
On the Quality of Deep Representations for Kepler Light Curves Using Variational Auto-Encoders

 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Light Curve Representation Methods
2.1.1. Model-Based Representations
2.1.2. Self-Generated Representations
2.1.3. Variational Auto-Encoders
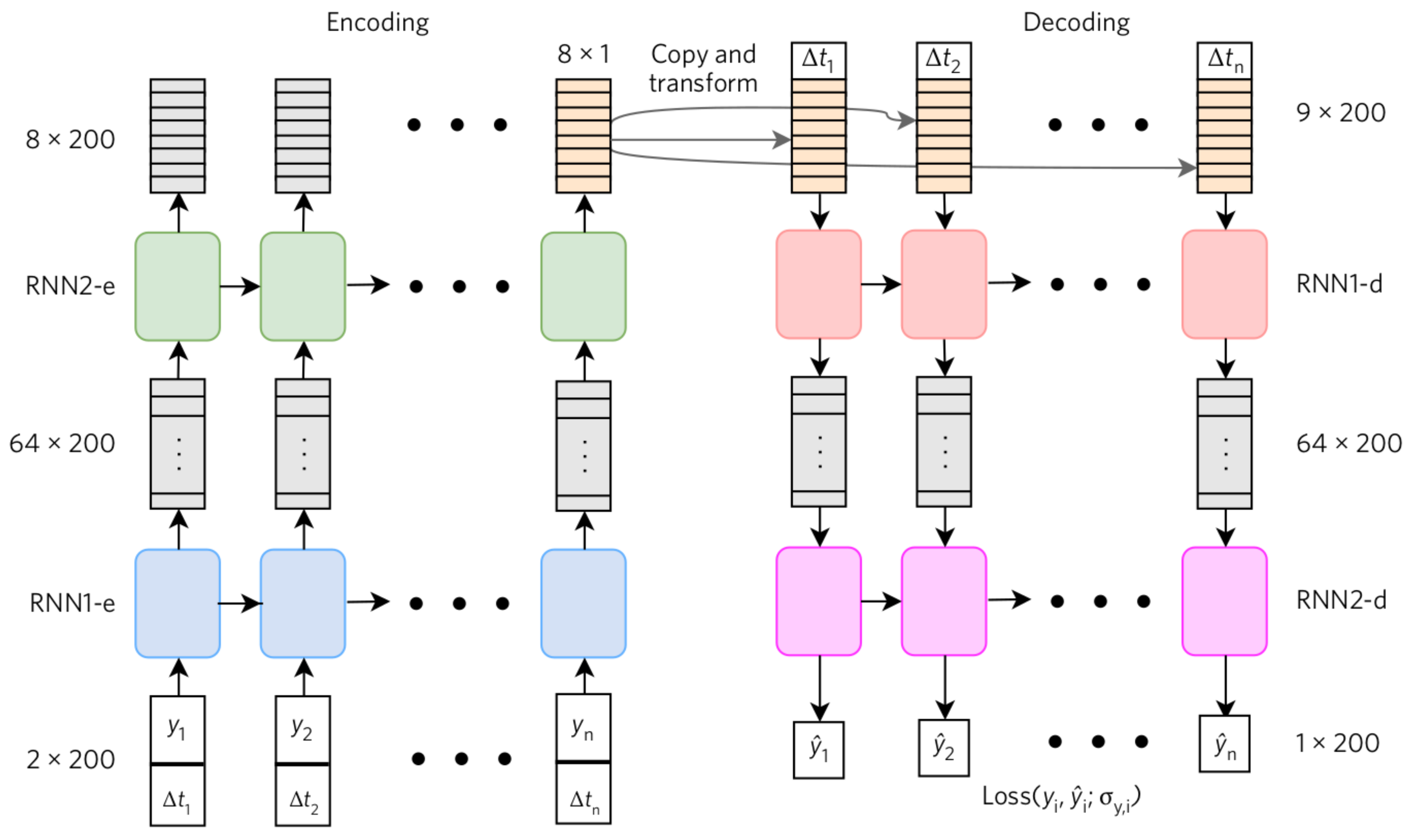
2.2. Extending VRAE to Include Temporal Information
2.2.1. Problem Setup
2.2.2. VRAE Including Delta Times
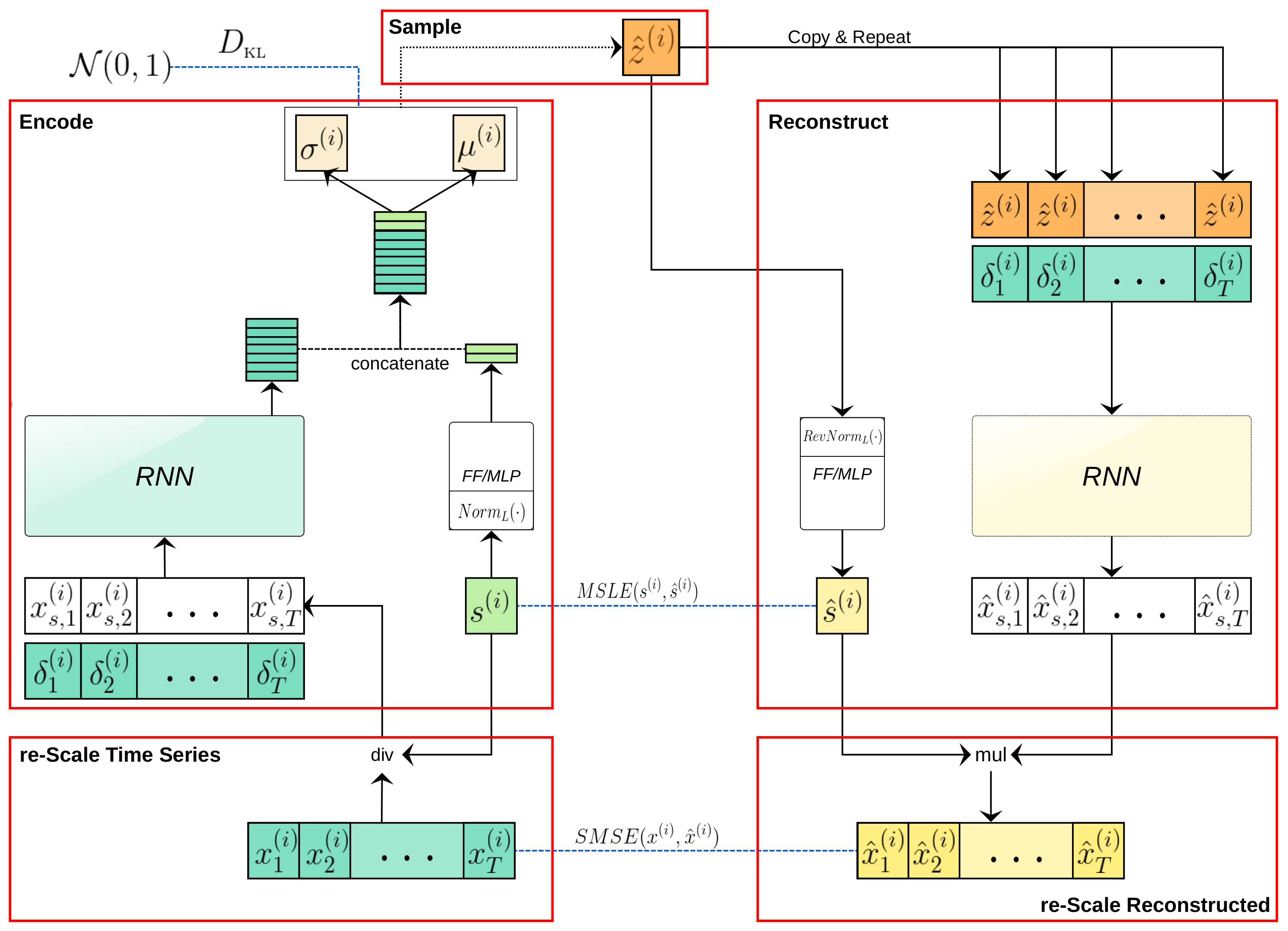
2.2.3. VRAE with Embedded Re-Scaling
- Re-scale data: The first layer of the encoder re-scales the data by dividing on the F-std. This step is performed in order to use the standardized version of the data, as the literature recommends.
- Encode: The encoder adds the F-std as an input pattern to the coding task by in order to extract the information on it.
- Sample: The sampled latent variable is given by: , with .
- Reconstruct: The decoder adds the F-std to the reconstruction task in order to estimate the original F-std by .
- Re-scale reconstruction: The last layer of the decoder re-scales the data, by returning the reconstructed F-std (multiplied by it). This final step is performed in order to obtain a reconstructed time series on the un-scaled values’ representation.
