
Model-Free Time-Aggregated Predictions for Econometric Datasets

Abstract
:1. Introduction
2. Method
2.1. The Existing NoVaS Method
2.2. A New Method with Less Parameters
- Remark (The advantage of removing the term): First, after removing the term, the prediction of the NoVaS method under the criterion is more stable. More details will be shown in Section 2.3. Second, the suggestion of removing can also lead to less time complexity of our new method. The reason for this phenomenon is simple. If we consider the limiting distribution of series, is required to be larger than or equal to 3 to ensure that has a sufficiently large range, i.e., is required to be less than or equal to 0.111 (recall that the mass of standard normal data is within ). However, the optimal combination of NoVaS coefficients may not render a suitable . For this situation, we need to increase the NoVaS transformation order p and repeat the normalizing and variance-stabilizing process till in the optimal combination of coefficients is suitable. This repeating process definitely increases the computation workload.
| Algorithm 1: The h-step ahead prediction for the GE-NoVaS-without- method. |
| Step 1 Define a grid of possible values, . Fix , then calculate the optimal combination of of the GE-NoVaS-without- method, which minimizes . |
| Step 2 Derive the analytic form of Equation (11) using from the first step. |
| Step 3 Generate M times from a standard normal distribution or the empirical distribution . Plug into the analytic form of Equation (11) to obtain M pseudo-values . |
