
Investigation of Machine Learning Techniques for Disruption Prediction Using JET Data



Abstract
1. Introduction
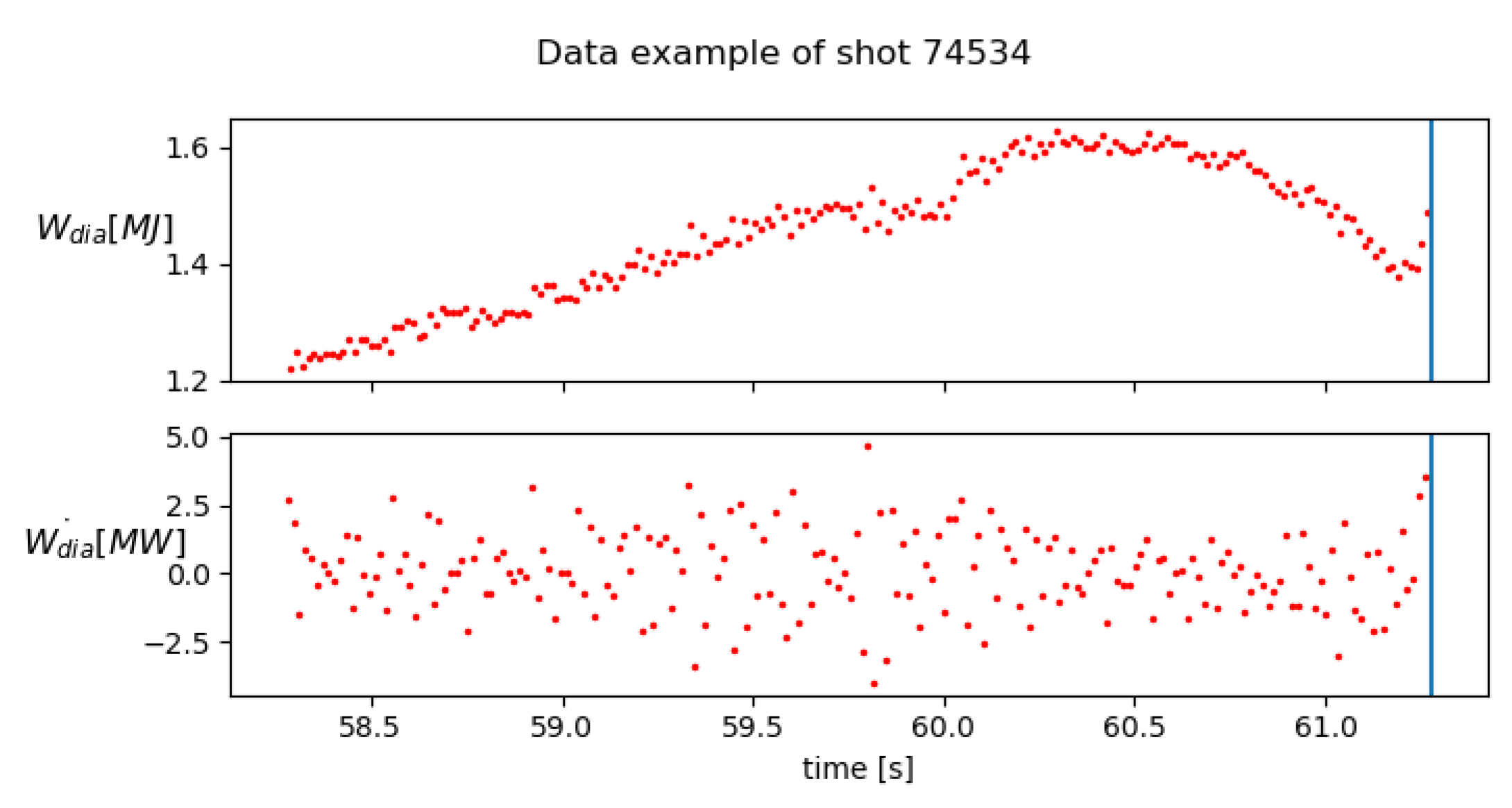
2. Data
3. Methods
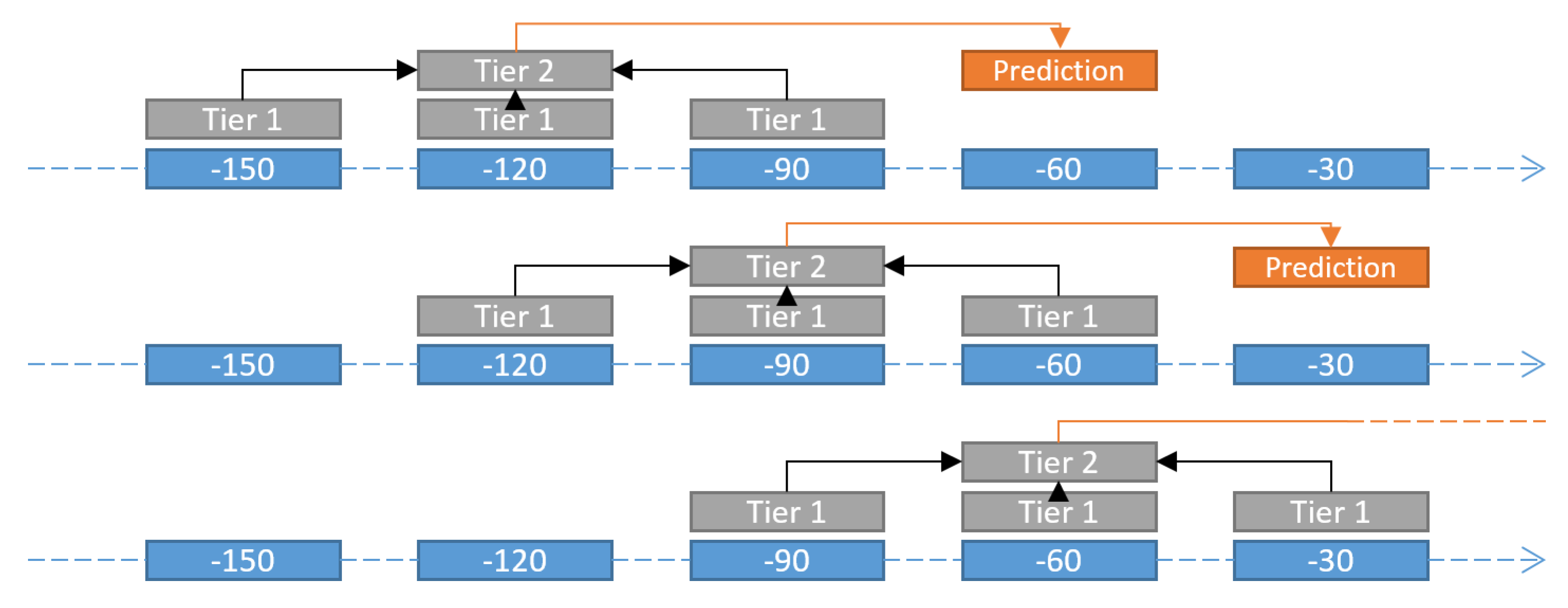
3.1. Support Vector Machines
3.2. Random Forest
3.3. Gradient-Boosted Trees
3.4. Long Short-Term Memory
4. Results
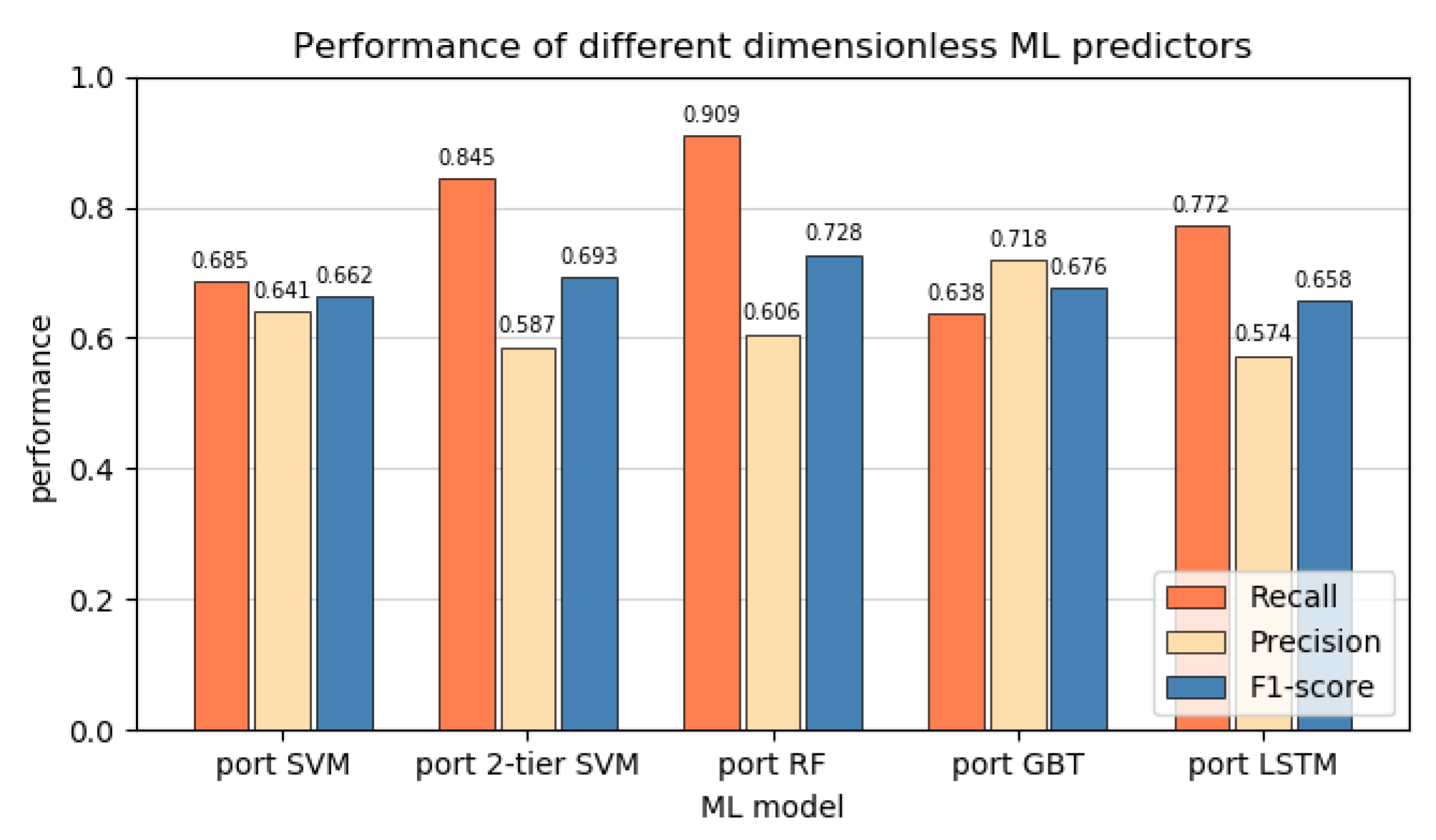
4.1. Predictor Performance
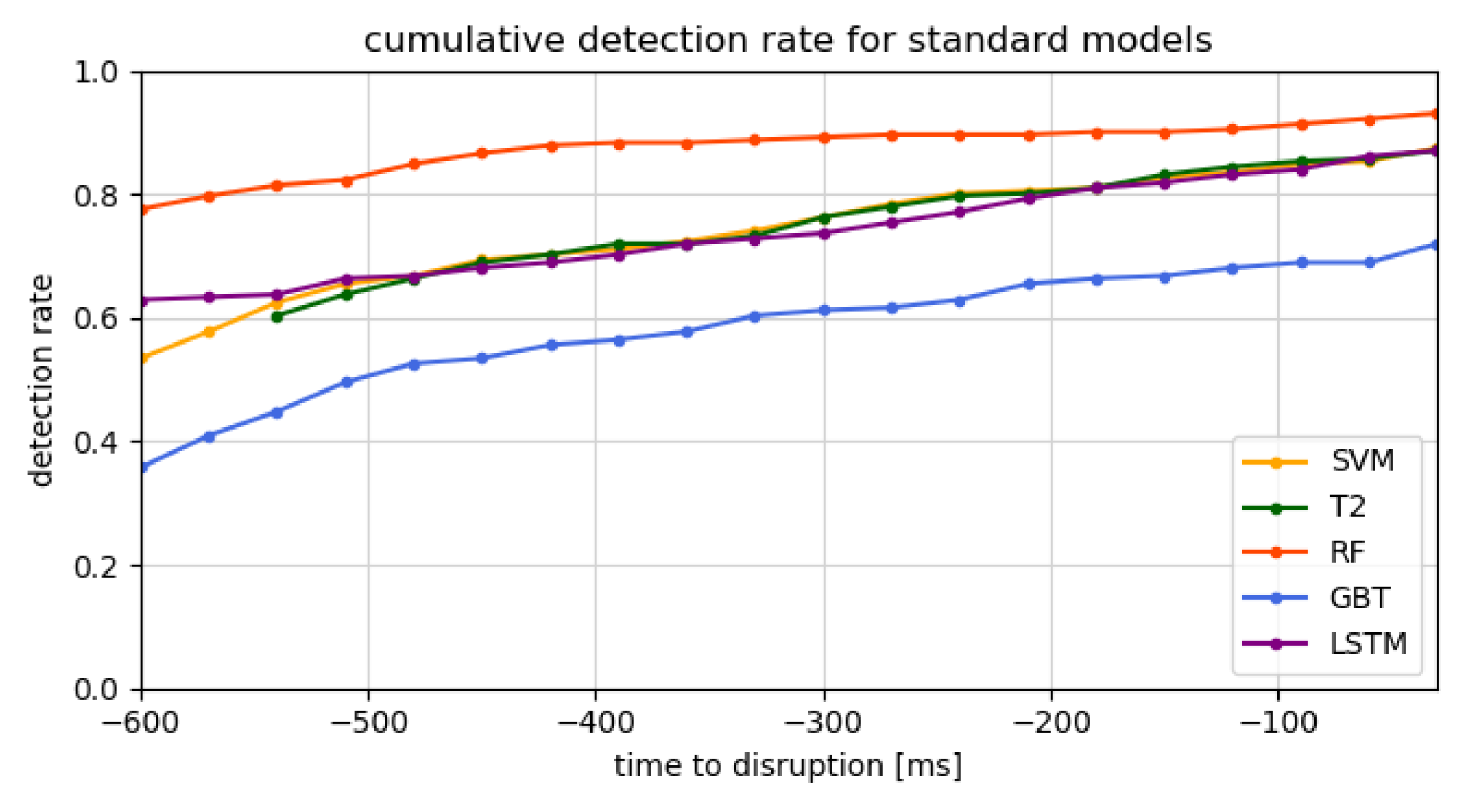
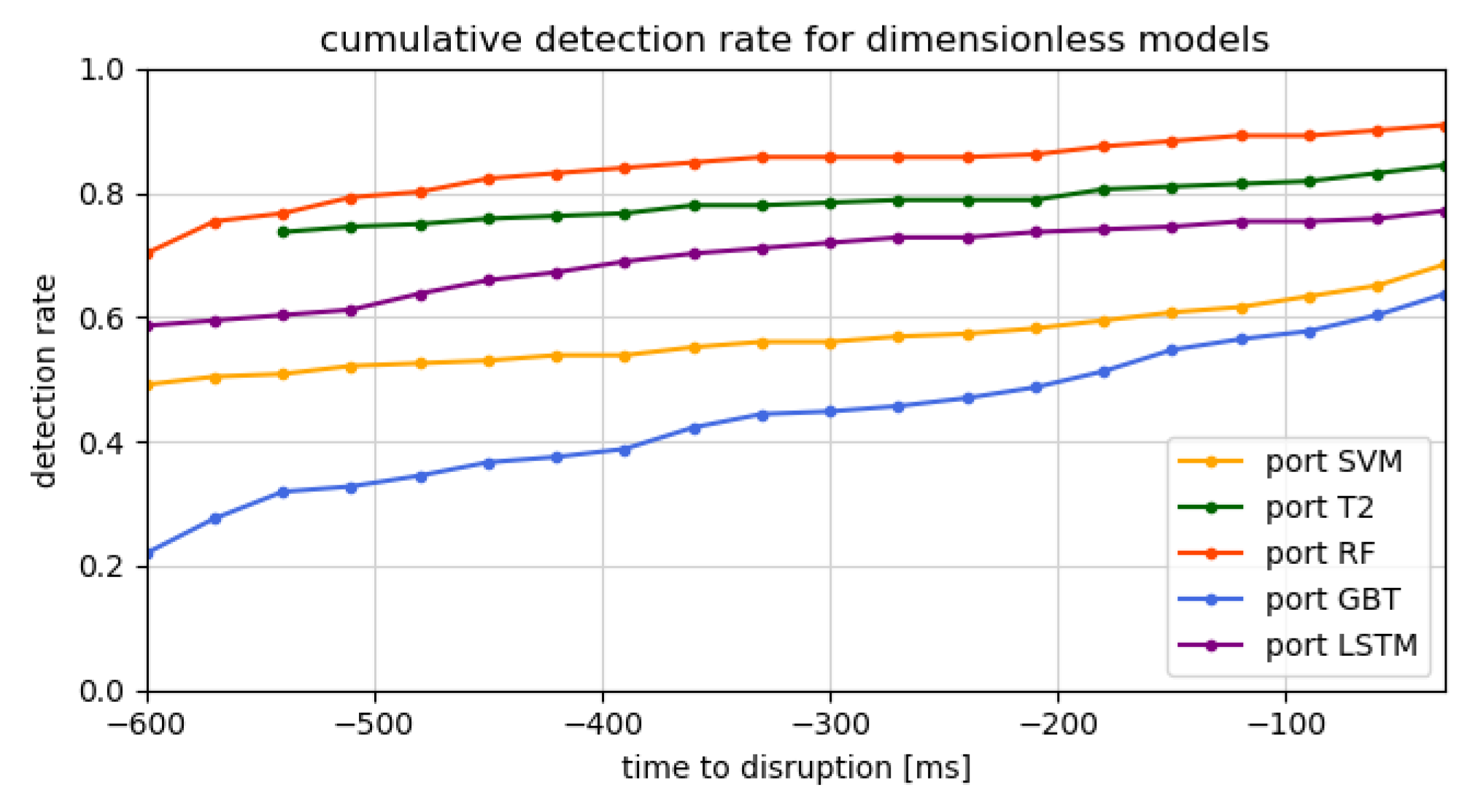
4.2. Detection Time and Cumulative Detection Rate
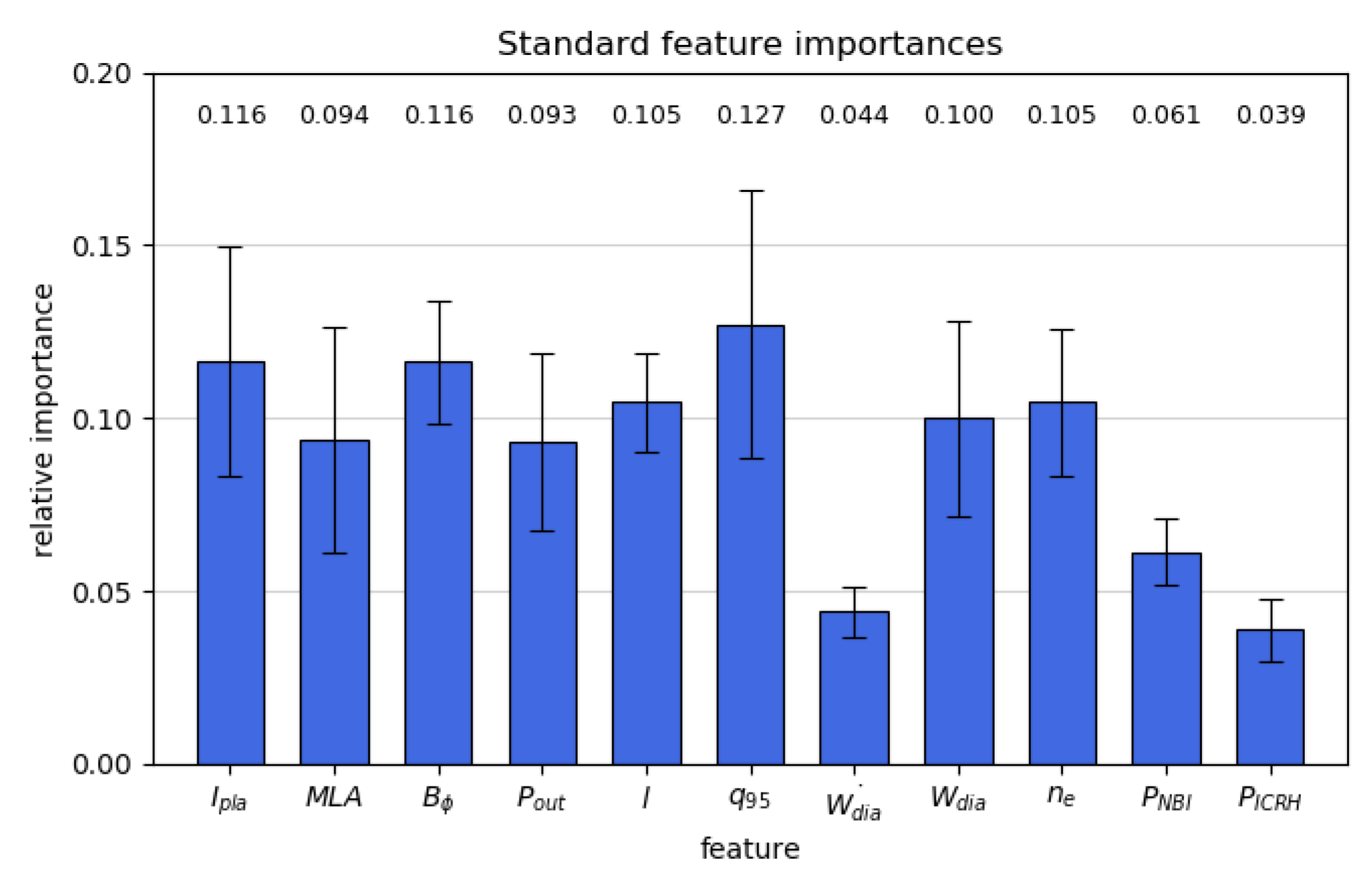
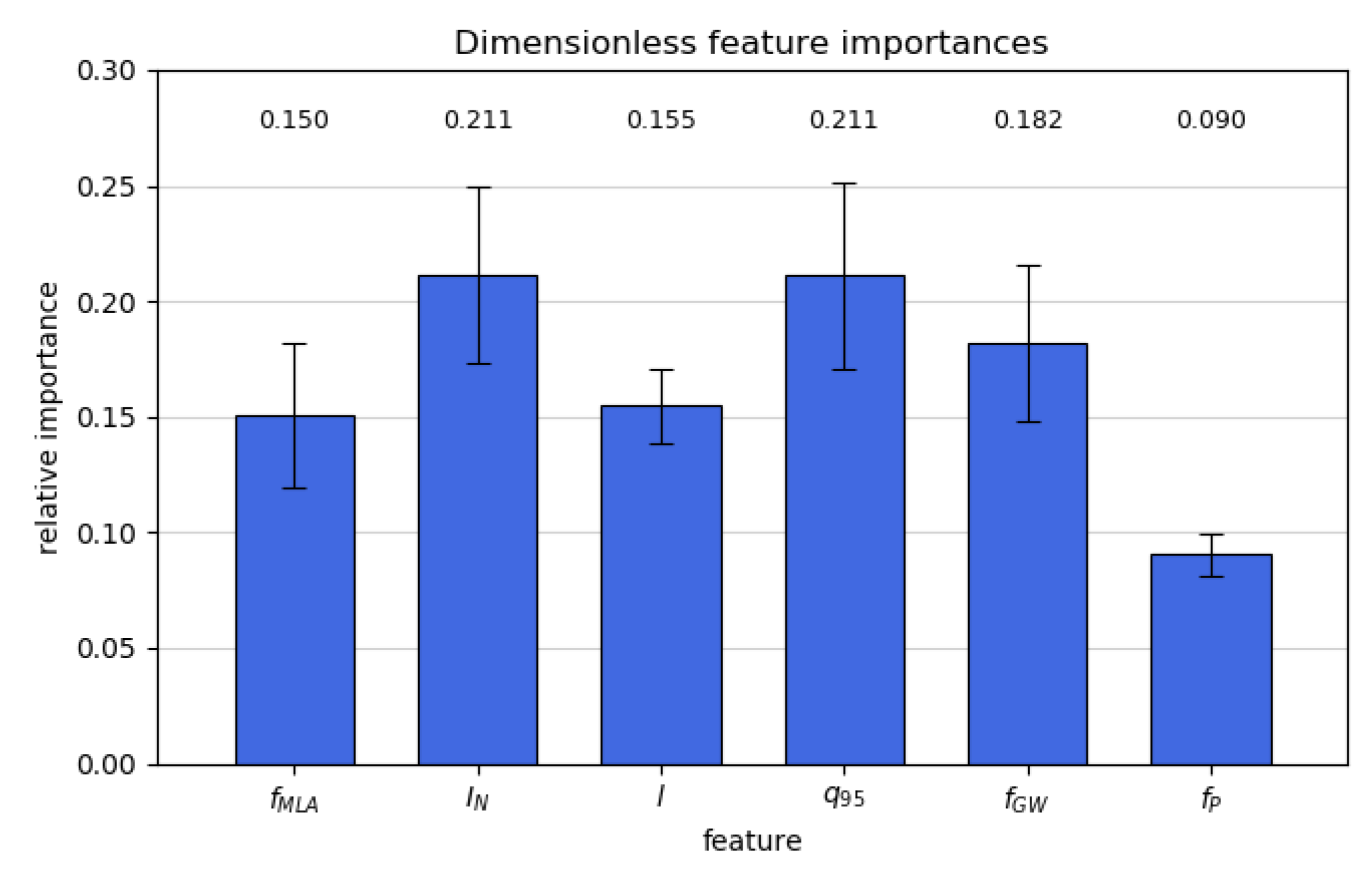
4.3. Relative Feature Importance
4.4. Computational Cost
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Boozer, A.H. Theory of tokamak disruptions. Phys. Plasmas 2012, 19, 058101. [Google Scholar] [CrossRef]
