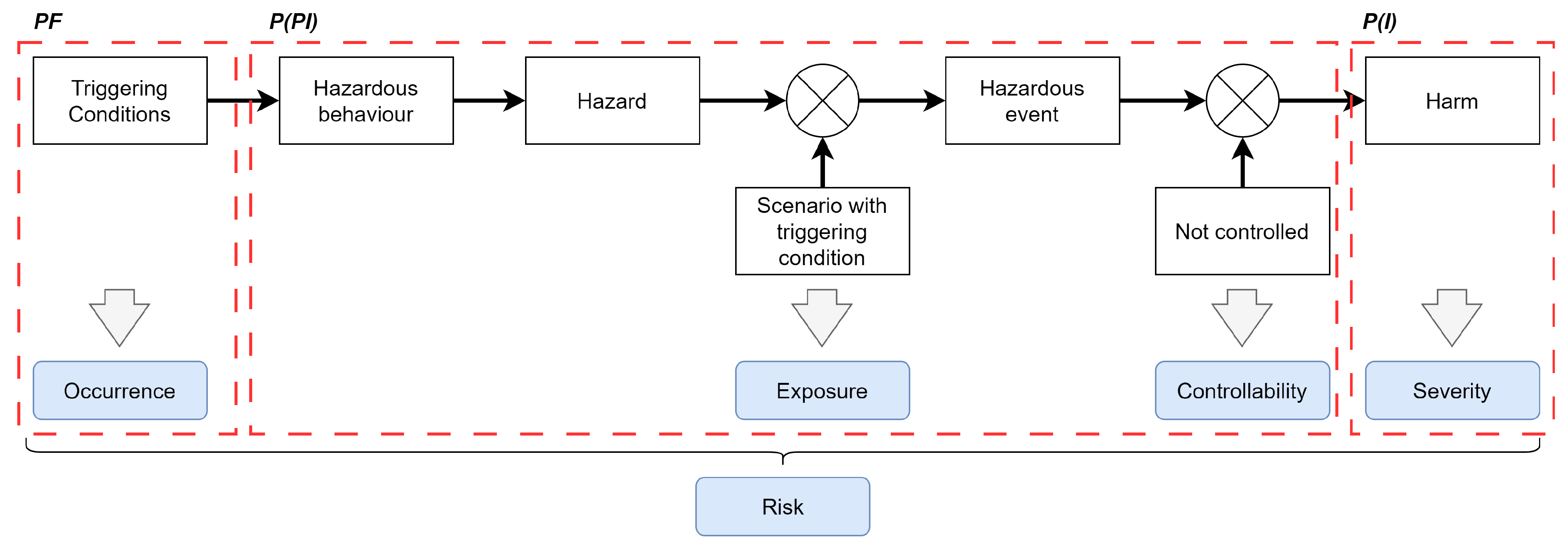
3. Risk Quantification
- Severity (S): the level of injury to the driver and passengers.
- Controllability (C): if the hazard could be controlled by the driver.
- Exposure (E): how often the hazard occurred during the driving time.
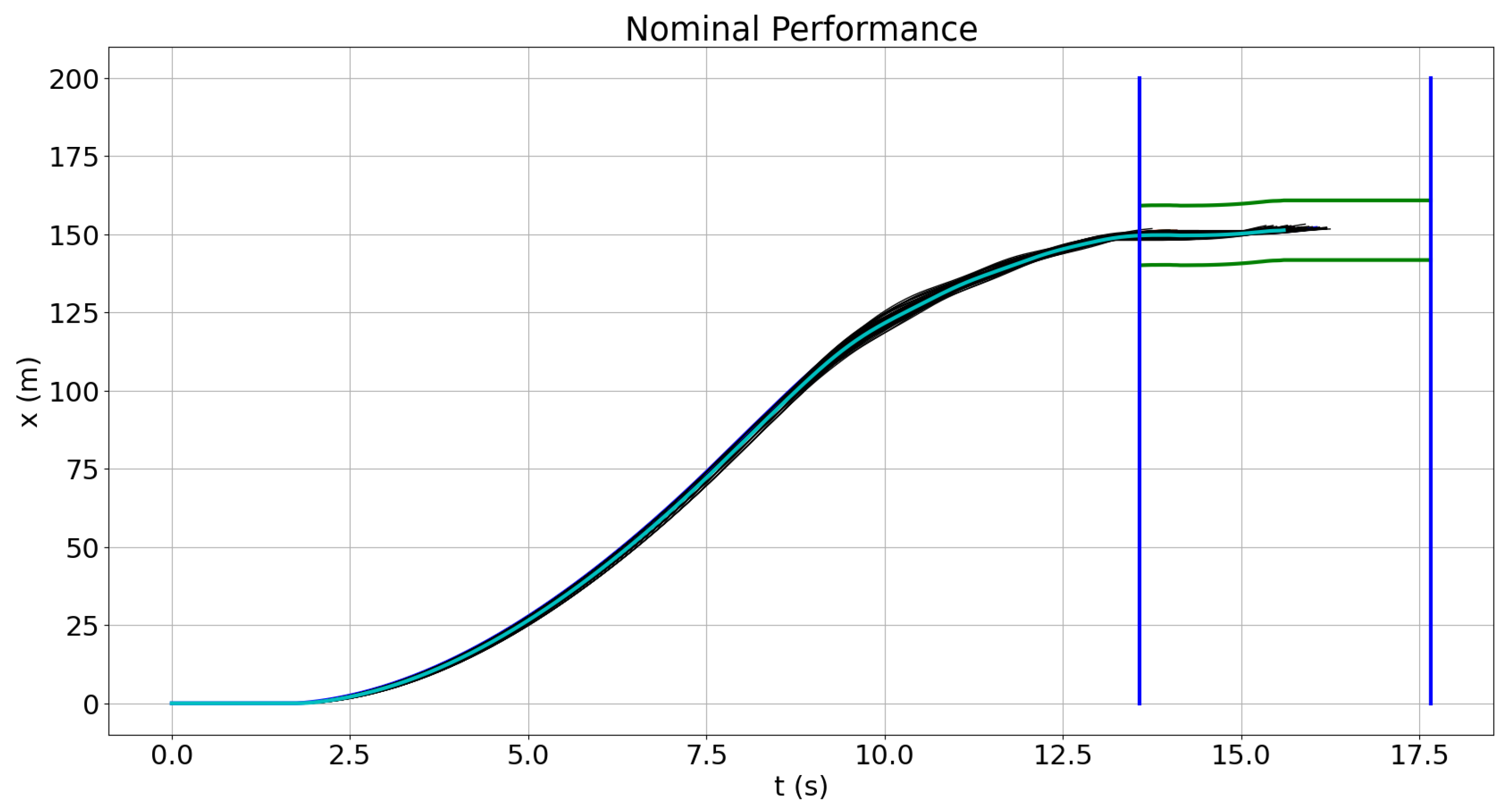
4. Use Case
4.1. Performance Insufficiencies Injection
