
Improving Time Series Regression Model Accuracy via Systematic Training Dataset Augmentation and Sampling



Abstract
1. Introduction
1.1. Augmentation for Image Data
1.2. Augmentation for Time Series Data
1.3. Summary and Research Deficit
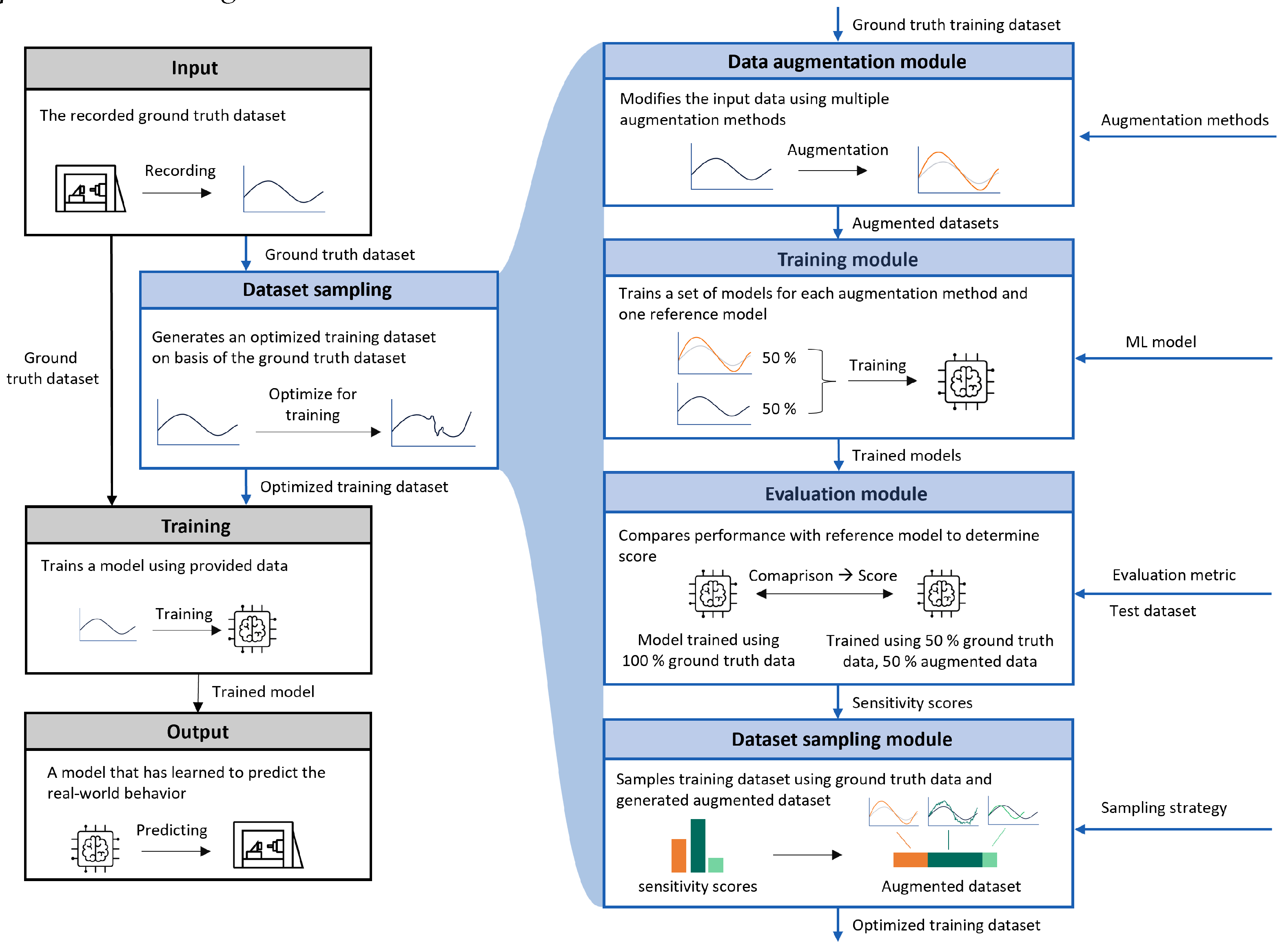
2. Framework for Training Dataset Sampling
3. Study and Methology
3.1. Datasets and Experiments
3.2. Models
3.3. Augmentation Methods
3.4. Dataset Sampling Strategies
3.5. Evaluation Metrics
- is the total deviation in %,
- is the integral of the absolute of the predicted current, i.e., ,
- is the integral of the absolute of the measured current, i.e., .
