1. Introduction
The CIDOC Conceptual Reference Model (CIDOC-CRM) is an ISO standard ontology for the cultural domain that is used for enabling semantic interoperability between museums, libraries, archives and other cultural institutions. It can be considered a very successful case since it is used by dozens/hundreds of institutions and, currently, in several ongoing research projects (
http://www.cidoc-crm.org/useCasesPage (accessed on 1 June 2022)). CIDOC-CRM ontology is maintained regularly by a special group, and the current (community) version is 7.1.1 (
https://cidoc-crm.org/versions-of-the-cidoc-crm (accessed on 1 June 2022)).
However, CIDOC-CRM is only one artifact. For achieving interoperability in a particular context, several processes and tasks related to this ontology have to be carried out, including schema and instance mapping, data transformation, information extraction, querying and others. It is therefore important to support and automate as much as possible these processes for facilitating interoperability. For this reason, in this paper, we describe the related tasks and then we survey recent works that apply machine learning (ML) techniques for reducing the costs related to CIDOC-CRM-based compliance and interoperability.
Since CIDOC-CRM is an ontology, one could argue that any ontology-based approach using ML is related. However, in this paper, we focus only on CIDOC-CRM since we are mainly interested in techniques that can tackle the difficulties stemming from the distinctive characteristics of CIDOC-CRM, i.e., that it is an event-centric ontology with a plethora of classes and associations structured in specialization hierarchies. After all, there are other surveys for the general case, i.e., about machine learning and ontologies in general, such as [
1] (where a ML approach is adopted for ontology matching) and [
2] (where knowledge graphs are used as tools for explainable machine learning), etc.
Note that ML may be used in earlier steps, e.g., for preparing the structured data, such as extracting tabular content from PDF documents [
3]. In general, there are several applications of ML for cultural heritage; e.g., [
4] describes an automatic method for chronological classification of ancient paintings. We do not include such works; we focus on applying ML for achieving semantic interoperability. Moreover, note that the application of ML is also aligned with the direction proposed in [
5], which stresses the value of data analysis and knowledge discovery and the need for tools that automatically find interesting serendipitous patterns in the data and even solve problems, preferably with explicit explanations. We also observe related initiatives, such as the EuropeanaTech Challenge for Europeana AI/ML (
https://pro.europeana.eu/post/europeanatech-challenge-for-europeana-ai-ml-datasets-announcing-the-winners (accessed on 1 June 2022)) where one of the winners proposed using CIDOC-CRM.
Given the aforementioned requirements and directions and the huge volume of cultural data, in this survey, we (a) analyze the main CIDOC-CRM processes and tasks, (b) identify tasks where the recent advances of ML (including Deep Learning) would be beneficial, (c) identify cases where ML has already been applied (and the results are successful/promising), and (d) suggest tasks that can be benefited by applying ML. Since there are only a few works that leverage ML over CIDOC-CRM data, we (e) present our vision for the given topic by providing examples and (f) provide a list of open datasets expressed through CIDOC-CRM model, which can be potentially used for ML tasks.
The rest of this paper is organized as follows:
Section 2 describes the required background (about CIDOC-CRM and related surveys);
Section 3 describes processes and tasks related to CIDOC-CRM;
Section 4 surveys works that involve both CIDOC-CRM and ML and discusses the main points from this collection and analysis, while
Section 5 provides visionary examples and available datasets. Finally,
Section 6 concludes the paper.
3. Using CIDOC-CRM: Processes and Tasks
The primary role of the CIDOC-CRM is to serve as a basis for the mediation of cultural heritage information and thereby provide the semantic ‘glue’ needed to transform disparate, localised information sources into a coherent and valuable global resource. Thus, its main use is for transforming one or more existing datasets to a CIDOC-CRM compliant dataset, i.e., to a rich semantic network of integrated information described through classes and properties of CIDOC-CRM. Nevertheless, there are also platforms, such as ResearchSpace [
12], that allow documenting cultural heritage information, which is directly represented through CIDOC-CRM, i.e., thus creating a semantic network/knowledge base from the very beginning. Other systems, such as FAST CAT [
13,
14] and SYNTHESIS [
15] for data transcription and documentation, include embedded processes that facilitate the construction of a CIDOC-CRM-compliant semantic network. Finally, there are processes where the main input is text; consequently, information extraction has to be performed [
16].
These are elaborated in the subsections that follow: in particular,
Section 3.1 describes the main use cases and processes,
Section 3.2 describes the tasks of these processes, and
Section 3.3 outlines the more time consuming tasks.
3.1. Use Case Scenarios and Processes
One main scenario starts with existing structured data (e.g., in relational databases) and the objective is to transform them into data expressed in CIDOC-CRM. A second scenario is where data have not been recorded but they have to be entered so the objective is to produce data expressed in CIDOC-CRM, but with less effort by humans. A third scenario is when we have data but they are unstructured, i.e., we have textual sources, and the objective is to produce data expressed in CIDOC-CRM by applying information extraction.
As regards structured data, we should also note that an attempt to formalize the processes and define a formal workflow has been carried out with the Synergy Reference Model (
https://cidoc-crm.org/Resources/the-synergy-reference-model-of-data-provision-and-aggregation (accessed on 1 June 2022)). It is a reference model for a better practice of data provisioning and aggregation processes, primarily in the cultural heritage sector but also for e-science. It defines a consistent set of business processes, user roles, generic software components, and open interfaces that form a harmonious whole. The goal of Synergy Reference Model is the following: (a) describe the provision of data between providers and aggregators including associated data mapping components, (b) address the lack of functionality in current models, (c) incorporate the necessary knowledge and input needed from providers to create quality sustainable aggregations and (d) define a modular architecture that can be developed and optimized by different developers with minimal interdependencies.
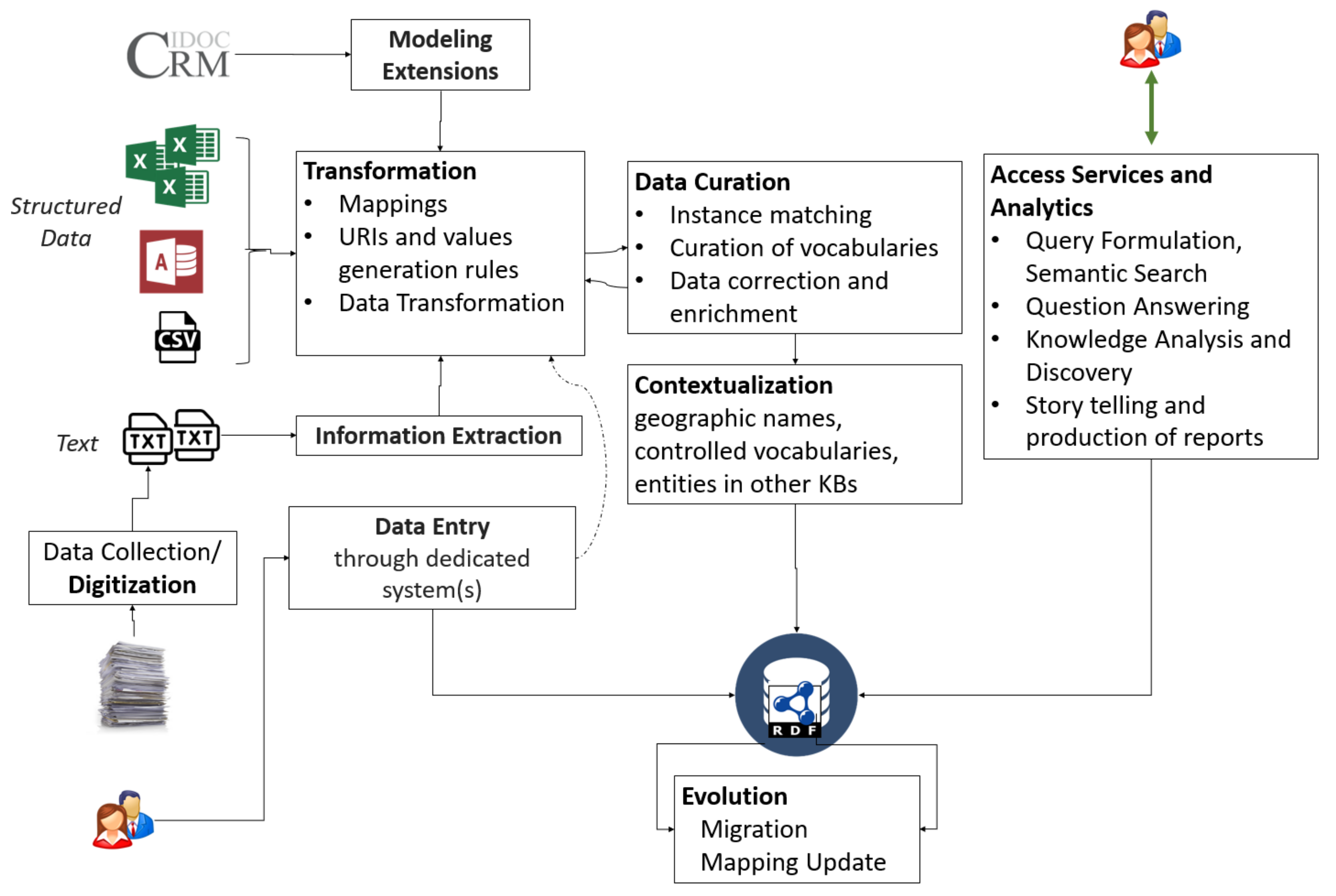
Figure 3 shows the different scenarios and the main tasks involved in the creation of a CIDOC-CRM-compliant semantic network (a
knowledge graph). The main tasks are described below.
3.2. Tasks
Here, we identify the main tasks that are required for supporting the aforementioned scenarios (presented in
Figure 3):
- (1)
Modeling. Sometimes, conceptual modeling extensions are required for tackling the requirements. Indicative papers that describe such extensions include [
17] (for the provenance of digital objects), [
18] (for archaeology), [
19] (for geospatial extensions), [
20] (for conservation processes), [
13,
21] (for maritime history) and others. Another related (complementary) modeling task is the one that aims at creating controlled vocabularies/thesauri for the domain, which are used in conjunction with CIDOC-CRM.
