
Bootstrapped Holt Method with Autoregressive Coefficients Based on Harmony Search Algorithm



Abstract
:1. Introduction
2. Harmony Search Algorithm
| Algorithm 1 The algorithm of HSA |
| Step 1. Determination of parameters to be used in HSA: |
| • XHM: Harmony memory; |
| • HMS: Harmony memory search; |
| • HMCR: Harmony memory considering rate; |
| • PAR: Pitch adjusting rate; |
| • n: the number of variables. |
| Step 2. Creating of the harmony memory. |
| HM for HSA is generated as in Equation (4).
|
| Here, is expressed as a note value and is generated randomly. |
| In HSA, each solution vector is denoted by . In HSA, there are HMS solution vectors. The representation of the first solution vector is given in Equation (5). |
| Step 3. Calculation of objective function values. |
| The objective function values are calculated for each solution vector generated randomly as given in Equation (6). |
| Step 4. Improvement of a new harmony. |
| While the probability of with a value between 0 and 1 is to select a value from the existing values in the HM, (1-HMCR) value is the ratio of a random value selected from the possible value ranges. The new harmony is obtained with the help of Equation (7). |
| It is decided by the parameter whether the toning process can be applied to each selected decision variable with the possibility of or not as given in Equation (8).
|
| In Equation (8), is generated randomly between . If this random number is smaller than the value, this value is changed to the closest value to it. If the tonalization will be made for each decision variable and the value of is assumed to be the value within the vector of the value variable, the new value of is , and is the neighboring index. |
| Step 5. Updating the harmony memory. |
| If the new harmony vector is better than the worst vector in the , the worst vector is removed from the memory, and the new harmony vector is included in the HM instead of the removed vector. |
| Step 6. Stop condition check. |
| Steps 4–6 are repeated until the termination criteria are met. Possible values for HMCR and PAR in literature are between 0.7–0.95 and 0.05–0.7, respectively [17]. |
3. Proposed Method
- The smoothing parameters are varied from observation to observation using first-order autoregressive equations;
- The optimal parameters of the Holt method are determined with HSA;
- The forecasts are obtained by the Sub-sampling Bootstrap method.
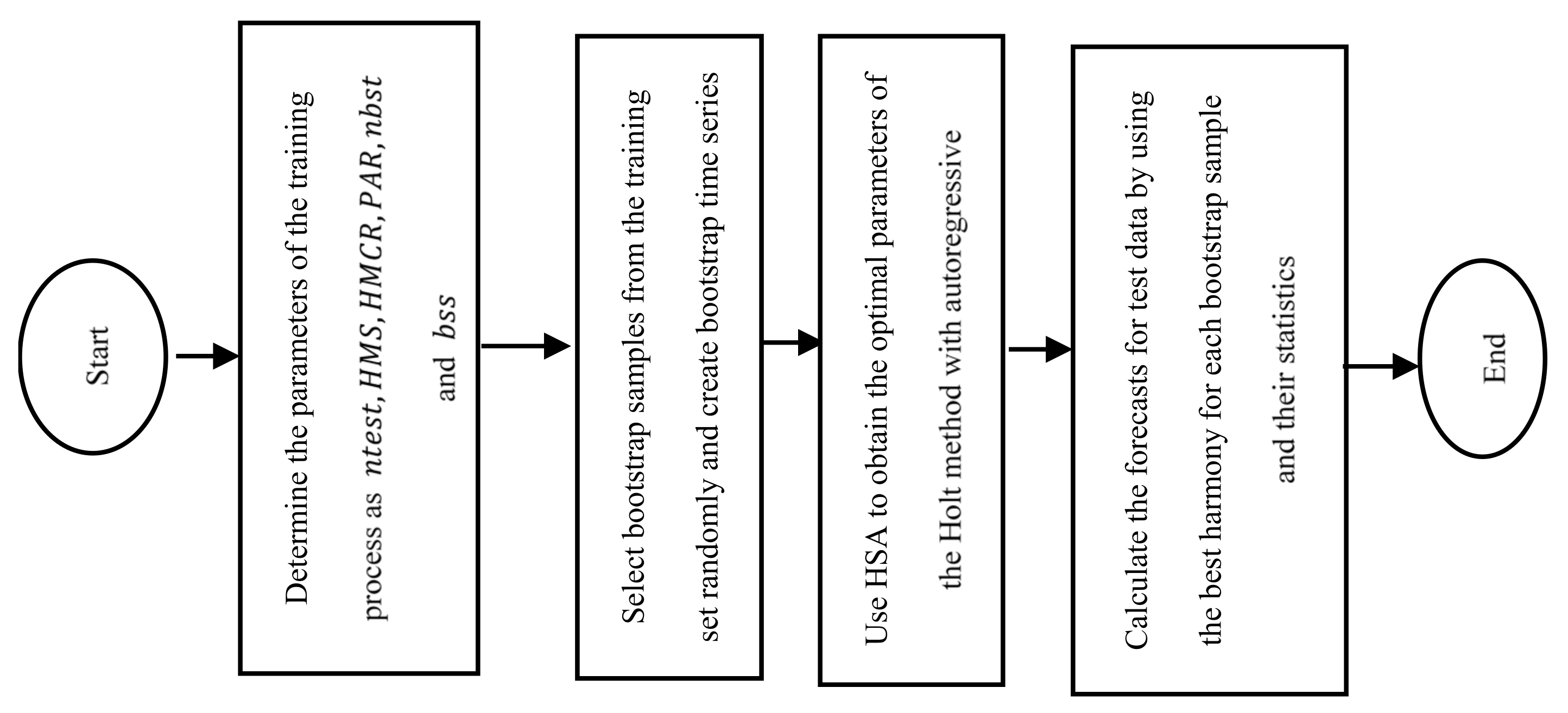
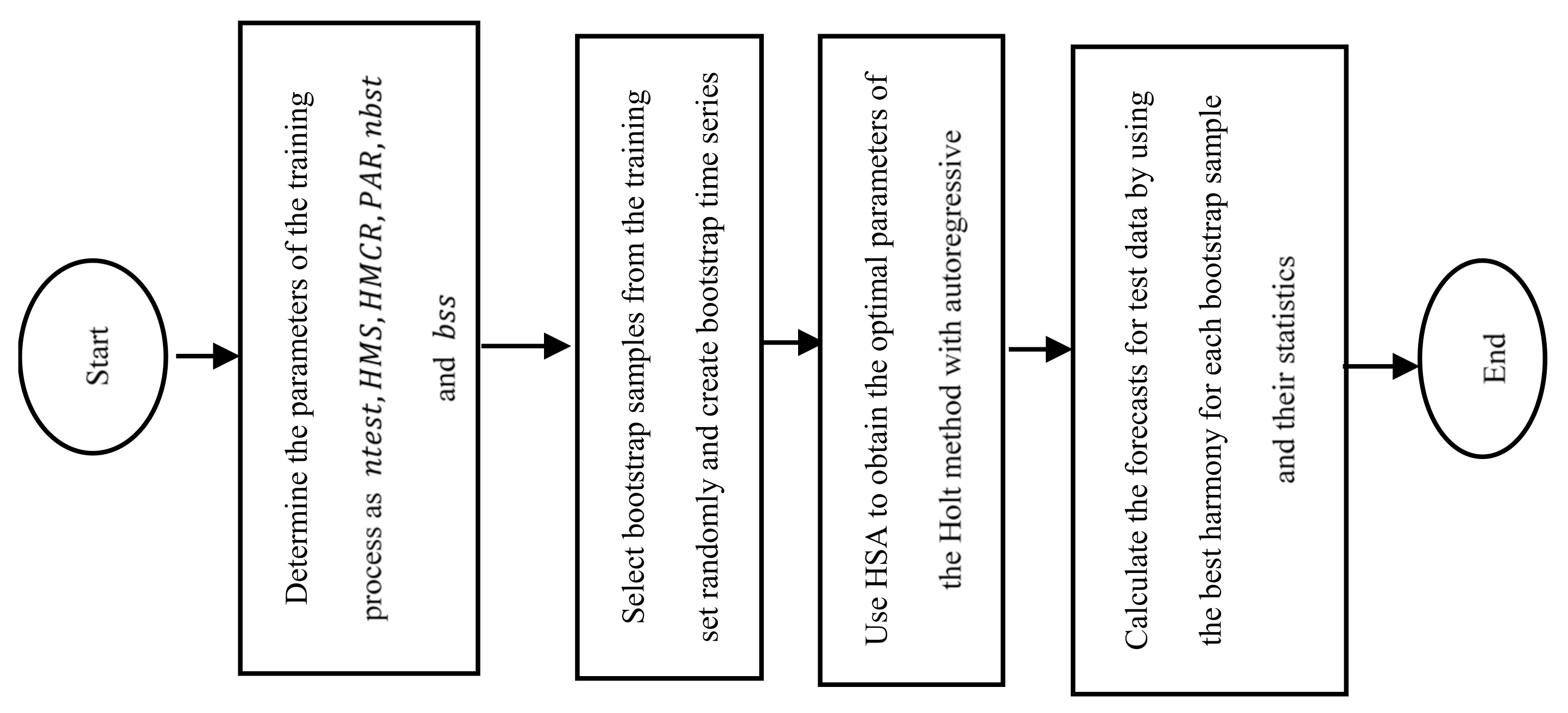
