3.1. Introduction
The representation of an object can be of different form and nature, can underline one specific aspect or feature, can have different degrees of faithfulness and can use different grammars to encode the same type of information. The purpose of these representations is not to display and interact with a simulacrum of the heritage object, but to actually use them as instrument of analysis, to make statements about the world through them, to find metrics to compare objects, study their behaviour, subdivide them into units, reconstruct their holes, re-define their existence, put them into their historical context, study how they interact with their ecology and how they shape it, or how they could be and how they were not. Representations of this type are not treated as simple depictions, but are instrumental to the knowledge we derive from our past, because we have the tendency to assign them the status of digital counterparts of heritage objects.
For these reasons, it is essential to understand how we assign meaning to them, as well as how we identify and differentiate between diverse visual compositions. In order to answer this question, we are obliged to start analysing the perceptual process, and, specifically, the interpretation of a percept, which heavily relies on the act of recognition, classification and reference of the sense data to a model using a specific visual code.
3.2. Cognitive Type
Ontologically speaking, the perceptual challenge revolves around two main subjects: the existence and the identity of a visual representation. It is necessary to define the subject of the percept, as well as to understand the mechanism used for the percept to be referenced as an instance of a class.
We argue that the interpretation of a visual message requires the connection of the sense data to a model using a specific visual code. The sense data themselves are selected portions of the continuum of reality, which Floridi [
12], building on the work of MacKay [
13] and Bateson [
14], calls a datum.
The recognition and categorisation of a datum is achieved by the relation of the datum to a reference type, using a schema to mediate between the concept and the manifold of the intuition. Eco [
15] suggested that to comprehend this process, we should start examining how we classify the unknown. We will delve deep into his thesis, identifying the nuclear elements which enable us to build a shared understanding of our visual reality. For such reason, it is of paramount importance to first introduce, analyse and explain Eco’s theory. Eco asked himself, and his readers, how we would be able to interpret and socially talk about something if we were to see it for the first time. He proposes a thought experiment using the Aztecs’ first encounter with the Spanish knights. During this occasion, the Aztecs were faced with an entirely new animal, mounted by individuals completely covered by metal plates.
“Oriented therefore by a system of previous knowledge but trying to coordinate it with what they were seeing, they must have soon worked out a perceptual judgment. An animal has appeared before us that seems like a deer but isn’t. Likewise, they must not have thought that each Spaniard was riding an animal of a different species, even though the horses brought by the men of Cortes had diverse coats. They must therefore have got a certain idea of that animal, which at first they called macatl, which is the word they used not only for deer but for all quadrupeds in general”.
What is interesting from this passage is not just the recognition of the nature of a horse as an animal, but the difficulties that such collective recognition impose on the exchanges between the messengers and the emperor. The messengers integrated their description with pictograms and performances, aiming to describe not only the form of this new animal, but also its behaviour. After listening to them, the emperor had formed an idea of the macatl his messengers were talking about, but it would probably have been different from the one in the minds of his messengers. Nonetheless, it was accurate enough to allow Montezuma to talk about a macatl, to be able to recognise one and differentiate it from the Spaniard riding it. Moreover, he was probably able to recognise not only the single macatl, but the entirety of them as a single species, even if they had differences in colours, size or carried armour. Gradually, he was able to acquire more and more knowledge about this macatl, about its usefulness in battle as well as its behaviour and origin (earthly or divine for example). Finally, the Aztec started using a specific word for it, modifying the Spanish word caballo into cauayo or kawayo. The story above presents an interesting perspective of the perceptual process, specifically of the recognition and categorisation of new objects, and it allows us to see how, on the basis of the object’s characteristics, we produce an idea of a percept. In his analysis, Eco [
15] calls this idea cognitive type (CT). In this case, the CT would be the concept that an Aztec used to recognise a horse as an exemplar of its kind. After having seen some horses, the Aztec would have constructed a morphological schema of it, which comprised not only an image-like concept of the horse, but included its peculiar characteristics such as the neigh, its motions, its capability of being mounted and perhaps even the smell. These elements are the base used for creating the CT of the horse, which appears to be then a multi-sensory idea of what we see.
For many readers, this concept will resemble that of the prototype [
16,
17], but the difference is in their nature. The prototype is an instance of a class which is seen by a cultural group as the one that best represents the class itself. The CT instead works within the primary semiosis field, assessing the membership to a specific category based on perceived characteristics, and it is not an instance, but merely an idea of the nuclear traits. The prototype is an instance of a class which we assume best covers the characteristics of that class, while the CT is nothing other than the idea that allows us to define the membership itself, more closely to an underlying grammar for the construction of the class than to another concept.
3.3. Semantic Marks
Unfortunately, Eco does not explain in detail how cognitive types do work, or how we can use this grammar to relate sense data to a semantic and conceptual model in order to achieve a similarity-based recognition. Therefore, it is essential to build up from his theory and define how we construct the identity of an element, correlating visual data to nuclear characteristics. In order to analyse this process, we introduce the concept of the semantic mark (SM). We define a SM as internal encoded functions which help classify external stimuli and discern their nature. SMs are sense based and help classify the perceptual experience by correlating perceived signals to the CT of a situation, and to the CT of a physical thing. Both SMs and CTs are based on equivalence-based criteria between the percept and a situation/object which are similar to. Further recognitions are achieved by a similarity-based degree of the newly perceived SMs and the SMs that characterise a previously constructed CT. SMs function as attributes of the identity of a percept. The number of signals received by the senses can be numerous, but the chosen ones that are used for the identification are fewer, and they present themselves as constituents of a perceptual manifestation. While a SM can be seen as another type of sign, it is instead an encoding of the percept on the basis of a classification, which reuses our experience and social ground for determining the significance of our reality.
Having outlined the gist of it, it is best to start formulating a formal analysis, because only through their definition can we comprehend their role in the perceptual process. A SM is the result of a semiotic process which works with three components:
At least one signal.
A situation.
An object.
The very first component is the signal, which is an external stimulus, a datum, identified on the basis of its difference and its form. We will flatten its definition, for a functional purpose, using logic, as:
Definition 1. ∀signal(x) → ∀x.((hasDimension(x, N) ∧ isPartOf(x, System)) ∧ different(x, Surrounding)), where x is the signal, which is identified by a dimension (N) in a specific system (could be a specific projection system as well as a topological relationship). The identity of the signal is, moreover, defined by its differences from the surrounding area, because it is exactly this element which grounds its identification into a single unit.
Having outlined the criteria for the identification of a signal, we should look to the other components of a SM, situation and object, in order to understand how it is interpreted. The notion of a situation is quite fuzzy. Situation theory and its semantics have been the subject of many academic debates [
18,
19,
20,
21] in the last thirty years. Many have written on the topic, but there is no real agreement in the community on what exactly is and how to define a situation. Nonetheless, we used some of the elements discussed in those debates to build our definition of a situation (s) as:
Definition 2. sdef = {R, a1, …, an, ωx}, where R is the relationship perceived by a viewer between a set of physical entities (a1,…,an) in a specific space-time volume (ω), a portion of the space-time continuum. The types of relationship (R) between the entities can be of diverse nature, such as mereotopological or temporal (for a better account of these, see the work of Smith [22,23], Varzi [24] and Freksa [25]). Situations, however, while carrying their own identity, are not unique temporal states that need to be determined every time, but can be approximated as an instance of a situation type (where the situation type is just the closest logical counterpart of the CT of a situation, used here to determine its membership function), which is a prototypical situation we have experience of, and helps us determine a specific perspective or a behavioural pattern to follow. The relation between a situation s and a situation type S is a degree of membership of the elements of s in S where:
Definition 3. A situation type S is a pair (S, m), where S is a set and m:S → [0,1] is the membership function. S is the universe of discourse, and for each s ∈ S the value m(s) is the grade of membership of s in (S, m). The function m = µ(A) is the membership function of the fuzzy set A = (S, m).
