

Shrinking the Variance in Experts’ “Classical” Weights Used in Expert Judgment Aggregation




Abstract
1. Introduction
2. Materials and Methods
2.1. CM Weights
2.2. Shrinkage Estimation of Weights
2.3. Deriving and Implementing Shrinkage CM Weights
2.4. Shrinkage CM Weights Based on 10 Seeds
- Select two data sets with more than 10 seed questions.
- Consider the first 10 seed questions of each data set as training questions for deriving normalized CM weights.
- Consider the remaining questions of each data set as testing questions of the analysis.
- Estimate the sample variances of normalized CMs weights using a randomly selected sample of 10 questions, from the testing questions, for each expert.
- Derive shrinkage CM weights from the normalized CM weights calculated using the training questions and the above-estimated sample variances of the CM weights.
- Obtain normalized shrinkage weights.
- Compute the DMs’ calibration and informativeness scores of testing questions using the normalized classical and shrinkage CM weights by applying the user define weights option of the Excalibur package.
- Compare the overall calibration and informativeness scores above to assess the impact of deriving shrinkage weights.
2.5. Shrinkage CM Weights Based on Fewer than 10 Seeds
- Select a data set from the 49 post-2006 studies.
- Choose a number of samples, N; a number of calibration questions, k; and degrees of freedom, d. For the following analysis, we used , and .
