
Quantitative Trading through Random Perturbation Q-Network with Nonlinear Transaction Costs



Abstract
:1. Introduction
2. Reinforcement Learning Structure
2.1. Markov Decision Process
2.2. Action–Value Functions and Q-Learning
2.3. Additive Profits, Multiplicative Profits and Sharpe Ratio
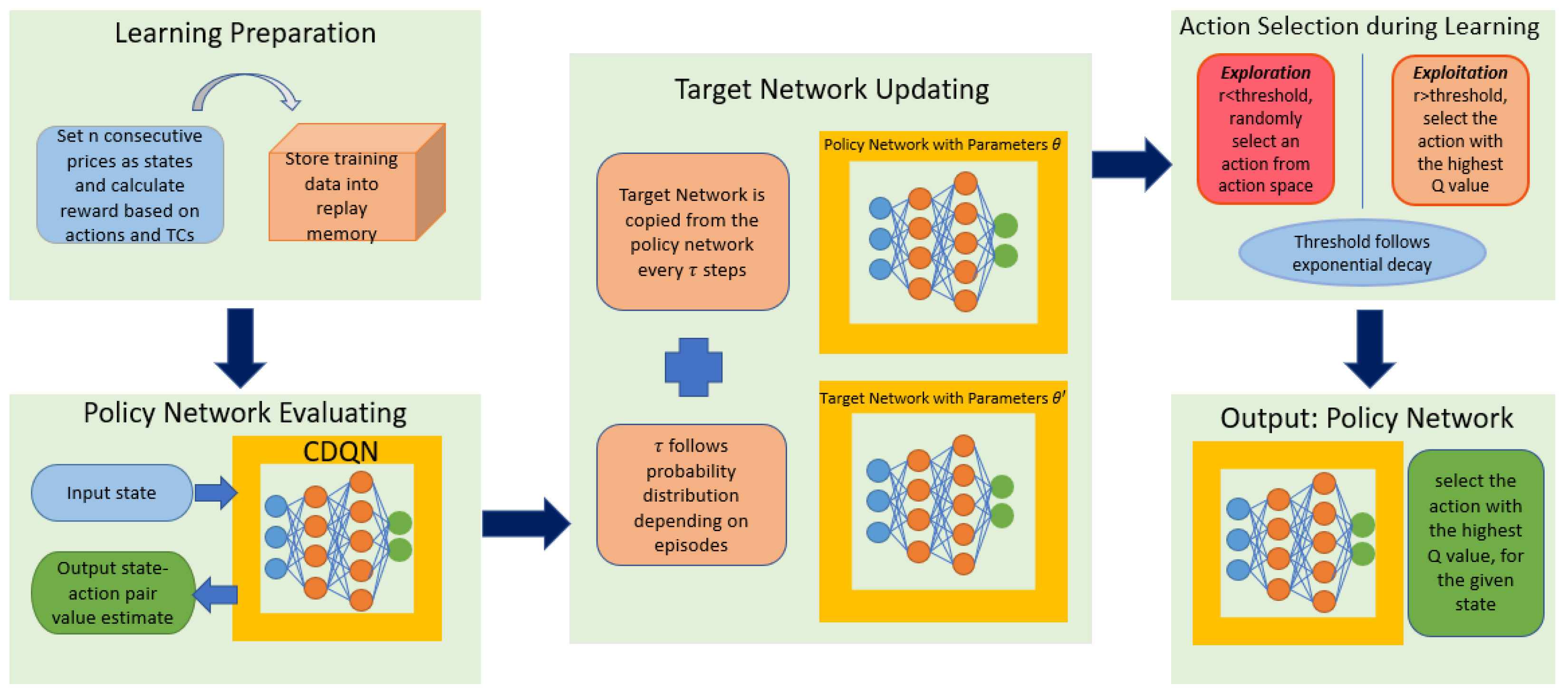
3. Methodology
3.1. Transaction Cost Model
3.2. Stacked Prices State
| Markov Decision Process Setting: State space: Action space: (short, neutral, long); Discount rate: , which is the continuous discount factor; Rewards: . |
3.3. Convolutional Deep Q-Learning Network
3.4. Deep Q Networks with Random Perturbation
- Step 1: initialize , and set and ;
- Step 2: generate according to the following probability mass function, where the constant controls the “tendency” of uniform weights, as all s have the same weights when , while or (depending on i) will have the weight close to 1 when :
- Step 3: update via deep Q network while keep for all ;
- Step 4: update and set when
- Step 5: repeat Step 2 to Step 4 until .
