
Effectiveness of MP3 Coding Depends on the Music Genre: Evaluation Using Semantic Differential Scales




Abstract
1. Introduction
2. Methods
2.1. Musical Excerpts
2.2. Participants
2.3. Questionnaire
2.4. Experimental Design and Procedure
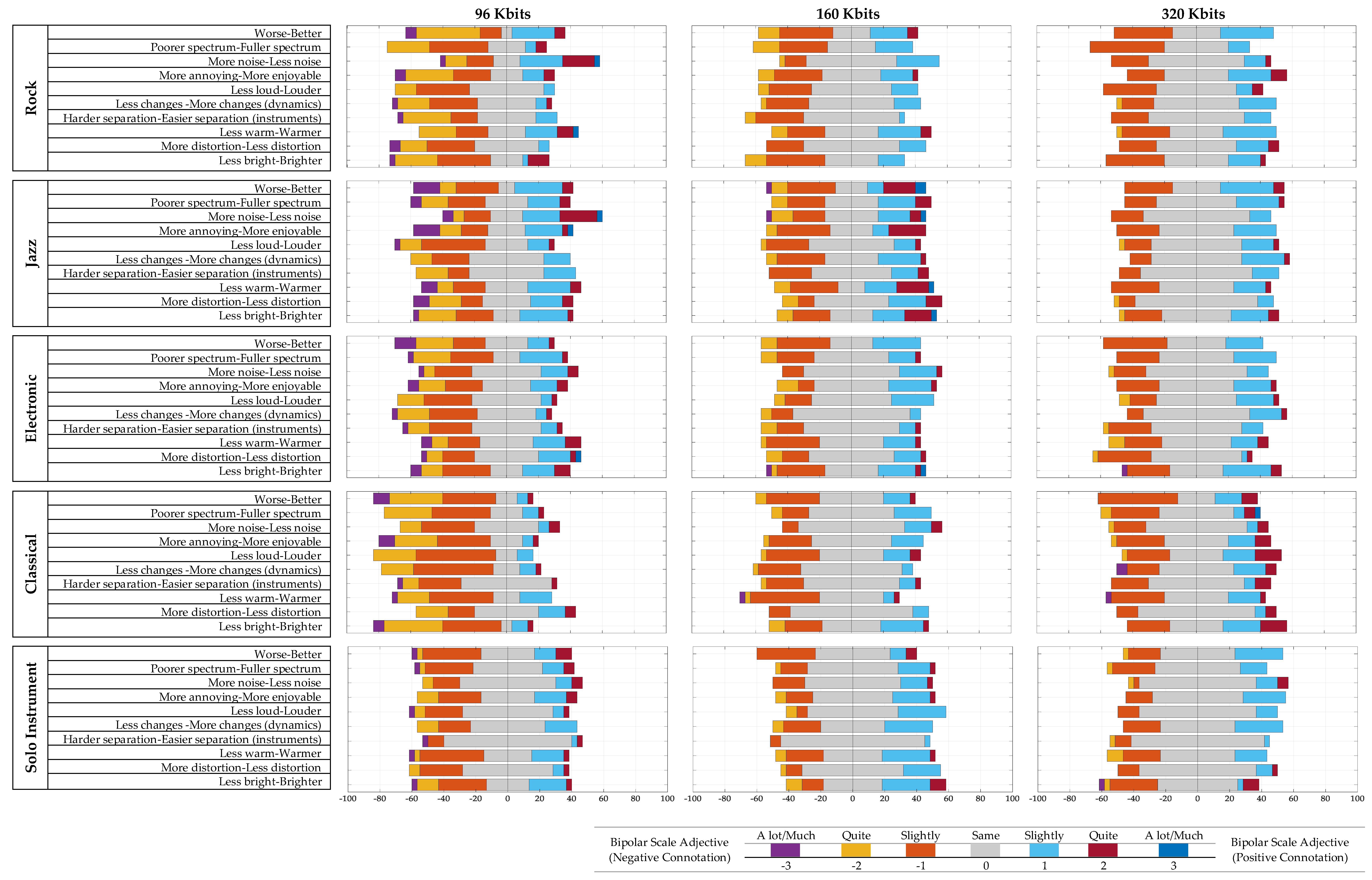
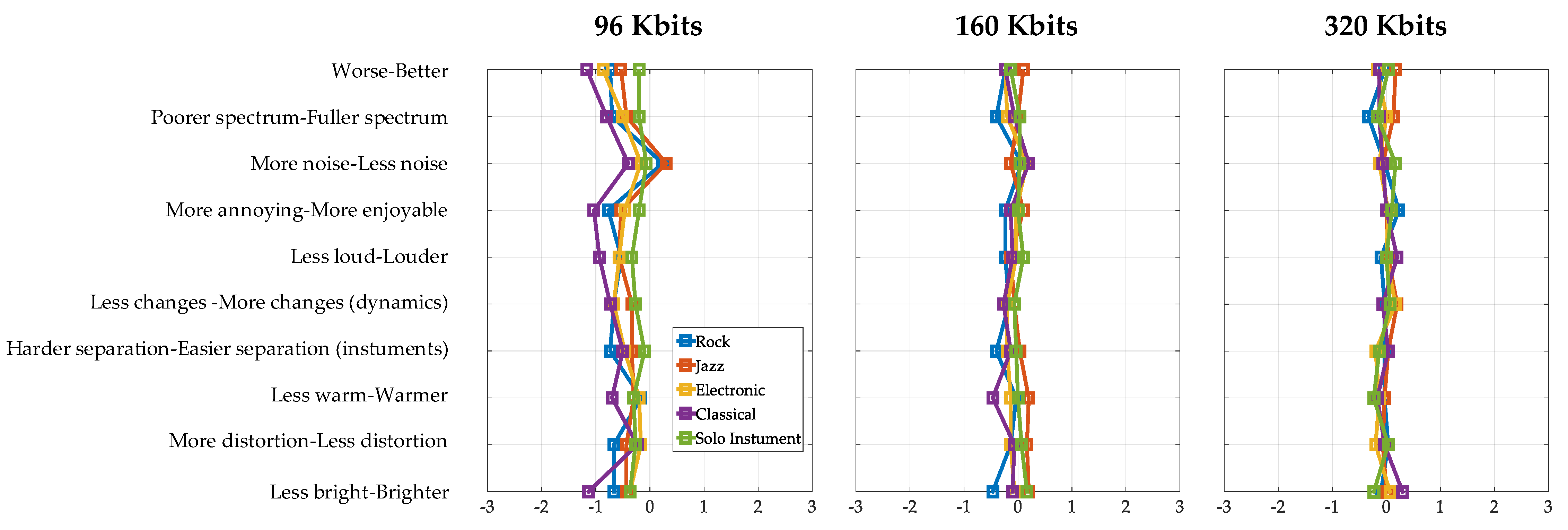
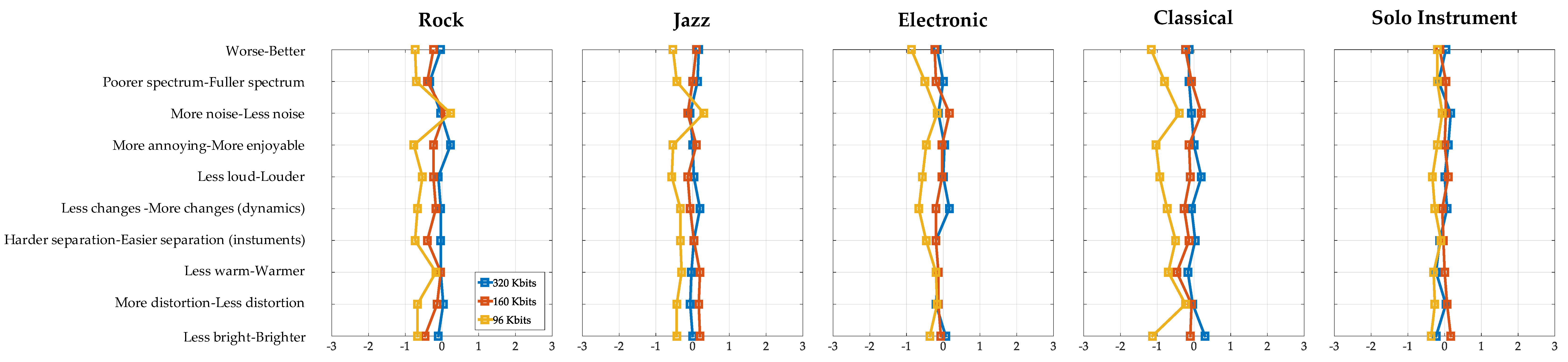
3. Results
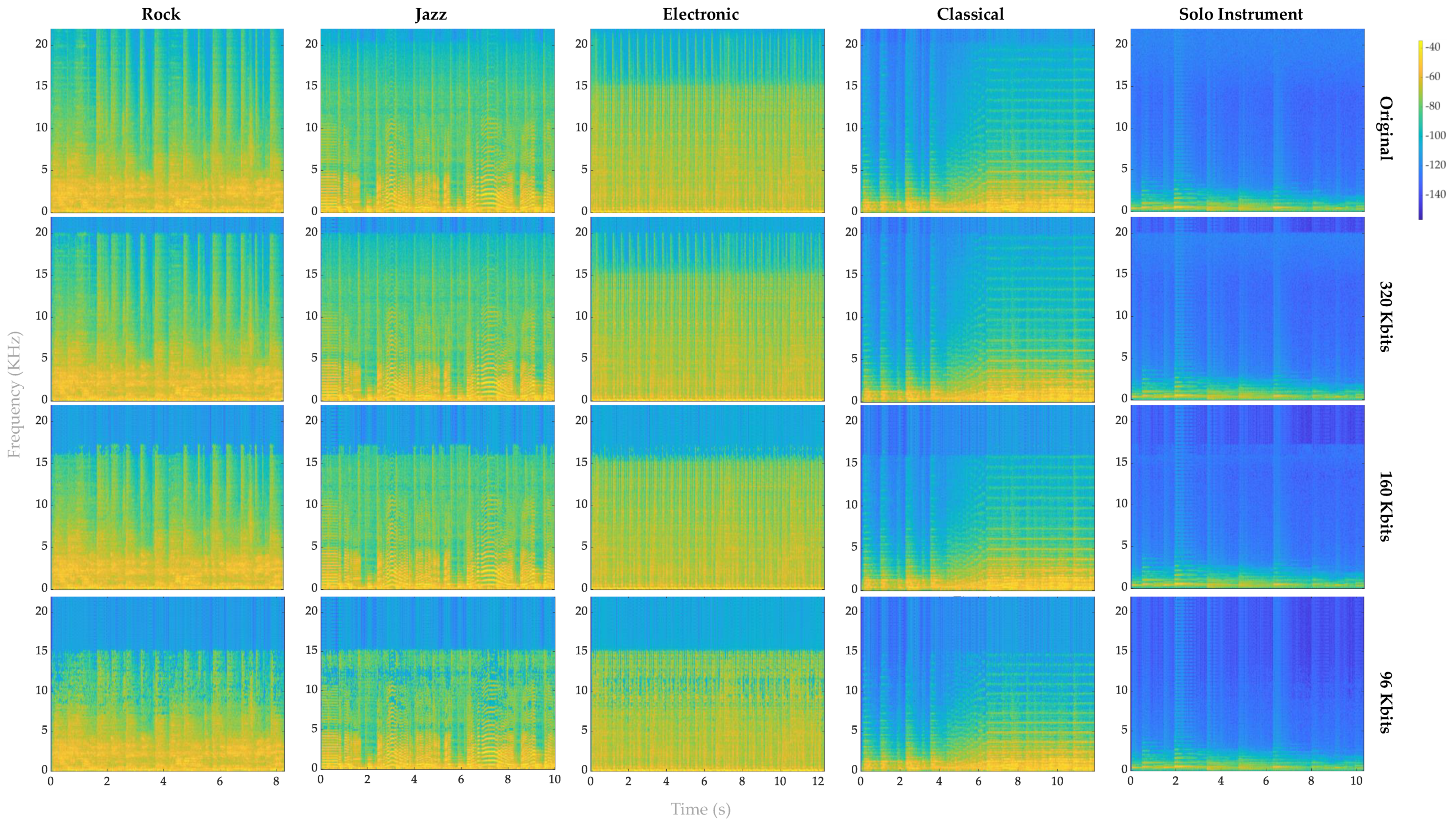
4. Discussion
4.1. Impact of MP3 Compression on Classical Music
4.2. Impact of MP3 Compression on Solo Instrument
4.3. Impact of MP3 Compression on Electronic, Rock and Jazz Music
4.4. General Remarks
4.5. Future Work
5. Conclusions
- Classical music had the greatest negative impact due to MP3 compression, among the genres (lowest ratings in 8 out of 10 bipolar scales).
- The solo instrument was least affected by the MP3 encoding, among the genres (highest rating in 7 out of 10 bipolar scales).
- For electronic, rock and jazz music, it seems that the results for these genres are somewhere in between the results for classical music and the solo instrument.
- A musical signal that has a large amount of musical information that spans the entire auditory spectrum is likely to be negatively affected the most from the application of the MP3 algorithm. The music genre is of great importance when choosing the compression bitrate.
- The findings of this study can be used to optimize and adapt the MP3 standard, depending on the music genre and the music piece that needs to be encoded.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
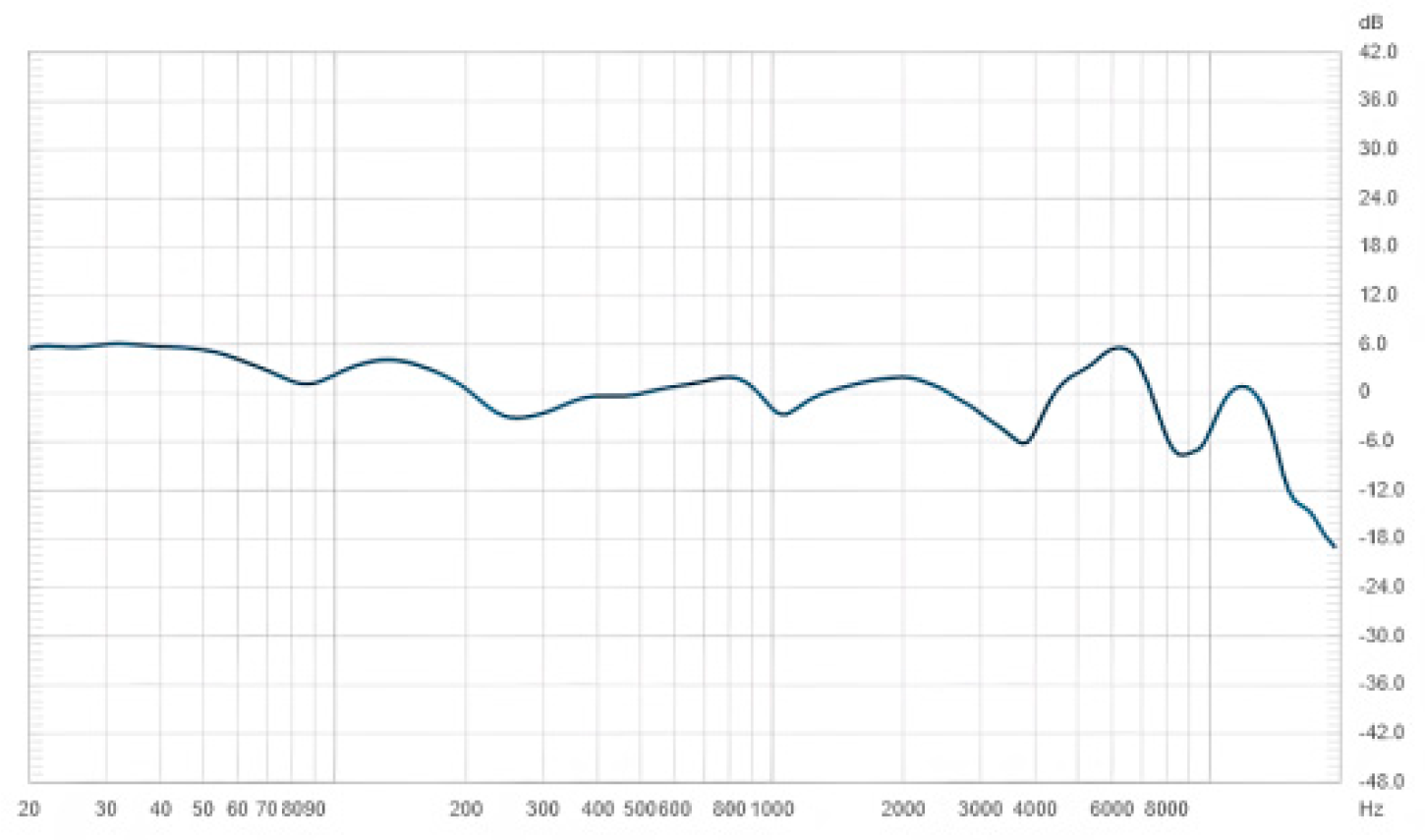{kind=link}
| Dynamic Range (dB) | ||||
|---|---|---|---|---|
| Music Genre | Original | 320 kbps | 160 kbps | 96 kbps |
| Rock | 12.0 | 11.8 | 11.8 | 11.9 |
| Jazz | 10.3 | 10.3 | 10.2 | 10.6 |
| Electronic | 6.4 | 6.9 | 6.8 | 6.3 |
| Classical | 8.5 | 8.6 | 8.6 | 8.7 |
| Solo instrument | 9.9 | 9.9 | 9.9 | 9.9 |
Appendix B

Appendix C
| Πολύ | Aρκετά | Λίγο | Το ίδιο | Λίγο | Aρκετά | Πολύ | ||
|---|---|---|---|---|---|---|---|---|
| Bipolar Scale Adjective (Negative Connotation) | Bipolar Scale Adjective (Positive Connotation) | |||||||
| −3 | −2 | −1 | 0 | 1 | 2 | 3 |
Appendix D
| Rock (96) | Jazz (96) | Electronic (96) | Classical (96) | Solo (96) | |
|---|---|---|---|---|---|
| Worse–Better | −0.733 | −0.533 | −0.867 | −1.167 | −0.200 |
| Poorer spectrum–Fuller spectrum | −0.700 | −0.433 | −0.500 | −0.800 | −0.200 |
| More noise–Less noise | 0.233 | 0.300 | −0.167 | −0.400 | −0.067 |
| More annoying–More enjoyable | −0.767 | −0.533 | −0.467 | −1.033 | −0.200 |
