1. Introduction
Pronunciation is pivotal for language acquisition and effective communication. However, it often receives insufficient attention in second language (L2) education, leading to persistent challenges for learners in achieving clarity. Technology, particularly Computer-Assisted Language Learning (CALL) has emerged as a significant aid in supporting L2 pronunciation development across formal and informal learning environments [
1]. Recent advancements in deep learning offer promising avenues for enhancing language learning by providing unlimited targeted and immediate feedback, addressing the class time and size limitations preventing educators from differentiating their pedagogy on such an individual skill.
To improve pronunciation, integrating speech processing technologies with traditional teaching methods can provide a comprehensive approach to language learning. One fundamental task in this domain is text-independent phone-to-audio alignment, a process that involves aligning phonetic representations with corresponding audio signals without relying on pre-determined text. This task is essential for accurately mapping the phonemes to their acoustic representations, contributing to the development of precise and effective speech processing technologies in language learning [
2,
3,
4]. Text-independent phone-to-audio alignment faces a significant challenge due to the difficulty in obtaining extensive and well-annotated datasets. A possible solution to this challenge entails using established systems (like text-dependent phone-to-audio alignment systems) to extract temporal information from publicly available speech datasets. This approach can be refined through the application of transfer learning and self-supervised learning methodologies in the development of a solution.
Transfer learning [
5] is a method within the field of deep learning. Its approach involves pre-training a model on a large dataset and subsequently fine-tuning it on a smaller dataset tailored to the specific task. This methodology has demonstrated considerable success across various domains, particularly in the context of self-supervised learning.
In self-supervised learning [
6], a model is trained to autonomously learn representations of input data without the need for explicit supervision. This proves particularly advantageous when labeled data are either limited or entirely unavailable. Within the field of speech technology, the application of self-supervised learning through transfer learning has proven invaluable in addressing several complex scenarios. For example, in Automatic Speech Recognition (ASR) for low-resource languages [
7], where annotated data may be scarce, transfer learning allows for the utilization of pre-trained models on more data-abundant languages, adapting them effectively to the target language. Likewise, the same method is applied in emotional or expressive speech synthesis [
8,
9,
10], speech emotion recognition [
11], voice conversion [
12], and pronunciation assessment [
13].
In this paper, we take full advantage of state-of-the-art methodologies in deep learning, self-supervised learning, and phonetic representation to present a novel approach to text-independent phone-to-audio alignment. Most state-of-the-art self-supervised systems perform well on American English, which means that other varieties of English are penalized and the model is biased towards American English. The rationale to develop the system proposed in this paper was the pedagogical needs to create a system that performs equally well on other variants of English as it does on American English. For our system, we use the self-supervised model Wav2Vec2, fine-tuned for phoneme recognition using CTC loss. We integrate this with a dimensional reduction model based on Principal Component Analysis (PCA) and a frame-level phoneme classifier. The resulting model pipeline produces a vector of probabilities for every audio frame. From the same model, we also extract predicted phonemes and their boundaries and hence use this information for a text-independent phone alignment system.
The major contributions of this paper are as follows: First, we propose a text-independent phoneme alignment system using self-supervised learning. This not only advances the state-of-the-art in this specific task but also opens avenues for broader applications in language learning and speech processing systems. Second, this system functions effectively with diverse English language variations (such as British English) and is capable of accommodating various languages, making it language-independent.
Herein, we discuss the related work, categorized into the subsections Phone-to-Audio Alignment, Phoneme Recognition, and Systems Predicting Phones and Boundaries.
1.1. Phone-to-Audio Alignment
Text-independent phone-to-audio alignment involves predicting a sequence of phones and their temporal locations within speech signals without prior linguistic information, such as a known text or phone sequence.
In contrast, text-dependent phone-to-audio alignment utilizes text information to align a phone sequence generated from a grapheme-to-phoneme model applied to textual inputs. Hidden Markov Models (HMMs) have traditionally played a prominent role in aligning phonetic and temporal information, including but not limited to Kaldi [
14] and HTK [
15]. Forced alignment systems using HMMs include Gentle (
https://github.com/lowerquality/gentle, accessed on 15 August 2024) and ProsodyLab [
16]. However, such models face limitations when attempting to predict both phones and phone boundaries simultaneously. The challenges for HMMs become apparent when confronted with long-range dependencies within a sequence. However, they struggle to effectively capture and understand the broader context of a word within a sentence. As a result, this hinders their ability to grasp nuanced linguistic relationships and context. Another reason why HMMs may not perform well is due to the incorrect phonetic transcriptions due to variations in conversational speech.