| Algorithm 2 The algorithm of the proposed method |
| Step 1. Determine the parameters of the training process: |
| • # observation of test set: ; |
| • HMS; |
| • HMCR; |
| • PAR; |
| • # bootstrap samples: nbst; |
| • bootstrap sample size: bss. |
| Step 2. Select bootstrap samples from the training set randomly. |
| Steps from 2.1. to 2.2 are repeated times. presents bootstrap time series. |
| Step 2.1. Select a starting point of the block as an integer from a discrete uniform distribution with parameters -bss+1. |
| Step 2.2. Create bootstrap time series as given in Equation (9).
|
| Step 3. Apply regression analysis to determine the initial bounds for level and trend parameters by using bootstrap time series as the training set by using Equations (10)–(12).
|
| and trend |
| Step 4. HSA is used to obtain the optimal parameters of the Holt method with autoregressive coefficients for each bootstrap time series. Steps 4.1 and 4.4 are repeated for each bootstrap time series. |
| Step 4.1. Generate the initial positions of HSA. The positions of harmony are . |
| and are generated from , respectively. , and are generated from . and are generated from . The creation of the harmony memory for the proposed method is given in Equation (13), and the parameters that correspond to harmony are given in Table 1.
|
| Step 4.2. According to the initial positions of each harmony, fitness functions are calculated. The root of mean square error (RMSE) is preferred to use as a fitness function and is calculated as given in Equation (14).
|
| In Equation (14), is the output for bootstrap time series data and harmony. is obtained by using Equations (15)–(19).
|
| Obtain RMSE values for each harmony, and save the best harmony which has the smallest RMSE. |
| Step 4.3. Improve new harmony. |
| shows the probability that the value of a decision variable is selected from the current harmony memory. (1-) represents the random selection of the new decision variable from the existing solution space. shows the new harmony, obtained as in Equation (20).
|
| After this step, each decision variable is evaluated to determine whether a tonal adjustment is necessary. This is determined by the PAR parameter, which is the tone adjustment ratio. The new harmony vector is produced according to the randomly selected tones in the memory of harmony as given in Equation (21). Whether the variables are selected from the harmonic memory is determined by the HMCR ratio, which is between 0 and 1.