| Less loud–Louder | −0.533 | −0.567 | −0.567 | −0.933 | −0.333 |
| Less changes–More changes (dynamics) | −0.667 | −0.333 | −0.667 | −0.733 | −0.267 |
| Harder separation–Easier separation (instuments) | −0.733 | −0.333 | −0.467 | −0.500 | −0.100 |
| Less warm–Warmer | −0.167 | −0.300 | −0.200 | −0.700 | −0.300 |
| More distortion–Less distortion | −0.667 | −0.433 | −0.167 | −0.233 | −0.267 |
| Less bright–Brighter | −0.667 | −0.433 | −0.367 | −1.133 | −0.367 |
| Rock (160) | Jazz (160) | Electronic (160) | Classical (160) | Solo (160) | |
|---|---|---|---|---|---|
| Worse–Better | −0.233 | 0.100 | −0.233 | −0.233 | −0.133 |
| Poorer spectrum–Fuller spectrum | −0.400 | 0.000 | −0.200 | −0.067 | 0.033 |
| More noise–Less noise | 0.067 | −0.133 | 0.167 | 0.200 | 0.033 |
| More annoying–More enjoyable | −0.233 | 0.100 | −0.033 | −0.133 | 0.000 |
| Less loud–Louder | −0.233 | −0.133 | −0.033 | −0.100 | 0.100 |
| Less changes–More changes (dynamics) | −0.167 | −0.067 | −0.200 | −0.267 | −0.067 |
| Harder separation–Easier separation (instuments) | −0.400 | 0.033 | −0.200 | −0.133 | −0.033 |
| Less warm–Warmer | −0.033 | 0.200 | −0.133 | −0.467 | 0.000 |
| More distortion–Less distortion | −0.133 | 0.167 | −0.133 | −0.067 | 0.067 |
| Less bright–Brighter | −0.467 | 0.200 | −0.067 | −0.100 | 0.167 |
| Rock (320) | Jazz (320) | Electronic (320) | Classical (320) | Solo (320) | |
|---|---|---|---|---|---|
| Worse–Better | −0.033 | 0.167 | −0.167 | −0.133 | 0.033 |
| Poorer spectrum–Fuller spectrum | −0.333 | 0.133 | 0.000 | −0.133 | −0.167 |
| More noise–Less noise | −0.033 | −0.067 | −0.133 | −0.067 | 0.167 |
| More annoying–More enjoyable | 0.233 | 0.000 | 0.033 | 0.000 | 0.100 |
| Less loud–Louder | −0.100 | 0.033 | 0.00 | 0.200 | 0.000 |
| Less changes–More changes (dynamics) | −0.033 | 0.200 | 0.167 | −0.067 | 0.067 |
| Harder separation–Easier separation (instuments) | −0.033 | 0.033 | −0.200 | 0.033 | −0.133 |
| Less warm–Warmer | −0.033 | −0.033 | −0.133 | −0.167 | −0.233 |
| More distortion–Less distortion | 0.033 | −0.067 | −0.200 | −0.033 | 0.033 |
| Less bright–Brighter | −0.100 | 0.000 | 0.067 | 0.300 | −0.233 |
References
- Falkowski-Gilski, P. On the consumption of multimedia content using mobile devices: A year to year user case study. Arch. Acoust. 2020, 45, 321–328. [Google Scholar]
- Crawford, W. MP3 Audiobooks: A New Library Medium? Am. Libr. 2001, 32, 64–66. [Google Scholar]
- Xiang, Z.; Bestagini, P.; Tubaro, S.; Delp, E.J. Forensic Analysis and Localization of Multiply Compressed MP3 Audio Using Transformers. arXiv 2022, arXiv:2203.16499. [Google Scholar]