Recent developments have witnessed a shift towards deep learning models like Recurrent Neural Networks (RNNs) [
17] and models trained with CTC loss [
18] for phoneme recognition. This shift towards deep learning models allows us to efficiently predict both phones and phone boundaries simultaneously.
1.2. Phoneme Recognition
Deep learning models are known for their ability to capture complex patterns in data and are frequently employed for phoneme recognition. CTC loss is a popular training criterion for such models in this context. It allows the model to learn the alignment between the input speech signal and the corresponding phoneme sequence, even when the temporal correspondence is not provided during training. Wav2Vec2 [
19,
20] stands out as a self-supervised model that has been fine-tuned specifically for phoneme recognition using the CTC loss.
One of the advantages of the Wav2Vec2 approach is its ability to generate multi-lingual phonetic representations. By leveraging self-supervised learning during pre-training, the model learns to extract robust features from speech signals, capturing phonetic information that is broadly applicable across different languages. Furthermore, the fine-tuning process with CTC loss refines the model’s ability to map these learned representations to specific phoneme sequences.
1.3. Systems Predicting Phones and Boundaries
Charsiu [
21] is recognized for its unique capability to predict both phones and phone boundaries. This integrated approach contributes to a more comprehensive understanding of the speech signal.
While HMMs coupled with Gaussian Mixture Models (GMMs) can perform similar tasks, they are primarily employed for forced-alignment tasks in text-dependent scenarios. Kaldi, for instance, employs HMM-GMM systems that typically begin with feature extraction using Mel-Frequency Cepstral Coefficients (MFCCs) or Perceptual Linear Predictive (PLP) features. These features are then used to train an acoustic model where each HMM state is modeled by a GMM. The process involves initial alignment with a monophone model, iterative refinement, and the eventual training of context-dependent triphone models. However, HMM-GMM systems in Kaldi often fall short in terms of precision and flexibility compared to more modern approaches.
Charsiu surpasses these traditional HMM-GMM methods by providing significantly higher accuracy in predicting phone boundaries. This is largely due to its ability to integrate phone and boundary prediction into a single, cohesive model, reducing errors that might arise from the separate stages of alignment and recognition in HMM-GMM systems. Charsiu’s end-to-end architecture allows for more precise alignment, making it a superior choice for tasks requiring high accuracy.
Therefore, in this paper, we conduct a comparative analysis between our proposed model and the text-independent aspect of the charsiu model, recognized as the state-of-the-art for this task. Our methodology, detailed in the following section, combines self-supervised learning with phoneme recognition.
2. Materials and Methods
2.1. Our Proposed Method
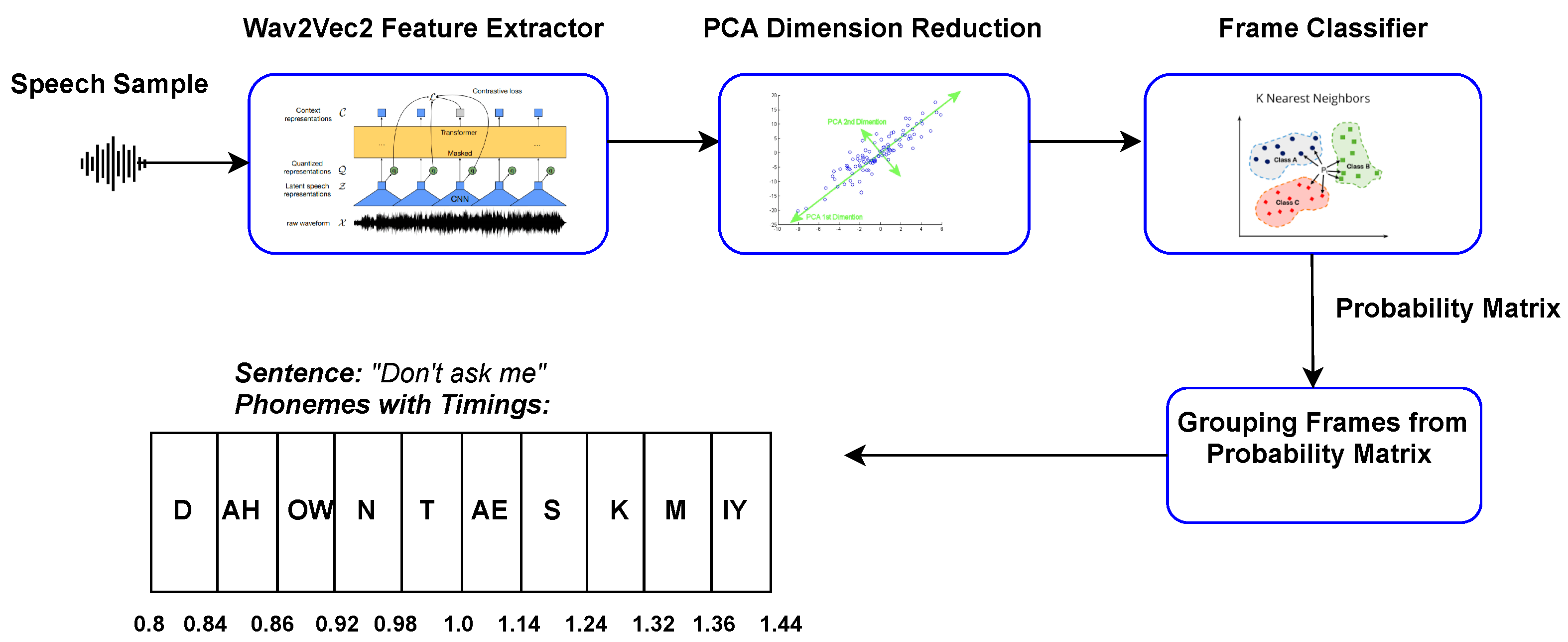
