
Supporting Sign Language Narrations in the Museum

 ,
,  ,
,  ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background and Related Work
2.1. Web Content Accessibility
2.2. Accessibility of CH Resources in the Museum
2.3. New Media in the Museum
2.4. Sign Language and the Museum
2.4.1. Sign Language Translators Captured on Video
2.4.2. Signing Virtual Humans
2.4.3. Sign Language Production through Video Synthesis
2.5. Human Motion Digitisation for Sign Language Production
- Collecting a Motion Capture Corpus of American Sign Language: two Immersion CyberGloves®, an applied Science Labs H6 eye-tracker, InterSense IS-900 acoustical/inertial motion capture system, and an Animazoo IGS-190 spandex bodysuit [53].
- Building French Sign Language Motion Capture Corpora: marker-based systems [54].
- VICON MoCap cameras and the use of VICON’s MX system [55].
- Computer-vision-based optical approaches: (a) The HANDYCap system [56] uses three cameras, which operate at a high frame rate of 120 Hz (120 frames/second). Two cameras are focused on the whole body, while the third one is focused only on the face and provides data for further processing (for sensing facial expressions); (b) ten cameras are used for the optical motion capture, the Tobii eye tracker, and the markers [57].
2.6. Sign Language Datasets
- Video and multi-angle video datasets: (a) the RWTH-PHOENIX-Weather corpus, a video-based, large vocabulary corpus of German sign language suitable for statistical sign language recognition and translation [60]; (b) the ASL Lexicon Video Dataset, a large and expanding public dataset containing video sequences of thousands of distinct ASL signs, as well as annotations of those sequences, including start/end frames and class labels of every sign [61]; and (c) SIGNUM: the database for Signer-Independent Continuous Sign Language Recognition [62].
- Video and ToF camera datasets: PSL ToF 84: gestures as well as hand postures acquired by a time-of-flight (ToF) camera [65].
2.7. Discussion
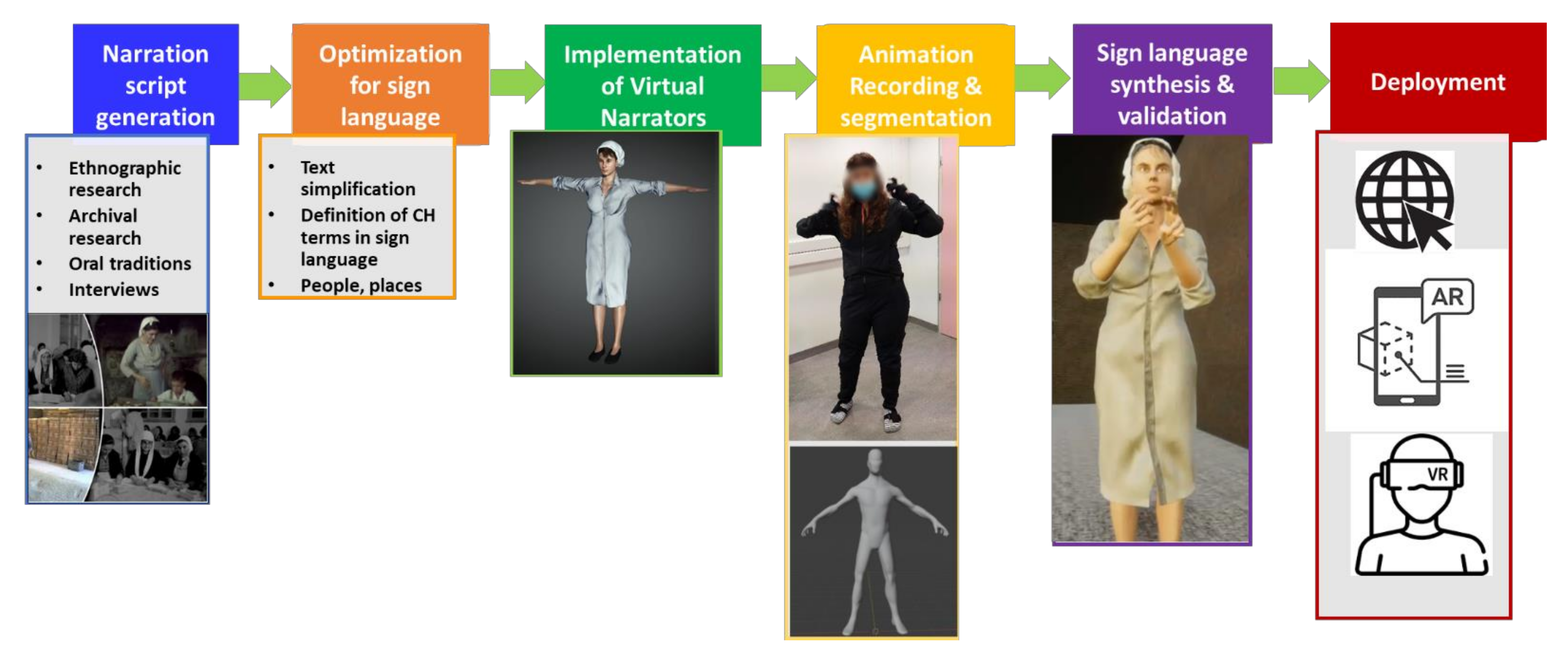
3. Proposed Method
3.1. Narration Script Generation
3.2. Optimisation for Sign Language
3.3. Implementation of Virtual Narrators
3.4. Animation Recording and Segmentation
3.5. Sign Language Synthesis and Validation
3.6. Deployment
4. Use Case
4.1. Use Case Context
4.2. Technical Setup and Accessibility Requirements
- Vertical movement: This allows the adjustment of the height of the tablet to support interaction by visitors of varying ages and heights and to support people that are using a wheelchair.
- Tilt: Regardless of the height of the tablet’s base, the tilt supports the adjustment of the field of view of the device’s camera.
