1. Introduction
Software vulnerability refers to weaknesses within an information system, its internal controls, its system security procedures, or its implementation that could be exploited by a threat source [
1]. These vulnerabilities often arise from design errors, poor coding practices, or inadequate security testing. In large-scale software systems, detecting vulnerabilities presents challenges in terms of the accuracy and transparency of both research [
2,
3,
4,
5] and industrial [
6,
7] practices. Applying vulnerability analyses and detection at the early stage of the software process, prior to deployment, is a proactive attack mitigation solution [
8]. The analysis involves learning existing patterns of vulnerability types and analyzing the underlying factors in the code structure that may contribute to the weakness [
9]. Vulnerability detection is the process that identifies, classifies, remediates, and mitigates code vulnerabilities.
Research in software vulnerability detection has progressed from static code analysis techniques to machine learning approaches. Static code analysis tools, such as security scanners, employ pattern matching [
10,
11] based on well-defined rules to identify bugs or flaws in the software [
12,
13,
14]. However, these tools suffer from high false-positive rates [
15].
Machine-learning-based approaches utilize source code, software complexity metrics, and version control system data to predict vulnerabilities [
5,
16,
17]. These approaches enable automatic feature extraction and the learning of complex patterns, reducing the need for expert-driven feature engineering [
3,
18,
19,
20]. Data-driven software vulnerability detection has been reported to improve the detection accuracy in practice [
21,
22].
A comprehensive study [
23] has identified the common limitations of six deep learning models in producing realistic code vulnerability detection. The main limitation is inadequate models that reduce their learning performance when transferred to real-world settings. Further reasons include the learning of irrelevant features, data duplication, and data imbalances. All these aspects impose limitations on model-specific approaches’ ability to provide transferable patterns beyond the training datasets. Questions remain regarding the scope of interpretability and explainability of AI, what kind of features these models are learning, and whether they can be effectively and reliably transferred to other datasets [
23].
One limitation is that practitioners cannot understand the features learned by a deep learning model without mapping the semantic meanings of vulnerable artifacts [
8]. The opacity leads to questions, such as the following: (1) How transferable are the signatures of vulnerable artifacts learned from one set of software projects to others [
24]? (2) What factors are mostly involved in the representation learning? (3) What variance is caused by factors from (2) in the classification results among different learning methods [
25]? A key to bridging the gap between the learned feature representations and human-understandable vulnerability semantics is to assess the importance of code features to the semantics of the vulnerability classification. Such an assessment necessitates that the techniques are model-agnostic, emphasizing only the code features as inputs and the resulting vulnerability classification as outputs.
EXplainable Artificial Intelligence (XAI) is an emerging research field that aims to enhance AI models as trustworthy and transparent [
26]. XAI encompasses diverse techniques, methods, and models to explain how the learning models reach their predictions. For instance, model-agnostic attribute-based XAI methods focus on identifying attributes that contribute the most to the model’s prediction. A manifesto of XAI was thoroughly defined based on a set of XAI survey papers and shared visions by scholars [
27]. Applications of XAI covered in the XAI manifesto [
27] include healthcare, medicine, bio-informatics, finance, environmental science, agriculture, and education. Additionally, the software development and software system domains have a large amount of code, documentation and diverse scenarios that require AI learning and explanation. In the context of code vulnerability learning, SHapley Additive exPlanations (SHAP) [
28], LIME [
29], Lemna [
30] and Mean-Centroid PredDiff [
31] have been applied to measure the feature contribution values of program code feature representation.
The current application of XAI techniques in software vulnerability analysis faces the issue that the covered attributes cannot be extrapolated beyond the domain of the input data. Thus the explanation is (1) limited to a few attributes and (2) disconnected from the semantically defined relations among CWE types. Such a semantic relation is embedded in the definition of CWE types accumulated over years of practice in the community. We consider explanations with a link to CWE semantics as human-understandable explanations. This type of research challenge has been identified and defined as one of the nine aspects of the XAI manifesto [
27].
Several studies have attempted to explain the importance of Abstract Syntax Tree (AST) path content [
32,
33] or individual code tokens [
34] using XAI methods such as SHAP [
28]. However, only limited syntactic constructs such as
name, parameters, statements are investigated, rather than the whole set of syntactic constructs. Moreover, there is a lack of studies that relate learned features’ representation to the semantic similarity collectively described by security experts for a variety of types of software vulnerabilities [
33]. In summary, a systematic method to correlate these meta syntactic constructs with common characteristics across multiple vulnerability types is the purpose of this study.
The work from CSAIL MIT [
35] has demonstrated, with a novel experiment design, that program synthesis trained as program corpus in textual input–output is well-suited for characterizing the meaning in language models. We are informed by the evidence in [
23] of the limitations of the token sequences at the program level to reveal the semantic meanings of feature contributions. We further consider the code tokens at the syntactic construct level to assess the feature contributions to vulnerability classification through XAI probing techniques.
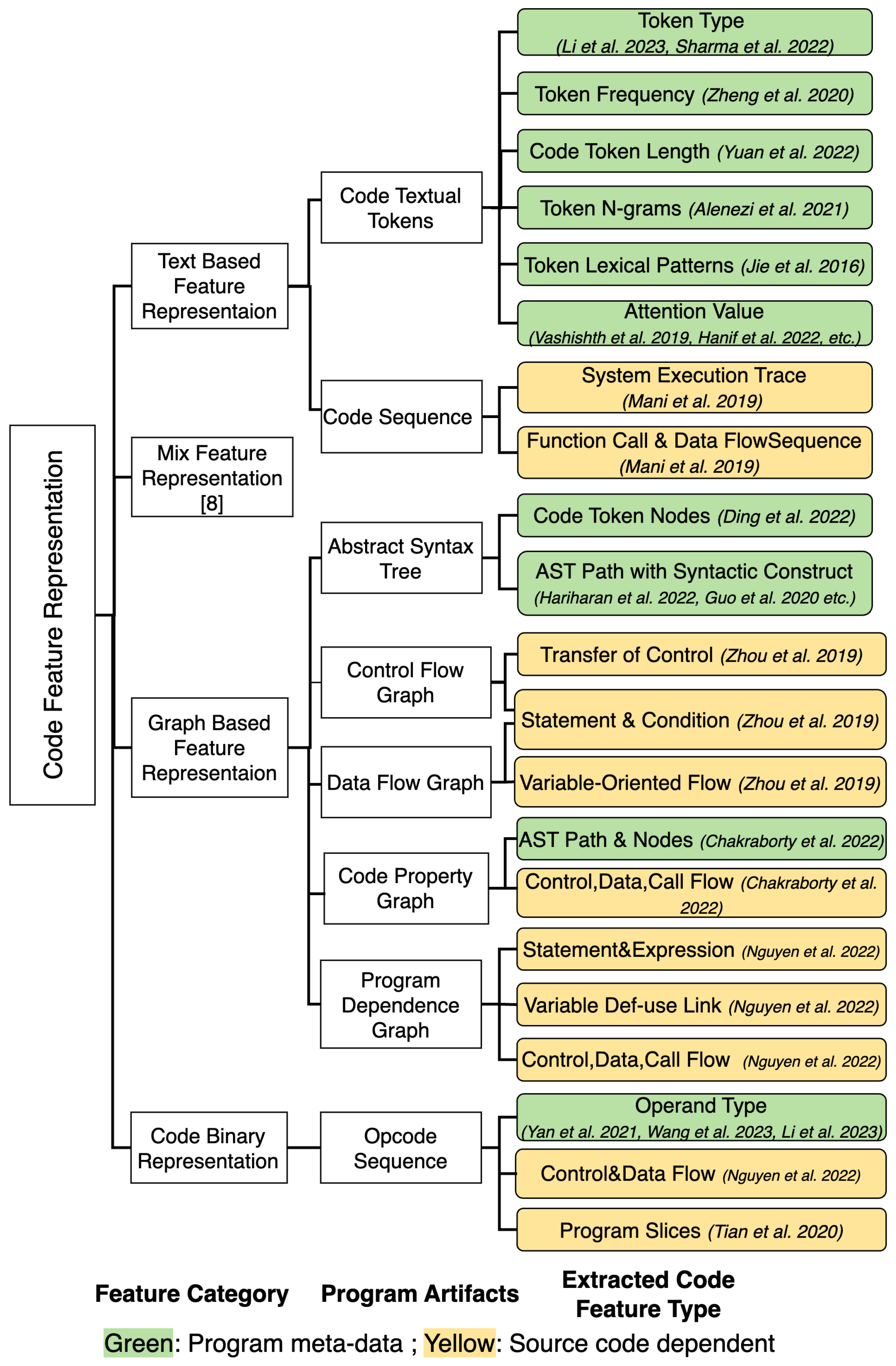
In this paper, our method first studies the inputs as code features by defining the taxonomy of the state-of-the-art works into four types, namely, text-based, graph-based, code binary, and mixed representation [
25], as discussed in
Section 3. For each type of code feature representation, we further categorize works into eight groups of program artifacts and twenty-one extracted code feature types. We mainly select
Abstract Syntax Tree out of the twenty-one extracted code feature types using the taxonomy shown in
Figure 1. The abstract syntax tree contains structured meta-data of a programming language and applies this to all the programming codes of the same language. Then, graph learning models can be used to encode and decode the hierarchical structure of the abstract syntax tree.