Our proposed method is an innovative approach, using Wav2Vec2, Principal Component Analysis (PCA) for dimensional reduction, and frame-level phoneme classification, and offers a robust text-independent phone-to-audio alignment. The system is explained in detail in
Section 2.3 and the system’s architecture is depicted in
Figure 1. The model’s robustness is demonstrated through evaluation, using the TIMIT [
22] and SCRIBE (
https://www.phon.ucl.ac.uk/resource/scribe/, accessed on 15 August 2024) dataset. Thanks to its versatility, we expect that our method will find applications in language learning and speech processing systems.
2.2. Pre-Trained Self-Supervised Model
The basis of this model is a self-supervised model (Wav2Vec2) trained to extract latent representations from the audio data. The Wav2Vec2 model is trained on a large dataset of unlabeled speech data, using a contrastive predictive coding loss function to learn a representation that is capable of predicting future audio frames and can then be utilized for downstream tasks. The pre-training loss is defined as [
23]:
where
is the contrastive loss,
is diversity loss, and
is the hypertuned parameter.
In the above equation, k represents the fixed temperature and sim signifies the cosine similarity between context representations and quantized latent speech representations. The term resembles the Softmax function, but it employs cosine similarity instead of a score. For ease of optimization, the negative logarithm of the fraction is also applied. is the context network output centered over masked time step t, and is the true quantized latent speech representation.
In this paper, we use the version of the model pre-trained on cross-lingual speech data (53 different languages) [
19] that were then fine-tuned [
20] for the task of phoneme sequence prediction using a CTC loss, and the result is an open-source model (
https://huggingface.co/facebook/Wav2Vec2-xlsr-53-espeak-cv-ft, accessed on 15 August 2024).
The model itself thus predicts sequences of phoneme labels, but no phone boundaries. What we propose in the following sections is an approach for leveraging the learned cross-lingual speech representations of this model that were already oriented to a phonetic space thanks to the CTC fine-tuning. The goal of this approach is to only require a limited amount of data and to be less biased towards the American English accent compared to existing models.
2.3. Data Processing and Knowledge Transfer
From
Section 2.2, we assume that the complex sequential relationships are handled by the Wav2Vec2 model and give us a well-structured phonetic space, robust to accent variation. The pre-trained model is used for extracting a latent representation of phones, but not phones directly. If we used the phones from the pre-trained model, we would be forced to use the IPA symbols used originally. Since the phoneme-sequence fine-tuned model was trained on IPA symbols generated by “eSpeak” (
https://github.com/espeak-ng/espeak-ng, accessed on 15 August 2024), this is problematic because the eSpeak set of phones is not always consistent (e.g., in terms of exclusivity between phones).
