
Unsupervised Particle Tracking with Neuromorphic Computing

 , , , , , , , and
, , , , , , , and
Abstract
1. Introduction
1.1. Neuromorphic Computing
1.2. Spiking Neural Networks
1.3. Neuromorphic Computing in High-Energy Physics
2. Track Reconstruction with the CMS Phase-2 Experiment at HL-LHC
- Seeding: Track seeds are formed using hits from the detector, focusing on high-efficiency seed generation even in high-density environments.
- Trajectory building: Using the Kalman filter, the algorithm extends the seed through the detector layers, accounting for multiple scattering and energy loss.
- Fitting: A final fit refines the trajectory, providing precise momentum, charge, and vertex information.
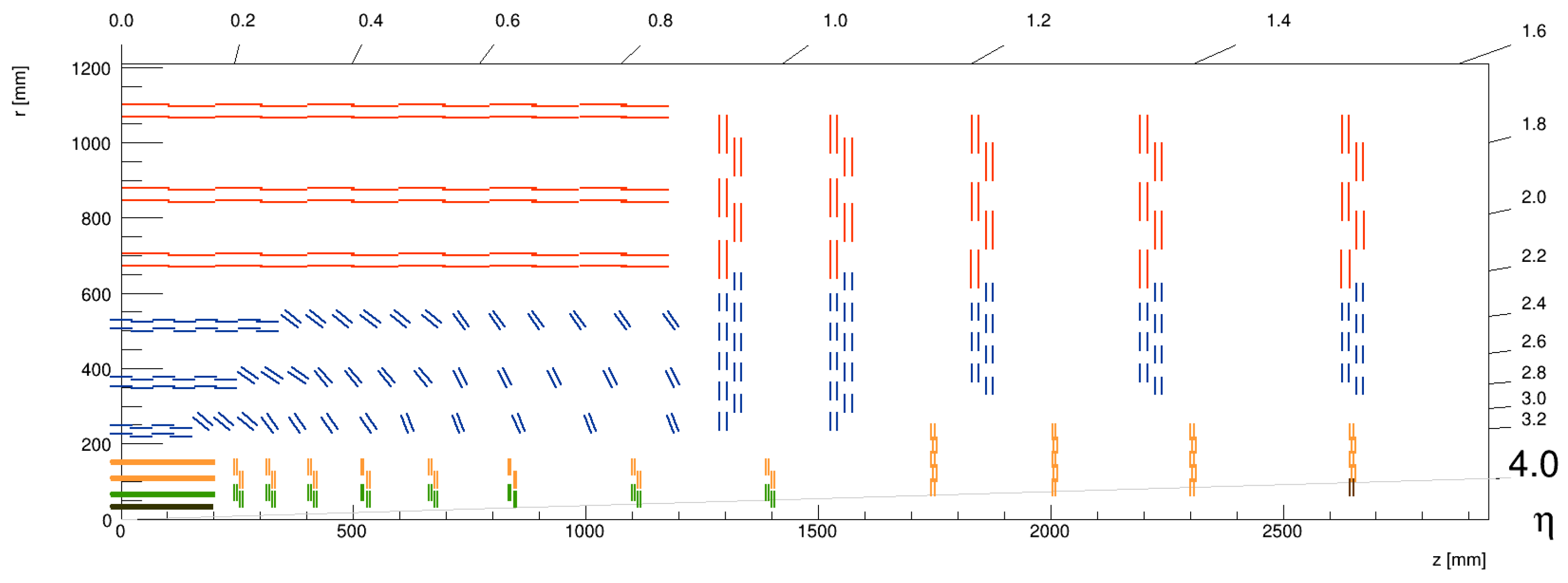
