

SIFT-Based Depth Estimation for Accurate 3D Reconstruction in Cultural Heritage Preservation



Abstract
1. Introduction
2. Materials and Methods
2.1. Recent Works on 3D Reconstruction
- (1)
- 3D reconstruction using dense image matching: This technique is mostly used for the 3D reconstruction of buildings and architecture from aerial images. The aerial images tend to provide only the detail of the top view of an object. However, by using the dense map, this method can compute differences in object intensity of the image in the form of shadow, shading, and reflection of the object. The algorithm can compute the dimensions of the object by using the measurement of these properties [17,18,27,28,29,30,31].
- (2)
- 3D reconstruction using the photogrammetry method: Commercial software, e.g., AgiSoft, Reality Capture, and ReCap, uses the point cloud as the extracted feature to generate the 3D model. This software commonly requires the images taken to have an overlap, conveyed throughout the series of images to build the 3D model using the overlapping relation. Figure 1 shows the mesh model of the Buddha generated from the point cloud [32,33,34,35,36].
2.2. Experimental Setup
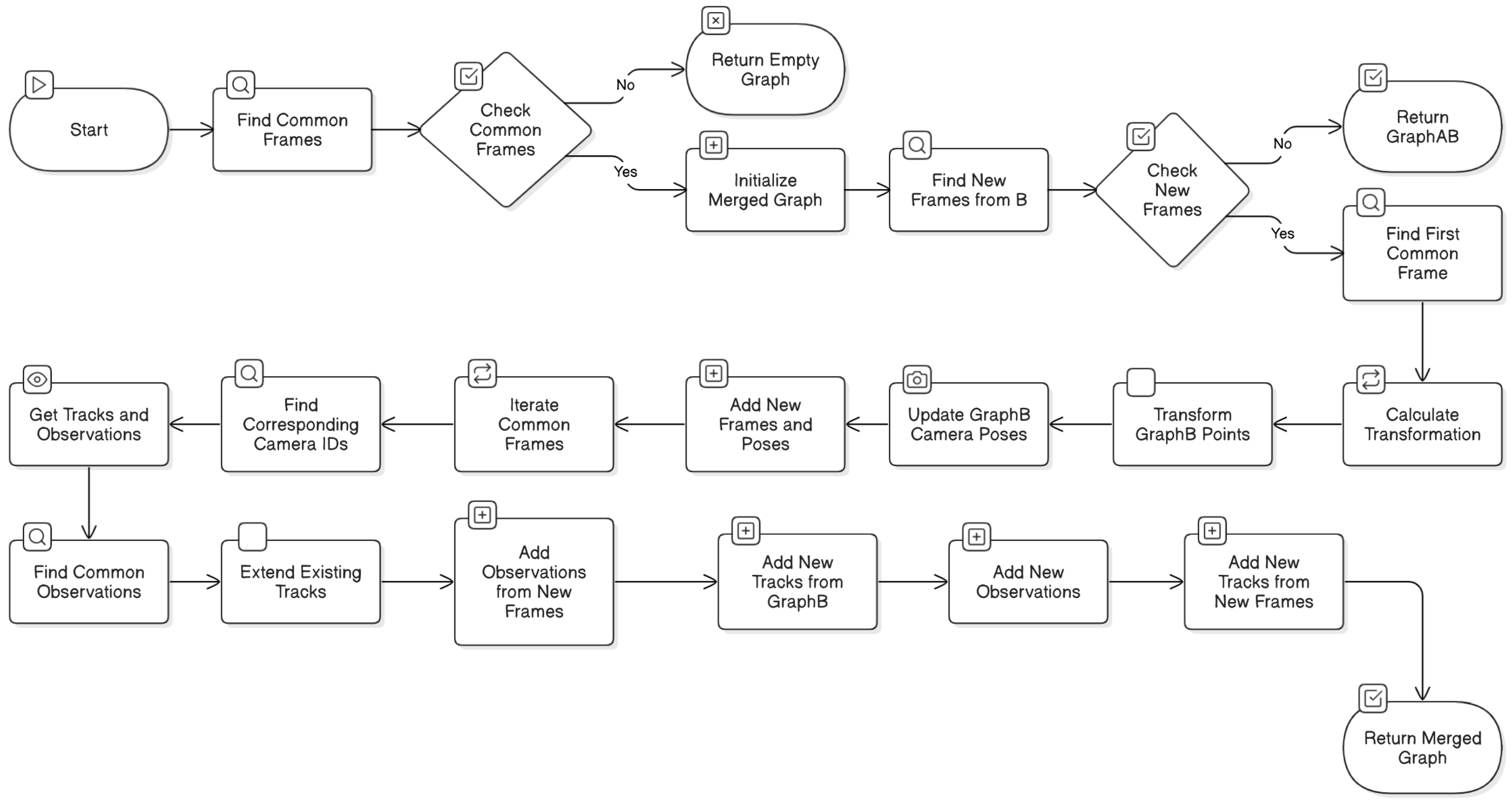
function merge2graphs(GraphA, GraphB): # Find common frames (images) between the two graphs commonFrames = intersect(GraphA.frames, GraphB.frames) # If no common frames, return empty graph if commonFrames is empty: return empty GraphAB # Initialize merged graph with GraphA GraphAB = GraphA # Find new frames from GraphB not present in GraphA newFramesFromB = setdiff(GraphB.frames, GraphA.frames) # If no new frames, return GraphAB as is if newFramesFromB is empty: return GraphAB # Find the first common frame firstCommonFrame = first element in commonFrames # Calculate transformation to align GraphB to GraphA's coordinate system RtBW2AW = concatenateRts(inverseRt(GraphA.Mot for firstCommonFrame), GraphB.Mot for firstCommonFrame) # Transform GraphB's 3D points using the calculated transformation GraphB.Str = transformPtsByRt(GraphB.Str, RtBW2AW) # Update GraphB's camera poses to reflect the new coordinate system for each frame in GraphB: GraphB.Mot for current frame = concatenateRts(GraphB.Mot for current frame, inverseRt(RtBW2AW)) # Add new frames and camera poses from GraphB to GraphAB GraphAB.frames = combine GraphA.frames and newFramesFromB GraphAB.Mot = combine GraphA.Mot and GraphB.Mot for new frames # Iterate through common frames to merge and update tracks (3D points