In the subsequent sections, we will refer to some R-code snippets and data examples to introduce the practical use of the R package confreq for CFA. The selected data examples are either already contained in the confreq package as R data, or are generated via the corresponding R code. Therefore, nothing else than the installation of a current R version and the package confreq is needed to follow this tutorial.
4.1. A First Look on a Classical Data Example
To introduce to the principle of analyzing associations and contingency with categorical variables and the need for doing so in a multivariate fashion, we will refer to a classical data example by Lienert [
11]. Based on the findings by Leuner [
20] on the
psychotoxic basic syndrome [Das psychotoxische Basis-Syndrom] after the intake of lysergic acid diethylamide (LSD) which is associated with symptoms such as clouding of consciousness, thought disturbance, and negative influence on affectivity, Lienert [
11] analyzed the experimental data from student volunteers who had taken LSD. Three symptoms were recorded while the volunteers had taken LSD:
Clouding of consciousness [Bewußtseinstrübungen] (C)
Thought disturbance [Denkstörung] (T)
Affective disturbance [Affektivitätsbeeinflussung] (A)
The observed symptoms were clinically rated according to their severeness in a dichotomous fashion in the way that ‘+’ indicates cases above the average and ‘−’ indicates cases below the average. From these variables,
possible patterns or configurations result from
volunteers who had participated in the LSD experiment (see
Table 3). The data are included in the package
confreq and the subsequent R-code snippet ‘
R_snippet_001’ loads the package and makes them available in R.
| Listing 1. R_snippet_001.R. |
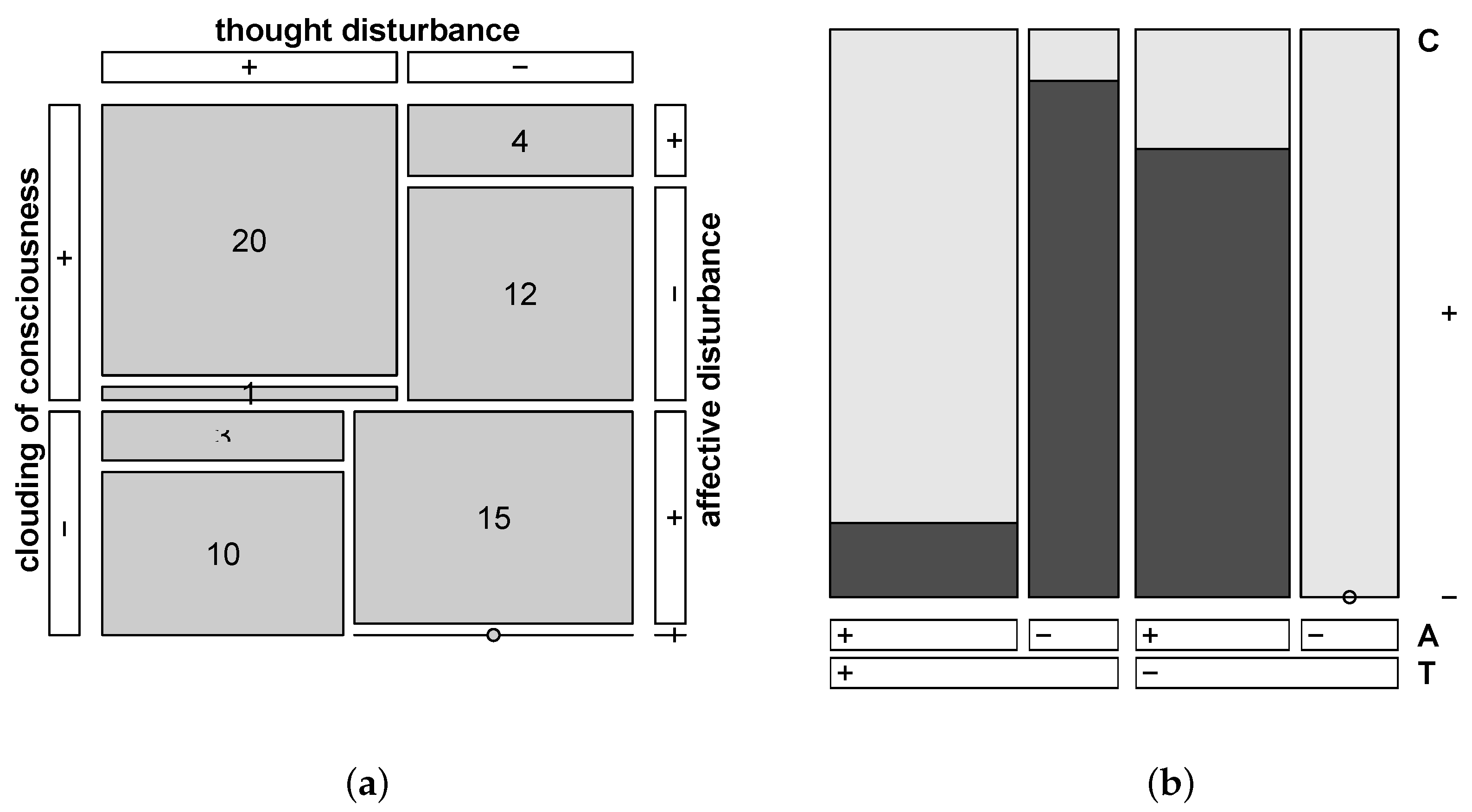
![Psych 03 00034 i001]() |
With
confreq the tabulated data depicted in
Table 3 can be visualized in different types of ‘heat maps’ using the link capability of
confreq to the graphic framework of the
vcd R package [
14,
15] an the the
grid graphics package [
13]. Running the code in the snippet ‘
R_snippet_002.R’, will result in two different forms of visualizing the cross tabulated data as shown in the two graphical panels in
