
Influence of Thermal Pretreatment on Lignin Destabilization in Harvest Residues: An Ensemble Machine Learning Approach




Abstract
1. Introduction
2. Materials and Methods
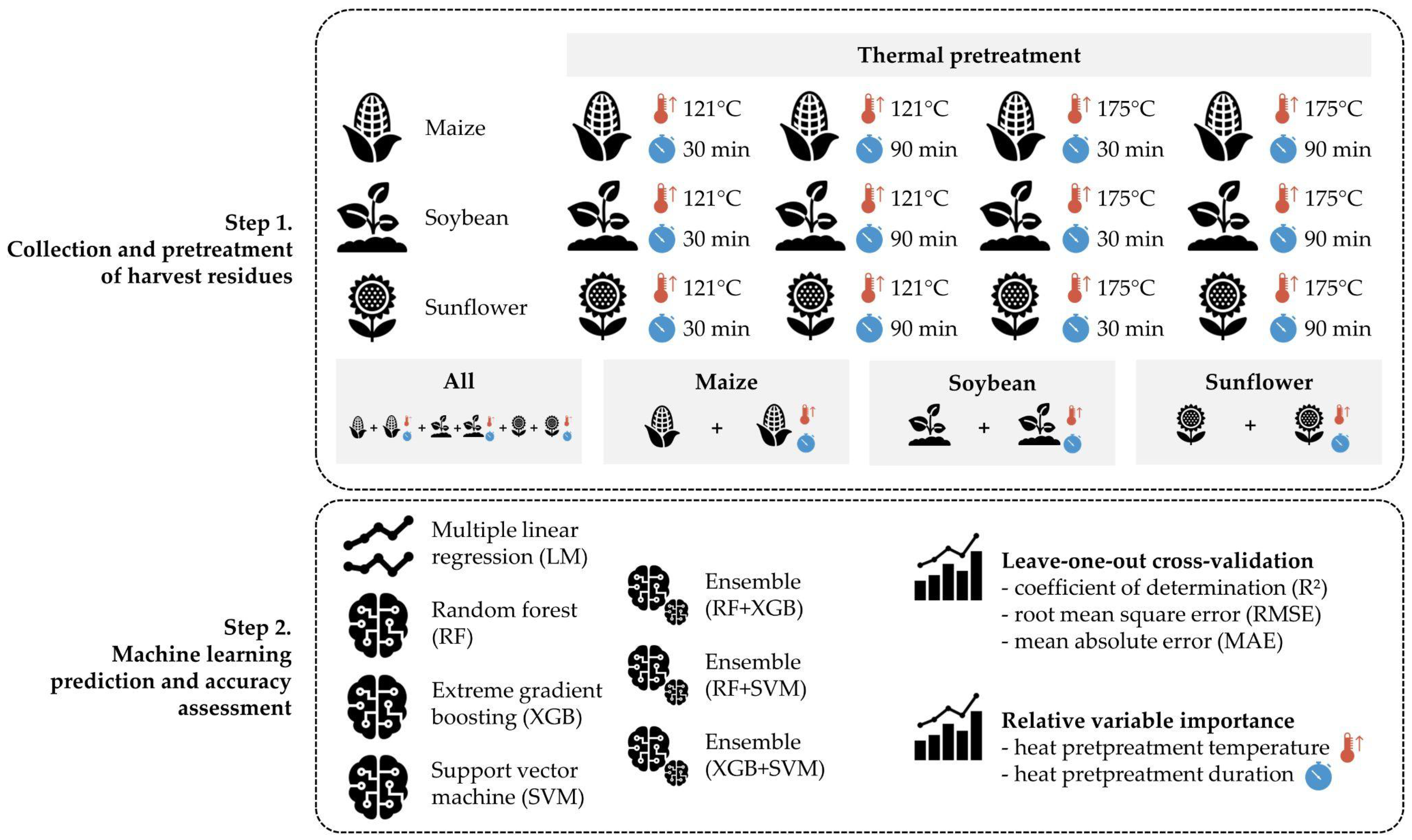
2.1. Experimental Set-Up
2.2. Machine Learning Prediction and Accuracy Assessment
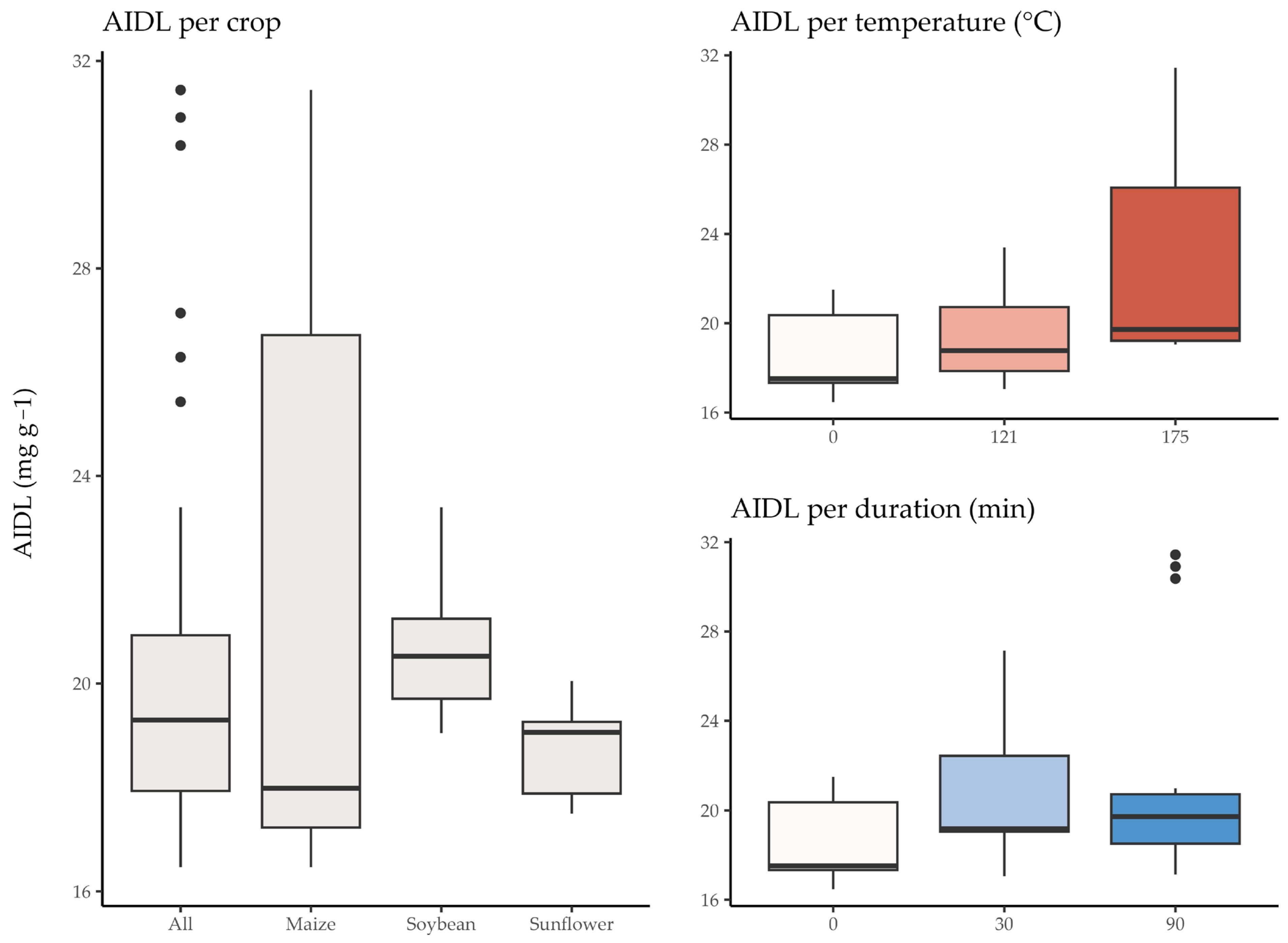
3. Results and Discussion
4. Conclusions
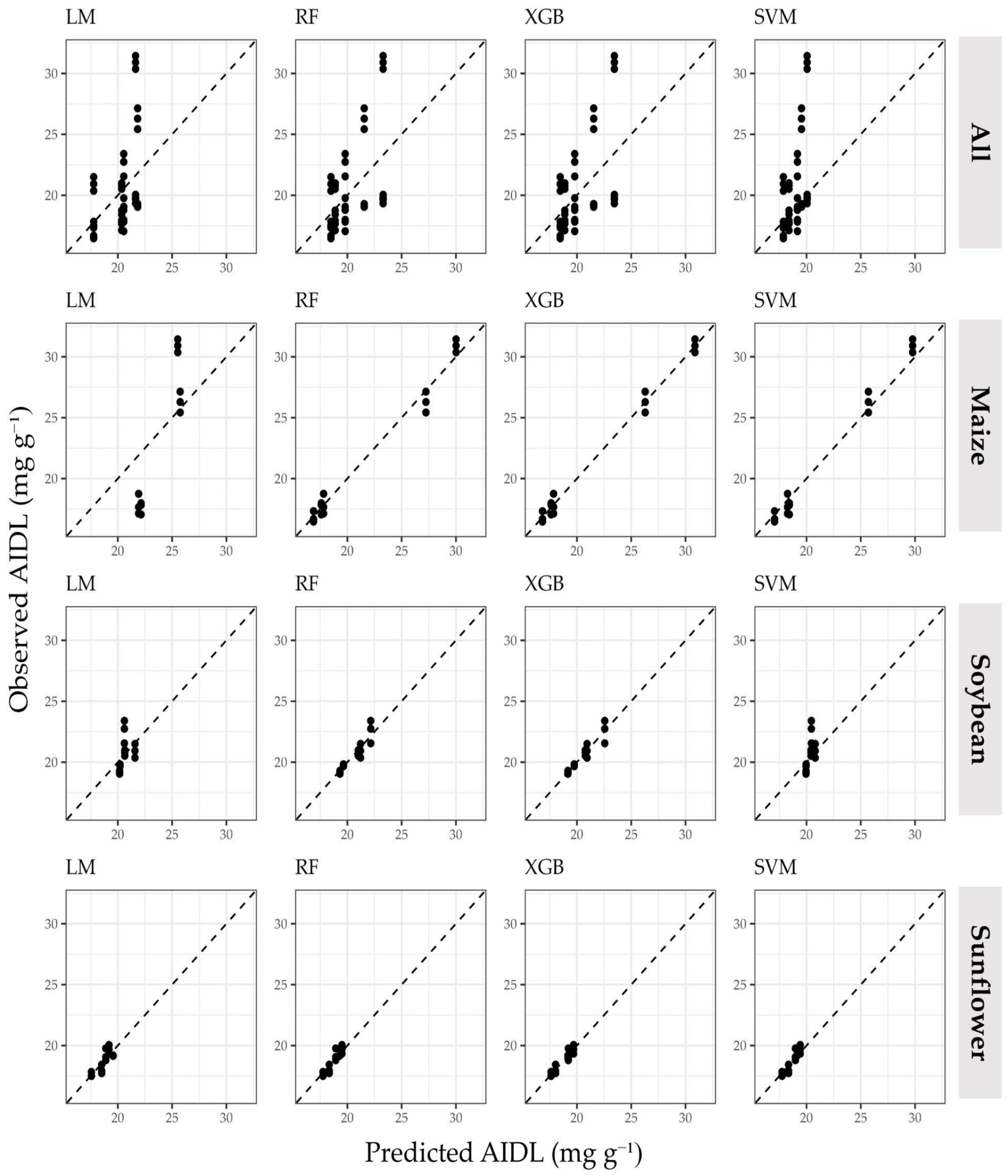
- all evaluated machine learning methods, including three individual methods (RF, XGB and SVM), as well as their ensembles provided a higher AIDL prediction accuracy in comparison to the conventional LM;
- high prediction accuracy of AIDL was achieved only when harvest residues were considered in separate training/test datasets, while their combination resulted in a very low accuracy;
- the individual machine learning algorithms based on decision trees (XGB and RF) were superior to the ensemble machine learning approach in terms of accuracy for AIDL prediction from separate harvest residue sources, achieving R2 up to 0.980;
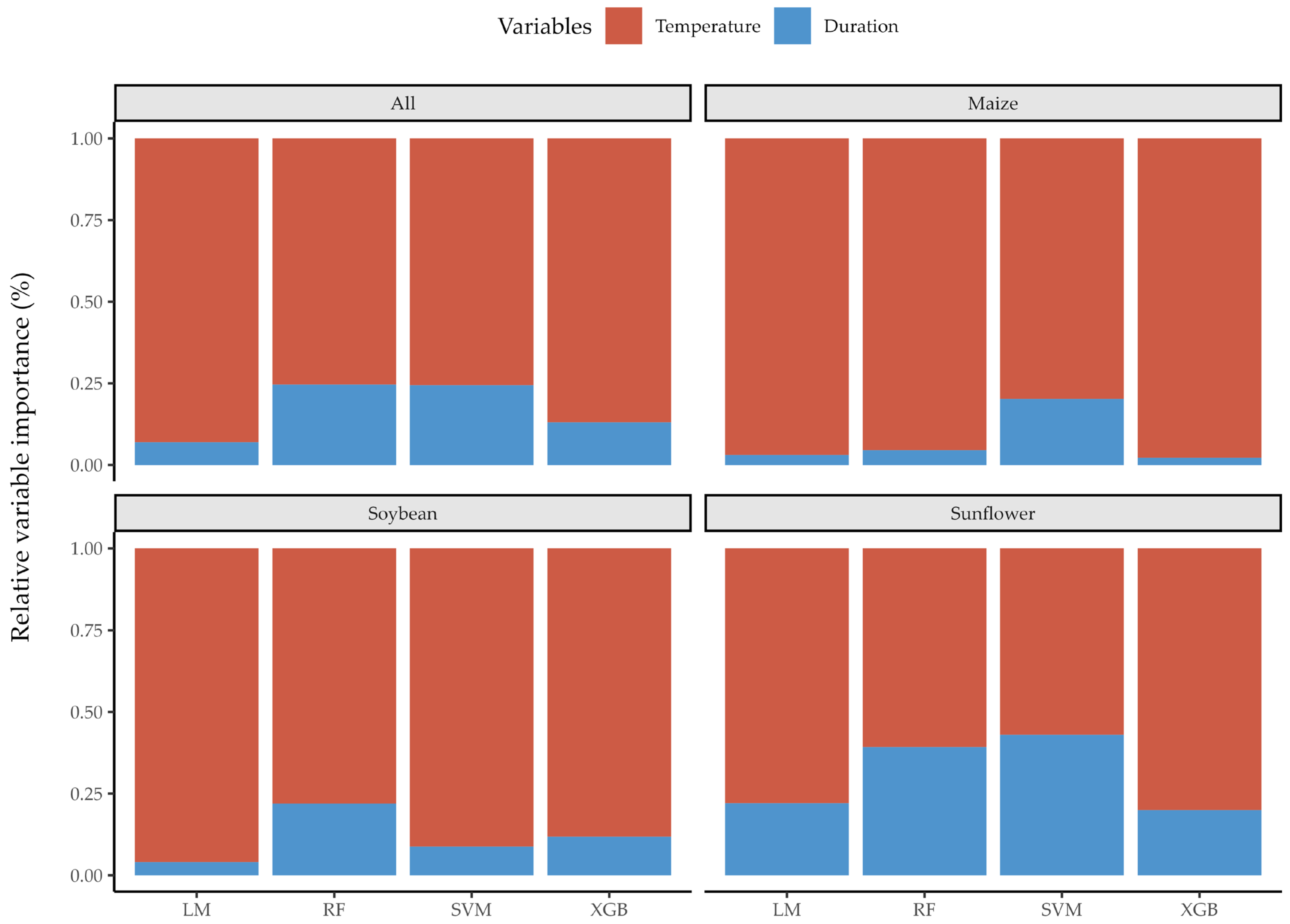
- pretreatment temperature had the dominant relative variable importance in comparison to its duration on lignin destabilization, leading to the basis for the optimization of pretreatment process.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Soltanian, S.; Aghbashlo, M.; Almasi, F.; Hosseinzadeh-Bandbafha, H.; Nizami, A.-S.; Ok, Y.S.; Lam, S.S.; Tabatabaei, M. A Critical Review of the Effects of Pretreatment Methods on the Exergetic Aspects of Lignocellulosic Biofuels. Energy Convers. Manag. 2020, 212, 112792. [Google Scholar] [CrossRef]
