
Entropy-Aware Time-Varying Graph Neural Networks with Generalized Temporal Hawkes Process: Dynamic Link Prediction in the Presence of Node Addition and Deletion


Abstract
:1. Introduction
2. Related Works
3. Temporal Point Process
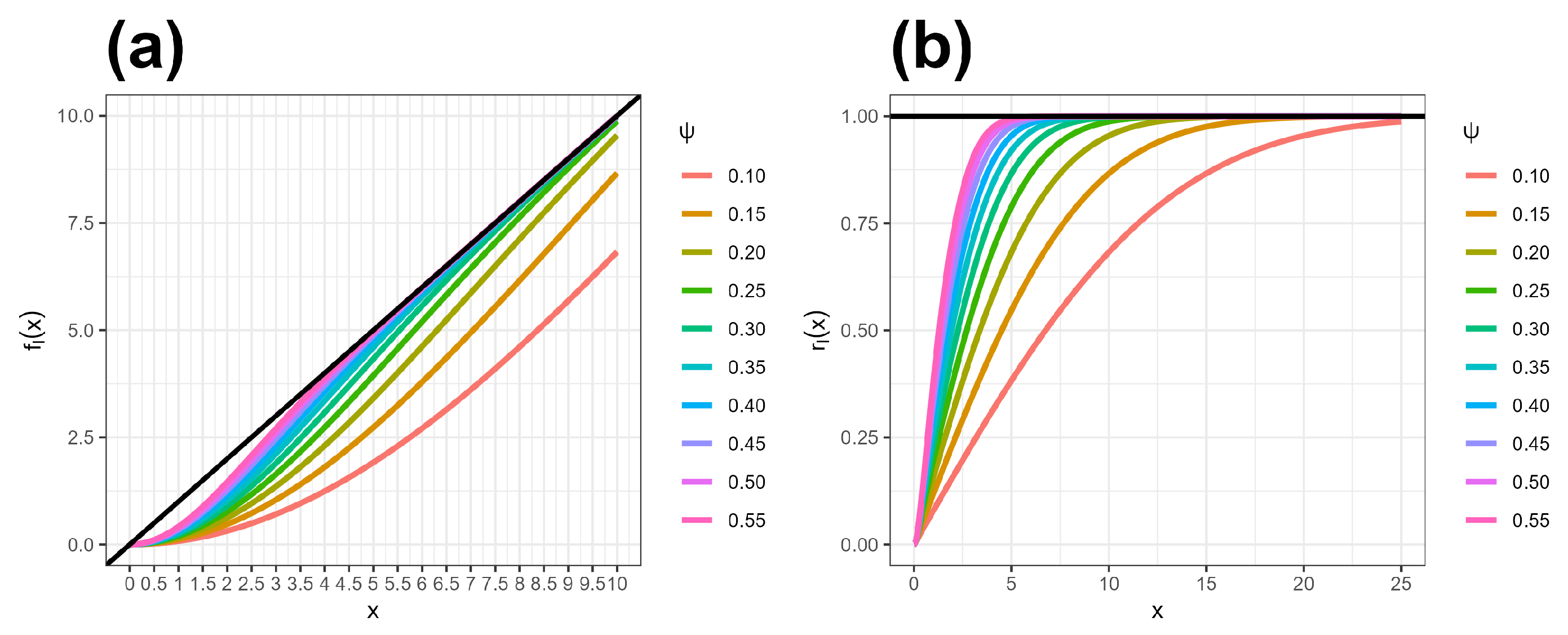
4. Network Entropy
5. Problem Formulation
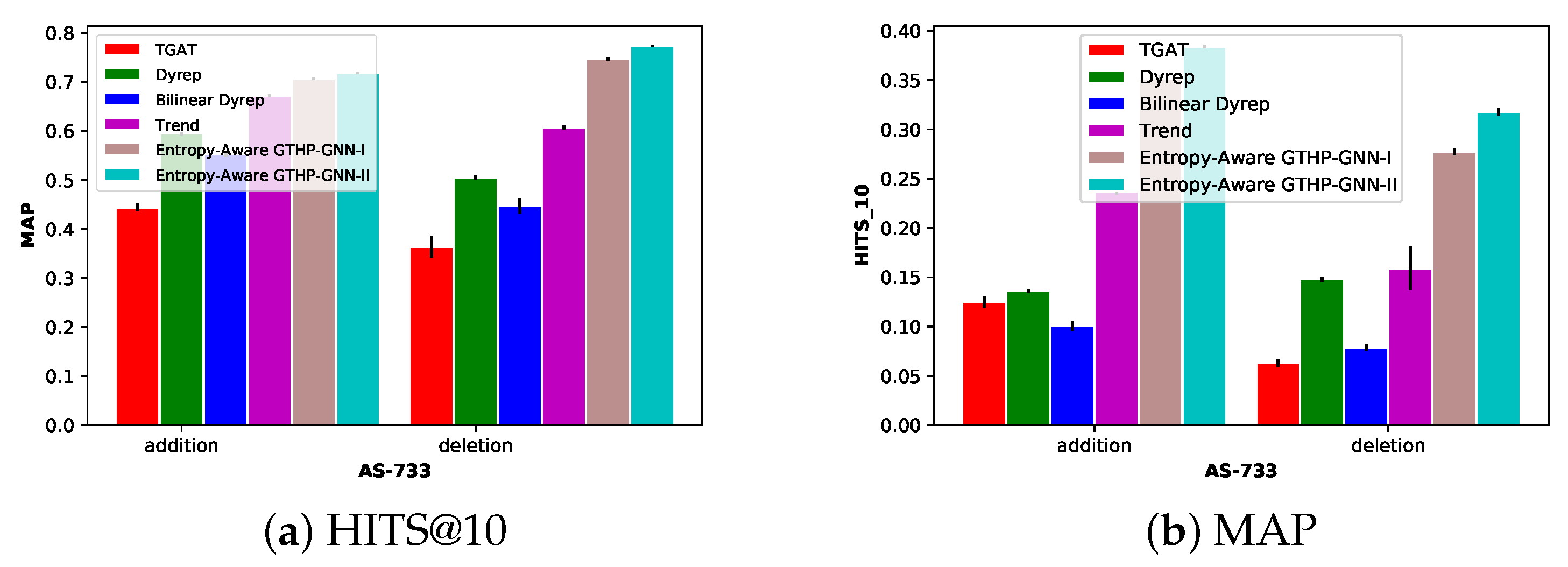
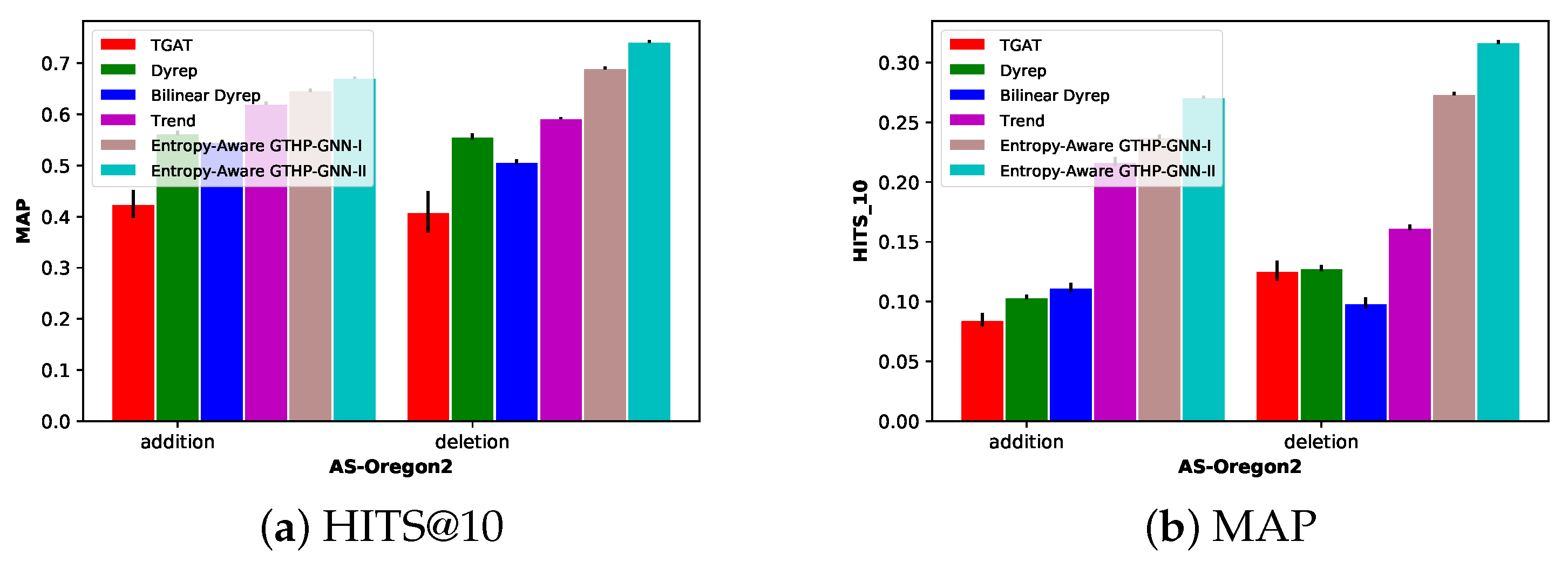
- They occur at a very different rate. For instance, in Autonomous System graph Oregon-2 (AS-Oregon-2) [26], deletion