Figure 1.
| Listing 2. R_snippet_002.R. |
![Psych 03 00034 i002]() |
While in the left panel (a) all three variables are considered in a symmetrical way in the graphical representation, in the right pannel (b) the variable ‘
C’ is used as dependent variable to define two (sub-)groups in order to visualize the differences between the two groups regarding the other two variables ‘
T’ and ‘
A’ (see
Figure 1).
In a first analysis, Lienert [
11] used
thought disturbance (T) and
affective disturbance (A) as predictor symptoms for
clouding of consciousness (C) as criterion or predictive symptom [
11] p. 103 and found the following relationships for both groups and the total sample respectively, as depicted in
Table 4. Note that these results refer to the visualization in the right panel (b) in
Figure 1.
We can see from the results in
Table 4 that for both sub groups (
and
) there is a significant relationship between
affective disturbance (A) and
thought disturbance (T), respectively, while for the total sample, these significant relationships seem to vanish (see
Table 4). Moreover, the other bivariate relationships between
clouding of consciousness (C) and
thought disturbance (T) as well as
clouding of consciousness (C) and
affective disturbance (A) suggest for the total sample that all three variables are unrelated (
,
).
The results presented here can be replicated using the Lienert-LSD-data in
confreq by ruining the subsequent R-code from snippet ‘
R_snippet_003.R’.
| Listing 3. R_snippet_003.R. |
![Psych 03 00034 i003]() |
From these findings Lienert [
11] generally concluded, that there can be connections between three characteristics, which are not reflected in bivariate relationships between two of the three characteristics each. Specifically, when using the categorical variable ‘C’ as to split the sample into two groups, different associations between the remaining two variable might emerge in the groups as compared to the total sample. Such nonlinear effects are well known as Meehl Paradox [
21] or Simpson Paradox [
22] see also Yule [
23]. Therefore, when multivariate hypotheses are tested in the form of single bivariate hypotheses, decisive information can be lost, see, e.g., in [
24] p. 516.
