
Compensation of Modeling Errors for the Aeroacoustic Inverse Problem with Tools from Deep Learning


Abstract
:1. Introduction
2. Problem Modeling
3. Source Power Reconstruction with FISTA
- A gradient step with respect to the first summand of the objective function;
- Application of the proximal mapping (see Definition 6.1, p. 129, [34]) of the regularization part.
- To ensure convergence, the step size must satisfywhere the upper bound may be estimated, e.g., by the power method (see p. 239, [36]).
- As the observed CSM is Hermitian, the upper diagonal part can be neglected. Therefore, denotes the index set of the lower triangular part of the CSM. The operation sets all entries to zero that do not belong to . Moreover, the principle of diagonal removal can be easily incorporated by defining as the lower triangular indices without the diagonal.
- The operation multiplies each column of component-wise by the vector .
- The operation takes the positive part component-wise, i.e., .

4. Optimization of Phase Modeling Parameters
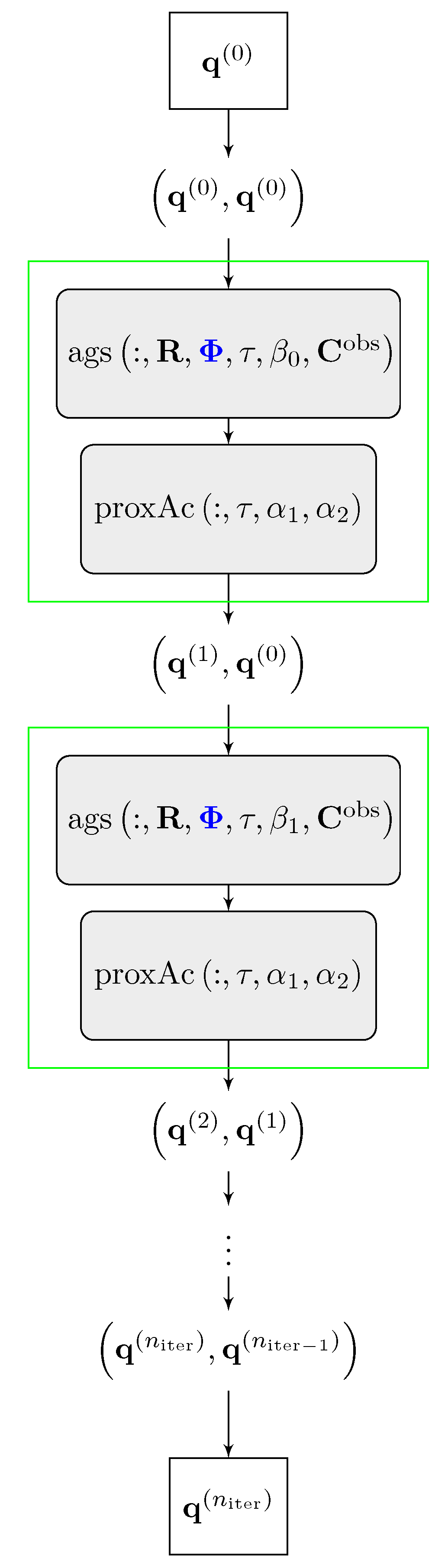
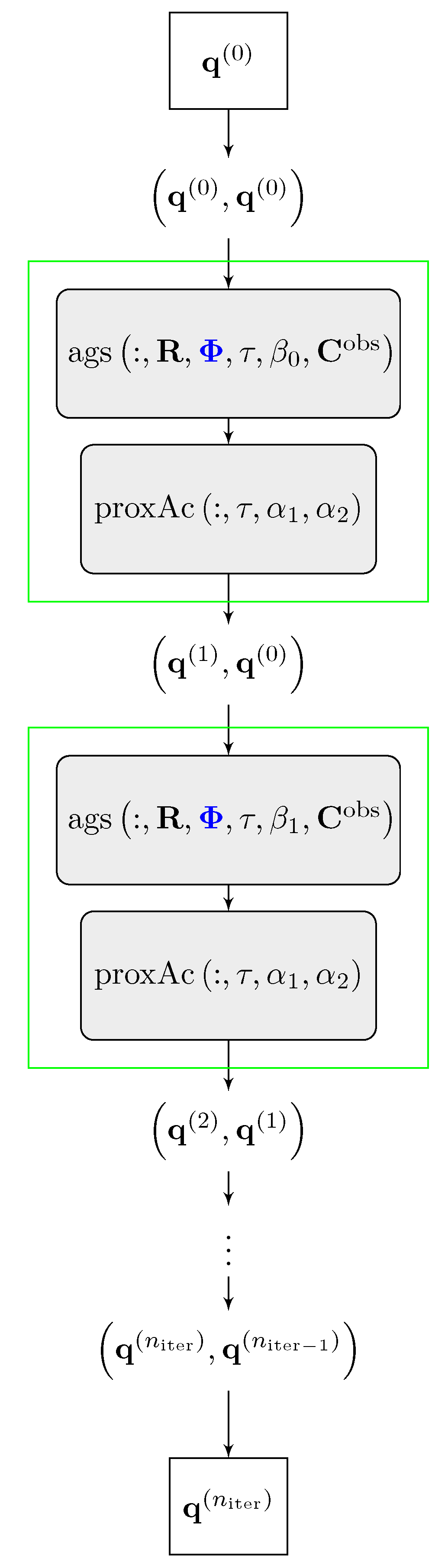
4.1. Unrolled FISTA
- The set of trainable parameters of are the entries of the phase matrix . Those are shared for each layer. Note that the set of trainable and non-trainable parameters can be varied but we will restrict our investigations to the case where is trainable.