We attempt to derive model-agnostic explanations for multi-classification in contrast to binary classification in [
23]. We focus on the graph context of code tokens as features that embed code token connections through traversing the abstract syntax tree. Code property graphs such as the control flow graph, data flow graph, and program dependency graph are analyzed at the program level, which faces the challenges of maintaining balanced data samples for every vulnerability type. The sufficient and balanced samples of feature types are suitable for XAI methods such as feature masking.
Our method then assesses the output of vulnerability classification based on the Common Weakness Enumeration (CWE) [
36]. CWE is a community-developed list of software and hardware security weaknesses that are commonly used as labels for supervised learning in vulnerability detection. The study [
37] has identified that various vulnerability types exhibit semantic similarities. Similarly, the vulnerability similarities are represented by organizing the CWE’s hierarchical structures [
36] or CWE clusters [
38].
We define and apply information retrieval metrics to measure the similarity between classified CWEs. Through XAI methods and techniques, we further assess the variance in CWE classification similarity under input feature changes. Thus, the machine-learned feature representations are quantitatively measured for their contributions to classifying community-defined and human-understandable code vulnerability types. Our contribution is three-fold:
We define the taxonomy of code representation into eight types of high-level categories, and a further twenty-one fine-grained code representations. This taxonomy distinguishes the fine-grained code representation set at the program source code level and the program meta-data level. This taxonomy clearly positions our XAI-based approach in the map of related works.
We design a model agnostic XAI framework that derives rankings of the feature contribution levels of a list of forty syntactic constructs in Abstract Syntax Trees (AST) across twenty CWE types for both Java and C++ datasets. This framework is applicable to different choices of classifiers and XAI methods.
We develop a novel feature masking technique for the graph context that varies the neighbourhood of code tokens and syntactic constructs. We define and apply information retrieval techniques to convert the change in the code token neighbourhood into the CWE type similarity.
Overall, we demonstrate that the similarity between CWE types derived from XAI explanations links subtle semantics that are understood by security experts to the learned code feature representations. Through experiments, we compare XAI-derived CWE similarities and sibling CWE types defined by security experts. Thus, our approach is able to retrospectly identify the misclassification of similar CWE types due to the variance in feature contributions. We open-sourced our code and made our dataset available on GitHub (
https://github.com/DataCentricClassificationofSmartCity/XAI-based-Software-Vulnerbility-Dection, accessed on 1 May 2024).
Figure 1.
The taxonomy of factors under code feature representation techniques [
21,
23,
31,
32,
33,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59].
Figure 1.
The taxonomy of factors under code feature representation techniques [
21,
23,
31,
32,
33,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59].
This paper is organized starting with an overview of model-agnostic XAI methods and the motivation for adopting XAI in
Section 2.
Section 3 reviews the existing literature on the code feature representation and vulnerability detection domain using XAI applications. We present our main research methodology and XAI-based framework in
Section 4. Then, we propose the research questions, conduct the experiments, and demonstrate our results in
Section 5. We present a retrospective of the motivation case in
Section 5.4. Finally, we discuss the potential threats to the validity in
Section 6 and draw conclusions in
Section 7.
3. Taxonomy of Related Work
The primary aim of this study is to fill the gap between practitioners’ understanding of vulnerability semantics and the code features learned by deep learning models. To achieve this, we summarized a taxonomy of code features based on four code representation techniques, which will be discussed in detail in this section along with relevant works. Different categories of code representation techniques were developed to transform the source code into a format that can be processed by machine learning models [
47,
68,
69]. These include text-based, graph-based, and mixed-feature representations, as well as code binary representations [
25] in
Figure 1.
Text-based Code Representation. Text-based code representation approaches the treat source code similarly to natural languages, embedding code tokens as the word token embedding [
70,
71,
72]. The code content is considered as plain text, disregarding structural information such as data flow and function call flow. With advancements in the natural language processing domain, representation techniques have evolved from static embeddings such as word2vec [
73] and fastText [
70] to self-attention transfer-learning-based models with large corpus embeddings, such as codeBERT [
74], XLNet [
75], Longformer [
76], BigBird [
77], and GPT [
78]. These models use pre-trained contextualized embeddings, which are more expressive than static embeddings. CodeBERT [
74] embeddings leverage a dual-transformer architecture, combining the strengths of masked language modelling and code summarization while facing the challenges of dealing with long code sequences. XLNet embeddings [
75] utilize a permutation-based approach, capturing the dependencies between tokens and allowing for bidirectional context and comprehensive token representations. BigBird [
77] and Longformer [
76] embeddings are specific for long token sequences, allowing for a longer input token length. Longformer uses a sliding window-based local attention mechanism for nearby tokens and a global attention mechanism for distant tokens, while BigBird combines dense and sparse attention patterns, efficiently handling long text sequences while preserving the ability to model long-range dependencies.
Feature Types Under Text-based Code Representation. In the context of text-based code representation, several feature types have been identified that can influence the model’s behavior when processing source code, including token type [
31,
48], token length [
50], token frequency [
49], token n-grams [
51], token lexical patterns [
52], and token attention values [
53]. Token types could be categorized as comments and code. Our previous work [
31] found that comment tokens provided by programmers can improve the understanding of code semantics and structure for learning models. Another work [
48] reveals that separator symbols also play an important role when the model makes a prediction by assessing the attention-based model. Hence, the token types are also categorized into textual tokens and symbol tokens. Limiting the code token length can result in information loss and negatively impact the model’s performance, as Yuan et al. [
50] show. However, their examination considered a maximum sequence length of 512 tokens. Serving as a key feature type for static text-based representation techniques, token frequency has been found to affect model performance. Zeng et al. [
49] concluded that a better model performance is achieved when preserving code frequency information. Token n-grams are fixed-size contiguous sequences of tokens that capture local context within a fixed window [
51], but their effectiveness may be limited for longer code sequences and transformer models. By representing recurring structures in the code [
52] token lexical patterns can help understand the code’s basic logic and structure. However, their effectiveness may be limited in capturing higher-level semantic and complex information and dependencies across distant tokens. Token attention values serve as a feature type in the transformer-based model, and are helpful in identifying key tokens or contents contributing to natural language processing tasks [
79]. The attention mechanism can adaptively learn the importance of even distant parts of the input code sequence for a better understating of the code’s contextual information and effectively fulfil software vulnerability detection tasks [
54,
55,
56,
57,
58]. Some researchers found that the attention values can serve as a proxy for the importance of tokens [
53]. Still, it is worth noting that this interpretation should be made with caution, as high attention values may not always correspond to high token importance [
80].