4. Results
4.1. Impact of Augmentation Methods
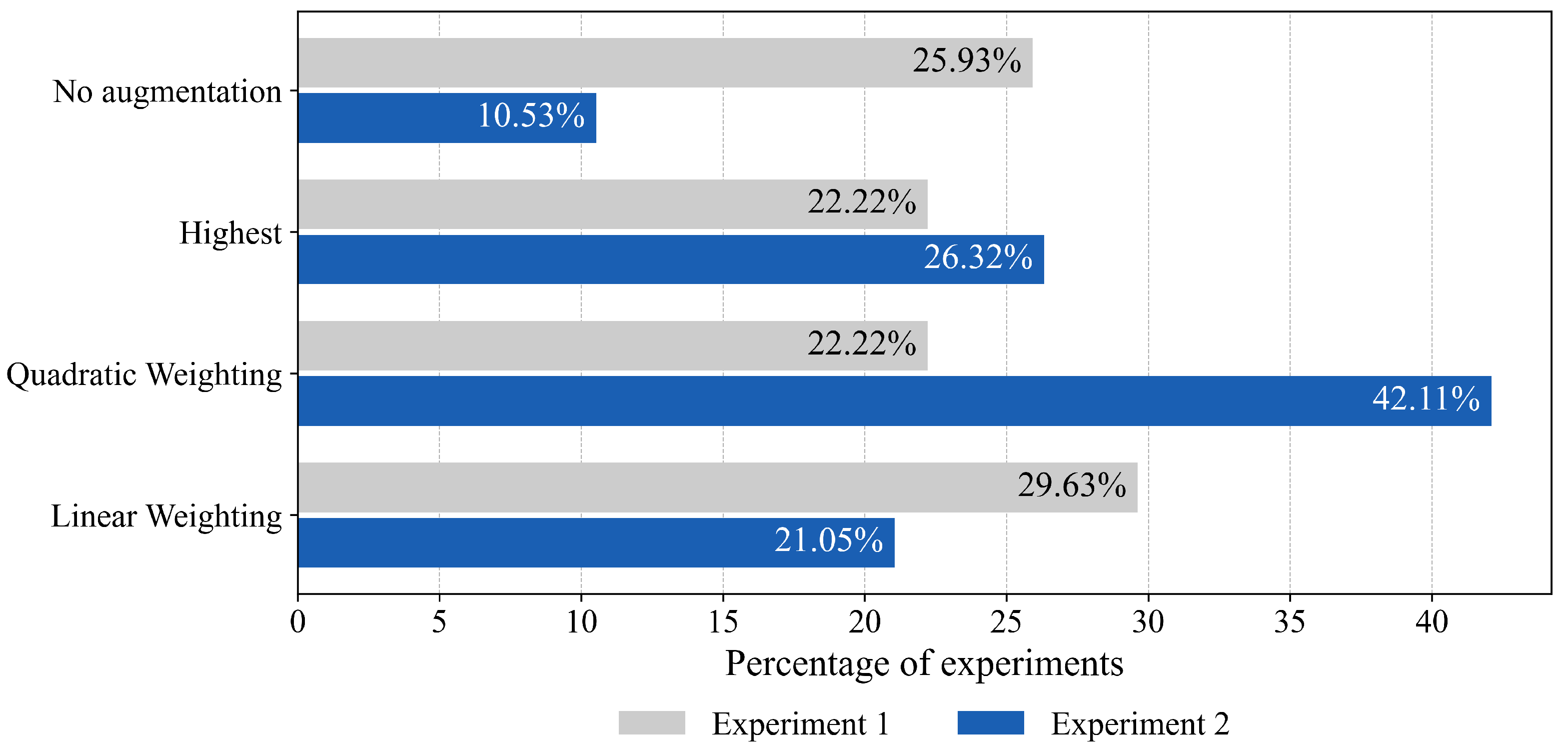
4.2. Impact of Dataset Sampling Strategies
5. Discussion
6. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNC | Computer Numerical Controlled |
| DGM | Deep Generative Model |
| GAN | Generative Adversarial Network |
| DTW | Dynamic Time Warping |
| ML | Machine Learning |
| MMR | Material Removal Rate |
| MSE | Mean Squared Error |
| NN | Neural Network |
| SP | Main Spindle |
| RF | Random Forest |
Appendix A
Software
- Python 3.10.10
- CUDA Version 11.8
- joblib==1.2.0
- matplotlib==3.6.3
- numpy==1.23.5
- pandas==2.0.2
- scikit_learn==1.2.2
- scipy==1.12.0
- shap==0.42.1
- torch==2.0.0+cu118
- tqdm==4.65.0
References
- Sharp, M.; Ak, R.; Hedberg, T. A survey of the advancing use and development of machine learning in smart manufacturing. J. Manuf. Syst. 2018, 48, 170–179. [Google Scholar] [CrossRef] [PubMed]
- Bertolini, M.; Mezzogori, D.; Neroni, M.; Zammori, F. Machine Learning for industrial applications: A comprehensive literature review. Expert Syst. Appl. 2021, 175, 114820. [Google Scholar] [CrossRef]
- Ajiboye, A.R.; Abdullah-Arshah, R.; Qin, H.; Isah-Kebbe, H. Evaluating the effect of dataset size on predictive model using supervised learning technique. Int. J. Softw. Eng. Comput. Sci. 2015, 1, 75–84. [Google Scholar] [CrossRef]
- Lwakatare, L.E.; Raj, A.; Crnkovic, I.; Bosch, J.; Olsson, H.H. Large-scale machine learning systems in real-world industrial settings: A review of challenges and solutions. Inf. Softw. Technol. 2020, 127, 106368. [Google Scholar] [CrossRef]
- Gaub, H. Customization of mass-produced parts by combining injection molding and additive manufacturing with Industry 4.0 technologies. Reinf. Plast. 2016, 60, 401–404. [Google Scholar] [CrossRef]
- Fawzi, A.; Samulowitz, H.; Turaga, D.; Frossard, P. Adaptive data augmentation for image classification. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: New York, NY, USA; pp. 3688–3692. [Google Scholar] [CrossRef]
- Schlagenhauf, T. Bildbasierte Quantifizierung und Prognose des Verschleißes an Kugelgewindetriebspindeln: Ein Beitrag zur Zustandsüberwachung von Kugelgewindetrieben Mittels Methoden des maschinellen Lernens; Shaker Verlag: Hercogenrat, Germany, 2022. [Google Scholar] [CrossRef]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time Series Data Augmentation for Deep Learning: A Survey. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–26 August 2021; pp. 4653–4660. [Google Scholar] [CrossRef]