- Cardella, A.; Gorenflo, H.; Lodato, A.; Ioki, K.; Raffray, R. Effects of plasma disruption events on iter first wall materials. J. Nucl. Mater. 2000, 283–287, 1105–1110. [Google Scholar] [CrossRef]
- Vega, J.; Citrin, J.; Ho, A.; Huijsmans, G.T.; Marin, M.; van de Plassche, K.L. Disruption prediction with artificial intelligence techniques in tokamak plasmas. Nat. Phys. 2022, 18, 741–750. [Google Scholar] [CrossRef]
- Lehnen, M.; Maruyama, S. Iter Disruption Mitigation Workshop; Technical Report, ITR-18-002; ITER Organisation: Saint-Paul-lez-Durance, France, 2017. [Google Scholar]
- De Vries, P.; Johnson, M.; Alper, B.; Buratti, P.; Hender, T.; Koslowski, H.; Riccardo, V. Survey of disruption causes at jet. Nucl. Fusion 2011, 5, 053018. [Google Scholar] [CrossRef]
- Baylor, L.; Combs, S.; Duckworth, R.; Lyttle, M.; Meitner, S.; Rasmussen, D.A.; Maruyama, S. Pellet injection technology and its application on iter. IEEE Trans. Plasma Sci. 2016, 44, 1489–1495. [Google Scholar] [CrossRef]
