

Speech Intelligibility in Virtual Avatars: Comparison Between Audio and Audio–Visual-Driven Facial Animation



Abstract
1. Introduction
2. Materials
2.1. Virtual Scene and Avatar Creation
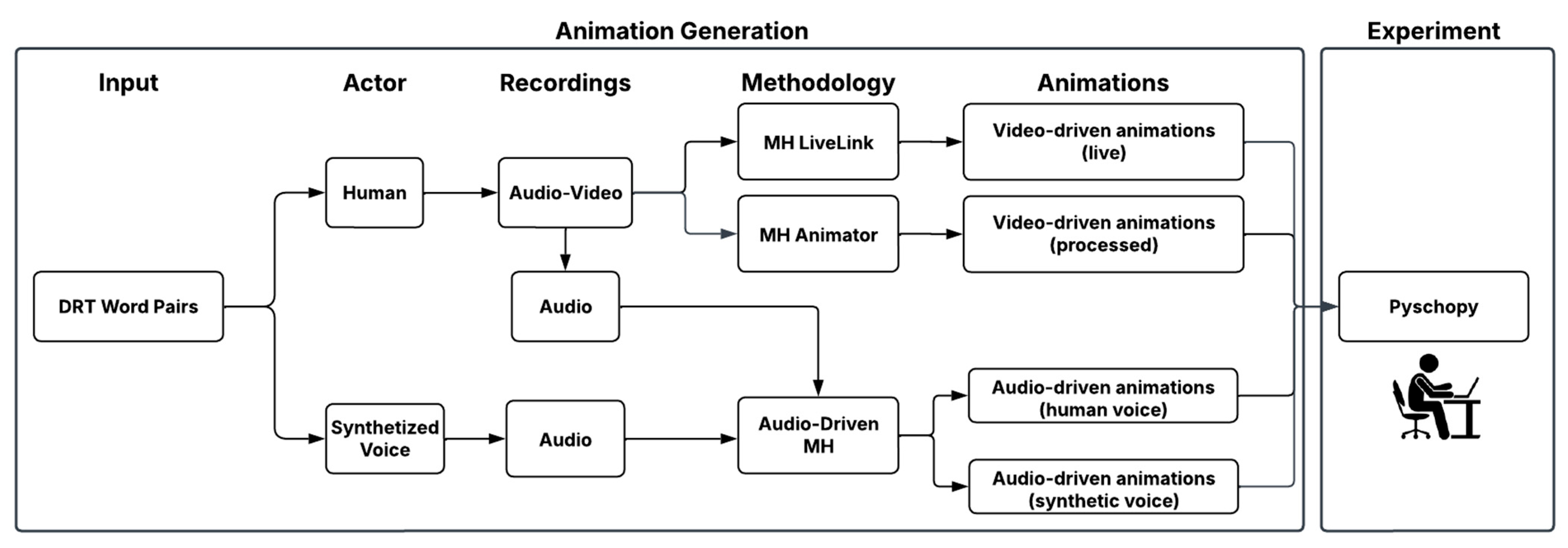
2.2. Audio and Visual Stimuli Acquisition
- Audio apparatus: A Rode NTG2 microphone connected to a Zoom H5 recorder was used for audio capture;
- Video apparatus: An iPhone 14 Pro was used as the camera for video capture by means of the LiveLink app. The LiveLink app was used for (A) live-streaming face captures on the MetaHuman and (B) recording and extracting videos from the actor’ s face captures to be further processed and attached onto the MetaHuman in Unreal Engine (see Figure 1).