4. Experimental Results
4.1. General Context
4.2. Different Trading Strategies in Cumulative Wealth and Sharpe Ratio
| Buy and Hold: traditional buy and hold strategy LSTM: trading based on LSTM predictions DQN: naive deep Q-network with single stock price DQNn: deep Q-network with n consecutive daily prices CDQNn: convolutional deep Q-network with n consecutive daily prices CDQNn_rp: convolutional deep Q-network with n consecutive daily prices, trained with random perturbation target network |
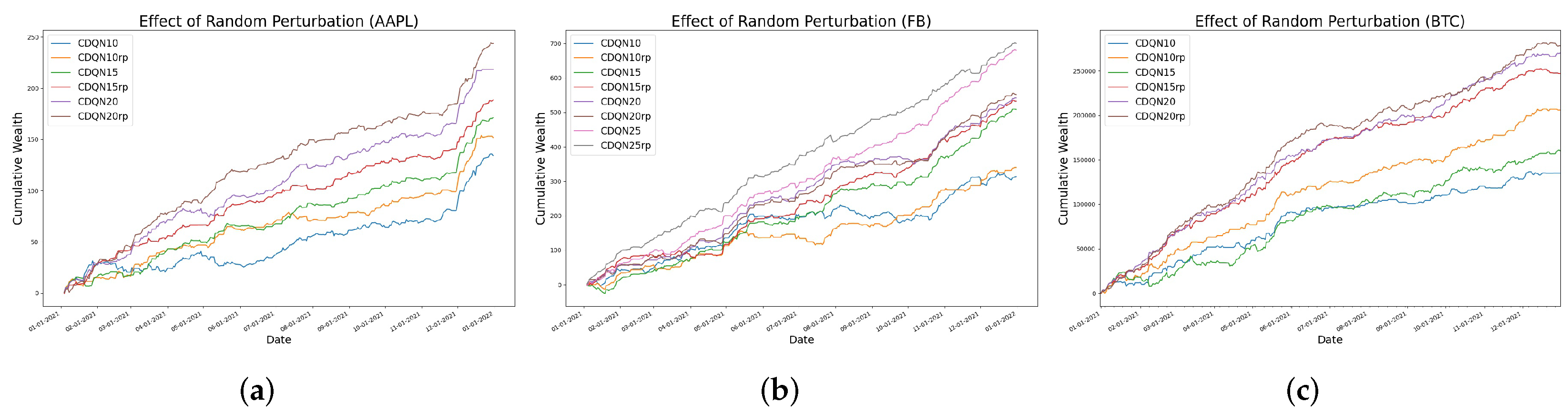
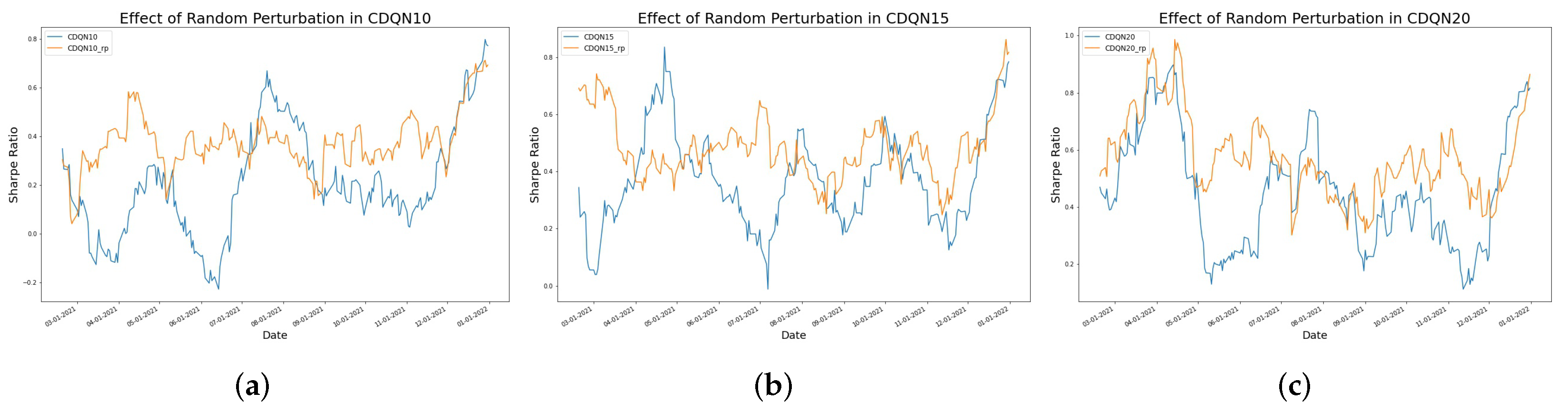
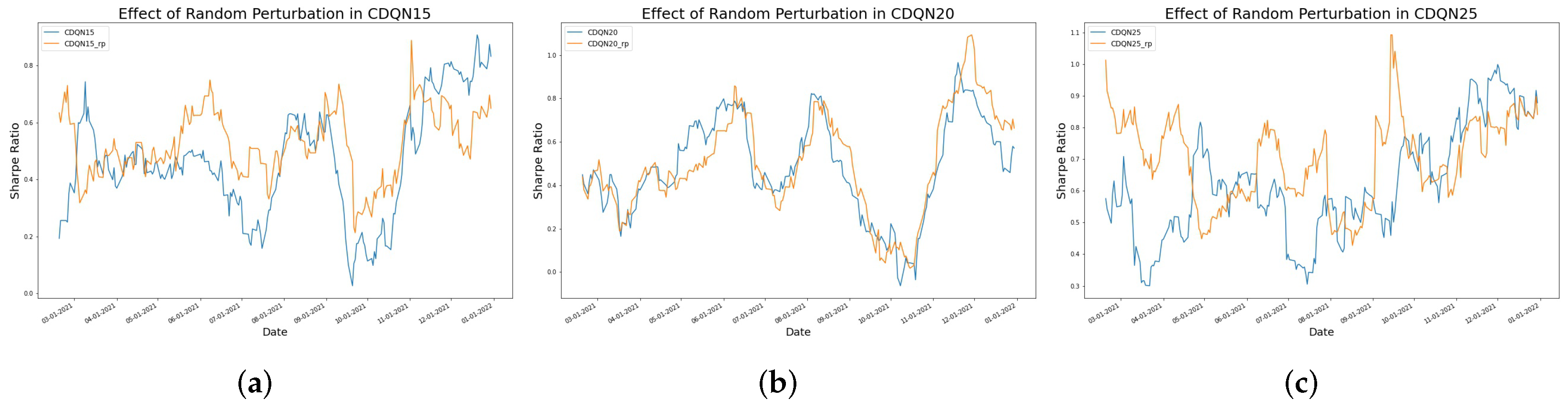
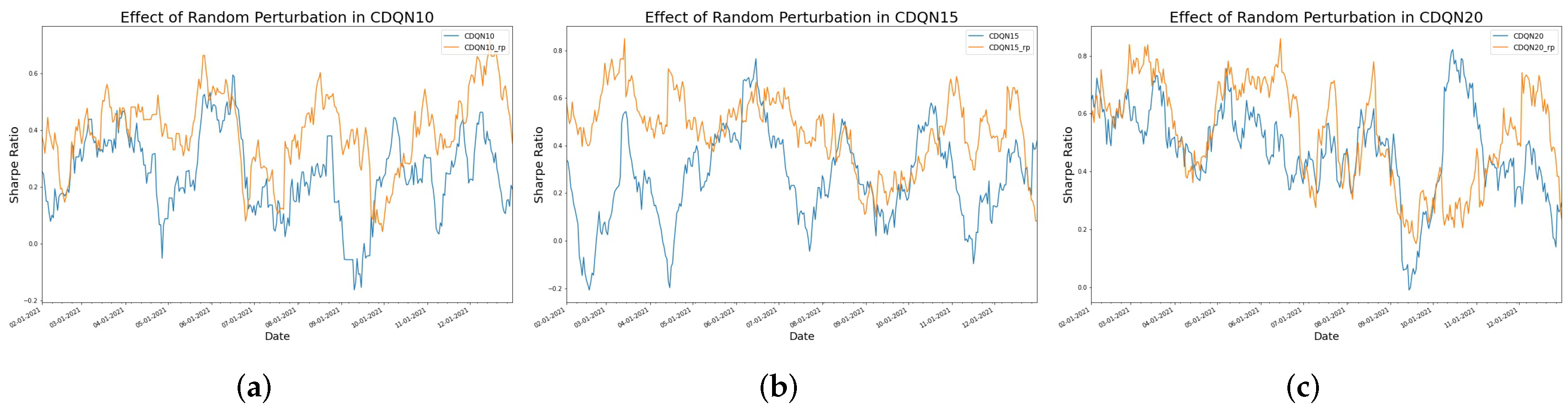
4.3. The Effect of Random Perturbation
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RL | reinforcement learning |
| AI | artificial intelligence |
| DQN | deep Q-network |
| CDQN | convoluntional deep Q-network |
| rp | random perturbation |
