4.1. Forecasting the Occurrence of Price Spikes
Each model in
Table 1 uses the same set of input features
to generate one-hour-ahead electricity price class predictions
. These forecasts are generated using a rolling calibration window [
13]. Moreover, the training period
m in Algorithm 1 in
Section 3 corresponds to one year of data, starting on 1 January 2018, at 00:00. Here, the last month is used as a validation set. For example, in the first training round, the month of December 2018 is used as a validation set. The total test period starts on 1 January 2019, at 00:00 and ends on 31 December 2022, at 23:00. Following the previous example, after the first training round, January 2019 is used as the test period.
Similarly as made by [
8] for the Australian market,
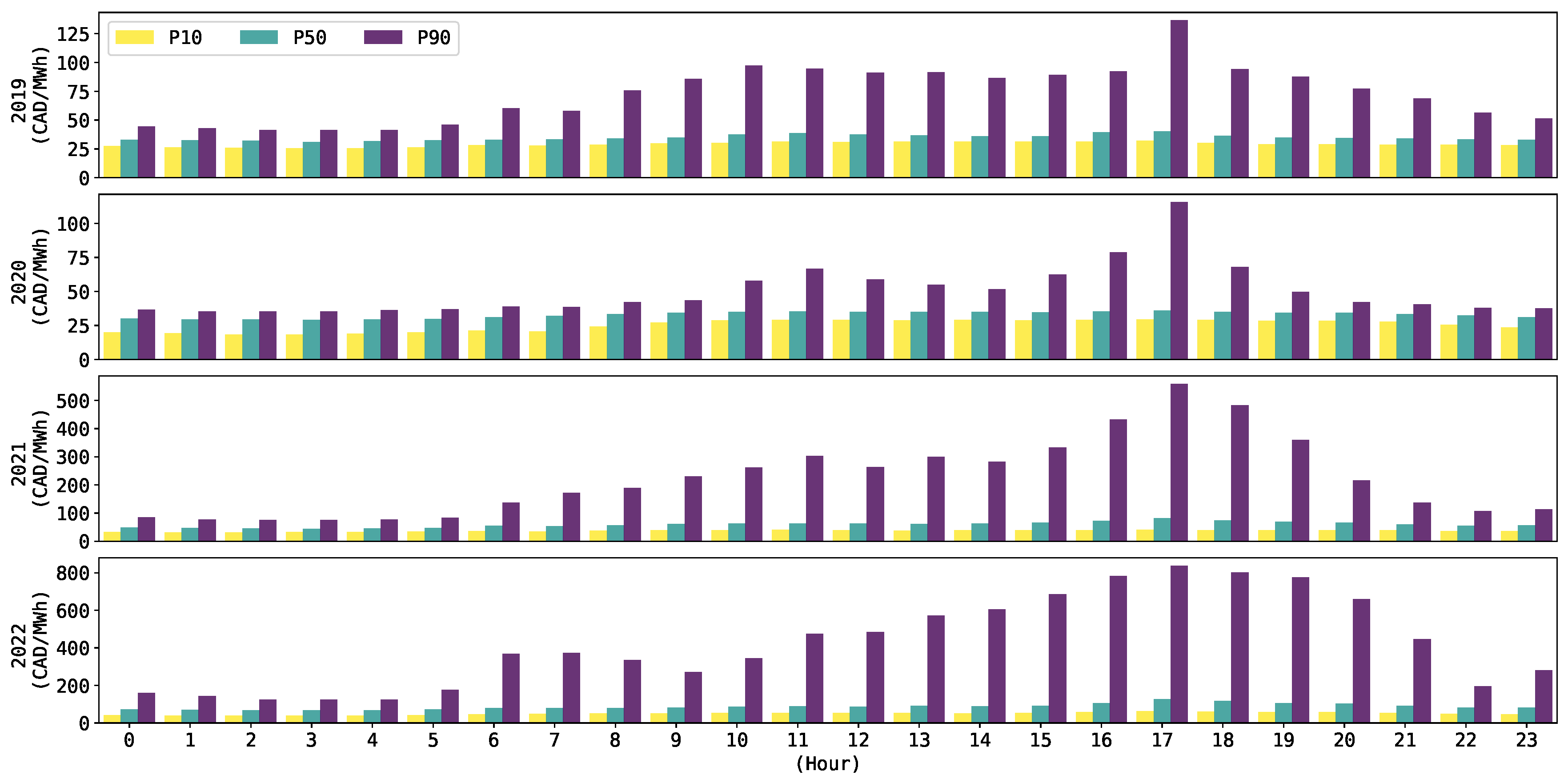
Figure 1 shows the 10, 50, and
percentiles (i.e., P10, P50, and P90) of the pool price dynamics in Alberta’s market for the years where class predictions
are generated.
