
Deep Learning for Demand Forecasting in the Fashion and Apparel Retail Industry


Abstract
:1. Introduction
2. State-of-the-Art
3. Research Methodology
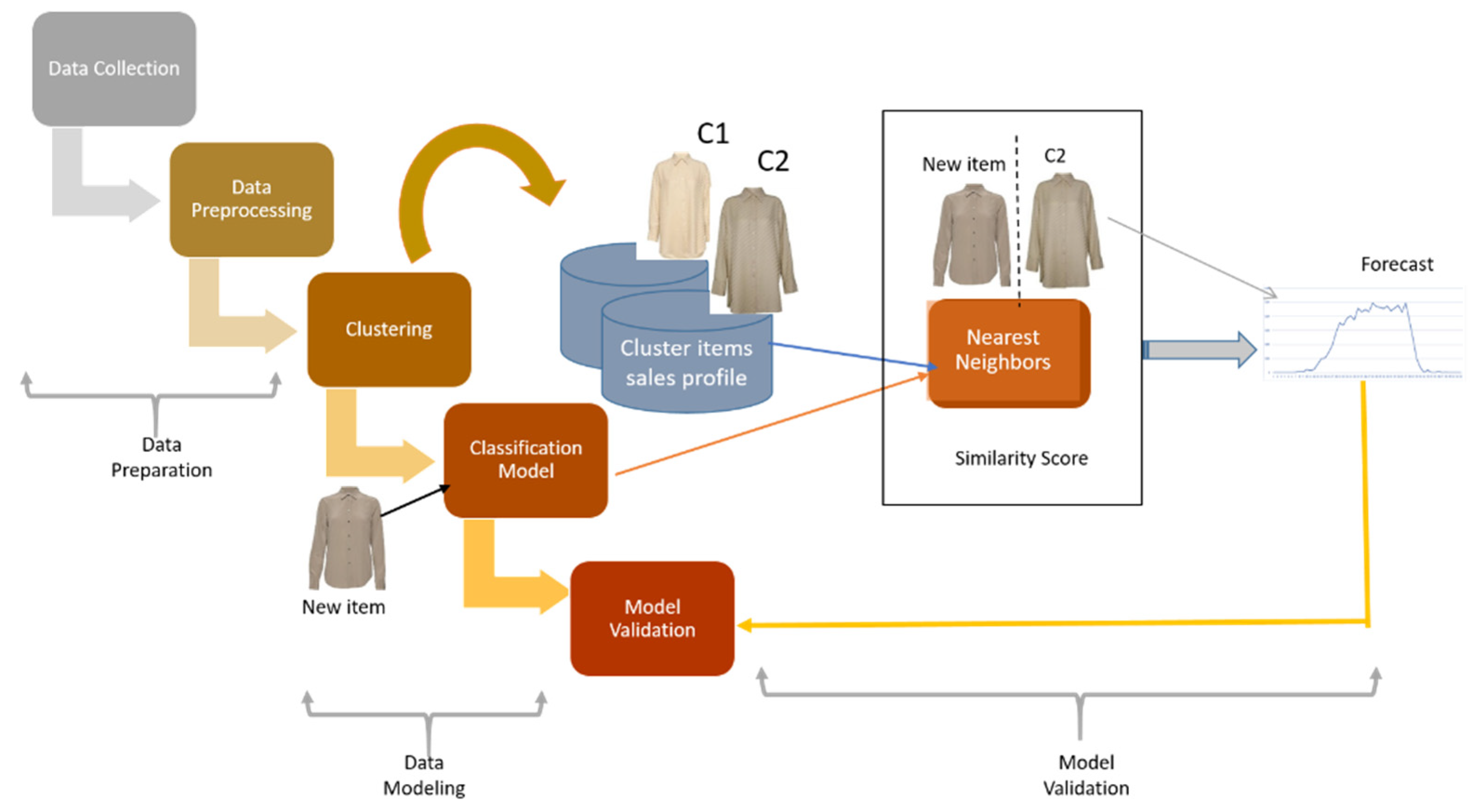
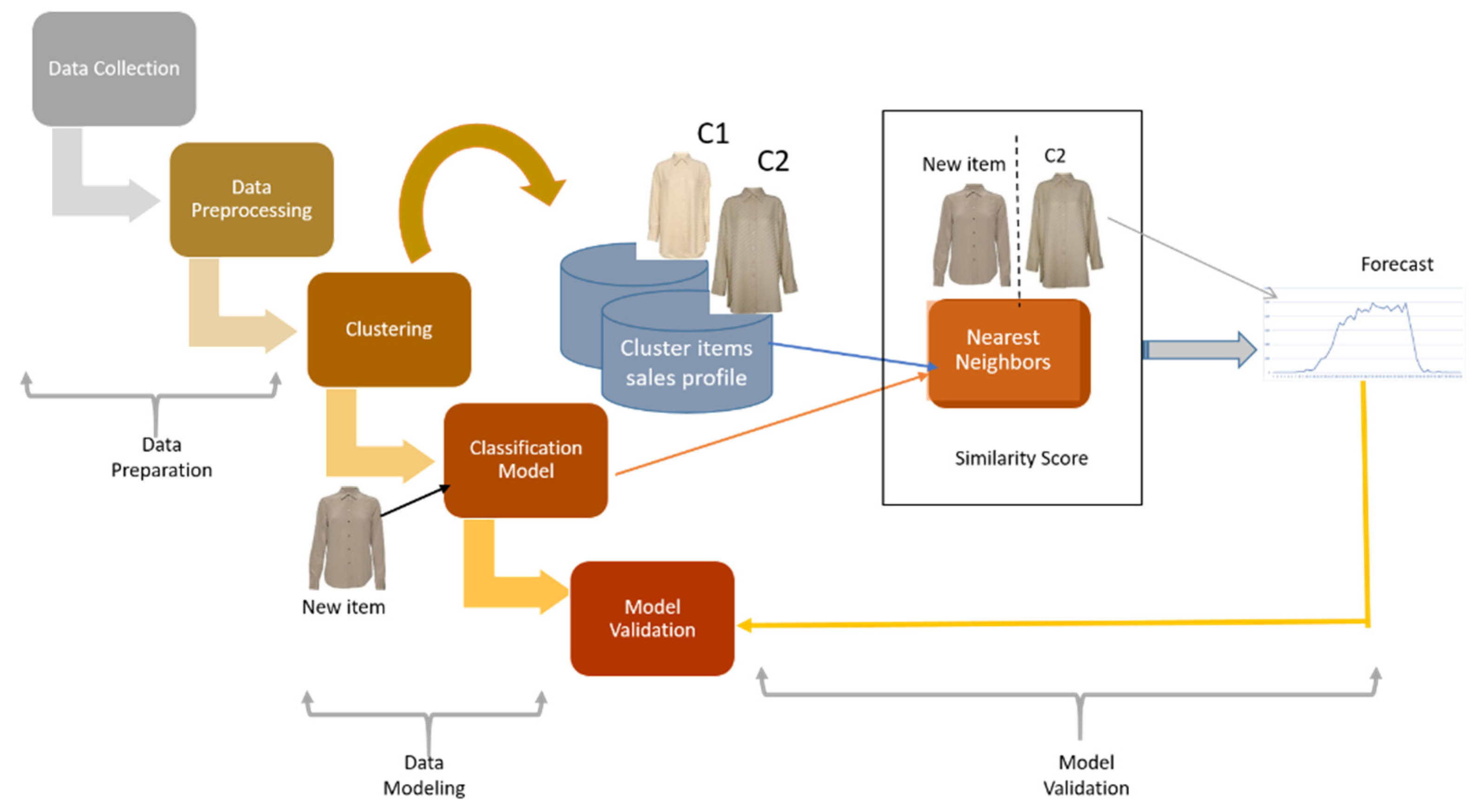
3.1. Experimental Design
- Data Preparation: This includes data collection and data pre-processing essential for data modelling.
- Data Modelling: In this step, pre-processed data are used for building the sales forecast model by using a machine learning algorithm.
- Model Validation: In this step, the performance of the machine-learning model and forecast model is assessed.
