
On the Disagreement of Forecasting Model Selection Criteria


Abstract
1. Introduction
2. Model Selection Criteria
2.1. Criteria Based on In-Sample Accuracy Measurements
2.2. Information Criteria
2.3. Criteria Based on Cross-Validation
3. Forecasting Models
4. Empirical Evaluation
4.1. Experimental Setup
4.2. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Forecasting Accuracy According to sMAPE

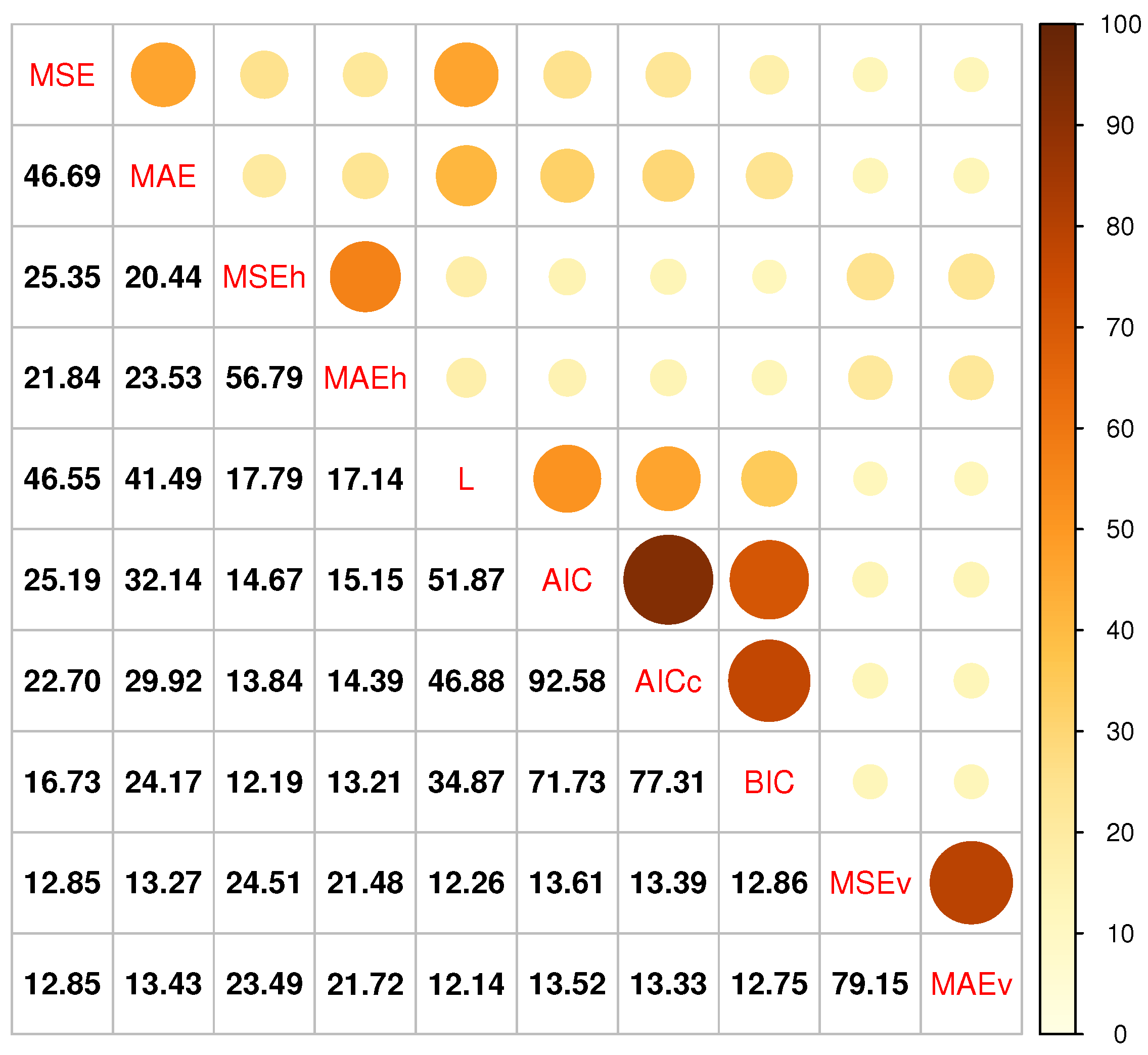{kind=link}
| Criterion | MASE | Average Rank | ||||||
|---|---|---|---|---|---|---|---|---|
| Yearly | Quarterly | Monthly | Total | Yearly | Quarterly | Monthly | Total | |
| MSE | 15.065 | 10.212 | 13.176 | 12.821 | 3.190 | 6.868 | 6.692 | 5.969 |
| MAE | 15.022 | 10.050 | 13.013 | 12.684 | 3.165 | 6.723 | 6.553 | 5.853 |
| MSEh | 15.183 | 10.306 | 13.084 | 12.823 | 3.230 | 6.964 | 6.671 | 5.992 |
| MAEh | 15.258 | 10.256 | 13.025 | 12.796 | 3.206 | 6.957 | 6.665 | 5.981 |
| L | 15.307 | 10.276 | 13.173 | 12.889 | 3.168 | 6.901 | 6.728 | 5.991 |
| AIC | 15.039 | 10.211 | 13.194 | 12.824 | 3.235 | 6.896 | 6.734 | 6.008 |
| AICc | 14.784 | 10.200 | 13.272 | 12.805 | 3.245 | 6.919 | 6.789 | 6.045 |
| BIC | 14.802 | 10.143 | 13.359 | 12.840 | 3.256 | 7.059 | 6.963 | 6.174 |
| MSEv | 14.463 | 10.401 | 13.331 | 12.818 | 3.168 | 7.190 | 6.893 | 6.152 |
| MAEv | 14.543 | 10.399 | 13.309 | 12.824 | 3.177 | 7.188 | 6.886 | 6.150 |
References
- Wolpert, D.; Macready, W. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Fildes, R. Beyond forecasting competitions. Int. J. Forecast. 2001, 17, 556–560. [Google Scholar]
- Petropoulos, F.; Hyndman, R.J.; Bergmeir, C. Exploring the sources of uncertainty: Why does bagging for time series forecasting work? Eur. J. Oper. Res. 2018, 268, 545–554. [Google Scholar] [CrossRef]
- Fildes, R.; Petropoulos, F. Simple versus complex selection rules for forecasting many time series. J. Bus. Res. 2015, 68, 1692–1701. [Google Scholar] [CrossRef]
- Doornik, J.A.; Castle, J.L.; Hendry, D.F. Short-term forecasting of the coronavirus pandemic. Int. J. Forecast. 2022, 38, 453–466. [Google Scholar] [CrossRef] [PubMed]
- Akaike, H. Information Theory and an Extension of the Maximum Likelihood Principle. In Selected Papers of Hirotugu Akaike; Springer: New York, NY, USA, 1998; pp. 199–213. [Google Scholar]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Collopy, F.; Armstrong, J.S. Rule-Based Forecasting: Development and Validation of an Expert Systems Approach to Combining Time Series Extrapolations. Manag. Sci. 1992, 38, 1394–1414. [Google Scholar] [CrossRef]
- Petropoulos, F.; Makridakis, S.; Assimakopoulos, V.; Nikolopoulos, K. ‘Horses for Courses’ in demand forecasting. Eur. J. Oper. Res. 2014, 237, 152–163. [Google Scholar] [CrossRef]
