3.1. Handset Control Data
For an overview of the discomfort experienced by passengers during the autonomous test ride,
Figure 3 displays handset control data of all 50 participants along the course of the test track.
The pattern of this data illustrates two characteristics of passengers’ discomfort experience in autonomous driving. First, perceived discomfort depends on the driving scenario. Thus, handset control data of most participants clearly peak at the same points along the test track. All of these shared peaks occur during complex scenarios, such as obstacles on the road or intersections. These scenarios are characterized by high traffic density and the necessity for driving maneuvers in close proximity to other road users, such as changing lanes or braking in convoy in front of a red traffic light. In contrast, only very low discomfort values indicated by only few participants are observable for less complex scenarios with low traffic density and no necessity of driving maneuvers other than driving straight ahead. Therefore, complex driving scenarios contain a comparably high likelihood of passenger discomfort in autonomous driving (cf. [
19,
20]). Second, perceived discomfort differs between individuals. Thus, the handset control values of the individual participants scatter visibly around the shared basic pattern. These interindividual differences relate to the driving scenario (i.e., which situations are perceived as uncomfortable?), the beginning and end of the discomfort experience (i.e., how long before approaching/after leaving such a situation does discomfort emerge/remain?), and the extent of discomfort (i.e.,: How uncomfortable was the situation?). It is likely that these individual differences in experiencing discomfort during autonomous driving can be attributed to passenger characteristics such as system experience, driving experience, or personality factors (cf. [
2]). In summary, these results strongly suggest that modelling approaches need to include data of the driving context as well as passenger-related data that allow to distinguish between different passengers (e.g., physiological and behavioral parameters) for a reliable real-time detection of individual passengers’ discomfort during autonomous driving.