| Algorithm 1 Forward pass VRAE. |
Input: — scaled measurements of the time series — delta times of the time series Output: — reconstructed scaled time series
|
| Algorithm 2 Forward pass S-VRAE. |
Input: — measurements of the time series — delta times of the time series Output: — reconstructed time series
|
2.2.4. Loss Function
3. Experimental Setup and Results
3.1. Dataset
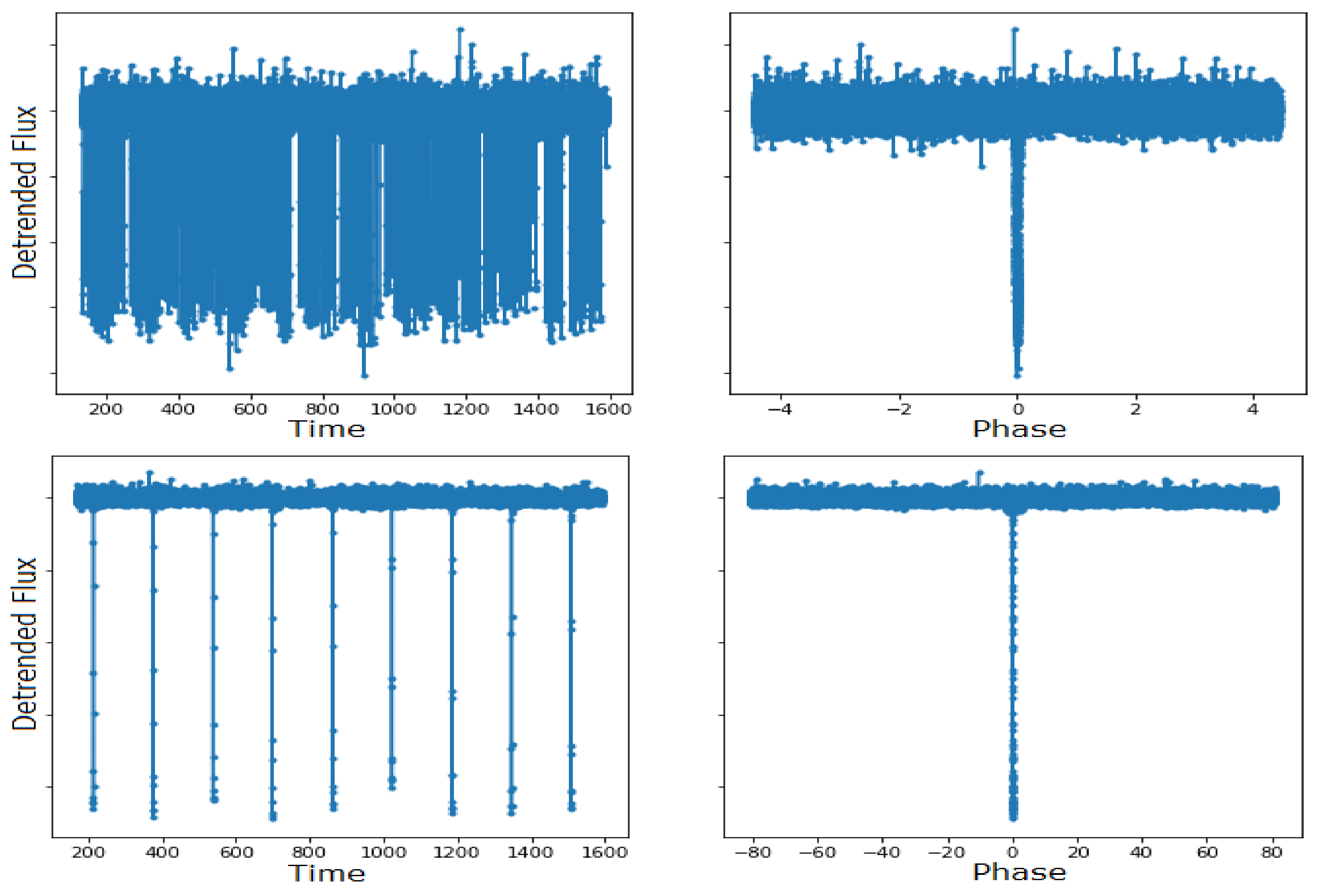
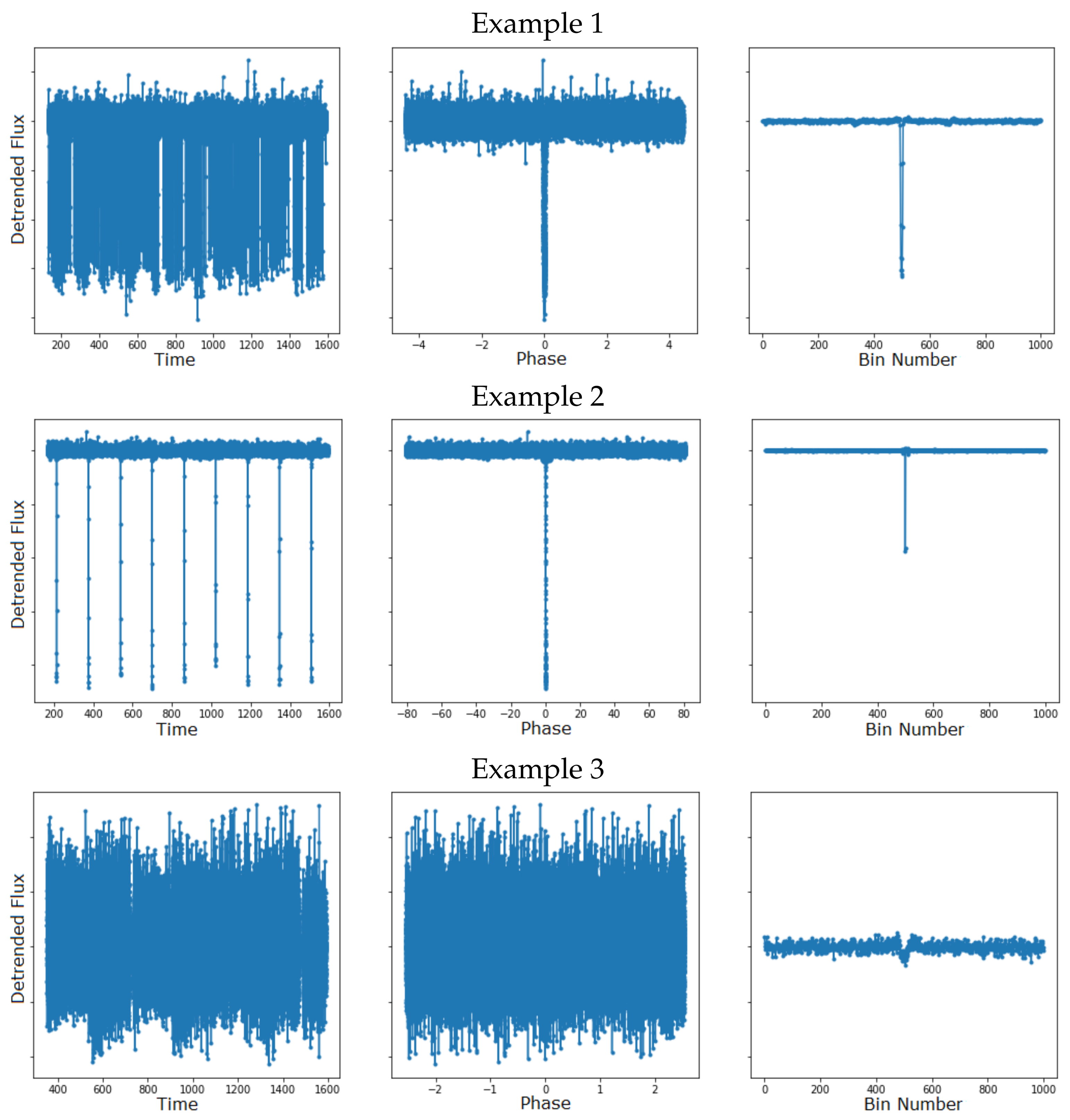
3.1.1. Data Representation
3.1.2. Data Selection and Augmentation
- Check for Kepler flags (in the metadata) and remove objects with “secondary event” or “not transit-like” flags;
- Remove objects with a “transit score” (in the Kepler metadata) less than ;
- Perform a Mandel–Agol fit and remove objects with (SMSE) residual greater than 1.
3.2. Model Assessment and Implementation
3.2.1. Reconstruction Validation
3.2.2. Disentanglement Validation
3.2.3. Classification Validation
3.2.4. Model Implementation
3.3. Results
3.3.1. Is the Time Needed?
3.3.2. Quality Evaluation
3.3.3. Application of the Learned Representation
4. Discussion
5. Conclusions
Future Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AE | Auto-Encoder |
| Auto-C | Auto-Correlation |
| BKJD | Barycentric Kepler Julian Day |
| BJD | Barycentric Julian Day |
| CRTS | Catalina Real-Time Transient Survey |
| CNN | Convolutional Neural Network |
| Diff-M | Mean of the Differences |
| F-PCA | Fourier plus PCA |
| GRU | Gated Recurrent Unit |
| KOI | Kepler Objects of Interest |
| LS | Least Squares |
| LSST | Legacy Survey of Space and Time |
| M-A | Mandel–Agol |
| MAST | Mikulski Archive for Space Telescopes |
| MAE | Mean Absolute Error |
| MCMC | Markov Chain Monte Carlo |
| MI | Mutual Information |
| MLP | Multi-Layer Perceptron |
| MSE | Mean Squared Error |
| MSLE | Mean Squared Logarithm Error |
| NASA | National Aeronautics and Space Administration |
| N-MI | Normalized MI |
| PCA | Principal Component Analysis |
| Pcorr | Pearson Correlation |
| Pcorr-A | Pcorr in Absolute Values |
| RNN | Recurrent Neural Network |
| RAE | Recurrent Auto-Encoder |
| RAE | RAE plus Time Information |
| S-VRAE | VRAE with Re-Scaling |
| SMSE | Re-Scaled Mean Squared Error |
| RMSE | Root Mean Squared Error |
| Spectral-H | Spectral Entropy |
| TESS | Transiting Exoplanet Survey Satellite |
| TCE | Threshold-Crossing Event |
| VAE | Variational Auto-Encoder |
| VRAE | Variational Recurrent Auto-Encoder |
| VRAE | VRAE plus Time Information |
References
- Tyson, J.A. Large Synoptic Survey Telescope: Overview. In Survey and Other Telescope Technologies and Discoveries; International Society for Optics and Photonics: Bellingham, WA, USA, 2002; Volume 4836, pp. 10–20. [Google Scholar] [CrossRef]
- Ricker, G.R.; Winn, J.N.; Vanderspek, R.; Latham, D.W.; Bakos, G.Á.; Bean, J.L.; Berta-Thompson, Z.K.; Brown, T.M.; Buchhave, L.; Butler, N.R.; et al. Transiting Exoplanet Survey Satellite. J. Astron. Telesc. Instrum. Syst. 2014, 1, 014003. [Google Scholar] [CrossRef]