Observe, for example, the tendency of the P10 and P50 for all of the years in
Figure 1 to not exceed 100 CAD/MWh at any hour of the day. Conversely, the P90 shows drastic changes when comparing between the years of 2019 and 2020 (e.g., approximately between 125 CAD/MWh and 100 CAD/MWh) against 2021 and 2022 (e.g., approximately between 500 CAD/MWh and 800 CAD/MWh). The diverse high price dynamics, as shown in
Figure 1, suggests the convenience of testing the models with different thresholds
.
The price spike threshold
defined in (
1) in
Section 3, can be represented either as a fixed (
) or variable (
) threshold. Let us define the set of fixed thresholds [
4,
8,
21]
v in
as the prices above or equal to 100 CAD/MWh, 200 CAD/MWh, 300 CAD/MWh, 400 CAD/MWh, here, expressed as
,
,
, and
, respectively. Likewise, the set of variable thresholds [
3,
16] in
is defined by
and
, i.e.,
and
; and are expressed as
, and
, respectively. For each threshold type, i.e.,
and
, the corresponding number of spikes is shown in
Table 2.
As expected,
Table 2 shows that the number of spiky samples decreases as the value of threshold
increases for every test period. Observe the notorious increment in the number of spikes in 2021 and 2022, compared to 2019 and 2020. Among others, an important reason for this is due to changes in the bidding strategies of some market participants looking to increase their asset profitability. Thus, resulting in higher market price offers from these market participants [
57]. Moreover, observe the number of hourly spiky samples in
Table 2 is small compared to, e.g., one year of hourly data. The high imbalance between the spiky and normal prices is one of the reasons why modeling electricity price spikes is a non-trivial task [
9].