Using the same logical notation, we can define the relationships between a physical thing p and its type P, such as that an object is equivalent to the entirety of the relationships of a set of physical parts identified by the combination of specific materials over time and P is:
Definition 4. A physical object type P is a pair (P, n) where P is a set, n:P → [0,1] is the membership function, and for each p ∈ P the value n(p) is the grade of membership of p in (P, n). The function n = µ(B) is the membership function of the fuzzy set B = (P, n).
As mentioned before, the resemblance is given by a degree of similarity. Therefore, the sets A and B, which are, respectively, the set of all the matching situations and the set of all the matching physical objects, which we can describe as:
Definition 5. A = {s, µA(s) | s ∈ S}.
Definition 6. B = {p, µB(p) | p ∈ P}.
should use a membership function type which takes as an input the value of a similarity-based degree calculation. However, similarity is not, as it is commonly understood, a juxtaposition between two anatomically similar elements, but a more complex phenomenon. Nevertheless, it is possible to map the correlation between elements in a multi-quality dimension, including, depending on the case, topological, feature, alignment or value information [
26]. The value information is based on different qualitative criteria, such as material property, colour, size or reflectance. For example, two representations portraying two different subjects could be grouped together if both had a golden background, or if the objects portrayed had the same size; topological information relating the closeness of two or more objects in a specific space reference; a local space, such as a portrait where two dots stand in proximity to each other, or a geographical space, such a country or a town. Feature similarity implies the presence of a few distinctive features that are considered more salient than others by the viewer and are taken as a key for grouping some objects. This could be the case of wearing a hat with a feather or carrying a Latin cross. In both cases, we use these elements to say that two objects are similar. The alignment similarity indicates the likeness of one or multiple parts of an object in respect to one or multiple parts of another object. It implies the possibility of juxtaposing the two parts together. We will not provide an indication as to which membership function should be chosen (Gaussian distribution function, the sigmoid curve, quadratic and cubic polynomial curves etc.), because the methodology depends on what kind of similarity information is being taken into account. For a full account of the methods, refer to great commentary on the subject given by Timothy J. Ross [
27]. At last, having determined that the relationship between situations is a physical thing and its CT (for functional purposes, logically expressed as type), we have all the elements for defining the semantic mark of an object, which we define as a tuple:
Definition 7. SMx = {(Sigx,…, Sign) A,B}, where (Sigx,…, Sign) is the set of signals identified, A and B are, respectively, the fuzzy set of all the matching situations and the one of all the matching physical objects in respect to a set of signals which were used to contextualise the signal. We define a semantic mark as the result of a function which relates the signals to a situation and a physical thing to create denotative expressions that link the initial signals to specific cultural content. Following this definition, a CT can be defined as a set of semantic marks. The recognition of this set implies the attribution of the type.
3.4. The Reading of the Image
The use of semantic marks to construct the cognitive type of visual items can be further examined throughout the lenses of art history, a discipline which has closely studied the history of representations and has provided us with some of the finest thought on the subject, thanks to major works by Warburg, Panofsky, Gombrich, Arasse and other scholars. In doing so, we follow Eco’s suggestion that iconography and iconology can be considered a fully formed chapter of semiotics [
28], as well as the thought of some other art historians who have noticed the congeniality of the analysis of Peirce and Saussure with the study of Riegl, Panofsky and Schapiro [
29].
Furthermore, art historians have been studying the formalisation of visual cues, the creation of canons and models of depiction for quite some time, and they are also responsible for the formalisation of several resources used as a nomenclature system for artistic motifs and subjects.
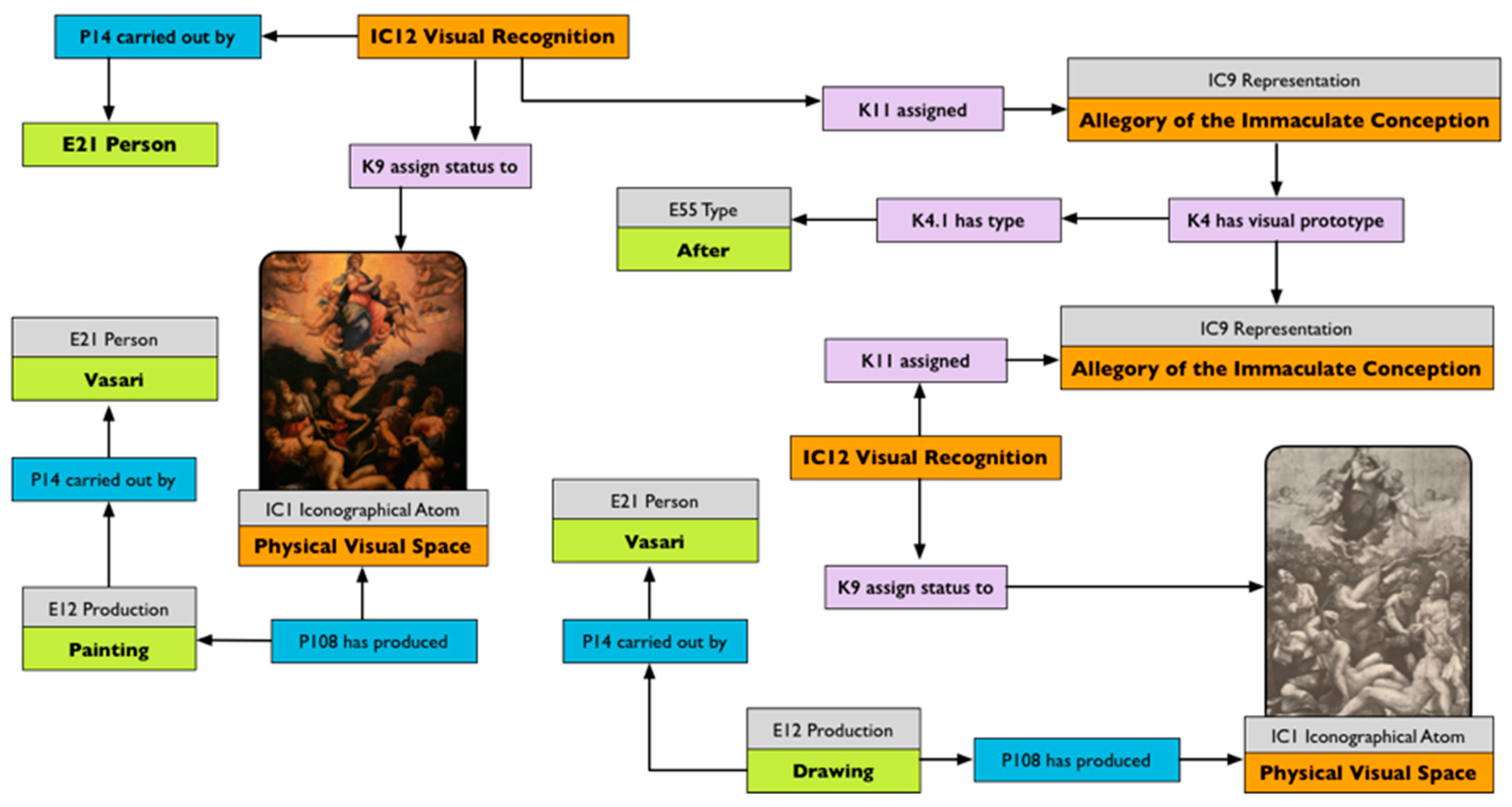
Art historians have long been studying visual cultures and their inner traits, recognising their commonalities and nuances and linking those to social arena. One of the results was the possible identification of the author of an artwork on the basis of his figurative and stylistic features. An author, in fact, learns and develops specific traits or features during their apprenticeship in a workshop, or by merely examining or studying their predecessor’s works. The usage of a set of traits to depict a figure standardises compositions and features, creating a representational canon. One great example is Renaissance art. In this period, thanks mainly to a rediscovered sensibility for the Roman and Greek period, artists and patrons felt the need to have a standardised and understandable canon of images, an easy instrument with which to get inspired and follow the design and conception of new works of art [
30]. While the need was, indeed, general, there were certain specific tasks, for instance, the representation of identifiable intangible concepts such as Love or Fortune, which benefited greatly from such formalisation. The illustration of these abstract ideas had to be done through the use of substitutes for the abstractions, such as symbols or personifications. The use of these visual devices as the embodiment of concepts and ideas, however, also fulfilled the communicative purpose of an image, providing the viewer with a possible reading of the scene. In order to do so, these figures needed to be acknowledged by a high number of people. Achieving such a goal required a figurative normalisation in accordance with specific models. It was bearing this prospect in mind that in the 16th century manuals like “Le imagini colla sposizione degli dei degli antichi” [
31] and “Mythologiae sive explicationis fabularum” [
32] started to appear. A major milestone in this direction was the publication of Ripa’s Iconologia [
33] in 1593. This work covers over 1200 personifications, comprising an extensive collection of visual representation drawn from both classical and contemporary works of art. Ripa’s book reported on not only visual representations (added only in the 1603 edition) together with their designated meanings, but included detailed descriptions of how they should look and why they should be depicted in that way. The impact that Ripa’s Iconologia had on his contemporaries, as well as on artists in the later centuries, was remarkable, and started to lose its importance only with the advent of realism [
34].