- The starting value is the data input of the neural network and is transformed to the pair before the first layer.
- The network consists of layers, where each layer represents one FISTA iteration. In each layer, the following two operations are applied to the pair :
- After the last layer, the output pair is transformed to the final output .
4.2. Constrained Residual Minimization

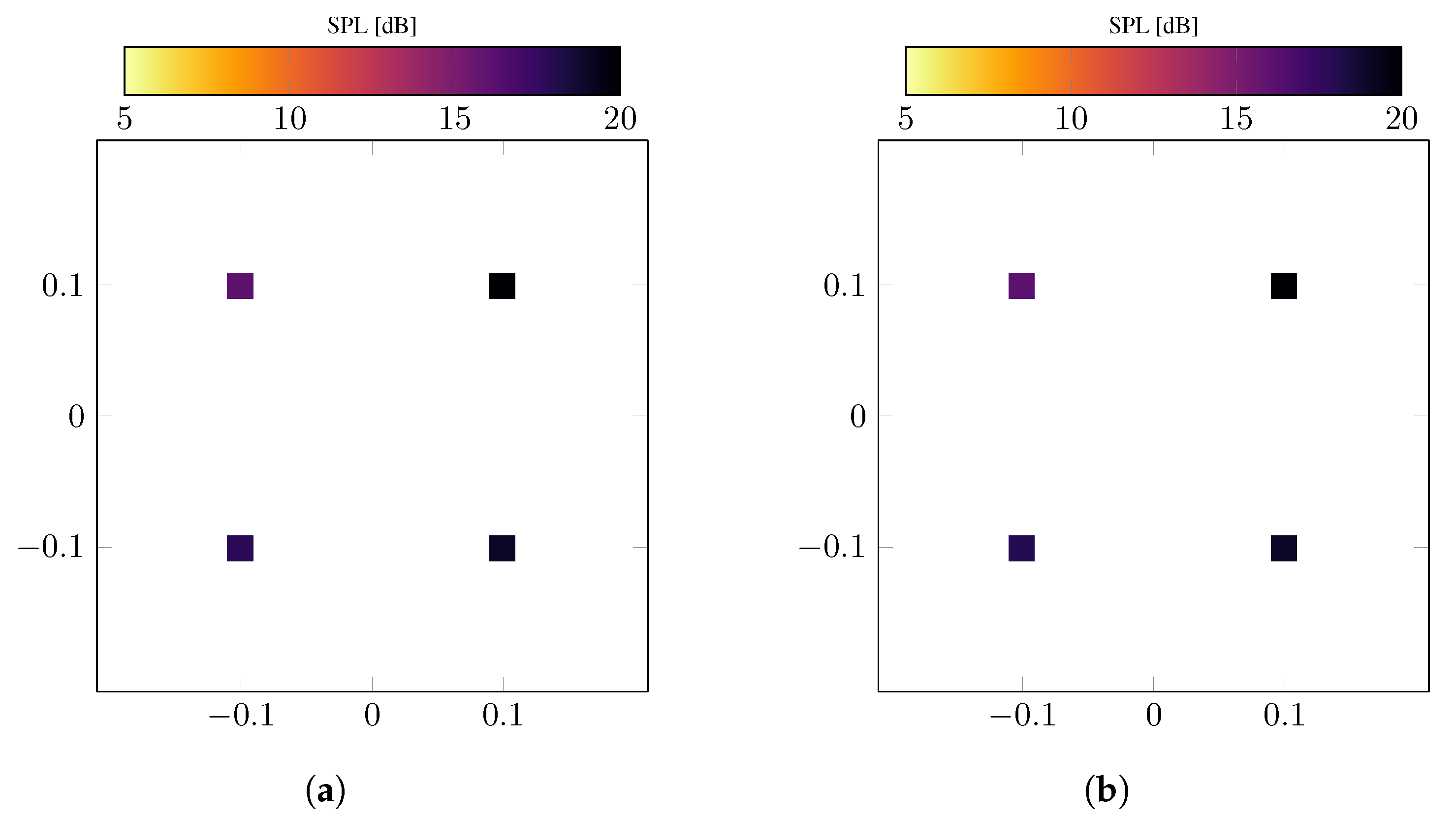
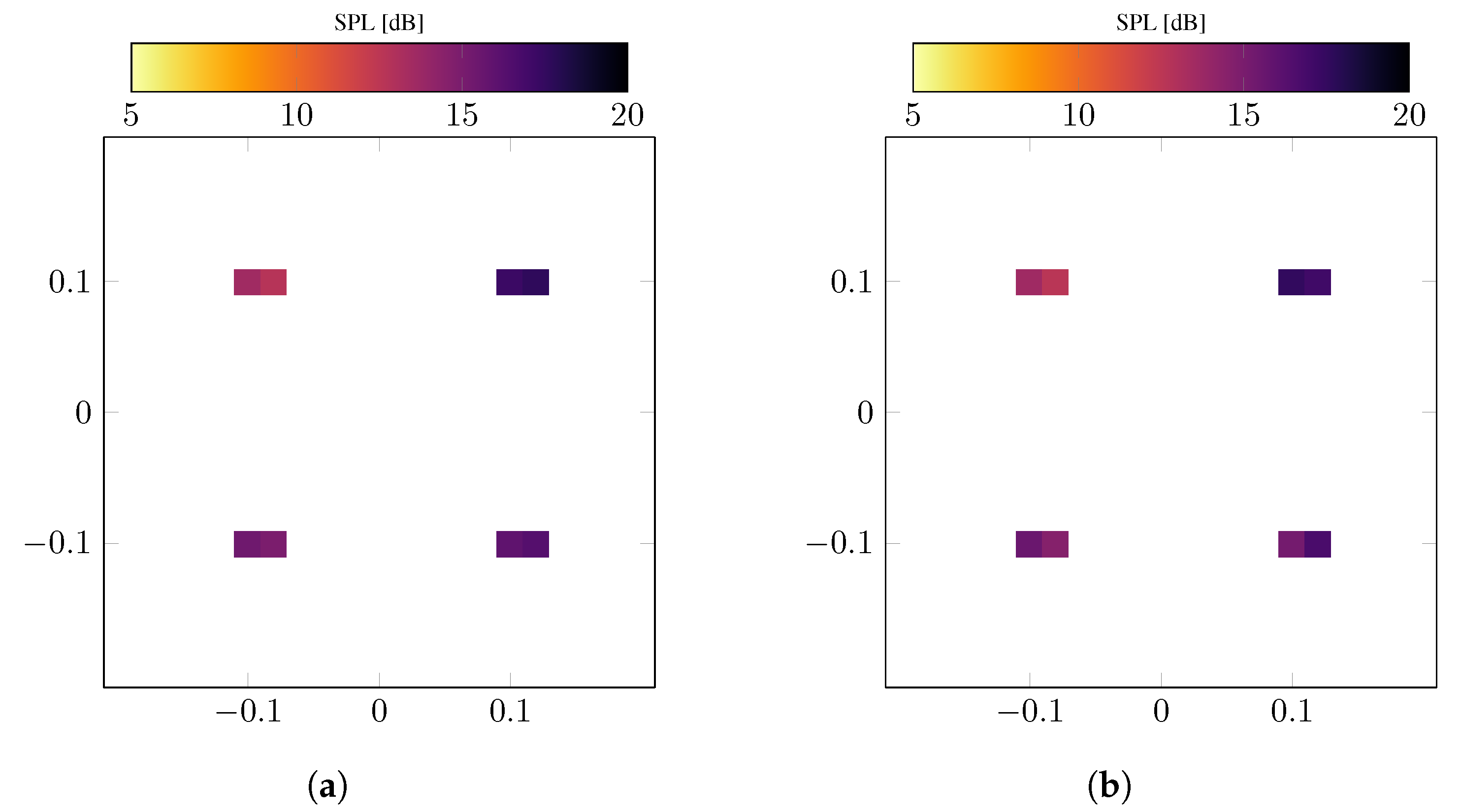
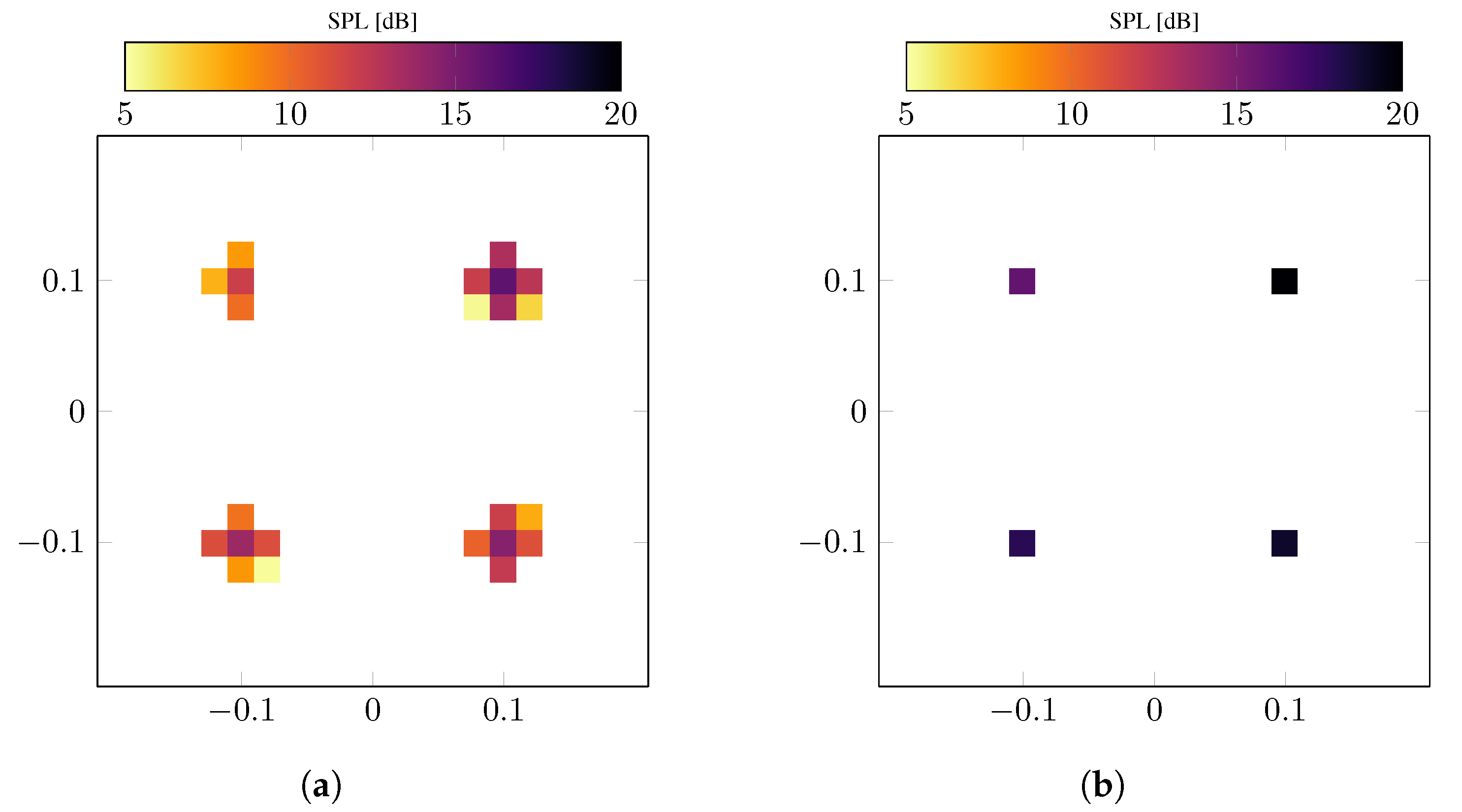
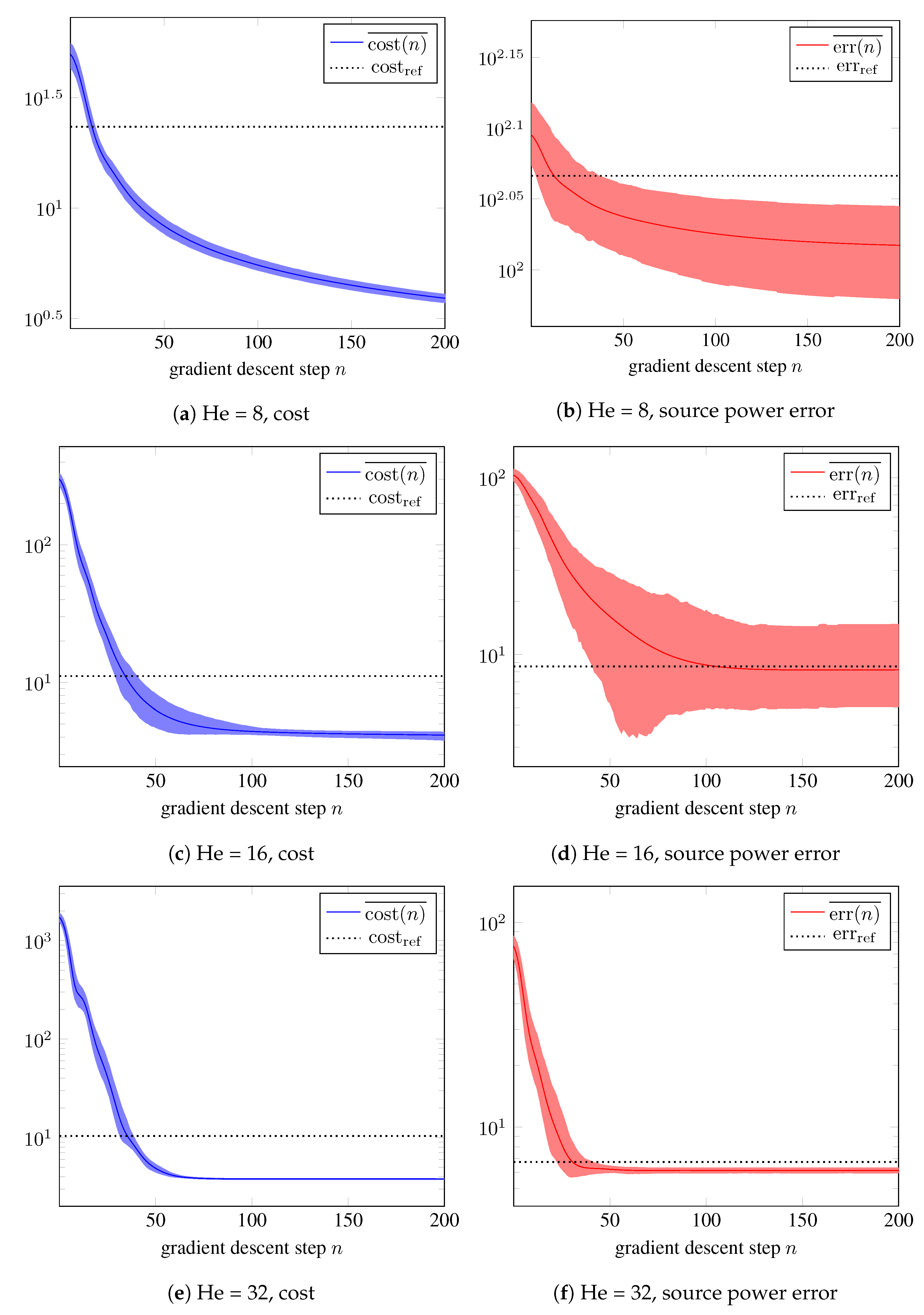
5. Numerical Examples
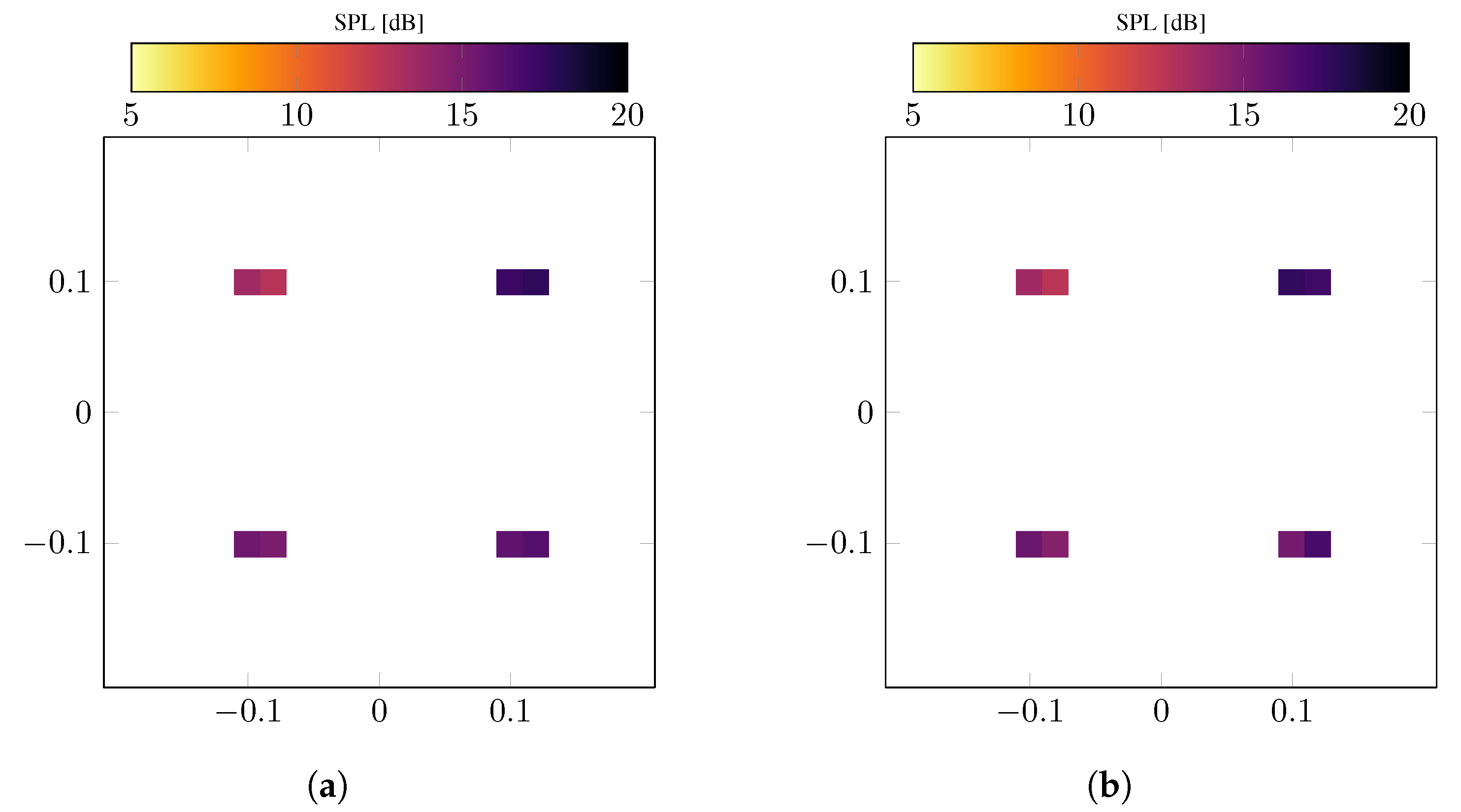
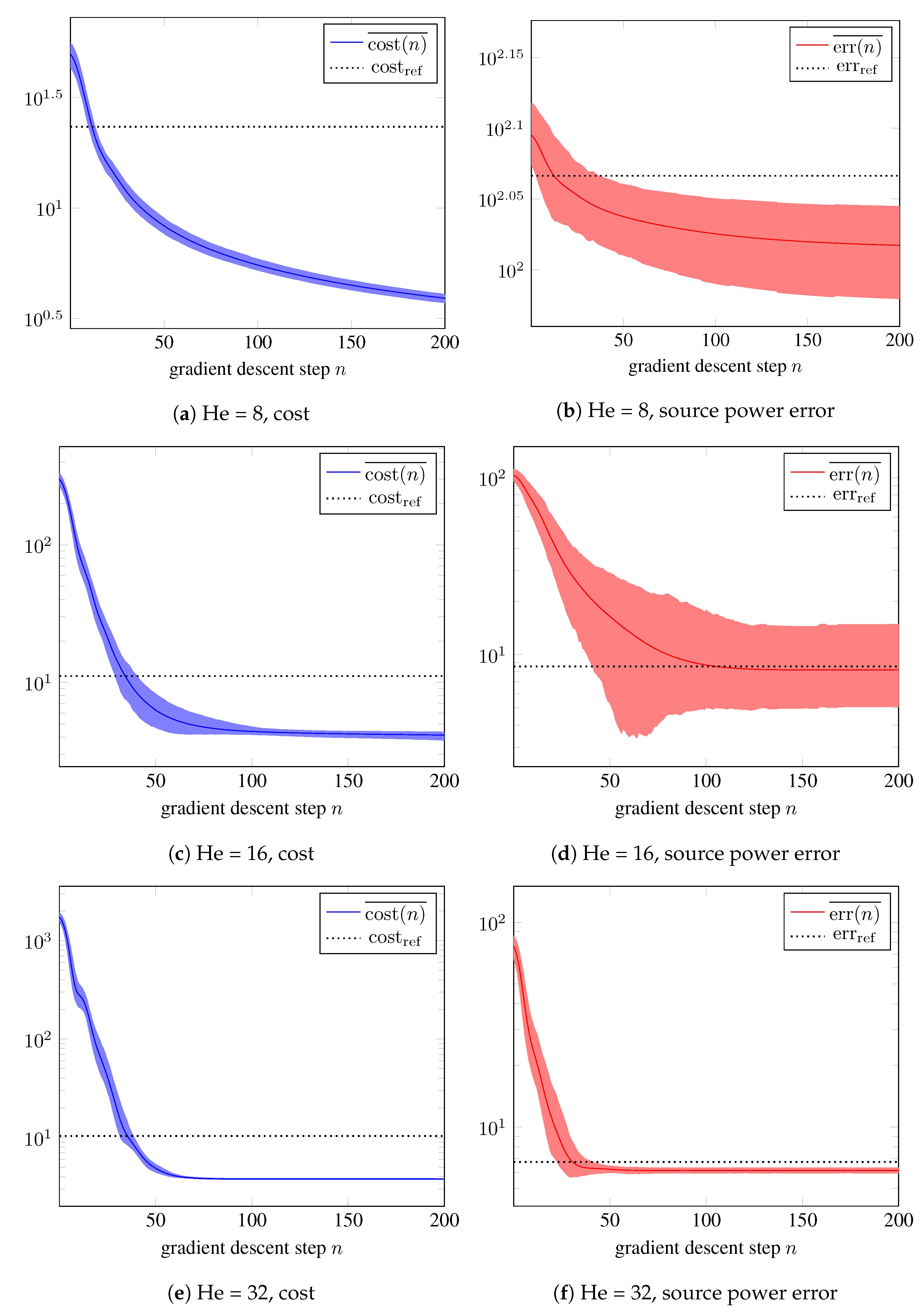
5.1. Systematic Modeling Error
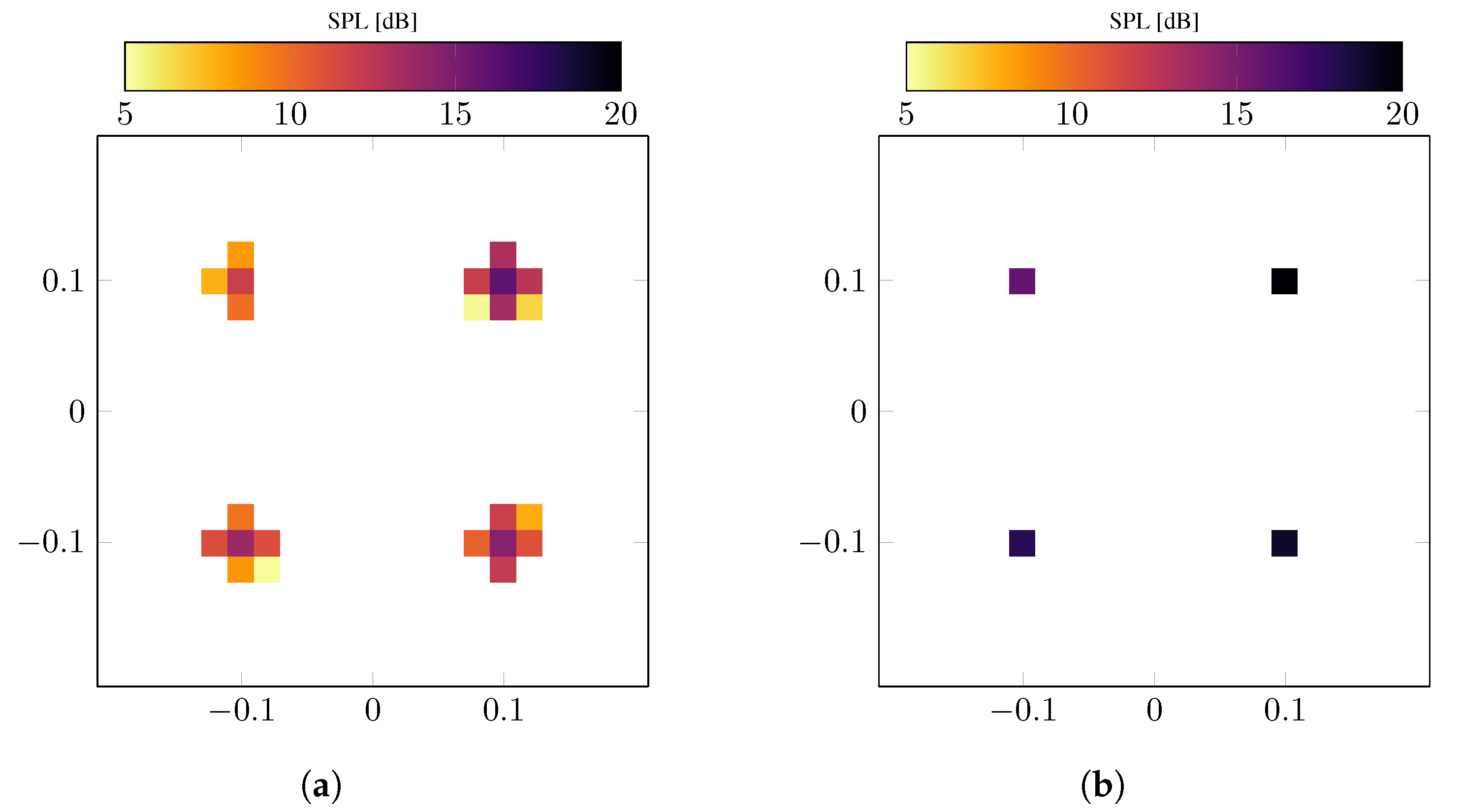
5.2. Random Modeling Error
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Billingsley, J.; Kinns, R. The acoustic telescope. J. Sound Vib. 1976, 48, 485–510. [Google Scholar] [CrossRef]
- Brooks, T.F.; Marcolini, M.A.; Pope, D.S. A directional array approach for the measurement of rotor noise source distributions with controlled spatial resolution. J. Sound Vib. 1987, 112, 192–197. [Google Scholar] [CrossRef]
- Allen, C.S.; Blake, W.K.; Dougherty, R.P.; Lynch, D.; Soderman, P.T.; Underbrink, J.R. Aeroacoustic Measurements; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar] [CrossRef]
