1. Introduction
Reliable streamflow forecasting is crucial for several applications, such as reservoir management [
1], predicting energy generation in hydroelectric installations [
2], flood mitigation [
3], designing hydraulic schemes [
4], assessing the impact of human-induced changes on water accessibility [
5], and estimating the occurrence of extreme climate phenomena [
6]. The wide spectrum of the mentioned applications highlights the essential need for accurate streamflow predictions [
7]. Consequently, there is an increasing demand for improved short-term and long-term streamflow predictions to enhance water-resource management practices [
7,
8]. However, reliability in streamflow forecasts remains a significant challenge within the field of water-resource management. Indeed, the difficulty in accurate hydrological forecasting is primarily due to the dynamic relations and considerable spatial and temporal variability of the elements that regulate the hydrological cycle that convert rainfall into river flows [
9]. Moreover, the transformation of rainfall into runoff is generally nonlinear [
10], thus leading to additional complexities in its proper modeling.
Precipitation is the primary source of water input into a river basin, directly influencing river flow through several hydrological processes [
7,
9,
11]: when precipitation occurs, it can either infiltrate the soil, contributing to groundwater recharge or become surface runoff, which flows over the land and into rivers and streams. The amount and intensity of precipitation, along with the characteristics of the watershed, such as soil type, vegetation cover, and topography, determine the proportion of water that becomes runoff versus infiltration [
7,
8]. During periods of heavy rainfall, the soil’s infiltration capacity can be exceeded, leading to increased surface runoff and higher river flows. Conversely, during dry periods, reduced precipitation results in lower river flow as groundwater contributions diminish [
5,
6]. Additionally, the temporal distribution of precipitation events, such as the occurrence of prolonged rainfall versus short, intense storms, plays a crucial role in shaping the river flow patterns [
9]. Understanding the reported dynamics is essential for accurate streamflow forecasting and effective water-resource management, particularly in regions with limited hydrological data like the Amazon basin [
7,
8,
9].
The transformation of rainfall into runoff has been modeled in multiple ways through physical [
12], conceptual [
13], and empirical approaches [
14]. Physical and conceptual models provide a comprehensive mathematical formulation of the hydrological elements that govern the transformation of rainfall into streamflow [
12,
13]. However, the application of the latter models requires comprehensive data about the considered basin, including climatic conditions, soil features, and characteristics of drainage channels. As a consequence, the need for such extensive hydrometeorological data can render physical and conceptual models impractical or result in subpar performance in predicting rainfall-runoff in watersheds with limited available data [
7]. On the other hand, empirical models, often based on Machine Learning (ML), can identify correlations between input and output data of hydrological systems without taking into account the involved physical processes [
15,
16,
17]. Indeed, ML models can forecast the hydrological components of interest by employing mathematical equations that only fit the available training data. Traditional ML-based hydrological models, for instance, based on
k-Nearest Neighbors (
k-NN), Support Vector Machine (SVM), Random Forest (RF), Artificial Neural Networks (ANNs), and Deep Learning (DL) have proven to be effective in predicting the streamflow in basins with limited hydrometeorological data [
16,
17].
Regarding ML models, according to Islam et al. [
18], it must be noted that within the field of hydrology, the latter models are particularly relevant when the focus is put on the model’s reliability and/or simplicity rather than the ability to effectively represent the underlying hydrological, physical processes. For instance, high reliability in predictions is crucial for operational uses both in reservoirs and flood alert systems [
1,
3]. Indeed, several recent research works, including the ones of De Sousa et al. [
19] and Filho et al. [
20], focused on the applicability of ML models to daily streamflow forecasting in the Amazon biomes and such authors underscored the remarkable performances of several traditional ML models in the context of Amazon basin, where limited hydrometeorological data were available. Incidentally, similar findings resulting in the successful application of ML-based forecasting models were obtained in other regions of Brazil with comparable hydrometeorological characteristics, e.g., in the Brazilian state of Pernambuco by Da Silva et al. [
21]. Furthermore, it was noted that the effectiveness of ML models in streamflow forecasting is not only due to their resilience in handling the scarcity of available hydrometeorological information but also in dealing with the frequent non-stationary nature of the considered data [
19,
22]. Finally, De Sousa et al. [
19] showed that historical rainfall and streamflow data alone are mostly sufficient to exploit ML for streamflow forecasting.
Even if the traditional ML models demonstrated their effectiveness in the context of streamflow forecasting, they often present several drawbacks to their effective applicability. In particular, traditional ML models typically require a deep understanding of each of the employed underlying ML algorithms and their adjustable parameters and hyperparameters for effective model selection and tuning [
23,
24,
25]. Furthermore, the process of manually training, selecting the proper model, and tuning the respective hyperparameters is often time-consuming, in particular when dealing with ML algorithms allowing the possibility of adjusting a wide set of parameters and hyperparameters, each with multiple or even continuous degrees of freedom [
24,
25,
26]. Last but not least, every step of the traditional ML pipeline required to obtain a fully working forecasting ML model, i.e., data preprocessing, feature extraction, repeated model training and testing, hyperparameter tuning, and final model selection must be done manually [
23,
24,
25].
Automated Machine-Learning (AutoML) models were introduced to mitigate the above-mentioned issues, and they offer several advantages over the traditional ML pipeline [
23,
24,
25]. First, AutoML models reduce the need for deep expertise in each of the employed ML algorithms, as they completely automate data preprocessing, feature extraction, repeated model training and testing, hyperparameter tuning, and final model selection by significantly simplifying the entire ML design process for researchers [
23,
24,
25]. Furthermore, the provided automation does not only reduce design complexity but also drastically cuts down the time required for developing reliable ML models, as it can efficiently test a vast space of candidate optimal models and respective hyperparameters, something that would often be impractical to do manually [
23,
24,
25,
26]. Finally, AutoML models streamline the entire ML pipeline—from data preprocessing to final model selection—ensuring that each step is optimally performed without or with minimal manual intervention [
23,
24,
25]. As a final result, the design of ML forecasting models becomes a completely end-to-end design process, which, in the context of hydrology, could accelerate the development of reliable ML-based models for streamflow prediction, even in environments with limited hydrometeorological data. Indeed, recently, AutoML was applied in a few related studies that focused on streamflow forecasting with remarkable forecasting performance [
27,
28,
29].
Designing streamflow ML forecasting models that both require minimal training data and can automate training, testing, tuning, and final model selection is crucial for hydrological studies in world regions with limited data available, such as the Amazon [
19,
20,
30]. Indeed, the Amazon basin has a lower density of hydrometeorological stations compared to other regions in Brazil and worldwide [
19,
20]. Moreover, the existing network of stations suffers from issues related to limited historical data, uneven distribution, data series inconsistencies, and limited measurement periods [
19,
20]. Such data gaps are partly due to the region’s vast size and the inaccessibility of areas where monitoring stations are located, such as national parks and indigenous lands where the Amazon rainforest is constantly preserved. In the presented scenario, ML models have highly proven effectiveness in accurately representing the hydrological behavior of the considered Amazon region even with limited data, as demonstrated by previous studies [
19,
20], and AutoML models could further enhance such forecasting performance.
Water resources in the Amazon basin hold significant value, primarily for the production of hydroelectric energy through the construction of dams [
31]. Unfortunately, the latter process leads to several environmental issues, including biodiversity loss [
32], local social impacts [
33], flooding of rainforest areas [
34], and disruptions of the region hydrological cycle [
35]. Currently, three Hydroelectric Power Plants (HPPs)—Sinop, Colíder Pesqueiro do Gil, and Teles Pires—are operational in the upper Teles Pires River basin [
36]. Furthermore, the construction of two additional HPPs in the Amazon region—the Jirau and Santo Antônio dams (on the Madeira River, Rondônia) and the Belo Monte dam (on the Xingu River, Pará)—recently indicated a growing demand for hydroelectric production in the considered region [
37]. As a consequence, the Brazilian National Electric System Operator (Operador Nacional do Sistema Elétrico—ONS) started to manage water accumulation reservoirs and to compute streamflow predictions relying on stochastic models [
19,
38]. As well as stochastic models, the ONS also employed conceptual models like SMAP [
39,
40], but such models reported limited precision [
38,
40]. Thus, the potential of other ML-based forecasting models, such as the ones represented by AutoML warrants exploration for improving the performance of the critical streamflow prediction task in the Amazon region.