and observations) for each commonFrame in commonFrames: # Find corresponding camera IDs in both graphs cameraIDA = index of commonFrame in GraphA.frames cameraIDB = index of commonFrame in GraphB.frames # Get tracks (3D point indices) and observations for the common frame in both graphs trA, xyA = get tracks and observations from GraphA for cameraIDA trB, xyB = get tracks and observations from GraphB for cameraIDB # Find common observations (matching 2D points) between the two graphs xyCommon, iA, iB = intersect(xyA, xyB) # Extend existing tracks in GraphAB with observations from GraphB for each common observation: idA = track index in GraphA corresponding to current common observation idB = track index in GraphB corresponding to current common observation # Add observations from new frames in GraphB to the existing track in GraphAB for each new frame in GraphB: if observation exists for idB in current new frame: add observation to GraphAB for track idA and current new frame # Add new tracks from GraphB that are not present in GraphA xyNewFromB, iB = setdiff(xyB, xyA) for each new observation from GraphB: idB = track index in GraphB corresponding to current new observation # Add new track to GraphAB with observation from common frame add new track to GraphAB with observation from GraphB for idB and cameraIDA # Add observations from new frames in GraphB to the new track in GraphAB for each new frame in GraphB: if observation exists for idB in current new frame: add observation to GraphAB for new track and current new frame # Add new tracks that are only present in the new frames of GraphB # ... (This part of the code handles tracks that are not connected to the common frames) return GraphAB |
- Identify Common Frames: The function identifies standard frames between the two graphs, which is crucial for establishing correspondences and aligning the coordinate systems.
- Transform to Common Coordinate System: The function calculates the transformation that aligns the second graph’s coordinate system with the first graph’s coordinate system. This transformation is based on the camera poses of the first standard frame in both graphs. The 3D points of the second graph are then transformed using this transformation, and the camera poses are updated accordingly.
- Merge Data: The frames, camera poses, and 3D points from both graphs are combined into a new graph. The observation indices are updated to ensure the 3D points are correctly associated with their corresponding image observations.
