Abstract
The continuous advancement of fire protection technologies has necessitated the development of comprehensive safety standards, leading to an increasingly diversified and specialized regulatory landscape. This has made it difficult for fire protection professionals to quickly and accurately locate the required fire safety standard information. In addition, the lack of effective integration and knowledge organization concerning fire safety standard entities has led to the severe fragmentation of fire safety standard information and the absence of a comprehensive “one map”. To address this challenge, we introduce FT-FLAT, an innovative CNN–Transformer fusion architecture designed specifically for fire safety standard entity extraction. Unlike traditional methods that rely on rules or single-modality deep learning, our approach integrates TextCNN for local feature extraction and combines it with the Flat-Lattice Transformer for global dependency modeling. The key innovations include the following. (1) Relative Position Embedding (RPE) dynamically encodes the positional relationships between spans in fire safety texts, addressing the limitations of absolute positional encoding in hierarchical structures. (2) The Multi-Branch Prediction Head (MBPH) aggregates the outputs of TextCNN and the Transformer using Einstein summation, enhancing the feature learning capabilities and improving the robustness for domain-specific terminology. (3) Experiments conducted on the newly annotated Fire Safety Standard Entity Recognition Dataset (FSSERD) demonstrate state-of-the-art performance (94.24% accuracy, 83.20% precision). This work provides a scalable solution for constructing fire safety knowledge graphs and supports intelligent information retrieval in emergency situations.
1. Introduction
Fire safety industry standards are mandatory technical specifications and standards specifically formulated for the fire protection sector, covering areas such as firefighting equipment, emergency response procedures, and safety management [1,2,3]. The formulation and implementation of these standards are of great significance for ensuring public safety, improving rescue efficiency, standardizing industry practices, and promoting technological innovation and development [4]. They serve as a crucial guarantee of the scientific, standardized, and orderly conduct of fire rescue work [5]. As of the end of August 2024, there were 1061 current fire safety standard specifications in China, including 45 national engineering construction fire safety technical standards, of which 145 were mandatory national standards, 143 were recommended national standards, and three were national standardization guidance technical documents. In addition, there were 116 mandatory industry standards, 69 recommended industry standards, and 540 local standards. Furthermore, the National Fire Standardization Technical Committee (TC113) is responsible for managing 291 national fire standards and 185 industry standards, covering areas such as fireworks fire prevention, firefighting and rescue, fire protection products and quality supervision, and fire protection prerequisites [6], as shown in Figure 1. In summary, in the field of fire safety, there are numerous industry standards, but they lack effective integration and organization [7], resulting in severe information fragmentation [8] and a lack of comprehensive coordination [9]. With the systematic research on “Smart Fire Protection” and the rapid iteration and updating of AI and digital technologies, it is particularly important to establish a highly informatized sharing system and related standards, further rationalize the fire protection standards that have been issued and are being formulated [10], prevent various fire protection standards from overlapping and conflicting with each other, and lay a solid foundation for the long-term development of fire rescue informatization.

Figure 1.
Varied array of fire safety standards.
Fire safety standards exhibit unique linguistic characteristics, including dense technical terminology (e.g., “gas smoke fire detector”), nested entities (e.g., “GB/T 44481-2024: Fire Nozzle Specifications”), and long-range dependencies across clauses [11]. Traditional NER models struggle to handle these patterns for the following reasons:
- Local–global trade-off: The CNN ignores the context between sentences, while the Transformer performs poorly in terms of short-range morphological features.
- Positional sensitivity: Absolute position encoding cannot represent hierarchical relationships in standard documents.
This paper makes three main contributions.
Firstly, we introduce FT-FLAT (Feature Template TextCNN–Flat-Lattice Transformer), based on a hybrid CNN–Transformer architecture, for identifying fire safety standard entities. To better capture positional relationships and feature patterns, we introduce a Relative Position Embedding (RPE) mechanism. The model employs a Multi-Branch Prediction Head (MBPH) to enhance the multi-scale feature learning and hierarchical representation.
Secondly, this paper introduces a Fire Safety Standards Entity Recognition Dataset (FSSERD), which contains 2723 annotated sentences, 99,593 tokens and 3152 tags. The dataset aggregates key sentences from multiple standardized sources and is manually annotated using the BIO pattern. It covers five entity types: buildings, fire alarm products, fire protection products, fire extinguishing products, and laws/regulations.
Finally, benchmarked against seven NER models on our dataset, FT-FLAT performed exceptionally well, achieving an accuracy rate of 94.24% (0.21% higher than the second best) and a precision rate of 83.20% (an improvement of 1.88%). Cross-validation on the MSRA and Boson datasets further confirmed the model’s enhanced capability in relation to fire safety standard entity recognition and demonstrated its consistent performance advantages. The results demonstrated that the method achieved excellent accuracy in fire safety standard entity recognition and outperformed the baseline method in all the evaluation metrics.