- Hollmann, E.M.; Aleynikov, P.B.; Fulop, T.; Humphreys, D.A.; Izzo, V.A.; Lehnen, M.; Lukash, V.E.; Papp, G.; Pautasso, G.; Saint-Laurent, F.; et al. Status of research toward the iter disruption mitigation system. Phys. Plasmas 2015, 22, 21802. [Google Scholar] [CrossRef]
- Jachmich, S.; Kruezi, U.; Card, P.; Deakin, K.; Kinna, D.; Koslowski, H.; Lambertz, H.; Lehnen, M. Implementation of a new disruption mitigation system into the control system of jet. Fusion Eng. Des. 2015, 96–97, 633–636. [Google Scholar] [CrossRef]
- Moreno, R.; Vega, J.; Dormido-Canto, S.; Pereira, A.; Murari, A.; Contributors JET. Disruption prediction on jet during the ilw experimental campaigns. Fusion Sci. Technol. 2016, 69, 485–494. [Google Scholar] [CrossRef]
- Rattá, G.A.; Vega, J.; Murari, A.; Vagliasindi, G.; Johnson, M.F.; de Vries, P.C. An advanced disruption predictor for jet tested in a simulated real-time environment. Nucl. Fusion 2010, 50, 025005. [Google Scholar] [CrossRef]