- Track efficiency: The track reconstruction algorithm achieves exceptionally high efficiency (defined as the fraction of charged particles in a given momentum range that are identified by the algorithm). For charged particles with transverse momentum , it exceeds 99% in the central region (pseudorapidity ), and it still remains above 95% in the forward region ().
- Transverse momentum resolution: Phase-2 track reconstruction achieves a resolution of transverse momentum (defined as the relative uncertainty in transverse momentum, ) that is better than 1–2% for high- tracks in the central region (), which is critical for high-precision measurements of particle momenta. Although the resolution slightly degrades in the forward region due to the increased material and multiple scattering effects, it remains within acceptable bounds for reliable track reconstruction across the entire detector.
- Fake track rate: the fraction of reconstructed tracks that do not correspond to real particle trajectories, often arising from noise, overlapping hits, or mis-reconstruction, is expected to be 0.5% to 1% for tracks with .
3. Spiking Neural Network Model for Particle Tracking
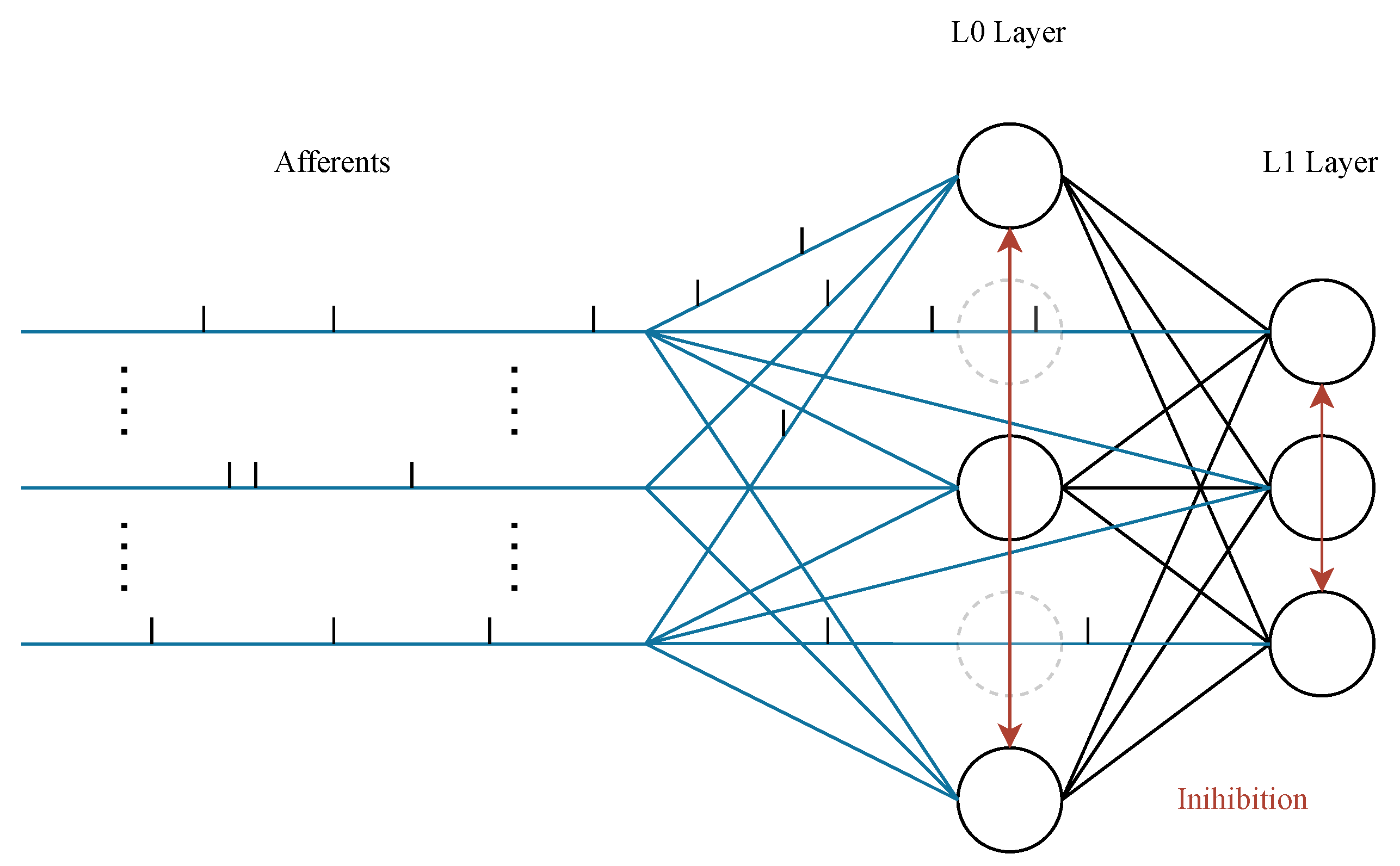
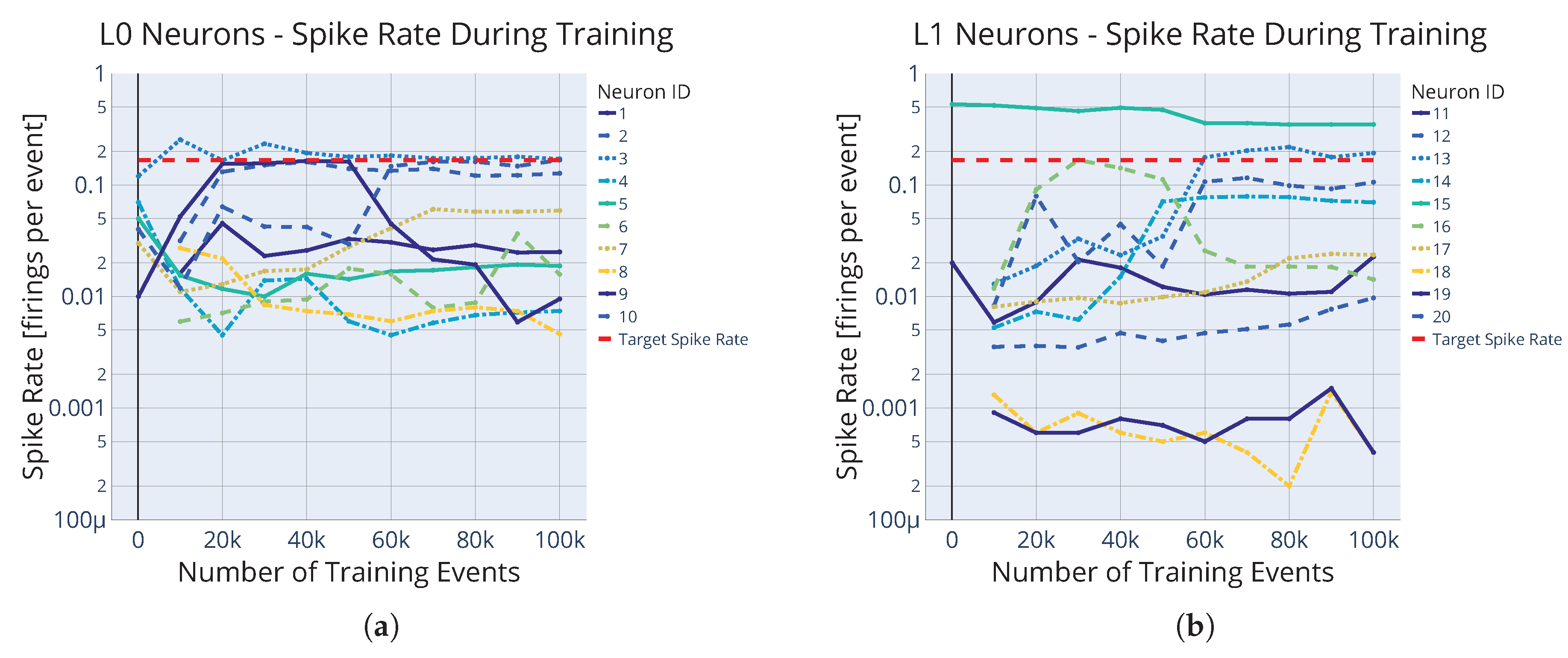
3.1. SNN Architecture
3.2. Initialization of the Synaptic Weights and Delays
3.3. Numerical Simulation of the Neuron Potentials
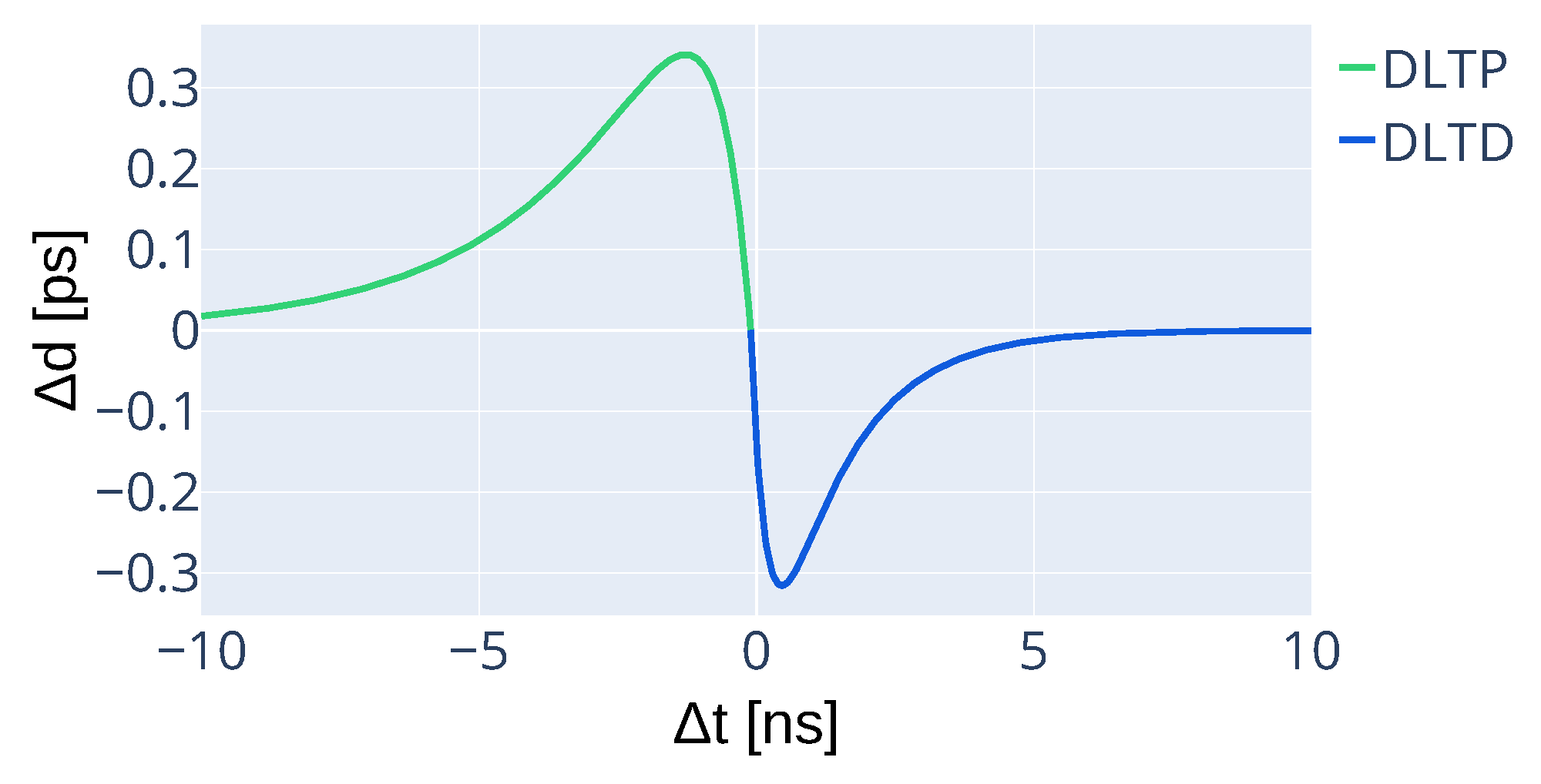
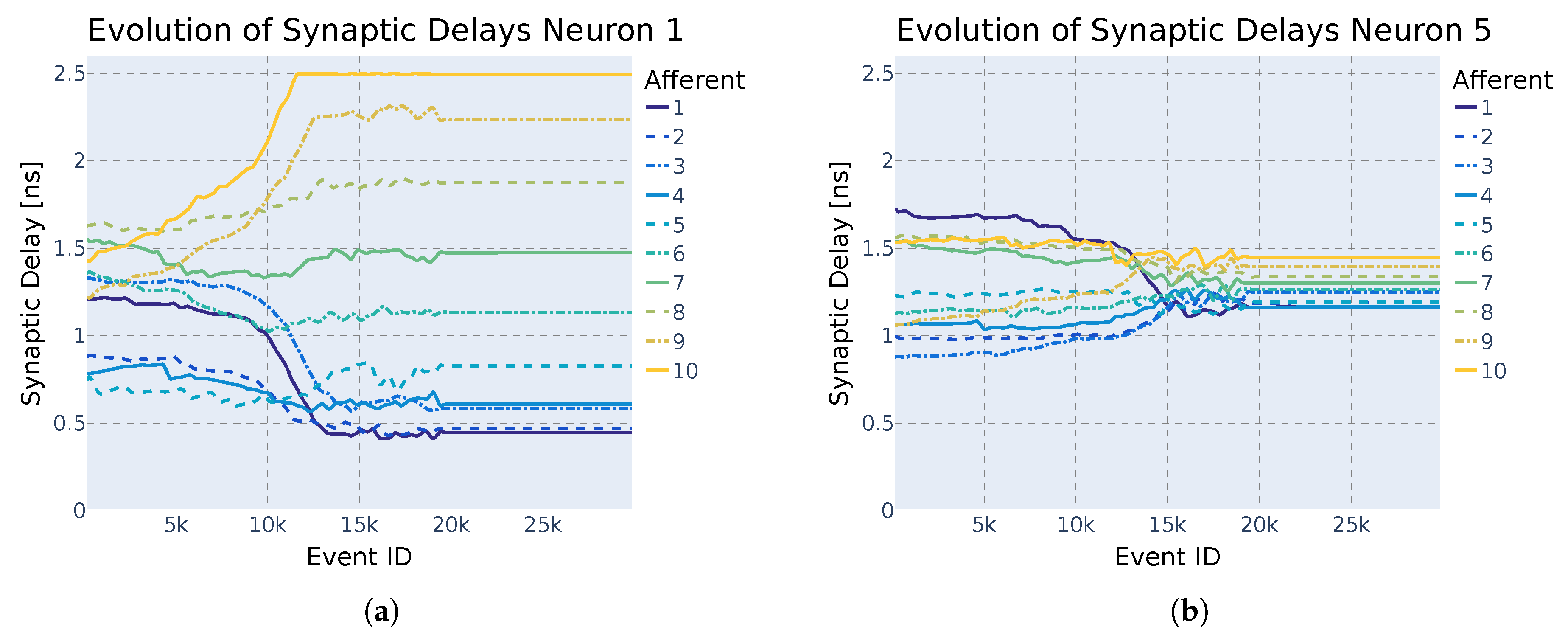
3.4. Modified STDP for Unsupervised Synaptic Delay Learning
- Delay potentiation (DLTP) If a pre-synaptic spike occurs before the neuron’s activation, the delay is increased, effectively delaying the pre-synaptic spike.