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nilsson, T.; Thorell, K. Cultural Heritage Preservation: The Past, the Present and the Future; Halmstad University Press: Halmstad, Sweden, 2018. [Google Scholar]
- De la Torre, M. Values and Heritage Conservation. Herit. Soc. 2013, 6, 155–166. [Google Scholar] [CrossRef]
- De la Torre, M. Values in Heritage Conservation: A Project of The Getty Conservation Institute. J. Preserv. Technol. 2014, 45, 19–24. [Google Scholar]
- Kosel, J.; Ropret, P. Overview of Fungal Isolates on Heritage Collections of Photographic Materials and Their Biological Potency. J. Cult. Herit. 2021, 48, 277–291. [Google Scholar] [CrossRef]
- Hiebel, G.; Aspöck, E.; Kopetzky, K. Ontological Modeling for Excavation Documentation and Virtual Reconstruction of an Ancient Egyptian Site. J. Comput. Cult. Herit. 2021, 14, 1–14. [Google Scholar] [CrossRef]
- Grbić, M.L.; Dimkić, I.; Janakiev, T.; Kosel, J.; Tavzes, Č.; Popović, S.; Knežević, A.; Legan, L.; Retko, K.; Ropret, P.; et al. Uncovering the Role of Autochthonous Deteriogenic Biofilm Community: Rožanec Mithraeum Monument (Slovenia). Microb. Ecol. 2024, 87, 87. [Google Scholar] [CrossRef] [PubMed]
- Stanco, F.; Battiato, S.; Gallo, G. Digital Imaging for Cultural Heritage Preservation. Analysis, Restoration, and Reconstruction of Ancient Artworks; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Neumüller, M.; Reichinger, A.; Rist, F.; Kern, C. 3D Printing for Cultural Heritage: Preservation, Accessibility, Research and Education. In 3D Research Challenges in Cultural Heritage: A Roadmap in Digital Heritage Preservation; Ioannides, M., Quak, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 119–134. [Google Scholar]
- Tucci, G.; Bonora, V.; Conti, A.; Fiorini, L. High-Quality 3D Models and Their Use in a Cultural Heritage Conservation Project. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 687–693. [Google Scholar] [CrossRef]
- Kolay, S. Cultural Heritage Preservation of Traditional Indian Art Through Virtual New-Media. Procedia Soc. Behav. Sci. 2016, 225, 309–320. [Google Scholar] [CrossRef]
- Trček, D. Cultural Heritage Preservation by Using Blockchain Technologies. Herit. Sci. 2022, 10, 6. [Google Scholar] [CrossRef]
- Selmanović, E.; Rizvic, S.; Harvey, C.; Boskovic, D.; Hulusic, V.; Chahin, M.; Sljivo, S. Improving Accessibility to Intangible Cultural Heritage Preservation Using Virtual Reality. J. Comput. Cult. Herit. 2020, 13, 1–19. [Google Scholar] [CrossRef]
- Alivizatou-Barakou, M.; Kitsikidis, A.; Tsalakanidou, F.; Dimitropoulos, K.; Giannis, C.; Nikolopoulos, S.; Al Kork, S.; Denby, B.; Buchman, L.; Adda-Decker, M.; et al. Intangible Cultural Heritage and New Technologies: Challenges and Opportunities for Cultural Preservation and Development. In Mixed Reality and Gamification for Cultural Heritage; Ioannides, M., Magnenat-Thalmann, N., Papagiannakis, G., Eds.; Springer: Cham, Switzerland, 2017; pp. 129–158. [Google Scholar]
- Gomes, L.; Bellon, O.R.P.; Silva, L. 3D Reconstruction Methods for Digital Preservation of Cultural Heritage: A Survey. Pattern Recognit. Lett. 2014, 50, 3–14. [Google Scholar] [CrossRef]
- Tychola, K.; Tsimperidis, I.; Papakostas, G. On 3D Reconstruction Using RGB-D Cameras. Digital 2022, 2, 401–421. [Google Scholar] [CrossRef]
- Doulamis, A.; Voulodimos, A.; Protopapadakis, E.; Doulamis, N.; Makantasis, K. Automatic 3D Modeling and Reconstruction of Cultural Heritage Sites from Twitter Images. Sustainability 2020, 12, 4223. [Google Scholar] [CrossRef]