- (2)
Transformation. This task constructs ontological instances with respect to CIDOC-CRM (and/or any of its extensions) from the existing structured resources. Before actually transforming them, we have to perform the following: (a) define the schema mappings between the existing data and CIDOC-CRM and (b) specify the rules for generating URIs and values. The X3ML framework [
22] provides a formal language called X3ML mapping definition language, as well as a set of tools for supporting the mapping definition process (e.g., 3M Editor (
https://www.ics.forth.gr/isl/x3ml-toolkit (accessed on 1 June 2022))) and data transformation (e.g., X3ML engine (
https://github.com/isl/x3ml/ (accessed on 1 June 2022))). We can identify the following subtasks:
Definition of mappings. This step provides the detailed guidelines demonstrating which parts from the original data will be used for constructing CIDOC-CRM based descriptions. They are called schema mappings and their role is to preserve and enhance the semantic descriptions of the existing data when they are transformed.
URIs and values generation rules specify how the identifiers and the values of the transformed data will be created. More specifically, they describe the syntax of URIs as a combination of constant values as well as values from the original data.
Data transformation uses the schema mappings and URI and value generation rules in order to create instances of the target model (i.e., CIDOC-CRM).
Note that, in some cases, the values that occur in an attribute of a source should become terms of a controlled vocabulary/thesaurus; therefore, the transformation could/should turn these values to references and into vocabulary terms.
- 3.
Data entry. Data entry can be either manual (through some dedicated system) or automatic (e.g., through information extraction from texts). A method of entering tabular data, which are subsequently transformed to CIDOC-CRM, is described in [
13], while the
Synthesis documentation system, offering embedded data transformation processes based on CIDOC-CRM, is described in [
15]. Moreover, [
23] describes a process for automating the creation of RDF triples from a repository containing life stories of common people.
- 4.
Data curation. This refers to tasks that are required for connecting the transformed (or extracted) entities. This includes instance matching (entity matching and entity resolution), data linking, curation of vocabularies, data correction or enrichment, etc.
For instance, [
24] performs entity matching for finding existing person instances between the different datasets, which are described by using the CIDOC-CRM model, while [
13] supports both automated (rule-based) and manual instance matching processes as well as manual vocabulary curation before data are transformed based on CIDOC-CRM. The authors of [
25] evaluate the quality of mappings between COURAGE and CIDOC-CRM ontologies by using mainly SPARQL queries and reasoners. The author of [
26] describes a process for relating paintings with events. Since CIDOC-CRM is event-centric, one important and challenging task is the instance matching over events.
In general, the curation aims at improving the quality of the data, and this has several dimensions, including data validation, data completeness, quality of data interlinking and many others [
11].
- 5.
Contextualization. This refers to the linking the CIDOC-CRM based entities with external data (e.g., geographic names, controlled vocabularies and entities in a different knowledge base (e.g., DBpedia, wikidata, etc). For instance, [
27] has linked events (described through CIDOC-CRM) to external sources, such as DBpedia. Moreover, [
28] describes a tool for enriching the connections of a LOD (Linked Open Data [
29]) dataset with the other LOD datasets, with emphasis on the cultural domain. It also quantifies the quality of data interlinking and detects possible errors for several datasets. In addition, [
30] contains connectivity analytics of hundreds of RDF datasets, included five datasets expressed through CIDOC-CRM. For the latter datasets, a high connectivity was obtained with external RDF datasets, mainly of the cultural heritage and publications domain.
- 6.
Access Services and Analytics. We can identify the following methods.
Query Formulation (from an information need to a SPARQL query over a CIDOC-CRM-based dataset). CIDOC-CRM is an adequate global schema, especially for integrating large amounts of cultural data, because of its rich schema of classes and properties and its event-based nature. However, this rich structure makes querying a complex procedure. A querying configuration that overcomes such problems is the fundamental categories and relationships [
31]. These categories are bare classes covering the domain and the relationships are deductions from complex path expressions. Two well-known implementations of this querying configuration are ResearchSpace [
12] and A-QuB [
32].
Question Answering (and Dialog) over a CIDOC-CRM based dataset. The authors of [
33] describe a QA system for the Cultural Heritage domain that gradually transforms input questions into queries that are executed on a CIDOC-compliant ontological knowledge base.
Knowledge Analysis and Discovery. This refers to analytics, knowledge discovery, and various mining tasks (as in [
5]).
Production of Reports. This refers to the exploitation of the CIDOC-CRM-based knowledge base for producing presentations/narratives. For instance, [
34] describes the process of producing narratives through the Narrative Ontology that has been implemented on top of CIDOC-CRM.
- 7.
Evolution. We can identify the following subtasks.
3.3. More Time Consuming Tasks
Even if this depends on the application context, from our experience on applying CIDOC-CRM, we have identified the following core tasks that are more crucial and time consuming:
Construction of mappings. The cost is analogous to the number and size of sources, the attributes of each source that has to be mapped in addition to a cost at the end for entity matching over the aggregated transformed (in CIDOC-CRM) datasets and testing using queries. Moreover, it is a manual process and the overall quality of the implemented mappings relies on the experience of the person carrying them out and the good knowledge of both source schemata and the target ontology (e.g., CIDOC-CRM).
Data entry. As mentioned earlier, data entry can be either manual (using some system), or automatic (e.g., using information extraction from texts). As regards manual data entry, its cost is analogous to the size of the data that have to be entered, which can be prohibitively expensive for a huge amount of data. Usually, the data are not entered in a graph-based format, but either through an appropriate system. Data can be entered in tabular form, as described in [
13], and subsequently, they can be transformed to ontological ones; hence, the data entry cost includes the cost for mappings.
Instance matching. If performed manually, this depends on the number of entities to be matched. If performed by custom rules, then this typically depends on the number of sources. If it is fully automatic, this depends on the effort required for checking (and approving/rejecting) matches. For example, the FAST CAT system [
13] (in the context of maritime history) supports a multi-level instance matching process. A first process considers a set of source-specific rules for giving the same identity to a set of entity instances (e.g., all person instances in a specific source having the same firstname, lastname, father’s name and birth date must be considered as the same person and obtain the same identity). Then, a second instance matching process allows historians (through a dedicated user interface) to manually indicate that two or more entity instances refer to the same real-world entity; thus, they must have the same identity, or a specific instance from a set of automatically matched instances is a different entity and, thus, must have a different identity.
Vocabulary curation. Similarly to instance matching, vocabulary curation can be manual (using a user interface), automatic or semi-automatic. Here, the objective is to align equal or related terms by providing a
preferred and a
broader (if any) term for each distinct term in a vocabulary (e.g., for a vocabulary of professions: ‘capitano’ has preferred term ‘captain’ and has broader term ‘sailor’). The FAST CAT system [
13] offers a user interface for manual vocabulary curation in the context of maritime history. The cost of curating a singe vocabulary depends on the number of vocabulary terms (if manual) or the effort required for checking and correcting automatically aligned terms. For instance, in the case of the SealiT project (
https://sealitproject.eu/ (accessed on 1 June 2022)), there are around 50 vocabularies that need curation, some of which contain thousands of terms (more in [
13]).
Information extraction from texts. The cost is analogous to the complexity of the information to be extracted, the effectiveness of the extraction method and the effort required for corrections. A related aspect of data entry from documents, is the classification of the documents according to various taxonomies, vocabularies and thesauri. For instance, [
37] presents a method for document subject indexing based both on Topic Modeling and automated labeling processes, aiming to improve the performance of the indexing and the quality of the indexing terms assigned to a document.
Query formulation and browsing/exploitation in general. This cost mainly affects the users of the integrated KG. Multiple access methods should be supported (as in [
38] for a keyword search over DBpedia), including keyword search (offering both triple ranking and entity ranking), graph-based browsing, question answering, query templates, etc. There is also the cost for setting up such services. This may require defining competency queries (query templates in general), configuring assistive query building interfaces (such as A-QuB [
32] or ResearchSpace [
12]) for interactive query formulation, customizing pipelines for QA, etc.
4. Surveying Existing Methods
Here, we survey the existing works; at first, in
Section 4.1, we describe the methodology that we have followed for finding approaches that exploit ML techniques for CIDOC-CRM data. In
Section 4.2, we analyze the found works by mentioning the correspondence between each work and the tasks presented in
Section 3, whereas
Section 4.3 provides an analysis of the material found.
4.1. Methodology
Selection Strategy. For finding the related works, we used Google Scholar in the period of June 2021–May 2022 without any restrictions on the publication date. We used the following queries: (i) “CIDOC-CRM Machine Learning”, (ii) “CIDOC-CRM Deep Learning”, (iii) “CIDOC-CRM word embeddings” and (iv) “CIDOC-CRM neural networks”. For each query, we performed a search on Google Scholar for related papers, i.e., we found approximately 1000 relevant papers for the given queries. For each paper, we manually checked its title, abstract and body by strictly keeping only the papers that use machine learning techniques over CIDOC-CRM data. In particular, we care about papers describing one or more processes that use a machine learning technique and the input or/and the output concerns data described using the CIDOC-CRM model.
Statistics.
Table 1 and
Table 2 provide some statistics about the publication years and venues for the surveyed papers, respectively. As we can see, although we did not use such filter, the majority of works that we retrieved concern the last 5 years; i.e., most of them are after 2021 (see the last two rows of
Table 1). On the contrary, concerning the publication venues, the most common one is the
Semantic Web journal (see
Table 2).