- Mandel, K.; Agol, E. Analytic Light Curves for Planetary Transit Searches. Astrophys. J. Lett. 2002, 580, L171. [Google Scholar] [CrossRef]
- Moutou, C.; Pont, F.; Barge, P.; Aigrain, S.; Auvergne, M.; Blouin, D.; Cautain, R.; Erikson, A.R.; Guis, V.; Guterman, P.; et al. Comparative Blind Test of Five Planetary Transit Detection Algorithms on Realistic Synthetic Light Curves. Astron. Astrophys. 2005, 437. [Google Scholar] [CrossRef]
- McCauliff, S.D.; Jenkins, J.M.; Catanzarite, J.; Burke, C.J.; Coughlin, J.L.; Twicken, J.D.; Tenenbaum, P.; Seader, S.; Li, J.; Cote, M. Automatic Classification of Kepler Planetary Transit Candidates. Astrophys. J. 2015, 806, 6. [Google Scholar] [CrossRef]
- Shallue, C.J.; Vanderburg, A. Identifying Exoplanets with Deep Learning: A Five-planet Resonant Chain around Kepler-80 and an Eighth Planet around Kepler-90. Astron. J. 2018, 155, 94. [Google Scholar] [CrossRef]
- Pearson, K.A.; Palafox, L.; Griffith, C.A. Searching for Exoplanets using Artificial Intelligence. Mon. Not. R. Astron. Soc. 2018, 474, 478–491. [Google Scholar] [CrossRef]
- Schanche, N.; Cameron, A.C.; Hébrard, G.; Nielsen, L.; Triaud, A.; Almenara, J.; Alsubai, K.; Anderson, D.; Armstrong, D.; Barros, S.; et al. Machine-learning Approaches to Exoplanet Transit Detection and Candidate Validation in Wide-Field Ground-based Surveys. Mon. Not. R. Astron. Soc. 2019, 483, 5534–5547. [Google Scholar] [CrossRef]
- Mackenzie, C.; Pichara, K.; Protopapas, P. Clustering-based Feature Learning on Variable Stars. Astrophys. J. 2016, 820, 138. [Google Scholar] [CrossRef]
- Naul, B.; Bloom, J.S.; Pérez, F.; van der Walt, S. A Recurrent Neural Network for Classification of Unevenly Sampled Variable Stars. Nat. Astron. 2018, 2, 151–155. [Google Scholar] [CrossRef]
- Thompson, S.E.; Mullally, F.; Coughlin, J.; Christiansen, J.L.; Henze, C.E.; Haas, M.R.; Burke, C.J. A Machine Learning Technique to Identify Transit Shaped Signals. Astrophys. J. 2015, 812, 46. [Google Scholar] [CrossRef]
- Richards, J.W.; Starr, D.L.; Butler, N.R.; Bloom, J.S.; Brewer, J.M.; Crellin-Quick, A.; Higgins, J.; Kennedy, R.; Rischard, M. On Machine-learned Classification of Variable Stars with Sparse and Noisy Time-series Data. Astrophys. J. 2011, 733, 10. [Google Scholar] [CrossRef]
- Lomb, N.R. Least-Squares Frequency Analysis of Unequally Spaced Data. Astrophys. Space Sci. 1976, 39, 447–462. [Google Scholar] [CrossRef]
- Aguirre, C.; Pichara, K.; Becker, I. Deep Multi-survey Classification of Variable Stars. Mon. Not. R. Astron. Soc. 2019, 482, 5078–5092. [Google Scholar] [CrossRef]