- Delay depression (DLTD) If a pre-synaptic spike occurs after the neuron’s activation, the delay is decreased, advancing the pre-synaptic spike.
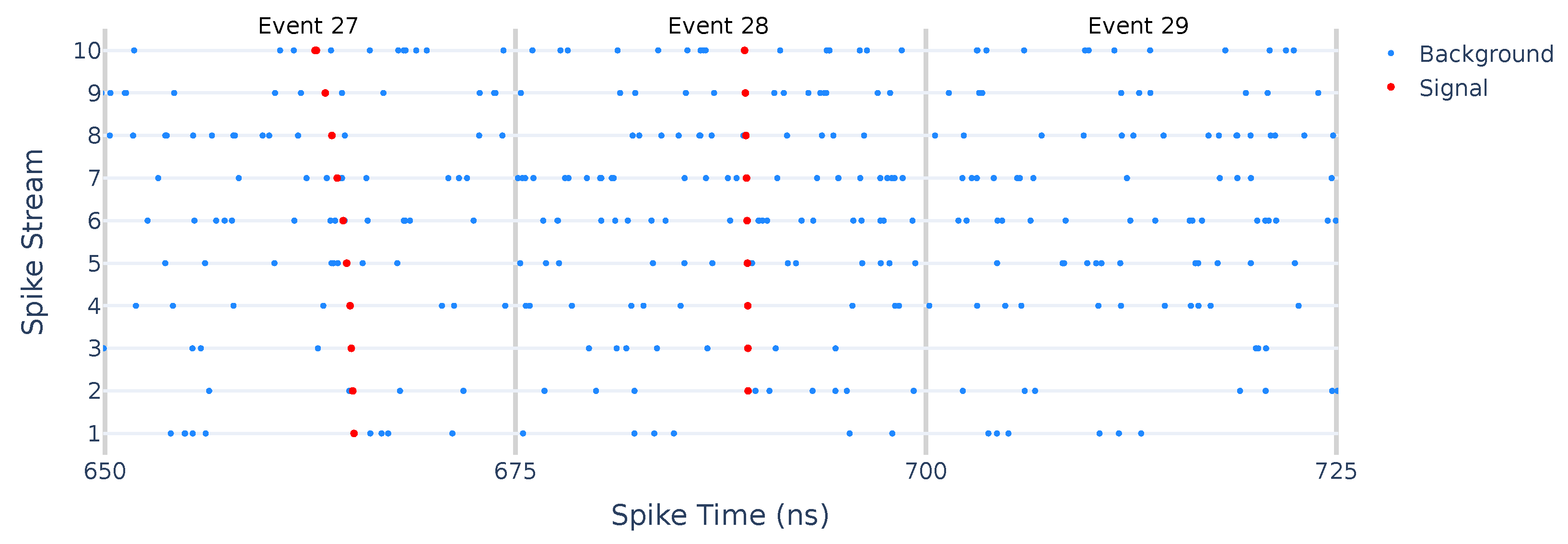
3.5. Spatio-Temporal Information Encoding of Detector Hits
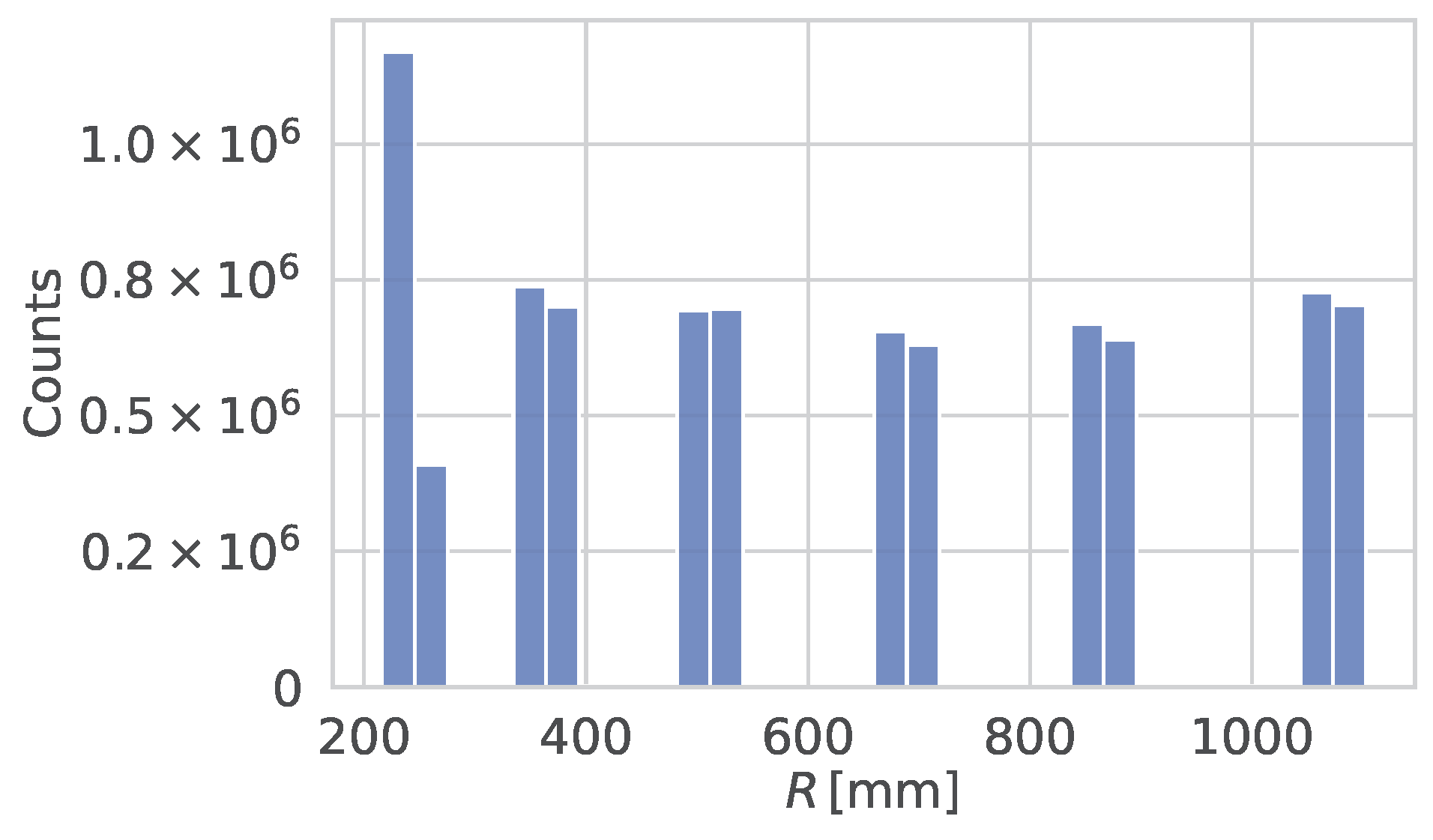
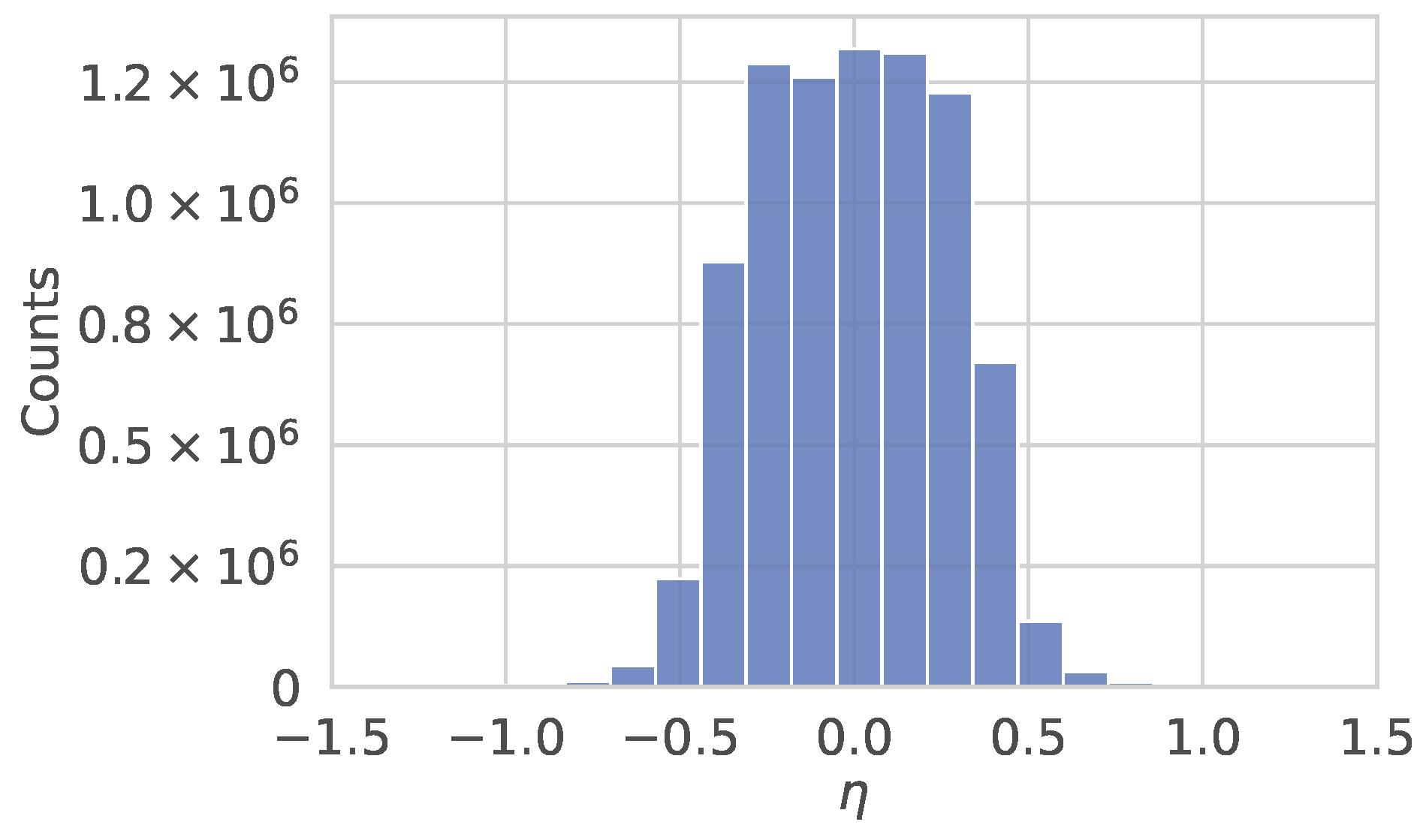
4. Simulated Dataset for Training and Validation
- Hits from the Monte Carlo simulations were collected into a reference set.
- Each hit was assigned a weight equal to 1.
- A cumulative distribution function was computed for the reference set.
- A random value x was drawn uniformly in , where is the maximum value of .
- The corresponding hit index was determined by inverting .
- Steps 4 and 5 were repeated until the desired number of noise hits was obtained.
