1. Introduction
Music is inextricably linked to emotions in a dual way: the emotion recognized in music (perceived emotion) and the emotion that listeners feel while listening to music (induced emotion) [
1]. A lot of progress has been observed in the music emotion recognition (MER) field, where advanced predicting models are used with the aim of automatically categorizing the perceived emotion, using the rhythm and tempo of the song as remarkable indicators [
2]. Moreover, previous research has shown that music induces changes in the human autonomic nervous system, which controls human emotional arousal (i.e., induced emotion) [
3]. In particular, a significant part of the reported emotions of the listeners can be predicted from a set of six psychoacoustic features of music, namely loudness, pitch level, pitch contour, tempo, texture, and sharpness [
4]. Perceived and induced emotions are usually identical; however, there are cases in which they differ from each other [
5]. Human emotional response to music stimuli is not so straightforward, as a range of underlying psychological mechanisms mediates, such as brain stem reflex, contagion, episodic memory, and musical expectancy [
6]. In general, recognizing the perceived emotion is easier than detecting the induced emotion, as the former can occur from analyzing the musical signal features while the latter depends on a variety of factors, such as personal taste in music, memories of the listener, etc. From the above considerations, it becomes clear that defining and controlling the effect of music on humans, by feature extraction techniques, is a challenging procedure.
Apart from emotion, mood is a psychological term used in the music industry. These two terms are usually used interchangeably; however, their difference is theoretically clearly defined: emotion corresponds to a brief but intense affective reaction, while mood corresponds to an unfocused low intensity state [
7]. While an emotion is a short-lasting feeling caused by an event, such as brief music content, mood is the long-lasting feeling that either can be recognized in the song (i.e., mood of music), or can characterize the emotional state of an individual (i.e., mood of the listener). Similarly to the distinction between perceived and induced emotion, the distinction between the perceived mood (i.e., the mood recognized in the music) and the induced mood (i.e., the mood of the listener while listening to music) is not always straightforward.
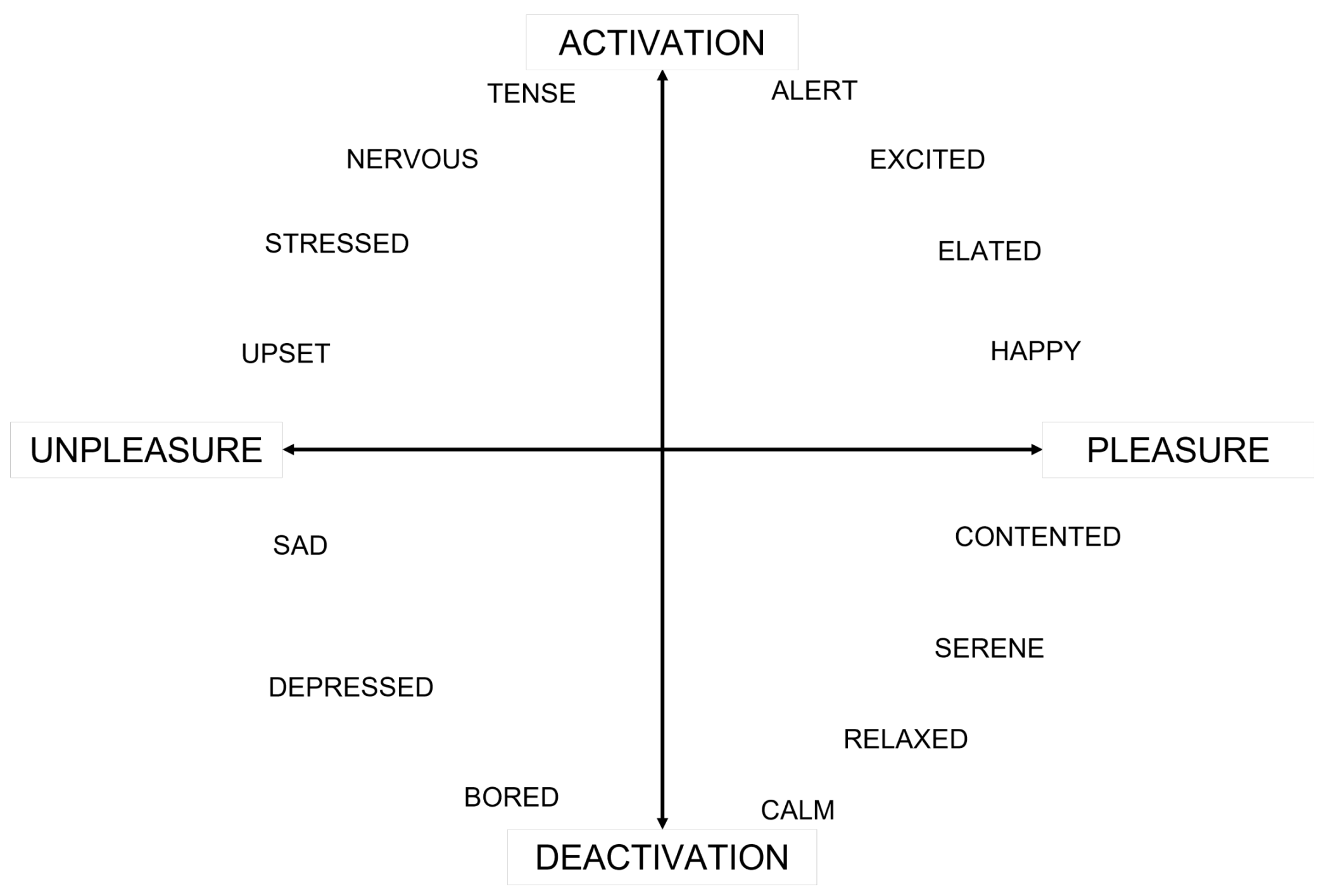
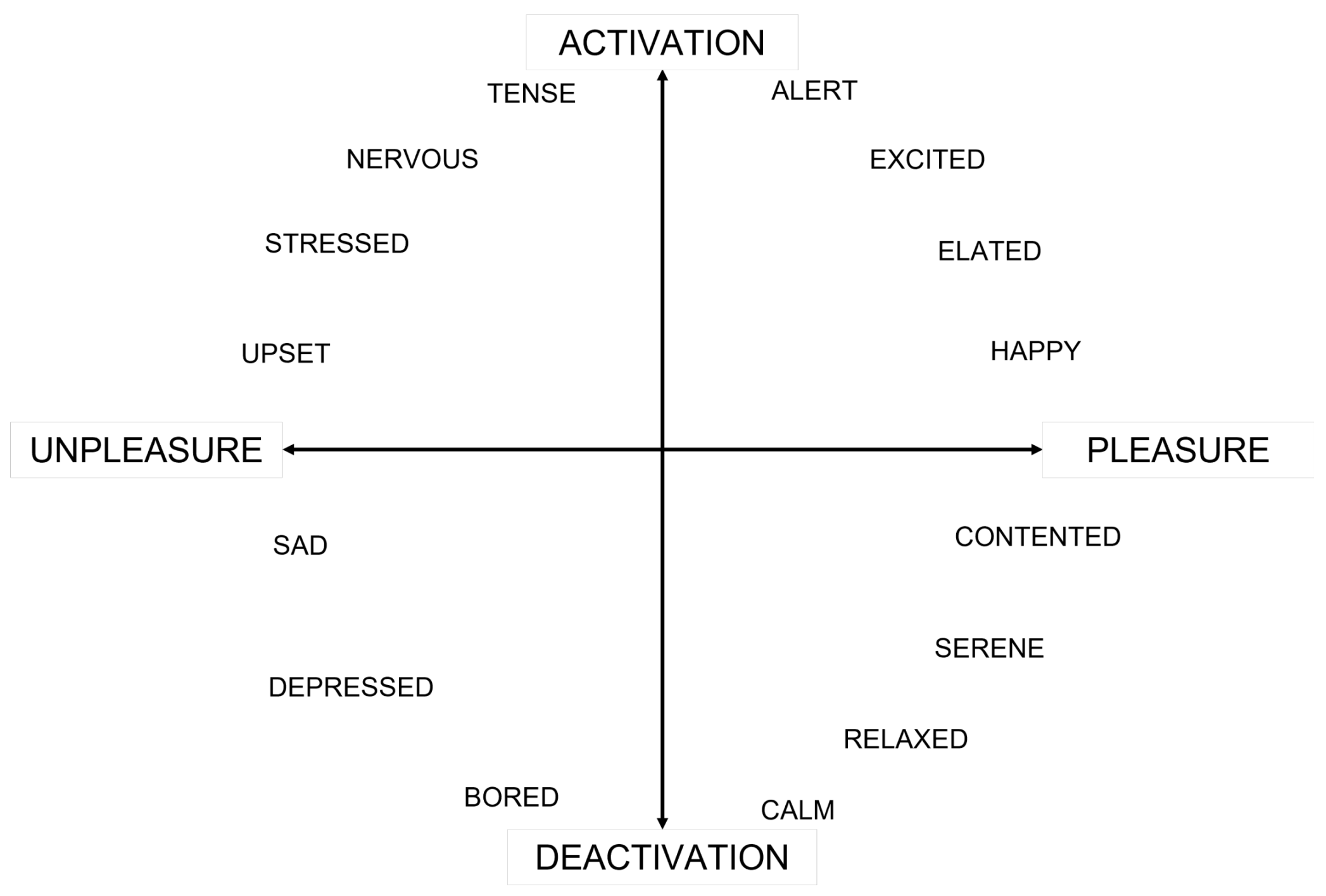
In a general sense, the identification of an individual’s emotion and mood is a difficult task. A commonly used evaluation method is a self-reporting procedure, that can use alternatively a categorical or a dimensional model. In the categorical model, the participant is asked to choose among a set of predefined words, while in the dimensional model, the words that describe the listener’s mood are arranged in a two-dimensional scheme composed by a vertical arousal axis and a horizontal valence (or pleasure) axis [
8]; however, the major problems of the self-reporting method are the different perception of mood descriptors among people and the inability of people to understand and articulate their feelings. In this study, a hybrid model that combines both dimensional and categorical evaluations is used in an attempt to reduce the above two problems. An alternative, promising way for capturing human emotion and mood is by measuring specific human physiological responses. Previous research has shown that electroencephalography (EEG), heart rate variability (HRV), and galvanic skin response (GSR) are some of the most meaningful indicators of participants’ mood and emotion [
9,
10]; however, the use of these parameters implies a long period of observation, while in this work we have decided to study the immediate impact of sound experience on listeners.
