Bag of ARSRG Words (BoAW)


Abstract
:1. Introduction
2. Related Work
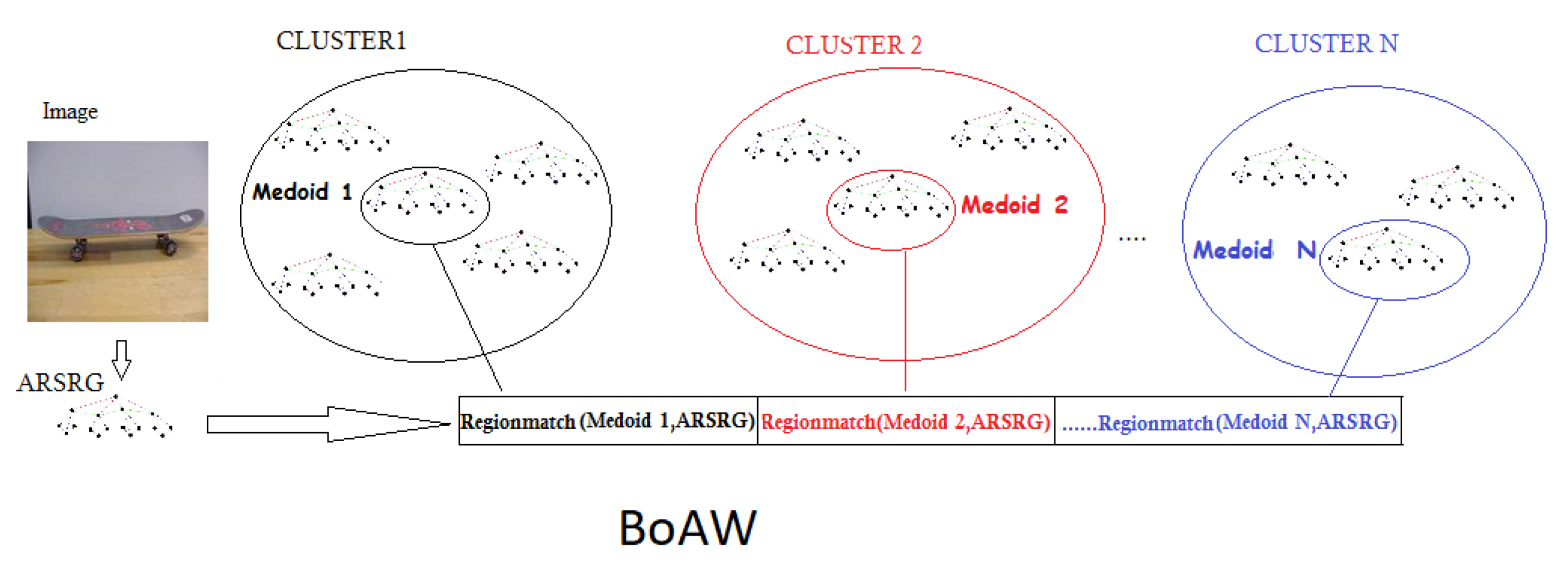
3. Bag of ARSRG Words
- Image to graph (lines 2–4). The image is represented using a graph structure named ARSRG [1]. From now, we will identify the ARSRG structure simply as a graph;
- Similarity matrix (line 8). A matrix to store the distance of a fixed number of graphs for each image class is created;
- Graph words vocabulary (line 9). A clustering algorithm on the similarity matrix is applied. The goal is the production of a vocabulary consisting of the graph prototypes of each cluster.