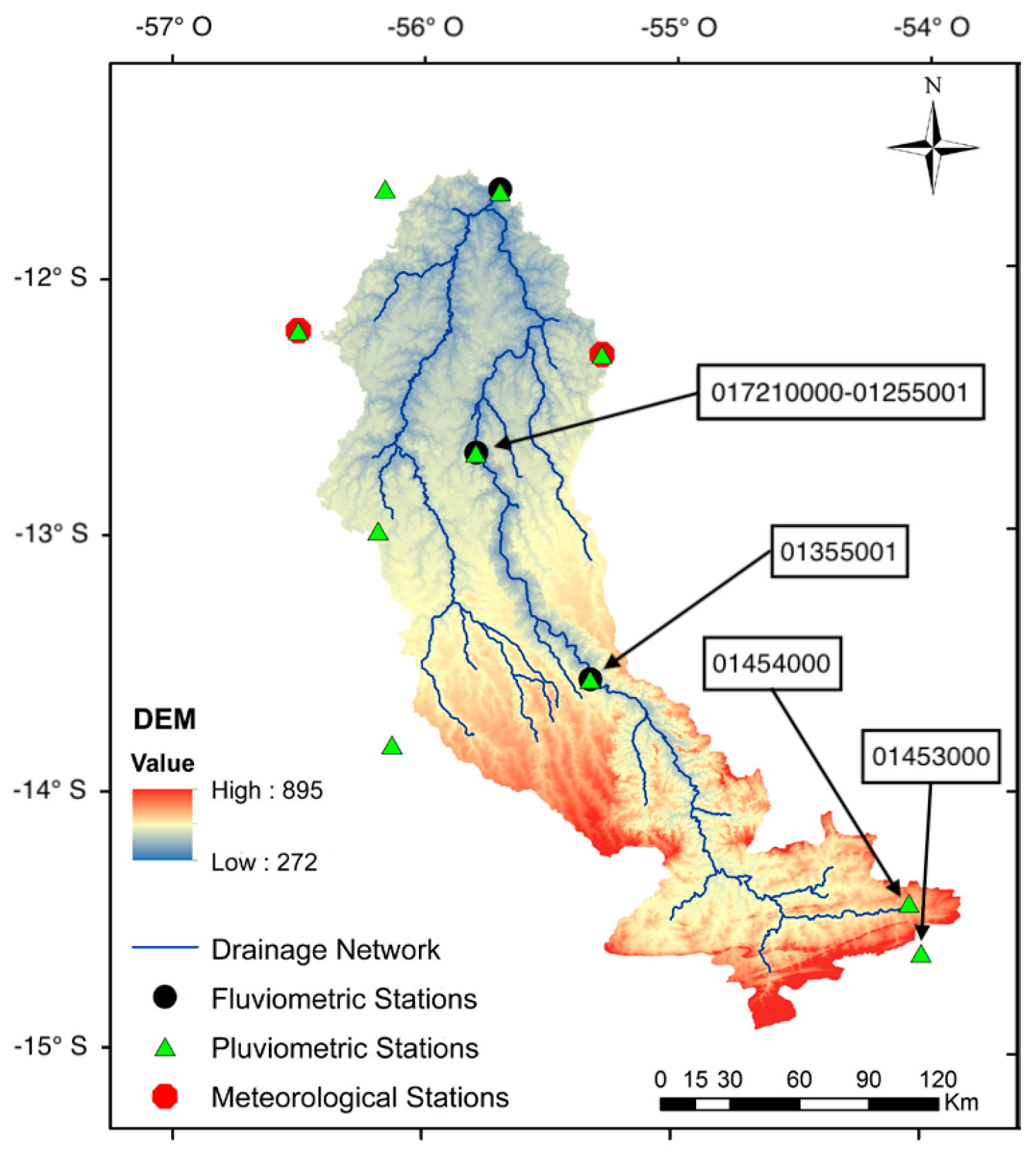
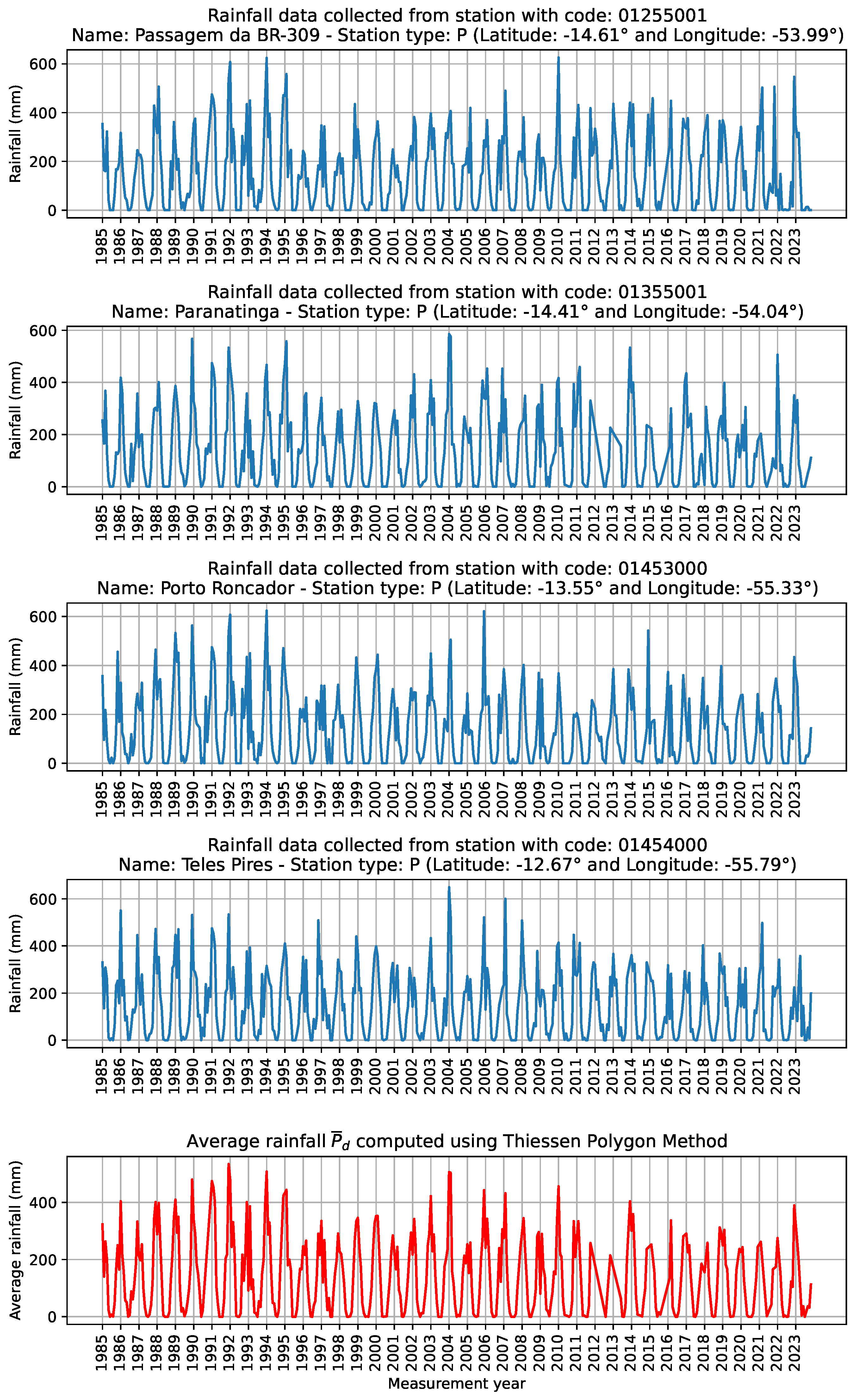
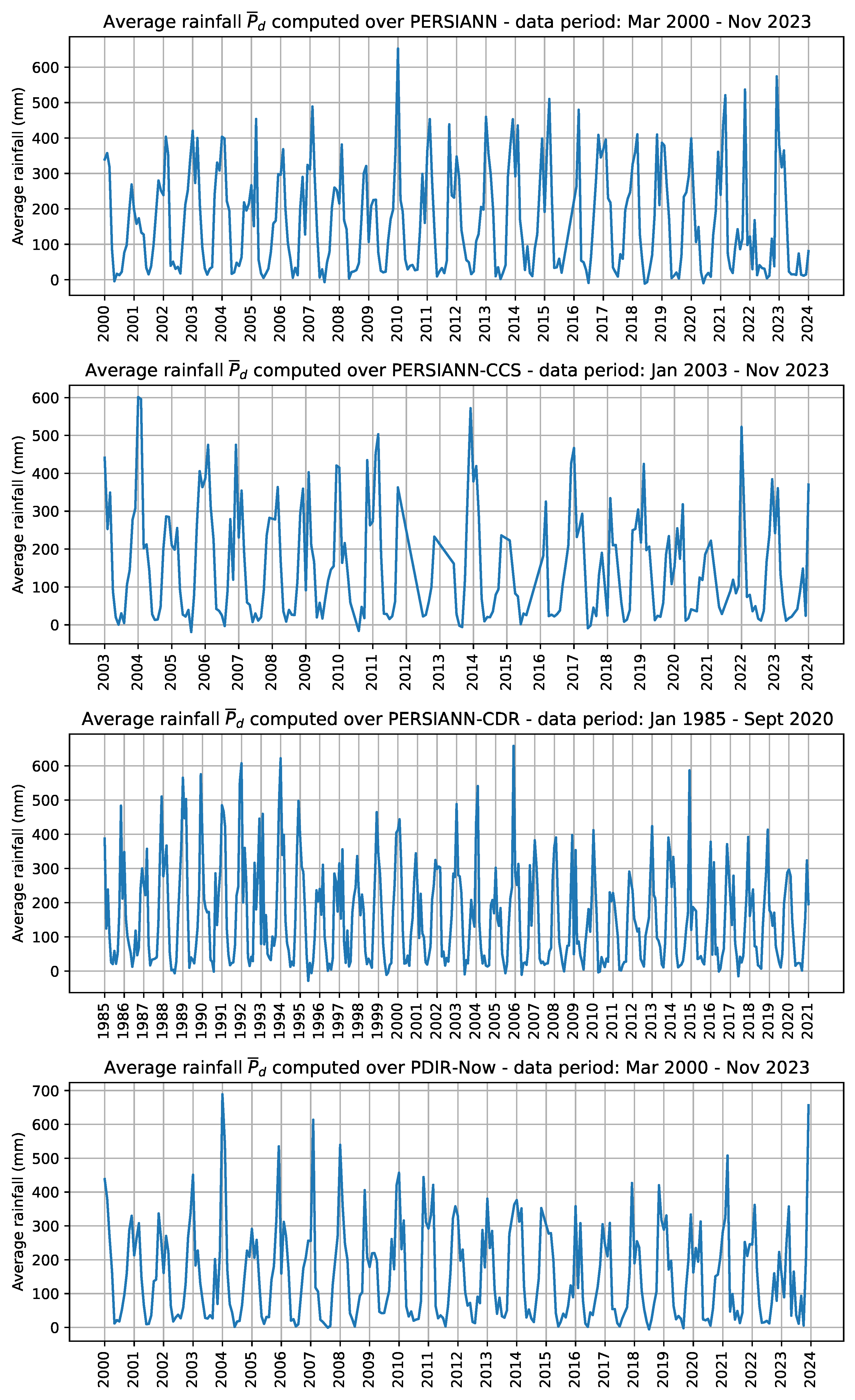
The importance of computing accurate streamflow forecasts cannot be understated for effective water-resource planning and management in the Amazon basin region. Thus, given the constraints of the existing hydrometeorological data and the requirement for reliable streamflow predictions, the objective of the present study is to exploit AutoML methods to effectively forecast the daily streamflow in the selected geographical area. Furthermore, the objective is even to improve the forecasting performances of the already existing ML-based forecasting methods previously applied in the same context. Towards the latter aims the present research relied both on data sourced from several rain and streamflow gauge stations and rainfall products estimated through remote sensing, in line with previously investigated approaches [
19,
20,
21,
30]. The employed estimates included Precipitation Estimation from Remotely Sensed Information using Artificial Neural Networks (PERSIANN), PERSIANN—Cloud Classification System (PERSIANN-CCS), PERSIANN—Climate Data Record (PERSIANN-CDR), and PERSIANN—Dynamic Infrared Rain rate near real-time (PDIR-Now), where the latter one represents a recently introduced product just recently tested in the context of streamflow forecasting [
41,
42].
The forthcoming part of the article is organized as follows:
Section 2 reports the latest ML-based approaches which addressed the problem of streamflow forecasting, even with particular focus on the Amazon biomes;
Section 3 describes the geographical area of interest on which it is focused the present study, the employed datasets, the selected AutoML models along with their experimental settings, and the analyzed metrics for final evaluation of the AutoML models;
Section 4 reports the obtained results of the present study;
Section 5 discusses the reported findings, even with respect to the previous research works which addressed the same objectives; and
Section 6 draws the conclusions of the carried research and suggests potential future directions.
2. Related Works
In recent years, researchers have employed several ML-based models to forecast the streamflow due to their high accuracy and flexibility [
16,
17]. For instance, ANNs/DL-based models [
43,
44], RF-based models [
18,
19,
45], SVM-based models [
46,
47,
48], and AutoML-based models [
27,
28,
29] have been used to provide reliable streamflow forecasts.
Adnan et al. [
46] evaluated several ML models for predicting monthly streamflows using precipitation and temperature inputs, including the Optimally Pruned Extreme Learning Machine (OP-ELM), Least Square Support Vector Machine (LSSVM), Multivariate Adaptive Regression Splines (MARS), and M5 Model Tree (M5Tree). The results obtained by the authors revealed that LSSVM and MARS-based models outperformed OP-ELM and M5Tree models in streamflow prediction, even without the necessity for local input data.
Meshram et al. [
44] compared three ML-based techniques, i.e., Adaptive Neuro-Fuzzy Inference System (ANFIS), Genetic Programming (GP), and ANNs, to forecast the streamflow in the Shakkar watershed (Narmada Basin, India). The latter models incorporated past streamflow data and cyclic terms in the input vector to create suitable time-series models for streamflow forecasting. To evaluate the models’ performances, standard time-series forecasting metrics were used. Results indicated that the ANFIS model achieved the best performance in time-series streamflow forecasting, with the GP model and the ANN model ranking second and third, respectively. The study highlighted that models incorporating cyclic terms significantly outperformed those relying solely on previous streamflow data.