3.2. Machine Learning Algorithm
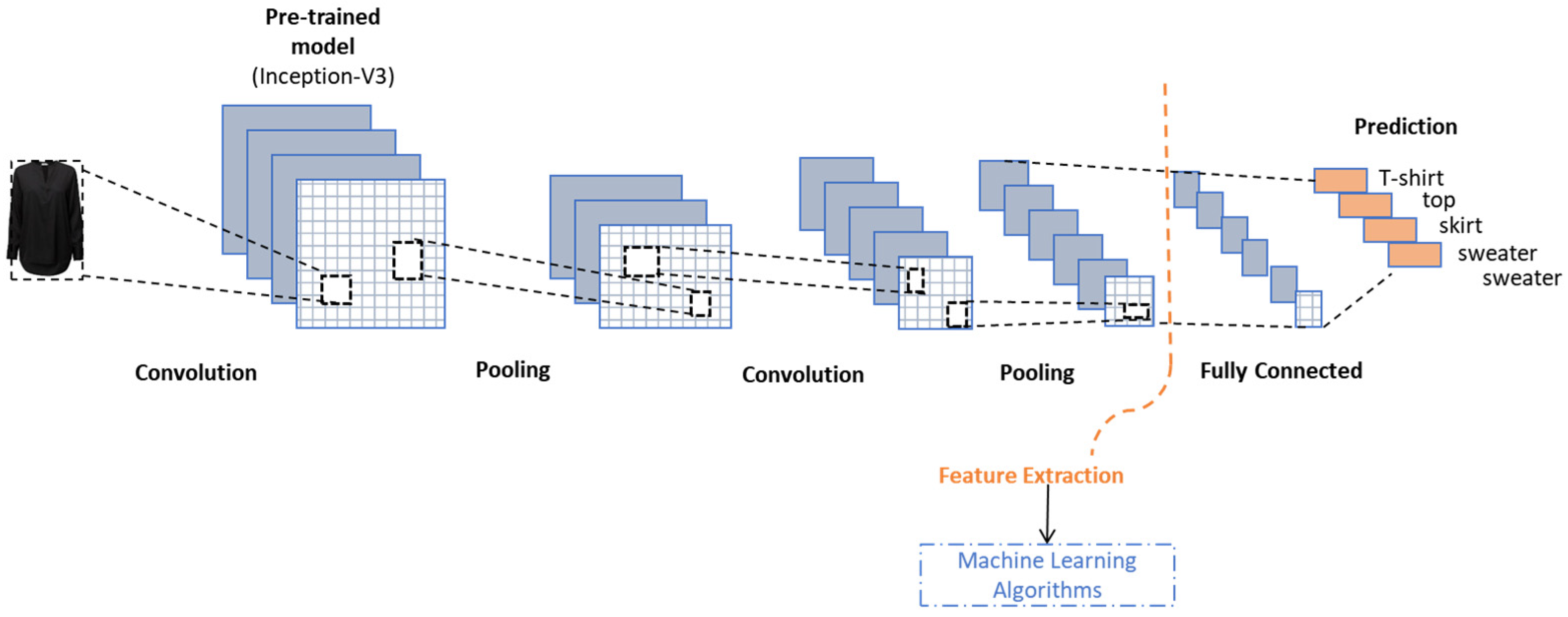
3.2.1. Deep Learning
3.2.2. Clustering
3.2.3. Classification
3.2.4. K Nearest Neighbour (k-NN)
3.2.5. Evaluation Metrics
- Classification:
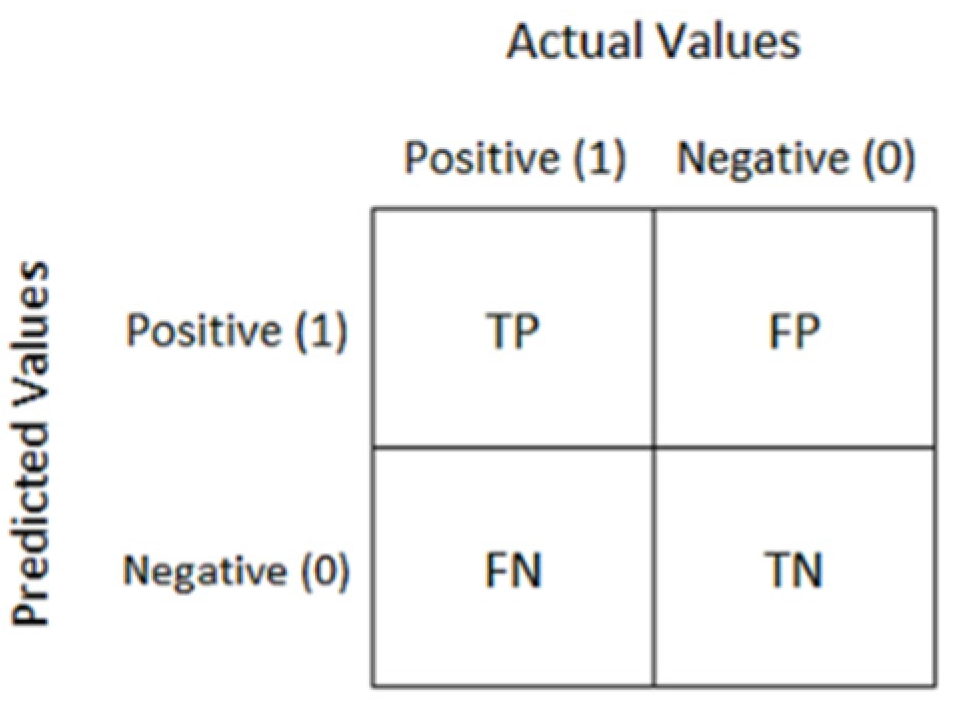
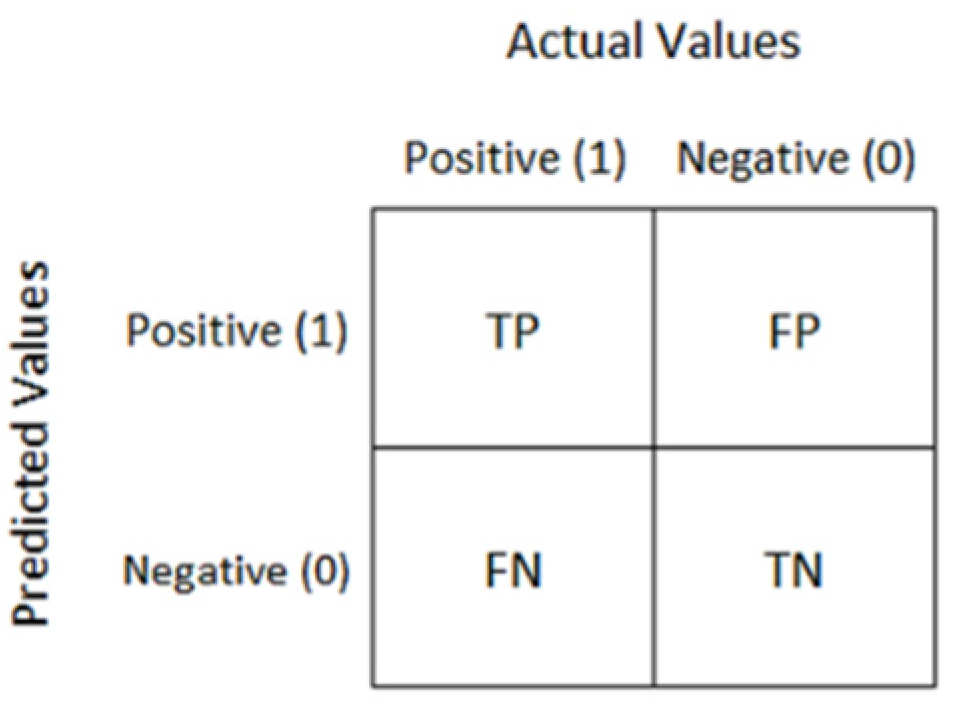
- Classification accuracy (CA) is the proportion of correctly classified instances.where,TP = True Positives, TN = True Negatives, FP = False Positives, and FN = False Negatives.
- Confusion Matrix: It is used to represent the output of a classification model in a matrix format, where the rows represent the number of instances with a certain predicted label and the columns represent the number of instances with a certain correct label. A sample confusion matrix is shown in Figure 4.
- Precision: It measures the proportion of positively classified instances that are actually positive.
- Recall: It measures the proportion of positive instances that are actually predicted as positive.
- F1 score: It is the harmonic mean of precision and recall. It provides a balance between Precision and Recall.
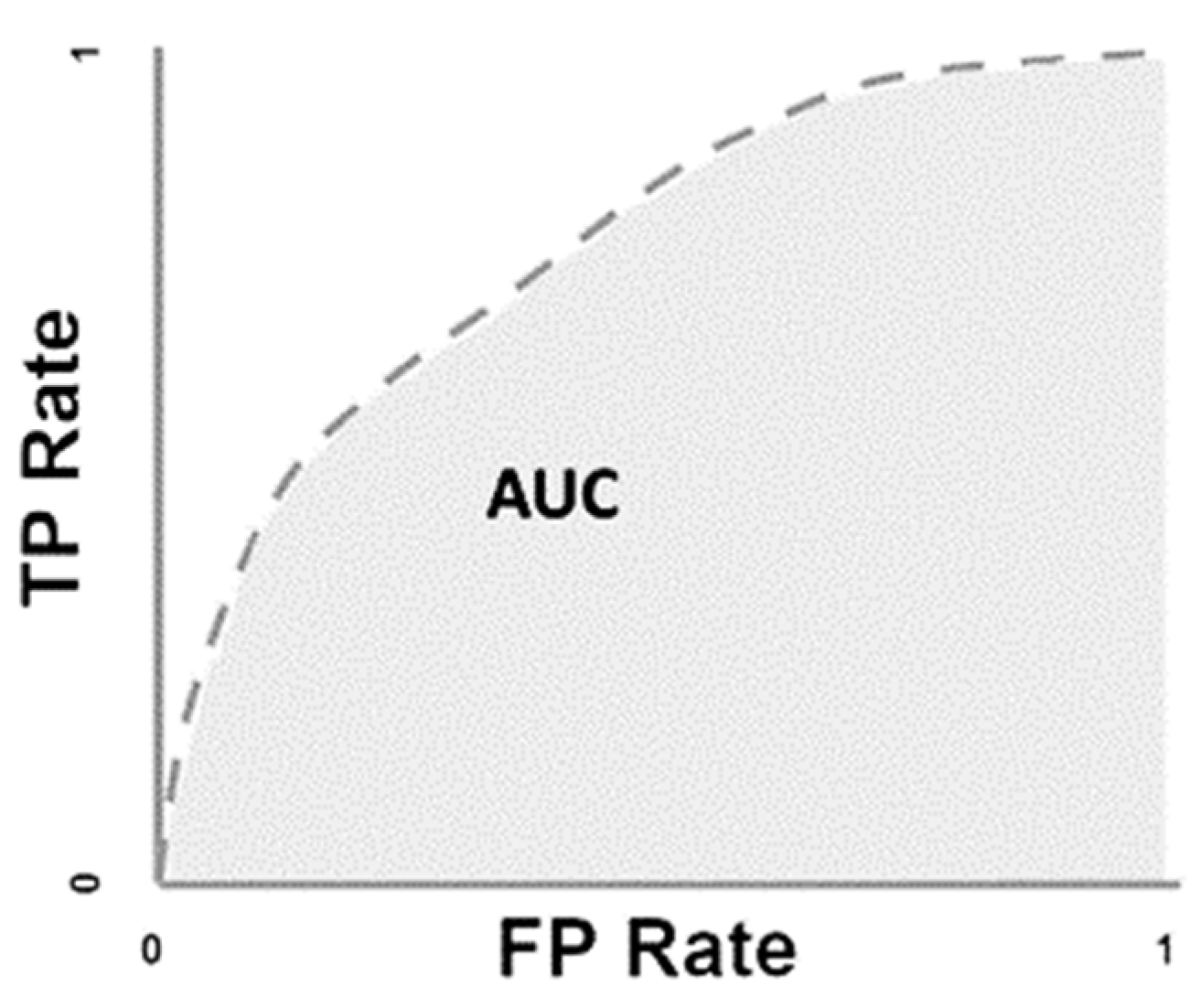
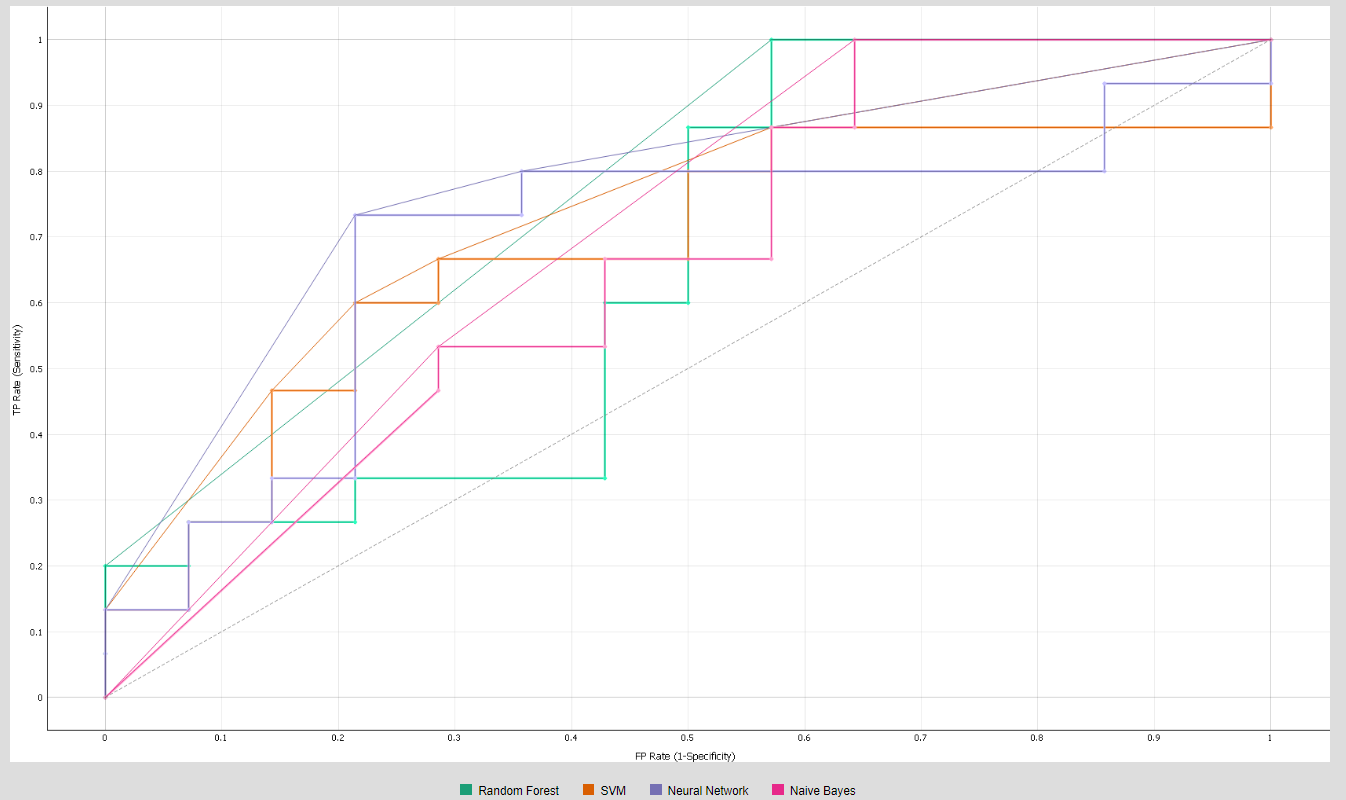
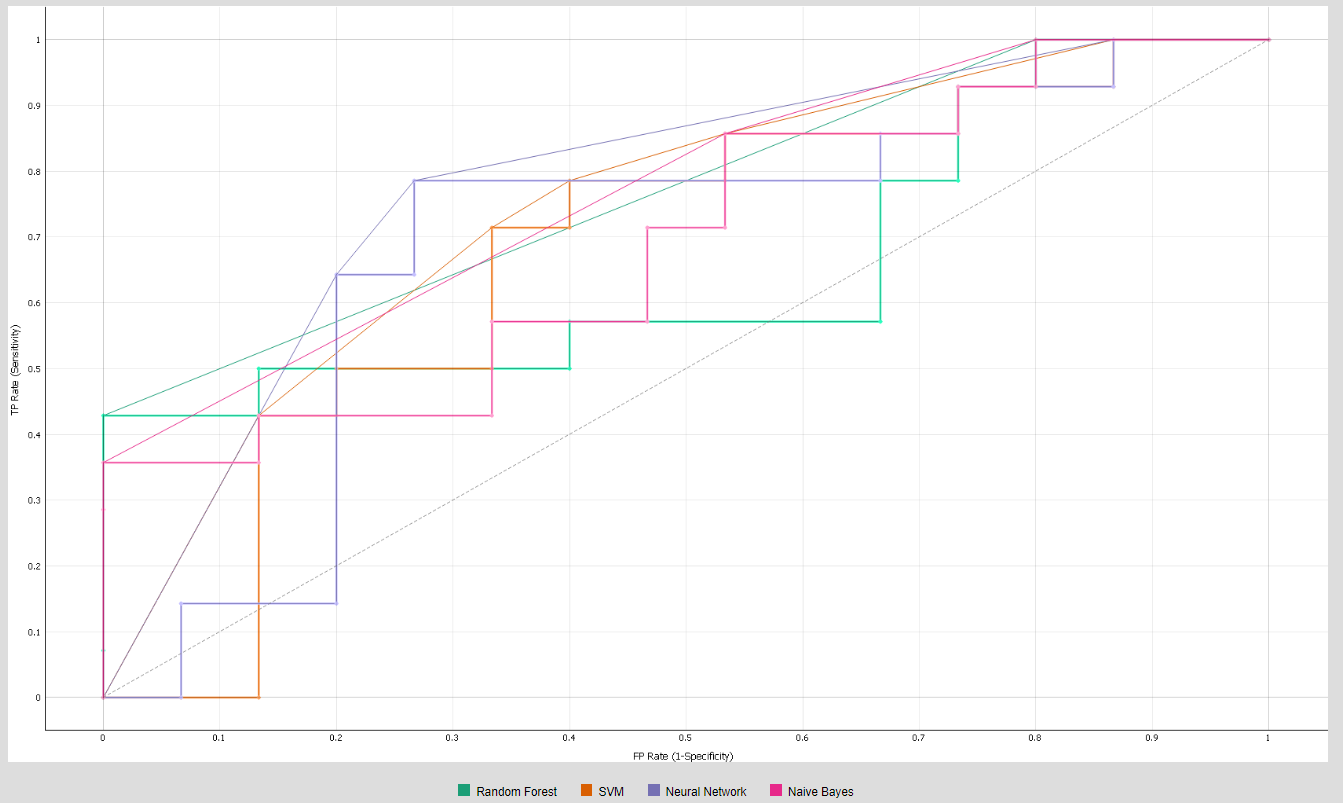
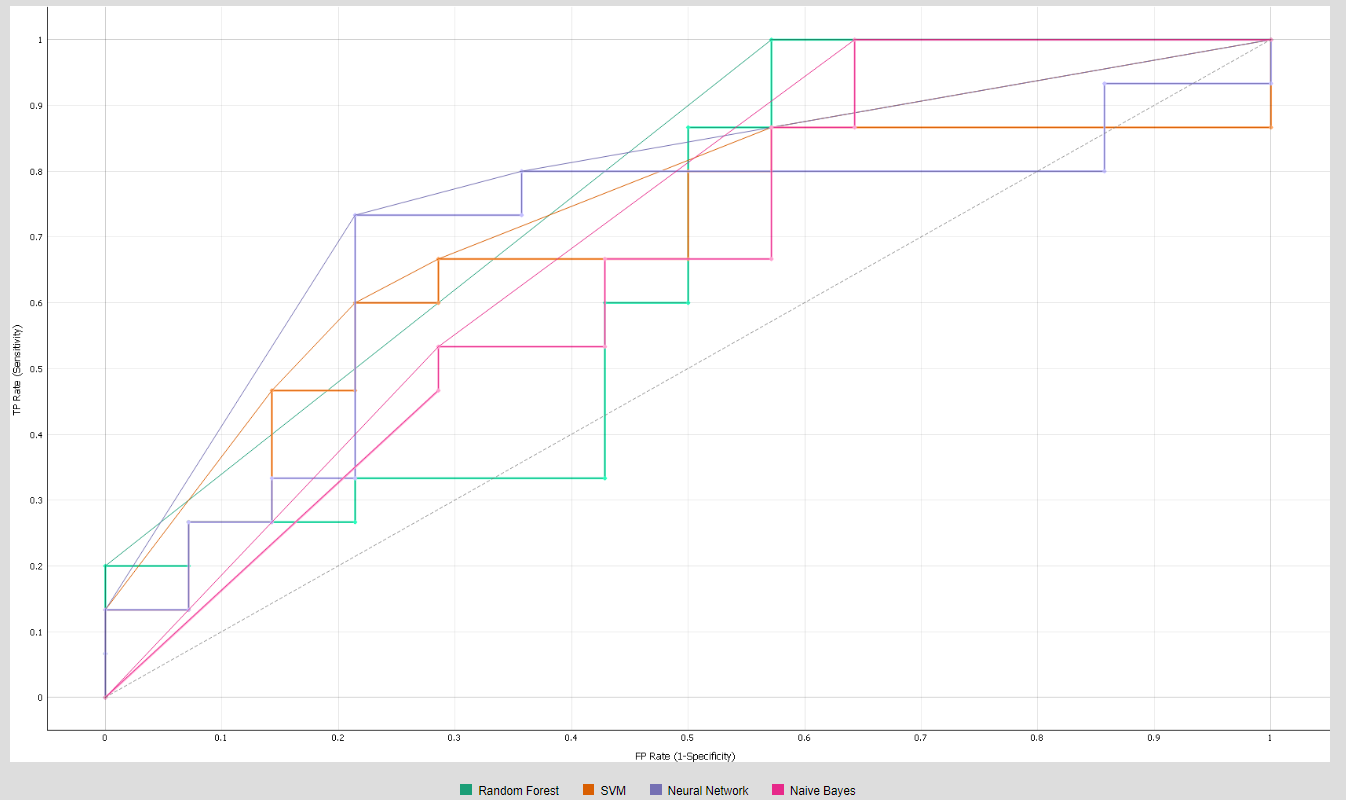
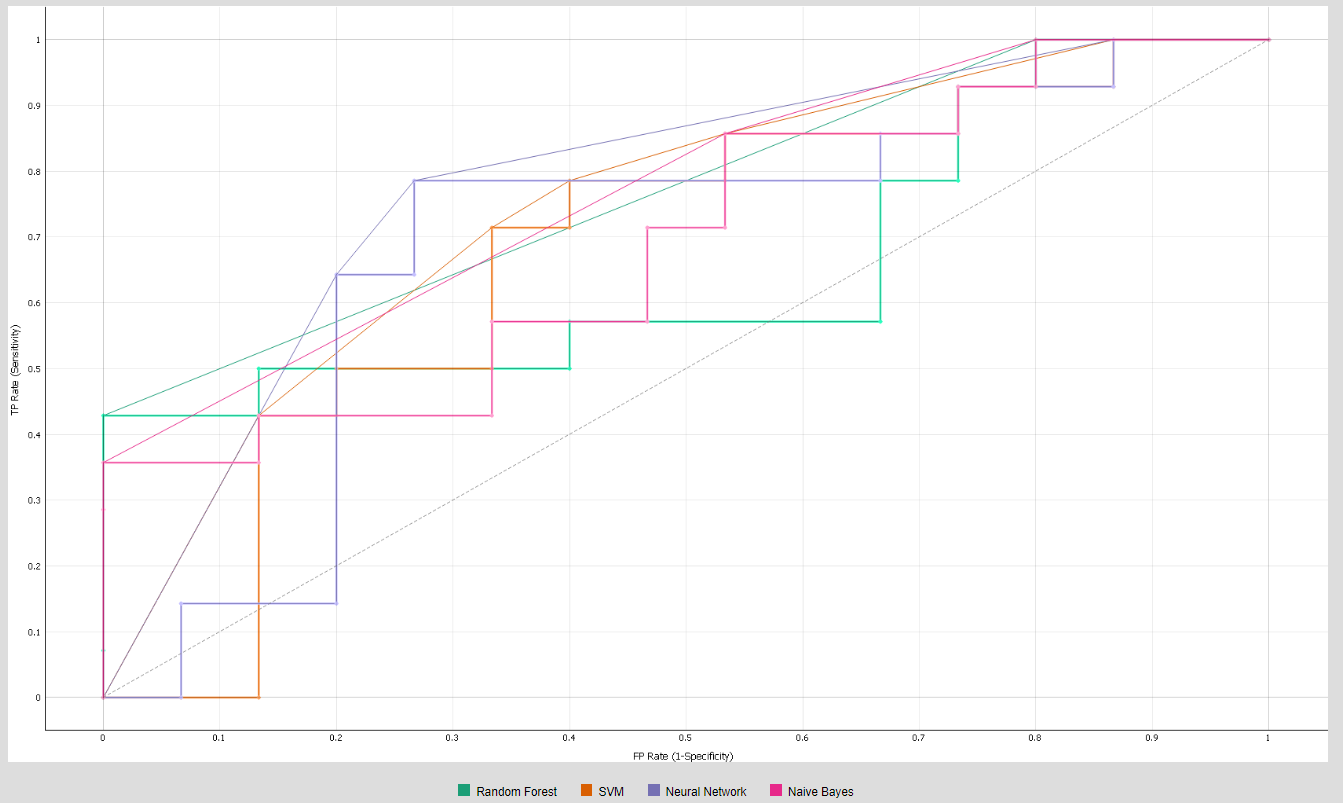
- ROC curve: ROC curve is the measure for evaluating the quality of the classifier by plotting FPR along the X axis and the TPR along the Y axis [36].
- AUC (Area Under the Curve): It measures the aggregated area under the ROC curve, and it comparatively evaluates the performances of different classification models. AUC threshold values range from (0, 0) to (1, 1), as represented in Figure 5. The value of AUC ranges from 0 to 1. The higher the value, the better the classification performance of the model.