- Cannas, B.; Fanni, A.; Pautasso, G.; Sias, G.; Sonato, P. An adaptive real-time disruption predictor for ASDEX upgrade. Nucl. Fusion 2010, 50, 075004. [Google Scholar] [CrossRef]
- Zheng, W.; Hu, F.; Zhang, M.; Chen, Z.; Zhao, X.; Wang, X.; Shi, P.; Zhang, X.; Zhang, X.; Zhou, Y.; et al. Hybrid neural network for density limit disruption prediction and avoidance on j-text tokamak. Nucl. Fusion 2018, 58, 056016. [Google Scholar] [CrossRef]
- Rea, C.; Granetz, R.; Montes, K.; Tinguely, R.; Eidietis, N.; Hanson, J.; Sammuli, B. Disruption prediction investigations using machine learning tools on diii-d and alcator c-mod. Plasma Phys. Control. Fusion 2018, 60, 084004. [Google Scholar] [CrossRef]
- Guo, B.H.; Chen, D.L.; Shen, B.; Rea, C.; Granetz, R.S.; Zeng, L.; Hu, W.H.; Qian, J.P.; Sun, Y.W.; Xiao, B.J. Disruption prediction on east tokamak using a deep learning algorithm. Plasma Phys. Control. Fusion. 2021, 63, 115007. [Google Scholar] [CrossRef]