Kumar et al. [
27] employed ML models to predict daily streamflow using hydrometeorological data related to rainfall, temperature, relative humidity, solar radiation, wind speed, and the one-day lag value of the streamflow. Among the employed ML models, i.e., bagging ensemble learning, boosting ensemble learning, Gaussian Process Regression (GPR), and the AutoML-GWL model [
49], the bagging ensemble-learning model resulted as the most effective with a correlation coefficient
and Root Mean Square Error
. The authors even tested the Soil and Water Assessment Tool (SWAT) physical-based model; however, even the bagging ensemble-learning ML model demonstrated superior predictive strength (SWAT:
;
).
Lee et al. [
28] developed a Multi-inflow Prediction Ensemble (MPE) model for dam inflow prediction using the auto-sklearn AutoML model [
50]. The MPE model combined ensemble models for high and low inflow prediction to enhance the prediction accuracy. The study compared the MPE model performance with a conventional auto-sklearn-based ensemble model, finding that the MPE model significantly improved predictions during both flood and non-flood periods. The MPE model reduced RMSE and Mean Absolute Error (MAE) by
and
, respectively, and the designed model increased the coefficient of determination (
) and Nash–Sutcliffe efficiency coefficient by
and
, respectively. The results indicated that the MPE model could enhance water-resource management and dam operation, benefiting the environment and society.
Tu et al. [
29] reconstructed long-term natural flow time-series for inflows into the Pearl River Delta (within the state of China) using global reanalysis datasets, observation data, and ensemble ML models. The study found that the quality of reconstruction provided by the employed AutoGluon AutoML model was superior with respect to the other employed ML models on large-scale datasets. Furthermore, the computed Indicator of Hydrologic Alteration and Range of Variability Analysis (IHA-RVA) revealed that climate variability, reservoir regulation, and human activities significantly altered the natural flow regime, typically smoothing the natural flow variability. As a final result, the research provided an efficient and reliable method for reconstructing natural river flows.
De Oliveira et al. [
30] evaluated the performance of the Large-Scale Distributed Hydrological Model (MGB-IPH) in forecasting water availability in the upper Teles Pires River basin. Despite the lack of climatic and hydrologic data in the region, the MGB-IPH model, calibrated and validated using data from three fluviometric stations, proved to be effective. The model performance was verified using the Nash–Sutcliffe Efficiency Index and the Bias metric. The results demonstrated that the MGB-IPH model could forecast the flow regimes in the upper Teles Pires basin with high reliability in terms of the employed metrics. Overall, the study indicated that the MGB-IPH model is applicable for water management in the basin, thus in areas with limited hydrometeorological data.
De Sousa et al. [
19] assessed the performance of
k-NN, SVM, RF, and ANNs ML-based models for daily streamflow prediction in a transitional region between the Savanna and Amazon biomes in the state of Brazil. The results reported by the authors indicated that the employed ML models provided reliable streamflow predictions for up to three days, even in the Amazon basin, where limited hydrometeorological data are available.