| Step 4 Calculate the optimal predictor of by taking the sample mean (under risk criterion) or sample median (under risk criterion) of the set . |
| Step 5 Repeat above steps with different values from to get K prediction results. |
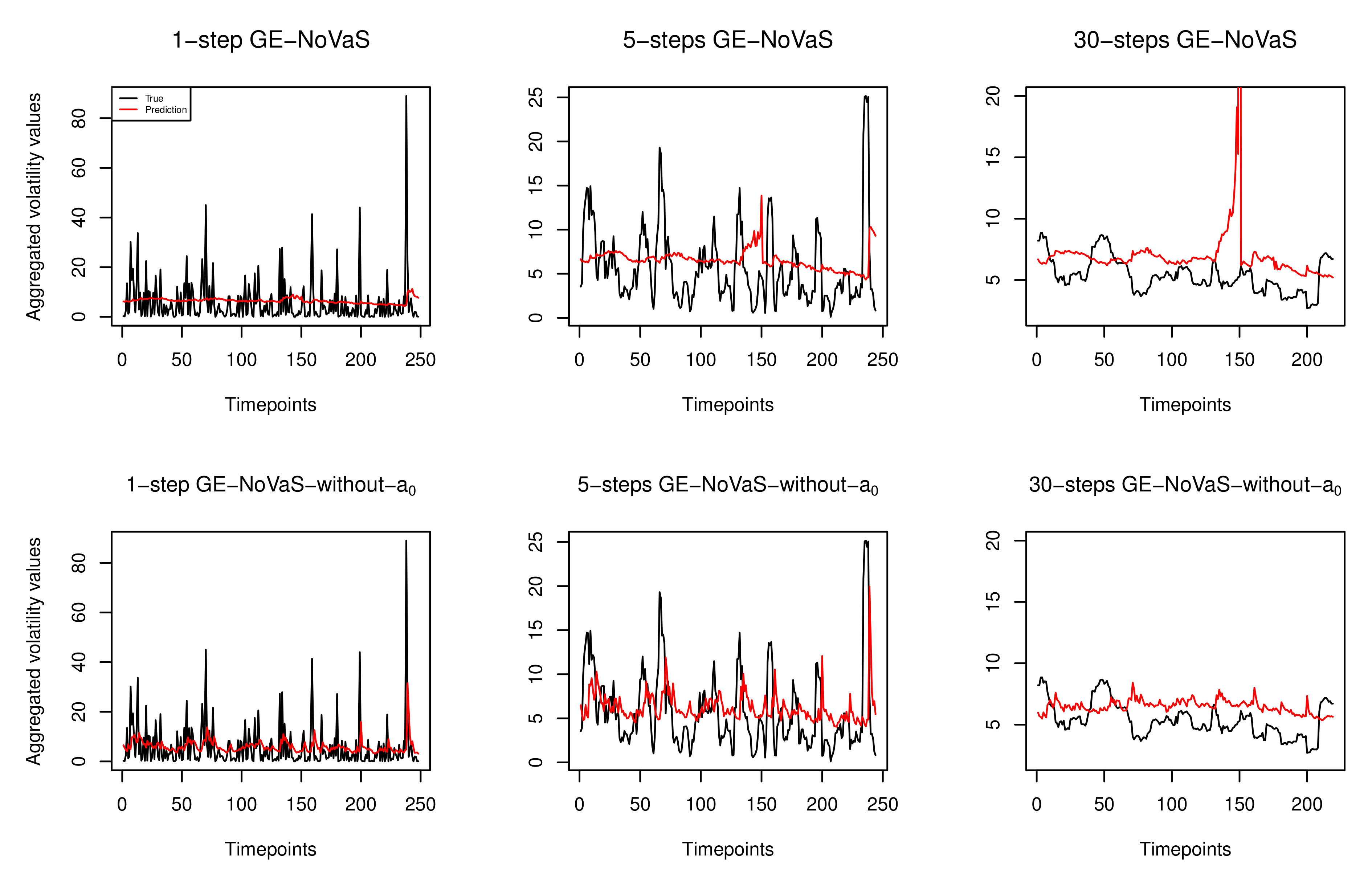
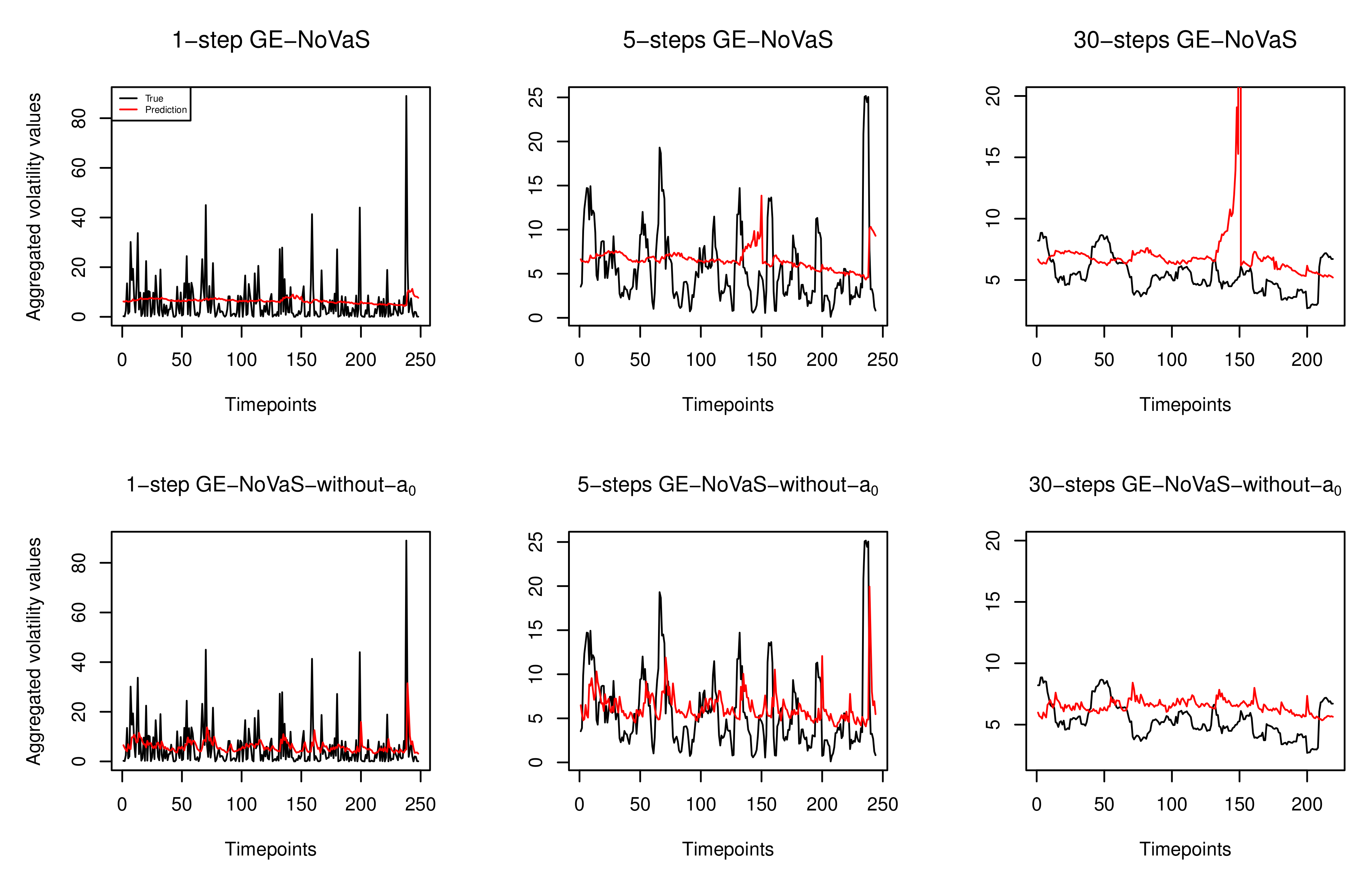
2.3. The Potential Instability of the GE-NoVaS Method
3. Data Analysis and Results
3.1. Simulation Study
- Model 1: Time-varying GARCH(1,1) with Gaussian errors;
- Model 2: Standard GARCH(1,1) with Gaussian errors
- Model 3: (Another) Standard GARCH(1,1) with Gaussian errors
- Model 4: Standard GARCH(1,1) with Student-t errors
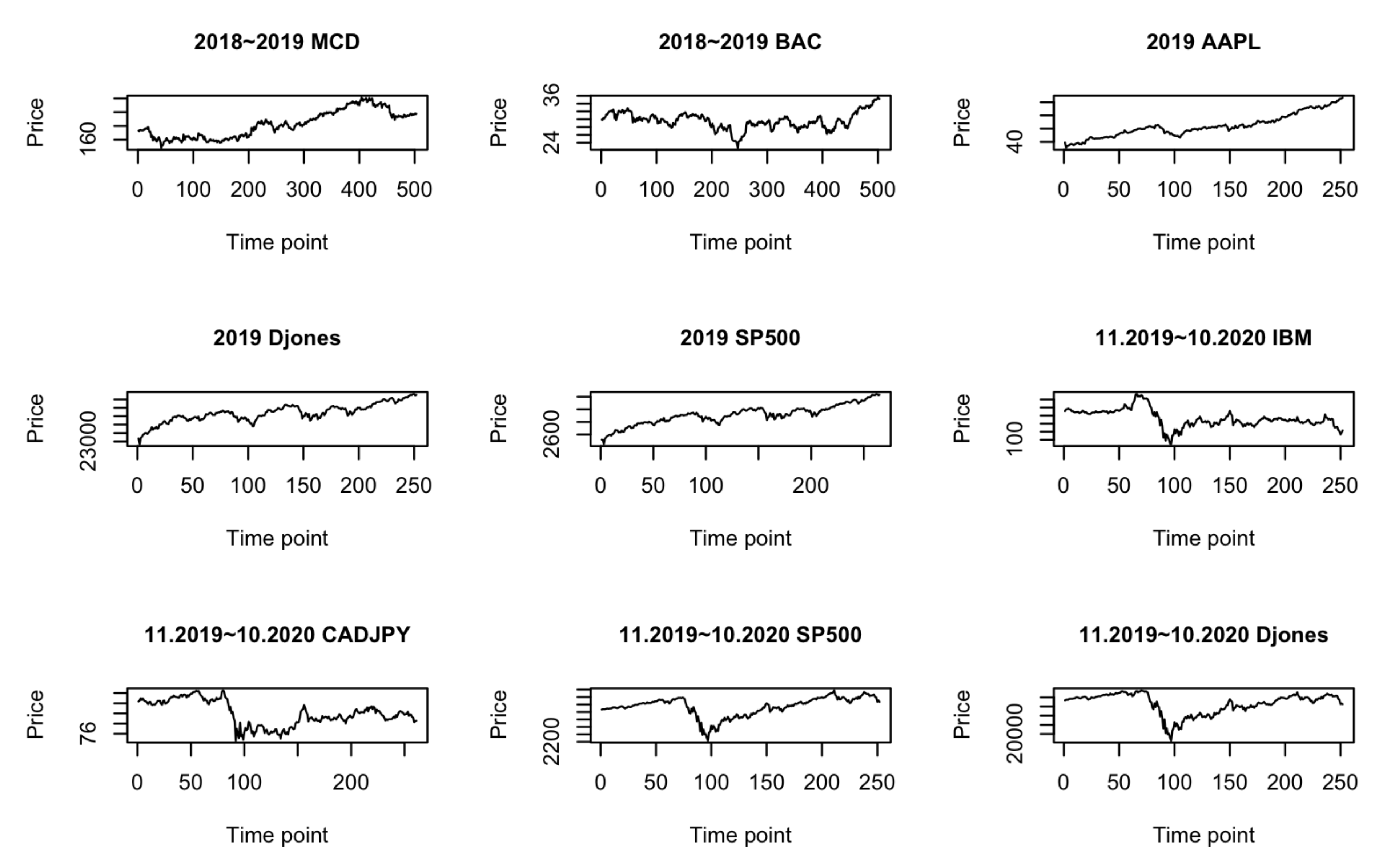
3.2. A Few Real Datasets
- 2-year period data: 2018∼2019 stock price data.
