
Investigating and Analyzing Self-Reporting of Long COVID on Twitter: Findings from Sentiment Analysis


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Overview of the SARS-CoV-2 Virus and Its Effect on Humans
1.2. Concept of “Long COVID”
1.3. Relevance of Mining and Analysis of Social Media Data during Virus Outbreaks
2. Literature Review
- Insufficient attention towards the phenomenon of Long COVID: These studies have covered various topics pertaining to COVID-19 such as traveling [87], current trends [88], worries of the general public [88], evaluation of events [89], opinions on mask-wearing [91], inquiries into influencer behaviors [92], detecting and tracking misinformation [93], studies of addiction trends [96], identifying loneliness [98], and evaluations of impulse purchases [100]. In the last couple of years, scholars from different disciplines have also conducted thorough investigations by analyzing pertinent Tweets in order to delve into the diverse inquiries of the global population in the context of COVID-19. However, such works [87,88,89,91,92,93,96,98,100] did not investigate Tweets pertaining to Long COVID.
- Limitations in the existing Long COVID studies: Although a few studies (e.g., [108,109]) have examined Long COVID-related Tweets, a significant constraint of these studies is the restricted temporal scope of the analyzed Tweets. For example, the research conducted in [108] focused its investigation on a specific timeframe from 25 March 2022 to 1 April 2022. Similarly, the investigation in [109] studied Tweets about Long COVID published between 11 December 2021 and 20 December 2021. These time periods constitute just a fraction of the total span for which Long COVID has had a lasting impact on the global population.
- Studying the self-reporting of healthcare conditions on Twitter has garnered attention from scholars across many disciplines, as can be seen from multiple studies wherein Tweets related to the self-reporting of mental health problems [110], autism [111], Alzheimer’s [112], depression [113], breast cancer [114], swine flu [115], flu [116], chronic stress [117], post-traumatic stress disorder [118], and dental issues [119] were analyzed. In light of the emergence of the COVID-19 pandemic, scholarly investigations in this domain, such as [99], have been focused on developing approaches to examine Tweets wherein individuals voluntarily disclosed symptoms related to COVID-19. However, previous studies have not specifically examined Tweets pertaining to the self-reporting of Long COVID.
