
Assessing the Value of Transfer Learning Metrics for Radio Frequency Domain Adaptation



Abstract
1. Introduction
2. Background and Related Work
2.1. Radio Frequency Machine Learning (RFML)
2.2. Automatic Modulation Classification (AMC)
2.3. RF Domain Adaptation
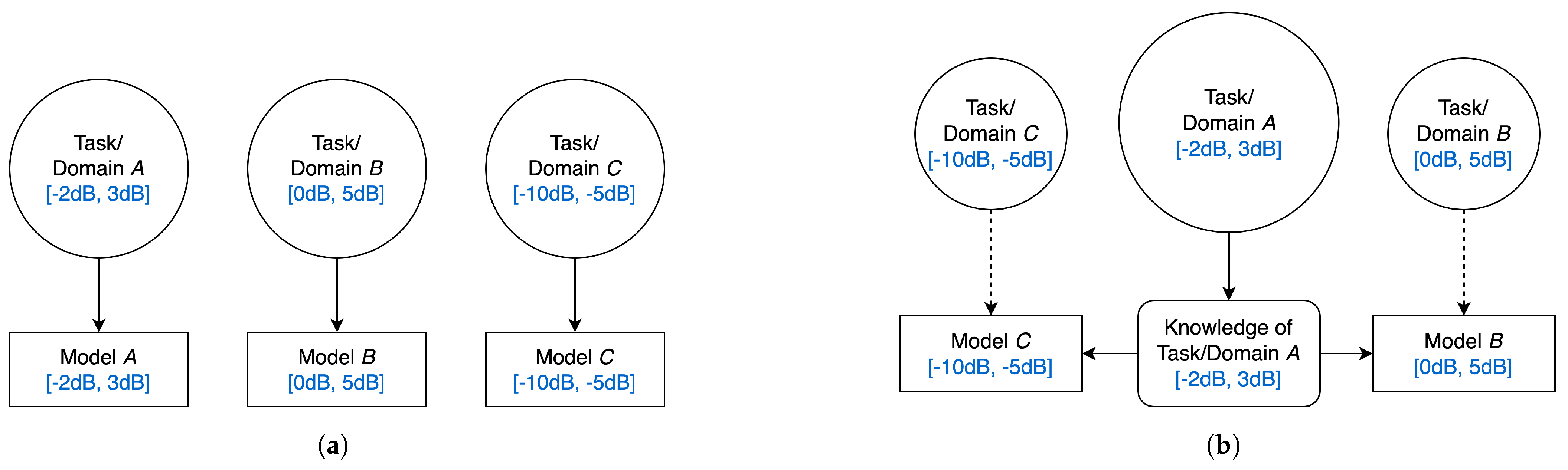
2.4. Transferability Metrics
2.5. Predicting Transfer Accuracy
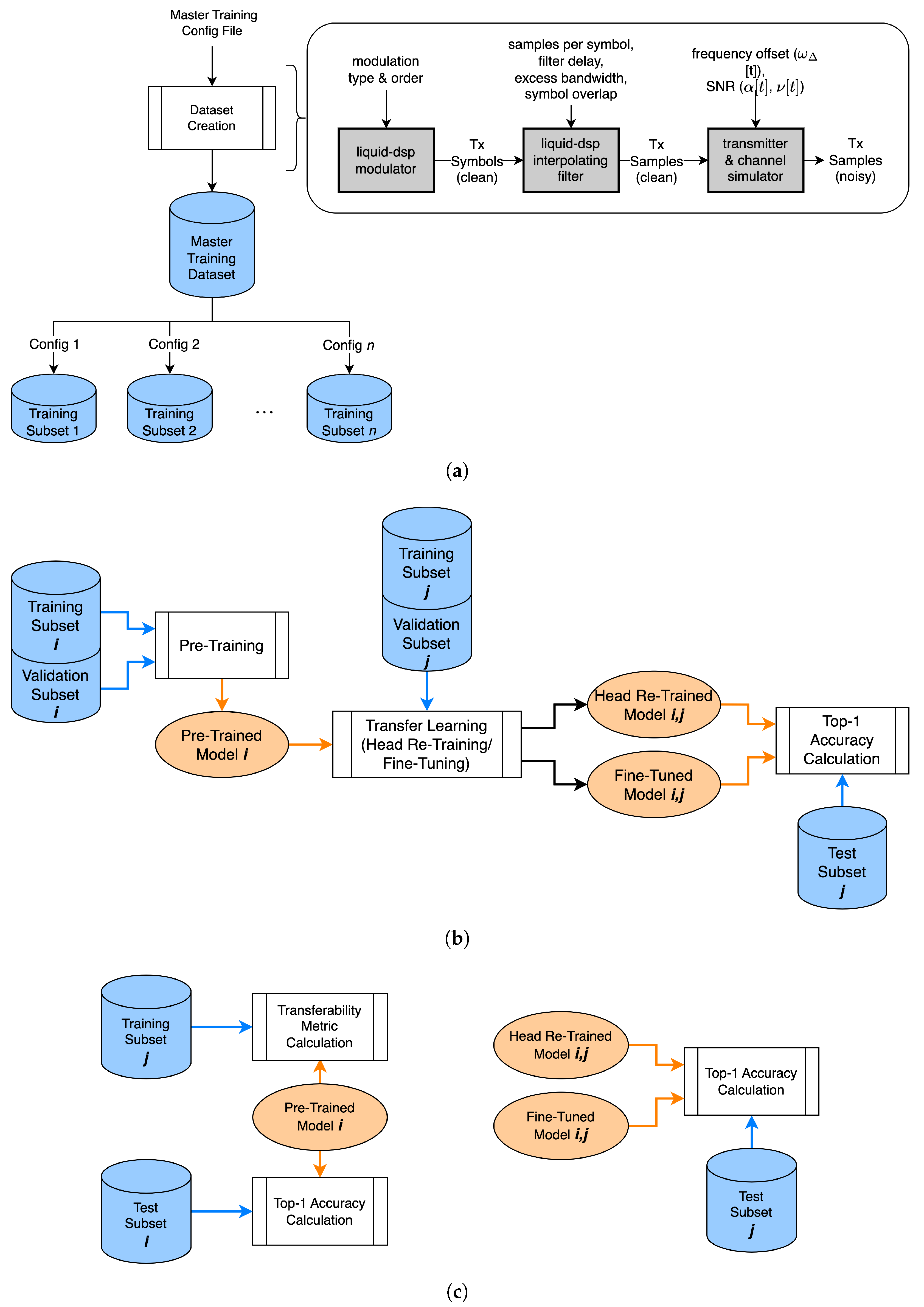
3. Methodology
3.1. Dataset Creation
- Only SNR—Varying only SNR represents an environment adaptation problem, characterized by a change in the RF channel environment (i.e., an increase/decrease in the additive interference, , of