1. Introduction
Recent advances in remote-sensing technologies and imaging devices have opened up new possibilities for digital recording of cultural heritage (CH) sites and collections. Indeed, these technologies allow for the production of very realistic digital replicas of CH sites and collections [
1]. This generated CH data is often geographically referenced, thereby incorporating geographical location and time references, the resulting geospatial data often appears in a wide range of geospatial file formats. In turn, geospatial data, and location and time references can be used to discover interesting connections and relationships among cultural heritage resources. Hence, geospatial data is a major component in the CH field [
2,
3].
Furthermore, the volume of digital cultural heritage data is growing significantly, as CH sites and CH collections are being digitized at exponentially accelerating rates by CH digitization projects, government bodies and CH institutions (galleries, libraries, archives, and museums) around the globe [
4,
5]. Accordingly, the ever-increasing growth of digital CH data facilitated the development of cultural heritage repositories, which are playing a major role in digital preservation and dissemination, tourism, and CH research among others [
6,
7]. An apt example of this is the Europeana portal, which provides metadata information about digital cultural heritage content from European countries [
8,
9]. However, there are many other smaller repositories all over the world, in which data is published as raw dumps in different file formats lacking structure and semantics. Some of the major technical challenges in these repositories are data integration and interoperability among distributed repositories at the national and regional level. As a result, poorly-linked CH data is fragmented in several national and regional repositories, backed by non-standardized search interfaces. All these technical challenges are limiting users’ attempts to contextualize information from distributed repositories [
10].
The semantic web is a new extension of the existing World Wide Web, it offers a set of best practices for publishing and interlinking structured data on the Web. In the semantic web, data is published in a machine-readable and processable format, and data has explicit meaning to machines defined by ontologies, and the resulting datasets are interlinked [
11]. The geospatial semantic web is an extension of the semantic web, where geospatial data has explicit meaning to machines defined by geospatial ontologies. Geospatial data has distinct features such as geometries, a coordinate reference system (CRS), a topology of geometries, all of which require special attention when encoding into a machine-readable and processable format. In return, the geospatial semantic web offers capabilities such as geographic information system (GIS)-based analysis, spatio-temporal queries and interlinking with other external data sources to provide geospatial context for the specific topic. These features of the geospatial semantic web are uncommon in the semantic web because the semantic web is not designed to deal with complex geospatial data [
12,
13]. Since the geospatial semantic web incorporates geospatial data as well as semantic web concepts, several new and existing CH repositories have adopted the geospatial semantic web concepts to deal with geospatial CH data and to overcome the aforementioned issues of interoperability and integration [
14,
15,
16]. Moreover, several web platforms based on these concepts have been developed to improve data integration, interoperability, long-term preservation, accessibility of digital CH data, such as WissKI
1, Arches
2, Omeka
3, etc.
As the geospatial semantic web is a new emerging concept, a limited number of surveys have been conducted. Li et al. [
17] reviewed the state of the geospatial semantic web, outlined challenges and opportunities of exploiting big geospatial data in the geospatial semantic web, and proposed future directions. Kuhn et al. [
18], Nalepa and Furmańska [
19] explained major innovations in the field of geographic information science brought about by semantic web concepts. Faye et al. [
20] and Rohloff et al. [
21] surveyed triple store technologies for linked data. Battle and Kolas [
22] discussed the overall state of geospatial data in the semantic web including state of a query language GeoSPARQL in industry and research. Buccella et al. [
23] surveyed widely used approaches to integrate geospatial data using ontologies. Ballatore et al. [
24] reviewed geospatial data in open knowledge bases such as DBpedia, LinkedGeoData, GeoNames, and OpenStreetMap, particularly paying attention to the quality of geodata, and to crowdsourced data.
However, there has not yet been conducted a conceptual survey of the geospatial semantic web concepts for a cultural heritage audience. A conceptual survey of these concepts pertinent to the cultural heritage field is, therefore, needed. Such a review equips CH professionals and practitioners with a useful overview of all the necessary tools, and free and open source (FOSS) semantic web and geospatial semantic web platforms that can be used to implement geospatial semantic web-based CH repositories.
Hence, the objectives of this article are as follows:
To review the state-of-the-art geospatial semantic web concepts pertinent to the CH field.
To propose a framework to turn geospatial CH data stored in a vector data model into machine-readable and processable RDF data in order to use in the geospatial semantic web with a case study to demonstrate its applicability.
To outline key FOSS semantic web and geospatial semantic web-based purpose-built platforms for CH institutions.
To summarize leading cultural heritage projects employing geospatial semantic web concepts.
To discusses attributes of the geospatial semantic web concepts requiring more attention, which can result in the generation of new ideas and research questions for both the field of the geospatial semantic web and CH.
The remainder of the article is structured as follows: In
Section 2, it discusses a web evolution and the state-of-art in the geospatial semantic web including cultural heritage domain ontologies. In
Section 3, it proposes a framework to turn CH data into machine-readable and processable RDF data with its subsequent storage and retrieval. It demonstrates the applicability of this framework with a case study.
Section 4 outlines key FOSS semantic web and geospatial semantic web-based purpose-built platforms for CH institutions. In
Section 5, leading CH projects are presented that employ semantic web and geospatial semantic web concepts.
Section 6 outlines challenges and technical limitations of the geospatial semantic web followed by a concluding summary in
Section 7.
2. Web Evolution and the Geospatial Semantic Web
The idea of the World Wide Web was first introduced by Tim-Berners-Lee in 1989. It has now become the largest global information space for sharing information. The web technologies witnessed a great deal of progress in the last two decades (see
Figure 1). The first generation of the web, also known as a read-only web, web of documents, and Web 1.0, allows users only to search for information and read it. The websites are based on static HTML pages represented as hypertext in which elements can be linked to different resources. Hypertext transfer protocol (HTTP) is used as a means of communication between clients and servers [
25].
The second phase in the evolution of the web is Web 2.0, also referred to as a read-write web and web of people. It has several interpretations (see for example [
26]), but in general, it can be understood as an idea to describe the web as a user-centric and socially-connected platform, where people have more interaction and collaboration than in its predecessor. A set of new technologies have been introduced along with Web 2.0 such as AJAX (JavaScript and XML), Adobe Flex, Google Web Toolkit, etc. This allowed development of more dynamic, interactive websites and web applications, in which users can publish content to the web and modify existing ones. The foundations of Web 2.0 can also be demonstrated by the development of well-known web applications including social networking platforms (e.g., Facebook), web-blogs (e.g., WordPress), Wikipedia, media-sharing platforms (e.g., YouTube) among others [
27].
In recent years, a new extension to the Web has started to emerge named Web 3.0, which is the third phase in web evolution. Web 3.0 is also known as the semantic web and the web of data. The previously discussed Web 1.0 is a read-only web to share information, and Web 2.0 is a read-write web which offers increased collaboration and social interaction among users. In the second phase, users have the capability to publish content to the web, with hypertext links to other resources, and machines can display it. However, it is only for human consumption and machines themselves do not have an ability to process and “understand” the content. The semantic web is being developed to overcome these problems. The semantic web extends the core principles of Web 2.0 rather than replacing them, and adds semantics to the web by structuring web content and facilitating software applications to process and ‘understand’ the structured content. The semantic web incorporates several standardized components by the World Wide Web Consortium (W3C) such as the resource description framework (RDF) data model to represent web resources in a machine-readable format, ontologies to give well-defined meaning to data, SPARQL Protocol and RDF Query Language (SPARQL) to query data in the semantic web, triple stores to store RDF data to name a few (to be discussed in later sections) [
11]. This standardization in the semantic web provides a shared concept allowing cultural heritage data to be published, interlinked, searched and consumed more effectively than with web 2.0.
However, as mentioned in the introduction section, a problem with the semantic web arises when CH data is supplied as geospatial data in various geospatial file formats along with coordinate reference system (CRS), and topology. Geospatial data management in the semantic web is, therefore, tackled by its extension termed the geospatial semantic web. The geospatial semantic web brings together concepts of the semantic web and geospatial data, and adds a spatio-temporal dimension to the semantic web. CH data often includes geospatial data, for instance, current and historical places, CH objects and artifacts, and historical maps are typically associated with some type of locational and time-based references. To encode geospatial CH data into a machine-readable and processable format, the geospatial semantic web offers distinct technical specifications, including:
A RDF data model;
Geospatial ontologies of the geospatial semantic web;
Geospatial query languages of the geospatial semantic web;
Spatio-temporal triple stores to store geospatial RDF data.
In the next sub-sections, these specifications are discussed in detail.
2.1. Data Models
RDF is an abstract data model to represent web resources in the semantic web. It is designed to be read and, most importantly, understood by machines to provide better interoperability among computer applications. RDF structures data in the form of subject, predicate, and object, known as triples. The subject defines resource being described, the predicate is the property being described with respect to the resource, and the object is the value for the property. The subject and predicate are both represented by the uniform resource identifier (URI), while the object can be a URI or a string literal. An important feature of RDF is flexibility for resources to be a subject in one triple and an object in another one [
11]. For instance, “Curtin University Bentley campus is based in Perth city” and “Perth city is the largest city in Western Australia”. From a semantic web perspective, in this example, Perth city is an object in the first example and a subject in the second. This allows RDF to find connections between triples, which is referred to as linked data. RDF is used in combination with ontologies to provide semantic information about resources being described. Ontologies and vocabularies are discussed in the next section. The RDF data model is not only stored in an XML file format, there are some alternative existing RDF formats. Despite the difference in formats, resulting triples are logically equivalent. Some of the most-used RDF serialization formats are RDF/XML, N-Triples, JSON-LD, Turtle, and Notation3 (N3). For an explanation of RDF formats we recommend an article by Gandon et al. [
28].