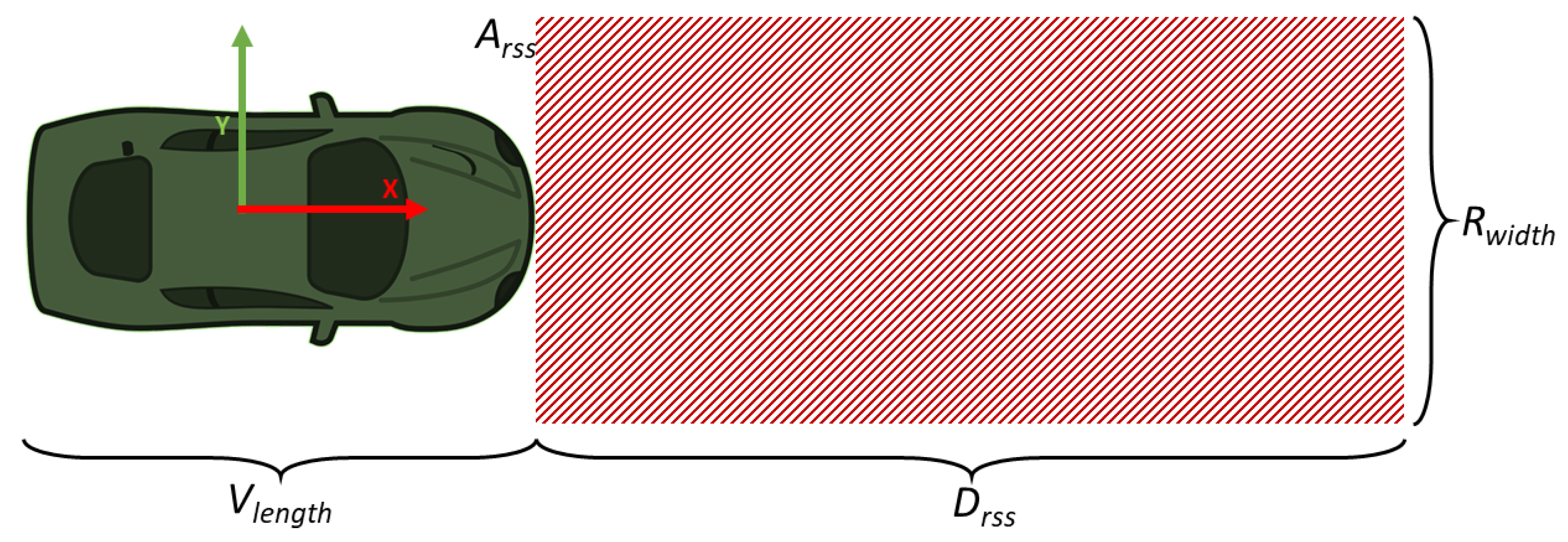
- DRSS: Minimum distance to ensure that there is no crash with the obstacle.
- vr: Max ego vehicle velocity (m/s) in the test scenario. Value: 22.22 m/s (80 km/h).
- ρ: Response time in seconds: 0.5 s.
- amax,accel: Maximum acceleration of the robot (m/s2). Value: 5.5 m/s2.
- amin,brake: Minimum braking acceleration of the robot (m/s2). Value: 4.5 m/s2.