- Yang, R.; Qu, Z.; Huang, J. Detecting digital audio forgeries by checking frame offsets. In Proceedings of the 10th ACM Workshop on Multimedia and Security, Oxford, UK, 22–23 September 2008; pp. 21–26. [Google Scholar]
- Pan, D.Y. Digital audio compression. Digit. Tech. J. 1993, 5, 28–40. [Google Scholar]
- Raissi, R. The Theory behind MP3. MP3’Tech 2002. Available online: http://www.mp3-tech.org/programmer/docs/mp3_theory.pdf (accessed on 25 June 2022).
- Zwicker, E. Subdivision of the audible frequency range into critical bands (Frequenzgruppen). J. Acoust. Soc. Am. 1961, 33, 248. [Google Scholar] [CrossRef]
- Greenwood, D.D. Critical bandwidth and the frequency coordinates of the basilar membrane. J. Acoust. Soc. Am. 1961, 33, 1344–1356. [Google Scholar] [CrossRef]
- Brandenburg, K. MP3 and AAC explained. In Proceedings of the Audio Engineering Society Conference: 17th International Conference: High-Quality Audio Coding, Florence, Italy, 2–5 September 1999. [Google Scholar]
- Hacker, S. MP3: The Definitive Guide; O’Reilly: Sebastopol, CA, USA, 2000. [Google Scholar]
- Musmann, H.G. Genesis of the MP3 audio coding standard. IEEE Trans. Consum. Electron. 2006, 52, 1043–1049. [Google Scholar] [CrossRef]
- Vaseghi, S.V. Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Pan, D. A tutorial on MPEG/audio compression. IEEE Multimed. 1995, 2, 60–74. [Google Scholar] [CrossRef]
- Yen, C.-H.; Wei, H.-Y.; Wu, B.-F. New Encryption Approaches to MP3 Compression; Department of Electrical and Controling Engineering, National Chiao Tung University: Hsinchu, Taiwan, 2003. [Google Scholar]
- Yang, Y.; Yi, X.; Zhao, X.; Zhang, J. A Robust MP3 Steganographic Method against Multiple Compressions Based on Modified Discrete Cosine Transform. Secur. Commun. Netw. 2021, 2021, 4471117. [Google Scholar] [CrossRef]
- Ito, A.; Konno, K.; Ito, M.; Makino, S. Robust Transmission of Audio Signals over the Internet: An Advanced Packet Loss Concealment for MP3-Based Audio Signals. Interdiscip. Inf. Sci. 2012, 18, 99–105. [Google Scholar] [CrossRef][Green Version]
- Cantzos, D.; Kyriakakis, C. Quality enhancement of low bit rate MPEG1-layer 3 audio based on audio resynthesis. In Proceedings of the Audio Engineering Society Convention 119, New York, NY, USA, 8 October 2005. [Google Scholar]
- Liu, C.-M.; Hsu, H.-W.; Lee, W.-C. Compression artifacts in perceptual audio coding. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 681–695. [Google Scholar] [CrossRef]