- Mohammad Rahmani, A.; Gahlot, P.; Moustakas, K.; Kazmi, A.A.; Shekhar Prasad Ojha, C.; Tyagi, V.K. Pretreatment Methods to Enhance Solubilization and Anaerobic Biodegradability of Lignocellulosic Biomass (Wheat Straw): Progress and Challenges. Fuel 2022, 319, 123726. [Google Scholar] [CrossRef]
- Roy, R.; Rahman, M.S.; Raynie, D.E. Recent Advances of Greener Pretreatment Technologies of Lignocellulose. Curr. Res. Green Sustain. Chem. 2020, 3, 100035. [Google Scholar] [CrossRef]
- Abraham, A.; Mathew, A.K.; Park, H.; Choi, O.; Sindhu, R.; Parameswaran, B.; Pandey, A.; Park, J.H.; Sang, B.-I. Pretreatment Strategies for Enhanced Biogas Production from Lignocellulosic Biomass. Bioresour. Technol. 2020, 301, 122725. [Google Scholar] [CrossRef]
- Mirmohamadsadeghi, S.; Karimi, K.; Azarbaijani, R.; Parsa Yeganeh, L.; Angelidaki, I.; Nizami, A.-S.; Bhat, R.; Dashora, K.; Vijay, V.K.; Aghbashlo, M.; et al. Pretreatment of Lignocelluloses for Enhanced Biogas Production: A Review on Influencing Mechanisms and the Importance of Microbial Diversity. Renew. Sustain. Energy Rev. 2021, 135, 110173. [Google Scholar] [CrossRef]
- Rahmati, S.; Doherty, W.; Dubal, D.; Atanda, L.; Moghaddam, L.; Sonar, P.; Hessel, V.; Ostrikov, K. (Ken) Pretreatment and Fermentation of Lignocellulosic Biomass: Reaction Mechanisms and Process Engineering. React. Chem. Eng. 2020, 5, 2017–2047. [Google Scholar] [CrossRef]