- Graph to vector (lines 10–12). Similarities between graphs and graph prototypes of vocabulary are calculated. The ith element of the BoAW vector represents a graph which will be equal to the distance between the ith element of the vocabulary and the graph itself;
- Image classification (line 13). An algorithm in the vector space for the classification phase is adopted;
| Algorithm 1 |
|
3.1. Image to Graph: ARSRG
- is a set of region nodes;
- is a set of unidirectional edge, where and is an edge between two nodes ;
- is a set of SIFT nodes;
- is a set of directional edge, where e is an edge from the source node to a destination node ;
3.2. Similarity Matrix
3.3. Graph Words Vocabulary
- k points are randomly chosen from the n data and are considered as initial medoids;
- Each point is associated with the nearest medoid, using the input similarity matrix;
- For each medoid m and for each non-medial point x, m with x is exchanged and the total cost configuration is calculated;
- The minimum cost configuration is chosen and the procedure is repeated from step 2. The cost is defined as
- The procedure is repeated until the configuration within each cluster remains practically unchanged.
3.4. Graph to Vector
4. Results
4.1. Datasets
- Amsterdam Library of Object Images (ALOI) [19]. It is a color image selection of 1000 small objects. Objects was recorded varying viewing angle, illumination angle and illumination color in order to capture the sensory variation. In addition was captured wide-baseline stereo image.
- Caltech 101 [20]. It is an objects image collection belonging to 101 categories, with about 40 to 800 images per category. Most categories have about 50 images.
- Columbia Object Image Library (COIL-100) [21]. It is a image collection of 100 objects. The images were taken at pose internals of 5 degrees.
- The ETH-80 [22]. It is a image collection of 80 objects from 8 categories. Each object is described by 41 different views, thus obtaining a total of 3280 images.
4.2. Experimental Setup
- TP. Positive classified image belonging to the positive class;
- TN. Negative classified image belonging to the negative class;
- FP. Positive classified image belonging to the negative class;
- FN. Negative classified image belonging to the positive class;
4.2.1. ALOI
4.2.2. Caltech 101
4.2.3. COIL-100
4.2.4. ETH-80
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Manzo, M.; Petrosino, A. Attributed relational sift-based regions graph for art painting retrieval. In Proceedings of the International Conference on Image Analysis and Processing, Naples, Italy, 9–13 September 2013; Springer: Berlin, Germany, 2013; pp. 833–842. [Google Scholar]
- Silva, F.B.; Werneck, R.d.O.; Goldenstein, S.; Tabbone, S.; Torres, R.d.S. Graph-based bag-of-words for classification. Pattern Recognit. 2018, 74, 266–285. [Google Scholar] [CrossRef]
- Bhuiyan, M.; Al Hasan, M. Representing Graphs as Bag of Vertices and Partitions for Graph Classification. Data Sci. Eng. 2018, 3, 150–165. [Google Scholar] [CrossRef] [Green Version]
- Da Silva, F.B.; Goldenstein, S.; Tabbone, S.; Torres, R.D.S. Image classification based on bag of visual graphs. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Melbourne, VIC, Australia, 15–18 September 2013; pp. 4312–4316. [Google Scholar]
- Hu, D.; Xu, Q.; Tang, J.; Luo, B. Multi-scale Attributed Graph Kernel for Image Categorization. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; Springer: Berlin, Germany, 2018; pp. 610–621. [Google Scholar]
- Clément, M.; Kurtz, C.; Wendling, L. Learning spatial relations and shapes for structural object description and scene recognition. Pattern Recognit. 2018, 84, 197–210. [Google Scholar] [CrossRef]
- Cortés, X.; Conte, D.; Cardot, H. Bags of Graphs for Human Action Recognition. In Proceedings of the Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR), Beijing, China, 17–19 August 2018; Springer: Berlin, Germany, 2018; pp. 429–438. [Google Scholar] [Green Version]
- Penatti, O.A.; Silva, F.B.; Valle, E.; Gouet-Brunet, V.; Torres, R.D.S. Visual word spatial arrangement for image retrieval and classification. Pattern Recognit. 2014, 47, 705–720. [Google Scholar] [CrossRef]
