
Accuracy Comparison of YOLOv7 and YOLOv4 Regarding Image Annotation Quality for Apple Flower Bud Classification


Abstract
1. Introduction
2. Materials and Methods
2.1. Apple Flower Bud Image Dataset
2.2. YOLOv7 Model Development
3. Results and Discussion
3.1. Training and Validation Datasets
3.2. Test Dataset
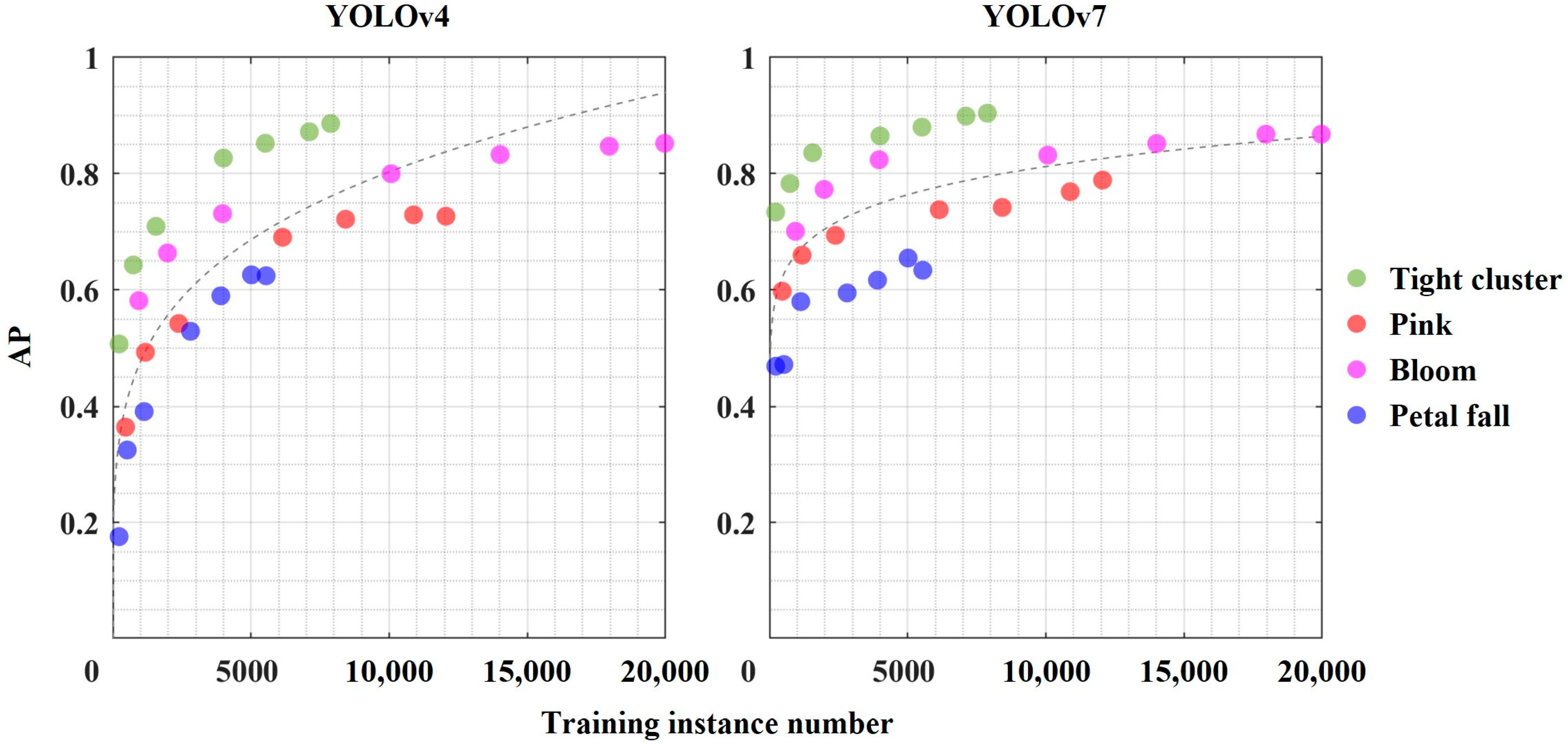
3.3. Optimal Training Instance Number
4. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Liu, Y.; Pu, H.; Sun, D.W. Efficient extraction of deep image features using convolutional neural network (CNN) for applications in detecting and analysing complex food matrices. Trends Food Sci. Technol. 2021, 113, 193–204. [Google Scholar] [CrossRef]
- Hafiz, A.M.; Bhat, G.M. A survey on instance segmentation: State of the art. Int. J. Multimed. Inf. Retr. 2020, 9, 171–189. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in CNN-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef]
- Cholakkal, H.; Sun, G.; Shahbaz Khan, F.; Shao, L. Object counting and instance segmentation with image-level supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June; pp. 12389–12397.