the channel). Twnety-six source data subsets were constructed from the larger master dataset, with SNRs selected uniformly at random from a 5 dB range sweeping from −10 dB to 20 dB in 1 dB steps (i.e., [−10 dB, −5 dB], [−9 dB, −4 dB], …, [15 dB, 20 dB]), and for each data subset in this SNR sweep, FO was selected uniformly at random within [−5%, 5%] of the sample rate.
- Only FO—Varying only FO represents a platform adaptation problem, characterized by a change in the transmitting and/or receiving devices (i.e., an increase/decrease in due to hardware imperfections or a lack of synchronization). Thirty-one source data subsets were constructed from the larger master dataset containing examples with FOs selected uniformly at random from a 5% range sweeping from −10% of sample rate to 10% of sample rate in 0.5% steps (i.e., [−10%, −5%], [−9.5%, −4.5%], …, [5%, 10%]). For each data subset in this FO sweep, SNR was selected uniformly at random within [0 dB, 20 dB].
- Both SNR and FO—Varying both SNR and FO, represents an environment platform co-adaptation problem, characterized by a change in both the RF channel environment and the transmitting/receiving devices. Twnty-five source data subsets were constructed from the larger master dataset containing examples with SNRs selected uniformly at random from a 10 dB range sweeping from −10 dB to 20 dB in 5 dB steps (i.e., [−10 dB, 0 dB], [−5 dB, 5 dB], …, [10 dB, 20 dB]) and with FOs selected uniformly at random from a 10% range sweeping from −10% of sample rate to 10% of sample rate in 2.5% steps (i.e., [−10%, 0%], [−7.5%, 2.5%], …, [0%, 10%]).
3.2. Simulation Environment
3.3. Model Architecture and Training
3.4. Transferability Metrics
4. Experimental Results and Analysis
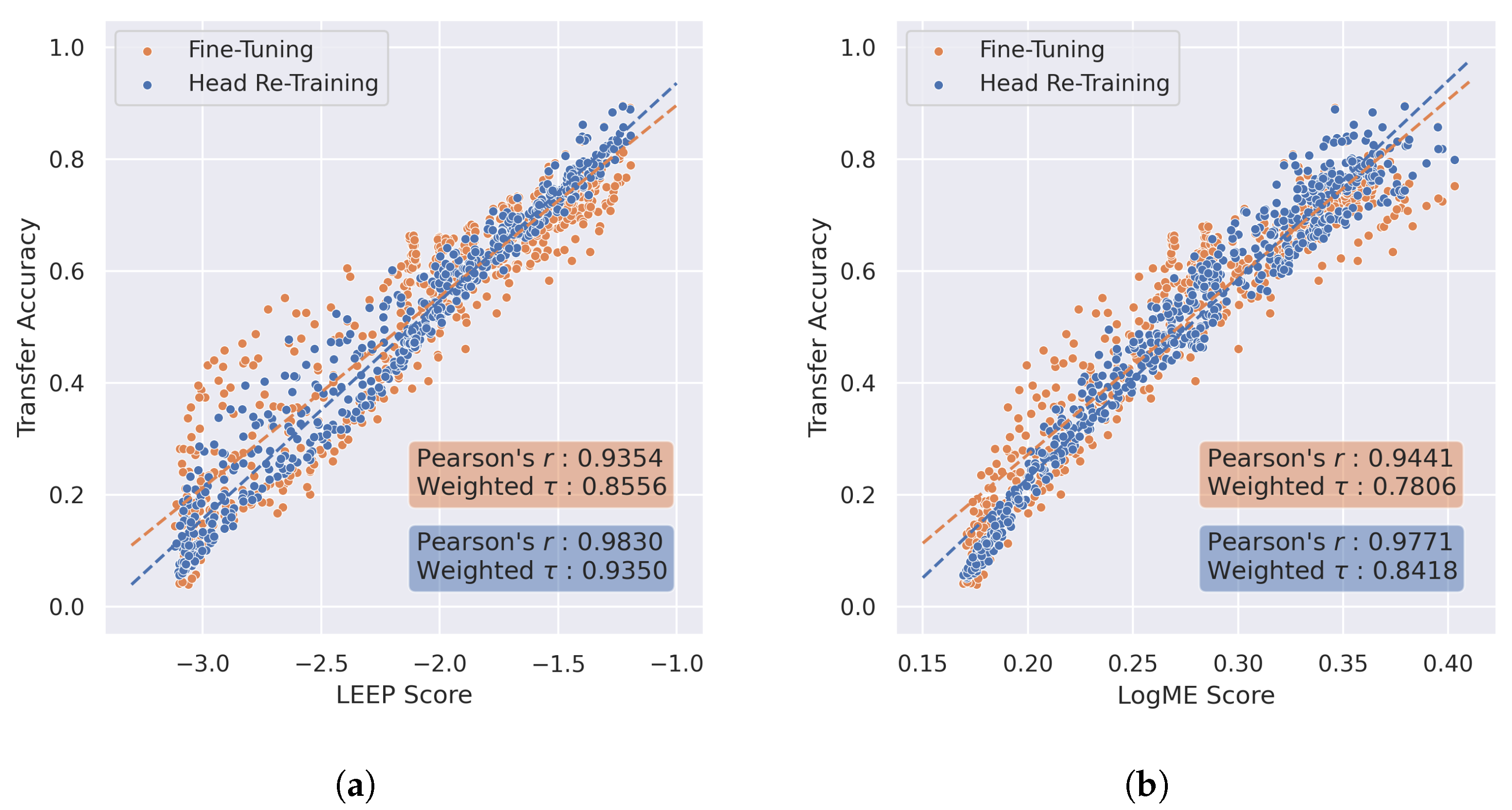
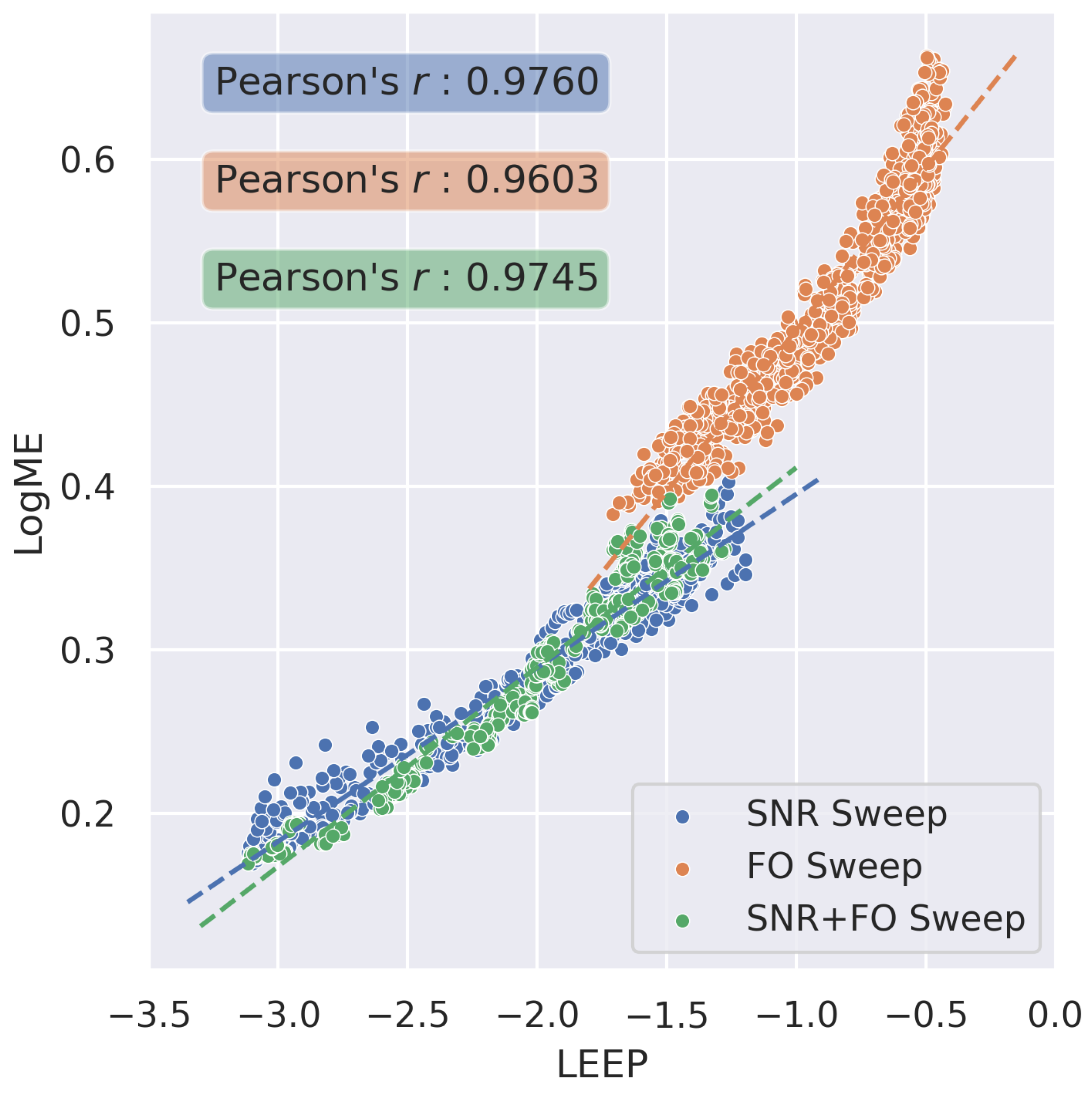
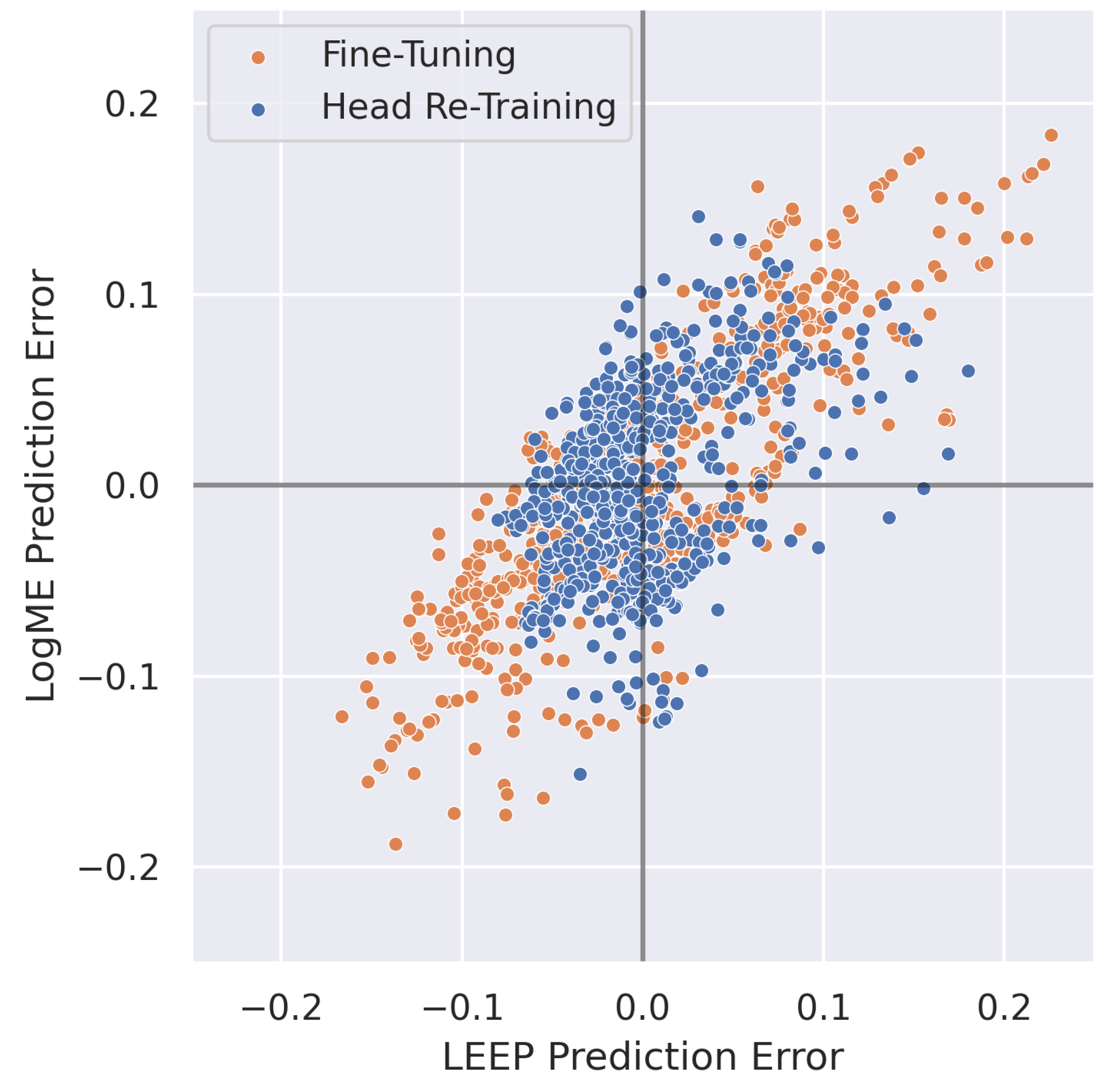
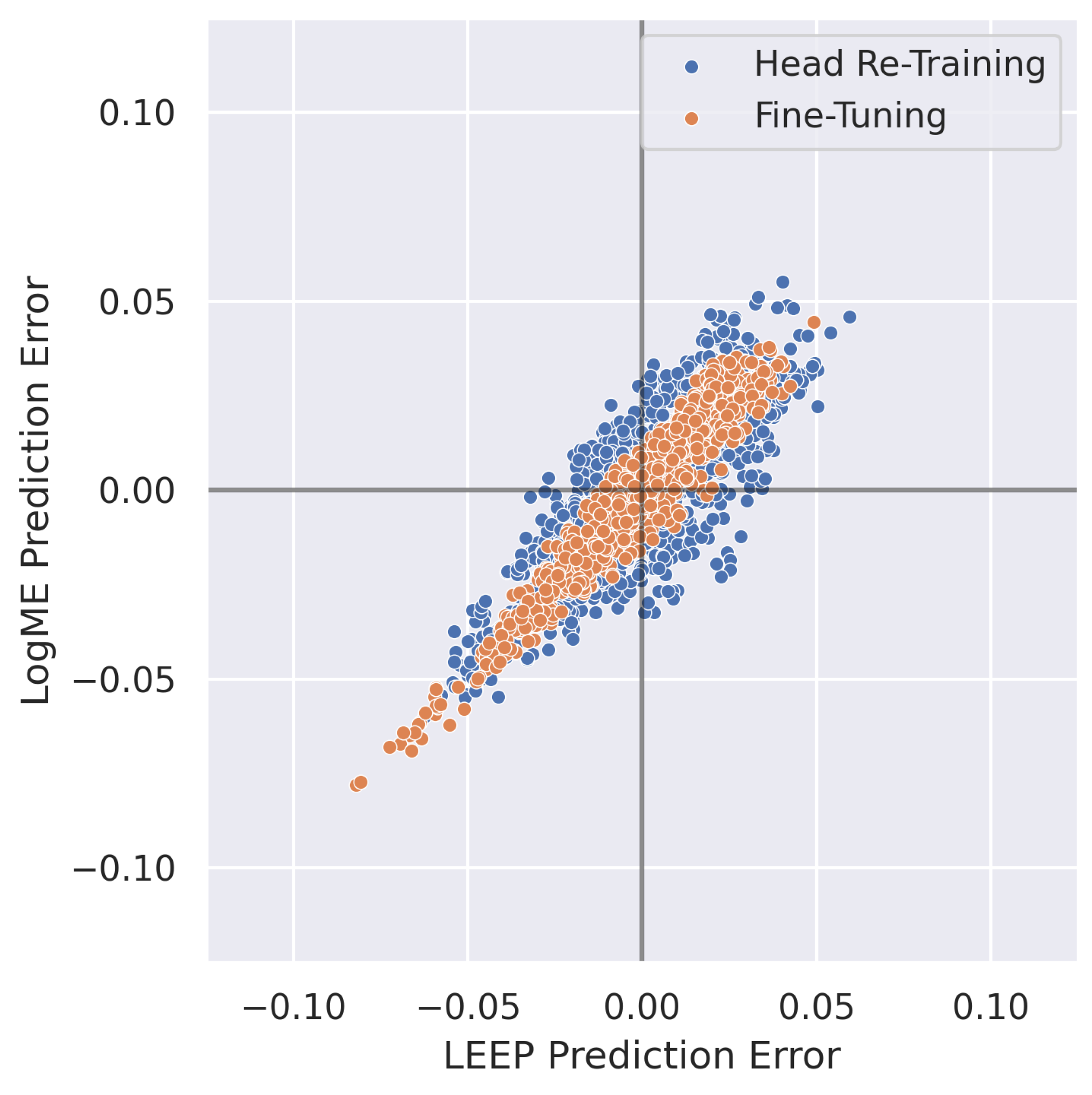