- Fu, Q.; Wang, H. A Novel Deep Learning System with Data Augmentation for Machine Fault Diagnosis from Vibration Signals. Appl. Sci. 2020, 10, 5765. [Google Scholar] [CrossRef]
- Bui, V.; Pham, T.L.; Nguyen, H.; Jang, Y.M. Data Augmentation Using Generative Adversarial Network for Automatic Machine Fault Detection Based on Vibration Signals. Appl. Sci. 2021, 11, 2166. [Google Scholar] [CrossRef]
- Lin, J.C.; Yang, F. Data Augmentation for Industrial Multivariate Time Series via a Spatial and Frequency Domain Knowledge GAN. In Proceedings of the 2022 IEEE International Symposium on Advanced Control of Industrial Processes (AdCONIP), Vancouver, BC, Canada, 7–9 August 2022; IEEE: New York, NY, USA; pp. 244–249. [Google Scholar] [CrossRef]
- Van Dyk, D.A.; Meng, X.L. The Art of Data Augmentation. J. Comput. Graph. Stat. 2001, 10, 1–50. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Dataset Augmentation in Feature Space. arXiv 2017, arXiv:1702.05538. [Google Scholar] [CrossRef]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding Data Augmentation for Classification: When to Warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, QLD, Australia, 30 November–2 December 2016; IEEE: New York, NY, USA; pp. 1–6. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, H.R.; Valiant, G.; Ré, C. On the Generalization Effects of Linear Transformations in Data Augmentation. arXiv 2020, arXiv:2005.00695. [Google Scholar] [CrossRef]
- Tran, T.; Pham, T.; Carneiro, G.; Palmer, L.; Reid, I. A Bayesian Data Augmentation Approach for Learning Deep Models. arXiv 2017, arXiv:1710.10564. [Google Scholar] [CrossRef]
- Hu, W.; Miyato, T.; Tokui, S.; Matsumoto, E.; Sugiyama, M. Learning Discrete Representations via Information Maximizing Self-Augmented Training. arXiv 2017, arXiv:1702.08720. [Google Scholar] [CrossRef]
- Chaitanya, K.; Karani, N.; Baumgartner, C.F.; Becker, A.; Donati, O.; Konukoglu, E. Semi-supervised and Task-Driven Data Augmentation. In Information Processing in Medical Imaging; Series Title: Lecture Notes in Computer Science; Chung, A.C.S., Gee, J.C., Yushkevich, P.A., Bao, S., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany; Volume 11492, pp. 29–41. [CrossRef]
- Hu, Z.; Tan, B.; Salakhutdinov, R.; Mitchell, T.; Xing, E.P. Learning Data Manipulation for Augmentation and Weighting. arXiv 2019. [Google Scholar]