- Rajput, A.A.; Zeshan; Visvanathan, C. Effect of Thermal Pretreatment on Chemical Composition, Physical Structure and Biogas Production Kinetics of Wheat Straw. J. Environ. Manag. 2018, 221, 45–52. [Google Scholar] [CrossRef]
- Rodriguez, C.; Alaswad, A.; Mooney, J.; Prescott, T.; Olabi, A.G. Pre-Treatment Techniques Used for Anaerobic Digestion of Algae. Fuel Process. Technol. 2015, 138, 765–779. [Google Scholar] [CrossRef]
- Mirmasoumi, S.; Khoshbakhti Saray, R.; Ebrahimi, S. Evaluation of Thermal Pretreatment and Digestion Temperature Rise in a Biogas Fueled Combined Cooling, Heat, and Power System Using Exergo-Economic Analysis. Energy Convers. Manag. 2018, 163, 219–238. [Google Scholar] [CrossRef]
- Veluchamy, C.; Kalamdhad, A.S. Enhancement of Hydrolysis of Lignocellulose Waste Pulp and Paper Mill Sludge through Different Heating Processes on Thermal Pretreatment. J. Clean. Prod. 2017, 168, 219–226. [Google Scholar] [CrossRef]
- Barua, V.B.; Kalamdhad, A.S. Effect of Various Types of Thermal Pretreatment Techniques on the Hydrolysis, Compositional Analysis and Characterization of Water Hyacinth. Bioresour. Technol. 2017, 227, 147–154. [Google Scholar] [CrossRef]
- Kainthola, J.; Shariq, M.; Kalamdhad, A.S.; Goud, V.V. Comparative Study of Different Thermal Pretreatment Techniques for Accelerated Methane Production from Rice Straw. Biomass Convers. Biorefinery 2021, 11, 1145–1154. [Google Scholar] [CrossRef]