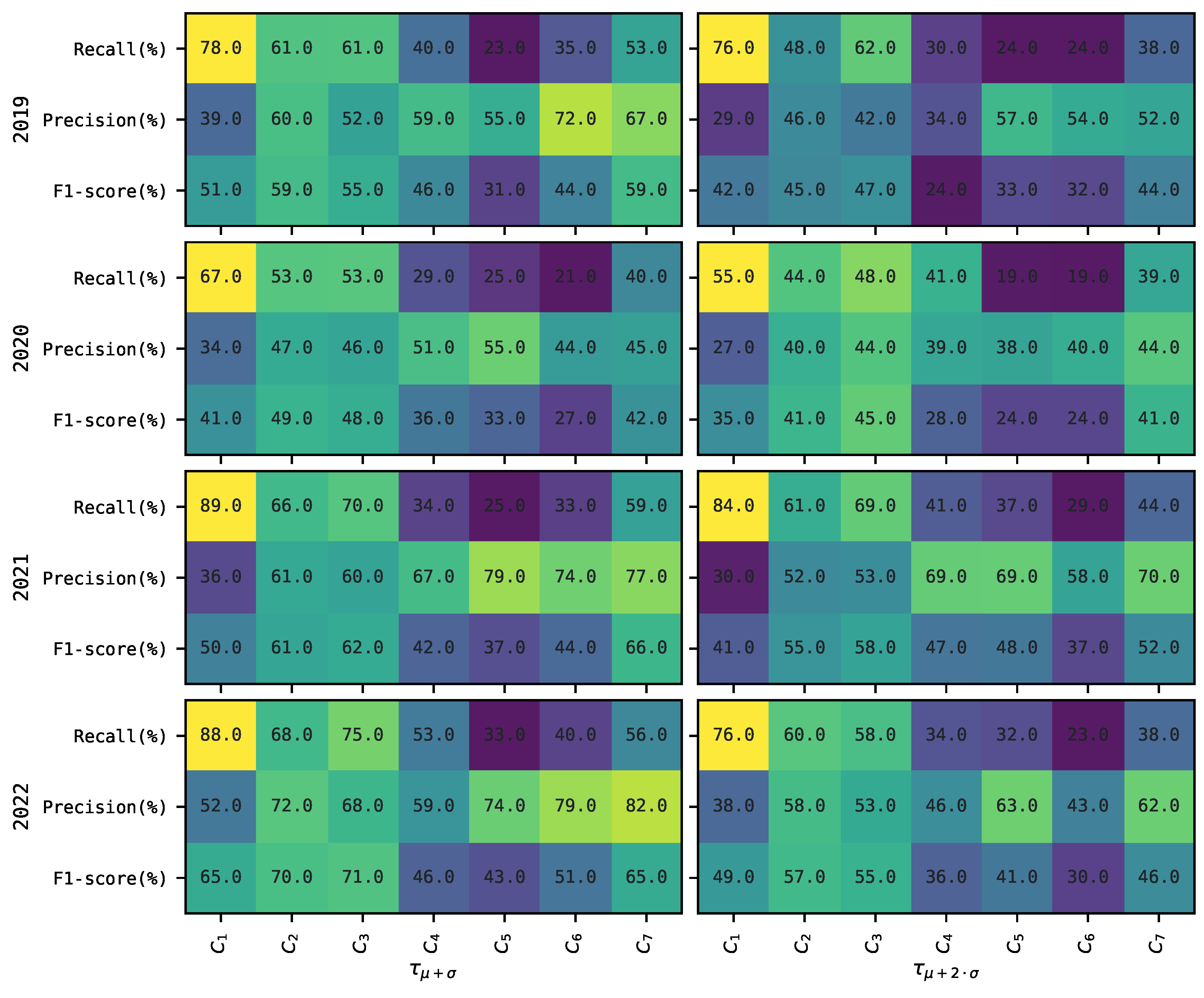
Figure 2 shows the mean recall (
2), precision (
3) and F1-score (
4) for each classifier
, and threshold
across the tests periods. Here, the value of each threshold in
remains fixed through every training period
m. For each of these performance metrics,
Figure 2 shows a general tendency for classifiers
to decrease their performance as the value of the threshold increases. For example, for most of the years, performance metrics, and threshold
, we observe this tendency to occur for more than 75% (and up to 90%) of the time. The only exception is 2020, where this only occurs 63% of the time.
Furthermore,
Figure 2 shows that in 2020, classifiers
tend to perform lower compared to other years. This is more (less) notorious for classifiers
to
and
(
to
). This may probably be associated with the impact of the COVID-19 pandemic on market price dynamics during that year. Furthermore, in general, in all years and thresholds
, it is possible to observe that the variations between mean performance metrics are not significant for classifiers
,
and
. In contrast, these variations in mean performance tend to be significant for classifiers
and
to
.
Among all classifiers,
tends to show the highest performance to predict the occurrence of price spikes in
Figure 2, i.e., see mean recall. However, the lower precision of
most times may suggest a possible tendency to overestimate predictions of the occurrence of price spikes. Moreover, in terms of precision, i.e., the capacity of classifier
to not overestimate the predictions of the occurrence of price spikes, classifier
shows the highest mean precision for most of the cases in
Figure 2. Finally,
has the highest mean F1-score most of the time but is not as evident as with the recall and precision cases.