3. Methodology
3.1. Theoretical Overview of Sentiment Analysis and Technical Overview of RapidMiner
- (a)
- VADER differentiates itself from LIWC by exhibiting enhanced sensitivity towards sentiment patterns that are often seen in the analysis of texts from social media.
- (b)
- The General Inquirer has a limitation in its incorporation of sentiment-relevant linguistic components frequently observed in conversations on social media.
- (c)
- The ANEW lexicon exhibits a reduced degree of reactivity regarding the linguistic components often linked to emotion in social media posts.
- (d)
- The SentiWordNet lexicon exhibits a significant level of noise, as a noteworthy fraction of its synsets lack clear opposite polarity.
- (e)
- The Naïve Bayes classifier is predicated on the premise of feature independence, which might be considered a simplistic premise. VADER’s more nuanced strategy effectively addresses this limitation.
- (f)
- The Maximum Entropy approach integrates the concept of information entropy by providing feature weightings without making the assumption of conditional independence between features.
- (g)
- Both machine learning classifiers and validated sentiment lexicons face the same obstacle of requiring a significant quantity of data for training. Furthermore, the efficacy of machine learning algorithms is contingent upon the training set’s ability to correctly capture a diverse array of properties.
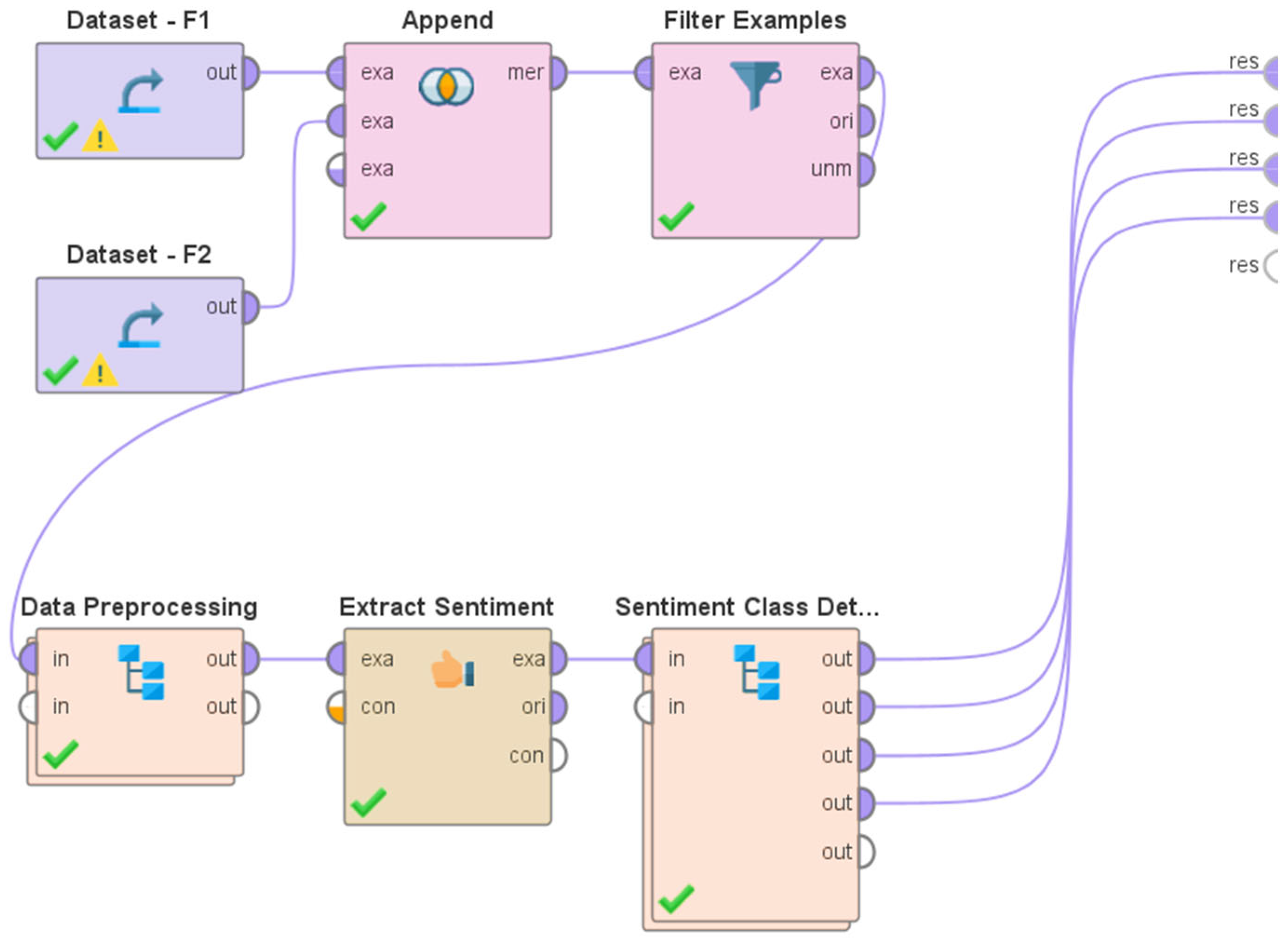
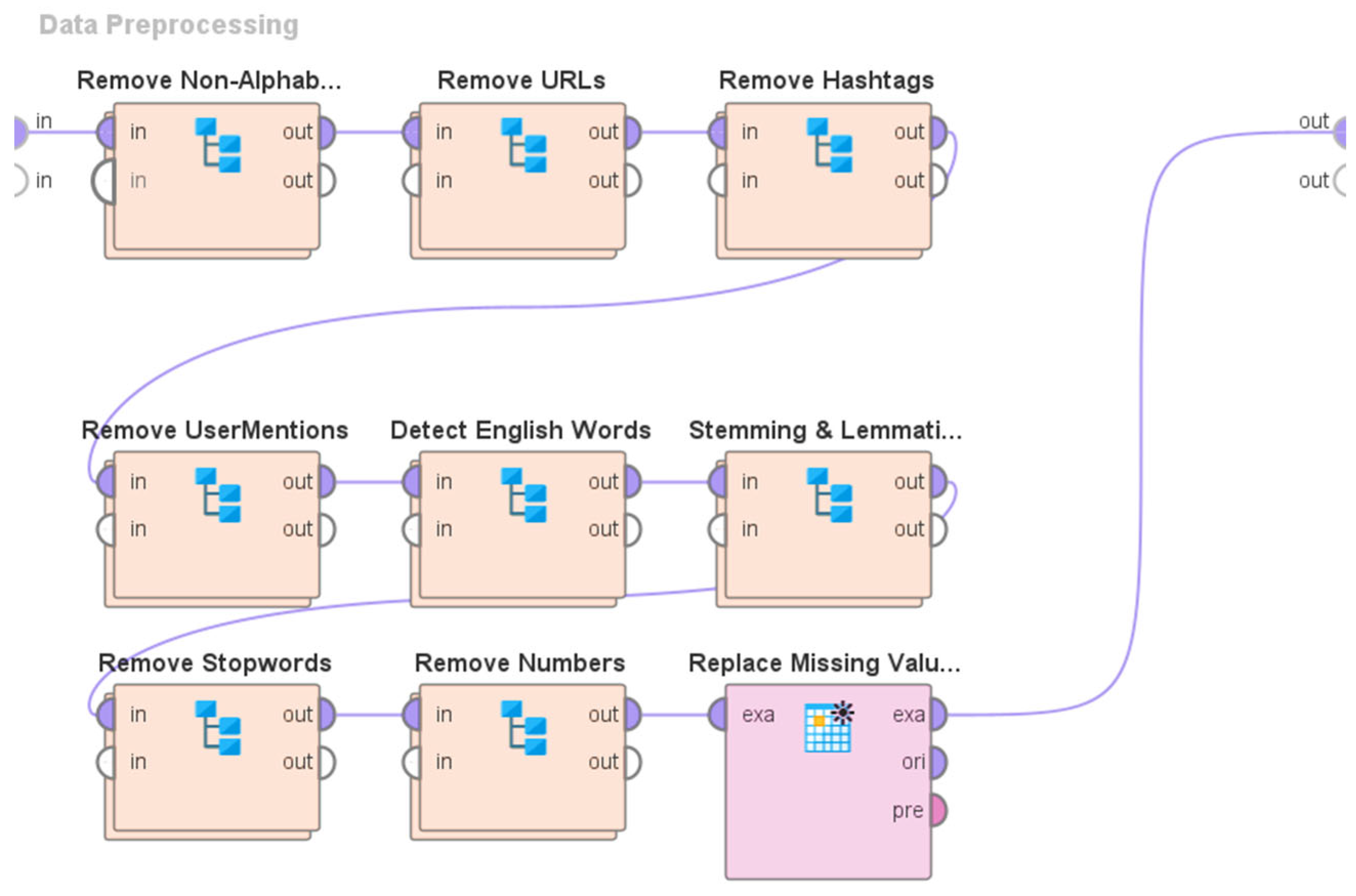
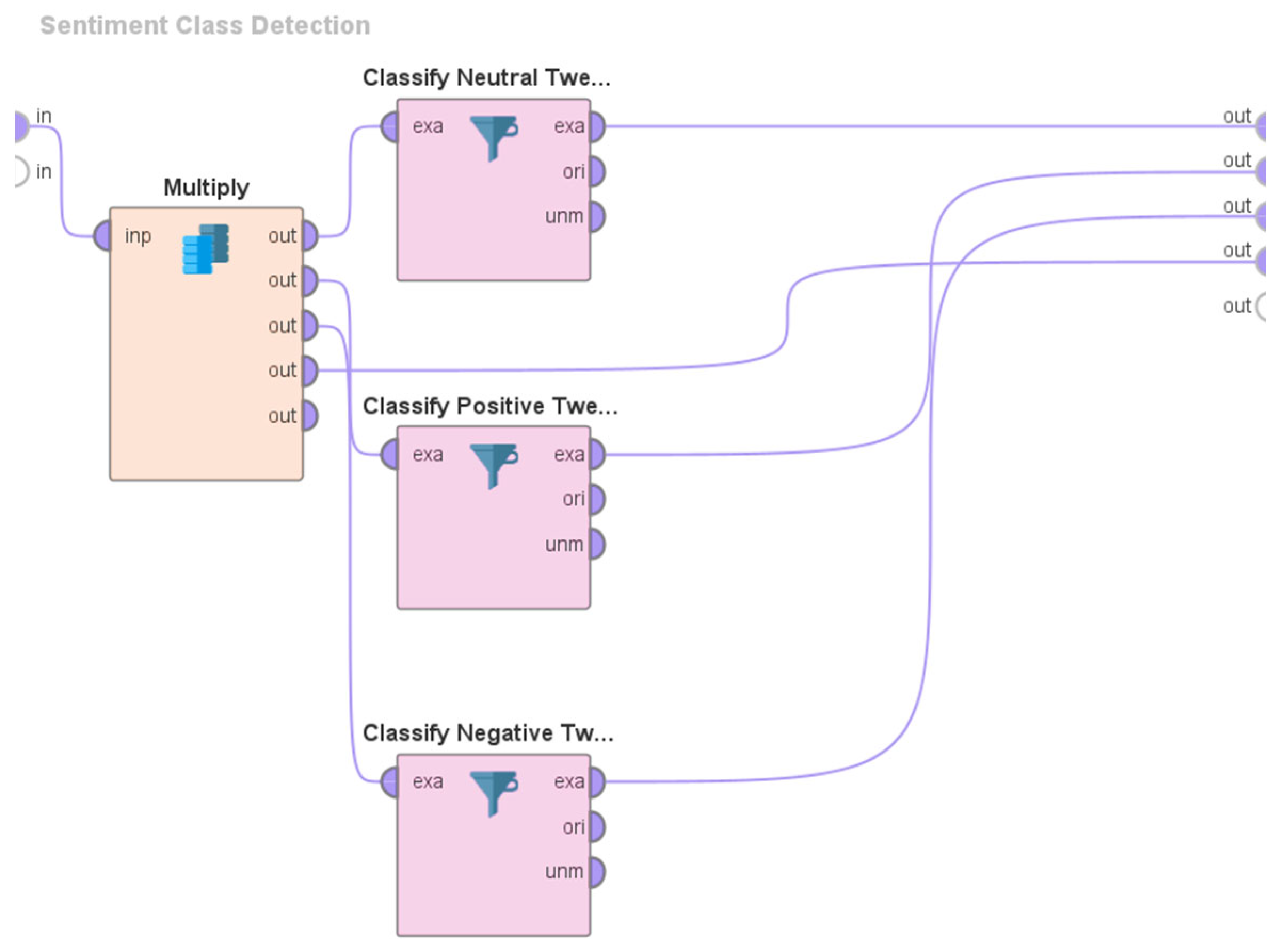
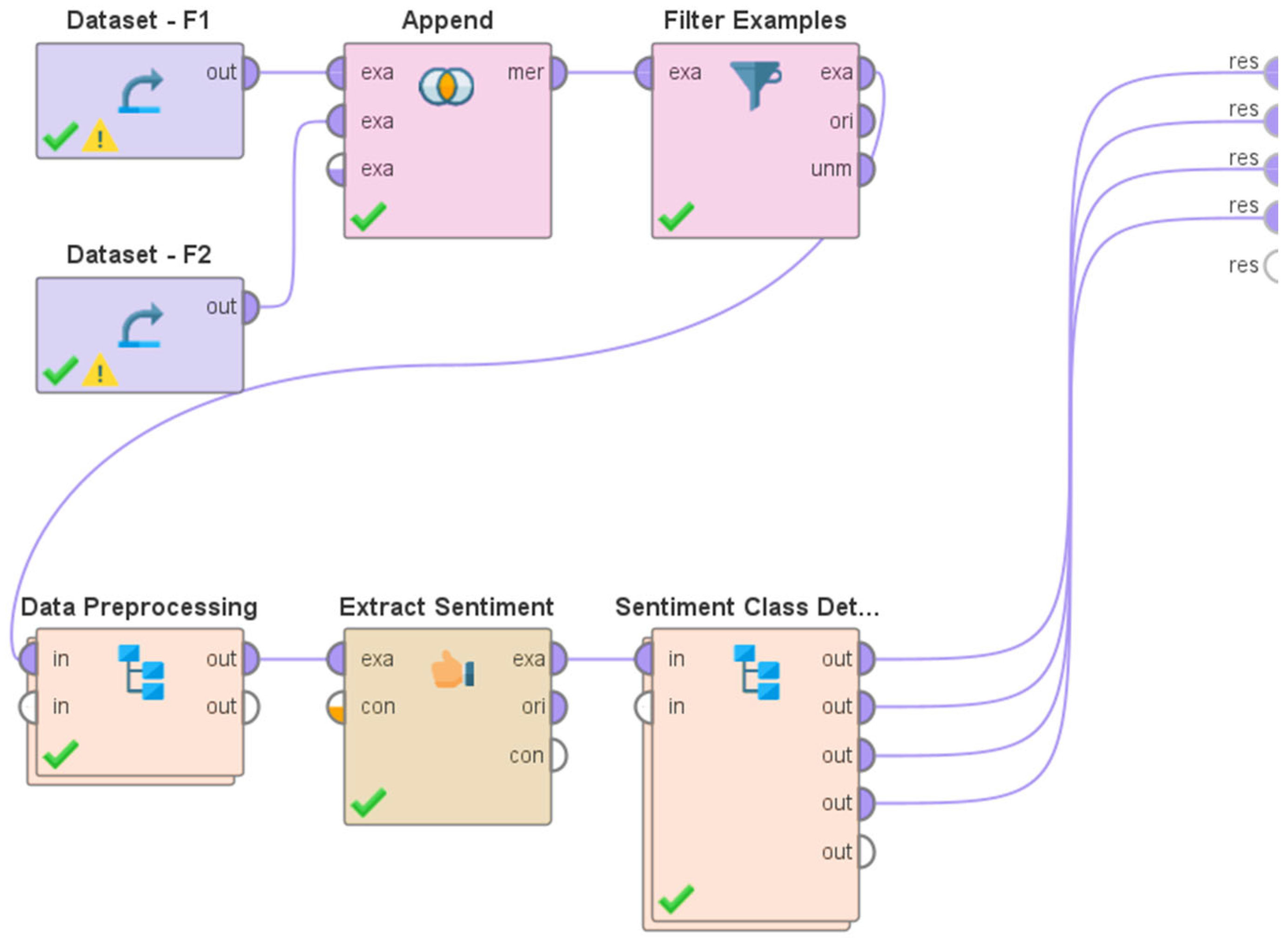
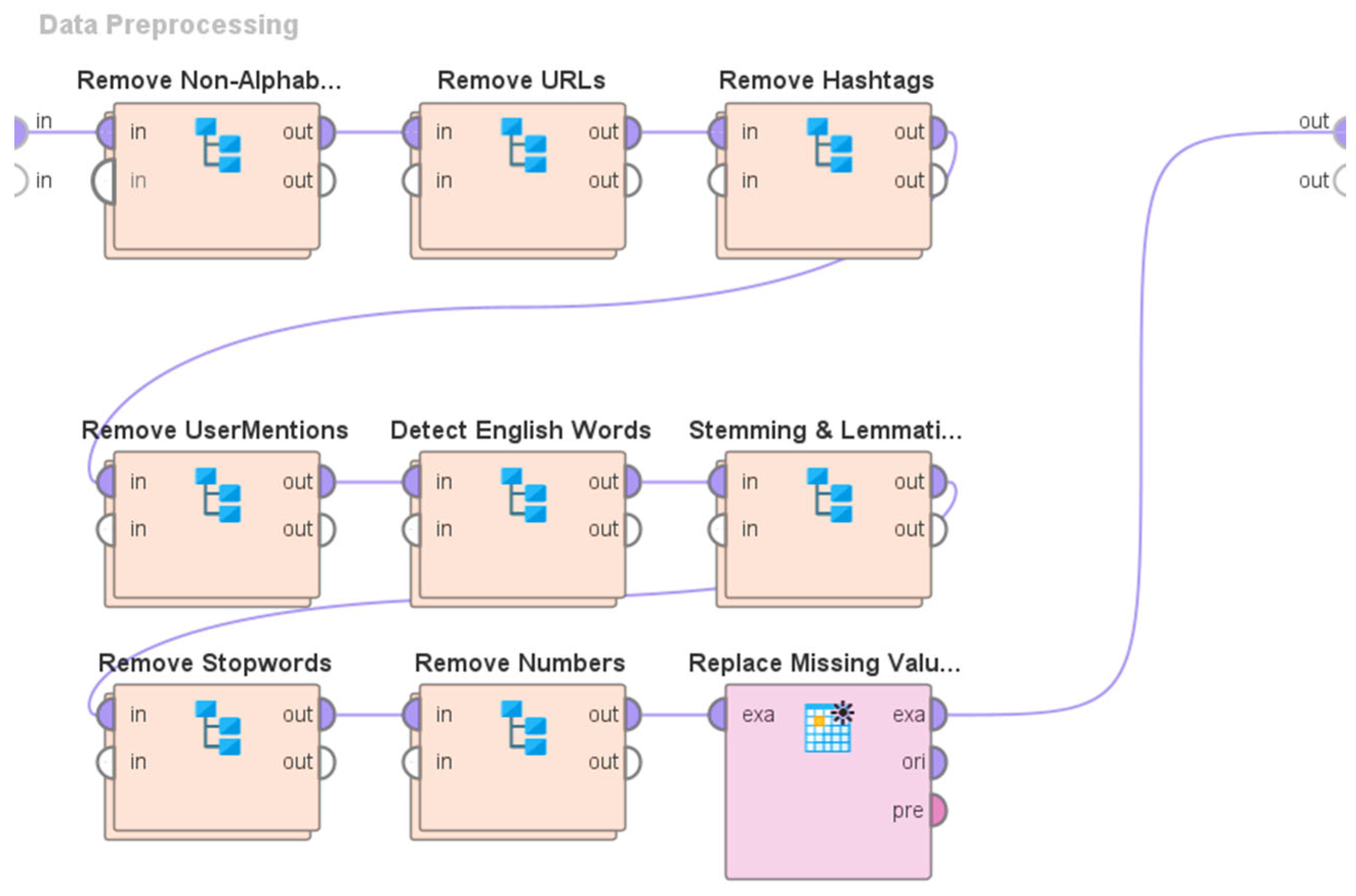
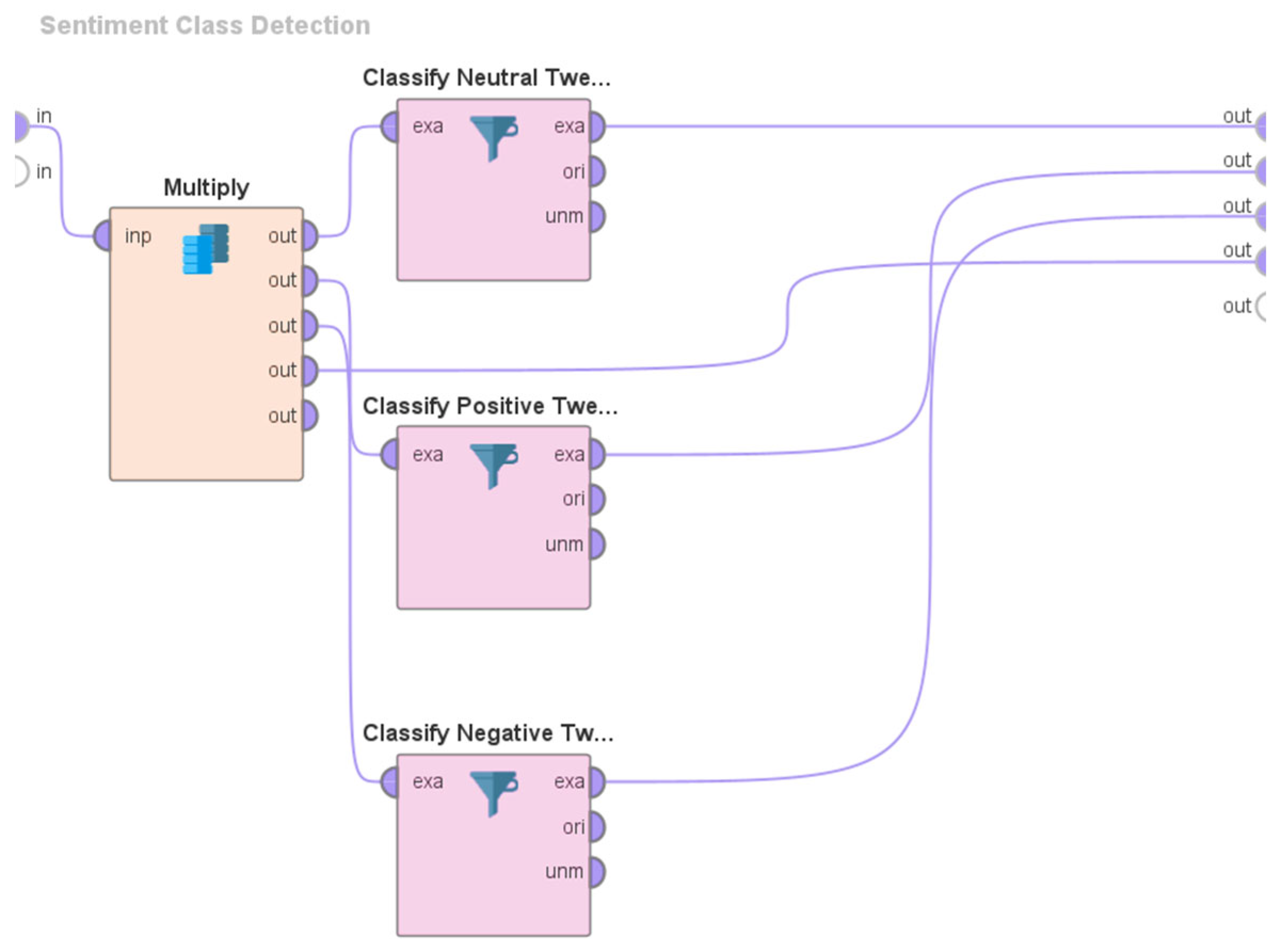
3.2. Overview of the System Architecture and Design
- (a)
- The elimination of non-alphabetic characters.
- (b)
- The elimination of URLs.
- (c)
- The elimination of hashtags.
- (d)
- The elimination of user mentions.
- (e)
- The identification of English words using the process of tokenization.
- (f)
- Stemming and Lemmatization.
- (g)
- The elimination of stop words.
- (h)
- The elimination of numerical values.
- (i)
- Addressing missing values.
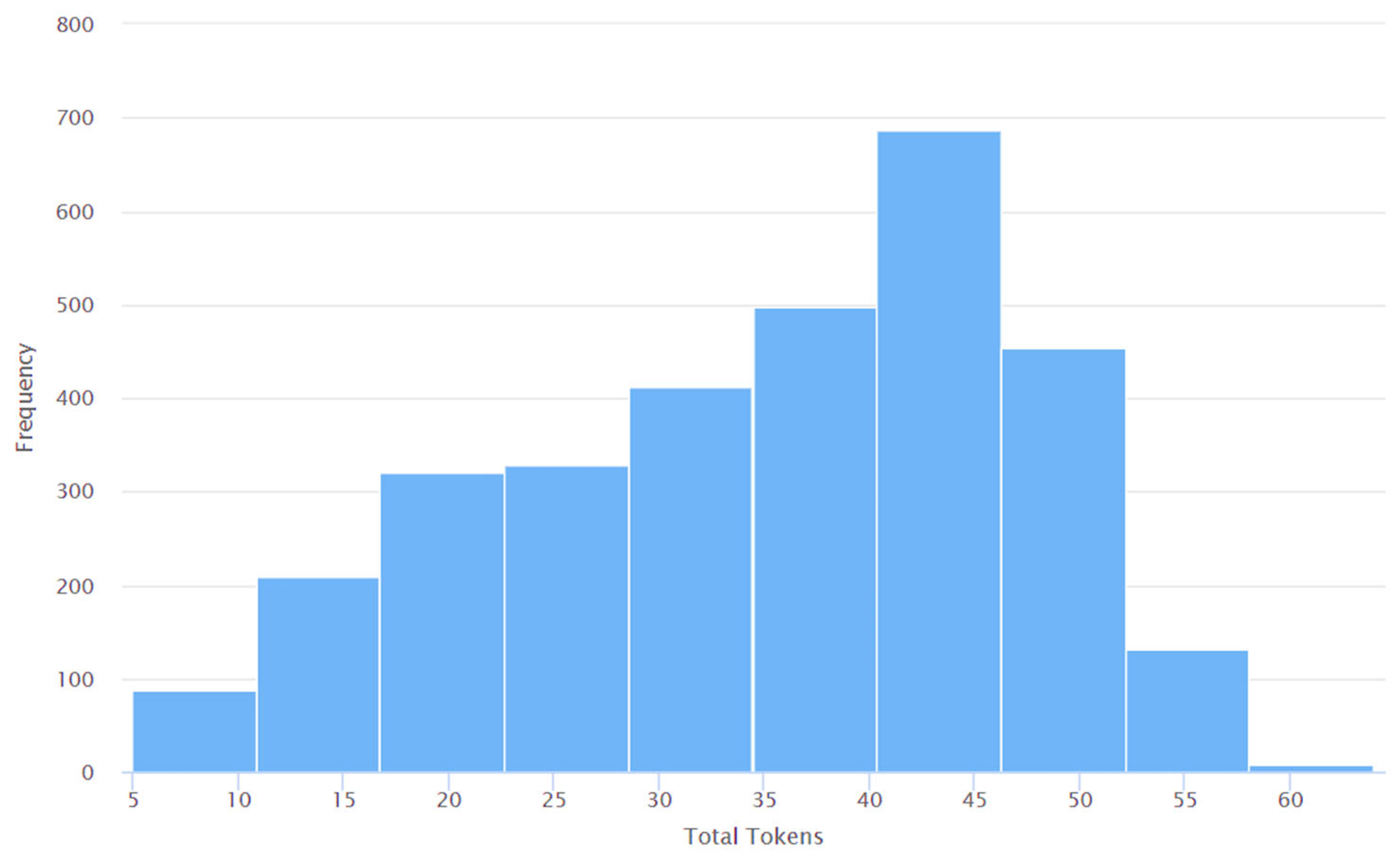
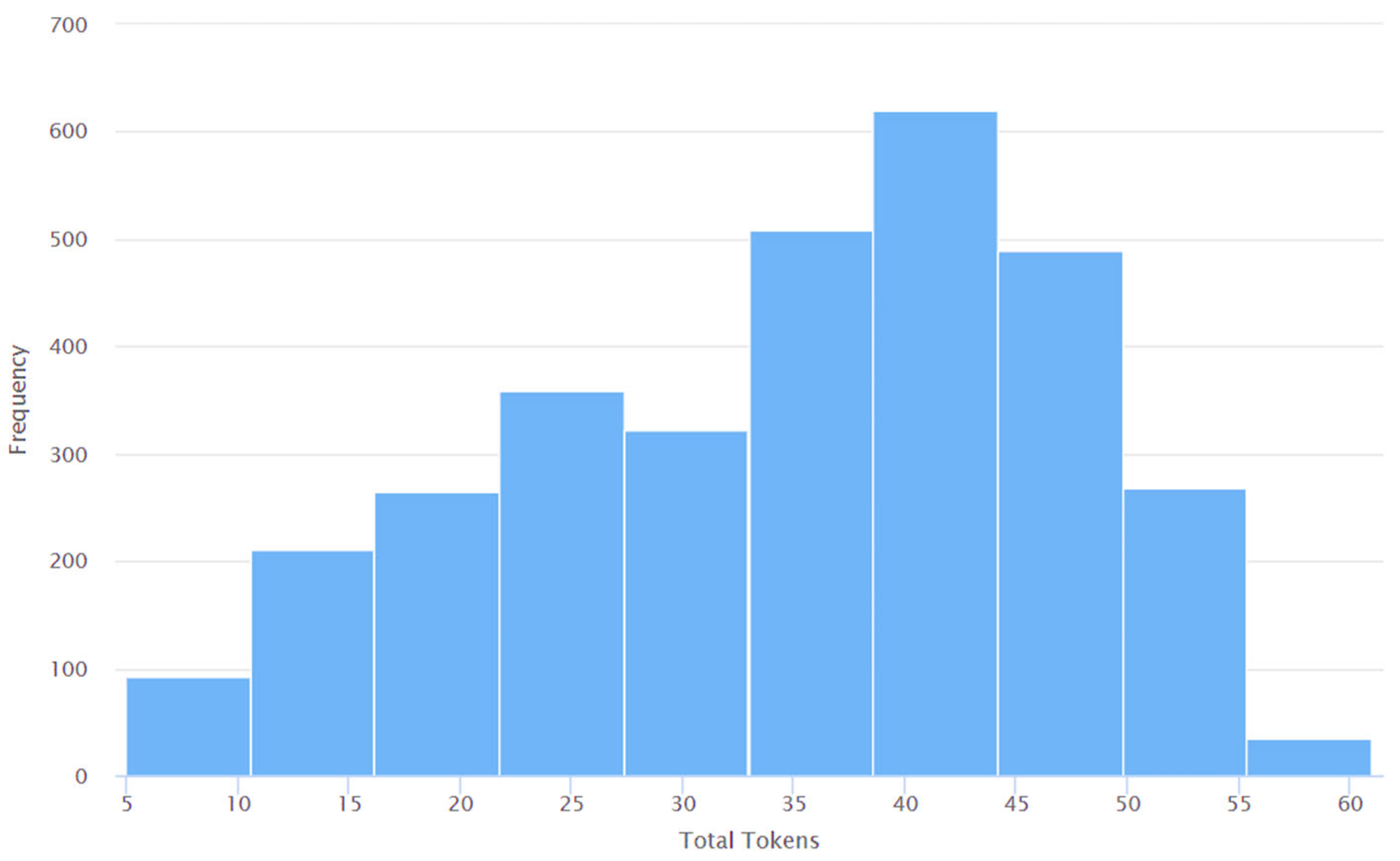
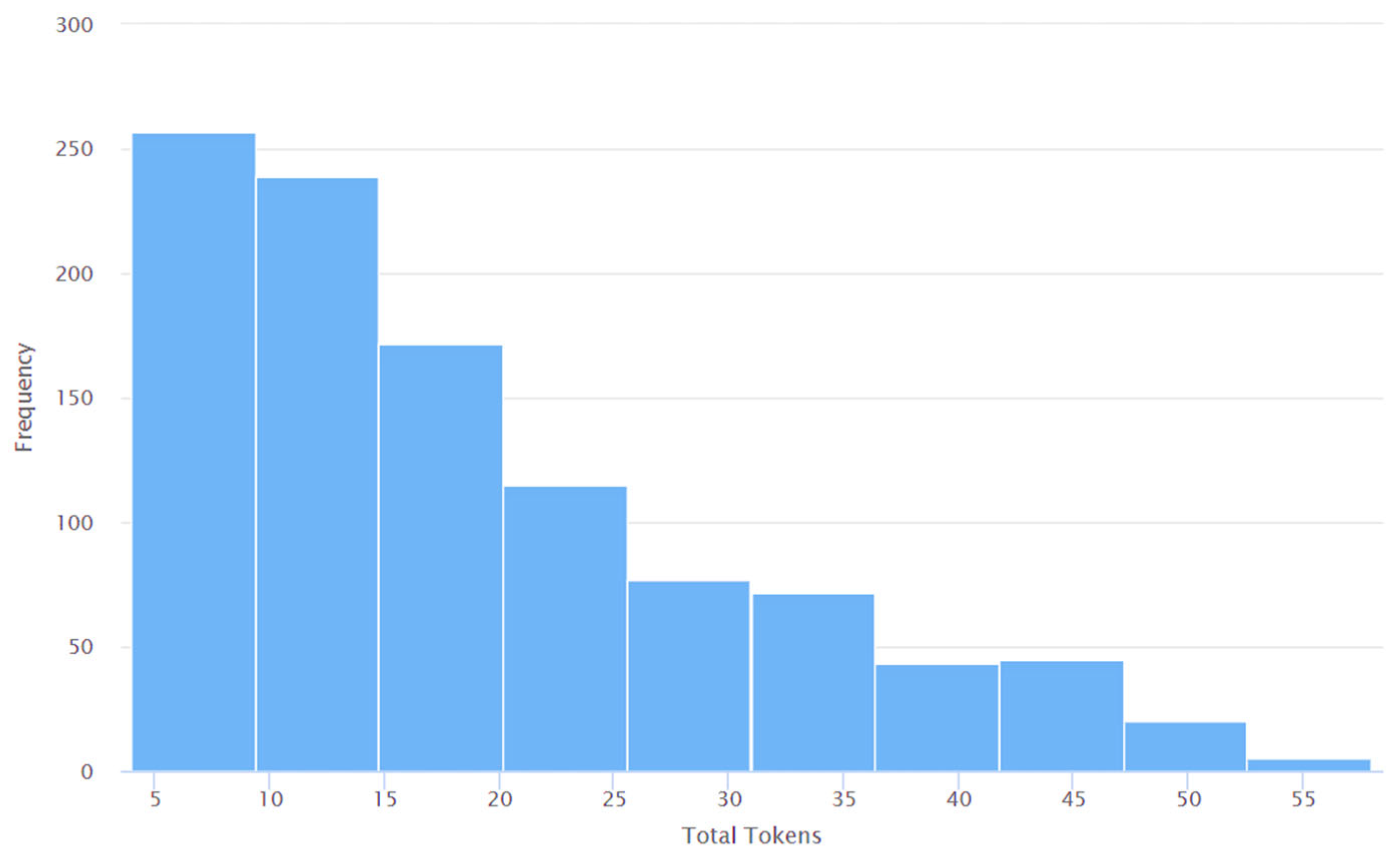
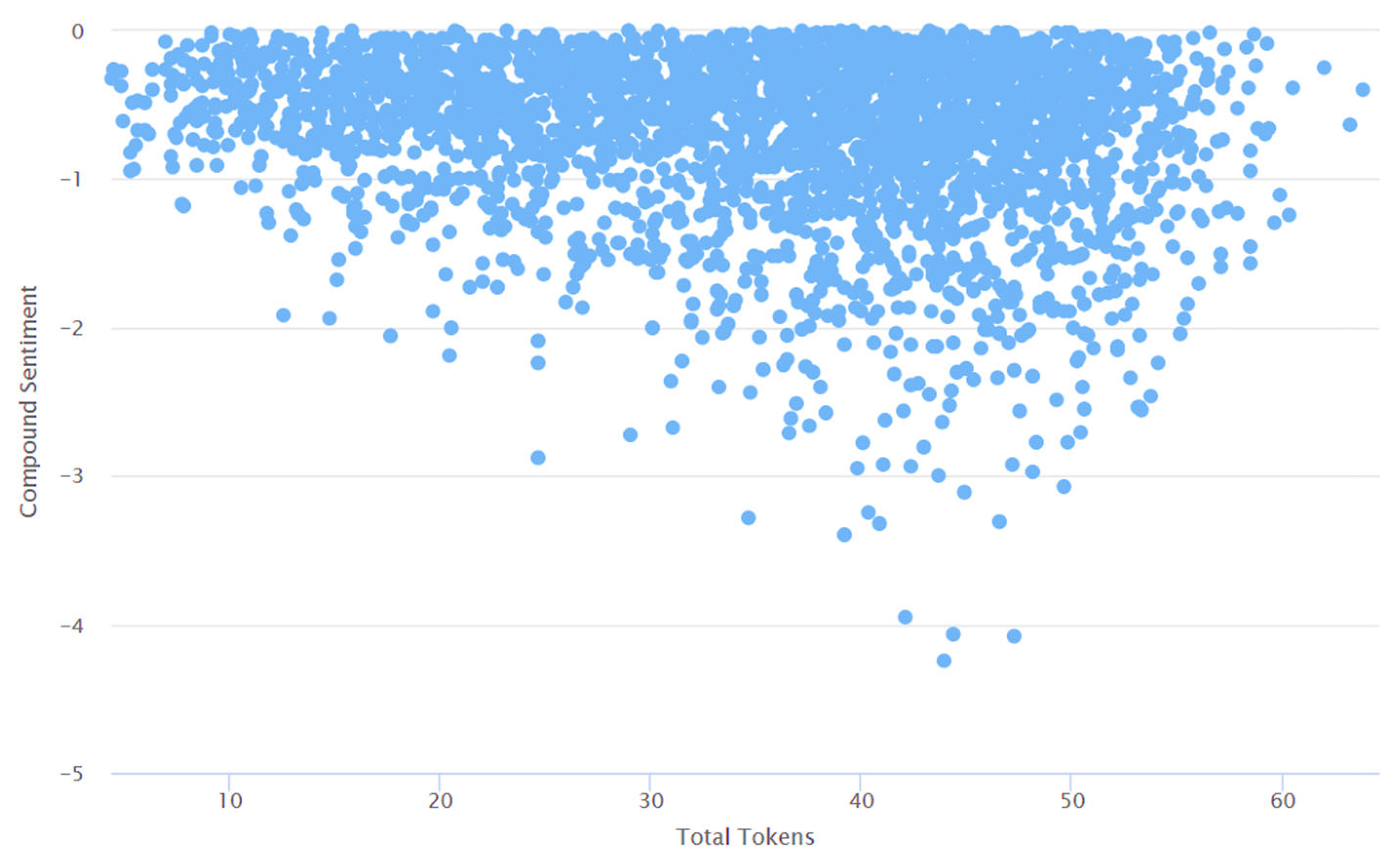
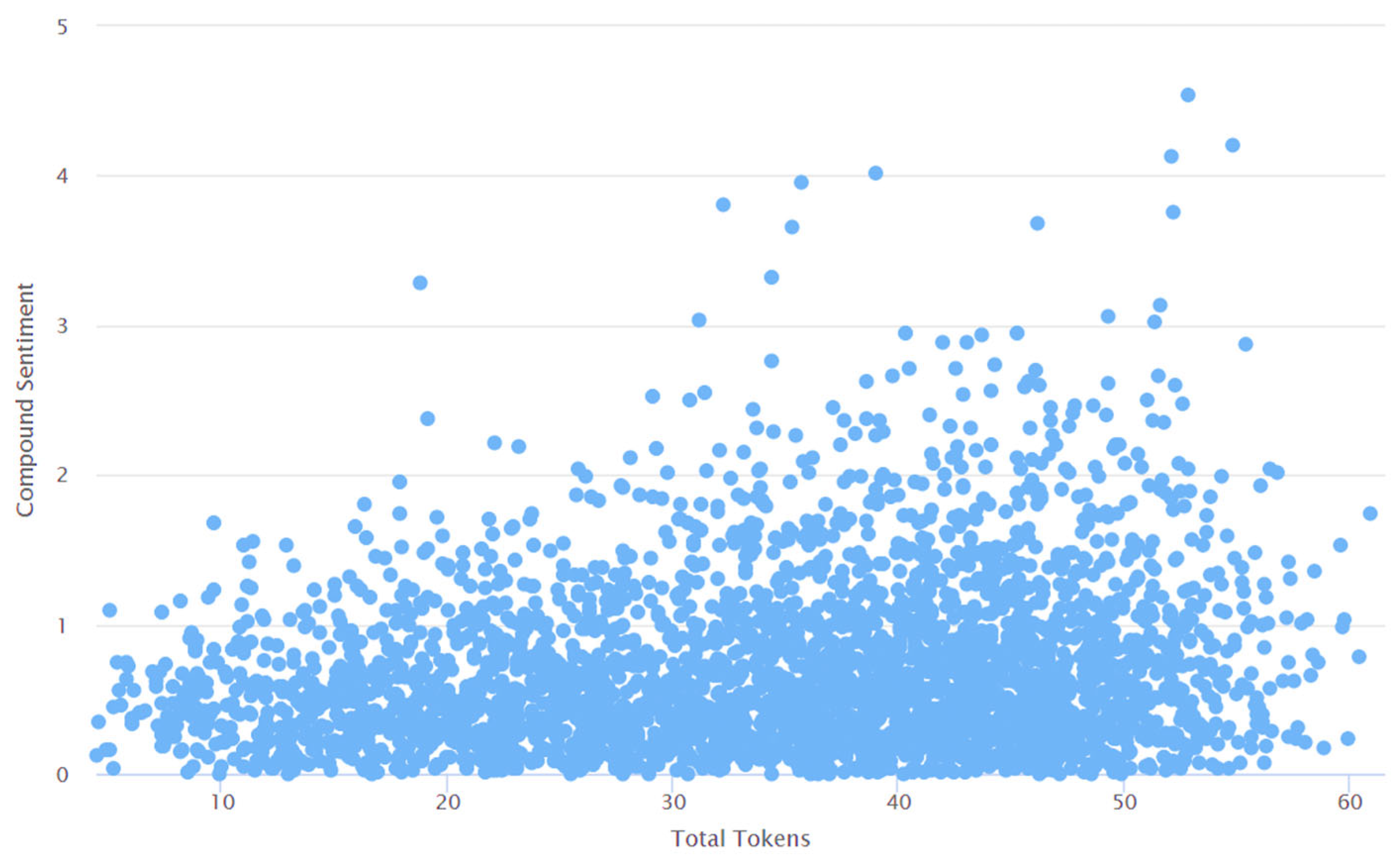
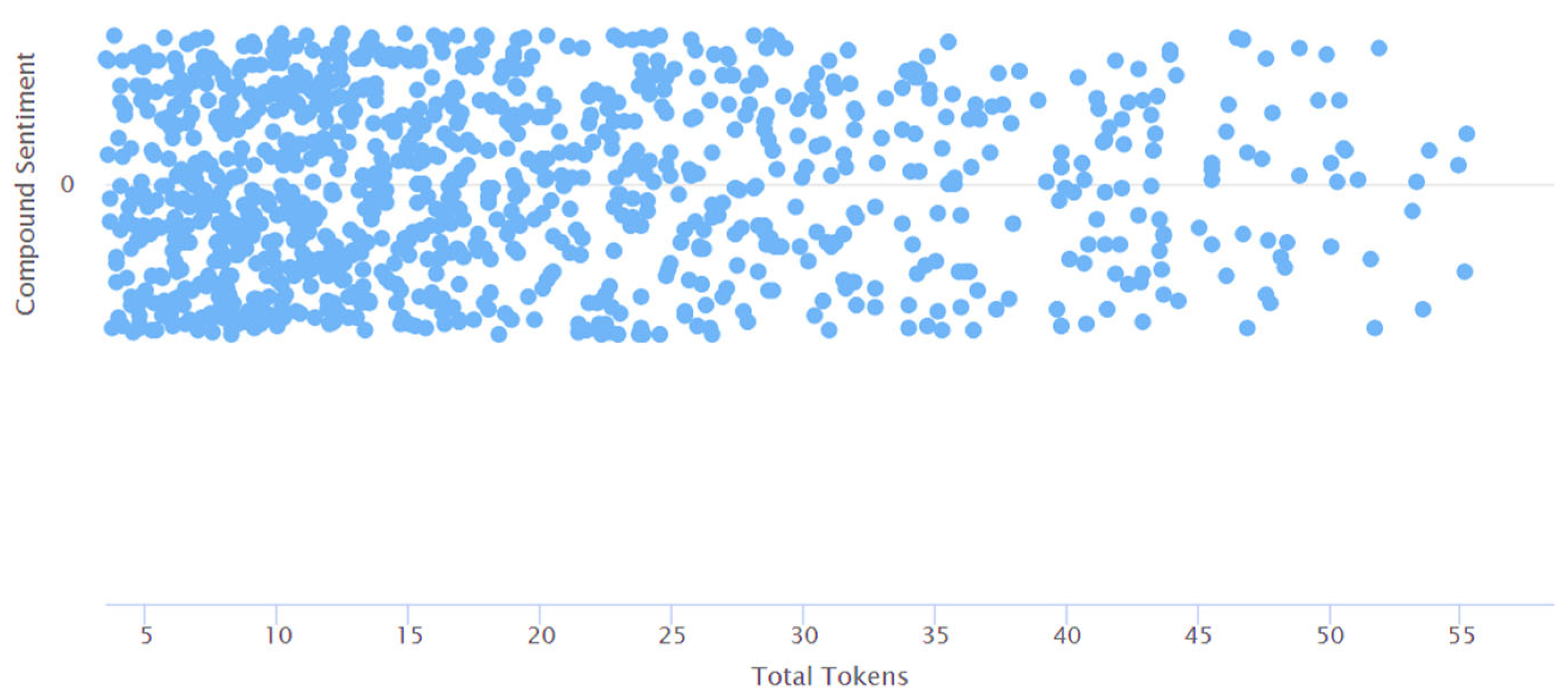
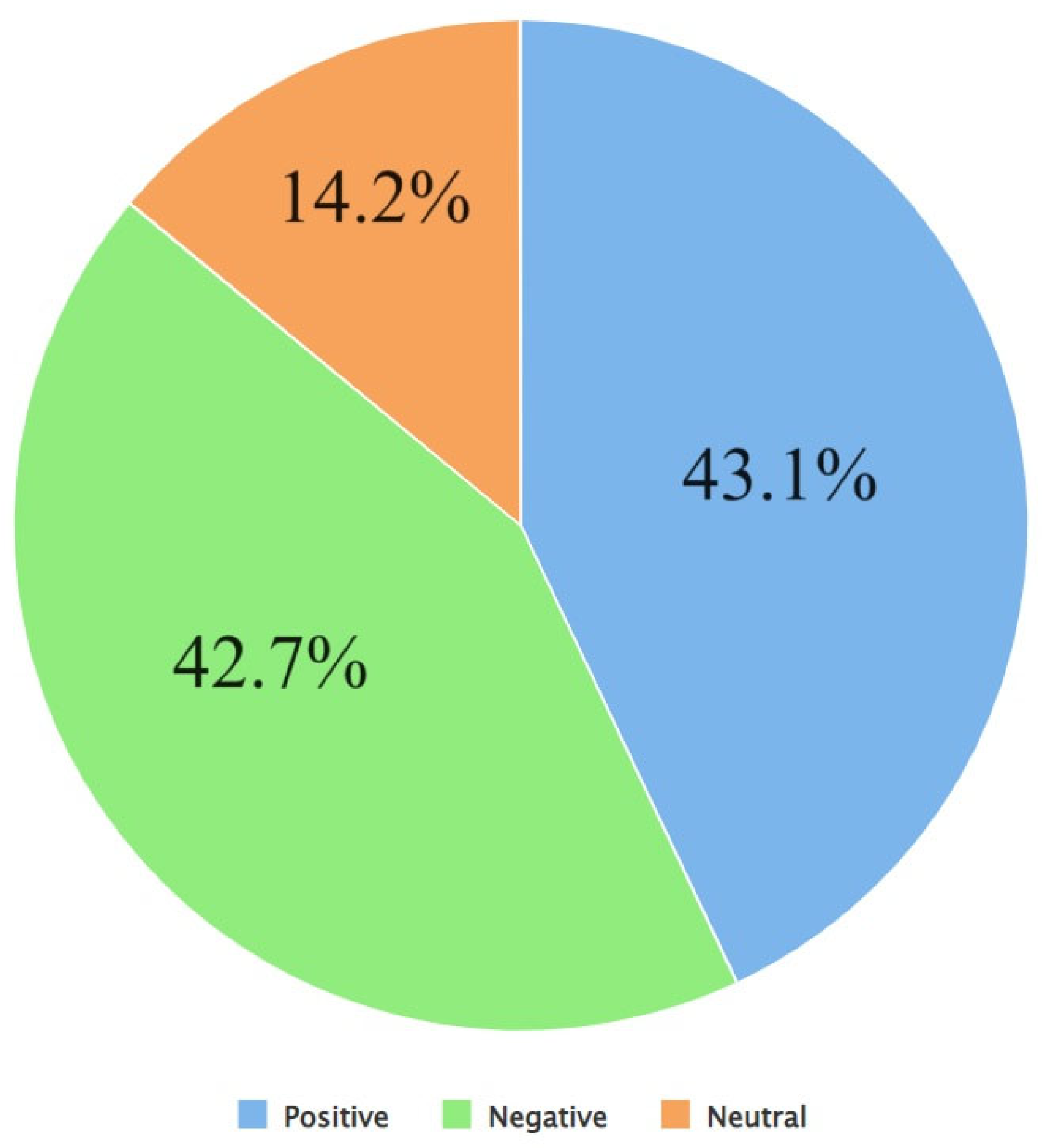
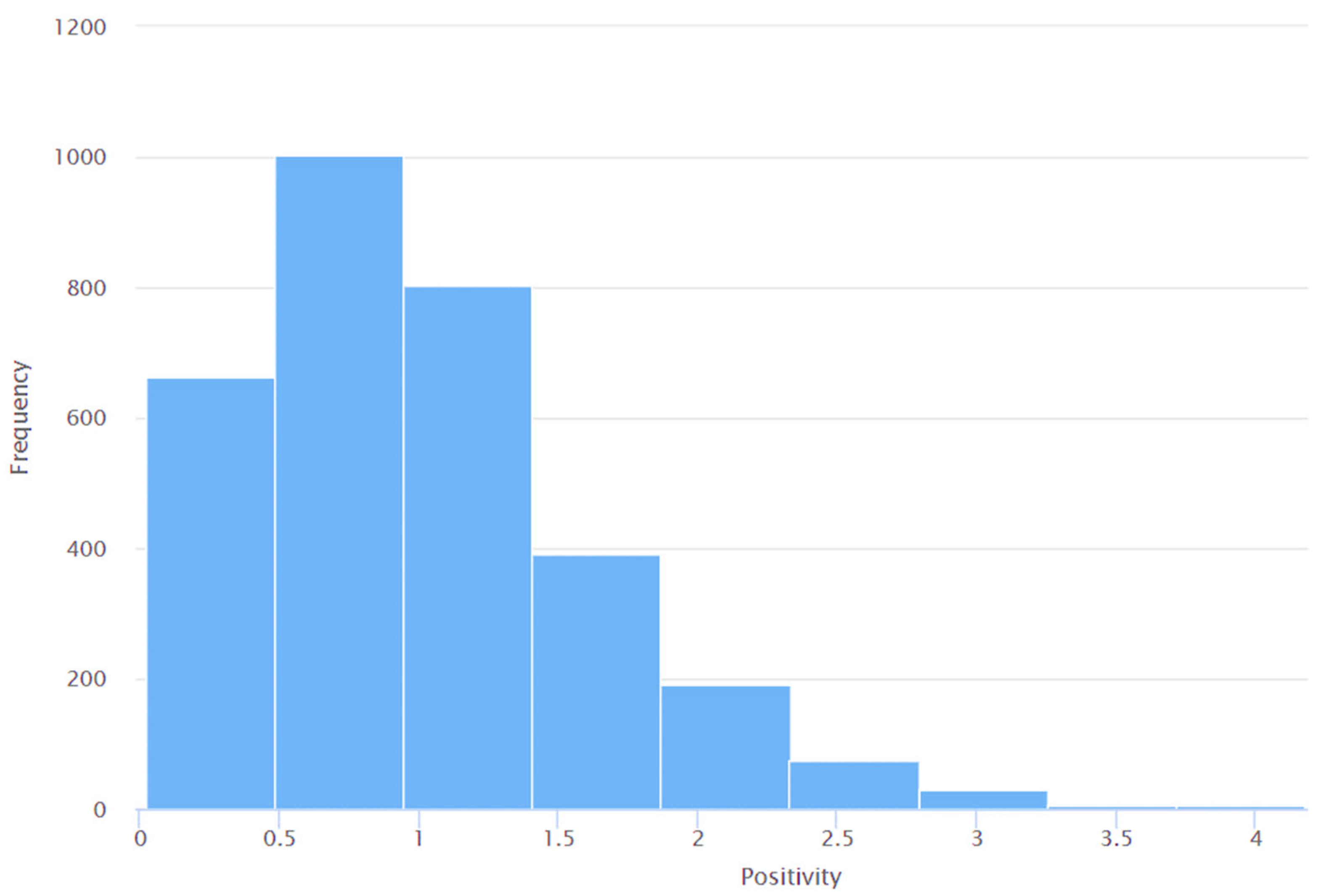
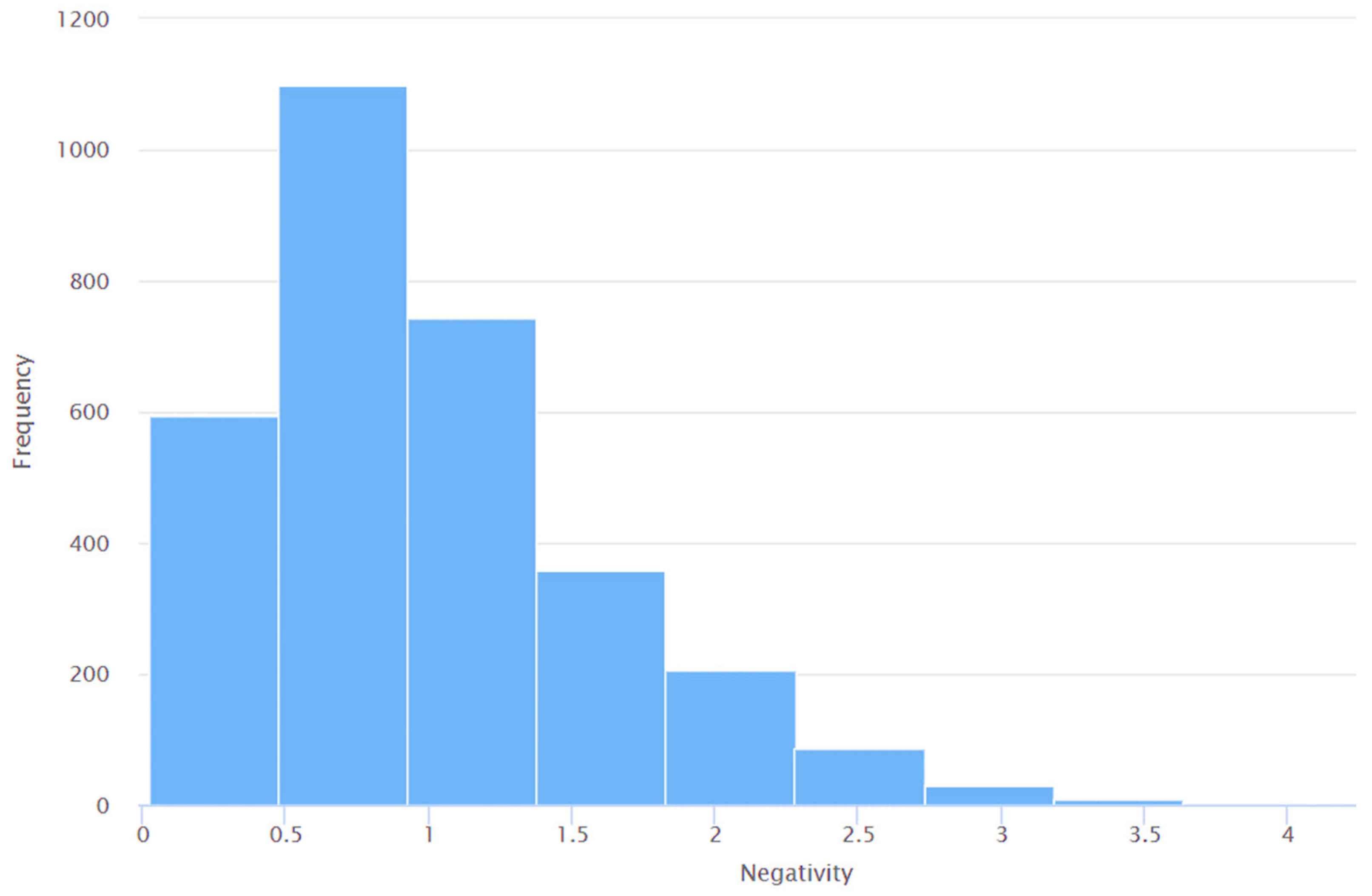
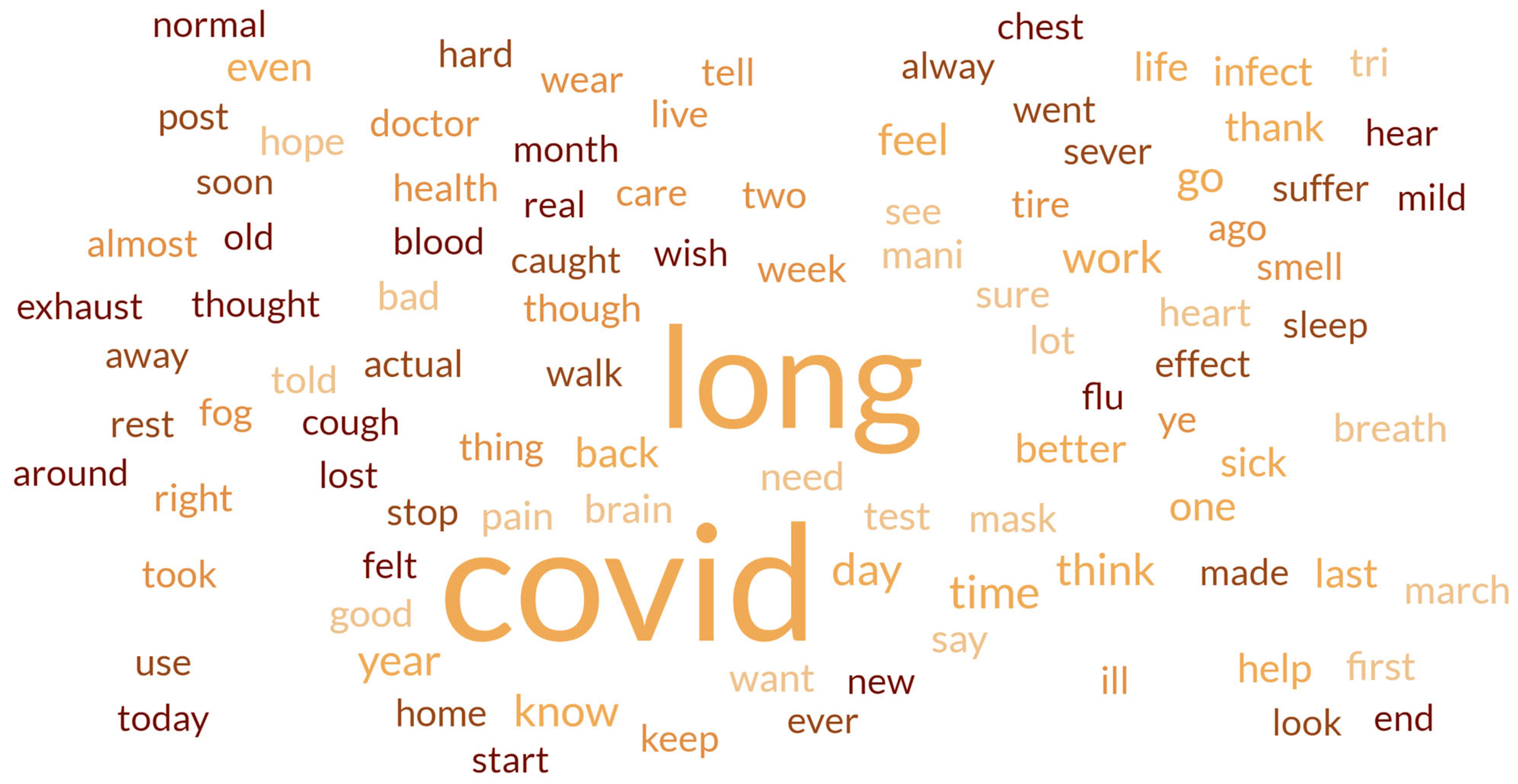