events comprise more than 70% of the total events in the entire dataset, whereas in AS-733 number of addition types is significantly larger than the number of deletion types.
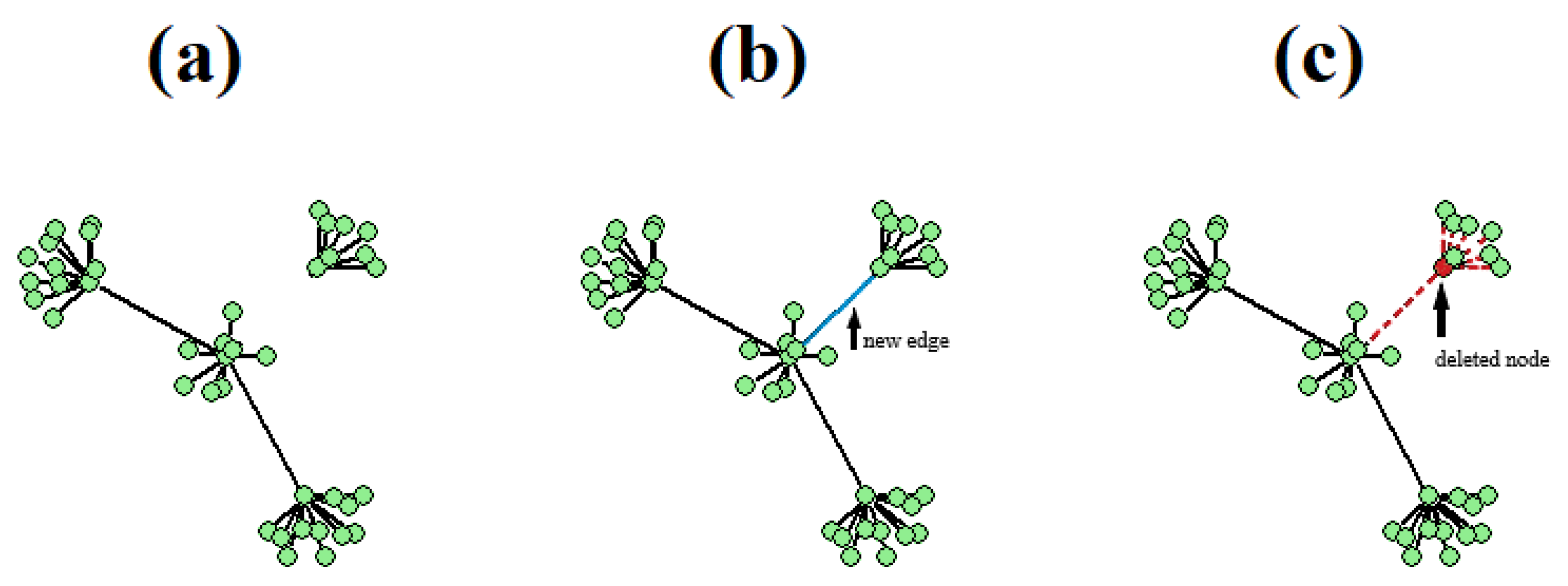
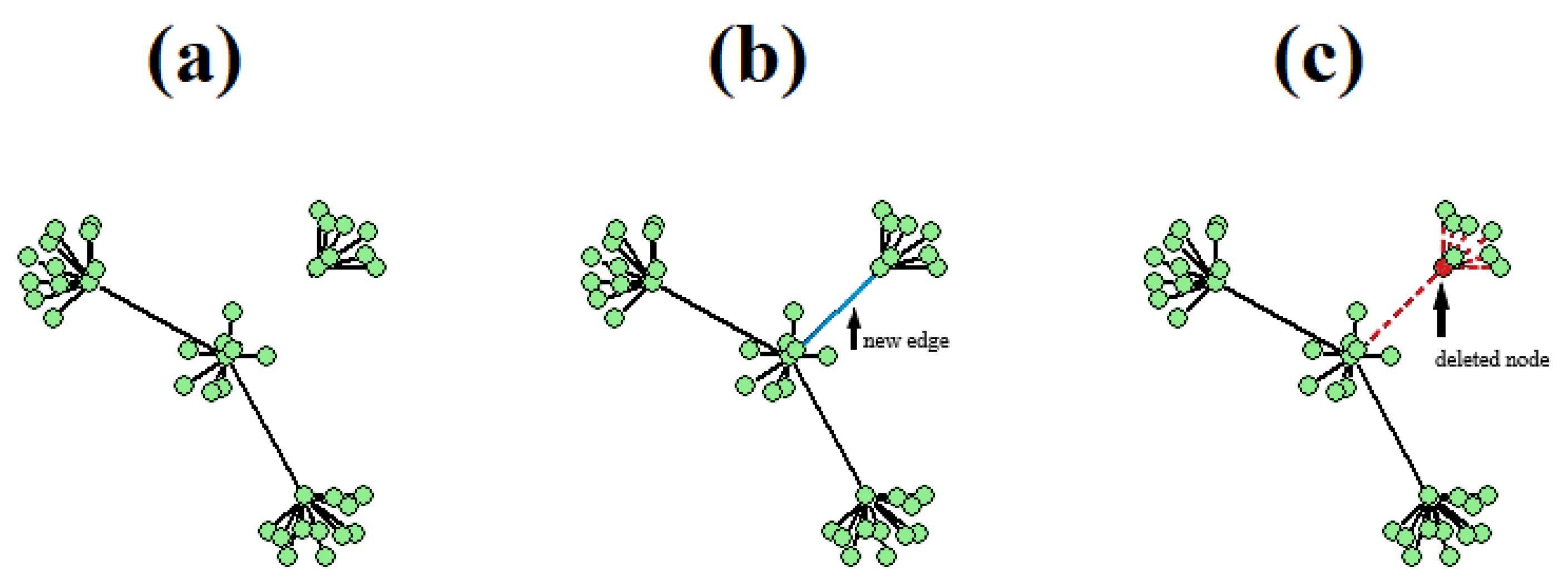
- Deletion of a node leads to the immediate removal of all the corresponding edges that the node used to connect to its neighbors, which may ultimately lead to breaking the graph to more than one isolated subgraph. This is not the case in addition event type, in which the new node does not instantly form a certain number of new edges.
- In many networks, the graph needs to be continuously connected and should thus respond adaptively to the combined effect of deletion and addition events by forming extra edges to maintain connectivity. For instance, in AS-733 dataset [26], for few selected subgraphs the graph is multiple nodes’ removal away from being disconnected. This explains why there are far more addition event types than deletion event types.