4.2. The CFA Main Effect Model of Independency
In order to avoid such inconsistencies and paradoxes in the analysis of multidimensional contingency tables, the multivariate analysis by means of the CFA is a useful alternative. To introduce the CFA with the package
confreq, we go on with analyzing the Lienert-LSD-data by applying the CFA main effect model. This model is also named model of independency, as the null hypothesis to be tested assumes the independency of each variable forming the configurations in the data. In the framework of log-linear modeling that means that only main effects (for each variable) are considered when calculating the expected cell (pattern) frequencies. For the Lienert-LSD-data the log linear model formulation as implemented in
confreq to compute the expected frequencies is given in Equation (
1) as
where
are the log expected frequencies of the configurations from the observed variables
C,
T, and
A, and
are their coefficients. A comprehensive introduction into the principle of log-linear model formulation of the CFA is given in [
9]. Applications of the CFA as a LLM using
confreq with empirical data on current research questions can be found, for example, in Sälzer and Heine [
25], Stemmler and Heine [
26], Börnert-Ringleb and Wilbert [
27], Lazarides et al. [
28], Heine and Stemmler [
29].
To run the CFA main effect model with the Lienert-LSD-data the second code line in the subsequent R-snippet ‘
R_snippet_004’ is used.
| Listing 4. R_snippet_004.R. |
![Psych 03 00034 i004]() |
Note that for didactic purposes here the argument ‘
form’ is explicitly defined using the R like representation of the equation given in (
1). However, if the argument ‘
form’ is not further specified, the CFA main effect model is automatically assumed in
confreq.
Executing the last line in ‘
R_snippet_004’ will return the summarized results, which are basically divided into three sections. The first section recapitulates the function call, the second section contains the results of the global model testing and the third part refers to the local tests for identifying types and antitypes (see console output below).
Both global tests considering the total cross-tabulation in the section for ‘global model testing’ suggest a significant result (
;
), which leads to the rejection of the null hypothesis of the CFA main effects model. In terms of LLM, this result implies a non-fitting model of independence, which conversely suggests a whatever relationship between the variables. Taken together with the finding that there are
no linear bivariate relationships between the variables (see initial analyses and
Table 4 above), this suggests the presence of (significant) nonlinear relationships. The CFA results in the third section on the ‘local tests’ provide a more sophisticated explanation by showing single
types (‘+’; over-frequented cells) and
antitypes (‘−’; under-frequented cells) that contribute the nonlinear relationship. However, with regard to these findings from the local tests, note that local significance testing must be regarded as a special form of multiple testing, which requires an adjustment of the alpha level, which has not yet been done here.
Currently, the package
confreq offers two types of alpha adjustment. These are the conservative method for probability thresholding according to Bonferroni cf. [
30], and the more lenient step-down ’Holm’ procedure cf. [
31] which sets the significance level individually. Both types of alpha adjustment, just like the omission of any alpha correction, are controlled by assigning the respective character expression to the argument ‘
adjalpha’ in the summary function (see examples in ‘
R_snippet_005’ below).
| Listing 5. R_snippet_005.R. |
![Psych 03 00034 i006]() |
Another factor that influences the search for types and antitypes is the type of significance test used. In the current version,
confreq can be used with five different procedures or test statistics. These are the Pearson
-test (
“pChi”), the
-approximation to the
z-test (
“z.pChi”), the binomial approximation to the
z-test (
“z.pBin”), the binomial test using Stirling’s approximation (
“p.stir”), see, e.g., in [
32] p. 52 for the
p values and Fisher’s exact binomial test (
“ex.bin.test”) [
33]. Further information on the different test statistics is given in Stemmler [
9]. Which test statistic is used is specified (post hoc) by selecting the appropriate character expression (one of
c(“pChi”, “z.pChi”, “z.pBin”, “p.stir”, “ex.bin.test”,)) in the argument
type in the
summary function (see examples in ‘
R_snippet_005’). When using the default settings in the function
CFA(), all test statistics are calculated in advance, so that their selection in the
summary function can be freely chosen later on when applying
summary to the respective result object. Note, however, that there is one exception to this principal functionality in
confreq, which arises from the necessary way of implementing Fisher’s exact test. As shown in [
9], for example, the test requires the (multiple) calculation of fractions with factorials of large numbers, especially for larger sample sizes and thus cell sizes, and for contingency tables of higher dimensionality. Using principles of multiple precision arithmetic as provided in the package ‘
gmp’ [
34], the test has been implemented in
confreq in such a way that for any computer system there are no principle numerical limitations with respect to the size of the contingency tables to be analyzed. However, the problem of increasing computation times with increasing size of the analysis task still remains. For this reason there is the option in the function
CFA() to suppress the (a priori) calculation of the exact test by setting the argument ’
bintest = FALSE’ – in contrast to the default setting which is ‘
bintest = TRUE’. In case of disabling the test when calling
CFA() and still requesting it with the method function
summary() confreq will return an error message suggesting to run
CFA() again while setting ‘
bintest = TRUE’ (try the subsequent ‘
R_snippet_006’).