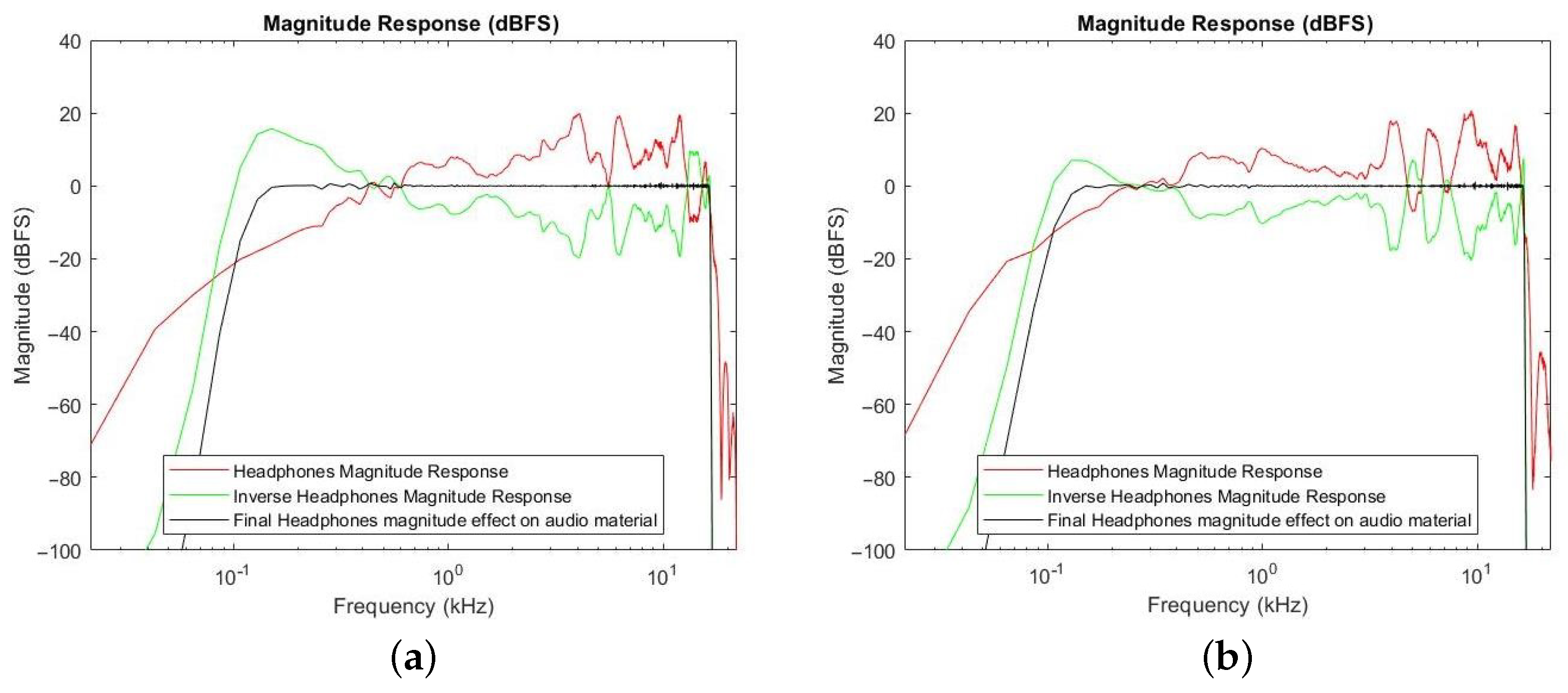
Regarding audio equalization, it is a powerful tool to improve the listening experience [
11]. An equalizer is used to adjust the sound level of frequency bands in a way that it meets the personal preference of the listener, so it could be evaluated through subjective analysis. An equalizer can be used either in the music production stage, in which experienced audio engineers equalize songs by means of specialized software, or in home/car stereo systems, or even in mobile smartphones where usually a parametric equalizer is implemented in the form of “Bass”, “Midrange”, and “Treble” knobs. Additionally, equalization is used to improve the performance of sound reproduction systems. A non-ideal audio system (i.e., small loudspeakers and non-linear amplifier) and the room environment characteristics can modify the listening experience, introducing undesired artifacts. In this context, several approaches can be found in the literature for room response equalization (RRE), which are used to improve the quality of the sound reproduction system. For a complete review on RRE, it is possible to refer to [
12]. In this study, we focus only on the first type of equalization, which is applied for modifying the audio experience according to personal preference, avoiding the correction of the reproduction system. Future studies will be focused on this scenario.
Another important aspect is the listener’s sound perception, which depends on the human auditory system that incorporates a sound weighting process, known as equal loudness level contour (ELC) [
13]. By definition, an equal-loudness contour is a measure of sound pressure level, over the frequency spectrum, for which a listener perceives a constant loudness when presented with pure steady tones. The ELC is not identical for every person, leading to different perception of sound among humans. Apart from the different ELC among humans, the preference on the type of equalization can differ from one listener to another depending on the age, the gender, and the prior listening experience [
14]. For example, previous research shows that women tend to prefer the normal treble over artificially boosted bass. This characteristic may be connected to the fact that the female ear canal is generally smaller than the male ear canal [
15]. In addition, younger and less experienced listeners tend to prefer more bass and treble [
14]. Moreover, the same person presents different ELC for different levels of audio reproduction gain. Towards this idea, in [
16] a novel equalization approach is proposed to achieve subjectively constant equalization irrespective of the audio reproduction gain, based on the established perceived loudness model. The above considerations make clear the fact that there is no standard equalization curve that optimizes the listening experience for all human, even for the same song. The question that arises is if a listener’s mood can affect the equalization preference.
The contemporary music industry relies heavily on music recommendation systems, providing the possibility of mood-based music selection. It would be very interesting to be able to modify a song by means of an equalizer based on the perceived mood, by adjusting the timbre features, without changing the rhythm, the melody, and the harmony of the reproduced music. Towards this idea, recent research is focused on mapping an acoustic concept expressed by means of descriptive words (e.g., make the sound more “warm”) to equalizing parameters [
17]. In particular, a weighting function algorithm is introduced to discover the relative influence of each frequency band on a descriptive word which characterizes the music mood. Adjusting the timbre (tonal quality) of a sound is a complicated procedure, because there are non-linear relationships between changed equalization settings and the perceived sound quality variation. Moreover, equalization is a context-dependent procedure and this means that the same equalization curve can have different effect on different songs. In an attempt to face these not-so-consistent concepts, descriptive words are suggested to be considered in two different groups: words that have monotonic relationship with parameters, and words with a non-monotonic relationship. In this sense, “brightness” is considered a monotonic descriptor, because the increasing of the treble-to-bass ratio always leads to the increase in “brightness”. On the contrary, “fullness”/“darkness” is considered a non-monotonic descriptor, as the reduction in the treble-to-bass ratio leads to increase the “fullness”/“darkness” until a point, but beyond that, the perceived “fullness”/“darkness” decreases or even the sound quality is degraded [
18,
19]. Following the above ideas, a perceptual assistant to do equalization is proposed in [
20] to adjust the timbres of brightness, darkness, and smoothness in a context-dependent fashion. In addition, the interface “Audealize”, introduced in [
21], allows the listener to adjust the equalization settings by selecting descriptive terms in a word map, which consists of word labels for audio effects. As mentioned above, this smart equalization is related to the perceived emotion but there are not clear indices about what is happening to the induced emotion.
As said, music can have an impact on the listener’s mood (i.e., induced feeling) but, at the same time, the current listener’s mood has an effect not only on the music track selection (reference), but also on the spectral features of a song that a listener wants to emphasize (i.e., equalization preference). So far, the field of correlating listeners’ mood and preferred music equalization is not established in the literature, leaving room for research. The novelty of this study lies in the idea of exploring the relation between audio equalization preference and listeners’ arousal and pleasure states.