- MetaHuman LiveLink (MHLL): The actor’s performances are captured through the LiveLink App and live streamed directly onto the MetaHuman as the acquisition process went on. While streaming, the captures were also saved as videos;
- MetaHuman Animator (MHA): The actor’s performance captured through the LiveLink App is saved as MetaHuman performance files. Unlike the first methodology, these are not live streamed but imported into Unreal Engine, where they are processed using the MetaHuman Animator plugin. This plugin tracks facial landmarks such as where the key points of the actor’s face—such as the eyes, eyebrows, nose, mouth, and jaw—are detected and translated into animation data. These data are then converted into animation curves, which drive the MetaHuman’s control rig. Once attached onto the MetaHuman, all the acquisitions are saved as video files;
- Audio-Driven Animation for MetaHuman (ADMH): From the MetaHuman performance files, only the audio from the human actor performance is extracted and used to create facial animations through the Audio-Driven Animation for MetaHuman plugin. This feature allows for the processing of only audio files into realistic facial animations. Once attached to the MetaHuman, all the acquisitions are saved as video files;
- Synthetic Audio-Driven Animation for MetaHuman (SADMH): For this condition, first a 1-minute-long speech audio file from the same human actor was fed into the software ElevenLabs (Eleven Turbo 2.5) [30] to clone his voice with AI technology. Once the voice cloning was complete, the written form of the stimuli, carrier phrase, and target word were uploaded in ElevenLabs to obtain the synthesized voice version of the stimuli. Finally, the obtained stimulus audio files with synthesis were used in the abovementioned Audio-Driven Animation for MetaHuman plugin for the last animation methodology.
3. Methodology
3.1. Participants
3.2. Procedure
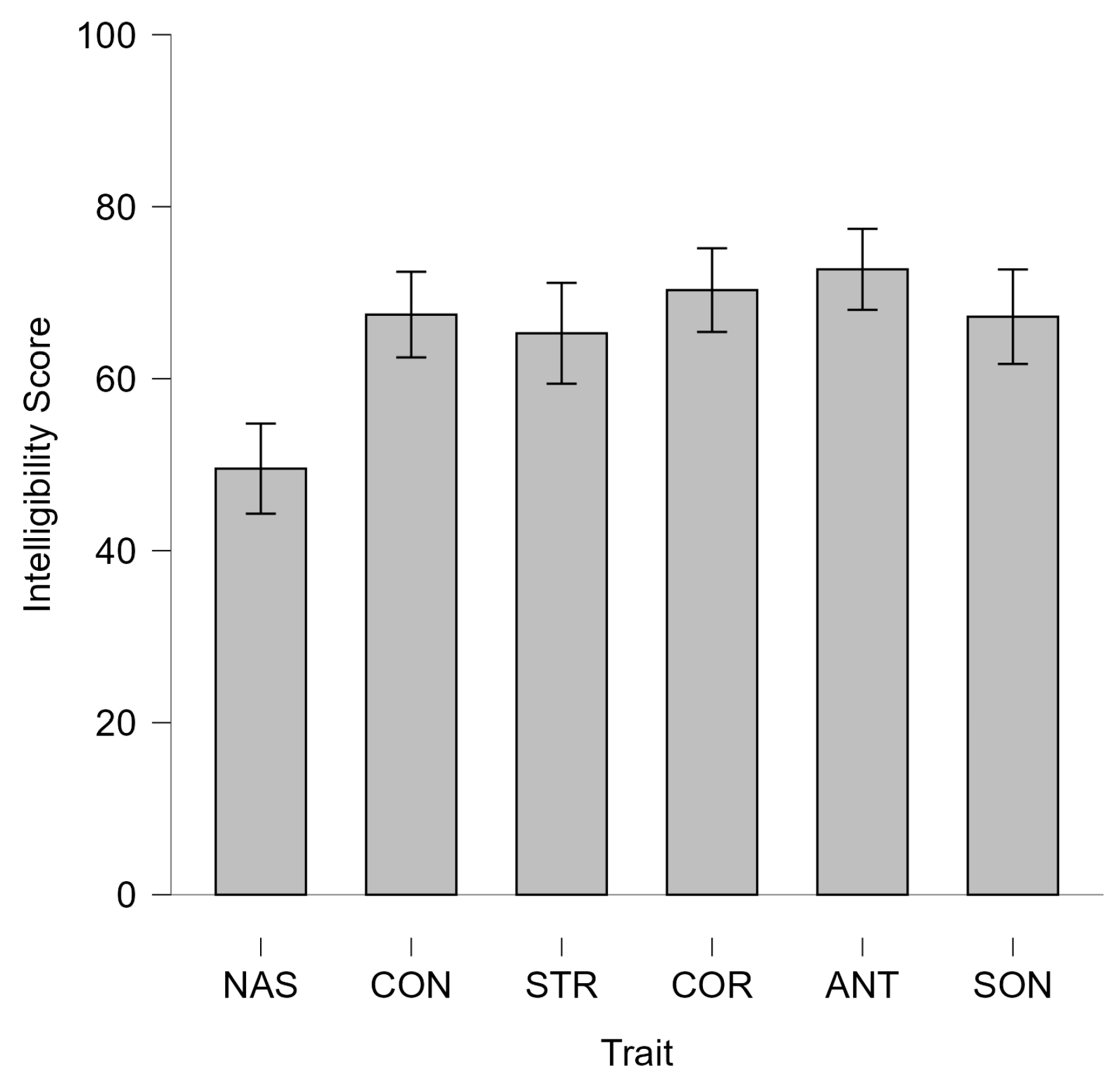
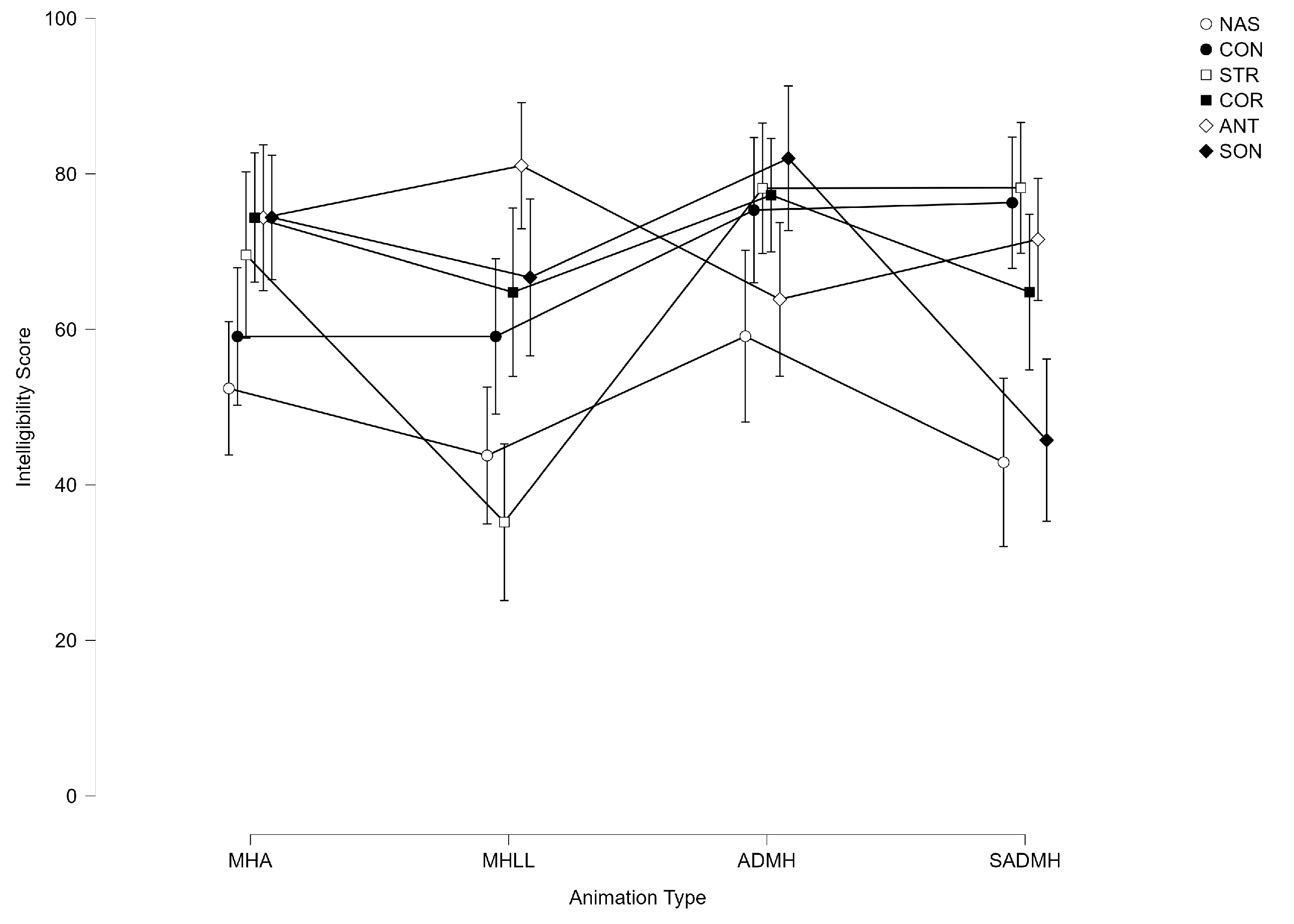
4. Results
- S = “Score”;
- W = Wrong answers;
- T = Total number of answers.