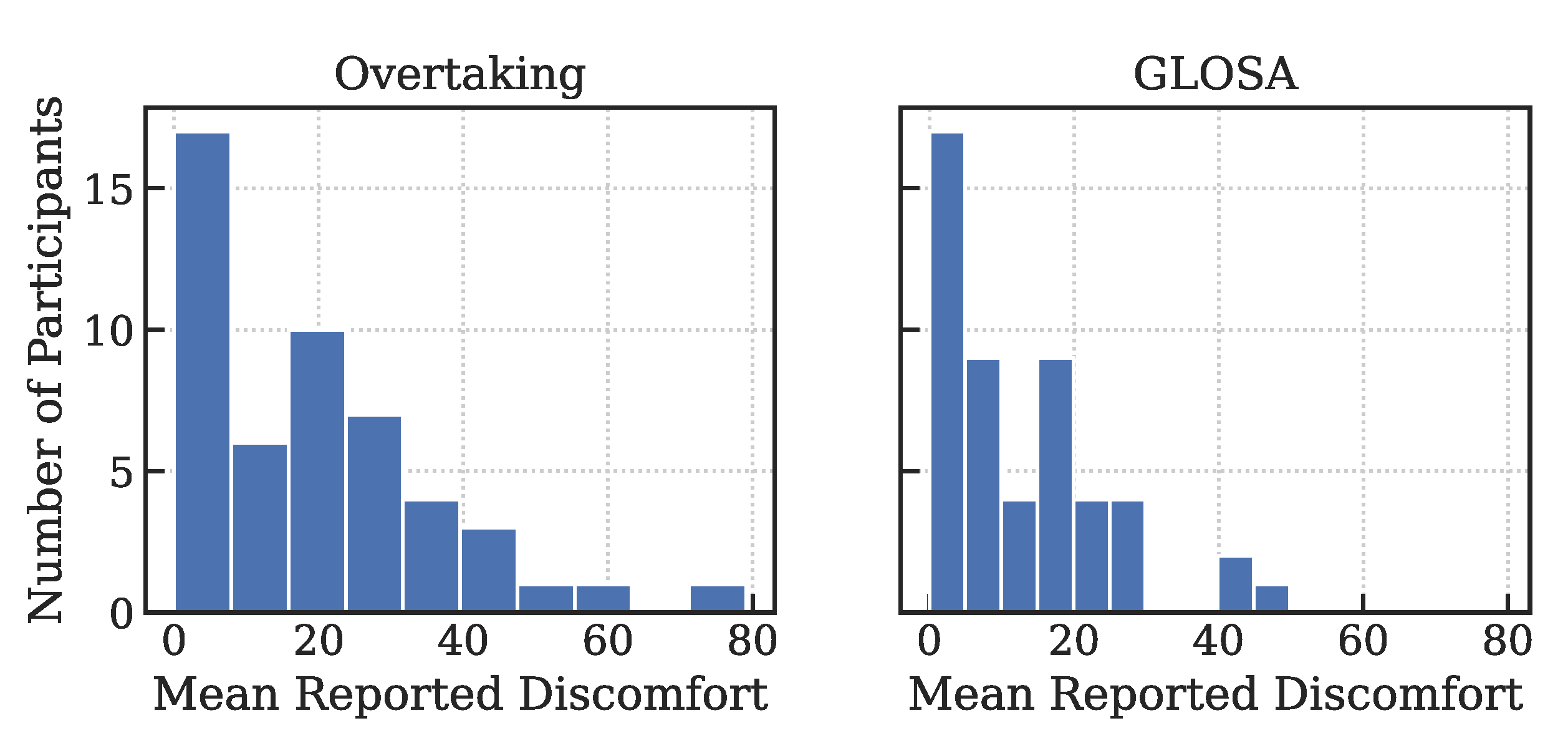
As exemplary driving scenarios with a high potential for passenger discomfort, modelling was focused on the overtaking scenarios (see
Figure 3: around 0.8 and km 3.2) and the GLOSA scenarios (see
Figure 3: around km 2.0 and km 2.5) (see
Section 2.1 for scenario descriptions).
Figure 4 provides an overview of the averaged discomfort values indicated during these scenarios per participant. In comparison, the bypassing scenarios were perceived as even more uncomfortable than the GLOSA scenarios.
3.2. User State Modelling Approaches
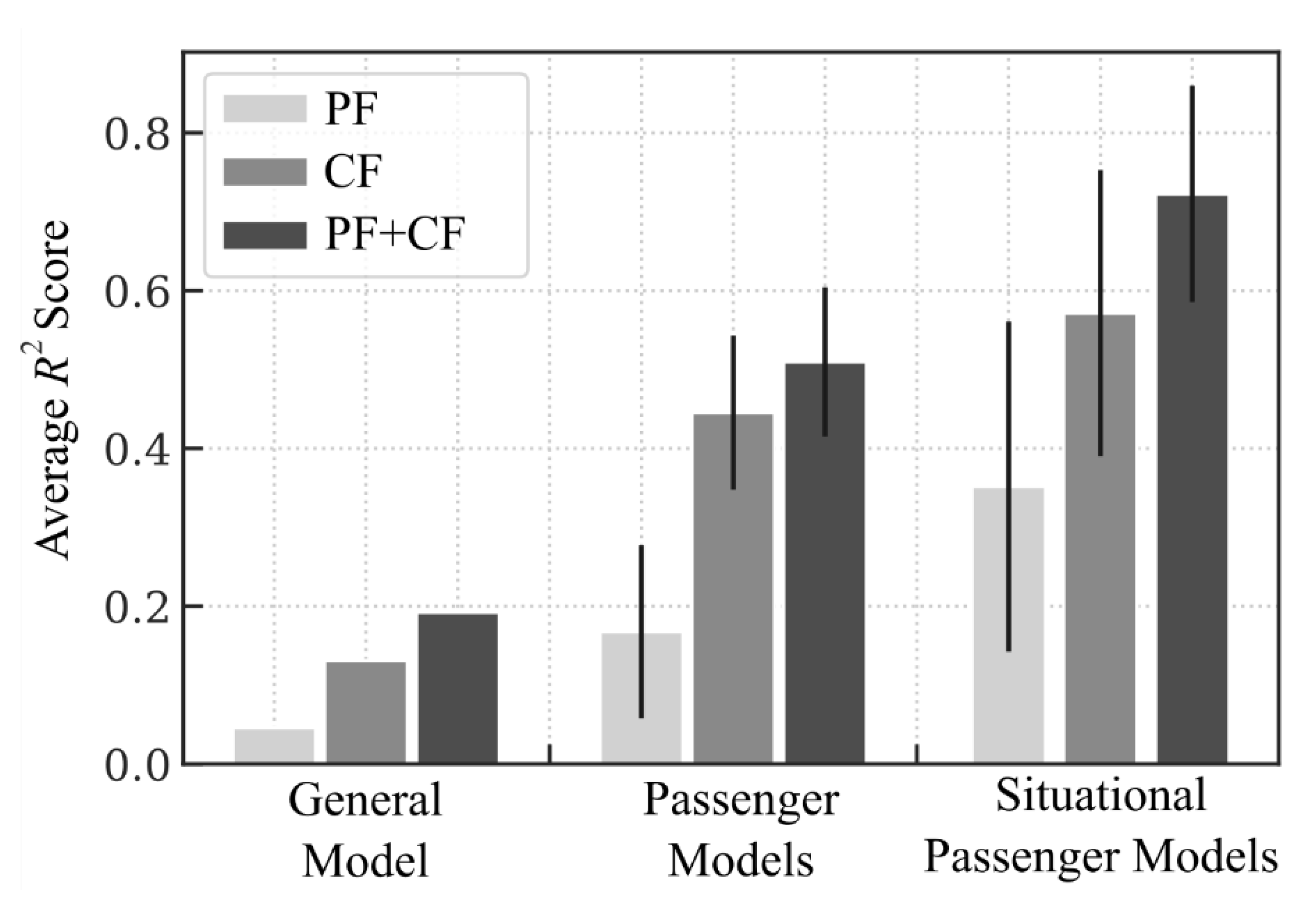
As shown in the previous section, the discomfort responses of the participants varied greatly across all scenarios. In this section, we investigate how different approaches for model training affect the overall performance of predicting passenger discomfort. Our three approaches are: (1) general model: training one model for the whole data set (all participants and all situations), (2) passenger models: training a separate model for each participant (one participant each, all situations) and (3) situational passenger models: training a separate model for each participant and each situation, which was carried out on the examples of the overtaking and GLOSA scenarios. To determine the importance of the passenger features and the accompanying sensory requirements, all of these approaches were done respectively using only PF, only CF and both feature sets. For modelling, we scaled the reported discomfort values from range (0, 100) to range (0, 1).
The resulting
scores of the three approaches are displayed in
Figure 5. The first approach, training one model for the whole data set (general model), yields the worst score. Even with PF and CF used, the score of the model is below 0.2. This shows that one model cannot accurately describe the relationships between features and discomfort of all participants.