| Listing 6. R_snippet_006.R. |
![Psych 03 00034 i007]() |
After the CFA model has been calculated and the appropriate procedure for significance testing of the types and antitypes has been chosen, the results can be displayed graphically. Basically, this works quite simply by applying the S3 method ‘
plot()’ provided in
confreq to the result object from the application of the
CFA() function to the tabulated data (cf. ‘
R_snippet_007’).
| Listing 7. R_snippet_007.R. |
![Psych 03 00034 i008]() |
As for the ‘
summary()’ method also for the ‘
plot()’ method, one can specify which significance test should be used for the display of the types and antitypes. In addition, the ‘
fill’ argument can be used to specify the colors with which the types, antitypes and non-significant cells are to be colored (see, e.g., code line 5 in ‘
R_snippet_007’). As the plotting functionality in
confreq is based on the grid graphics package [
13], as it is also used in the package
vcd [
14], single cells in the graphical display can be controlled and colored individually at a later time (cf. last code lines 14 and 16 in ‘
R_snippet_007’).
4.3. Modifying the CFA-Model Design Matrices
As noted above, in confreq the expected frequencies are calculated within the framework of a CFA model via a LLM formulation. This principle implies that a model design matrix is established which represents the respective formulated model. In confreq, this model design matrix can first be inspected in the evolving result object (after applying the function CFA()) and second modified or extended, and then, third, used for a recalculation of the expected frequencies based on the new model. This offers the maximum flexibility for the realization of the most different CFA models. Let us first look at the design matrix from the previous CFA main effect model. The result object from the ’CFA()’ function is ultimately a list with different entries and one of them relates to the design matrix. Therefore, based on the Lienert LSD data example, this can be displayed by simply entering the command ‘res1$designmatrix’ (see second line in ‘R_snippet_008’). Below there is a shortened display of the output of the design matrix for the CFA main effect model with the Lienert-LSD-data.
As you can see, the design matrix has as many rows as there are cells (configurations) and
columns. The three main effects are mapped over the last three columns representing the effect for each of the three variables, respectively. The first column represents the intercept as a constant, which is coded with ones. The main effects are
effect-coded that is, we use coefficients
(
) for each category of a variable, which have to sum to zero for each column see also [
9], for a more in-depth explanation of effect coding.
In order to inspect different design matrices that result from different CFA model formulations, you may execute code lines 4 to 10 in the ‘
R_snippet_008’.
| Listing 8. R_snippet_008.R. |
![Psych 03 00034 i010]() |
The CFA model which is calculated in code line 5 (see ‘
R_snippet_008’) assumes the null hypothesis that the cells are equally distributed. In concrete terms, the underlying assumption is that the frequencies are the same for each cell (configuration) of the multidimensional contingency table. This model is referred to as configural cluster analysis (CCA) or named as the
zero-order CFA model because it does not contain any main effects cf. [
9].
The next model (cf. code line 6) considers the two interaction terms between the variables
C:T and
C:A and thus represents a link to the first analysis by Lienert (see
Table 4), according to which the two groups
C = + and
C = − were analyzed separately. The finding from this model that the configuration ‘
C = +, T = −, A = −’ is shown as a significant type suggests that this configuration is apparently (at least partly) responsible for the nonlinear relationship between the variables in reference to the total sample. Moreover, if the model does not fit, it is a test of significance for the 3-way interaction.