- Tsang, B.T.H.; Schultz, W.C. Deep Neural Network Classifier for Variable Stars with Novelty Detection Capability. Astrophys. J. Lett. 2019, 877, L14. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A Survey of Deep Neural Network Architectures and their Applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Donalek, C.; Djorgovski, S.G.; Mahabal, A.A.; Graham, M.J.; Drake, A.J.; Fuchs, T.J.; Turmon, M.J.; Kumar, A.A.; Philip, N.S.; Yang, M.T.C.; et al. Feature selection strategies for classifying high dimensional astronomical data sets. In Proceedings of the 2013 IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 35–41. [Google Scholar]
- Nun, I.; Pichara, K.; Protopapas, P.; Kim, D.W. Supervised Detection of Anomalous Light Curves in Massive Astronomical Catalogs. Astrophys. J. 2014, 793, 23. [Google Scholar] [CrossRef]
- Armstrong, D.J.; Pollacco, D.; Santerne, A. Transit Shapes and Self Organising Maps as a Tool for Ranking Planetary Candidates: Application to Kepler and K2. Mon. Not. R. Astron. Soc. 2016, 465, 2634–2642. [Google Scholar] [CrossRef]
- Bugueno, M.; Mena, F.; Araya, M. Refining Exoplanet Detection Using Supervised Learning and Feature Engineering. In Proceedings of the 2018 XLIV Latin American Computer Conference (CLEI), Sao Paulo, Brazil, 1–5 October 2018; pp. 278–287. [Google Scholar] [CrossRef]
- Mahabal, A.; Sheth, K.; Gieseke, F.; Pai, A.; Djorgovski, S.G.; Drake, A.J.; Graham, M.J. Deep-Learnt Classification of Light Curves. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Rehfeld, K.; Marwan, N.; Heitzig, J.; Kurths, J. Comparison of Correlation Analysis Techniques for Irregularly Sampled Time Series. Nonlinear Process. Geophys. 2011, 18, 389–404. [Google Scholar] [CrossRef]
- Mondal, D.; Percival, D.B. Wavelet Variance Analysis for Gappy Time Series. Ann. Inst. Stat. Math. 2010, 62, 943–966. [Google Scholar] [CrossRef]
- Marquardt, D.; Acuff, S. Direct Quadratic Spectrum Estimation with Irregularly Spaced Data. In Time Series Analysis of Irregularly Observed Data; Springer: New York, NY, USA, 1984; pp. 211–223. [Google Scholar] [CrossRef]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent Neural Networks for Multivariate Time Series with Missing Values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Fabius, O.; van Amersfoort, J.R. Variational Recurrent Auto-encoders. arXiv 2014, arXiv:1412.6581. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Guo, Y.; Liao, W.; Wang, Q.; Yu, L.; Ji, T.; Li, P. Multidimensional Time Series Anomaly Detection: A GRU-based Gaussian Mixture Variational Autoencoder Approach. In Proceedings of the Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 97–112. [Google Scholar]
- Park, D.; Hoshi, Y.; Kemp, C.C. A Multimodal Anomaly Detector for Robot-Assisted Feeding Using an LSTM-based Variational Autoencoder. IEEE Robot. Autom. Lett. 2018, 3, 1544–1551. [Google Scholar] [CrossRef]
- Xu, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; Liu, Y.; Zhao, Y.; Pei, D.; Feng, Y.; et al. Unsupervised Anomaly Detection via Variational Auto-encoder for Seasonal KPIs in Web Applications. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 187–196. [Google Scholar]