- 1-year period data: 2019 stock price and index data.
- 1-year period volatile data due to pandemic: 11.2019∼10.2020 stock price, currency and index data.
- Remark (One ARCH-type model for non-stationary data): Since our stationarity tests suggest that some series may not be stationary, we can consider applying ARCH-without-intercept, which is a variant of the ARCH model. This variant is non-stationary but stable in the sense that the observed process has non-degenerated distribution. Moreover, it appears to be an alternative to common stationary but highly persistent GARCH models [18]. Inspired by this ARCH-type model, the NoVaS method may be further improved by removing the corresponding intercept term in Equations (1) and (6). More empirical experiments could be conducted along this direction.
- Result analysis: From the last three blocks of Table 1, there is no optimal result that comes from the GARCH(1,1) method. When the target data are short and volatile, GARCH(1,1) gives poor results for 30-step-ahead time-aggregated predictions, such as the volatile Djones, CADJPY and IBM cases. Among the two NoVaS methods, the GE-NoVaS-without- method outperforms the GE-NoVaS method for the three types of real-world data. More specifically, around 70% and 30% improvements are created by our new method compared to the existing GE-NoVaS method when forecasting 30-step-ahead time-aggregated volatile Djones and CADJPY data, respectively. We should also notice that the GE-NoVaS method is again surpassed by the GARCH(1,1) model on 30-step-ahead aggregated predictions of 2018∼2019 BAC data. On the other hand, the GE-NoVaS-without- method performs stably. These comprehensive prediction comparisons cover the shortage of empirical analyses of NoVaS methods, and imply that NoVaS-type methods are indeed valid and efficient for real-world short- or long-term predictions of three main types of econometric data. See Appendix A for more results.
3.3. Statistical Significance
4. Summary
- Existing GE-NoVaS and new GE-NoVaS-without- methods provide substantial improvements for time-aggregated prediction, which hints towards the stability of NoVaS-type methods for providing long-horizon inferences.
- Our new method has superior performance to the GE-NoVaS method, especially for shorter sample sizes or more volatile data. This is significant given that GARCH-type models are difficult to estimate in shorter samples.
- We provide a statistical hypothesis test that shows that our model provides a more parsimonious fit, especially for long-term time-aggregated predictions.