Filho et al. [
20] developed ANNs ML-based models to predict floods in the Branco River within the Amazon basin. The ML models leveraged river levels and average rainfall data estimated from the remotely sensed rainfall PDIR-Now product. Hourly water level data were recorded by fluviometric telemetric stations of the Brazilian National Water Agency (Agência Nacional de Águas—ANA). The multilayer perceptron served as the framework for the ANNs, with the number of neurons in each layer determined through proper hyperparameter tuning methods.
Da Silva et al. [
21] investigated ML models to predict streamflows for proper management of the Jucazinho Dam in the state of Pernambuco, Brazil. Relying on SVR, RF, and ANNs models, the study aimed to forecast the streamflow at the considered dam. Data normalization and Spearman’s correlation were used to enhance the final ML model’s accuracy. Evaluated using metrics such as the Nash–Sutcliffe efficiency coefficient and the coefficient of determination (
), the SVM model showed the best forecasting performance but was prone to underestimate long-term streamflow values, while RF and ANN models overestimated them likely due to overfitting. The study highlighted the effectiveness of ML in improving dam management in water-scarce regions such as Pernambuco, Brazil.
As reported in the previous paragraphs, recent research works have significantly enhanced the application of ML models for streamflow forecasting, offering various advantages and limitations depending on the specific model and context. ANNs and DL models [
43,
44] have gained attention due to their ability to model complex nonlinear relationships between inputs and outputs, making them particularly effective when ample data are available. However, such models often suffer from overfitting, particularly when applied to small datasets or regions with limited hydrometeorological data, as observed by Meshram et al. [
44]. In contrast, RF-based models [
18,
19,
45] offer robustness and interpretability, making them a preferred choice in scenarios where the dataset includes noise or missing values. However, their computational cost and the potential for overfitting in high-dimensional datasets remain challenges. SVM models [
46,
47,
48] have shown remarkable accuracy in streamflow prediction, particularly for small-to-moderate datasets, thanks to their ability to manage nonlinear patterns. Yet, SVMs are computationally intensive and require careful tuning of hyperparameters, which can be a disadvantage in practical applications. AutoML approaches [
27,
28,
29] have recently emerged as powerful tools that automate the model selection and tuning process, offering a balanced trade-off between performance and ease of use. The AutoML-based models have demonstrated superior performance in various hydrological contexts by optimizing the selection of algorithms and hyperparameters, though their black-box nature may limit interpretability and user trust in certain applications. Overall, while the choice of model depends on the specific requirements of the study, the latest research suggests that a combination of ensemble methods and automated model optimization techniques, such as those provided by AutoML frameworks, can significantly enhance the accuracy and reliability of streamflow forecasts, particularly in data-scarce or highly variable climatic regions.
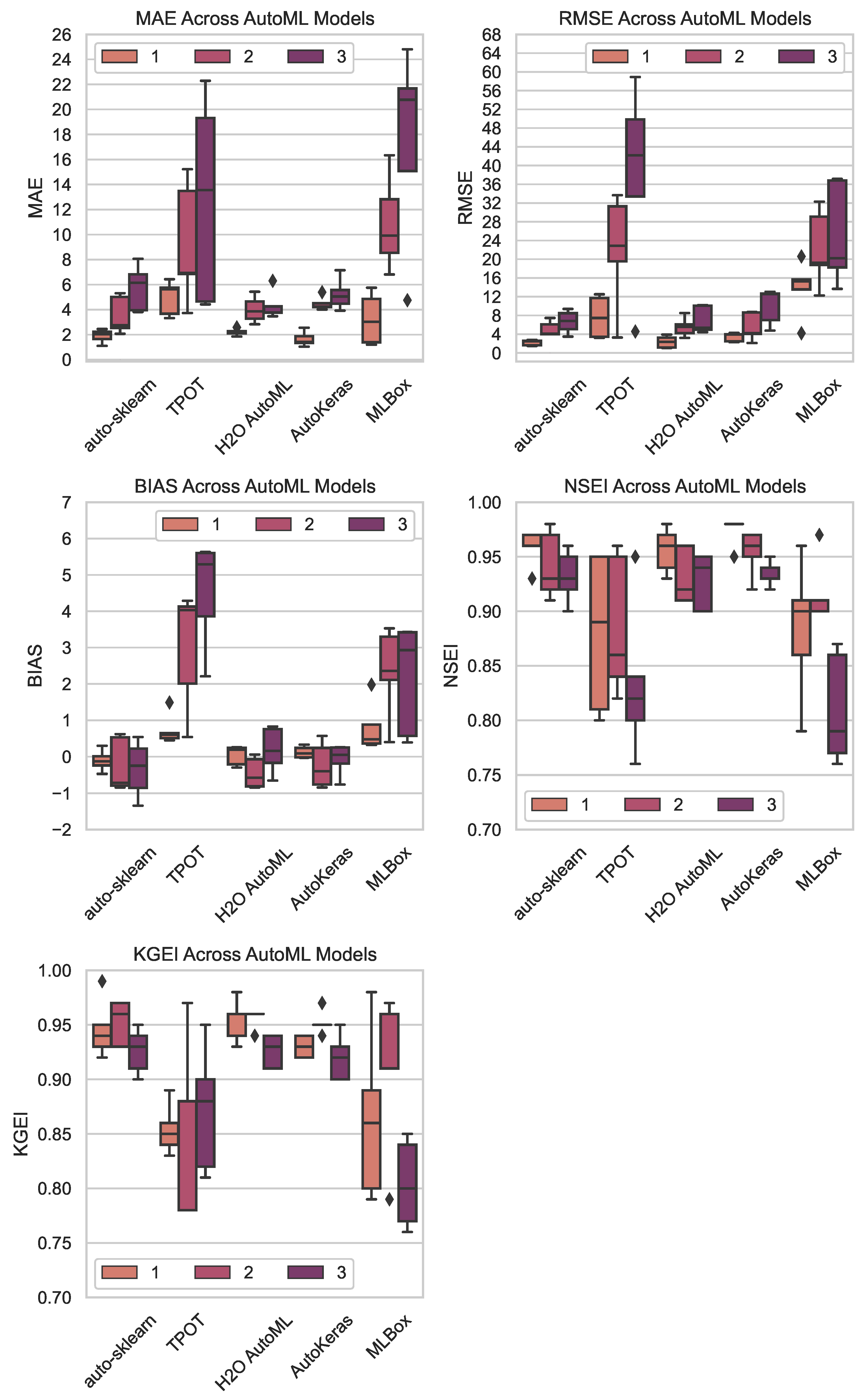
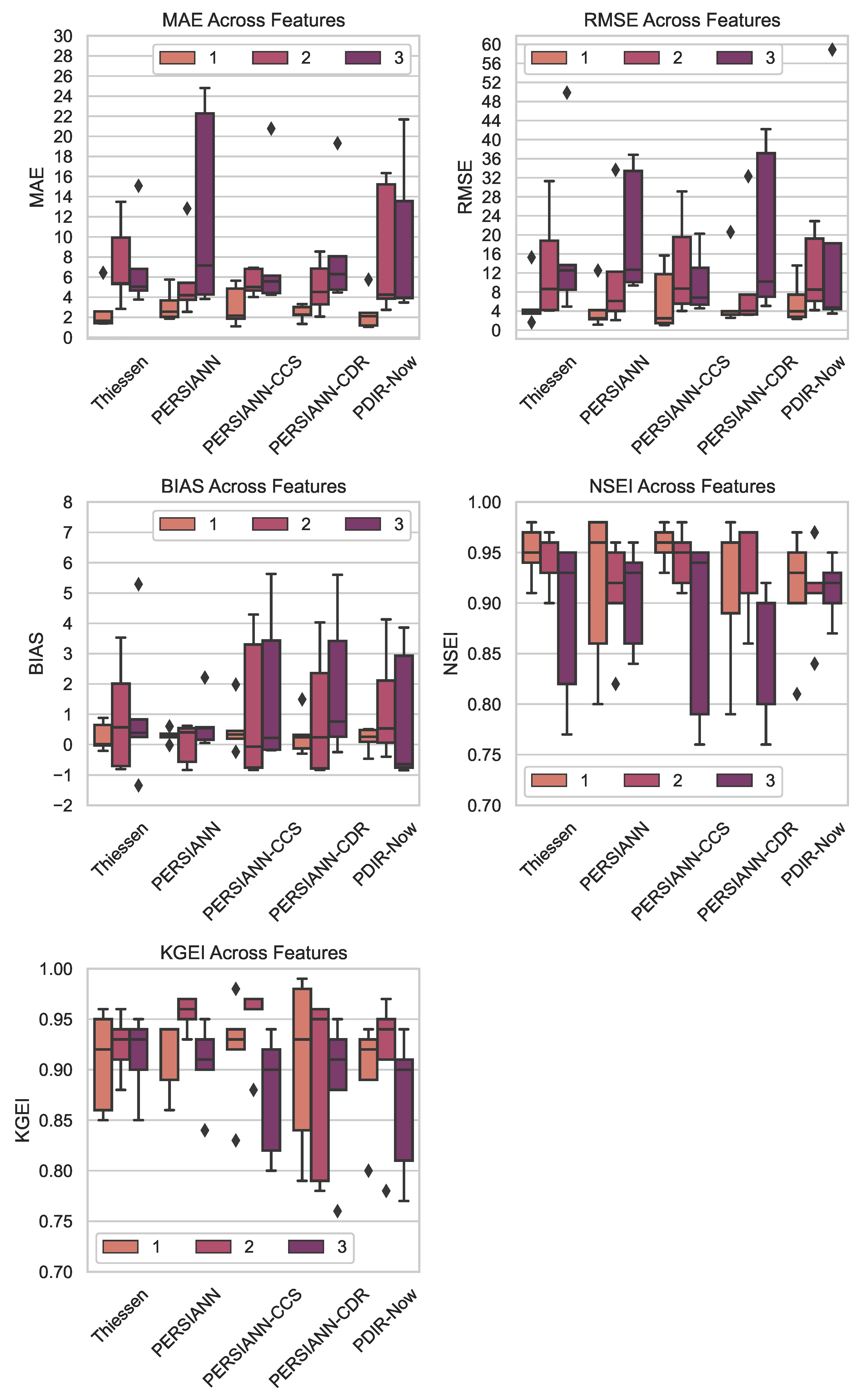
4. Results
The
Figure 6 and
Figure 7 present the daily streamflow forecasting performance on the test set for the five employed AutoML models, five feature sets, and three different forecasting time-lags. Both the figures report the test set forecasting performance through five separate subplots, each corresponding to a different performance metric, previously described in
Section 3.4. Specifically,
Figure 6 shows the forecasting performance gained by AutoML models for each selected metric over all the employed features. On the other hand,
Figure 7 displays the forecasting performance gained for each metric when each selected feature was used as input over all the employed AutoML models. Both
Figure 6 and
Figure 7 display results by providing summary statistics in each subplot through box plots, color-coded with three different colors, each representing a different time-lag.