- Rotation: This allows the rotation of the tablet to target different exhibits in the museum in the case where the same device is used to augment a larger space than the one covered by its camera field of view.
4.3. Narration Script and Optimisation for Sign language
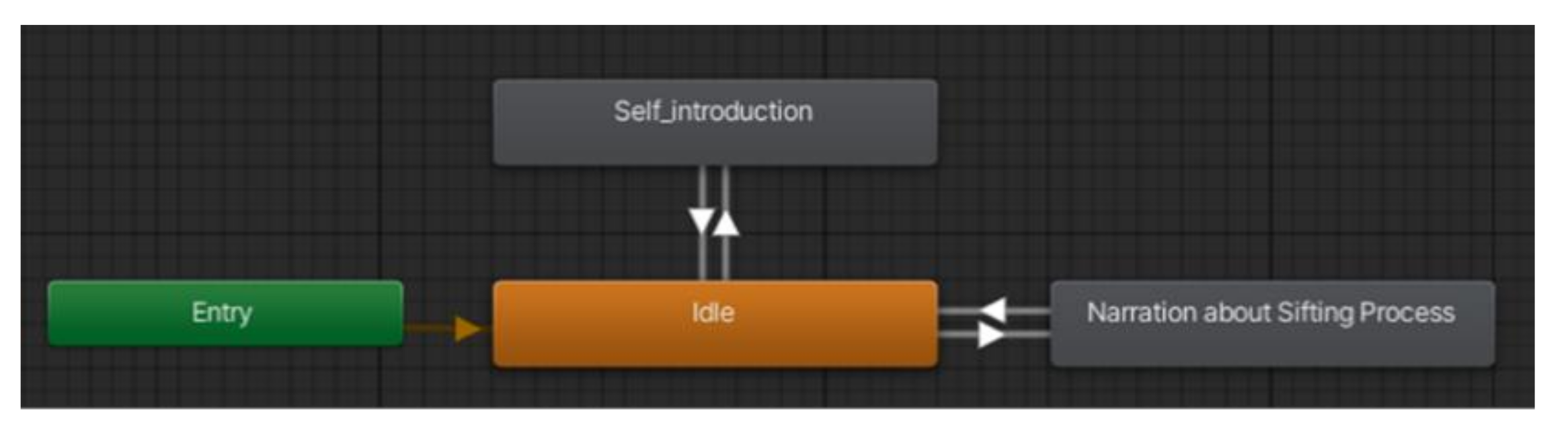
4.4. Implementation of Virtual Narrators and Optimisation
4.5. Animation Recording and Segmentation
4.6. Sign Language Synthesis and Validation
4.7. Mobile-AR App
4.8. Deployment and Preliminary Evaluation
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Weisen, M. How accessible are museums today? In Touch in Museums; Routledge: Oxfordshire, UK, 2020; pp. 243–252. [Google Scholar]
- Caldwell, B.; Cooper, M.; Reid, L.G.; Vanderheiden, G.; Chisholm, W.; Slatin, J.; White, J. Web content accessibility guidelines (WCAG) 2.0. WWW Consort. (W3C) 2008, 290, 1–34. [Google Scholar]
- Gunderson, J. W3C user agent accessibility guidelines 1.0 for graphical Web browsers. Univers. Access Inf. Soc. 2004, 3, 38–47. [Google Scholar] [CrossRef]
- Oikonomou, T.; Kaklanis, N.; Votis, K.; Kastori, G.E.; Partarakis, N.; Tzovaras, D. Waat: Personalised web accessibility evaluation tool. In Proceedings of the International Cross-Disciplinary Conference on Web Accessibility, Hyderabad Andhra Pradesh, India, 28–29 March 2011; pp. 1–2. [Google Scholar]
- Doulgeraki, C.; Partarakis, N.; Mourouzis, A.; Stephanidis, C. A development toolkit for unified web-based user interfaces. In Proceedings of the International Conference on Computers for Handicapped Persons, Linz, Austria, 9–11 July 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 346–353. [Google Scholar]
- Mourouzis, A.; Partarakis, N.; Doulgeraki, C.; Galanakis, C.; Stephanidis, C. An accessible media player as a user agent for the web. In Proceedings of the International Conference on Computers for Handicapped Persons, Linz, Austria, 9–11 July 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 474–481. [Google Scholar]
- Leas, D.; Persoon, E.; Soiffer, N.; Zacherle, M. Daisy 3: A Standard for Accessible Multimedia Books. IEEE MultiMedia 2008, 15, 28–37. [Google Scholar] [CrossRef][Green Version]
- Partarakis, N.; Klironomos, I.; Antona, M.; Margetis, G.; Grammenos, D.; Stephanidis, C. Accessibility of cultural heritage exhibits. In Proceedings of the International Conference on Universal Access in Human-Computer Interaction, Toronto, ON, Canada, 17 July 2016; Springer: Cham, Switzerland, 2016; pp. 444–455. [Google Scholar]
- Partarakis, N.; Antona, M.; Zidianakis, E.; Stephanidis, C. Adaptation and Content Personalization in the Context of Multi User Museum Exhibits. In Proceedings of the 1st Workshop on Advanced Visual Interfaces for Cultural Heritage co-located with the International Working Conference on Advanced Visual Interfaces (AVI* CH), Bari, Italy, 7–10 June 2016; pp. 5–10. [Google Scholar]