- Barua, V.B.; Rathore, V.; Kalamdhad, A.S. Anaerobic Co-Digestion of Water Hyacinth and Banana Peels with and without Thermal Pretreatment. Renew. Energy 2019, 134, 103–112. [Google Scholar] [CrossRef]
- Gao, W.; Zhou, L.; Liu, S.; Guan, Y.; Gao, H.; Hui, B. Machine Learning Prediction of Lignin Content in Poplar with Raman Spectroscopy. Bioresour. Technol. 2022, 348, 126812. [Google Scholar] [CrossRef] [PubMed]
- Kartal, F.; Özveren, U. An Improved Machine Learning Approach to Estimate Hemicellulose, Cellulose, and Lignin in Biomass. Carbohydr. Polym. Technol. Appl. 2021, 2, 100148. [Google Scholar] [CrossRef]
- Löfgren, J.; Tarasov, D.; Koitto, T.; Rinke, P.; Balakshin, M.; Todorović, M. Machine Learning Optimization of Lignin Properties in Green Biorefineries. ACS Sustain. Chem. Eng. 2022, 10, 9469–9479. [Google Scholar] [CrossRef]
- Kardani, N.; Hedayati Marzbali, M.; Shah, K.; Zhou, A. Machine Learning Prediction of the Conversion of Lignocellulosic Biomass during Hydrothermal Carbonization. Biofuels 2022, 13, 703–715. [Google Scholar] [CrossRef]
- Yildirim, O.; Ozkaya, B. Prediction of Biogas Production of Industrial Scale Anaerobic Digestion Plant by Machine Learning Algorithms. Chemosphere 2023, 335, 138976. [Google Scholar] [CrossRef]
- Chiu, M.-C.; Wen, C.-Y.; Hsu, H.-W.; Wang, W.-C. Key Wastes Selection and Prediction Improvement for Biogas Production through Hybrid Machine Learning Methods. Sustain. Energy Technol. Assess. 2022, 52, 102223. [Google Scholar] [CrossRef]
