
Visual Speech Recognition for Kannada Language Using VGG16 Convolutional Neural Network

 , ,
, , 
 and
and
Abstract
1. Introduction
2. Implementation Steps
2.1. Dataset Development
2.2. Parameters
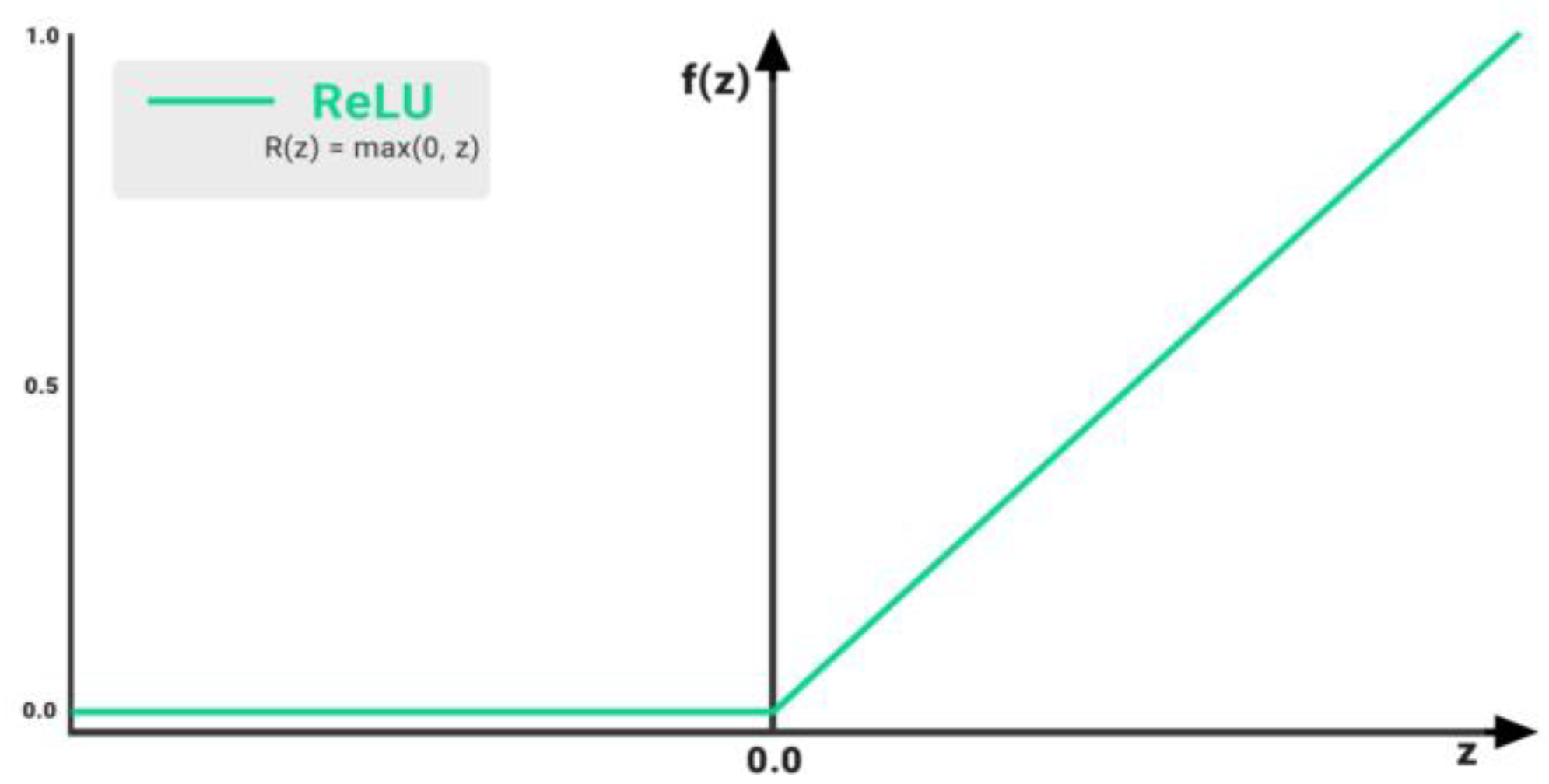