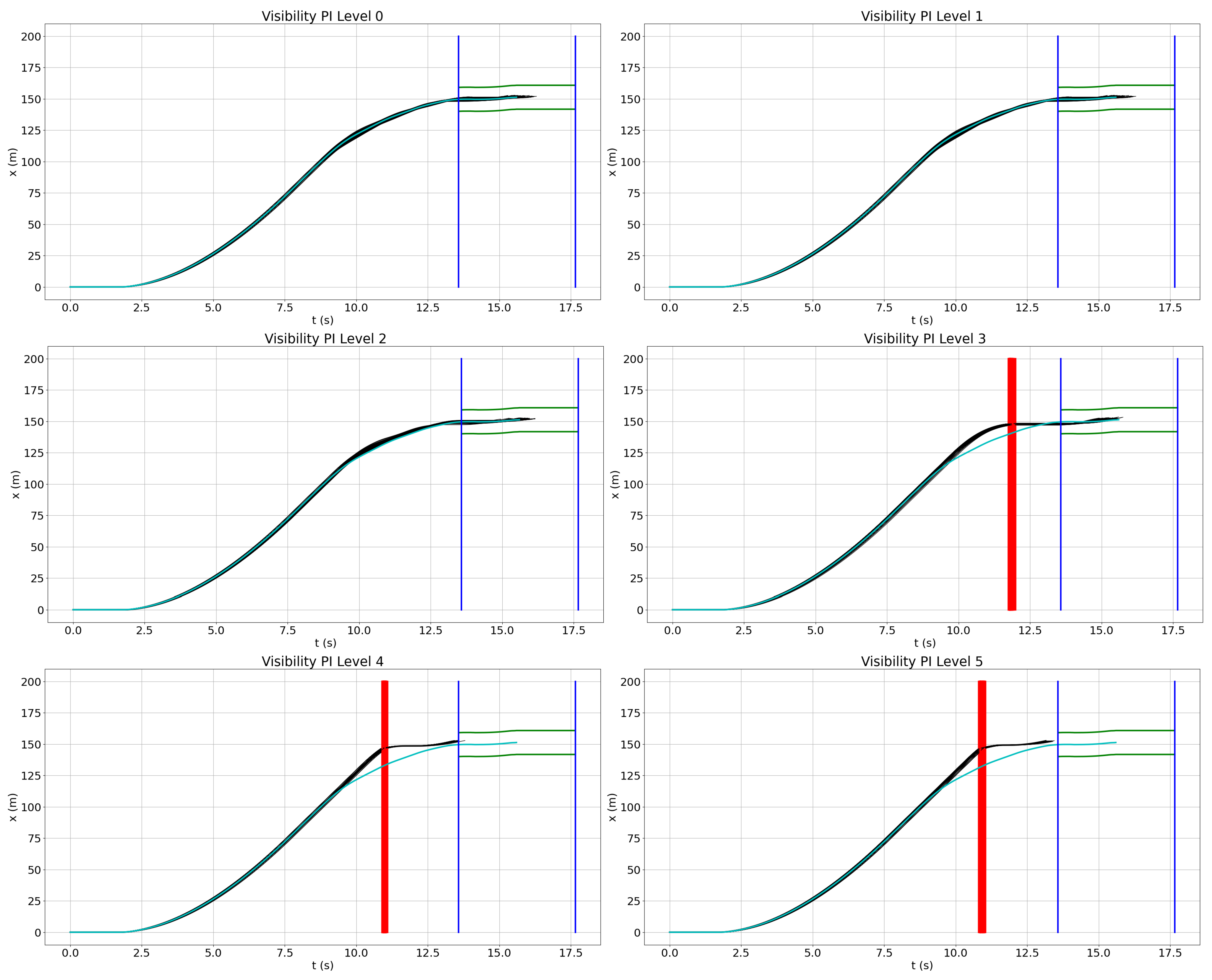
4.2. Field of View Reduction
Quantitative Risk Evaluation
- Level 5: 0 m ≤ visibility < 61 m
- Level 4: 61 m ≤ visibility < 244 m
- Level 3: 244 m ≤ visibility < 805 m
- Level 2: 805 m ≤ visibility < 1609 m
- Level 1: visibility ≥ 1609 m
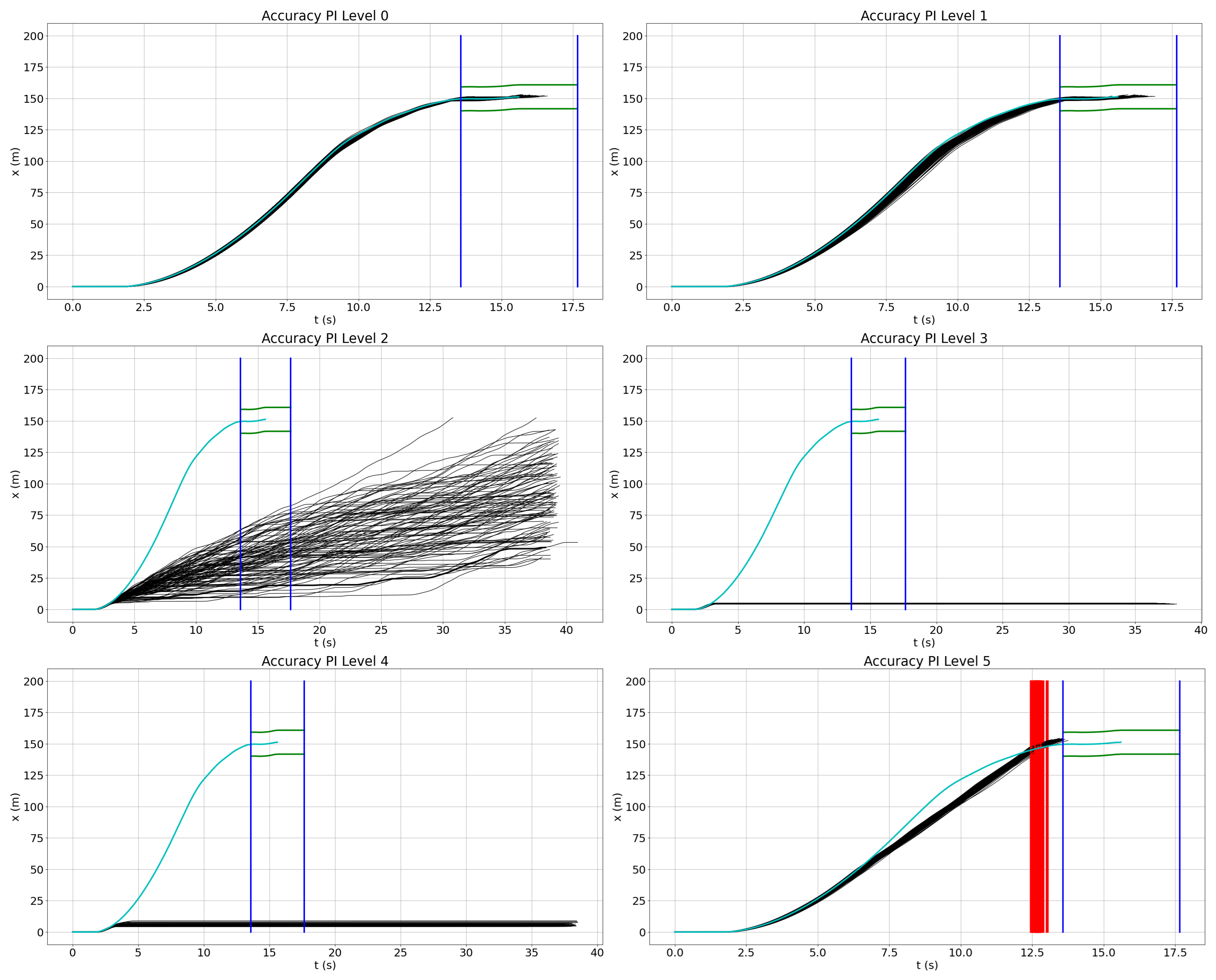
4.3. Accuracy Reduction
4.3.1. Performance Insufficiencies Injection
4.3.2. Quantitative Risk Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADAS | Advanced Driver-Assistance System |
| ADS | Automated Driving System |
| ALARP | As Low As Reasonably Practicable |
| ASIL | Automotive Safety Integrity Level |
| GPI | Generic Performance Insufficiency |
| HARA | Hazard Analysis and Risk Assessment |
| HIL | Hardware-In-Loop |
| KPI | Key Performance Indicator |
| MDPI | Multidisciplinary Digital Publishing Institute |
| ODD | Operational Design Domain |
| PF | Plausibility Factor |
| PI | Performance Insufficiency |
| RSS | Responsibility-Sensitive Safety |
| SOTIF | Safety Of The Intended Functionality |
| SPI | Safety Performance Indicator |
| TCPI | Triggering Condition Performance Insufficiency |
| TPI | Technology Performance Insufficiency |
References
- (EU) 2022/1426; Commission Implementing Regulation (EU) 2022/1426—Commision Implementing Act AD v4.1. European Commission: Brussel, Belgium, 2022.
- National Transportation Safety Board (NTSB). Collision between a Sport Utility Vehicle Operating with Partial Driving Automation and a Crash Attenuator, Mountain View, California, March 23, 2018. 2020. Available online: https://www.ntsb.gov/investigations/AccidentReports/Reports/HAR2001.pdf (accessed on 12 May 2023).
- Bonnefon, J.F. 18 The Uber Accident. In The Car That Knew Too Much: Can a Machine Be Moral? The MIT Press: Cambridge, MA, USA, 2021; pp. 93–98. [Google Scholar]
- Shah, S.A. Safe-AV: A Fault Tolerant Safety Architecture for Autonomous Vehicles. Ph.D. Thesis, McMaster University, Hamilton, ON, USA, 2019. [Google Scholar]
- AI Incident Database. Incident 293: Cruise’s Self-Driving Car Involved in a Multiple-Injury Collision at an San Francisco Intersection. 2022. Available online: https://incidentdatabase.ai/cite/293/ (accessed on 3 March 2024).