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Additional Simulation Study and Data Analysis Results
Appendix A.1. Additional Simulation Study: Model Misspecification
- Model 5: Another time-varying GARCH(1,1) with Gaussian errors
- Model 6: Exponential GARCH(1,1) with Gaussian errors
- Model 7: GJR-GARCH(1,1) with Gaussian errors
- Model 8: Another GJR-GARCH(1,1) with Gaussian errors

{kind=link}
{kind=link}
| GE-NoVaS | GE-NoVaS-without- | GARCH(1,1) | |
|---|---|---|---|
| M5-1step | 0.91538 | 0.83168 | 1.00000 |
| M5-5steps | 0.49169 | 0.43772 | 1.00000 |
| M5-30steps | 0.25009 | 0.22659 | 1.00000 |
| M6-1step | 0.95939 | 0.94661 | 1.00000 |
| M6-5steps | 0.93594 | 0.84719 | 1.00000 |
| M6-30steps | 0.84401 | 0.70301 | 1.00000 |
| M7-1step | 0.84813 | 0.73553 | 1.00000 |
| M7-5steps | 0.50849 | 0.46618 | 1.00000 |
| M7-30steps | 0.06832 | 0.06479 | 1.00000 |
| M8-1step | 0.79561 | 0.76586 | 1.00000 |
| M8-5steps | 0.48028 | 0.38107 | 1.00000 |
| M8-30steps | 0.00977 | 0.00918 | 1.00000 |
Appendix A.2. Additional Data Analysis: 1-Year Datasets
| GE-NoVaS | GE-NoVaS-without- | GARCH(1,1) | |
|---|---|---|---|
| 2019-MCD-1step | 0.95959 | 0.93141 | 1.00000 |
| 2019-MCD-5steps | 1.00723 | 0.90061 | 1.00000 |
| 2019-MCD-30steps | 1.05239 | 0.80805 | 1.00000 |
| 2019-BAC-1step | 1.04272 | 0.97757 | 1.00000 |
| 2019-BAC-5steps | 1.22761 | 0.89571 | 1.00000 |
| 2019-BAC-30steps | 1.45020 | 1.01175 | 1.00000 |
| 2019-MSFT-1step | 1.03308 | 0.98469 | 1.00000 |
| 2019-MSFT-5steps | 1.22340 | 1.02387 | 1.00000 |
| 2019-MSFT-30steps | 1.23020 | 0.97585 | 1.00000 |
| 2019-TSLA-1step | 1.00428 | 0.98646 | 1.00000 |
| 2019-TSLA-5steps | 1.06610 | 0.97523 | 1.00000 |
| 2019-TSLA-30steps | 2.00623 | 0.87158 | 1.00000 |
| 2019-Bitcoin-1step | 0.89929 | 0.86795 | 1.00000 |
| 2019-Bitcoin-5steps | 0.62312 | 0.55620 | 1.00000 |
| 2019-Bitcoin-30steps | 0.00733 | 0.00624 | 1.00000 |
| 2019-Nasdaq-1step | 0.99960 | 0.93558 | 1.00000 |
| 2019-Nasdaq-5steps | 1.15282 | 0.84459 | 1.00000 |
| 2019-Nasdaq-30steps | 0.68994 | 0.58924 | 1.00000 |
| 2019-NYSE-1step | 0.92486 | 0.90407 | 1.00000 |
| 2019-NYSE-5steps | 0.86249 | 0.69822 | 1.00000 |
| 2019-NYSE-30steps | 0.22122 | 0.18173 | 1.00000 |
| 2019-Smallcap-1step | 1.02041 | 0.98731 | 1.00000 |
| 2019-Smallcap-5steps | 1.15868 | 0.87700 | 1.00000 |
| 2019-Samllcap-30steps | 1.30467 | 0.88825 | 1.00000 |
| 2019-BSE-1step | 0.70667 | 0.67694 | 1.00000 |
| 2019-BSE-5steps | 0.25675 | 0.23665 | 1.00000 |
| 2019-BSE-30steps | 0.03764 | 0.02890 | 1.00000 |
| 2019-BIST-1step | 0.96807 | 0.95467 | 1.00000 |
| 2019-BIST-5steps | 0.98944 | 0.82898 | 1.00000 |
| 2019-BIST-30steps | 2.21996 | 0.88511 | 1.00000 |
Appendix A.3. Additional Data Analysis: Volatile 1-Year Datasets
| GE-NoVaS | GE-NoVaS-without- | GARCH(1,1) | |
|---|---|---|---|
| 11.2019∼10.2020-MCD-1step | 0.51755 | 0.58018 | 1.00000 |
| 11.2019∼10.2020-MCD-5steps | 0.10725 | 0.17887 | 1.00000 |
| 11.2019∼10.2020-MCD-30steps | 3.32 × | 7.48 × | 1.00000 |
| 11.2019∼10.2020-AMZN-1step | 0.97099 | 0.90200 | 1.00000 |