| CDQN-rp | convoluntional deep Q-network with random perturbation target network |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameters | Value |
|---|---|
| batch size | 64 |
| replay memory size | 100,000 |
| target network update frequency | 5000, 8000, 10,000, 20,000 |
| uniform tendency c | 5000 |
| learning rate | 0.00025 |
| initial exploration | 1 |
| final exploration | 0.01 |
| decay rate | 0.00025 |
| number of episodes | 1000 |
| LSTM forecast | one-step ahead |
| LSTM input units | 50 |
References
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, L.; Babaeizadeh, M.; Milos, P.; Osinski, B.; Campbell, R.H.; Czechowski, K.; Erhan, D.; Finn, C.; Kozakowski, P.; Levine, S.; et al. Model-based reinforcement learning for atari. arXiv 2019, arXiv:1903.00374. [Google Scholar]
- Mosavi, A.; Faghan, Y.; Ghamisi, P.; Duan, P.; Ardabili, S.F.; Salwana, E.; Band, S.S. Comprehensive review of deep reinforcement learning methods and applications in economics. Mathematics 2020, 8, 1640. [Google Scholar] [CrossRef]
- Collins, A.G.E. Reinforcement learning: Bringing together computation and cognition. Curr. Opin. Behav. Sci. 2019, 29, 63–68. [Google Scholar] [CrossRef]
- Zhong, Y.; Wang, C.; Wang, L. Survival Augmented Patient Preference Incorporated Reinforcement Learning to Evaluate Tailoring Variables for Personalized Healthcare. Stats 2021, 4, 776–792. [Google Scholar] [CrossRef]
- Sun, S.; Wang, R.; An, B. Reinforcement Learning for Quantitative Trading. arXiv 2021, arXiv:2109.13851. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Moody, J.; Saffell, M. Reinforcement learning for trading. Adv. Neural Inf. Process. Syst. 1998, 11, 918–923. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Edelen, R.; Evans, R.; Kadlec, G. Shedding light on “invisible” costs: Trading costs and mutual fund performance. Financ. Anal. J. 2013, 69, 33–44. [Google Scholar] [CrossRef]