Interestingly,
Figure 2 shows that classifier
, optimized with recall, obtains a higher average precision than recall for most of the years and thresholds
. A possible reason for this is that the explainable model requires, among others, a minimum recall and precision as hyperparameters to select the best-performing rules (see
Appendix A.2). Here, for example, when optimized with
where
{recall}, we use a search range within a minimum recall (precision) of
. Observe we try to set higher limits for recall than precision, to try to find an optimal rule able to detect as much FN as possible (see (
2) in
Section 3.2). However, due to the challenging nature of the imbalance problem, as shown in
Table 2, the rules seem to have difficulties in achieving such a task.
To corroborate our previous assumption, we run a new simulation for
using
, where minimum recall is now set using the default hyperparameter, as found in [
31], i.e., equal to 0.01. Conversely, we set minimum precision to a ‘high’ range, i.e.,
, to try to enforce the model to ‘easily’ find a higher recall. However, results from this simulation are similar to those in
Figure 2 for
, where higher average precision tends to prevail in most cases. Thus, there may be evidence that empirically shows that in our problem, the extracted rules used to generate predictions
, tend to be better, on average, at detecting FP than FN.
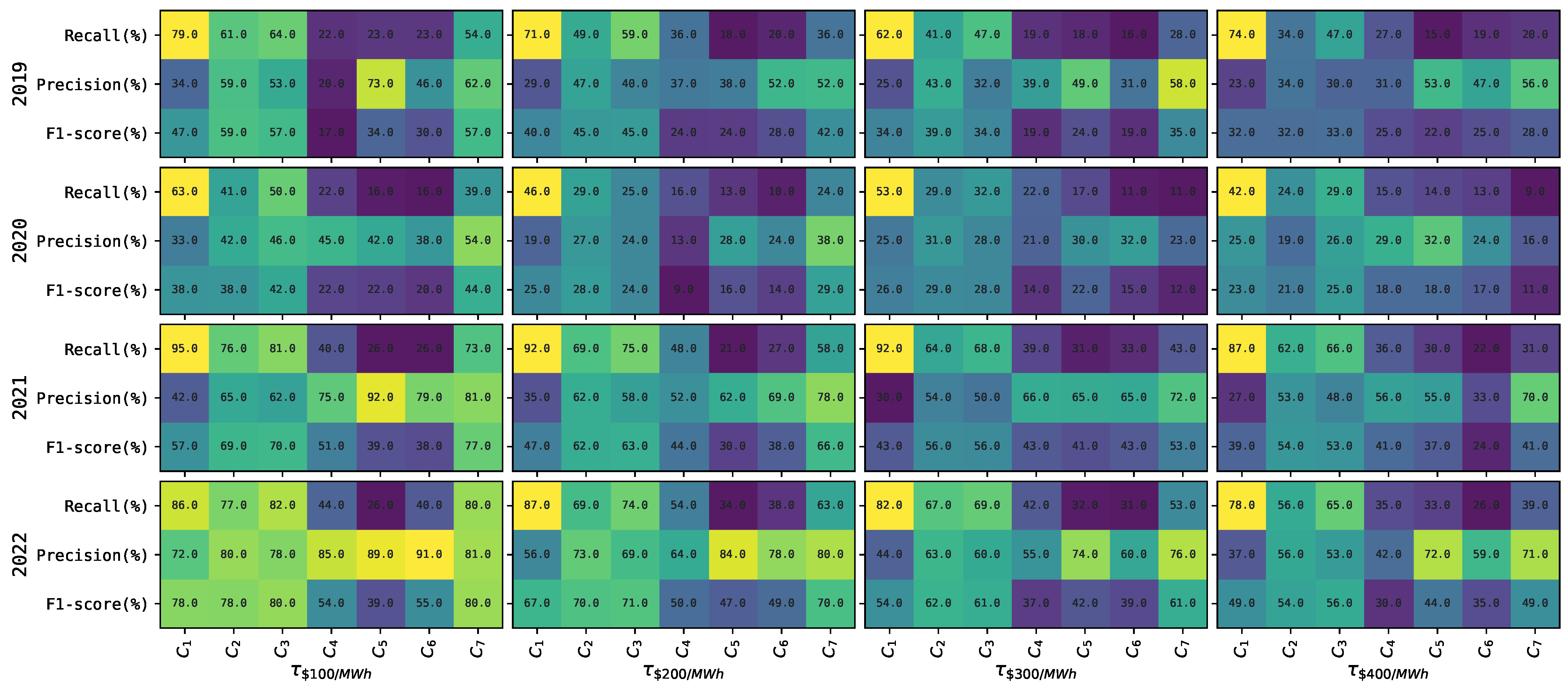
The mean recall, precision, and F1-score for each classifier
using a variable threshold in
are presented in
Figure 3. A variable threshold
in (
1) is estimated using the spot price observed on the last month of each training period (excluding the validation period)
m, i.e., month 11. Here, using the last month would allow the threshold to include the most recent possible market information and its impact on the price dynamics.
Observe from
Figure 3 that the performance of the classifiers
also tends to decrease as the threshold
increases. In general, this occurs on average 88% of the time for all thresholds, performance metrics, and most test periods.
Figure 3 shows that the classifier with the best mean recall across all thresholds
and test periods is again
. Moreover, in this case, classifier
shows the highest mean precision most of the time for thresholds
. Regarding the F1-score,