The impact of Ripa’s Iconologia was not only to be searched for standardisation of the features and poses for the recognition of depicted types, but also on the influence that those standardisations had on the Western-based vision of art. Art historians became used to employing a type-based thinking for their studies as well as heavily applied prescribed literary sources for their figurative reading; they finally become “hunters of prototype,” famously criticised for leaving matters there, and not exploring them further. While the hunting of the prototype has been seen as an infatuation, from which many, fortunately, have recovered, it also helped deliver a methodology which, even if criticised, has not yet found a real challenger or an alternative [
35]. We are talking specifically about the work of Panofsky, which helped establish the discipline of art history as we know it now, and it helped investigate those visual cues that we use to identify representations.
In his work, Panofsky [
36] outlined a method for reading a work of art that required the distinction of an artwork in three layers:
The primary or natural subject matter, which identifies pure forms such as a configuration of lines or representations of an object, which could be called the world of artistic motifs. The collection of these motifs pertains to the pre-iconographical description of a work of art.
The secondary or conventional subject matter is the assignment of theme and concept to the composition of artistic motifs, which are recognised to be the carrier of a conventional (how specific themes and concepts are usually depicted in the visual arts) meaning. The subject(s) of a representation are identified in this layer, thanks to an iconographical analysis.
The intrinsic meaning or content is the interpretation of “the work of art as a symptom of something else which expresses itself in a countless variety of other symptoms, and we interpret its compositional and iconographical features as more particularized evidence of this ‘something else’” [
36]. The intrinsic meaning is defined by how cultural-historical developments are reflected in a representation, and such meaning is displayed independent of the will of the artist, who could be completely unaware of it. In a later stage, Panofsky called this phase the iconological interpretation.