- Edelen, R.M.; Evans, R.B.; Kadlec, G.B. Scale Effects in Mutual Fund Performance: The Role of Trading Costs. 17 March 2007. Available online: https://ssrn.com/abstract=951367 (accessed on 1 May 2022). [CrossRef] [Green Version]
- Scherer, B.; Martin, R.D. Modern Portfolio Optimization with NuOPTTM, S-PLUS®, and S+ BayesTM; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Lecesne, L.; Roncoroni, A. Optimal allocation in the S&P 600 under size-driven illiquidity. In ESSEC Working Paper; Amundi Institute: Paris, France, 2019. [Google Scholar]
- Chen, P.; Lezmi, E.; Roncalli, T.; Xu, J. A note on portfolio optimization with quadratic transaction costs. arXiv 2020, arXiv:2001.01612. [Google Scholar] [CrossRef]
- Murphy, J.J. Technical Analysis of the Financial Markets: A Comprehensive Guide to Trading Methods and Applications; Penguin: New York, NY, USA, 1999. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Spoerer, C.J.; Kietzmann, T.C.; Mehrer, J.; Charest, I.; Kriegeskorte, N. Recurrent neural networks can explain flexible trading of speed and accuracy in biological vision. PLoS Comput. Biol. 2020, 16, e1008215. [Google Scholar] [CrossRef] [PubMed]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]

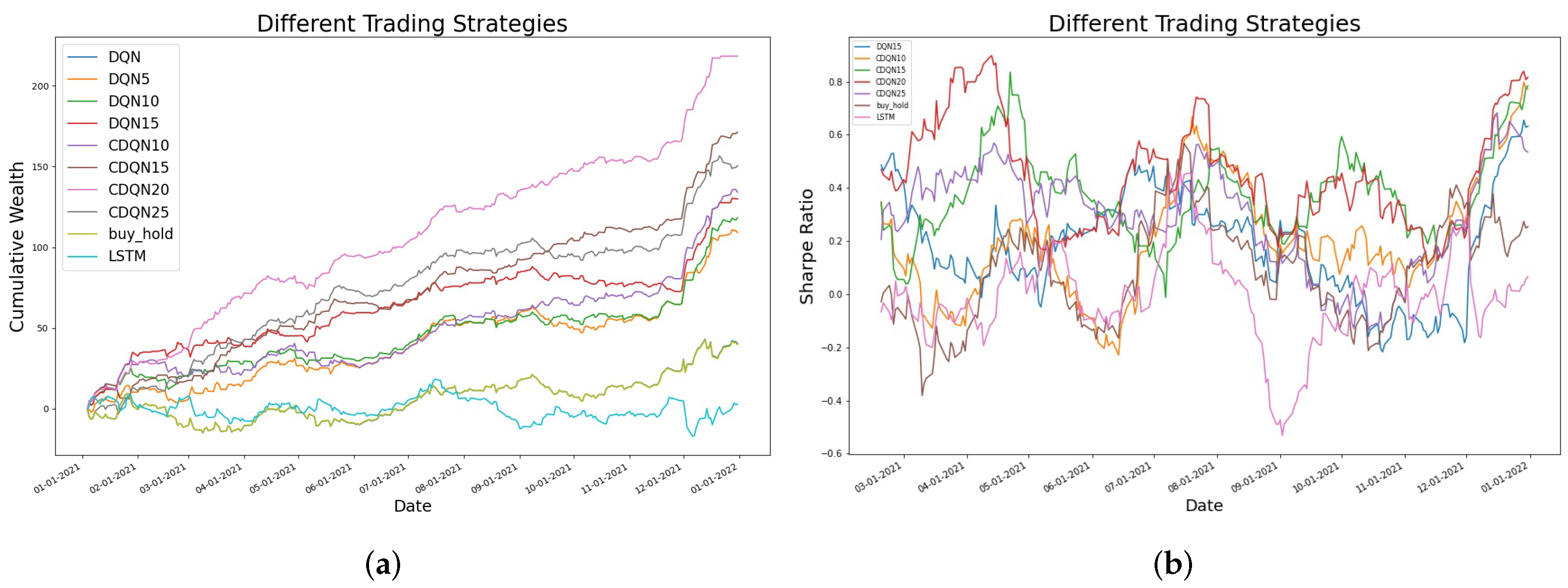
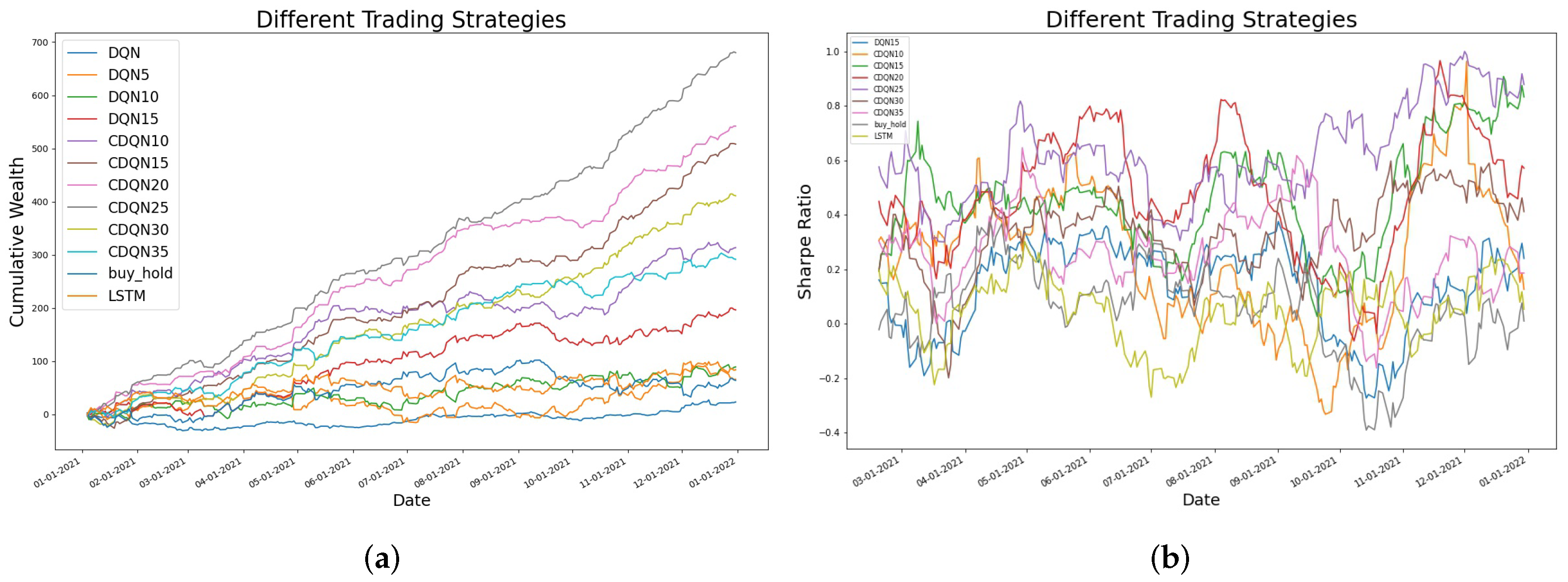
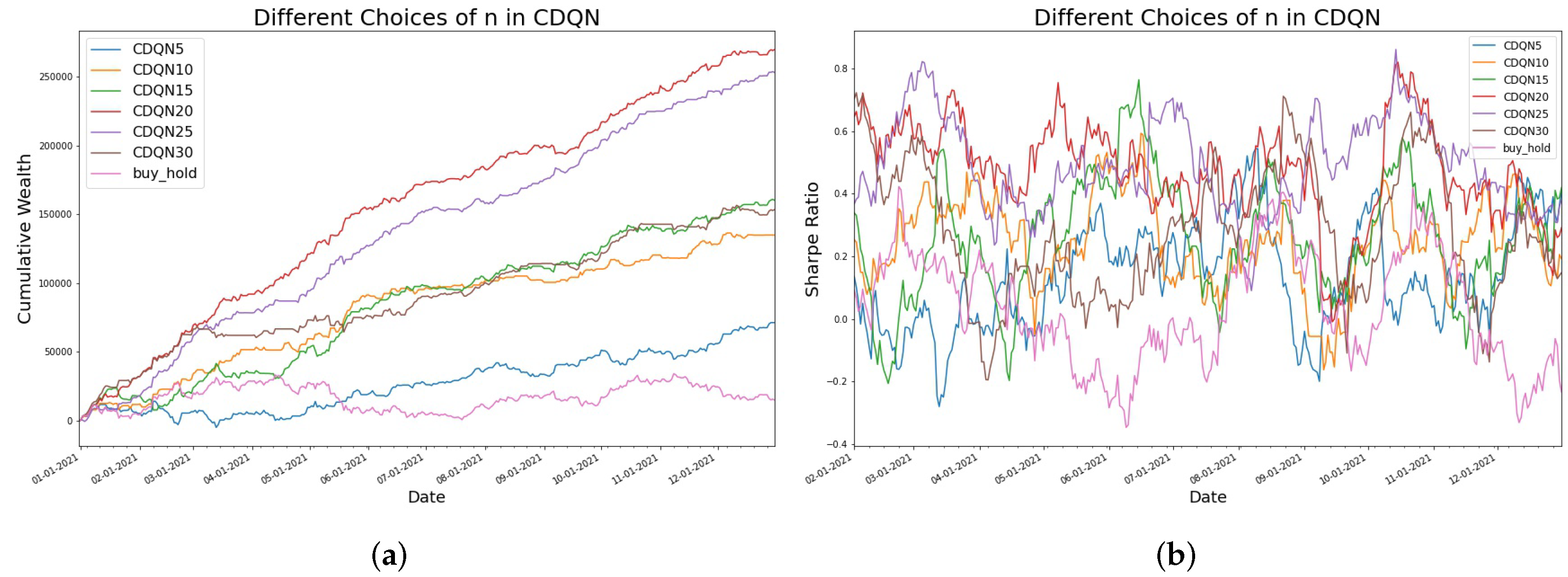
| Methods | AAPL | FB | BTC |
|---|---|---|---|
| DQN | 40.34 | 23.37 | |
| DQN10 | 118.11 | 89.26 | |
| CDQN10 | 134.13 | 313.58 | 134,939 |
| CDQN15 | 171.20 | 508.15 | 160,155 |
| CDQN20 | 218.26 | 541.91 | 269,967 |
| CDQN25 | 150.47 | 680.13 | 258,032 |
| CDQN30 | 411.05 | 153,604 | |
| Buy and Hold | 39.74 | 64.06 | 14,861 |
| Methods | AAPL | AAPL(rp) | FB | FB(rp) | BTC | BTC(rp) |
|---|---|---|---|---|---|---|
| CDQN10 | 134.13 | 151.77 | 313.58 | 340.12 | 134,939 | 205,791 |
| CDQN15 | 171.20 | 188.49 | 508.15 | 531.92 | 160,155 | 247,023 |
| CDQN20 | 218.26 | 243.83 | 541.91 | 551.52 | 269,967 | 278,092 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, T.; Zhu, W. Quantitative Trading through Random Perturbation Q-Network with Nonlinear Transaction Costs. Stats 2022, 5, 546-560. https://doi.org/10.3390/stats5020033
Zhu T, Zhu W. Quantitative Trading through Random Perturbation Q-Network with Nonlinear Transaction Costs. Stats. 2022; 5(2):546-560. https://doi.org/10.3390/stats5020033
Chicago/Turabian StyleZhu, Tian, and Wei Zhu. 2022. "Quantitative Trading through Random Perturbation Q-Network with Nonlinear Transaction Costs" Stats 5, no. 2: 546-560. https://doi.org/10.3390/stats5020033
APA StyleZhu, T., & Zhu, W. (2022). Quantitative Trading through Random Perturbation Q-Network with Nonlinear Transaction Costs. Stats, 5(2), 546-560. https://doi.org/10.3390/stats5020033