has the highest one for most of the cases when compared to other classifiers. Again, we observe that classifiers
, and
to
have a higher variability between mean recall, precision and F1-score. In contrast,
,
, and
tend to show a more stable mean performance across these metrics.
Again, we observe that the classifier
has a higher mean precision than recall. Here, since the hyperparameter search space for minimum recall (precision) is the same regardless of the price spike threshold
, we believe the same idea, as previously explained for
Figure 2, prevails.
General conclusions are derived from
Figure 2 and
Figure 3. For any threshold type, classifier
, i.e., optimized to enhance recall performance, heavily trades-off precision and, therefore, F1-score. As previously stated, this may be an indication of this classifier overestimating the class predictions of price spikes. For the generality of this conclusion, we try to investigate if in our experiment, classifier
would behave similarly to
. That is, if instead of using
’s rules to generate the predictions (i.e., see Algorithm 1 in
Section 3.4), we use the model, i.e., as with any machine learning algorithm. We run our experiment for
following these ideas. Results are shown in
Table 3.
For the sake of preserving space,
Table 3 shows the results of the experiment only for
. However, similar results are observed for
. Observe that, when predictions
are generated using
as a model, its performance tends to be biased towards increasing the recall at the cost of decreasing precision and F1-score; as observed with
. Thus, in our experiment,
’s derived conclusion is extended to
, only if rules from
, are not used to generate predictions.
In contrast, for those classifiers optimized to improve precision and F1-score performance, i.e., and , and, and , the optimal set of hyperparameters appears to be those decreasing the chances of overestimating (higher precision) the occurrence of a price spike, at the cost of underestimating (lower recall) them. This idea applies to classifier , too.
It is difficult to observe a general tendency for a classifier
to have a significantly better statistical performance for thresholds in
than those in
. Finally, in the proposed investigation study, observing a single model achieving high performance across the different error metrics, is challenging. A similar conclusion is derived in [
4,
8].