The paper is organized as follows. In
Section 2, the equalization curves and audio dataset used in the experiment, the equipment calibration, and the experimental procedure are presented. In
Section 3, the results of the experiments, given by 52 participants for 10 tracks, are presented. Specifically, the equalization preference for the different listener mood states, interpreted in terms of listener’s arousal and pleasure, is analyzed. In
Section 4, the conclusions are drawn.
4. Conclusions and Future Work
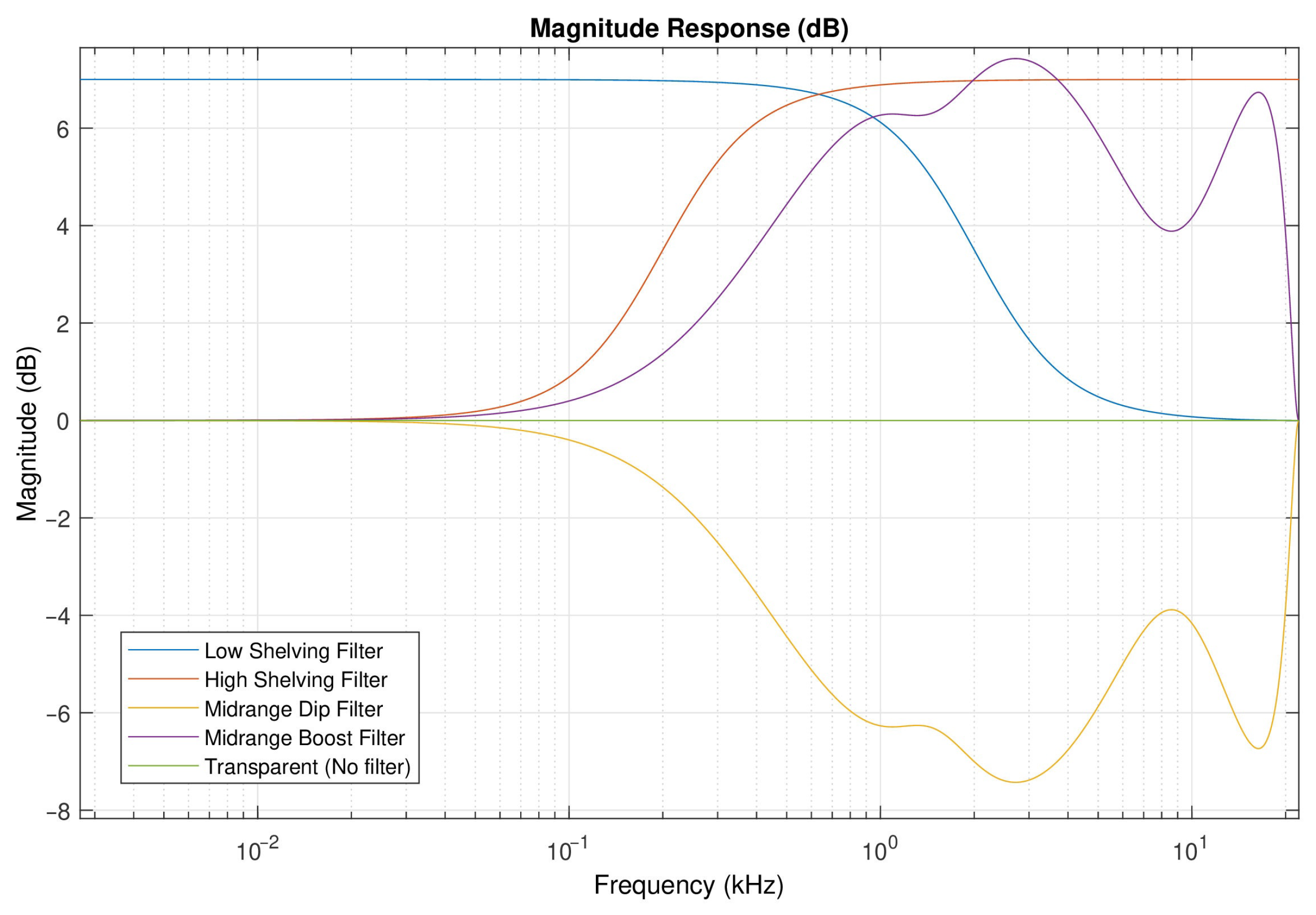
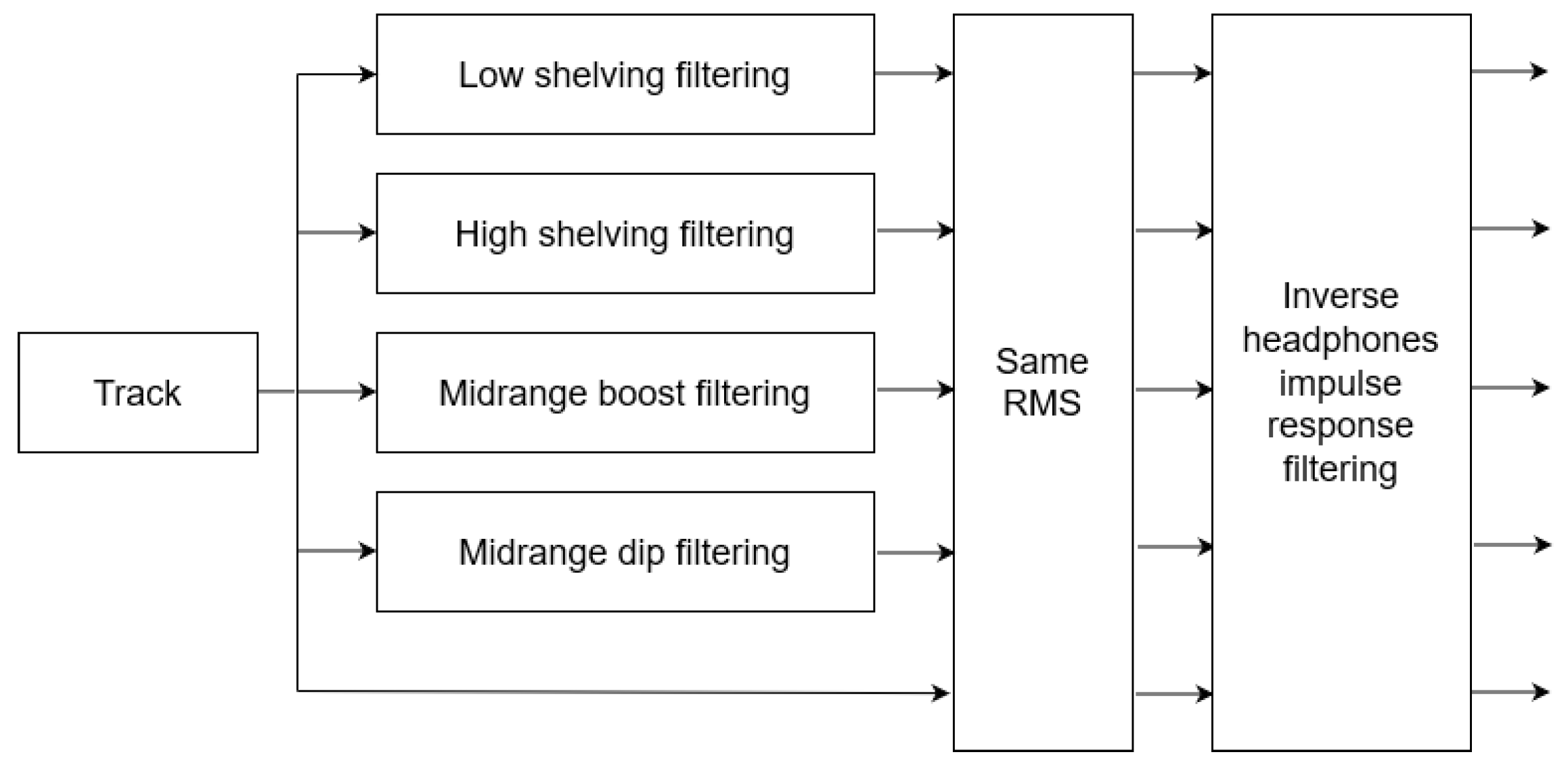
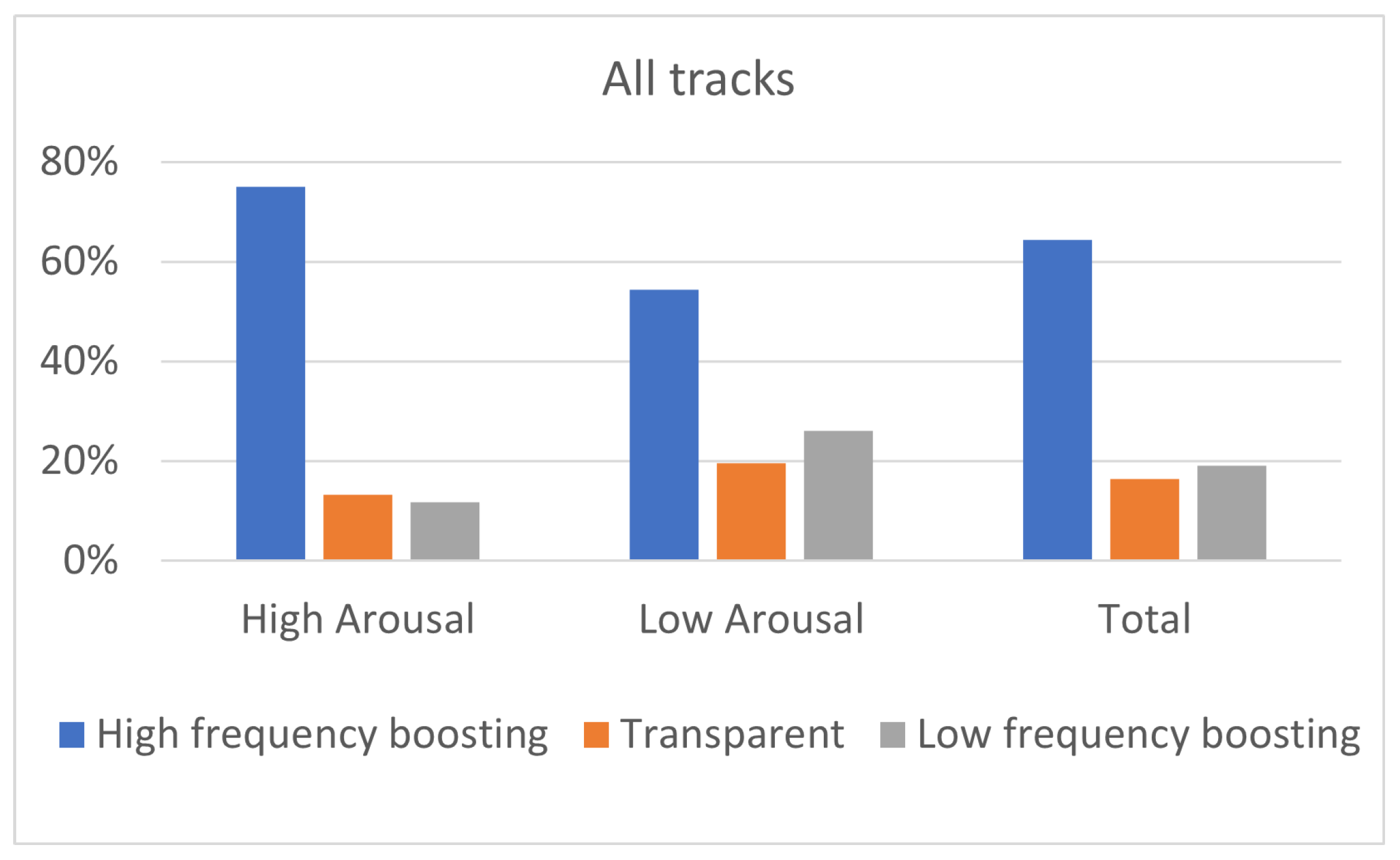
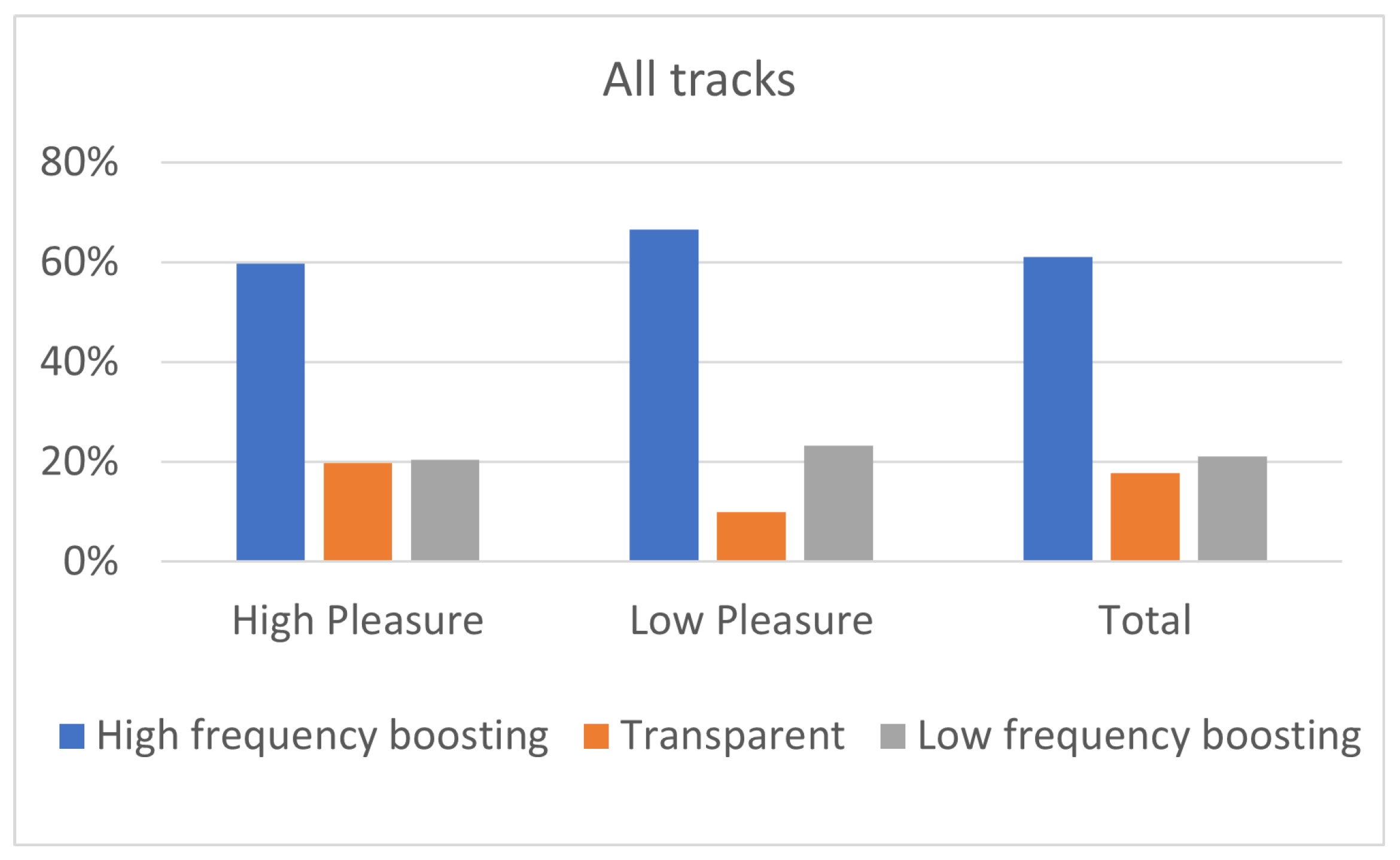
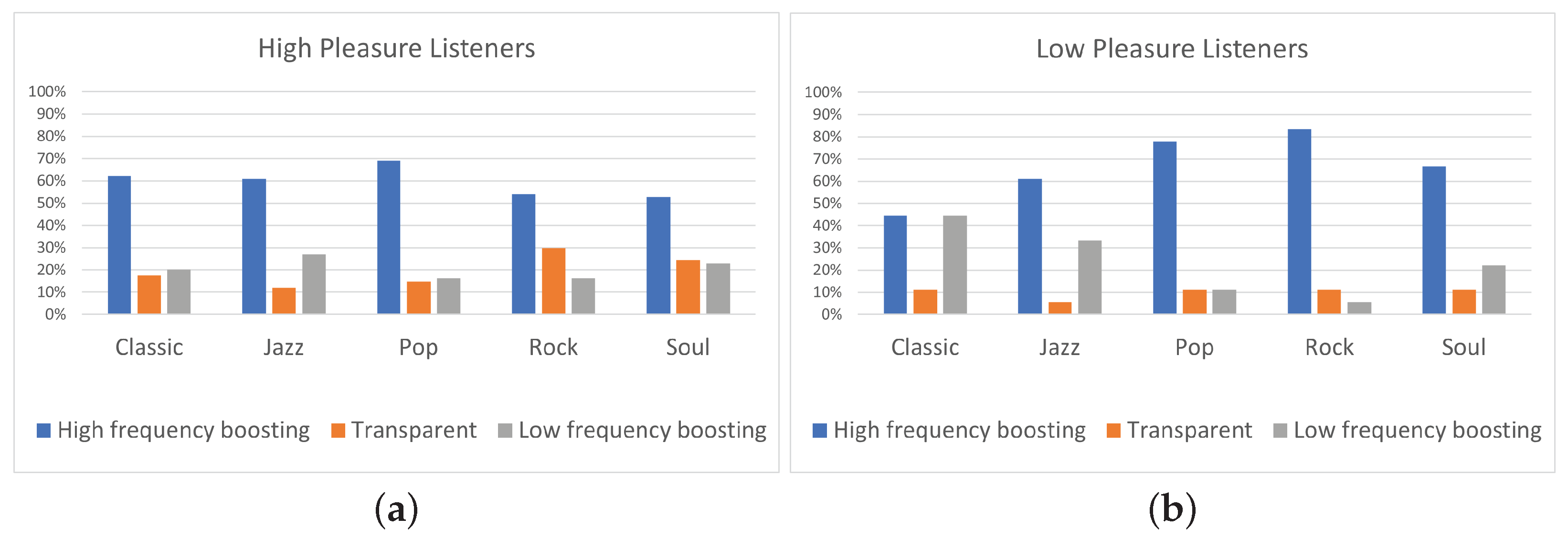
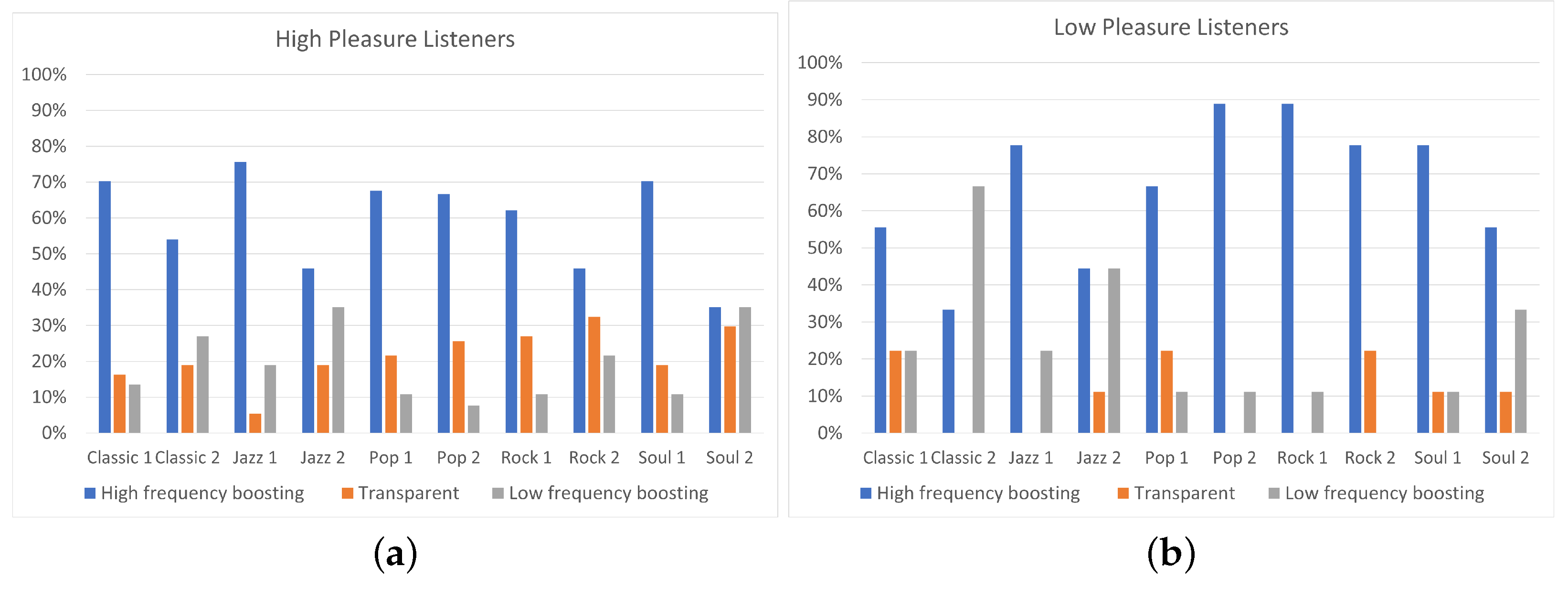
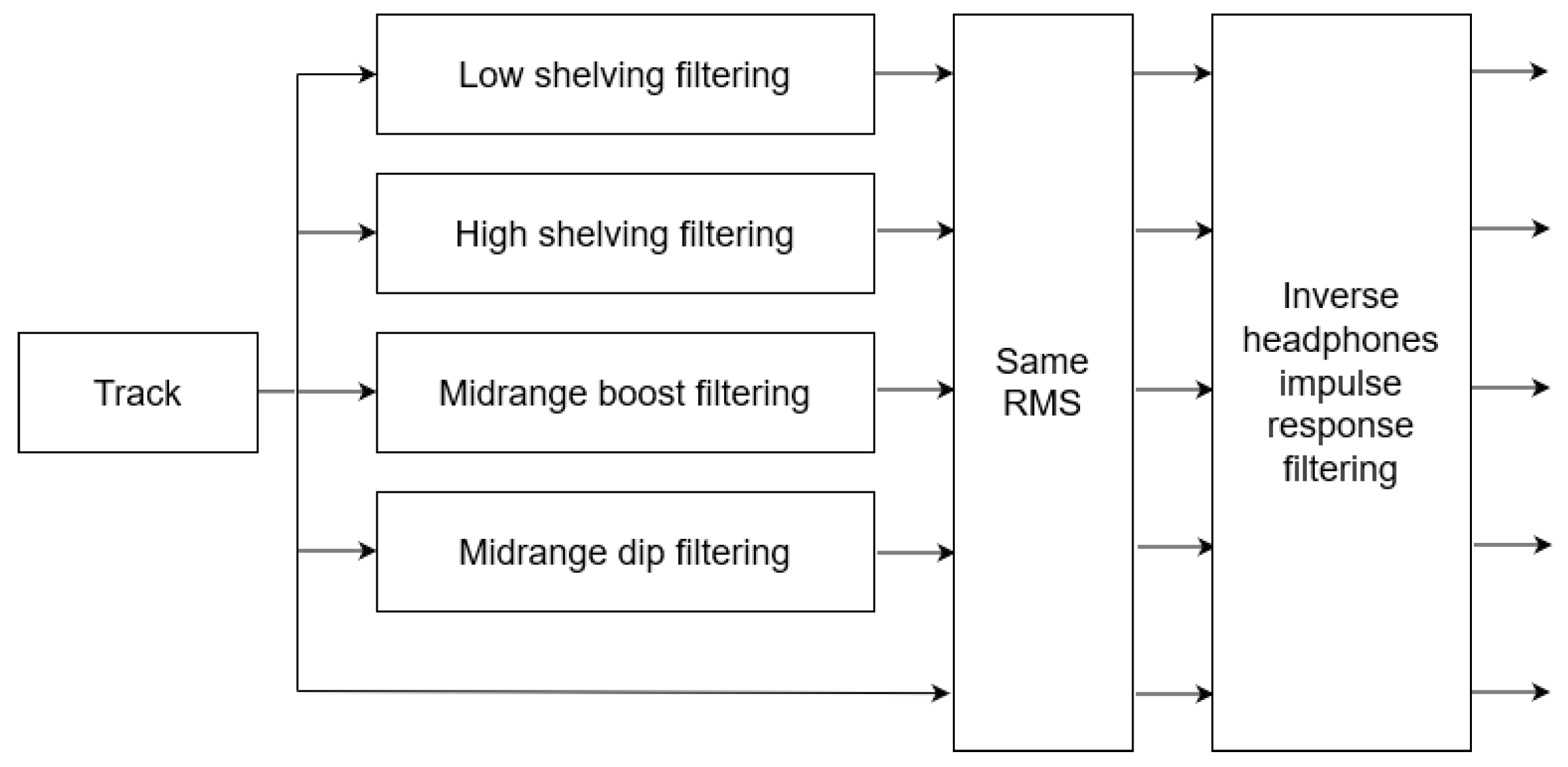
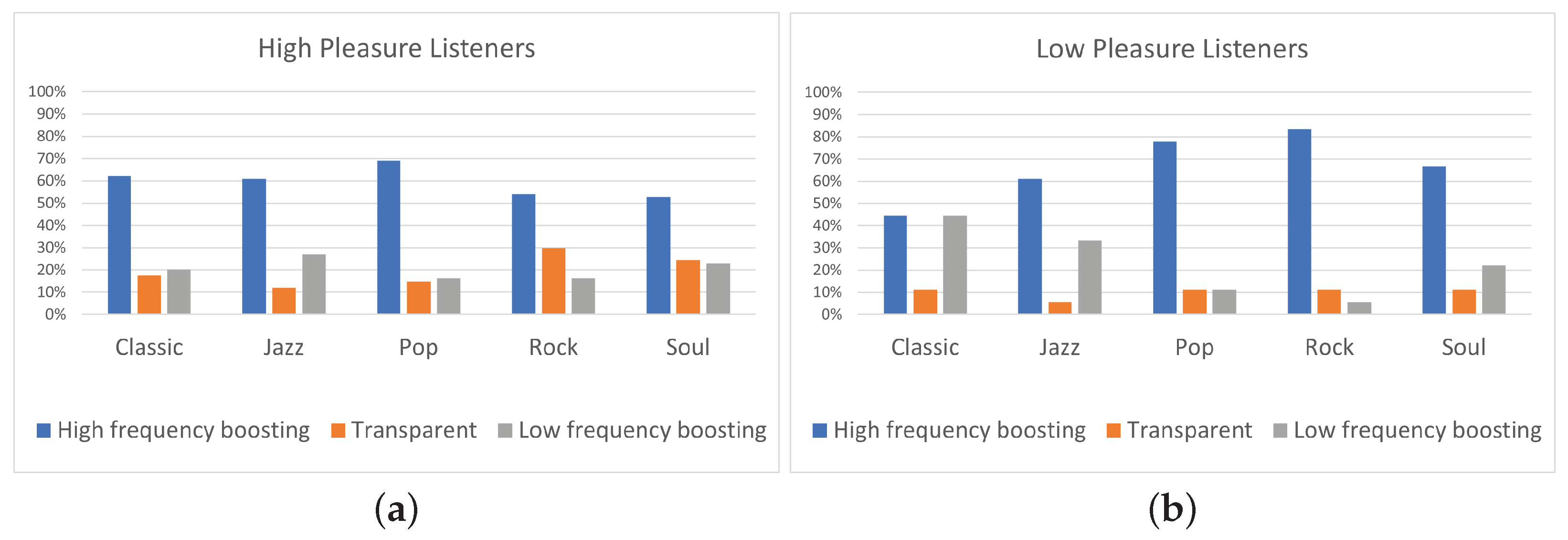
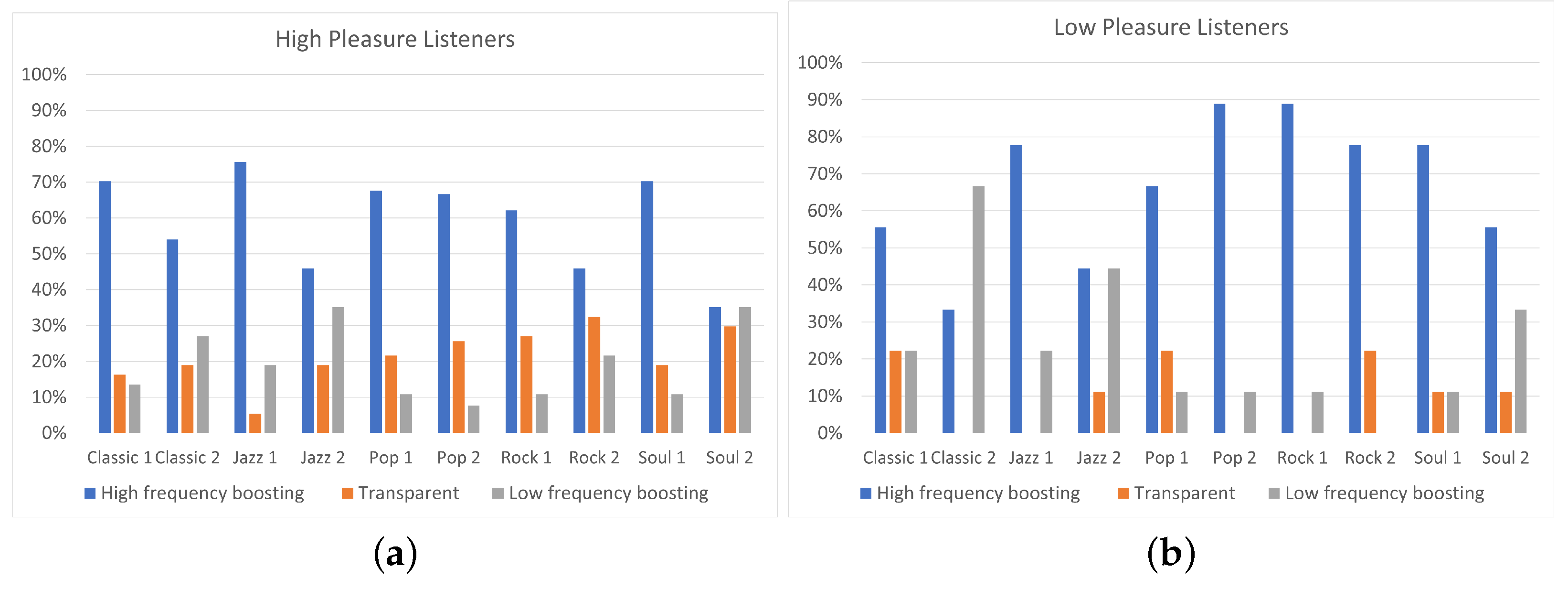