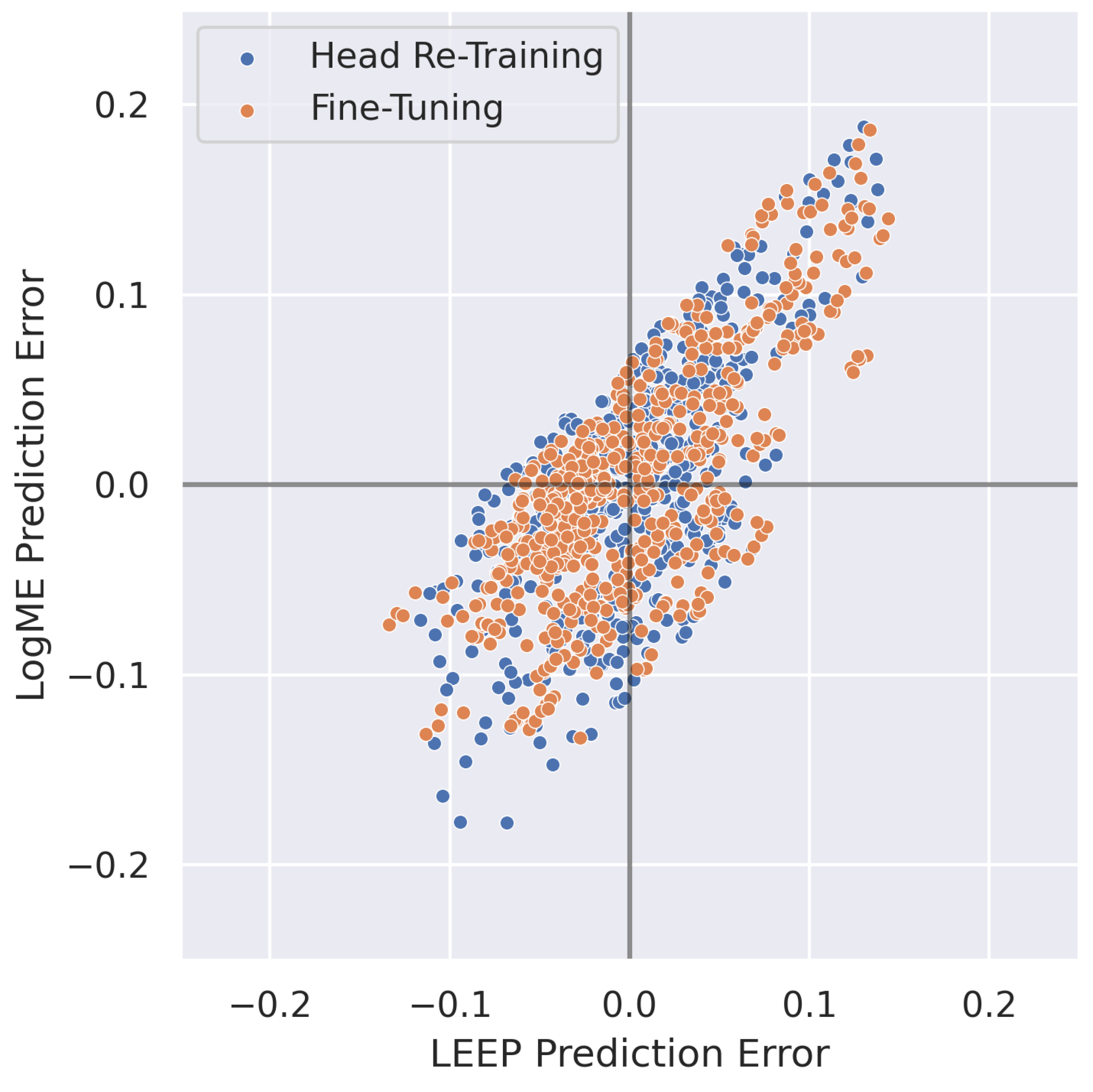
4.1. Transferability Metrics for Model Selection in RF Domain Adaptation
4.2. When and How RF Domain Adaptation Is Most Successful
4.2.1. Environment Adaptation vs. Platform Adaptation
4.2.2. Head Re-Training vs. Fine-Tuning
4.3. Transferability Metrics for Predicting Post-Transfer Accuracy
- Run baseline simulations for all n known domains, including pre-training source models on all domains, and use head re-training and/or fine-tuning to transfer each source model to the remaining known domains
- Compute LEEP/LogME scores using all n pre-trained source models and the remaining known domains.
