1. Introduction
The normal or Gaussian distribution plays a prominent role in almost all fields of science, as the sum of random variables tends to the normal distribution if the quite general conditions of the central limit theorem [
1] are satisfied. Besides the unbounded normal integral, the bounded integral or error function is crucial for the determination of probabilities. However, there is no analytic expression found for this function, a fact that can be tested by using the Risch algorithm [
2,
3]. Powerful modern computer facilities but also simple personal computers allow for a numerical calculation of the error function with any needed precision. However, if a multitude of such calculations has to be performed in a limited time, for instance, in Monte Carlo simulations, the processing time becomes essential. In order to speed up these calculations, simple and more educated approximations have been proposed in the literature. The spectrum of approximations contains, for instance, the Gaussian exponential function, including either numerical constants [
4] or powers and square roots [
5], approximations using ordinary and hyperbolic tangent functions [
6], a rational function of an exponential function with the exponent given by a power series [
7], or an approximation by Jacobi theta functions [
8]. Without knowing the error function explicitly, expectation values can be calculated by an approximation of the normal distribution by a series in ordinary exponential functions [
9].
The present paper contains a continuation of this topic. Employing a geometric approach, we provide an approximation of the squared error function by a finite sum of
N Gaussian exponential functions with different widths, where the values of which are constrained to fixed intervals. We show that, by fine-tuning these width parameters, one can optimise the precision, which, even for the leading order
, is better than the error estimates given by the constraints in Ref. [
5]. In addition, by choosing
N as appropriately large, one can afford an arbitrary precision. On the other hand, even on a personal computer, the calculation with our leading order approximation is obtained 34 times faster than an exact numerical calculation, the processing time for higher orders being multiplied by
N.
Our paper is organised as follows. In
Section 2, we introduce the basic concepts for the calculation of the Gaussian integral that are necessary for the understanding of our geometric approach. The precisions of the leading order approximation obtained here and simple, straightforward extensions of this approximation are discussed in
Section 3. In
Section 4, we explain the geometric background for our approximation and provide a systematic way to create higher order approximations. The iterative construction of higher order approximations is explained in general in
Section 5 in terms of partitions before we turn to the partition into
intervals for increasing values of
p. In
Section 6, we explain a similar ternary construction. In
Section 7, we provide our conclusions and an outlook on possible extensions. The convergence of our iterative procedure is discussed in more detail in
Appendix A. In addition, we discuss the continuum limit, which, of course, cannot be part of the algorithm but allows, as a bonus, for a different representation of the error function.
2. Basic Concepts
The error function is based on the standard normal density distribution
which does not have a direct practical meaning, while it is desirable to evaluate the integral of this function over a bounded interval
, leading to the probability
to find the result within this interval,
From Equations (
1) and (
2), the square of probability is given by
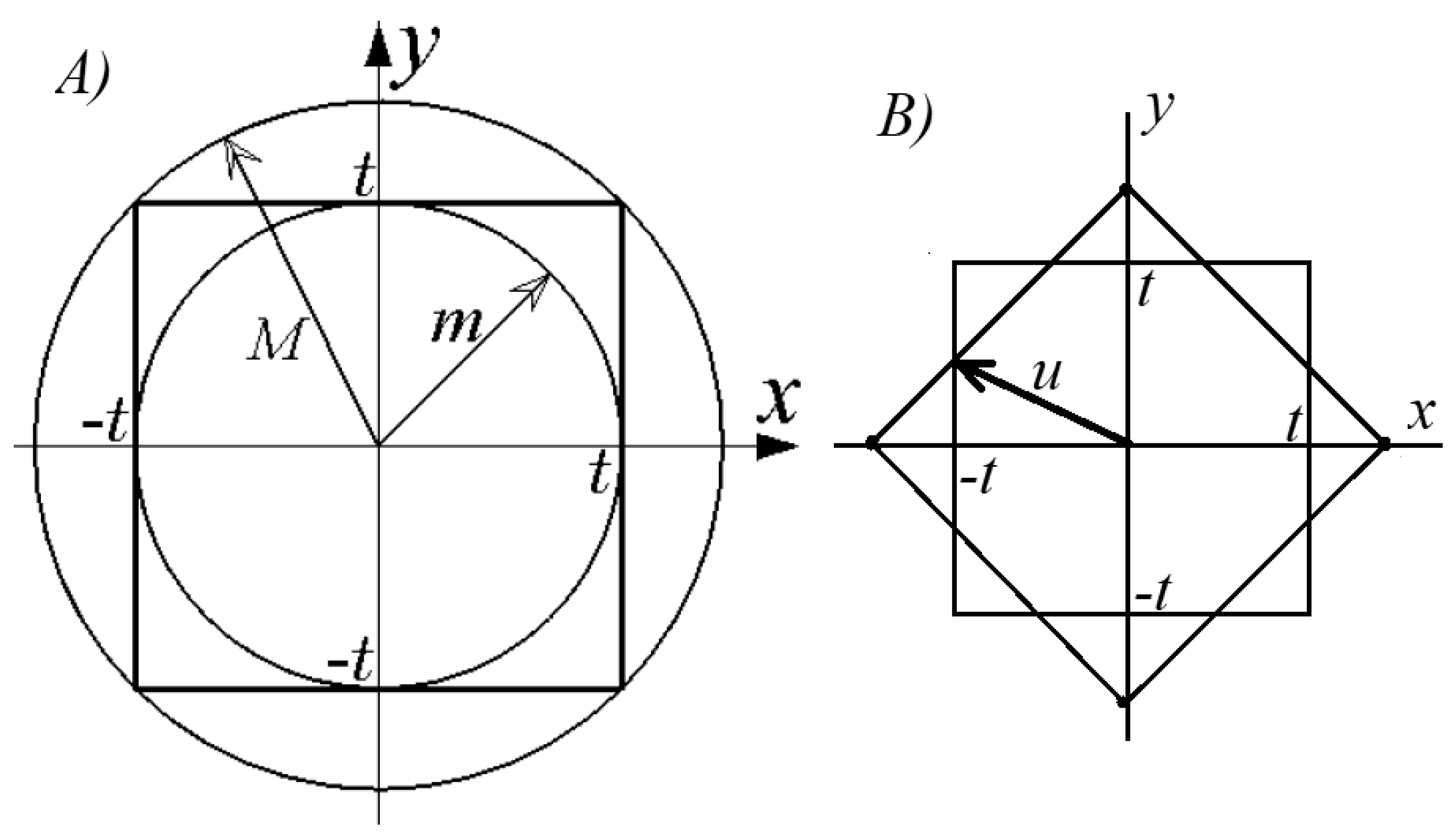
where the integration area is a square in
Figure 1A. Introducing polar coordinates
and
, one obtains
The integral in Equation (
4) is analytically calculable if the integration is performed over the interior of some circle with radius
R. Indeed,
Here, the function
increases monotonically with
R as the integral in Equation (
4) is taken over a positive function. This is why
, with
and
; see
Figure 1A. Therefore,
where
. Using a PC for analyzing the set of Equations (
1), (
2), and (
6), one concludes that
is even more constrained by
. Hence,
and
has a maximum of
at
. The Inequality (
7) proves to be incomparably elegant, easy to remember, and much more accurate than the best result of Ref. [
5], which, if transformed into the present formalism, will be
The largest range
for these constraints occurs for
. Compared to this, even at the leading order observed so far, our value for
is more restrictive. In more detail, if, in Equation (
6), we choose
, the error will be below