|
| is a bandwidth selected randomly; (0; 1) represents a random number generated between 0 and 1. |
| Step 4.4. Harmony memory update. |
| In this step, the comparison between the newly created harmonies and the worst harmonies in the memory is made in terms of the values of the objective functions. If the newly created harmony vector is better than the worst harmony, the worst harmony vector is removed from the memory, and the new harmony vector is substituted for it. |
| Calculate RMSE values for bootstrap time series data and harmony. Find the best harmony which has the minimum RMSE value for bootstrap time series data. |
| Step 5. Calculate the forecasts for test data by using the best harmony for each bootstrap sample and their statistics. |
| The obtained forecasts from the updated Equations for bootstrap time series at time is represented by . Forecasts and their statistics are calculated just as in Table 2. In addition, the flowchart of the proposed method is given in Figure 1. |
4. Applications
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Brown, R.G. Statistical Forecasting for Inventory Control; McGraw-Hill: New York, NY, USA, 1959. [Google Scholar]
- Holt, C.E. Forecasting Seasonals and Trends by Exponentially Weighted Averages (O.N.R. Memorandum No. 52); Carnegie Institute of Technology Pittsburgh: Pittsburgh, PA, USA, 1957. [Google Scholar]
- Winters, P.R. Forecasting sales by exponentially weighted moving averages. Manag. Sci. 1960, 6, 324–342. [Google Scholar] [CrossRef]
- Gardner, E.S., Jr.; McKenzie, E. Forecasting trends in time series. Manag. Sci. 1985, 31, 1237–1246. [Google Scholar] [CrossRef]
- Makridakis, S.G.; Fildes, R.; Hibon, M.; Parzen, E. The forecasting accuracy of major time series methods. J. R. Stat. Soc. Ser. D Stat. 1985, 34, 261–262. [Google Scholar]
- Makridakis, S.; Hibon, M. The M3-competition: Results, conclusions and implications. Int. J. Forecast. 2000, 16, 451–476. [Google Scholar] [CrossRef]