4.2. Analysis of the Surveyed Works
We categorize the surveyed approaches into several dimensions, including (a) the
Related Tasks to
Section 3.2, and each approach tries to solve using machine learning techniques; and (b) the
Subcategory (of the related tasks) of each approach and (c) their
Domain, e.g., archaeology. Moreover, we categorize the approaches according to some technical details, including (d)
Data Category, i.e., whether the used data are texts, structured data, images, etc.; (e) the
Usage of CIDOC-CRM data, i.e., whether CIDOC-CRM data are used as an input or/and as an output for the corresponding machine learning task; (f) the
Volume of Data used in each approach; and finally, (g) the
machine learning tools/algorithms that were applied for solving the required tasks.
Table 3 provides a synopsis of the categorized works for the dimensions (a)–(c), whereas
Table 4 presents the values for dimensions (d)–(g). The works are presented in chronological order in the mentioned tables. Below, we provide more details for each of the surveyed works.
Table 1.
Publication Years of Surveyed Works.
Table 1.
Publication Years of Surveyed Works.
Table 2.
Publication venues of the Surveyed Works in descending order with respect to the total number of publications.
Table 2.
Publication venues of the Surveyed Works in descending order with respect to the total number of publications.
| Publication Venue (Conference, Journal) | Papers | Total Number |
|---|
| Semantic Web Journal | [24,45,46,47] | 4 |
| Information, MDPI | [44] | 1 |
| Data and
Journal of Visual Languages and
Computing | [41] | 1 |
| Journal of Information Science | [43] | 1 |
| ERCIM News | [39] | 1 |
| Proceedings of ECIR Conference | [42] | 1 |
| Knowledge Engineering | [48] | 1 |
| Proceedings of Digital Heritage International Congress | [40] | 1 |
TEXTCROWD [
39,
40] is a cloud based tool (developed within the framework of EOSCpilot project) for processing textual archaeological reports. The general objective is to aid the data entry process by building a system capable of reading excavation reports, recognising relevant archaeological entities and linking them to each other on linguistic bases. TEXTCROWD was initially trained on a set of vocabularies and a corpus of archaeological excavation reports. It offers POS tagging and Named Entity Recognition using two different ML tools, i.e., OpeNER and OpenNLP. TEXTCROWD is able to generate metadata encoding the knowledge extracted from the documents into CIDOC-CRM.
An approach for aiding the Data Entry process is described in [
41], which extracts the entities and relations from Chinese intangible cultural heritage texts and exploits CIDOC-CRM classes for describing the extracted entities (and their relations). In more detail, this paper focuses on knowledge extraction for the domain of intangible cultural heritage (ICH). The authors have created a training corpus and then applied deep learning through a Bidirectional Gated Recurrent Units (GRU) model with attention to extract entities and relations from ICH text data and for finding their corresponding CIDOC-CRM class.
The authors in [
42] proposed an approach for improving data entry by offering event detection and extraction over CIDOC-CRM data, based on directional Long Short-Term Memory (LSTM), which is a type of recurrent neural network. The target of this approach is to create narratives from the extracted data. It has been evaluated for hundreds of events by using a digital library containing narratives for the tasks of event detection and classification. Specifically, comparing to the baseline model, they observed a small improvement, e.g., for the event detection task, the F1-Score was 0.73 versus 0.66 (baseline).
WarSampo knowledge graph [
24] contains data about the Second World War by focusing on Finnish military history by using CIDOC-CRM (and extensions). Concerning the related Machine Learning task, the resulted data, expressed through CIDOC-CRM, are given as input for performing entity matching (i.e., a subtask belonging to data curation) for thousands of persons between the different datasets by using probabilistic linkage techniques and logistic regression.
The authors in [
43] exploit a cultural knowledge base and machine learning techniques for offering advanced access services, i.e., recommendation of similar items. The Knowledge base is mainly constructed by using CIDOC-CRM ontology and other popular ontologies, such as SKOS, and word embeddings for computing personalised recommendations by taking into account the profile of a museum visitor. The data, which are expressed through CIDOC-CRM, and the details of the personal profile of the user are given as input for providing recommendations, based on embeddings produced using the word2vec model.
The word embeddings are also used over CIDOC-CRM knowledge graphs in [
44] for generating similarity recommendations and they demonstrate its functionality on the Sphaera Dataset, which was modeled according to the CIDOC-CRM data structure. The embeddings have been produced by using Relative Sentence Walk (RSW) and doc2vec model for hundreds of entities.
In [
45], the authors proposed an approach for improving the Data Entry process by performing text classification, extraction and representation for Portuguese National Archives records. The target is the extracted information (from text) to be represented by using CIDOC-CRM ontology and then is visualized by using a Query Ontology Interface. The tool has been evaluated by using 200 texts, and the classifiers have been built through models, such as N-Grams and TF-IDF, by using a decision tree.
A method for improving data curation is described in [
46] by predicting missing metadata in a given knowledge graph by using both image and text analysis. The data model is based on CIDOC-CRM model, and the missing metadata are predicted by using Deep Learning and Convolutional Neural Networks and multi-task learning over thousands of samples. Indicatively, they managed to predict, with an accuracy of over 92%, the class labels of previously unseen images.
Table 3.
Overview of the surveyed works applying machine learning techniques over CIDOC-CRM—Dimensions (a)–(c).
Table 3.
Overview of the surveyed works applying machine learning techniques over CIDOC-CRM—Dimensions (a)–(c).
| Work | Related Task
(to Section 3.2) | Subcategory | Domain |
|---|
| [39,40] | Data Entry | POS Tagging and Named Entity Recognition (NER) | Archaeology |
| [41] | Data Entry | NER and Relation Extraction | Cultural Heritage data of China |
| [42] | Data Entry, Access Services and Analytics | Information Extraction, Classification and Narratives | Digital Library with Narratives |
| [24] | Data Curation | Entity Matching | Finnish Military History |
| [43] | Access Services and Analytics | Context Personalisation and Recommendation | Personalised Cultural Heritage |
| [44] | Access Services and Analytics. | Knowledge Graph Embeddings | Access services in general |
| [45] | Data Entry | NER and Relation Extraction | Portuguese National Archives Records |
| [46] | Data Curation | Predicting missing metadata (mainly about images) | Culture-related objects |
| [47] | Access Services and Analytics | Question Answering | Genealogical data |
| [48] | Access Services and Analytics | Document Clustering and Classification | French Historical Data (BNF) |
In another context, i.e., genealogical data, CIDOC-CRM data are used for offering Question Answering [
47]. In particular, ti generates text passages from knowledge sub-graphs that contain genealogical data for creating questions and answers and for building a Question Answering system by exploiting deep neural network techniques with the Uncle-BERT model. The process has been trained and tested for millions of entities and events that belong to CIDOC-CRM classes, including Person, Birth and others. They managed to achieve a higher accuracy by using the Uncle-BERT model comparing to BERT; i.e., their F1-score was 0.81 versus 0.6 (BERT).
Finally, the authors in [
48] describe historical documents from France through an extension of CIDOC-CRM and exploit the K-Means algorithm for performing clustering by classifying whether a CIDOC-CRM-based document is either deteriorated or available. The experiments have been performed over 8000 documents, and they identified even 95% accuracy in the test set.
Table 4.
Overview of the surveyed works applying machine learning techniques over CIDOC-CRM—Dimensions (d)–(f).
Table 4.
Overview of the surveyed works applying machine learning techniques over CIDOC-CRM—Dimensions (d)–(f).
