Deep Learning Based Object Recognition Using Physically-Realistic Synthetic Depth Scenes

 , ,
, ,
Abstract
1. Introduction
- developing a method of generating physically realistic synthetic depth data with automated labeling including bounding box refinement;
- sdapting Faster R-CNN architecture designed for training on 8-bit three-channel RGB images to 16-bit one-channel depth images and training it from scratch; and
- demonstrating that an object detector trained only on synthetic depth images is capable of detecting real-world depth images with high accuracy.
2. Depth-Image-Based Object Detection
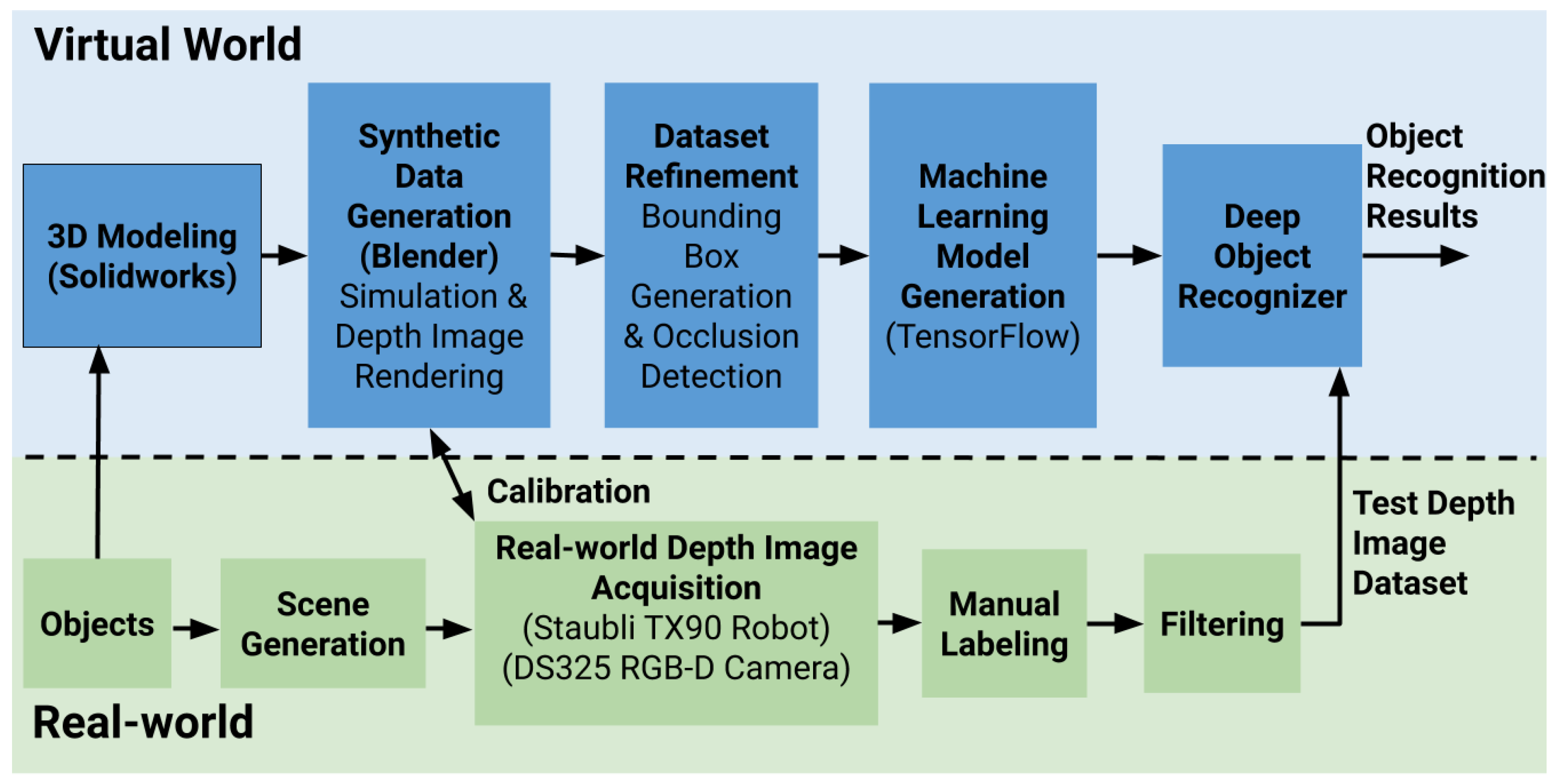
3. Dataset Generation
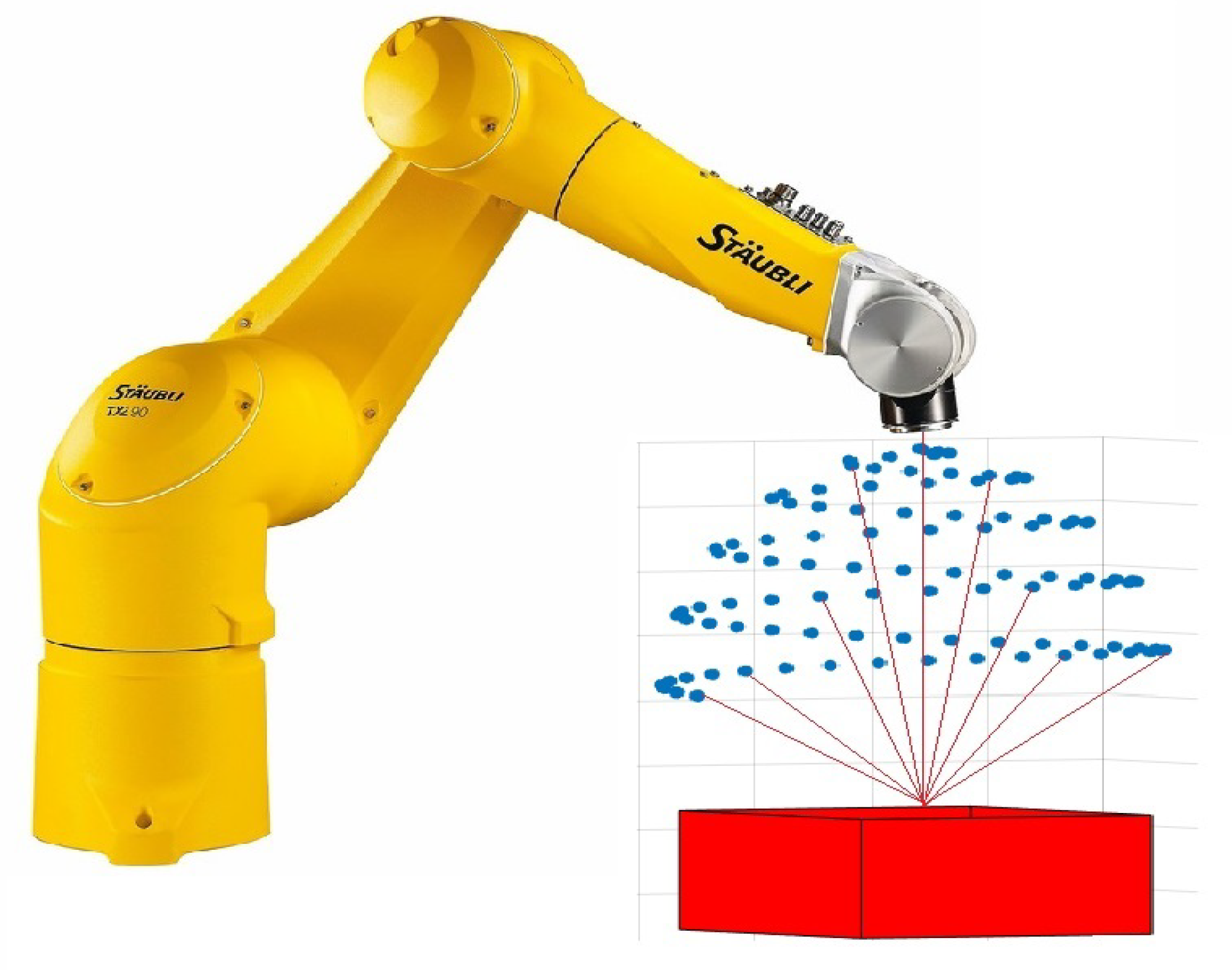
3.1. Real-World Dataset Generation
3.2. Synthetic Dataset Generation
- Synthesis of a realistic scene (i.e., the box with objects)
- Generation of depth and object silhouette images
- Generation of bounding boxes and occlusion refinement
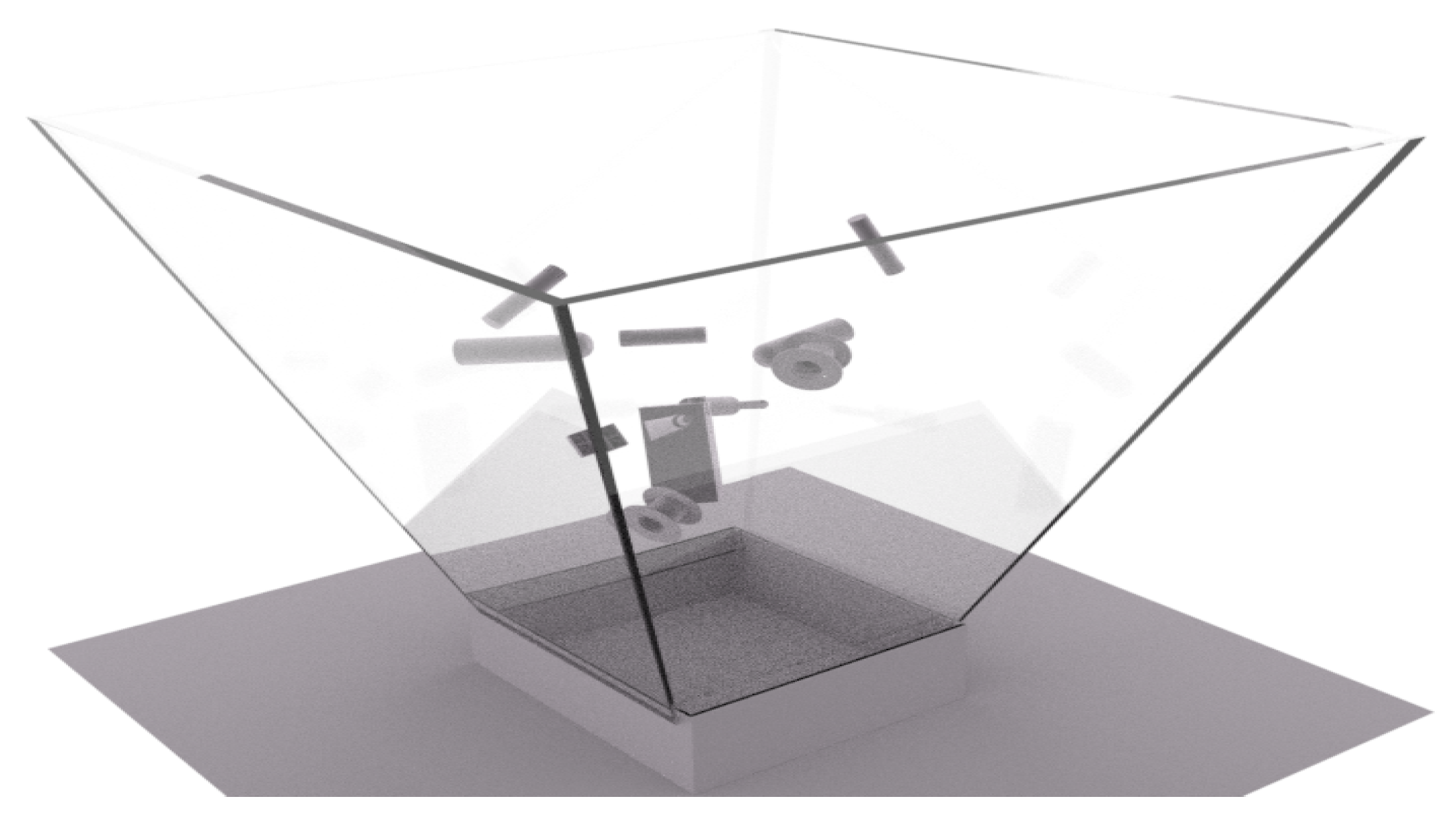
3.2.1. Cluttered Scene Synthesis
- Set the camera pose for the frame i.