- Webb, E.K.; Robson, S.; Evans, R. Quantifying Depth of Field and Sharpness for Image-Based 3D Reconstruction of Heritage Objects. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 439, 911–918. [Google Scholar] [CrossRef]
- Jung, S.; Lee, Y.S.; Lee, Y.; Lee, K.J. 3D Reconstruction Using 3D Registration-Based ToF-Stereo Fusion. Sensors 2022, 22, 8369. [Google Scholar] [PubMed]
- Liang, Y.; Yang, Y.; Fan, X.; Cui, T. Efficient and Accurate Hierarchical SfM Based on Adaptive Track Selection for Large-Scale Oblique Images. Remote Sens. 2023, 15, 1374. [Google Scholar] [CrossRef]
- Ye, Z.; Bao, C.; Zhou, X.; Liu, H.; Bao, H.; Zhang, G. EC-SfM: Efficient Covisibility-Based Structure-from-Motion for Both Sequential and Unordered Images. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 110–123. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, Z.; Song, S.; Yu, T.; Li, J.; Lee, G.H. AdaSfM: From Coarse Global to Fine Incremental Adaptive Structure from Motion. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–1 June 2023; pp. 1–11. [Google Scholar]
- Kar, A.; Häne, C.; Malik, J. Learning a Multi-View Stereo Machine. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: New York, NY, USA, 2017; pp. 364–375. [Google Scholar]
- Papaioannou, G.; Schreck, T.; Andreadis, A.; Mavridis, P.; Gregor, R.; Sipiran, I.; Vardis, K. From Reassembly to Object Completion: A Complete Systems Pipeline. J. Comput. Cult. Herit. 2017, 10, 1–22. [Google Scholar]
- Gomes, L.; Silva, L.; Bellon, O.R.P. Exploring RGB-D Cameras for 3D Reconstruction of Cultural Heritage: A New Approach Applied to Brazilian Baroque Sculptures. J. Comput. Cult. Herit. 2018, 11, 1–24. [Google Scholar]
- Utomo, P.; Wibowo, C.P. 3D Reconstruction of Temples in the Special Region of Yogyakarta by Using Close-Range Photogrammetry. Proc. Semin. Nas. Teknol. Inf. Multimedia. 2017, 5, 1–15. [Google Scholar]
- Cripps, P.; Greenhalgh, A.; Fellows, D.; May, K.; Robinson, D. Ontological Modelling of the Work of the Centre for Archaeology; CIDOC CRM Technical Paper; Univerzita Karlova: Prague, Czech Republic, 2004; pp. 1–33. [Google Scholar]
- Shekhovtsov, A.; Reinbacher, C.; Graber, G.; Pock, T. Solving Dense Image Matching in Real-Time Using Discrete-Continuous Optimization. In Proceedings of the CVWW’16: Proceedings of the 21st Computer Vision Winter Workshop, Rimske Toplice, Slovenia, 3–5 February 2016; Slovenian Pattern Recognition Society: Rimske Toplice, Slovenia, 2016; pp. 1–13. [Google Scholar]
- Geiger, A.; Ziegler, J.; Stiller, C. Stereoscan: Dense 3D Reconstruction in Real-Time. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 963–968. [Google Scholar]
- Hinzmann, T.; Schönberger, J.; Pollefeys, M.; Siegwart, R. Mapping on the Fly: Real-Time 3D Dense Reconstruction, Digital Surface Map and Incremental Orthomosaic Generation for Unmanned Aerial Vehicles. In Proceedings of the Field and Service Robotics—Results of the 11th International Conference, Zurich, Switzerland, 12–15 September 2018; Springer: Zurich, Switzerland, 2018; pp. 383–396. [Google Scholar]
- Vokhmintcev, A.; Timchenko, M. The New Combined Method of the Generation of a 3D Dense Map of Environment Based on History of Camera Positions and the Robot’s Movements. Acta Polytech. Hung. 2020, 17, 95–108. [Google Scholar]
- Zhao, C.; Li, S.; Purkait, P.; Duckett, T.; Stolkin, R. Learning Monocular Visual Odometry with Dense 3D Mapping from Dense 3D Flow. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6864–6871. [Google Scholar]
- Visutsak, P. Stereo-Photogrammetry Technique for 3D Reconstruction; Technical Report; KMUTNB: Bangkok, Thailand, 2023. (In Thai) [Google Scholar]