- Dong, Z.; Bai, X.; Xu, D.; Li, W. Machine Learning Prediction of Pyrolytic Products of Lignocellulosic Biomass Based on Physicochemical Characteristics and Pyrolysis Conditions. Bioresour. Technol. 2023, 367, 128182. [Google Scholar] [CrossRef]
- Demir, S.; Şahin, E.K. Liquefaction Prediction with Robust Machine Learning Algorithms (SVM, RF, and XGBoost) Supported by Genetic Algorithm-Based Feature Selection and Parameter Optimization from the Perspective of Data Processing. Environ. Earth Sci. 2022, 81, 459. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Wu, L.; Zhou, H.; Zhang, F.; Yu, X.; Lu, X.; Xiang, Y. Comparison of Support Vector Machine and Extreme Gradient Boosting for Predicting Daily Global Solar Radiation Using Temperature and Precipitation in Humid Subtropical Climates: A Case Study in China. Energy Convers. Manag. 2018, 164, 102–111. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble Learning. In Ensemble Machine Learning: Methods and Applications; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012; pp. 1–34. ISBN 978-1-4419-9326-7. [Google Scholar]
- Zhou, Z.-H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012; ISBN 978-1-4398-3003-1. [Google Scholar]
- De Clercq, D.; Wen, Z.; Fei, F.; Caicedo, L.; Yuan, K.; Shang, R. Interpretable Machine Learning for Predicting Biomethane Production in Industrial-Scale Anaerobic Co-Digestion. Sci. Total Environ. 2020, 712, 134574. [Google Scholar] [CrossRef] [PubMed]