2.2.1. Activation Function (AF)
2.2.2. Batch Size
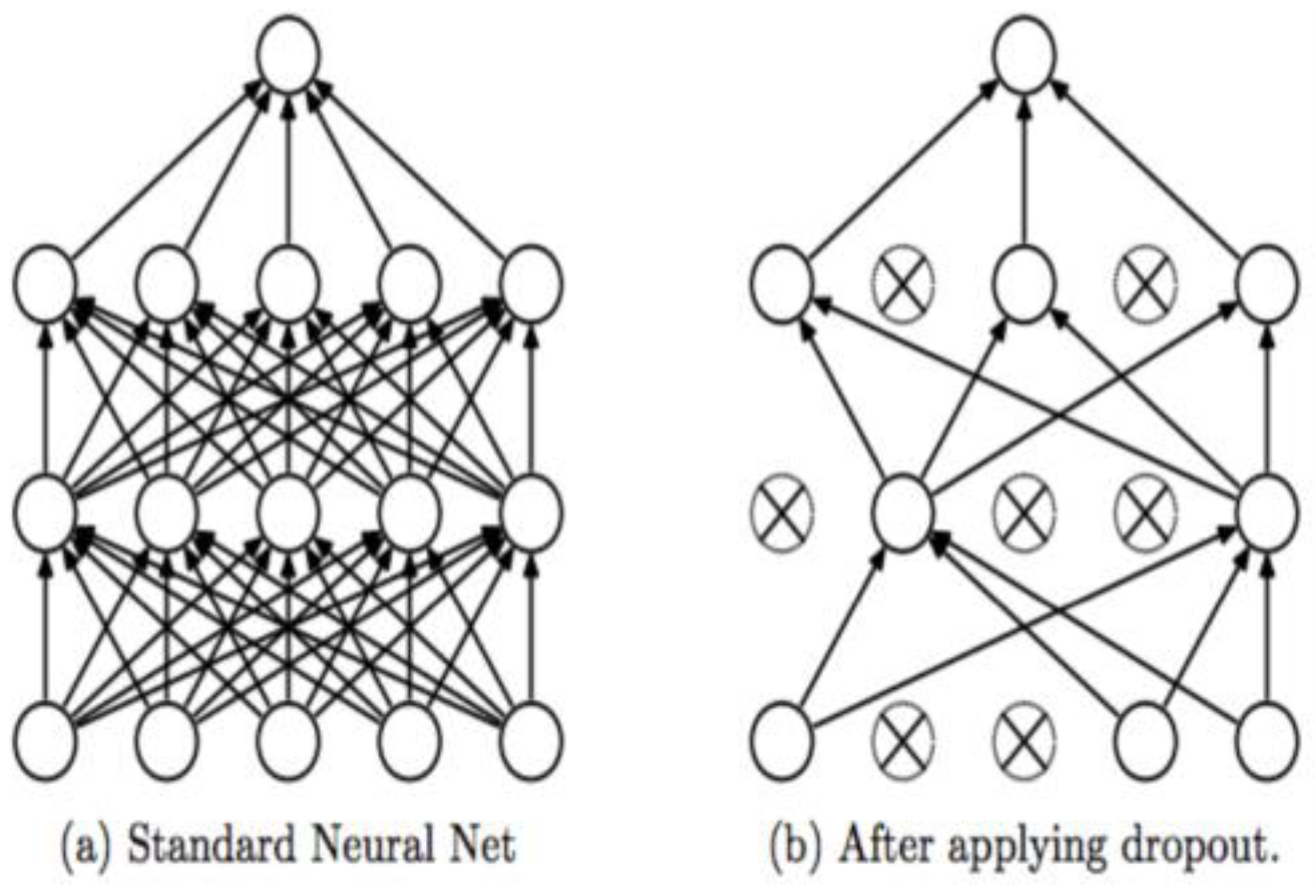
2.2.3. Drop Out
2.2.4. Cross-Entropy
2.2.5. Epochs
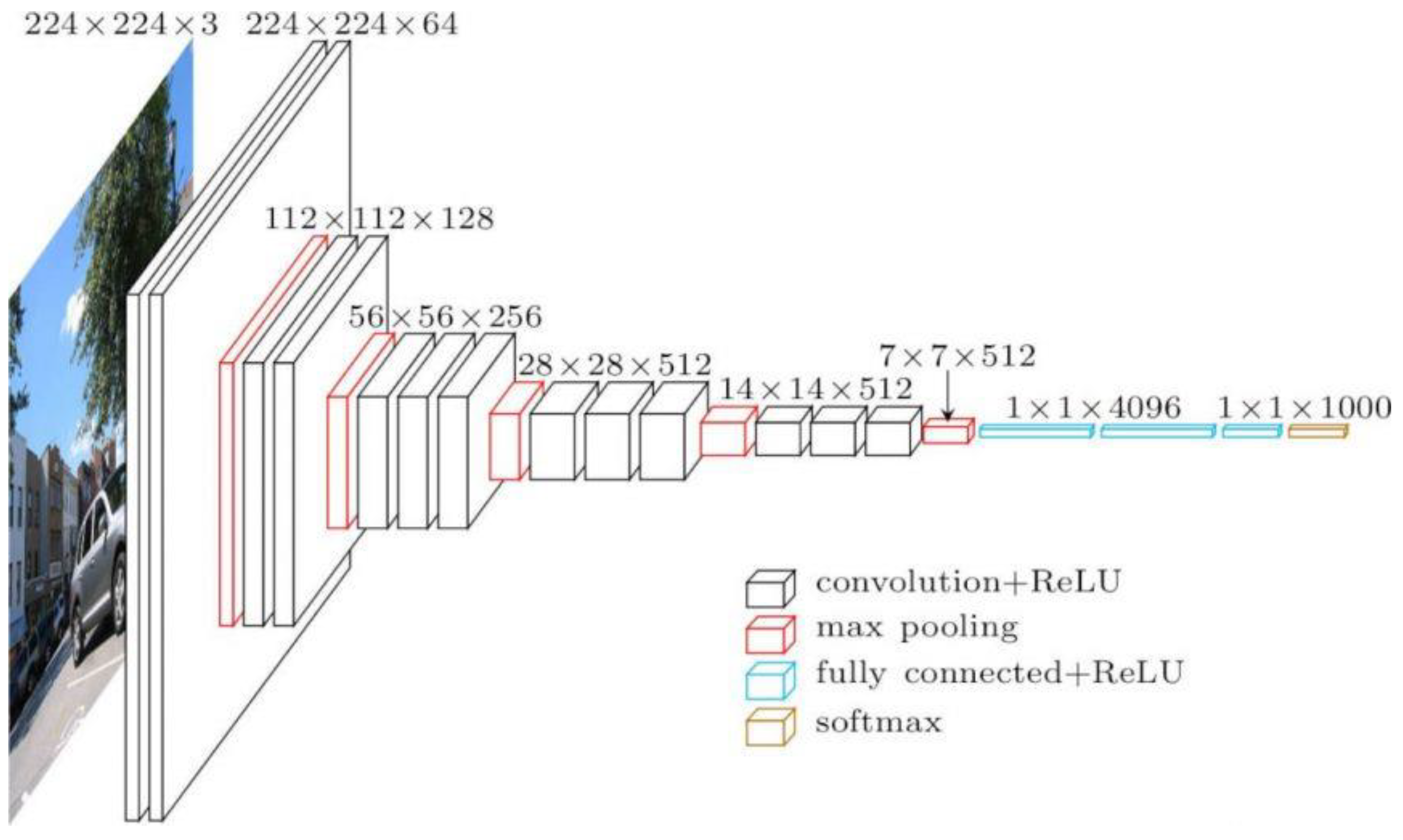
3. VGG16 Architecture
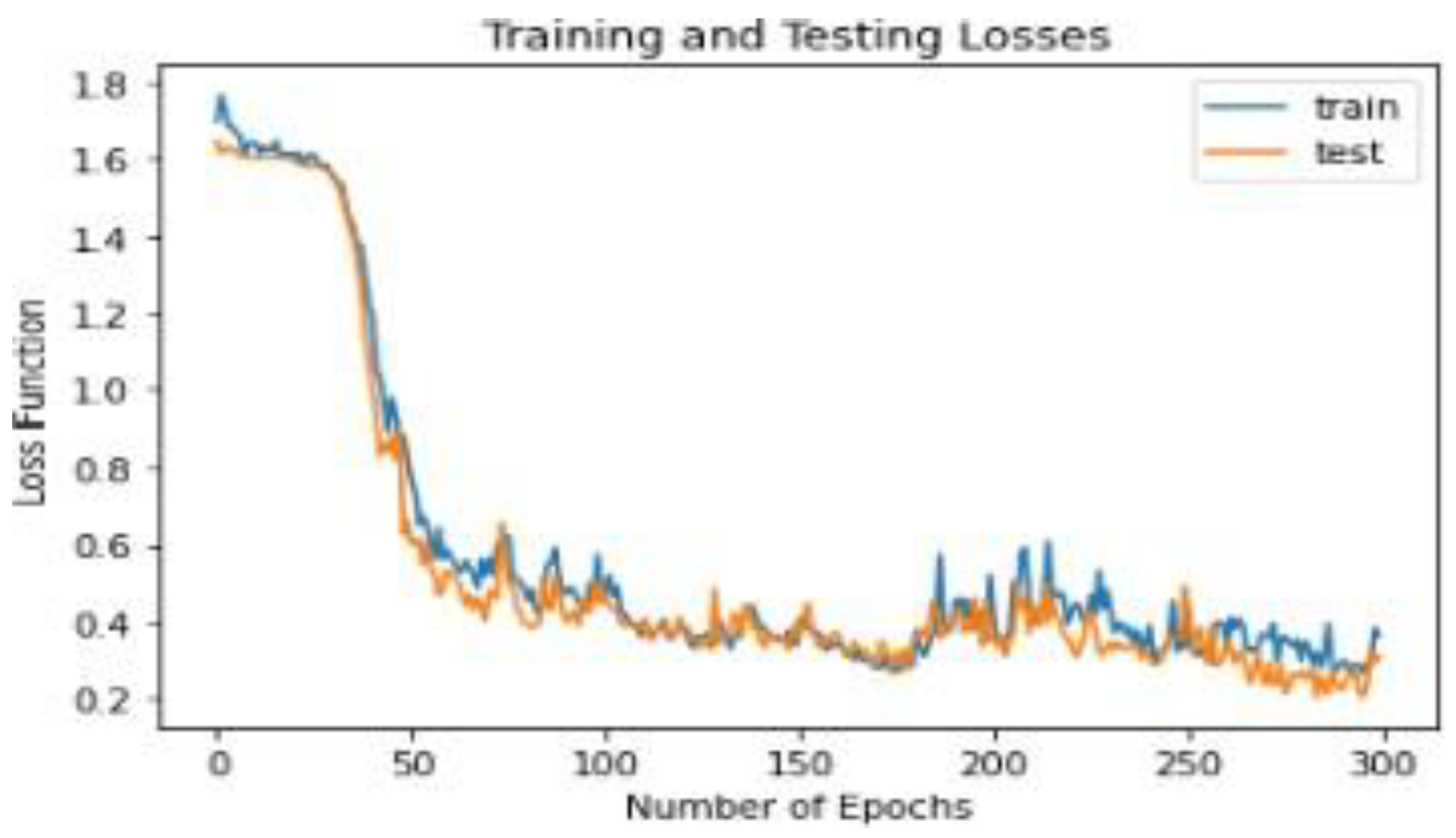