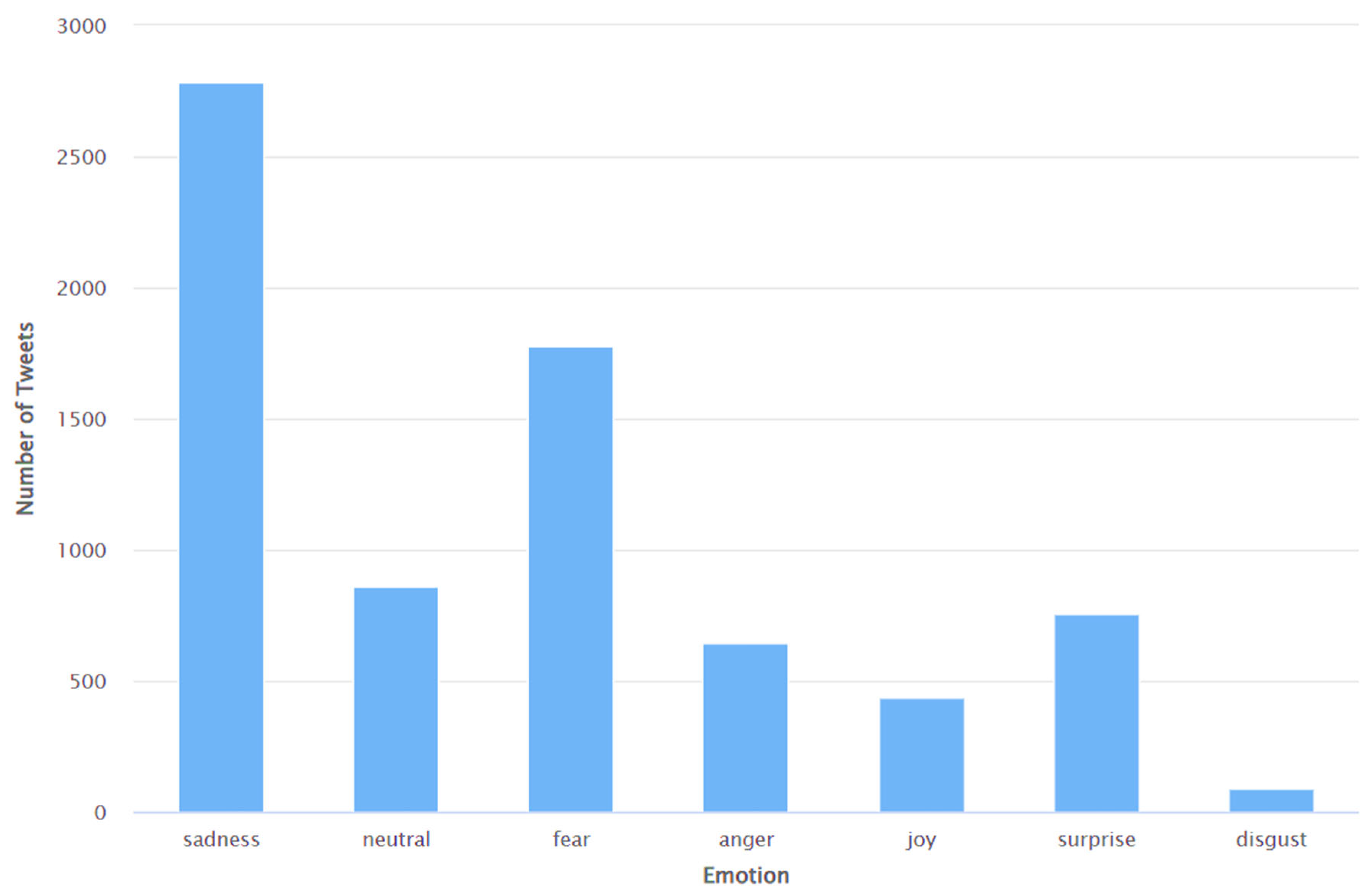
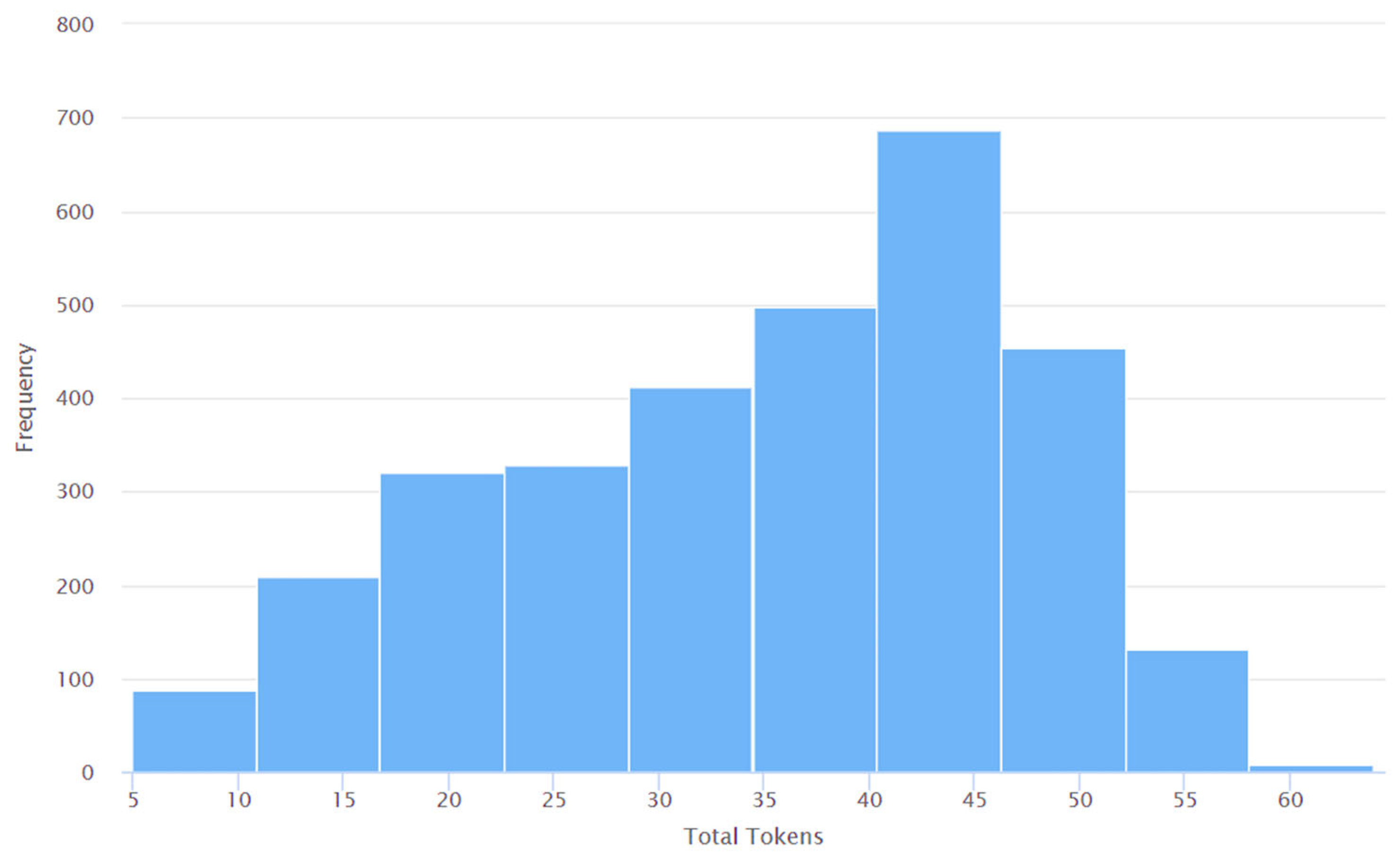
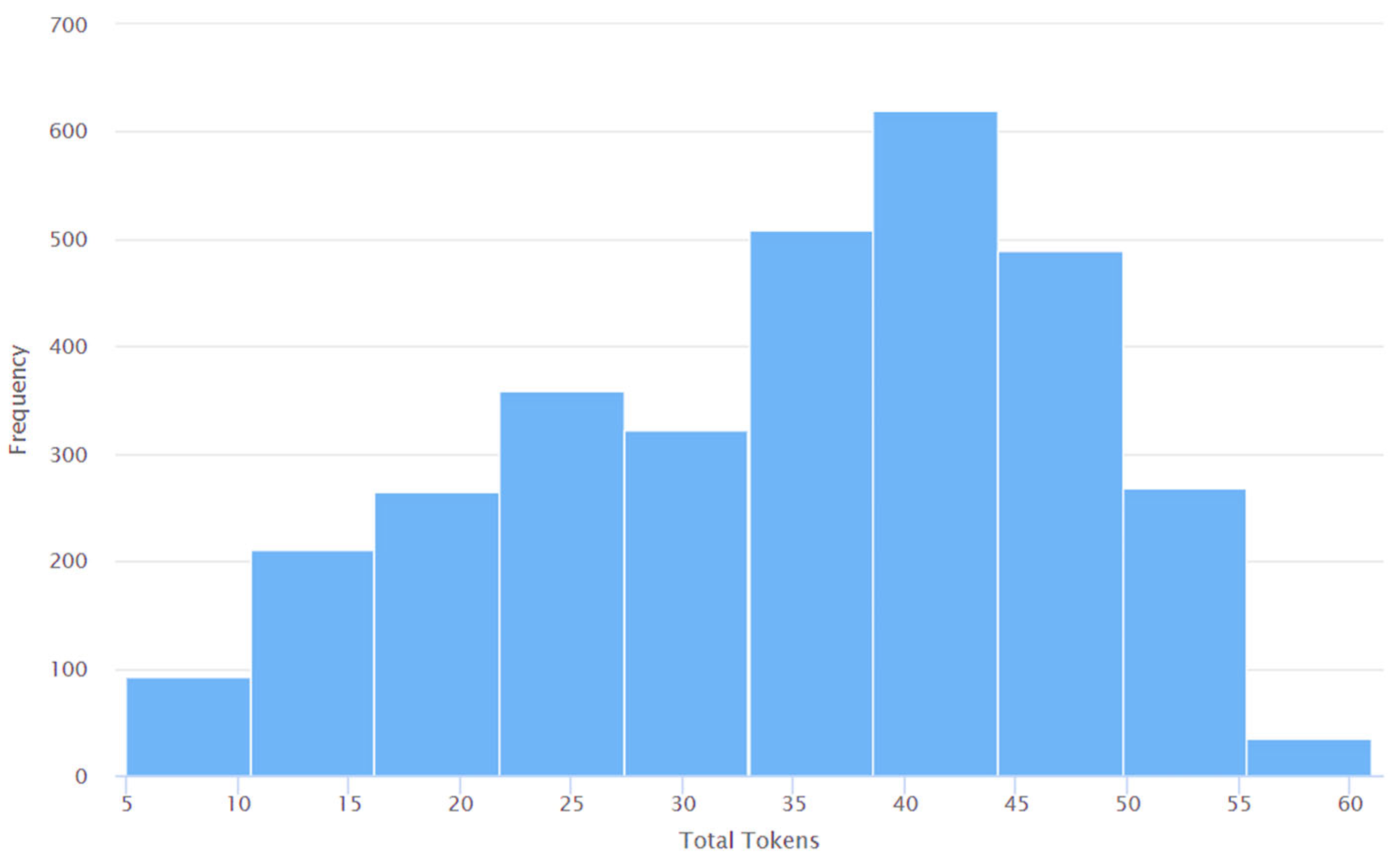
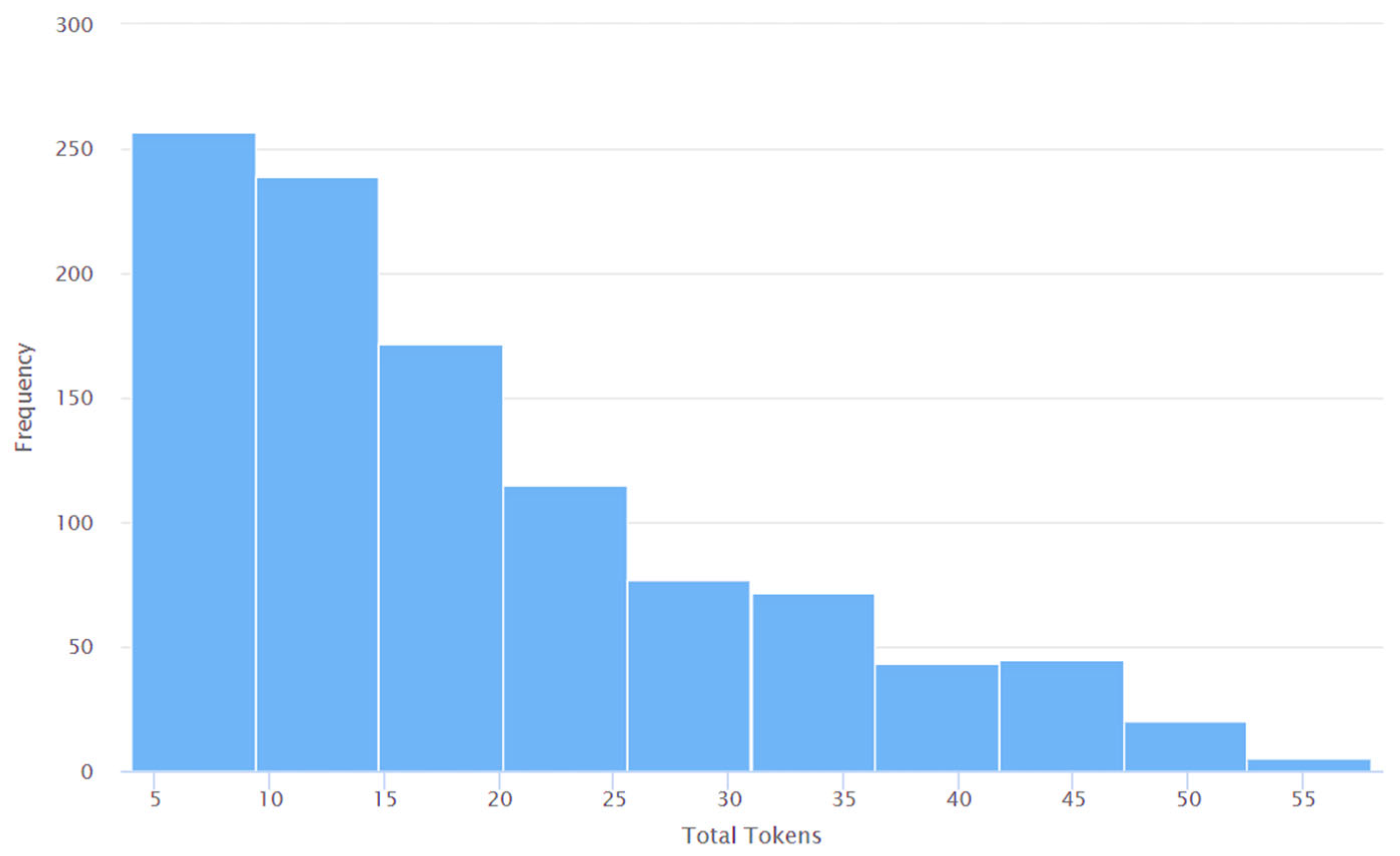
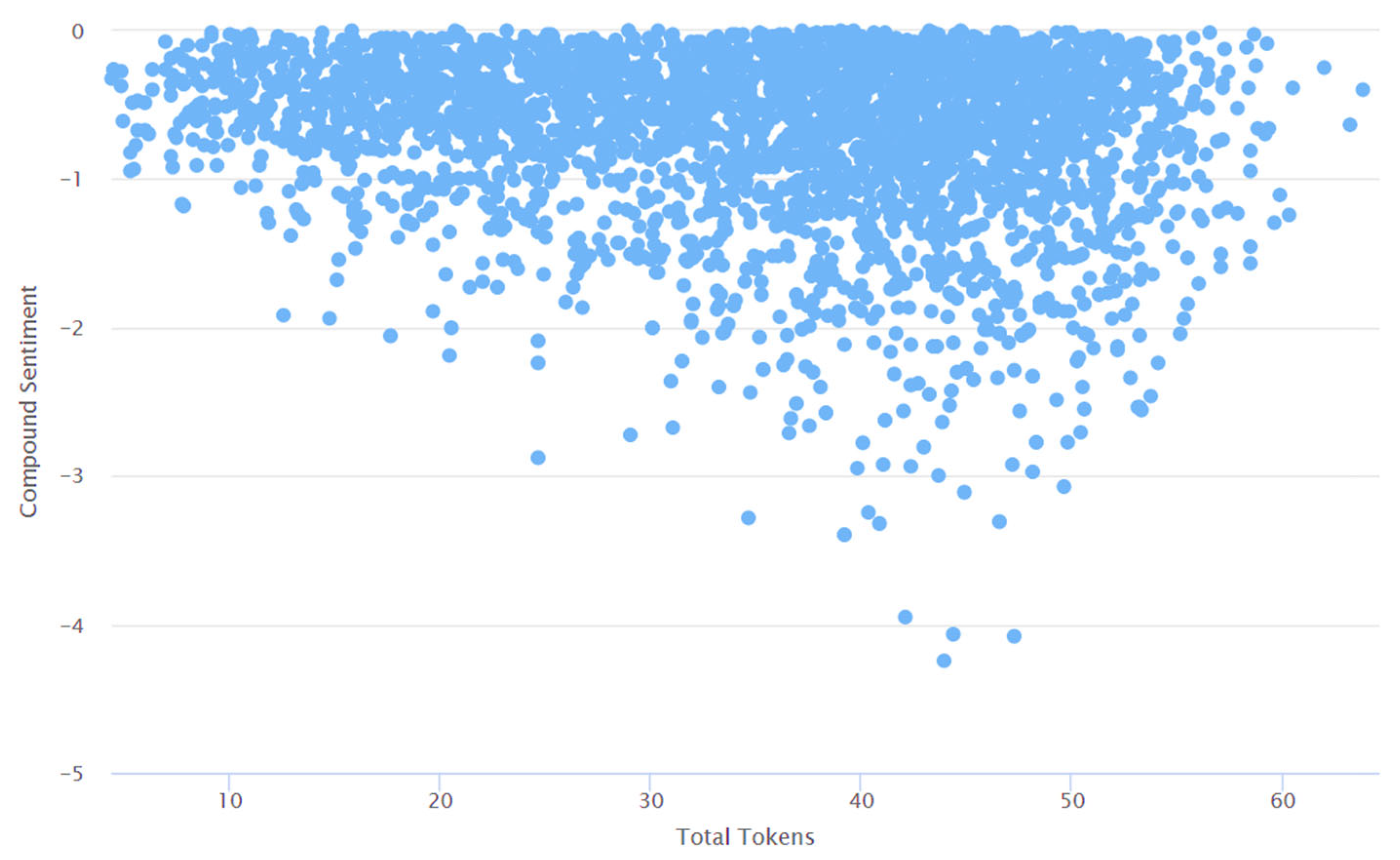
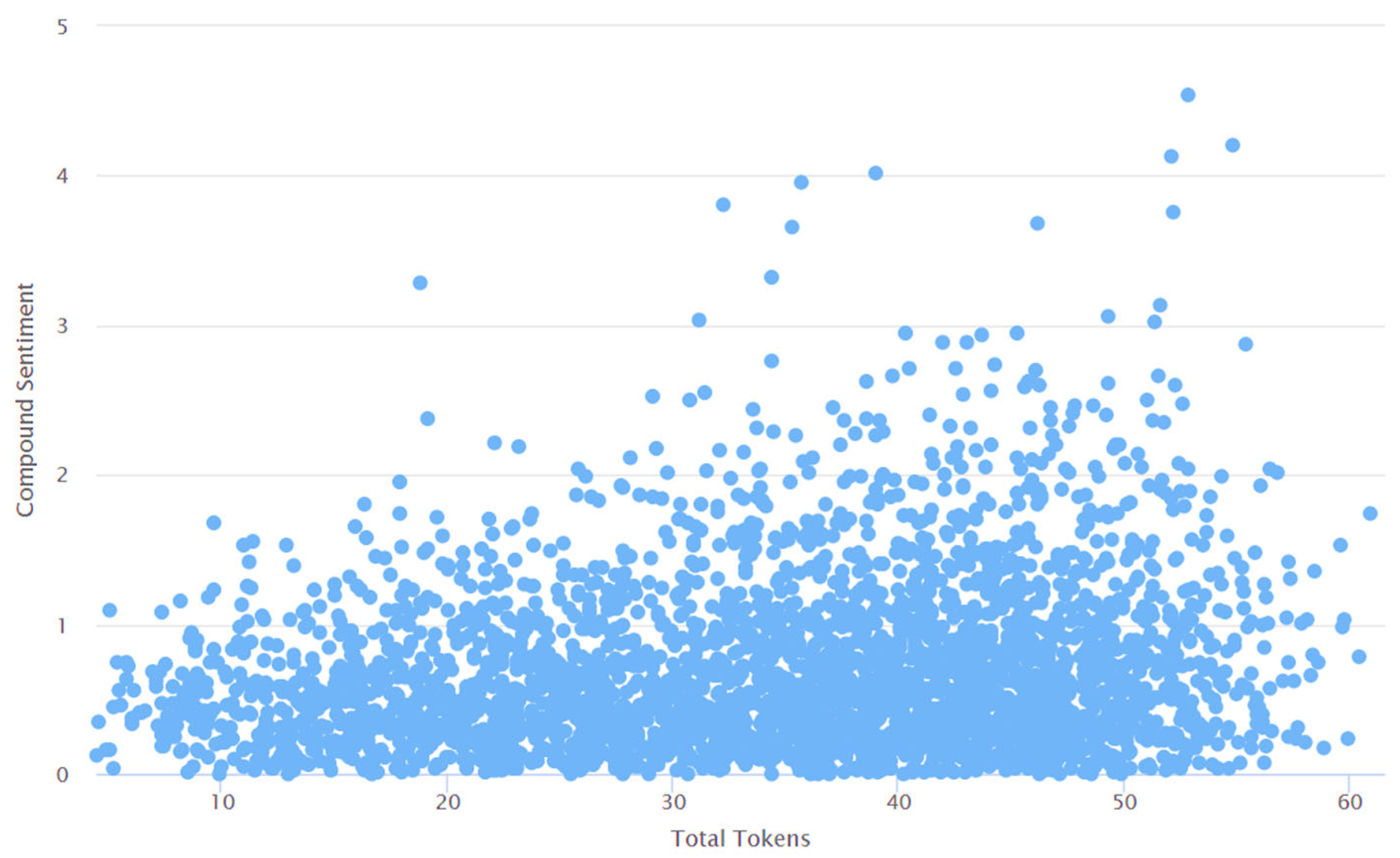
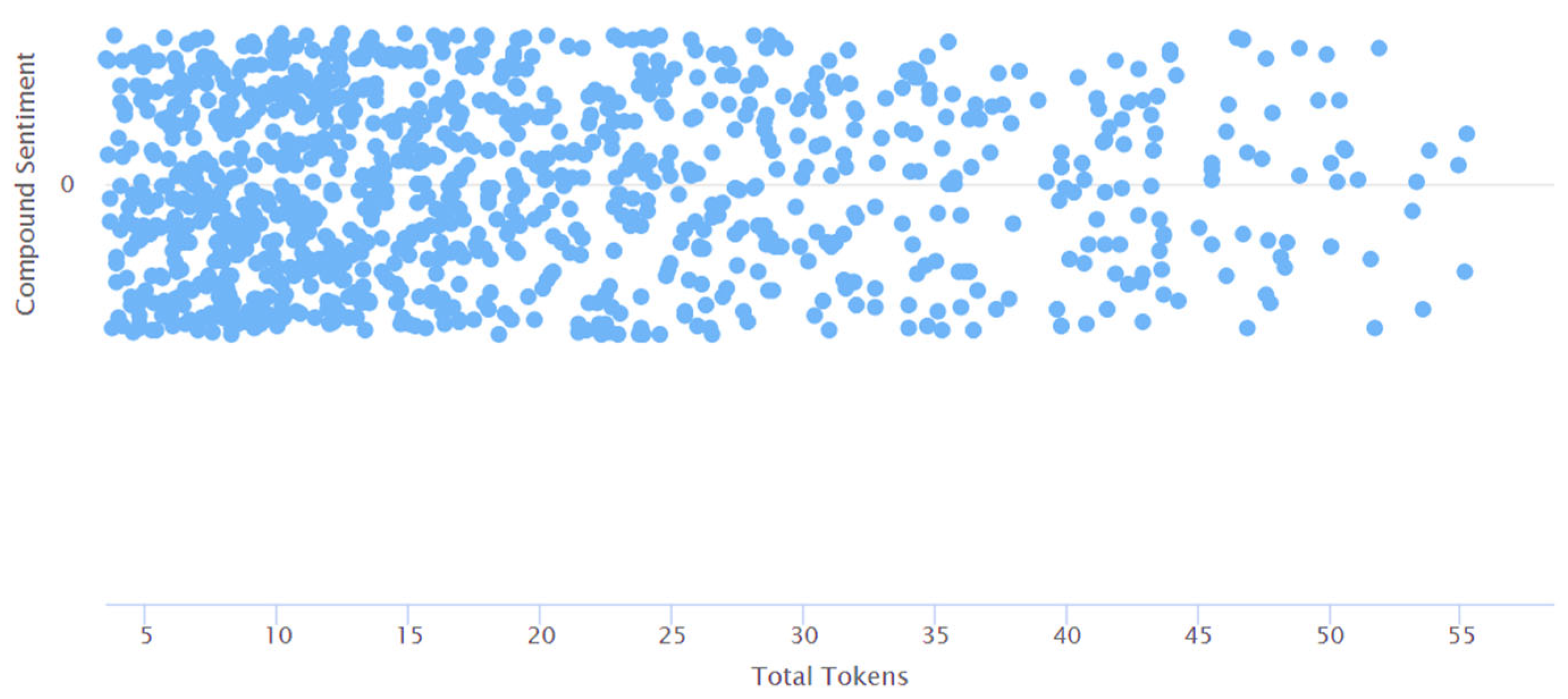
4. Results and Discussions
- As explained in Section 2, a wide range of research challenges pertaining to COVID-19 have been explored and investigated via the analysis of relevant Tweets in scholarly works over the past few years. These include traveling [87], current trends [88], worries of the general public [88], the evaluation of events [89], opinions on mask-wearing [91], inquiries into influencer behaviors [92], detecting and tracking misinformation [93], studies of addiction trends [96], identifying loneliness [98], and the evaluation of impulse purchases [100]. Despite the extensive exploration of many research questions within this particular domain, the existing body of literature [87,88,89,91,92,93,96,98,100] has not specifically investigated the Twitter discourse pertaining to Long COVID. The research described in this study addresses this limitation found in previous studies in this field [87,88,89,91,92,93,96,98,100] by focusing on the analysis of Tweets related to Long COVID.