- Montero-Manso, P.; Athanasopoulos, G.; Hyndman, R.J.; Talagala, T.S. FFORMA: Feature-based forecast model averaging. Int. J. Forecast. 2020, 36, 86–92. [Google Scholar] [CrossRef]
- Han, W.; Wang, X.; Petropoulos, F.; Wang, J. Brain imaging and forecasting: Insights from judgmental model selection. Omega 2019, 87, 1–9. [Google Scholar] [CrossRef]
- Petropoulos, F.; Kourentzes, N.; Nikolopoulos, K.; Siemsen, E. Judgmental selection of forecasting models. J. Oper. Manag. 2018, 60, 34–46. [Google Scholar] [CrossRef]
- Kourentzes, N.; Barrow, D.; Petropoulos, F. Another look at forecast selection and combination: Evidence from forecast pooling. Int. J. Prod. Econ. 2019, 209, 226–235. [Google Scholar] [CrossRef]
- Stone, M. Cross-Validatory Choice and Assessment of Statistical Predictions. J. R. Stat. Soc. Ser. (Methodol.) 1974, 36, 111–147. [Google Scholar] [CrossRef]
- Bergmeir, C.; Benítez, J.M. On the use of cross-validation for time series predictor evaluation. Inf. Sci. 2012, 191, 192–213. [Google Scholar] [CrossRef]
- Racine, J. Consistent cross-validatory model-selection for dependent data: hv-block cross-validation. J. Econom. 2000, 99, 39–61. [Google Scholar] [CrossRef]
- Burman, P.; Chow, E.; Nolan, D. A Cross-Validatory Method for Dependent Data. Biometrika 1994, 81, 351–358. [Google Scholar] [CrossRef]
- Bergmeir, C.; Hyndman, R.J.; Koo, B. A note on the validity of cross-validation for evaluating autoregressive time series prediction. Comput. Stat. Data Anal. 2018, 120, 70–83. [Google Scholar] [CrossRef]
- Koutsandreas, D.; Spiliotis, E.; Petropoulos, F.; Assimakopoulos, V. On the selection of forecasting accuracy measures. J. Oper. Res. Soc. 2022, 73, 937–954. [Google Scholar] [CrossRef]
- Schwertman, N.C.; Gilks, A.J.; Cameron, J. A Simple Noncalculus Proof That the Median Minimizes the Sum of the Absolute Deviations. Am. Stat. 1990, 44, 38–39. [Google Scholar]
- Kolassa, S. Evaluating predictive count data distributions in retail sales forecasting. Int. J. Forecast. 2016, 32, 788–803. [Google Scholar] [CrossRef]
- Armstrong, J.S. Standards and practices for forecasting. In Principles of Forecasting; Springer: Berlin/Heidelberg, Germany, 2001; pp. 679–732. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B.; Snyder, R.D.; Grose, S. A state space framework for automatic forecasting using exponential smoothing methods. Int. J. Forecast. 2002, 18, 439–454. [Google Scholar] [CrossRef]
- Burnham, K.P.; Anderson, D.R. Multimodel Inference: Understanding AIC and BIC in Model Selection. Sociol. Methods Res. 2004, 33, 261–304. [Google Scholar] [CrossRef]
- Billah, B.; King, M.L.; Snyder, R.D.; Koehler, A.B. Exponential smoothing model selection for forecasting. Int. J. Forecast. 2006, 22, 239–247. [Google Scholar] [CrossRef]