| 11.2019∼10.2020-AMZN-5steps | 0.88705 | 0.71789 | 1.00000 |
| 11.2019∼10.2020-AMZN-30steps | 0.58124 | 0.53460 | 1.00000 |
| 11.2019∼10.2020-SBUX-1step | 0.68206 | 0.69943 | 1.00000 |
| 11.2019∼10.2020-SBUX-5steps | 0.24255 | 0.30528 | 1.00000 |
| 11.2019∼10.2020-SBUX-30steps | 0.00499 | 0.00289 | 1.00000 |
| 11.2019∼10.2020-MSFT-1step | 0.80133 | 0.84502 | 1.00000 |
| 11.2019∼10.2020-MSFT-5steps | 0.35567 | 0.37528 | 1.00000 |
| 11.2019∼10.2020-MSFT-30steps | 0.01342 | 0.00732 | 1.00000 |
| 11.2019∼10.2020-EURJPY-1step | 0.95093 | 0.94206 | 1.00000 |
| 11.2019∼10.2020-EURJPY-5steps | 0.76182 | 0.76727 | 1.00000 |
| 11.2019∼10.2020-EURJPY-30steps | 0.16202 | 0.15350 | 1.00000 |
| 11.2019∼10.2020-CNYJPY-1step | 0.77812 | 0.79877 | 1.00000 |
| 11.2019∼10.2020-CNYJPY-5steps | 0.38875 | 0.40569 | 1.00000 |
| 11.2019∼10.2020-CNYJPY-30steps | 0.08398 | 0.06270 | 1.00000 |
| 11.2019∼10.2020-Smallcap-1step | 0.58170 | 0.60931 | 1.00000 |
| 11.2019∼10.2020-Smallcap-5steps | 0.10270 | 0.10337 | 1.00000 |
| 11.2019∼10.2020-Smallcap-30steps | 7.00 × | 5.96 × | 1.00000 |
| 11.2019∼10.2020-BSE-1step | 0.39493 | 0.39745 | 1.00000 |
| 11.2019∼10.2020-BSE-5steps | 0.03320 | 0.04109 | 1.00000 |
| 11.2019∼10.2020-BSE-30steps | 2.45 × | 1.82 × | 1.00000 |
| 11.2019∼10.2020-NYSE-1step | 0.55741 | 0.57174 | 1.00000 |
| 11.2019∼10.2020-NYSE-5steps | 0.08994 | 0.10182 | 1.00000 |
| 11.2019∼10.2020-NYSE-30steps | 1.36 × | 6.64 × | 1.00000 |
| 11.2019∼10.2020-USDXfuture-1step | 1.14621 | 0.99640 | 1.00000 |
| 11.2019∼10.2020-USDXfuture-5steps | 0.61075 | 0.54834 | 1.00000 |
| 11.2019∼10.2020-USDXfuture-30steps | 0.10723 | 0.10278 | 1.00000 |
| 11.2019∼10.2020-Nasdaq-1step | 0.71380 | 0.75350 | 1.00000 |
| 11.2019∼10.2020-Nasdaq-5steps | 0.29332 | 0.33519 | 1.00000 |
| 11.2019∼10.2020-Nasdaq-30steps | 0.01223 | 0.00599 | 1.00000 |
| 11.2019∼10.2020-Bovespa-1step | 0.60031 | 0.57558 | 1.00000 |
| 11.2019∼10.2020-Bovespa-5steps | 0.08603 | 0.07447 | 1.00000 |
| 11.2019∼10.2020-Bovespa-30steps | 6.87 × | 2.04 × | 1.00000 |
Appendix B. Stationarity Test Results of Some Real-World Datasets
| ADF | KPSS | PP | |
|---|---|---|---|
| 2018∼2019 MCD | 0.01 | 0.10 | 0.01 |
| 2018∼2019 BAC | 0.01 | 0.10 | 0.01 |
| 2019 AAPL | 0.01 | 0.10 | 0.01 |
| 2019 Djones | 0.10 | 0.10 | 0.01 |
| 2019 SP500 | 0.18 | 0.10 | 0.01 |
| 11.2019∼10.2020 IBM | 0.31 | 0.05 | 0.01 |
| 11.2019∼10.2020 CADJPY | 0.01 | 0.10 | 0.01 |
| 11.2019∼10.2020 SP500 | 0.23 | 0.08 | 0.01 |
| 11.2019∼10.2020 Djones | 0.22 | 0.08 | 0.01 |
References
- Politis, D.N. A Normalizing and Variance-Stabilizing Transformation for Financial Time Series; Elsevier Inc.: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Gulay, E.; Emec, H. Comparison of forecasting performances: Does normalization and variance stabilization method beat GARCH (1, 1)-type models? Empirical evidence from the stock markets. J. Forecast. 2018, 37, 133–150. [Google Scholar] [CrossRef]
- Chen, J.; Politis, D.N. Time-varying NoVaS Versus GARCH: Point Prediction, Volatility Estimation and Prediction Intervals. J. Time Ser. Econom. 2020, 1. [Google Scholar] [CrossRef]