- Marins, P.; Rumsey, F.; Zielinski, S.K. The relationship between selected artifacts and basic audio quality in perceptual audio codecs. In Proceedings of the Audio Engineering Society Convention 120, Paris, France, 20–23 May 2006. [Google Scholar]
- D’Alessandro, B.; Shi, Y.Q. MP3 bit rate quality detection through frequency spectrum analysis. In Proceedings of the 11th ACM Workshop on Multimedia and Security, Princeton, NJ, USA, 7–8 September 2009; pp. 57–62. [Google Scholar]
- Luo, D.; Luo, W.; Yang, R.; Huang, J. Identifying compression history of wave audio and its applications. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2014, 10, 1–19. [Google Scholar] [CrossRef]
- Nishimura, A.; Unoki, M.; Kondo, K.; Ogihara, A. Objective evaluation of sound quality for attacks on robust audio watermarking. In Proceedings of the Meetings on Acoustics ICA2013, Montreal, QC, Canada, 2–7 June 2013; p. 030052. [Google Scholar]
- Kanetada, N.; Yamamoto, R.; Mizumachi, M. Evaluation of sound quality of high resolution audio. In Proceedings of the IEEE/IIAE International Conference on Intelligent Systems and Image Processing, Kitakyushu, Japan, 26–27 September 2013. [Google Scholar]
- Cunningham, S.; McGregor, I. Subjective evaluation of music compressed with the ACER codec compared to AAC, MP3, and uncompressed PCM. Int. J. Digit. Multimed. Broadcast. 2019, 2019, 8265301. [Google Scholar] [CrossRef]
- Pras, A.; Zimmerman, R.; Levitin, D.; Guastavino, C. Subjective evaluation of mp3 compression for different musical genres. In Proceedings of the Audio Engineering Society Convention 127; Audio Engineering Society: New York, NY, USA, 2009. [Google Scholar]
- Ruzanski, E.P. Effects of MP3 encoding on the sounds of music. IEEE Potentials 2006, 25, 43–45. [Google Scholar] [CrossRef]
- Osgood, C.E.; Suci, G.J.; Tannenbaum, P.H. The Measurement of Meaning; University of Illinois press: Chicago, IL, USA, 1957. [Google Scholar]
- North, A.C.; Hargreaves, D.J.; O’Neill, S.A. The importance of music to adolescents. Br. J. Educ. Psychol. 2000, 70, 255–272. [Google Scholar] [CrossRef]
- Schäfer, T.; Sedlmeier, P. From the functions of music to music preference. Psychol. Music 2009, 37, 279–300. [Google Scholar] [CrossRef]
- Pilgrim, L.; Norris, J.I.; Hackathorn, J. Music is awesome: Influences of emotion, personality, and preference on experienced awe. J. Consum. Behav. 2017, 16, 442–451. [Google Scholar] [CrossRef]
- Costa, Y.M.; Oliveira, L.; Koerich, A.L.; Gouyon, F.; Martins, J.G. Music genre classification using LBP textural features. Signal Process 2012, 92, 2723–2737. [Google Scholar] [CrossRef]