Finally, the last model in code line 7 in ‘R_snippet_008’ represents the so-called saturated model. The saturated model takes into account all interaction terms of each order (here all double and one triple interaction) between the variables involved. This model reproduces the observed frequencies perfectly and thus represents a baseline for the comparison of different CFA models. Furthermore, the saturated model (in comparison with others) can emphasize the importance of the interaction terms.
In the code lines 5 to 7 in ‘R_snippet_008’, the different CFA models are specified by entering a model formula in the argument ‘form’. In confreq, however, the argument form in the function CFA() can also be directly assigned a design matrix, which was previously modified according to the own model ideas. In the code lines 17 to 19 in ‘R_snippet_008’ the model specification using a modified design matrix is demonstrated on the example of the CFA zero order model. The comparison with the specification of the same model via the model formula (cf. code lines 22, 23) shows that there are no differences here.
All of the CFA models discussed so far always refer to the entire contingency table when calculating the expected cell frequencies within the framework of their basic formulation under the respective null hypothesis. This fact corresponds to the assumption associated with their underlying null hypothesis that the frequencies of the types or antitypes belong to the same population as all other (possible) configurations. This assumption of a common population and thus common (multinomial) distribution can, however, be violated in the local significance test for single types and antitypes if, for example, extreme local cell frequencies (outliers) are present. Such extreme cell frequencies can result, on the one hand, simply from the sparseness of the data collected or, on the other hand, from substantive, structural, and logical reasons due to the nature of the recorded attributes—leading to
impossible configurations. A typical example for such impossible configurations sometimes called
structural zeros is given by [
9] as it might result from meteorological observation variables, “
e.g., a pattern of heavy rain together with a beautiful blue sky” [
9] p. 54. Such limits of CFA were first observed and addressed in the 1970s [
35,
36]. The problem of (falsely) assuming a common population is addressed in an interesting extension of CFA by Victor and Kieser [
37]. To account for the problem of structural extreme cell frequencies potentially affecting the results of significance testing of the other cells, Victor [
38] proposed to include the existence of certain configurations as
types within the definition of the basic model [
37,
39,
40]—which simply means excluding the configuration in question from the analysis.
The need to exclude certain cells (configurations) from the analysis of the observed and expected frequencies is another area of application that makes use of the flexibility of the model formulation via a modification of the design matrix in confreq.
For the (mainly technical) demonstration of the possibility of excluding one (or possibly more) cells from the calculations of the expected frequencies, we look again at the Lienert-LSD-data. In these data (see
Table 3), it is noticeable that configuration number 8 (‘
C = −, T = −, A = −’) has a frequency of zero for the data collected. We now assume (hypothetically, for demonstration purposes) that this combination of (non) observed symptoms is an impossible combination of attributes—which, by the way, might not seem so implausible from a clinical perspective, as this configuration would imply the complete ineffectiveness of LSD.
As a logical consequence of our substantiated classification of the cell in question as an
impossible configuration, we now want to exclude this from the CFA analyzes. To do this we use the argument ‘
blank’ in the
CFA() function (see examples in ‘
R_snippet_009’).
| Listing 9. R_snippet_009.R. |
![Psych 03 00034 i011]() |
This procedure checks whether the assumption of independence can be confirmed for the rest of the contingency table after removing the extreme configuration(s). If the rest of the contingency table proves to be independent, this is called quasi-independence in the presence of a type (antitype); thus, such a model can be called a
quasi-independence model [
9]. Comparing the results from the two main effect models, i.e., the initial one for the whole contingency table (cf. summary of result object ‘
res1’ in code line 7 in ‘
R_snippet_005’) and the other one with the excluded configuration number 8 (cf. summary of result object ‘
res6’ in code line 3 in ‘
R_snippet_009’) clearly shows the biasing influence of the structural extreme cell frequencies. It becomes clear that the local testing of the most frequent pattern number 1 in the Lienert data (‘
C = +, T = +, A = +’;
) in the first model (‘
res1’) with
surprisingly does not lead to a significant type, whereas in the second model (‘
res6’) this pattern is (correctly) recognized as a significant type with
. This finding underlines the importance of the comparative application of different CFA models to the data.