- Partarakis, N.; Antona, M.; Stephanidis, C. Adaptable, personalizable and multi user museum exhibits. In Curating the Digital; England, D., Schiphorst, T., Bryan-Kinns, N., Eds.; Springer: Cham, Germany, 2016; pp. 167–179. [Google Scholar]
- Machidon, O.M.; Duguleana, M.; Carrozzino, M. Virtual humans in cultural heritage ICT applications: A review. J. Cult. Heritage 2018, 33, 249–260. [Google Scholar] [CrossRef]
- Addison, A. Emerging trends in virtual heritage. IEEE MultiMedia 2000, 7, 22–25. [Google Scholar] [CrossRef]
- Karuzaki, E.; Partarakis, N.; Patsiouras, N.; Zidianakis, E.; Katzourakis, A.; Pattakos, A.; Kaplanidi, D.; Baka, E.; Cadi, N.; Magnenat-Thalmann, N.; et al. Realistic Virtual Humans for Cultural Heritage Applications. Heritage 2021, 4, 4148–4171. [Google Scholar] [CrossRef]
- Sylaiou, S.; Kasapakis, V.; Gavalas, D.; Dzardanova, E. Avatars as storytellers: Affective narratives in virtual museums. Pers. Ubiquitous Comput. 2020, 24, 829–841. [Google Scholar] [CrossRef]
- Partarakis, N.; Doulgeraki, P.; Karuzaki, E.; Adami, I.; Ntoa, S.; Metilli, D.; Bartalesi, V.; Meghini, C.; Marketakis, Y.; Kaplanidi, D.; et al. Representation of socio-historical context tosupport the authoring and presentation of multimodal narratives: The Mingei Online Platform. J. Comput. Cult. Herit. 2022, 15. in press. [Google Scholar] [CrossRef]
- Geigel, J.; Shitut, K.S.; Decker, J.; Doherty, A.; Jacobs, G. The digital docent: Xr storytelling for a living history museum. In Proceedings of the 26th ACM Symposium on Virtual Reality Software and Technology, Ottawa, ON, Canada, 1–4 November 2020; pp. 1–3. [Google Scholar]
- Dzardanova, E.; Kasapakis, V.; Gavalas, D.; Sylaiou, S. Exploring aspects of obedience in VR-mediated communication. In Proceedings of the 2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), Berlin, Germany, 5–7 June 2009; pp. 1–3. [Google Scholar]
- Carrozzino, M.; Colombo, M.; Tecchia, F.; Evangelista, C.; Bergamasco, M. Comparing different storytelling approaches for virtual guides in digital immersive museums. In Proceedings of the International Conference on Augmented Reality, Virtual Reality and Computer Graphics, Otranto, Italy, 24–27 June 2018; Springer: Cham, Switzerland, 2018; pp. 292–302. [Google Scholar]
- Kacorri, H. TR-2015001: A Survey and Critique of Facial Expression Synthesis in Sign Language Animation; CUNY Academic Works: Brooklyn, NY, USA, 2015. [Google Scholar]
- Huenerfauth, M. Learning to Generate Understandable Animations of American Sign Language; Rochester Institute of Technology: Rochester, NY, USA, 2014. [Google Scholar]