- Ali, N.; Zafar, B.; Riaz, F.; Dar, S.H.; Ratyal, N.I.; Bajwa, K.B.; Iqbal, M.K.; Sajid, M. A hybrid geometric spatial image representation for scene classification. PLoS ONE 2018, 13, e0203339. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Tang, J.; Jin, G.; Zhang, Y.; Tian, Q. Region similarity arrangement for large-scale image retrieval. Neurocomputing 2018, 272, 461–470. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Liu, Y.; Liu, S.; Wang, Z. Multi-focus image fusion with dense SIFT. Inform. Fus. 2015, 23, 139–155. [Google Scholar] [CrossRef]
- Trémeau, A.; Colantoni, P. Regions adjacency graph applied to color image segmentation. IEEE Trans. Image Process. 2000, 9, 735–744. [Google Scholar] [CrossRef] [PubMed]
- Deng, Y.; Manjunath, B. Unsupervised segmentation of color-texture regions in images and video. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 800–810. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 99, pp. 1150–1157. [Google Scholar]
- Sanromà Güell, G.; Alquézar Mancho, R.; Serratosa Casanelles, F. Graph matching using sift descriptors: an application to pose recovery of a mobile robot. In Proceedings of the 5th International Conference on Computer Vision Theory and Applications, Angers, France, 17–21 May 2010; pp. 249–254. [Google Scholar]
- Szeliski, R. Computer Vision Algorithms and Application; Springer: Berlin, Germany, 2003. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction To Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Geusebroek, J.M.; Burghouts, G.J.; Smeulders, A.W. The Amsterdam library of object images. Int. J. Comput. Vis. 2005, 61, 103–112. [Google Scholar] [CrossRef]
- Fei-Fei, L.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. Comput. Vis. Image Underst. 2007, 106, 59–70. [Google Scholar] [CrossRef]
- Nene, S.A.; Nayar, S.K.; Murase, H. Object Image Library (Coil-100). Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.360.6420 (accessed on 1 August 2019).
- Leibe, B.; Schiele, B. Analyzing appearance and contour based methods for object categorization. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; Volume 2, p. II–409. [Google Scholar]
- Kobayashi, T.; Watanabe, K.; Otsu, N. Logistic label propagation. Pattern Recognit. Lett. 2012, 33, 580–588. [Google Scholar] [CrossRef] [Green Version]
- Uray, M.; Skocaj, D.; Roth, P.M.; Bischof, H.; Leonardis, A. Incremental LDA Learning by Combining Reconstructive and Discriminative Approaches. In Proceedings of the British Machine Vision Conference 2007 (BMVC), Warwick, UK, 10–13 September 2007; pp. 1–10. [Google Scholar]
- Manzo, M.; Pellino, S.; Petrosino, A.; Rozza, A. A novel graph embedding framework for object recognition. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 341–352. [Google Scholar]
- Morales-González, A.; Acosta-Mendoza, N.; Gago-Alonso, A.; García-Reyes, E.B.; Medina-Pagola, J.E. A new proposal for graph-based image classification using frequent approximate subgraphs. Pattern Recognit. 2014, 47, 169–177. [Google Scholar] [CrossRef]
- Morales-González, A.; García-Reyes, E.B. Simple object recognition based on spatial relations and visual features represented using irregular pyramids. Multimed. Tools Appl. 2013, 63, 875–897. [Google Scholar] [CrossRef]
- Gago-Alonso, A.; Carrasco-Ochoa, J.A.; Medina-Pagola, J.E.; Fco, J.; Martínez-Trinidad, J.F. Full duplicate candidate pruning for frequent connected subgraph mining. Integr. Comput. Aided Eng. 2010, 17, 211–225. [Google Scholar] [CrossRef] [Green Version]
- Jia, Y.; Zhang, J.; Huan, J. An efficient graph-mining method for complicated and noisy data with real-world applications. Knowl. Inf. Syst. 2011, 28, 423–447. [Google Scholar] [CrossRef]
- Acosta-Mendoza, N.; Gago-Alonso, A.; Medina-Pagola, J.E. Frequent approximate subgraphs as features for graph-based image classification. Knowl. Based Syst. 2012, 27, 381–392. [Google Scholar] [CrossRef]
- Wang, Y.; Gong, S. Tensor discriminant analysis for view-based object recognition. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; Volume 3, pp. 33–36. [Google Scholar]
- Marée, R.; Geurts, P.; Piater, J.; Wehenkel, L. Decision trees and random subwindows for object recognition. In Proceedings of the ICML Workshop on Machine Learning Techniques for Processing Multimedia Content (MLMM2005), Bonn, Germany, 11 August 2005. [Google Scholar]
- Morioka, N. Learning object representations using sequential patterns. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Auckland, New Zealand, 1–5 December 2008; Springer: Berlin, Germany, 2008; pp. 551–561. [Google Scholar]
- Obdrzalek, S.; Matas, J. Proceedings of the Object Recognition using Local Affine Frames on Distinguished Regions, Cardiff, UK, 2–5 September 2002; Volume 2, pp. 113–122.