2.2. Geospatial Ontologies and Geospatial Semantic Web Query Languages
The term “ontology” originated in the field of philosophy, in which it refers to the subject of existence. In computer science and information science fields, an ontology is a data model, which is used to specify domain-based concepts and relationships between these concepts [
29]. There also exists a term called “vocabulary” in the semantic web, which is often referred to be equal to the term “ontology”. According to W3C
4, “There is no clear division between what is referred to as ‘vocabularies’ and ‘ontologies’. The trend is to use the word ‘ontology’ for more complex, and possibly quite formal collection of terms, whereas ‘vocabulary’ is used when such strict formalism is not necessarily used or only in a very loose sense.” Ontologies and vocabularies in the semantic web provide a structure for organizing implicit and explicit concepts and relationships. There are several reasons to use an ontology in the semantic web and the geospatial semantic web such as to analyze domain knowledge, or to separate domain knowledge from operational knowledge [
30]. However, the main reason to use ontologies in the semantic web and the geospatial semantic web is to improve data integration by tackling an issue of semantic heterogeneity.
5 Semantic heterogeneity is a term to describe a disagreement about the meaning and interpretation of data [
31]. Ontologies can be one of three types, namely, domain ontology, and upper ontology (also known as top-level ontology) and hybrid ontology. Domain ontology specifies concepts, terminologies, and thesauri that are associated within a certain domain. For instance, a geospatial ontology defines concepts and relationships for geospatial data. To be more precise, spatio-temporal concepts and geospatial relations such as equal, disjoint, touch, within, contain can be mapped to geospatial ontologies, which then can facilitate shareable and reusable geospatial information. Upper ontology specifies concepts which can be used across a wide range of domains. It represents concepts for general things such as an object, properties, space, roles, functions and relation, which can be found in many domains. Hybrid ontology is a combination of domain ontology and upper ontology [
32]. In the following sub-sections, the article discusses geospatial ontologies and a cultural heritage domain ontology CIDOC-Conceptual Reference Model (CRM) in more detail. Furthermore, there are query languages termed SPARQL and GeoSPARQL, which are query languages for data in RDF in semantic web and the geospatial semantic web respectively. SPARQL is a standard by W3C, while GeoSPARQL is a standard by the Open Geospatial Consortium (OGC). The next sub-sections cover those languages in detail as well.
2.2.1. GeoSPARQL Vocabulary and Query Language
In recent years, geospatial organizations, research groups, triple store vendors have attempted to implement their own geospatial ontologies and strategies in order to deploy geospatial data in the semantic web. Unfortunately, this led to inconsistency. Hence, properly represented spatial RDF data in one organization became incompatible with spatial RDF data from another organization [
33]. To resolve this, a standardized geospatial ontology and query language termed GeoSPARQL has been proposed by OGC. OGC is an international not-for-profit organization which implements quality open standards for the global geospatial community. GeoSPARQL is a small vocabulary to describe geospatial information to supply for the geospatial semantic web as well as a geospatial extension of the semantic web query language of SPARQL. It can be combined with other domain-based ontologies to fulfill the needs for geospatial RDF data. GeoSPARQL implements a basic core for representing and accessing geospatial data published in a machine-readable and processable format in the geospatial semantic web [