5. Methodology—Hyperparameter Search and Optimization
5.1. Utilities Definition
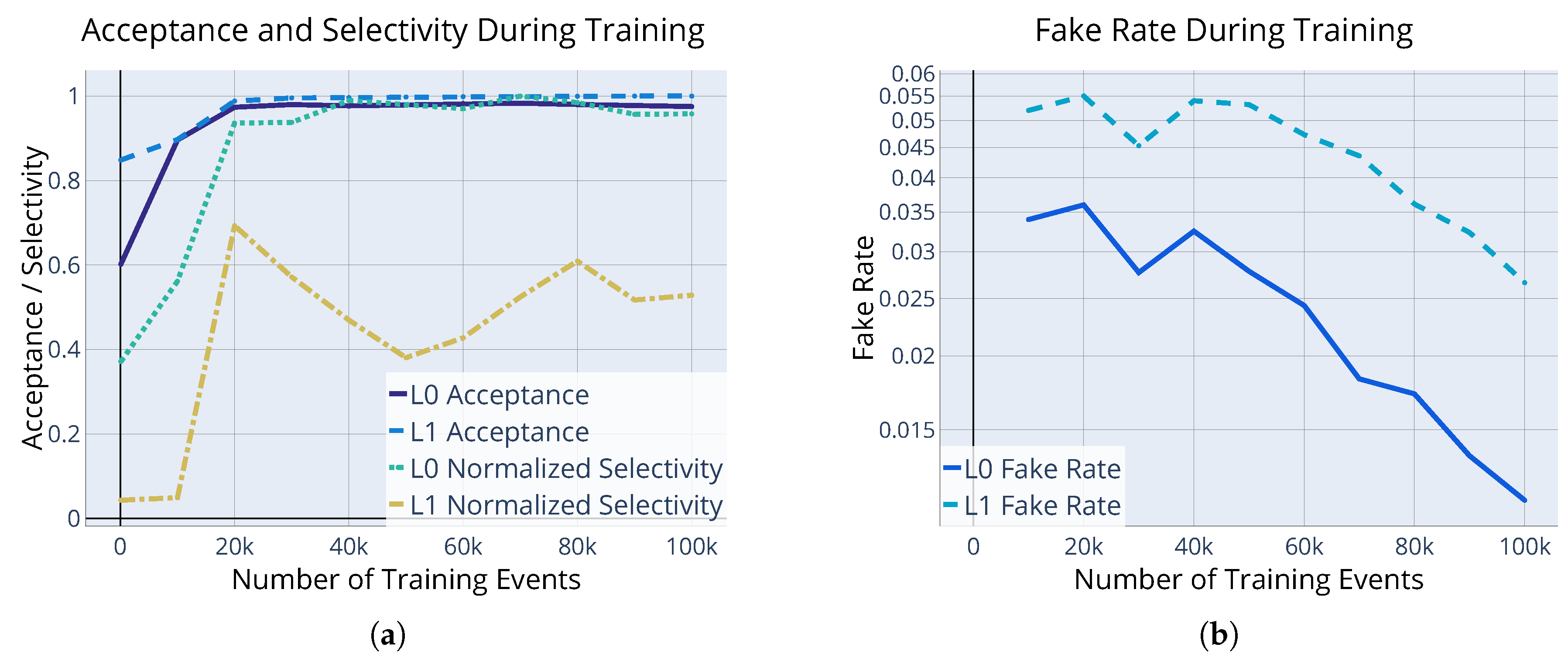
5.2. The Problem of Specializing Neurons
5.3. Hyperparameter Tuning and Genetic Algorithm
5.4. Optimization Workflow for Spiking Neural Networks in Noisy Environments
- Stage 1: Simplified Problem with Minimal Background
- -
- Background noise is controlled, with the average number of background hits set to .
- -
- The GA optimizes the network for a reduced classification task focused on identifying negative muons with transverse momenta , resulting in a three-class classification problem.
- -
- Delay learning, a mechanism for modulating synaptic delays, is employed to enhance selectivity and minimize false positives.
- -
- The hyperparameter search space for this stage includes all the ones defined in Table 2.
- Stage 2: Incorporating Antimuon Classification
- -
- The optimal network configuration from Stage 1 is selected as a baseline. The most active and specialized neurons are preserved, while their delay properties are mirrored and adjusted to initialize new neurons. Initial individuals in the GA are mutations of this configuration.
- -
- Antimuon events are introduced into the training and validation datasets, expanding the classification task.
- -
- The hyperparameter search space is refined by fixing the values of , , , , , , , , and constraining the ranges of , , , .
- -
- Delay learning rates () are reduced to allow finer convergence during training.
- Stage 3: Evaluating Network Robustness Across Noise Levels
- -
- The optimal network from Stage 2 undergoes additional refinement, where neurons with high activation and specialization are retained, and less significant neurons are pruned.
- -
- The network is tested at varying noise levels to assess robustness. Based on these results, the network undergoes further retraining at elevated noise levels during the next stage.