- Chen, J.; Politis, D.N. Optimal multi-step-ahead prediction of ARCH/GARCH models and NoVaS transformation. Econometrics 2019, 7, 34. [Google Scholar] [CrossRef] [Green Version]
- Chudỳ, M.; Karmakar, S.; Wu, W.B. Long-term prediction intervals of economic time series. Empir. Econ. 2020, 58, 191–222. [Google Scholar] [CrossRef] [Green Version]
- Karmakar, S.; Chudy, M.; Wu, W.B. Long-term prediction intervals with many covariates. arXiv 2020, arXiv:2012.08223. [Google Scholar] [CrossRef]
- Kitsul, Y.; Wright, J.H. The economics of options-implied inflation probability density functions. J. Financ. Econ. 2013, 110, 696–711. [Google Scholar] [CrossRef] [Green Version]
- Bansal, R.; Kiku, D.; Yaron, A. Risks for the long run: Estimation with time aggregation. J. Monet. Econ. 2016, 82, 52–69. [Google Scholar] [CrossRef] [Green Version]
- Starica, C. Is GARCH (1, 1) as Good a Model as the Accolades of the Nobel Prize Would Imply? University Library of Munich: Munich, Germany, 2003; SSRN 637322. [Google Scholar]
- Fryzlewicz, P.; Sapatinas, T.; Rao, S.S. Normalized least-squares estimation in time-varying ARCH models. Ann. Stat. 2008, 36, 742–786. [Google Scholar] [CrossRef]
- Politis, D.N. The Model-Free Prediction Principle. In Model-Free Prediction and Regression; Springer: Berlin/Heidelberg, Germany, 2015; pp. 13–30. [Google Scholar]
- Engle, R.F. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econom. J. Econom. Soc. 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Chen, J. Prediction in Time Series Models and Model-free Inference with a Specialization in Financial Return Data. Ph.D. Thesis, University of California, San Diego, CA, USA, 2018. [Google Scholar]
- Awartani, B.M.; Corradi, V. Predicting the volatility of the S&P-500 stock index via GARCH models: The role of asymmetries. Int. J. Forecast. 2005, 21, 167–183. [Google Scholar]
- Said, S.E.; Dickey, D.A. Testing for unit roots in autoregressive-moving average models of unknown order. Biometrika 1984, 71, 599–607. [Google Scholar] [CrossRef]
- Perron, P. Trends and random walks in macroeconomic time series: Further evidence from a new approach. J. Econ. Dyn. Control 1988, 12, 297–332. [Google Scholar] [CrossRef]
- Kwiatkowski, D.; Phillips, P.C.; Schmidt, P.; Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]
- Hafner, C.M.; Preminger, A. An ARCH model without intercept. Econ. Lett. 2015, 129, 13–17. [Google Scholar] [CrossRef]
- Clark, T.E.; West, K.D. Approximately normal tests for equal predictive accuracy in nested models. J. Econom. 2007, 138, 291–311. [Google Scholar] [CrossRef] [Green Version]

| GE-NoVaS | GE-NoVaS-without- | GARCH(1,1) | p-Value(CW Test) | ||
|---|---|---|---|---|---|
| Simulated-1-year-data | Model-1-1step | 0.91369 | 0.88781 | 1.00000 | |
| Model-1-5steps | 0.61001 | 0.52872 | 1.00000 | ||
| Model-1-30steps | 0.77250 | 0.73604 | 1.00000 | ||
| Model-2-1step | 0.97796 | 0.94635 | 1.00000 | ||