- Kolassa, S. Combining exponential smoothing forecasts using Akaike weights. Int. J. Forecast. 2011, 27, 238–251. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series Forecasting: The forecast Package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef]
- Tashman, L.J. Out-of-sample tests of forecasting accuracy: An analysis and review. Int. J. Forecast. 2000, 16, 437–450. [Google Scholar] [CrossRef]
- Brown, R.G. Exponential Smoothing for Predicting Demand; Little: Cambridge, MA, USA, 1956. [Google Scholar]
- Petropoulos, F.; Apiletti, D.; Assimakopoulos, V.; Babai, M.Z.; Barrow, D.K.; Ben Taieb, S.; Bergmeir, C.; Bessa, R.J.; Bijak, J.; Boylan, J.E.; et al. Forecasting: Theory and practice. Int. J. Forecast. 2022, 38, 705–871. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef]
- Fildes, R.; Goodwin, P.; Lawrence, M.; Nikolopoulos, K. Effective forecasting and judgmental adjustments: An empirical evaluation and strategies for improvement in supply-chain planning. Int. J. Forecast. 2009, 25, 3–23. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. M5 accuracy competition: Results, findings, and conclusions. Int. J. Forecast. 2022, 38, 1346–1364. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer: Berlin, Germany, 2008. [Google Scholar]
- Petropoulos, F.; Grushka-Cockayne, Y.; Siemsen, E.; Spiliotis, E. Wielding Occam’s razor: Fast and frugal retail forecasting. arXiv 2022, arXiv:2102.13209. [Google Scholar]
- Gardner, E.S. Exponential smoothing: The state of the art—Part II. Int. J. Forecast. 2006, 22, 637–666. [Google Scholar] [CrossRef]
- Winters, P.R. Forecasting sales by exponentially weighted moving averages. Manag. Sci. 1960, 6, 324–342. [Google Scholar] [CrossRef]
- Spiliotis, E.; Kouloumos, A.; Assimakopoulos, V.; Makridakis, S. Are forecasting competitions data representative of the reality? Int. J. Forecast. 2020, 36, 37–53. [Google Scholar] [CrossRef]
- Makridakis, S.; Assimakopoulos, V.; Spiliotis, E. Objectivity, reproducibility and replicability in forecasting research. Int. J. Forecast. 2018, 34, 835–838. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Petropoulos, F.; Spiliotis, E.; Panagiotelis, A. Model combinations through revised base rates. Int. J. Forecast. 2023, 39, 1477–1492. [Google Scholar] [CrossRef]
- Petropoulos, F.; Siemsen, E. Forecast Selection and Representativeness. Manag. Sci. 2022, 69, 2672–2690. [Google Scholar] [CrossRef]

| Additive Error | Multiplicative Error | ||||||
|---|---|---|---|---|---|---|---|
| Seasonality | Seasonality | ||||||
| Trend | N | A | M | Trend | N | A | M |
| N | ANN | ANA | ANM | N | MNN | MNA | MNM |
| A | AAN | AAA | AAM | A | MAN | MAA | MAM |
| Ad | AAdN | AAdA | AAdM | Ad | MAdN | MAdA | MAdM |
| M | AMN | AMA | AMM | M | MMN | MMA | MMM |
| Md | AMdN | AMdA | AMdM | Md | MMdN | MMdA | MMdM |
| Complexity | Models |
|---|---|
| Low | ANN, MNN |
| Moderate | AAN, MAN, ANA, MNA, MNM |