A look at the design matrix of the quasi-independence model for the Lienert-LSD-data, which we obtain via the input of the R command ‘
res6$designmatrix’, shows how this is implemented in the context of the log-linear modeling of the expected frequencies (cf. R-output below).
In addition to the already known three columns for the main effects, another column is added here, which, except for cell number 8 (‘C = −, T = −, A = −’), is consistently coded with ‘0’. Note that if several configurations are to be excluded from the analyses as ‘extreme cells’, a column must be added to the model matrix for each configuration to code this ‘effect’, respectively.
A systematic examination of the design matrices used so far, such as, for example, in the three models in the R-objects
res3,
res4, and
res5 (see ‘
R_snippet_008’) as well as in the R-object
res6 (see ‘
R_snippet_009’) in conjunction with the respective degrees of freedom (
) of the global model test shows that the degrees of freedom of any CFA model is determined by the number of rows and columns of the respective design matrix. The number of rows of the design matrix minus 1 represents the information
s given by the data and the number of columns (without intercept) represents the number of parameters
t ‘consumed’ by the respective (explanatory) model. The degrees of freedom for any CFA model are generally defined as the difference between the given information
s and the number of model parameters
t as given in Equation (
2), cf. also in [
29]:
Here, the given information
s is defined by the number of possible combinations or
configurations from the variables under study
i (with
) with
categories minus 1 each (cf. Equation (
3)):
The number of parameters
t is based on the particular model formulated. For a simple CFA
main effect model with
k variables (
) each with
categories, the number of model parameters is calculated according to Equation (
4):
The number of ‘consumed’ model parameters may need to be increased, depending on the complexity of the chosen model. Thus, each functional expansion to exclude single ‘extreme cells’ consumes one degree of freedom each, as well as each single interaction term.
4.4. Introducing Covariates into the CFA-Model
In the previous section, we have shown that different CFA models can be realized via the modification or the addition of the design matrix. We focused on the realization of different H0 hypotheses that implement either only main effects (of the variables), complementary interaction terms (of different order) or also functional model definitions with structural configurations as in the quasi-independence model.
In this section, we will go a step further and show how to use the extension of the design matrix to account for covariates in a CFA model. In a CFA model, covariates can help to elucidate the “cause” of the types and antitypes found (initially). In this sense, the covariates in a CFA model help to predict the expected frequencies more accurately. Substantial covariates thus reduce the difference between observed and expected frequencies and then may lead to the result that (in the “ideal” case) after the inclusion of suitable covariates no types or antitypes can be observed anymore. For a recent example from the literature that demonstrates the relevance of considering covariates when analyzing categorical data from the international 2015 PISA study, see [
29].
For the practical demonstration of the CFA model with covariates, we will leave behind the Lienert-LSD-data used so far and turn to another handy data example from the literature. The data are not included in
confreq, but can be easily reconstructed as tabulated data with R from the information given in the corresponding publication by Glück and von Eye [
41], pp. 410,411 using the following R script ‘
R_snippet_010’.
| Listing 10. R_snippet_0010.R. |
![Psych 03 00034 i013]() |
Code lines 3 to 9 in ‘
R_snippet_010’ create a
data.frame assigned to R object ‘
d’ comprising four categorical variables (as ‘R factors’) with their respective frequencies and code line 10 assigns a special ‘
class’ to ‘
d’ to let
confreq “know” that these are tabulated data. Code lines 13 to 20 create a matrix object (‘
dcov’) comprising the means of the covariates for the 16 configurations given in ‘
d’, respectively. Stemmler [
9] points out that, as in this example, “
Usually, the cell means of the continuous covariate are used …” [
9] p. 105 but also other summary statistics of the covariates can be used for the respective configuration (cell of the contingency table).