Instead, we use the last hidden layer before classification heads as our speech representations. We thus apply a classical model selection procedure in order to tackle the problem of frame classification. We experiment with a set of mainstream classifiers using scikit-learn implementations (
https://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html, accessed on 15 August 2024). The best performance we obtained were with K-Nearest Neighbors (KNNs) with 10 neighbours, after a dimensional reduction with PCA.
Based on the representations that we can extract from the model explained in the previous section, we used PCA to reduce dimensionality while retaining most of the variance in the data.
Experimenting without PCA and with varying levels of variance retention (99%, 95%, and 90%), we determined that retaining 95% offers the most favorable compromise in terms of classification results. We hypothesized that this choice may serve as a means of noise filtration and provided a more manageable space for classifiers to process effectively. To train this dimension reduction model and the subsequent frame classifier model, we used the MAILABS [
24] dataset which is a large dataset of speech data, containing recordings from various languages and accents to train our reducer and classifier. We used the American and British English datasets from MAILABS.
We used Montreal Forced Aligner (MFA) [
25] to generate ground truth phone alignments on MAILABS data that do not have timing information but only speech and text. We used MFA as it is able to extract phone boundaries when speech and text are provided (i.e., in a text-dependent manner). MFA has many models in different languages, and also has a British and an American acoustic model. Our approach can thus use knowledge extracted by this system for fast adaptation and build a system that is able to extract phones and phone boundaries only from audio, while being robust to a variability of accents.
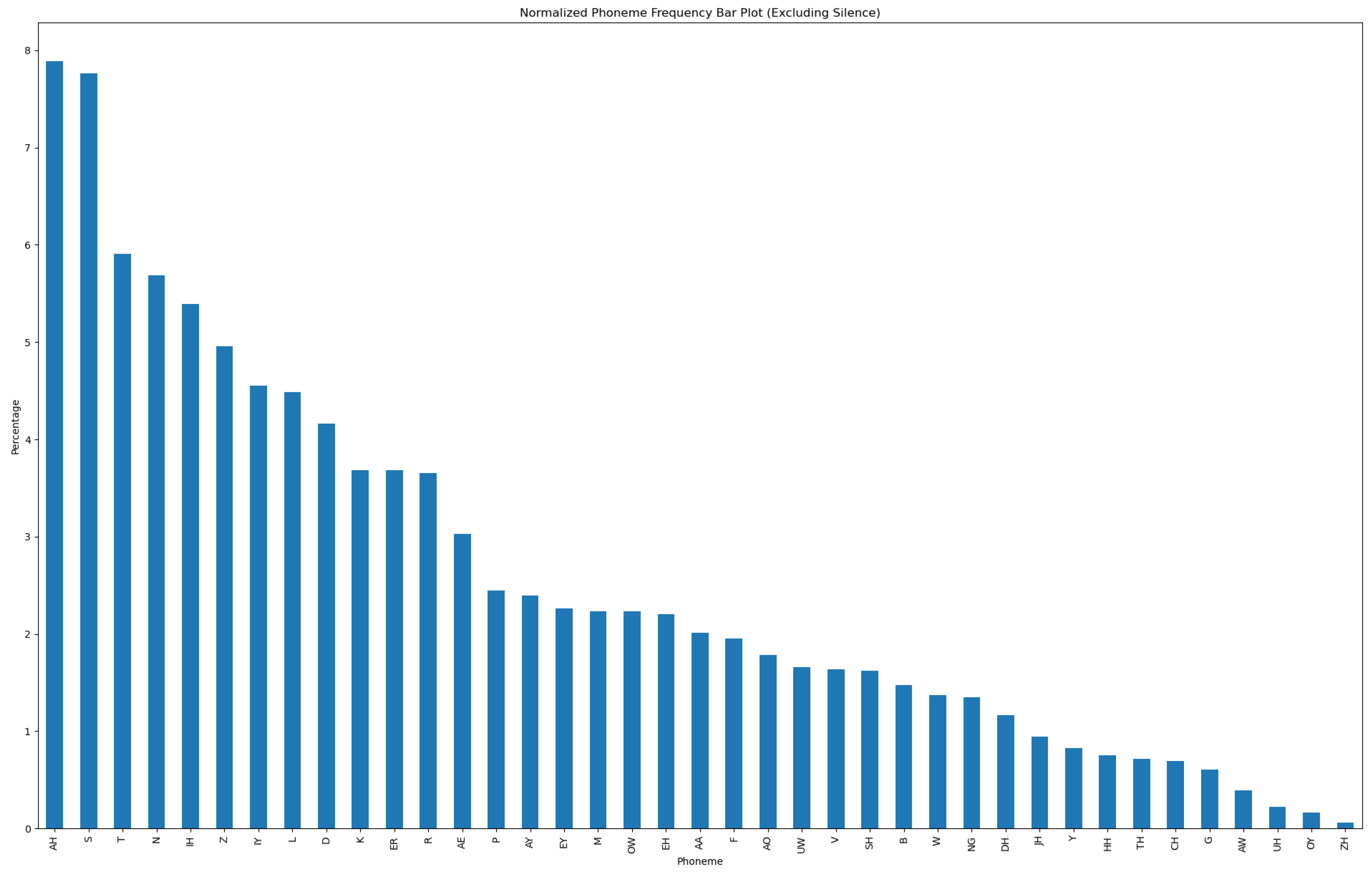
We worked at the frame level for training the shallow dimension reduction and classifier models. As we observe from
Figure 2, the frequency of phonemes in natural languages is not uniform. Hence, it is essential to perform data balancing on the data extracted from MAILABS for unbiased training. To perform data balancing, we randomly selected an equal number of latent frames in order to have a balanced set of labeled latent frames for every phoneme.
Silence is treated as a special phone class. During training and alignment, silent models are incorporated to accurately segment and recognize non-speech segments within the audio. This is consistent with [
21] in order to have fair comparisons.
