3.1. Surrogate Principle
The main idea behind surrogate modelling is to approximate an expensive function , where , and is the image of through the mapping function f with a cheaper model. The variable D represents the number of input parameters, whereas and are respectively the lower and upper bounds of the ith dimension. and are respectively subsets of and . To construct an approximation of the considered function, the surrogate model hinges on the acquisition of a priori knowledge. This a priori knowledge is given by a training set, from which the statistical relationship between the inputs and the outputs is deduced.
Let be a training set such as }, where denotes an input vector of () dimension, and is a scalar corresponding to the image of through f. In addition, the matrix and the vector contain all the inputs and outputs of the training set .
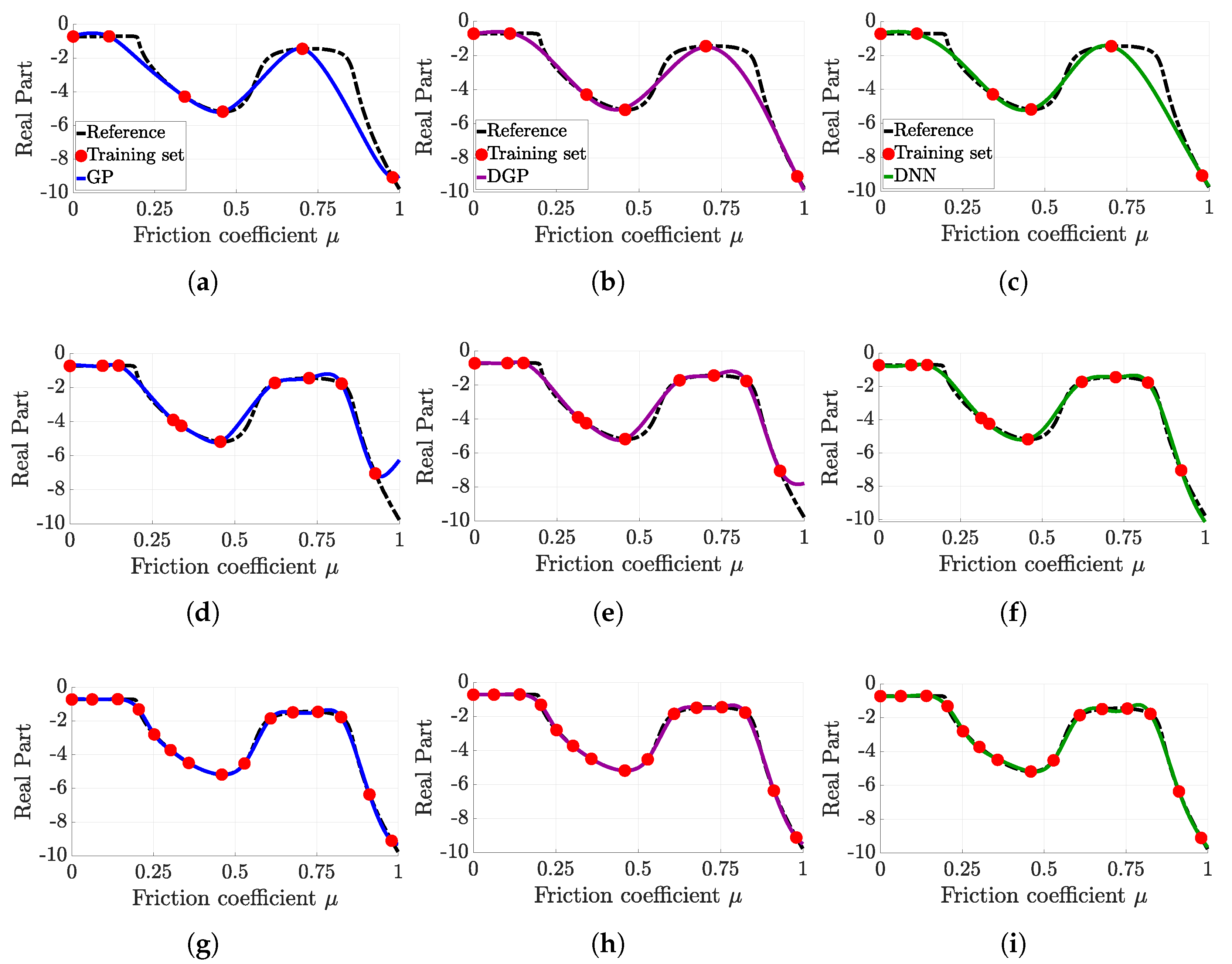
First, the training set is defined using a space filling strategy, such as the LHS [
33], and the evaluation of this training set through a simulator. Then, the surrogate model is chosen, and its parameters are defined. They are commonly divided into two categories: the fixed ones and the optimised ones. The distinction is done through the consideration of several hypotheses about the training set and the given simulator. Finally, the surrogate model is fed with the information from the training set to carry out the predictions.
For a fixed training set, the prediction efficiency and time computation of a surrogate model is clearly dependent on the setting of its parameters. Consequently, the techniques used to tune these data are presented in the following subsections for both surrogate models. Throughout this sequel, the fixed parameters are denoted as hyperparameters, as they can be denoted in the literature, and the optimised parameters are simply denoted as parameters.
3.2. Gaussian Process
A GP [
34] is a stochastic process
G, indexed by a set
, such that any finite number of random variables is jointly Gaussian:
with
, where
and
respectively stand for the mean and covariance function of the GP. Using a GP as a surrogate model consists in considering the output prediction, denoted by the random variable
as a realisation of this stochastic process.
Since
is also Gaussian, its density function is described by its first two momenta
and
, given respectively by Equations (5) and (6).
where
is any vector defined in
,
is the mean of the GP,
is its covariance function,
is the noise of the data, and
I is the identity matrix.