- Compute the margin of error by first calculating the mean difference between the true post-transfer top-1 accuracy and the predicted post-transfer top-1 accuracy (using the linear fit), and then multiply this mean by the appropriate z-score(s) for the desired confidence interval(s) [49].
- Compute LEEP/LogME scores for all pre-trained source models and the new target dataset.
- Select the pre-trained source model yielding the highest LEEP/LogME score for TL.
- Use the fitted linear function to estimate post-transfer accuracy, given the highest LEEP/LogME score, and add/subtract the margin of error to construct the confidence interval.
5. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AM-DSB | amplitude modulation, double-sideband |
| AM-DSBSC | amplitude modulation, double-sideband suppressed-carrier |
| AM-LSB | amplitude modulation, lower-sideband |
| AM-USB | amplitude modulation, upper-sideband |
| AMC | automatic modulation classification |
| APSK16 | amplitude and phase-shift keying, order 16 |
| APSK32 | amplitude and phase-shift keying, order 32 |
| AWGN | additive white Gaussian noise |
| BPSK | binary phase-shift keying |
| CNN | convolutional neural network |
| CR | cognitive radio |
| CV | computer vision |
| DL | deep learning |
| FM-NB | narrow band frequency modulation |
| FM-WB | wide band frequency modulation |
| FO | frequency offset |
| FSK5k | frequency-shift keying, 5 kHz carrier spacing |
| FSK75k | frequency-shift keying, 75 kHz carrier spacing |
| GFSK5k | Gaussian frequency-shift keying, 5 kHz carrier spacing |
| GFSK75k | Gaussian frequency-shift keying, 75 kHz carrier spacing |
| GMSK | Gaussian minimum-shift keying |
| IQ | in-phase/quadrature |
| LEEP | Log Expected Empirical Prediction |
| LogME | Logarithm of Maximum Evidence |
| ML | machine learning |
| MSK | minimum-shift keying |
| NLP | natural language processing |
| NN | neural network |
| OQPSK | offset quadrature phase-shift keying |
| PSK16 | phase-shift keying, order 16 |
| PSK8 | phase-shift keying, order 8 |
| QAM16 | quadrature amplitude modulation, order 16 |
| QAM32 | quadrature amplitude modulation, order 32 |
| QAM64 | quadrature amplitude modulation, order 64 |
| QPSK | quadrature phase-shift keying |
| RF | radio frequency |
| RRC | root-raised cosine |
| SNR | signal-to-noise ratio |
| TL | transfer learning |
References
- Mitola, J. Cognitive Radio: An Integrated Agent Architecture for Software Defined Radio. Ph.D. Dissertation, Royal Institute of Technology, Stockholm, Sweden, 2000. [Google Scholar]
- Rondeau, T. Radio Frequency Machine Learning Systems (RFMLS). 2017. Available online: https://www.darpa.mil/program/radio-frequency-machine-learning-systems (accessed on 24 March 2022).
- Kolb, P. Securing Compartmented Information with Smart Radio Systems (SCISRS). 2021. Available online: https://www.iarpa.gov/index.php/research-programs/scisrs (accessed on 24 March 2022).
- Conference, IEEE Communications Society. In Proceedings of the DySPAN 2021: 2020 IEEE International Symposium on Dynamic Spectrum Access Networks, Los Angeles, CA, USA, 13–15 December 2021. Available online: https://dyspan2021.ieee-dyspan.org/index.html (accessed on 24 March 2024).