In this paper, the effect of listeners’ arousal and pleasure on equalization preference was investigated. Participants considered, among a pool of five predefined equalization curves, namely two high-frequency boosting (i.e., “High shelving” and “Midrange boost”), two low-frequency boosting (i.e., “Low shelving” and ”Midrange dip”), and “Transparent” filtering. The dataset consisted of 10 songs, belonging to five different music genres, namely classic, jazz, pop, rock, and soul. Listeners’ arousal and pleasure were classified as high and low. The influence of listeners’ arousal on the equalization preference was analyzed between listeners of high and low arousal. Likewise, the influence of listener pleasure on the equalization preference was analyzed between listeners of high and low pleasure.
Participants’ mood was transcribed by means of 15 predefined mood descriptors located on the pleasure/arousal plane through a self-report procedure, prior to the equalization preference test. Participant’s arousal and pleasure state was decided by, firstly, transforming the categorical mood descriptors to arousal and pleasure binary categorization (“high” and “low”) values, and then, by applying a majority rule over the binary categorization values, as analytically described in
Section 3.1. The effect of listeners’ arousal on equalization preference was investigated by analyzing results derived from 45 participants, and the effect of listeners’ pleasure on equalization preference by analyzing results derived from 46 participants.
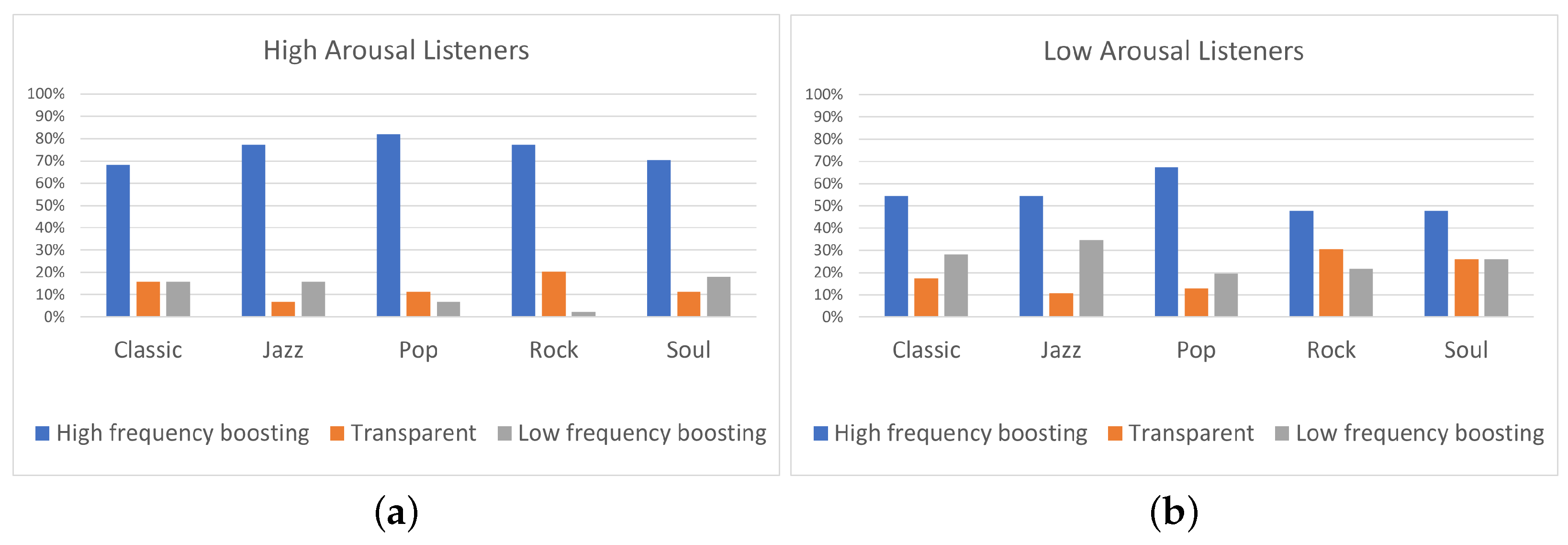
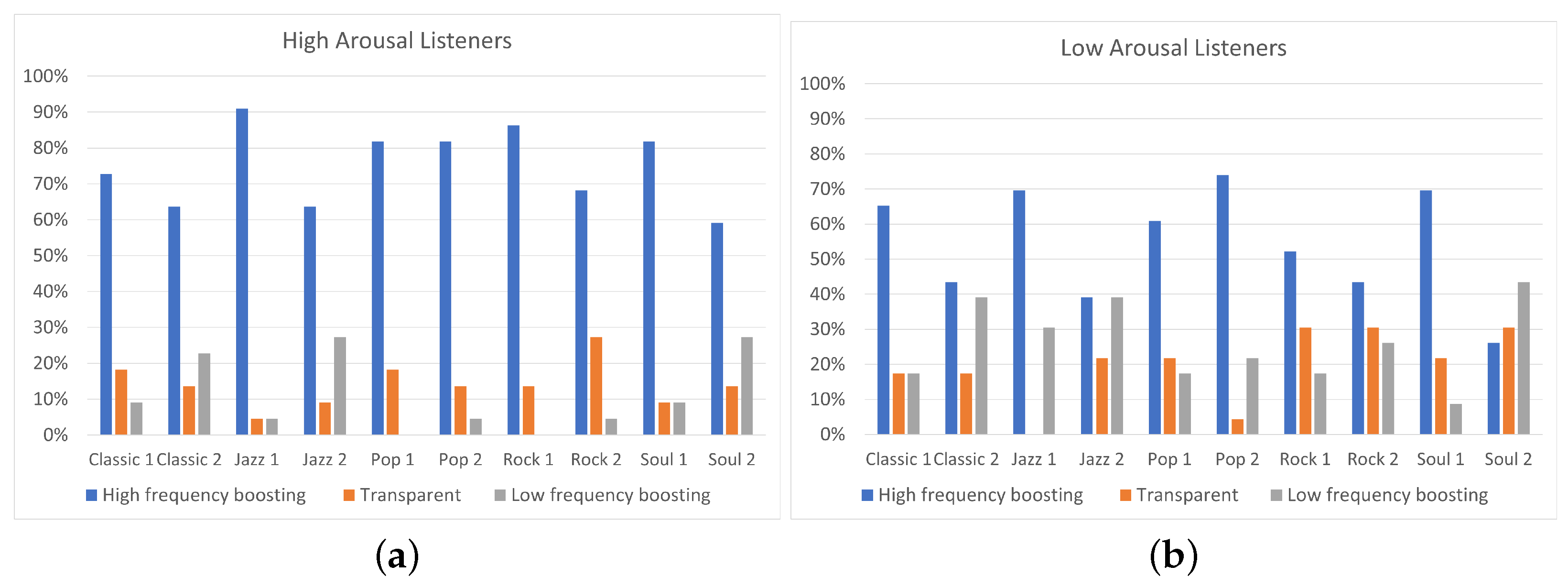
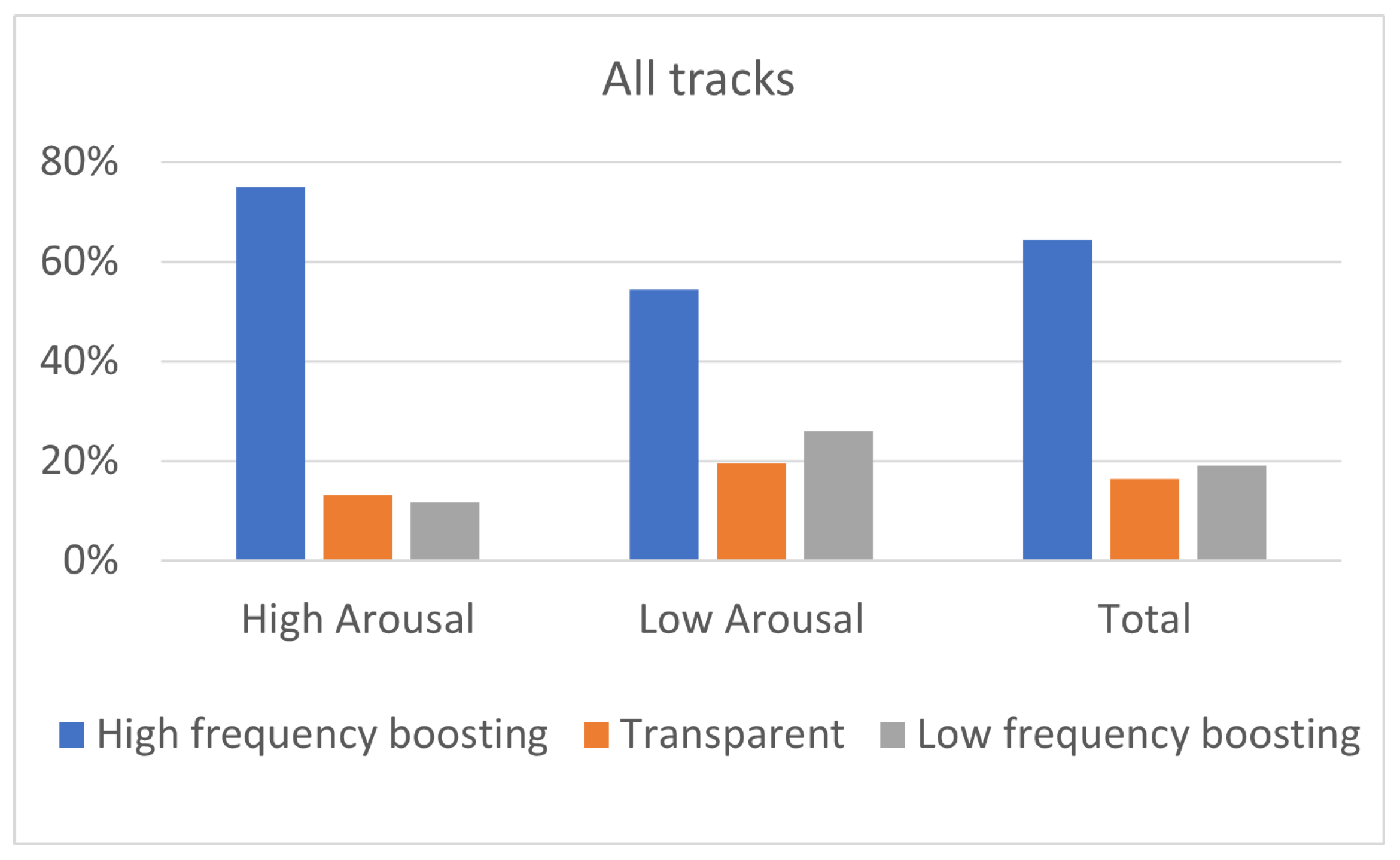
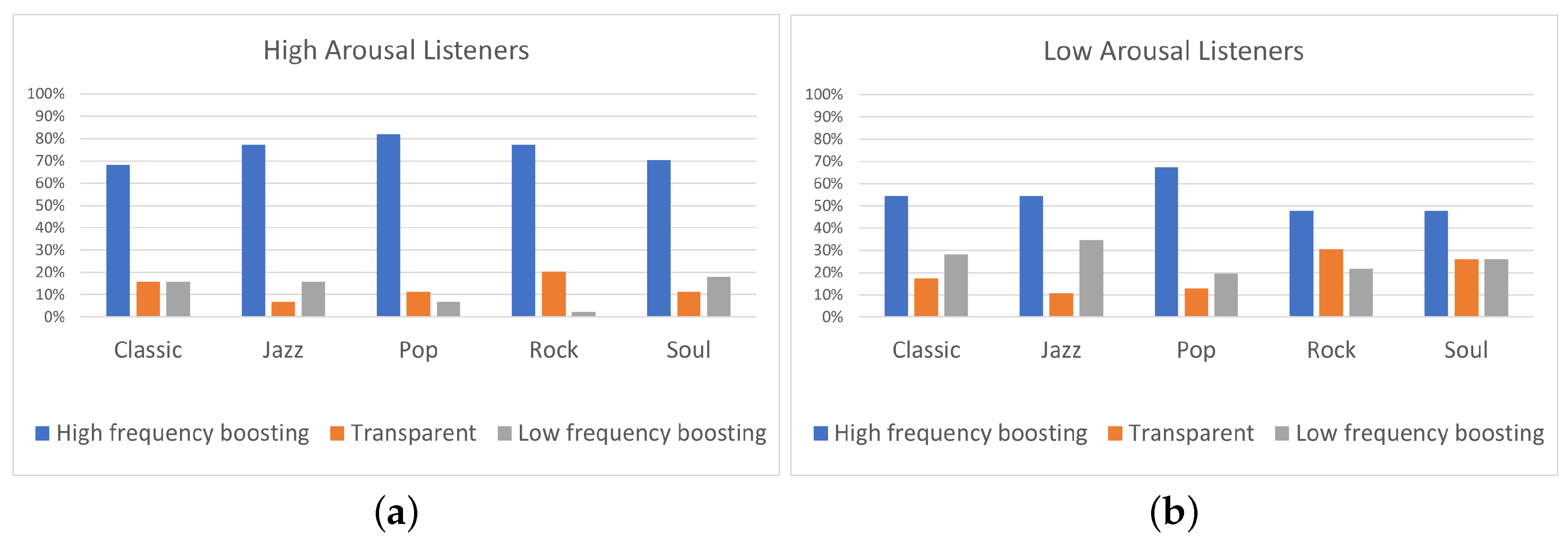
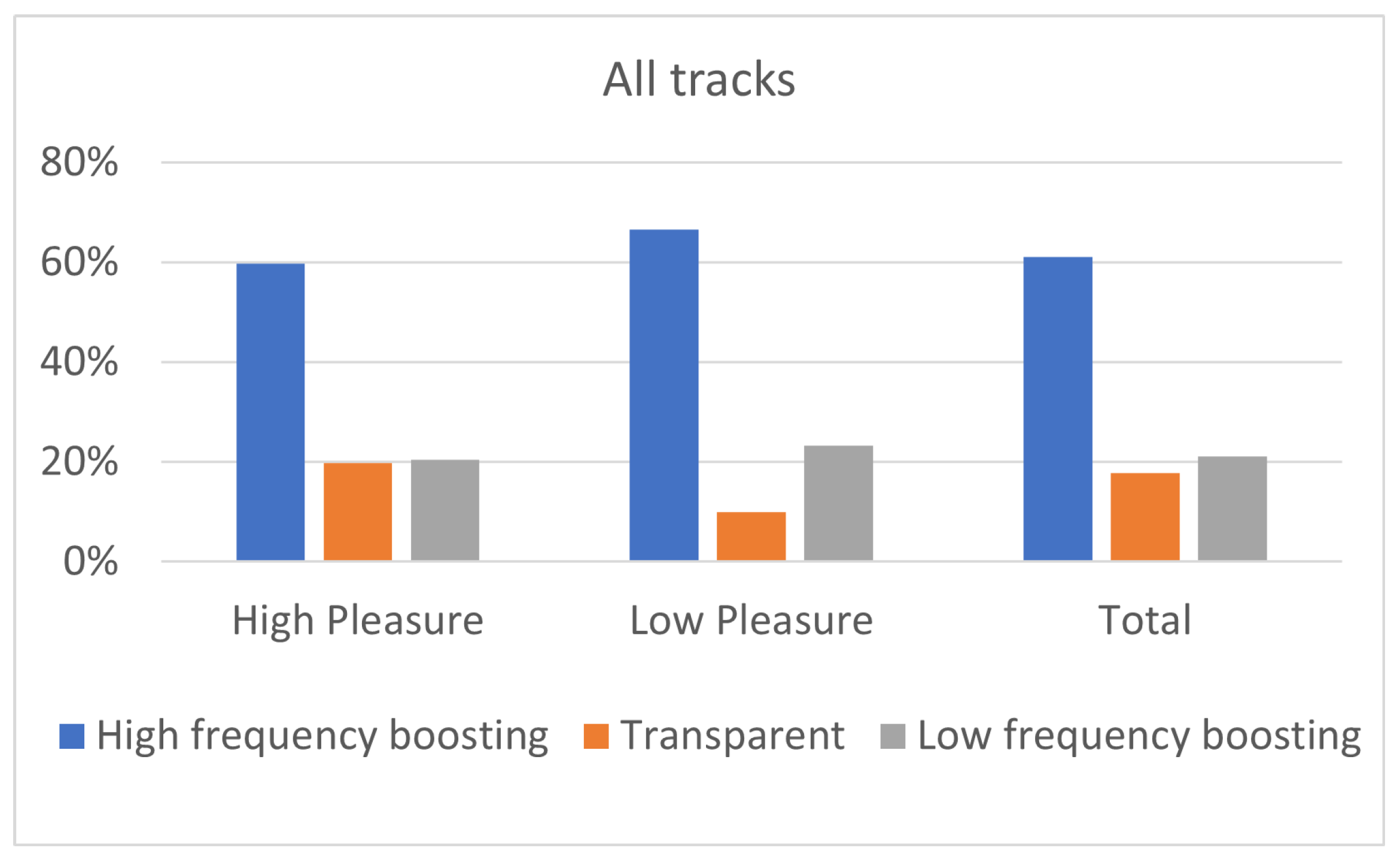
The results of the experiment indicated that the two high-frequency boosting curves, denoted as a single category labeled “High-frequency boosting”, were the most preferred ones among the five predefined equalization curves, independently of the listener’s arousal and pleasure state. Listeners on high arousal (N = 22) presented higher percentages of “High-frequency boosting” preference, comparing to listeners on low arousal (N = 23). Moreover, low-arousal listeners