Next, considering the covariance function defined by Equation (
7).
where
,
is the signal variance (also called the noise of the kernel) and
is the correlation matrix (also called the kernel function or kernel matrix).
Table 2 presents the most common choice for the kernel function. They are presented from the least smooth to the smoothest. This property has a direct impact on the approximation of functions. Indeed, the smoothness drives the GP prediction: the more the kernel is non-smooth, the greater the non-linearity of the prediction will be.
represents the weighted Euclidean distance with being a weight coefficient, called the lengthscale, allowing increasing or reducing the importance of a dimension.
For the estimation of the parameters of a linear model, the best linear unbiased estimator equals the minimum variance unbiased (or MVU) if the noise is Gaussian. For the linear Gaussian model, the maximum likelihood estimator (hereby denoted MLE) is equivalent to the MVU estimator. Here, we follow the common way to optimise the GP parameters through the model evidence
, which is the multivariate probability density function of the random variable
Y, given the random variable
X. This function is supposed to be the Gaussian of mean
and of variance
, and it is traditionally optimised to obtain the MLE by updating the value components of the lengthscale vector. To ease the optimisation process, the log form of the probability density function is considered and gives the Equation (
8). At last, non-Gaussian behaviours (e.g., positivity, heterogeneity, and discontinuities) could be captured by the physically informed kernels, and this approach could be the subject of future work.
where
is the vector of lengthscale.
The second term of the sum is the regularisation coefficient that prevents the GP from overfitting. The third term of the sum corresponds to the terms that try to fit the data.
The different surrogate parameters (hyperparameters and parameters) considered for the GP are summarised in
Table 3.
3.3. Deep Neural Network
A DNN [
35] is a deterministic surrogate model composed of artificial neurons. An artificial neuron corresponds to a coarse and over-simplified version of a brain neuron, called a perceptron, and aims at mimicking the biological phenomenon that generates a signal between two neurons. A DNN is then obtained by connecting perceptrons with each other and organising them in layers.
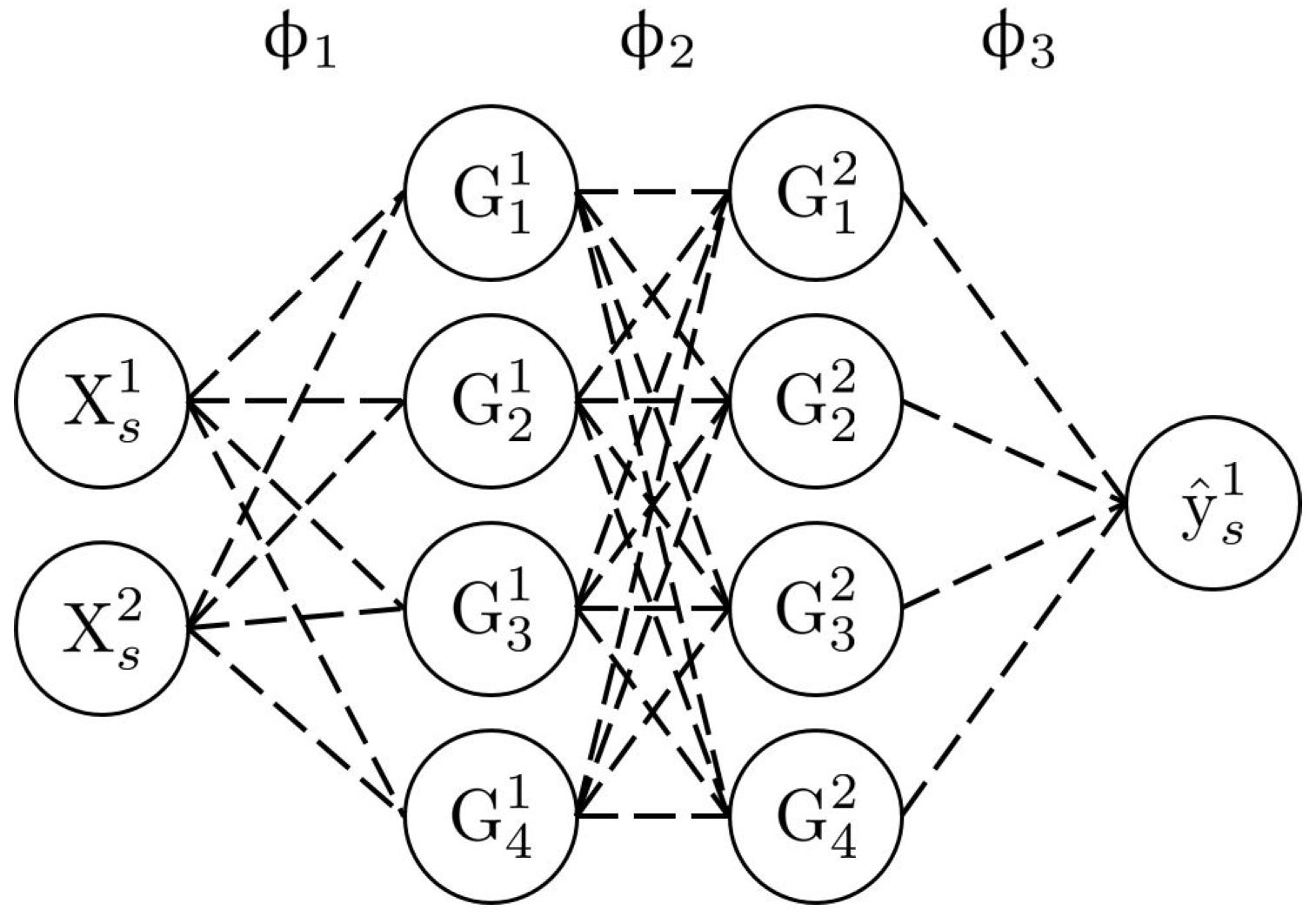
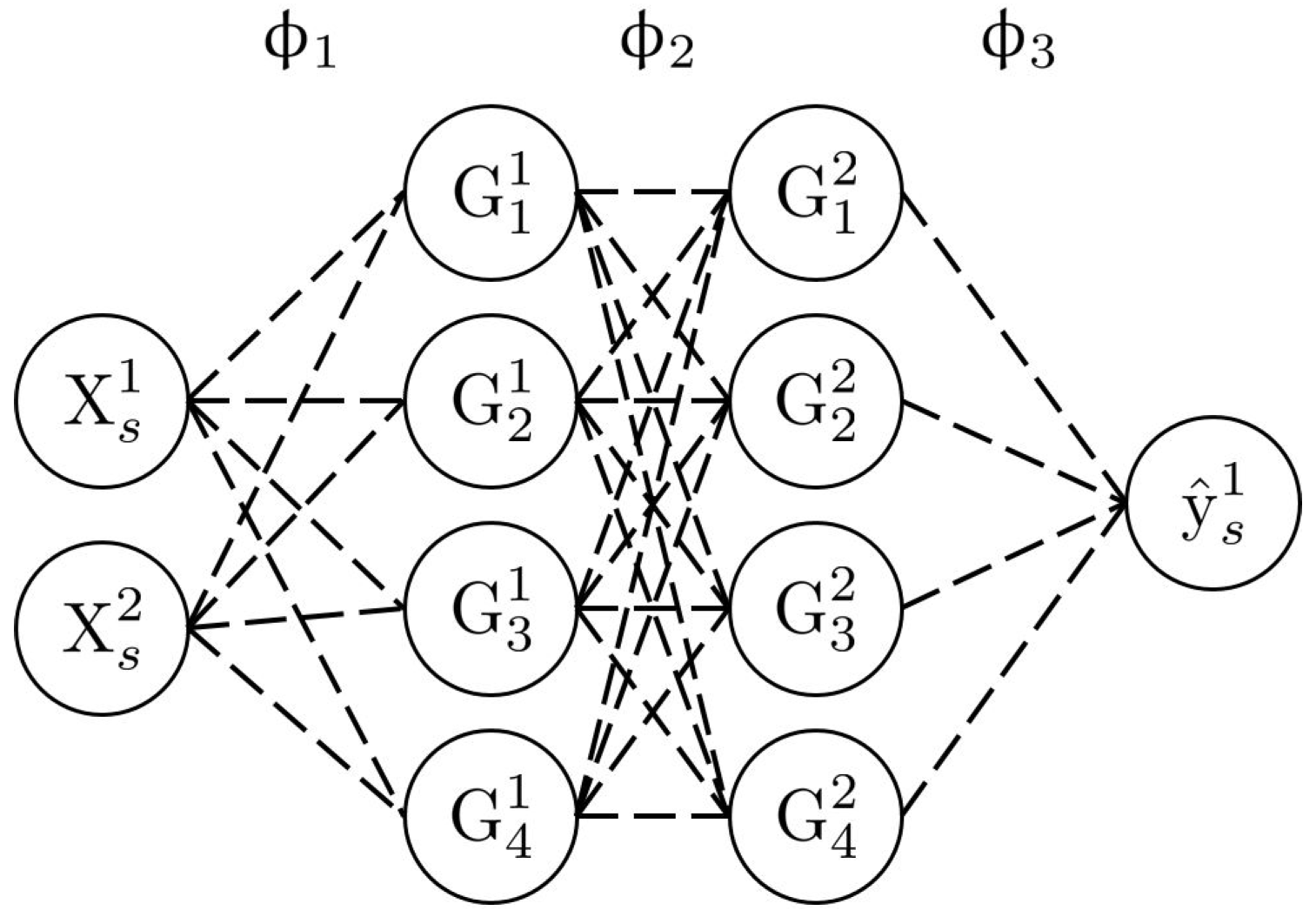