Graph-based Code Representation. A considerable number of studies applied deep learning models to learn code structures from graph-based representations, including Abstract Syntax Tree (AST), Program Dependence Graph (PDG), Control Flow Graph (CFG), Data Flow Graph (DFG), and mixed-method approaches combining these graphs [
23]. The study [
25] summarizes that, among these graph-based approaches, the AST-based method is used in the majority of existing studies. The syntax nodes in an abstract syntax tree represent the syntactic constructs of the code, such as expressions, declarations, and loops, which are intuitive to practitioners [
81]. AST-based methods: Code2Vec [
32] presents a graph-based, continuously distributed vector learning approach, quantifying the importance of AST path context for code semantic properties’ prediction tasks. Hariharan M. et al. [
33] introduce a Multiple Instance Learning (MIL) technique that differentiates each AST path as an instance for supervised learning. GraphCodeBERT [
40] is a hybrid approach combining the graph structure information from AST and the transformer-based techniques to represent the code structure. GraphCodeVec [
39] learns more generalizable code embeddings from code tokens and AST structure and achieves state-of-the-art results in six downstream code tasks, including vulnerability detection. Other graph-based methods: VulDeeLocator [
82] leverages PDG and combines the AST information to learn discriminative vulnerable features. Devign [
21] constructs a hybrid graph representation that combines AST, CFG, and the data dependence graph to enhance the ability to capture complex structural code information, but it may be computationally expensive. REVEAL [
23] extract the syntax and semantics features in the Code Property Graph (CPG) that consist of the elements from the data-flow, control-flow, AST nodes, and program dependency.
Feature Types under Graph-based Code Representation. The feature type behind graph-based code representation depends on each specific graph structure, node, and edge, and their definitions. For feature types within the AST, leaf nodes represent code tokens belonging to particular syntactic constructs [
81]. Thus, code token nodes serve as one feature type. Additionally, path-based representations with inflection nodes as syntax can effectively capture a code’s contextual semantics and are widely used in state-of-the-art approaches [
32,
33,
39]. CFG- and DFG-based factors [
21,
41,
42], on the other hand, primarily focus on the flows in a program, such as control flow, the data flow through variables, and the statements and conditions. Lastly, PDG-based factors encompass both the control and data flow dependencies within a program, capturing statements, expressions, variable def-use links, and function call flow [
42,
43]. These factors are more representative of an individual program rather than the whole software project.
Other Code Representation and Feature Types. Several studies have focused on the use of code binary representation for vulnerability detection. BVDetector [
47] uses program slices and a BGRU network for fine-grained vulnerability detection. HAN-BSVD [
44] employs a hierarchical attention network for context preservation and highlighting crucial regions, while BinVulDet [
45] leverages decompiled pseudo-code and BiLSTM-attention for robust vulnerability pattern extraction. Finally, VulANalyzeR [
46] introduces an explainable approach with multi-task learning and attentional graph convolution. We summarized the feature types under binary features into operand types, control flows, and program slicing. Additionally, various aspects of code sequence representation in text-based systems have been explored, such as system execution traces, function call sequences, and data flow sequences. Approaches like DeepTriage [
59] analyze system execution traces for software defect prediction.
4. An XAI-Based Framework for Feature Contribution and Vulnerability Assessment
We propose a framework that retrieves the feature contribution values utilizing XAI techniques and analyzes the XAI explanation summaries. We quantitatively assess the feature contributions to the multi-classification of the code vulnerability of CWE types to identify the factors. As discussed in
Section 2, CWE types are defined and categorized by experts from many real-world samples. The similarities of CWE types have subtle effects on the learning tasks of vulnerability classification. Hence, our workflow utilizes XAI methods to probe into the high-dimension code features and relate feature variations to the classification results.
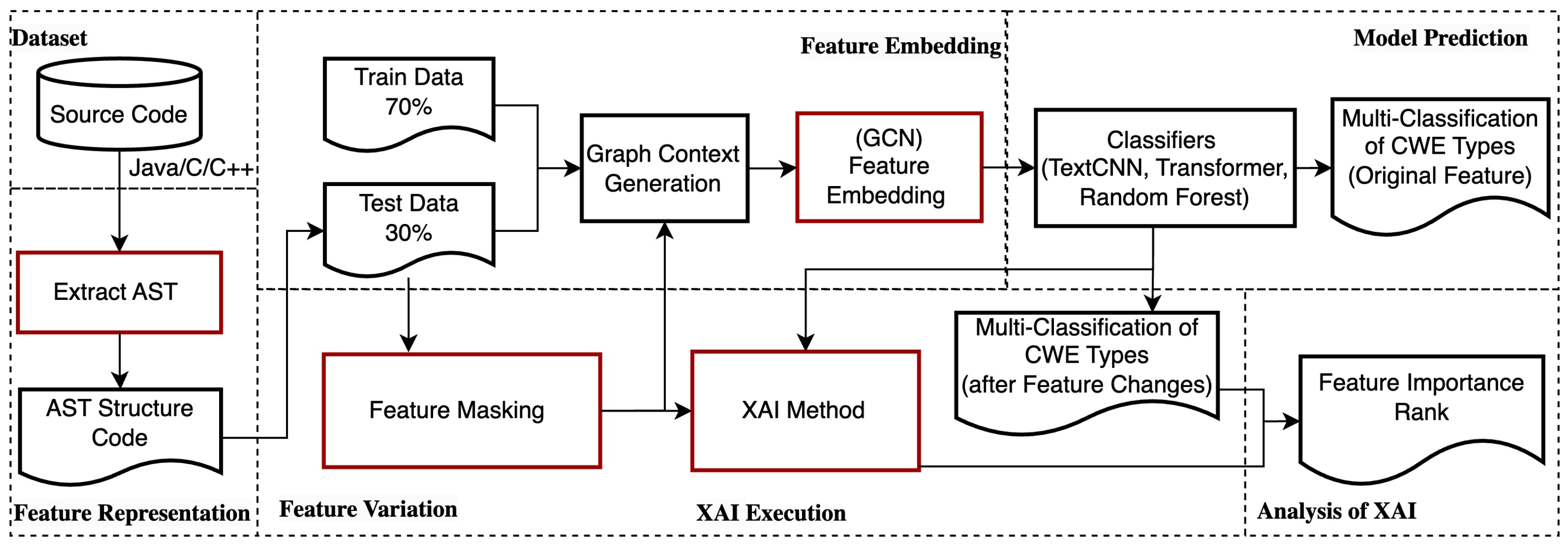
The main components of the workflow are shown in
Figure 3. Compared to existing code vulnerability classification solutions, our workflow has three additional components: feature variation, XAI method, and an analysis of XAI outputs. Our workflow applies post-hoc and model-agnostic XAI methods that compute the feature contribution values under the variations in feature mutations, feature masking, and feature removal. The outputs from XAI methods are further analyzed to identify high-ranking code features.
4.1. The Graph Context Extraction of Program Code
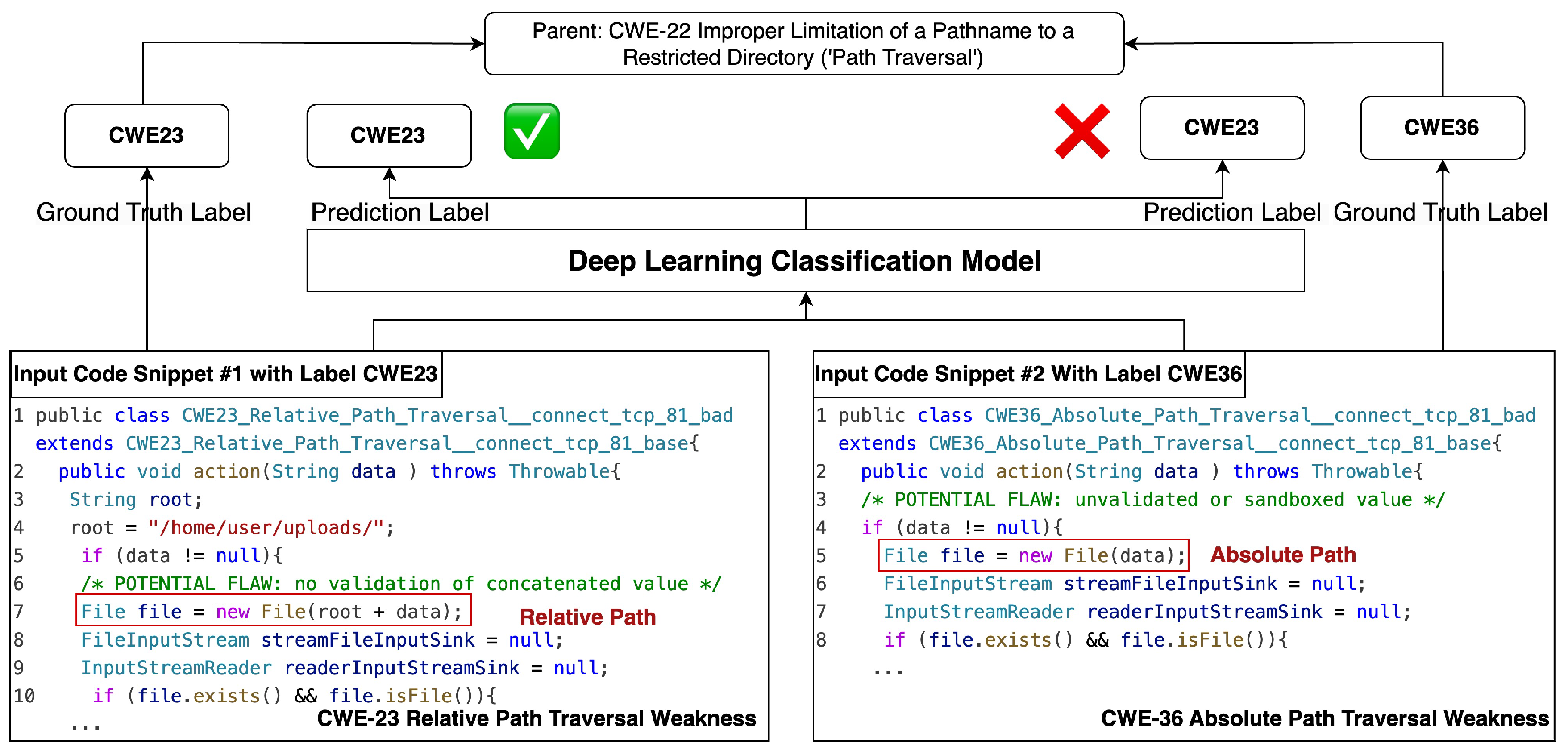
We extracted the program paths of the input program source code derived from abstract syntax trees, which preserves the semantic properties of the program code. For example,
Figure 2 illustrates the difference between two sibling CWE types that derive from the semantic meanings of arguments. One type is the relative path, and the other is the absolute path. Both are traced back to the syntax of the argument construction.