exhibited higher percentages of ”Low-frequency boosting” filtering choice, comparing to listeners of high arousal. Listeners on high pleasure (N = 37) exhibited higher percentages of ”Transparent” filtering selection, comparing to listeners of low pleasure (N = 9); however, it should be remarked that participants allocation over high and low pleasure states was unbalanced, leading to conclusions that should be further verified by means of additional tests.
Moreover, a statistical analysis has been conducted using Fisher’s exact test showing that the listener’s arousal is a more significant factor for the equalization preference in contrast to pleasure. However, the limited sample dimension does not allow us to obtain a robust indication of the relation between track and pleasure or arousal attitude of a subject. In particular, regarding the pleasure analysis, none of the tracks presented a p-value lower than 0.05. A possible reason for the high p-values is the unbalanced distribution of participants between “high” and “low” pleasure states.
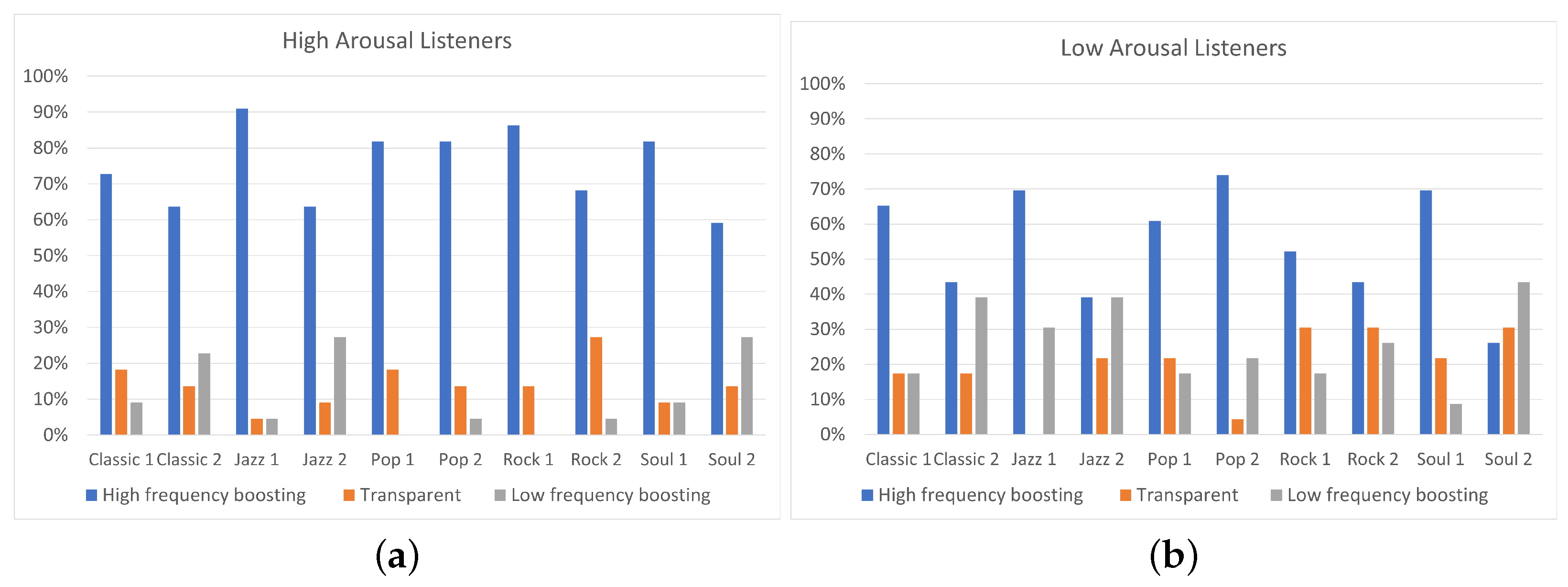
Future research will be oriented to overcome some limitations we found in this study. In particular, regarding the program material, the study included only five music genres, each one represented by only two stimuli. A deeper analysis on different genres with more stimuli would be included for future developments. In addition to this, the small number of participants involved in the study (i.e., 45 for the arousal analysis and 46 for the pleasure analysis) and the unbalanced allocation of participants over the two pleasure states (“high” and “low”), probably led to the obtained statistically non-significant results. In a future work, the participants’ panel could be expanded to eliminate, as well, the impact of personal equalization preference on the results. Furthermore, despite the fact that binary categorization of pleasure/arousal values is commonly used in these kinds of experiments, it is not, to the authors’ best knowledge, part of a validated psychological scale. Moreover, further experiments for the evaluation of listeners’ mood could be conducted using not only self-reporting procedures, but also measuring physiological parameters such as heart rate variability (HRV), galvanic skin response (GSR), and electroencephalography (EEG) to obtain more objective indices of a listener’s mood. This way, several problems affecting the self-reporting procedure, such as difficulties in the awareness of one’s emotions and self-presentation biases (referred to individuals’ tendency to feel uneasy about reporting states that may be seen as undesirable, e.g., depressed mood) would be avoided. Additionally, further research will be conducted on analyzing why equalization preference between high and low arousal/pleasure listeners is different for some tracks and similar for other tracks. A first step towards this concept could be to indicate the specific song’s characteristics that are responsible for this variation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}