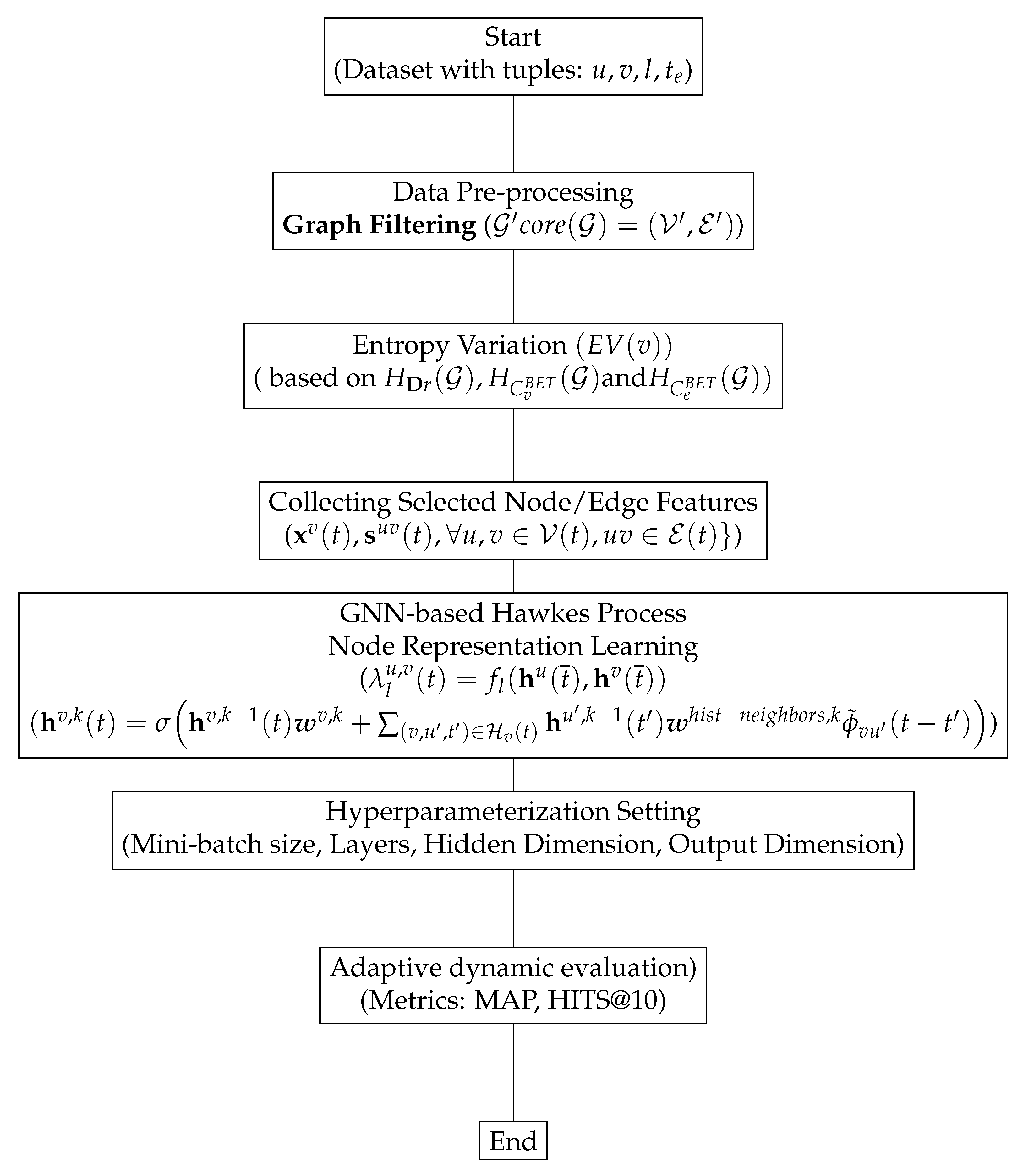
6. GNN-Based Hawkes Process for Node Representation Learning
Generalized Hawkes Process
7. Entropy-Aware GNN-Based Generalized Temporal Hawkes Process for Dynamic Link Prediction
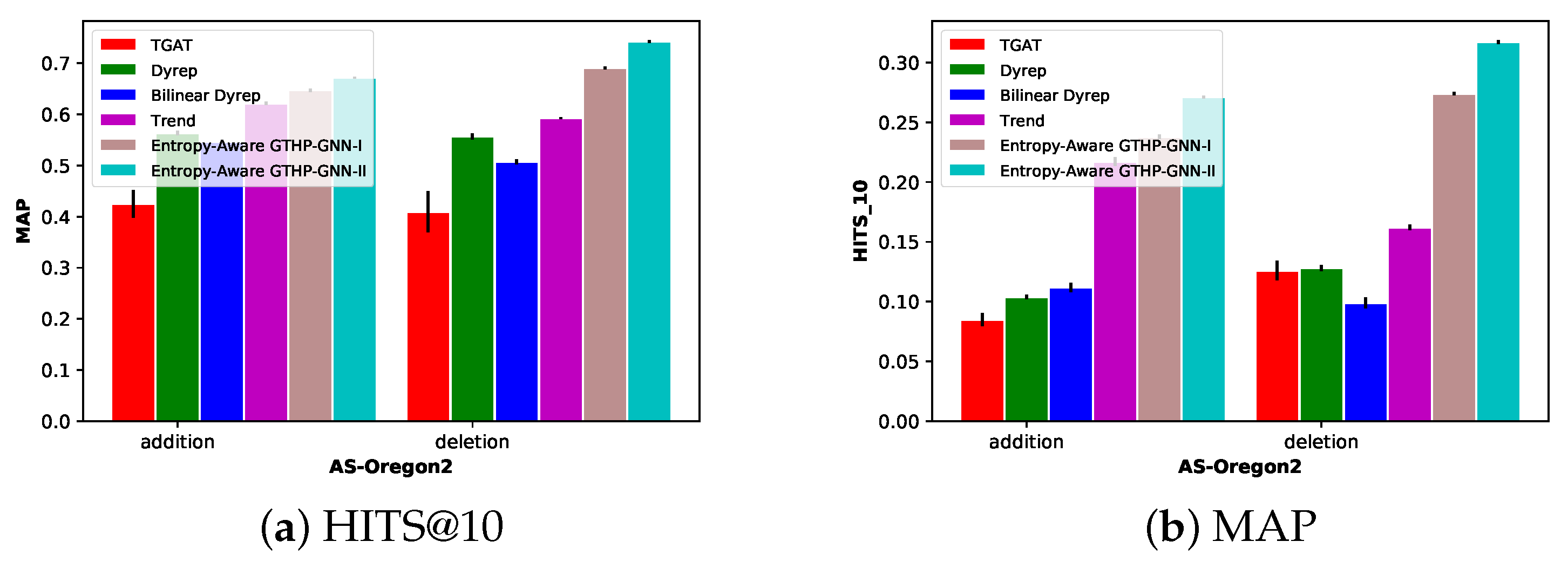
8. Performance Evaluation
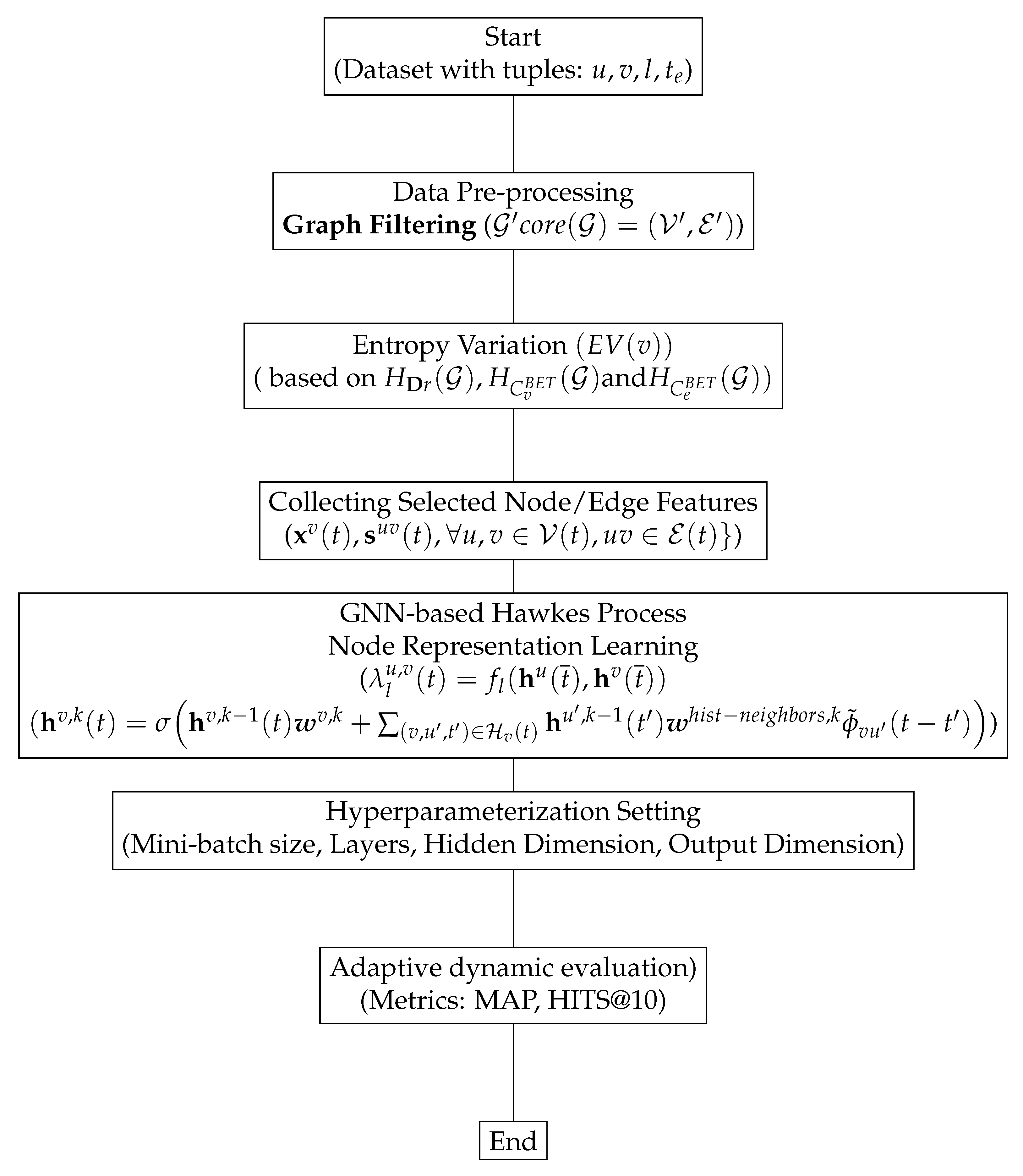
| Algorithm 1 Adaptive dynamic evaluation for Entropy-Aware GTHP-GNN |
| Input: Dynamic graph representation , Initial node states , Node features |
| Output: Updated node state representation , Mean average precision MAP |
|
8.1. Datasets
8.1.1. Autonomous System Dataset
8.1.2. AS-Oregon-2
8.2. Data Pre-Processing
- (I)
- Prominent ASes Highlighted: By eliminating nodes with fewer connections, the focus shifts towards the influential ASes, which often play a pivotal role in network operations.