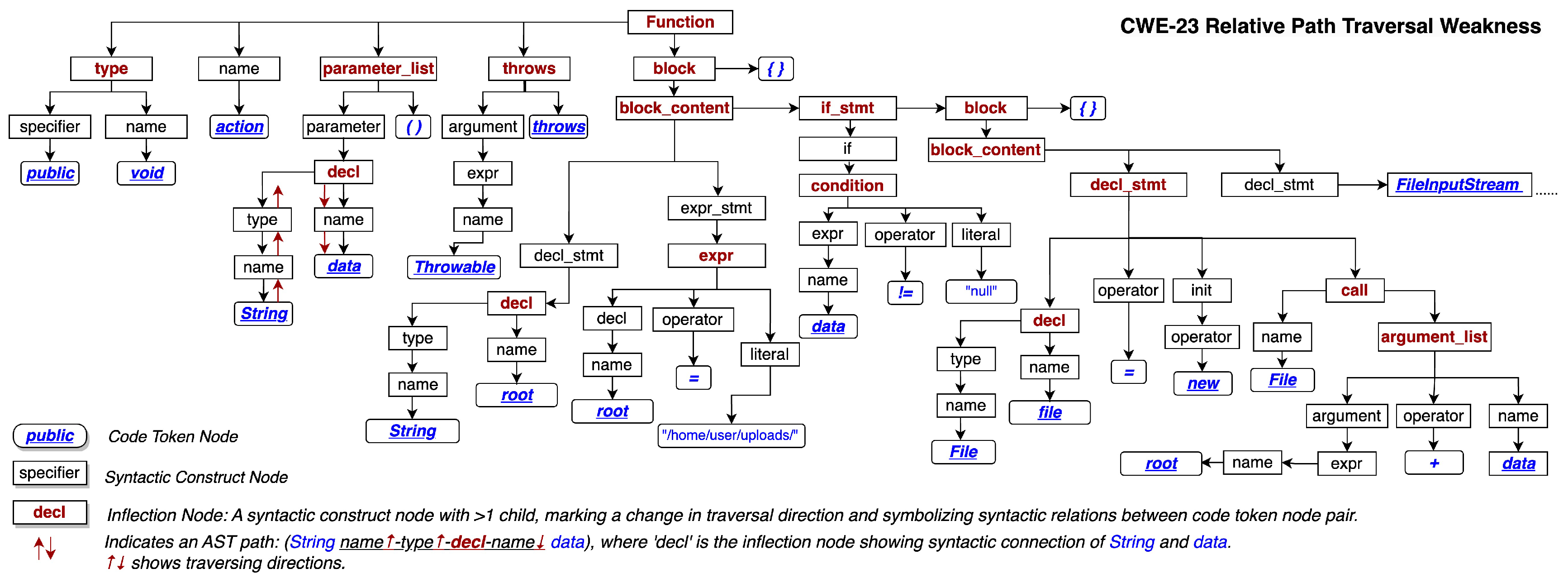
To capture links between semantic meanings and the syntax constructs, we considered extracting a path that has leaf nodes as code tokens and non-leaf nodes as the syntax constructs derived from Abstract Syntax Trees (AST).
Figure 4 shows the complete syntactic constructs of the code example with the CWE23 Relative Path Traversal Weakness.
Syntactic constructs are the program syntax’s building blocks, including forty constructs such as loops, conditionals, declarations, and expressions.
Table 1 lists a summary of syntactic constructs and the higher-level categorized meta syntactic constructs defined in the work [
83]. The meta syntactic constructs preserve the semantic roles within a program. For instance, the
Declarations, Definitions, Initializations meta construct category consists of syntactic constructs related to defining and initializing variables, functions, and objects.
Further, traversing from one code token through the syntax paths to another shows the connection between code tokens and preserves the functional meanings. An example syntactic construct tree in
Figure 4 represents the code listed in Listing 1, which contains the vulnerability type CWE23 relative path’s traversal weakness. The syntactic path,
String↑-name↑-type↑-decl↓-name↓-root, extends from the source code token
String to the target code token
root, where ↑ and ↓ are the traversing directions. In this example,
decl changes the traversing direction from upward of the path to downward of the path. We call a node that converts the traversing directions an
inflection node. Through an inflection node, two code tokens in a pair are linked together by the
shortest path that traverses the nearest inflection node.
| Listing 1. Code snippet from the Juliet dataset [62]. The code is of vulnerability type CWE23—Relative Path Traversal Weakness. |
![Make 06 00050 i001]() |
Therefore, the source code of programs is extracted into paths. Each path traverses pairs of code tokens through the shortest path. The set of all the paths leading from the source leaf nodes to the target source node contains the graph context of the target nodes. All the source leaf nodes become the neighbor nodes of the target code token. In the graph context, the syntactic constructs along the paths are on the edges that connect the source code tokens to the target code token. For example,
Figure 5 illustrates the graph context extracted from the complete syntactic paths that cover the CWE23 vulnerability sample code in Listing 1.
Two configurations
path length and
window are involved in the graph context generation. The
path length is the length of the shortest AST syntactic path connecting two leaf nodes (code tokens). The term
window refers to the maximum distance between the target code token and its neighboring code token within a code function, considering both upward and downward directions, as illustrated in
Figure 6. When learning a target code token, only neighboring tokens located within this window, either upward or downward of it, are selected as source code token nodes in the graph context. Both
path length and
window are utilized to shape the scope of the graph context, as illustrated in
Figure 5.