- Use all seed questions of each data set to derive normalized CM weights.
- Sample without replacement k seed questions N times. Calculate the normalized CM weights each of the N times for each expert, using the subset of k seeds.
- Derive the sample variance of the normalized CM weights calculated as before.
- Derive shrinkage CM weights using the variance above and the choice of d.
- Obtain normalized shrinkage CM weights.
- Compute the DMs’ calibration and informativeness scores using the normalized CM and shrinkage CM weights.
- Compare the DMs’ calibration and informativeness scores above to assess the impact of deriving shrinkage CM weights.
3. Results
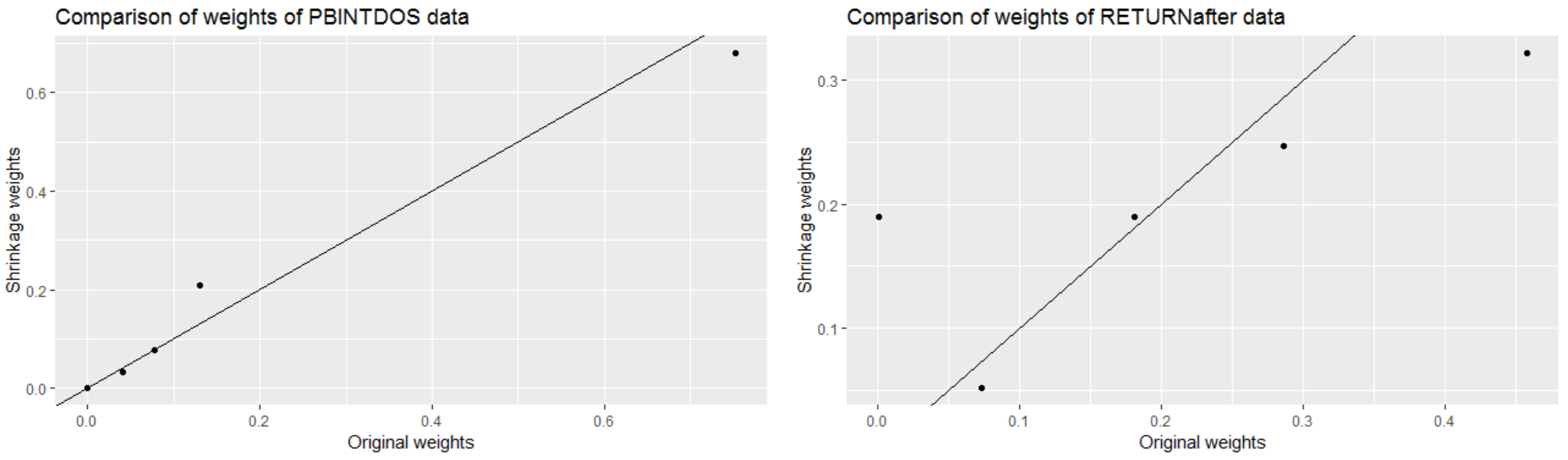
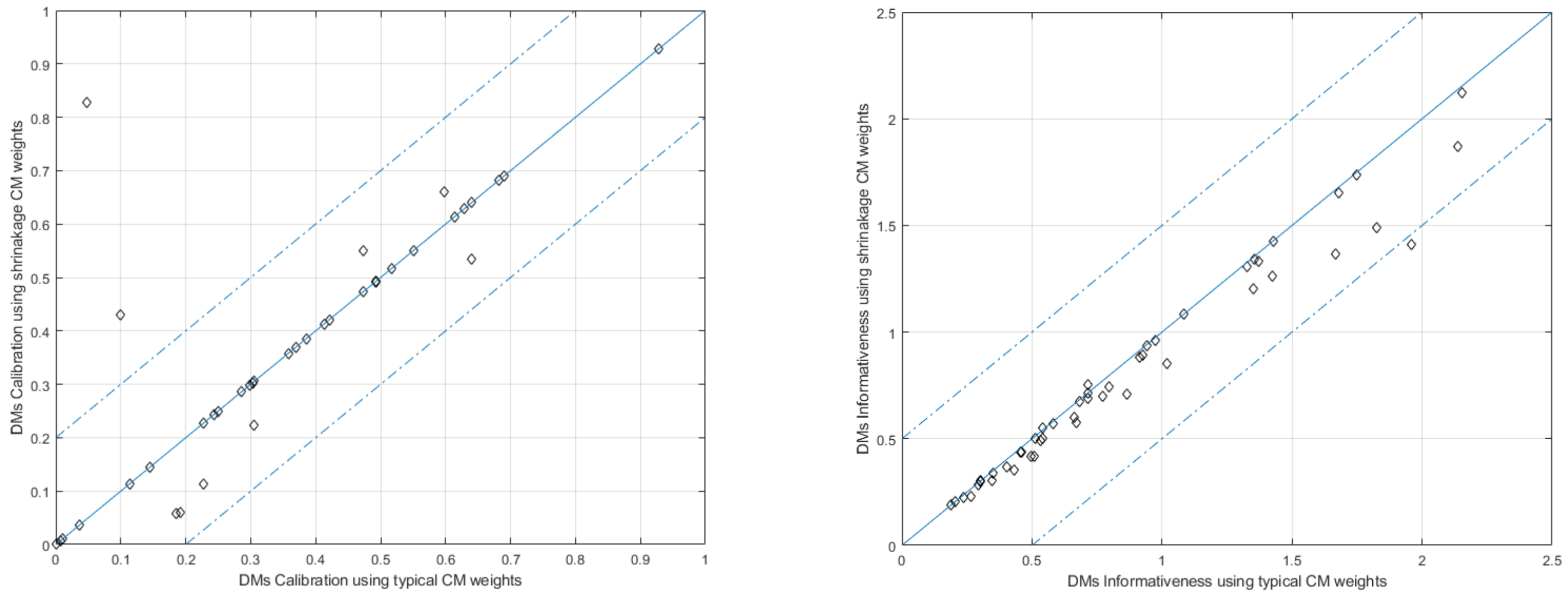
3.1. Deriving Weights Using 10 Seed Questions
Results Addressing the First Research Question
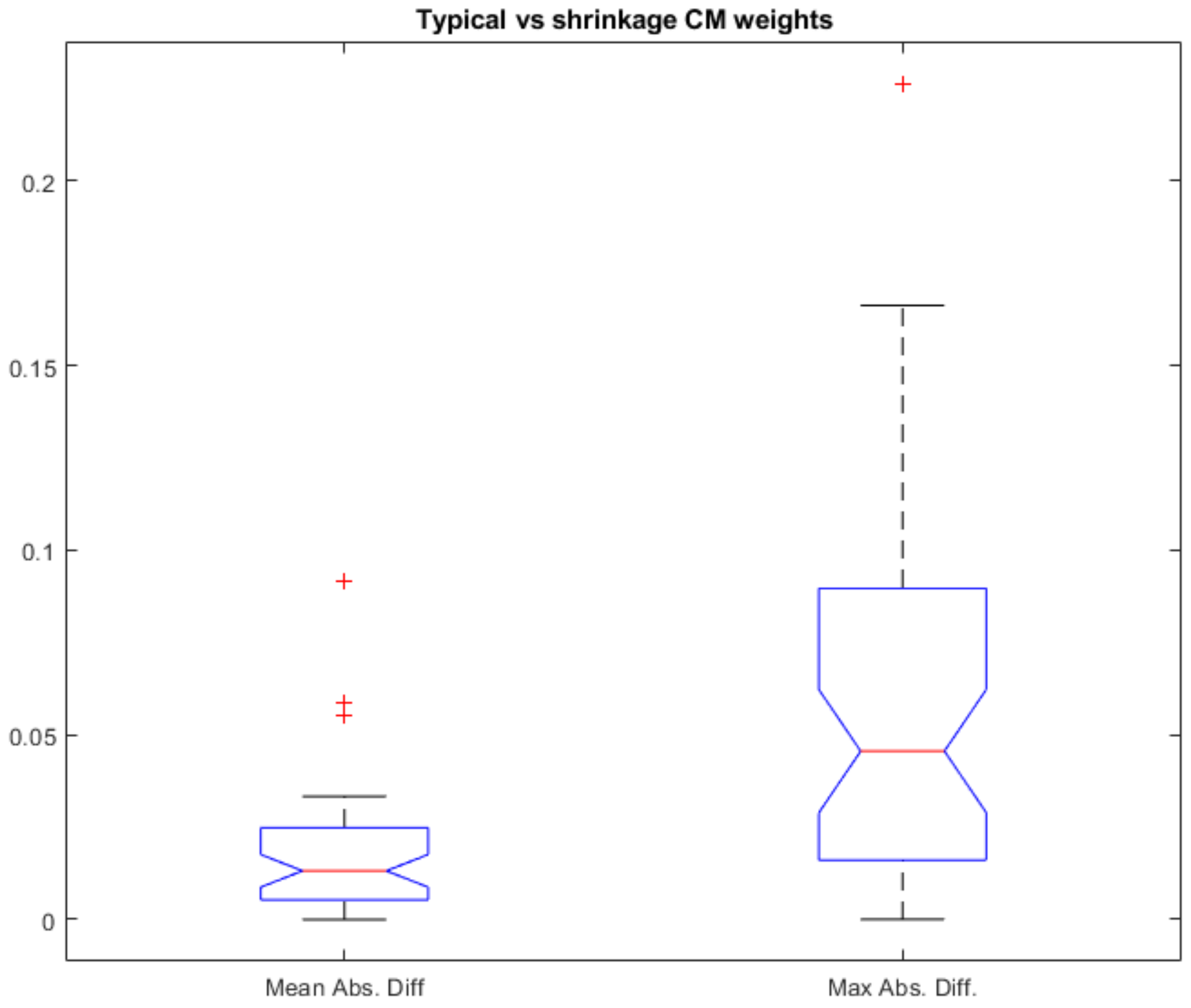
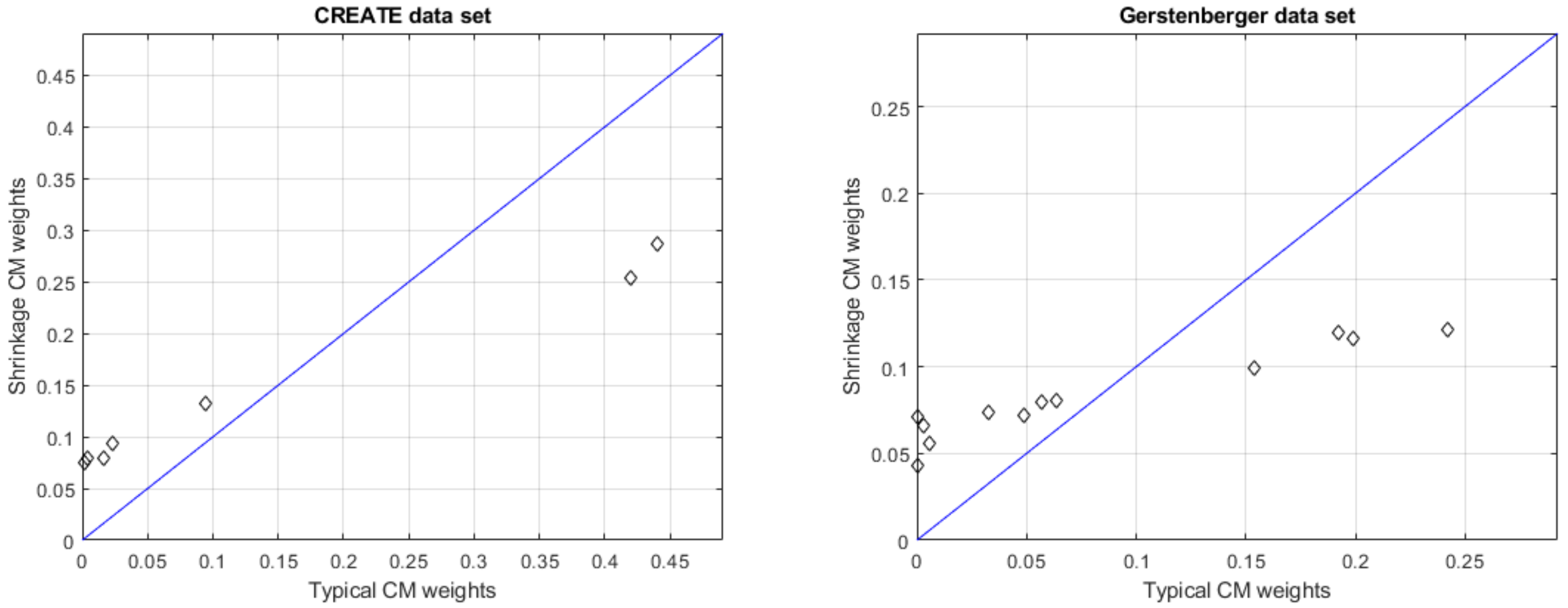
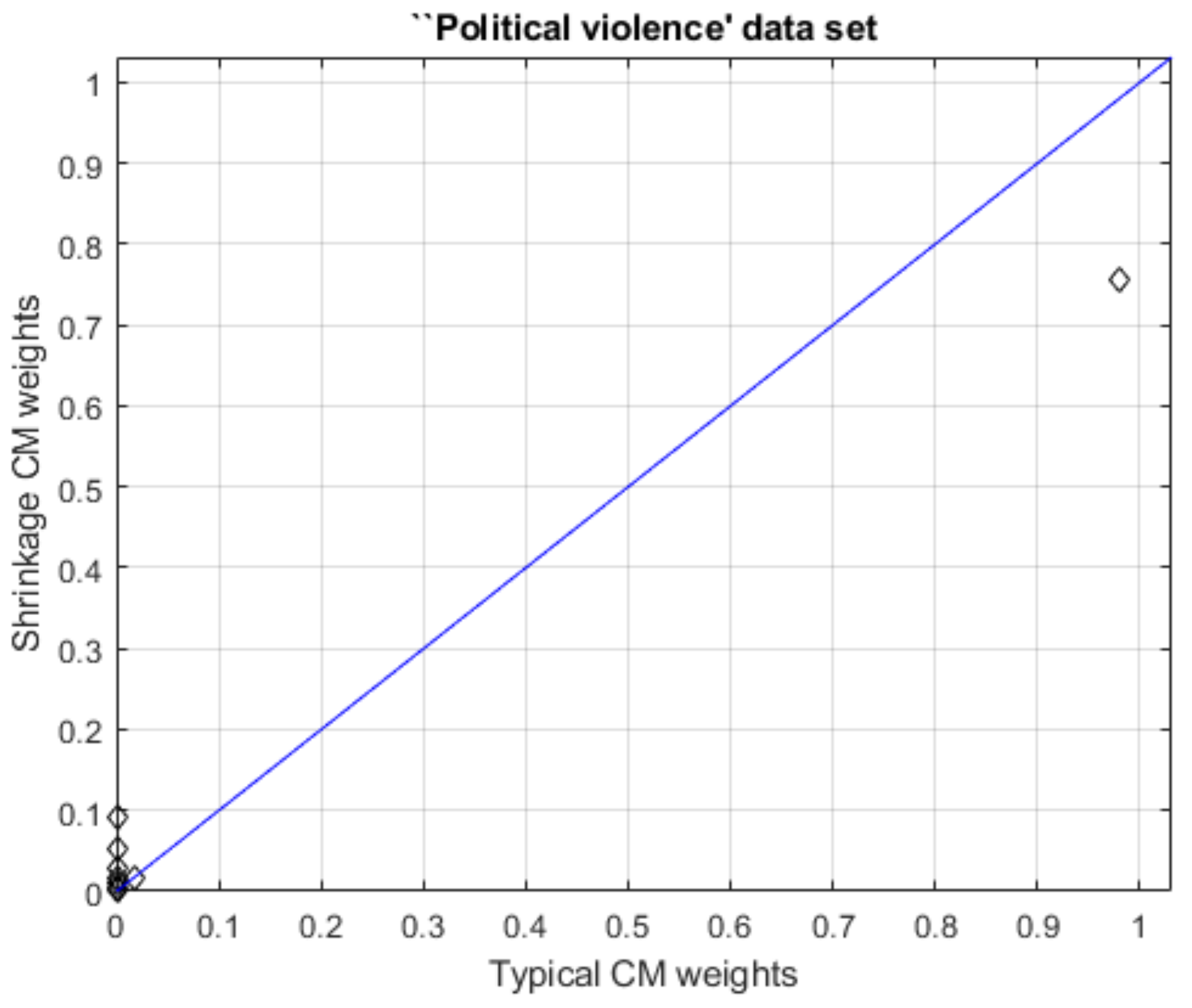
3.2. Deriving Weights Using Fewer than 10 Seed Questions
Results Addressing the Second Research Question
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- O’Hagan, A. Expert Knowledge Elicitation: Subjective but Scientific. Am. Stat. 2019, 73, 69–81. [Google Scholar] [CrossRef]
- Cooke, R. Experts in Uncertainty: Opinion and Subjective Probability in Science; Oxford University Press on Demand: Oxford, UK, 1991. [Google Scholar]