| Work | Data Category | How CIDOC-CRM Data Are Used | Volume of Data | Machine Learning Tools/Algorithms |
|---|
| [39,40] | Texts | Output | 30 large reports | OpeNER, OpenNLP |
| [41] | Texts | Output | ∼1500 entities | Bidirectional (Gated Recurrent Units) GRU model with attention. |
| [42] | Texts | Input | ∼600 events | Event extraction based on LSTM, a type of recurrent neural network. |
| [24] | Structured data | Input | 94,676 entities | Probabilistic record linkage with a logistic regression based machine learning implementation |
| [43] | Structured data | Input | ∼1,000,000 axioms | word2Vec, through pre-trained Google News corpus |
| [44] | Structured data | Input | 359 entities (book editions) | Relative Sentence Walk (RSW) and doc2vec |
| [45] | Texts | Output | 200 texts | A classifier using a N-Gram and a TF-IDF model for the sample data and a decision tree |
| [46] | Structured data and Images | Input | ∼30,000 samples | Deep Learning and Convolutional Neural Networks (CNNs), and multi-task learning |
| [47] | Structured data | Input | 1,847,224 entities | Deep Neural Networks with Uncle-BERT |
| [48] | Structured data | Input | 8000 documents | K-means algorithm |
4.3. Comparative Analysis of the Surveyed Works
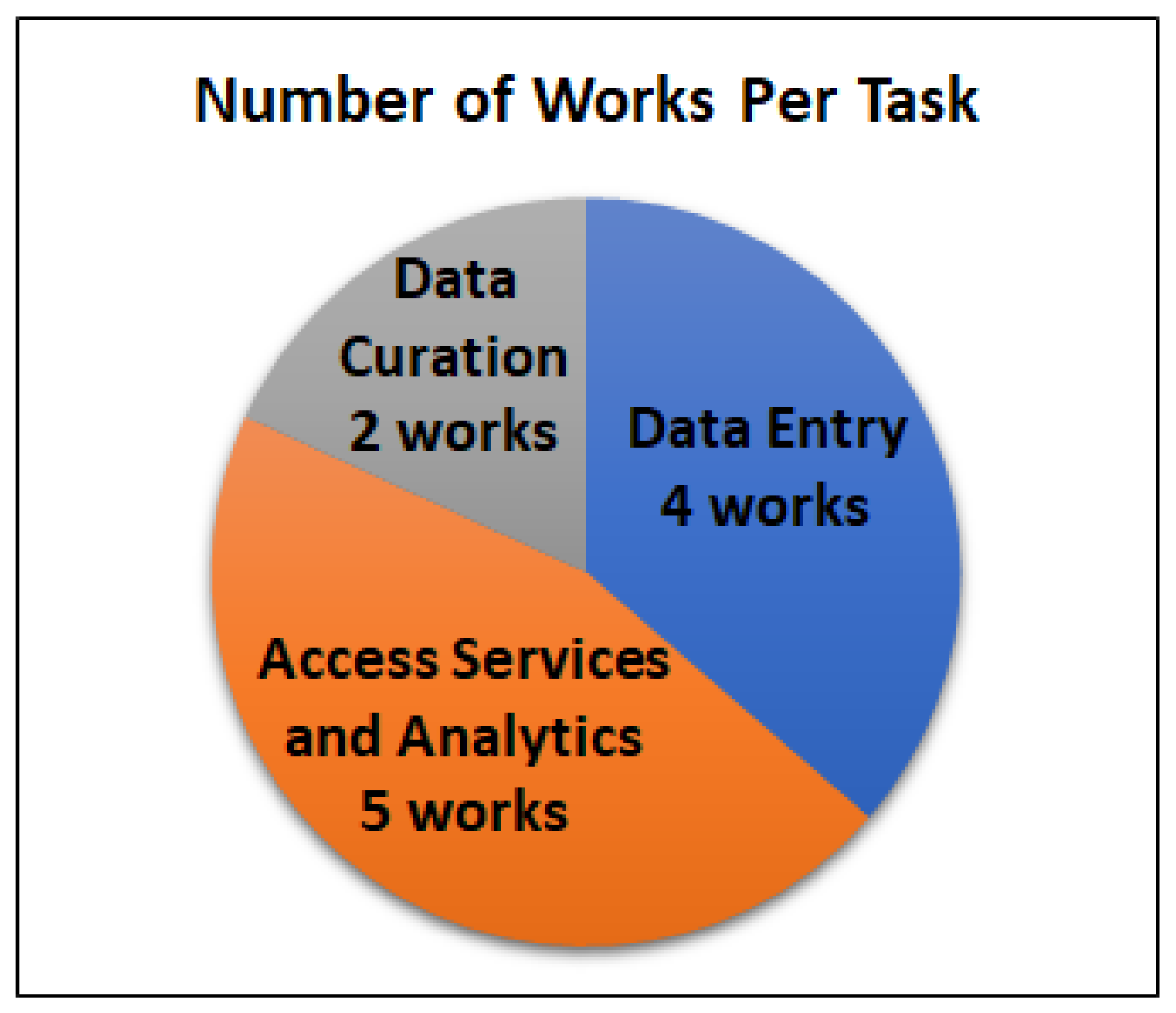
First, we can observe, in
Figure 4, that the most common tasks concern the exploitation of CIDOC-CRM data for offering more advanced access services and analytics (5 out of 10), especially through the creation of word embeddings and the process of Data Entry (4 out of 10 approaches), mainly for extracting information from texts, which can be expressed through CIDOC-CRM model. On the contrary, 2 out of 10 works provide solutions related to the
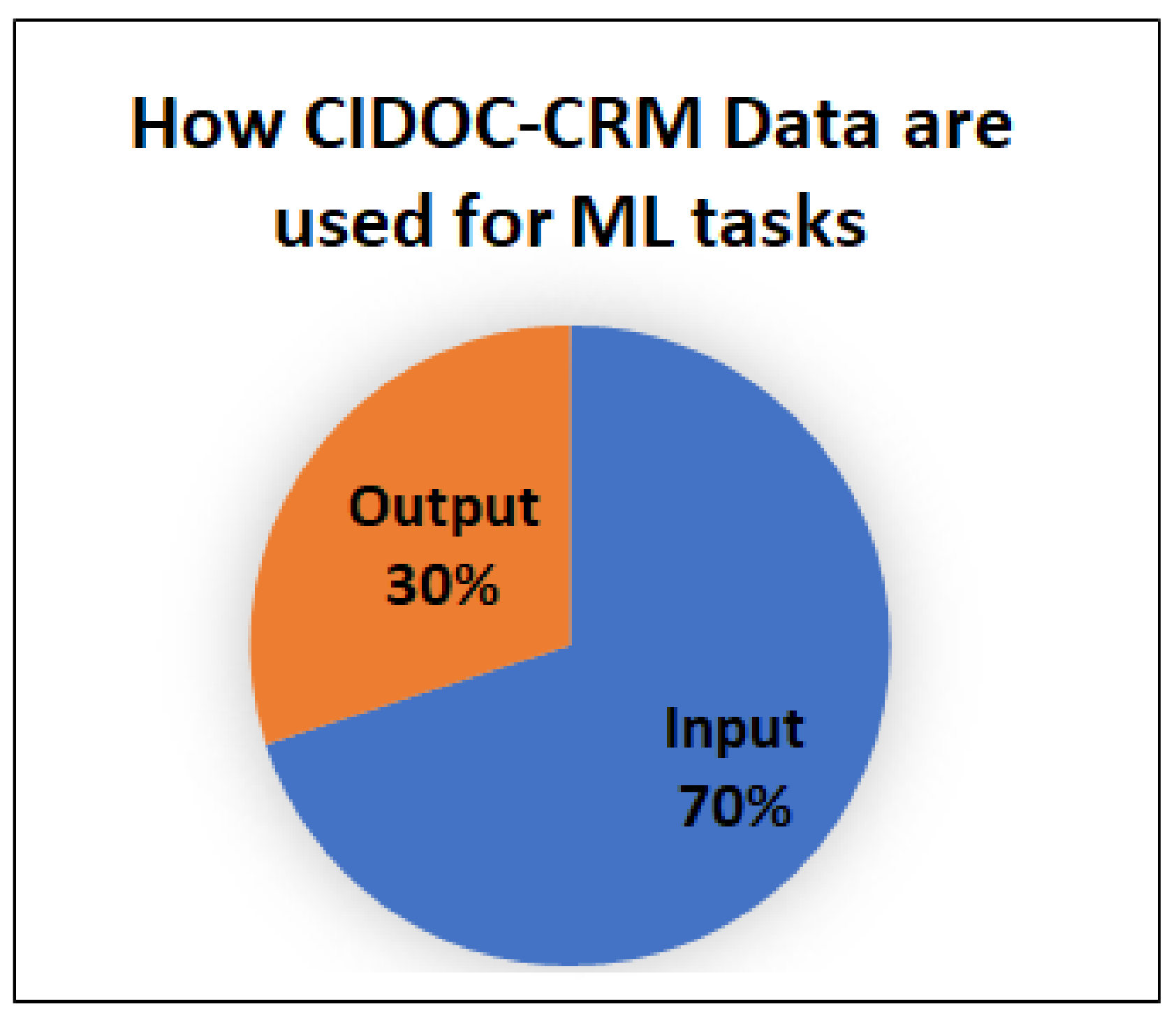
data curation task, i.e., for entity matching and data enrichment (prediction of missing metadata). Moreover, CIDOC-CRM data were used both as input and as output, i.e., 70% of cases as input, as it is shown in
Figure 5 for the described machine learning approaches. Finally, most approaches exploit deep learning models, e.g., word embeddings, for improving the desired task.
Concerning the major limitations, the number of approaches is quite low, although we observed an increase in the last two years (2021–2022). Moreover, we did not find approaches for numerous tasks of
Section 3.2, including modeling, transformation, evolution and others, whereas most approaches have been evaluated with a small amount of data, i.e., only few approaches used and evaluated for millions of data. However, since we strongly believe that more CIDOC-CRM tasks (and even at large scale) can be assisted using machine learning, in
Section 5, we introduce our vision and examples of how CIDOC-CRM could be highly benefited using ML techniques.
5. Vision, Examples and Datasets
Section 5.1 discusses a vision related to CIDOC-CRM and ML,
Section 5.2 provides some concrete visionary examples and finally,
Section 5.3 provides a list of open datasets expressed in CIDOC-CRM that could be exploited for training ML models.
5.1. Vision (CIDOC-CRM and ML)
Machine learning could facilitate and, thus, speedup various CIDOC-CRM-related tasks and processes. According to our opinion, it could greatly speed up tasks that are related to unstructured data. Below, we describe some indicative scenarios.
Data Entry. Since manual data entry can be very time consuming for large scale data; below, we identify tasks (categorized according to the input type) where ML could speed up this process.
Text Analysis. For the automatic identification of actors and mainly
events as the latter are very important for connecting the aggregated data, a recent survey [
49] provides state-of-the-art deep learning methods for named entity recognition and relation extraction.
Images Understanding. For automatically obtaining the descriptions of the form “This painting depicts 3 persons and one church”. An interesting work for automatic art analysis is described in [
50]. Note that there are several works that detect and identify objects from images: [
51] describes the system YOLO that can be also used for detecting objects in moving images due to its fast response, [
52] makes use of artificial neural networks to support the identification of objects in images and [
53] proposes a fast and more accurate object detector. Finally, we could also mention Detector2 [
54], which includes various object detection and segmentation algorithms and has been implemented by Facebook AI Research. Moreover, a recent large collection for visual QA for cultural heritage has been published [
55]. It contains a list of question–answer pairs, where each of these pairs is associated to one image, which is derived from the ArCo Knowledge Graph of the Italian Cultural Heritage.
Music Classification: For the automatic classification of music to genre, refer to [
56].
Video Understanding: For the automatic identification of persons, topics, etc. A 2008 survey for automatic video classification is [
57], whereas a recent survey [
58] lists several approaches that use deep learning methods for video understanding tasks, including the automatic generation of descriptions from videos.