- Koning, A.J.; Franses, P.H.; Hibon, M.; Stekler, H.O. The M3 competition: Statistical tests of the results. Int. J. Forecast. 2005, 21, 397–409. [Google Scholar] [CrossRef]
- Yapar, G.; Selamlar, H.T.; Capar, S.; Yavuz, I. ATA method. Hacet. J. Math. Stat. 2019, 48, 1838–1844. [Google Scholar] [CrossRef]
- Gardner, E.S., Jr. Exponential smoothing. The state of the art. J. Forecast. 1985, 4, 1–28. [Google Scholar] [CrossRef]
- Gardner, E.S., Jr. Exponential smoothing: The state of the art—Part II. Int. J. Forecast. 2006, 22, 637–666. [Google Scholar] [CrossRef]
- Pandit, S.M.; Wu, S.M. Exponential smoothing as a special case of a linear stochastic system. Oper. Res. 1974, 22, 868–879. [Google Scholar] [CrossRef]
- Imani, M.; Braga-Neto, U.M. Optimal finite-horizon sensor selection for Boolean Kalman Filter. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, IEEE, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 1481–1485. [Google Scholar]
- Oprea, M. A general framework and guidelines for benchmarking computational intelligence algorithms applied to forecasting problems derived from an application domain-oriented survey. Appl. Soft Comput. 2020, 89, 106103. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Peng, L.; Zeng, Y.R. Effective energy consumption forecasting using enhanced bagged echo state network. Energy 2020, 193, 116778. [Google Scholar] [CrossRef]
- Imani, M.; Ghoreishi, S.F. Two-Stage Bayesian Optimization for Scalable Inference in State-Space Models. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–12. [Google Scholar] [CrossRef]
- Geem, Z.W.; Kim, J.H.; Loganathan, G.V. A new heuristic optimization algorithm: Harmony search. Simulation 2001, 76, 60–68. [Google Scholar] [CrossRef]
- Geem, Z.W. Optimal cost design of water distribution networks using harmony search. Eng. Optim. 2006, 38, 259–277. [Google Scholar] [CrossRef]