- Stein, C. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 26–31 December 1954; University of California Press: Berkeley, CA, USA, 1956; pp. 197–206. [Google Scholar]
- James, W.; Stein, C. Estimation with quadratic loss. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 20–30 July 1960; University of California Press: Berkeley, CA, USA, 1961; pp. 361–379. [Google Scholar]
- Zhao, Z. Double shrinkage empirical Bayesian estimation for unknown and unequal variances. Stat. Its Interface 2010, 3, 533–541. [Google Scholar] [CrossRef]
- Voinov, V.G.; Nikulin, M.S. A review of the results on the Stein approach for estimators improvement. Qüestiió 1995, 19, 1–3. [Google Scholar]
- Cooke, R.M.; Wittmann, M.E.; Lodge, D.M.; Rothlisberger, J.D.; Rutherford, E.S.; Zhang, H.; Mason, D.M. Out-of-sample validation for structured expert judgment of Asian carp establishment in Lake Erie. Integr. Environ. Assess. Manag. 2014, 10, 522–528. [Google Scholar] [CrossRef] [PubMed]
- Cooke, R.M.; Goossens, L.L. TU Delft expert judgment data base. Reliab. Eng. Syst. Saf. 2008, 93, 657–674. [Google Scholar] [CrossRef]
- O’Hagan, A.; Buck, C.E.; Daneshkhah, A.; Eiser, J.R.; Garthwaite, P.H.; Jenkinson, D.J.; Oakley, J.E.; Rakow, T. Uncertain Judgements: Eliciting Experts’ Probabilities; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Quigley, J.; Colson, A.; Aspinall, W.; Cooke, R.M. Elicitation in the Classical Model. In Elicitation: The Science and Art of Structuring Judgement; Dias, L.C., Morton, A., Quigley, J., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 15–36. [Google Scholar] [CrossRef]