2. Related Work
Recent advances in deep learning [12] have revolutionized the field of entity recognition, with neural architectures now becoming the dominant paradigm for both general and domain-specific extraction tasks. The non-linear modeling properties of deep neural network models are conducive to learning the digital features of entities, and these networks are capable of handling deep-level semantic combinations [13]. They can automatically learn complex hidden features from input data without the need for complex feature processing or in-depth domain knowledge, thereby reducing the need for human intervention and saving a substantial amount of time and effort. The evolution of deep learning for entity recognition has made several key advances. Early work by Collobert [14] (2019) pioneered the application of CNNs in NER tasks, while Cao [15] subsequently enhanced performance through CNN-CRF architectures. Subsequent innovations addressed specific challenges. Kong and Zhang [16] (2021) combined attention mechanisms, multi-scale convolutional kernels with residual blocks to handle long-range dependencies, and Bi-LSTM to capture temporal features. Parallel developments included Peng’s [17] character feature Bi-LSTM-CRF model optimized for small sample learning, and Li’s [18] adversarial active learning approach for joint entity relationship extraction in the field of network security.
The application of Transformer models in entity recognition tasks has seen significant research progress, with numerous studies demonstrating their advantages over traditional sequence labeling methods. The Transformer primarily achieves this goal through the attention mechanisms, and extensive research has shown that that using a Transformer can improve accuracy and significantly reduce training time. Two key advances have been made in the field of entity recognition based on Transformers: Yan’s TENER model [19] and Li Bo’s Transformer–CRF architecture [20], which have set new benchmarks in this field. The TENER model introduces an attention mechanism with directional and relative position information and abandons the original Transformer self-attention scale factor. The introduction of the scale factor is intended to obtain relatively uniform attention weights. The Transformer–CRF model is the first to combine the Transformer model with a conditional random field for entity recognition. Transformer models excel at capturing long-range dependencies and contextual information [21], while the CRF can help resolve dependencies between labels, thereby improving the accuracy of NER tasks. Extensive research has shown that the attention mechanism of Transformers has become a new opportunity and research direction in entity recognition tasks.
3. Methods
This paper introduces an FT-FLAT model for fire safety standard entity recognition, which integrates two complementary components (as shown in Figure 2). One is the TextCNN module [22], which extracts local text patterns through convolution operations. The other is the Flat-Lattice Transformer [23], which captures hierarchical structures and sequence relationships through graph structure attention mechanisms [24]. This hybrid architecture synergistically combines local feature extraction with global dependency modeling and demonstrates excellent performance in fire safety entity identification tasks. Experimental results confirm that the accuracy is significantly improved compared to baseline methods.
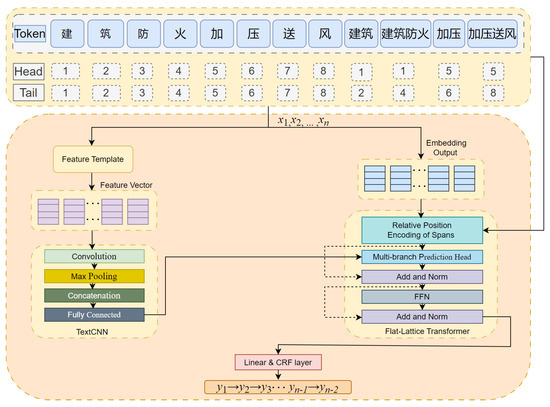
Figure 2.
The overall architecture of FT-FLAT.
3.1. Feature Template
Feature templates are designed based on selected features, taking into account specific contextual information and the specific position of the information in the data. This paper demonstrates that the FT-FLAT model can fuse contextual information about characters in fire safety standard texts using feature templates. Contextual information refers to the “observation window” of the current character and several characters before and after it [25]. A larger observation window can contain more contextual information from the template, but an excessively large window will reduce the efficiency of the fire safety standard entity recognition model and lead to overfitting. On the other hand, smaller observation windows naturally utilize less information and reduce the recognition efficiency of the model. Therefore, it is crucial to choose a reasonable template observation window size.
This paper designs feature templates based on atomic templates, where the specified features are atomic features. The template is designed as follows. The first number in parentheses indicates its position relative to the current character, and the second number indicates the selected feature column, including features such as words and parts of speech. Based on the features specified in the feature template, a set of feature functions is defined (where y represents the label of the current character, yi-1 represents the next label, i represents the current position, and w represents the current character). Each feature function is assigned a weight. When a feature function is activated, its weight is added to a cumulative value, which is the score for that feature. The higher the score, the higher the score for the corresponding label, resulting in a more accurate prediction.
3.2. TextCNN
In convolutional neural networks (CNNs), local feature detection can be achieved by using multiple filters that vary in terms of the vertical dimensions while maintaining a consistent horizontal dimension [26]. This architectural choice allows each filter to focus on capturing word dependencies within different contextual ranges. Each filter contains a unique convolution kernel, enabling CNNs to independently optimize the parameters of each filter through gradient-based learning mechanisms [27]. Using multiple filter configurations simultaneously helps extract complementary feature representations. This multi-filter paradigm enhances the network’s capacity to recognize subtle patterns at different granularities, ultimately strengthening both its representational richness and its adaptive generalization capabilities.