- Li, T.; Ogihara, M.; Li, Q. A comparative study on content-based music genre classification. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, Toronto, ON, Canada, 28 July 2003–1 August 2003; pp. 282–289. [Google Scholar]
- Li, T.; Ogihara, M. Music genre classification with taxonomy. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23 March 2005; Volume 195, pp. v/197–v/200. [Google Scholar]
- Vercellesi, G.; Zerbini, M.; Vitali, A.L. Objective and subjective evaluation MPEG layer III perceived quality. In Proceedings of the 2006 14th European Signal Processing Conference, Florence, Italy, 4–8 September 2006; pp. 1–5. [Google Scholar]
- Salovarda, M.; Bolkovac, I.; Domitrovic, H. Estimating perceptual audio system quality using PEAQ algorithm. In Proceedings of the 2005 18th International Conference on Applied Electromagnetics and Communications, Dubrovnik, Croatia, 12–14 October 2005; pp. 1–4. [Google Scholar]
- Heise, D.R. Some methodological issues in semantic differential research. Psychol. Bull. 1969, 72, 406. [Google Scholar] [CrossRef]
- Takeda, S.; Morioka, I.; Miyashita, K.; Okumura, A.; Yoshida, Y.; Matsumoto, K. Age variation in the upper limit of hearing. Eur. J. Appl. Physiol. Occup. Physiol. 1992, 65, 403–408. [Google Scholar] [CrossRef]
- Dal Palù, D.; Buiatti, E.; Puglisi, G.E.; Houix, O.; Susini, P.; De Giorgi, C.; Astolfi, A. The use of semantic differential scales in listening tests: A comparison between context and laboratory test conditions for the rolling sounds of office chairs. Appl. Acoust. 2017, 127, 270–283. [Google Scholar] [CrossRef]
- Guski, R. Psychological methods for evaluating sound quality and assessing acoustic information. Acta Acust. United Acust. 1997, 83, 765–774. [Google Scholar]
- Schütte, M.; Müller, U.; Sandrock, S.; Griefahn, B.; Lavandier, C.; Barbot, B. Perceived quality features of aircraft sounds: An analysis of the measurement characteristics of a newly created semantic differential. Appl. Acoust. 2009, 70, 903–914. [Google Scholar] [CrossRef]
- Vieira, J.; Santos, J.A.; Noriega, P. Using semantic differential scales to assess the subjective perception of auditory warning signals. In Proceedings of the 21st International Conference on Digital Audio Effects (DAFx-18), Aveiro, Portugal, 4–8 September 2018; pp. 126–132. [Google Scholar]
- Hülsmeier, D.; Schell-Majoor, L.; Rennies, J.; van de Par, S. Perception of sound quality of product sounds a subjective study using a semantic differential. In Proceedings of the International Congress on Noise Control Engineering, Melbourne, Australia, 16–19 November 2014; pp. 843–851. [Google Scholar]