- Yeong, T.J.; Jern, K.P.; Yao, L.K.; Hannan, M.A.; Hoon, S.T.G. Applications of photonics in agriculture sector: A review. Molecules 2019, 24, 2025. [Google Scholar]
- Mavridou, E.; Vrochidou, E.; Papakostas, G.A.; Pachidis, T.; Kaburlasos, V.G. Machine vision systems in precision agriculture for crop farming. J. Imaging 2019, 5, 89. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Gong, C.; Chen, Y.; Yu, H. Applications of deep learning for dense scenes analysis in agriculture: A review. Sensors 2020, 20, 1520. [Google Scholar] [CrossRef]
- Li, G.; Huang, Y.; Chen, Z.; Chesser, G.D.; Purswell, J.L.; Linhoss, J.; Zhao, Y. Practices and applications of convolutional neural network-based computer vision systems in animal farming: A review. Sensors 2021, 21, 1492. [Google Scholar] [CrossRef]
- Taverriti, G.; Lombini, S.; Seidenari, L.; Bertini, M.; Del Bimbo, A. Real-Time Wearable Computer Vision System for Improved Museum Experience. In Proceedings of the MM ’16: Proceedings of the 24th ACM international conference on Multimedia, Santa Barbara, CA, USA, 23–27 October 2016; pp. 703–704. [Google Scholar]
- Chen, C.; Lu, J.; Zhou, M.; Yi, J.; Liao, M.; Gao, Z. A YOLOv3-based computer vision system for identification of tea buds and the picking point. Comput. Electron. Agric. 2022, 198, 107116. [Google Scholar] [CrossRef]
- Soviany, P.; Ionescu, R.T. Optimizing the trade-off between single-stage and two-stage deep object detectors using image difficulty prediction. In Proceedings of the 2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 20–23 September 2018; pp. 209–214. [Google Scholar]
- Fan, J.; Huo, T.; Li, X. A review of one-stage detection algorithms in autonomous driving. In Proceedings of the 2020 4th CAA International Conference on Vehicular Control and Intelligence (CVCI), Hangzhou, China, 18–20 December 2020; pp. 210–214. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J. Ultralytics/yolov5: V6.2—YOLOv5 Classification Models, Apple M1, Reproducibility, ClearML and Deci.ai integrations. GitHub 2022. [Google Scholar]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E.; et al. PP-YOLO: An Effective and Efficient Implementation of Object Detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. arXiv 2020, arXiv:2011.08036. [Google Scholar]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A Practical Object Detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Xu, M.; Bai, Y.; Ghanem, B. Missing Labels in Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–10. [Google Scholar]
- Ma, J.; Ushiku, Y.; Sagara, M. The Effect of Improving Annotation Quality on Object Detection Datasets: A Preliminary Study. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, New Orleans, LA, USA, 19–20 June 2022; pp. 4850–4859. [Google Scholar]