The frame classifier produces a probability matrix, with each row representing a frame and its corresponding predicted probability for a phoneme. We selected the phoneme which has the maximum posterior probability for each frame. Subsequently, consecutive frames with identical phonemes were grouped together and the start and end timings of each group were computed using frame indices and timestamps. To filter noise, we applied a threshold of 0.5 over the probabilities to remove phonemes that have less than the threshold value. After this step, we merged the consecutive groups to obtain the final timings of the audio sequence.
Our proposed approach, which integrates a reduction model with a classifier model, can adeptly model intricate relationships stemming from the speech representation learning model. The task of mapping between these learned representations and phonetic units is efficiently managed by a compact and effective model. This ensures our ability to comprehend the complex relationships within the data while maintaining computational efficiency.
3. Results
In this section, we describe the experiments conducted to evaluate the performance of our proposed phone-to-audio alignment model.
As explained in
Section 2, our approach aims at leveraging the phoneme representations from a model that was first pre-trained on many different languages and therefore with a great variety of phones. This first phase was carried out with large unannotated speech datasets.
What we aim to demonstrate in these experiments is that the additional modules are able to take advantage of this, leading to a low-cost and low-resource adaptation technique robust to varying accents. We also want to highlight that this two-step procedure enables us to re-balance phonetic content at the frame classification step.
We thus would not expect to have better performances by adding the new modules on top of charsiu variants, since the limitations in terms of bias and phonetic variability come from the training procedure.
3.1. Text-Independent Phone-to-Audio Alignment on TIMIT
In evaluating the performance of our text-independent phone-to-audio alignment model, we conducted a comprehensive comparison with the state-of-the-art model: charsiu [
21]. In the charsiu model, the authors compare two systems: text-independent phone-to-audio alignment and text-dependent phone-to-audio alignment using Wav2Vec2. The Wav2Vec2-FS is a semi-supervised model which learns alignment using contrastive learning and a forward sum loss. The second model, Wav2Vec2-FC, is a frame classification model trained on labels for forced alignment, capable of both forced alignment and text-independent segmentation. The evaluation of both the systems for charsiu has been performed on the TIMIT dataset. It has been used for this evaluation because of the availability of human annotations, especially at the phoneme level. We use a similar approach to evaluate the same metrics for our model. The assessment is based on statistical measures, namely precision, recall, F1 score, and r-value. In the referenced work, the authors present their best-performing model, W2V2-FC-32k-Libris, as can be observed in
Table 1.