- Ballingall, S.; Sarvi, M.; Sweatman, P. Standards relevant to automated driving system safety: A systematic assessment. Transp. Eng. 2023, 13, 100202. [Google Scholar] [CrossRef]
- Koopman, P. How Safe Is Safe Enough?: Measuring and Predicting Autonomous Vehicle Safety; Amazon Digital Services LLC: Seattle, WA, USA, 2022. [Google Scholar]
- UL4600; Standard for Safety: Evaluation of Autonomous Products. Standards and Engagement Inc.: Evanston, IL, USA, 2021.
- ISO 21448:2022; Road vehicles—Safety of the Intended Functionality. International Organization for Standardization: Geneva, Switzerland, 2022.
- Westhofen, L.; Neurohr, C.; Koopmann, T.; Butz, M.; Schütt, B.; Utesch, F.; Neurohr, B.; Gutenkunst, C.; Böde, E. Criticality Metrics for Automated Driving: A Review and Suitability Analysis of the State of the Art. Arch. Comput. Methods Eng. 2022, 30, 1–35. [Google Scholar] [CrossRef]
- Sun, C.; Zhang, R.; Lu, Y.; Cui, Y.; Deng, Z.; Cao, D.; Khajepour, A. Toward Ensuring Safety for Autonomous Driving Perception: Standardization Progress, Research Advances, and Perspectives. IEEE Trans. Intell. Transp. Syst. 2023, 25, 3286–3304. [Google Scholar] [CrossRef]
- Wang, H.; Shao, W.; Sun, C.; Yang, K.; Cao, D.; Li, J. A Survey on an Emerging Safety Challenge for Autonomous Vehicles: Safety of the Intended Functionality. Engineering 2024, 33, 17–34. [Google Scholar] [CrossRef]
- Hoss, M.; Scholtes, M.; Eckstein, L. A Review of Testing Object-Based Environment Perception for Safe Automated Driving. Automot. Innov. 2022, 5, 223–250. [Google Scholar] [CrossRef]
- Zhu, Z.; Philipp, R.; Hungar, C.; Howar, F. Systematization and Identification of Triggering Conditions: A Preliminary Step for Efficient Testing of Autonomous Vehicles. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 798–805. [Google Scholar] [CrossRef]
- Expósito Jiménez, V.J.; Martin, H.; Schwarzl, C.; Macher, G.; Brenner, E. Triggering Conditions Analysis and Use Case for Validation of ADAS/ADS Functions. In International Conference on Computer Safety, Reliability, and Security; SAFECOMP 2022 Workshops; Trapp, M., Schoitsch, E., Guiochet, J., Bitsch, F., Eds.; Springer: Cham, Switzerland, 2022; pp. 11–22. [Google Scholar]
- ISO 26262:2018; Road Vehicles—Functional Safety. International Organization for Standardization: Geneva, Switzerland, 2018.
- Koopman, P.; Kane, A.; Black, J. Credible Autonomy Safety Argumentation. In Proceedings of the 27th Safety-Critical Systems Symposium 2019, Bristol, UK, 5–7 February 2019. [Google Scholar]
- United Nations Economic Commission for Europe (UNECE). New Assessment/Test Method for Automated Driving (NATM)—Master Document (Final Draft). 2021. Available online: https://unece.org/sites/default/files/2021-01/GRVA-09-07e.pdf (accessed on 9 February 2024).
- ISO/DIS 34505; Road Vehicles—Test Scenarios for Automated Driving Systems—Scenario Based Safety Evaluation Framework. International Organization for Standardization: Geneva, Switzerland, 2022.
- AVSC00002202004; AVSC Best Practice for Describing an Operational Design Domain: Conceptual Framework and Lexicon. Society of Automotive Engineers (SAE) International: Pittsburgh, PA, USA, 2020.
- BSI PAS 1883:2020; Operational Design Domain (ODD) Taxonomy for an Automated Driving System (ADS). Specification. The British Standards Institution: London, UK, 2020.
- Weissensteiner, P.; Stettinger, G.; Khastgir, S.; Watzenig, D. Operational Design Domain-Driven Coverage for the Safety Argumentation of Automated Vehicles. IEEE Access 2023, 11, 12263–12284. [Google Scholar] [CrossRef]
- Weissensteiner, P.; Stettinger, G.; Rumetshofer, J.; Watzenig, D. Virtual Validation of an Automated Lane-Keeping System with an Extended Operational Design Domain. Electronics 2022, 11, 72. [Google Scholar] [CrossRef]
- Scholtes, M.; Westhofen, L.; Turner, L.R.; Lotto, K.; Schuldes, M.; Weber, H.; Wagener, N.; Neurohr, C.; Bollmann, M.H.; Körtke, F.; et al. 6-Layer Model for a Structured Description and Categorization of Urban Traffic and Environment. IEEE Access 2021, 9, 59131–59147. [Google Scholar] [CrossRef]
- ASAM e.V. ASAM OpenODD. 2021. Available online: https://www.asam.net/project-detail/asam-openodd/ (accessed on 5 December 2023).