- Oerlemans, S.; Sijtsma, P. Acoustic Array Measurements of a 1:10.6 Scaled Airbus A340 Model. In Proceedings of the 10th AIAA/CEAS Aeroacoustics Conference, Manchester, UK, 10–12 May 2004; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2004; p. 2924. [Google Scholar] [CrossRef]
- Soderman, P.; Kafyeke, F.; Boudreau, J.; Burnside, N.; Jaeger, S.; Chandrasekharan, R. Airframe Noise Study of a Bombardier CRJ-700 Aircraft Model in the NASA Ames 7-by 10-Foot Wind Tunnel. Int. J. Aeroacoustics 2004, 3, 1–42. [Google Scholar] [CrossRef]
- Johnson, D.H.; Dudgeon, D.E. Array Signal Processing; P T R Prentice Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Sijtsma, P. CLEAN Based on Spatial Source Coherence. Int. J. Aeroacoustics 2007, 6, 357–374. [Google Scholar] [CrossRef]
- Brooks, T.F.; Humphreys, W.M. A deconvolution approach for the mapping of acoustic sources (DAMAS) determined from phased microphone arrays. J. Sound Vib. 2006, 294, 856–879. [Google Scholar] [CrossRef]
- Blacodon, D.; Elias, G. Level Estimation of Extended Acoustic Sources Using a Parametric Method. J. Aircraft 2004, 41, 1360–1369. [Google Scholar] [CrossRef]
- Yardibi, T.; Li, J.; Stoica, P.; Cattafesta, L.N. Sparsity constrained deconvolution approaches for acoustic source mapping. J. Acoust. Soc. Am. 2008, 123, 2631–2642. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef] [Green Version]