- Morocho-Cayamcela, M.E.; Lee, H.; Lim, W. Machine Learning for 5G/B5G Mobile and Wireless Communications: Potential, Limitations, and Future Directions. IEEE Access 2019, 7, 137184–137206. [Google Scholar] [CrossRef]
- Wong, L.J.; Michaels, A.J. Transfer Learning for Radio Frequency Machine Learning: A Taxonomy and Survey. Sensors 2022, 22, 1416. [Google Scholar] [CrossRef]
- Hauser, S.C. Real-World Considerations for Deep Learning in Spectrum Sensing. Master’s Thesis, Virginia Tech, Blacksburg, VA, USA, 2018. [Google Scholar]
- Sankhe, K.; Belgiovine, M.; Zhou, F.; Riyaz, S.; Ioannidis, S.; Chowdhury, K. ORACLE: Optimized Radio Classification through Convolutional Neural Networks. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April 2019–2 May 2019; IEEE: Piscataway Township, NJ, USA, 2019; pp. 370–378. [Google Scholar]
- Wong, L.J.; Clark, W.H.; Flowers, B.; Buehrer, R.M.; Headley, W.C.; Michaels, A.J. An RFML Ecosystem: Considerations for the Application of Deep Learning to Spectrum Situational Awareness. IEEE Open J. Commun. Soc. 2021, 2, 2243–2264. [Google Scholar] [CrossRef]
- Wong, L.J.; Muller, B.P.; McPherson, S.; Michaels, A.J. An Analysis of Radio Frequency Transfer Learning Behavior. Mach. Learn. Knowl. Extr. 2024, 6, 57. [Google Scholar] [CrossRef]
- Nguyen, C.; Hassner, T.; Seeger, M.; Archambeau, C. LEEP: A new measure to evaluate transferability of learned representations. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; pp. 7294–7305. [Google Scholar]
- You, K.; Liu, Y.; Long, M.; Wang, J. LogME: Practical Assessment of Pre-trained Models for Transfer Learning. arXiv 2021, arXiv:2102.11005. [Google Scholar]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef]
- West, N.E.; O’Shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; pp. 1–6. [Google Scholar]
- Chen, S.; Zheng, S.; Yang, L.; Yang, X. Deep Learning for Large-Scale Real-World ACARS and ADS-B Radio Signal Classification. IEEE Access 2019, 7, 89256–89264. [Google Scholar] [CrossRef]
- Pati, B.M.; Kaneko, M.; Taparugssanagorn, A. A Deep Convolutional Neural Network Based Transfer Learning Method for Non-Cooperative Spectrum Sensing. IEEE Access 2020, 8, 164529–164545. [Google Scholar] [CrossRef]
- Kuzdeba, S.; Robinson, J.; Carmack, J. Transfer Learning with Radio Frequency Signals. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Robinson, J.; Kuzdeba, S. RiftNet: Radio Frequency Classification for Large Populations. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–6. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-Air Deep Learning Based Radio Signal Classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef]
- Dörner, S.; Cammerer, S.; Hoydis, J.; Brink, S.t. Deep Learning Based Communication Over the Air. IEEE J. Sel. Top. Signal Process. 2018, 12, 132–143. [Google Scholar] [CrossRef]
- Zheng, S.; Chen, S.; Qi, P.; Zhou, H.; Yang, X. Spectrum sensing based on deep learning classification for cognitive radios. China Comm. 2020, 17, 138–148. [Google Scholar] [CrossRef]
- Clark, B.; Leffke, Z.; Headley, C.; Michaels, A. Cyborg Phase II Final Report; Technical report; Ted and Karyn Hume Center for National Security and Technology: Blacksburg, VA, USA, 2019. [Google Scholar]
- Clark IV, W.H.; Hauser, S.; Headley, W.C.; Michaels, A.J. Training data augmentation for deep learning radio frequency systems. J. Def. Model. Simul. 2020, 18, 154851292199124. [Google Scholar] [CrossRef]
- Merchant, K. Deep Neural Networks for Radio Frequency Fingerprinting. PhD Thesis, University of Maryland, College Park, MD, USA, 2019. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zamir, A.R.; Sax, A.; Shen, W.; Guibas, L.J.; Malik, J.; Savarese, S. Taskonomy: Disentangling task transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3712–3722. [Google Scholar]
- Achille, A.; Lam, M.; Tewari, R.; Ravichandran, A.; Maji, S.; Fowlkes, C.C.; Soatto, S.; Perona, P. Task2Vec: Task embedding for meta-learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 6430–6439. [Google Scholar]
- Huang, L.K.; Wei, Y.; Rong, Y.; Yang, Q.; Huang, J. Frustratingly Easy Transferability Estimation. arXiv 2021, arXiv:2106.09362. [Google Scholar]
- Tan, Y.; Li, Y.; Huang, S.L. OTCE: A Transferability Metric for Cross-Domain Cross-Task Representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15779–15788. [Google Scholar]
- Tan, Y.; Li, Y.; Huang, S.L. Practical Transferability Estimation for Image Classification Tasks. arXiv 2021, arXiv:2106.10479. [Google Scholar]
- Pándy, M.; Agostinelli, A.; Uijlings, J.; Ferrari, V.; Mensink, T. Transferability Estimation using Bhattacharyya Class Separability. arXiv 2021, arXiv:2111.12780. [Google Scholar]
- Tran, A.T.; Nguyen, C.V.; Hassner, T. Transferability and hardness of supervised classification tasks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 1395–1405. [Google Scholar]
- Bao, Y.; Li, Y.; Huang, S.L.; Zhang, L.; Zheng, L.; Zamir, A.; Guibas, L. An Information-Theoretic Approach to Transferability in Task Transfer Learning. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2309–2313. [Google Scholar] [CrossRef]
- Renggli, C.; Pinto, A.S.; Rimanic, L.; Puigcerver, J.; Riquelme, C.; Zhang, C.; Lucic, M. Which model to transfer? Finding the needle in the growing haystack. arXiv 2020, arXiv:2010.06402. [Google Scholar]
- Li, Y.; Jia, X.; Sang, R.; Zhu, Y.; Green, B.; Wang, L.; Gong, B. Ranking neural checkpoints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2663–2673. [Google Scholar]
- Bhattacharjee, B.; Kender, J.R.; Hill, M.; Dube, P.; Huo, S.; Glass, M.R.; Belgodere, B.; Pankanti, S.; Codella, N.; Watson, P. P2L: Predicting transfer learning for images and semantic relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 760–761. [Google Scholar]
- Ruder, S.; Plank, B. Learning to select data for transfer learning with bayesian optimization. arXiv 2017, arXiv:1707.05246. [Google Scholar]
- Kashyap, A.R.; Hazarika, D.; Kan, M.Y.; Zimmermann, R. Domain divergences: A survey and empirical analysis. arXiv 2020, arXiv:2010.12198. [Google Scholar]
- Van Asch, V.; Daelemans, W. Using domain similarity for performance estimation. In Proceedings of the 2010 Workshop on Domain Adaptation for Natural Language Processing, Uppsala, Sweden, 15 July 2010; pp. 31–36. [Google Scholar]
- Elsahar, H.; Gallé, M. To annotate or not? Predicting performance drop under domain shift. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2163–2173. [Google Scholar]
- Pogrebnyakov, N.; Shaghaghian, S. Predicting the Success of Domain Adaptation in Text Similarity. arXiv 2021, arXiv:2106.04641. [Google Scholar]
- Wong, L.; McPherson, S.; Michaels, A. Transfer Learning for RF Domain Adaptation-Synthetic Dataset. 2022. Available online: https://ieee-dataport.org/open-access/transfer-learning-rf-domain-adaptation-%E2%80%93-synthetic-dataset (accessed on 24 March 2022).