Regarding the results shown in
Figure 6, proper statistical tests were applied to understand: (1) if there were any statistically significant differences among the employed AutoML models regarding the test set performance; (2) If the answer to the first point was positive, which specific AutoML models showed statistically significantly different performance with respect to other ones. Among the most common statistical tests to assess the first point, we may find the Analysis of Variance (ANOVA) [
61]. However, the application of ANOVA requires that several assumptions be met to obtain reliable findings, such as normality (groups should be approximately normally distributed), homogeneity of variances (variances among groups should be approximately equal), and independence (observations must be independent of each other). Even if independence may be reasonably assumed in the present study, normality and homogeneity of variances were not guaranteed by the analyzed results. Indeed, the Shapiro–Wilk test [
62] and the Fligner–Killeen test [
63] were computed over results to check the latter two properties, with test groups defined by grouping the obtained model results by AutoML model and performance metric.
First, the Shapiro–Wilk test was applied. The null hypothesis of the Shapiro–Wilk test assumes that the data follow a Normal distribution, and if the p-value obtained from the test is less than the chosen significance level (commonly set to ), the null hypothesis is rejected and there is sufficient evidence to conclude that the data do not follow a Normal distribution. The tested AutoML models showed a p-value greater than , except for TPOT in MAE (), AutoKeras in RMSE (), MLBox () and TPOT () in BIAS, and finally TPOT in NSEI (). As a result, normality was not guaranteed within five out of twenty-five (the 20%) of the defined groups.
Next, the Fligner–Killeen test was applied to check the homogeneity of variances among groups. The null hypothesis of the latter test set all the group variances to be equal, and with a p-value less than the chosen significance level (typically ), the null hypothesis is rejected. In particular, a different Fligner–Killeen test was performed for each performance metric to compare the AutoML model’s performance variances on the same metric scale. As a result, the performed tests showed statistically significant differences in variances for all the metrics, as all the computed p-values were less than . In particular, the p-values found by the executed Fligner–Killeen tests ranged within .
As a consequence of the found non-normality and non-homogeneity of variances, the ANOVA test could not be leveraged and, as an alternative, the Kruskal–Wallis test [
64] was applied to understand if it existed any statistically significant difference among the employed AutoML models regarding the test set performance. The Kruskal–Wallis test allows the complete dropping of the normality and homogeneity of variances assumptions while requiring only the independence one. The null hypothesis of the latter test states that the medians of all the selected groups are equal, and the alternative hypothesis states that at least one group has a different median from the other ones. In the case the computed
p-value is under a chosen significance level
(typically
), the null hypothesis is rejected, and at least one group median is statistically significantly different from the other group medians. As with the previously applied statistical tests, the Kruskal–Wallis test was applied with test groups defined by grouping the obtained model results by AutoML model and performance metric. In particular, a different Kruskal–Wallis test was performed for each metric to compare the AutoML model median performances on the same metric scale. As a result, the Kruskal–Wallis test indicated statistically significant differences in the AutoML model median performances for all the employed metrics, as all the computed
p-values were inferior to the chosen significance level
. In particular, the
p-values found by the executed Kruskal–Wallis were equal to
for all the analyzed performance metrics.
Since the Kruskal–Wallis test indicated that the selected AutoML models showed statistically significantly different median performances, the Dunn post hoc test [
65] was then executed to understand which specific AutoML models showed different median performances above other ones. As with the Kruskal–Wallis test, the Dunn test does not require the normality and homogeneity of variances assumptions, but only the independence one. The Dunn test is leveraged to perform multiple pairwise comparisons, and for each pair of groups being compared, the null hypothesis states that there is no difference in the central tendency, typically the median, between the two groups. On the other hand, the alternative hypothesis states that there is a statistically significant difference in the central tendency between the two groups being compared. The null hypothesis in the Dunn test is rejected when the
p-value is less than a chosen significance level
(usually
).
As with the previously applied statistical tests, the Dunn test was applied with test groups defined by grouping the obtained model results by AutoML model and performance metric. In particular, different pairwise Dunn tests were performed for each metric to compare the AutoML models’ median performances on the same metric scale. The Dunn test computed
p-values, reported in
Table 4, indicated two distinct groups of AutoML models in terms of median performance: Indeed, the first one consisting of AutoKeras, H2O AutoML, and auto-sklearn, generally showed no statistically significant difference in median performance among themselves across all the employed metrics, as indicated by their respective
p-values close to
; The second one, including MLBox and TPOT, also showed no significant difference in median performance between them. However, the two latter models showed significant differences when compared to the ones included in the first group across all the metrics. The last point is due to the
p-values less than
when comparing MLBox and TPOT with the models in the first group.
Upon analyzing the AutoML models performance results displayed in
Figure 6, the above-noted statistically significant differences in the computed
p-values are reflected in the reported performance metrics. Indeed, auto-sklearn consistently achieves lower median MAE, RMSE, and BIAS across different features compared to MLBox and TPOT for each of the considered time-lags. Moreover, auto-sklearn gained NSEI and KGEI median values closer to
with respect to MLBox and TPOT. Similarly, H2O AutoML and AutoKeras also tended to perform better in terms of all the employed performance metrics with respect to MLBox and TPOT. On the other hand, the two latter AutoML models still showed competitive performance, particularly in terms of the NSEI and KGEI metrics, where they all reached median performance above the value of
, which still suggests high-quality model predictions, according to the categorization reported in the
Section 3.4.
Regarding the results shown in
Figure 7, part of the statistical tests previously applied was used to understand: (1) if there were any statistically significant differences among the employed input features regarding the test set performance; (2) If the answer to the first point was positive, which specific feature sets allowed to gain statistically significantly different forecasting performance with respect to other ones. Tests were performed with test groups defined by grouping the obtained model results by feature kind and performance metric. The Shapiro–Wilk test and Fligner–Killeen test were computed over results to check the normality and homogeneity of variance assumptions.