- Chambolle, A.; Vore, R.D.; Lee, N.Y.; Lucier, B. Nonlinear wavelet image processing: Variational problems, compression, and noise removal through wavelet shrinkage. IEEE Trans. Image Process. 1998, 7, 319–335. [Google Scholar] [CrossRef]
- Daubechies, I.; Defrise, M.; Mol, C.D. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 2004, 57, 1413–1457. [Google Scholar] [CrossRef]
- Chen, L.; Xiao, Y.; Yang, T. Application of the improved fast iterative shrinkage-thresholding algorithms in sound source localization. Appl. Acoust. 2021, 180, 108101. [Google Scholar] [CrossRef]
- Lylloff, O.; Fernández-Grande, E.; Agerkvist, F.; Hald, J.; Tiana-Roig, E.; Andersen, M.S. Improving the efficiency of deconvolution algorithms for sound source localization. J. Acoust. Soc. Am. 2015, 138, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Shen, L.; Chu, Z.; Yang, Y.; Wang, G. Periodic boundary based FFT-FISTA for sound source identification. Appl. Acoust. 2018, 130, 87–91. [Google Scholar] [CrossRef]
- Shen, L.; Chu, Z.; Tan, L.; Chen, D.; Ye, F. Improving the Sound Source Identification Performance of Sparsity Constrained Deconvolution Beamforming Utilizing SFISTA. Shock Vib. 2020, 2020, 1482812. [Google Scholar] [CrossRef]