- Turkşen, I.B. Fuzzy functions with LSE. Appl. Soft Comput. 2008, 8, 1178–1188. [Google Scholar] [CrossRef]
- Jang, J.S. Anfis: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Kim, S.; Kim, H. A new metric of absolute percentage error for intermittent demand forecasts. Int. J. Forecast. 2016, 32, 669–679. [Google Scholar] [CrossRef]
- Neill, S.P.; Hashemi, M.R. Ocean Modelling for Resource Characterization. Fundam. Ocean Renew. Energy 2018, 193–235. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time /Bootstrap Sample | Median | Standard Deviation | ||||
|---|---|---|---|---|---|---|
| 1 | SE | |||||
| 2 | SE | |||||
| ntest | SE |
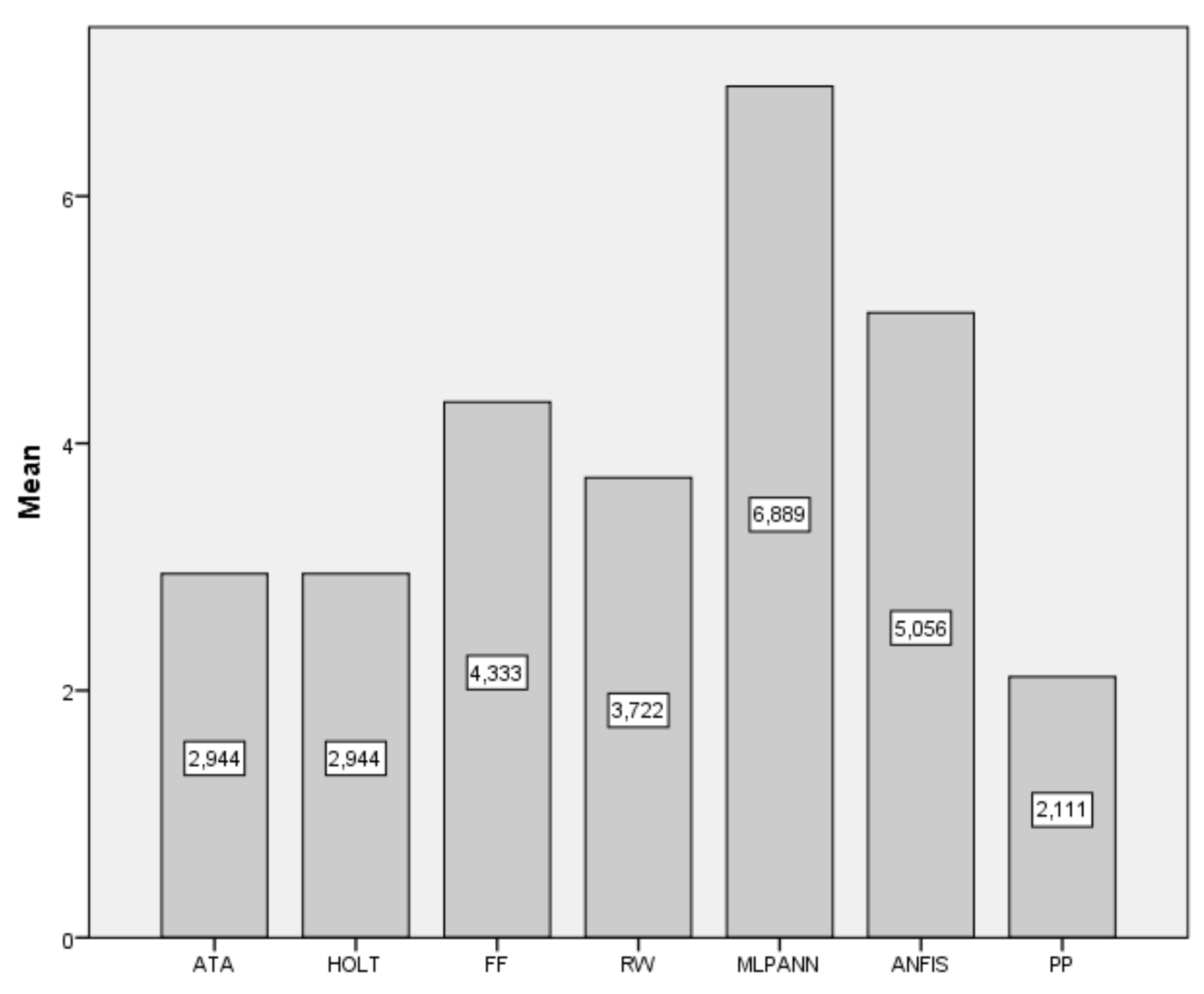
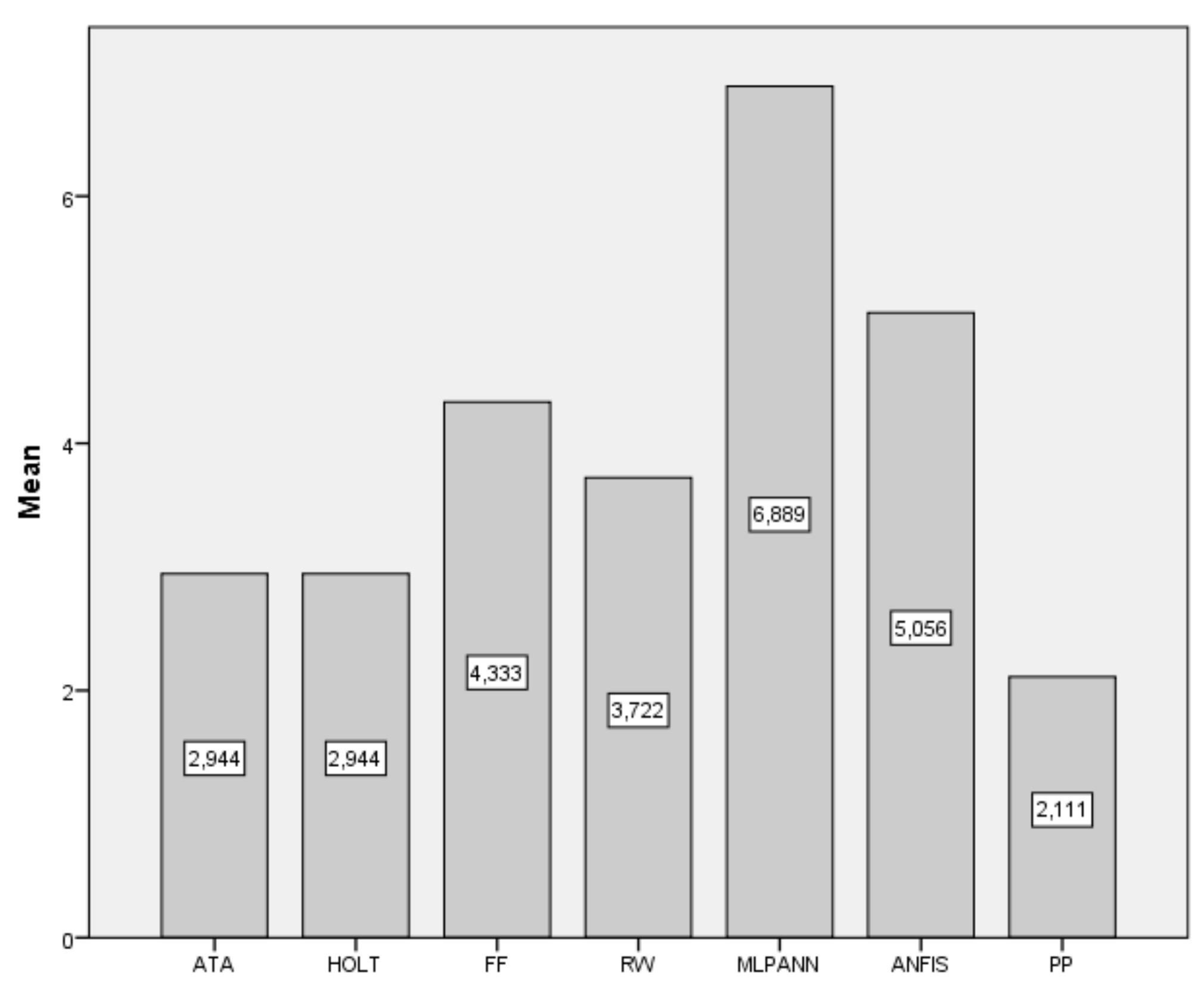
| Data | ATA | Holt | FF | RW | MLP-ANN | ANFIS | PP |
|---|---|---|---|---|---|---|---|
| BIST2000 | 279.79 | 296.17 | 310.42 | 286.15 | 343.9 | 619.21 | 278.82 |
| BIST2001 | 204.84 | 237.69 | 272.31 | 206.5 | 1106.89 | 710.82 | 189.75 |
| BIST2002 | 325.08 | 319.78 | 357 | 331.87 | 620.78 | 399.13 | 332.13 |
| BIST2003 | 354.79 | 355.55 | 380.82 | 349.79 | 1859.21 | 420.75 | 328.25 |
| BIST2004 | 315.62 | 315.79 | 390.15 | 325.69 | 1807.8 | 641.43 | 313.7 |
| BIST2005 | 316.75 | 315.36 | 328.84 | 342.69 | 2071.98 | 559.2 | 304.98 |
| BIST2006 | 354.03 | 348.58 | 352.07 | 356.81 | 423.98 | 389.3 | 346.98 |
| BIST2007 | 768.29 | 734.55 | 673.14 | 734.14 | 897.02 | 550.97 | 728.92 |
| BIST2008 | 283.99 | 277.2 | 256.98 | 253.67 | 444.74 | 340.41 | 260.52 |
| BIST2009 | 505.05 | 483.8 | 558.06 | 551.97 | 3117.96 | 736.78 | 473.4 |
| BIST2010 | 577.68 | 594.9 | 583.52 | 591.88 | 725.15 | 588.36 | 576.4 |
| BIST2011 | 697.64 | 710.04 | 849.68 | 726.5 | 1733.88 | 1037.87 | 737.83 |
| BIST2012 | 355.5 | 350.46 | 368.26 | 358.17 | 3237.45 | 406.68 | 358.15 |
| BIST2013 | 1905.64 | 1898.61 | 2105.05 | 1922.14 | 4369.35 | 2104.39 | 1871.45 |