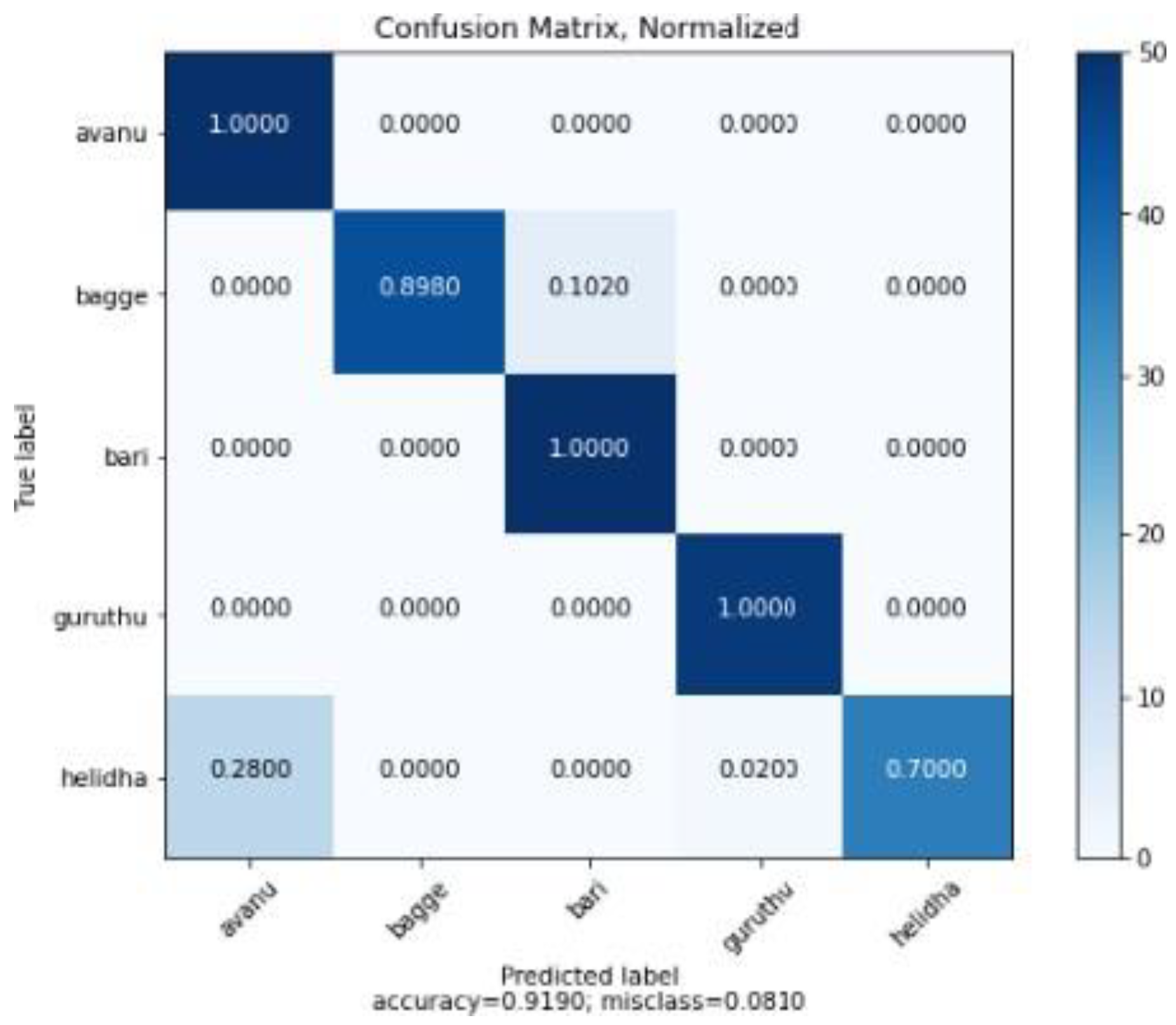
4. Result and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Radha, N.; Shahina, A.; Khan, A.N. Visual Speech Recognition using Fusion of Motion and Geometric Features. Procedia Comput. Sci. 2020, 171, 924–933. [Google Scholar] [CrossRef]
- Fernandez-lopez, A.; Karaali, A.; Harte, N.; Sukno, F.M. Cogans For Unsupervised Visual Speech Adaptation To New Speakers. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; Volume 2, pp. 6289–6293. [Google Scholar]
- Movellan, J.R. Visual Speech Recognition with Stochastic Networks. Adv. Neural Inf. Process. Syst. 1995, 7, 851–858. Available online: https://papers.nips.cc/paper/1994/hash/7b13b2203029ed80337f27127a9f1d28-Abstract.html (accessed on 11 October 2022).
