Natural Virtual Reality User Interface to Define Assembly Sequences for Digital Human Models

Abstract
1. Introduction
1.1. Natural User Interfaces
- Naïve physics (NP) describes simple physical behavior like gravity, friction, speed, and adhesion, as well as scaling.
- Body awareness and skills (BAS) addresses the point that users have a body independent of the environment.
- Environment awareness and skills (EAS) describe the fact that humans have a physical presence in a 3D environment, which includes objects and landscapes. They increase the spacial orientation.
- Social awareness and skills (SAS) describes that humans are aware of the presence of other humans that can interact with other people socially. These interactions include verbal and non-verbal communication.
1.2. Problem Statement
2. Materials and Methods
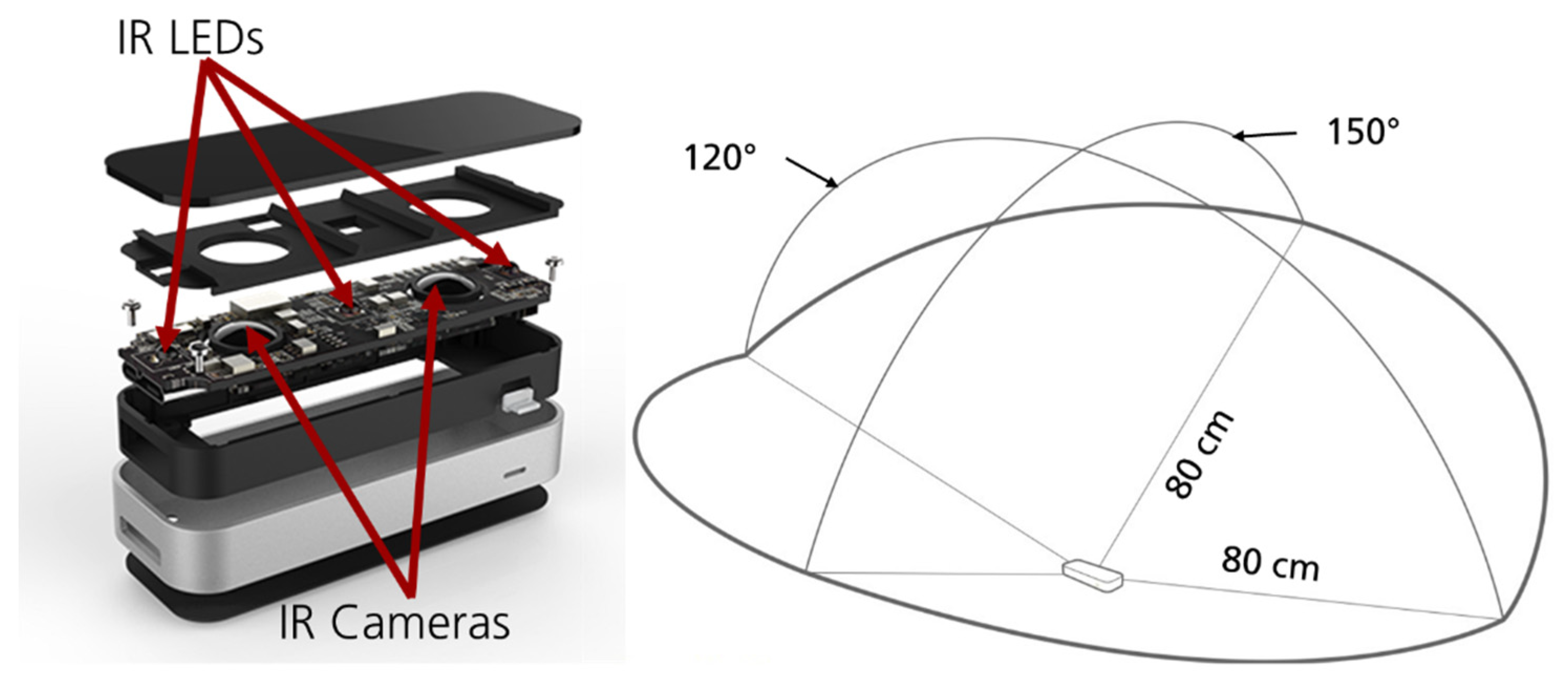
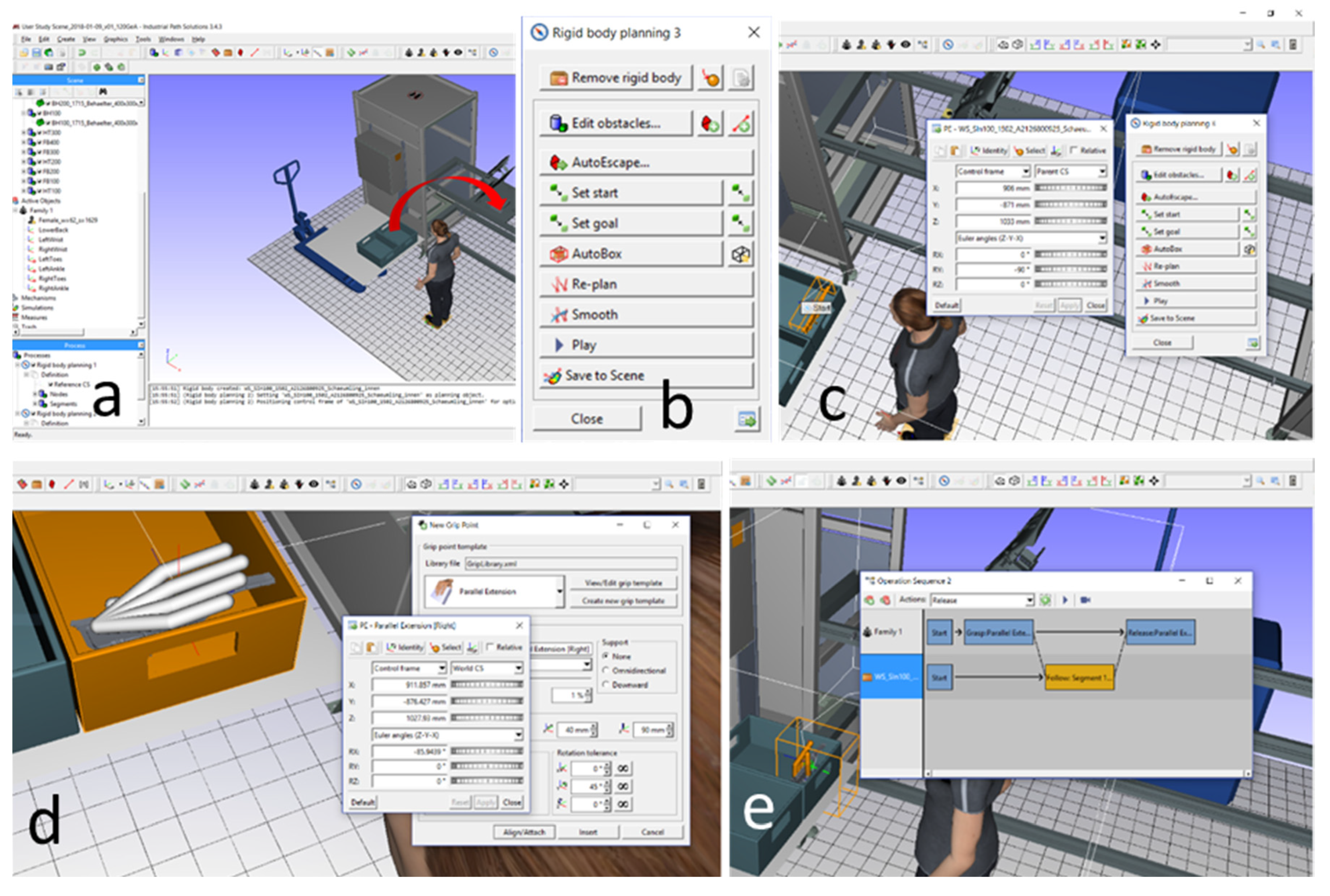
2.1. Virtual Action Tracking System (VATS)
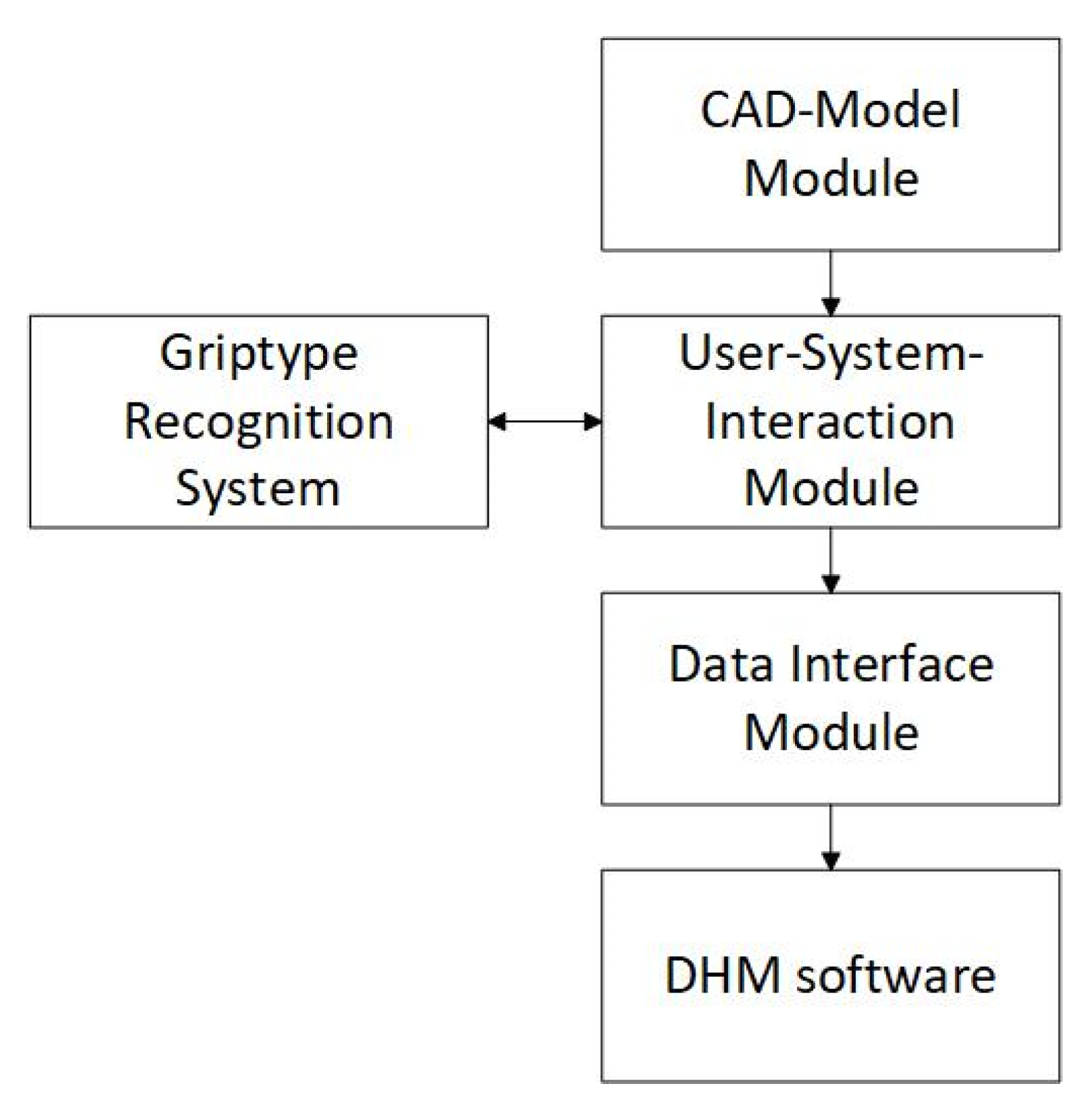
2.2. Technical System
2.2.1. CAD-Data Interface
2.2.2. User-System-Interaction Module