| BIST2014 | 1068.36 | 1025.18 | 1177.56 | 1059.97 | 2631.25 | 1435.01 | 1036.6 |
| BIST2015 | 772.84 | 767.71 | 758.89 | 779.07 | 1080.69 | 714.69 | 751.41 |
| BIST2016 | 431.86 | 433.52 | 450.67 | 434.01 | 520.1 | 424.34 | 652.25 |
| BIST2017 | 861.26 | 869.23 | 1113.74 | 911.21 | 3777.62 | 1283.75 | 827.15 |
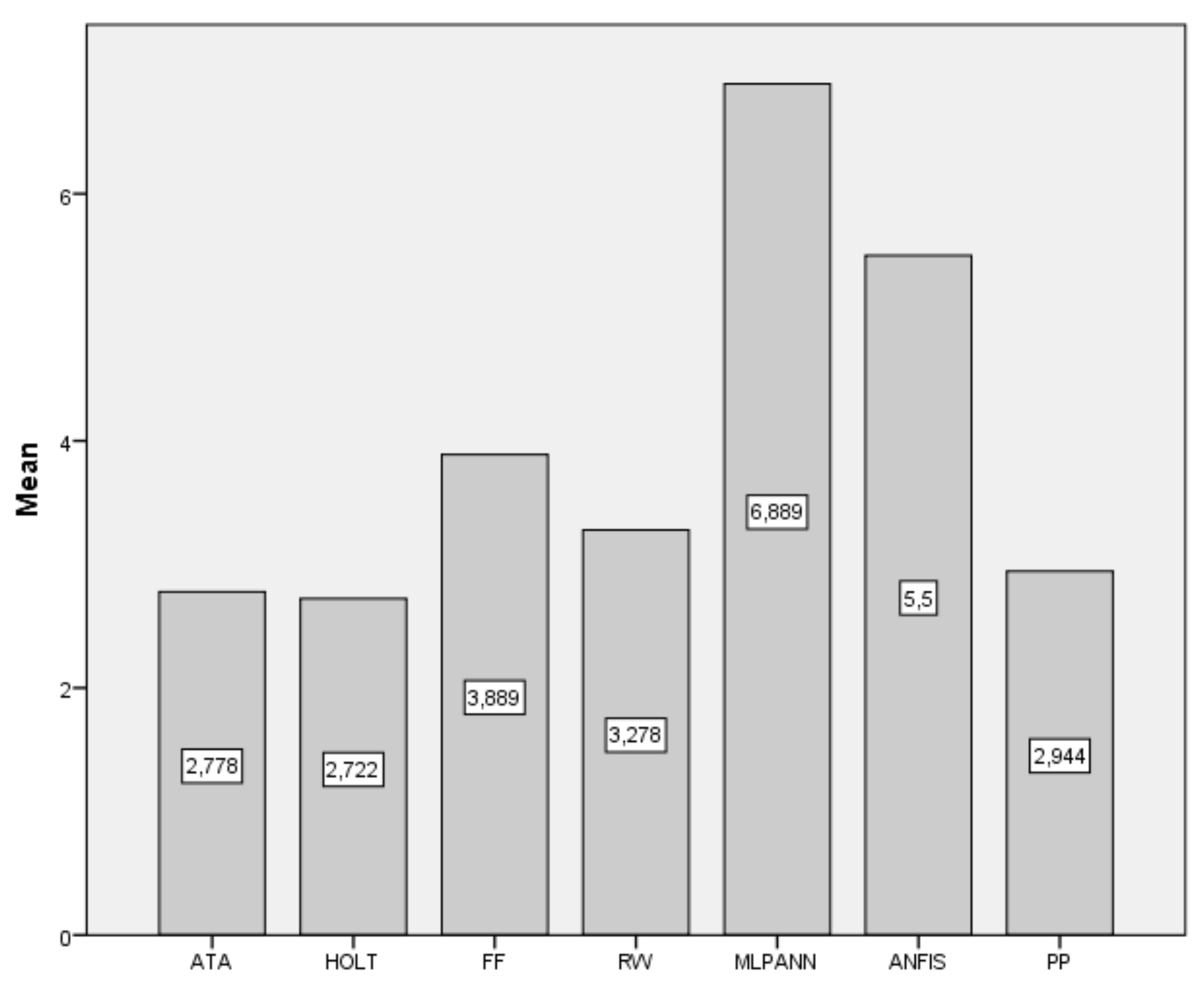
| Data | ATA | Holt | FF | RW | MLP-ANN | ANFIS | PP |
|---|---|---|---|---|---|---|---|
| BIST2000 | 0.0222 | 0.0233 | 0.0268 | 0.0236 | 0.0293 | 0.0507 | 0.0223 |
| BIST2001 | 0.011 | 0.0124 | 0.0161 | 0.0112 | 0.0818 | 0.0506 | 0.0103 |
| BIST2002 | 0.0253 | 0.0241 | 0.0267 | 0.0256 | 0.043 | 0.0287 | 0.0256 |
| BIST2003 | 0.0163 | 0.0163 | 0.0178 | 0.0162 | 0.1008 | 0.0208 | 0.0154 |
| BIST2004 | 0.0099 | 0.01 | 0.0129 | 0.0103 | 0.0735 | 0.0241 | 0.0099 |
| BIST2005 | 0.0068 | 0.0069 | 0.0069 | 0.0074 | 0.0519 | 0.0126 | 0.0066 |
| BIST2006 | 0.0068 | 0.0066 | 0.007 | 0.0067 | 0.0082 | 0.0076 | 0.0073 |
| BIST2007 | 0.0098 | 0.01 | 0.0087 | 0.0095 | 0.0138 | 0.008 | 0.0095 |
| BIST2008 | 0.0082 | 0.0075 | 0.0073 | 0.0071 | 0.0154 | 0.0093 | 0.0075 |
| BIST2009 | 0.0067 | 0.0066 | 0.0077 | 0.0076 | 0.0595 | 0.0114 | 0.0071 |
| BIST2010 | 0.006 | 0.0064 | 0.0058 | 0.0063 | 0.0085 | 0.0068 | 0.0061 |
| BIST2011 | 0.0113 | 0.0116 | 0.0137 | 0.0118 | 0.0316 | 0.0165 | 0.0119 |
| BIST2012 | 0.004 | 0.0039 | 0.004 | 0.0039 | 0.041 | 0.0042 | 0.004 |
| BIST2013 | 0.022 | 0.0219 | 0.0254 | 0.0223 | 0.0608 | 0.0258 | 0.0216 |
| BIST2014 | 0.0092 | 0.009 | 0.0101 | 0.0094 | 0.0304 | 0.0118 | 0.0089 |
| BIST2015 | 0.0083 | 0.0082 | 0.0078 | 0.0082 | 0.0109 | 0.0087 | 0.0082 |
| BIST2016 | 0.0049 | 0.0048 | 0.0047 | 0.0048 | 0.0051 | 0.0046 | 0.0062 |
| BIST2017 | 0.0052 | 0.0053 | 0.0076 | 0.0058 | 0.0318 | 0.0092 | 0.0049 |
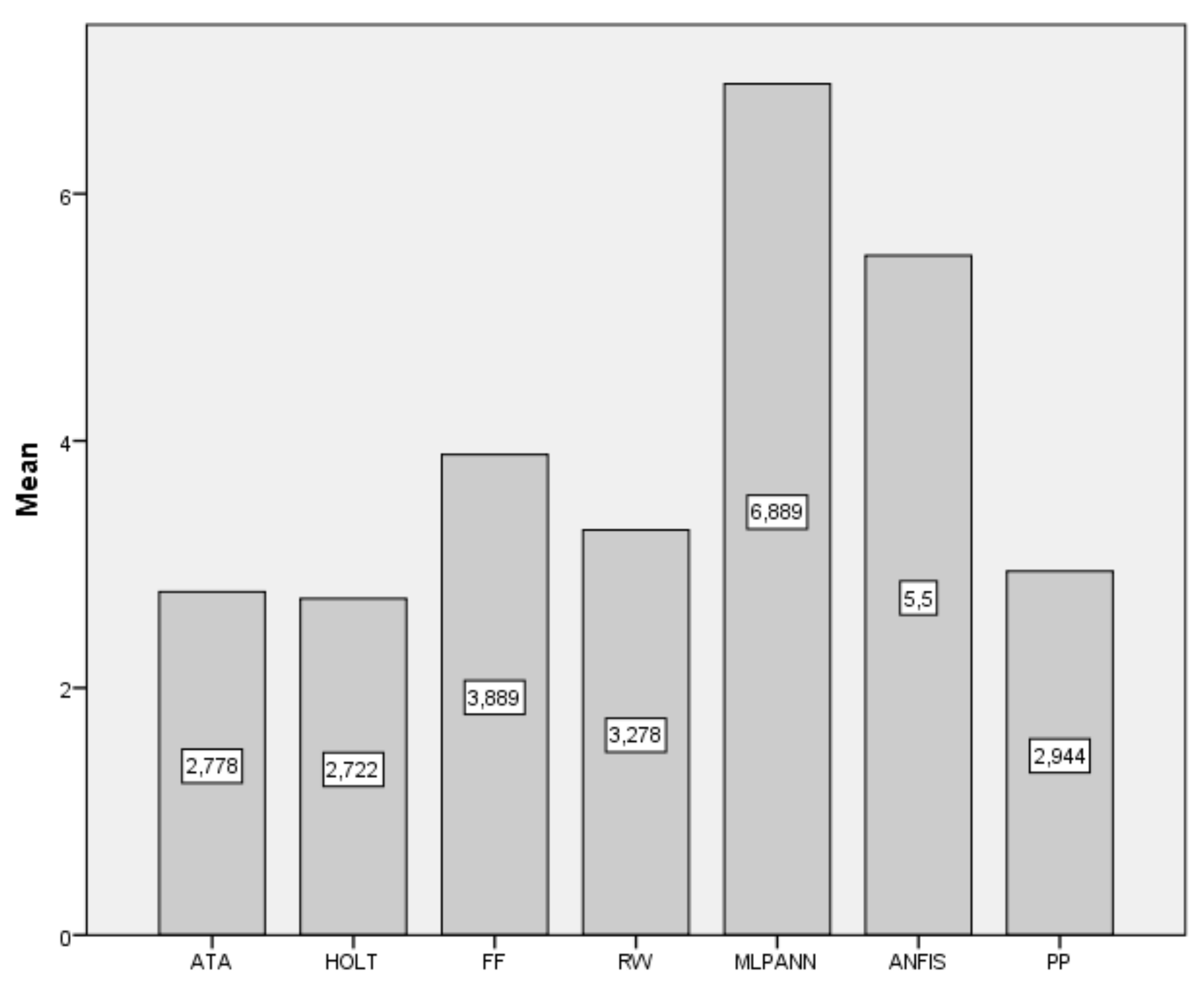
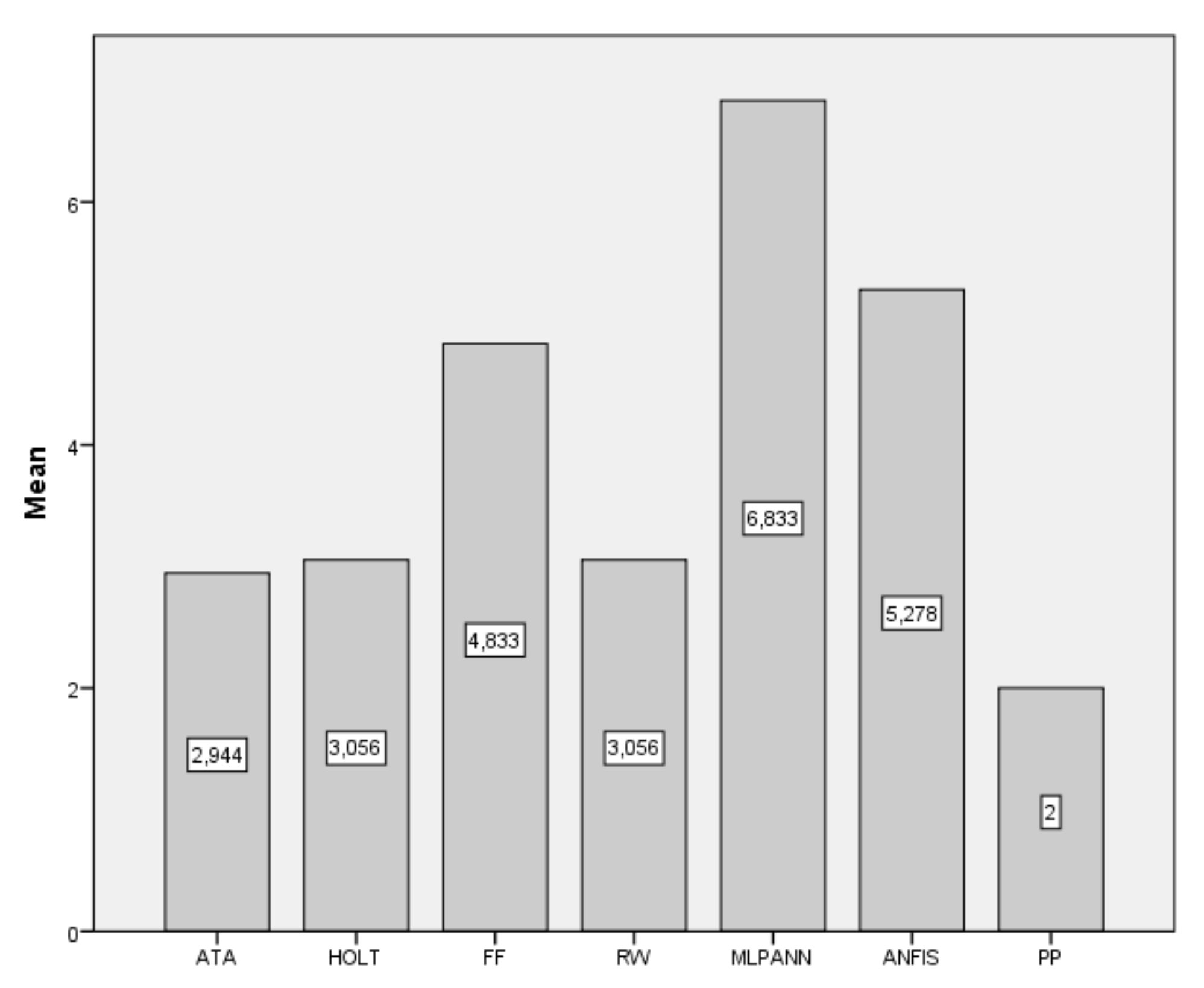
| Data | ATA | Holt | FF | RW | MLP-ANN | ANFIS | PP |