Following his methodology, the signs that compose a representation are identified during the pre-iconographical phase through the identification of artistic motifs. This step was also identified by Barthes, who called this immediate visual impact, which defines the primary subject matter, the denoted meaning of an image, and the process it originates, denotation [
37,
38,
39].
The second act of interpretation is the iconographical analysis, which requires more specialised knowledge and the use, in this case, of vocabularies of forms in order to describe the content of the image. These vocabularies do not have to be external resources, but they easily can be embedded in our knowledge repositories and inherited in a social arena (see Bourdieu [
40] and Lemonnier [
41] for a theoretical treatise on the subject). The recognition of the meaning of the image is based on identification of the diverse signs incorporated into the image, usually consisting of sets of attributes and characteristics. The combination of these attributes, such as objects, plants, animals or other icons/symbols, help identify a personification/character in a specific situation/narrative in a work of art. Attributes can also help identify certain qualities (kindness, rage etc.) of the depicted character, or his belonging to a distinct group (blacksmith, noble, saint etc.). The use and harmonisation of this combination have helped to create iconographical types and defined archetypical situations, providing tools for the identification of diverse types of representations [
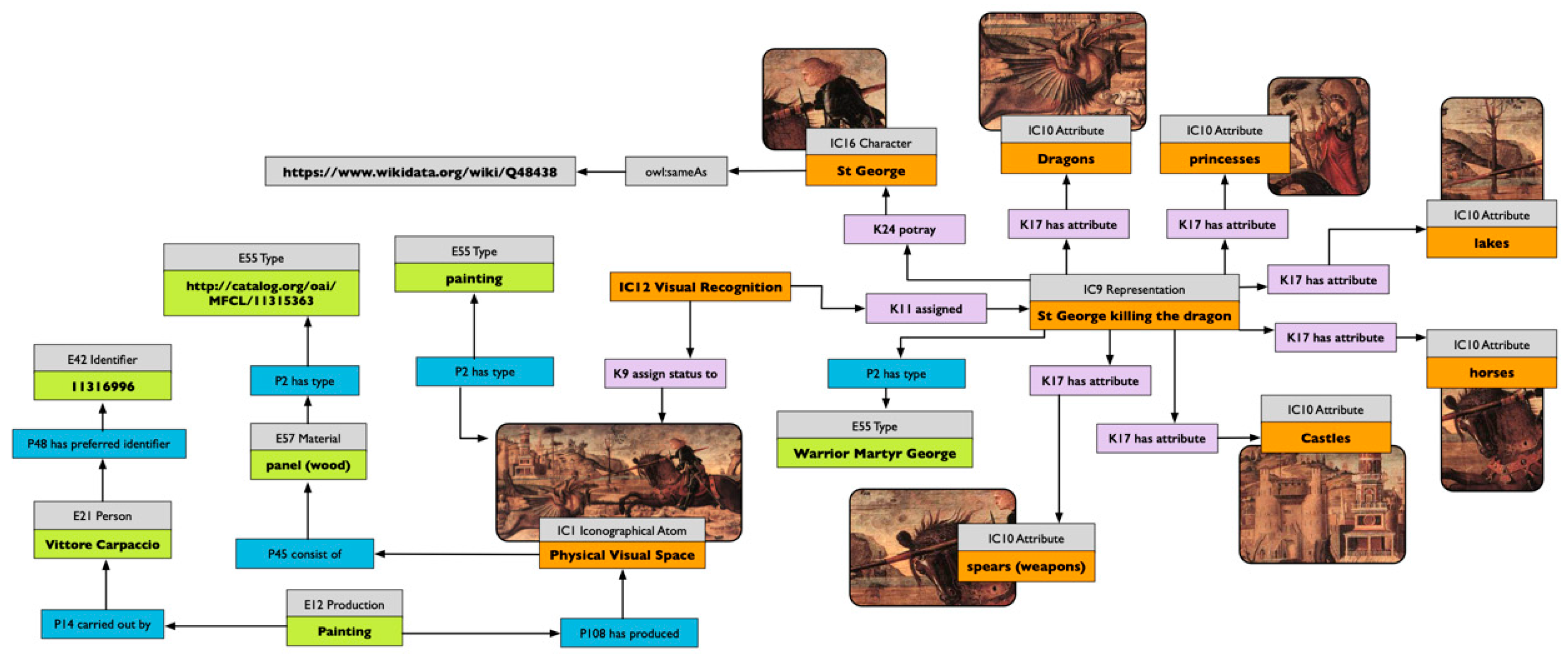
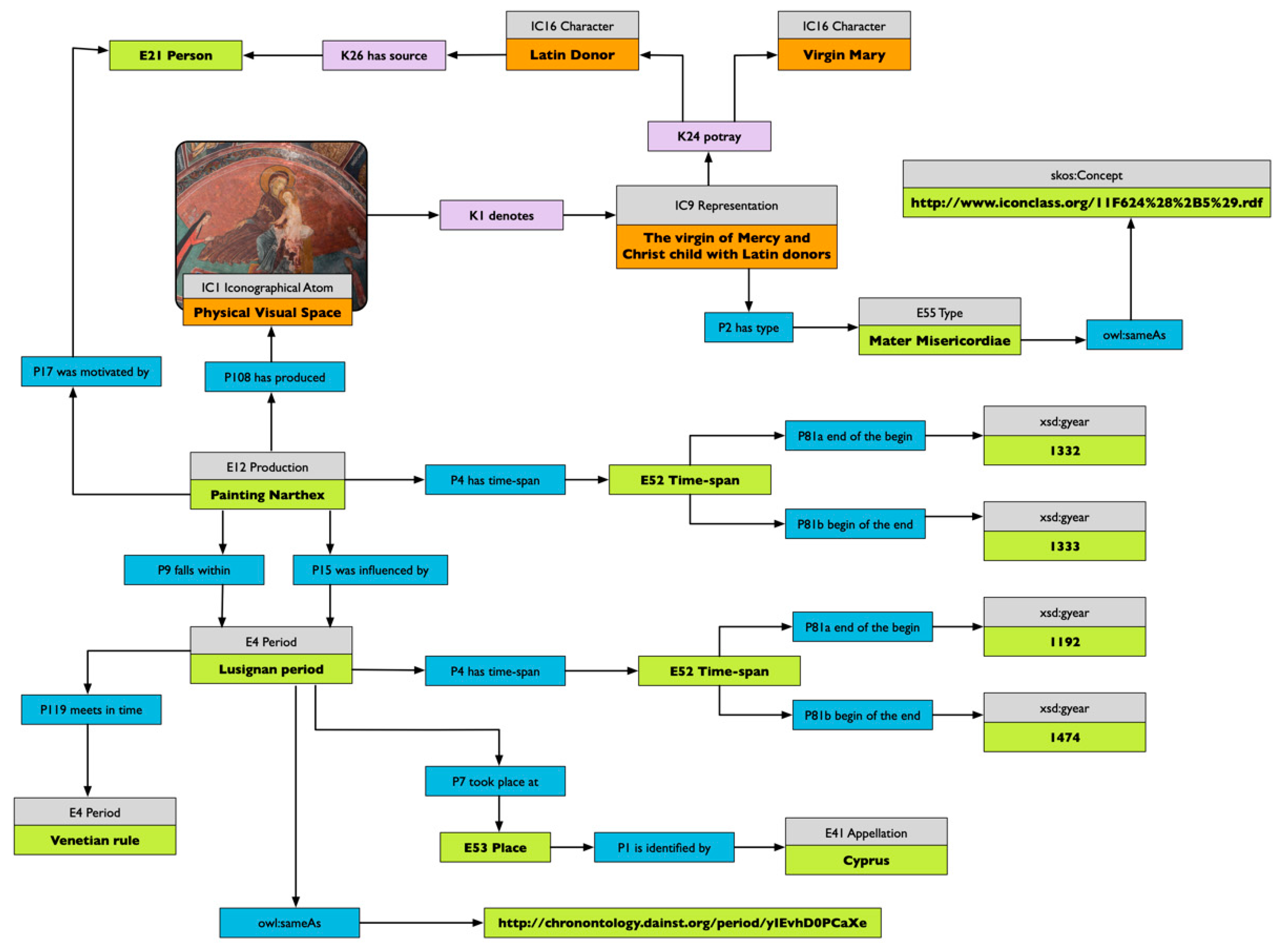
34,
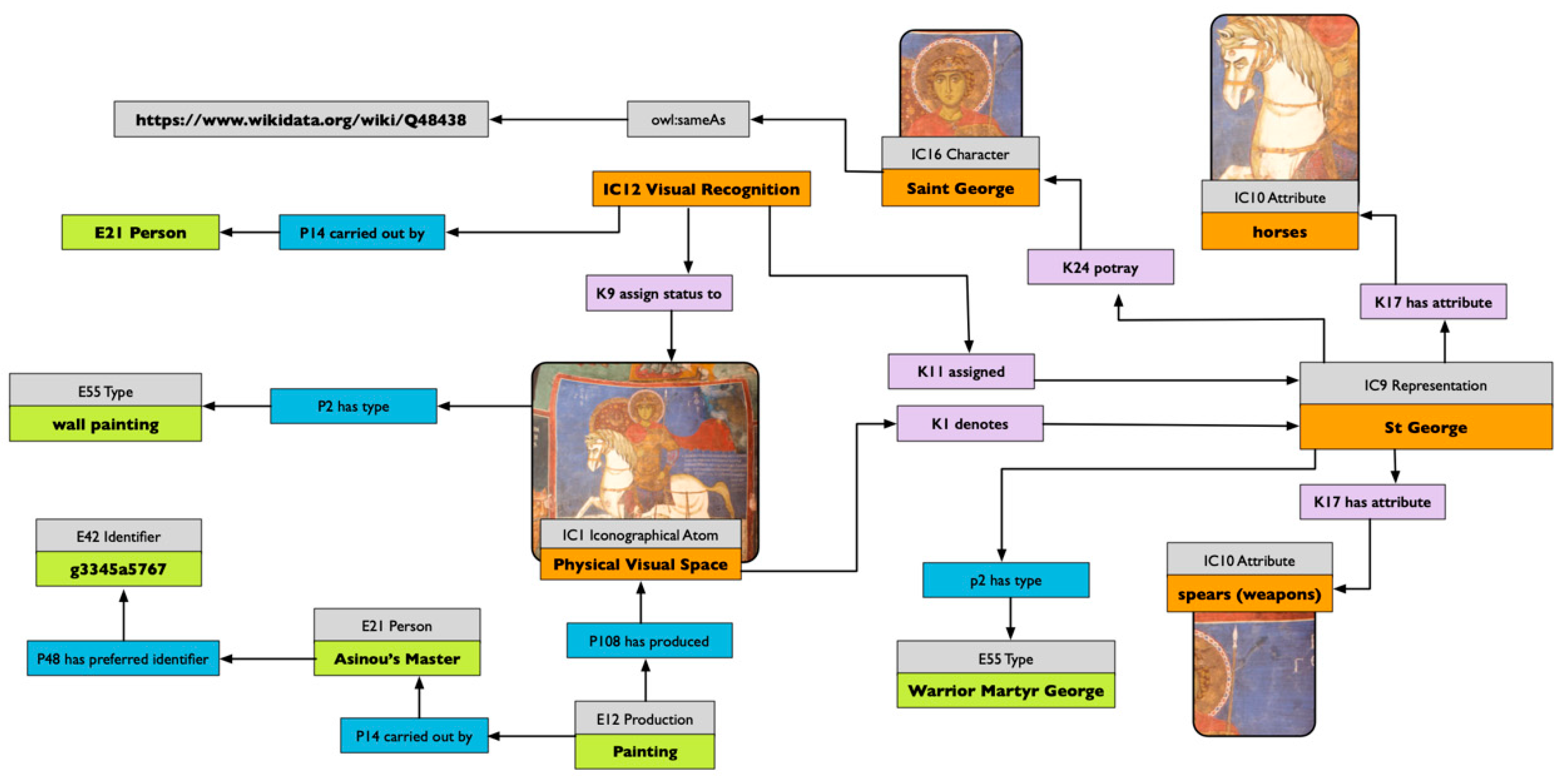
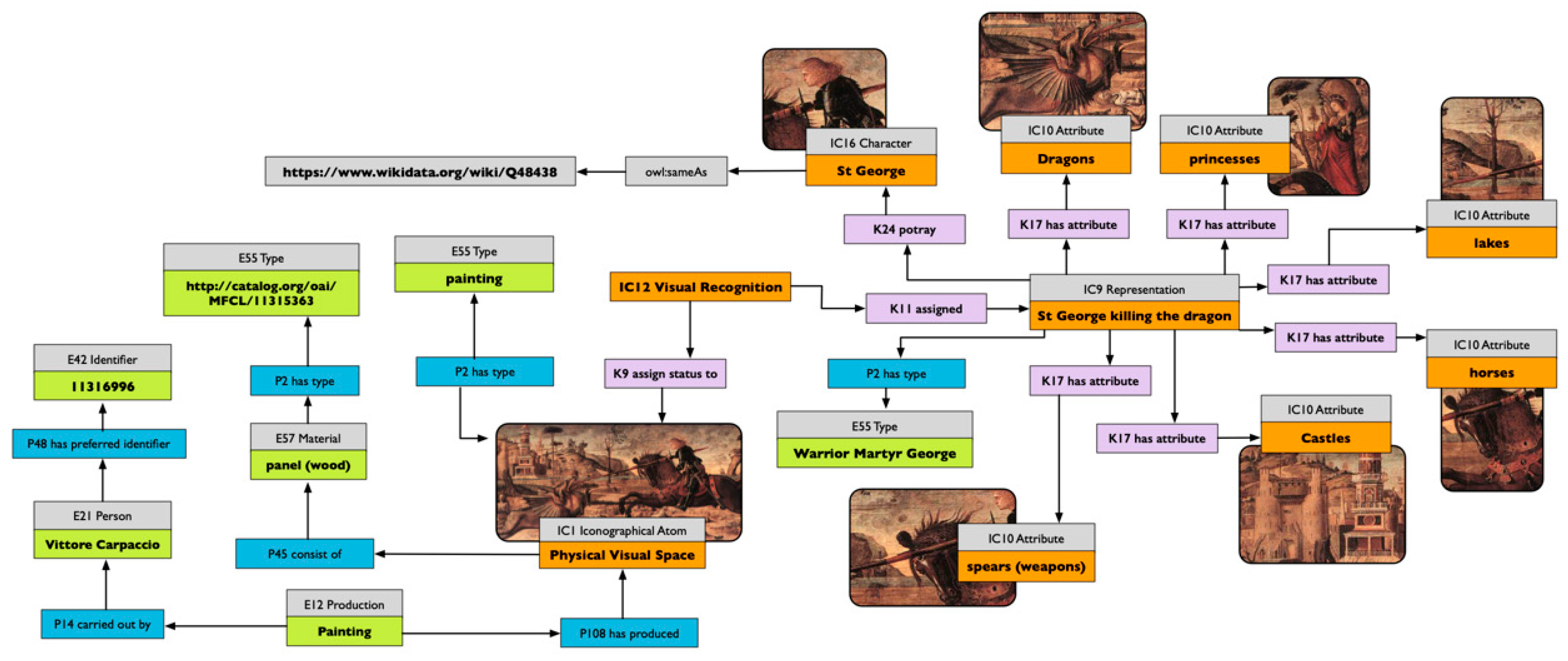
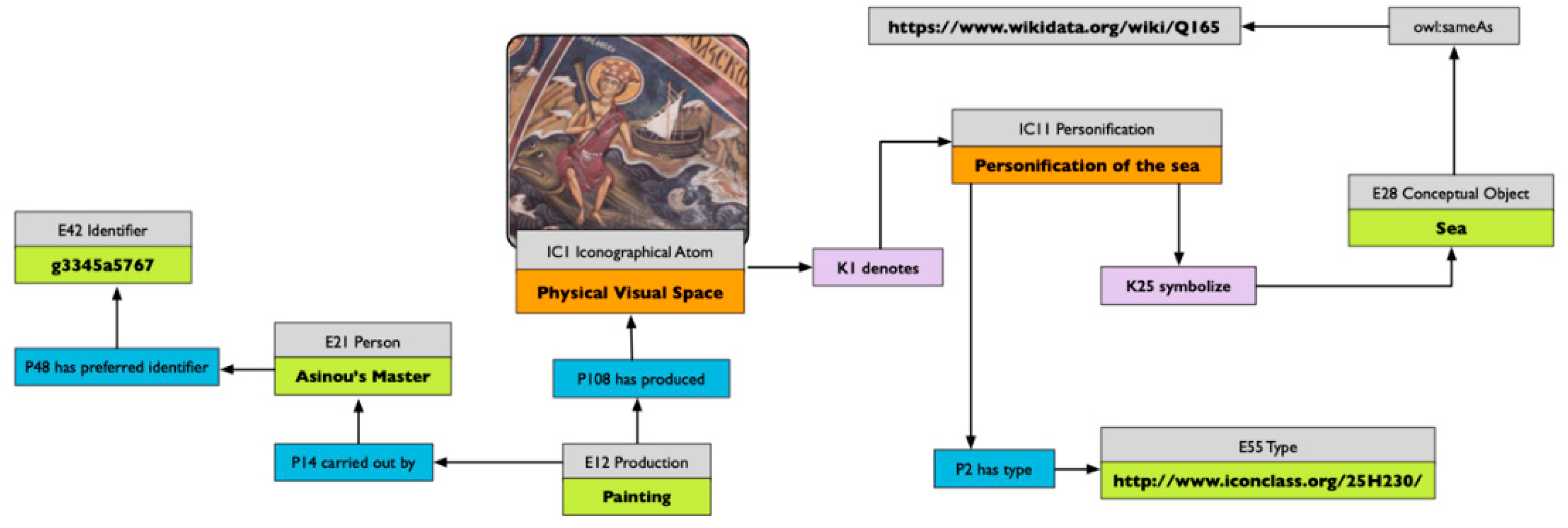
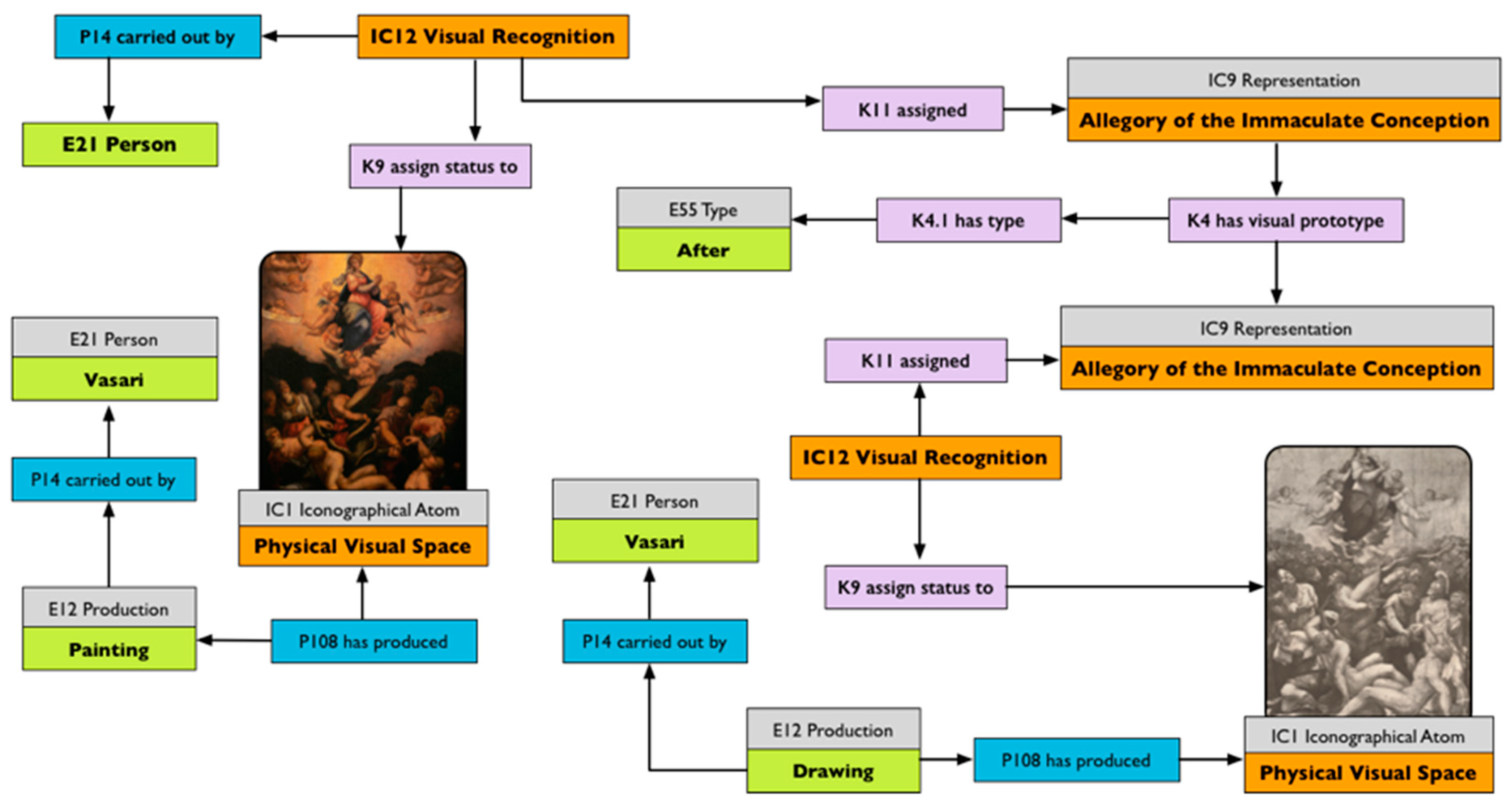
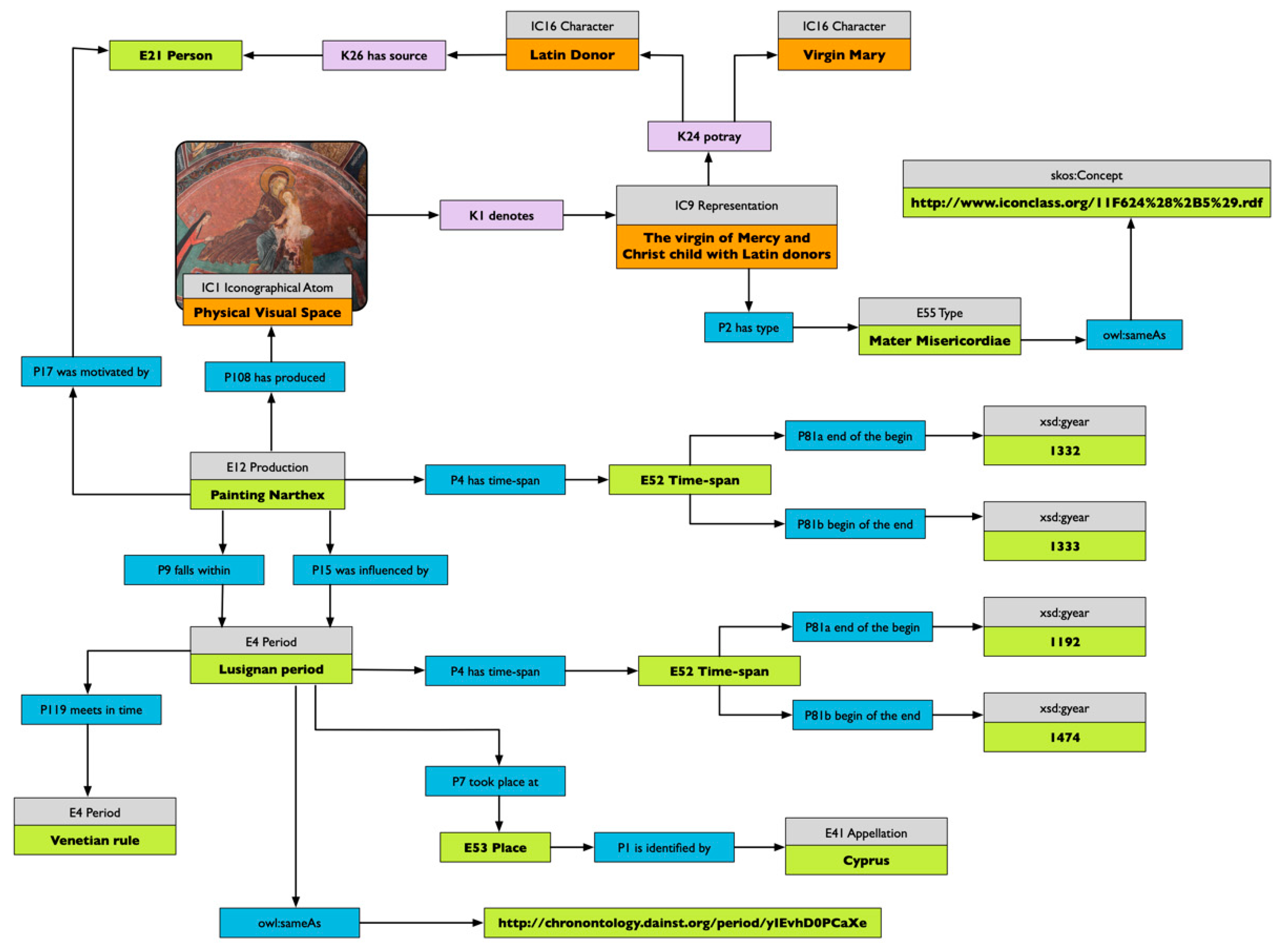
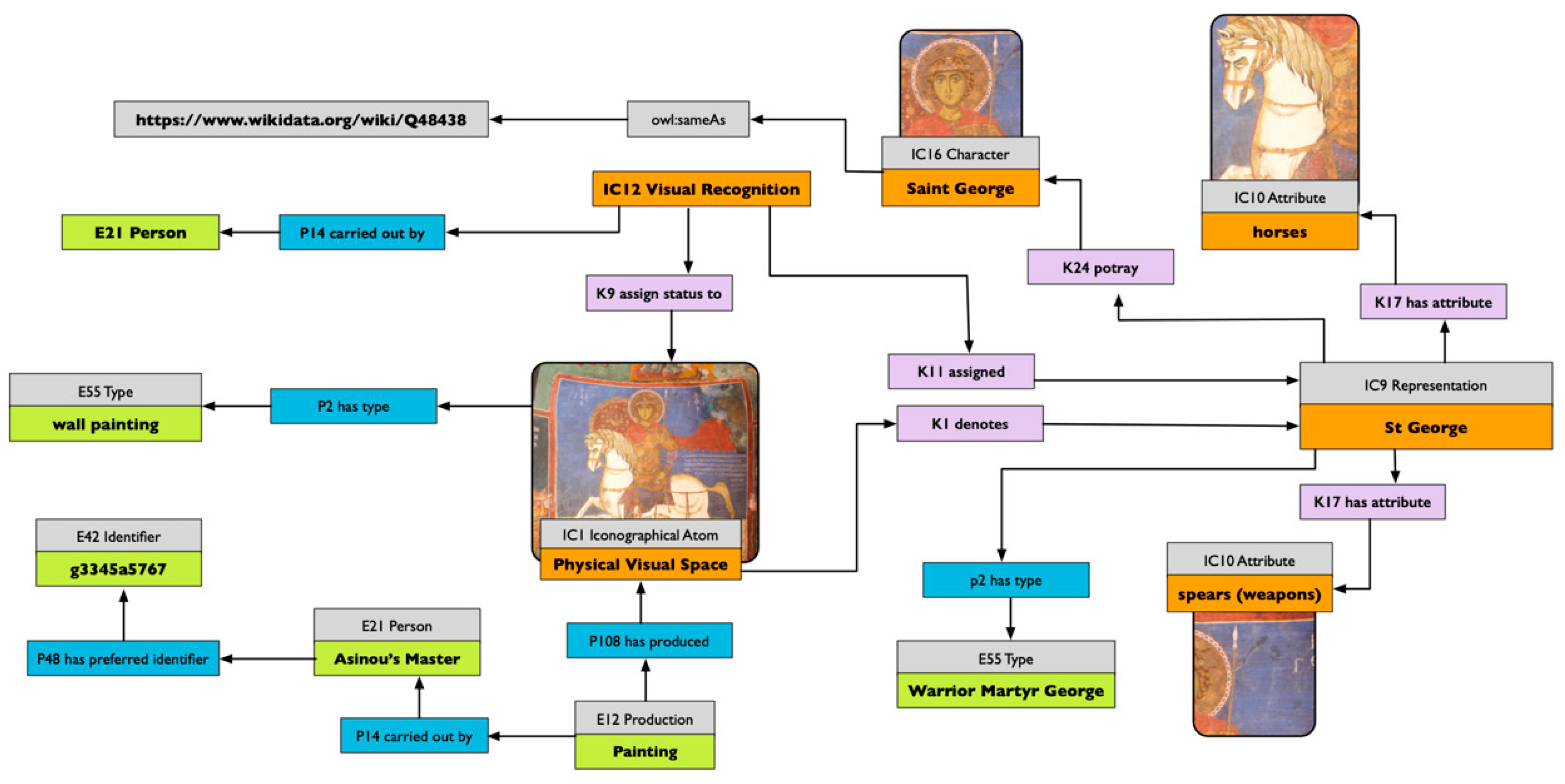
38]. Attributes can be seen as a subset of the semantic marks formalised in 3.3. In that case, it appears that iconographical types are nothing other than cognitive types we use for describing and communicating stances about our visual world.