Figure 4 shows an example of a neural network architecture. In this case, the input dimension
d is 2, and the output dimension is 1. There are two intermediate layers, each composed of four neurons. The input neurons on the left are associated with the input data (labelled
), whereas the output neuron on the right is associated with the output data (labelled
). The value of a neuron on the intermediate layers is determined by carrying the linear combinations of the connected neurons from the previous layer and then applying an activation function (Equation (
9)).
where
,
p is the number of hidden layers,
, the number of neurons per hidden layer,
is the activation function of the
ith hidden layer,
is the weight vector associated with the
ith hidden layer, and
is the neuron vector associated with the previous hidden layer.
The most common activation functions used in DNN are summarised in
Table 4. These functions, coupled with the architecture of the neural network, allow capturing the full complexity of the considered functions. Nielsen [
36] proved that one characteristic of this surrogate model is that it is a universal approximator. Nevertheless, this strength is also one of its biggest weaknesses. Indeed, this capacity to increase the complexity of the learning via the increase in neurons in hidden layers can lead to overfitting [
37]. Typically, this overfitting phenomenon is associated with weight values, which are too high. One way to try to remove this flaw is penalising the weight values with a regularisation coefficient, such as in Equation (
10).
where
is the coefficient matrix for which each column corresponds to the coefficient vector from the
ith hidden layer and
the regularisation coefficient.
The Equation (
10) gives the loss function used for the neural network. This equation is equivalent to the least squares method with an additional contribution, which allows controlling overfitting. This control is done by adding all the weight values together and multiplying them with a coefficient, which modifies the impact of the sum on the loss function. Typically, from the observations made on these considered functions, a value of
lower than 0.005 corresponds to a small regularisation, between 0.005 and 0.05 corresponds to a medium regularisation, and a value above 0.05 corresponds to a strong regularisation. This hyperparameter has to be tuned cautiously since a high value prevents the surrogate model from going through the training set points, inducing important error values, and a small value increases the chance of overfitting.