- Monga, V.; Li, Y.; Eldar, Y.C. Algorithm Unrolling: Interpretable, Efficient Deep Learning for Signal and Image Processing. IEEE Signal Process. Mag. 2021, 38, 18–44. [Google Scholar] [CrossRef]
- Castellini, P.; Giulietti, N.; Falcionelli, N.; Dragoni, A.F.; Chiariotti, P. A neural network based microphone array approach to grid-less noise source localization. Appl. Acoust. 2021, 177, 107947. [Google Scholar] [CrossRef]
- Lee, S.Y.; Chang, J.; Lee, S. Deep learning-based method for multiple sound source localization with high resolution and accuracy. Mech. Syst. Signal Process. 2021, 161, 107959. [Google Scholar] [CrossRef]
- Lee, S.Y.; Chang, J.; Lee, S. Deep Learning-Enabled High-Resolution and Fast Sound Source Localization in Spherical Microphone Array System. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Ma, W.; Liu, X. Phased microphone array for sound source localization with deep learning. Aerosp. Syst. 2019, 2, 71–81. [Google Scholar] [CrossRef]
- Mukherjee, S.; Dittmer, S.; Shumaylov, Z.; Lunz, S.; Öktem, O.; Schönlieb, C.B. Learned Convex Regularizers for Inverse Problems. arXiv 2020, arXiv:2008.02839. [Google Scholar]
- Li, H.; Schwab, J.; Antholzer, S.; Haltmeier, M. NETT: Solving inverse problems with deep neural networks. Inverse Probl. 2020, 36, 065005. [Google Scholar] [CrossRef]