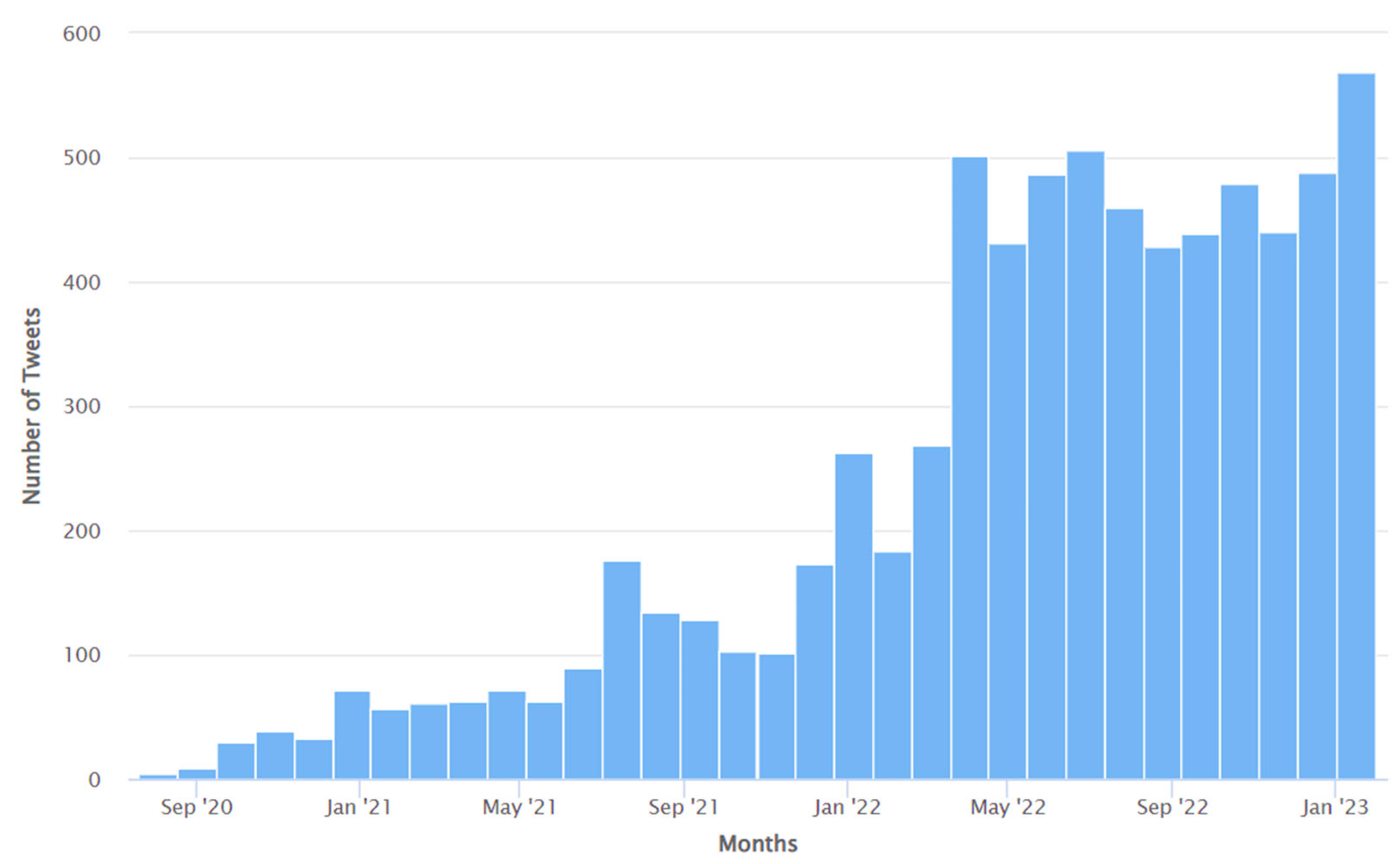
- Despite the existence of some studies, such as those conducted by Awoyemi et al. [108] and Pitroda et al. [109], which investigated Tweets pertaining to Long COVID, a significant limitation of these studies is the restricted temporal scope of the analyzed Tweets. In [108], the examined Tweets were published between 25 March 2022 and 1 April 2022. Similarly, the Tweets analyzed in [109] were published between 11 December 2021 and 20 December 2021. These durations constitute a small portion of the complete timeframe over which Long COVID has had its impact on the global population. This study addresses this limitation by conducting an analysis of Tweets pertaining to Long COVID, published between 25 May 2020 and 31 January 2023.
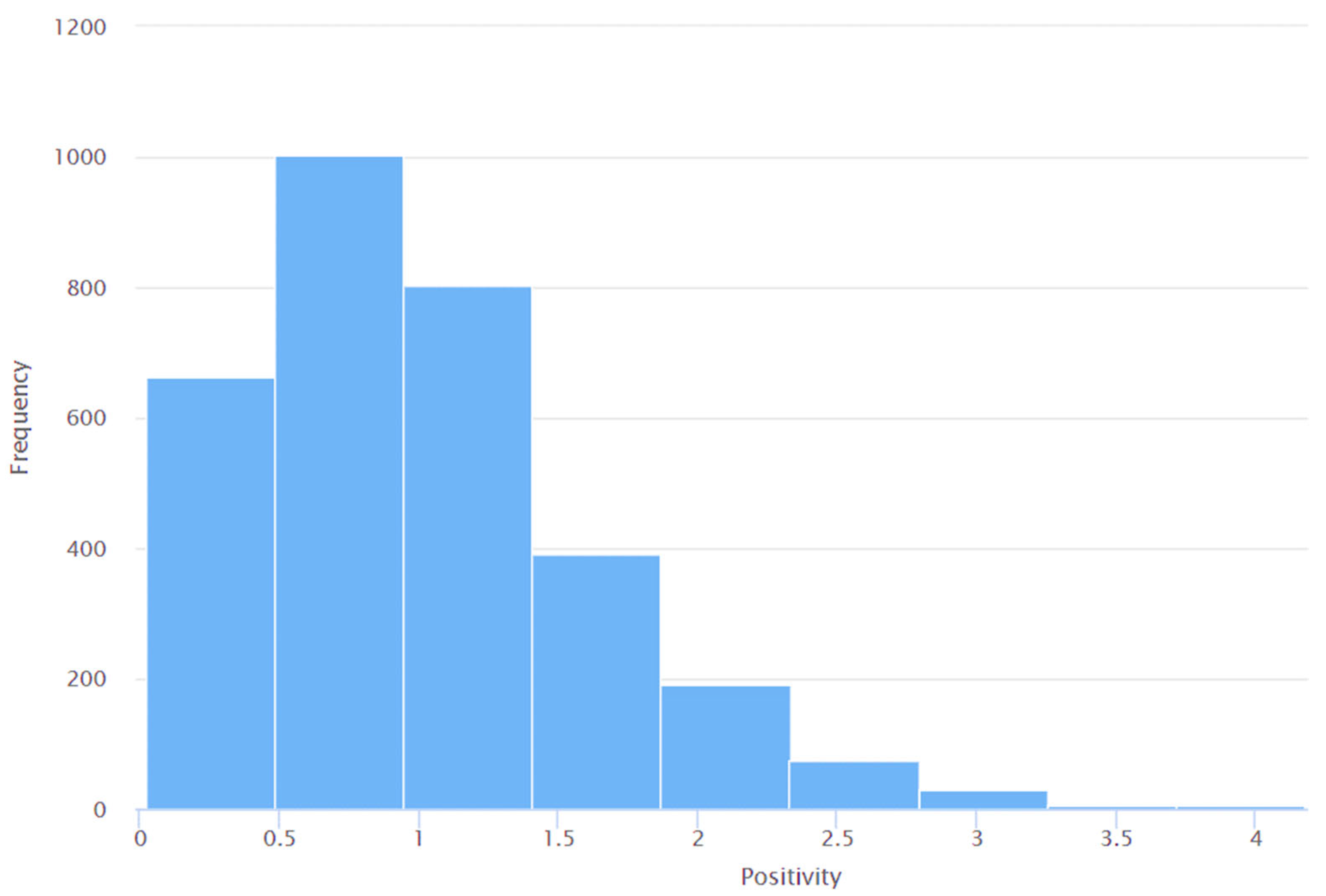
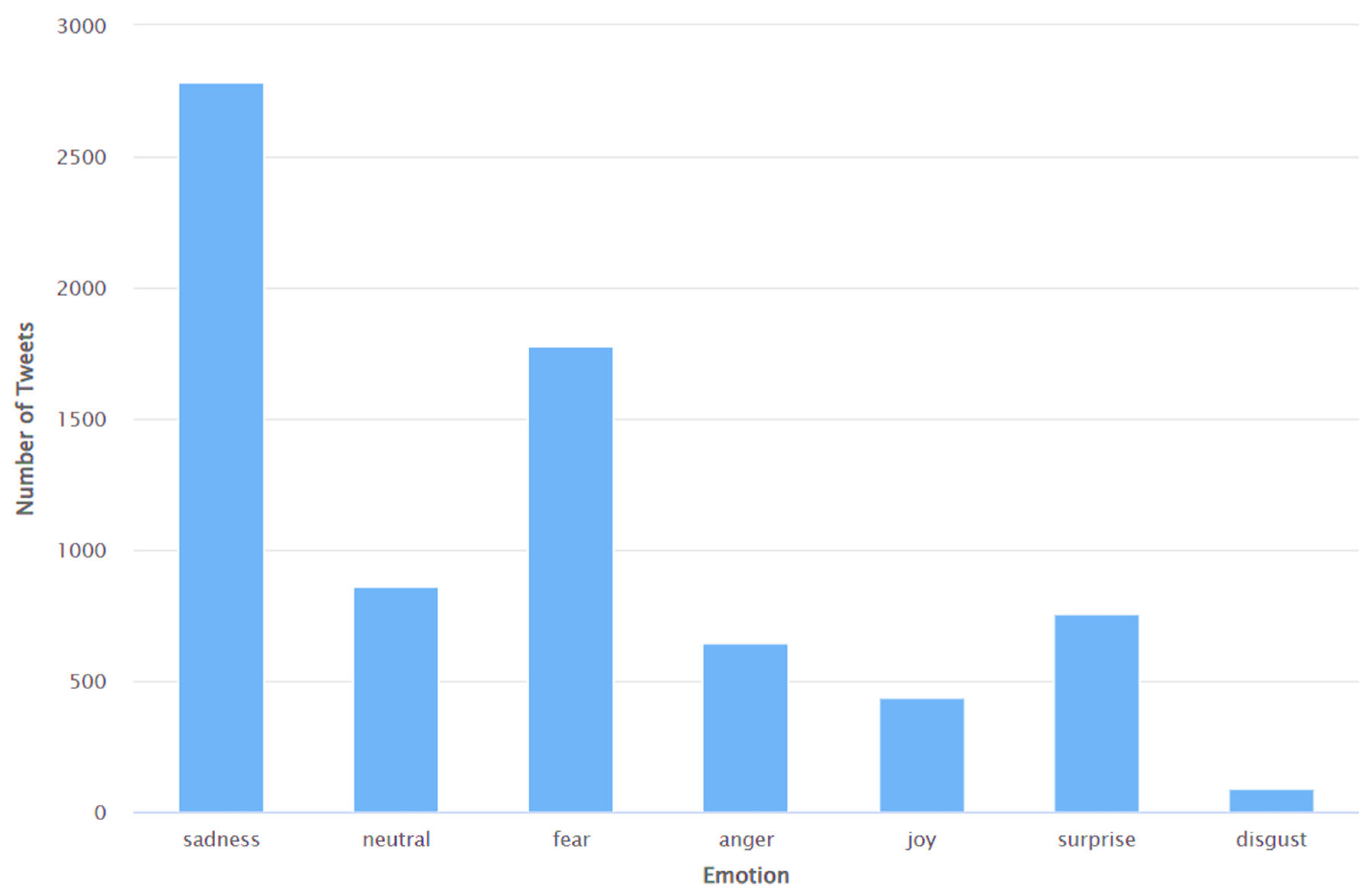
- The application of sentiment analysis to Tweets has proven valuable in discerning the range of views and opinions expressed by the global population on Twitter about various subjects of discussion during previous instances of virus outbreaks. Consequently, there has been a notable surge in the volume of literature pertaining to sentiment analysis since the onset of the COVID-19 pandemic. Despite the existence of many studies (e.g., [86,87,94,101,102,103,104,106,107]) that have performed sentiment analyses of Tweets pertaining to COVID-19, none of these studies have specifically examined the sentiments expressed in Tweets related to Long COVID. This study addresses this limitation using the Valence Aware Dictionary for Sentiment Reasoning (VADER) methodology to perform sentiment analyses of Tweets about Long COVID.
- The examination of conversation patterns of people on Twitter who self-report health-related issues has received significant attention from researchers across a wide range of disciplines. This can be observed through the increasing number of studies that have focused on analyzing such Tweets in the context of mental health [110], autism [111], dementia [112], depression [113], breast cancer [114], swine flu [115], influenza [116], chronic stress [117], post-traumatic stress disorder [118], and dental issues [119]. Since the beginning of the COVID-19 pandemic, scholars in this field, as exemplified by the work of researchers in [99], have redirected their attention toward devising approaches for the acquisition and analysis of Tweets in which individuals willingly disclose how they contracted COVID-19, including self-reported instances of COVID-19. However, previous studies in this area of research did not specifically examine Tweets wherein people self-reported Long COVID. This study addresses this limitation by examining Tweets in which Twitter users self-reported Long COVID.