- Zounemat-Kermani, M.; Batelaan, O.; Fadaee, M.; Hinkelmann, R. Ensemble Machine Learning Paradigms in Hydrology: A Review. J. Hydrol. 2021, 598, 126266. [Google Scholar] [CrossRef]
- American Public Health Association (APHA). Standard Methods for the Examination of Water and Wastewater; American Public Health Association: Washington, DC, USA, 1998. [Google Scholar]
- Goering, H.K.; Van Soest, P.J. Forage Fiber Analyses (Apparatus, Reagents, Procedures, and Some Applications); US Agricultural Research Service: Beltsville, MD, USA, 1970.
- Gilbertson, J.K.; van Niekerk, A. Value of Dimensionality Reduction for Crop Differentiation with Multi-Temporal Imagery and Machine Learning. Comput. Electron. Agric. 2017, 142, 50–58. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hatwell, J.; Gaber, M.M.; Azad, R.M.A. CHIRPS: Explaining Random Forest Classification. Artif. Intell. Rev. 2020, 53, 5747–5788. [Google Scholar] [CrossRef]
- Ferreira, A.J.; Figueiredo, M.A.T. Boosting Algorithms: A Review of Methods, Theory, and Applications. In Ensemble Machine Learning: Methods and Applications; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012; pp. 35–85. ISBN 978-1-4419-9326-7. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. Xgboost: Extreme Gradient Boosting. Available online: https://CRAN.R-project.org/package=xgboost (accessed on 23 October 2023).