Classification of cultural objects in general: There are several works that apply ML for automatically classifying cultural objects. This includes, digital artwork classification [
59], pottery types [
60,
61], ceramic artefacts [
62], chronological classification of ancient paintings [
4], prediction of painting style [
63] and others. In CIDOC-CRM, the classification of a cultural object is represented using the classes
E22:Human-Made Object and
E28:Conceptual Object, and the property
P2:has type, which points to
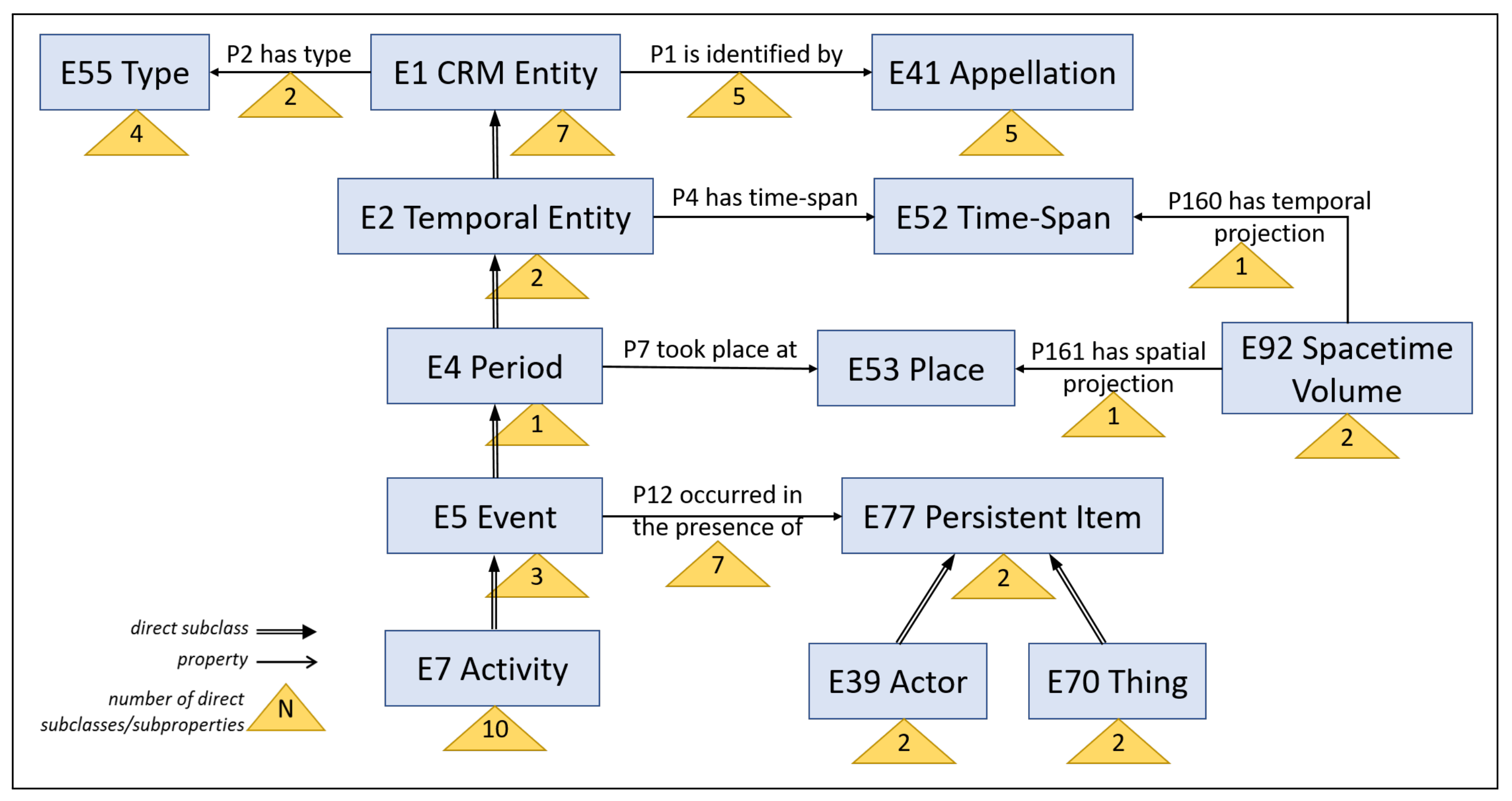
E55:Type and can be used for further classifying them. Consequently, all these methods can be leveraged for populating this relation.
Access and Exploitation. One important task is the translation of an information need expressed in
natural language to a formal query over CIDOC-CRM or answered by a QA pipeline that returns a SPARQL query. Another task is
similarity-based browsing for tackling the information overload, i.e., for being able to reveal the more important connections and for various kinds of recommendation services. An example is RDFSim [
64] that offers similarity-based browsing over DBpedia based on knowledge graph embeddings.
Data Linking. With respect to data linking, ML could be used to link data from different sources. This concerns data enrichment and verification, e.g., [
65], automatic labelling, [
66], vocabulary curation, and others.
5.2. Examples of Machine Learning Tasks over CIDOC-CRM Data
Here, we describe five indicative examples of exploiting ML for CIDOC-CRM; some of them have already been tested with existing tools.
5.2.1. Example 1. Multi-Source Data Entry
The input data can be expressed in many formats including either unstructured data, such as texts in natural language, semi-structured data [
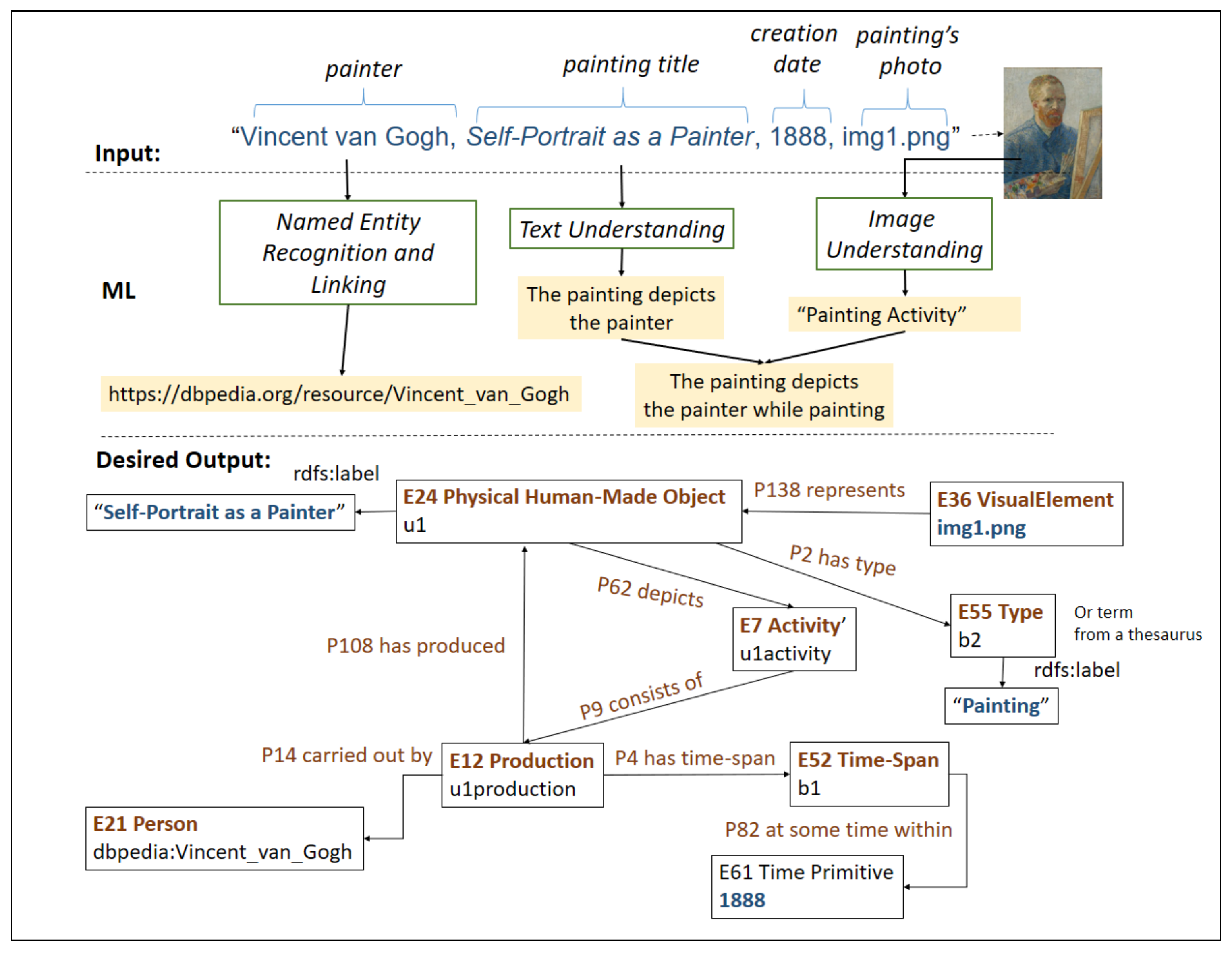
67], such as CSV files, structured data, e.g., in RDF format, or even other files such as images, sounds and videos. Here, we provide an example of a typical input: a CSV file and an image. In particular, the indicative example is shown in
Figure 6.