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, N.; Zhang, D.; Wang, W.; Li, X.; Yang, B.; Song, J.; Zhao, X.; Huang, B.; Shi, W.; Lu, R.; et al. A Novel Coronavirus from Patients with Pneumonia in China, 2019. N. Engl. J. Med. 2020, 382, 727–733. [Google Scholar] [CrossRef]
- Drosten, C.; Günther, S.; Preiser, W.; van der Werf, S.; Brodt, H.-R.; Becker, S.; Rabenau, H.; Panning, M.; Kolesnikova, L.; Fouchier, R.A.M.; et al. Identification of a Novel Coronavirus in Patients with Severe Acute Respiratory Syndrome. N. Engl. J. Med. 2003, 348, 1967–1976. [Google Scholar] [CrossRef]
- Ksiazek, T.G.; Erdman, D.; Goldsmith, C.S.; Zaki, S.R.; Peret, T.; Emery, S.; Tong, S.; Urbani, C.; Comer, J.A.; Lim, W.; et al. A Novel Coronavirus Associated with Severe Acute Respiratory Syndrome. N. Engl. J. Med. 2003, 348, 1953–1966. [Google Scholar] [CrossRef] [PubMed]
- Zaki, A.M.; van Boheemen, S.; Bestebroer, T.M.; Osterhaus, A.D.M.E.; Fouchier, R.A.M. Isolation of a Novel Coronavirus from a Man with Pneumonia in Saudi Arabia. N. Engl. J. Med. 2012, 367, 1814–1820. [Google Scholar] [CrossRef] [PubMed]
- WHO Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 21 September 2023).
- Zhou, P.; Yang, X.-L.; Wang, X.-G.; Hu, B.; Zhang, L.; Zhang, W.; Si, H.-R.; Zhu, Y.; Li, B.; Huang, C.-L.; et al. A Pneumonia Outbreak Associated with a New Coronavirus of Probable Bat Origin. Nature 2020, 579, 270–273. [Google Scholar] [CrossRef] [PubMed]
- Chan, J.F.-W.; Yuan, S.; Kok, K.-H.; To, K.K.-W.; Chu, H.; Yang, J.; Xing, F.; Liu, J.; Yip, C.C.-Y.; Poon, R.W.-S.; et al. A Familial Cluster of Pneumonia Associated with the 2019 Novel Coronavirus Indicating Person-to-Person Transmission: A Study of a Family Cluster. Lancet 2020, 395, 514–523. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Zeng, Y.; Tong, Y.; Chen, C. Ophthalmologic Evidence against the Interpersonal Transmission of 2019 Novel Coronavirus through Conjunctiva. bioRxiv 2020. [Google Scholar] [CrossRef]
- Cui, H.; Gao, Z.; Liu, M.; Lu, S.; Mo, S.; Mkandawire, W.; Narykov, O.; Srinivasan, S.; Korkin, D. Structural Genomics and Interactomics of 2019 Wuhan Novel Coronavirus, 2019-NCoV, Indicate Evolutionary Conserved Functional Regions of Viral Proteins. bioRxiv 2020. [Google Scholar] [CrossRef]
- Chen, L.; Liu, W.; Zhang, Q.; Xu, K.; Ye, G.; Wu, W.; Sun, Z.; Liu, F.; Wu, K.; Zhong, B.; et al. RNA Based MNGS Approach Identifies a Novel Human Coronavirus from Two Individual Pneumonia Cases in 2019 Wuhan Outbreak. Emerg. Microbes Infect. 2020, 9, 313–319. [Google Scholar] [CrossRef] [PubMed]
- Ceraolo, C.; Giorgi, F.M. Genomic Variance of the 2019-nCoV Coronavirus. J. Med. Virol. 2020, 92, 522–528. [Google Scholar] [CrossRef] [PubMed]
- Gallagher, T.M.; Buchmeier, M.J. Coronavirus Spike Proteins in Viral Entry and Pathogenesis. Virology 2001, 279, 371–374. [Google Scholar] [CrossRef]
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Zhang, L.; Fan, G.; Xu, J.; Gu, X.; et al. Clinical Features of Patients Infected with 2019 Novel Coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef]
- Lauring, A.S.; Hodcroft, E.B. Genetic Variants of SARS-CoV-2—What Do They Mean? JAMA 2021, 325, 529. [Google Scholar] [CrossRef]
- Khare, S.; GISAID Global Data Science Initiative (GISAID); Gurry, C.; Freitas, L.; Schultz, M.B.; Bach, G.; Diallo, A.; Akite, N.; Ho, J.; TC Lee, R.; et al. GISAID’s Role in Pandemic Response. China CDC Wkly. 2021, 3, 1049–1051. [Google Scholar] [CrossRef] [PubMed]
- GISAID—Gisaid.org. Available online: https://www.gisaid.org/ (accessed on 3 September 2023).
- Perego, E. The #LongCovid #COVID19. Available online: https://twitter.com/elisaperego78/status/1263172084055838721?s=20 (accessed on 3 September 2023).
- Crook, H.; Raza, S.; Nowell, J.; Young, M.; Edison, P. Long Covid—Mechanisms, Risk Factors, and Management. BMJ 2021, 374, n1648. [Google Scholar] [CrossRef] [PubMed]
- Nabavi, N. Long Covid: How to Define It and How to Manage It. BMJ 2020, 370, m3489. [Google Scholar] [CrossRef]
- Garg, P.; Arora, U.; Kumar, A.; Wig, N. The “Post-COVID” Syndrome: How Deep Is the Damage? J. Med. Virol. 2021, 93, 673–674. [Google Scholar] [CrossRef]
- Greenhalgh, T.; Knight, M.; A’Court, C.; Buxton, M.; Husain, L. Management of Post-Acute COVID-19 in Primary Care. BMJ 2020, 370, m3026. [Google Scholar] [CrossRef]
- Raveendran, A.V. Long COVID-19: Challenges in the Diagnosis and Proposed Diagnostic Criteria. Diabetes Metab. Syndrome 2021, 15, 145–146. [Google Scholar] [CrossRef]
- Van Elslande, J.; Vermeersch, P.; Vandervoort, K.; Wawina-Bokalanga, T.; Vanmechelen, B.; Wollants, E.; Laenen, L.; André, E.; Van Ranst, M.; Lagrou, K.; et al. Symptomatic Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2) Reinfection by a Phylogenetically Distinct Strain. Clin. Infect. Dis. 2021, 73, 354–356. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. Pervasive Activity Logging for Indoor Localization in Smart Homes. In Proceedings of the 2021 4th International Conference on Data Science and Information Technology, Shanghai China, 23–25 July 2021; ACM: New York, NY, USA, 2021. [Google Scholar]
- Thakur, N.; Han, C.Y. An Approach for Detection of Walking Related Falls during Activities of Daily Living. In Proceedings of the 2020 International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Fuzhou, China, 12–14 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 280–283. [Google Scholar]
- Thakur, N.; Han, C.Y. A Framework for Prediction of Cramps during Activities of Daily Living in Elderly. In Proceedings of the 2020 International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Fuzhou, China, 12–14 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 284–287. [Google Scholar]
- Fung, K.W.; Baye, F.; Baik, S.H.; Zheng, Z.; McDonald, C.J. Prevalence and Characteristics of Long COVID in Elderly Patients: An Observational Cohort Study of over 2 Million Adults in the US. PLoS Med. 2023, 20, e1004194. [Google Scholar] [CrossRef]
- Falahi, S.; Kenarkoohi, A. COVID-19 Reinfection: Prolonged Shedding or True Reinfection? New Microbes New Infect. 2020, 38, 100812. [Google Scholar] [CrossRef]
- Carfì, A.; Bernabei, R.; Landi, F. For the Gemelli Against COVID-19 Post-Acute Care Study Group Persistent Symptoms in Patients after Acute COVID-19. JAMA 2020, 324, 603. [Google Scholar] [CrossRef] [PubMed]
- Arnold, D.T.; Hamilton, F.W.; Milne, A.; Morley, A.J.; Viner, J.; Attwood, M.; Noel, A.; Gunning, S.; Hatrick, J.; Hamilton, S.; et al. Patient Outcomes after Hospitalisation with COVID-19 and Implications for Follow-up: Results from a Prospective UK Cohort. Thorax 2021, 76, 399–401. [Google Scholar] [CrossRef] [PubMed]
- Tenforde, M.W.; Kim, S.S.; Lindsell, C.J.; Billig Rose, E.; Shapiro, N.I.; Files, D.C.; Gibbs, K.W.; Erickson, H.L.; Steingrub, J.S.; Smithline, H.A.; et al. Symptom Duration and Risk Factors for Delayed Return to Usual Health among Outpatients with COVID-19 in a Multistate Health Care Systems Network—United States, March–June 2020. MMWR Morb. Mortal. Wkly. Rep. 2020, 69, 993–998. [Google Scholar] [CrossRef]
- Lopez-Leon, S.; Wegman-Ostrosky, T.; Perelman, C.; Sepulveda, R.; Rebolledo, P.A.; Cuapio, A.; Villapol, S. More than 50 Long-Term Effects of COVID-19: A Systematic Review and Meta-Analysis. Sci. Rep. 2021, 11, 16144. [Google Scholar] [CrossRef] [PubMed]
- Fernández-de-las-Peñas, C. Long COVID: Current Definition. Infection 2022, 50, 285–286. [Google Scholar] [CrossRef]
- Cutler, D.M. The Costs of Long COVID. JAMA Health Forum 2022, 3, e221809. [Google Scholar] [CrossRef]
- Altmann, D.M.; Whettlock, E.M.; Liu, S.; Arachchillage, D.J.; Boyton, R.J. The Immunology of Long COVID. Nat. Rev. Immunol. 2023, 23, 618–634. [Google Scholar] [CrossRef]
- Greenhalgh, T.; Knight, M. Long COVID: A Primer for Family Physicians. Am. Fam. Physician 2020, 102, 716–717. [Google Scholar] [PubMed]
- Siddiq, M.A.B. Pulmonary Rehabilitation in COVID-19 Patients: A Scoping Review of Current Practice and Its Application during the Pandemic. Turk. J. Phys. Med. Rehabil. 2020, 66, 480–494. [Google Scholar] [CrossRef]
- Liu, K.; Zhang, W.; Yang, Y.; Zhang, J.; Li, Y.; Chen, Y. Respiratory Rehabilitation in Elderly Patients with COVID-19: A Randomized Controlled Study. Complement. Ther. Clin. Pract. 2020, 39, 101166. [Google Scholar] [CrossRef] [PubMed]
- Yong, S.J. Long COVID or Post-COVID-19 Syndrome: Putative Pathophysiology, Risk Factors, and Treatments. Infect. Dis. 2021, 53, 737–754. [Google Scholar] [CrossRef]
- Blitshteyn, S.; Whitelaw, S. Postural Orthostatic Tachycardia Syndrome (POTS) and Other Autonomic Disorders after COVID-19 Infection: A Case Series of 20 Patients. Immunol. Res. 2021, 69, 205–211. [Google Scholar] [CrossRef]
- Johansson, M.; Ståhlberg, M.; Runold, M.; Nygren-Bonnier, M.; Nilsson, J.; Olshansky, B.; Bruchfeld, J.; Fedorowski, A. Long-Haul Post–COVID-19 Symptoms Presenting as a Variant of Postural Orthostatic Tachycardia Syndrome. JACC Case Rep. 2021, 3, 573–580. [Google Scholar] [CrossRef]
- Kanjwal, K.; Jamal, S.; Kichloo, A.; Grubb, B. New-Onset Postural Orthostatic Tachycardia Syndrome Following Coronavirus Disease 2019 Infection. J. Innov. Card. Rhythm Manag. 2020, 11, 4302–4304. [Google Scholar] [CrossRef] [PubMed]
- Miglis, M.G.; Prieto, T.; Shaik, R.; Muppidi, S.; Sinn, D.-I.; Jaradeh, S. A Case Report of Postural Tachycardia Syndrome after COVID-19. Clin. Auton. Res. 2020, 30, 449–451. [Google Scholar] [CrossRef] [PubMed]
- Davis, H.E.; Assaf, G.S.; McCorkell, L.; Wei, H.; Low, R.J.; Re’em, Y.; Redfield, S.; Austin, J.P.; Akrami, A. Characterizing Long COVID in an International Cohort: 7 Months of Symptoms and Their Impact. EClinicalMedicine 2021, 38, 101019. [Google Scholar] [CrossRef]
- Thakur, N. Social Media Mining and Analysis: A Brief Review of Recent Challenges. Information 2023, 14, 484. [Google Scholar] [CrossRef]
- Injadat, M.; Salo, F.; Nassif, A.B. Data Mining Techniques in Social Media: A Survey. Neurocomputing 2016, 214, 654–670. [Google Scholar] [CrossRef]
- Zubiaga, A. Mining Social Media for Newsgathering: A Review. Online Soc. Netw. Media 2019, 13, 100049. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. Country-Specific Interests towards Fall Detection from 2004–2021: An Open Access Dataset and Research Questions. Data 2021, 6, 92. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. Google Trends to Investigate the Degree of Global Interest Related to Indoor Location Detection. In Human Interaction, Emerging Technologies and Future Systems V; Springer International Publishing: Cham, Switzerland, 2022; pp. 580–588. ISBN 9783030855390. [Google Scholar]
- Mayrhofer, M.; Matthes, J.; Einwiller, S.; Naderer, B. User Generated Content Presenting Brands on Social Media Increases Young Adults’ Purchase Intention. Int. J. Advert. 2020, 39, 166–186. [Google Scholar] [CrossRef]
- Roma, P.; Aloini, D. How Does Brand-Related User-Generated Content Differ across Social Media? Evidence Reloaded. J. Bus. Res. 2019, 96, 322–339. [Google Scholar] [CrossRef]
- Charles-Smith, L.E.; Reynolds, T.L.; Cameron, M.A.; Conway, M.; Lau, E.H.Y.; Olsen, J.M.; Pavlin, J.A.; Shigematsu, M.; Streichert, L.C.; Suda, K.J.; et al. Using Social Media for Actionable Disease Surveillance and Outbreak Management: A Systematic Literature Review. PLoS ONE 2015, 10, e0139701. [Google Scholar] [CrossRef] [PubMed]
- Chew, C.; Eysenbach, G. Pandemics in the Age of Twitter: Content Analysis of Tweets during the 2009 H1N1 Outbreak. PLoS ONE 2010, 5, e14118. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Wang, Y.; Xue, J.; Zhao, N.; Zhu, T. The Impact of COVID-19 Epidemic Declaration on Psychological Consequences: A Study on Active Weibo Users. Int. J. Environ. Res. Public Health 2020, 17, 2032. [Google Scholar] [CrossRef]
- Thakur, N. Sentiment Analysis and Text Analysis of the Public Discourse on Twitter about COVID-19 and MPox. Big Data Cogn. Comput. 2023, 7, 116. [Google Scholar] [CrossRef]
- Bartlett, C.; Wurtz, R. Twitter and Public Health. J. Public Health Manag. Pract. 2015, 21, 375–383. [Google Scholar] [CrossRef]
- Tomaszewski, T.; Morales, A.; Lourentzou, I.; Caskey, R.; Liu, B.; Schwartz, A.; Chin, J. Identifying False Human Papillomavirus (HPV) Vaccine Information and Corresponding Risk Perceptions from Twitter: Advanced Predictive Models. J. Med. Internet Res. 2021, 23, e30451. [Google Scholar] [CrossRef]
- Lee, S.Y.; Khang, Y.-H.; Lim, H.-K. Impact of the 2015 Middle East Respiratory Syndrome Outbreak on Emergency Care Utilization and Mortality in South Korea. Yonsei. Med. J. 2019, 60, 796. [Google Scholar] [CrossRef]
- Radzikowski, J.; Stefanidis, A.; Jacobsen, K.H.; Croitoru, A.; Crooks, A.; Delamater, P.L. The Measles Vaccination Narrative in Twitter: A Quantitative Analysis. JMIR Public Health Surveill. 2016, 2, e1. [Google Scholar] [CrossRef]
- Fu, K.-W.; Liang, H.; Saroha, N.; Tse, Z.T.H.; Ip, P.; Fung, I.C.-H. How People React to Zika Virus Outbreaks on Twitter? A Computational Content Analysis. Am. J. Infect. Control 2016, 44, 1700–1702. [Google Scholar] [CrossRef]
- Thakur, N. MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions. Infect. Dis. Rep. 2022, 14, 855–883. [Google Scholar] [CrossRef] [PubMed]
- Kraaijeveld, O.; De Smedt, J. The Predictive Power of Public Twitter Sentiment for Forecasting Cryptocurrency Prices. J. Int. Financ. Mark. Inst. Money 2020, 65, 101188. [Google Scholar] [CrossRef]
- Aharon, D.Y.; Demir, E.; Lau, C.K.M.; Zaremba, A. Twitter-Based Uncertainty and Cryptocurrency Returns. Res. Int. Bus. Fin. 2022, 59, 101546. [Google Scholar] [CrossRef]
- Alkouz, B.; Al Aghbari, Z.; Al-Garadi, M.A.; Sarker, A. Deepluenza: Deep Learning for Influenza Detection from Twitter. Expert Syst. Appl. 2022, 198, 116845. [Google Scholar] [CrossRef]
- Oyeyemi, S.O.; Gabarron, E.; Wynn, R. Ebola, Twitter, and Misinformation: A Dangerous Combination? BMJ 2014, 349, g6178. [Google Scholar] [CrossRef]
- Thakur, N.; Hall, I.; Han, C.Y. A Comprehensive Study to Analyze Trends in Web Search Interests Related to Fall Detection before and after COVID-19. In Proceedings of the 2022 5th International Conference on Computer Science and Software Engineering (CSSE 2022), Guilin, China, 21–23 October 2022; ACM: New York, NY, USA, 2022. [Google Scholar]
- Thakur, N.; Duggal, Y.N.; Liu, Z. Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets. Computers 2023, 12, 191. [Google Scholar] [CrossRef]
- Mouronte-López, M.L.; Ceres, J.S.; Columbrans, A.M. Analysing the Sentiments about the Education System Trough Twitter. Educ. Inf. Technol. 2023, 28, 10965–10994. [Google Scholar] [CrossRef]