34]. Published RDF data can be queried with spatial functions provided by GeoSPARQL to discover interesting connections and relationships among cultural heritage resources.
An example of a GeoSPARQL query is illustrated in
Figure 2. This GeoSPARQL query finds all performing arts centers—in this case, denoted as PAC—which are located within 30,000 m from the place “The Perth Mint” in the city of Perth, Western Australia. It uses the GeoSPARQL “geof:distance” function to calculate the distance between each performing arts centre and “The Perth Mint”. In this example, it is assumed that URI for the data is located at
http://example.com/.
2.2.2. CIDOC-Conceptual Reference Model (CRM) and CRMgeo
CIDOC-Conceptual Reference Model (CRM) is an ontology developed to define concepts and relationships in CH data. It has been developed by two working groups of CIDOC namely the CIDOC Documentation and Standards Working Group and CIDOC CRM SIG. The ontology is not developed for CH institutions in any one country or a region, but any CH institution in the world can benefit from using it. In addition, it is an ISO standard since 2006. The main aim of the ontology is to provide semantic interoperability and integration among heterogenous CH resources. It offers more than 80 classes and 130 properties, which CH organizations can organize their datasets with and define relationships among them. It follows an object-oriented data model and offers the possibility for extensions [
35].
As mentioned earlier, CH data is often accompanied by a spatio-temporal reference. Hence, there have been many projects which attempted to integrate geoinformation with CIDOC-CRM. For instance, AnnoMAD System integrated geographic markup language (GML) with CIDOC-CRM to annotate spatial descriptions in free-text archeological data [
36], the CLAROS
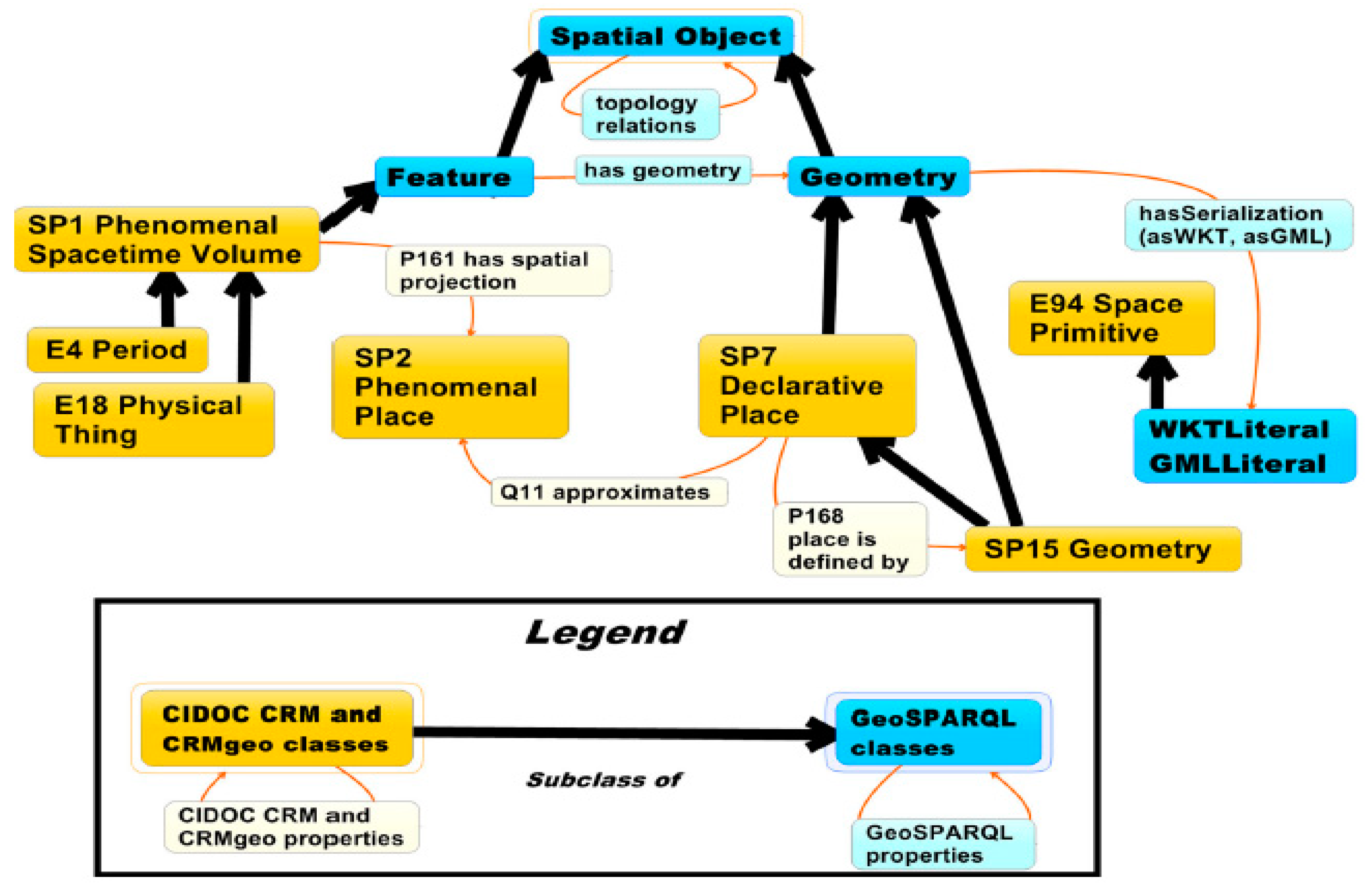
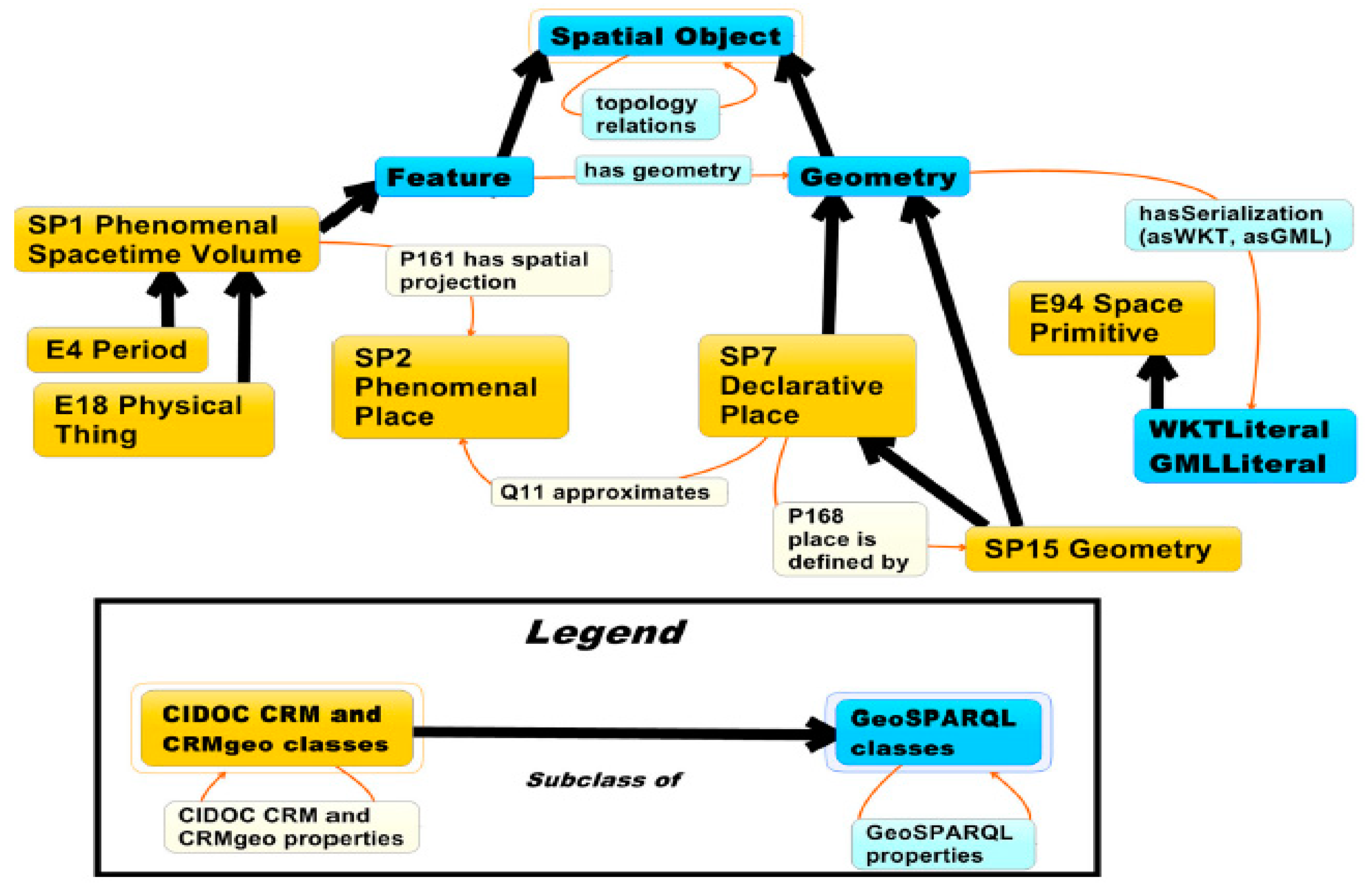
6 project used basic spatial coordinates together with CIDOC-CRM. Recently a formal geospatial extension to CIDOC-CRM termed CRMgeo has been developed. CRMgeo has been integrated with the GeoSPARQL vocabulary to add spatio-temporal classes and properties to the ontology. It allows encoding location and time-related concepts and relationships of CH data under CIDOC-CRM. It adheres to formal definitions, encoding standards and topological relations used in the GeoSPARQL vocabulary, thus geospatial functionalities of GeoSPARQL can be fully utilized on CH data published under CRMgeo. The integration method of CIDOC-CRM with the GeoSPARQL vocabulary is given in
Figure 3. The letters ‘SP’ denote classes and ‘E’ represents properties. GeoSPARQL properties are highlighted in blue, where “Feature” is a subclass of “Spatial Object” and can have “Geometry” in one of two serialization formats, well-known text (WKT) or GML [
37].
2.2.3. Geospatial Functions in SPARQL Query Language
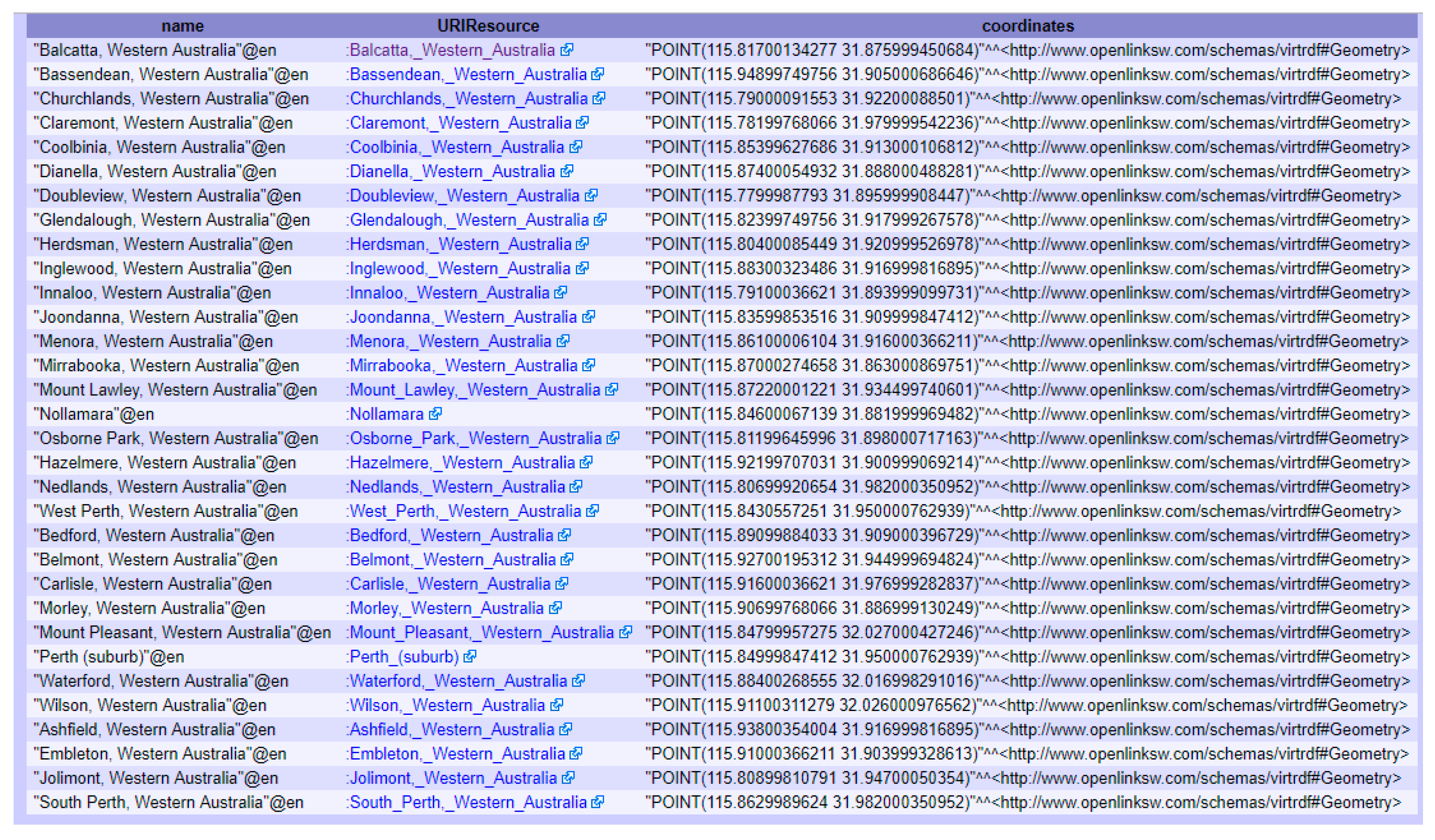
SPARQL Protocol and RDF Query Language is a query language for the semantic web. It is one of the key pieces of technology stack of the semantic web. SPARQL is not designed to query geospatial data and does not provide a comprehensive set of geospatial query capabilities. However, it supports several simple geospatial functionalities such as “st_intersects” (intersection between two geometries), “st_within” (check if geometry A is within geometry B) and others. If the case is to use simple geospatial queries on the semantic web, such as to check if a CH site is located within specified proximity or to check if geometries of two or more CH sites intersect, then SPARQL can handle them. The following example of a SPARQL query in
Figure 4 demonstrates geospatial functionality of “st_intersects”, performed on a DBPedia semantic web endpoint
7 at
http://dbpedia.org/snorql/. DBPedia is a semantic web version of a Wikipedia project and allows the querying of Wikipedia content using SPARQL.