First, the Shapiro–Wilk test results indicated that the null hypothesis of normality was rejected for most of the employed features at a significance level of . In particular, for MAE and Bias, the null hypothesis was rejected for all the employed features. For RMSE, all the features rejected the null hypothesis except PERSIANN-CCS (). For NSEI, PDIR-Now (with ), PERSIANN (), and PERSIANN-CDR () did not reject the null hypothesis. Lastly, for KGEI, PERSIANN () and Thiessen () did not reject the null hypothesis. As a result, the normality assumption was not guaranteed within 19 out of 25 (the ) of the analyzed groups.
Next, the Fligner–Killeen test was applied to check the homogeneity of variances among groups. In particular, a different Fligner–Killeen test was performed for each performance metric to compare performance variances on the same metric scale gained when leveraging each input feature. As a result, the performed tests showed no statistically significant differences in-group variances for all the employed metrics, as all the computed p-values were greater than the significance level . In particular, the p-values found by the executed Fligner–Killeen tests ranged within .
The Kruskal–Wallis was finally executed, with test groups defined by grouping the obtained model results by feature kind and performance metric. In particular, a different Kruskal–Wallis test was performed for each performance metric to compare performance medians on the same metric scale, gained when leveraging each employed feature. As a final result, the Kruskal–Wallis test indicated no statistically significant differences in the AutoML model median performances with respect to the employed features, as all the computed p-values were greater than the chosen significance level . In particular, the p-values found by the executed Kruskal–Wallis tests ranged between for all the analyzed metrics. Therefore, post hoc pairwise Dunn tests were not executed.
Furthermore, the forecasting performances of all the possible combinations of AutoML models and input features were ranked by providing them a performance score: The score
was calculated for each combination of AutoML model
m, input feature
f, and time-lag
l, by taking the sum of the absolute differences between the test set performance of the AutoML model
m and the optimum value for each employed performance metric (value 0 for MAE, RMSE, and BIAS; value 1 for NSEI and KGEI). The obtained scores were then summed over the time-lag values
l to obtain the total score
for each combination of AutoML model
m and feature
f. The lower the total score, the better the considered combination of model and feature. In
Table 5, the
is reported for each combination of AutoML model and feature.
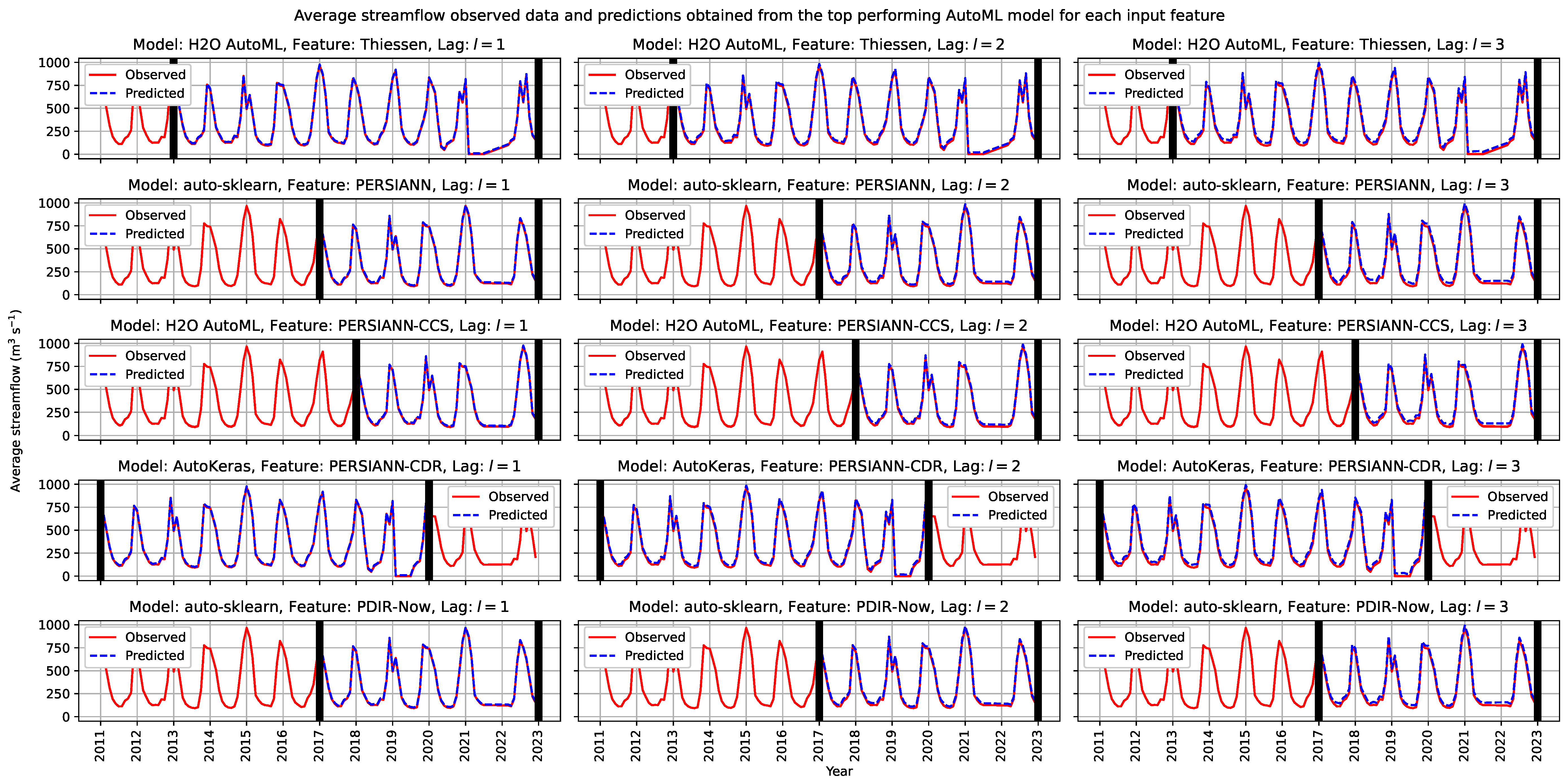
Finally, the top performing AutoML model for each input feature was additionally run on the test data for each of the selected time-lag,
. The latter data were unseen by the trained AutoML models for all the selected input features. According to
Table 5, the top performing AutoML models for each input feature set according to the
metric were, respectively, H2O AutoML for Thiessen, auto-sklearn for PERSIANN, H2O AutoML for PERSIANN-CCS, AutoKeras for PERSIANN-CDR, and auto-sklearn for PDIR-Now. The average streamflow observed data and predictions obtained from the AutoML models were reported in
Figure 8.
Regarding
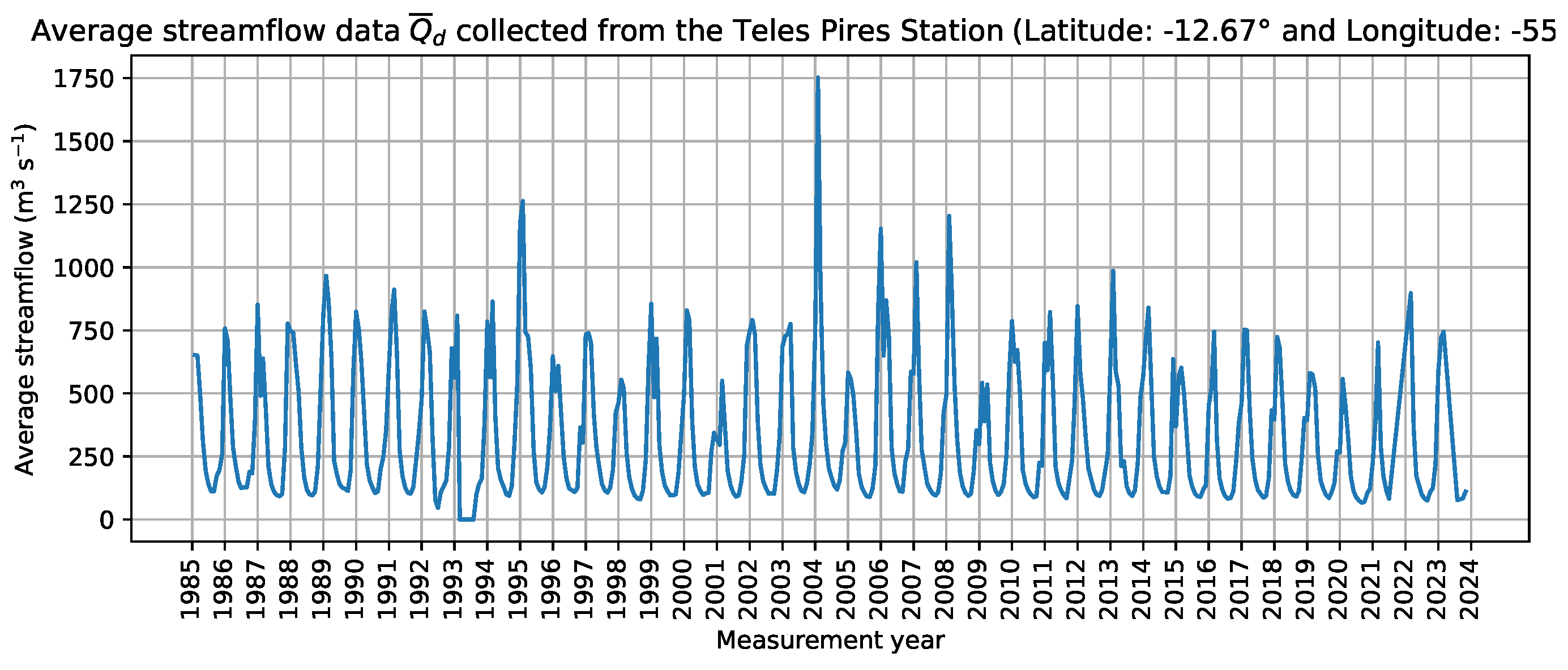
Figure 8, the performance of the AutoML models was evaluated across different seasons to understand their robustness and reliability under varying climatic conditions. The Amazon basin experiences distinct wet and dry seasons, which significantly influence streamflow patterns. During the wet season (October to April), the models demonstrated higher prediction accuracy due to the increased availability of rainfall data, which is a primary driver of streamflow. Conversely, during the dry season (May to September), the prediction accuracy slightly decreased, reflecting the reduced rainfall input and the increased reliance on historical streamflow data. This seasonal variation highlights the models’ dependency on accurate and timely rainfall data for optimal performance.