- Hanea, A.M.; Nane, G.F. An In-Depth Perspective on the Classical Model. In Expert Judgement in Risk and Decision Analysis; Hanea, A.M., Nane, G.F., Bedford, T., French, S., Eds.; International Series in Operations Research & Management Science; Springer: Berlin/Heidelberg, Germany, 2021; pp. 225–256. [Google Scholar] [CrossRef]
- Efron, B.; Morris, C. Data analysis using Stein’s estimator and its generalizations. J. Am. Stat. Assoc. 1975, 70, 311–319. [Google Scholar] [CrossRef]
- Kwon, Y.; Zhao, Z. On F-modelling-based empirical Bayes estimation of variances. Biometrika 2023, 110, 69–81. [Google Scholar] [CrossRef]
- Wang, Z.; Lin, L.; Hodges, J.S.; MacLehose, R.; Chu, H. A variance shrinkage method improves arm-based Bayesian network meta-analysis. Stat. Methods Med. Res. 2021, 30, 151–165. [Google Scholar] [CrossRef] [PubMed]
- Ragain, S.; Peysakhovich, A.; Ugander, J. Improving pairwise comparison models using empirical bayes shrinkage. arXiv 2018, arXiv:1807.09236. [Google Scholar]
- Jing, B.Y.; Li, Z.; Pan, G.; Zhou, W. On sure-type double shrinkage estimation. J. Am. Stat. Assoc. 2016, 111, 1696–1704. [Google Scholar] [CrossRef]
- Dharmarathne, H.A.S.G. Exploring the Statistical Aspects of Expert Elicited Experiments. Ph.D. Thesis, The University of Melbourne, Melbourne, VIC, Australia, 2020. [Google Scholar]