The optimisation of the weight values linking the different neurons is done via the backpropagation procedure. First, the weight values are initialised randomly. Then, the loss function is computed and minimised using a classical gradient descent algorithm. In this research, since the data are scarce, the optimisation is ensured by an L-BFGS (limited-memory Broyden–Fletcher–Goldfard–Shanno) algorithm [
38].
Once the weight matrix is optimised, the prediction is carried with the Equation (
11).
Table 5 summarises the different quantities considered in the DNN surrogate model.
3.4. Deep Gaussian Process
The DGP is a recent class of surrogate models [
25] and is inspired by the deep learning theory. The main idea is to capture complex variations of the underlying function by decomposing the information embedded in the training set, i.e., through nested structures. Thus, the DGP hinges on neurons and layers, being a stack of GPs.
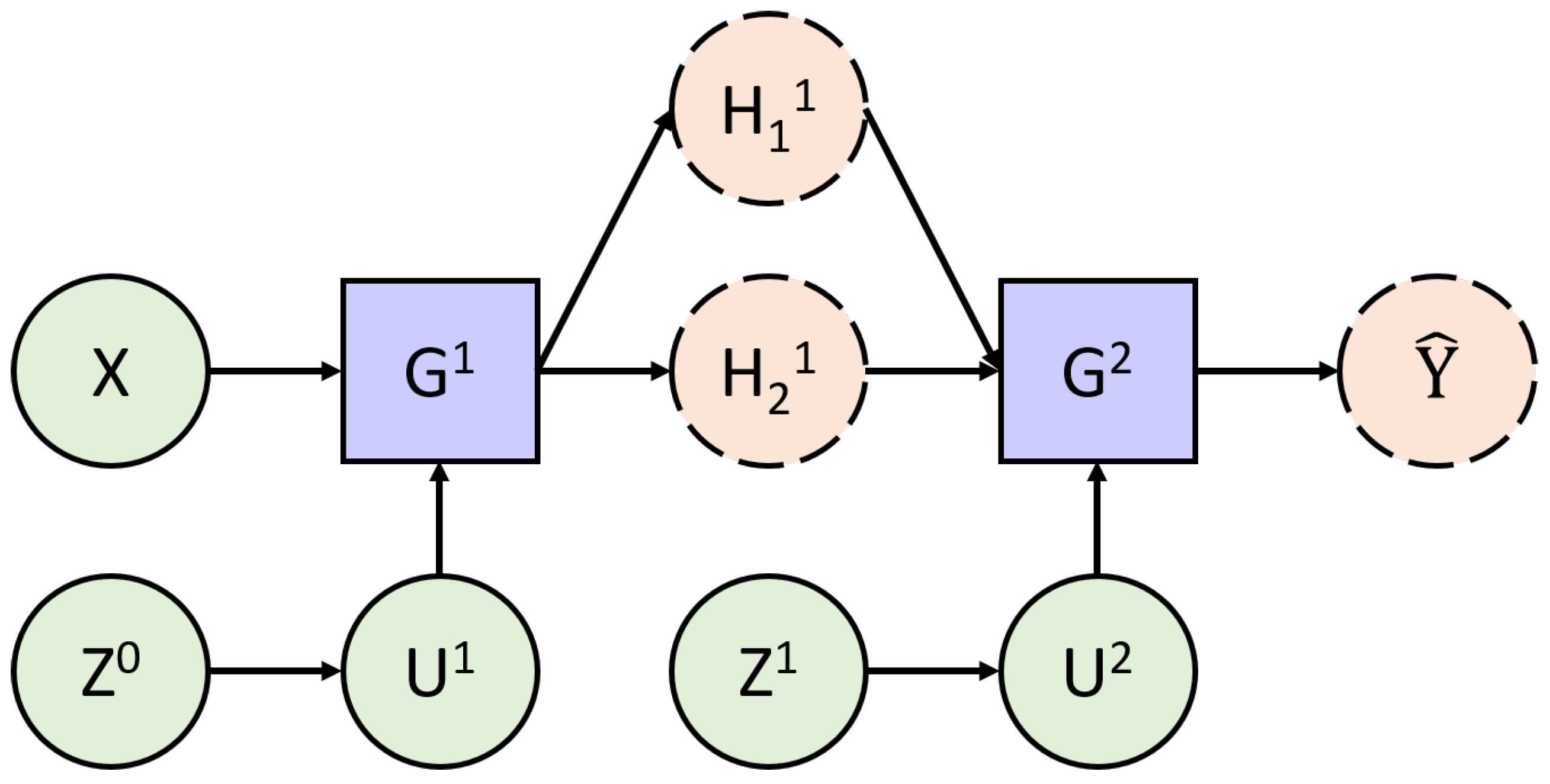
Hence, a random vector
(Equation (
13)) is introduced for each layer of the DGP. This random vector is defined by a GP
given by Equation (
12). This prior hinges on the fundamental assumption that the current layer is only conditionally dependent on the previous layer random vector
.
for
,
and
L is the number of hidden layers.
and
C are respectively the mean and the covariance function of the
ℓth layer.
where
is the number of neurons per hidden layer.
These priors are quite expensive to compute since they involve an inversion of the covariance matrix
, which is
for each layer of the surrogate model. To reduce the computational cost of the matrix inversion, the pseudo-inputs [
39] (also called inducing points in the literature) are introduced. The main idea behind this trick is to increase the probability space with non-observed points which will, to a certain extent, summarise the data and reduce the cost of the inversion to
, where
m is the number of pseudo-inputs. For significant effects,
m has to be a lot smaller than
n when considering large training sets. If the number of samples is small, this number can be chosen with more flexibility.
For each layer, a random vector
and a set of pseudo-inputs, denoted as
, are introduced. The random vector
is defined using the aforementioned GP (Equation (
14)).
where
and
.