- Forecasting:
- MAE (Mean Absolute Error) is the metric used for evaluating the forecast model performance.where, .
- RMSE (root mean square error): It is the square root of MSE. It has the same unit as the target variable. MSE (Mean Squared Error) is a commonly used metric that measures the average squared difference between the target variable’s predicted value and its actual value
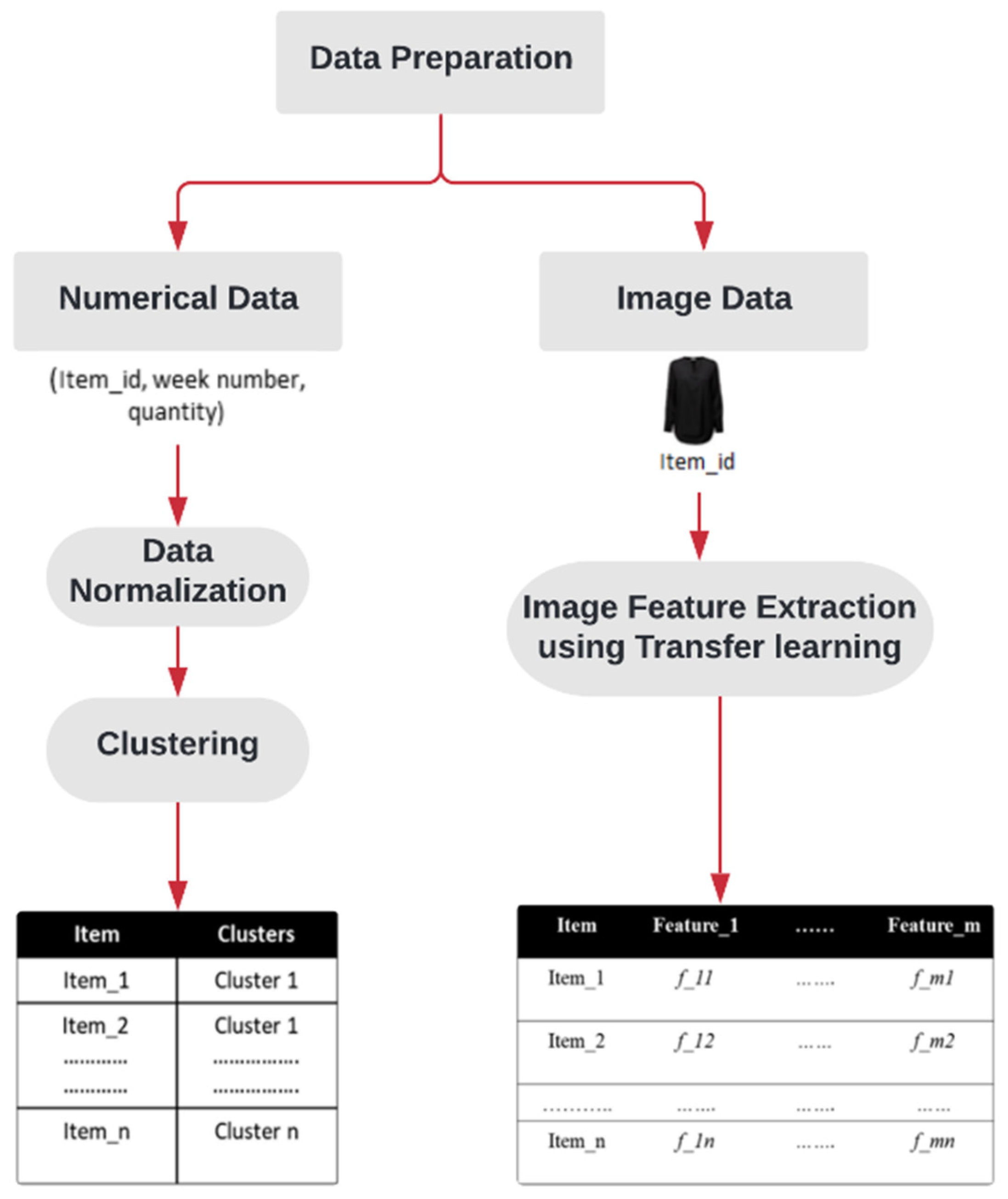
3.3. Data Preparation
3.3.1. Numerical Data
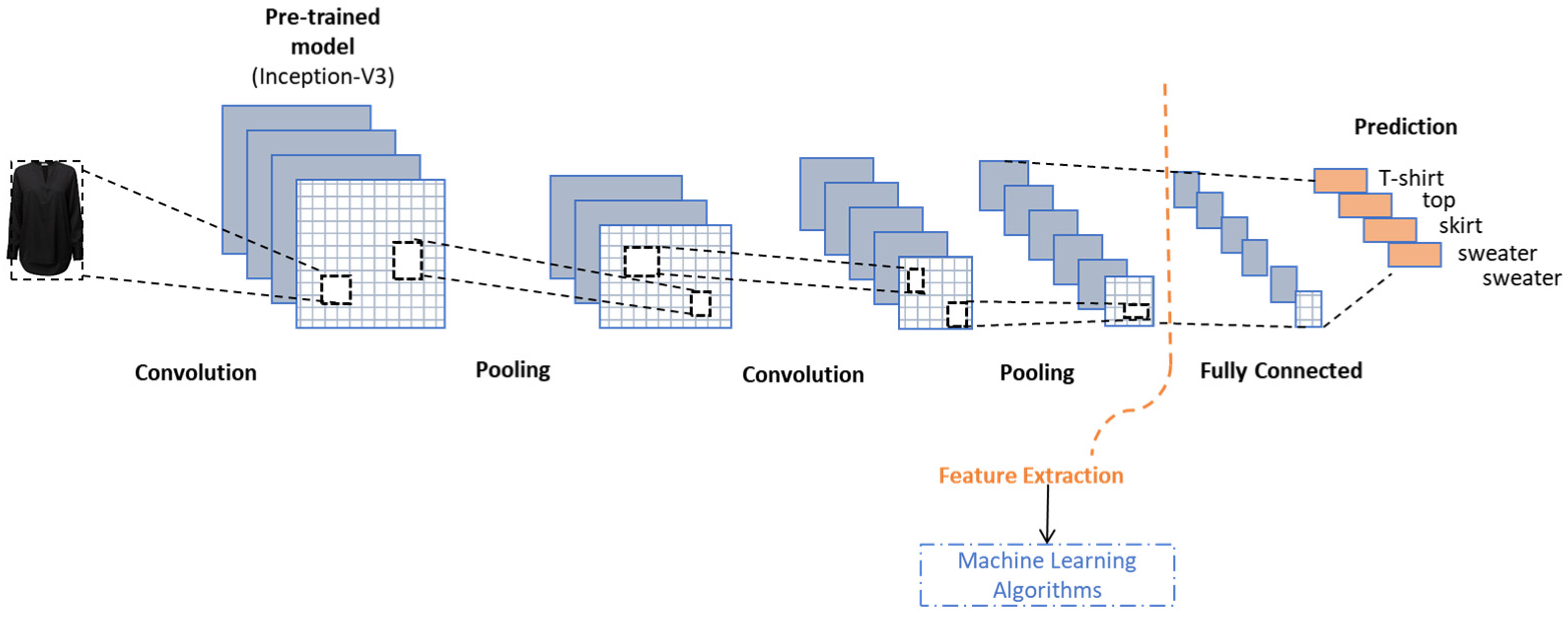
3.3.2. Image Data
3.4. Modelling
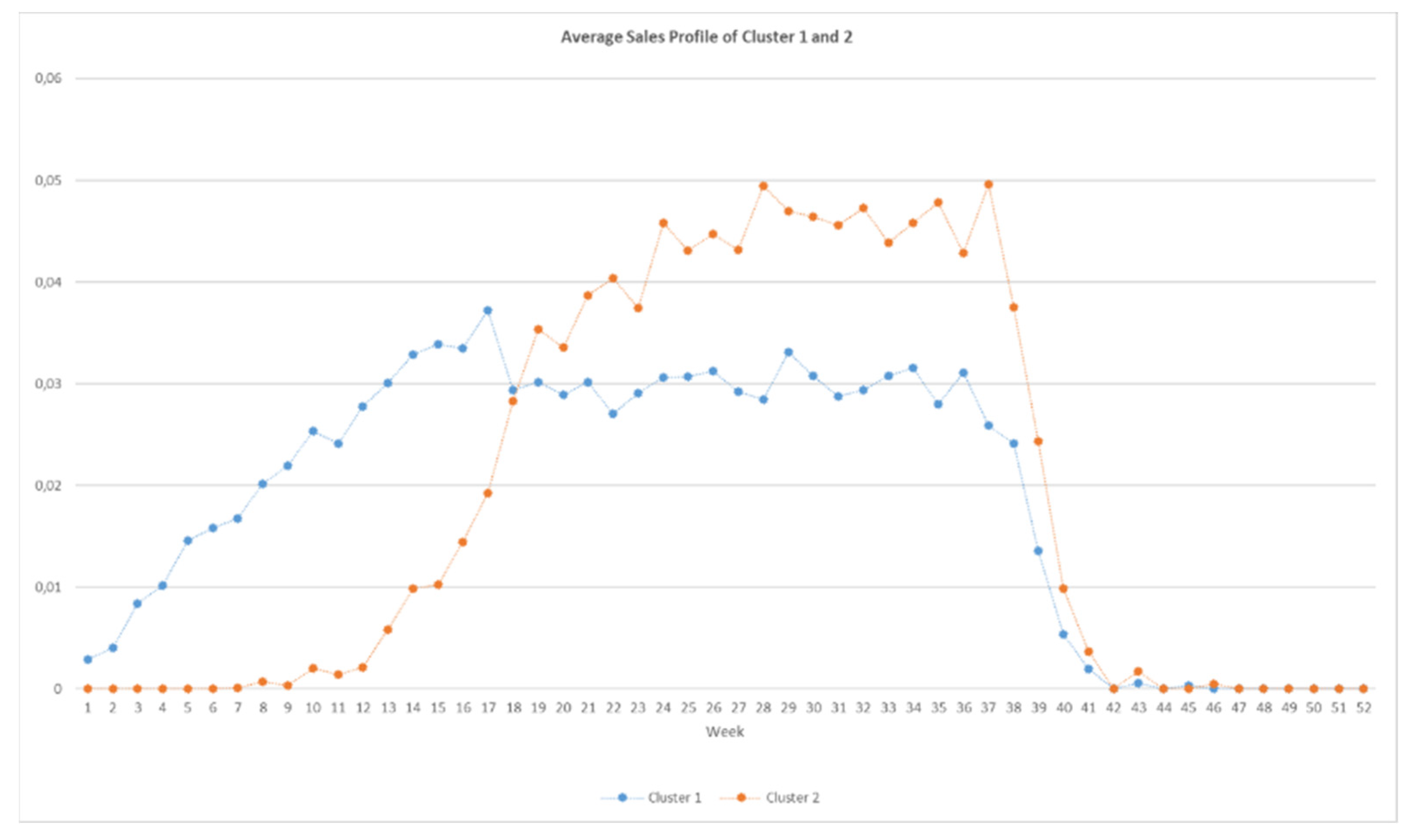
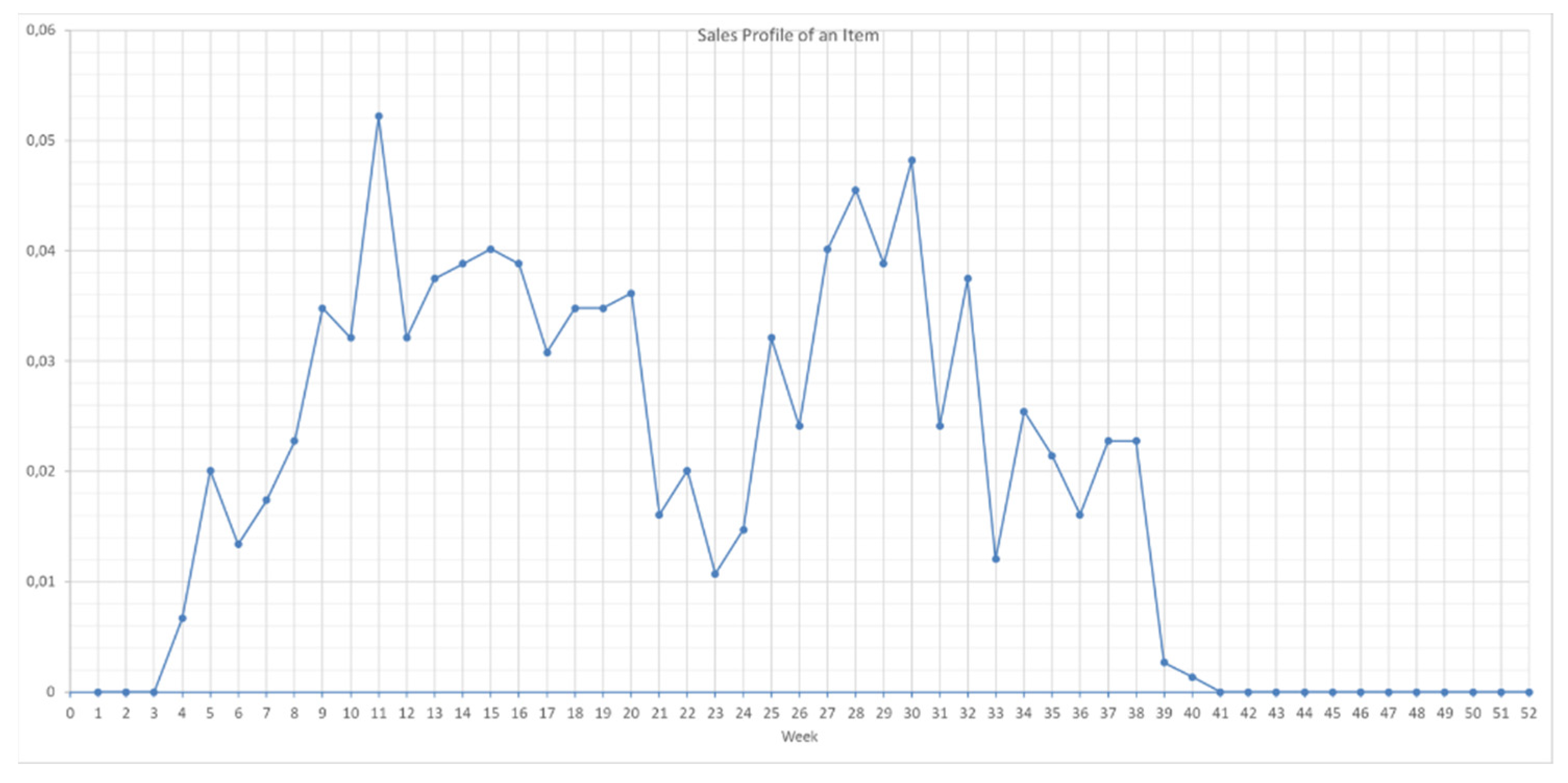
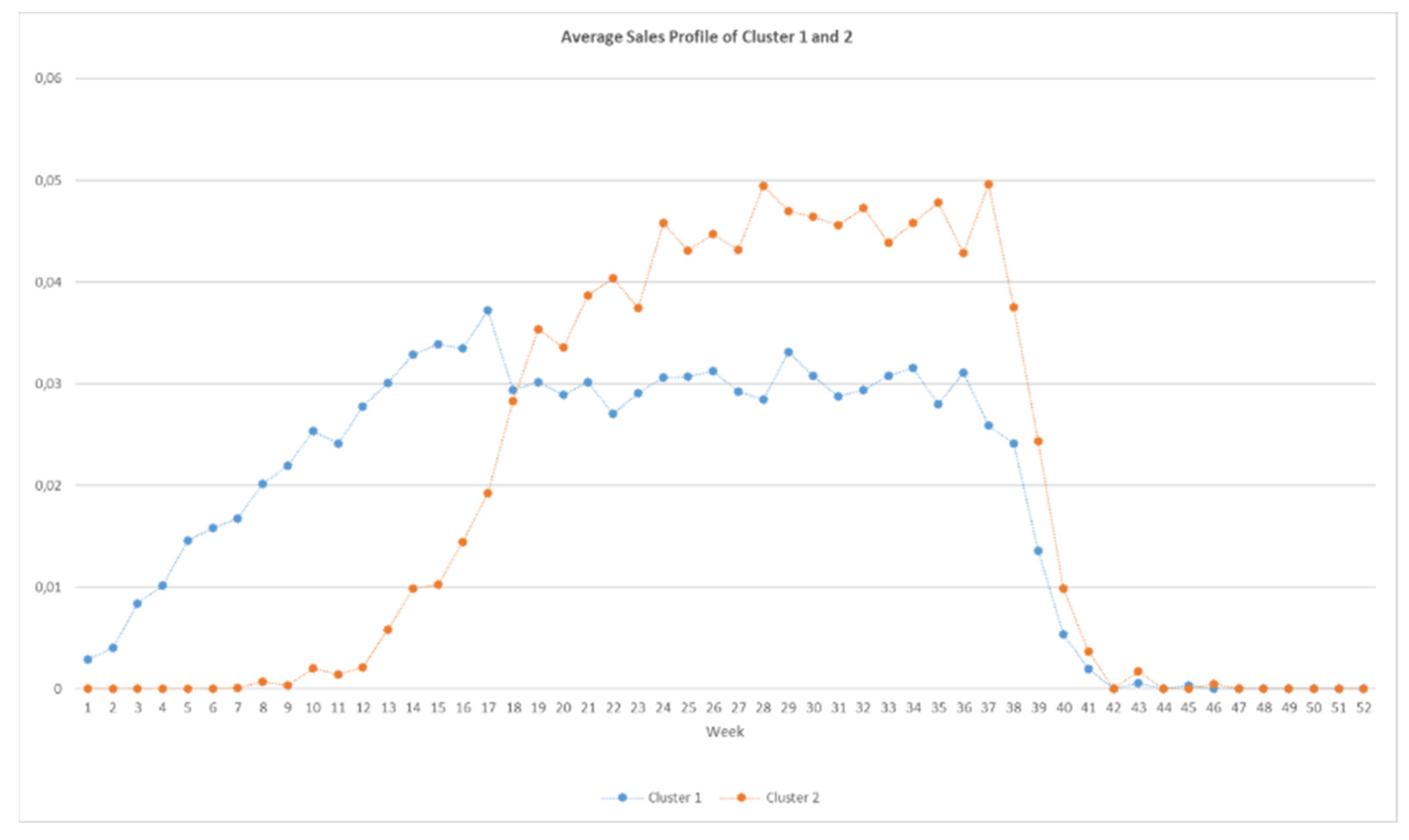
3.4.1. Clustering Sales Profile
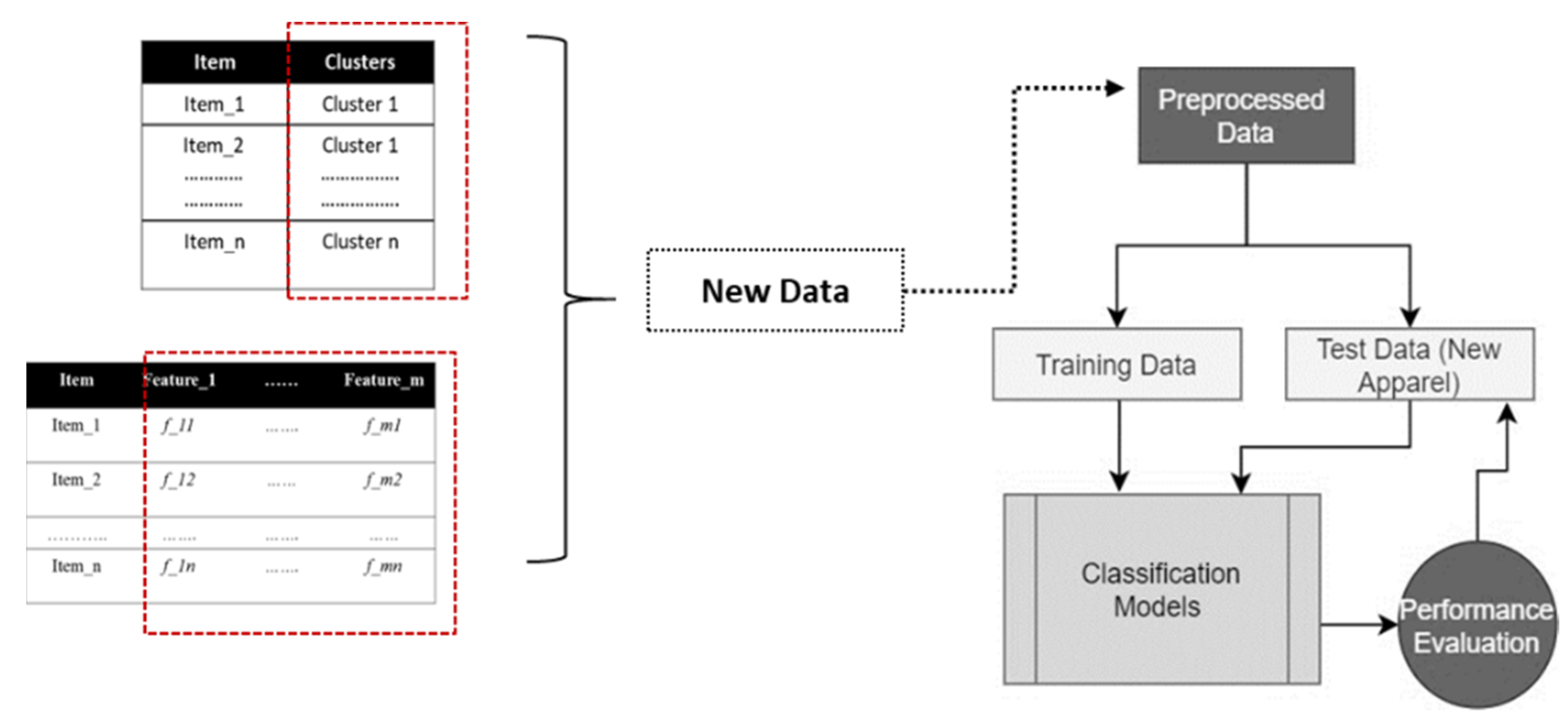
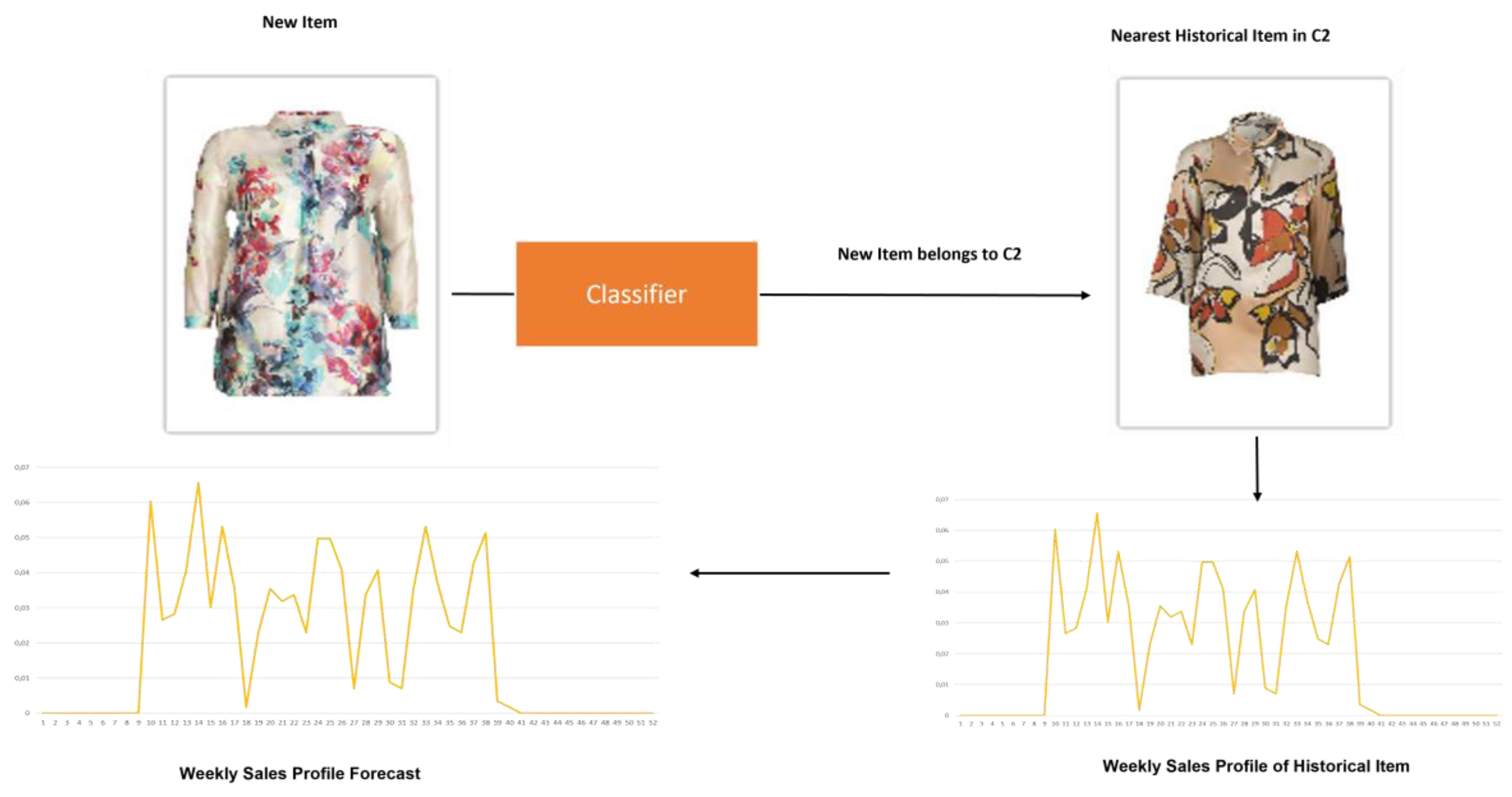
3.4.2. Cluster Classification Model
4. Experimental Results
4.1. Classification Model Performance
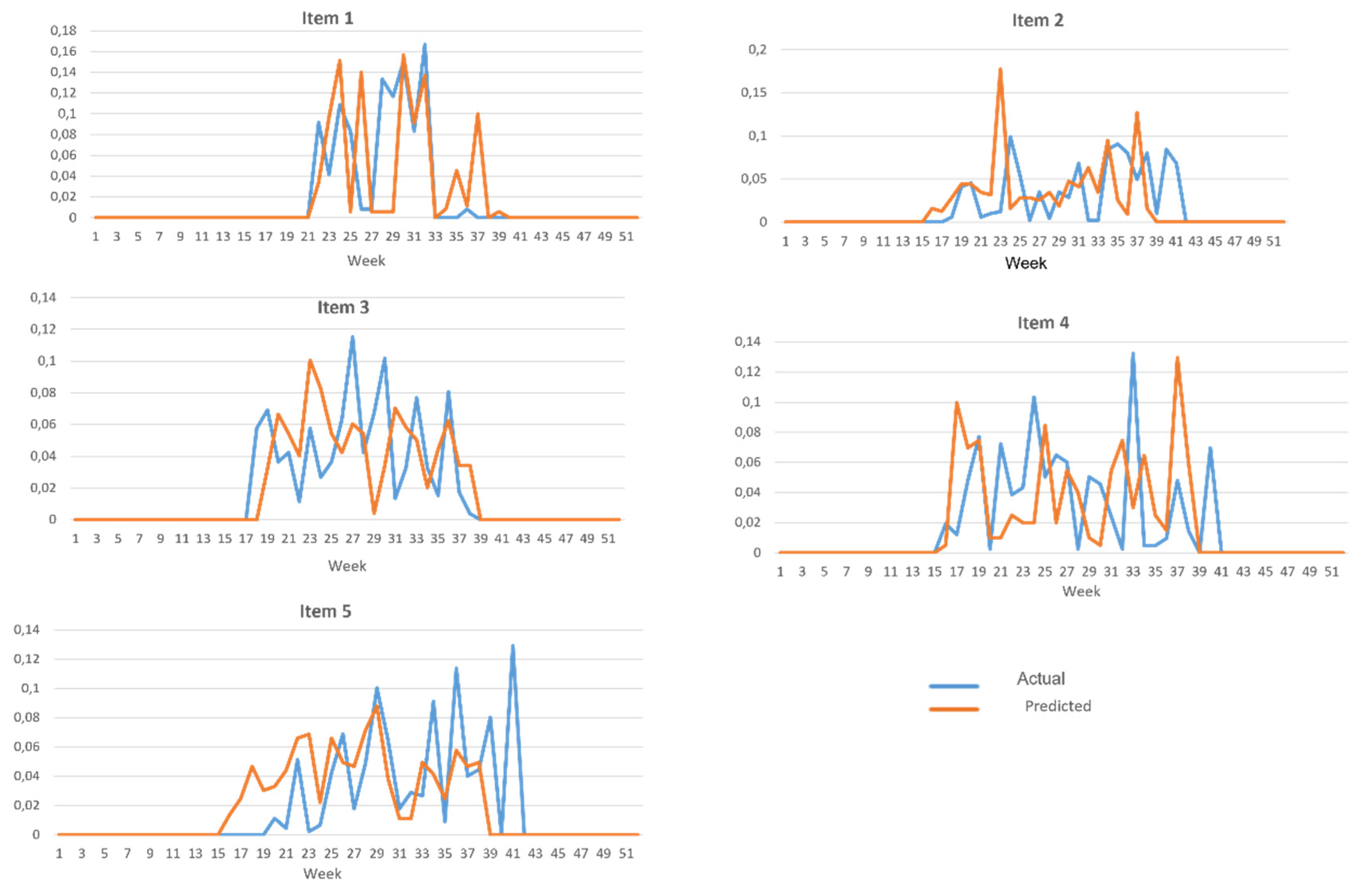
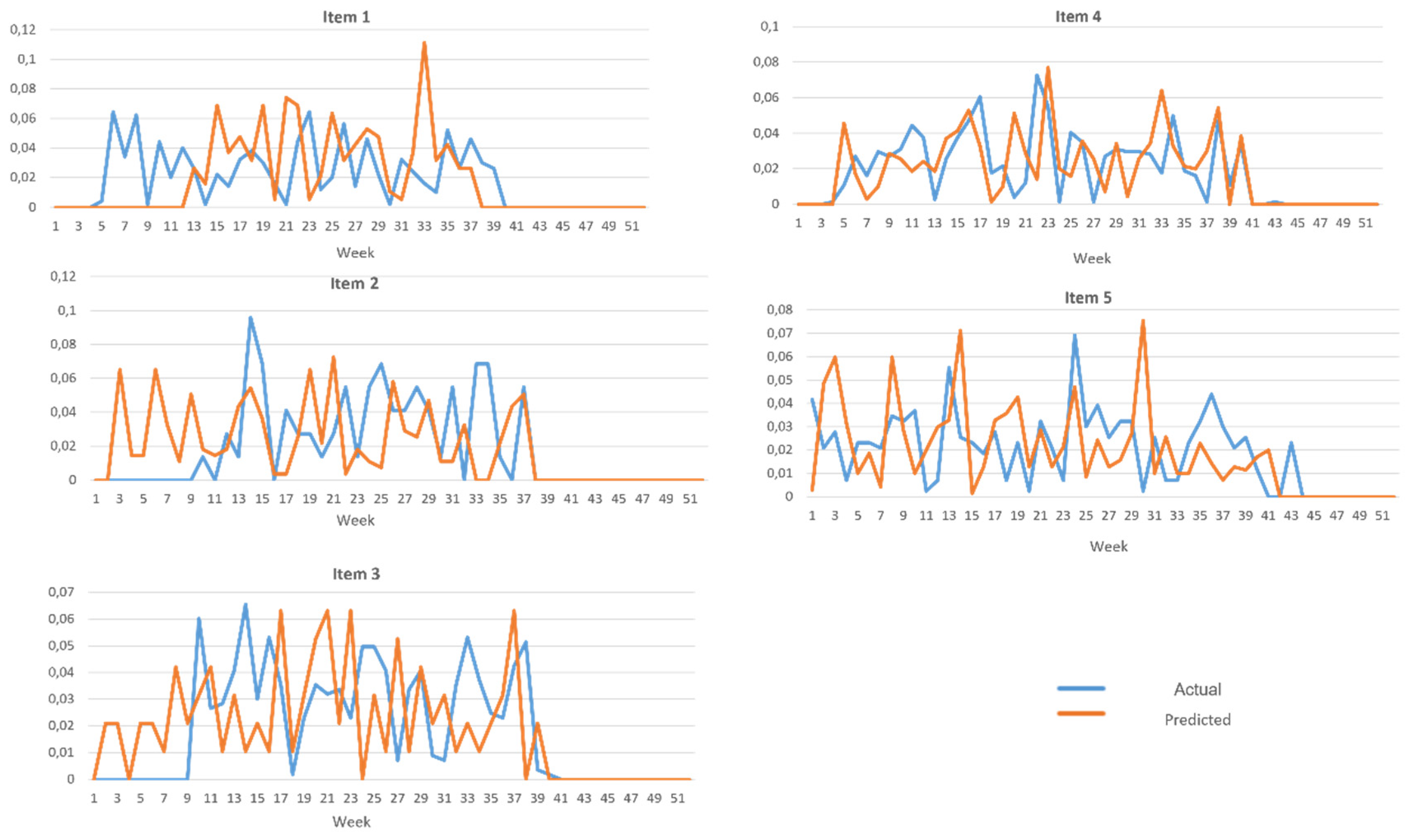
4.2. Forecast Performance Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Giri, C.; Thomassey, S.; Zeng, X. Customer Analytics in Fashion Retail Industry. In Functional Textiles and Clothing; Springer: Singapore, 2019; pp. 349–361. [Google Scholar]
- Minner, S.; Kiesmller, G.P. Dynamic product acquisition in closed loop supply chains. Int. J. Prod. Res. 2012, 50, 2836–2851. [Google Scholar] [CrossRef] [Green Version]