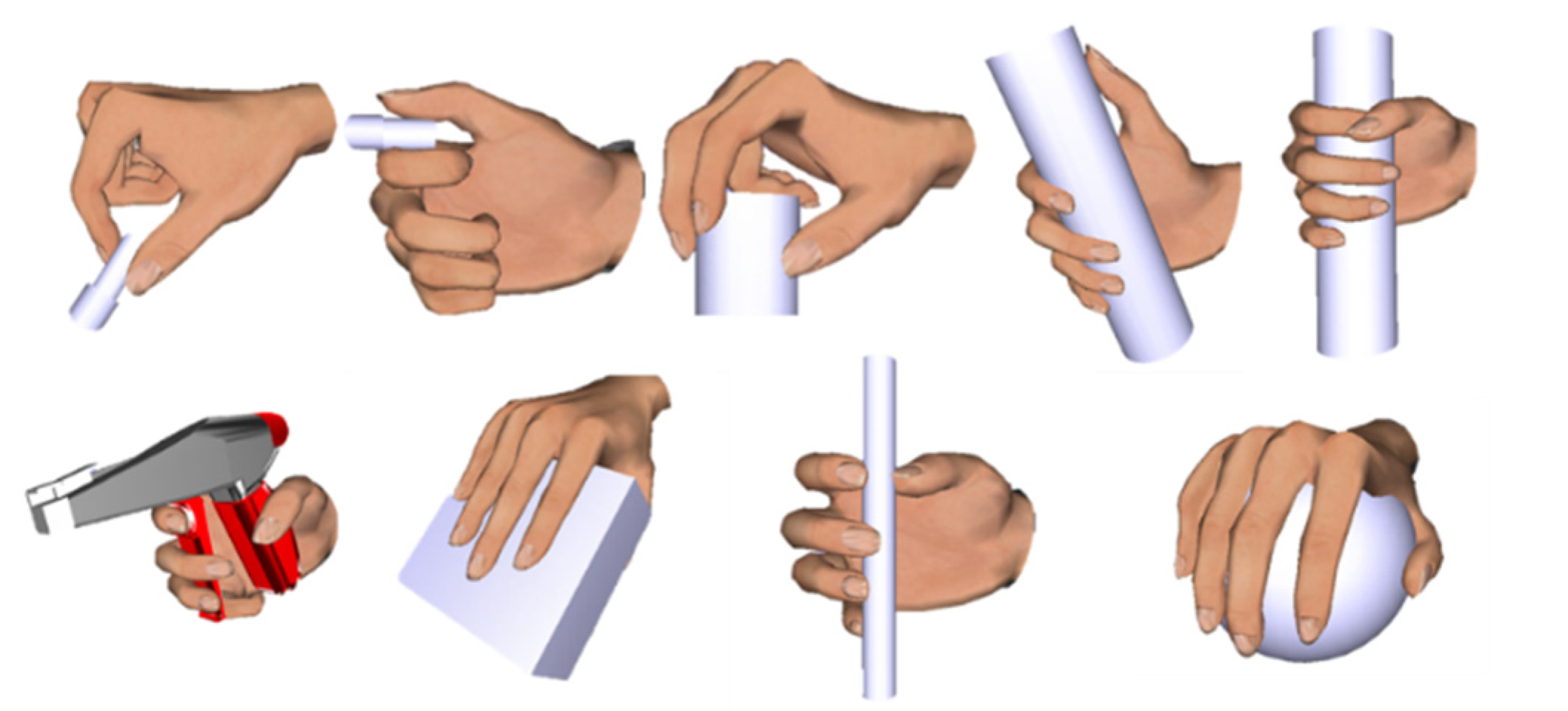
2.2.3. Grip Type Recognition System
- There were 14 joint angles: angles of one hand: two for the thumb, three for index, middle, ring, and pinky;
- Four finger distances: distances between thumb to index finger; index to the middle finger, middle finger to ring finger and ring finger to pinky finger;
- Four thumb distances between the thumb and the index, middle, ring and pinky finger;
- Two values for the orientation of the hand;
- Six binary values: information if a finger or the palm is in contact with the surface.