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bernstein, L.E.; Auer, E.T., Jr.; Takayanagi, S. Auditory speech detection in noise enhanced by lipreading. Speech Commun. 2004, 44, 5–18. [Google Scholar] [CrossRef]
- Ma, W.J.; Zhou, X.; Ross, L.A.; Foxe, J.J.; Parra, L.C. Lip-reading aids word recognition most in moderate noise: A Bayesian explanation using high-dimensional feature space. PLoS ONE 2009, 4, e4638. [Google Scholar] [CrossRef]
- Okada, K.; Matchin, W.; Hickok, G. Neural evidence for predictive coding in auditory cortex during speech production. Psychon. Bull. Rev. 2018, 25, 423–430. [Google Scholar] [CrossRef] [PubMed]
- Chandrasekaran, C.; Lemus, L.; Ghazanfar, A.A. Dynamic faces speed up the onset of auditory cortical spiking responses during vocal detection. Proc. Natl. Acad. Sci. USA 2013, 110, E4668–E4677. [Google Scholar] [CrossRef]
- McGurk, H.; MacDonald, J. Hearing lips and seeing voices. Nature 1976, 264, 746–748. [Google Scholar] [CrossRef] [PubMed]
- Anderson Gosselin, P.; Gagné, J.P. Older adults expend more listening effort than young adults recognizing speech in noise. J. Speech Lang. Hear. Res. 2011, 54, 944–958. [Google Scholar] [CrossRef]
- Tristán-Hernández, E.; Pavón García, I.; López Navarro, J.M.; Campos-Cantón, I.; Kolosovas-Machuca, E.S. Evaluation of psychoacoustic annoyance and perception of noise annoyance inside university facilities. Int. J. Acoust. Vib. 2018, 23, 3–8. [Google Scholar] [CrossRef]
- Lamotte, A.-S.; Essadek, A.; Shadili, G.; Perez, J.-M.; Raft, J. The impact of classroom chatter noise on comprehension: A systematic review. Percept. Mot. Skills 2021, 128, 1275–1291. [Google Scholar] [CrossRef]
- Hodgson, M.; Rempel, R.; Kennedy, S. Measurement and prediction of typical speech and background-noise levels in university classrooms during lectures. J. Acoust. Soc. Am. 1999, 105, 226–233. [Google Scholar] [CrossRef]
- Choudhary, Z.D.; Bruder, G.; Welch, G.F. Visual facial enhancements can significantly improve speech perception in the presence of noise. IEEE Trans. Vis. Comput. Graph. 2023, 29, 4751–4760. [Google Scholar] [CrossRef]
- Guastamacchia, A.; Riente, F.; Shtrepi, L.; Puglisi, G.E.; Pellerey, F.; Astolfi, A. Speech intelligibility in reverberation based on audio-visual scenes recordings reproduced in a 3D virtual environment. Build. Environ. 2024, 258, 111554. [Google Scholar] [CrossRef]
- Visentin, C.; Prodi, N.; Cappelletti, F.; Torresin, S.; Gasparella, A. Speech intelligibility and listening effort in university classrooms for native and non-native Italian listeners. Build. Acoust. 2019, 26, 275–291. [Google Scholar] [CrossRef]
- Hirata, Y.; Kelly, S.D. Effects of lips and hands on auditory learning of second language speech sounds. J. Speech Lang. Hear. Res. 2010, 53, 298–310. [Google Scholar] [CrossRef]
- Buechel, L.L. Lip syncs: Speaking… with a twist. In English Teaching Forum; ERIC: Manhattan, MY, USA, 2019; Volume 57, pp. 46–52. [Google Scholar]