- Thomassey, S. Economics and undefined 2010, Sales forecasts in clothing industry: The key success factor of the supply chain management. Int. J. Prod. Econ. 2010, 128, 470–483. [Google Scholar] [CrossRef]
- Giri, C.; Thomassey, S.; Zeng, X. Exploitation of Social Network Data for forecasting Garment Sales. Int. J. Comput. Intell. Syst. 2019, 12, 1423. [Google Scholar] [CrossRef] [Green Version]
- Giri, C.; Thomassey, S.; Balkow, J.; Zeng, X. Forecasting New Apparel Sales Using Deep Learning and Nonlinear Neural Network Regression. In Proceedings of the 2019 International Conference on Engineering, Science, and Industrial Applications, Tokyo, Japan, 22–24 August 2019; ICESI 2019. [Google Scholar]
- Christopher, M.; Lee, H. Mitigating supply chain risk through improved confidence. Int. J. Phys. Distrib. Logist. Manag. 2004, 34, 388–396. [Google Scholar] [CrossRef] [Green Version]
- Christopher, M.; Towill, D. An integrated model for the design of agile supply chains. Int. J. Phys. Distrib. Logist. Manag. 2001, 31, 235–246. [Google Scholar] [CrossRef] [Green Version]
- Battista, C.; Schiraldi, M.M. The Logistic Maturity Model: Application to a fashion firm. Int. J. Eng. Bus. Manag. 2013, 5, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Nayak, R.; Padhye, R. Artificial intelligence and its application in the apparel industry. In Automation in Garment Manufacturing; Elsevier Inc.: Amsterdam, The Netherlands, 2018; pp. 109–138. [Google Scholar] [CrossRef]
- Giri, C.; Jain, S.; Zeng, X.; Bruniaux, P. A Detailed Review of Artificial Intelligence Applied in the Fashion and Apparel Industry. IEEE Access 2019, 7, 95376–95396. [Google Scholar] [CrossRef]