- Petridis, S.; Wang, Y.; Ma, P.; Li, Z.; Pantic, M. End-to-end visual speech recognition for small-scale datasets. Pattern Recognit. Lett. 2020, 131, 421–427. [Google Scholar] [CrossRef]
- Koumparoulis, A.; Potamianos, G.; Thomas, S.; da Silva Morais, E. Resource-adaptive deep learning for visual speech recognition. Proc. Annu. Conf. Int. Speech Commun. Assoc. Interspeech 2020, 2020, 3510–3514. [Google Scholar] [CrossRef]
- Shridhara, M.V.; Banahatti, B.K.; Narthan, L.; Karjigi, V.; Kumaraswamy, R. Development of Kannada speech corpus for prosodically guided phonetic search engine. In Proceedings of the 2013 International Conference Oriental COCOSDA held jointly with 2013 Conference on Asian Spoken Language Research and Evaluation (O-COCOSDA/CASLRE), Gurgaon, India, 25–27 November 2013. [Google Scholar] [CrossRef]
- Saenko, K.; Livescu, K.; Siracusa, M.; Wilson, K.; Glass, J.; Darrell, T. Visual speech recognition with loosely synchronized feature streams. Proc. IEEE Int. Conf. Comput. Vis. 2005, II, 1424–1431. [Google Scholar] [CrossRef]
- Kumar, P.S.P.; Yadava, G.T.; Jayanna, H.S. Continuous Kannada Speech Recognition System Under Degraded Condition. Circuits Syst. Signal Process. 2020, 39, 391–419. [Google Scholar] [CrossRef]
- AKandagal, P.; Udayashankara, V. Visual Speech Recognition Based on Lip Movement for Indian Languages. Int. J. Comput. Intell. Res. 2017, 13, 2029–2041. Available online: http://www.ripublication.com (accessed on 11 October 2022).
- Ozcan, T.; Basturk, A. Lip Reading Using Convolutional Neural Networks with and without Pre-Trained Models. Balk. J. Electr. Comput. Eng. 2019, 7, 195–201. [Google Scholar] [CrossRef]
- Hong, J.; Nisbet, D.A.; Vlissidis, A.; Zhao, Q. Deep Learning Methods for Lipreading; The University of California, Berkeley Department of Electrical Engineering & Computer Sciences: Berkeley, CA, USA, 2017. [Google Scholar]
- Mesbah, A.; Berrahou, A.; Hammouchi, H.; Berbia, H.; Qjidaa, H.; Daoudi, M. Lip reading with Hahn Convolutional Neural Networks. Image Vis. Comput. 2019, 88, 76–83. [Google Scholar] [CrossRef]
- Kumar, Y.; Sahrawat, D.; Maheshwari, S.; Mahata, D.; Stent, A.; Yin, Y.; Shah, R.R.; Zimmermann, R. Harnessing GANs for Zero-Shot Learning of New Classes in Visual Speech Recognition. arXiv 2019. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, S.; Xiao, J.; Shan, S.; Chen, X. Can We Read Speech beyond the Lips? Rethinking RoI Selection for Deep Visual Speech Recognition. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 356–363. [Google Scholar] [CrossRef]
- Hassanat, A.B.A. Visual Speech Recognition. In Speech and Language Technologies; IntechOpen Limited: London, UK, 2011. [Google Scholar] [CrossRef]
- Soundarya, B.; Krishnaraj, R.; Mythili, S. Visual Speech Recognition using Convolutional Neural Network. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1084, 012020. [Google Scholar] [CrossRef]
- Grewal, J.K.; Krzywinski, M.; Altman, N. Markov models—Hidden Markov models. Nat. Methods 2019, 16, 795–796. [Google Scholar] [CrossRef] [PubMed]