- Virtual Vehicle Research GmbH. SPIDER: Mobile Platform for the Development and Testing of Autnomous Driving Functions. 2021. Available online: https://www.v2c2.at/spider/ (accessed on 5 December 2023).
- AVL List GmbH. AVL DRIVINGCUBE. 2023. Available online: https://www.avl.com/en/testing-solutions/automated-and-connected-mobility-testing/avl-drivingcube (accessed on 7 February 2024).
- de Gelder, E.; Paardekooper, J.P.; Op den Camp, O.; De Schutter, B. Safety assessment of automated vehicles: How to determine whether we have collected enough field data? Traffic Inj. Prev. 2019, 20, S162–S170. [Google Scholar] [CrossRef]
- Linnhoff, C.; Hofrichter, K.; Elster, L.; Rosenberger, P.; Winner, H. Measuring the Influence of Environmental Conditions on Automotive Lidar Sensors. Sensors 2022, 22, 5266. [Google Scholar] [CrossRef]
- Fang, J.; Zhou, D.; Zhao, J.; Tang, C.; Xu, C.Z.; Zhang, L. LiDAR-CS Dataset: LiDAR Point Cloud Dataset with Cross-Sensors for 3D Object Detection. arXiv 2023, arXiv:cs.CV/2301.12515. [Google Scholar]
- Schlager, B.; Muckenhuber, S.; Schmidt, S.; Holzer, H.; Rott, R.; Maier, F.M.; Saad, K.; Kirchengast, M.; Stettinger, G.; Watzenig, D.; et al. State-of-the-Art Sensor Models for Virtual Testing of Advanced Driver Assistance Systems/Autonomous Driving Functions. SAE Int. J. Connect. Autom. Veh. 2020, 3, 233–261. [Google Scholar] [CrossRef]
- Bijelic, M.; Gruber, T.; Mannan, F.; Kraus, F.; Ritter, W.; Dietmayer, K.; Heide, F. Seeing Through Fog Without Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11679–11689. [Google Scholar] [CrossRef]
- Dreissig, M.; Scheuble, D.; Piewak, F.; Boedecker, J. Survey on LiDAR Perception in Adverse Weather Conditions. arXiv 2023, arXiv:cs.RO/2304.06312. [Google Scholar]
- Minh Mai, N.A.; Duthon, P.; Salmane, P.H.; Khoudour, L.; Crouzil, A.; Velastin, S.A. Camera and LiDAR analysis for 3D object detection in foggy weather conditions. In Proceedings of the 2022 12th International Conference on Pattern Recognition Systems (ICPRS), Etienne, France, 7–10 June 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Hahner, M.; Sakaridis, C.; Dai, D.; Van Gool, L. Fog Simulation on Real LiDAR Point Clouds for 3D Object Detection in Adverse Weather. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Hahner, M.; Sakaridis, C.; Bijelic, M.; Heide, F.; Yu, F.; Dai, D.; Van Gool, L. LiDAR Snowfall Simulation for Robust 3D Object Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, US, 18–24 June 2022; pp. 16343–16353. [Google Scholar] [CrossRef]
- Skender, I. Robustness Test for ADAS Function. Master’s Thesis, Graz University of Technology, Graz, Austria, 2022. [Google Scholar]
- Pizzati, F.; Cerri, P.; de Charette, R. Model-Based Occlusion Disentanglement for Image-to-Image Translation. In Proceedings of the Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 447–463. [Google Scholar]
- Sadeghi, J.; Rogers, B.; Gunn, J.; Saunders, T.; Samangooei, S.; Dokania, P.K.; Redford, J. A Step Towards Efficient Evaluation of Complex Perception Tasks in Simulation. arXiv 2021, arXiv:cs.LG/2110.02739. [Google Scholar]
- Piazzoni, A. Modeling Perception Errors in Autonomous Vehicles and Their Impact on Behavior; Nanyang Technological University: Nanyang, China, 2023. [Google Scholar] [CrossRef]
- Piazzoni, A.; Cherian, J.; Slavik, M.; Dauwels, J. Modeling perception errors towards robust decision making in autonomous vehicles. In Proceedings of the IJCAI’20: Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2021. [Google Scholar]
- Piazzoni, A.; Cherian, J.; Dauwels, J.; Chau, L.P. PEM: Perception Error Model for Virtual Testing of Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2024, 25, 670–681. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:cs.CV/1312.6199. [Google Scholar]
- Sadeghi, J.; Lord, N.A.; Redford, J.; Mueller, R. Attacking Motion Planners Using Adversarial Perception Errors. arXiv 2023, arXiv:cs.RO/2311.12722. [Google Scholar]