- Papalexopoulos, A.D.; Hesterberg, T.C. A regression-based approach to short-term system load forecasting. In Proceedings of the Conference Papers Power Industry Computer Application Conference, Roanoke, VA, USA, 21 May 1999; pp. 414–423. [Google Scholar]
- Healy, M.J.R.; Brown, R.G. Smoothing, Forecasting and Prediction of Discrete Time Series. J. R. Stat. Soc. Ser. A 1964, 127, 292. [Google Scholar] [CrossRef]
- de Gooijer, J.G.; Hyndman, R.J. 25 Years of Time Series Forecasting; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar] [CrossRef] [Green Version]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Prentice Hall: Hoboken, NJ, USA, 1976. [Google Scholar]
- Hui, P.C.L.; Choi, T.-M. Using artificial neural networks to improve decision making in apparel supply chain systems. In Information Systems for the Fashion and Apparel Industry; Elsevier: Amsterdam, The Netherlands, 2016; pp. 97–107. [Google Scholar]
- Makridakis, S.; Wheelwright, S.; Hyndman, R. Forecasting Methods and Applications; John Wiley & Sons: New York, NY, USA, 1998. [Google Scholar]
- Wong, W.K.; Guo, Z.X. A Hybrid Intelligent Model for Medium-Term Sales Forecasting in Fashion Retail Supply Chains Using Extreme Learning Machine and Harmony Search Algorithm; Elsevier: Amsterdam, The Netherlands, 2010. [Google Scholar]
- Chu, W.C.; Zhang, P.G. A comparative study of linear and nonlinear models for aggregate retail sales forecasting. Int. J. Prod. Econ. 2003, 86, 217–231. [Google Scholar] [CrossRef]
- Thiesing, F.M.; Vornberger, O. Forecasting sales using neural networks. In International Conference on Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 1997; Volume 1226, pp. 321–328. [Google Scholar]