- Stage 4: Fine-tuning at High Noise Levels Results for this stage are presented in Section 6.1.
- -
- The optimized network from Stage 3 is selected as the basis for this stage. Initial individuals in the GA are mutations of this configuration.
- -
- Background noise is increased, with the average number of background hits raised to .
- -
- The hyperparameter search space is limited to , , , , , , with narrower parameter ranges to focus on fine adjustments.
- -
- The delay in learning rates () is further reduced to achieve incremental improvements in accuracy and robustness.
6. Results
6.1. Single Track Pattern Recognition Under High Levels of Noise
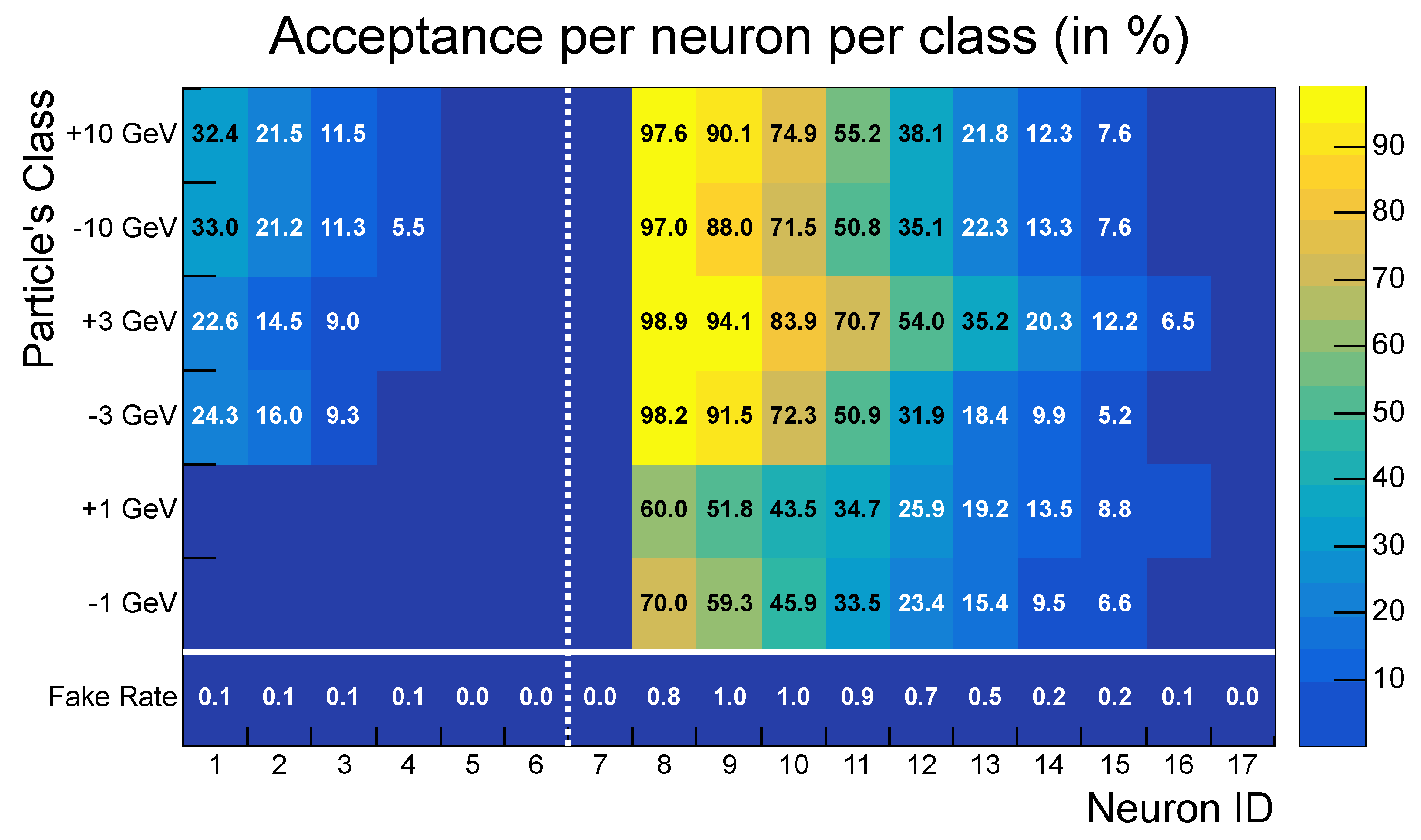
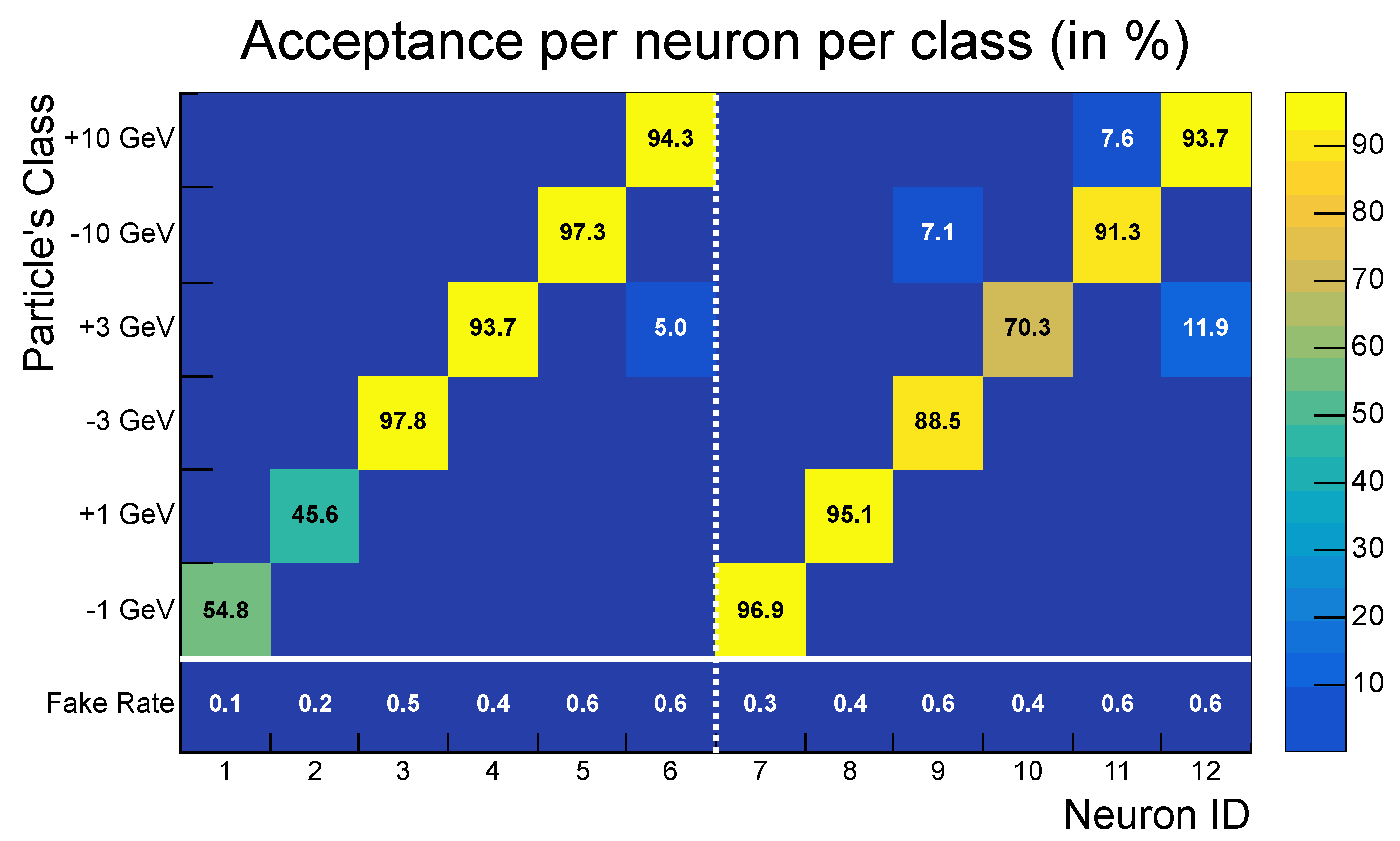
- High acceptance: the SNN achieved greater than 98% acceptance for all transverse momentum classes, with peak values reaching 100% for particles with .
- Low fake rate: The network effectively suppressed noise, achieving a fake rate of approximately . This aggregate fake rate is higher than the individual fake rates of neurons (<1%) because it accounts for the global response of the entire network: even if only a single neuron activates in a background-only event, the event is considered a false positive.
- Strong selectivity: a selectivity score of 3.48 indicates robust discrimination between signal and noise patterns.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [%] | [%] | [%] | [%] | [%] | [%] | F [%] | S | |
|---|---|---|---|---|---|---|---|---|
| 300 |
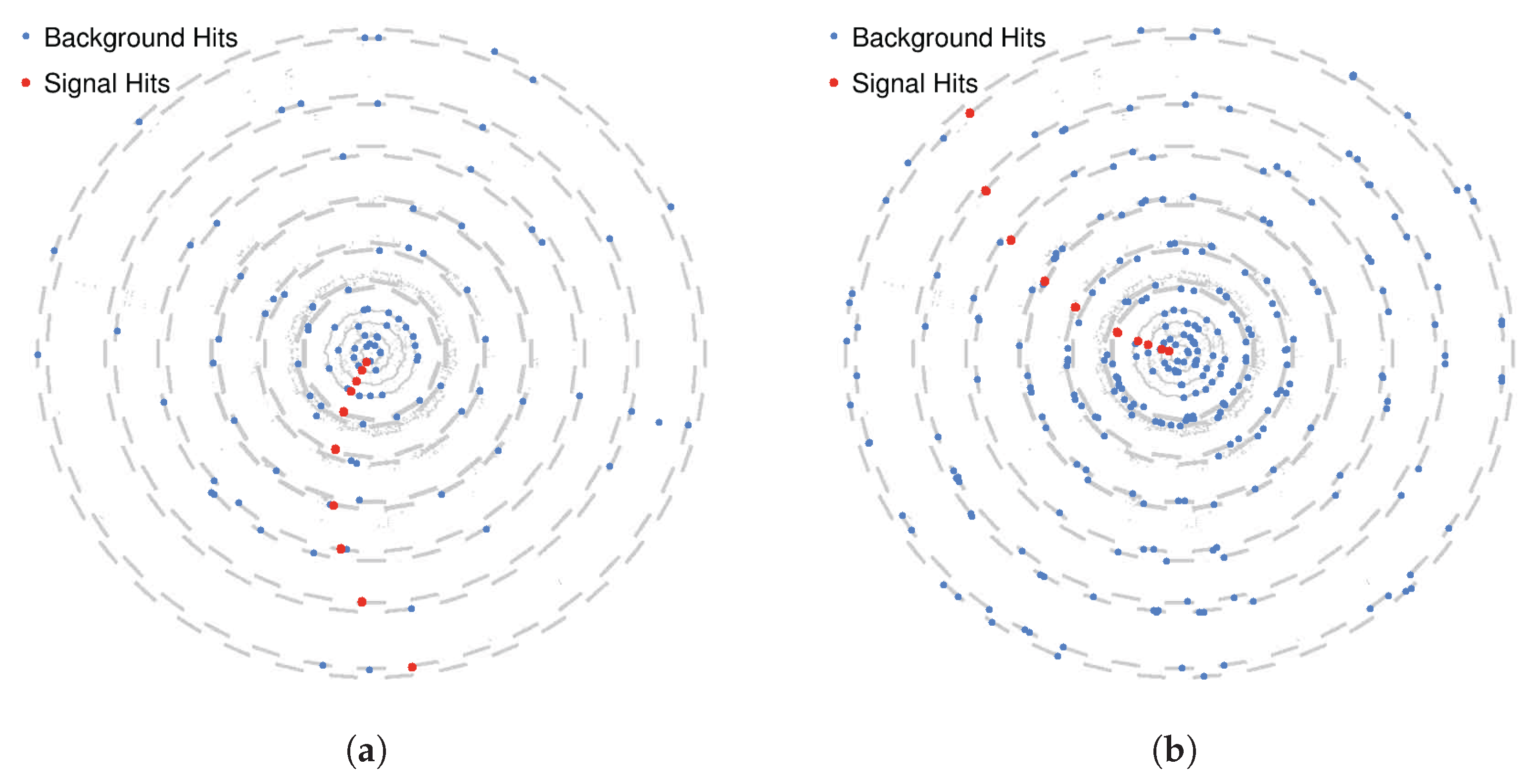
6.2. Searching for Multiple Tracks
- Temporal overlap: tracks appearing within the same time window may produce closely spaced spikes, making it difficult for the network to distinguish separate trajectories.