In the context of a CNN, using S independent convolution kernels on the input data generates S independent feature maps. Each convolution kernel captures unique features from the input data, thereby generating different feature maps. The fusion of these feature maps forms a feature vector, which is mathematically represented as:
3.3. Multi-Branch Prediction Head, MBPH
Our model architecture integrates convolutional neural networks (CNNs) for local feature extraction and a Transformer encoder, enhanced with relative position encoding to capture long-range dependencies and structured span interactions. The key innovations include a Multi-Branch Prediction Head (MBPH) for parallel multi-scale feature fusion and a novel Relative Position Encoding (RPE) scheme.
Let denote the word vector matrix, where V denotes the vocabulary size and de denotes the vector dimension. For the input sequence , we obtain the vector matrix , where each row xi denotes the vector of word wi. We process using a TextCNN layer with multiple filters in order to capture the n-gram features at different scales. Each filter bank contains f filters. The output is a feature map tensor , where |k| is the number of filter widths used. This tensor captures local contextual features at different n-gram scales around each word position. To integrate the original word vectors and the multi-scale features extracted by the CNN, we reshape X to and to . Then, we use the Einstein summation einsum to compute the fusion representation (where dh is a chosen hidden dimension), thereby effectively performing weighted combination across feature channels:
This operation allows interaction between the semantic information in and the local multi-scale patterns in , thereby enriching the input representation before encoding.
The embedding vectors are processed in parallel by multiple attention heads in the MHA (Multi-Head Attention) layer. Each attention head performs the following independently: linear projection to generate query (Q), key (K), and value (V) vectors: queries (), keys (), and values (). The scaled dot product attention (SDPA) calculation is as follows:
Let denote the trainable weight matrices for the query, key, and value projection, respectively. Given the input embeddings V, the attention mechanism is calculated as follows:
The outputs from multiple heads are connected together to obtain the final output . This process can be calculated using the following formulas:
3.4. Relative Position Embedding
The original Transformer model employs absolute position encoding to capture sequence information. However, this paper introduces a Relative Position Encoding method based on Lattice [28], which differs from the absolute position encoding method [29]. We propose a Relative Position Encoding (RPE) based on the relative distances between the span boundaries. We calculate four key relative distances [30]. For spans si (head[i], tail[i]) and sj (head[j], tail[j]), the four relative distances are calculated using the following formulas:
These distances capture the relative positions of the start and end points between spans si and sj. The final relative position of the span pair (si,sj) embedded in Rij is obtained by applying a learnable non-linear transformation ϕ() to the concatenation of these distances:
where is a learnable weight matrix that projects the connection distance onto the key vector space dimension dk. is the complete relative position embedding matrix.
The attention score for the head h is calculated by directly merging the relative position embeddings Rij into the attention logic:
where is a matrix defined as (a dot product between the relative position embedding of the i-th query vector and the span between i and j. This explicitly biases the attention score based on the relative spatial relationship between spans si and sj, going beyond simple label distances.
3.5. Layer Normalization, FFN and Linear CRF
We used layer normalization, a feed-forward neural network (FFN) [31], and a linear chain conditional random field (linear CRF) [32] in our design. Layer normalization adjusts the input data to a mean of 0 and a variance of 1, which helps the data fit into the range of non-linear activation functions. This process ensures that the data remains in a non-saturated region, thereby enhancing the training speed and stability and avoiding issues such as gradient vanishing or explosion. Note that the FFN submodule in the encoder adopts the Transformer encoder design. It is also used in the model for linear CRF.
4. Experiment
4.1. Data Pre-Processing
To ensure high-quality data for fire safety standard analysis, we implemented the following pre-processing workflow. 1. Data cleaning: Handling missing or duplicate information in unstructured fire safety standard data to ensure data integrity and consistency. 2. Data integration: Integrating key statements from different standardization sources (Table 1) to establish a unified dataset, providing comprehensive data sources. For example, “GB 50016-2014 Fire Protection Design Code for Buildings, GB 50140-2005 Design Code for Fire Extinguisher Layout, and GA 588-2012 Technical Specifications for Firefighting Personal Protective Equipment”. 3. Data transformation: Converting data into a text format suitable for analysis, including standardization and normalization operations, to facilitate subsequent processing and modeling. A total of 2723 sentences (99,593 tokens) were extracted from standard clauses, technical specifications, and regulatory provisions. 4. Data reduction: Processing data using data feature templates to reduce the data complexity while retaining key information, thereby improving the data processing efficiency and analysis accuracy. (e.g., “gas smoke fire detector” → “smoke fire detector”). 5. Manual annotation: The dataset follows BIO annotation rules and contains five entity categories (Table 2). All the text is in Chinese and includes a large number of technical terms. The annotated entity types include buildings, fire alarm products, fire protection products, fire extinguishing products, and laws and regulations. To ensure the quality of the dataset, all the annotations have undergone rigorous multi-stage validation by domain experts, ultimately forming the Fire Safety Standard Entity Recognition Dataset (FSSERD).