5. Discussion
The experimental results confirmed that the usage of time-delayed rainfall and streamflow data provided reliable input features to train AutoML models designed to forecast future streamflow. Indeed, rainfall data plays a crucial role within hydrological forecasting models, being the primary way of water influx into a hydrographic basin [
19,
66]. Moreover, the time-delayed streamflow provides a representation of the moisture condition in watersheds, given that runoff happens post-soil saturation [
19,
67]. As previously noted by De Sousa et al. [
19] and Filho et al. [
20], the application of ML for predicting the daily streamflow in the Amazon basin offers significant benefits, particularly due to the lack of available hydrometeorological data. Indeed, even the findings described in the present study indicate that ML-based models are a viable solution in the context of basins with inadequate hydrological monitoring and a lack of fundamental information required for the proper implementation of physical and/or conceptual rainfall-runoff models.
According to the results shown in
Figure 6, the executed Dunn post hoc tests revealed two groups of AutoML models with similar in-group median forecasting performances: Group 1 includes auto-sklearn, AutoKeras, and H2O AutoML, while Group 2 includes TPOT and MLBox. In addition to the results of the executed Dunn tests, even the computed AutoML model score
highlighted the difference in forecasting performance between the two found groups of AutoML models: Regarding the scored combinations of employed models and features reported in
Table 5, over the
ranked position (included) only combinations with AutoML models within Group 1 do appear. On the other hand, under the
ranked position (included), only combinations with models within Group 2 are listed. Indeed, it must be noted that if pairwise score differences are computed between the sorted scored combinations, the highest score difference found is between the
and
combination, with a score difference of
. As already described in
Section 4, not only did the AutoML models within Group 1 show median forecasting performances superior with respect to the models contained in Group 2, but they even achieved a minimal loss of median forecasting performance when increasing the time-lag prediction
l up to
. Indeed, for the models contained in the first group, median test forecasting performances were contained in the same order of magnitude for MAE and RMSE for each set lag. On the other hand, for the AutoML models contained in the second group the order of magnitude of the latter two metrics tended to increase by one unit when increasing the prediction time-lag up to
. Minimal variations were observed with respect to the Bias metric. Regarding NSEI and KGEI, the median performances of AutoML models within Group 1 were greater than the value of
for each employed time-lag, while for models of Group 2, they tended to reach inferior values, even below
.
The structural differences between the AutoML models led to varying performances in streamflow forecasting. Indeed, auto-sklearn, AutoKeras, and H2O AutoML consistently outperformed TPOT and MLBox across most of the employed metrics. The superior performance of auto-sklearn, AutoKeras, and H2O AutoML can be attributed to their advanced optimization techniques and the ability to integrate a broader range of ML algorithms and hyperparameters. In contrast, TPOT’s reliance on genetic programming and MLBox’s limited model selection and feature processing capabilities resulted in less optimal predictions. Such differences underscore the importance of selecting appropriate AutoML models based on their structural characteristics to achieve reliable and accurate streamflow forecasts.
Regarding the above-reported findings, as already noted by previous literature, it was found that TPOT could underperform if compared to other AutoML models due to several reasons: (1) The TPOT training phase is highly computationally expensive [
68]. Indeed, the TPOT GP search process involves evolving a potentially huge population of ML models and respective configurations over several generations, which can be significantly more time-consuming with respect to the techniques leveraged by other AutoML models. The latter point is particularly relevant in the case when large datasets or complex ML models are employed; (2) The TPOT performance can be highly sensitive to the difficult setting of its GP-related parameters, such as population size and mutation rate, which can lead to sub-optimal results [
69]; (3) Last, but not least, TPOT may not perform optimally in situations where the optimal ML pipeline requires advanced ML models that are not included in the TPOT available configuration, such as advanced DL models. Indeed, the pipeline elements leveraged by TPOT only include algorithms and ML models borrowed from the well-known Python scikit-learn library [
55].
As with TPOT, MLBox may underperform if compared to other AutoML models for several reasons: (1) One of the primary reasons is represented by the lack of available ML models to be leveraged, with respect to the other employed AutoML models in the present study [
58]. Indeed, MLBox only includes LightGBM, RF, Extra Trees, Trees, Bagging, AdaBoost, and Linear ML models. The limited availability of usable ML models could limit the MLBox capability of capturing complex patterns in the training data that more advanced ML models are capable of, such as Stacking, SVM, ANNs, and DL models; (2) Additionally, the MLBox feature selection process is limited to standard feature processing techniques, which could lead to sub-optimal feature sets being used for ML models training; (3) Finally, while the MLBox limited amount of adjustable parameters could be seen as an advantage towards the fast developing of ML models, it could also represent a drawback in scenarios where a careful selection of the ML pipeline settings is required. As a result, the high MLBox emphasis on ease of usage may result in a trade-off with the resulting ML model performance, particularly when complex or large-scale datasets are leveraged.
The AutoML models employed in the present research were selected based on their proven effectiveness in handling limited training data and their previous remarkable performances reported in the previous literature [
23,
24,
25]. Moreover, the employed dataset and forecasting performance metrics were selected according to the previous work of De Sousa et al. [
19], which focused on streamflow forecasting with ML models in the same Amazon sub-region analyzed in the present study. Furthermore, the same forecasting metrics were even leveraged by Filho et al. [
20], which even focused on the Amazon basin. In particular, the first group of AutoML models showed, for each employed time-lag, median forecasting performances better of an order of magnitude with respect to the ones reported in De Sousa et al. [
19], in terms of MAE and RMSE. Comparable performances were reached in terms of BIAS, NSEI, and KGEI. It must be noted that even regarding the second group of AutoML models, TPOT and MLBox reached superior median forecasting performances regarding MAE and RMSE with respect to De Sousa et al. [
19] for each employed time-lag. Superior median test performances were even obtained with respect to De Oliveira et al. [
30], which focused on the same sub-region of the present study in terms of the computed NSEI and Bias metrics. Comparable forecasting performances were obtained with respect to Filho et al. [
20], which computed predictions within another sub-region of the Amazon basin relying on the PDIR-Now product and ANNs. However, in the latter case, it must be noted that in contrast with De Sousa et al. [
19] and De Oliveira et al. [
30], the employed dataset was based on an Amazon sub-region different with respect to the one analyzed by the present study, since the authors focused on data related to the Branco River basin. As a result, it is difficult to compare the ML model performances reported by Filho et al. [
20] with the ones of the present research. Last, but not least, it must be noted that the authors developed an ANN-based forecasting model with a forecast horizon only limited to a 1 day time-lag.