- Innes, C.; Ramamoorthy, S. Testing Rare Downstream Safety Violations via Upstream Adaptive Sampling of Perception Error Models. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May –2 June 2023 2023; pp. 12744–12750. [Google Scholar] [CrossRef]
- Putze, L.; Westhofen, L.; Koopmann, T.; Böde, E.; Neurohr, C. On Quantification for SOTIF Validation of Automated Driving Systems. In Proceedings of the 2023 IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023; pp. 1–8. [Google Scholar] [CrossRef]
- de Gelder, E.; Elrofai, H.; Saberi, A.K.; Paardekooper, J.P.; Op den Camp, O.; de Schutter, B. Risk Quantification for Automated Driving Systems in Real-World Driving Scenarios. IEEE Access 2021, 9, 168953–168970. [Google Scholar] [CrossRef]
- Kramer, B.; Neurohr, C.; Büker, M.; Böde, E.; Fränzle, M.; Damm, W. Identification and Quantification of Hazardous Scenarios for Automated Driving. In International Symposium on Model-Based Safety and Assessment; Zeller, M., Höfig, K., Eds.; Springer: Cham, Switzerland, 2020; pp. 163–178. [Google Scholar]
- Vaicenavicius, J.; Wiklund, T.; Grigaite, A.; Kalkauskas, A.; Vysniauskas, I.; Keen, S.D. Self-Driving Car Safety Quantification via Component-Level Analysis. SAE Int. J. Connect. Autom. Veh. 2021, 4, 35–45. [Google Scholar] [CrossRef]
- Karunakaran, D.; Worrall, S.; Nebot, E.M. Efficient Statistical Validation with Edge Cases to Evaluate Highly Automated Vehicles. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–8. [Google Scholar]
- Chu, J.; Zhao, T.; Jiao, J.; Yuan, Y.; Jing, Y. SOTIF-Oriented Perception Evaluation Method for Forward Obstacle Detection of Autonomous Vehicles. IEEE Syst. J. 2023, 17, 2319–2330. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. On a Formal Model of Safe and Scalable Self-driving Cars. arXiv 2017, arXiv:1708.06374. [Google Scholar]
- Peng, L.; Li, B.; Yu, W.; Yang, K.; Shao, W.; Wang, H. SOTIF Entropy: Online SOTIF Risk Quantification and Mitigation for Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2024, 25, 1530–1546. [Google Scholar] [CrossRef]
- ISO/SAE PAS 22736:2021; Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. Society of Automotive Engineers (SAE) International: Pittsburgh, PA, USA, 2021.
- Expósito Jiménez, V.J.; Winkler, B.; Castella Triginer, J.M.; Scharke, H.; Schneider, H.; Brenner, E.; Macher, G. Safety of the Intended Functionality Concept Integration into a Validation Tool Suite. Ada User J. 2023, 44, 244–447. [Google Scholar] [CrossRef]
- Zhao, D.; Huang, X.; Peng, H.; Lam, H.; LeBlanc, D.J. Accelerated Evaluation of Automated Vehicles in Car-Following Maneuvers. IEEE Trans. Intell. Transp. Syst. 2018, 19, 733–744. [Google Scholar] [CrossRef]
- Kusano, K.D.; Gabler, H.C. Potential Occupant Injury Reduction in Pre-Crash System Equipped Vehicles in the Striking Vehicle of Rear-end Crashes. In Annals of Advances in Automotive Medicine; Annual Scientific Conference; Association for the Advancement of Automotive Medicine: Chicago, IL, USA, 2010; Volume 54, pp. 203–214. [Google Scholar]
- Gennarelli, T.A.; Wodzin, E. AIS 2005: A contemporary injury scale. Injury 2006, 37, 1083–1091. [Google Scholar] [CrossRef]
- Kusano, K.D.; Gabler, H.C. Safety Benefits of Forward Collision Warning, Brake Assist, and Autonomous Braking Systems in Rear-End Collisions. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1546–1555. [Google Scholar] [CrossRef]
- EN50126-2; Railway Applications—The Specification and Demonstration of Reliability, Availability, Maintainability and Safety (RAMS) Part 2: Systems Approach to Safety. CENELEC—European Committee for Electrotechnical Standardization: Brussel, Belgium, 2017.
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- The Autoware Foundation. Autoware. 2021. Available online: https://www.autoware.org/autoware (accessed on 3 May 2023).
- Open Source Robotics Foundation, Inc. ROS—Robot Operating System. 2023. Available online: https://www.ros.org/ (accessed on 3 May 2023).