4.2. Economic Evaluation of the Occurrence of Price Spike Predictions
Based on the statistical performance of a classifier
in
Figure 2 and
Figure 3, we evaluate the economic implications of the forecasts
based on the threshold
in the decision making of a market participant. This is achieved following (
5c) and (
6) in
Section 3.2. The example case study evaluates a demand-side management strategy [
38] for a 1 MW load
. In other words, we quantify the economic value of the forecasts using a one-sided approach [
42]. Finally, this application can be extended to other markets, too.
For each threshold
and test period, we first quantify the total profit or loss for operating
following (
6) in
Section 3.3. Therefore, for all thresholds in
, the total profits
are CAD 299,165; CAD 3,805,565; CAD 7,311,965, and CAD 10,818,365, respectively. Likewise, for thresholds in
, total profits
correspond to CAD 3,192,417 and CAD 6,675,959 respectively. Using these profits as a base comparison, we evaluate if operating load
based on forecasts from classifier
, represents an economic benefit.
Table 4 shows the total profit (positive) or loss (negative) from the difference between
for each classifier
and fixed threshold
. Here, it is shown that load
benefits the most using predictions from classifier
. As referenced from
Section 4.1,
Figure 2 shows
as the model with the highest mean precision performance for most of the cases. Moreover, as discussed in
Section 4.1,
benefits from having a more stable mean predictive performance for all metrics, most of the time. From a practical perspective, it means an optimal balance between FP and FN predictions in (
2) and (
3); thus, translating into less economic damage reflected in
.
For example, has a lower total economic loss due to the overestimation of predictions of the occurrence of price spikes for but not for , and , being the one with the lowest economic losses. However, for all thresholds , benefits from having much lower losses than due to the underestimation of predictions of the occurrence of price spikes. The total sum of these losses i.e., underestimation plus overestimation, corresponds to −CAD 631,974 and −CAD 1,644,171 for and , respectively.
Likewise,
Table 4 shows that
has a high economic loss when the threshold is
. Nevertheless, we also observe that there is a profit for the other thresholds for
. However, to contrast with the ideas based on observations from
Figure 2, our numerical results show that
has the highest economic losses due to FP among all classifiers
for
,
, and
. These losses represent −CAD 134,032; −CAD 463,566, and −CAD 555,493, respectively. For
, the highest loss is for
(i.e., −CAD 379,676), but just CAD 2,182 higher than
. In contrast,
has the lowest economic losses due to FN (i.e., −CAD 42,190; −CAD 43,450; −CAD 36,212 and −CAD 26,892, respectively) across all thresholds. Thus, as previously mentioned,
shows a tendency to trade off high levels of recall with low levels of precision.
In regards to
,
Table 4 shows negative economic impacts in
and
.
Figure 2 shows that
has a tendency that, on average, benefits precision over recall, however, this is not restrictive for all the periods. For instance, take
when
in
Table 4. Here, our results show that in August 2022,
incurs a big economic loss associated with the overestimation of the occurrence of price spikes. Moreover, the recall is high but precision is low in this period. Thus, negatively affecting the total
.
Table 5 shows the economic results of operating load
using a variable threshold
. These results are also obtained as the difference between (
5c) and (
6) introduced in
Section 3, i.e.,
.
It is also possible to observe from
Table 5 that the best economic results for both thresholds in
, correspond again to classifier
. From
Figure 3, we show
as the model with the highest precision most of the time. However, the variability between metrics in terms of average performance is higher when compared to
. For instance, the economic impact due to FP is less (bigger) for
(
). Conversely, losses due to FN are smaller (bigger) for
(
). The total of these losses represent −CAD 640,739 and −CAD 289,672 for
and
, respectively.
Evidence from
Table 5 shows that, when thresholds are variable, the higher trade-off between recall and precision in
Figure 3 does not necessarily translate in the highest economic losses for model
. However, numerical evidence from our results shows that
has the highest (lowest) economic losses due to FP (FN) for each threshold in
, i.e., the total in −CAD 761,344 (−CAD 50,193), respectively.