- Render the depth image for the frame i.
- Generate n black and white (BW) object shape silhouettes for n objects within each frame i.
3.2.2. Generation of Depth and Object Silhouette Images
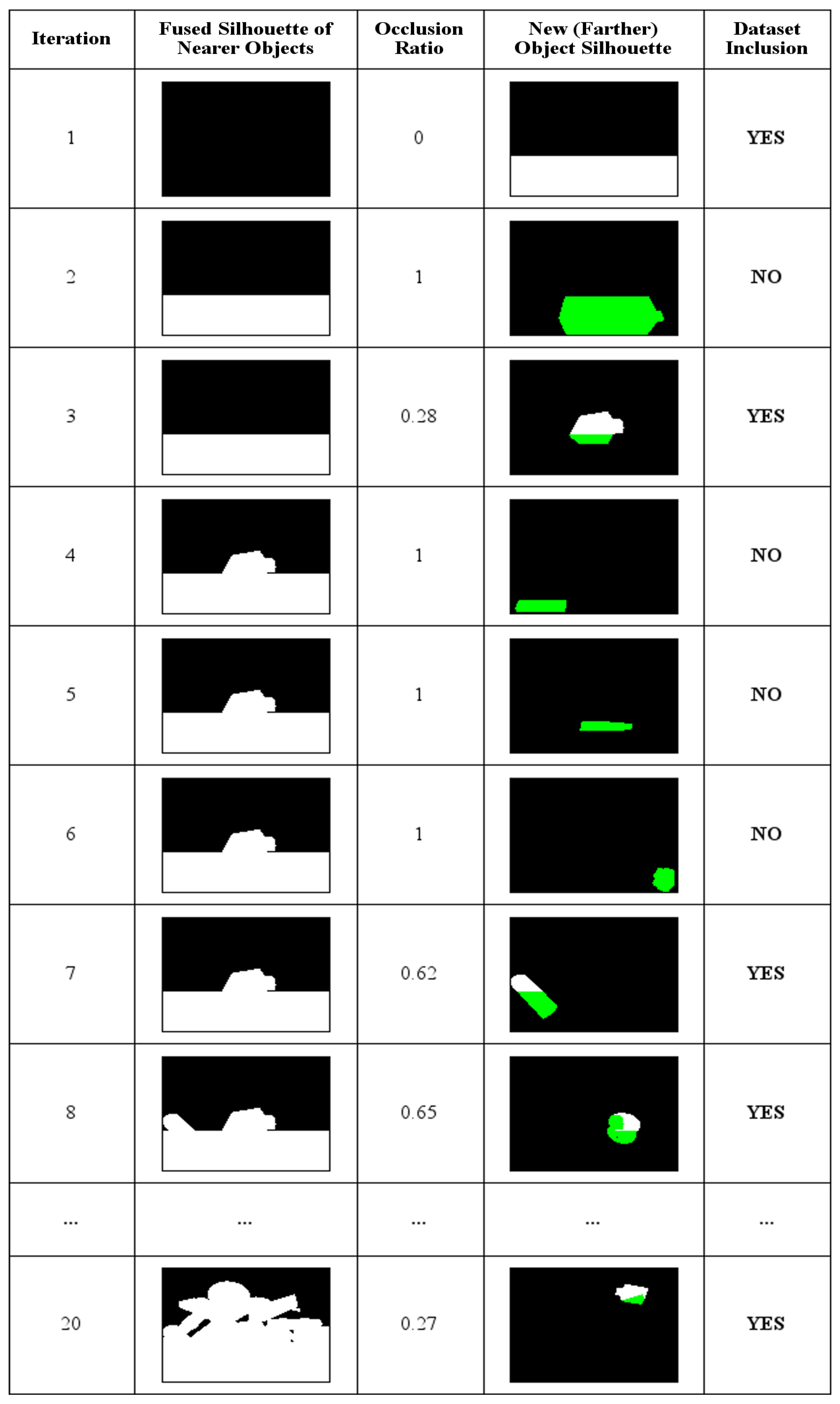
3.2.3. Generation of Bounding Boxes and Occlusion Refinement
- More than 70% of the object is occluded.
- The object is fully or mostly out of the camera’s view.
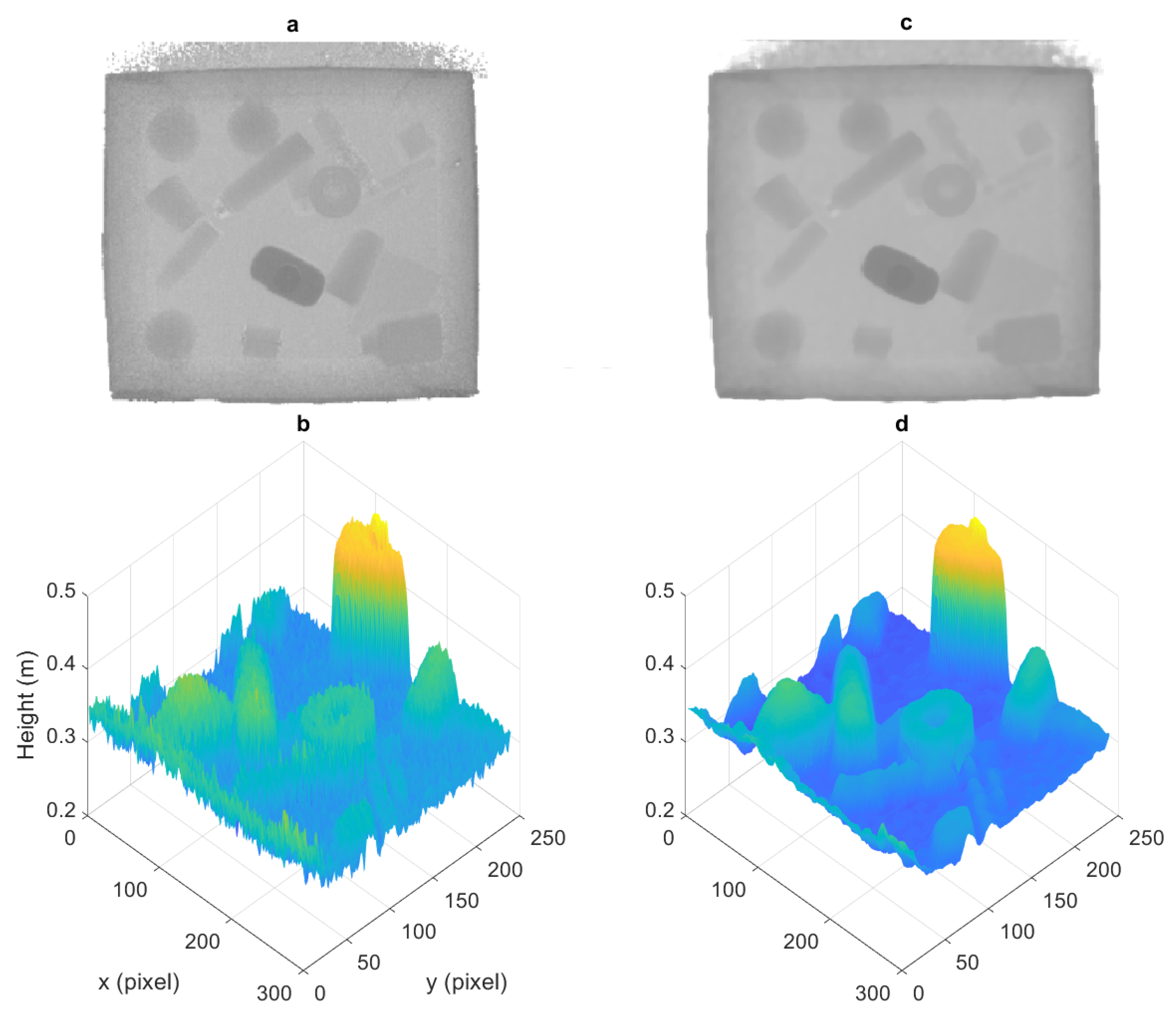
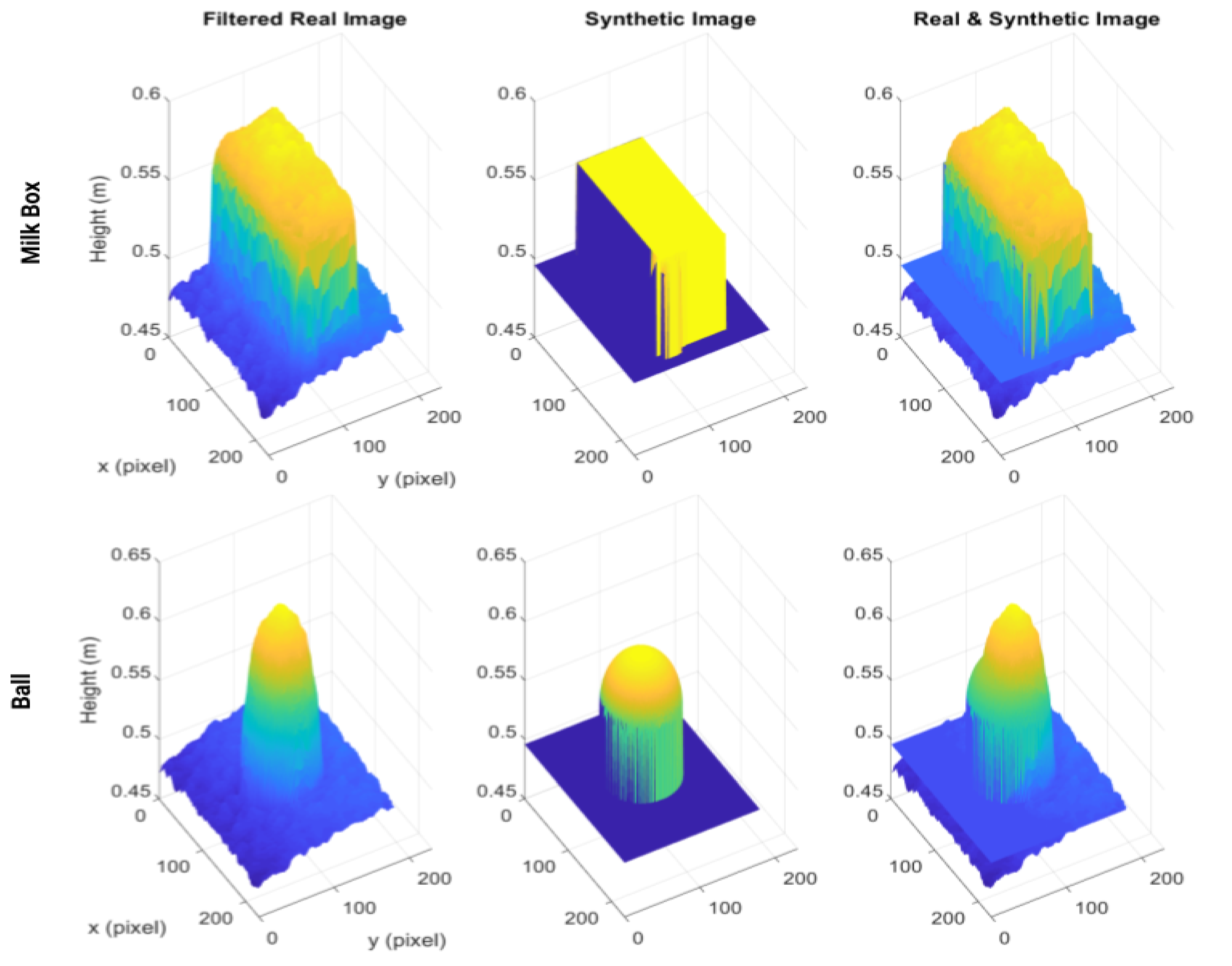
3.3. Comparison of Synthetic and Real-World Depth Images
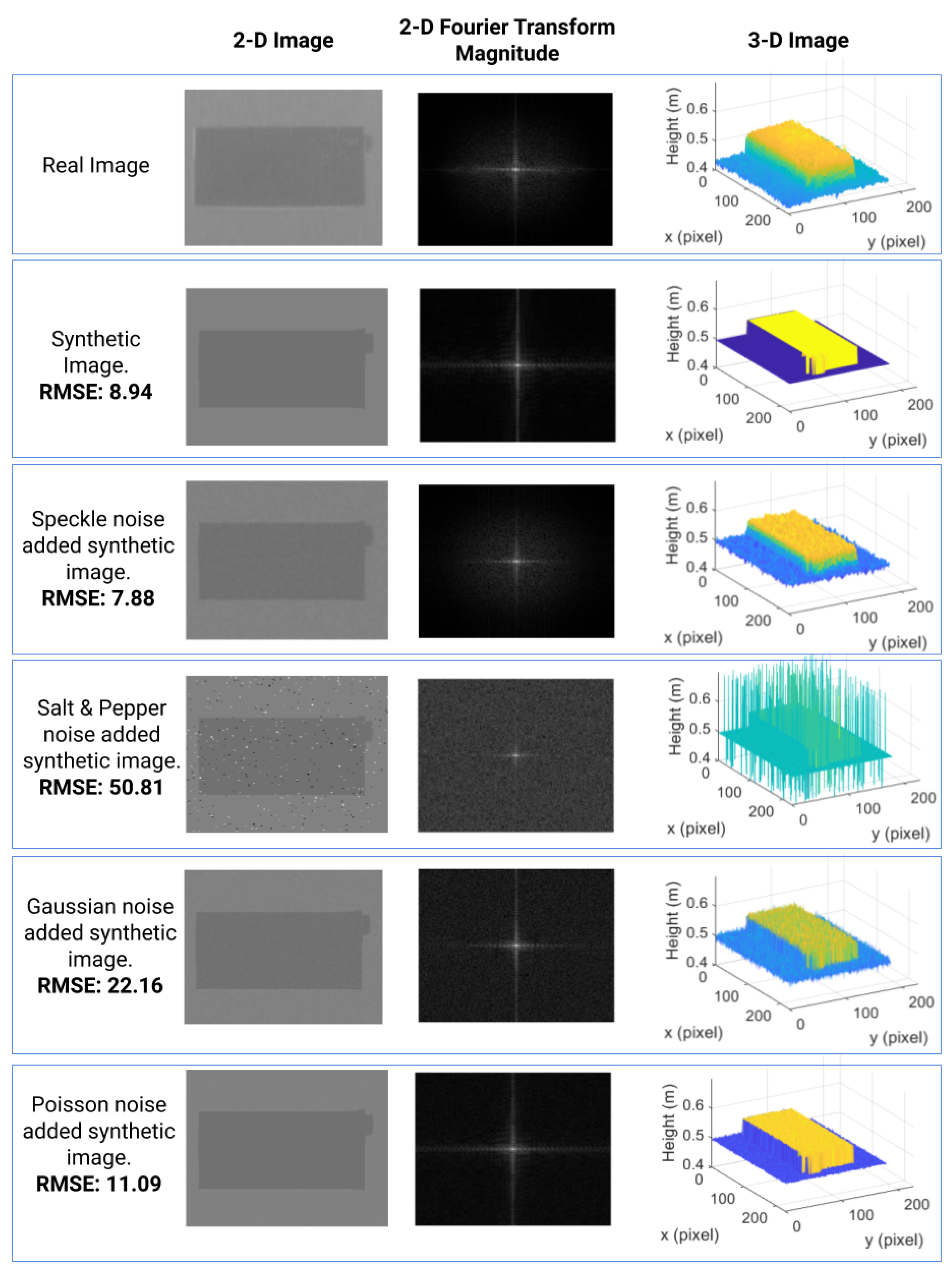
3.4. Generation of Noise-Added Depth Images
4. Deep Learning Model
4.1. Meta-Architectures: SSD, Faster R-CNN, and YOLO
4.2. Feature Extractors
5. Experiments
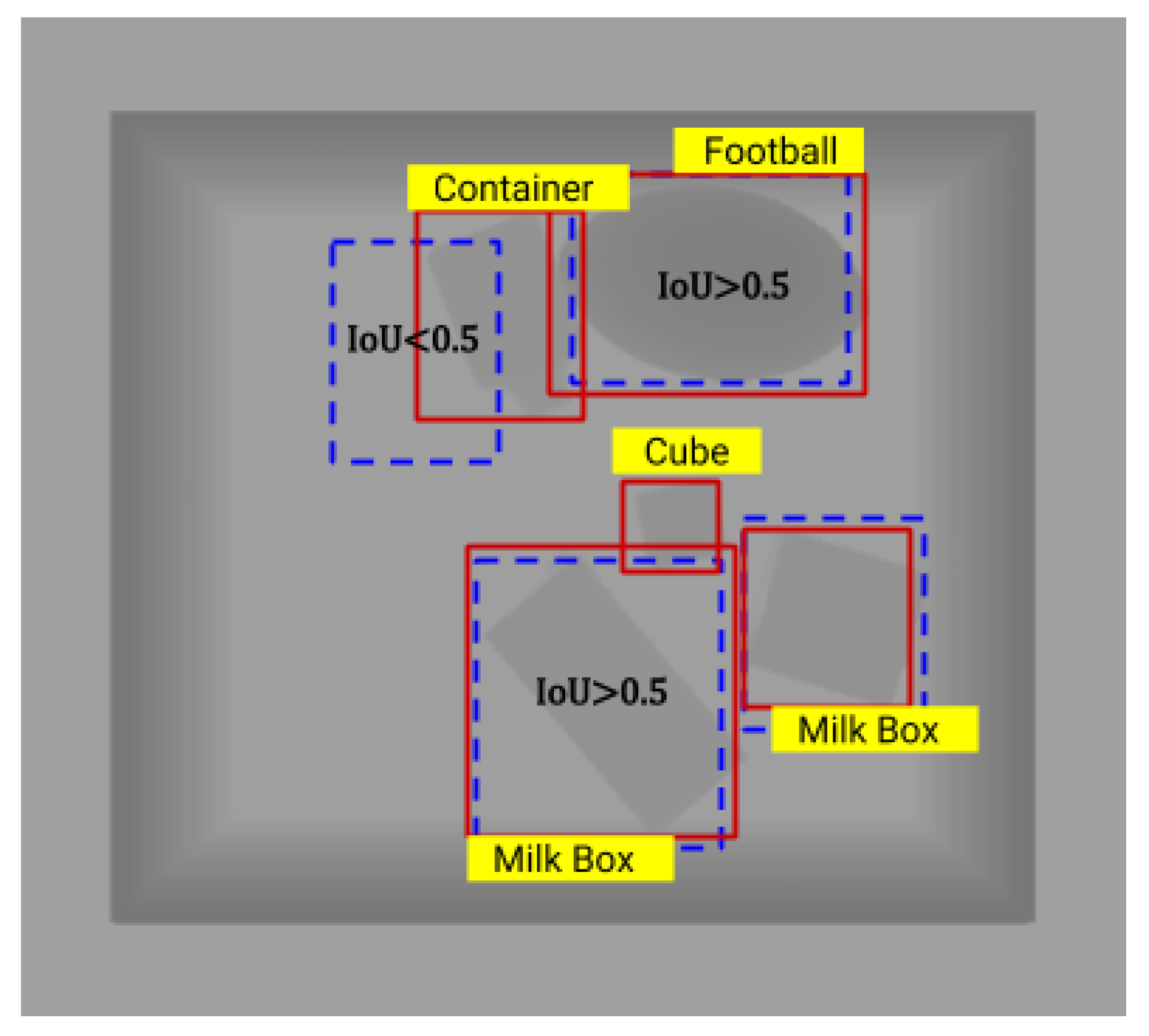
Accuracy Evaluation
| Algorithm 1 Accuracy evaluation routine. |
| 1: procedure Metric(P, ) 2: 3: 4: 5: for n do 6: for do 7: if , ) then 8: (∩) 9: if then 10: 11: end if 12: end if 13: end for 14: end for 15: 16: 17: + + ) 18: end procedure |