In the original monograph by Glück [
42], the data were used to examine how male and female students (categorical variable ‘
G’) in a high school perform spatial reasoning tasks. The students were presented with different views of cubes as a paper-and-pencil test, which they were asked to judge for equality. After each spatial imagination task, the strategies used were queried. The categorical variables ‘
R’, ‘
P’, and ‘
V’ (
R: Rotation strategy;
P: Strategy of comparative patterns;
V: Strategy of change of perspective) in the data example represent re-coded response data on three strategies in dichotomous form, where ‘0’ represents the absence of the corresponding strategy and ‘1’ represents the presence of the corresponding strategy cf. [
41]. In addition, there are continuous variables such as task difficulty (’
’), spatial ability score (‘
’), self-confidence (’
’), and scores for right-handedness (’
’) cf. [
41]. As pointed out in Glück and von Eye [
41], the two “topmost” configurations (for male and female students) who seemed to report none of the three strategies refer to “
…subjects that did not fill in the strategy questionnaire …” [
41] p. 410 and thus were treated as “
…structural cells” [
41] p. 410, which basically means that these cells were excluded when calculating the expected frequencies as demonstrated in the section above.
To replicate and output the results from an initial CFA main effects model analysis with functional extension to skip the two structural cells as reported in Glück and von Eye [
41] you can run the code lines 3 and 4 in ‘
R_snippet_011.R’.
| Listing 11. R_snippet_0011.R. |
![Psych 03 00034 i014]() |
In order to use additional covariates in the CFA, the term
for the covariates is added to the log-linear model equation (cf. Equation (
5)):
In this general notation in Equation (
5),
X is the design matrix with the vectors for the effect-coded contrasts of the main effects (and as well as specified interactions and functional extensions) and
is the vector of the respective coefficients; thus, for the main effects model with the data from Glück and von Eye [
41], the first part of the right hand sided term given in Equation (
5) would be
. The inclusion of the covariates in the model equation is obtained with
as a vector of the covariates and
stands for the vector of coefficients of the covariates. Thus, as the Equation (
5) illustrates, one simply has to add the covariates as additional column(s) in the design matrix see [
43], for a further specific introduction into the issue of covariates in CFA.
In confreq, the inclusion of covariates is controlled by the argument ‘cova’, where we can assign a matrix object, holding the means of the covariates for the configurations, respectively. The code line 7 in ‘R_snippet_011.R’ will run a model that contains three covariates (‘’, ‘’, and ‘’) in addition to the CFA main effects model, which itself contains a functional extension as a quasi-independence model. The code line 11 in ‘R_snippet_011.R’ performs the CFA model with only one covariate: right-handedness (‘’).
We can view the inclusion of the covariates in the model matrix by outputting the corresponding design matrix with the R command, as for example by typing ‘
res8$designmatrix’ into the R console (see output below).
Note that, just as with the functional extensions or interaction terms, each single covariate increases the model complexity and consumes one degree of freedom each, which corresponds with the addition of one column each in the design matrix.
4.5. Comparing Pattern Frequencies for Two Samples with CFA
As the last hands-on section in this tutorial, we will focus on a variant of the CFA that is suitable for examining the differences between two (sub)samples.
To demonstrate the two-sample CFA, we turn to a new data example from the literature by Schmid and Lutz [
44]. The study by Schmid and Lutz [
44] investigates epistemological beliefs (epistemological views) among academics from different disciplines (variable ‘
W’) that can be assigned to either the natural (category ‘
N’) or the social sciences (category ‘
S’). To investigate the coherence of epistemological beliefs, three aspects were recorded: The
ontological aspect ‘
O’, which refers to the question whether there is a reality independent of our representations, our thinking, our language, and our perceptions, at all. The
epistemological aspect ‘
E’, which refers to the, in the narrower sense of philosophical terminology, epistemological question if the truth of scientific knowledge can be established in principle. As well as the
science-critical aspect ‘
K’, which refers to a more or less optimistic or pessimistic view of the present state of knowledge in the sciences. The three variables were re-coded in a dichotomous manner, with ‘
+’ representing agreement and ‘
−’ representing disagreement. Based on theoretical considerations, Schmid and Lutz [
44] initially state that some combinations of the three aspects represent non-coherent belief systems. The data can be reconstructed using the information from the original publication given in Schmid and Lutz [
44] p. 36 by running the code lines 3 to 11 within the ‘
R_snippet_012’ below.
| Listing 12. R_snippet_0012.R. |
![Psych 03 00034 i016]() |
In addition to the question of whether, for example, incoherent belief systems represent an over-frequented (type) or under-frequented (antitype) feature configuration, the present data can be used to analyze by means of a two-sample CFA whether and, if so, which feature configuration significantly discriminates between the two scientific disciplines.