Therefore, the second approach (passenger models) is more suitable for predicting passenger discomfort. Since one model is trained here for each participant (‘participant models’), each model can focus on the participants’ individual discomfort responses to the environment and more accurately describe the relationships between features and reported discomfort. Because multiple models are trained in this approach,
Figure 5 now displays the average score all of these models, with the respective SD as error bar. As displayed, the performance of these models reaches 0.51 ± 0.09 in the best case (using PF and CF).
Our third approach uses additional knowledge that can originate from the AV, namely the current contextual situation, and uses it to create situation-specific passenger models as explained in
Section 2.3. The idea is to create multiple simple models that only operate within a certain contextual scope. This approach increases performance because each model has to consider only contextualized feature–target-relationships. In
Figure 5, the scores are displayed, averaged over both scopes and all participants. As shown, the performance increases to a score of up to 0.72 ± 0.14 using PF and CF. This absolute score cannot be compared directly to the scores of the other two approaches, because only a subset of data is modelled. However, the full data set would be predicted by using the model from approach 2, when no overtaking maneuver or GLOSA situation is given, and the situational passenger model approach, when these situations occur. This way, the overall score would lay between the two approaches, depending on how often these situations occur. Besides the performance increase, the situational passenger models can fit feature–target-relationships, which are specific for their respective scenario, without needing to adhere to all other scenarios. These specific relations can be used for explainability, which will be more precise than the more general models. Using the SHAP method, we will subsequently analyze the different relationships between discomfort and features calculated by the situational passenger models in comparison to the personal model approach, and will cover the topic of explainability.