According to the results shown in
Figure 7, the Kruskal–Wallis test performed in
Section 4 indicated no statistically significant differences in the AutoML model’s median performances with respect to all the employed features. In particular, the performance related to the remotely sensed estimated products (PERSIANN, PERSIAN-CSS, PERSIANN-CDR, and PDIR-Now) showed considerable promising results as input factors for predicting the streamflow with AutoML models. Indeed, such features based on remote sensing can augment the data used for training and testing ML models, particularly in wide areas like the Amazon basin, therefore enhancing the reliability of streamflow forecasts for the management of HPPs. The latter features could serve as a viable alternative to mitigate the uncertainties arising from the sparse distribution of rainfall gauge stations, thus leading to limited data available. Moreover, it must be noted that remotely sensed estimated products could have a superior representation of average rainfall in the considered basin. Indeed, it must be noted that the rainfall in the Amazon basin is primarily convective, characterized by high intensity, brief duration, and limited spatial distribution [
70]. As a result, the average rainfall recorded by surface pluviometric stations could be skewed, especially in the considered area where hydrological data-monitoring networks are sparse. It must be finally noted that new fluviometric and pluviometric stations were installed in the upper Teles Pires River basin, but they registered only a few years of data for training and testing of ML models. Hence, we decided not to employ the available data related to the latter stations, as done by the previous recent study of De Sousa et al. [
19].
Satellite rainfall products have been successfully employed in the past literature as input data for hydrological models to forecast the streamflow [
19,
20,
66,
71]. In addition to the products employed in the present study, other products were leveraged in the past literature, such as the Tropical Rainfall Measuring Mission (TRMM) products [
72]. However, within the present research, we opted not to employ the TRMM product since it has been no longer in operation since 2015. Furthermore, it must be noted that sometimes, the process of updating remotely sensed databases is time-consuming, and it is carried out with several days of delay, rendering it impractical for short-term streamflow predictions. Indeed, the products selected for the present study (refer to
Table 2) are mostly promptly updated, facilitating reliable predictions for HPPs, except for the PERSIANN-CDR, which was last updated in September 2020. Thus, the latter product may represent a secondary option when deciding to employ one of the AutoML models and feature sets developed in the present study. To facilitate the selection of which AutoML models and input feature sets researchers could employ, it must be noted that recent studies compared the hydrological application and reliability of the employed satellite rainfall products: Eini et al. [
73] reported that PERSIANN-CDR and PDIR-Now tend to show better estimates if compared to other products, while the PERSIANN product tends to be less reliable in daily precipitation and runoff modeling. Similarly, Baig et al. [
74] found that PERSIANN-CDR and PDIR-Now tend to provide better rainfall estimates with respect to other products, particularly in terms of capturing extreme rainfall events and the spatial distribution of rainfall. Hence, even though the results found by the present study indicated no statistically significant differences in the AutoML models median performance with respect to all the employed input features, we suggest relying on AutoML models where input features are represented by the PDIR-Now product. In particular, not only the last product is currently updated constantly every 15–60 min (refer to
Table 2), but with respect to the PERSIANN-CDR product, it is still currently updated and maintained. Moreover, according to the
performance evaluation reported in
Table 5, both the two highest ranked combinations of employed AutoML models and features leveraged PDIR-Now as input feature, respectively, with the auto-sklearn and AutoKeras AutoML models.
It must finally mentioned that the current study on daily streamflow forecasting using AutoML presents a few limitations: (1) the study relies heavily on the availability and accuracy of remote-sensing data, which, even if data are usually validated, can be subject to errors and inconsistencies, particularly in regions with dense forest cover like the Amazon. The sparse distribution of ground-based hydrometeorological stations in the Amazon basin further exacerbates this issue, as it limits the ability to validate and calibrate remote-sensing data effectively. Additionally, the study’s focus on a specific sub-region of the Amazon basin means that the findings may not be generalizable to other areas with different hydrological and climatic conditions. The use of historical data for model training also poses a limitation, as it may not fully capture the impacts of recent land use changes and climate variability on streamflow patterns. Moreover, while the AutoML models employed in the study automate many aspects of the machine-learning pipeline, they still require significant computational resources and a certain, even if limited, level of expertise to set up and interpret the results. The present study also acknowledges that the transformation of rainfall into runoff is a complex, nonlinear process influenced by numerous factors, which may not be fully captured by the models used. Finally, the reliance on daily average rainfall and streamflow data may overlook important sub-daily variations and extreme events that could significantly impact streamflow forecasting accuracy. The reported limitations highlight the need for ongoing improvements in data collection, model development, and computational techniques to enhance the reliability and applicability of streamflow forecasts in the Amazon basin and similar regions.
6. Conclusions and Future Directions
The objective of the present research was to assess the effectiveness of AutoML models and remote-sensing-estimated rainfall datasets in forecasting the daily streamflow in the upper reaches of the Teles Pires River in the Amazon basin. Moreover, the aim was to improve the existing forecasting results obtained by the previous research works which addressed the same task in the context of the considered Amazon sub-region. A final review of the above-reported findings underscores the following main points:
The employed AutoML models have proven to be effective in forecasting the daily streamflow of the upper Teles Pires River up to 3 days. A specific group of AutoML models, including auto-sklearn, AutoKeras, and H2O AutoML, showed superior median performance in streamflow forecasting. Thus, the latter AutoML models represented a practical solution for predicting the daily streamflow in basins that lack extensive hydrometeorological data, like the Amazon one.
The streamflow of the upper Teles Pires River can be predicted using precipitation data estimated through remote sensing. Indeed, all the employed products showed comparable forecasting performances when they were used as input features for the AutoML models, even if PDIR-Now represented a preferable input feature due to its highest obtained performance score, fast refresh rate, and current active maintenance.
In addition to the above-mentioned findings, in the present study, we introduced several novel approaches to enhance the application of AutoML for daily streamflow forecasting in the Amazon biomes. Such innovations include:
Customized feature engineering: we developed a novel feature engineering pipeline that integrates both time-lagged streamflow and the latest remote-sensing-estimated rainfall data. Such a pipeline was specifically tailored to address the challenges posed by the limited hydrological data available in the Amazon basin.
Hybrid data integration: unlike traditional approaches that rely solely on ground-based measurements, we incorporated multiple remote-sensing products, i.e., PERSIANN, PERSIANN-CCS, PERSIANN-CDR, and PDIR-Now, to enrich the training dataset. This hybrid integration significantly improved the AutoML models’ ability to generalize and predict streamflow accurately.
Advanced model selection and hyperparameter tuning: a multi-stage AutoML process was employed. Such an approach not only automated the model selection and hyperparameter tuning but also ensured that the most optimal models were selected based on a comprehensive evaluation of multiple performance metrics.
Performance metrics customization: the standard performance metrics built in the AutoML models were customized to include MAE, RMSE, Bias, NSEI, and KGEI. Such a comprehensive set of metrics provided a holistic evaluation of the model’s predictive capabilities.
Strong statistical analysis: an extensive statistical analysis was performed, including the Kruskal–Wallis test and Dunn post hoc test, to rigorously compare the performance of different AutoML models and feature sets. Such level of statistical scrutiny, to the best of our knowledge not done in previous studies, ensured the robustness and reliability of the presented findings.
These innovative approaches underscore the significant contributions of our research in advancing the application of AutoML for hydrological forecasting in data-scarce regions like the Amazon basin.
The developed AutoML models demonstrated reliable streamflow forecasts up to 3 days, serving as potential tools for decision-makers, particularly in relation to the appropriate planning and management of water resources within the Amazon basin. The ultimate goal of the latter is to improve the efficiency of reservoir operations for various purposes, including the hydroelectric production of electricity, flood control, providing water for human consumption, and proper irrigation.
Despite the promising reported results, future developments could still arise from the present study. In particular, future works could take into account remote sensing and reanalysis data as input for ML models aimed at streamflow predictions. For instance, Lian et al. [
75] employed Evapotranspiration (ET) data to limit the uncertainty of ET and enhance streamflow predictions, showing that incorporating additional variables could enhance the outcome of the forecasts. Furthermore, Touseef et al. [
76] also reported that the usage of ET data obtained through remote sensing could improve streamflow forecasting.
Furthermore, in the present research, time-lagged streamflow and daily average rainfall data were leveraged as input features. However, for future works, it might be interesting to include the surface runoff as an additional input feature. To achieve the latter point, the underground flow component could be eliminated using numerical filters, as done in previous research works which employed daily precipitation and runoff with a 2 day lag to forecast the streamflow in mountainous regions [
77,
78,
79]. The latter method could potentially enhance the prediction of peak streamflows in the basin. Finally, despite the obtained satisfactory results in predicting the streamflow using rainfall data derived from remote sensing, the employed data were not calibrated with respect to surface data. Lack of calibration could lead to estimation errors caused by the global scale of the employed products. Therefore, calibrating data could enhance the effectiveness of the used products.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}