- Zoph, B.; Cubuk, E.D.; Ghiasi, G.; Lin, T.Y.; Shlens, J.; Le, Q.V. Learning Data Augmentation Strategies for Object Detection. In Computer Vision—ECCV 2020; Series Title: Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany; Volume 12372, pp. 566–583. [CrossRef]
- Sakai, A.; Minoda, Y.; Morikawa, K. Data augmentation methods for machine-learning-based classification of bio-signals. In Proceedings of the 2017 10th Biomedical Engineering International Conference (BMEiCON), Hokkaido, Japan, 31 August–2 September 2017; IEEE: New York, NY, USA; pp. 1–4. [Google Scholar] [CrossRef]
- Bandara, K.; Hewamalage, H.; Liu, Y.H.; Kang, Y.; Bergmeir, C. Improving the accuracy of global forecasting models using time series data augmentation. Pattern Recognit. 2021, 120, 108148. [Google Scholar] [CrossRef]
- Forestier, G.; Petitjean, F.; Dau, H.A.; Webb, G.I.; Keogh, E. Generating Synthetic Time Series to Augment Sparse Datasets. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; IEEE: New York, NY, USA; pp. 865–870. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Data augmentation using synthetic data for time series classification with deep residual networks. arXiv 2018, arXiv:1808.02455. [Google Scholar] [CrossRef]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef]
- Fu, B.; Kirchbuchner, F.; Kuijper, A. Data augmentation for time series: Traditional vs generative models on capacitive proximity time series. In Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 30 June–3 July 2020; pp. 1–10. [Google Scholar] [CrossRef]
- Brophy, E.; Wang, Z.; She, Q.; Ward, T. Generative Adversarial Networks in Time Series: A Systematic Literature Review. ACM Comput. Surv. 2023, 55, 1–31. [Google Scholar] [CrossRef]
- Tanaka, F.H.K.d.S.; Aranha, C. Data Augmentation Using GANs. arXiv 2019, arXiv:1904.09135. [Google Scholar] [CrossRef]
- Ramponi, G.; Protopapas, P.; Brambilla, M.; Janssen, R. T-CGAN: Conditional Generative Adversarial Network for Data Augmentation in Noisy Time Series with Irregular Sampling. arXiv 2018, arXiv:1811.08295. [Google Scholar] [CrossRef]
- Gatta, F.; Giampaolo, F.; Prezioso, E.; Mei, G.; Cuomo, S.; Piccialli, F. Neural networks generative models for time series. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 7920–7939. [Google Scholar] [CrossRef]