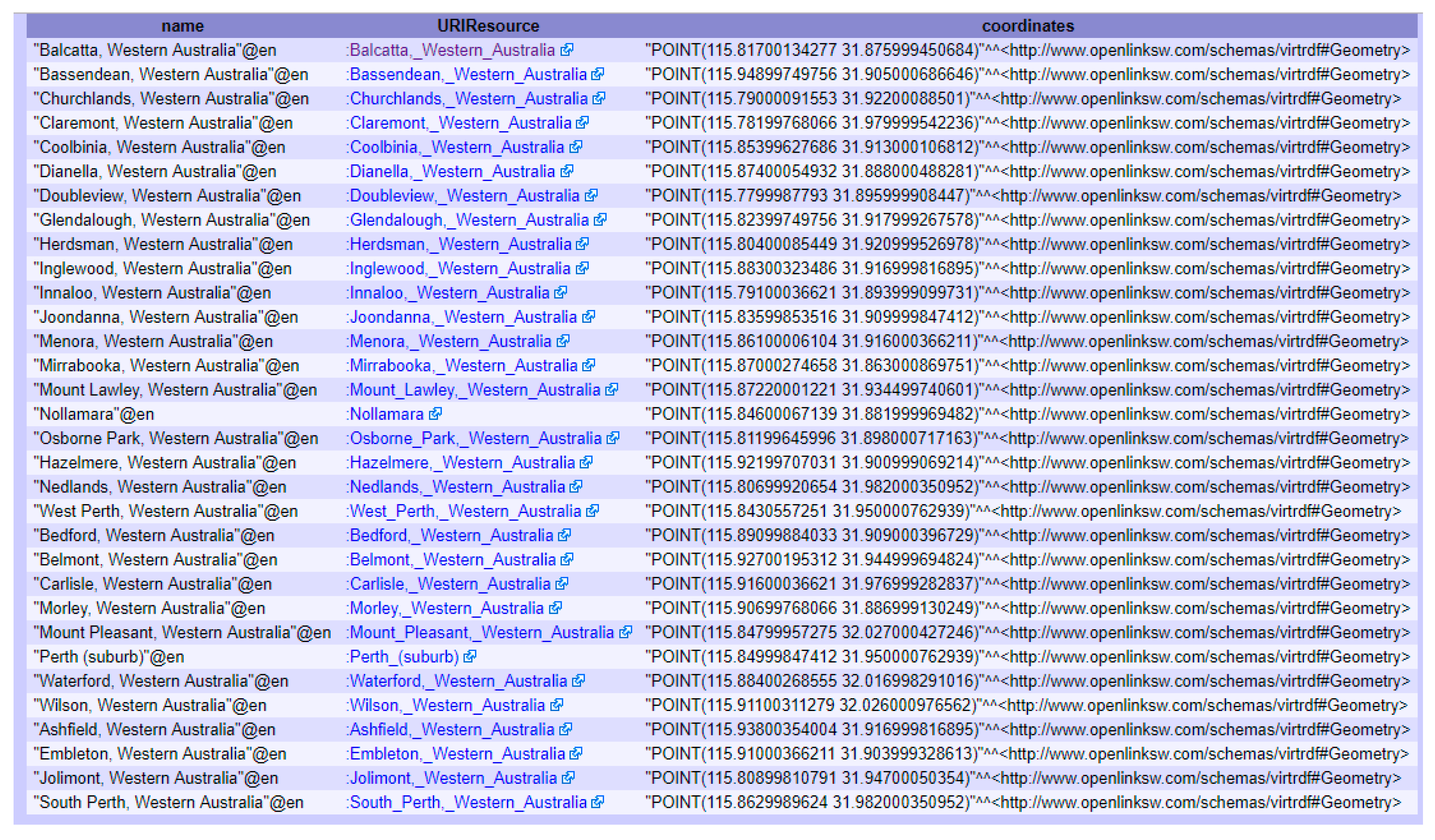
This query returns all places that lie within 10 km of Perth city in Western Australia.
The result of the query is shown in
Figure 5. The DBpedia semantic web endpoint provides results in JSON, XML and XML+XSLT formats.
2.3. Spatio-Temporal Triple Stores
Currently there are two existing approaches to make RDF data available for use by the geospatial semantic web. The first approach is to use direct mapping languages that can construct RDF data from relational database management systems (RDBMS). This allows the accessing of data in RDBMS as if it were RDF data in a triple store. The RDF data in this case becomes virtual or read-only RDF data. The main advantage of using this approach is there is no need to duplicate data and store them in an actual triple store. There are some RDBMS which are shipped together with this RDBMS to RDF capability. For instance, databases such as Jena SDB, IBM DB2-RDF have this RDBMS to RDF capability. If a database does not support this capability, then additional systems can be used such as D2RQ, R2RML and Ultrawrap. The second approach is to use a triple store to store RDF data. A triple store is a database which allows storing and accessing RDF data. This article discusses the second approach in detail.
The semantic web stores RDF data in a different data model to SQL-based RDBMS or non-relational database systems (NoSQL) databases. In the semantic web an RDF database, a graph database, and a triple store are used interchangeably to refer to storage systems for RDF data. Currently, there are various existing triple stores that can store RDF data, such as Blazegraph,
8 Apache Jena,
9 and others. However, for storing RDF data with spatio-temporal information, dedicated spatio-temporal triple stores should be used, such as Parliament, Oracle Spatial and Graph 12c, and Strabon. Hence, a feature matrix for a few of the well-known triple stores (see
Table 1) is provided. It can be seen from
Table 1 that all five spatio-temporal triple stores support GeoSPARQL query language capabilities, and GeoSPARQL geometry and topology extensions except OpenLink Virtuosa. It supports the GeoSPARQL query language. However, as regards geometry it supports only point data and thus no support is available for lines and polygons. All of them can handle multiple CRS (coordinate reference systems) but uSeekM manages only WGS_84 (World Geodetic System 1984).
Parliament is a triple store and rule engine compliant with RDF and OWL semantic web concepts, however, it does not have an integrated query processor to accept semantic web queries. Hence, it is usually paired with Jena or Sesame to process queries and thanks to third-party integrations it has extra possibilities such as spatio-temporal support and numerical indexing [
38]. Regards Parliament’s limitations, it is difficult to configure for novice developers, and—at the time of writing—it does not support Sesame version 2 or later versions.
Oracle Spatial and Graph 12c is the most advanced triple store for enterprise-class deployments at the time of writing. It provides management features including graph database access and analysis operations, which can involve geospatial analyses as well through a Groovy-based shell console. Furthermore, it offers a considerable number of advanced performance accelerators and other enhancements for the semantic web, in particular, optimized schema to store and index RDF data, fast retrieval of RDF data based on Oracle-text and Apache Lucene technologies and RDB-to-RDF conversion among others [
39]. A limitation of this triple store is its proprietary license, in addition to its complexity, which requires technical professionals to set-up and maintain.
uSeekM is not a triple store but an extension library for triple stores based on Sesame. This extension, when paired with Sesame based triple stores, supports OpenGIS Simple Features including Point, Line, Polygon and GIS relations such as Intersects, Overlaps, and Crosses.
10 One of the advantages of using this extension is it provides new modern types of indexing such as GeoHash and Quadtree, PostgisIndexer, which should result in better performance, particularly in searching and retrieval of spatio-temporal data in the geospatial semantic web. On the other hand, the limitation of uSeekM is that it does not support multiple CRS but only WGS_84.
OpenLink Virtuosa is an engine which incorporates a web server, RDF quad-store (i.e., graph, subject, object, and tuples), SPARQL processor, and OpenLink Data Spaces for a Linked Open Data based Collaboration Platform (i.e., application suite for a wiki, webmail, bookmarks, etc.) [
40].
Strabon is an open source RDF triple store based on the well-known Sesame RDF store. It extends the Sesame with a query processor engine and storage of their custom-build stRDF (data model for the representation of spatio-temporal RDF data) and stSPARQL (an extension to SPARQL) query language similar to OGC GeoSPARQL to query stRDF data [
41]. A major limitation of Strabon is that most OGC GeoSPARQL functionalities were not supported at the time this article was written.
3. Proposed Framework for the Geospatial Semantic Web
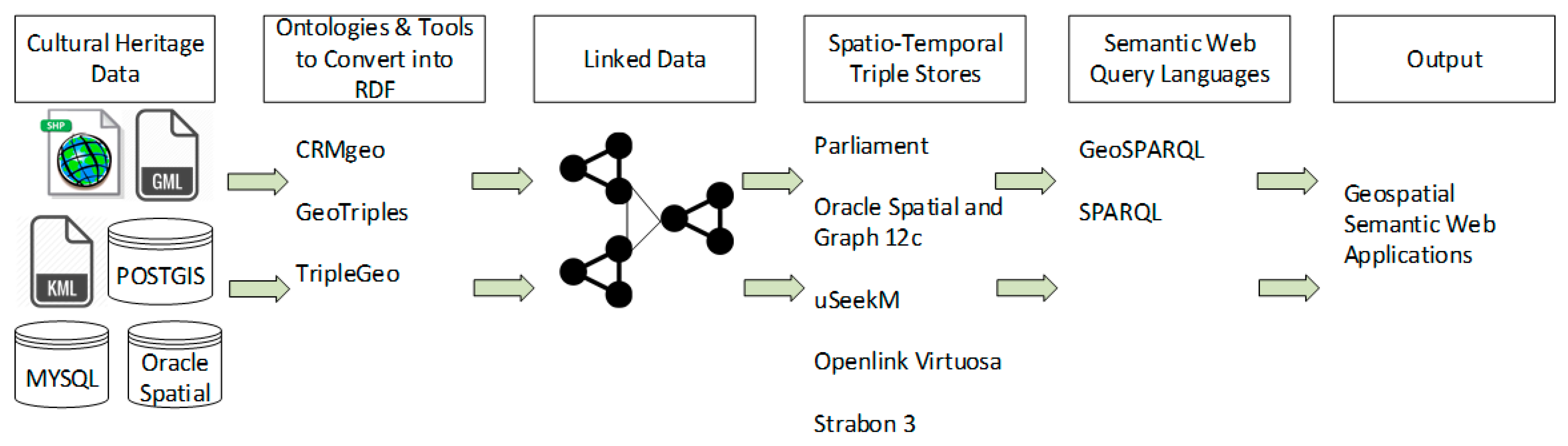
As mentioned before, CH data is often accompanied by spatio-temporal references, which comes in various geospatial file formats. This section demonstrates a workflow to turn geospatial CH data in a vector file format into RDF data, with its subsequent storage and retrieval features, illustrated in
Figure 6.