4.2. Embedding by Graph Convolutional Networks
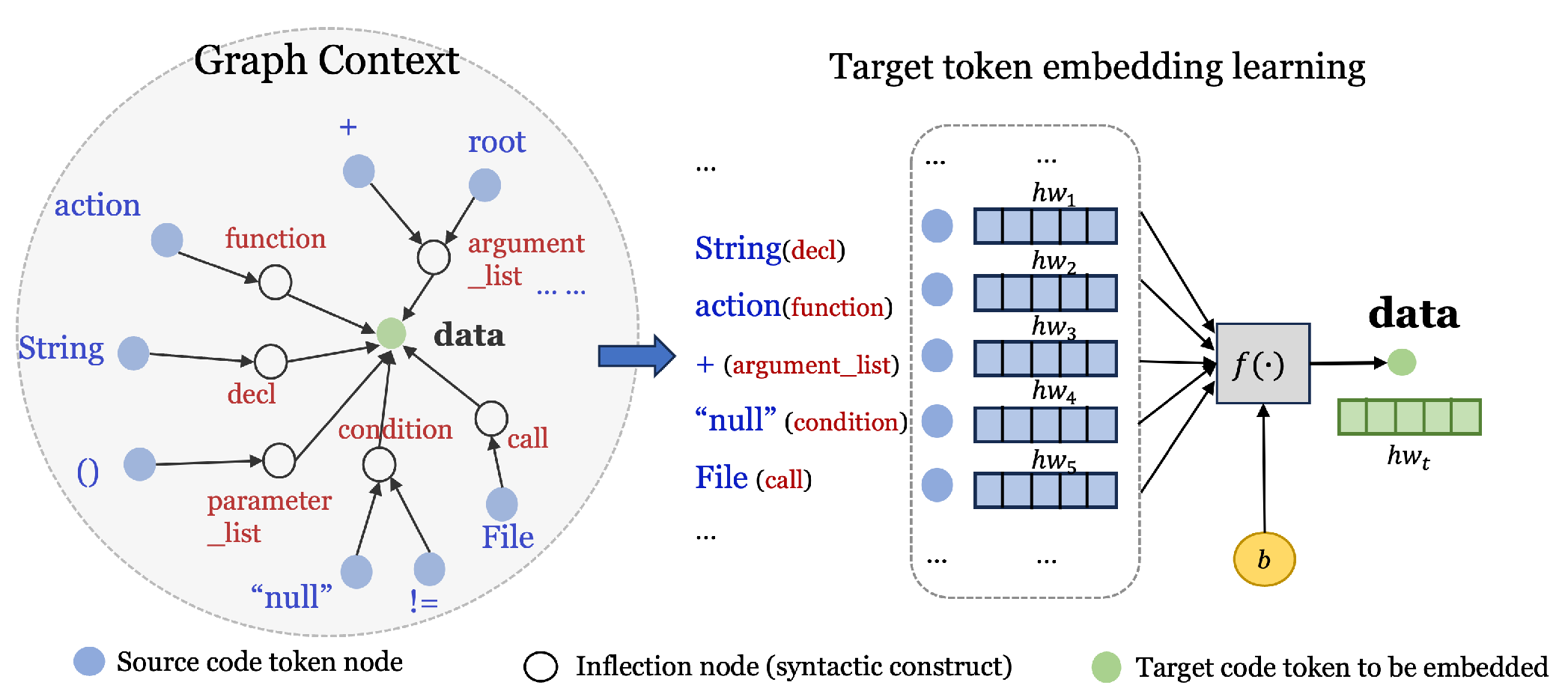
The graph context of each target token is used to learn the embedding of the target token. The source tokens within the graph context form the input vector to a learning model, and the output is the target token data.
Figure 5 shows that the graph context vector is input to a one-layer Graph Convolutional Network (GCN). We adopted the GCN model developed in [
39,
84], which demonstrated its use in six software repository analysis tasks, including code classification. The output embeddings for each code token are 128-dimensional vectors containing information about the code token and syntactic constructs.
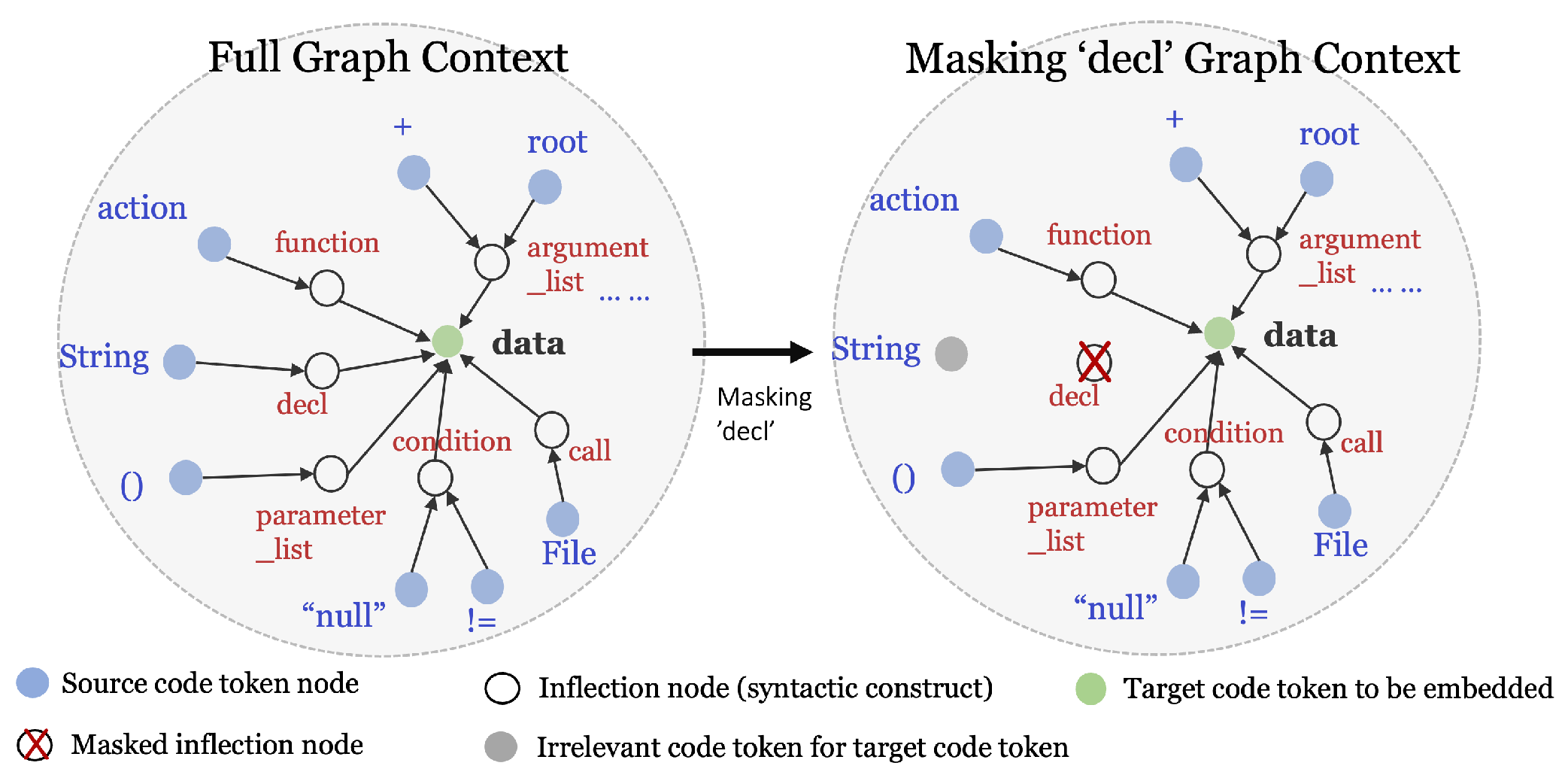
4.3. Feature Masking
XAI methods such as SHAP and Mean-Centroid PredDiff assess the feature contribution values by means of changing features and measuring the learning models’ outputs. By masking a syntactic construct, the graph context of a targeted node is mutated, which results in the masking of neighboring tokens of the target token.
Figure 7 shows, as an example, an inflection node
decl (as an abbreviation for
declaration) in the path of
String↑-name↑-type↑-decl↓-name↓-data. When
declaration is masked, the syntactic construct
decl is not embedded in any graph context feature presentation. Correspondingly,
String is excluded from the graph context of
data. Through the masking of syntactic constructions, we can mutate the embedding of each target node and further assess the feature contribution values of each syntactic construct.
4.4. Integrating XAI Methods in Multi-Classification
The graph context is processed through a Graph Convolutional Network (GCN) [
39] model to generate code token embeddings with a 128-dimension vector. These embeddings are then classified into CWE types using various classifiers, such as the Text Convolutional Neural Network (TextCNN)[
85], Random Forest[
86], and Transformer [
79].