- Pelachaud, C.; Caldognetto, E.M.; Zmarich, C.; Cosi, P. Modelling an Italian talking head. In Proceedings of the AVSP 2001 International Conference on Auditory-Visual Speech Processin Processing, Scheelsminde, Denmark, 7–9 September 2001; pp. 72–77. [Google Scholar]
- Lv, C.; Wu, Z.; Wang, X.; Zhou, M. 3D facial expression modeling based on facial landmarks in single image. Neurocomputing 2019, 355, 155–167. [Google Scholar] [CrossRef]
- Ling, J.; Wang, Z.; Lu, M.; Wang, Q.; Qian, C.; Xu, F. Semantically disentangled variational autoencoder for modeling 3D facial details. IEEE Trans. Vis. Comput. Graph. 2022, 29, 3630–3641. [Google Scholar] [CrossRef]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Fan, Y.; Tao, J.; Yi, J.; Wang, W.; Komura, T. FaceFormer: Speech-driven 3D facial animation with transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Ward, W.; Cole, R.; Bolaños, D.; Buchenroth-Martin, C.; Svirsky, E.; Weston, T. My science tutor: A conversational multimedia virtual tutor. J. Educ. Psychol. 2013, 105, 1115. [Google Scholar] [CrossRef]
- Peng, X.; Chen, H.; Wang, L.; Wang, H. Evaluating a 3-D virtual talking head on pronunciation learning. Int. J. Hum.-Comput. Stud. 2018, 109, 26–40. [Google Scholar] [CrossRef]
- Devesse, A.; Dudek, A.; van Wieringen, A.; Wouters, J. Speech intelligibility of virtual humans. Int. J. Audiol. 2018, 57, 914–922. [Google Scholar] [CrossRef]
- Schiller, I.S.; Breuer, C.; Aspöck, L.; Ehret, J.; Bönsch, A.; Kuhlen, T.W.; Schlittmeier, S.J. A lecturer’s voice quality and its effect on memory, listening effort, and perception in a VR environment. Sci. Rep. 2024, 14, 12407. [Google Scholar] [CrossRef]
- International Epic Games. Epic Games Metahuman Creator. Available online: https://metahuman.unrealengine.com (accessed on 21 October 2024).
- Alkawaz, M.H.; Mohamad, D.; Basori, A.H.; Saba, T. Blend shape interpolation and FACS for realistic avatar. 3D Res. 2015, 6, 6. [Google Scholar] [CrossRef]
- Purushothaman, R. Morph animation and facial rigging. In Character Rigging and Advanced Animation: Bring Your Character to Life Using Autodesk 3ds Max; Apress: New York, NY, USA, 2019; pp. 243–274. [Google Scholar]
- Bonaventura, P.; Paoloni, A.; Canavesio, F.; Usai, P. Realizzazione di un Test Diagnostico di Intelligibilità per la Lingua Italiana; Fondazione Ugo Bordoni: Roma, Italy, 1986. [Google Scholar]
- Astolfi, A.; Bottalico, P.; Barbato, G. Subjective and objective speech intelligibility investigations in primary school classrooms. J. Acoust. Soc. Am. 2012, 131, 247. [Google Scholar] [CrossRef] [PubMed]
- Prodi, N.; Visentin, C.; Farnetani, A. Intelligibility, listening difficulty and listening efficiency in auralized classrooms. J. Acoust. Soc. Am. 2010, 128, 172–181. [Google Scholar] [CrossRef] [PubMed]
- ElevenLabs. ElevenLabs: AI Text-to-Speech Platform. Available online: https://elevenlabs.io (accessed on 15 November 2024).
- ISO 9921:2003; Ergonomics—Assessment of Speech Communication. International Organization for Standardization: Geneva, Switzerland, 2003.