Geospatial CH data in a vector data model that is stored in spatio-temporal databases such as PostGIS and Oracle Spatial or in vector file formats such as Esri Shapefiles, Keyhole Markup Language (KML), GML can be converted into RDF data using tools, as for example GeoTriples
11 and TripleGeo.
12 These tools extract geospatial features in vector files such as points, lines, polygons along with thematic attributes such as identifiers, names from the geospatial CH files and transform them into machine-readable and processable RDF data. Once the data is converted into RDF data using these tools, it can be populated into a spatio-temporal triple store for storage and retrieval. A triple store provides an endpoint, which is designed to publish and access RDF data in addition to alter existing RDF data. Semantic web query languages such as GeoSPARQL and SPARQL allow querying RDF data from the endpoint and the resulting query can be used by geospatial semantic web applications.
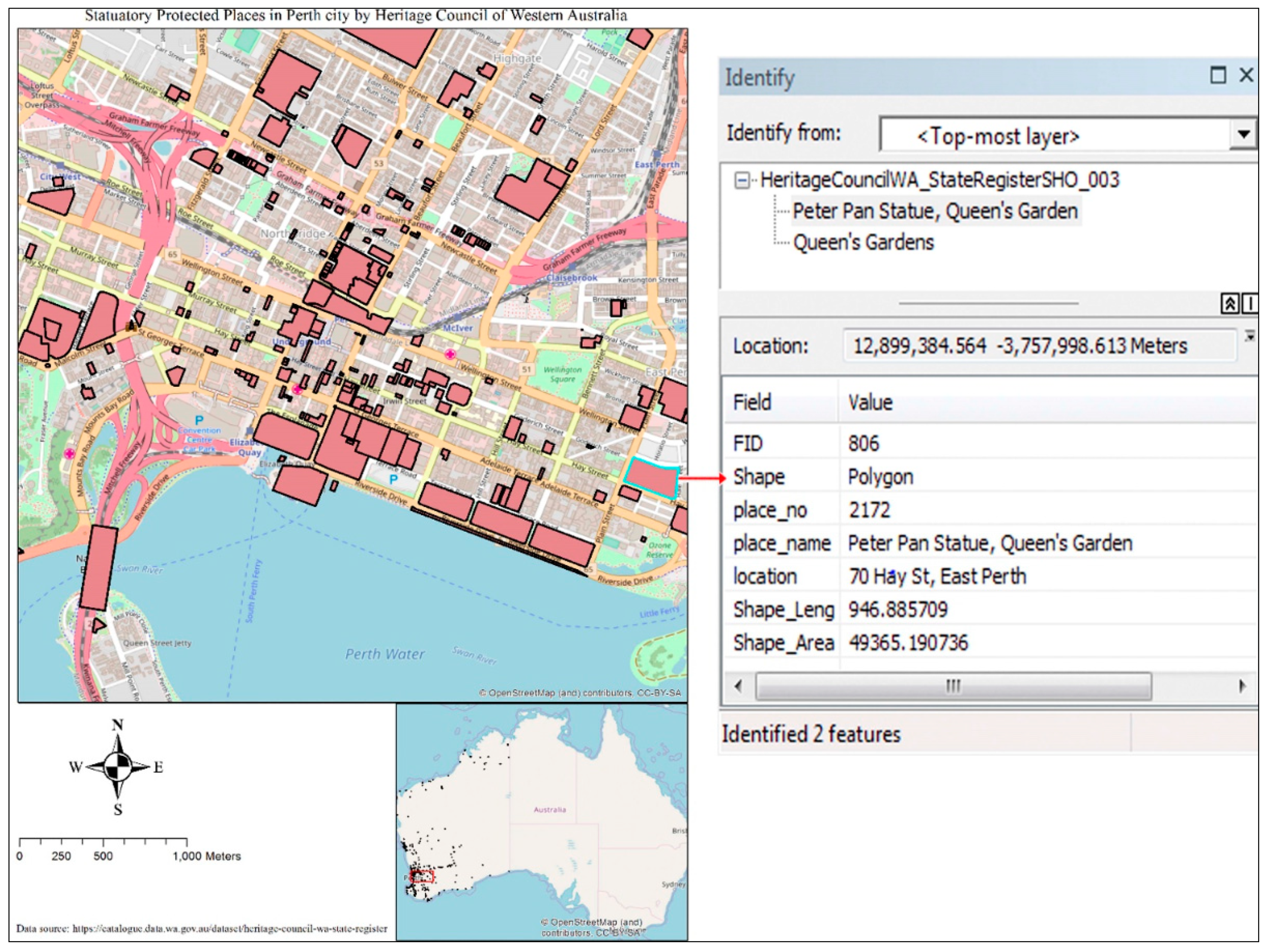
The following paragraphs present this framework with a case study. The tool TripleGeo can encode data represented only in a vector data model, hence, it is the main criteria for data suitable for this framework. Also the geometry, and thematic attributes such as ID, name are other important data characteristics to take into account, but temporality has not been considered in this framework. For this case study, data about statutorily protected places in Perth city in Western Australia is used, available under a Creative Commons license at the webpage of the Heritage Council of Western Australia.