- Yuan, W.; Choi, D. UAV-Based Heating Requirement Determination for Frost Management in Apple Orchard. Remote Sens. 2021, 13, 273. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Yuan, W.; Choi, D.; Bolkas, D.; Heinemann, P.H.; He, L. Sensitivity Examination of YOLOv4 Regarding Test Image Distortion and Training Dataset Attribute for Apple Flower Bud Classification. Int. J. Remote Sens. 2022, 43, 3106–3130. [Google Scholar] [CrossRef]
- Böselt, L.; Thürlemann, M.; Riniker, S. Machine Learning in QM/MM Molecular Dynamics Simulations of Condensed-Phase Systems. J. Chem. Theory Comput. 2021, 17, 2641–2658. [Google Scholar] [CrossRef] [PubMed]
- Nowell, D.; Nowell, P.W. A machine learning approach to the prediction of fretting fatigue life. Tribol. Int. 2020, 141, 105913. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lee, D.-H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the ICML 2013 Workshop on Challenges in Representation Learning, Atlanta, GA, USA, 21 June 2013; pp. 1–6. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Image Annotation Quality | 100% | 90% | 70% | 50% | 20% | 10% | 5% | ||
|---|---|---|---|---|---|---|---|---|---|
| YOLOv4 | AP | Tight cluster | 0.939 | 0.866 | 0.692 | 0.525 | 0.166 | 0.085 | 0.043 |
| Pink | 0.855 | 0.776 | 0.621 | 0.455 | 0.128 | 0.067 | 0.030 | ||
| Bloom | 0.923 | 0.844 | 0.671 | 0.501 | 0.161 | 0.079 | 0.041 | ||
| Petal fall | 0.790 | 0.713 | 0.565 | 0.422 | 0.085 | 0.037 | 0.017 | ||
| mAP | 0.877 | 0.800 | 0.637 | 0.476 | 0.135 | 0.067 | 0.032 | ||
| YOLOv7 | AP | Tight cluster | 0.946 | 0.858 | 0.699 | 0.552 | 0.252 | 0.114 | 0.106 |
| Pink | 0.850 | 0.758 | 0.614 | 0.486 | 0.207 | 0.102 | 0.078 | ||
| Bloom | 0.914 | 0.830 | 0.672 | 0.509 | 0.243 | 0.112 | 0.090 | ||
| Petal fall | 0.773 | 0.659 | 0.569 | 0.447 | 0.193 | 0.087 | 0.117 | ||
| mAP | 0.871 | 0.776 | 0.638 | 0.498 | 0.224 | 0.104 | 0.098 | ||
| RC (%) | AP | Tight cluster | 0.745 | −0.924 | 0.953 | 5.203 | 51.716 | 34.118 | 146.512 |
| Pink | −0.585 | −2.370 | −1.111 | 6.790 | 61.215 | 52.012 | 164.865 | ||
| Bloom | −0.954 | −1.635 | 0.194 | 1.698 | 50.932 | 41.058 | 122.963 | ||
| Petal fall | −2.090 | −7.535 | 0.708 | 6.050 | 127.059 | 133.602 | 609.091 | ||
| mAP | −0.639 | −2.964 | 0.110 | 4.732 | 65.803 | 54.762 | 202.160 | ||
| Training Image Annotation Quality | 100% | 90% | 70% | 50% | 20% | 10% | 5% | ||
|---|---|---|---|---|---|---|---|---|---|
| YOLOv4 | AP | Tight cluster | 0.885 | 0.875 | 0.850 | 0.831 | 0.727 | 0.611 | 0.497 |
| Pink | 0.753 | 0.748 | 0.726 | 0.695 | 0.554 | 0.500 | 0.374 | ||
| Bloom | 0.854 | 0.846 | 0.831 | 0.797 | 0.734 | 0.669 | 0.586 | ||
| Petal fall | 0.626 | 0.622 | 0.594 | 0.547 | 0.362 | 0.291 | 0.158 | ||
| mAP | 0.780 | 0.773 | 0.750 | 0.718 | 0.594 | 0.518 | 0.404 | ||
| YOLOv7 | AP | Tight cluster | 0.915 | 0.912 | 0.892 | 0.879 | 0.862 | 0.813 | 0.748 |