- Naveed, M.H.; Hashmi, U.S.; Tajved, N.; Sultan, N.; Imran, A. Assessing Deep Generative Models on Time Series Network Data. IEEE Access 2022, 10, 64601–64617. [Google Scholar] [CrossRef]
- Haradal, S.; Hayashi, H.; Uchida, S. Biosignal Data Augmentation Based on Generative Adversarial Networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; IEEE: New York, NY, USA; pp. 368–371. [Google Scholar] [CrossRef]
- Ströbel, R.; Probst, Y.; Deucker, S.; Fleischer, J. Time Series Prediction for Energy Consumption of Computer Numerical Control Axes Using Hybrid Machine Learning Models. Machines 2023, 11, 1015. [Google Scholar] [CrossRef]
- Ströbel, R.; Mau, M.; Deucker, S.; Fleischer, J. Training and Validation Dataset 2 of Milling Processes for Time Series Prediction; Karlsruhe Institute of Technology: Karlsruhe, Germany, 2023. [Google Scholar] [CrossRef]
- Ströbel, R.; Probst, Y.; Fleischer, J. Training and Validation Dataset of Milling Processes for Time Series Prediction; Karlsruhe Institute of Technology: Karlsruhe, Germany, 2023. [Google Scholar] [CrossRef]
- Iglesias, G.; Talavera, E.; González-Prieto, A.; Mozo, A.; Gómez-Canaval, S. Data Augmentation techniques in time series domain: A survey and taxonomy. Neural Comput. Appl. 2023, 35, 10123–10145. [Google Scholar] [CrossRef]
- Um, T.T.; Pfister, F.M.J.; Pichler, D.; Endo, S.; Lang, M.; Hirche, S.; Fietzek, U.; Kulić, D. Data augmentation of wearable sensor data for parkinson’s disease monitoring using convolutional neural networks. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, New York, NY, USA, 13–17 November 2017; pp. 216–220. [Google Scholar] [CrossRef]
- Le Guennec, A.; Malinowski, S.; Tavenard, R. Data Augmentation for Time Series Classification using Convolutional Neural Networks. In Proceedings of the ECML/PKDD Workshop on Advanced Analytics and Learning on Temporal Data, Bilbao, Spain, 13 September 2021. [Google Scholar]
- Demir, S.; Mincev, K.; Kok, K.; Paterakis, N.G. Data augmentation for time series regression: Applying transformations, autoencoders and adversarial networks to electricity price forecasting. Appl. Energy 2021, 304, 117695. [Google Scholar] [CrossRef]
- Nanni, L.; Paci, M.; Brahnam, S.; Lumini, A. Comparison of Different Image Data Augmentation Approaches. J. Imaging 2021, 7, 254. [Google Scholar] [CrossRef] [PubMed]
- Bao, Y.; Xing, T.; Chen, X. Confidence-based interactable neural-symbolic visual question answering. Neurocomputing 2024, 564, 126991. [Google Scholar] [CrossRef]