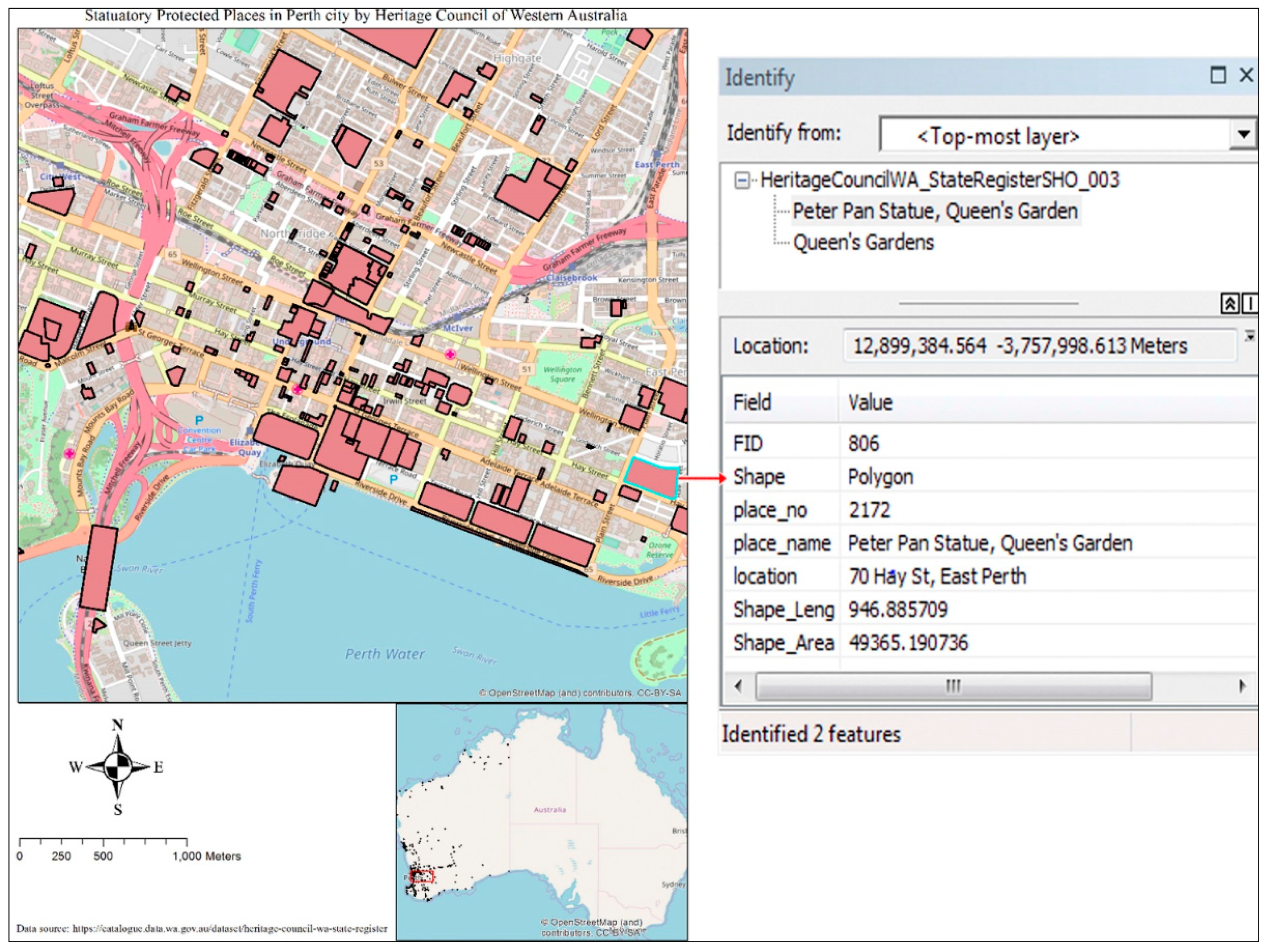
13 The geometry of the data is represented in a vector data model and stored in an ESRI Shapefile format. It contains 2017 polygons, each polygon hold thematic attributes such as FID (identifying number for each polygon), shape name (polygon), unique place number, place name, place location, length and area of for the shape, as shown in
Figure 7. This data is then converted into RDF Turtle syntax using the aforementioned tool TripleGeo. The RDF file contains all the polygons included in the original file (a link for the file can be found in the “
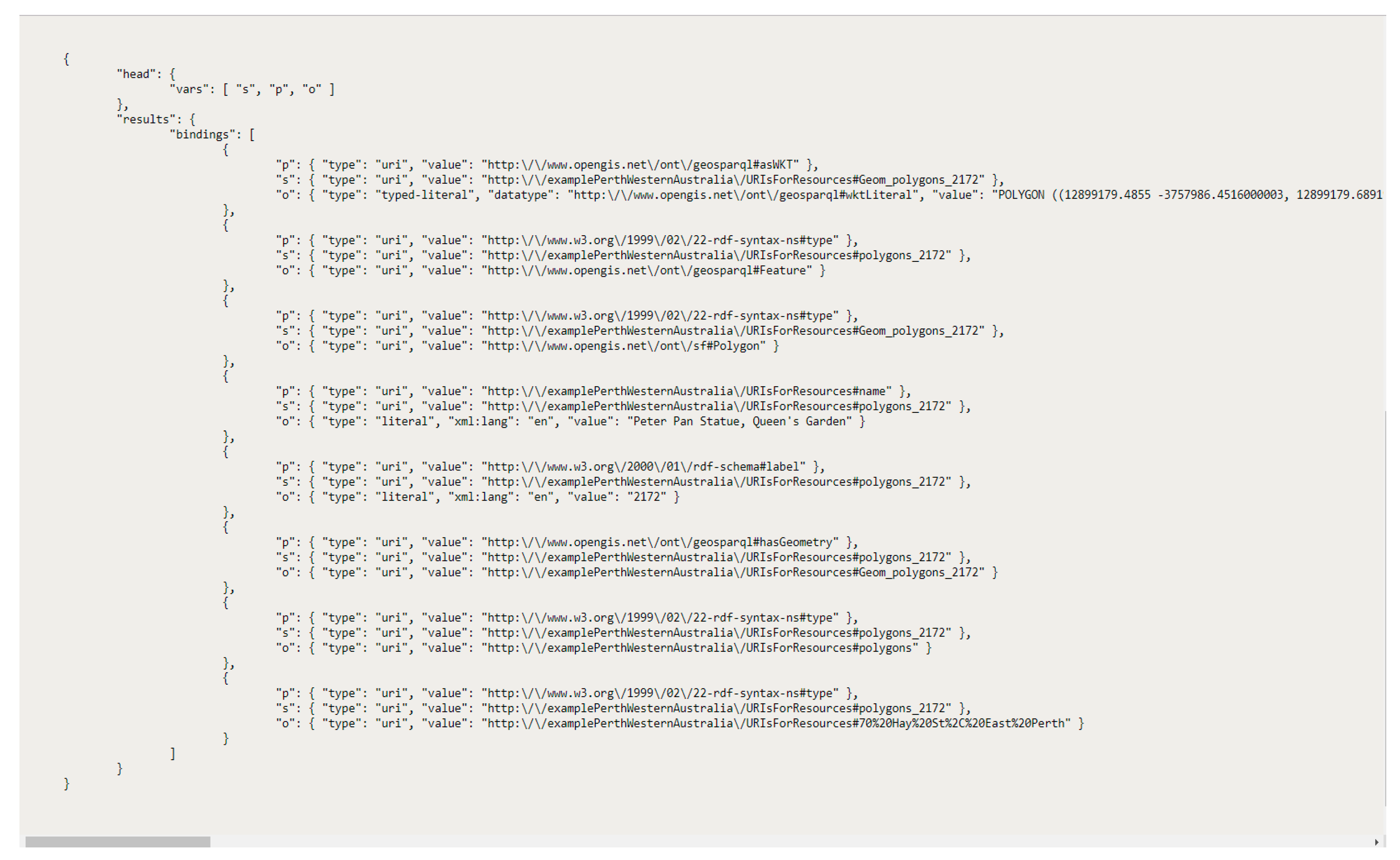
Supplementary Materials” section of this article), however, a sample from the RDF file that is the place named Peter Pan Statue, Queen’s Garden, is illustrated in
Figure 8. The prefixes in the RDF data are URI namespaces for GeoSPARQL ontology, for XML schema, for URI resource of the file (
http://examplePerthWesternAustralia/URI#). A property “Georesource” in the RDF data represents an identity of the polygon, which is “Geom_polygons_2172”. The geometry of the polygon is in RDF based on WKT, which is linked to WKT via the property “geo:asWKT”.
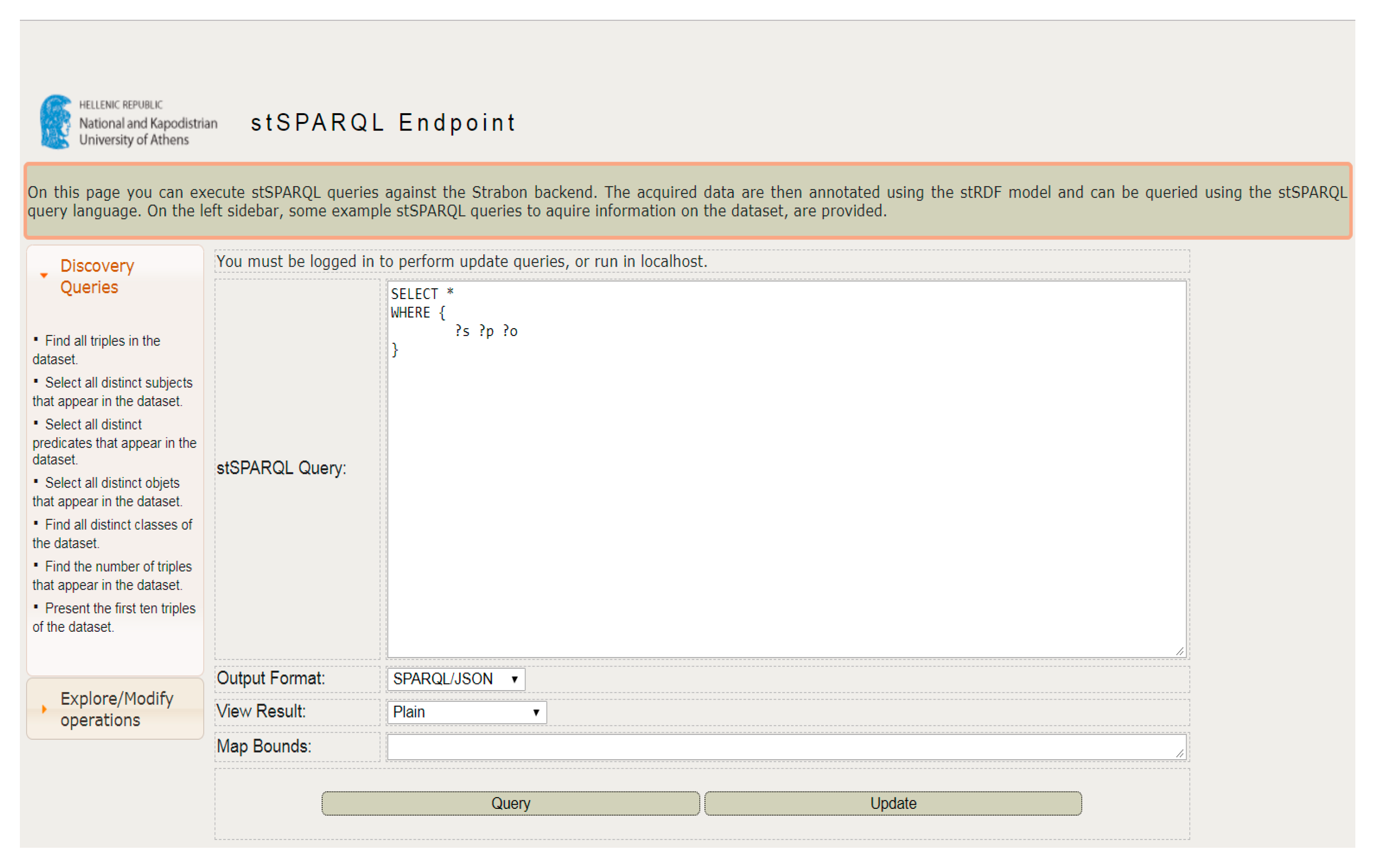
Once the data is converted into RDF data, it is populated into a spatio-temporal triple store “Strabon”, which offers an endpoint as shown in
Figure 9. This endpoint then allows the accessing of RDF data stored in the triple store.