- Lunz, S.; Hauptmann, A.; Tarvainen, T.; Schönlieb, C.B.; Arridge, S. On Learned Operator Correction in Inverse Problems. SIAM J. Imaging Sci. 2021, 14, 92–127. [Google Scholar] [CrossRef]
- Borgerding, M.; Schniter, P.; Rangan, S. AMP-Inspired Deep Networks for Sparse Linear Inverse Problems. IEEE Trans. Signal Process. 2017, 65, 4293–4308. [Google Scholar] [CrossRef]
- Gregor, K.; LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the ICML 2010—Proceedings, 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 399–406. [Google Scholar]
- Ito, D.; Takabe, S.; Wadayama, T. Trainable ISTA for Sparse Signal Recovery. IEEE Trans. Signal Process. 2019, 67, 3113–3125. [Google Scholar] [CrossRef]
- Takabe, S.; Wadayama, T.; Eldar, Y.C. Complex Trainable Ista for Linear and Nonlinear Inverse Problems. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 5020–5024. [Google Scholar] [CrossRef]
- Kayser, C.; Kujawski, A.; Sarradj, E. A trainable iterative soft thresholding algorithm for microphone array source mapping. In Proceedings of the CD of the 9th Berlin Beamforming Conference, Berlin, Germany, 8–9 June 2022; pp. 1–17. [Google Scholar]