| Significant | AAdN, MAdN, AAA, MAA, MAM |
| High | AAdA, MAdA, MAdM |
| Criterion | MASE | Average Rank | ||||||
|---|---|---|---|---|---|---|---|---|
| Yearly | Quarterly | Monthly | Total | Yearly | Quarterly | Monthly | Total | |
| MSE | 3.471 | 1.151 | 0.923 | 1.542 | 3.200 | 6.865 | 6.675 | 5.962 |
| MAE | 3.441 | 1.141 | 0.921 | 1.531 | 3.177 | 6.721 | 6.543 | 5.850 |
| MSEh | 3.485 | 1.162 | 0.925 | 1.548 | 3.240 | 6.962 | 6.663 | 5.989 |
| MAEh | 3.459 | 1.163 | 0.924 | 1.543 | 3.219 | 6.959 | 6.656 | 5.980 |
| L | 3.432 | 1.159 | 0.934 | 1.541 | 3.180 | 6.906 | 6.728 | 5.995 |
| AIC | 3.436 | 1.158 | 0.936 | 1.543 | 3.246 | 6.900 | 6.739 | 6.014 |
| AICc | 3.407 | 1.158 | 0.939 | 1.538 | 3.256 | 6.924 | 6.795 | 6.051 |
| BIC | 3.426 | 1.162 | 0.948 | 1.548 | 3.265 | 7.057 | 6.971 | 6.180 |
| MSEv | 3.349 | 1.175 | 0.940 | 1.530 | 3.178 | 7.194 | 6.887 | 6.152 |
| MAEv | 3.367 | 1.175 | 0.940 | 1.534 | 3.187 | 7.190 | 6.881 | 6.150 |
| Complexity | MSE | MAE | MSEh | MAEh | L | AIC | AICc | BIC | MSEv | MAEv | Actual |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Low | 1.81 | 8.15 | 7.04 | 8.92 | 1.96 | 23.77 | 27.99 | 41.78 | 12.31 | 12.44 | 12.12 |
| Moderate | 22.59 | 25.85 | 36.13 | 35.93 | 24.82 | 39.48 | 39.18 | 36.98 | 40.06 | 39.94 | 37.14 |
| Significant | 33.11 | 32.92 | 37.20 | 36.38 | 32.93 | 23.27 | 21.16 | 15.51 | 36.17 | 35.92 | 38.68 |
| High | 42.49 | 33.08 | 19.63 | 18.77 | 40.30 | 13.48 | 11.67 | 5.74 | 11.45 | 11.70 | 12.07 |
| Criterion | Yearly | Quarterly | Monthly | Total |
|---|---|---|---|---|
| MSE | 19.95 | 7.62 | 7.77 | 10.40 |
| MAE | 20.70 | 9.26 | 8.94 | 11.61 |
| MSEh | 22.11 | 11.68 | 11.76 | 14.01 |
| MAEh | 22.33 | 11.47 | 11.70 | 13.97 |
| L | 19.86 | 8.17 | 8.09 | 10.69 |
| AIC | 20.46 | 9.25 | 8.46 | 11.30 |
| AICc | 20.44 | 9.28 | 8.36 | 11.25 |
| BIC | 20.39 | 9.02 | 7.86 | 10.91 |
| MSEv | 20.86 | 11.27 | 11.37 | 13.43 |
| MAEv | 20.76 | 11.14 | 11.38 | 13.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spiliotis, E.; Petropoulos, F.; Assimakopoulos, V. On the Disagreement of Forecasting Model Selection Criteria. Forecasting 2023, 5, 487-498. https://doi.org/10.3390/forecast5020027
Spiliotis E, Petropoulos F, Assimakopoulos V. On the Disagreement of Forecasting Model Selection Criteria. Forecasting. 2023; 5(2):487-498. https://doi.org/10.3390/forecast5020027
Chicago/Turabian StyleSpiliotis, Evangelos, Fotios Petropoulos, and Vassilios Assimakopoulos. 2023. "On the Disagreement of Forecasting Model Selection Criteria" Forecasting 5, no. 2: 487-498. https://doi.org/10.3390/forecast5020027
APA StyleSpiliotis, E., Petropoulos, F., & Assimakopoulos, V. (2023). On the Disagreement of Forecasting Model Selection Criteria. Forecasting, 5(2), 487-498. https://doi.org/10.3390/forecast5020027