- Woodward, D.; Stevens, E.; Linstead, E. Generating Transit Light Curves with Variational Autoencoders. In Proceedings of the 2019 IEEE International Conference on Space Mission Challenges for Information Technology (SMC-IT), Pasadena, CA, USA, 30 July–1 August 2019; pp. 24–32. [Google Scholar] [CrossRef]
- Locatello, F.; Bauer, S.; Lucic, M.; Raetsch, G.; Gelly, S.; Schölkopf, B.; Bachem, O. Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 4114–4124. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Montavon, G.; Orr, G.; Müller, K.R. Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7700. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning 2015, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. In Proceedings of the European Conference on Computational Learning Theory, Barcelona, Spain, 13–15 March 1995; Springer: Berlin/Heidelberg, Germany, 1995; pp. 23–37. [Google Scholar] [CrossRef]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. Int. Conf. Learn. Represent. (ICLR) 2017, 2, 6. [Google Scholar]
- Thompson, S.E.; Coughlin, J.L.; Hoffman, K.; Mullally, F.; Christiansen, J.L.; Burke, C.J.; Bryson, S.; Batalha, N.; Haas, M.R.; Catanzarite, J.; et al. Planetary Candidates Observed by Kepler. VIII. A Fully Automated Catalog with Measured Completeness and Reliability Based on Data Release 25. Astrophys. J. Suppl. Ser. 2018, 235, 38. [Google Scholar] [CrossRef] [PubMed]
- Akeson, R.; Chen, X.; Ciardi, D.; Crane, M.; Good, J.; Harbut, M.; Jackson, E.; Kane, S.; Laity, A.; Leifer, S.; et al. The NASA Exoplanet Archive: Data and Tools for Exoplanet Research. Publ. Astron. Soc. Pac. 2013, 125, 989. [Google Scholar] [CrossRef]
- Stumpe, M.C.; Smith, J.C.; Van Cleve, J.E.; Twicken, J.D.; Barclay, T.S.; Fanelli, M.N.; Girouard, F.R.; Jenkins, J.M.; Kolodziejczak, J.J.; McCauliff, S.D.; et al. Kepler Presearch Data Conditioning I-Architecture and Algorithms for Error Correction in Kepler Light Curves. Publ. Astron. Soc. Pac. 2012, 124, 985. [Google Scholar] [CrossRef]
- Smith, J.C.; Stumpe, M.C.; Van Cleve, J.E.; Jenkins, J.M.; Barclay, T.S.; Fanelli, M.N.; Girouard, F.R.; Kolodziejczak, J.J.; McCauliff, S.D.; Morris, R.L.; et al. Kepler Presearch Data Conditioning II-A Bayesian Approach to Systematic Error Correction. Publ. Astron. Soc. Pac. 2012, 124, 1000. [Google Scholar] [CrossRef]
- Stumpe, M.C.; Smith, J.C.; Catanzarite, J.H.; Van Cleve, J.E.; Jenkins, J.M.; Twicken, J.D.; Girouard, F.R. Multiscale Systematic Error Correction via Wavelet-Based Bandsplitting in Kepler Data. Publ. Astron. Soc. Pac. 2014, 126, 100. [Google Scholar] [CrossRef]
- Gilliland, R.L.; Chaplin, W.J.; Dunham, E.W.; Argabright, V.S.; Borucki, W.J.; Basri, G.; Bryson, S.T.; Buzasi, D.L.; Caldwell, D.A.; Elsworth, Y.P.; et al. Kepler Mission Stellar and Instrument Noise Properties. Astrophys. J. Suppl. Ser. 2011, 197, 6. [Google Scholar] [CrossRef]
- Christiansen, J.; Machalek, P. Kepler Data Release 7 Notes; Technical Report, KSCI-19047-001; NASA Ames Research Center: Moffett Field, CA, USA, 2010.