- Golub, G.H.; Hansen, P.C.; O’Leary, D.P. Tikhonov Regularization and Total Least Squares. SIAM J. Matrix Anal. Appl. 1999, 21, 185–194. [Google Scholar] [CrossRef]
- Kluth, T.; Maass, P. Model uncertainty in magnetic particle imaging: Nonlinear problem formulation and model-based sparse reconstruction. Int. J. Magn. Part. Imaging 2017, 3, 1707004. [Google Scholar] [CrossRef]
- Dittmer, S.; Kluth, T.; Maass, P.; Baguer, D.O. Regularization by Architecture: A Deep Prior Approach for Inverse Problems. J. Math. Imaging Vis. 2019, 62, 456–470. [Google Scholar] [CrossRef]
- Beck, A. First-Order Methods in Optimization; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Chardon, G.; Picheral, J.; Ollivier, F. Theoretical analysis of the DAMAS algorithm and efficient implementation of the covariance matrix fitting method for large-scale problems. J. Sound Vib. 2021, 508, 116208. [Google Scholar] [CrossRef]
- Engl, H.W.; Hanke, M.; Neubauer, A. Regularization of Inverse Problems; Springer: Dordrecht, The Netherlands, 1996. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sarradj, E.; Herold, G.; Sijtsma, P.; Martinez, R.M.; Geyer, T.F.; Bahr, C.J.; Porteous, R.; Moreau, D.; Doolan, C.J. A Microphone Array Method Benchmarking Exercise using Synthesized Input Data. In Proceedings of the 23rd AIAA/CEAS Aeroacoustics Conference. American Institute of Aeronautics and Astronautics, Denver, CO, USA, 5–9 June 2017; p. 3719. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 24 August 2022).