- Lu, P.; Huenerfauth, M. Collecting and evaluating the CUNY ASL corpus for research on American Sign Language animation. Comput. Speech Lang. 2014, 28, 812–831. [Google Scholar] [CrossRef]
- Heloir, A.; Kipp, M. EMBR—A realtime animation engine for interactive embodied agents. In Proceedings of the 9th International Conferente on Intelligent Agents, Amsterdam, Netherlands, 10–12 September 2009; pp. 393–404. [Google Scholar]
- Jennings, V.; Elliott, R.; Kenneway, R.; Glauert, J. Requirements for a signing avatar. In Proceedings of the 4th Workshop on the Representation and Processing of Sign Languages: Corporal and Sign Language Technologies, Valletta, Malta, 17–23 May 2010; pp. 33–136. [Google Scholar]
- Huenerfauth, M.; Zhao, L.; Gu, E.; Allbeck, J. Evaluation of American Sign Language Generation by Native ASL Signers. ACM Trans. Access. Comput. 2008, 1, 1–27. [Google Scholar] [CrossRef]
- Elliott, R.; Glauert, J.R.W.; Kennaway, J.R.; Marshall, I.; Safar, E. Linguistic modelling and language-processing technologies for Avatar-based sign language presentation. Univers. Access Inf. Soc. 2007, 6, 375–391. [Google Scholar] [CrossRef]
- Fotinea, S.E.; Efthimiou, E.; Caridakis, G.; Karpouzis, K. A knowledge-based sign synthesis architecture. Univ. Access Inf. Soc. 2008, 6, 405–418. [Google Scholar] [CrossRef]
- Segundo, S. Design, development and field evaluation of a Spanish into sign language translation system. Pattern Anal. Appl. 2012, 15, 203–224. [Google Scholar] [CrossRef]
- Kennaway, R.; Glauert, J.R.W.; Zwitserlood, I. Providing signed content on the Internet by synthesized animation. ACM Trans. Comput. Interact. 2007, 14, 15. [Google Scholar] [CrossRef]
- Huenerfauth, M.; Lu, P.; Rosenberg, A. Evaluating importance of facial expression in american sign language and pidgin signed english animations. In Proceedings of the 13th International ACM SIGACCESS Conference on Computer and Accessibility, Dundee, Scotland, 24–26 October 2011; pp. 99–106. [Google Scholar]
- Gibet, S.; Courty, N.; Duarte, K.; le Naour, T. The SignCom system for data-driven animation of interactive virtual signers: Methodology and Evaluation. ACM Trans. Interact. Intell. Syst. (TiiS) 2011, 1, 1–23. [Google Scholar] [CrossRef]
- McDonald, J.; Alkoby, K.; Carter, R.; Christopher, J.; Davidson, M.; Ethridge, D.; Furst, J.; Hinkle, D.; Lancaster, G.; Smallwood, L.; et al. A Direct Method for Positioning the Arms of a Human Model. In Proceedings of the Graphics Interface 2002, Calgary, AB, Canada, 27–29 May 2002; pp. 99–106. [Google Scholar]
- Signing Avatars. Available online: http://www.bbcworld.com/content/clickonline_archive_35_2002.asp (accessed on 10 August 2021).