- Do, P.N.B.; Nguyen, Q.C. A Review of Stereo-Photogrammetry Method for 3-D Reconstruction in Computer Vision. In Proceedings of the 19th International Symposium on Communications and Information Technologies (ISCIT), Ho Chi Minh City, Vietnam, 25–27 September 2019; pp. 138–143. [Google Scholar]
- Eulitz, M.; Reiss, G. 3D Reconstruction of SEM Images by Use of Optical Photogrammetry Software. J. Struct. Biol. 2015, 191, 190–196. [Google Scholar] [PubMed]
- Karami, A.; Menna, F.; Remondino, F. Combining Photogrammetry and Photometric Stereo to Achieve Precise and Complete 3D Reconstruction. Sensors 2022, 22, 8172. [Google Scholar] [CrossRef]
- Torresani, A.; Remondino, F. Videogrammetry vs. Photogrammetry for Heritage 3D Reconstruction. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W15, 1157–1162. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust Wide Baseline Stereo from Maximally Stable Extremal Regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar]
- Bansal, M.; Kumar, M. 2D Object Recognition: A Comparative Analysis of SIFT, SURF and ORB Feature Descriptors. Multimedia. Tools Appl. 2021, 80, 18839–18857. [Google Scholar]
- Panchal, P.; Panchal, S.R.; Shah, S. A Comparison of SIFT and SURF. Int. J. Innov. Res. Comput. Commun. Eng. 2013, 1, 323–327. [Google Scholar]
- Setiawan, R.; Yunmar, A.; Tantriawan, H. Comparison of Speeded-Up Robust Feature (SURF) and Oriented FAST and Rotated BRIEF (ORB) Methods in Identifying Museum Objects Using Low Light Intensity Images. In Proceedings of the International Conference on Science, Infrastructure Technology and Regional Development, South Lampung, Indonesia, 25–26 October 2019; IOP Publishing: South Lampung, Indonesia, 2020; pp. 1–9. [Google Scholar]
- Kim, D.; Ga, W.; Ahn, P.; Joo, D.; Chun, S.; Kim, J. Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDept. arXiv 2022, arXiv:2201.07436. [Google Scholar]
- Kazhdan, M.; Bolitho, M.; abd Hoppe, H. Poisson Surface Reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing, Cagliari, Italy, 26–28 June 2006; Eurographics Association: Goslar, Germany, 2006; pp. 61–70. [Google Scholar]
- Whelan, T.; Leutenegger, S.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J. ElasticFusion: Dense SLAM without a pose graph. Robot. Sci. Syst. 2015, 11, 3. [Google Scholar]
- Choi, S.; Zhou, Q.-Y.; Koltun, V. Robust reconstruction of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Liu, B.; Yang, F.; Huang, Y.; Zhang, Y.; Wu, G. Single-shot 3D reconstruction using grid pattern-based structured-light vision method. Appl. Sci. 2022, 12, 10602. [Google Scholar]
- Hepp, B.; Nießner, M.; Hilliges, O. Plan3d: Viewpoint and trajectory optimization for aerial multi-view stereo reconstruction. ACM Trans. Graph. TOG 2018, 38, 1–17. [Google Scholar] [CrossRef]
- Zhu, Q.; Wang, Z.; Hu, H.; Xie, L.; Ge, X.; Zhang, Y. Leveraging photogrammetric mesh models for aerial-ground feature point matching toward integrated 3D reconstruction. ISPRS J. Photogramm. Remote Sens. 2020, 166, 26–40. [Google Scholar] [CrossRef]






| Preservation Techniques | Advantage | Disadvantage |
|---|---|---|
| 1. Measuring by hand | 1. Cost-effective: The primary advantage is the low cost. 2. Tradition: This method holds historical value. | 1. Damage risk: Direct contact can damage delicate artifacts. 2. Error-prone: Human error leads to inaccurate measurements. 3. Time-consuming: Measuring intricate artifacts by hand is a slow process. 4. Difficult to replicate: Inconsistency of the technique hinders replication. 5. Limited data: Hand measurements miss subtle details. |