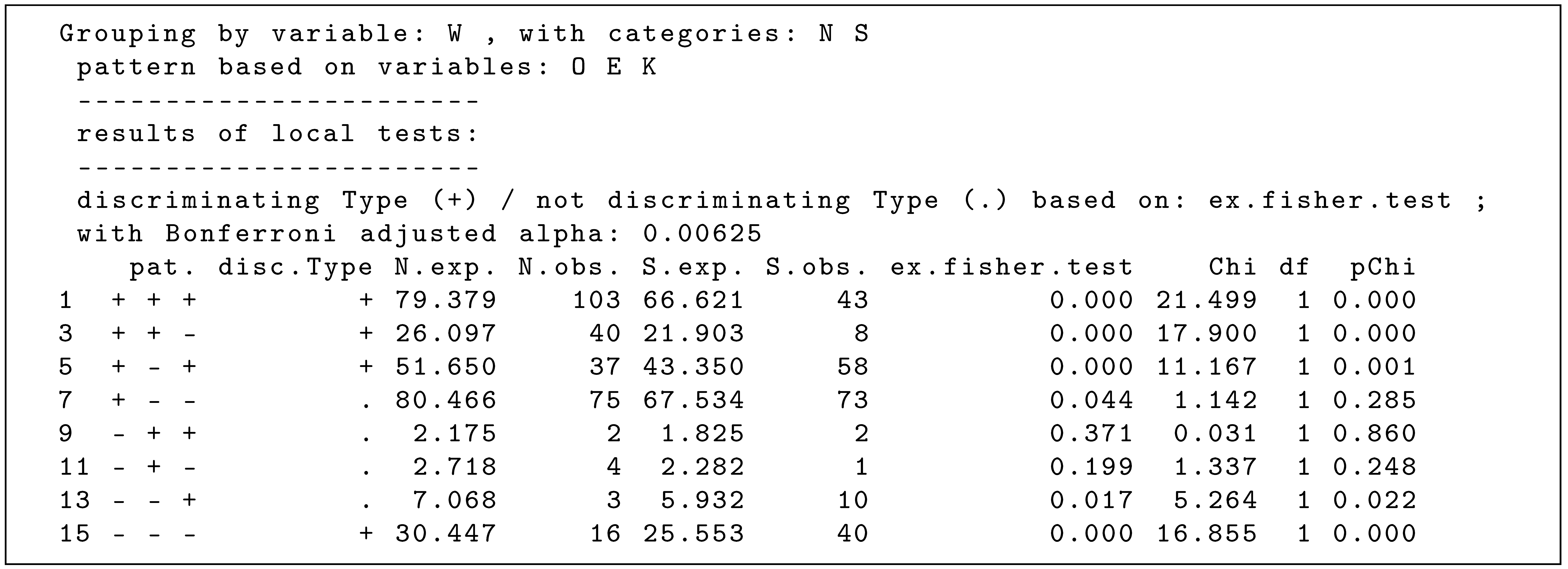
To perform such a two-sample CFA with confreq, code line 13 in ’R_snippet_012’ can be executed for the calculations and code line 14 can be used to output the results to the R console (see display of the results below).
The R output of the results above suggest that 4 configurations differ in their frequencies between the two science disciplines. For example, in the group of natural scientists more often than expected (
) and in the group of social scientists less often than expected (
), there are persons who agree with the question of the existence of an independent reality, affirm the question that science can produce truth and overall have an optimistic view of the current state of scientific knowledge (configuration
). To visualize the results, the result object of the two-sample CFA can be plotted, as shown in the last code line in ‘
R_snippet_012’.





















{kind=link}