- Refractory periods: once a neuron fires in response to one track, it enters a refractory period, which may hinder the detection of other nearby tracks.
- Neuron competition: Lateral inhibition is a crucial mechanism that prevents multiple neurons from firing for the same pattern, allowing them to specialize. However, when two patterns occur within the same time window, this mechanism can become counterproductive, reducing the network’s ability to specialize effectively.
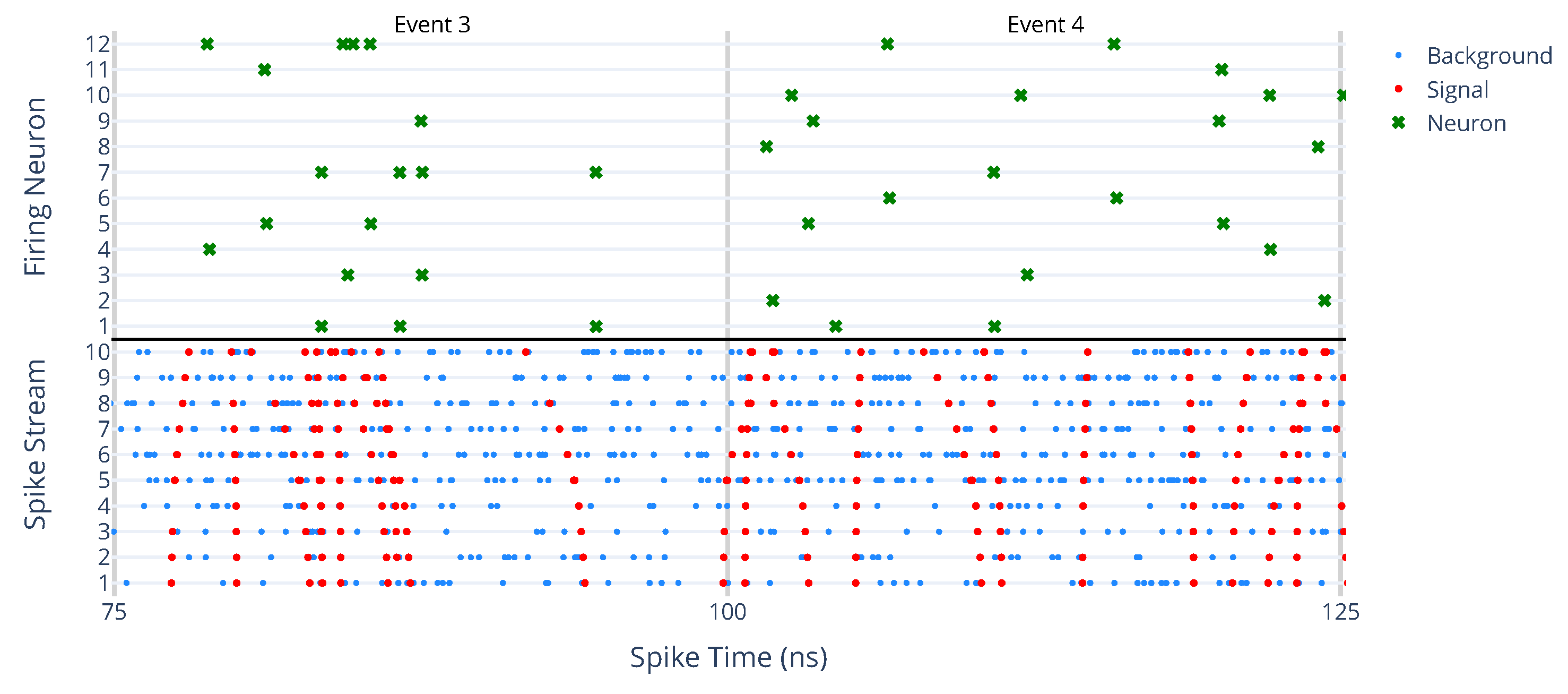
- (True Positives) are correctly classified events.
- (False Negatives) are missed events.
- (True Positives) are correctly classified particle track events.
- (False Positives) are events mistakenly classified.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Parameters
| Parameter | Value | Description |
|---|---|---|
| 0.167 | Temporal Scaling Factor for Inhibitory Post-Synaptic Potential (IPSP) dynamics. | |
| K | 2.27 V | Scaling constant for Excitatory Post-Synaptic Potential (EPSP). |
| 3.45 V | Scaling constant for the Reset Potential after neuron activation. | |
| 5.00 V | Scaling constant for the Reset Potential after neuron activation. | |
| s | Maximum allowable synaptic delay. | |
| s | Defines the initial spread of the synaptic delays. | |
| 1.58 V | Membrane potential threshold for neuron activation in Layer 0. | |
| 0.733 V | Membrane potential threshold for neuron activation in Layer 1. | |
| 1.31 | Strength coefficient for Inhibitory Post-Synaptic Potential (IPSP) dynamics. | |
| s | Learning rate for synaptic delay depression. | |
| s | Learning rate for synaptic delay potentiation. | |
| s | Membrane potential decay time constant. | |
| s | Synaptic potential time constant for EPSP dynamics. | |
| s | Time constant for synaptic delay depression. | |
| s | Auxiliary time constant for synaptic delay depression. | |
| s | Time constant for synaptic delay potentiation. | |
| s | Auxiliary time constant for synaptic delay potentiation. | |
| s | Peak time for Excitatory Post-Synaptic Potential (EPSP). |
References
- CERN Yellow Reports: Monographs; High-Luminosity Large Hadron Collider (HL-LHC): Technical Design Report; CERN: Geneva, Switzerland, 2020; Volume 10. [CrossRef]
- Dorigo, T.; Giammanco, A.; Vischia, P.; Aehle, M.; Bawaj, M.; Boldyrev, A.; de Castro Manzano, P.; Derkach, D.; Donini, J.; Edelen, A.; et al. Toward the end-to-end optimization of particle physics instruments with differentiable programming. Rev. Phys. 2023, 10, 100085. [Google Scholar] [CrossRef]
- Mehonic, A.; Ielmini, D.; Roy, K.; Mutlu, O.; Kvatinsky, S.; Serrano-Gotarredona, T.; Linares-Barranco, B.; Spiga, S.; Savel’ev, S.; Balanov, A.G.; et al. Roadmap to neuromorphic computing with emerging technologies. APL Mater. 2024, 12, 109201. [Google Scholar] [CrossRef]
- Jaeger, H.; Noheda, B.; van der Wiel, W.G. Toward a formal theory for computing machines made out of whatever physics offers. Nat. Commun. 2023, 14, 4911. [Google Scholar] [CrossRef] [PubMed]
- Mead, C. How we created neuromorphic engineering. Nat. Electron. 2020, 3, 434–435. [Google Scholar] [CrossRef]
- Kudithipudi, D.; Schuman, C.; Vineyard, C.M.; Panditit, T.; Merkel, C.; Kubendran, R.; Aimone, J.B.; Orchard, G.; Mayr, C.; Benosman, R.; et al. Neuromorphic computing at scale. Nature 2025, 637, 801. [Google Scholar] [CrossRef] [PubMed]
- Home—Deep South. Available online: https://www.deepsouth.org.au (accessed on 1 January 2025).