As shown with the scores, models that work purely with CF do not perform well, since the discomfort values indicated by different participants vary greatly across contextually similar situations. Thus, the addition of passenger features and the approach of training one model per participant increases performance through the usage of participants’ individual feature responses instead of the average response over all participants.
Figure 6 illustrates these improvements for a section of the time series data of one overtaking scenario for three participants. From left to right, the examples show an increasingly larger difference between CF and CF + PF, i.e., on the left is only a very minor improvement noticeable, on the right a larger one. In all three cases, the CF model predicts the situations of discomfort with less precision than the model using CF + PF. It predicts discomfort with less temporal accuracy, i.e., the discomfort value is higher for times where no discomfort was reported and also does not predict the reported discomfort magnitude as precise as the CF + PF model.
3.3. Model Explanation
As mentioned, the situational passenger model approach leads to more specific modelling and thus to better explainability. We now use the SHAP method to analyze how the features influence the prediction and how this influence varies across the general model and the situational passenger model approach. For this purpose, we use the SHAP summary plot explained in
Section 2. For the situational passenger model approach, we pooled together all SHAP values from all participants, since we have 50 models to be looked at. This can lead to non-linearly appearing relationships between features and model output, which are in fact just inter-participant differences of the models.
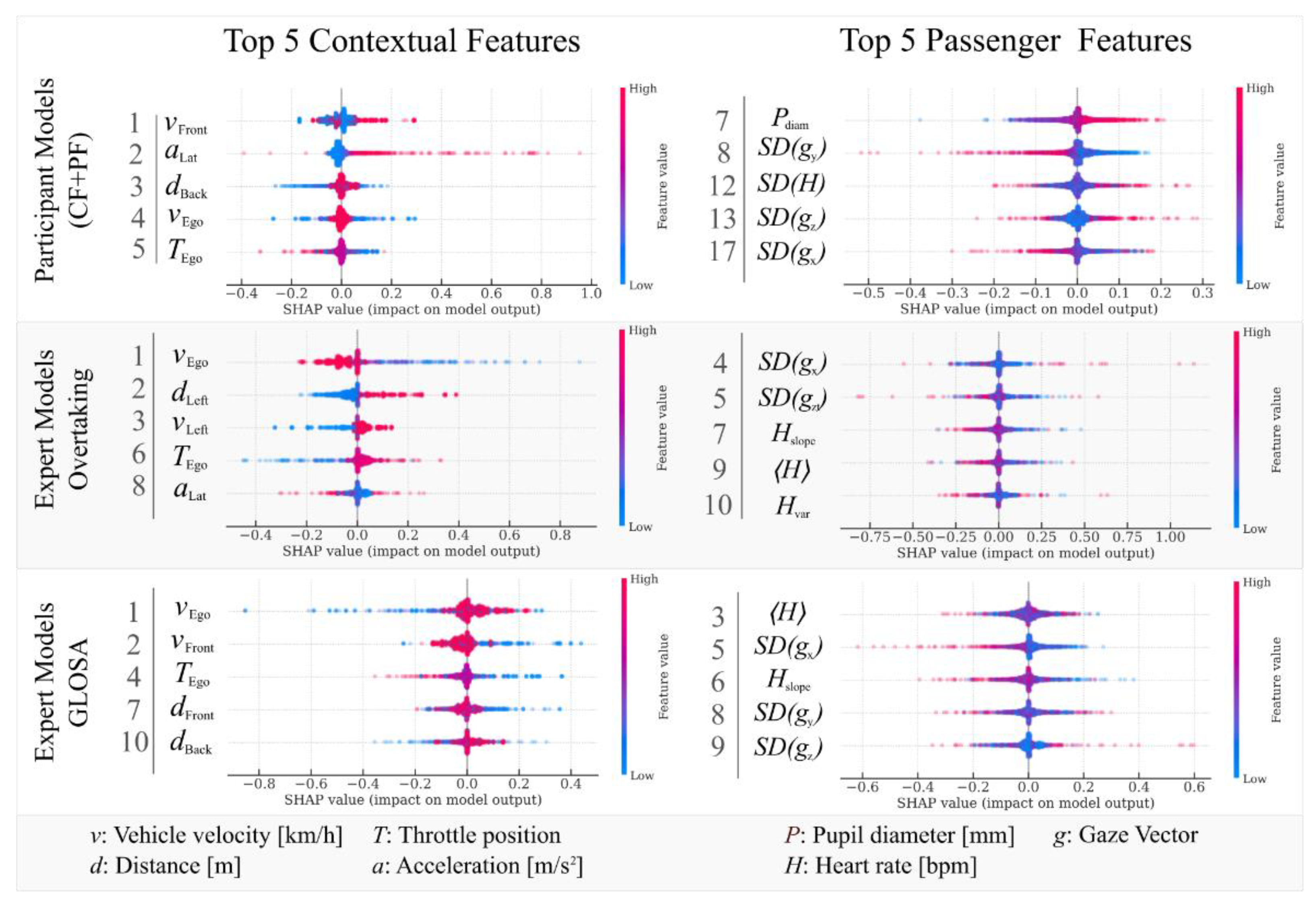
For this analysis, we use three different model types: the participant models (
Figure 7, first row) and the situational passenger models for overtaking (
Figure 7, second row) as well as GLOSA (
Figure 7, third row). For each of these model types we show the SHAP summary plots with the top 5 contextual features (first column) and the top five passenger features (second column), according to the SHAP value rating. Next to the feature symbols are the ranking numbers for the according feature in the combined ranking, i.e., CF + PF. This ranking is the sum of the according absolute SHAP values for each feature.
It can be noted that most of the SHAP value distributions have very long tails and are not normal distributed. This results from the short moments of maneuvers in relation to the whole study duration where discomfort is reported and the SHAP values being most relevant in these situations. Thus, most data points over the duration of the ride have SHAP values close to zero and only a few have extreme values.
To demonstrate how the situational passenger model approach increases explainability and changes the feature–target relations in contrast to the participant models, we analyze the situational passenger model SHAP values and the participant models’ SHAP values of the contextual features. In