- Clark IV, W.H.; Michaels, A.J. Quantifying and extrapolating data needs in radio frequency machine learning. arXiv 2022, arXiv:2205.03703. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cross Entropy Loss, PyTorch 1.10.1 Documentation. 2021. Available online: https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html (accessed on 24 March 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation coefficients: Appropriate use and interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Kendall, M.G. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Hazra, A. Using the confidence interval confidently. J. Thorac. Dis. 2017, 9, 4125. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modulation Name | Parameter Space |
|---|---|
| BPSK | Symbol Order {2} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| QPSK | Symbol Order {4} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| PSK8 | Symbol Order {8} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| PSK16 | Symbol Order {16} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| OQPSK | Symbol Order {4} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| QAM16 | Symbol Order {16} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| QAM32 | Symbol Order {32} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| QAM64 | Symbol Order {64} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| APSK16 | Symbol Order {16} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| APSK32 | Symbol Order {32} RRC Pulse Shape Excess Bandwidth {0.35, 0.5} Symbol Overlap ∈ [3, 5] |
| FSK5k | Carrier Spacing {5 kHz} Rect Phase Shape Symbol Overlap {1} |
| FSK75k | Carrier Spacing {75 kHz} Rect Phase Shape Symbol Overlap {1} |
| GFSK5k | Carrier Spacing {5 kHz} Gaussian Phase Shape Symbol Overlap {2, 3, 4} Beta ∈ [0.3, 0.5] |
| GFSK75k | Carrier Spacing {75 kHz} Gaussian Phase Shape Symbol Overlap {2, 3, 4} Beta ∈ [0.3, 0.5] |
| MSK | Carrier Spacing {2.5 kHz} Rect Phase Shape Symbol Overlap {1} |
| GMSK | Carrier Spacing {2.5 kHz} Gaussian Phase Shape Symbol Overlap {2, 3, 4} Beta ∈ [0.3, 0.5] |
| FM-NB | Modulation Index ∈ [0.05, 0.4] |
| FM-WB | Modulation Index ∈ [0.825, 1.88] |
| AM-DSB | Modulation Index ∈ [0.5, 0.9] |
| AM-DSBSC | Modulation Index ∈ [0.5, 0.9] |
| AM-LSB | Modulation Index ∈ [0.5, 0.9] |
| AM-USB | Modulation Index ∈ [0.5, 0.9] |
| AWGN |
| Layer Type | Num Kernels/Nodes | Kernel Size |
|---|---|---|
| Input | size = (2, 128) | |
| Conv2d | 1500 | (1, 7) |
| ReLU | ||
| Conv2d | 96 | (2, 7) |
| ReLU | ||
| Dropout | rate = 0.5 | |
| Flatten | ||
| Linear | 65 | |
| Linear | 23 | |
| Trainable Parameters: 7,434,243 | ||
| SNR Sweep | FO Sweep | SNR + FO Sweep | |
|---|---|---|---|
| Head Re-Training | 0.6175 | 0.7856 | 0.7258 |
| Fine-Tuning | 0.7496 | 0.8803 | 0.7468 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wong, L.J.; Muller, B.P.; McPherson, S.; Michaels, A.J. Assessing the Value of Transfer Learning Metrics for Radio Frequency Domain Adaptation. Mach. Learn. Knowl. Extr. 2024, 6, 1699-1719. https://doi.org/10.3390/make6030084
Wong LJ, Muller BP, McPherson S, Michaels AJ. Assessing the Value of Transfer Learning Metrics for Radio Frequency Domain Adaptation. Machine Learning and Knowledge Extraction. 2024; 6(3):1699-1719. https://doi.org/10.3390/make6030084
Chicago/Turabian StyleWong, Lauren J., Braeden P. Muller, Sean McPherson, and Alan J. Michaels. 2024. "Assessing the Value of Transfer Learning Metrics for Radio Frequency Domain Adaptation" Machine Learning and Knowledge Extraction 6, no. 3: 1699-1719. https://doi.org/10.3390/make6030084
APA StyleWong, L. J., Muller, B. P., McPherson, S., & Michaels, A. J. (2024). Assessing the Value of Transfer Learning Metrics for Radio Frequency Domain Adaptation. Machine Learning and Knowledge Extraction, 6(3), 1699-1719. https://doi.org/10.3390/make6030084