- Al-Hindawe, J. Considerations when constructing a semantic differential scale. La Trobe Pap. Linguist. 1996, 9, 1–9. [Google Scholar]
- Messick, S.J. Metric properties of the semantic differential. Educ. Psychol. Meas. 1957, 17, 200–206. [Google Scholar] [CrossRef]
- Norman, W.T. Stability-characteristics of the semantic differential. Am. J. Psychol. 1959, 72, 581–584. [Google Scholar] [CrossRef] [PubMed]
- ITU-R. General Methods for the Subjective Assessment of Sound Quality. In Proceedings of the International Telecommunication Union Recommendation; 2003. Available online: https://www.itu.int/rec/R-REC-BS.1284/en (accessed on 25 June 2022).
- ITU-R. Methods for the Subjective Assessment of Small Impairments in Audio Systems. In Proceedings of the International Telecommunication Union Recommendation; 2015. Available online: https://www.itu.int/rec/R-REC-BS.1116 (accessed on 25 June 2022).
- Okabe, D.; Nakatoh, Y. Study on headphone hearing loss prevention methods based on the melody structure of music on portable music player. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018; pp. 1–2. [Google Scholar]
- Higashi, T.; Tanaka, Y.; Nakatoh, Y. Study of volume limit for headphone hearing loss prevention on portable music player. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 7–11 January 2016; pp. 397–398. [Google Scholar]
- Iannace, G.; Ciaburro, G.; Trematerra, A. Video games noise exposure in teenagers and young adults. Noise Vib. Worldw. 2020, 51, 3–11. [Google Scholar] [CrossRef]
- Heiberger, R.; Robbins, N. Design of diverging stacked bar charts for Likert scales and other applications. J. Stat. Softw. 2014, 57, 1–32. [Google Scholar] [CrossRef]
- Gratzl, S.; Lex, A.; Gehlenborg, N.; Pfister, H.; Streit, M. Lineup: Visual analysis of multi-attribute rankings. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2277–2286. [Google Scholar] [CrossRef]
- Robbins, N.B.; Heiberger, R.M. Plotting Likert and other rating scales. In Proceedings of the 2011 Joint Statistical Meeting, Miami Beach, FL, USA, 30 July–4 August 2011. [Google Scholar]
- Kang, J.; Zhang, M. Semantic differential analysis of the soundscape in urban open public spaces. Build. Environ. 2010, 45, 150–157. [Google Scholar] [CrossRef]
- Jeon, J.Y.; Lee, P.J.; You, J.; Kang, J. Acoustical characteristics of water sounds for soundscape enhancement in urban open spaces. J. Acoust. Soc. Am. 2012, 131, 2101–2109. [Google Scholar] [CrossRef] [PubMed]