- Grieve-Smith, A. A Demonstration of Text-to-Sign Synthesis, Presented at the Fourth Workshop on Gesture and Human-Computer Interaction, London. 2001. Available online: www.unm.edu/~grvsmth/signsynth/gw2001/ (accessed on 5 September 2021).
- Zwiterslood, I.; Verlinden, M.; Ros, J.; van der Schoot, S. Synthetic Signing for the Deaf: eSIGN. In Proceedings of the Conference and Workshop on Assistive Technologies for Vision and Hearing Impairment, CVHI 2004, Granada, Spain, 29 June–2 July 2004. [Google Scholar]
- McDonald, J.; Wolfe, R.; Schnepp, J.; Hochgesang, J.; Jamrozik, D.G.; Stumbo, M.; Berke, L.; Bialek, M.; Thomas, F. An automated technique for real-time production of lifelike animations of American Sign Language. Univers. Access Inf. Soc. 2015, 15, 551–566. [Google Scholar] [CrossRef]
- Karpouzis, K.; Caridakis, G.; Fotinea, S.-E.; Efthimiou, E. Educational resources and implementation of a Greek sign language synthesis architecture. Comput. Educ. 2007, 49, 54–74. [Google Scholar] [CrossRef]
- Elliott, R.; Glauert, J.R.W.; Kennaway, J.R.; Marshall, I. The development of language processing support for the ViSiCAST project. In Proceedings of the fourth international ACM conference on Assistive technologies, Arlington, VI, USA, 13–15 November 2000. [Google Scholar]
- Braffort, A.; Filhol, M.; Delorme, M.; Bolot, L.; Choisier, A.; Verrecchia, C. KAZOO: A sign language generation platform based on production rules. Univers. Access Inf. Soc. 2015, 15, 541–550. [Google Scholar] [CrossRef]
- Adamo-Villani, N.; Wilbur, R.B. ASL-Pro: American Sign Language Animation with Prosodic Elements. In Universal Access in Human-Computer Interaction. Access to Interaction; Antona, M., Stephanidis, C., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 307–318. [Google Scholar]
- Huenerfauth, M.; Kacorri, H. Release of Experimental Stimuli and Questions for Evaluating Facial Expressions in Animations of American Sign Language. In Proceedings of the the 6th Workshop on the Representation and Processing of Sign Languages: Beyond the Manual Channel, The 9th International Conference on Language Resources and Evaluation (LREC), Reykjavik, Iceland, 31 May 2014. [Google Scholar]
- Ebling, S.; Glauert, J. Building a Swiss German Sign Language avatar with JASigning and evaluating it among the Deaf community. Univers. Access Inf. Soc. 2015, 15, 577–587. [Google Scholar] [CrossRef]
- Segouat, J.; Braffort, A. Toward the Study of Sign Language Coarticulation: Methodology Proposal. IEEE 2009, 369–374. [Google Scholar] [CrossRef]
- Duarte, K.; Gibet, S. Heterogeneous data sources for signed language analysis and synthesis: The signcom project. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC 2010) (Vol. 2, pp. 1–8), Valletta, Malta, 17–23 May 2010; European Language Resources Association: Luxembourg, 2010. [Google Scholar]
- Huenerfauth, M.; Marcus, M.; Palmer, M. Generating American Sign Language Classifierpredicates for English-to-ASL Ma-chine Translation. Ph.D. Thesis, University of Pennsylvania, Philadelphia, PA, USA, 2006. [Google Scholar]
- Kacorri, H.; Huenerfauth, M. Continuous Profile Models in ASL Syntactic Facial Expression Synthesis. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016. [Google Scholar] [CrossRef]
- Ebling, S.; Glauert, J. Exploiting the full potential of JASigning to build an avatar signing train announcements. In Proceedings of the Third International Symposium on Sign Language Translation and Avatar Technology, Chicago, IL, USA, 18–19 October 2013. [Google Scholar] [CrossRef]
- Al-khazraji, S.; Berke, L.; Kafle, S.; Yeung, P.; Huenerfauth, M. Modeling the Speed and Timing of American Sign Language to Generate Realistic Animations. In Proceedings of the 20th International ACM SIGACCESS Conference on Computers and Accessibility, Galway, Ireland, 22–24 October 2018; pp. 259–270. [Google Scholar]