- Peirce, J.W.; Gray, J.R.; Simpson, S.; MacAskill, M.R.; Höchenberger, R.; Sogo, H.; Kastman, E.; Lindeløv, J. PsychoPy2: Experiments in behavior made easy. Behav. Res. Methods 2019, 51, 195–203. [Google Scholar] [CrossRef]
- Maffei, L.; Masullo, M. Sens i-Lab: A key facility to expand the traditional approaches in experimental acoustics. In INTER-NOISE and NOISE-CON Congress and Conference; Institute of Noise Control Engineering: Grand Rapids, MI, USA, 2023. [Google Scholar]
- Grasso, C.; Quaglia, D.; Farinetti, L.; Fiorio, G.; De Martin, J.C. Wide-band compensation of presbycusis. In Signal Processing, Pattern Recognition and Applications; ACTA Press: Calgary, AB, Canada, 2003. [Google Scholar]
- Kondo, K. Estimation of speech intelligibility using objective measures. Appl. Acoust. 2013, 74, 63–70. [Google Scholar] [CrossRef]
- Peixoto, B.; Melo, M.; Cabral, L.; Bessa, M. Evaluation of animation and lip-sync of avatars, and user interaction in immersive virtual reality learning environments. In Proceedings of the 2021 International Conference on Graphics and Interaction (ICGI), Porto, Portugal, 4–5 November 2021; IEEE: New York, NY, USA, 2021; pp. 1–7. [Google Scholar]
- Makransky, G.; Terkildsen, T.S.; Mayer, R.E. Adding immersive virtual reality to a science lab simulation causes more presence but less learning. Learn. Instr. 2019, 60, 225–236. [Google Scholar] [CrossRef]
- Mori, M.; MacDorman, K.F.; Kageki, N. The uncanny valley [From the Field]. IEEE Robot. Autom. Mag. 2012, 19, 98–100. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trait | Description | Example |
|---|---|---|
| Nasalità | Whether the air flows through the nasal cavity. | Nido/Lido |
| Continuità | Whether the air flows through the oral cavity in a prolonged way over time. | Riso/Liso |
| Stridulità | Whether airflow passes through a small slit between two very close surfaces. | Cina/China |
| Anteriorità | Whether the alveolar region is obstructed. | Nesso/Messo |
| Coronalità | Whether the coronal part of the tongue is raised compared to its resting position. | Sisma/Scisma |
| Sonorità | Whether vocal cords are close together and therefore vibrate due to the airflow during sound production. | Vino/Fino |
| Cases | Sum of Squares | df | Mean Square | F | p | η2p |
|---|---|---|---|---|---|---|
| Animation Type | 2.460 | 3 | 0.820 | 11.287 | <0.001 | 0.249 |
| Residuals | 7.500 | 102 | 0.074 | |||
| Trait | 4.952 | 5 | 0.990 | 10.665 | <0.001 | 0.239 |
| Residuals | 15.391 | 170 | 0.091 | |||
| Animation Type × Trait | 7.584 | 15 | 0.506 | 6.828 | <0.001 | 0.167 |
| Residuals | 38.248 | 510 | 0.075 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cioffi, F.; Masullo, M.; Pascale, A.; Maffei, L. Speech Intelligibility in Virtual Avatars: Comparison Between Audio and Audio–Visual-Driven Facial Animation. Acoustics 2025, 7, 30. https://doi.org/10.3390/acoustics7020030
Cioffi F, Masullo M, Pascale A, Maffei L. Speech Intelligibility in Virtual Avatars: Comparison Between Audio and Audio–Visual-Driven Facial Animation. Acoustics. 2025; 7(2):30. https://doi.org/10.3390/acoustics7020030
Chicago/Turabian StyleCioffi, Federico, Massimiliano Masullo, Aniello Pascale, and Luigi Maffei. 2025. "Speech Intelligibility in Virtual Avatars: Comparison Between Audio and Audio–Visual-Driven Facial Animation" Acoustics 7, no. 2: 30. https://doi.org/10.3390/acoustics7020030
APA StyleCioffi, F., Masullo, M., Pascale, A., & Maffei, L. (2025). Speech Intelligibility in Virtual Avatars: Comparison Between Audio and Audio–Visual-Driven Facial Animation. Acoustics, 7(2), 30. https://doi.org/10.3390/acoustics7020030