Figure 5 graphically exhibits how the different random variables interact with each other. The straight green circles correspond to variables, which are strictly Gaussian. The dashed orange circles correspond to variables that are not conditionally Gaussian, and the blue rectangles symbolise the conditioning process. In addition, each layer is conditionally independent to the others.
From this additional assumption, the model evidence
can be written as Equation (
15) and similarly to the GP, it is optimised to obtain optimal values for the parameters.
where
,
,
,
and
.
This model evidence can be decomposed into two parts. The first member of the integrand corresponds to the likelihood of the data. The second member is the DGP prior. Unfortunately, this prior is not analytically tractable due to the successive inversion of the covariance matrix which prevents the computation of the conditional density function .
Following a variational inference approach, the variational distribution
, reminded in Equation (
16), is introduced to remove this issue of tractability. The representativeness of the distribution is maintained over the conditional density function
and the approximation is carried out on the inducing variables.
where
is the variational distribution of
and is Gaussian distributed with
. The subscript
q refers to the variational nature of the distribution describing the random variable.
and
are the mean and the variance of
.
The inducing variables can be marginalised to obtain the variational distribution of
, which is still Gaussian distributed with the mean given by Equation (
17) and the variance given by Equation (
18).
where
,
,
and
Thus, due to the conditional dependence of each layer given the previous layer, the computation of a realisation of the density function is carried out by propagating the given input x through each layer.
Combining the Equation (
16) with the Equation (
15) gives the logarithmic mathematical expectation of the model evidence over the variational distribution of inducing variables (Equation (
19)).
Since the logarithmic function is a concave function, the Jensen’s inequality [
40] can be used to obtain a lower bound of the model evidence.
where
is the Kullback–Leibler divergence between the variational and the true distribution of