After the iconographical analysis, the methodology of Panofsky passes over to iconological analysis, which comprises the socio-historical interpretation of the symbolic value of the painting, which is part of a bigger cultural visual history and is not a conscious process for the author. The indeterminacy of these symbolic values created some significant issues in the art historical community, because sometimes the use of symbols was strongly driven by the author’s intention (as in 16th century Dutch art for example). In order to overcome these issues, and to stay true to the idea that an author can use symbolic representation consciously, we prefer to adopt the revised scheme of Van Straten (
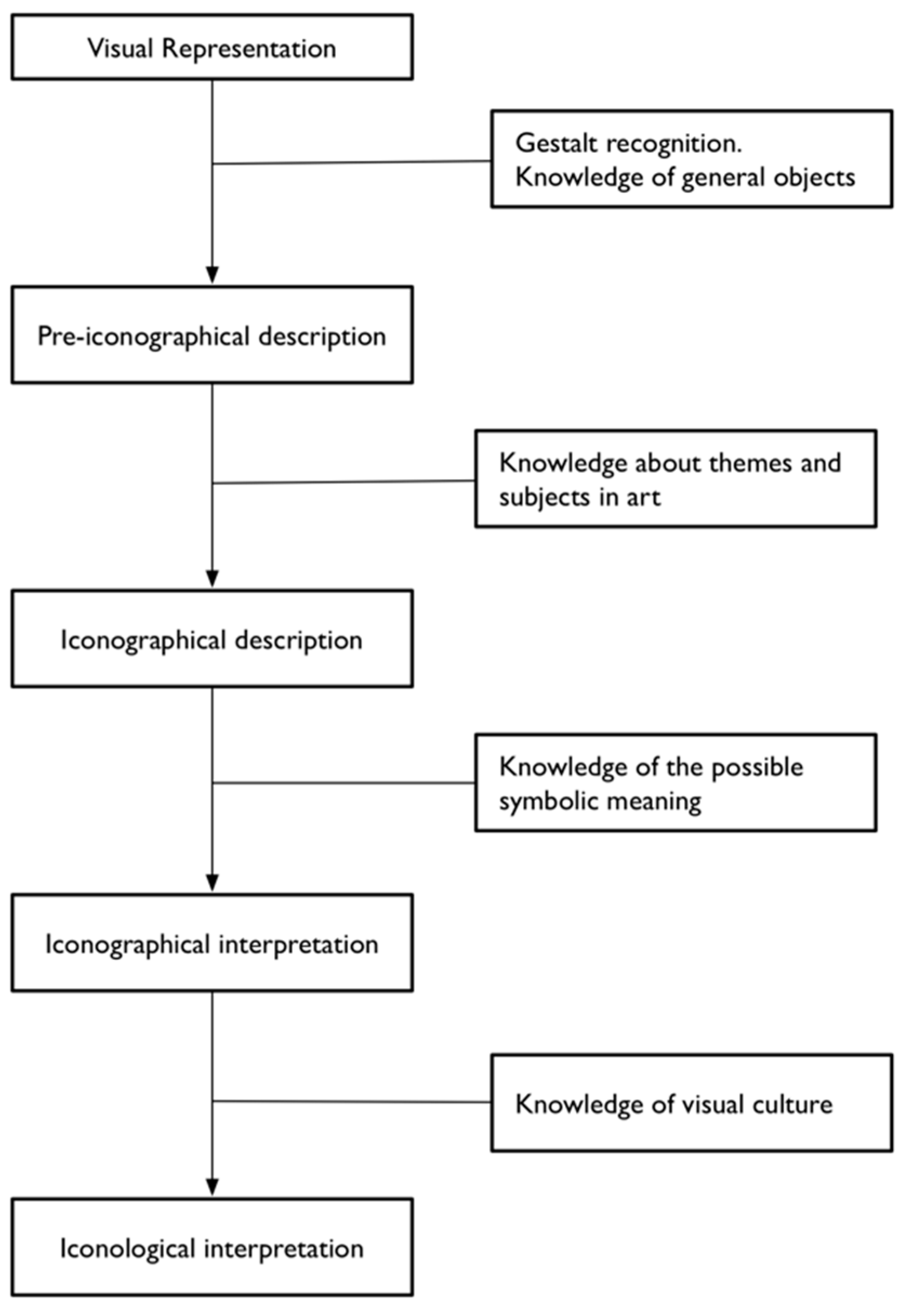
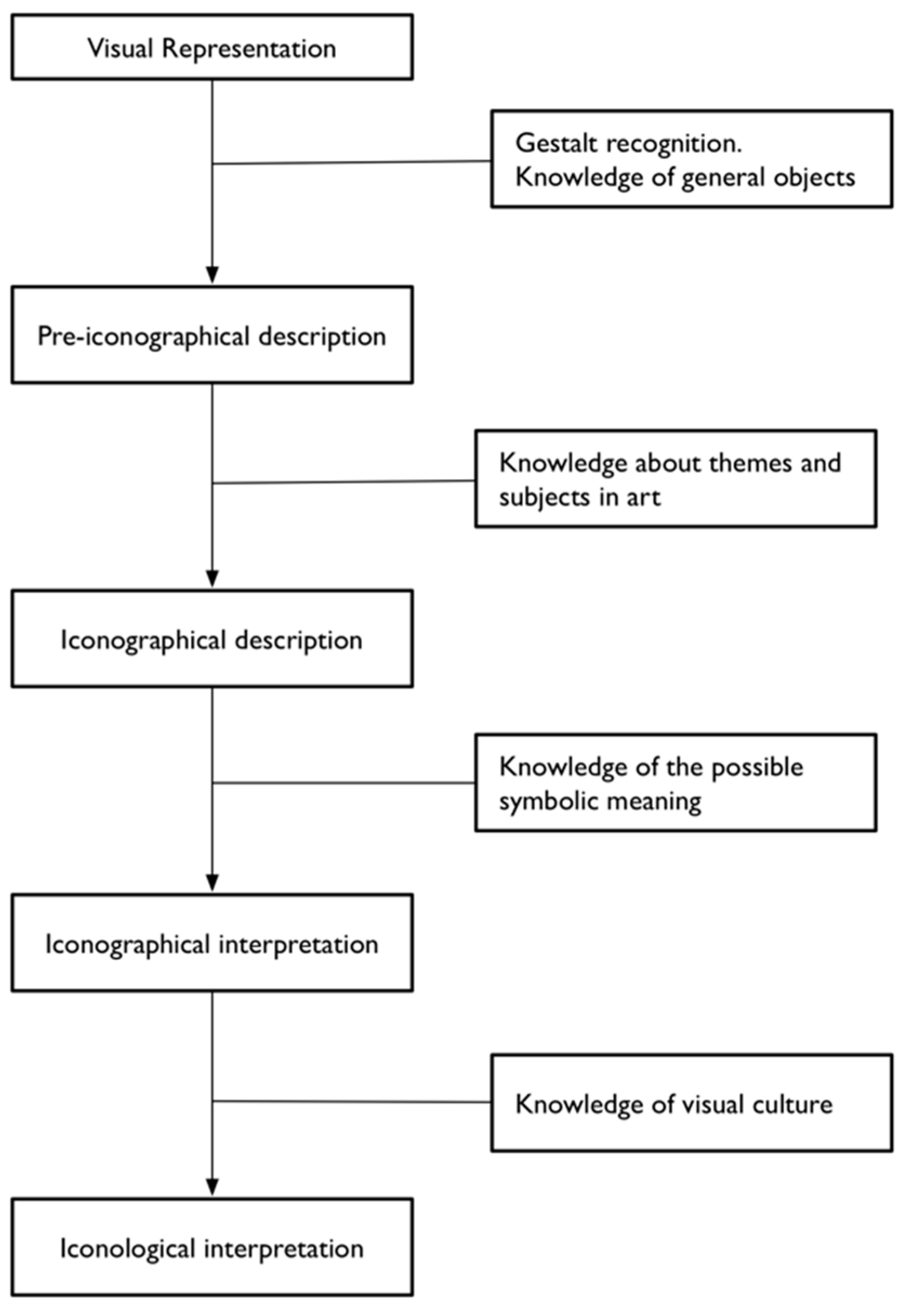
Figure 1) [
34]. Van Straten does not challenge the first pre-iconographical phase of analysis, focused only on the identification of the artistic motifs such as lines and shapes, but he concentrates instead on identification of the secondary subject matter and the intrinsic meaning. The iconographical analysis is divided into iconographical description (second phase) and interpretation (third phase). The iconographical description is the analytical phase, where the subject of the representation is established (for example “Saint George and the Dragon”) but deeper meaning is not searched for. In this scheme, we can attribute an iconographical description to all works of art, in contrast with the analysis of Panofsky, which recognises the possibility of assigning a secondary subject matter only to a limited set of works of art (landscape, for example, could not be iconographically analysed).
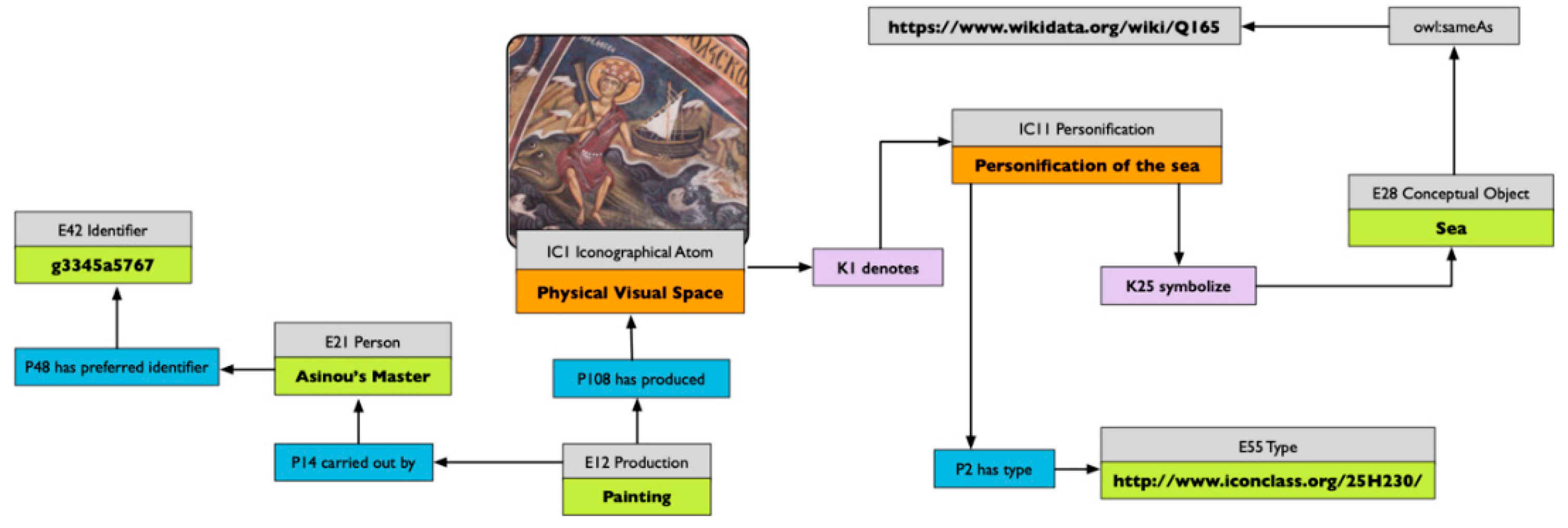
Iconographical interpretation examines the explicit use of symbols by the artist, and formalises the deeper meaning of a representation. One of the results of an iconographical interpretation is the decoding of symbols and the formalisation of what they express. We can envision the re-use of the codification of these signs to computationally track and analyse them, grounding their use in time and space, and discovering how they originate, evolve and spread across communities.