An XAI method
works on the trained model and estimates feature contributions by masking or mutating feature representation. In
Section 2, we introduced two XAI methods, SHAP and Mean-Centroid PredDiff, which are applicable as
. The XAI outputs are vectors for each CWE type, ranked by the contribution values of each syntactic construct. An example of the XAI outputs is illustrated in Listing 2. The syntactic constructs are ranked in descending order according to the feature contribution value. Hence, we obtained a ranked sequence of syntactic constructs of CWE types that are classified for the dataset.
| Listing 2. CWE23 vector with syntactic constructs and their feature contribution values. |
![Make 06 00050 i002]() |
Specifically, each XAI method produces one CWE vector, as demonstrated in Algorithm 1. We aggregated and computed the average of the contribution values indexed by the syntactic constructs from different XAI methods and derived the final CWE vector. This result helps us to quantify the contributions at the level of the syntactic constructs, in addition to the code tokens, in the classification task of vulnerability code CWE types.
| Algorithm 1 Compute the CWE vector of each syntactic construct’s contribution value |
Input:The input dataset X; The full AST construct forms the feature set ; The subset by masking feature j; The feature j contribution value ; The model prediction under feature j masking ; The CWE label set .
|
- 1:
/* Partition dataset by ground truth CWE label */ - 2:
for all do - 3:
if owns label then - 4:
Add to - 5:
end if - 6:
end for - 7:
/* Compute CWE vector of feature contribution value */ - 8:
for all do - 9:
for all do - 10:
- 11:
end for - 12:
- 13:
/* Create CWE vector */ - 14:
for all do - 15:
- 16:
end for - 17:
end for - 18:
/* Sort elements in descending order by feature contribution values */ - 19:
for all do - 20:
- 21:
end for
|
| Output: The CWE vector for each CWE label . |
We analyzed the complexity of our algorithms. Given the size of the dataset samples N, the feature number P, and the CWE label number K, the complexity of Algorithm 1 is , in which, for SHAP, , and for Mean-Centroid PredDiff, .
4.5. CWE Similarity Assessment
The assessment of CWE similarity consists of two steps. The first step is to derive the CWE similarity pairs from the XAI explanation summary. The second step is to validate the CWE similarity from the baseline (ground truth) from the knowledge base of the CWE community.
CWE Similarity Score. We represent the similarity score between CWEs as
. It is derived from the normalized ranking distance [
87] between two sorted CWE vectors. The value of
ranges from zero, indicating identical CWE pairs, to one, indicating complete dissimilarity. A lower
value indicates a higher similarity between a pair of CWEs. We sorted the
values of CWEs and listed CWEs in descending order of their similarity in terms of ranking with a given CWE.
The CWE similarity assessment follows the simplified steps below, with details outlined in Algorithm 2:
Based on the sorted CWE vectors, we compute the similarity score between CWE types. Therefore, any pair of CWE types has a similarity score.
Given a CWE type, we rank the highest similarity score in all the pairs that involve this CWE type.
Given a CWE type, the CWE type that has the highest similarity score becomes the most similar to the given CWE type.
| Algorithm 2 Compute CWE similarity vector for CWE types |
Input:Sorted vectors of feature importance for each CWE label output from Algorithm 1; The CWE label set .
|
- 1:
Initialize an empty array d for storing ranking distances. - 2:
for all distinct pairs of CWE labels do - 3:
/*Calculate Kendall Tau ranking distance between CWE vectors*/ - 4:
. - 5:
Store in vector d. - 6:
end for - 7:
. - 8:
/* Compute normalized CWE similarity distance */ - 9:
for all CWE label do - 10:
. - 11:
. - 12:
end for - 13:
/* Sort elements in descending order by value of */ - 14:
for all do - 15:
. - 16:
end for
|
| Output: The CWE similarity vector for each CWE label . |
These pair-wise CWE similarity results are derived from the learning process combined with XAI methods. Meanwhile, we developed the baseline similarity pairs. As an example, in
Figure 2, any siblings of two CWE types in [
60] from the same parent CWE type form a pair of CWE similarities. The complexity is
, where
K is the number of CWE types.
CWE Similarity Validation. Further, we compared the pair-wise CWE similarity derived by XAI methods with the baseline CWE similarity in terms of four metrics, namely Top-N Similarity Hit, Mean Reciprocal Rank (MRR), Mean Average Precision (MAP), and Average Normalized Similarity Score . Top-N Similarity Hit and Average Normalized Similarity Score focus on the occurrence of a certain CWE type in our explanation in the baseline. MRR and MAP focus on the occurrence ranking of a CWE type in the baseline. The better the score values, the better the explanation quality; thus, the more accurate the syntactic constructs’ contribution values.
The complexity of Algorithm 2 depends on the number of CWE pair combinations.
Table 2 shows the baseline of CWE similarity defined by the open community. The CWE types are classified in a tree structure. The sibling leaves share a commonality with the parent CWE type. CWE22, CWE23, and CWE36 fall under the path’s traversal weakness. Then, CWE22, CWE23, and CWE36 form three CWE similarity pairs.
To validate the CWE’s similarity to the XAI explanation, we apply four metrics to compare with the baseline: Top-N Similarity Hit, Mean Reciprocal Rank (MRR), Mean Average Precision (MAP), and Average Normalized Similarity Score . is the set that contains all the CWE types that are siblings to defined in the baseline. is the set of CWE types derived from Algorithm 2. Given the example of CWE23, and , each metric can be illustrated as follows.
Top-N Similarity Hit is defined as a boolean value. For example, Top-1 Similarity Hit of CWE22 equals one.
Mean Reciprocal Rank (MRR) measures the mean reciprocal rank given a CWE type
.
where
is the position index value of
in
. In the example of
, CWE22 is ranked as one and CWE36 is ranked as
.
.
Mean Average Precision (MAP) is a metric used to measure the XAI explanation accuracy of CWE type similarity by averaging the precision of each CWE type’s similarity rank. Let
represent the top-N subset of
, where N represents a cut-off rank. For a given CWE type
, Average Precision (AP) is calculated as the mean precision value at each rank:
where
is an indicator function that equals one if the item at rank
is a ground truth sibling CWE type of
, that is,
, and is zero otherwise. In the example of
, CWE22 is ranked as one and CWE36 is ranked as
.
. Finally, given an XAI explanation method
, MAP is calculated as the mean average precision of all
Q number of CWE types:
Average Normalized Similarity Score () measures the average normalized similarity score for all CWE types in the baseline.
where
represents the similarity between a CWE type
in the baseline and a CWE type
derived using an XAI method.
is calculated in Algorithm 2.
5. The Evaluation and Results
The evaluation aims to assess the importance of the contribution of syntactic constructs. These syntactic constructs are inflection nodes in the Abstract Syntax Tree (AST) that connect code token nodes in a path that convey semantic meanings [
88]. We summarize the feature importance of syntactic constructs using XAI methods. We also validate the CWE similarity pairs from XAI explanations in comparison with the baseline from the community knowledge base. We present research experiments that could answer two specific research questions, as follows.
RQ1. What are the top-ranking syntactic constructs that contribute most to the multi-classification of software vulnerability? This question relies on the XAI methods to determine the importance of code tokens traversing syntactic construct paths that contribute to the deep learning model’s prediction for various vulnerability types.
RQ2. How does the CWE similarity summarized by XAI methods align with the expert-defined similarity? This question applies the measurement of CWE similarity pairs to the baseline CWE similarity pairs to validate whether the explanations of syntactic constructs correspond to the expert-established ground truth. Thus, the explanation maps the syntactic constructs to human-understandable CWE types of semantic meanings of vulnerable artifacts.
5.1. Datasets
Our experiment examined three benchmark software vulnerability datasets at the method or function level, including the Juliet Test Suite (Java) [
62], OWASP Benchmark (Java) [
89], and Draper (C/C++) [
6]. These datasets can be sorted into three categories [
23] based on the method of collection and annotation of the code samples. They represent synthetic, semi-synthetic, and real data, respectively.
Synthetic data refer to instances where both the vulnerability code example and its annotations are artificially constructed. The Juliet Test Suite, a product of the National Security Agency’s Center for Assured Software, falls under this category. By comprising 217 vulnerable methods (42%) and 297 non-vulnerable methods (58%), this dataset provides a balanced distribution of method-level examples, all synthesized based on recognized vulnerable patterns.
Semi-synthetic data involve either the code or its annotation being artificially derived. The OWASP Benchmark dataset, also Java-based, is an example of semi-synthetic data. We captured 1415 vulnerable methods (52%) and 1325 non-vulnerable methods (48%) from this dataset.