| Model-2-5steps | 0.98127 | 0.96361 | 1.00000 | ||
| Model-2-30steps | 1.38353 | 0.98872 | 1.00000 | ||
| Model-3-1step | 0.99183 | 0.92829 | 1.00000 | ||
| Model-3-5steps | 0.77088 | 0.67482 | 1.00000 | ||
| Model-3-30steps | 0.79672 | 0.71003 | 1.00000 | ||
| Model-4-1step | 0.83631 | 0.78087 | 1.00000 | ||
| Model-4-5steps | 0.38296 | 0.34396 | 1.00000 | ||
| Model-4-30steps | 0.00199 | 0.00201 | 1.00000 | ||
| 2-years-data | 2018∼2019-MCD-1step | 0.99631 | 0.99614 | 1.00000 | 0.00053 |
| 2018∼2019-MCD-5steps | 0.95403 | 0.92120 | 1.00000 | 0.03386 | |
| 2018∼2019-MCD-30steps | 0.75730 | 0.62618 | 1.00000 | 0.19691 | |
| 2018∼2019-BAC-1step | 0.98393 | 0.97966 | 1.00000 | 0.09568 | |
| 2018∼2019-BAC-5steps | 0.98885 | 0.95124 | 1.00000 | 0.07437 | |
| 2018∼2019-BAC-30steps | 1.14111 | 0.87414 | 1.00000 | 0.03643 | |
| 1-year-data | 2019-AAPL-1step | 0.84533 | 0.80948 | 1.00000 | 0.25096 |
| 2019-AAPL-5steps | 0.85401 | 0.68191 | 1.00000 | 0.06387 | |
| 2019-AAPL-30steps | 0.99043 | 0.73823 | 1.00000 | 0.17726 | |
| 2019-Djones-1step | 0.96752 | 0.96365 | 1.00000 | 0.34514 | |
| 2019-Djones-5steps | 0.98725 | 0.89542 | 1.00000 | 0.24529 | |
| 2019-Djones-30steps | 0.86333 | 0.80304 | 1.00000 | 0.23766 | |
| 2019-SP500-1step | 0.96978 | 0.92183 | 1.00000 | 0.45693 | |
| 2019-SP500-5steps | 0.96704 | 0.75579 | 1.00000 | 0.24402 | |
| 2019-SP500-30steps | 0.34389 | 0.29796 | 1.00000 | 0.08148 | |
| Volatile-1-year-data | 11.2019∼10.2020-IBM-1step | 0.80222 | 0.80744 | 1.00000 | 0.16568 |
| 11.2019∼10.2020-IBM-5steps | 0.38933 | 0.40743 | 1.00000 | 0.03664 | |
| 11.2019∼10.2020-IBM-30steps | 0.01143 | 0.00918 | 1.00000 | 0.15364 | |
| 11.2019∼10.2020-CADJPY-1step | 0.46940 | 0.48712 | 1.00000 | 0.16230 | |
| 11.2019∼10.2020-CADJPY-5steps | 0.11678 | 0.13549 | 1.00000 | 0.06828 | |
| 11.2019∼10.2020-CADJPY-30steps | 0.00584 | 0.00394 | 1.00000 | 0.15174 | |
| 11.2019∼10.2020-SP500-1step | 0.97294 | 0.92349 | 1.00000 | 0.05536 | |
| 11.2019∼10.2020-SP500-5steps | 0.96590 | 0.75183 | 1.00000 | 0.17380 | |
| 11.2019∼10.2020-SP500-30steps | 0.34357 | 0.29793 | 1.00000 | 0.16022 | |
| 11.2019∼10.2020-Djones-1step | 0.56357 | 0.57550 | 1.00000 | 0.11099 | |
| 11.2019∼10.2020-Djones-5steps | 0.09810 | 0.11554 | 1.00000 | 0.45057 | |
| 11.2019∼10.2020-Djones-30steps | 4.32 × | 1.24 × | 1.00000 | 0.68487 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, K.; Karmakar, S. Model-Free Time-Aggregated Predictions for Econometric Datasets. Forecasting 2021, 3, 920-933. https://doi.org/10.3390/forecast3040055
Wu K, Karmakar S. Model-Free Time-Aggregated Predictions for Econometric Datasets. Forecasting. 2021; 3(4):920-933. https://doi.org/10.3390/forecast3040055
Chicago/Turabian StyleWu, Kejin, and Sayar Karmakar. 2021. "Model-Free Time-Aggregated Predictions for Econometric Datasets" Forecasting 3, no. 4: 920-933. https://doi.org/10.3390/forecast3040055
APA StyleWu, K., & Karmakar, S. (2021). Model-Free Time-Aggregated Predictions for Econometric Datasets. Forecasting, 3(4), 920-933. https://doi.org/10.3390/forecast3040055