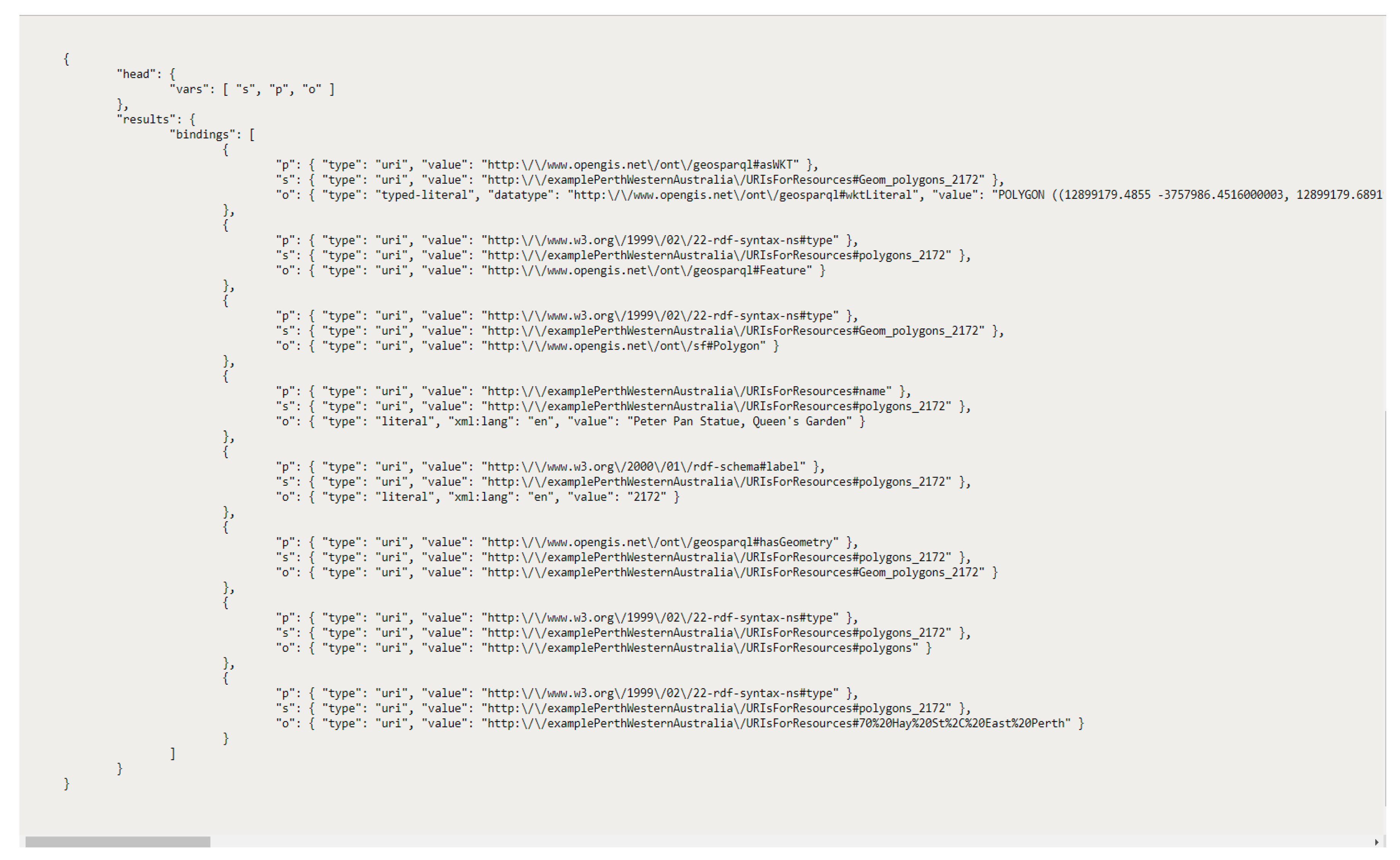
Figure 10 illustrates the query respond that contains the previously discussed Peter Pan Statue, Queen’s Garden, as a polygon in SPARQL/JSON format. This endpoint can accept queries and the result of the query can be used to build geospatial semantic web applications. Variables
s,
p and
o denotes subject, predicate and object, respectively.
4. Free and Open Source Semantic Web and Geospatial Semantic Web-Based Purpose-Built Platforms for Cultural Heritage (CH) Institutions
In past years, some FOSS purpose-built platforms for CH instructions have been developed, which incorporate semantic web or geospatial semantic web concepts. As these platforms are FOSS, they are completely free to use, and the source code is also available for free, which can be configured and extended without any restrictions in order to meet the needs of CH projects. Not only can this type of platforms offer unlimited flexibility, but also decrease software costs for CH institutions.
Table 2 provides some information about these platforms such as supported semantic web and geospatial semantic web concepts, supported content types and visualizations. The following paragraphs discuss each one of them in more detail.
WissKI is a web-based virtual research environment (VRE) and content management system (CMS), which aims to become a Swiss army knife for scholars from any discipline who work with object-centric documentation. It has been developed by three scientific institutions, namely the Digital Humanities Research Group of the Department of Computer Science at the Friedrich Alexander University of Erlangen-Nuremberg (FAU), the Department of Museum Informatics at the Germanisches Nationalmuseum (GNM), and the Biodiversity Informatics Group at the Zoologisches Forschungsmuseum Alexander Koenig (ZFMK). It implements semantic web concepts to support scientific projects in CH institutions that collect, store, manage and communicate knowledge, and it provides long-term availability and interoperability of research outputs, as well as the identity of authorship and the authenticity of the information. People with a limited technical background can benefit from this easy-to-use platform to create enriched content for the World Wide Web, including for the semantic web and geospatial semantic web, presented in a Wikipedia-like style incorporating textual, visual and structured information. It supports two ways of creating content on the platform. The first way is to enter data using traditional form-based interfaces and the second is to perform an aggregation of data in free texts by utilizing web-based knowledge management approaches. In the latter case, a parser in the system recognizes named entities such as date and time phrases, names, and place names, and enters them to the system. Users of this platform can perform semantic text annotations by submitting free text, which is then analyzed to connect entities (e.g., names, places, dates) to the system’s knowledge base. WissKI is a modular extension of the well-known Drupal CMS. It is shipped with an ontology Erlangen CRM, which is an OWL-DL 1.0 (Web Ontology Language) implementation of CIDOC-CRM, however, any other ontology can also be imported to the system. A triple store called ARC
14 is used as a storage for RDF, which offers a SPARQL endpoint to query available data in the knowledge base [
42].
Arches is a heritage inventory and management system developed through a collaboration between the Getty Conservation Institute and the World Monuments Fund. It is a geospatially-enabled platform for the CH field to document immovable heritage such as CH buildings, CH landscapes, and archeological sites. The goals of the platform are to offer long-term preservation and interoperability for CH datasets. It employs CIDOC-CRM as an ontology to define concepts and relationships within datasets. This relationships in the system can be visualized using an interactive and exploration software called Gephi.
15 International Core Data Standards for Archeological and Architectural Heritage (CDS) are used to define data fields in the platform. These fields can then be mapped to entity classes in CIDOC-CRM. Furthermore, it follows OGC standards which means the platform is compatible with desktop GIS applications. GIS features of the platform include a map-based visualization with comprehensive spatial queries, as well as drawing, importing and editing CH resource geometries. Results derived from the spatial query and editing of CH resource geometries can be exported into GIS formats (e.g., shapefile), and vocabulary concepts can be exported into the SKOS format. Another interesting feature of the Arches platform is its mobile app called “Arches Collector
16”, which allows the collecting of heritage data in the field. The collected data is then synchronized with the installed Arches platform. Through use of this feature, administrators of the platform can design projects by setting up participants, type of data to be collected, place of the data collection, and collection time. Approved users can then connect to the Arches platform, download the project, collect the data and save it to the Arches platform. Arches is developed using a Python-based Django
17 web framework together with other web frameworks (Require.js, Backbone.js, jQuery, Bootstrap). Arches platform is fully customizable, which means other controlled vocabularies including the semantic web, and related geospatial semantic web standards can be implemented on top of the existing platform [
43].
ResearchSpace is a web-based platform that offers a collaborative environment for humanities and CH research projects. It has been developed by the British Museum and utilizes semantic web concepts. It includes work to integrate heterogeneous datasets without losing meaning or perspective. This platform uses CIDOC-CRM to define concepts and relationships in the datasets. The project also aims to implement a contextual search system and other tools to enhance collaboration in projects. It offers several types of instruments to explore and visualize complex datasets. For instance, “Narratives”—this tool allows creating documents incorporating semantically defined entities and interactive visualizations. “Semantic Diagram” is another tool to explore connections between objects, people, events, and places in the system. An image annotation tool is another interesting feature of the platform, which allows the attaching of text information to a selected area of the image. ResearchSpace is based on “metaphacts”,
18 which is a knowledge graph platform.
19Omeka is a content management system developed jointly by Corporation for Digital Scholarship, the Roy Rosenzweig Center for History and New Media, and George Mason University. According to Cohen [
44] who introduced Omeka, “Omeka, [derives]from the Swahili word meaning ‘to display or layout goods or wares; to speak out; to spread out; to unpack.’”. It provides a web platform for CH institutions to publish and manage digital CH collections. Omeka offers three options for using this platform. The first option is “Omeka S”, which is a web-based platform for publishing CH data, and for interlinking datasets with other online resources using semantic web concepts. The second option “Omeka Classic” offers a web-publishing platform but without the use of semantic web concepts. “Omeka.net” is the third option, which provides a web-publishing platform without involving semantic web concepts in their hosted service. In this article, “Omeka S” is discussed as it includes publishing data for the use in the semantic web and the geospatial semantic web. A feature distinguishing “Omeka S” from other platforms that are otherwise similar is that it allows the management of multiple sites from one single installation. This could be helpful for organizations needing to run multiple sites and manage them from a single platform. Not only can “Omeka S” provide an easy-to-use platform, but it also provides a possibility to extend the functionality with modules. It is shipped with four pre-built ontologies namely Bibliographic Ontology, Dublin Core, Dublin Core Type, and Friend of a Friend. In addition, other ontologies can also be imported to the platform. In regards to visualization methods, it supports map, image, and 3D model visualizations. Omeka is written in a PHP programming language and requires a LAMP web service stack to run, which are developed via Linux, Apache HTTP Server, MYSQL and PHP.