Real data, on the other hand, involve code and corresponding vulnerability annotations sourced from real-world repositories. The Draper dataset fits into this category. The functions in this dataset are collected from open-source repositories and annotated using static analyzers. While the original dataset presented an imbalanced distribution, we reprocessed it into a balanced dataset to analyze vulnerable code typed and their constructs and characters, and to preserve all comments and code. Consequently, this dataset includes 43,506 (50.1%) vulnerable functions. In
Table 3, we summarize the vulnerability types and their respective distributions in each dataset. For vulnerability types that have less than 1% distribution, we group them all into a
CWE-Other type.
5.2. Assessing Contribution of Syntactic Constructs (RQ1)
The three-step approach for assessing syntactic construct importance with settings includes the following:
Step 1: Converting Graph Context. We utilized the srcML tool [
83] to transform the method-level program into an AST structure. In this process, we removed code comments and retained mathematical and logical operators. The output from srcML is the XML-based content, encompassing both the code token (the leaf nodes in AST) and the AST path. This content was subsequently converted into a graph context, as introduced in
Section 4.1. We retained the maximum
edge length of eight and the
window of ten as default values in the graph neural network model [
39].
Step 2: Learning Embedding for Code Tokens. The graph context of each target token was used to learn the embedding of the target token. The graph convolutional neural network model was connected with a classifier layer for downstream classification tasks. The graph convolutional neural network model has one layer with a batch size of 64 and a dropout rate of 0. The embedding vector dimension is 128, which represents each code token for the classification models.
Step 3: Feature Masking and Feature Importance Ranking. We maintained the full graph context to retrieve embedding sets for the entire program’s code tokens. After masking each syntactic construct, we obtained altered neighbour tokens in a graph context as a form of feature masking to XAI methods SHAP and Mean-Centroid PredDiff. We compiled the results by averaging the contribution values across XAI methods.
Results. Table 4 (for Step 2) presents the performance of three classifiers augmented with GCN-based embeddings on Juliet, OWASP, and Draper datasets. The TextCNN classifier outperforms Random Forest and Transformer on all three datasets. We then chose TextCNN as the classifier with GCN embeddings to perform the following XAI tasks.
Figure 8 (for Step 3) shows, for each CWE type, the importance ranking of the meta syntactic constructs categorized in
Table 1. We observe that despite the varying importance orders of the syntactic constructs for each CWE type, certain constructs such as
statement_subelements, parameters, name, statement are consistently ranked highly across multiple CWEs, suggesting their general impact on code vulnerabilities. For instance, CWE78, CWE79, and CWE89 share similar top-ranked constructs, such as
statement_subelements, name, decl_def_init, and operators. On the other hand, syntactic constructs such as
specifier, classes have a lower importance across CWEs.
| Answer summary to RQ1: Syntactic constructs statement_subelements, statement, name, and parameters consistently rank highly across sixteen CWE types, approximately 80% of all CWE types, indicating their contribution to code vulnerability classification. |
5.3. CWE Similarity Explained by XAI Methods (RQ2)
Driven by the observations of syntactic similarities among certain CWE types, we further quantified CWE similarity based on the feature importance rank. We then compared these results with an expert-defined CWE similarity baseline.
Step 1: We computed the CWE similarity based on the importance rank of syntactic constructs.
Figure 8 shows the importance values of nine metadata syntactic constructs grouped by CWE type. We further expanded the assessment of forty syntactic constructs to obtain the CWE similarity distance of any two CWE pairs using the full list of syntactic construct importance ranking, following Algorithm 2.
Step 2: We validated our XAI-based CWE similarity against the expert-defined baseline [
60]. The similar sibling set for each CWE (required in Algorithm 2) is listed in
Table 2. To assess our results, we employed four metrics to measure each CWE type, including Top-N Similarity Hit, Mean Reciprocal Rank (MRR), Mean Average Precision (MAP), and Average Normalized Similarity Score (ANSS) (
Section 4.5). We obtained an aggregated score by averaging across all CWE types listed in
Table 5.
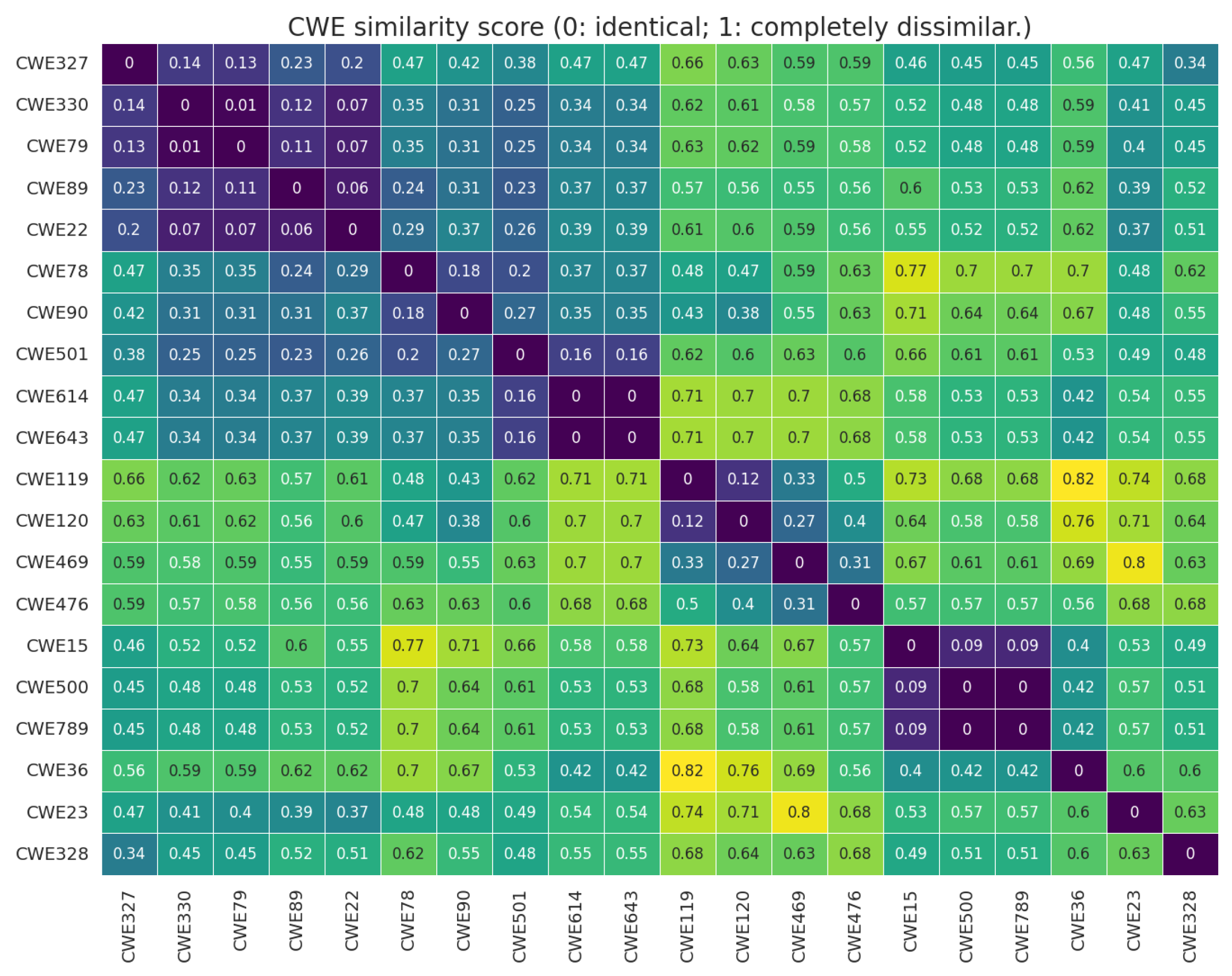
Results. Figure 9 (for step 1) presents the CWE similarity
of three datasets. For instance, CWE23 and CWE22 show a strong similarity with a low distance value, indicating that they share similar syntactic constructs. On the other hand, the pair consisting of CWE23 and CWE328 has a high distance value in the matrix, indicating low similarity between the pair.
The results presented in
Table 5 (for step 2) evaluate the similarity of CWE types, explained by XAI methods, compared to the baseline. The average Top-1 hit is approximately 78%, which means our XAI approach is able to identify accurate siblings for 78% of CWE types. Considering the Top-5 hit, the accuracy in identifying the siblings improved to 89%. Top-N metrics focus on the existence of a sibling CWE using the XAI explanation.