2.2.4. DHM Data Interface
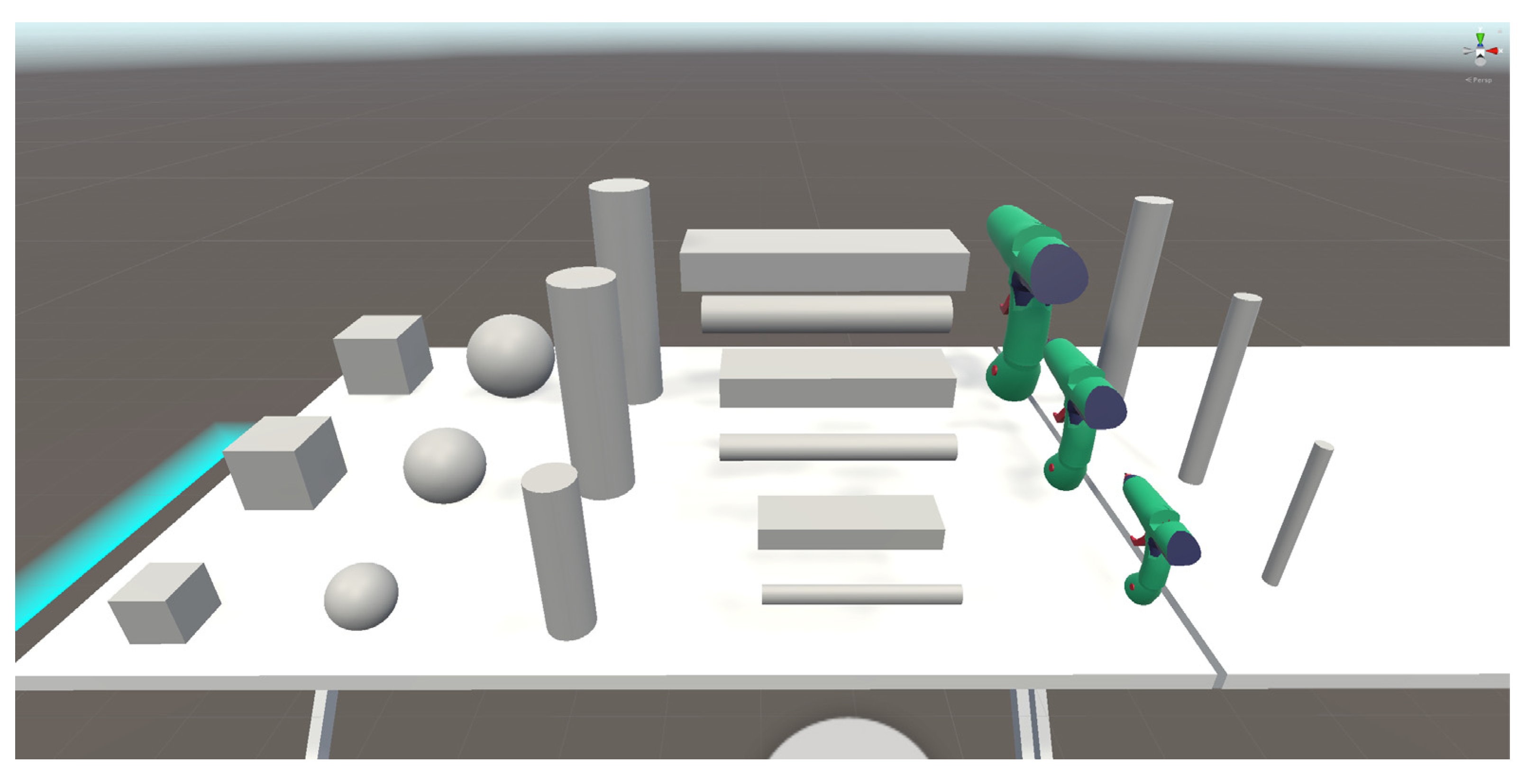
2.3. User Study
2.3.1. Participants
2.3.2. Measures
2.3.3. Study Environment
2.3.4. Procedure
3. Results
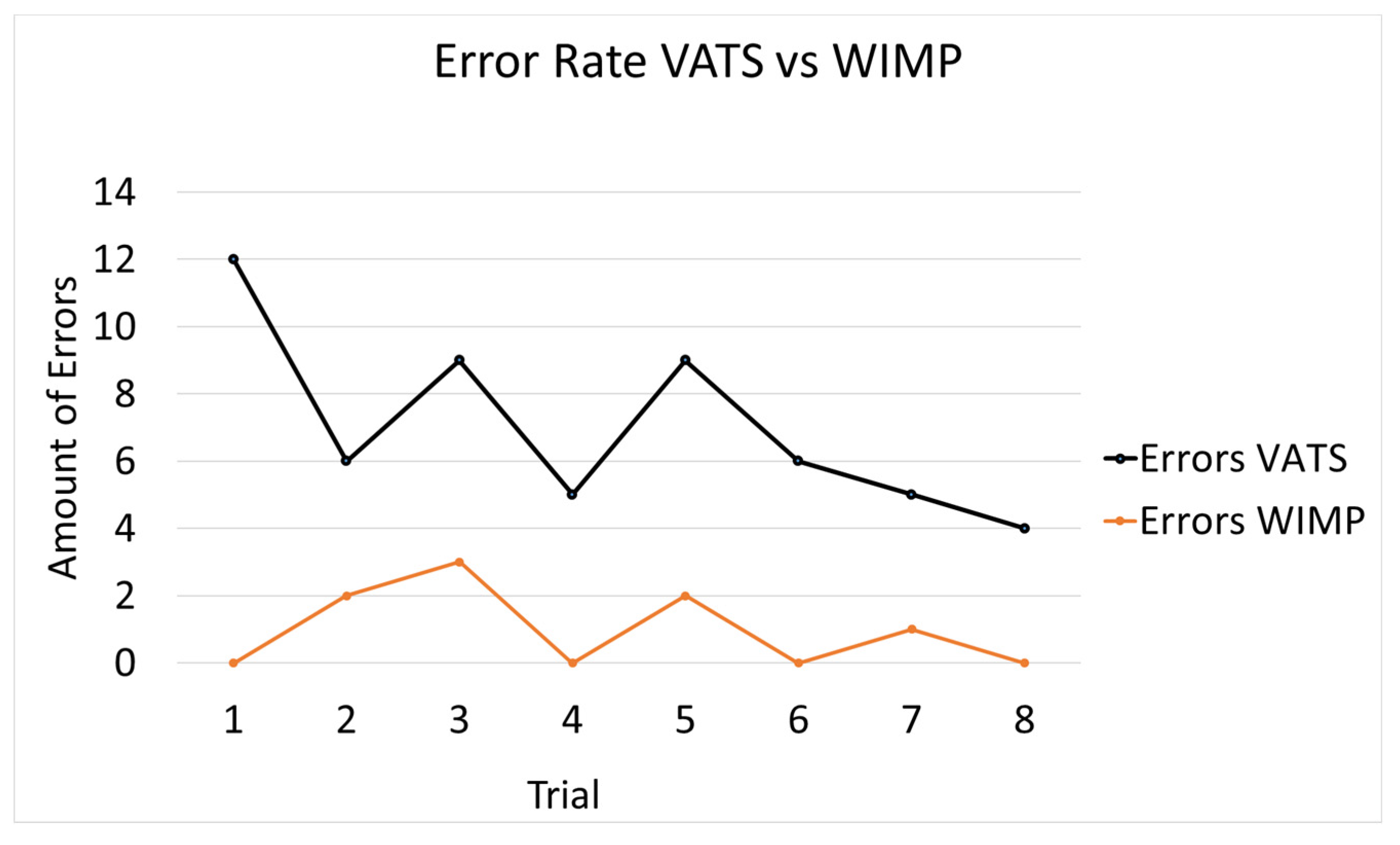
3.1. Objective Measures
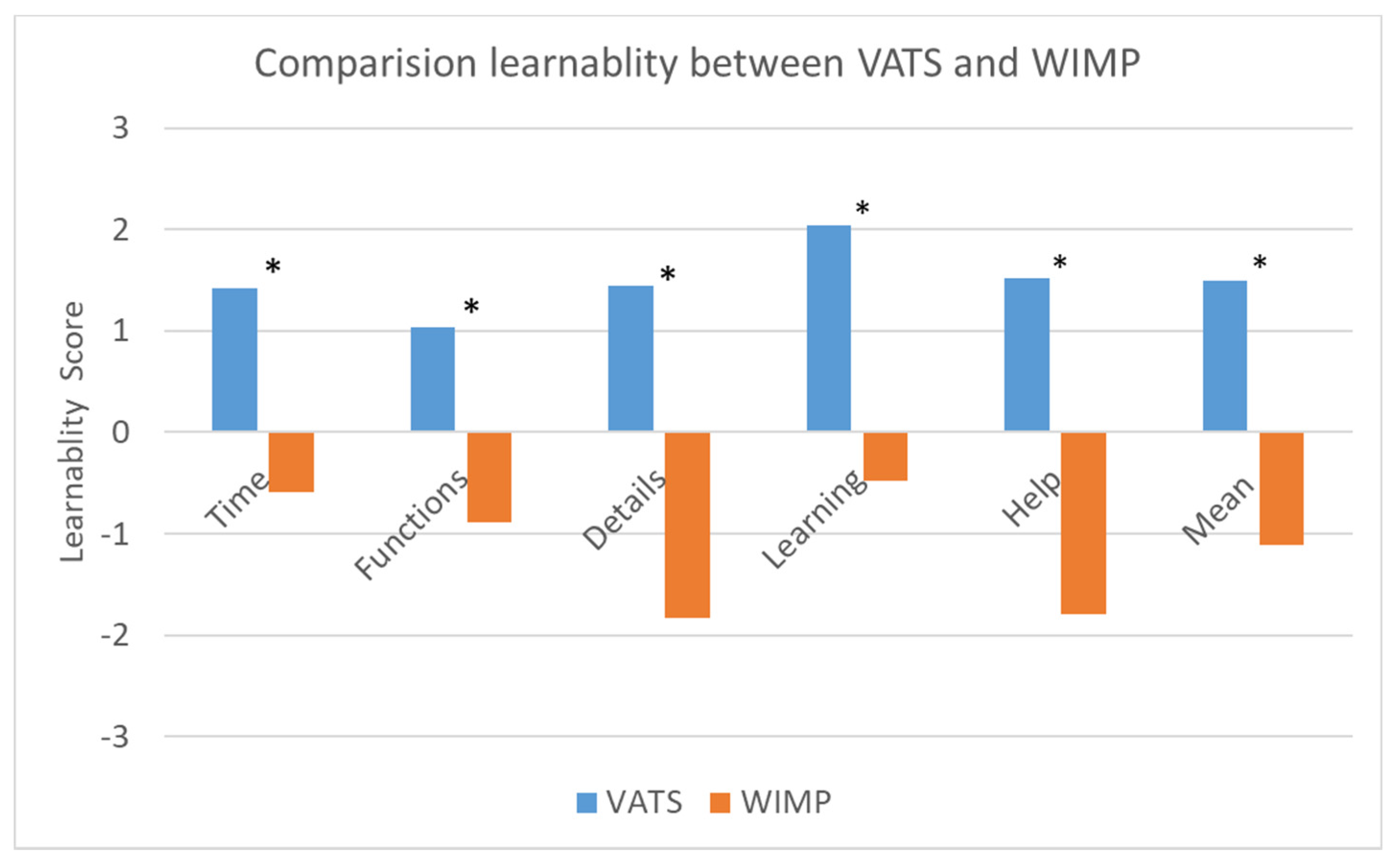
3.2. Subjective Measures
4. Discussion
- Creation and validation of training for assembly and MRO (maintenance, repair, and overhaul);
- Creation and validation of assembly and MRO assistance systems, e.g., Augmented Reality, digital worktables, adaptive instructions;
- Creation and validation of fitting and assembly processes itself, e.g., collision-free assembly planning.
Author Contributions
Funding
Ethics Statement
Conflicts of Interest
References
- Anderl, R.; Eigner, M.; Sendler, U.; Stark, R. Smart Engineering. Interdisziplinäre Produktentstehung; Springer: Berlin, Germany, 2012; ISBN 978-3-642-29371-9. [Google Scholar]
- Bubb, H.; Bengler, K.; Grünen, R.E.; Vollrath, M. Automobilergonomie; Springer Fachmedien: Wiesbaden, Germany, 2015; ISBN 9783834822970. [Google Scholar]
- Hs Group. RAMSIS Automotive—Effiziente Innenraumentwicklung—Ohne Nachbessern. Available online: https://www.human-solutions.com/mobility/front_content.php?idcat=252&lang=3 (accessed on 12 March 2020).
- Dassault Systèmes®. 3D Design & Engineering Software. Available online: https://www.3ds.com/ (accessed on 12 March 2020).