- Kates-Harbeck, J.; Svyatkovskiy, A.; Tang, W. Predicting disruptive instabilities in controlled fusion plasmas through deep learning. Nature 2019, 568, 526–531. [Google Scholar] [CrossRef]
- Pau, A.; Fanni, A.; Carcangiu, S.; Cannas, B.; Sias, G.; Murari, A.; Rimini, F. A machine learning approach based on generative topographic mapping for disruption prevention and avoidance at JET. Nucl. Fusion 2019, 59, 106017. [Google Scholar] [CrossRef]
- Zhu, J.X.; Rea, C.; Montes, K.; Granetz, R.S.; Sweeney, R.; Tinguely, R.A. Hybrid deep learning architecture for general disruption prediction across tokamaks. Nucl. Fusion 2021, 61, 026007. [Google Scholar] [CrossRef]
- Croonen, J. Predicting Plasma Disruptions in Tokamak Fusion Reactors Using Machine Learning. Master’s Thesis, KU Leuven, Leuven, Belgium, 2019. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Eidietis, N.; Gerhardt, S.; Granetz, R.; Kawano, Y.; Lehnen, M.; Lister, J.; Pautasso, G.; Riccardo, V.; Tanna, R.; Thornton, A. The ITPA disruption database. Nucl. Fusion 2015, 55, 063030. [Google Scholar] [CrossRef]
- Rattá, G.; Vega, J.; Murari, A. Improved feature selection based on genetic algorithms for real time disruption prediction on jet. Fusion Eng. Des. 2012, 87, 1670–1678. [Google Scholar] [CrossRef]
- Pustovitov, V.D.; Ryabushev, E.A. Effect of pressure anisotropy on diamagnetic signal in a tokamak with noncircular plasma cross section. Plasma Phys. Rep. 2021, 47, 947–955. [Google Scholar] [CrossRef]
- Schlisio, G. Analysis of the Gas Balance for Wendelstein 7-x; Technical Report; University of Greifswald: Greifswald, Germany, 2020; p. 9. [Google Scholar]
- Aledda, R.; Cannas, B.; Fanni, A.; Pau, A.; Sias, G. Improvements in disruption prediction at asdex upgrade. Fusion Eng. Des. 2015, 96–97, 698–702. [Google Scholar] [CrossRef]
- Tang, W.; Parsons, M.; Feigbush, E.; Choi, J.; Kurc, T. Big data machine learning for disruption prediction. In Proceedings of the 26th IAEA Fusion Energy Conference, Kyoto, Japan, 17–22 October 2016. [Google Scholar]
- Windsor, C.; Pautasso, G.; Tichmann, C.; Buttery, R.; Hende, T.; JET EFDA Contributors the ASDEX Upgrade Team. A cross-tokamak neural network disruption predictor for the JET and ASDEX upgrade tokamaks. Nucl. Fusion 2005, 45, 337–350. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Pedregosa, F. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Paszke, A. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Sydney, NSW, Australia, 2019; pp. 8024–8035. Available online: http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf (accessed on 4 December 2022).