.
The lower bound given by the Equation (
20) is called the efficient lower bound (hereby denoted ELBO) and provides a tight bound for the model evidence. The Kullback–Leibler divergence is in closed form since both distributions are Gaussian distributed. Nevertheless, the tractability of the first term is dependent on the type of likelihood chosen. Indeed, for the Gaussian and Poisson likelihood, this term can be determined analytically. Otherwise, a Gaussian quadrature or a Monte Carlo sampling can be used. For either case, the computation of the first term is done by propagating each instance into the surrogate model.
Considering the expectation of the likelihood given the variational distribution, the first ELBO term becomes (Equation (
21)) since each sample from the training set
is independent.
where
is a realisation of the variational distribution of
for the sample
;
is the image of
through the function
f; and
is a realisation of the distribution of
for the sample
.
In addition, the re-parameterisation trick, introduced by Rezende et al. [
41] and Kingma et al. [
42], in the context of Bayesian inference, is considered and given by Equation (
22). This trick allows a better optimisation of variational distributions.
where
is a Gaussian-distributed random variable given by
with
being the identity matrix.
Considering this trick and the Equation (
21), the ELBO reduces to (Equation (
23)).
where
is determined with the Equation (
22). The analytical forms for both terms are given in (Equations (A1) and (A2)) from the Appendices
Appendix A and
Appendix B.
Once the parameters are optimised, the prediction is done by propagating vectors
x through the surrogate model with the Equation (
24). Since
is not Gaussian distributed and depends on the
random variable, T samples are drawn from its distribution and then averaged.
where
is the
tth realisation of the variational distribution of
.
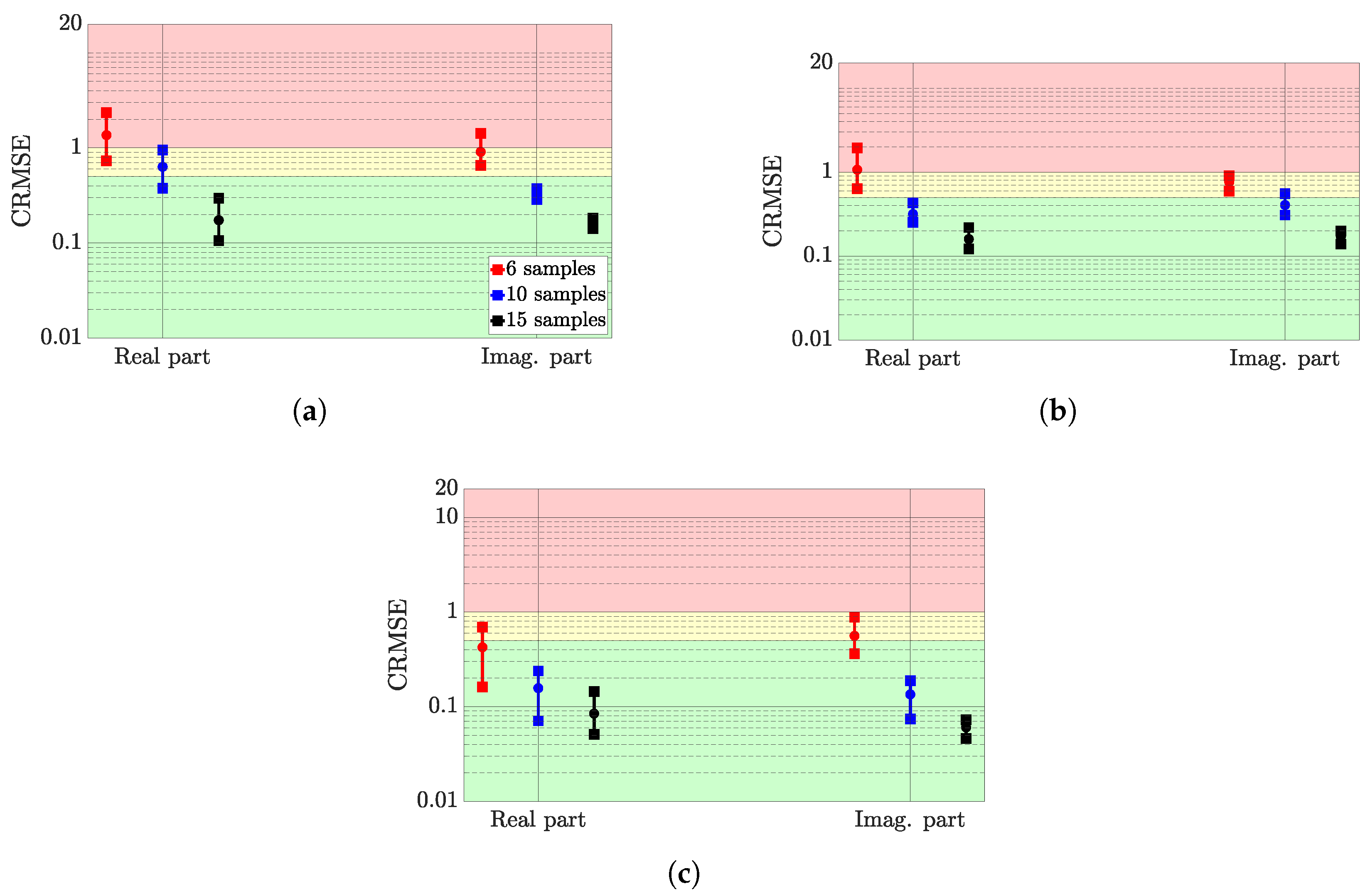
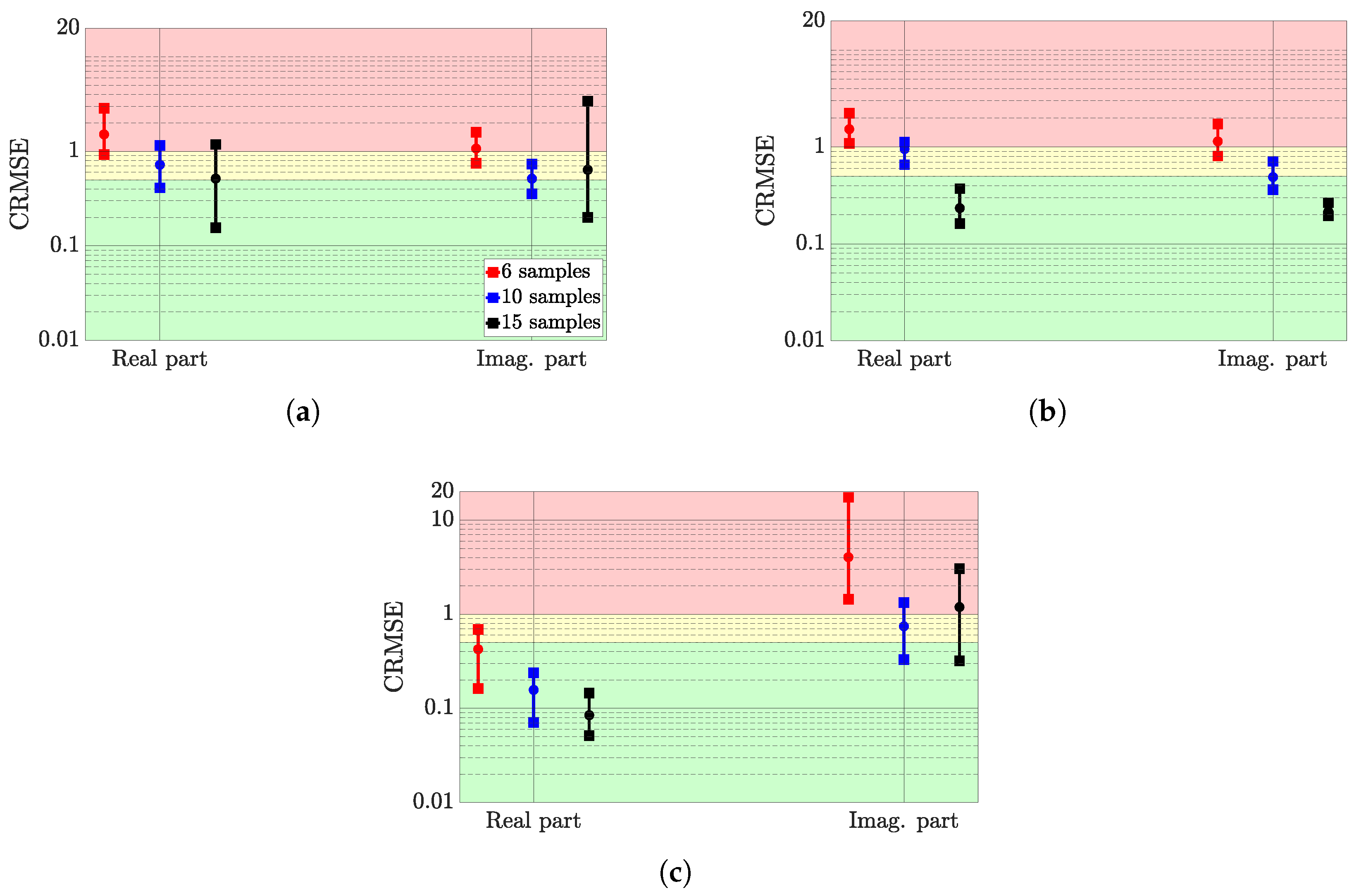
Table 6 summarises the different quantities considered in the DGP surrogate model. The hyperparameters and parameters in italics are repeated for each layer. The signal variance and data noise are fixed, invoking the same reasons as for the GP.