- Awad, M.; Khanna, R. Support Vector Machines for Classification. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Awad, M., Khanna, R., Eds.; Apress: Berkeley, CA, USA, 2015; pp. 39–66. ISBN 978-1-4302-5990-9. [Google Scholar]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Benesty, M.; et al. Caret: Classification and Regression Training. Available online: https://CRAN.R-project.org/package=caret (accessed on 30 May 2022).
- Deane-Mayer, Z.A.; Knowles, J.E. caretEnsemble: Ensembles of Caret Models. Available online: https://cran.r-project.org/web/packages/caretEnsemble/index.html (accessed on 24 December 2023).
- Wong, T.-T. Performance Evaluation of Classification Algorithms by K-Fold and Leave-One-out Cross Validation. Pattern Recognit. 2015, 48, 2839–2846. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The Coefficient of Determination R-Squared Is More Informative than SMAPE, MAE, MAPE, MSE and RMSE in Regression Analysis Evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root Mean Square Error (RMSE) or Mean Absolute Error (MAE)?—Arguments against Avoiding RMSE in the Literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Yoo, C.G.; Meng, X.; Pu, Y.; Ragauskas, A.J. The Critical Role of Lignin in Lignocellulosic Biomass Conversion and Recent Pretreatment Strategies: A Comprehensive Review. Bioresour. Technol. 2020, 301, 122784. [Google Scholar] [CrossRef] [PubMed]
- Kai, D.; Chow, L.P.; Loh, X.J. Lignin and Its Properties. In Functional Materials from Lignin; Sustainable Chemistry Series; World Scientific (Europe): London, UK, 2017; Volume 3, pp. 1–28. ISBN 978-1-78634-520-2. [Google Scholar]
- Buranov, A.U.; Mazza, G. Lignin in Straw of Herbaceous Crops. Ind. Crops Prod. 2008, 28, 237–259. [Google Scholar] [CrossRef]
- Tursi, A. A Review on Biomass: Importance, Chemistry, Classification, and Conversion. Biofuel Res. J. 2019, 6, 962–979. [Google Scholar] [CrossRef]
- Smuga-Kogut, M.; Kogut, T.; Markiewicz, R.; Słowik, A. Use of Machine Learning Methods for Predicting Amount of Bioethanol Obtained from Lignocellulosic Biomass with the Use of Ionic Liquids for Pretreatment. Energies 2021, 14, 243. [Google Scholar] [CrossRef]
- Ma, Z.; Wang, R.; Song, G.; Zhang, K.; Zhao, Z.; Wang, J. Interpretable Ensemble Prediction for Anaerobic Digestion Performance of Hydrothermal Carbonization Wastewater. Sci. Total Environ. 2024, 908, 168279. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Xu, Y.; Nairat, S.; Zhou, J.; He, Z. Prediction of Biogas Production in Anaerobic Digestion of a Full-Scale Wastewater Treatment Plant Using Ensembled Machine Learning Models. Water Environ. Res. 2023, 95, e10893. [Google Scholar] [CrossRef] [PubMed]
- Radočaj, D.; Jurišić, M.; Tadić, V. The Effect of Bioclimatic Covariates on Ensemble Machine Learning Prediction of Total Soil Carbon in the Pannonian Biogeoregion. Agronomy 2023, 13, 2516. [Google Scholar] [CrossRef]
- Yates, L.A.; Aandahl, Z.; Richards, S.A.; Brook, B.W. Cross Validation for Model Selection: A Review with Examples from Ecology. Ecol. Monogr. 2023, 93, e1557. [Google Scholar] [CrossRef]