- Xu, H.; Mannor, S. Robustness and generalization. Mach. Learn. 2012, 86, 391–423. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Name | Hidden Layers | Hidden Dimensions | Epochs | Learning Rate | Optimizer |
|---|---|---|---|---|---|
| 2 | 64 | 1000 | 0.001 | Adam | |
| 7 | 128 | 1000 | 0.001 | Adam | |
| Name | Estimators | Maximum Depth | Split Minimum | Leaf Minimum | Criteriom |
| 10 | 3 | 2 | 1 | squared error | |
| 10 | 20 | 2 | 1 | squared error |
| Axis | Model | Original Dataset | Magnitude Warping | Noise | Random Delete | Time Warping | Window Warping |
|---|---|---|---|---|---|---|---|
| Experiment 1A (DEV) | 6.58 (0.08) | 3.24 (3.52) | 5.77 (0.14) | 6.52 (0.03) | 6.04 (1.02) | 5.94 (0.57) | |
| 1.12 (0.80) | 1.20 (0.16) | 0.93 (0.02) | 0.86 (0.11) | 0.94 (0.42) | 1.07 (0.57) | ||
| 1.60 (0.52) | 3.71 (0.64) | 1.33 (0.47) | 3.51 (0.48) | 2.31 (0.44) | 1.88 (0.50) | ||
| 1.80 (1.81) | 2.17 (3.00) | 1.49 (1.34) | 2.43 (1.16) | 2.22 (2.13) | 1.86 (1.56) | ||
| Experiment 1A (MSE) | 0.22 (0.00) | 0.65 (0.14) | 0.45 (0.00) | 0.38 (0.00) | 0.38 (0.01) | 0.45 (0.00) | |
| 0.05 (0.00) | 0.17 (0.00) | 0.15 (0.00) | 0.16 (0.01) | 0.16 (0.01) | 0.18 (0.03) | ||
| 0.11 (0.00) | 0.32 (0.04) | 0.27 (0.00) | 0.28 (0.00) | 0.28 (0.02) | 0.27 (0.00) | ||
| 0.06 (0.01) | 0.30 (0.03) | 0.27 (0.02) | 0.27 (0.01) | 0.26 (0.01) | 0.27 (0.02) | ||
| Experiment 1B (DEV) | 7.83 (0.04) | 5.30 (4.61) | 8.45 (2.73) | 3.00 (0.42) | 4.69 (1.18) | 7.78 (0.52) | |
| 0.74 (0.08) | 0.59 (0.17) | 0.87 (0.63) | 0.72 (0.56) | 0.73 (0.26) | 0.76 (0.11) | ||
| 0.76 (0.53) | 1.45 (0.82) | 0.90 (0.46) | 1.12 (0.63) | 1.15 (0.64) | 1.31 (1.34) | ||
| 1.41 (1.47) | 1.70 (3.11) | 2.60 (2.18) | 2.96 (2.02) | 1.96 (2.32) | 1.59 (2.01) | ||
| Experiment 1B (MSE) | 0.36 (0.00) | 0.64 (0.14) | 0.46 (0.01) | 0.68 (0.02) | 0.69 (0.01) | 0.35 (0.02) | |
| 0.01 (0.00) | 0.03 (0.00) | 0.02 (0.00) | 0.01 (0.00) | 0.03 (0.01) | 0.01 (0.00) | ||
| 0.47 (0.02) | 0.50 (0.02) | 0.53 (0.01) | 0.52 (0.01) | 0.51 (0.01) | 0.49 (0.02) | ||
| 0.25 (0.59) | 0.24 (0.04) | 0.36 (0.07) | 0.45 (0.04) | 0.31 (0.06) | 0.24 (0.13) | ||
| Experiment 2A (DEV) | 9.59 (2.96) | 15.14 (6.82) | 8.68 (3.95) | 27.75 (4.41) | 23.72 (3.19) | 8.99 (3.31) | |
| 5.51 (4.88) | 7.58 (6.89) | 4.07 (3.24) | 27.33 (6.07) | 26.67 (6.21) | 13.40 (4.28) | ||
| 15.33 (6.06) | 32.93 (6.71) | 10.91 (6.39) | 17.09 (4.45) | 17.88 (4.36) | 13.96 (4.10) | ||