6. Results and Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Correll, N.; Bekris, K.E.; Berenson, D.; Brock, O.; Causo, A.; Hauser, K.; Okada, K.; Rodriguez, A.; Romano, J.M.; Wurman, P.R. Analysis and Observations From the First Amazon Picking Challenge. IEEE Trans. Autom. Sci. Eng. 2018, 15, 172–188. [Google Scholar] [CrossRef]
- Li, W.; Luo, Y.; Wang, P.; Qin, Z.; Zhou, H.; Qiao, H. Recent advances on application of deep learning for recovering object pose. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Qingdao, China, 3–7 December 2016; pp. 1273–1280. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.; Arbeláez, P.; Girshick, R.; Malik, J. Aligning 3D models to RGB-D images of cluttered scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4731–4740. [Google Scholar] [CrossRef]
- Peng, X.; Sun, B.; Ali, K.; Saenko, K. Learning deep object detectors from 3D models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1278–1286. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Carlucci, F.M.; Russo, P.; Caputo, B. A deep representation for depth images from synthetic data. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1362–1369. [Google Scholar]
- Zhang, Y.; Song, S.; Yumer, E.; Savva, M.; Lee, J.Y.; Jin, H.; Funkhouser, T. Physically-based rendering for indoor scene understanding using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5057–5065. [Google Scholar]
- Mitash, C.; Bekris, K.E.; Boularias, A. A self-supervised learning system for object detection using physics simulation and multi-view pose estimation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 545–551. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of representations for domain adaptation. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 137–144. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Wohlhart, P.; Konolige, K. On Pre-trained Image Features and Synthetic Images for Deep Learning. In Proceedings of the ECCV Workshops, Munich, Germany, 8–14 September 2018; pp. 682–697. [Google Scholar]