Notice that, with text understanding from the word “self-portrait” in the title, we could deduce that the painting “depicts the painter”. By image understanding, we cab infer that the image refers to a “painting activity”. In particular,
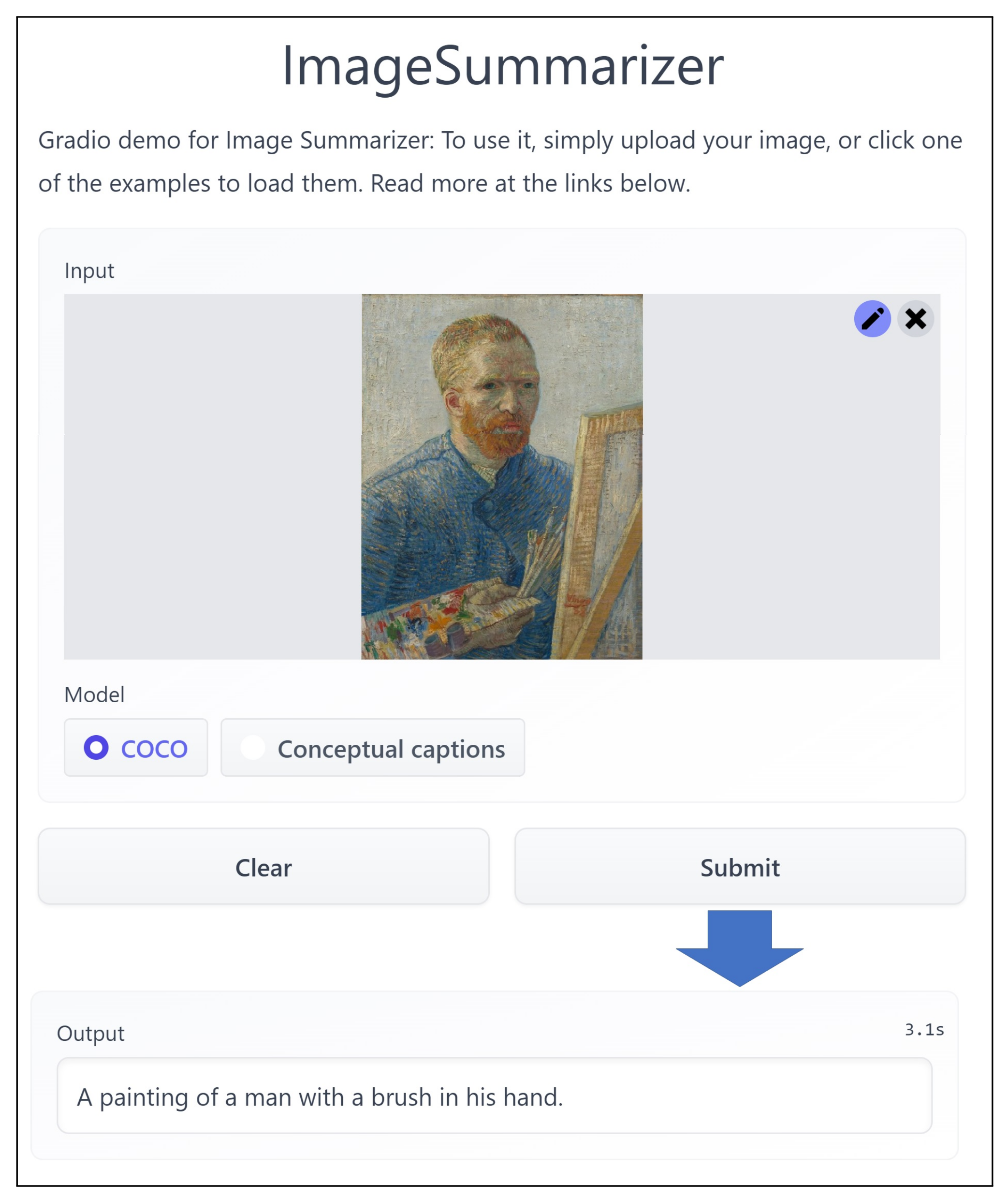
Figure 7 depicts a screenshot of the real output of an existing tool (
https://huggingface.co/spaces/sohaibcs1/Image-to-Text-Summary (accessed on 1 June 2022)) for that portrait. As we can see, a summary is provided, which mentions that the portrait shows a painting where a man has a brush in his hand.
By combining the above facts, we could conclude that “the painting depicts the painter while painting”. Now at the bottom of
Figure 6, we can see a possible modeling of this information according to CIDOC-CRM (We use an UML Object Diagrams-like notation: We denote individuals by boxes with two rows: the first has the class of the individual, the second the URI or blank node of the individual). Notice that the fact inferred from image understanding is modeled as an
activity (connected with P62). The fact that this activity depicts the painter while painting enables us to state that painting activity contains the creation event of that painting (i.e., we connect them through P9). The latter enables answering questions of the form “paintings that depict their creation”, “paintings that depict painting activities” and so on.
The following block shows the structured form (in XML) of the short narrative from
Figure 6, which can be used as input, in order to describe the schema mappings for generating the corresponding CIDOC-CRM-related instances. The schema mappings have been described using X3ML.
1 <root>
2 <painting>
3 <creator>Vincent van Gogh</creator>
4 <title>Self-Portrait as a Painter</title>
5 <creation_date>1888</creation_date>
6 <filename>img1.png</filename>
7 </painting>
8 </root>
|
The XML input and the X3ML mappings can be used for producing the instances with respect to CIDOC-CRM. The details of the X3ML mappings are shown later in
Section 5.2.3. The following block shows the output in Turtle format.
1 @prefix crm: <http://www.cidoc-crm.org/cidoc-crm/> .
2 @prefix crm-ex: <http://www.cidoc-crm.org/examples/> .
3 @prefix dbpedia: <https://dbpedia.org/resource/> .
4 @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
5
6 crm-ex:visual_item/E98F243A-B982-4142-83AE-88FE0BD058CE
7 a crm:E36_Visual_Item ;
8 rdfs:label ‘‘Digital representation of painting Self-Portrait as a Painter’’;
9 crm:P1_is_identified_by crm-ex:identifier/img1.png .
10
11 crm-ex:identifier/img1.png
12 a crm:E42_Identifier ;
13 rdfs:label ‘‘img1.png’’ .
14
15 dbpedia:Vincent_van_Gogh
16 a crm:E21_Person ;
17 rdfs:label ‘‘Vincent van Gogh’’ .
18
19 crm-ex:painting/F16671D1-7D69-354E-91E8-CDAD152A77B0
20 a crm:E22_Human-Made_Object ;
21 rdfs:label
22 ‘‘Painting Self-Portrait as a Painter’’ ;
23 crm:P102_has_title
24 crm-ex:title/F16671D1-7D69-354E-91E8-CDAD152A77B0 ;
25 crm:P108i_was_produced_by
26 crm-ex:production/748525A0-2E27-4274-A1DE-71F29ECB56DE ;
27 crm:P138i_has_representation
28 crm-ex:visual_item/E98F243A-B982-4142-83AE-88FE0BD058CE ;
29 crm:P2_has_type
30 crm-ex:object_type/painting .
31
32 crm-ex:object_type/painting
33 a crm:E55_Type ;
34 rdfs:label ‘‘Painting’’ .
35
36 crm-ex:title/F16671D1-7D69-354E-91E8-CDAD152A77B0
37 a crm:E35_Title ;
38 rdfs:label ‘‘Self-Portrait as a Painter’’ .
39
40 crm-ex:timespan/F61F62D8-A608-4B8F-AE02-F0607FBA2D93
41 a crm:E52_Time-Span ;
42 crm:P82_at_some_time_within ‘‘1888’’ .
43
44 crm-ex:production/748525A0-2E27-4274-A1DE-71F29ECB56DE
45 a crm:E12_Production ;
46 rdfs:label ‘‘Creation of painting Self-Portrait as a Painter’’ ;
47 crm:P14_carried_out_by dbpedia:Vincent_van_Gogh ;
48 crm:P4_has_time-span
49 crm-ex:timespan/F61F62D8-A608-4B8F-AE02-F0607FBA2D93 .
|
5.2.2. Example 2. Text Analysis (with Emphasis on Event Detection)
Here, we provide an example of having a longer (in comparison to Example 1) text as input. In particular, consider the following text (derived from Wikipedia):
“Vincent van Gogh (30 March 1853–29 July 1890) was a Dutch post-Impressionist painter who posthumously became one of the most famous and influential figures in Western art history.“ Text analysis can be used to extract information and express it according to CIDOC-CRM. For instance, from the above description, we can extract the birth and death date of the painter and his style. Indeed, by using huggingface (
https://huggingface.co/ (accessed on 1 June 2022)), we can extract this information and then represent it using CIDOC-CRM, as shown in the following block. For creating the mentioned output, post-processing tasks are required, including the creation of mappings (which can be quite complex and time consuming, as it is described in Example 3 in
Section 5.2.3). However, a challenge is how to detect, extract and name various kinds of events. Related work that identifies events (and the constituents of events: actors, etc.), includes [
68,
69], whereas a pipeline for converting a text describing cultural data to RDF is described in [
70].
1 @prefix crm: <http://www.cidoc-crm.org/cidoc-crm/> .
2 @prefix crm-ex: <http://www.cidoc-crm.org/examples/> .
3 @prefix dbpedia: <https://dbpedia.org/resource/> .
4 @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
5 @prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
6
7 dbpedia:Vincent_van_Gogh
8 a crm:E21_Person ;
9 rdfs:label ‘‘Vincent van Gogh’’ ;
10 crm:P2_has_type crm-ex:painter-post-impressionist .
11
12 crm-ex:painter-post-impressionist
13 a crm:E55_Type ;
14 rdfs:label ‘‘Post-Impressionist Painter’’ .
15
16 crm-ex:birthOfVvG
17 a crm:E67_Birth ;
18 rdfs:label ‘‘Birth of Vincent van Gogh’’ ;
19 crm:P98_brought_into_life dbpedia:Vincent_van_Gogh ;
20 crm:P7_took_place_at dbpedia:Netherlands ;
21 crm:P4_has_timespan crm-ex:birthTimeSpan .
22
23 dbpedia:Netherlands
24 a crm:E53_Place ;
25 rdfs:label ‘‘Netherlands’’ .
26
27 crm-ex:birthTimeSpan
28 a crm:E52_Time-Span ;
29 crm:P82_at_some_time_within ‘‘1863’’^^xsd:gYear .
30
31 crm-ex:deathOfVvG
32 a crm:E69_Death ;
33 rdfs:label ‘‘Death of Vincent van Gogh’’ ;
34 crm:P100_was_death_of dbpedia:Vincent_van_Gogh ;
35 crm:P4_has_timespan crm-ex:deathTimeSpan .