| Pink | 0.773 | 0.766 | 0.735 | 0.732 | 0.699 | 0.651 | 0.597 | ||
| Bloom | 0.866 | 0.867 | 0.851 | 0.836 | 0.817 | 0.773 | 0.716 | ||
| Petal fall | 0.638 | 0.635 | 0.647 | 0.592 | 0.559 | 0.475 | 0.450 | ||
| mAP | 0.798 | 0.795 | 0.781 | 0.760 | 0.734 | 0.678 | 0.628 | ||
| RC (%) | AP | Tight cluster | 3.343 | 4.193 | 5.003 | 5.751 | 18.537 | 33.061 | 50.473 |
| Pink | 2.629 | 2.420 | 1.226 | 5.324 | 26.287 | 30.148 | 59.540 | ||
| Bloom | 1.405 | 2.482 | 2.456 | 4.920 | 11.278 | 15.477 | 22.122 | ||
| Petal fall | 1.998 | 2.156 | 8.959 | 8.148 | 54.377 | 63.230 | 184.450 | ||
| mAP | 2.360 | 2.886 | 4.133 | 5.909 | 23.527 | 30.913 | 55.484 | ||
| Training Image Annotation Quality | 100% | 90% | 70% | 50% | 20% | 10% | 5% | ||
|---|---|---|---|---|---|---|---|---|---|
| YOLOv4 | AP | Tight cluster | 0.886 | 0.872 | 0.852 | 0.827 | 0.710 | 0.643 | 0.507 |
| Pink | 0.727 | 0.729 | 0.722 | 0.691 | 0.542 | 0.493 | 0.364 | ||
| Bloom | 0.852 | 0.847 | 0.833 | 0.800 | 0.731 | 0.664 | 0.582 | ||
| Petal fall | 0.625 | 0.626 | 0.590 | 0.529 | 0.391 | 0.325 | 0.176 | ||
| mAP | 0.773 | 0.769 | 0.749 | 0.712 | 0.594 | 0.531 | 0.407 | ||
| YOLOv7 | AP | Tight cluster | 0.904 | 0.899 | 0.880 | 0.865 | 0.836 | 0.783 | 0.734 |
| Pink | 0.789 | 0.769 | 0.742 | 0.738 | 0.694 | 0.660 | 0.598 | ||
| Bloom | 0.868 | 0.868 | 0.852 | 0.832 | 0.824 | 0.773 | 0.701 | ||
| Petal fall | 0.634 | 0.655 | 0.617 | 0.595 | 0.580 | 0.472 | 0.469 | ||
| mAP | 0.799 | 0.798 | 0.773 | 0.758 | 0.734 | 0.672 | 0.625 | ||
| RC (%) | AP | Tight cluster | 1.997 | 3.096 | 3.250 | 4.608 | 17.829 | 21.754 | 44.688 |
| Pink | 8.543 | 5.444 | 2.813 | 6.848 | 27.950 | 33.874 | 64.150 | ||
| Bloom | 1.842 | 2.443 | 2.281 | 4.013 | 12.676 | 16.468 | 20.509 | ||
| Petal fall | 1.521 | 4.616 | 4.576 | 12.455 | 48.338 | 45.231 | 166.477 | ||
| mAP | 3.430 | 3.812 | 3.163 | 6.521 | 23.652 | 26.506 | 53.450 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, W. Accuracy Comparison of YOLOv7 and YOLOv4 Regarding Image Annotation Quality for Apple Flower Bud Classification. AgriEngineering 2023, 5, 413-424. https://doi.org/10.3390/agriengineering5010027
Yuan W. Accuracy Comparison of YOLOv7 and YOLOv4 Regarding Image Annotation Quality for Apple Flower Bud Classification. AgriEngineering. 2023; 5(1):413-424. https://doi.org/10.3390/agriengineering5010027
Chicago/Turabian StyleYuan, Wenan. 2023. "Accuracy Comparison of YOLOv7 and YOLOv4 Regarding Image Annotation Quality for Apple Flower Bud Classification" AgriEngineering 5, no. 1: 413-424. https://doi.org/10.3390/agriengineering5010027
APA StyleYuan, W. (2023). Accuracy Comparison of YOLOv7 and YOLOv4 Regarding Image Annotation Quality for Apple Flower Bud Classification. AgriEngineering, 5(1), 413-424. https://doi.org/10.3390/agriengineering5010027