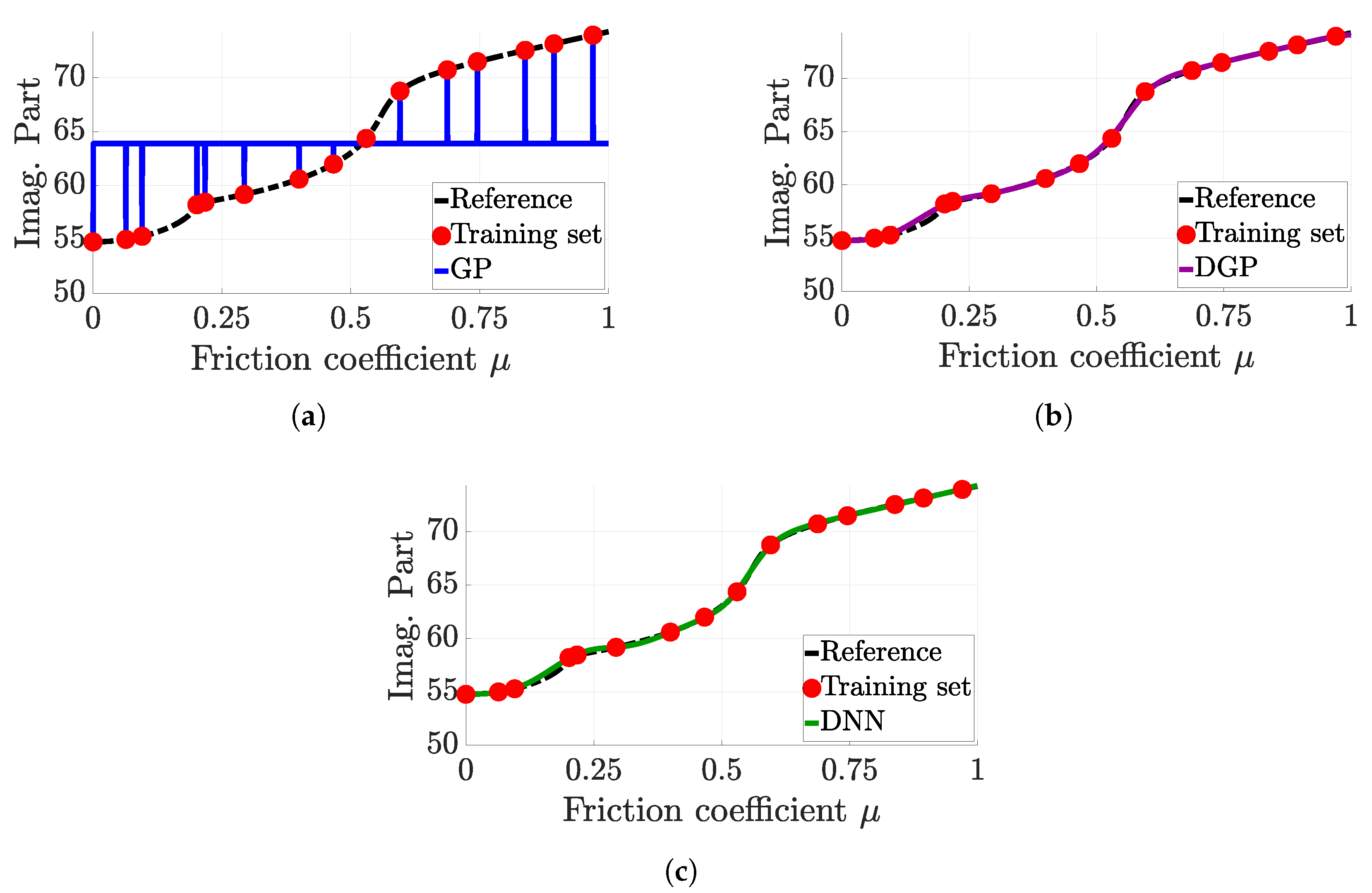
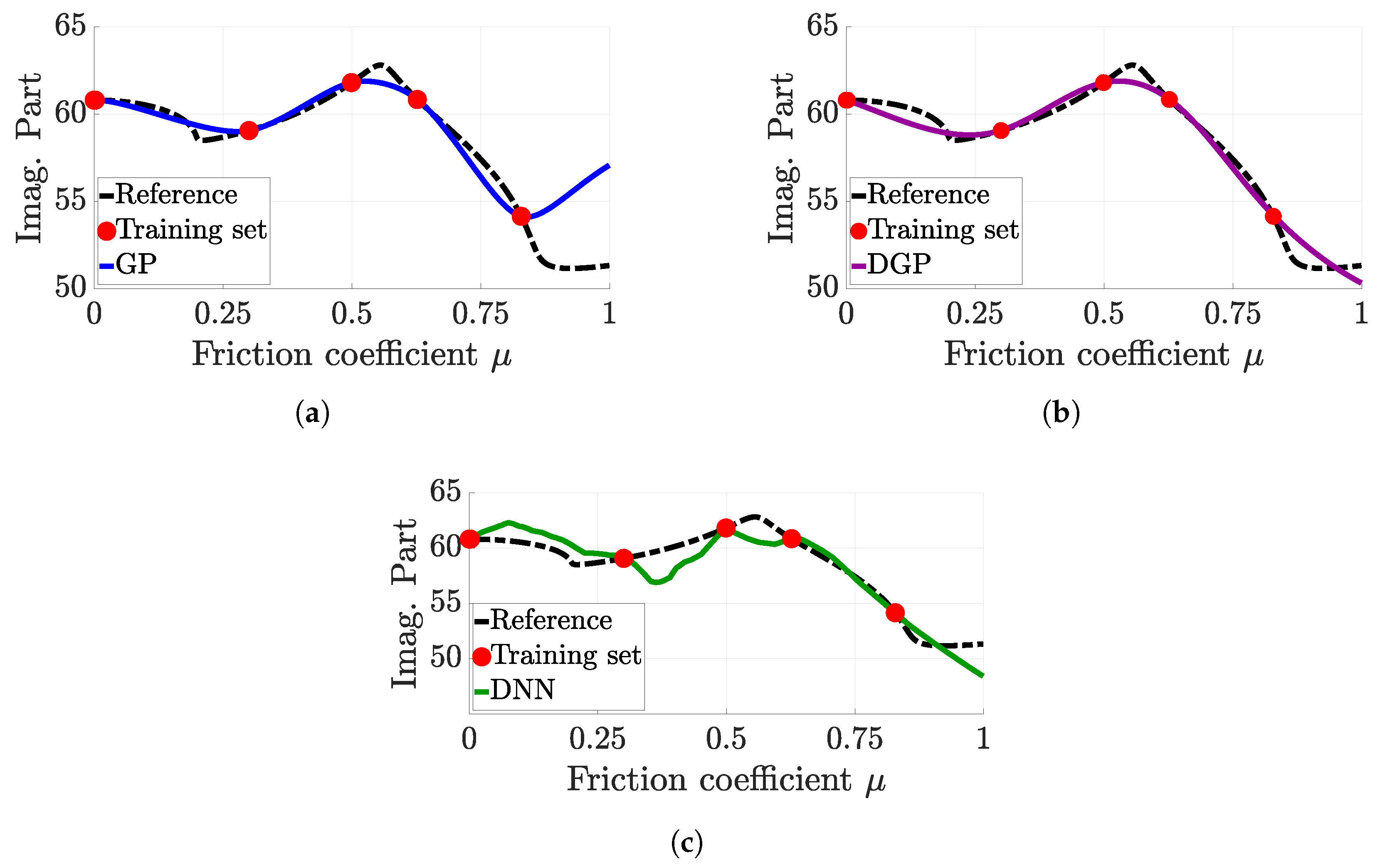

{kind=link}
{kind=link}