- Partarakis, N.; Zabulis, X.; Chatziantoniou, A.; Patsiouras, N.; Adami, I. An Approach to the Creation and Presentation of Reference Gesture Datasets, for the Preservation of Traditional Crafts. Appl. Sci. 2020, 10, 7325. [Google Scholar] [CrossRef]
- Solina, F.; Krapež, S. Synthesis of the sign language of the deaf from the sign video clips. Electrotech. Rev. 1999, 66, 260–265. [Google Scholar]
- Bachmann, E.R.; Yun, X.; McGhee, R.B. Sourceless tracking of human posture using small inertial/magnetic sensors. In Proceedings of the 2003 IEEE International Symposium on Computational Intelligence in Robotics and Automation. Computational Intelligence in Robotics and Automation for the New Millennium (Cat. No. 03EX694), Kobe, Japan, 16–20 July 2003; IEEE: Manhattan, NY, USA, 2003; Volume 2, pp. 822–829. [Google Scholar]
- Brigante, C.M.N.; Abbate, N.; Basile, A.; Faulisi, A.C.; Sessa, S. Towards Miniaturization of a MEMS-Based Wearable Motion Capture System. IEEE Trans. Ind. Electron. 2011, 58, 3234–3241. [Google Scholar] [CrossRef]
- Madgwick, S. An Efficient Orientation Filter for Inertial and Inertial/Magnetic Sensor Arrays; Report x-io and University of Bristol (UK): Bristol, UK, 2010; Volume 25, pp. 113–118. [Google Scholar]
- Lu, P.; Huenerfauth, M. Collecting a motion-capture corpus of American Sign Language for data-driven generation research. In Proceedings of the NAACL HLT 2010 Workshop on Speech and Language Processing for Assistive Technologies, Los Angeles, CA, USA, 5 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 89–97. [Google Scholar]
- Gibet, S. Building French Sign Language Motion Capture Corpora for Signing Avatars. In Proceedings of the Workshop on the Representation and Processing of Sign Languages: Involving the Language Community, LREC, Miyazaki, Japan, 30 May 2018. [Google Scholar]
- Jedlička, P. Sign Language Motion Capture Database Recorded by One Device. In Studentská Vědecká Konference: Magisterské a Doktorské Studijní Pogramy, Sborník Rozšířených Abstraktů, Květen 2018; Západočeská univerzita v Plzni: Plzni, Czech Republic, 2019. [Google Scholar]
- Havasi, L.; Szabó, H.M. A motion capture system for sign language synthesis: Overview and related issues. In Proceedings of the EUROCON 2005-The International Conference on “Computer as a Tool”, Belgrade, Serbia, 21–24 November 2005; IEEE: Manhattan, NY, USA, 2005; Volume 1, pp. 445–448. [Google Scholar]
- Benchiheub, M.; Berret, B.; Braffort, A. Collecting and Analysing a Motion-Capture Corpus of French Sign Language. In Proceedings of the 7th LREC Workshop on the Representation and Processing of Sign Languages: Corpus Mining, Portorož, Slovenia, 28 May 2016. [Google Scholar]
- Barczak, A.L.C.; Reyes, N.H.; Abastillas, M.; Piccio, A.; Susnjak, T. A new 2D static hand gesture colour image dataset for ASL gestures. Res. Lett. Inf. Math. Sci. 2011, 15, 12–20. [Google Scholar]
- Oliveira, M.; Chatbri, H.; Ferstl, Y.; Farouk, M.; Little, S.; O’Connor, N.E.; Sutherland, A. A dataset for irish sign language recognition; Doras: Dublin, Ireland, 2017. [Google Scholar]
- Forster, J.; Schmidt, C.; Hoyoux, T.; Koller, O.; Zelle, U.; Piater, J.H.; Ney, H. RWTH-PHOENIX-Weather: A Large Vocabulary Sign Language Recognition and Translation Corpus. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 21–27 May 2012; pp. 3785–3789. [Google Scholar]
- Athitsos, V.; Neidle, C.; Sclaroff, S.; Nash, J.; Stefan, A.; Yuan, Q.; Thangali, A. The american sign language lexicon video dataset. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; IEEE: Manhattan, NY, USA, 2008; pp. 1–8. [Google Scholar]
- SIGNUM. Available online: https://www.bas.uni-muenchen.de/Bas/SIGNUM/ (accessed on 2 September 2021).