- Mithun, N.C.; Munir, S.; Guo, K.; Shelton, C. ODDS: Real-Time Object Detection Using Depth Sensors on Embedded GPUs. In Proceedings of the 2018 17th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Porto, Portugal, 11–13 April 2018; pp. 230–241. [Google Scholar] [CrossRef]
- Pinto, N.; Barhomi, Y.; Cox, D.D.; DiCarlo, J.J. Comparing state-of-the-art visual features on invariant object recognition tasks. In Proceedings of the IEEE Workshop on Applications of Computer Vision (WACV), Kona, HI, USA, 5–7 January 2011; pp. 463–470. [Google Scholar]
- Rajpura, P.S.; Hegde, R.S.; Bojinov, H. Object Detection Using Deep CNNs Trained on Synthetic Images. arXiv, 2017; arXiv:1706.06782. [Google Scholar]
- Georgakis, G.; Mousavian, A.; Berg, A.C.; Kosecka, J. Synthesizing Training Data for Object Detection in Indoor Scenes. arXiv, 2017; arXiv:1702.07836. [Google Scholar]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-D object dataset. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar]
- Socher, R.; Huval, B.; Bath, B.; Manning, C.D.; Ng, A.Y. Convolutional-recursive deep learning for 3D object classification. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 656–664. [Google Scholar]