{kind=link}
{kind=link}
| Method | 200 | 400 | 800 | 1200 | 1600 | 2000 | 2400 | 2800 | 3200 | 3600 |
|---|---|---|---|---|---|---|---|---|---|---|
| BoAW | 98.29% | 92.83% | 98.80% | 96.80% | 96.76% | 98.15% | 89.52% | 82.65% | 79.96% | 79.88% |
| ARSRGemb | 86.00% | 90.00% | 93.00% | 96.00% | 95.62% | 96.00% | 88.00% | 81.89% | 79.17% | 79.78% |
| BoVW | 49.60% | 55.00% | 50.42% | 50.13% | 49.81% | 48.88% | 49.52% | 49.65% | 48.96% | 49.10% |
| batchLDA | 51.00% | 52.00% | 62.00% | 62.00% | 70.00% | 71.00% | 74.00% | 75.00% | 75.00% | 77.00% |
| ILDAaPCA | 51.00% | 42.00% | 53.00% | 48.00% | 45.00% | 50.00% | 51.00% | 49.00% | 49.00% | 50.00% |
| ILDAonK | 42.00% | 45.00% | 53.00% | 48.00% | 45.00% | 51.00% | 51.00% | 49.00% | 49.00% | 50.00% |
| ILDAonL | 51.00% | 52.00% | 61.00% | 61.00% | 65.00% | 69.00% | 71.00% | 70.00% | 71.00% | 72.00% |
| Method | Accuracy |
|---|---|
| BoAW | 74.00% |
| BoVW | 83.00% |
| Method | Accuracy |
|---|---|
| BoAW | 99.77% |
| ARSRGemb | 99.55% |
| BoVW | 51.71% |
| gdFil | 32.61% |
| VFSR | 91.60% |
| APGM | 99.11% |
| VEAM | 99.44% |
| DTROD-AdaBoost | 84.50% |
| RSW+Boosting | 89.20% |
| Sequential Patterns | 89.80% |
| LAF | 99.40% |
| Method | Accuracy |
|---|---|
| BoAW | 89.29% |
| ARSRGemb | 89.26% |
| BoW | 58.83% |
| gdFil | 47.59% |
| APGM | 84.39% |
| VEAM | 82.68% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Manzo, M.; Pellino, S. Bag of ARSRG Words (BoAW). Mach. Learn. Knowl. Extr. 2019, 1, 871-882. https://doi.org/10.3390/make1030050
Manzo M, Pellino S. Bag of ARSRG Words (BoAW). Machine Learning and Knowledge Extraction. 2019; 1(3):871-882. https://doi.org/10.3390/make1030050
Chicago/Turabian StyleManzo, Mario, and Simone Pellino. 2019. "Bag of ARSRG Words (BoAW)" Machine Learning and Knowledge Extraction 1, no. 3: 871-882. https://doi.org/10.3390/make1030050
APA StyleManzo, M., & Pellino, S. (2019). Bag of ARSRG Words (BoAW). Machine Learning and Knowledge Extraction, 1(3), 871-882. https://doi.org/10.3390/make1030050