- Eggstaff, J.W.; Mazzuchi, T.A.; Sarkani, S. The effect of the number of seed variables on the performance of Cooke’ s classical model. Reliab. Eng. Syst. Saf. 2014, 121, 72–82. [Google Scholar] [CrossRef]
- Marti, D.; Mazzuchi, T.A.; Cooke, R.M. Are Performance Weights Beneficial? Investigating the Random Expert Hypothesis. In Expert Judgement in Risk and Decision Analysis; Hanea, A.M., Nane, G.F., Bedford, T., French, S., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 53–82. [Google Scholar] [CrossRef]
- Cooke, R.M.; Marti, D.; Mazzuchi, T. Expert forecasting with and without uncertainty quantification and weighting: What do the data say? Int. J. Forecast. 2021, 37, 378–387. [Google Scholar] [CrossRef]
- Cooke, R.M.; Solomatine, D. EXCALIBR Integrated System for Processing Expert Judgements Version 3.0; Delft University of Technology and SoLogic Delft: Delft, The Netherlands, 1992. [Google Scholar]
- Colonna, K.J.; Nane, G.F.; Choma, E.F.; Cooke, R.M.; Evans, J.S. A retrospective assessment of COVID-19 model performance in the USA. R. Soc. Open Sci. 2022, 9, 220021. [Google Scholar] [CrossRef] [PubMed]
- Efron, B.; Stein, C. The jackknife estimate of variance. Ann. Stat. 1981, 9, 586–596. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set ID | Experts | Seeds | Date | Subject |
|---|---|---|---|---|
| Brexit food | 10 | 10 | 2019 | Food price change after Brexit |
| Tadini_Clermont | 12 | 13 | 2019 | Somma–Vesuvio volcanic geodatabase |