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Optimization algorithm | Gradient descent with Nesterov momentum (p. 353, [40]) |
|---|---|
| Learning rate | lr |
| Momentum parameter | momentum |
| Gradient descent steps |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raumer, H.-G.; Ernst, D.; Spehr, C. Compensation of Modeling Errors for the Aeroacoustic Inverse Problem with Tools from Deep Learning. Acoustics 2022, 4, 834-848. https://doi.org/10.3390/acoustics4040050
Raumer H-G, Ernst D, Spehr C. Compensation of Modeling Errors for the Aeroacoustic Inverse Problem with Tools from Deep Learning. Acoustics. 2022; 4(4):834-848. https://doi.org/10.3390/acoustics4040050
Chicago/Turabian StyleRaumer, Hans-Georg, Daniel Ernst, and Carsten Spehr. 2022. "Compensation of Modeling Errors for the Aeroacoustic Inverse Problem with Tools from Deep Learning" Acoustics 4, no. 4: 834-848. https://doi.org/10.3390/acoustics4040050
APA StyleRaumer, H.-G., Ernst, D., & Spehr, C. (2022). Compensation of Modeling Errors for the Aeroacoustic Inverse Problem with Tools from Deep Learning. Acoustics, 4(4), 834-848. https://doi.org/10.3390/acoustics4040050