- Alon, I.; Qi, M.; Sadowski, R.J. Forecasting aggregate retail sales: A comparison of artificial neural networks and traditional methods. J. Retail. Consum. Serv. 2001, 8, 147–156. [Google Scholar] [CrossRef]
- Ansuj, A.P.; Camargo, M.; Radharamanan, R.; Petry, D. Sales forecasting using time series and neural networks. Comput. Ind. Eng. 1996, 31, 421–424. [Google Scholar] [CrossRef]
- Chang, P.-C.; Wang, Y.; Tsai, C. Evolving neural network for printed circuit board sales forecasting. Expert Syst. Appl. 2005, 29, 83–92. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P.; Davis, E. Artificial Intelligence: A Modern Approach; Pearson Education, Inc.: New York, NY, USA, 2010. [Google Scholar]
- Laney, D. 3D Data Management: Controlling Data Volume, Velocity, and Variety. META Group Res. Note 2001, 6, 1. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 38–353. [Google Scholar] [CrossRef] [Green Version]
- Tan, P.-N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Pearson Addison Wesley: Boston, MA, USA, 2005. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–446. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Chin, K.-S.; Wang, L.; Qu, G.; Tsui, K.L. Modified genetic algorithm-based feature selection combined with pre-trained deep neural network for demand forecasting in outpatient department. Expert Syst. Appl. 2017, 82, 216–230. [Google Scholar] [CrossRef]
- Xu, S.; Chan, H.K.; Zhang, T. Forecasting the demand of the aviation industry using hybrid time series SARIMA-SVR approach. Transp. Res. Part E Logist. Transp. Rev. 2019, 122, 169–180. [Google Scholar] [CrossRef]