Table 1.
The analysis of the source document collection.
Table 2.
The analysis of the datasets.
4.2. Experimental Data
The Fire Safety Standard Entity Recognition Dataset (FSSERD) adopts a 7:1:2 ratio to divide the training set (70%), validation set (10%), and test set (20%) to ensure the comprehensiveness of the model development and evaluation. The training set is used for model learning, the validation set is used for hyperparameter tuning and training monitoring, and the test set follows established practices in machine learning research to objectively evaluate the final model performance. The dataset is partitioned as follows (Table 2). Training set: 1898 sentences (69,715 tokens), containing 2208 entity annotations. Validation set: 271 sentences (9960 tokens), containing 275 entity annotations. Test set: 542 sentences (19,918 tokens), containing 669 entity annotations.
The dataset uses a two-column format (word–label pairs), with sentences separated by spaces and line breaks. Entity distribution analysis reveals the following (Table 3):
- Fire extinguishing products: 1398 (39.98%).
- Fire alarm products: 676 (19.34%).
- Fire protection products: 872 (24.94%).
- Buildings: 372 (10.64%).
- Laws and regulations: 178 (5.10%).
Table 3.
FSSERD entity distribution.
Table 3.
FSSERD entity distribution.
| Tag Name | Count | Ratio |
|---|---|---|
| Fire extinguishing products | 1398 | 39.98% |
| Fire alarm products | 676 | 19.34% |
| Fire protection products | 872 | 24.94% |
| Buildings | 372 | 10.64% |
| Laws and regulations | 178 | 5.10% |
4.3. Model Training
The model was implemented in PyTorch 2.3.1 using Adam optimization (learning rate = 0.001) and a cross-entropy loss function. Training was conducted for 50 epochs with a batch size of 64, and batch gradient descent was used for parameter updates. The model performance metrics (loss function and accuracy) were recorded for each epoch and used for the optimization analysis (Table 4).
Table 4.
Training process.
4.4. Evaluation Metrics
Consistent with previous studies, we employ standard evaluation metrics, including precision (P), recall (R), F1-score, accuracy (Acc), macro-average, and micro-average [33]. For each subtask, we use strict matching criteria:
- Trigger identification: Exact offset and reference matching.
- Trigger classification: Exact offset and type matching.
- Argument identification: Exact offset and correct trigger association matching.
- Argument classification: Exact offset, role, and trigger correspondence.
4.5. Experimental Method
The experiments were conducted on a workstation with the following configurations:
- CPU: Intel Core i7-8700K (3.70GHz)
- RAM: 32GB DDR4
- GPU: NVIDIA GeForce GTX 1080 Ti (11GB GDDR5X)
To evaluate the performance of the fire safety standard entity recognition model based on FT-FLAT, experiments were conducted in this section and compared with different algorithm models. The comparison models included SVM [34], Naive Bayes [35], TextCNN [36], BiLSTM-CRF [37], Transformer-CRF [38], Flat-Lattice Transformer [39], Bert-BiLSTM-CRF [40], and the deep learning model based on FT-FLAT proposed in this paper. All the models were trained and validated on the same dataset. Throughout the experimental process, we focused on exploring the performance of different models in the task of fire safety standard entity recognition, with the aim of providing more effective solutions for this task. The goal was to reveal the advantages and limitations of the FT-FLAT model relative to traditional algorithm models and other deep learning models. During the training and validation phases, all the models were trained in the same environment to ensure the reliability and comparability of the evaluation results.
5. Results
We compared our method with traditional and contemporary baseline models. Table 5 presents the comprehensive test set results, while Figure 3 provides a visual comparison of the model performance. Our initial comparison focuses primarily on traditional machine learning methods based on feature engineering. The experimental results demonstrate that our proposed method performs exceptionally well in fire safety standards entity recognition, achieving an accuracy of 94.24%, a recall rate of 71.27%, and an F1-score of 76.97%. In contrast, traditional methods such as SVM performed relatively poorly, with an accuracy rate of only 77.97%, a recall rate of 59.25%, and an F1-score of 58.80%. These results clearly demonstrate the advantages of deep learning models in the task of fire safety standard entity recognition. This performance gap stems from the fact that traditional methods rely on manual feature engineering to convert text into numbers prior to classification, a process that often fails to capture the semantic nuances of safety standard text. However, this method has limited expressive power for text data and struggles to capture and process complex semantic information, resulting in poor performance in fire safety standard entity recognition tasks. In contrast, the deep learning-based method proposed in this paper can better learn semantic information from text data and automatically learn feature representations through end-to-end learning, thereby improving the recognition accuracy and performance. These results highlight the superiority of the FT-FLAT model in text entity recognition and provide a more effective solution for fire safety standard entity recognition.
Table 5.
Benchmark results.