| 21.23 (7.31) | 28.12 (7.02) | 12.67 (6.68) | 13.44 (5.59) | 10.73 (5.10) | 14.64 (6.46) | ||
| Experiment 2A (MSE) | 0.41 (0.03) | 1.74 (0.24) | 2.06 (0.02) | 2.03 (0.01) | 2.05 (0.02) | 2.07 (0.01) | |
| 0.39 (0.04) | 1.75 (0.33) | 2.08 (0.02) | 2.19 (0.02) | 2.20 (0.01) | 2.23 (0.04) | ||
| 0.53 (0.12) | 1.48 (0.08) | 1.55 (0.06) | 1.38 (0.04) | 1.35 (0.04) | 1.45 (0.09) | ||
| 1.43 (0.43) | 1.46 (0.10) | 1.65 (0.06) | 1.57 (0.07) | 1.69 (0.09) | 1.59 (0.06) | ||
| Experiment 2B (DEV) | 1.00 (0.40) | 5.98 (8.33) | 1.07 (0.64) | 6.16 (0.98) | 2.08 (1.70) | 2.80 (1.04) | |
| 4.20 (4.67) | 5.08 (4.33) | 5.10 (4.15) | 4.74 (4.31) | 6.52 (5.92) | 5.11 (4.10) | ||
| 9.44 (4.44) | 8.40 (4.72) | 7.64 (2.35) | 10.19 (5.93) | 8.70 (3.74) | 9.10 (3.62) | ||
| 11.50 (6.22) | 8.95 (7.22) | 6.54 (4.46) | 8.09 (7.86) | 6.42 (7.44) | 9.59 (7.17) | ||
| Experiment 2B (MSE) | 0.99 (0.01) | 1.53 (0.19) | 1.09 (0.07) | 1.57 (0.02) | 1.57 (0.02) | 1.18 (0.10) | |
| 0.69 (0.07) | 0.87 (0.15) | 0.88 (0.06) | 0.85 (0.07) | 1.24 (0.28) | 0.85 (0.13) | ||
| 3.24 (1.27) | 2.66 (0.75) | 2.48 (0.13) | 2.10 (0.34) | 3.14 (0.70) | 3.23 (1.61) | ||
| 32.71 (21.09) | 1.81 (0.31) | 3.92 (0.47) | 1.65 (0.34) | 4.10 (2.34) | 11.96 (12.18) |
| Axis | Model | Original Dataset | |||
|---|---|---|---|---|---|
| Experiment 1A (DEV) | 6.58 (0.08) | 5.50 (0.21) | 5.68 (0.23) | 5.67 (0.15) | |
| 1.12 (0.80) | 0.94 (0.06) | 1.00 (0.05) | 0.98 (0.06) | ||
| 1.60 (0.52) | 1.32 (0.45) | 1.43 (0.55) | 1.29 (0.53) | ||
| 1.80 (1.81) | 1.86 (1.30) | 2.67 (3.08) | 0.72 (1.68) | ||
| Experiment 1A (MSE) | 0.22 (0.00) | 0.22 (0.00) | 0.23 (0.00) | 0.22 (0.00) | |
| 0.05 (0.00) | 0.05 (0.00) | 0.05 (0.00) | 0.05 (0.00) | ||
| 0.11 (0.00) | 0.11 (0.00) | 0.11 (0.00) | 0.11 (0.00) | ||
| 0.06 (0.01) | 0.08 (0.01) | 0.08 (0.02) | 0.08 (0.02) | ||
| Experiment 1B (DEV) | 7.83 (0.04) | 7.79 (0.24) | 7.67 (0.12) | 7.72 (0.13) | |
| 0.74 (0.08) | 0.76 (0.11) | 0.71 (0.12) | 0.74 (0.14) | ||
| 0.76 (0.53) | 0.80 (0.39) | 1.02 (0.77) | 0.85 (0.58) | ||
| 1.41 (1.47) | 1.14 (1.05) | 1.29 (1.69) | 1.71 (2.39) | ||
| Experiment 1B (MSE) | 0.36 (0.00) | 0.36 (0.00) | 0.35 (0.01) | 0.35 (0.01) | |
| 0.01 (0.00) | 0.01 (0.00) | 0.02 (0.00) | 0.01 (0.00) | ||
| 0.47 (0.02) | 0.53 (0.01) | 0.52 (0.01) | 0.53 (0.01) | ||
| 0.25 (0.59) | 0.20 (0.02) | 0.25 (0.07) | 0.19 (0.03) | ||