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014; p. 12. [Google Scholar]
- Moreno, R.; Vega, J.; Murari, A.; Dormido-Canto, S.; López, J.M.; Ramírez, J.M. Robustness and increased time resolution of jet advanced predictor of disruptions. Plasma Phys. Control. Fusion 2014, 56, 114003. [Google Scholar] [CrossRef]
- Rattá, G.A.; Vega, J.; Murari, A. Simulation and real-time replacement of missing plasma signals for disruption prediction: An implementation with apodis. Plasma Phys. Control. Fusion 2014, 56, 114004. [Google Scholar] [CrossRef]
- Lin, W.C.; Tsai, C.F. Missing value imputation: A review and analysis of the literature (2006–2017). Artif. Intell. Rev. 2020, 53, 1487–1509. [Google Scholar] [CrossRef]
- López, J.M.; Vega, J.; Alves, D.; Dormido-Canto, S.; Murari, A.; Ramírez, J.M.; Felton, R.; Ruiz, M.; de Arcas, G. Implementation of the disruption predictor apodis in jet’s real-time network using the marte framework. IEEE Trans. Nucl. Sci. 2014, 61, 741–744. [Google Scholar] [CrossRef]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding variable importances in forests of randomized trees. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 26. Available online: https://proceedings.neurips.cc (accessed on 4 December 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Data Availability | |
|---|---|---|---|
| Plasma current | 100% | 0.83 | |
| Mode lock amplitude | 100% | 2.19 | |
| Plasma internal inductance | 81.3% | 0.90 | |
| Diamagnetic energy | 99.0% | 1.35 | |
| Time derivative of the diamagnetic energy | 99.0% | 64.37 | |
| Electron density | 99.7% | 1.17 | |
| Radiated output power | 99.7% | 1.80 | |
| Neutral beam injection input power | 70.0% | 1.75 | |
| Ion cyclotron radio heating input power | 42.5% | 3.05 | |
| Edge safety factor | 100% | 1.08 | |
| Toroidal magnetic field strength | 100% | 0.81 |
| Name | Description | Formula |
|---|---|---|
| Normalized plasma current | ||
| Mode lock amplitude fraction | ||
| Plasma internal inductance | ||
| Greenwald density fraction | ||
| Radiated power fraction | ||
| Edge safety factor |
| SVM | T2 | RF | GBT | LSTM | |
|---|---|---|---|---|---|
| Standard | 0.136 | 0.155 | 0.223 | 0.123 | 0.149 |
| Dimensionless | 0.189 | 0.294 | 0.291 | 0.123 | 0.283 |
| SVM | T2 | RF | GBT | LSTM | |
|---|---|---|---|---|---|
| Train time [s] | 28.21 | 184.89 | 138.52 | 24.88 | 79.18 * |
| Inference time [ms] | 0.43 | 0.52 | 0.11 | 0.007 | 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Croonen, J.; Amaya, J.; Lapenta, G. Investigation of Machine Learning Techniques for Disruption Prediction Using JET Data. Plasma 2023, 6, 89-102. https://doi.org/10.3390/plasma6010008
Croonen J, Amaya J, Lapenta G. Investigation of Machine Learning Techniques for Disruption Prediction Using JET Data. Plasma. 2023; 6(1):89-102. https://doi.org/10.3390/plasma6010008
Chicago/Turabian StyleCroonen, Joost, Jorge Amaya, and Giovanni Lapenta. 2023. "Investigation of Machine Learning Techniques for Disruption Prediction Using JET Data" Plasma 6, no. 1: 89-102. https://doi.org/10.3390/plasma6010008
APA StyleCroonen, J., Amaya, J., & Lapenta, G. (2023). Investigation of Machine Learning Techniques for Disruption Prediction Using JET Data. Plasma, 6(1), 89-102. https://doi.org/10.3390/plasma6010008