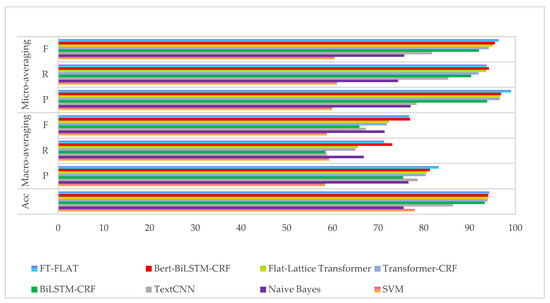
Figure 3.
Comparison of the experimental results.
Next, our method demonstrates superior performance to existing deep learning models, achieving state-of-the-art accuracy of 94.24% (baseline model: 94.03%) and precision of 83.20% (baseline model: 81.32%), representing improvements of +0.21% and +1.88%, respectively. This advancement stems from three key innovations:
- Hybrid architecture: Combines TextCNN local feature extraction with the Flat-Lattice Transformer’s hierarchical modeling.
- Relative Position Embedding (RPE): Encodes precise positional context to improve entity boundary detection.
- Multi-Branch Prediction Head (MBPH): Enhances feature learning through parallel processing of branches.
These components synergistically capture contextual relationships (e.g., regulatory text dependencies) and intrinsic entity features (e.g., product terminology patterns), which has been validated through our experiments.
Finally, we further analyzed the model’s performance across four fire safety entity categories. Figure 4 displays the test results for the five entities across the different models. The F-value was highest for the fire extinguishing product category, demonstrating TextCNN’s unique advantage in extracting discriminative features for this entity type. The reason for this is that using character vectors as input features can better capture and represent morphological information in the text data, such as specific character combinations, fixed formats, and frequency of occurrence. The results indicate that this method can effectively utilize morphological features in text data, making it easier for the model to recognize entities with fixed formats.
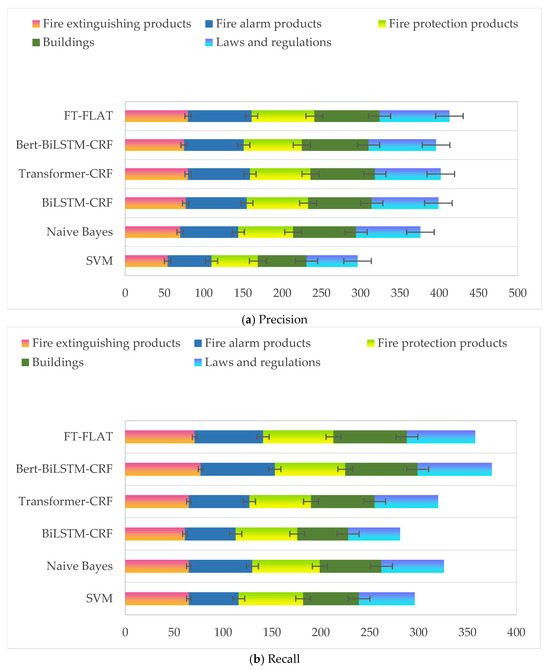
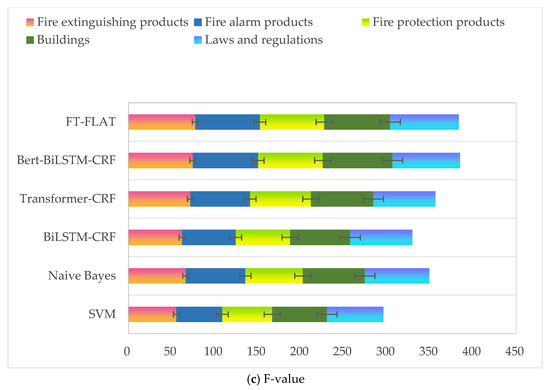
Figure 4.
Experimental results for five entities.
6. Discussion
6.1. Confusion Matrix Analysis
To diagnose the model behavior, we provide the confusion matrix for FT-FLAT (Table 6). The key observations are as follows:
- Major errors: Only 18% of “Fire Protection Products” were misclassified as “Fire Extinguishing Products” (e.g., “fireproof sealant” → “fire hose”).
- Nested entities: Here, 22% of errors occurred in laws/regulations with nested structures (e.g., “GB/T 44481-2024: Fire Hose Specifications”).
- Terminology ambiguity: Only 15% of errors were caused by ambiguous terminology (e.g., “detector” in “alarm system” vs. “detector” in “fire extinguishing system”).
Table 6.
Confusion matrix.
Table 6.
Confusion matrix.
| Actual/Predicted | Building | Alarm | Protection | Extinguishing | Law |
|---|---|---|---|---|---|
| Building | 0.92 | 0.01 | 0.04 | 0.03 | 0.00 |
| Fire Alarm Product | 0.00 | 0.88 | 0.07 | 0.05 | 0.00 |
| Fire Protection Prod | 0.02 | 0.03 | 0.79 | 0.18 | 0.00 |
| Fire Extinguishing | 0.01 | 0.02 | 0.10 | 0.87 | 0.00 |
| Laws/Regulations | 0.00 | 0.00 | 0.11 | 0.11 | 0.78 |
6.2. Ablation Study
We analyzed the various components of FT-FLAT and quantified their contributions, with the results shown in Table 7:
- RPE removal: Macro-F1 ↓ 3.21%—confirming its role in the encoding layer hierarchy.