- Savitzky, A.; Golay, M.J. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Bugueño, M.; Molina, G.; Mena, F.; Olivares, P.; Araya, M. Harnessing the Power of CNNs for Unevenly-sampled Light-curves Using Markov Transition Field. Astron. Comput. 2021, 35, 100461. [Google Scholar] [CrossRef]
- Inouye, T.; Shinosaki, K.; Sakamoto, H.; Toi, S.; Ukai, S.; Iyama, A.; Katsuda, Y.; Hirano, M. Quantification of EEG Irregularity by Use of the Entropy of the Power Spectrum. Electroencephalogr. Clin. Neurophysiol. 1991, 79, 204–210. [Google Scholar] [CrossRef]
- Chandrakar, B.; Yadav, O.; Chandra, V. A Survey of Noise Removal Techniques for ECG Signals. Int. J. Adv. Res. Comput. Commun. Eng. 2013, 2, 1354–1357. [Google Scholar]
- Barclay, T. Ktransit: Exoplanet Transit Modeling Tool in Python. Available online: https://ascl.net/1807.028 (accessed on 10 April 2021).
- Claret, A.; Bloemen, S. Gravity and Limb-darkening Coefficients for the Kepler, CoRoT, Spitzer, uvby, UBVRIJHK, and Sloan Photometric Systems. Astron. Astrophys. 2011, 529, A75. [Google Scholar] [CrossRef]
- Ross, B.C. Mutual Information between Discrete and Continuous Data Sets. PLoS ONE 2014, 9. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Solar, M.; Araya, M.; Arévalo, L.; Parada, V.; Contreras, R.; Mardones, D. Chilean Virtual Observatory. In Proceedings of the 2015 Latin American Computing Conference (CLEI), Arequipa, Peru, 19–23 October 2015; pp. 1–7. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
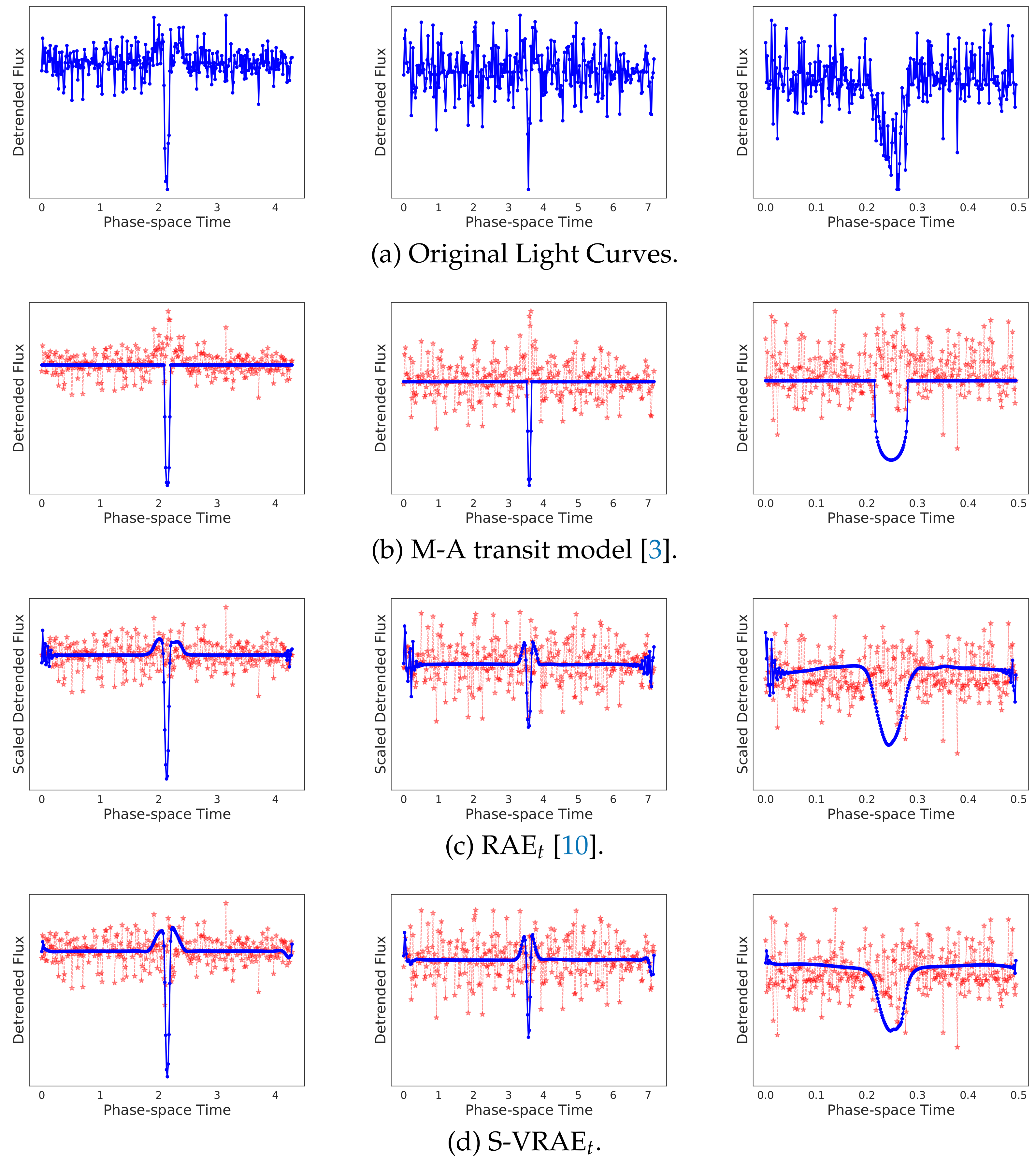{kind=link}
| Reconstruction | Denoising | Residual Noise | ||||
|---|---|---|---|---|---|---|
| Method | Time | RMSE ↓ | MAE ↓ | Auto-C ↑ | Diff-M ↓ | Spectral-H ↑ |
| RAE | × | 0.630 | 0.448 | 0.429 | 0.206 | 0.889 |
| ✓ | 0.680 | 0.475 | 0.502 | 0.125 | 0.895 | |
| VRAE | × | 0.689 | 0.480 | 0.559 | 0.074 | 0.900 |
| ✓ | 0.688 | 0.484 | 0.594 | 0.068 | 0.901 | |
| Reconstruction | Denoising | Residual Noise | ||||
|---|---|---|---|---|---|---|
| Method | Config. | RMSE ↓ | MAE ↓ | Auto-C ↑ | Diff-M ↓ | Spectral-H ↑ |
| Light Curve | - | - | 0.273 | 0.784 | 0.840 | |