- Li, X.; Hasan, S.; Culotta, A. Identifying Hurricane Evacuation Intent on Twitter. Proc. Int. AAAI Conf. Web Soc. Media 2022, 16, 618–627. [Google Scholar] [CrossRef]
- Lawelai, H.; Sadat, A.; Suherman, A. Democracy and Freedom of Opinion in Social Media: Sentiment Analysis on Twitter. PRJ 2022, 10, 40–48. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. A Framework for Facilitating Human-Human Interactions to Mitigate Loneliness in Elderly. In Human Interaction, Emerging Technologies and Future Applications III; Springer International Publishing: Cham, Switzerland, 2021; pp. 322–327. ISBN 9783030553067. [Google Scholar]
- Thakur, N.; Han, C.Y. A Human-Human Interaction-Driven Framework to Address Societal Issues. In Human Interaction, Emerging Technologies and Future Systems V; Springer International Publishing: Cham, Switzerland, 2022; pp. 563–571. ISBN 9783030855390. [Google Scholar]
- Grover, P.; Kar, A.K.; Janssen, M.; Ilavarasan, P.V. Perceived Usefulness, Ease of Use and User Acceptance of Blockchain Technology for Digital Transactions—Insights from User-Generated Content on Twitter. Enterp. Inf. Syst. 2019, 13, 771–800. [Google Scholar] [CrossRef]
- Mnif, E.; Mouakhar, K.; Jarboui, A. Blockchain Technology Awareness on Social Media: Insights from Twitter Analytics. J. High Technol. Manag. Res. 2021, 32, 100416. [Google Scholar] [CrossRef]
- Lu, X.; Brelsford, C. Network Structure and Community Evolution on Twitter: Human Behavior Change in Response to the 2011 Japanese Earthquake and Tsunami. Sci. Rep. 2014, 4, 6773. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. An Intelligent Ubiquitous Activity Aware Framework for Smart Home. In Human Interaction, Emerging Technologies and Future Applications III; Springer International Publishing: Cham, Switzerland, 2021; pp. 296–302. ISBN 9783030553067. [Google Scholar]
- Buccafurri, F.; Lax, G.; Nicolazzo, S.; Nocera, A. Comparing Twitter and Facebook User Behavior: Privacy and Other Aspects. Comput. Human Behav. 2015, 52, 87–95. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. Indoor Localization for Personalized Ambient Assisted Living of Multiple Users in Multi-Floor Smart Environments. Big Data Cogn. Comput. 2021, 5, 42. [Google Scholar] [CrossRef]
- Golder, S.; Stevens, R.; O’Connor, K.; James, R.; Gonzalez-Hernandez, G. Methods to Establish Race or Ethnicity of Twitter Users: Scoping Review. J. Med. Internet Res. 2022, 24, e35788. [Google Scholar] [CrossRef]
- Chang, R.-C.; Rao, A.; Zhong, Q.; Wojcieszak, M.; Lerman, K. #RoeOverturned: Twitter Dataset on the Abortion Rights Controversy. Proc. Int. AAAI Conf. Web Soc. Media 2023, 17, 997–1005. [Google Scholar] [CrossRef]
- Bhatia, K.V. Hindu Nationalism Online: Twitter as Discourse and Interface. Religions 2022, 13, 739. [Google Scholar] [CrossRef]
- Peña-Fernández, S.; Larrondo-Ureta, A.; Morales-i-Gras, J. Feminism, gender identity and polarization in TikTok and Twitter. Comunicar 2023, 31, 49–60. [Google Scholar] [CrossRef]
- Goetz, S.J.; Heaton, C.; Imran, M.; Pan, Y.; Tian, Z.; Schmidt, C.; Qazi, U.; Ofli, F.; Mitra, P. Food Insufficiency and Twitter Emotions during a Pandemic. Appl. Econ. Perspect. Policy 2023, 45, 1189–1210. [Google Scholar] [CrossRef]
- Lin, Q.; Zhao, S.; Gao, D.; Lou, Y.; Yang, S.; Musa, S.S.; Wang, M.H.; Cai, Y.; Wang, W.; Yang, L.; et al. A Conceptual Model for the Coronavirus Disease 2019 (COVID-19) Outbreak in Wuhan, China with Individual Reaction and Governmental Action. Int. J. Infect. Dis. 2020, 93, 211–216. [Google Scholar] [CrossRef]
- Öcal, A.; Cvetković, V.M.; Baytiyeh, H.; Tedim, F.M.S.; Zečević, M. Public Reactions to the Disaster COVID-19: A Comparative Study in Italy, Lebanon, Portugal, and Serbia. Geomat. Nat. Hazards Risk 2020, 11, 1864–1885. [Google Scholar] [CrossRef]
- Mehedi Shamrat, F.M.J.; Chakraborty, S.; Imran, M.M.; Muna, J.N.; Billah, M.M.; Das, P.; Rahman, M.O. Sentiment Analysis on Twitter Tweets about COVID-19 Vaccines Usi Ng NLP and Supervised KNN Classification Algorithm. Indones. J. Electr. Eng. Comput. Sci. 2021, 23, 463. [Google Scholar] [CrossRef]
- Sontayasara, T.; Jariyapongpaiboon, S.; Promjun, A.; Seelpipat, N.; Saengtabtim, K.; Tang, J.; Leelawat, N. Twitter Sentiment Analysis of Bangkok Tourism during COVID-19 Pandemic Using Support Vector Machine Algorithm. J. Disaster Res. 2021, 16, 24–30. [Google Scholar] [CrossRef]
- Asgari-Chenaghlu, M.; Nikzad-Khasmakhi, N.; Minaee, S. Covid-Transformer: Detecting COVID-19 Trending Topics on Twitter Using Universal Sentence Encoder. arXiv 2020, arXiv:2009.03947. [Google Scholar]
- Amen, B.; Faiz, S.; Do, T.-T. Big Data Directed Acyclic Graph Model for Real-Time COVID-19 Twitter Stream Detection. Pattern Recognit. 2022, 123, 108404. [Google Scholar] [CrossRef]
- Lyu, J.C.; Luli, G.K. Understanding the Public Discussion about the Centers for Disease Control and Prevention during the COVID-19 Pandemic Using Twitter Data: Text Mining Analysis Study. J. Med. Internet Res. 2021, 23, e25108. [Google Scholar] [CrossRef]
- Al-Ramahi, M.; Elnoshokaty, A.; El-Gayar, O.; Nasralah, T.; Wahbeh, A. Public Discourse against Masks in the COVID-19 Era: Infodemiology Study of Twitter Data. JMIR Public Health Surveill. 2021, 7, e26780. [Google Scholar] [CrossRef] [PubMed]
- Jain, S.; Sinha, A. Identification of Influential Users on Twitter: A Novel Weighted Correlated Influence Measure for COVID-19. Chaos Solitons Fractals 2020, 139, 110037. [Google Scholar] [CrossRef]
- Madani, Y.; Erritali, M.; Bouikhalene, B. Using Artificial Intelligence Techniques for Detecting Covid-19 Epidemic Fake News in Moroccan Tweets. Results Phys. 2021, 25, 104266. [Google Scholar] [CrossRef]
- Shokoohyar, S.; Rikhtehgar Berenji, H.; Dang, J. Exploring the Heated Debate over Reopening for Economy or Continuing Lockdown for Public Health Safety Concerns about COVID-19 in Twitter. Int. J. Bus. Syst. Res. 2021, 15, 650. [Google Scholar] [CrossRef]
- Chehal, D.; Gupta, P.; Gulati, P. COVID-19 Pandemic Lockdown: An Emotional Health Perspective of Indians on Twitter. Int. J. Soc. Psychiatry 2021, 67, 64–72. [Google Scholar] [CrossRef]
- Glowacki, E.M.; Wilcox, G.B.; Glowacki, J.B. Identifying #addiction Concerns on Twitter during the Covid-19 Pandemic: A Text Mining Analysis. Subst. Abus. 2021, 42, 39–46. [Google Scholar] [CrossRef]
- Selman, L.E.; Chamberlain, C.; Sowden, R.; Chao, D.; Selman, D.; Taubert, M.; Braude, P. Sadness, Despair and Anger When a Patient Dies Alone from COVID-19: A Thematic Content Analysis of Twitter Data from Bereaved Family Members and Friends. Palliat. Med. 2021, 35, 1267–1276. [Google Scholar] [CrossRef]
- Koh, J.X.; Liew, T.M. How Loneliness Is Talked about in Social Media during COVID-19 Pandemic: Text Mining of 4,492 Twitter Feeds. J. Psychiatr. Res. 2022, 145, 317–324. [Google Scholar] [CrossRef]
- Mackey, T.; Purushothaman, V.; Li, J.; Shah, N.; Nali, M.; Bardier, C.; Liang, B.; Cai, M.; Cuomo, R. Machine Learning to Detect Self-Reporting of Symptoms, Testing Access, and Recovery Associated with COVID-19 on Twitter: Retrospective Big Data Infoveillance Study. JMIR Public Health Surveill. 2020, 6, e19509. [Google Scholar] [CrossRef]
- Leung, J.; Chung, J.Y.C.; Tisdale, C.; Chiu, V.; Lim, C.C.W.; Chan, G. Anxiety and Panic Buying Behaviour during COVID-19 Pandemic—A Qualitative Analysis of Toilet Paper Hoarding Contents on Twitter. Int. J. Environ. Res. Public Health 2021, 18, 1127. [Google Scholar] [CrossRef]
- Pokharel, B.P. Twitter Sentiment Analysis during Covid-19 Outbreak in Nepal. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Vijay, T.; Chawla, A.; Dhanka, B.; Karmakar, P. Sentiment Analysis on COVID-19 Twitter Data. In Proceedings of the 2020 5th IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE), Jaipur, India, 1–3 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Shofiya, C.; Abidi, S. Sentiment Analysis on COVID-19-Related Social Distancing in Canada Using Twitter Data. Int. J. Environ. Res. Public Health 2021, 18, 5993. [Google Scholar] [CrossRef]
- Sahir, S.H.; Ayu Ramadhana, R.S.; Romadhon Marpaung, M.F.; Munthe, S.R.; Watrianthos, R. Online Learning Sentiment Analysis during the Covid-19 Indonesia Pandemic Using Twitter Data. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1156, 012011. [Google Scholar] [CrossRef]
- Thakur, N. A Large-Scale Dataset of Twitter Chatter about Online Learning during the Current COVID-19 Omicron Wave. Data 2022, 7, 109. [Google Scholar] [CrossRef]
- Pristiyono; Ritonga, M.; Ihsan, M.A.A.; Anjar, A.; Rambe, F.H. Sentiment Analysis of COVID-19 Vaccine in Indonesia Using Naïve Bayes Algorithm. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1088, 012045. [Google Scholar] [CrossRef]
- Lohar, P.; Xie, G.; Bendechache, M.; Brennan, R.; Celeste, E.; Trestian, R.; Tal, I. Irish Attitudes toward COVID Tracker App & Privacy: Sentiment Analysis on Twitter and Survey Data. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–21 August 2021; ACM: New York, NY, USA, 2021. [Google Scholar]
- Awoyemi, T.; Ebili, U.; Olusanya, A.; Ogunniyi, K.E.; Adejumo, A.V. Twitter Sentiment Analysis of Long COVID Syndrome. Cureus 2022, 14, e25901. [Google Scholar] [CrossRef] [PubMed]
- Pitroda, H. Long Covid Sentiment Analysis of Twitter Posts to Understand Public Concerns. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; IEEE: Piscataway, NJ, USA, 2022; Volume 1, pp. 140–148. [Google Scholar]
- Coppersmith, G.; Dredze, M.; Harman, C.; Hollingshead, K. From ADHD to SAD: Analyzing the Language of Mental Health on Twitter through Self-Reported Diagnoses. Available online: https://aclanthology.org/W15-1201.pdf (accessed on 4 September 2023).
- Hswen, Y.; Gopaluni, A.; Brownstein, J.S.; Hawkins, J.B. Using Twitter to Detect Psychological Characteristics of Self-Identified Persons with Autism Spectrum Disorder: A Feasibility Study. JMIR MHealth UHealth 2019, 7, e12264. [Google Scholar] [CrossRef] [PubMed]
- Talbot, C.; O’Dwyer, S.; Clare, L.; Heaton, J.; Anderson, J. Identifying People with Dementia on Twitter. Dementia 2020, 19, 965–974. [Google Scholar] [CrossRef] [PubMed]
- Almouzini, S.; Khemakhem, M.; Alageel, A. Detecting Arabic Depressed Users from Twitter Data. Procedia Comput. Sci. 2019, 163, 257–265. [Google Scholar] [CrossRef]
- Clark, E.M.; James, T.; Jones, C.A.; Alapati, A.; Ukandu, P.; Danforth, C.M.; Dodds, P.S. A Sentiment Analysis of Breast Cancer Treatment Experiences and Healthcare Perceptions across Twitter. arXiv 2018, arXiv:1805.09959. [Google Scholar] [CrossRef]
- Szomszor, M.; Kostkova, P.; de Quincey, E. #swineflu: Twitter Predicts Swine Flu Outbreak in 2009. In Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Berlin/Heidelberg, Germany, 2011; pp. 18–26. ISBN 9783642236341. [Google Scholar]
- Alshammari, S.M.; Nielsen, R.D. Less Is More: With a 280-Character Limit, Twitter Provides a Valuable Source for Detecting Self-Reported Flu Cases. In Proceedings of the 2018 International Conference on Computing and Big Data, Tokyo, Japan, 25–28 November 2018; ACM: New York, NY, USA, 2018. [Google Scholar]
- Yang, Y.-C.; Xie, A.; Kim, S.; Hair, J.; Al-Garadi, M.; Sarker, A. Automatic Detection of Twitter Users Who Express Chronic Stress Experiences via Supervised Machine Learning and Natural Language Processing. Comput. Inform. Nurs. 2022; Publish Ahead of Print. [Google Scholar] [CrossRef]
- Coppersmith, G.; Harman, C.; Dredze, M. Measuring Post Traumatic Stress Disorder in Twitter. Proc. Int. AAAI Conf. Web Soc. Media 2014, 8, 579–582. [Google Scholar] [CrossRef]
- Al-Khalifa, K.S.; Bakhurji, E.; Halawany, H.S.; Alabdurubalnabi, E.M.; Nasser, W.W.; Shetty, A.C.; Sadaf, S. Pattern of Dental Needs and Advice on Twitter during the COVID-19 Pandemic in Saudi Arabia. BMC Oral Health 2021, 21, 456. [Google Scholar] [CrossRef]
- Tsytsarau, M.; Palpanas, T. Survey on Mining Subjective Data on the Web. Data Min. Knowl. Discov. 2012, 24, 478–514. [Google Scholar] [CrossRef]
- Saberi, B.; Saad, S. Sentiment Analysis or Opinion Mining: A Review. Available online: https://core.ac.uk/download/pdf/296919524.pdf (accessed on 4 September 2023).
- Liu, B. Sentiment Analysis and Opinion Mining; Springer Nature: Cham, Switzerland, 2022; ISBN 9783031021459. [Google Scholar]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment Analysis Algorithms and Applications: A Survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing Contextual Polarity in Phrase-Level Sentiment Analysis. Available online: https://aclanthology.org/H05-1044.pdf (accessed on 4 September 2023).
- Do, H.H.; Prasad, P.W.C.; Maag, A.; Alsadoon, A. Deep Learning for Aspect-Based Sentiment Analysis: A Comparative Review. Expert Syst. Appl. 2019, 118, 272–299. [Google Scholar] [CrossRef]
- Nazir, A.; Rao, Y.; Wu, L.; Sun, L. Issues and Challenges of Aspect-Based Sentiment Analysis: A Comprehensive Survey. IEEE Trans. Affect. Comput. 2022, 13, 845–863. [Google Scholar] [CrossRef]
- Hutto, C.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. Proc. Int. AAAI Conf. Web Soc. Media 2014, 8, 216–225. [Google Scholar] [CrossRef]
- Mierswa, I.; Wurst, M.; Klinkenberg, R.; Scholz, M.; Euler, T. YALE: Rapid Prototyping for Complex Data Mining Tasks. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; ACM: New York, NY, USA, 2006. [Google Scholar]
- Fung, M. Twitter-Long COVID 2023. Available online: https://www.kaggle.com/datasets/matt0922/twitter-long-covid-2023 (accessed on 15 August 2023).
- Orellana-Rodriguez, C.; Keane, M.T. Attention to News and Its Dissemination on Twitter: A Survey. Comput. Sci. Rev. 2018, 29, 74–94. [Google Scholar] [CrossRef]
- Bruns, A.; Burgess, J. Researching News Discussion on Twitter: New Methodologies. J. Stud. 2012, 13, 801–814. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thakur, N. Investigating and Analyzing Self-Reporting of Long COVID on Twitter: Findings from Sentiment Analysis. Appl. Syst. Innov. 2023, 6, 92. https://doi.org/10.3390/asi6050092
Thakur N. Investigating and Analyzing Self-Reporting of Long COVID on Twitter: Findings from Sentiment Analysis. Applied System Innovation. 2023; 6(5):92. https://doi.org/10.3390/asi6050092
Chicago/Turabian StyleThakur, Nirmalya. 2023. "Investigating and Analyzing Self-Reporting of Long COVID on Twitter: Findings from Sentiment Analysis" Applied System Innovation 6, no. 5: 92. https://doi.org/10.3390/asi6050092
APA StyleThakur, N. (2023). Investigating and Analyzing Self-Reporting of Long COVID on Twitter: Findings from Sentiment Analysis. Applied System Innovation, 6(5), 92. https://doi.org/10.3390/asi6050092