The Mean Reciprocal Rank (MRR) and Mean Average Precision (MAP) further consider the ranking of a sibling CWE type derived from the XAI explanation. In addition, MAP is approximately 70%, considering both the number of existing CWEs and their rankings. We revisit the example of CWE23, which has CWE22 and CWE36. The XAI methods provide the similarity assessment with CWE22 in the first position and CWE36 in the 14th position. This is the reason for CWE23’s lower MRR value and MAP value.
| Answer summary to RQ2: The XAI approach identifies the similarity between CWE types through the changes incurred in deep learning model’s classification due to feature masking. We applied metrics to evaluate the alignment of the XAI-derived similarity with the expert-established baseline by measuring both the occurrence and occurrence rankings of similar CWE types. The alignment connects the deep learning feature representations with the human-understandable CWE types. In addition to deep learning’s vulnerability classification, our XAI approach returns along the syntactic construct paths to locate the code that could lead to the misclassification of a similar CWE type. |
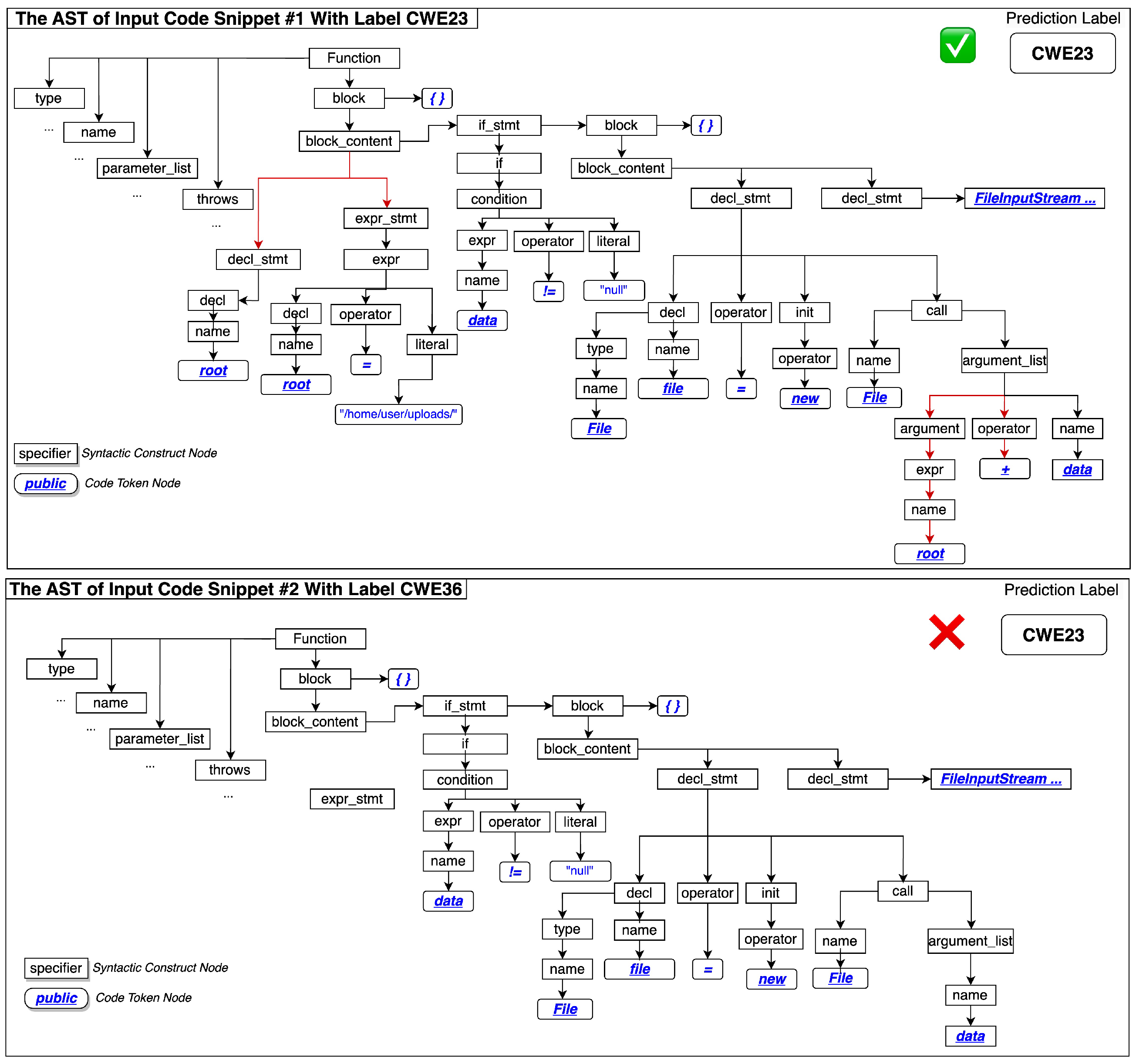
5.4. Reflection on the Motivating Case
Studying the case presented in
Section 2.1, we observe that the graph-based learning model faces misclassification among similar CWE types, as illustrated in
Figure 10. In the example presented in
Figure 2, a key difference in the processing of paths in CWE23 and CWE36 becomes evident. CWE23 employs a relative path embodied in the expression
File file = new File(root + data), while CWE36 uses an absolute path, represented as
File file = new File(data). Our XAI approach probes the feature importance in the terms of syntactic constructs to explain the potential cause of miscalculation. Both CWE23 and CWE36 cases exhibit similar overall feature importance ranking sequences, with
name and
if ranked in the top two syntactic constructs. However, in the case of CWE23, constructs such as
argument_list, argument and
operator are ranked higher than they are in the case of CWE36. This subtle feature ranking difference aligns with the unique characteristics of CWE23, which incorporates an additional argument
root and an operator with
+ into the file, thereby creating the relative path.
5.5. Summary of Findings and Existing Research
We analyzed our findings via a comparative summary of previous studies. We focused on the insights drawn from the current research, areas of alignment, and novel discoveries listed in
Table 6.
According to the manifesto of XAI [
27], our work is within the scope of the application of attribute-based XAI methods. We demonstrate that our work relates to two aspects of the manifesto, as follows: (1) evaluating XAI methods and the explanation—we integrated the SOTA XAI methods within a pipeline where the semantic relations among the CWE types defined by domain experts are encoded as the XAI output ranking and explanation evaluation; (2) supporting the human-centeredness of explanations—we were able to identify and rank the contributions of syntactic constructs across languages. Such information helps to explain the difference at the syntactic level between entities relative to the misclassification of similar CWE types in a human-understandable way.
6. Threats to Validity
The validity of our work includes the following factors: (1) internal validity stemming from limited model evaluation and the use of specific datasets for XAI and (2) external validity threats related to the transferability of the identified importance and similarity of syntactic constructs to the emerging CWE types.
Dataset. We employed three datasets, namely Juliet, OWASP, and Draper. Both Juliet and OWASP consist of synthetic samples with artificially constructed annotations, which may limit their generalizability to real-world data. Draper consists of samples derived from real-world source codes. However, Draper does not share overlapping CWE types with either Juliet or OWASP. The disjointed datasets in the common CWE types mean that we cannot obtain a cross-validation of the top-ranking sequences of the syntactic constructs of the common CWE types across multiple datasets. As a result, we cannot further validate the consistency of the XAI explanation across datasets. In our previous work [
31,
61], we defined the explanation consistency metrics to measure the explanations across multiple datasets.
Models. Our XAI-based framework, depicted in
Figure 3, is model-agnostic, including the embedding and classifier models. We applied one graph-embedding model adopted from GraphCodeVec [
39], three deep learning models to be used as classifiers, and two XAI methods. The variance incurred by different models can be further evaluated by introducing more models to assess the explanation stability [
31,
61] across multiple models on the same datasets.
Transferability to Broader CWE Sets. Our study involves 20 CWE types beyond the 1% distribution percentage from three datasets. These 20 CWE types include six of the top twenty-five most dangerous software weaknesses listed by the CWE community [
90]. In the full list of CWE types, the issue is the imbalanced data samples and the lack of labelled real datasets akin to Draper. In this paper, we preprocessed the Draper dataset to ensure it was balanced, since a poor classification performance from the imbalanced dataset causes the explanation results to be meaningless. Both the explanation stability and the consistency can be further validated with larger, balanced datasets.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}