- Schwarz, M.; Milan, A.; Periyasamy, A.S.; Behnke, S. RGB-D object detection and semantic segmentation for autonomous manipulation in clutter. Int. J. Robot. Res. 2018, 37, 437–451. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar]
- Biswas, J.; Veloso, M. Depth camera based indoor mobile robot localization and navigation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), St Paul, MN, USA, 14–18 May 2012; pp. 1697–1702. [Google Scholar]
- Maier, D.; Hornung, A.; Bennewitz, M. Real-time navigation in 3D environments based on depth camera data. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots, Osaka, Japan, 29 November–1 December 2012; pp. 692–697. [Google Scholar]
- Saudabayev, A.; Kungozhin, F.; Nurseitov, D.; Varol, H.A. Locomotion strategy selection for a hybrid mobile robot using time of flight depth sensor. J. Sens. 2015, 2015, 425732. [Google Scholar] [CrossRef]
- Massalin, Y.; Abdrakhmanova, M.; Varol, H.A. User-Independent Intent Recognition for Lower Limb Prostheses Using Depth Sensing. IEEE Trans. Biomed. Eng. 2018, 65, 1759–1770. [Google Scholar] [PubMed]
- Saudabayev, A.; Rysbek, Z.; Khassenova, R.; Varol, H.A. Human grasping database for activities of daily living with depth, color and kinematic data streams. Sci. Data 2018, 5, 180101. [Google Scholar] [CrossRef] [PubMed]
- Koenig, N.P.; Howard, A. Design and use paradigms for Gazebo, an open-source multi-robot simulator. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004; Volume 4, pp. 2149–2154. [Google Scholar]
- Gschwandtner, M.; Kwitt, R.; Uhl, A.; Pree, W. BlenSor: Blender Sensor Simulation Toolbox. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 26–28 September 2011; pp. 199–208. [Google Scholar]
- Liebelt, J.; Schmid, C. Multi-view object class detection with a 3D geometric model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1688–1695. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2315–2324. [Google Scholar]