- European Road Safety Observation—European Commission. Motorways 2018. 2018. Available online: https://road-safety.transport.ec.europa.eu/system/files/2021-07/ersosynthesis2018-motorways.pdf (accessed on 7 September 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GPI ID | Generic Performance Insufficiency (GPI) | Impact |
|---|---|---|
| PI-01 | Reduction of Field of View (FoV) | The visual range of the sensor is reduced from the nominal sensor performance. |
| PI-02 | Light disturbance | An external light source affects the sensor perception. |
| PI-03 | Misalignment | The position of the sensor was changed from the calibrated sensor position. |
| PI-04 | Reduction of resolution | Sensor resolution is reduced according to the nominal performance provided by the manufacturer. |
| PI-05 | Reduction of accuracy | Sensor accuracy decreases according to the nominal performance. |
| PI-06 | Reduction of luminous intensity | The luminous intensity of the sensor is reduced according to the technical specifications. |
| PI-07 | Slower processing time | Sensor processing time is slower than the maximum processing time in nominal conditions. |
| Technology Performance Insufficiency (TPI) | Parent Generic Performance Insufficiency (GPI) | Potential Triggering Conditions | Performance Insufficiency Injection |
|---|---|---|---|
| Reduction of Field of View (FoV) | PI-01 | Snowfall, fog conditions, etc. | Crop the raw point cloud (vertical and horizontal cropping) generated by the lidar sensor. |
| Light Disturbance | PI-02 | Mirrors, water on the street, etc. | Add random points into the point cloud message. |
| Misalignment | PI-03 | Wrong calibration, earthen or gravel roads, potholes, etc. | Change the position of the sensor. |
| Reduction of accuracy | PI-05 | Sensor cover, housing dirtiness, occlusion, etc. | Include noise into the point cloud message. |
| Slower Processing Time | PI-07 | Driving in urban areas, etc. | Include random objects into the point cloud message. |
| Level (Meters) | Hazardous Behaviour | Collision | |
|---|---|---|---|
| Level 0 (80 m) | 0.00 | 0.00 | 0.00 |
| Level 1 (60 m) | 0.00 | 0.00 | 0.00 |
| Level 2 (45 m) | 0.00 | 0.00 | 0.00 |
| Level 3 (30 m) | 0.66 | 0.66 | 0.66 |
| Level 4 (20 m) | 1.00 | 1.00 | 1.00 |
| Level 5 (15 m) | 1.00 | 1.00 | 1.00 |
| Level | Visibility Limitation | X | Given |
|---|---|---|---|
| Level 0 | 80 m | P(X ≥ 0) | = 1.00000 |
| Level 1 | 60 m | P(X ≥ 1) | = 0.36788 |
| Level 2 | 45 m | P(X ≥ 2) | = 0.13534 |
| Level 3 | 30 m | P(X ≥ 3) | = 4.979 × 10−2 |
| Level 4 | 20 m | P(X ≥ 4) | = 1.832 × 10−2 |
| Level 5 | 15 m | P(X ≥ 5) | = 6.74 × 10−3 |
| Level (Meters) | Risk | |||
|---|---|---|---|---|
| Level 0 (80 m) | 1.00000 | 0.00 | 0.00 | 0.00 |
| Level 1 (60 m) | 0.36788 | 0.00 | 0.00 | 0.00 |
| Level 2 (45 m) | 0.13534 | 0.00 | 0.00 | 0.00 |
| Level 3 (30 m) | 0.04979 | 0.66 | 1.22966 × 10−2 | 4.04083 × 10−4 |
| Level 4 (20 m) | 0.01832 | 1.00 | 3.83674 × 10−2 | 7.02891 × 10−4 |
| Level 5 (15 m) | 0.00674 | 1.00 | 3.83675 × 10−2 | 2.58597 × 10−4 |
| Level (Injection Density in %) | Hazardous Behaviour | Collision | |
|---|---|---|---|
| Level 0 (0.15%) | 0.00 | 0.00 | 0.0 |
| Level 1 (0.30%) | 0.00 | 0.00 | 0.00 |
| Level 2 (0.75%) | 1.00 | 0.00 | 1.00 |
| Level 3 (1.49%) | 1.00 | 0.00 | 1.00 |
| Level 4 (2.99%) | 1.00 | 0.00 | 1.00 |
| Level 5 (5.97%) | 1.00 | 1.00 | 1.00 |
| Level (Injection Density in %) | Risk | |||
|---|---|---|---|---|
| Level 0 (0.15%) | 1.00000 | 0.00 | 0.00 | 0.00 |
| Level 1 (0.30%) | 0.36788 | 0.00 | 0.00 | 0.00 |
| Level 2 (0.75%) | 0.13534 | 1.00 | 0.00 | 0.00 |
| Level 3 (1.49%) | 0.04979 | 1.00 | 0.00 | 0.00 |
| Level 4 (2.99%) | 0.01832 | 1.00 | 0.00 | 0.00 |
| Level 5 (5.97%) | 0.00674 | 1.00 | 1.26752 × 10−2 | 8.54309 × 10−5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Expósito Jiménez, V.J.; Macher, G.; Watzenig, D.; Brenner, E. Safety of the Intended Functionality Validation for Automated Driving Systems by Using Perception Performance Insufficiencies Injection. Vehicles 2024, 6, 1164-1184. https://doi.org/10.3390/vehicles6030055
Expósito Jiménez VJ, Macher G, Watzenig D, Brenner E. Safety of the Intended Functionality Validation for Automated Driving Systems by Using Perception Performance Insufficiencies Injection. Vehicles. 2024; 6(3):1164-1184. https://doi.org/10.3390/vehicles6030055
Chicago/Turabian StyleExpósito Jiménez, Víctor J., Georg Macher, Daniel Watzenig, and Eugen Brenner. 2024. "Safety of the Intended Functionality Validation for Automated Driving Systems by Using Perception Performance Insufficiencies Injection" Vehicles 6, no. 3: 1164-1184. https://doi.org/10.3390/vehicles6030055
APA StyleExpósito Jiménez, V. J., Macher, G., Watzenig, D., & Brenner, E. (2024). Safety of the Intended Functionality Validation for Automated Driving Systems by Using Perception Performance Insufficiencies Injection. Vehicles, 6(3), 1164-1184. https://doi.org/10.3390/vehicles6030055