- (II)
- Computational Efficiency Improved: The reduction in network size enhances the computational efficiency of the graph-based algorithms employed.
- (III)
- Noise Reduction: In complex networks, nodes with weak or trivial connections often contribute to noise. This noise is minimized by our filtering process, thereby emphasizing the more significant connections.
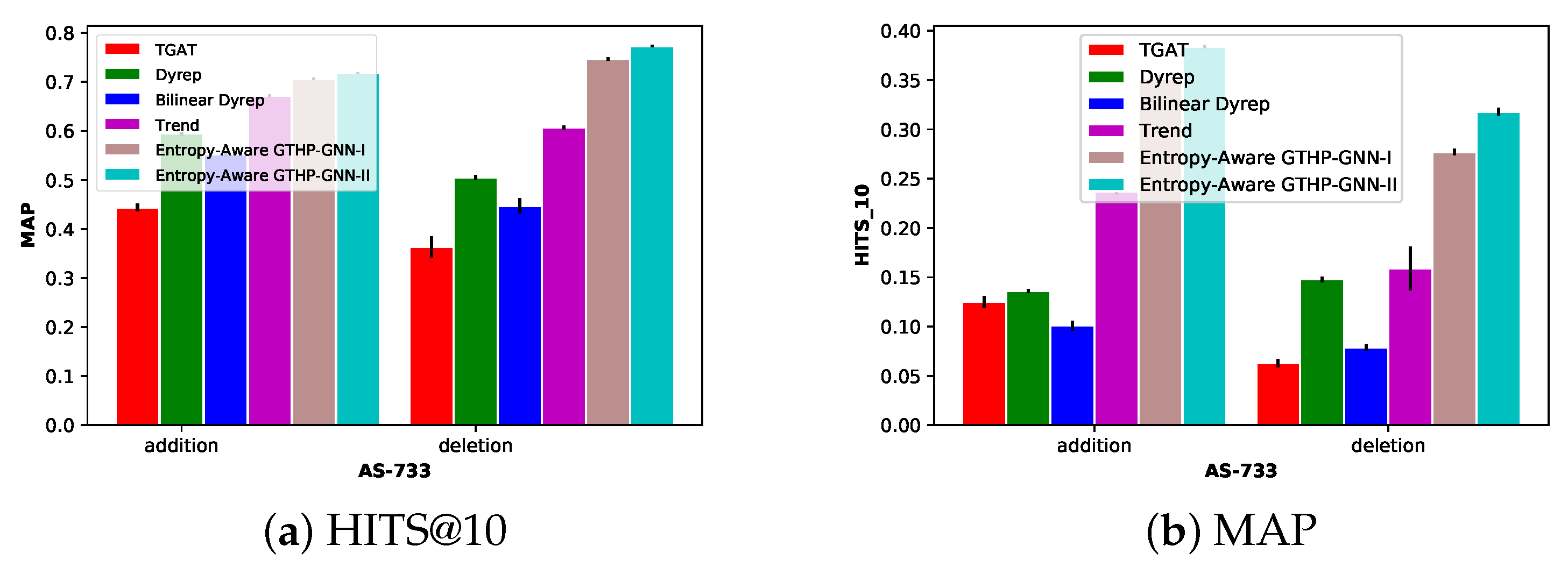
- (I)
- Generalized Hawkes Process: Unlike some benchmark models, the Entropy-Aware GTHP-GNN models, through the generalized Hawkes process, adeptly capture the temporal intricacies within the network. This ensures that the likelihood of an event’s occurrence is substantially influenced by past events, a critical feature in dynamic networks.