- Cronbach, L.J. Coefficient alpha and the internal structure of tests. Psychometrika 1951, 16, 297–334. [Google Scholar] [CrossRef]
- Bland, J.M.; Altman, D.G. Statistics notes: Cronbach’s alpha. BMJ 1997, 314, 572. [Google Scholar] [CrossRef]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E.; Tatham, R.L. Multivariate Data Analysis; Cengage: Hampshire, UK, 2006; Volume 6. [Google Scholar]
- Streiner, D.L. Starting at the beginning: An introduction to coefficient alpha and internal consistency. J. Personal. Assess. 2003, 80, 99–103. [Google Scholar] [CrossRef] [PubMed]
- Tavakol, M.; Dennick, R. Making sense of Cronbach’s alpha. Int. J. Med. Educ. 2011, 2, 53. [Google Scholar] [CrossRef] [PubMed]
- Borch, D.Z.; Sundberg, J. Spectral distribution of solo voice and accompaniment in pop music. Logop. Phoniatr. Vocology 2002, 27, 37–41. [Google Scholar] [CrossRef] [PubMed]
- Yokoyama, M.; Awahara, Y.; Yagawa, G. Relation between violin timbre and harmony overtone. In Proceedings of the Meetings on Acoustics, Honolulu, HI, USA, 28 November–2 December 2016; p. 035001. [Google Scholar]
- Kirchberger, M.; Russo, F.A. Dynamic range across music genres and the perception of dynamic compression in hearing-impaired listeners. Trends Hear. 2016, 20, 2331216516630549. [Google Scholar] [CrossRef]
- Silla, C.N.; Koerich, A.L.; Kaestner, C.A. A machine learning approach to automatic music genre classification. J. Braz. Comput. Soc. 2008, 14, 7–18. [Google Scholar] [CrossRef]
- Bahuleyan, H. Music genre classification using machine learning techniques. arXiv 2018, arXiv:1804.01149. [Google Scholar]
- Chillara, S.; Kavitha, A.; Neginhal, S.A.; Haldia, S.; Vidyullatha, K. Music genre classification using machine learning algorithms: A comparison. Int. Res. J. Eng. Technol. 2019, 6, 851–858. [Google Scholar]
- Costa, Y.M.; Oliveira, L.S.; Koericb, A.L.; Gouyon, F. Music genre recognition using spectrograms. In Proceedings of the 2011 18th International Conference on Systems, Signals and Image Processing, Sarajevo, Bosnia and Herzegovina, 16–18 June 2011; pp. 1–4. [Google Scholar]
- Ghosal, D.; Kolekar, M.H. Music Genre Recognition Using Deep Neural Networks and Transfer Learning. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2087–2091. [Google Scholar]
- Analyzer, R.A. Sennheiser HD 215 (Report for a Pro). Available online: https://reference-audio-analyzer.pro/en/report/hp/sennheiser-hd-215.php#gsc.tab=0 (accessed on 18 July 2022).
- Papadakis, N.M.; Aletta, F.; Kang, J.; Oberman, T.; Mitchell, A.; Stavroulakis, G.E. Translation and Cross-Cultural Adaptation Methodology for Soundscape Attributes—A study with Independent Translation Groups from English to Greek. Appl. Acoust. 2022. [Google Scholar]