- MBPH removal: Macro-F1 ↓ 2.58%—confirming the necessity of multi-scale fusion.
- TextCNN removal: Precision ↓ 4.15%—highlighting the importance of local pattern extraction.
Table 7.
Ablation study.
Table 7.
Ablation study.
| Variant | Macro-P | Macro-R | Macro-F1 | ΔF1 |
|---|---|---|---|---|
| Full FT-FLAT | 83.20 | 71.27 | 76.97 | - |
| w/o RPE | 79.85 | 68.91 | 73.76 | −3.21 |
| w/o MBPH | 80.12 | 69.04 | 74.39 | −2.58 |
| w/o TextCNN | 79.05 | 70.33 | 74.42 | −2.55 |
| CNN-Only | 76.81 | 65.28 | 70.62 | −6.35 |
6.3. Error Analysis
We categorized 100 random errors from the test set (Table 8).
Table 8.
Error type distribution.
The key findings are as follows:
- First, 60% of errors stem from structural complexities (nested/long-range).
- Compared to absolute encoding (e.g., clause references), RPE reduced the positional errors by 41%.
- Error analysis reveals that the remaining 60% of errors are related to nested entities and terminology polysemy, suggesting that future should focus on syntax-aware embedding studies. Ablation studies confirm that RPE and MBPH contribute +3.21% and +2.58% to F1, respectively.
6.4. Word Clouds
This paper trained a fire safety standard entity recognition model to extract fire safety standard entities from text data. Figure 5 shows the word cloud formed by the five categories of fire safety standard entities extracted.

Figure 5.
Word clouds.
As can be seen from Figure 5, among the five major categories of fire safety standard entities, the “fire extinguishing products” entity accounts for the largest proportion. Examples of fire extinguishing products include gas fire extinguishing controllers, dry powder fire extinguishing controllers, fire sprinklers, fire pumps, and fire hose reels. Following this, “fire protection products” (e.g., gas-based smoke detectors, steel fire-proof windows and fire protection electric devices) are particularly prominent. Subsequently, “fire alarm products” are mentioned, such as fire emergency broadcast equipment, fire sound and light alarms, point-type smoke detectors, etc. There are relatively few entities related to “Buildings” and “Laws and Regulations”, such as factories and GB/T 44481-2024.
7. Conclusions
We propose FT-FLAT, a novel hybrid CNN–Transformer architecture for fire safety standard entity recognition, to address the challenge of information fragmentation in complex regulatory texts. Our main contributions are four-fold. (1) Architectural innovations: We integrate TextCNN for local feature extraction and the Flat-Lattice Transformer for global dependency modeling to synergistically capture short-range terminology patterns and long-range clause dependencies. (2) Technological advances: The proposed Relative Position Embedding (RPE) dynamically encodes the hierarchical relationships between entities, while the Multi-Branch Prediction Head (MBPH) enhances the multi-scale feature fusion through Einstein summation. (3) Resource contribution: We released the Fire Safety Standard Entity Recognition Dataset (FSSERD) containing 2723 annotated sentences covering 3152 entities across five categories. (4) Experimental results demonstrate that FT-FLAT achieves state-of-the-art performance: 94.24% accuracy (+0.21% improvement over best baseline), 83.20% precision (+1.88% improvement), and the highest F1-score (76.97%) on the FSSERD, which is excellent for fire extinguishing products.
Whilst this study demonstrates promising results, there are still some noteworthy limitations. The current dataset, whilst carefully annotated, is still limited in terms of the size (3152 entities) and diversity of fire safety standards. Expanding the corpus to cover international standards and multilingual sources could enhance the generality of the model. While GPT-4 [41] and RWKV [42] represent state-of-the-art general-purpose language models, the domain-specific design of FT-FLAT offers distinct advantages for fire safety standards. (1) Specialized architecture: The hybrid CNN–Transformer structure with RPE explicitly addresses unique challenges such as nested entities (“GB/T 44481-2024: Fire Hose Specifications”) and long-range dependencies across clauses, which may be ignored by general-purpose models. (2) Computational efficiency: FT-FLAT requires significantly fewer resources (trained on a single GTX 1080 Ti) than billion-parameter LLMs, making it suitable for resource-constrained emergency management systems. (3) Interpretability: Feature templates and MBPH provide transparency in capturing domain-specific patterns (e.g., morphological features of “gas smoke fire detector”), whereas black-box LLMs lack this fine-grained control. Future work will benchmark FT-FLAT against these models to quantify the trade-offs between generality and domain precision. These limitations provide concrete ways to advance fire safety NLP research while maintaining the interpretability advantage of our method over black-box alternatives.