20Fedora (Flexible Extensible Digital Object Repository Architecture) is a robust and modular repository system, which includes integration with semantic web concepts. A number of universities, research institutions, government agencies and CH organizations around the globe have contributed to the development of the framework. It is currently led by the Fedora Leadership Group. Fedora is fully customizable and is used by CH institutions, universities, research institutions to store and manage digital content. Nevertheless, it is not a complete application that can be used from uploading data to the presentation of digital content. It is a framework upon which institutions can build their platforms. Middleware solutions such as Samvera
21 and Islandora
22 can also be used on top of it. Fedora supports defining relationships using ontologies and expressing them in RDF. It supports integration with external triple stores so resulting RDF triples can be stored in a plugged-in triple store. Fedora is written in a Java programming language and supports MYSQL and PostgreSQL databases. Files in Fedora can be stored in a local storage or in cloud storage solutions such as Amazon S3 [
45].
5. Applications of the Geospatial Semantic Web in CH Domain
Linked CH data can be accessed from various sources. These sources can be divided into three categories, namely data aggregating platforms (e.g., Europeana, Advanced Research Infrastructure for Archeological Dataset Networking in Europe (ARIADNE)), metadata connectivity platforms (e.g., Pelagios), Gazetters or APIs (e.g., Geonames). In the following sections, we discuss key projects related to those categories that employed geospatial semantic web concepts.
5.1. Pelagios Commons
One of the first steps in applying the geospatial semantic web in the CH domain or a project in a closely aligned direction is Pelagios, run by a consortium of Pelagios Commons, funded by The Andrew W. Mellon Foundation. The aims of the project are as follows:
They achieve the above aims by providing a web-based infrastructure which allows the Recogito tool to annotate text against images (i.e., ancient maps, images in digital books). Pleiades Gazetteer of the Ancient World can retrieve referenced places of the ancient world as URIs. The storage of the data in the system is in RDF format and the vocabulary used to describe places is the Open Annotation Data Model
23. Furthermore, VoID (vocabulary of interlinked datasets)
24 is used to describe general metadata about places including a general description, details of a publisher and license information. The infrastructure does not store data being referenced as it is not a data repository nor is it a data aggregator platform, rather it stores metadata about places and refers to URIs of places. As for visualization of referenced ancient places, Pelagios offers map-based visualization where users can search for ancient places that are of interest to them and examine the network of visualization of ancient places, and extract relevant data. Pelagios offers an HTTP API that allows other third-party applications to send a request and consume raw data from the API in different RDF formats. This provides an opportunity to take Linked Open Data from Pelagios and deploy it in other projects or develop mashups and applications [
46].
5.2. Advanced Research Infrastructure for Archeological Dataset Networking in Europe (ARIADNE) (Now ARIADNE PLUS)
ARIADNE is a project of the European Union (EU) funded by the Seventh Framework Programme of the European Commission. It was built upon a consortium of 24 partners in EU as well as 15 associate partners. The main objective of the project was to develop an aggregator infrastructure that facilitates data connection, sharing and searching among European archeological institutions, hence achieve better interoperability across disperse archeological data collections. To achieve it they developed the ARIADNE Catalogue Data Model as archeological institutions in Europe store collections of data in different formats, languages, and metadata schemas.
This model stores metadata information about archeological data and follows a “who, what, where, when” paradigm. To describe and encode information (e.g., monuments, pottery, and excavations) related to the “what” pattern, they used the Art and Architecture Thesaurus (AAT)
25 of the Getty Research Institute. For the “where” pattern the spatial coordinates (longitude, latitude) in WGS_84 CRS have been used, whereas the information and a schema for encoding the information related to a “when” pattern have been facilitated in collaboration with a PeroidO
26 temporal gazetteer of historical periods. The portal itself has been developed using a PHP-based Laravel MVC (model-viewer-controller) frameworks and conceptual classes for archeological data have been implemented by CIDOC-CRM, and the above mentioned “who, where, what, when” paradigm information mapped into DCAT (data catalog)
27 vocabulary [
47].
5.3. Pooling Activities, Resources, and Tools for Heritage E-Research Networking, Optimization, and Synergies (PARTHENOS)
PARTHENOS (Pooling Activities, Resources, and Tools for Heritage E-research Networking, Optimization, and Synergies) is an EU project funded by the EU Horizon 2020 program. The main aim of the project is to build a framework, which would work as a bridge between existing EU digital humanities aggregator infrastructures namely ARIADNE, CENDARI, CLARIN, CulturalItalia, DARIAH, EHRI, and TGIR. The partners argue that this framework eventually will facilitate an environment where humanists can find and use available humanities data resources including: download and process the data, share digital tools to re-use data, build dynamic virtual environments to find specific resources relevant to their research area, run different computational services on the data, and share the results between collaborators. To accomplish this, they have been developing a framework called the Content Cloud Framework, comprising a common data model that describes available data, services, and tools of all involving infrastructures but in a standardized manner. The data and tools are made available via user interfaces and semantic endpoints of SPARQL [
48].
5.4. Geospatially Linked Data in Digital Gazetteers
Digital gazetteers can be loosely defined as a geodatabase for place names or toponyms. They usually include attributes and features for places such as a name of the place, location details (coordinates representing point, line or polygon), type of place (region, country, etc.) and others [
49]. Digital gazetteers have paramount importance in providing access to location information that is used in research projects [
50], geographic context retrieval systems [
51], and location-based services, to name but a few. With the advancement of the geospatial semantic web technologies, new digital geospatial semantic gazetteers have been evolving and existing non-semantic ones have been transforming into geospatial semantic ones. Geospatial semantic web gazetteers are rich sources of geo-linked open data that are readily available for consumption in the geospatial semantic web and related projects. Examples of gazetteers available as geo-linked open data include the Getty Thesaurus of Geographic Names (TGN), Geonames, the Pleaidas Gazeetter of Ancient World and so on.
TGN is based on the Getty vocabulary and includes geo-information (location, relationships, bibliography) related to historical places and, most importantly, has a focus on places relevant to CH, art, and humanities. Despite the fact that it does not provide information on the map interface, the results returned from the queries can be visualized on top of maps using other open source mapping libraries [
52].
Geonames gazetteer is a world geographical database containing location information of all countries in different languages, and users can add new place names and edit existing ones. Geonames have developed their own ontology to represent geospatial data in RDF to the geospatial semantic web, and there is a semantic query endpoint available that can return queries in RDF format.
28In fact, all geospatial semantic digital gazetteers provide access to their linked data via a semantic query endpoint, which accepts geospatial semantic web queries, processes them and returns a response. The notable advantage of the semantic and the geospatial semantic web regarding querying is their ability to send federated queries. This can be explained as dividing a query into subqueries and sending it to semantic query endpoints. This allows the easy integration of linked data from different semantic query endpoints, in a standardized data model (RDF) [
53]. This is one of the powerful features of the semantic web and geospatial semantic web, and it facilitates an easier way to build applications with a suitable combination of heterogeneous data from various resources.
7. Conclusions
Currently in many CH repositories data is published as raw dumps in different file formats lacking structure and semantics. Some of the biggest technical challenges in these repositories are data integration and interoperability among distributed repositories at the national and regional level. Poorly-linked CH data is fragmented in several national and regional repositories, backed by non-standardized search interfaces. All these technical challenges are limiting the capabilities of users to contextualize information from distributed repositories. The geospatial semantic web is a new paradigm of publishing, interconnecting, and consuming data on the Web, and it is being adopted by many CH research projects and CH repositories as a solution. Furthermore, in recent years a few FOSS semantic web and geospatial semantic web purpose-built platforms have been developed for CH institutions in order to ease the adoption of this technological progress.
This article provided a conceptual survey of the geospatial semantic web for a CH audience. Firstly, it discussed the state-of-the-art geospatial semantic web concepts pertinent to the cultural heritage field including standardized ontologies by OGC—GeoSPARQL and ISO—CIDOC-CRM. Also, it discussed a geospatial extension to CIDOC-CRM ontology CRMgeo. Furthermore, it compared the technical features of widely used geospatial triple stores to identify their advantages, benefits, disadvantages, and pitfalls. Secondly, it proposed a framework to turn geospatial cultural heritage data stored in a vector data model into machine-readable and processable RDF data to use in the geospatial semantic web (with a case study to demonstrate its applicability). Thirdly, it outlined key FOSS semantic web and geospatial semantic web-based purpose-built platforms for CH institutions. Next, it summarized leading CH projects that employed the geospatial semantic web concepts. Finally, it provided attributes of the geospatial semantic web requiring more attention, which may generate new ideas and research questions for both the field of the geospatial semantic web and CH.
We strongly suggest that employing standardized geospatial semantic web concepts will allow the creation of heterogeneous, multi-format, dispersed cultural heritage data that will prove to be more accessible, interoperable and reusable than ever before. However, raster data representation and query, 3D data representation and query, and big geospatial data, are some of the challenges of the geospatial semantic web, requiring both more thoughtful attention and more results-oriented research projects.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}