- Spanner-Ulmer, B.; Mühlstedt, J. Digitale Menschmodelle als Werkzeuge virtueller Ergonomie. Ind. Manag. 2010, 69–72. (In Deutsch) [Google Scholar]
- Wischniewski, S. Digitale Ergonomie 2025. Trends und Strategien zur Gestaltung Gebrauchstauglicher Produkte und Sicherer, Gesunder und Wettbewerbsfähiger Sozio-Technischer Arbeitssysteme Forschung Projekt F 2313; [Abschlussbericht]; Bundesanstalt für Arbeitsschutz und Arbeitsmedizin: Berlin, Germany, 2013; ISBN 3882610042. [Google Scholar]
- Hanson, L.; Högberg, L.; Bohlin, R.; Carlson, J.S. IMMA—Intelligently Moving Manikins—Project Status 2011. In Proceedings of the First International Symposium on Digital Human Modeling, Lyon, France, 14–16 June 2011; ISBN 2953951504. [Google Scholar]
- Bertilsson, E.; Hanson, L.; Högberg, D. Creation of the IMMA manikin with consideration of anthropometric diversity. In Proceedings of the 21st International Conference on Production Research, Stuttgart, Germany, 31 July–4 August 2011; pp. 416–420, ISBN 978-1-63439-826-8. [Google Scholar]
- Arnaldi, B.; Guitton, P.; Moreau, G. Virtual Reality and Augmented Reality: Myths and Realities; Wiley: Hoboken, NJ, USA, 2018; ISBN 9781119341048. [Google Scholar]
- Cruz-Neira, C.; Sandin, D.J.; DeFanti, T.A. Surround-screen projection-based virtual reality. In Proceedings of the 20th Annual Conference on Computer Graphics and Interactive Techniques, Anaheim, CA, USA, 2–6 August 1993; pp. 135–142. [Google Scholar]
- Brandenburg, E. VR-Twin: Monteurgerechte Anlagenumplanung. In FUTUR: Vision Innovation Realisierung: Vernetzung in der Produktion; Uhlmann, E., Ed.; Fraunhofer IPK: Berlin, Germany; p. 12.
- Dittrich, E.; Israel, J.H. Arrangement of Product Data in CAVE Systems. Available online: http://web.cse.ohio-state.edu/~raghu/teaching/CSE5544/Visweek2012/scivis/posters/ (accessed on 27 February 2020).
- middleVR. VR Teleconferencing Software For CAD Teams–Improov, Collaboration in VR. Available online: https://www.improovr.com/home-v2/ (accessed on 27 February 2020).
- ESI Group. IC.IDO|ESI Group. Available online: https://www.esi-group.com/de/software-loesungen/virtual-reality/icido (accessed on 27 February 2020).
- van Dam, A. Beyond WIMP. IEEE Comput. Grap. Appl. 2000, 20, 50–51. [Google Scholar] [CrossRef]
- Jacob, R.J.K.; Girouard, A.; Hirshfield, L.M.; Horn, M.S.; Shaer, O.; Solovey, E.T.; Zigelbaum, J. Reality-based interaction: A Framework for Post-WIMP Interfaces. Proceeding of the Twenty-Sixth Annual CHI Conference on Human Factors in Computing Systems—CHI ‘08, Florence, Italy, 5–10 April 2008; ISBN 9781605580111. [Google Scholar]
- Using Pinch Gloves for both Natural and Abstract Interaction Techniques in Virtual Environments. Available online: http://eprints.cs.vt.edu/archive/00000547/ (accessed on 12 March 2020).
- LaViola, J.J.; Kruijff, E.; McMahan, R.P.; Bowman, D.A.; Poupyrev, I. 3D User Interfaces. Theory and Practice; Addison-Wesley: London, UK, 2017; ISBN 9780134034324. [Google Scholar]
- Ergonomie der Mensch-System-Interaktion Teil 11: Anforderungen an die Gebrauchstauglichkeit—Leitsätze; Deutsches Institut für Normung e.V.: Berlin, Germany, 1999.
- DIN. Ergonomie der Mensch-System-Interaktion Teil 110: Grundsätze der Dialoggestaltung; DIN: Berlin, Germany, 2008. [Google Scholar]
- Bleser, G.; Damen, D.; Behera, A.; Hendeby, G.; Mura, K.; Miezal, M.; Gee, A.; Petersen, N.; Maçães, G.; Domingues, H.; et al. Cognitive Learning, Monitoring and Assistance of Industrial Workflows Using Egocentric Sensor Networks. PLoS ONE 2015, 10, e0127769. [Google Scholar] [CrossRef] [PubMed]
- Brandenburg, E.; Geiger, A.; Rothenburg, U.; Stark, R. Anforderungsanalyse einer Montagesimulationssoftware zwecks Aufwandsminimierung manueller Konfigurationsaufgaben. In Useware 2016: Mensch-Technik-Interaktion im Industrie 4.0 Zeitalter; VDI-Verlag: Düsseldorf, Germany, 2016; pp. 15–23. ISBN 978-3-18-092271-3. [Google Scholar]
- Leap Motion. Available online: https://www.leapmotion.com/ (accessed on 21 May 2018).