36
37 crm-ex:deathTimeSpan
38 a crm:E52_Time-Span ;
39 crm:P82_at_some_time_within ‘‘1890"^^xsd:gYear .
|
5.2.3. Example 3. Mapping Process
The mapping process can include both mappings of ontologies and instances among different data sources. This process aims at identifying which parts from the input will be mapped to particular classes and properties of CIDOC-CRM. This is a rather complex task that requires good knowledge of the involved schemata. In the sequel, we show the X3ML mappings (specifically their representation in XML) that are used for transforming the input from Example 1 (of
Section 5.2.1). It is only one part of the overall schema mappings (The complete version of the schema mappings and the XML input can be found at
https://github.com/isl/CIDOC-CRM-datasets (CIDOC-CRM and Machine Learning/Example Dataset/) (accessed on 1 June 2022)), showing how the painting and its title from the XML input are mapped to the corresponding classes and properties (
crm:E22_Human-Made_Object and
crm:E35_Title, respectively). Apart from the definition of the mappings, we have also described how the URIs will be generated (i.e., using
instance_generator and
value_generator definitions).
1 <mapping>
2 <domain>
3 <source_node>/root/painting</source_node>
4 <target_node>
5 <entity>
6 <type>crm:E22_Human-Made_Object</type>
7 <instance_generator name="LocalTermURI">
8 <arg name=‘‘hierarchy’’ type=‘‘constant’’>panting</arg>
9 <arg name=‘‘term’’ type=‘‘xpath’’>title/text()</arg>
10 </instance_generator>
11 <label_generator name=’’CompositeLabel’’>
12 <arg name=‘‘label_part1’’ type=‘‘constant’’>Painting</arg>
13 <arg name=‘‘label_part2’’ type=‘‘xpath’’>title/text()</arg>
14 </label_generator>
15 <additional>
16 <relationship>crm:P2_has_type</relationship>
17 <entity>
18 <type>crm:E55_Type</type>
19 <instance_generator name=‘‘LocalTermURI’’>
20 <arg name=‘‘hierarchy’’ type=‘‘constant’’>object_type</arg>
21 <arg name=‘‘term’’ type=‘‘constant’’>painting</arg>
22 </instance_generator>
23 <label_generator name=‘‘SimpleLabel’’>
24 <arg name=‘‘label’’ type=‘‘constant’’>Painting</arg>
25 </label_generator>
26 </entity>
27 </additional>
28 </entity>
29 </target_node>
30 </domain>
31 <link>
32 <path>
33 <source_relation>
34 <relation>title</relation>
35 </source_relation>
36 <target_relation>
37 <relationship>crm:P102_has_title</relationship>
38 </target_relation>
39 </path>
40 <range>
41 <source_node>title</source_node>
42 <target_node>
43 <entity>
44 <type>crm:E35_Title</type>
45 <instance_generator name=‘‘LocalTermURI’’>
46 <arg name=‘‘hierarchy’’ type=‘‘constant’’>title</arg>
47 <arg name=‘‘term’’ type=‘‘xpath’’>text()</arg>
48 </instance_generator>
49 <label_generator name=‘‘SimpleLabel’’>
50 <arg name=‘‘label’’ type=‘‘xpath’’>text()</arg>
51 </label_generator>
52 </entity>
53 </target_node>
54 </range>
55 </link>
56 </mapping>
|
Although such tasks can be performed through instance and schema matching tools that are based on predefined rules [
11], there is a trend for machine learning-based algorithms based on embeddings for solving such tasks, e.g., [
71]. A possible approach could be to exploit past manually created mappings as training data for learning mapping patterns using machine learning algorithms and then suggesting future data mapping rules. Mapping such as the one that is provided above could also be used to propose such mappings. More specifically, it could train a model to construct a mapping that creates instances of
crm:E22_Human-Made_Object linked with a proper type (
crm:P2_has_type ->
crm:E55_Type) for elements in the input with name Painting. Moreover, in case that the input is given in a structured format, e.g., XML, neural networks solutions can be applied for transforming the data to RDF, e.g., [
72].
5.2.4. Example 4. Question Answering
The user formulates a question in natural language, and the objective is to either produce a SPARQL query or directly provide an answer, as in a classical QA task. This can complement the other access methods (SPARQL, Fundamental Categories, Plain and similarity-based browsing). Consider for instance, a CIDOC-CRM-compliant knowledge graph describing data about popular painters and that the graph includes the triples of the desired output in the example of
Figure 6. The natural language question
What is the creation date of Van Gogh’s painting ‘Self-Portrait as a Painter’ can be transformed to the following SPARQL query that provides the correct answer.
1 SELECT ?creationDate
2 WHERE {
3 ?production crm:P14_carried_out_by dbpedia:Vincent_van_Gogh ;
4 crm:P108_has_produced ?painting ;
5 crm:P4_has_time-span/crm:P82_at_some_time_within ?creationDate .
6 ?painting rdfs:label ?label
7 FILTER (REGEX (STR(?label), ‘‘self-portrait as a painter’’, ‘‘i’’)) }
|
To the best of our knowledge, no system can produce that query since it is not trivial. In particular, it requires techniques of natural language Processing, such as Named Entity Recognition, e.g., for detecting the entity Van Gogh and finding its DBpedia link, and relation extraction, e.g., for finding the relevant CIDOC-CRM properties that can be used for answering the query.
However note that transforming to SPARQL is not a panacea, since, for answering some questions, one has to extract the answers from the literals. Therefore, instead of transforming a natural language question to am SPARQL query, one can apply various QA pipelines (see [
73] for a survey), e.g., an alternative method is to transform the resulting CIDOC-CRM graph to natural text and to use existing BERT-based models for answering the question. Returning to our example, the approach presented in [
74] (that relies on keyword search, SPARQL and pre-trained neural networks) can answer the above question (over the DBpedia dataset). In general, the more complex the question is the harder it is to answer it, especially in cases where one has to exploit various deductions from the knowledge graph. For this purpose, an interesting direction that is worth researching is to build a QA pipeline over the query model of the fundamental categories and relationships [
31] (described earlier in
Section 3.2).
5.2.5. Example 5. Knowledge Graph Embeddings in Data Access and Exploration
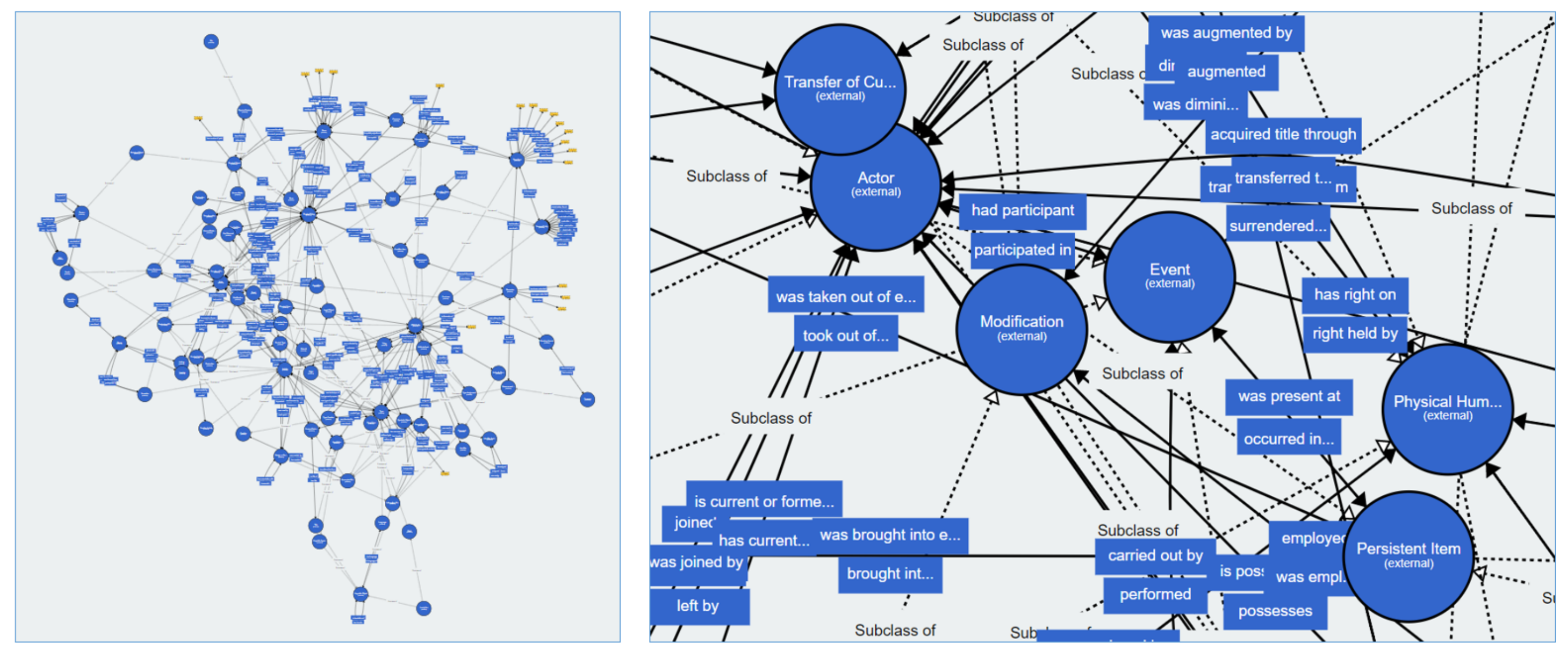
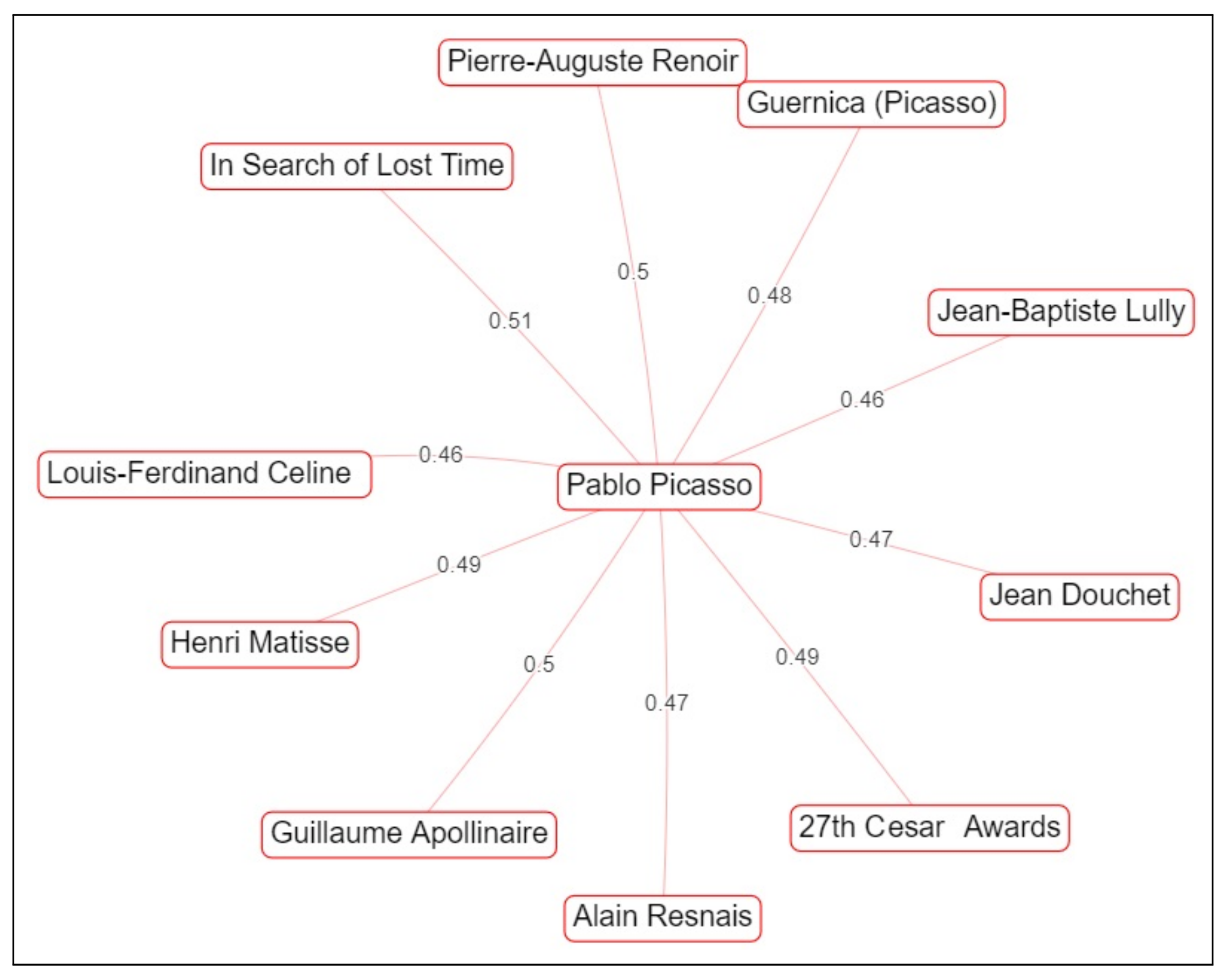