In our case, for the task of phoneme recognition, we compare our model with the text-independent W2V2-FC-10 ms charsiu model. The statistical metrics for our proposed model outperform that of the charsiu model. We compare the TIMIT test dataset to assess our model and we observe from
Table 1 that the r-value for our model deteriorates in performance. Apart from r-value, all the other metrics (precision, recall, and F1 value) have shown to perform well for our model.
The tests for our model were also performed on the TIMIT dataset but have the possibility to extend to other datasets with real speech and also other languages.
The r-value, which is known as the Pearson correlation coefficient, measures the similarity between the ground truth phonemes and the predicted phonemes. Some of the reasons for low r-value could be alignment errors, variability in the pronunciation of speakers, or changes in speaking style within the dataset. However, we need more experiments to confirm this hypothesis.
3.2. Text-Independent Phone-to-Audio Alignment on SCRIBE
A second part of the experiments in our proposed model is to evaluate it on British English.
The SCRIBE (
https://www.phon.ucl.ac.uk/resource/scribe/, accessed on 15 August 2024) dataset is a small corpus of read speech and spontaneous speech specializing in British English. It consists of 200 ‘phonetically rich’ sentences and 460 ‘phonetically compact’ sentences. The ‘phonetically rich’ sentences are phonetically balanced. The ‘phonetically compact’ sentences are based on a British version of the MIT compact sentences (as in TIMIT). There are 45 files in the dataset of 30–50 s containing 5–10 sentences.
The audio files and the phoneme annotations needed some processing before we could start using the dataset. The phonemes are in SAMPA form and needed to be converted to the English ARPABET. Even after the conversion from SAMPA to ARPABET, there were symbols that we could not retrieve, so we filtered them out.
We evaluated the charsiu model and our proposed model using SCRIBE and achieved the metrics that are depicted in
Table 2.
Upon close examination of the results presented in
Table 2, it becomes evident that the metrics associated with our proposed model exhibit a greater uniformity in values when compared to charsiu. Furthermore, these metrics generally surpass those of charsiu, albeit with the exception of precision. The uniformity observed in our model’s metrics can be attributed to the utilization of a more balanced reduced-frame dataset during training, which serves to mitigate biases and yield more consistent outcomes. Moreover, the superior quality of audio files within the SCRIBE dataset, resembling professional studio recordings with minimal noise, likely contributes to the heightened metrics observed for both charsiu and our proposed model when contrasted with the TIMIT dataset.
Consequently, our system demonstrates enhanced generalization across various accents, laying the foundation for potential expansion to other languages. The key lies in leveraging the underlying Wav2Vec2 XLSR framework, and the methodology employed with MAILABS can seamlessly be replicated with different datasets, opening avenues for utilizing non-native English accents and broader linguistic applications.
4. Conclusions
In this paper, we introduced an innovative text-independent phone alignment system designed to be language-independent. Our method harnesses a self-supervised model (Wav2Vec2) fine-tuned for phoneme recognition through a CTC loss, alongside a dimensional reduction model (PCA) and a frame-level phoneme classifier. Through experiments using native data with varying accents, we assessed our model’s performance on both American and British English, benchmarking it against the state-of-the-art charsiu model. Encouragingly, our results demonstrate robustness and applicability to diverse accents, such as British English.
However, certain limitations are acknowledged. Firstly, the reducer and classifier have been trained on a restricted amount of data specific to native English, posing a constraint. Secondly, our model relies on forced-aligned datasets of native speech for effective learning, introducing another limitation. Thirdly, the SCRIBE dataset that we used is a smaller dataset of British English as compared to the TIMIT dataset. A lack of well-annotated datasets, especially on the phoneme level, is one of our biggest challenges.
Future research directions could explore the incorporation of datasets containing non-native English data. This involves re-training the shallow reducer and classifier models using non-native speech data. Furthermore, extending our approach to languages beyond English and evaluating its performance with real-world data from language learners presents an intriguing avenue for exploration. Our work lays the foundation for further experiments in the realm of text-independent phone-to-audio alignment, especially in the context of non-native English.





{kind=link}
{kind=link}