- Raghavan, A.M.; Lipschitz, N.; Breen, J.T.; Samy, R.N.; Kohlberg, G.D. Visual Speech Recognition: Improving Speech Perception in Noise through Artificial Intelligence. Otolaryngol.—Head Neck Surg. 2020, 163, 771–777. [Google Scholar] [CrossRef] [PubMed]
- Shashidhar, R.; Patilkulkarni, S.; Puneeth, S.B. Audio Visual Speech Recognition using Feed Forward Neural Network Architecture. In Proceedings of the 2020 IEEE International Conference for Innovation in Technology (INOCONF 2020), Banglore, India, 6–8 November 2020. [Google Scholar] [CrossRef]
- Morade, S.S.; Patnaik, S. A novel lip reading algorithm by using localized ACM and HMM: Tested for digit recognition. Optik 2014, 125, 5181–5186. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Learning to lip read words by watching videos. Comput. Vis. Image Underst. 2018, 173, 76–85. [Google Scholar] [CrossRef]
- Thabet, Z.; Nabih, A.; Azmi, K.; Samy, Y.; Khoriba, G.; Elshehaly, M. Lipreading using a comparative machine learning approach. In Proceedings of the 2018 First International Workshop on Deep and Representation Learning (IWDRL), Cairo, Egypt, 29 March 2018; pp. 19–25. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Lip reading in profile. In Proceedings of the British Machine Vision Conference 2017, London, UK, 4–7 September 2017; pp. 1–11. [Google Scholar] [CrossRef]
- Garg, A.; Noyola, J. Lip Reading Using CNN and LSTM. 2016; Available online: http://cs231n.stanford.edu/reports/2016/pdfs/217_Report.pdf (accessed on 11 October 2022).
- Wand, M.; Koutník, J.; Schmidhuber, J. Lipreading With Long Short-Term Memory. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6115–6119. [Google Scholar] [CrossRef]
- Paleček, K. Lipreading using spatiotemporal histogram of oriented gradients. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 28 August–2 September 2016; pp. 1882–1885. [Google Scholar] [CrossRef]
- Jha, A.; Namboodiri, V.P.; Jawahar, C.V. Word Spotting in Silent Lip Videos. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 150–159. [Google Scholar] [CrossRef]
- Sooraj, V.; Hardhik, M.; Murthy, N.S.; Sandesh, C.; Shashidhar, R. Lip-Reading Techniques: A Review. Int. J. Sci. Technol. Res. 2020, 9, 4378–4383. [Google Scholar]
- Patilkulkarni, S. Visual speech recognition for small scale dataset using VGG16 convolution neural network. Multimed Tools Appl. 2021, 80, 28941–28952. [Google Scholar] [CrossRef]
- Saade, P.; Jammal, R.E.; Hayek, S.E.; Zeid, J.A.; Falou, O.; Azar, D. Computer-aided Detection of White Blood Cells Using Geometric Features and Color. In Proceedings of the 2018 9th Cairo International Biomedical Engineering Conference (CIBEC), Cairo, Egypt, 20–22 December 2018; pp. 142–145. [Google Scholar] [CrossRef]
- Dhasarathan, C.; Hasan, M.K.; Islam, S.; Abdullah, S.; Mokhtar, U.A.; Javed, A.R.; Goundar, S. COVID-19 health data analysis and personal data preserving: A homomorphic privacy enforcement approach. Comput Commun. 2023, 199, 87–97. [Google Scholar] [CrossRef] [PubMed]