- Qiu, X.; Ren, Y.; Suganthan, P.N.; Amaratunga, G.A.J. Empirical Mode Decomposition based ensemble deep learning for load demand time series forecasting. Appl. Soft Comput. 2017, 54, 246–255. [Google Scholar] [CrossRef]
- Alibabaei, K.; Gaspar, P.D.; Lima, T.M.; Campos, R.M.; Girão, I.; Monteiro, J.; Lopes, C.M. A Review of the Challenges of Using Deep Learning Algorithms to Support Decision-Making in Agricultural Activities. Remote Sens. 2022, 14, 638. [Google Scholar] [CrossRef]
- Thomassey, S.; Happiette, M. A neural clustering and classification system for sales forecasting of new apparel items. Appl. Soft Comput. 2007, 7, 1177–1187. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Aranganayagi, S.; Thangavel, K. Clustering categorical data using silhouette coefficient as a relocating measure. In Proceedings of the International Conference on Computational Intelligence and Multimedia Applications (ICCIMA 2007), Sivakasi, Tamil Nadu, 13–15 December 2007. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schutze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Attributes | Description |
|---|---|
| Item No | Unique id |
| Image | 360 × 540 × 3 pixels |
| Quantity Sold | Amount of the items sold |
| Time | weeks |
| K | Silhouette Scores |
|---|---|
| 2 | 0,994 |
| 3 | 0,600 |
| 4 | 0,435 |
| 5 | 0,227 |
| 6 | 0,210 |
| 7 | 0,236 |
| 8 | 0,111 |
| 9 | 0,131 |
| 10 | 0,120 |
| Model | AUC | CA | F1 | Precision | Recall |
|---|---|---|---|---|---|
| SVM | 0,621 | 0,690 | 0,630 | 0,683 | 0,689 |
| RF | 0,526 | 0,655 | 0,570 | 0,609 | 0,655 |
| NN | 0,716 | 0,724 | 0,716 | 0,714 | 0,724 |