- ElSahly, O.; Abdelfatah, A. An Incident Detection Model Using Random Forest Classifier. Smart Cities 2023, 6, 1786–1813. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | χ2 | p | Significance Level |
|---|---|---|---|
| Temperature | 9.285 | 0.0096 | ** |
| Duration | 4.420 | 0.1097 |
| Harvest Residues | Method | R2 | RMSE | MAE |
|---|---|---|---|---|
| All | LM | 0.066 | 3.56 | 2.76 |
| RF | 0.098 | 3.54 | 2.91 | |
| XGB | 0.101 | 3.53 | 2.90 | |
| SVM | 0.121 | 3.73 | 2.25 | |
| Ensemble (RF + XGB) | 0.092 | 3.44 | 2.71 | |
| Ensemble (RF + SVM) | 0.049 | 3.53 | 2.74 | |
| Ensemble (XGB + SVM) | 0.100 | 3.73 | 2.92 | |
| Maize | LM | 0.360 | 4.68 | 4.26 |
| RF | 0.946 | 1.33 | 1.08 | |
| XGB | 0.980 | 0.80 | 0.67 | |
| SVM | 0.328 | 5.69 | 4.25 | |
| Ensemble (RF + XGB) | 0.967 | 1.04 | 0.85 | |
| Ensemble (RF + SVM) | 0.910 | 1.76 | 1.27 | |
| Ensemble (XGB + SVM) | 0.948 | 1.29 | 0.91 | |
| Soybean | LM | 0.006 | 1.33 | 1.04 |
| RF | 0.633 | 0.75 | 0.60 | |
| XGB | 0.756 | 0.62 | 0.41 | |
| SVM | 0.001 | 1.28 | 0.99 | |
| Ensemble (RF + XGB) | 0.489 | 0.78 | 0.57 | |
| Ensemble (RF + SVM) | 0.565 | 0.88 | 0.64 | |
| Ensemble (XGB + SVM) | 0.671 | 0.77 | 0.57 | |
| Sunflower | LM | 0.537 | 0.57 | 0.47 |
| RF | 0.600 | 0.54 | 0.40 | |
| XGB | 0.768 | 0.41 | 0.31 | |
| SVM | 0.512 | 0.67 | 0.56 | |
| Ensemble (RF + XGB) | 0.511 | 0.56 | 0.42 | |
| Ensemble (RF + SVM) | 0.514 | 0.60 | 0.44 | |
| Ensemble (XGB + SVM) | 0.532 | 0.58 | 0.45 |
| Harvest Residues | Individual Machine Learning Methods | ||
|---|---|---|---|
| RF | XGB | SVM | |
| All | mtry = 2 | nrounds = 50, lambda = 0.0001, alpha = 0, eta = 0.3 | sigma = 0.778, C = 1 |
| Maize | mtry = 2 | nrounds = 100, lambda = 0.1, alpha = 0.1, eta = 0.3 | sigma = 0.944, C = 1 |
| Soybean | mtry = 2 | nrounds = 50, lambda = 0, alpha = 0.0001, eta = 0.3 | sigma = 0.136, C = 0.5 |
| Sunflower | mtry = 2 | nrounds = 50, lambda = 0.1, alpha = 0.0001, eta = 0.3 | sigma = 0.800, C = 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kovačić, Đ.; Radočaj, D.; Samac, D.; Jurišić, M. Influence of Thermal Pretreatment on Lignin Destabilization in Harvest Residues: An Ensemble Machine Learning Approach. AgriEngineering 2024, 6, 171-184. https://doi.org/10.3390/agriengineering6010011
Kovačić Đ, Radočaj D, Samac D, Jurišić M. Influence of Thermal Pretreatment on Lignin Destabilization in Harvest Residues: An Ensemble Machine Learning Approach. AgriEngineering. 2024; 6(1):171-184. https://doi.org/10.3390/agriengineering6010011
Chicago/Turabian StyleKovačić, Đurđica, Dorijan Radočaj, Danijela Samac, and Mladen Jurišić. 2024. "Influence of Thermal Pretreatment on Lignin Destabilization in Harvest Residues: An Ensemble Machine Learning Approach" AgriEngineering 6, no. 1: 171-184. https://doi.org/10.3390/agriengineering6010011
APA StyleKovačić, Đ., Radočaj, D., Samac, D., & Jurišić, M. (2024). Influence of Thermal Pretreatment on Lignin Destabilization in Harvest Residues: An Ensemble Machine Learning Approach. AgriEngineering, 6(1), 171-184. https://doi.org/10.3390/agriengineering6010011