|---|---|---|---|---|---|---|---|
| BIST2000 | 680.61 | 680.33 | 713.87 | 682.74 | 2868.94 | 825.58 | 681.58 |
| BIST2001 | 315.19 | 326.20 | 372.36 | 312.96 | 1030.82 | 540.36 | 296.32 |
| BIST2002 | 388.51 | 389.17 | 390.47 | 393.48 | 392.16 | 432.21 | 383.70 |
| BIST2003 | 313.25 | 339.08 | 456.83 | 311.18 | 2201.77 | 558.18 | 288.38 |
| BIST2004 | 329.12 | 329.30 | 366.48 | 335.16 | 1479.79 | 554.62 | 319.35 |
| BIST2005 | 426.84 | 415.74 | 496.57 | 433.66 | 2940.74 | 632.79 | 463.17 |
| BIST2006 | 539.71 | 551.20 | 581.55 | 547.72 | 742.07 | 625.98 | 556.77 |
| BIST2007 | 814.90 | 783.40 | 789.45 | 774.91 | 854.08 | 660.30 | 762.16 |
| BIST2008 | 575.72 | 571.80 | 589.64 | 542.31 | 766.02 | 624.59 | 541.21 |
| BIST2009 | 492.91 | 510.09 | 518.55 | 516.25 | 2794.96 | 623.04 | 492.17 |
| BIST2010 | 867.04 | 921.85 | 885.97 | 850.14 | 1193.33 | 965.97 | 864.93 |
| BIST2011 | 757.81 | 728.63 | 849.50 | 790.69 | 1141.08 | 772.13 | 774.14 |
| BIST2012 | 592.96 | 564.85 | 605.32 | 544.81 | 5641.93 | 1224.80 | 517.44 |
| BIST2013 | 1687.26 | 1680.69 | 1888.99 | 1709.07 | 2453.56 | 1821.80 | 1669.36 |
| BIST2014 | 1318.63 | 1315.91 | 1323.78 | 1315.91 | 1936.51 | 1610.11 | 1318.91 |
| BIST2015 | 1242.98 | 1263.71 | 1223.85 | 1225.07 | 2322.70 | 1189.75 | 1213.33 |
| BIST2016 | 650.22 | 662.26 | 648.96 | 599.52 | 699.81 | 728.46 | 604.62 |
| BIST2017 | 1010.73 | 1011.04 | 1165.70 | 1031.37 | 2981.64 | 1134.55 | 833.03 |
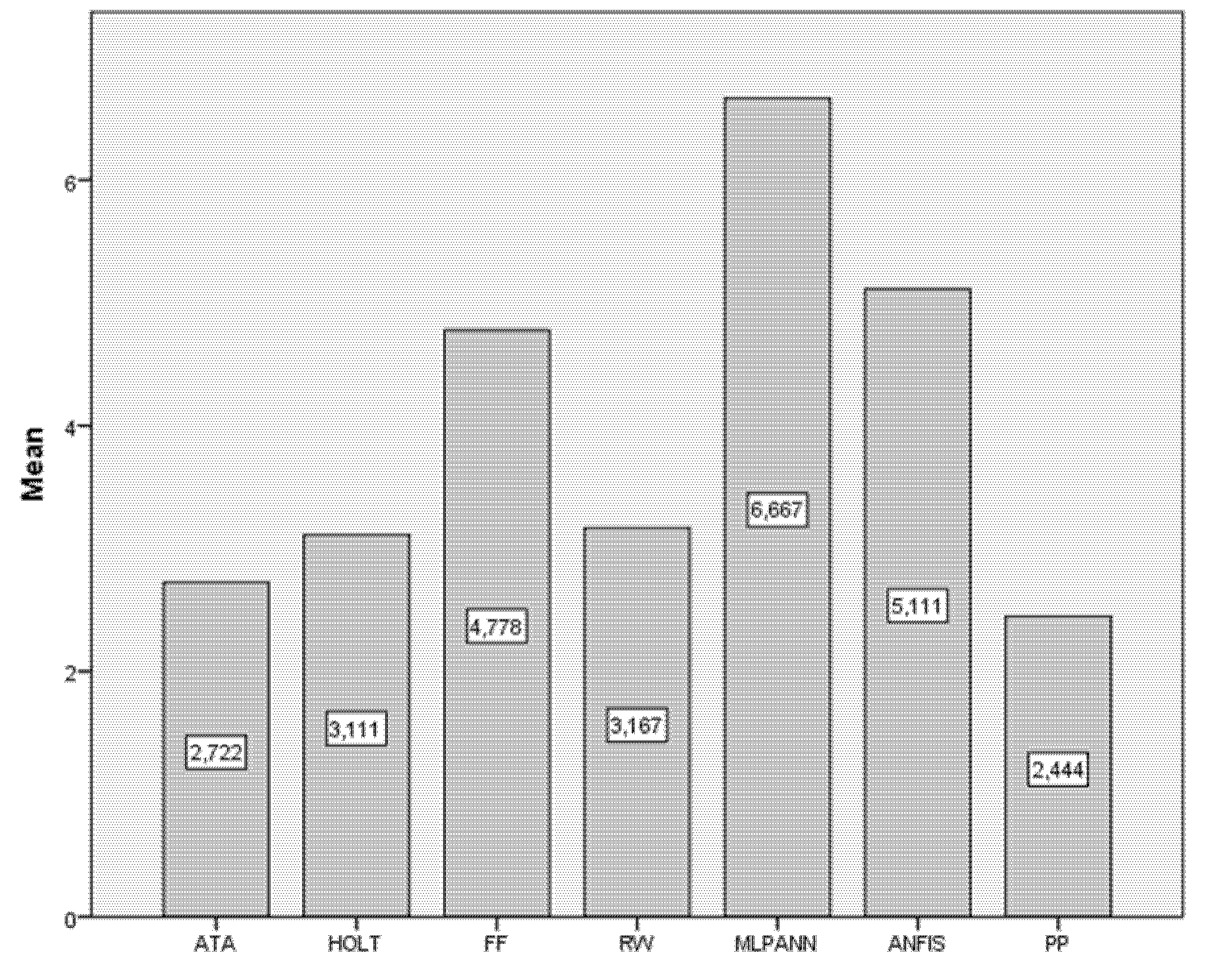
| Data | ATA | Holt | FF | RW | MLP-ANN | ANFIS | PP |
|---|---|---|---|---|---|---|---|
| BIST2000 | 0.0540 | 0.0547 | 0.0615 | 0.0557 | 0.3091 | 0.0748 | 0.0546 |
| BIST2001 | 0.0176 | 0.0182 | 0.0212 | 0.0175 | 0.0746 | 0.0355 | 0.0178 |
| BIST2002 | 0.0261 | 0.0263 | 0.0275 | 0.0272 | 0.0260 | 0.0311 | 0.0269 |
| BIST2003 | 0.0145 | 0.0147 | 0.0219 | 0.0146 | 0.1216 | 0.0242 | 0.0144 |