In many cases, the users desire to browse similar things, e.g., similar painters or paintings, and usually similarity methods are required that proceed beyond manually designed similarity functions.. For example, by searching for related entities to the Painter El Greco, we expect to find his paintings, similar paintings from other painters or similar painters. It would also be desirable to discover as a similar entity the Italian mathematician Fransesco Barozzi, since these two persons that lived in the 16th century were of primary importance for the Kingdom of Candia (the official name of Crete from 1205 to 1667). For making it feasible to discover such similarities and also to reveal the most important connections for any Actor or Event, knowledge graph embeddings and similarity-based models can be used, such as Word2Vec, Doc2Vec, BERT and others. An example of similarity-based browsing over DBpedia using the tool RDFSim is described in [
64] and a real screenshot of that tool is provided in
Figure 8, where we can see relevant entities relative to Pablo Picasso, such as his famous painting Guernica; the french poet Guillaume Apollinaire, who was a friend of Picasso; painters, such as Renoir; and the novel “
In Search of Lost Time”, which was written from Proust at the period when Picasso was living in Paris.
5.3. Available Datasets Expressed through the CIDOC-CRM Model
For applying Machine Learning to CIDOC-CRM data, it would be useful to test and evaluate machine learning methods over real datasets that have been created through that model. For this reason, in
Table 5, we provide a list of 18 datasets that have been expressed using the CIDOC-CRM model, and their data can be derived online through an API (e.g., SPARQL service) or a data dump. Most datasets were found through the official webpage of CIDOC-CRM and particularly via the
CRM Community Activity Documentation (
https://www.cidoc-crm.org/useCasesPage (accessed on 1 June 2022)), whereas some additional datasets were found by searching through Google Dataset Search (
https://datasetsearch.research.google.com/ (accessed on 1 June 2022)).
Table 5 shows only the datasets that are accessible online (i.e., all links of
Table 5 accessed on 1 June 2022), since there are several datasets that were published in the past and their corresponding websites are currently down. For instance, some of these datasets were mentioned in [
30], and although they were quite connected with several other RDF datasets, they are not accessible anymore. Moreover, some datasets are not publicly available, e.g., due to privacy reasons. As we can see, most datasets offer a SPARQL endpoint or another API for accessing/querying the data, whereas in many cases, a data dump is provided. Moreover, most datasets offer millions of triples and they cover various disciplines of cultural heritage data, including music, historical data, museums and others. Finally, we should also mention attempts to develop crowd-sourcing approaches that are CIDOC-CRM compatible, such as [
75].
Given the increasing number of available datasets expressed through CIDOC-CRM, it would be interesting to create a centralized service for storing and for finding fast all the available datasets expressed by CIDOC-CRM, or at least a metadata-based service providing rich metadata for each dataset. For the time being, for making it feasible to i) keep track of any updates on the existing datasets and ii) add new datasets in the future, we have created a github repository (
https://github.com/isl/CIDOC-CRM-datasets, accessed on 1 June 2022), which contains the up-to-date list of available CIDOC-CRM datasets. This would be also beneficial for the preservation and maintenance of datasets, since many of them are not available after a period of time [
76]. Finally, it would be quite helpful to create open CIDOC-CRM datasets that could be used for training and comparative evaluation, e.g., either subsets of real datasets or/and synthetic ones for covering complex cases.
Table 5.
Online datasets expressed through CIDOC-CRM (alphabetical order).
Table 5.
Online datasets expressed through CIDOC-CRM (alphabetical order).
| ID | Dataset | Link | Domain | Number of Triples | SPARQL Endpoint/API | Data Dump |
|---|
| 1 | Archaeology Data Service | http://data.archaeologydataservice.ac.uk (accessed on 1 June 2022) | Heritage Data of United Kingdom | 1,559,912 | 🗸 | |
| 2 | Auckland Museum | https://api.aucklandmuseum.com/ (accessed on 1 June 2022) | Auckland Museum, New Zealand | >10,000,000 | 🗸 | |
| 3 | Beni Culturali | https://dati.cultura.gov.it/linked-open-data/ (accessed on 1 June 2022) | Cultural Institutions in Italy | 755,702,389 | 🗸 | 🗸 |
| 4 | Corago LOD | https://zenodo.org/record/3377586 (accessed on 1 June 2022) | Italian Opera, 1600 to 1900 | 22,399,698 | | 🗸 |
| 5 | Cultura Italia | https://dati.culturaitalia.it/ (accessed on 1 June 2022) | Italian Painting, Painters, Sounds and Videos | 41,901,551 | 🗸 | |
| 6 | Doremus | https://data.doremus.org/ (accessed on 1 June 2022) | World Classical Music | 91,093,377 | 🗸 | |
| 7 | Foundation Zeri | http://data.fondazionezeri.unibo.it/ (accessed on 1 June 2022) | Photography and Italian Painters | 11,827,416 | 🗸 | 🗸 |
| 8 | Joconde Database | https://zenodo.org/record/3986498 (accessed on 1 June 2022) | French cultural heritage | ∼11,000,000 | | 🗸 |
| 9 | Kerameikos | http://kerameikos.org (accessed on 1 June 2022) | Ceramics of Ancient Greece | 289,590 | 🗸 | 🗸 |
| 10 | Nomisma.org | https://nomisma.org/ (accessed on 1 June 2022) | Numismatic concepts | 9,933,870 | 🗸 | 🗸 |
| 11 | OEBL | https://zenodo.org/record/3873203 (accessed on 1 June 2022) | Austrian Biographical Dictionary | ∼600,000 | | 🗸 |
| 12 | OpenArchaeo | http://openarchaeo.huma-num.fr/explorateur/home (accessed on 1 June 2022) | Platform for archaeological data | 1,548,827 | 🗸 | |
| 13 | Persons and Names of the Middle Kingdom | https://pnm.uni-mainz.de/ (accessed on 1 June 2022) | Egyptian Middle Kingdom Persons and Names | 1,490,284 | 🗸 | |
| 14 | RePIM | https://zenodo.org/record/5692109 (accessed on 1 June 2022) | Italian Music, 1500–1700 | 4,427,647 | | 🗸 |
| 15 | SeaLiT Knowledge Graphs | https://zenodo.org/record/6460841 (accessed on 1 June 2022) | Maritime History, 1850s–1920s | ∼18,500,000 | | 🗸 |
| 16 | Smithsonian Museum | https://triplydb.com/smithsonian/-/overview (accessed on 1 June 2022) | Smithsonian American Art Museum | 2,802,768 | 🗸 | 🗸 |
| 17 | WarSampoo | https://seco.cs.aalto.fi/projects/sotasampo/en/ (accessed on 1 June 2022) | Finnish World War II | 14,322,426 | 🗸 | 🗸 |
| 18 | WW1LOD | https://www.ldf.fi/dataset/ww1lod/ (accessed on 1 June 2022) | Finnish World War I | 47,616 | 🗸 | 🗸 |
How to Apply ML. In the context of scientific documentation, where precision is important, ML-based tasks can be used to assist the humans and not to replace them. Therefore, for applying effectively ML in a professional context, implementing workflow systems that allow the users to inspect the output of such tools and to approve, improve or reject the outputs is required to [
77,
78].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