- Winge, D.O.; Limpert, S.; Linke, H.; Borgström, M.T.; Webb, B.; Heinze, S.; Mikkelsen, A. Implementing an Insect Brain Computational Circuit Using III–V Nanowire Components in a Single Shared Waveguide Optical Network. ACS Photonics 2020, 7, 2787. [Google Scholar] [CrossRef] [PubMed]
- Wittenbecher, L.; Viñas Boström, E.; Vogelsang, J.; Lehman, S.; Dick, K.A.; Verdozzi, C.; Zigmantas, D.; Mikkelsen, A. Unraveling the Ultrafast Hot Electron Dynamics in Semiconductor Nanowires. ACS Nano 2021, 15, 1133. [Google Scholar] [CrossRef] [PubMed]
- Winge, D.; Borgström, M.; Lind, E.; Mikkelsen, A. Artificial nanophotonic neuron with internal memory for biologically inspired and reservoir network computing. Neuromorphic Comput. Eng. 2023, 3, 034011. [Google Scholar] [CrossRef]
- Nilsson, M.; Schelén, O.; Lindgren, A.; Bodin, U.; Paniagua, C.; Delsing, J.; Sandin, F. Integration of neuromorphic AI in event-driven distributed digitized systems: Concepts and research directions. Front. Neurosci. 2023, 17, 1074439. [Google Scholar] [CrossRef] [PubMed]
- Gerstner, W.; Kistler, W.M.; Naud, R.; Paninski, L. Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Verhelst, M.; Bahai, A. Where Analog Meets Digital: Analog-to-Information Conversion and Beyond. IEEE Solid-State Circuits Mag. 2015, 7, 67–80. [Google Scholar] [CrossRef]
- Calafiura, P.; Rousseau, D.; Terao, K. AI For High-Energy Physics; World Scientific: Singapore, 2022. [Google Scholar]
- di Torino, P.; Lazarescu, M.T.; Lazarescu, M.T. FPGA-Based Deep Learning Inference Acceleration at the Edge. Ph.D. Thesis, Politecnico di Torino, Torino, Italy, 2021. [Google Scholar]
- Di Meglio, A.; Jansen, K.; Tavernelli, I.; Alexandrou, C.; Arunachalam, S.; Bauer, C.W.; Borras, K.; Carrazza, S.; Crippa, A.; Croft, V.; et al. Quantum Computing for High-Energy Physics: State of the Art and Challenges. PRX Quantum 2024, 5, 037001. [Google Scholar] [CrossRef]
- CMS Collaboration. The Phase-2 Upgrade of the CMS Tracker; CERN: Geneva, Switzerland, 2017. [Google Scholar] [CrossRef]
- The Tracker Group of the CMS Collaboration. Phase-2 CMS Tracker Layout Information. Available online: https://cms-tklayout.web.cern.ch/cms-tklayout/layouts/recent-layouts/OT801_IT701/index.html (accessed on 1 September 2023).
- Masquelier, T.; Guyonneau, R.; Thorpe, S.J. Competitive STDP-Based Spike Pattern Learning. Neural Comput. 2009, 21, 1259–1276. [Google Scholar] [CrossRef] [PubMed]
- Bear, M.; Connors, B.; Paradiso, M. Neuroscience: Exploring the Brain; Wolters Kluwer: Alphen aan den Rijn, The Netherlands, 2016. [Google Scholar]
- Hammouamri, I.; Khalfaoui-Hassani, I.; Masquelier, T. Learning Delays in Spiking Neural Networks using Dilated Convolutions with Learnable Spacings. arXiv 2023, arXiv:2306.17670. [Google Scholar]
- Nadafian, A.; Ganjtabesh, M. Bio-plausible Unsupervised Delay Learning for Extracting Temporal Features in Spiking Neural Networks. arXiv 2020, arXiv:2011.09380. [Google Scholar]
- Hazan, H.; Caby, S.; Earl, C.; Siegelmann, H.; Levin, M. Memory via Temporal Delays in weightless Spiking Neural Network. arXiv 2022, arXiv:2202.07132. [Google Scholar]
- Song, S.; Miller, K.D.; Abbott, L.F. Competitive Hebbian learning through spike-timing-dependent synaptic plasticity. Nat. Neurosci. 2000, 3, 919–926. [Google Scholar] [CrossRef] [PubMed]
- Bi, G.Q.; Poo, M.M. Synaptic modification by correlated activity: Hebb’s postulate revisited. Annu. Rev. Neurosci. 2001, 24, 139–166. [Google Scholar] [CrossRef] [PubMed]
- Gad, A.F. PyGAD: An Intuitive Genetic Algorithm Python Library. arXiv 2021, arXiv:2106.06158. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]







| [%] | [%] | [%] | [%] | [%] | [%] | F [%] | |
|---|---|---|---|---|---|---|---|
| 50 | |||||||
| 100 | |||||||
| 200 |
| Parameter | Description |
|---|---|
| , | Temporal scaling factor and strength coefficient for IPSP dynamics. |
| , | Scaling constants for the reset potential after neuron activation. |
| , | Membrane potential thresholds for neuron activation in Layer 0 and Layer 1. |
| , | Learning rates for synaptic delay depression and potentiation. |
| , | Membrane potential decay time constant and synaptic potential time constant. |
| , | Time constant and auxiliary time constant for synaptic delay depression. |
| , | Time constant and auxiliary time constant for synaptic delay potentiation. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coradin, E.; Cufino, F.; Awais, M.; Dorigo, T.; Lupi, E.; Porcu, E.; Raj, J.; Sandin, F.; Tosi, M. Unsupervised Particle Tracking with Neuromorphic Computing. Particles 2025, 8, 40. https://doi.org/10.3390/particles8020040
Coradin E, Cufino F, Awais M, Dorigo T, Lupi E, Porcu E, Raj J, Sandin F, Tosi M. Unsupervised Particle Tracking with Neuromorphic Computing. Particles. 2025; 8(2):40. https://doi.org/10.3390/particles8020040
Chicago/Turabian StyleCoradin, Emanuele, Fabio Cufino, Muhammad Awais, Tommaso Dorigo, Enrico Lupi, Eleonora Porcu, Jinu Raj, Fredrik Sandin, and Mia Tosi. 2025. "Unsupervised Particle Tracking with Neuromorphic Computing" Particles 8, no. 2: 40. https://doi.org/10.3390/particles8020040
APA StyleCoradin, E., Cufino, F., Awais, M., Dorigo, T., Lupi, E., Porcu, E., Raj, J., Sandin, F., & Tosi, M. (2025). Unsupervised Particle Tracking with Neuromorphic Computing. Particles, 8(2), 40. https://doi.org/10.3390/particles8020040