- (II)
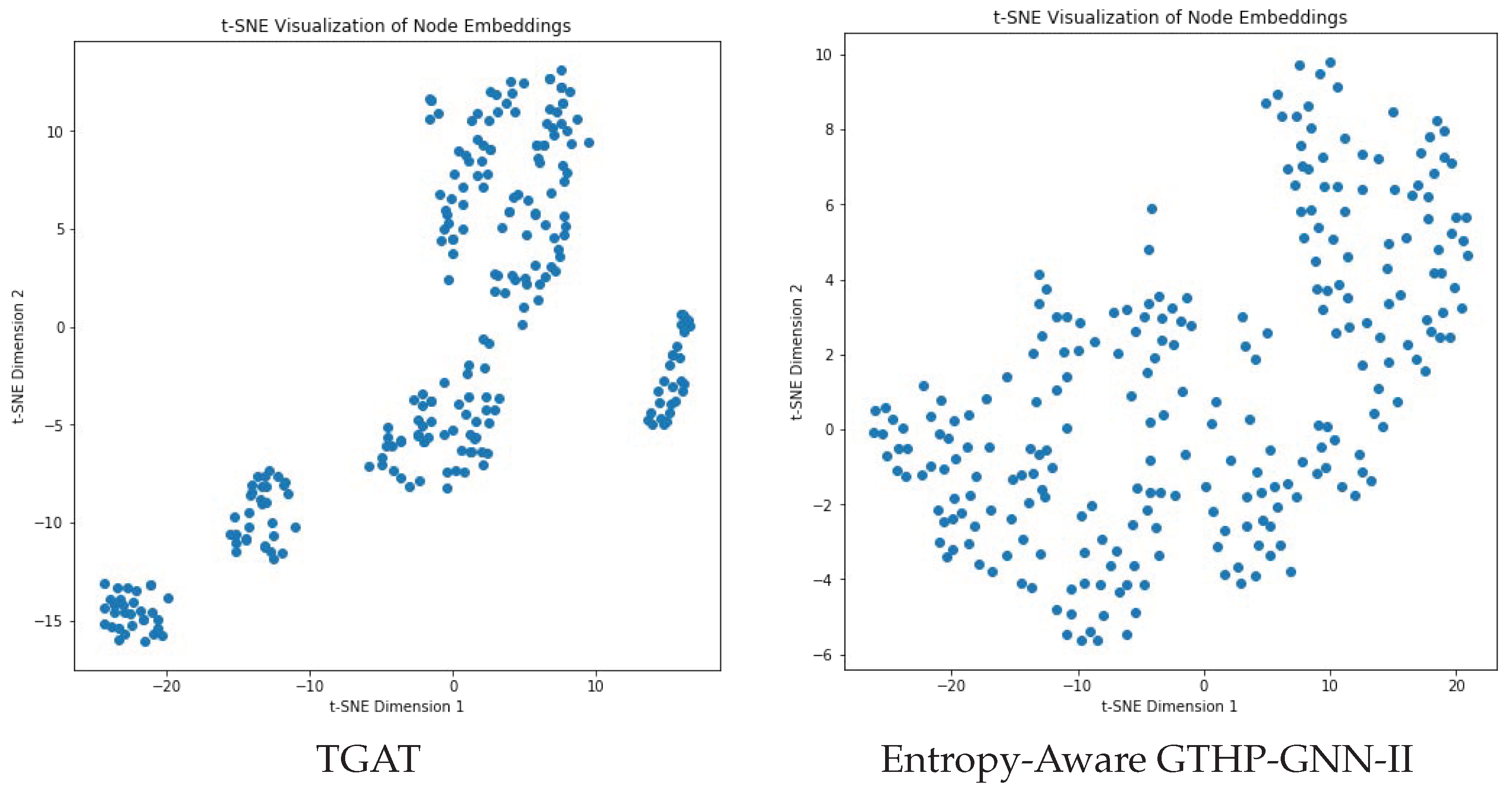
- Entropy Awareness: This model’s entropy-aware approach enables a deep comprehension of the evolving graph structure. By gauging the uncertainty or randomness of a node’s connections over time, the model can better predict connection trends, contributing to its high performance.
- (III)
- Dynamic Training: The adaptive nature of the model, which iteratively updates based on past graph snapshots and gauges performance on the most recent snapshot, bolsters its adaptability to changing graph structures and temporal dependencies.