| Passband | 1–500 | 1.081 | 0.624 | 0.968 | 0.047 | 0.824 |
| 50–1500 | 1.041 | 0.655 | 0.831 | 0.200 | 0.842 | |
| 50–2500 | 0.959 | 0.640 | 0.670 | 0.363 | 0.846 | |
| Moving avg | 3 | 0.719 | 0.461 | 0.704 | 0.274 | 0.876 |
| 5 | 0.841 | 0.513 | 0.784 | 0.170 | 0.860 | |
| 10 | 0.937 | 0.553 | 0.843 | 0.089 | 0.843 | |
| M-A fit | ktransit | 0.799 | 0.514 | 0.693 | 0.028 | 0.873 |
| RAE | 16 | 0.680 | 0.475 | 0.502 | 0.125 | 0.895 |
| VRAE | 16 | 0.688 | 0.484 | 0.594 | 0.068 | 0.901 |
| S-VRAE | 16 | 0.724 | 0.489 | 0.611 | 0.064 | 0.898 |
| Representation | Pcorr | Pcorr-A | MI | N-MI |
|---|---|---|---|---|
| Metadata | ||||
| (Raw) F-PCA | ||||
| (Fold) F-PCA | ||||
| RAE | ||||
| VRAE | ||||
| S-VRAE |
| Representation | Input | Non-Exoplanet | Exoplanet | Global | ||||
|---|---|---|---|---|---|---|---|---|
| Dim | P | R | P | R | -Ma | |||
| Metadata | 10 | |||||||
| Global-Folded | T | |||||||
| Unsupervised Methods | ||||||||
| (Raw) F-PCA | 16 | |||||||
| (Fold) F-PCA | 16 | |||||||
| RAE | 16 | |||||||
| VRAE | 16 | |||||||
| S-VRAE | 16 | |||||||
| Supervised Methods | ||||||||
| RNN | T | |||||||
| 1D CNN | T | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mena, F.; Olivares, P.; Bugueño, M.; Molina, G.; Araya, M. On the Quality of Deep Representations for Kepler Light Curves Using Variational Auto-Encoders. Signals 2021, 2, 706-728. https://doi.org/10.3390/signals2040042
Mena F, Olivares P, Bugueño M, Molina G, Araya M. On the Quality of Deep Representations for Kepler Light Curves Using Variational Auto-Encoders. Signals. 2021; 2(4):706-728. https://doi.org/10.3390/signals2040042
Chicago/Turabian StyleMena, Francisco, Patricio Olivares, Margarita Bugueño, Gabriel Molina, and Mauricio Araya. 2021. "On the Quality of Deep Representations for Kepler Light Curves Using Variational Auto-Encoders" Signals 2, no. 4: 706-728. https://doi.org/10.3390/signals2040042
APA StyleMena, F., Olivares, P., Bugueño, M., Molina, G., & Araya, M. (2021). On the Quality of Deep Representations for Kepler Light Curves Using Variational Auto-Encoders. Signals, 2(4), 706-728. https://doi.org/10.3390/signals2040042