Again, we investigate reasons for having a negative impact, i.e., observe . Here, for example, during May 2019 and December 2020, profits are affected by the negative economic impact due to overestimation of the occurrence of price spikes. These balances are observed to significantly trade off good recall against a bad precision score in these months. Thus, negatively impacting the difference , and hence the total accounted for .
In general, results from
Table 4 and
Table 5 show that classifiers
,
,
,
and
consistently generate predictions that economically benefit the operation of load
when compared to the blind operation benchmark
, using threshold
. Moreover, these results demonstrate that, in price spike occurrence forecasting, a higher performance in one statistical error metric, would not necessarily translate into a high economic benefit [
35], e.g.,
in our study. Likewise, in contrast to [
8], who concludes that a false negative of the probability of occurrence of a price spike would be more detrimental for an energy retailer than a false positive, our results suggest that a balance between recall and precision, with some bias towards the latter, brings higher economic benefits for the proposed case study, i.e., see
. This conclusion extends to
and
, whose results are also competitive. Moreover, based on
’s performance, our results are better aligned to those in [
35]. Here, the authors show the spike prediction confidence (i.e., precision) translates as beneficial in the cost-benefit analysis for the supply bids of a market participant in the Australian market. Finally, we agree with [
35], who emphasizes the importance of integrating the price spike forecasting method with the decision-making process.
4.3. The Trade-Off between Performance and Explainability
In recent years, interpretable AI in energy forecasting has started to capture the attention of researchers. The goal is to enhance the acceptability of AI models with the industry stakeholders [
5,
29]. Additionally, interpretability allows for the comparison between expert knowledge and model decisions. This is particularly important, for example, in the engineering field [
43]. However, the methodological trade-offs between a model’s performance and interpretability [
43] remain as a challenge. Here, to the best of our knowledge, the economic impact of this trade-off on a market’s participant has not been explored yet in price spike occurrence forecasting.
In this investigative study, we quantify the trade-off between model predictive performance and interpretability. Results in
Table 4 and
Table 5 show that, for the proposed case study,
is the model that brings the highest profits with respect to
, among all models
and thresholds
. Moreover, among the explainable classifiers
to
,
and
tend to be competitive across thresholds
in
and
. Thus, we arbitrarily pick
for showcasing purposes.
Table 6 shows the economic trade-off between the model’s performance and interpretability for the demand-side management case in this study. For the sake of showing the idea behind this trade-off in price spike forecasting, we are comparing the best non-interpretable performing model, i.e.,
, against a competitive interpretable model, i.e.,
.
For the demand-side management application, the economic differences between
and
displayed in
Table 6 for each spike threshold
, represent the trade-off due to the lost of
’s statistical forecasting performance. These differences indicate that, if one would pick using human-interpretable decision rules from
to predict the occurrence of price spikes at any selected threshold
, the cost of it would have been
for each case, respectively. Finally, observe from
Table 4 and
Table 5 that forecasts from
would still have economically benefited the operation of load
.
Predictions
are made using decision rules from the explainable model introduced in
Appendix A.2. Here, we show an example of a decision rule used to generate forecasts
during July 2022 using
[
21]. We select this period because it corresponds to the Summer season, where price spikes are likely to occur due to the high demand associated with extreme temperatures [
8,
57].
Thus, the decision rule used to generate the class price spike forecasts is pool_price_lag_1 > 379 AND wind_7d_forecast_lag_24 > 26. This predictive rule has a recall, precision, and F1-score of 53.6, 87, and 66.3%, respectively. Observe that this rule has a cardinality of two, and is the best-performing rule selected from the semantic deduplication process introduced in
Appendix A.2. In other words, two features from the total in
(i.e., see
Section 3) have been found by Skope Rules [
31] as relevant, to generate one-hour-ahead forecasts of the occurrence of price spikes during July 2022 using threshold
.






{kind=link}
{kind=link}
{kind=link}