- El Zarif, O.; Haraty, R.A. Toward information preservation in healthcare systems. In Innovation in Health Informatics, A Smart Healthcare Primer; Academic Press: Cambridge, MA, USA, 2020; pp. 163–185. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Resolution | 1080 × 1920 p |
| Frames/Second | 60 FPS |
| Average Duration of Video | 1–1.20 s |
| Average Size of Video | 10 Mb |
| Parameters | Language |
|---|---|
| Kannada | |
| Quantity of Words | 05 |
| Quantity of Subjects | 10 |
| Samples per Subject | 5 |
| Total Number of Samples | 250 |
| Layer | Feature Map | Size | Kernel Size | Stride | Activation | |
|---|---|---|---|---|---|---|
| Input | Image | 1 | 224 × 224 × 3 | - | - | - |
| 1 | 2 × Convolution | 64 | 224 × 224 × 64 | 3 × 3 | 1 | Relu |
| Max Pooling | 64 | 112 × 112 × 64 | 3 × 3 | 2 | Relu | |
| 3 | 2 × Convolution | 128 | 112 × 112 × 128 | 3 × 3 | 1 | Relu |
| Max Pooling | 128 | 56 × 56 × 128 | 3 × 3 | 2 | Relu | |
| 5 | 2 × Convolution | 256 | 56 × 56 × 256 | 3 × 3 | 1 | Relu |
| Max Pooling | 256 | 28 × 28 × 256 | 3 × 3 | 2 | Relu | |
| 7 | 3 × Convolution | 512 | 28 × 28 × 512 | 3 × 3 | 1 | Relu |
| Max Pooling | 512 | 14 × 14 × 512 | 3 × 3 | 2 | Relu | |
| 10 | 3 × Convolution | 512 | 14 × 14 × 512 | 3 × 3 | 1 | Relu |
| Max Pooling | 512 | 7 × 7 × 512 | 3 × 3 | 2 | Relu | |
| 13 | FC | - | 25,088 | - | - | Relu |
| 14 | FC | - | 4096 | - | - | Relu |
| 15 | FC | - | 4096 | - | - | Relu |
| Output | FC | - | 1000 | - | - | Softmax |
| Precision | Recall | FI-Score | Support | |
|---|---|---|---|---|
| avanu | 0.781 | 1000 | 0.877 | 50 |
| bagge | 1000 | 0.898 | 0.946 | 49 |
| bari | 0.909 | 1000 | 0.952 | 50 |
| guruthu | 0.980 | 1000 | 0.990 | 48 |
| helidha | 1000 | 0.700 | 0.824 | 50 |
| accuracy | 0.919 | 247 | ||
| macro avg | 0.934 | 0.920 | 0.918 | 247 |
| weighted avg | 0.933 | 0.919 | 0.917 | 247 |
| Methodology | Dataset | Classes | Accuracy |
|---|---|---|---|
| HCNN (Without DA) [12] | BBC LRW | 500 | 55.86% |
| HCNN (With DA) [12] | BBC LRW | 500 | 58.02% |
| GLCM-ANN [9] | Custom | 10 English, 10 Kannada, 10 Telugu | 90.00% |
| VGG16 [29] | Custom | 250 English | 75.2% |
| VGG16 [Proposed] | Custom | 10 Kannada = 10 × 10 × 5 = 500 | 91.90% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rudregowda, S.; Patil Kulkarni, S.; H L, G.; Ravi, V.; Krichen, M. Visual Speech Recognition for Kannada Language Using VGG16 Convolutional Neural Network. Acoustics 2023, 5, 343-353. https://doi.org/10.3390/acoustics5010020
Rudregowda S, Patil Kulkarni S, H L G, Ravi V, Krichen M. Visual Speech Recognition for Kannada Language Using VGG16 Convolutional Neural Network. Acoustics. 2023; 5(1):343-353. https://doi.org/10.3390/acoustics5010020
Chicago/Turabian StyleRudregowda, Shashidhar, Sudarshan Patil Kulkarni, Gururaj H L, Vinayakumar Ravi, and Moez Krichen. 2023. "Visual Speech Recognition for Kannada Language Using VGG16 Convolutional Neural Network" Acoustics 5, no. 1: 343-353. https://doi.org/10.3390/acoustics5010020
APA StyleRudregowda, S., Patil Kulkarni, S., H L, G., Ravi, V., & Krichen, M. (2023). Visual Speech Recognition for Kannada Language Using VGG16 Convolutional Neural Network. Acoustics, 5(1), 343-353. https://doi.org/10.3390/acoustics5010020