| Music Genre | Piece | Artist/Composer | Music Sample (s) |
|---|---|---|---|
| Rock | Poison | Alice Cooper | 1:52–2:00 (8 s) |
| Jazz | Blue Train | John Coltrane | 0:52–1:03 (10 s) |
| Electronic | Traffic | DJ Tiesto | 1:15–1:25 (12 s) |
| Classical | Symphony No. 3 | Ludwig van Beethoven | 0:42–0:53 (11 s) |
| Solo instrument | Piano Sonata No. 14 | Ludwig van Beethoven | 1:15–1:25 (10 s) |
| Evaluation | Potency | Activity |
|---|---|---|
| Better–Worse | Fuller spectrum– Poorer spectrum | More changes in dynamics– Less changes in dynamics |
| More enjoyable–More annoying | Louder–Less loud | Less noise–More noise |
| Easier instrument separation– Harder instrument separation | Warmer– Less warm | Less distortion– More distortion |
| Brighter–Less bright |
| A Lot/Much | Quite | Slightly | Same | Slightly | Quite | A Lot/Much | ||
|---|---|---|---|---|---|---|---|---|
| Bipolar Scale Adjective (Negative Connotation) | Bipolar Scale Adjective (Positive Connotation) | |||||||
| −3 | −2 | −1 | 0 | 1 | 2 | 3 |
| Scales | Cronbach’s Alpha |
|---|---|
| Worse–Better | 0.782 |
| Poorer spectrum–Fuller spectrum | 0.760 |
| More noise–Less noise | 0.612 |
| More annoying–More enjoyable | 0.744 |
| Less loud–Louder | 0.713 |
| Less changes–More changes (dynamics) | 0.734 |
| Harder separation–Easier separation (instruments) | 0.705 |
| Less warm–Warmer | 0.739 |
| More distortion–Less distortion | 0.720 |
| Less bright–Brighter | 0.741 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadakis, N.M.; Aroni, I.; Stavroulakis, G.E. Effectiveness of MP3 Coding Depends on the Music Genre: Evaluation Using Semantic Differential Scales. Acoustics 2022, 4, 704-719. https://doi.org/10.3390/acoustics4030042
Papadakis NM, Aroni I, Stavroulakis GE. Effectiveness of MP3 Coding Depends on the Music Genre: Evaluation Using Semantic Differential Scales. Acoustics. 2022; 4(3):704-719. https://doi.org/10.3390/acoustics4030042
Chicago/Turabian StylePapadakis, Nikolaos M., Ioanna Aroni, and Georgios E. Stavroulakis. 2022. "Effectiveness of MP3 Coding Depends on the Music Genre: Evaluation Using Semantic Differential Scales" Acoustics 4, no. 3: 704-719. https://doi.org/10.3390/acoustics4030042
APA StylePapadakis, N. M., Aroni, I., & Stavroulakis, G. E. (2022). Effectiveness of MP3 Coding Depends on the Music Genre: Evaluation Using Semantic Differential Scales. Acoustics, 4(3), 704-719. https://doi.org/10.3390/acoustics4030042