{kind=link}
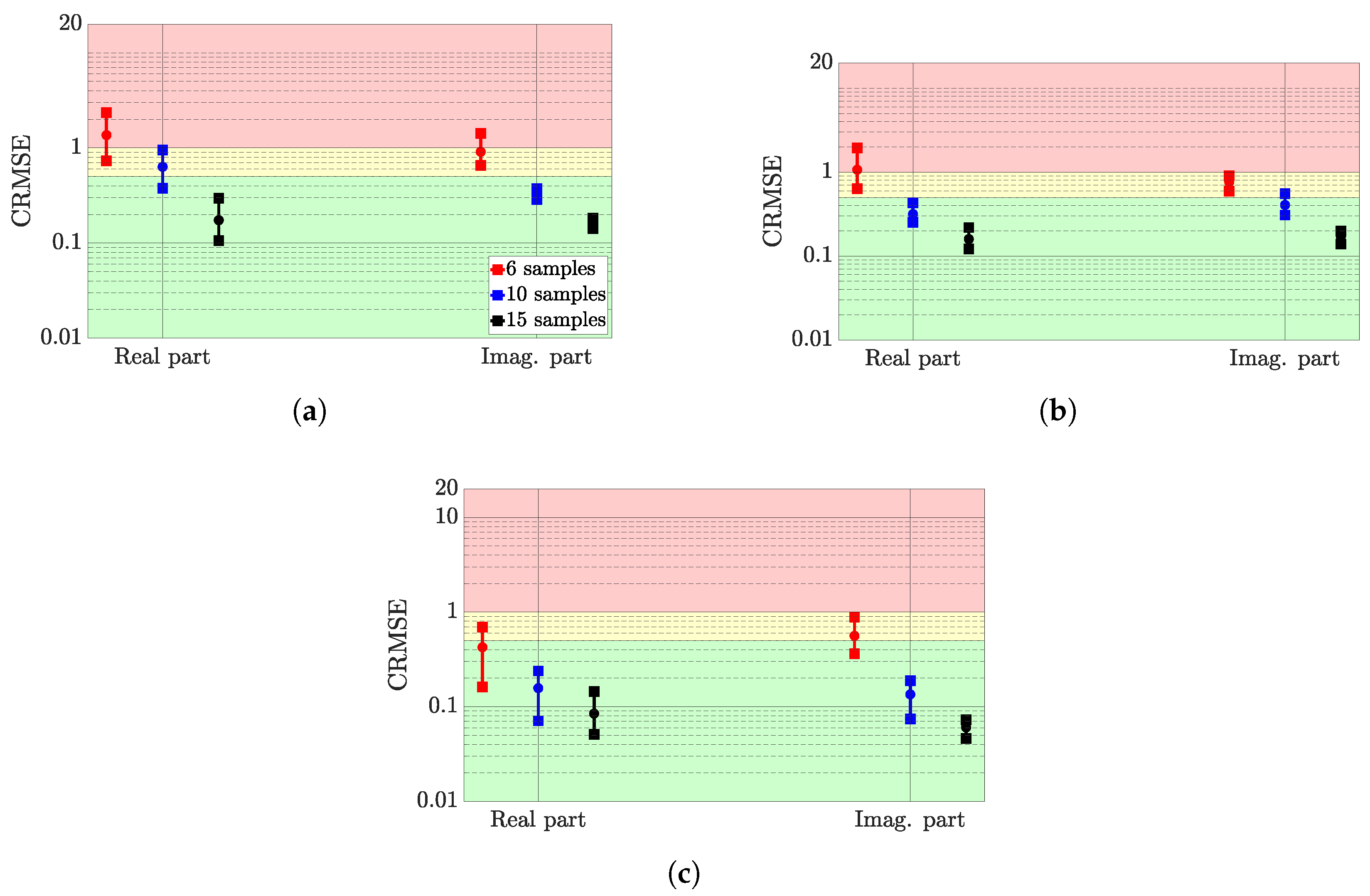
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}