| NB | 0,626 | 0,517 | 0,528 | 0,583 | 0,517 |
| Correctly Classified Items | RMSE | MAE | |
|---|---|---|---|
| Cluster 1 (C1) | Item 1 | 0,0375 | 0,0156 |
| Item 2 | 0,0383 | 0,0202 | |
| Item 3 | 0,0245 | 0,0138 | |
| Item 4 | 0,0345 | 0,0193 | |
| Item 5 | 0,0290 | 0,0153 | |
| Average | 0,0328 | 0,0169 | |
| Cluster 2(C2) | Item 1 | 0,0291 | 0,0187 |
| Item 2 | 0,0296 | 0,0195 | |
| Item 3 | 0,0229 | 0,0168 | |
| Item 4 | 0,0180 | 0,0117 | |
| Item 5 | 0,0205 | 0,0152 | |
| Item 6 | 0,0236 | 0,0168 | |
| Item 7 | 0,0303 | 0,0182 | |
| Item 8 | 0,0216 | 0,0141 | |
| Item 9 | 0,0232 | 0,0155 | |
| Item 10 | 0,0310 | 0,0204 | |
| Item 11 | 0,0229 | 0,0136 | |
| Item 12 | 0,0204 | 0,0131 | |
| Item 13 | 0,0201 | 0,0123 | |
| Item 14 | 0,0340 | 0,0201 | |
| Item 15 | 0,0283 | 0,0186 | |
| Item 16 | 0,0220 | 0,0134 | |
| Average | 0,0248 | 0,0163 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giri, C.; Chen, Y. Deep Learning for Demand Forecasting in the Fashion and Apparel Retail Industry. Forecasting 2022, 4, 565-581. https://doi.org/10.3390/forecast4020031
Giri C, Chen Y. Deep Learning for Demand Forecasting in the Fashion and Apparel Retail Industry. Forecasting. 2022; 4(2):565-581. https://doi.org/10.3390/forecast4020031
Chicago/Turabian StyleGiri, Chandadevi, and Yan Chen. 2022. "Deep Learning for Demand Forecasting in the Fashion and Apparel Retail Industry" Forecasting 4, no. 2: 565-581. https://doi.org/10.3390/forecast4020031
APA StyleGiri, C., & Chen, Y. (2022). Deep Learning for Demand Forecasting in the Fashion and Apparel Retail Industry. Forecasting, 4(2), 565-581. https://doi.org/10.3390/forecast4020031