- Colgan, A. Leap Motion and HTC Vive FAQ: What You Need to Know. Available online: http://blog.leapmotion.com/leap-motion-htc-vive-faq/ (accessed on 27 February 2020).
- International Organization for Standardization. Industrial Automation Systems and Integration—JT File Format Specification for 3D Visualization, 2nd ed.; ISO: Geneva, Switzerland, 2017. [Google Scholar]
- Weichert, F.; Bachmann, D.; Rudak, B.; Fisseler, D. Analysis of the accuracy and robustness of the leap motion controller. Sensors 2013, 13, 6380–6393. [Google Scholar] [CrossRef] [PubMed]
- Colgan, A. How Does the Leap Motion Controller Work? Available online: http://blog.leapmotion.com/hardware-to-software-how-does-the-leap-motion-controller-work/ (accessed on 11 March 2020).
- Geiger, A.; Bewersdorf, I.; Brandenburg, E.; Stark, R. Visual feedback for grasping in virtual reality environments for an interface to instruct digital human models. In Proceedings of the AHFE 2017 International Conference on Usability and User Experience, Los Angeles, CA, USA, 17–21 July 2017; ISBN 9783319604916. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research; Elsevier: Amsterdam, The Netherlands, 1988; pp. 139–183. ISBN 9780444703880. [Google Scholar]
- Prümper, J.; Anft, M. Die Evaluation von Software auf Grundlage des Entwurfs zur internationalen Ergonomie-Norm ISO 9241 Teil 10 als Beitrag zur partizipativen Systemgestaltung—Ein Fallbeispiel. In Software-Ergonomie ’93; Rödiger, K.-H., Ed.; Vieweg + Teubner Verlag: Wiesbaden, Germany, 1993; pp. 145–156. ISBN 978-3-519-02680-8. [Google Scholar]
- Prümper, J. Test IT: ISONORM 9241/10. In Proceedings of the HCI International ‘99 (the 8th International Conference on Human-Computer Interaction), Munich, Germany, 22–26 August 1999; pp. 1028–1032, ISBN 0805833919. [Google Scholar]
- Wigdor, D.; Wixon, D. Brave NUI World: Designing Natural User Interfaces for Touch and Gesture; Morgan Kaufmann/Elsevier: Amsterdam, The Netherland, 2011; ISBN 978-0-12-382231-4. [Google Scholar]
- Geiger, A.; Brandenburg, E.; Stark, R. Virtual User Interaction to Instruct Digital Human Models for Effective Model Based Engineering—An Expert Review. In Virtual Reality and Augmented Reality; Barbic, J., D’Cruz, M., Latoschik, M.E., Slater, M., Bourdot, P., Eds.; Springer: Cham, Switzerland, 2017; pp. 13–14. ISBN 978-3-319-72322-8. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | |
|---|---|---|---|---|---|---|---|---|
| mean TCT VATS | 59 s | 35 s | 25 s | 27 s | 24 s | 25 s | 24 s | 23 s |
| p (t-test R/R + 1) VATS | 0.001 | 0.018 | 0.601 | 0.582 | 0.769 | 0.867 | 0.735 | 0.186 |
| mean TCT WIMP | 435 s | 281 s | 210 s | 179 s | 166 s | 142 s | 132 s | 128 s |
| p (t-test R/R + 1) WIMP | <0.01 | <0.01 | <0.01 | 0.193 | <0.01 | 0,02 | 0.314 |
| Mean Values | p (T-Test Mean Values/Mean of Questionnaire Scale) | |
|---|---|---|
| Improves Interface | 4.34 | <0.01 |
| Higher Efficiency | 4.69 | <0.01 |
| Less time consuming | 5.41 | <0.01 |
| Higher intuitiveness | 5.17 | <0.01 |
| Increases the use | 4.66 | <0.01 |
| Sequence definition is easier | 5.1 | <0.01 |
| System accuracy | 3.41 | 0.77 |
| System supports user | 5.17 | <0.01 |
| Tracking is precise enough | 3 | 0.06 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geiger, A.; Brandenburg, E.; Stark, R. Natural Virtual Reality User Interface to Define Assembly Sequences for Digital Human Models. Appl. Syst. Innov. 2020, 3, 15. https://doi.org/10.3390/asi3010015
Geiger A, Brandenburg E, Stark R. Natural Virtual Reality User Interface to Define Assembly Sequences for Digital Human Models. Applied System Innovation. 2020; 3(1):15. https://doi.org/10.3390/asi3010015
Chicago/Turabian StyleGeiger, Andreas, Elisabeth Brandenburg, and Rainer Stark. 2020. "Natural Virtual Reality User Interface to Define Assembly Sequences for Digital Human Models" Applied System Innovation 3, no. 1: 15. https://doi.org/10.3390/asi3010015
APA StyleGeiger, A., Brandenburg, E., & Stark, R. (2020). Natural Virtual Reality User Interface to Define Assembly Sequences for Digital Human Models. Applied System Innovation, 3(1), 15. https://doi.org/10.3390/asi3010015