| Tadini_Quito | 8 | 13 | 2019 | Volcanic risk |
| PoliticalViolence | 15 | 21 | 2018 | Political violence |
| ICE_2018 | 20 | 16 | 2018 | Sea-level rise from ice sheets melting due to global warming |
| Data Set | Types of Weight | Calibration Score | Information Score |
|---|---|---|---|
| PBINTDOS | Classical | 0.7496 | 1.044 |
| Shrinkage | 0.7587 | 1.077 | |
| RETURNafter | Classical | 0.01487 | 0.2433 |
| Shrinkage | 0.004452 | 0.2837 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dharmarathne, G.; Nane, G.F.; Robinson, A.; Hanea, A.M. Shrinking the Variance in Experts’ “Classical” Weights Used in Expert Judgment Aggregation. Forecasting 2023, 5, 522-535. https://doi.org/10.3390/forecast5030029
Dharmarathne G, Nane GF, Robinson A, Hanea AM. Shrinking the Variance in Experts’ “Classical” Weights Used in Expert Judgment Aggregation. Forecasting. 2023; 5(3):522-535. https://doi.org/10.3390/forecast5030029
Chicago/Turabian StyleDharmarathne, Gayan, Gabriela F. Nane, Andrew Robinson, and Anca M. Hanea. 2023. "Shrinking the Variance in Experts’ “Classical” Weights Used in Expert Judgment Aggregation" Forecasting 5, no. 3: 522-535. https://doi.org/10.3390/forecast5030029
APA StyleDharmarathne, G., Nane, G. F., Robinson, A., & Hanea, A. M. (2023). Shrinking the Variance in Experts’ “Classical” Weights Used in Expert Judgment Aggregation. Forecasting, 5(3), 522-535. https://doi.org/10.3390/forecast5030029