Author Contributions
Methodology, Z.Y.; Software, C.L.; Validation, C.L. and S.Y.; Investigation, S.Y.; Resources, J.T.; Data curation, Q.H.; Writing—original draft, Z.Y.; Supervision, J.T.; Funding acquisition, W.K. All authors have read and agreed to the published version of the manuscript.
Funding
National Fire and Rescue Administration: 2024XFCX44.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
For intellectual property reasons, the data supporting the results of this study have not been made publicly available. Therefore, the data from this study will be made available to researchers who meet the criteria for access to confidential data. To apply, please email ysxcccf@aliyun.com.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Diaz, L.B.; He, X.; Hu, Z.; Restuccia, F.; Marinescu, M.; Barreras, J.V.; Patel, Y.; Offer, G.; Rein, G. Meta-review of fire safety of lithium-ion batteries: Industry challenges and research contributions. J. Electrochem. Soc. 2020, 167, 090559. [Google Scholar] [CrossRef]
- Nguyen, K.T.; Navaratnam, S.; Mendis, P.; Zhang, K.; Barnett, J.; Wang, H. Fire safety of composites in prefabricated buildings: From fibre reinforced polymer to textile reinforced concrete. Compos. Part B Eng. 2020, 187, 107815. [Google Scholar] [CrossRef]
- Gabbar, H.A.; Othman, A.M.; Abdussami, M.R. Review of battery management systems (BMS) development and industrial standards. Technologies 2021, 9, 28. [Google Scholar] [CrossRef]
- Chen, H.; Hou, L.; Zhang, G.K.; Moon, S. Development of BIM, IoT and AR/VR technologies for fire safety and upskilling. Autom. Constr. 2021, 125, 103631. [Google Scholar] [CrossRef]
- Thevega, T.; Jayasinghe, J.A.S.C.; Robert, D.; Bandara, C.S.; Kandare, E.; Setunge, S. Fire compliance of construction materials for building claddings: A critical review. Constr. Build. Mater. 2022, 361, 129582. [Google Scholar] [CrossRef]
- Himoto, K. Conceptual framework for quantifying fire resilience—A new perspective on fire safety performance of buildings. Fire Saf. J. 2021, 120, 103052. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; D’amato, C.; De Melo, G.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge graphs. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Li, Z.; Liu, H.; Zhang, Z.; Liu, T.; Xiong, N.N. Learning knowledge graph embedding with heterogeneous relation attention networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 3961–3973. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Law, A.; Bisby, L. The rise and rise of fire resistance. Fire Saf. J. 2020, 116, 103188. [Google Scholar] [CrossRef]
- Mathew, A.; Amudha, P.; Sivakumari, S. Deep learning techniques: An overview. In Advanced Machine Learning Technologies and Applications. AMLTA 2020; Springer: Singapore, 2021; pp. 599–608. [Google Scholar]
- Zheng, X.; Wang, B.; Zhao, Y.; Mao, S.; Tang, Y. A knowledge graph method for hazardous chemical management: Ontology design and entity identification. Neurocomputing 2021, 430, 104–111. [Google Scholar] [CrossRef]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised pre-training for speech recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]
- Cao, Y.; Zhou, Y.; Shen, F.; Li, Z.X. Research on Named Entity Recognition of Chinese Electronic Medical Records Based on CNN-CRF. J. Chongqing Univ. Posts Telecommun. 2019, 6, 869–875. [Google Scholar]
- Kong, J.; Zhang, L.; Jiang, M.; Liu, T. Incorporating multi-level CNN and attention mechanism for Chinese clinical named entity recognition. J. Biomed. Inform. 2021, 116, 103737. [Google Scholar] [CrossRef]
- Gao, C.; Zhang, X.; Han, M.; Liu, H. A review on cyber security named entity recognition. Front. Inf. Technol. Electron. Eng. 2021, 22, 1153–1168. [Google Scholar] [CrossRef]
- Li, T.; Guo, Y.; Ju, A. Knowledge triple extraction in cybersecurity with adversarial active learning. J. Commun. 2020, 41, 80–91. [Google Scholar]
- Yan, H.; Deng, B.; Li, X.; Qiu, X. TENER: Adapting transformer encoder for named entity recognition. arXiv 2019, arXiv:1911.04474. [Google Scholar] [CrossRef]
- Li, B.; Kang, X.; Zhang, H.; Wang, Y.; Chen, Y.; Bai, F. Named entity recognition in Chinese electronic medical records using transformer-CRF. Comput. Eng. Appl. 2020, 56, 153–159. [Google Scholar]
- Berragan, C.; Singleton, A.; Calafiore, A.; Morley, J. Transformer based named entity recognition for place name extraction from unstructured text. Int. J. Geogr. Inf. Sci. 2023, 37, 747–766. [Google Scholar] [CrossRef]