The fourth and final step of the analysis is iconological interpretation, which deals with those symbolic values that are not explicitly intended by the artist, and are part of the visual culture of the time.
These symbolic values can be analysed historically and ethnographically, and not only from an art historian’s perspective. Iconological interpretation adds a new level of meaning to a representation, the connoted meaning. If the denoted meaning previously introduced is about the object as expressed by form, the connotation is an interpretation on the basis of a socio-historical analysis of the symbols of an image [
37,
39]. The codification, description and tracking of connotative references between visual and conceptual objects is another important aspect to track, because it is even more socially grounded than explicit reference. Integration of the study of symbolic values in visual images could help us make sense of how we use semantic marks to classify reality, and how it does change on the basis of the context in which the visual classification takes place.
It is clear that Panofsky’s methodology, and the revised version proposed by Van Straten, can be easily integrated with the theory of cognitive type and our addendum about semantic marks. The two methods should be then seen as complementary (
Table 1). In fact, semantic marks help us formalise the relationship between a percept and its interpretation, while Panofsky’s methodology provides a path for the reading of a work of art, defining a way to take into account the propositional assumptions of a viewer in relation to a visual representation. The division of the assumptions in layers of meaning is hypothetical, and just a formal way of proposing a reading, which Panofsky uses in his attempt to eliminate subjective distortions. These distortions are, however, always present in the understanding of a visual work, and do not depend on the work itself, but the situation and social context of the assessment, as proven in
Section 3.3. A non-Western centred approach to classification would provide different readings and understanding, and that is why it is important to clarify when and how the interpretation of visual signs take place.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}