| BIST2004 | 0.0104 | 0.0101 | 0.0121 | 0.0108 | 0.0587 | 0.0184 | 0.0107 |
| BIST2005 | 0.0087 | 0.0082 | 0.0097 | 0.0091 | 0.0744 | 0.0134 | 0.0096 |
| BIST2006 | 0.0098 | 0.0102 | 0.0109 | 0.0102 | 0.0143 | 0.0124 | 0.0105 |
| BIST2007 | 0.0113 | 0.0108 | 0.0106 | 0.0104 | 0.0127 | 0.0095 | 0.0105 |
| BIST2008 | 0.0180 | 0.0175 | 0.0193 | 0.0164 | 0.0223 | 0.0183 | 0.0167 |
| BIST2009 | 0.0076 | 0.0079 | 0.0080 | 0.0080 | 0.0529 | 0.0097 | 0.0074 |
| BIST2010 | 0.0101 | 0.0112 | 0.0103 | 0.0099 | 0.0129 | 0.0125 | 0.0100 |
| BIST2011 | 0.0118 | 0.0110 | 0.0131 | 0.0124 | 0.0188 | 0.0117 | 0.0121 |
| BIST2012 | 0.0063 | 0.0061 | 0.0064 | 0.0058 | 0.0728 | 0.0142 | 0.0056 |
| BIST2013 | 0.0180 | 0.0179 | 0.0206 | 0.0182 | 0.0278 | 0.0202 | 0.0180 |
| BIST2014 | 0.0121 | 0.0121 | 0.0122 | 0.0122 | 0.0203 | 0.0151 | 0.0120 |
| BIST2015 | 0.0140 | 0.0145 | 0.0133 | 0.0135 | 0.0285 | 0.0129 | 0.0134 |
| BIST2016 | 0.0065 | 0.0065 | 0.0059 | 0.0058 | 0.0068 | 0.0067 | 0.0058 |
| BIST2017 | 0.0073 | 0.0073 | 0.0088 | 0.0077 | 0.0246 | 0.0087 | 0.0065 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bas, E.; Egrioglu, E.; Yolcu, U. Bootstrapped Holt Method with Autoregressive Coefficients Based on Harmony Search Algorithm. Forecasting 2021, 3, 839-849. https://doi.org/10.3390/forecast3040050
Bas E, Egrioglu E, Yolcu U. Bootstrapped Holt Method with Autoregressive Coefficients Based on Harmony Search Algorithm. Forecasting. 2021; 3(4):839-849. https://doi.org/10.3390/forecast3040050
Chicago/Turabian StyleBas, Eren, Erol Egrioglu, and Ufuk Yolcu. 2021. "Bootstrapped Holt Method with Autoregressive Coefficients Based on Harmony Search Algorithm" Forecasting 3, no. 4: 839-849. https://doi.org/10.3390/forecast3040050
APA StyleBas, E., Egrioglu, E., & Yolcu, U. (2021). Bootstrapped Holt Method with Autoregressive Coefficients Based on Harmony Search Algorithm. Forecasting, 3(4), 839-849. https://doi.org/10.3390/forecast3040050