, but if we take
, the maximal error is only
. Even modern reviews on this subject do not have better results [
10].
3. Simple Extensions
By adding additional terms to the leading order approximation, one can increase the precision further. For the normal integral
and the leading order approximation, for
, one has
However, the precision increases by a factor of
by using
where
,
. The next order of precision has
where
,
, and
. Therefore, this formula with three exponentials is at least 8 times more precise than the one with two exponentials, and it is at least 110 times more precise than Equation (
11) with one exponential only. Finally, it is
times more precise than the approximation in Ref. [
5]. As it turns out, the values for the parameters
for
i running from 1 to
N take values between 1 and
, while the sum of the exponential factors is divided by
N. Still, there is a degree of arbitrariness in the determination of these parameters. In order to remove this arbitrariness, in the following, we develop an iterative method based on geometry.
5. Basic Construction of the Procedure
In order to construct the iteration, one performs a partition of the figure describing , , or both of these, by repeating the geometric construction shown before. For instance, taking only the larger eight-angle figure describing , one can turn this figure by an angle and overlay the new figure with the old one. In doing so, one can separate a new larger and smaller 16-angle figure in the same way as was carried out before for the 8-angle figures. Accordingly, by geometric means, one obtains new constraints. In order to describe the procedure in a unique way, in each iterative step, we rename by , and, if this new is subject to a partition, the smaller and larger figure of this partition are related to the values and , respectively.
Using the case in the previous section as an illustrative example for the procedure, we might keep the smaller eight-angle figure related to
but apply a partition to the larger eight-angle figure related to
. Accordingly,
is replaced by
and
is replaced by
, but this new
is again split up into
and
. The constraint for the lowest parameter
(the former
) remains the same,
whereas, for the two new higher parameters, we obtain
and
The intervals are consecutive, but
is replaced by
in order to indicate the new partition. Finally, the upper limit stays at
. For these values
,
, and
, one obtains the approximation
with
because of the geometric transformations of
Figure 1 and the corresponding double use of Equation (
14). Note that the set of parameters
,
,
is different from the set
,
, and
in Equation (
13). Indeed, if, for Equation (
23), one uses
,
, and
, the precision improves to
. Still, it is obvious that this example is only half of an iteration step, and one could definitely achieve a greater result by also performing the partition for the smaller eight-angle figure, leading to four parameters separated uniformly,
Therefore, a full iteration step is increasing the number of parameters
by a factor of two, and, after
p full iteration steps, one has
parameters. Each iteration step is finalized by optimizing the
N (or less) parameters
. For any finite (or even very large)
N, the constraints
with
can be calculated from geometry observations in a similar fashion. In practice, for a small set of parameters, we use a graphical method. For instance, the method applied to obtain the three values
,
, and
in Equation (
23) was to look for the solution of the system of three equations
where
The values
,
, and 2 are used as nodes for this approximation. Their choice depends on the application of the approximation and has to be adjusted to the number of width parameters to be determined. Each equation in (
26) can be treated individually. Therefore, the solution is very easy to find. From
, one extracts the function
. Inserting these solutions into
, one extracts the two positive functions
and
. Inserting these solutions into
and plotting the function
, one finds the position of the zero, which proves to be
. Using this knowledge, one obtains
and
as well. However, as
is given for
only, this is not a valid solution, as
for all
n. Note that the graphical method cannot be applied any more for
. Instead, we used a random number generator to create values for the parameters
in the respective intervals in Equation (
24). Proceeding in this way, for
(
), we obtain the values
,
,
, and
, and a precision of
, which is, again, the lowest precision for a given
N. As becomes obvious, the lowest precisions are obtained for uniform partitions. This is not only the case for
N being a power of 2 but also for
N being a power of 3, as discussed in the next section.





{kind=link}
{kind=link}