Figure 7 top row, the SHAP values of the participant models are shown. The most important feature over all participants is the velocity of the vehicle in front of the ego vehicle
, which increases the discomfort the higher the velocity gets, for most of the participants. The lateral acceleration
is especially important when very high, as seen on the second rank with the very long tail towards the higher model output impacts. The following features are the distance to the vehicle behind the ego vehicle
, the velocity of the ego vehicle
, and the throttle of the ego vehicle
. These variables, although important, do not share a common relationship across all participants; low values of one feature can impact the model output either positively or negatively. Overall, in these models which have to take into account data of the whole ride, very general features, for example speed, lateral acceleration, and distance, the front and back vehicles are most important.
To show how an expert model changes the feature importance and relationships to discomfort prediction, the situational passenger models for overtaking are displayed in the second row. Here, the most important feature is , which is not only increased from rank 4 in comparison to the participant models, but now also with a very strong negative correlation to the model output. When overtaking, low speeds are associated with high discomfort. An interpretation of this will follow below. The next most important features are the distance and velocity to the opposing traffic vehicle on the left lane. This shows a strong relation to overtaking maneuvers, since the lane crossing into opposing traffic is a strong cause for discomfort. These two features do not occur within the top ranks of the participant models, showing that they are not important enough during the whole ride. This is understandable, since an overtaking maneuverer typically does not last long in comparison to the ride duration. The same principle applies to the situational passenger models for GLOSA scenarios. Here, is again the most important feature, but the direction of influence is switched with regards to the overtaking manoeuvre. Also, one can notice an increase in the importance of features related to the vehicle directly in front of the ego vehicle, thus now the velocity and the distance are on rank 2 and 4. The importance of the front vehicle is expected in GLOSA scenarios, since a sudden brake of this vehicle in response to a red light is a potential hazard. These two examples demonstrate that different maneuvers and scenarios cannot be captured by general, cross-situational models, and how expert models select more situation-specific features. Notice that these explanations occur without putting any more knowledge into the model, but only the correct contextual data split. Thus, this approach is scalable to large amounts of data and arbitrary more contexts.