| 2. Kinect camera | 1. Depth of information: Kinect captures depth data for accurate 3D models. 2. Non-contact method: Kinect is non-invasive, reducing damage risk. 3. Relatively low cost: Kinect is affordable compared to high-end scanners. | 1. Limited field of view: Kinect’s narrow field of view might require multiple capture and stitching. 2. Operational range: Kinect’s limited range might not be suitable for large artifacts or specific distance requirements. 3. Resolution limitations: Kinect might not capture intricate details. 4. Accuracy for complex shapes: Kinect may struggle with capturing highly intricate shapes or deep cavities. |
| 3. 3D laser scanner | 1. Unmatched precision: 3D laser scanners offer the highest level of accuracy for digital preservation. 2. Speed and efficiency: Laser scanners capture data quickly, streamlining the process. 3. Richness of data: 3D laser scanners capture geometry and color for visually rich models. | 1. High cost: 3D laser scanners are the most expensive option. 2. Accessibility and setup: Setting up and using laser scanners requires specialized training. 3. Data storage: High-density scans require significant storage capacity. |
| 4. Photogrammetry | 1. Accessibility: Photogrammetry is accessible with a camera and software. 2. Portability: Photogrammetry is highly portable due to the use of a camera. 3. Color and texture preservation: Photogrammetry captures realistic textures and colors. | 1. Overlapping images: Accurate photogrammetry requires carefully planned, overlapping images. 2. Processing power: Photogrammetry can be computationally demanding. 3. Limitations with certain surfaces: Photogrammetry struggles with reflective, transparent, or featureless surfaces. |
| Accuracy of Depth Information | Running Time | Number of Point Clouds | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Image Dataset 1 | Image Dataset 2 | Image Dataset 3 | Image Dataset 1 | Image Dataset 2 | Image Dataset 3 | Image Dataset 1 | Image Dataset 2 | Image Dataset 3 |
| Proposed method | 70.7% | 79.0% | 67.3% | 120 | 72 | 96 | 978,490 | 2,588,931 | 2,759,780 |
| Depth map (Photogrammetry) | 28.9% | 20.4% | 25.5% | 0.805 | 0.345 | 0.69 | 725,830 | 814,300 | 943,360 |
| SfM [19] | 72.2% | 71.1% | 65.5% | 156 | 98 | 128 | 684,210 | 985,600 | 724,350 |
| MVS [22] | 68.4% | 69.9% | 66.2% | 220 | 160 | 184 | 583,420 | 876,540 | 637,400 |











































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Institute of Knowledge Innovation and Invention. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Visutsak, P.; Liu, X.; Choothong, C.; Pensiri, F. SIFT-Based Depth Estimation for Accurate 3D Reconstruction in Cultural Heritage Preservation. Appl. Syst. Innov. 2025, 8, 43. https://doi.org/10.3390/asi8020043
Visutsak P, Liu X, Choothong C, Pensiri F. SIFT-Based Depth Estimation for Accurate 3D Reconstruction in Cultural Heritage Preservation. Applied System Innovation. 2025; 8(2):43. https://doi.org/10.3390/asi8020043
Chicago/Turabian StyleVisutsak, Porawat, Xiabi Liu, Chalothon Choothong, and Fuangfar Pensiri. 2025. "SIFT-Based Depth Estimation for Accurate 3D Reconstruction in Cultural Heritage Preservation" Applied System Innovation 8, no. 2: 43. https://doi.org/10.3390/asi8020043
APA StyleVisutsak, P., Liu, X., Choothong, C., & Pensiri, F. (2025). SIFT-Based Depth Estimation for Accurate 3D Reconstruction in Cultural Heritage Preservation. Applied System Innovation, 8(2), 43. https://doi.org/10.3390/asi8020043