- (IV)
- Transfer Functions: The dual approach of integrating both softmax and a creative GELU-based function accentuates the model’s versatility. While softmax offers a probabilistic classification of node connections, the modified GELU captures the complex, nuanced relationships within the graph.
8.3. Training Challenges and Limitations
9. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thakur, N.; Han, C.Y. A study of fall detection in assisted living: Identifying and improving the optimal machine learning method. J. Sens. Actuator Netw. 2021, 10, 39. [Google Scholar] [CrossRef]
- Bergamaschi, S.; De Nardis, S.; Martoglia, R.; Ruozzi, F.; Sala, L.; Vanzini, M.; Vigliermo, R.A. Novel perspectives for the management of multilingual and multialphabetic heritages through automatic knowledge extraction: The digitalmaktaba approach. Sensors 2022, 22, 3995. [Google Scholar] [CrossRef] [PubMed]
- Rizoiu, M.A.; Xie, L.; Sanner, S.; Cebrian, M.; Yu, H.; Van Hentenryck, P. Expecting to be hip: Hawkes intensity processes for social media popularity. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 735–744. [Google Scholar]
- Rossi, E.; Chamberlain, B.; Frasca, F.; Eynard, D.; Monti, F.; Bronstein, M. Temporal graph networks for deep learning on dynamic graphs. arXiv 2020, arXiv:2006.10637. [Google Scholar]
- Kumar, S.; Zhang, X.; Leskovec, J. Predicting dynamic embedding trajectory in temporal interaction networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1269–1278. [Google Scholar]
- Zhou, H.; Zheng, D.; Nisa, I.; Ioannidis, V.; Song, X.; Karypis, G. Tgl: A general framework for temporal gnn training on billion-scale graphs. arXiv 2022, arXiv:2203.14883. [Google Scholar] [CrossRef]
- Lee, D.; Lee, J.; Shin, K. Spear and Shield: Adversarial Attacks and Defense Methods for Model-Based Link Prediction on Continuous-Time Dynamic Graphs. arXiv 2023, arXiv:2308.10779. [Google Scholar]
- Cong, W.; Zhang, S.; Kang, J.; Yuan, B.; Wu, H.; Zhou, X.; Tong, H.; Mahdavi, M. Do We Really Need Complicated Model Architectures For Temporal Networks? arXiv 2023, arXiv:2302.11636. [Google Scholar]
- Xu, D.; Ruan, C.; Korpeoglu, E.; Kumar, S.; Achan, K. Inductive representation learning on temporal graphs. arXiv 2020, arXiv:2002.07962. [Google Scholar]
- Trivedi, R.; Farajtabar, M.; Biswal, P.; Zha, H. Dyrep: Learning representations over dynamic graphs. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Knyazev, B.; Augusta, C.; Taylor, G.W. Learning temporal attention in dynamic graphs with bilinear interactions. PLoS ONE 2021, 16, e0247936. [Google Scholar] [CrossRef]
- Kipf, T.; Fetaya, E.; Wang, K.C.; Welling, M.; Zemel, R. Neural relational inference for interacting systems. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2688–2697. [Google Scholar]
- Wen, Z.; Fang, Y. TREND: TempoRal Event and Node Dynamics for Graph Representation Learning. In Proceedings of the ACM Web Conference 2022, Virtual, 25–29 April 2022; pp. 1159–1169. [Google Scholar]
- Moallemy-Oureh, A.; Beddar-Wiesing, S.; Nather, R.; Thomas, J.M. FDGNN: Fully Dynamic Graph Neural Network. arXiv 2022, arXiv:2206.03469. [Google Scholar]
- Muro, C.; Li, B.; He, K. Link Prediction and Unlink Prediction on Dynamic Networks. IEEE Trans. Comput. Soc. Syst. 2022, 10, 590–601. [Google Scholar] [CrossRef]
- Daley, D.J.; Vere-Jones, D. An Introduction to the Theory of Point Processes: Volume I: Elementary Theory and Methods; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Therneau, T.; Crowson, C.; Atkinson, E. Using time dependent covariates and time dependent coefficients in the cox model. Surviv. Vignettes 2017, 2, 1–25. [Google Scholar]
- Ai, X. Node importance ranking of complex networks with entropy variation. Entropy 2017, 19, 303. [Google Scholar] [CrossRef]
- Borgatti, S.P.; Everett, M.G. A graph-theoretic perspective on centrality. Soc. Netw. 2006, 28, 466–484. [Google Scholar] [CrossRef]
- Goh, K.I.; Kahng, B.; Kim, D. Fluctuation-driven dynamics of the Internet topology. Phys. Rev. Lett. 2002, 88, 108701. [Google Scholar] [CrossRef] [PubMed]
- Maslov, S.; Sneppen, K. Specificity and stability in topology of protein networks. Science 2002, 296, 910–913. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E. Mixing patterns in networks. Phys. Rev. E 2003, 67, 026126. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E. Assortative mixing in networks. Phys. Rev. Lett. 2002, 89, 208701. [Google Scholar] [CrossRef]
- Deng, K.; Zhao, H.; Li, D. Effect of node deleting on network structure. Phys. A Stat. Mech. Its Appl. 2007, 379, 714–726. [Google Scholar] [CrossRef]
- Brandes, U. On variants of shortest-path betweenness centrality and their generic computation. Soc. Netw. 2008, 30, 136–145. [Google Scholar] [CrossRef]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graphs over time: Densification laws, shrinking diameters and possible explanations. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 177–187. [Google Scholar]
- Mei, H.; Eisner, J.M. The neural hawkes process: A neurally self-modulating multivariate point process. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Holme, P.; Saramäki, J. Temporal networks. Phys. Rep. 2012, 519, 97–125. [Google Scholar] [CrossRef]