| Experiment 2A (DEV) | 9.59 (2.96) | 8.85 (2.83) | 9.40 (1.76) | 9.39 (4.46) | |
| 5.51 (4.88) | 4.84 (2.22) | 5.00 (2.48) | 3.88 (3.68) | ||
| 15.33 (6.06) | 10.80 (5.66) | 7.98 (6.39) | 10.83 (5.10) | ||
| 21.23 (7.31) | 21.66 (4.90) | 12.60 (6.86) | 11.42 (5.46) | ||
| Experiment 2A (MSE) | 0.41 (0.03) | 0.39 (0.02) | 0.40 (0.02) | 0.40 (0.02) | |
| 0.39 (0.04) | 0.40 (0.08) | 0.40 (0.05) | 0.39 (0.06) | ||
| 0.53 (0.12) | 0.42 (0.08) | 0.37 (0.04) | 0.46 (0.11) | ||
| 1.43 (0.43) | 1.99 (0.64) | 1.12 (0.25) | 1.55 (0.35) | ||
| Experiment 2B (DEV) | 1.00 (0.40) | 0.97 (0.42) | 1.39 (0.86) | 1.13 (0.38) | |
| 4.20 (4.67) | 4.15 (4.68) | 4.05 (4.01) | 3.47 (2.45) | ||
| 9.44 (4.44) | 9.17 (3.45) | 7.38 (1.55) | 8.64 (2.93) | ||
| 11.50 (6.22) | 8.62 (7.83) | 7.35 (4.67) | 7.48 (5.57) | ||
| Experiment 2B (MSE) | 0.99 (0.01) | 0.97 (0.04) | 0.98 (0.04) | 0.99 (0.05) | |
| 0.69 (0.07) | 0.71 (0.05) | 0.69 (0.09) | 0.71 (0.03) | ||
| 3.24 (1.27) | 2.30 (0.21) | 2.30 (0.15) | 2.47 (0.22) | ||
| 32.71 (21.09) | 23.26 (15.68) | 11.57 (12.75) | 12.70 (13.05) |
| Original Dataset | ||||
|---|---|---|---|---|
| 3.47 | 2.28 | 1.81 | 2.44 | |
| 0 | 1.19 | 1.66 | 1.03 |
| Experiment | Ground Truth Dataset is Better | Sampling via Quadratic Weighting is Better |
|---|---|---|
| Experiment 1 | 6 | 7 |
| Experiment 2 | 2 | 13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ströbel, R.; Mau, M.; Puchta, A.; Fleischer, J. Improving Time Series Regression Model Accuracy via Systematic Training Dataset Augmentation and Sampling. Mach. Learn. Knowl. Extr. 2024, 6, 1072-1086. https://doi.org/10.3390/make6020049
Ströbel R, Mau M, Puchta A, Fleischer J. Improving Time Series Regression Model Accuracy via Systematic Training Dataset Augmentation and Sampling. Machine Learning and Knowledge Extraction. 2024; 6(2):1072-1086. https://doi.org/10.3390/make6020049
Chicago/Turabian StyleStröbel, Robin, Marcus Mau, Alexander Puchta, and Jürgen Fleischer. 2024. "Improving Time Series Regression Model Accuracy via Systematic Training Dataset Augmentation and Sampling" Machine Learning and Knowledge Extraction 6, no. 2: 1072-1086. https://doi.org/10.3390/make6020049
APA StyleStröbel, R., Mau, M., Puchta, A., & Fleischer, J. (2024). Improving Time Series Regression Model Accuracy via Systematic Training Dataset Augmentation and Sampling. Machine Learning and Knowledge Extraction, 6(2), 1072-1086. https://doi.org/10.3390/make6020049