- Yoo, J.; Cho, Y. ICSA: Intelligent chatbot security assistant using Text-CNN and multi-phase real-time defense against SNS phishing attacks. Expert Syst. Appl. 2022, 207, 117893. [Google Scholar] [CrossRef]
- Sandhan, J.; Singha, R.; Rao, N.; Samanta, S.; Behera, L.; Goyal, P. TransLIST: A transformer-based linguistically informed Sanskrit tokenizer. arXiv 2022, arXiv:2210.11753. [Google Scholar]
- Hussain, M.S.; Zaki, M.J.; Subramanian, D. Global self-attention as a replacement for graph convolution. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022. [Google Scholar]
- Majidian, H.; Enshaei, H.; Howe, D. Nonlinear Transient Switching Filter for Automatic Buffer Window Adjustment in Short-term Ship Response Prediction. Procedia Comput. Sci. 2024, 232, 1045–1054. [Google Scholar] [CrossRef]
- Al-Kbodi, B.H.; Rajeh, T.; Zayed, M.E.; Li, Y.; Zhao, J.; Wu, J.; Liu, Y. Transient heat transfer simulation, sensitivity analysis, and design optimization of shallow ground heat exchangers with hollow-finned structures for enhanced performance of ground-coupled heat pumps. Energy Build. 2024, 305, 113870. [Google Scholar] [CrossRef]
- Cimrman, R. Fast evaluation of finite element weak forms using python tensor contraction packages. Adv. Eng. Softw. 2021, 159, 103033. [Google Scholar] [CrossRef]
- Korkmaz, M.E.; Gupta, M.K.; Robak, G.; Moj, K.; Krolczyk, G.M.; Kuntoğlu, M. Development of lattice structure with selective laser melting process: A state of the art on properties, future trends and challenges. J. Manuf. Process. 2022, 81, 1040–1063. [Google Scholar] [CrossRef]
- Foumani, N.M.; Tan, C.W.; Webb, G.I.; Salehi, M. Improving position encoding of transformers for multivariate time series classification. Data Min. Knowl. Discov. 2024, 38, 22–48. [Google Scholar] [CrossRef]
- Avsec, Ž.; Agarwal, V.; Visentin, D.; Ledsam, J.R.; Grabska-Barwinska, A.; Taylor, K.R.; Assael, Y.; Jumper, J.; Kohli, P.; Kelley, D.R. Effective gene expression prediction from sequence by integrating long-range interactions. Nat. Methods 2021, 18, 1196–1203. [Google Scholar] [CrossRef]
- Aldakheel, F.; Satari, R.; Wriggers, P. Feed-forward neural networks for failure mechanics problems. Appl. Sci. 2021, 11, 6483. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F.C.N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML ′01), San Francisco, CA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Riyanto, S.; Imas, S.S.; Djatna, T.; Atikah, T.D. Comparative analysis using various performance metrics in imbalanced data for multi-class text classification. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Chauhan, V.K.; Dahiya, K.; Sharma, A. Problem formulations and solvers in linear SVM: A review. Artif. Intell. Rev. 2019, 52, 803–855. [Google Scholar] [CrossRef]
- Webb, G.I.; Keogh, E.; Miikkulainen, R. Naïve Bayes. Encycl. Mach. Learn. 2010, 15, 713–714. [Google Scholar]
- Zhang, T.; You, F. Research on short text classification based on textcnn. J. Phys. Conf. Ser. 2021, 1757, 012092. [Google Scholar] [CrossRef]
- Umanesan, R.; Shunmugasundaram, M.; Rani, P.; Balasubramanian, K.; Rakesh, K.; Chandel, P.S. Application of BiLSTM-CRF Approach and its Application for Better Decisions in Human Resource Management Processes. In Proceedings of the 2023 International Conference on Sustainable Communication Networks and Application (ICSCNA), Theni, India, 15–17 November 2023; pp. 877–882. [Google Scholar]
- Belkadi, S.; Han, L.; Wu, Y.; Nenadic, G. Exploring the value of pre-trained language models for clinical named entity recognition. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 3660–3669. [Google Scholar]
- Lv, H.; Ning, Y.; Ning, K.; Ji, X.; He, S. Chinese Text Classification Using BERT and Flat-Lattice Transformer. In Proceedings of the International Conference on AI and Mobile Services, Honolulu, HI, USA, 10 December 2022; pp. 64–75. [Google Scholar]
- Riyanto, S.; Sitanggang, I.S.; Djatna, T.; Atikah, T.D. Plant-Disease Relation Model through BERT-BiLSTM-CRF Approach. Indones. J. Electr. Eng. Inform. 2024, 12, 113–124. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, C.; Zheng, S.; Qiao, Y.; Li, C.; Zhang, M.; Dam, S.K.; Thwal, C.M.; Tun, Y.L.; Huy, L.L.; et al. A Complete Survey on Generative AI (AIGC): Is ChatGPT from GPT-4 to GPT-5 All You Need? arXiv 2023, arXiv:2303.11717. [Google Scholar] [CrossRef]
- Peng, B.; Alcaide, E.; Anthony, Q.; Albalak, A.; Arcadinho, S.; Biderman, S.; Cao, H.; Cheng, X.; Chung, M.; Grella, M.; et al. RWKV: Reinventing RNNs for the Transformer Era. arXiv 2023, arXiv:2305.13048. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).