The SHAP method also allows for interpreting the features in regard to the model impact direction, which proved to be a challenging task, but also gives lots of insights on how complex further interpretation of sensor data can be. For example, the feature in the overtaking expert model has a positive relation to the model output: The larger the distance between ego vehicle and the left lane opposing vehicle, the more discomfort is predicted. This seems unintuitive at first, since one would expect close distances to induce higher discomfort. However, in the general, in a safely driven overtaking scenario, a passenger experiences the highest discomfort in the initial stages of the maneuver (when approaching the obstacle on the own lane), when the oncoming vehicle on the left lane typically is still far away. At this stage, discomfort is induced by the decreasing distance to the obstacle on the own lane and the passenger’s uncertainty about whether or not the automation will initiate the overtaking maneuver in time. In contrast, the distance to the oncoming traffic on the left lane is the smallest when the obstacle is already safely bypassed and discomfort is therefore removed, resulting in a statistical association between a small distance and low discomfort. Another exemplary feature in this model is . According to the model, lower speed is associated with higher predicted discomfort. This seems unintuitive at first, but can again be explained by the discomfort reasons during the initial stages of this scenario. Thus, the vehicle is reducing speed slightly before initiating the overtaking process, when passenger discomfort is at its highest point. When the vehicle is at normal speeds again, the overtaking is already in process, and the passenger’s uncertainty regarding the obstacle is already dissolved. This is contrary to the GLOSA expert model, where high levels of cause high discomfort, which makes sense because the ego vehicle is moving towards a red light, thus it should slow down to reduce discomfort. These examples show how difficult an analysis of the impact direction of the features is. It does not only depend on the scenario and the human response to it, but also can be complicated by indirect relations between perceived discomfort and certain context features, which make the automatic modelling using the SHAP method even more useful.
The passenger features also contribute significantly to the model output, although generally not as much as the contextual features. In the participant models, the SHAP importance for PF is starting at rank 7 with the pupil diameter . Overall, in the PF data, we observe larger differences in contrast to the CF across the participants: Many PF have different directions of impact on the models. These differences coupled with the low amounts of data in the situational passenger models leads to poor quality SHAP results for situational passenger models for Overtaking and GLOSA. Therefore, we will concentrate on the participant approach for the PF analysis.
As mentioned, over the whole ride, the pupil diameter is the best passenger-related predictor for discomfort. Across all participants, the larger the diameter, the more discomfort was reported, which is consistent with previous statistical analyses of this relationship [
3]. Additionally, the next best predictor is the standard deviation of the y component of the gaze vector SD(
). For all participants, the lower this value, the more discomfort was reported. This suggests the fixation of the eye onto certain objects on the simulator screen. The next passenger feature is the standard deviation of the heart rate SD(H), although the high values of both suggest low and high discomfort, which suggests that the participants heart rate did not react in the same way to discomfort across all participants. A more detailed data analysis with more data should be conducted to analyze this relationship more thoroughly. Similarly, the SHAP values of all passenger features in the situational passenger models are very noisy and do not show a clear direction in their relation to discomfort. We believe that this is due to the fact that the PF are overall noisier than the CF and thus need more observations to be fitted correctly.
Overall, the eye-related PF over the whole ride shows a strong, directed relation to discomfort over all participants, which suggests that an eye tracking device should be applied to future studies and application context and combined with contextual feature loggers to enhance the prediction of discomfort.


 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}