- Oszust, M.; Wysocki, M. Polish sign language words recognition with kinect. In Proceedings of the 2013 6th International Conference on Human System Interactions (HSI), Sopot, Poland, 6–8 June 2013; IEEE: Manhattan, NY, USA, 2013; pp. 219–226. [Google Scholar]
- Conly, C.; Doliotis, P.; Jangyodsuk, P.; Alonzo, R.; Athitsos, V. Toward a 3D body part detection video dataset and hand tracking benchmark. In Proceedings of the 6th International Conference on PErvasive Technologies Related to Assistive Environments, Rhodes, Greece, 29–31 May 2013; pp. 1–6. [Google Scholar]
- Kapuscinski, T.; Oszust, M.; Wysocki, M.; Warchol, D. Recognition of hand gestures observed by depth cameras. Int. J. Adv. Robot. Syst. 2015, 12, 36. [Google Scholar] [CrossRef]
- Zabulis, X.; Meghini, C.; Partarakis, N.; Beisswenger, C.; Dubois, A.; Fasoula, M.; Nitti, V.; Ntoa, S.; Adami, I.; Chatziantoniou, A.; et al. Representation and preservation of Heritage Crafts. Sustainability 2020, 12, 1461. [Google Scholar] [CrossRef]
- Aluísio, S.M.; Specia, L.; Pardo, T.A.; Maziero, E.G.; Fortes, R.P. Towards Brazilian Portuguese automatic text simplification systems. In Proceedings of the eighth ACM symposium on Document engineering, Sao Paulo, Brazil, 16–19 September 2008; pp. 240–248. [Google Scholar] [CrossRef]
- Alonzo, O.; Seita, M.; Glasser, A.; Huenerfauth, M. Automatic Text Simplification Tools for Deaf and Hard of Hearing Adults: Benefits of Lexical Simplification and Providing Users with Autonomy. In Proceedings of the CHI ’20: CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020. [Google Scholar] [CrossRef]
- ARCore Supported Devices. Available online: https://developers.google.com/ar/devices (accessed on 9 December 2021).
- ARKit Supported Devices. Available online: https://developer.apple.com/library/archive/documentation/DeviceInformation/Reference/iOSDeviceCompatibility/DeviceCompatibilityMatrix/DeviceCompatibilityMatrix.html (accessed on 9 December 2021).
- Adobe Systems Incorporated. Mixamo. Available online: https://www.mixamo.com/#/?page=1&query=Y-Bot&type=Character (accessed on 30 August 2021).
- ds-Max. Available online: https://www.autodesk.fr/products/3ds-max (accessed on 10 September 2021).








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Partarakis, N.; Zabulis, X.; Foukarakis, M.; Moutsaki, M.; Zidianakis, E.; Patakos, A.; Adami, I.; Kaplanidi, D.; Ringas, C.; Tasiopoulou, E. Supporting Sign Language Narrations in the Museum. Heritage 2022, 5, 1-20. https://doi.org/10.3390/heritage5010001
Partarakis N, Zabulis X, Foukarakis M, Moutsaki M, Zidianakis E, Patakos A, Adami I, Kaplanidi D, Ringas C, Tasiopoulou E. Supporting Sign Language Narrations in the Museum. Heritage. 2022; 5(1):1-20. https://doi.org/10.3390/heritage5010001
Chicago/Turabian StylePartarakis, Nikolaos, Xenophon Zabulis, Michalis Foukarakis, Mirοdanthi Moutsaki, Emmanouil Zidianakis, Andreas Patakos, Ilia Adami, Danae Kaplanidi, Christodoulos Ringas, and Eleana Tasiopoulou. 2022. "Supporting Sign Language Narrations in the Museum" Heritage 5, no. 1: 1-20. https://doi.org/10.3390/heritage5010001
APA StylePartarakis, N., Zabulis, X., Foukarakis, M., Moutsaki, M., Zidianakis, E., Patakos, A., Adami, I., Kaplanidi, D., Ringas, C., & Tasiopoulou, E. (2022). Supporting Sign Language Narrations in the Museum. Heritage, 5(1), 1-20. https://doi.org/10.3390/heritage5010001