- Goyal, P.; Kamra, N.; He, X.; Liu, Y. Dyngem: Deep embedding method for dynamic graphs. arXiv 2018, arXiv:1805.11273. [Google Scholar]
- Li, T.; Zhang, J.; Philip, S.Y.; Zhang, Y.; Yan, Y. Deep dynamic network embedding for link prediction. IEEE Access 2018, 6, 29219–29230. [Google Scholar] [CrossRef]
- Sankar, A.; Wu, Y.; Gou, L.; Zhang, W.; Yang, H. Dysat: Deep neural representation learning on dynamic graphs via self-attention networks. In Proceedings of the 13th International Conference on Web Search and Data Mining, Virtual, 10–13 July 2020; pp. 519–527. [Google Scholar]
- Zhou, L.; Yang, Y.; Ren, X.; Wu, F.; Zhuang, Y. Dynamic network embedding by modeling triadic closure process. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Nguyen, G.H.; Lee, J.B.; Rossi, R.A.; Ahmed, N.K.; Koh, E.; Kim, S. Continuous-time dynamic network embeddings. In Proceedings of the Companion Proceedings of the the Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 969–976. [Google Scholar]
- Zuo, Y.; Liu, G.; Lin, H.; Guo, J.; Hu, X.; Wu, J. Embedding temporal network via neighborhood formation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2857–2866. [Google Scholar]
- Hawkes, A.G. Spectra of some self-exciting and mutually exciting point processes. Biometrika 1971, 58, 83–90. [Google Scholar] [CrossRef]
- Lu, Y.; Wang, X.; Shi, C.; Yu, P.S.; Ye, Y. Temporal network embedding with micro-and macro-dynamics. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 469–478. [Google Scholar]
- Jensen, A. Statistical Equilibrium. In Traffic Equilibrium Methods, Proceedings of the International Symposium Held at the University of Montreal, Montreal, QC, Canada, 21–23 November 1974; Springer: Berlin/Heidelberg, Germany, 1974; pp. 132–146. [Google Scholar]
- You, J.; Du, T.; Leskovec, J. ROLAND: Graph learning framework for dynamic graphs. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2358–2366. [Google Scholar]
- Siganos, G.; Faloutsos, M.; Faloutsos, P.; Faloutsos, C. Power laws and the AS-level Internet topology. IEEE/ACM Trans. Netw. 2003, 11, 514–524. [Google Scholar] [CrossRef]
- Tauro, S.L.; Palmer, C.; Siganos, G.; Faloutsos, M. A simple conceptual model for the internet topology. In Proceedings of the GLOBECOM’01, IEEE Global Telecommunications Conference (Cat. No. 01CH37270), San Antonio, TX, USA, 25–29 November 2001; Volume 3, pp. 1667–1671. [Google Scholar]
- Gaertler, M.; Patrignani, M. Dynamic analysis of the autonomous system graph. In Proceedings of the IPS 2004, International Workshop on Inter-Domain Performance and Simulation, Budapest, Hungary, 22–23 March 2004; pp. 13–24. [Google Scholar]
- Seidman, S.B. Network structure and minimum degree. Soc. Netw. 1983, 5, 269–287. [Google Scholar] [CrossRef]
- Brandes, U.; Gaertler, M.; Wagner, D. Experiments on graph clustering algorithms. In Proceedings of the Algorithms-ESA 2003: 11th Annual European Symposium, Budapest, Hungary, 16–19 September 2003; Proceedings 11. Springer: Berlin/Heidelberg, Germany, 2003; pp. 568–579. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Gastaldi, X. Shake-shake regularization. arXiv 2017, arXiv:1705.07485. [Google Scholar]
- Gavin, D.G. K1D: Multivariate Ripley’s K-Function for One-Dimensional Data; University of Oregon: Eugene, OR, USA, 2010; Volume 80. [Google Scholar]
- Wiegand, T.; A. Moloney, K. Rings, circles, and null-models for point pattern analysis in ecology. Oikos 2004, 104, 209–229. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Node/Link Addition | Node/Link Removal | Graph Structural Information | Node Attributes | Edge Attributes |
|---|---|---|---|---|---|
| Bilinear Dyrep [11] | ✔ | × | × | ✔ | × |
| FDGNN [14] | ✔ | ✔ | × | ✔ | × |
| LULS [15] | ✔ | ✔ | ✔ | × | × |
| Trend [13] | ✔ | × | × | × | × |
| Dyrep [10] | ✔ | × | ✔ | × | × |
| Entropy-Aware GTHP-GNN | ✔ | ✔ | ✔ | ✔ | ✔ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Najafi, B.; Parsaeefard, S.; Leon-Garcia, A. Entropy-Aware Time-Varying Graph Neural Networks with Generalized Temporal Hawkes Process: Dynamic Link Prediction in the Presence of Node Addition and Deletion. Mach. Learn. Knowl. Extr. 2023, 5, 1359-1381. https://doi.org/10.3390/make5040069
Najafi B, Parsaeefard S, Leon-Garcia A. Entropy-Aware Time-Varying Graph Neural Networks with Generalized Temporal Hawkes Process: Dynamic Link Prediction in the Presence of Node Addition and Deletion. Machine Learning and Knowledge Extraction. 2023; 5(4):1359-1381. https://doi.org/10.3390/make5040069
Chicago/Turabian StyleNajafi, Bahareh, Saeedeh Parsaeefard, and Alberto Leon-Garcia. 2023. "Entropy-Aware Time-Varying Graph Neural Networks with Generalized Temporal Hawkes Process: Dynamic Link Prediction in the Presence of Node Addition and Deletion" Machine Learning and Knowledge Extraction 5, no. 4: 1359-1381. https://doi.org/10.3390/make5040069
APA StyleNajafi, B., Parsaeefard, S., & Leon-Garcia, A. (2023). Entropy-Aware Time-Varying Graph Neural Networks with Generalized Temporal Hawkes Process: Dynamic Link Prediction in the Presence of Node Addition and Deletion. Machine Learning and Knowledge Extraction, 5(4), 1359-1381. https://doi.org/10.3390/make5040069