- Wanner, S.; Goldluecke, B. Globally consistent depth labeling of 4D light fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 18–20 June 2012; pp. 41–48. [Google Scholar]
- Zhang, L.; Tam, W.J. Stereoscopic image generation based on depth images for 3D TV. IEEE Trans. Broadcast. 2005, 51, 191–199. [Google Scholar] [CrossRef]
- Cheng, C.M.; Lin, S.J.; Lai, S.H.; Yang, J.C. Improved novel view synthesis from depth image with large baseline. In Proceedings of the International Conference on Pattern Recognition (ICPR), Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Park, Y.K.; Jung, K.; Oh, Y.; Lee, S.; Kim, J.K.; Lee, G.; Lee, H.; Yun, K.; Hur, N.; Kim, J. Depth-image-based rendering for 3DTV service over T-DMB. Signal Process. Image Commun. 2009, 24, 122–136. [Google Scholar] [CrossRef]
- Forster, B.; Van De Ville, D.; Berent, J.; Sage, D.; Unser, M. Complex wavelets for extended depth-of-field: A new method for the fusion of multichannel microscopy images. Microsc. Res. Tech. 2004, 65, 33–42. [Google Scholar] [CrossRef] [PubMed]
- Weiss, B. Fast median and bilateral filtering. ACM Trans. Graph. (TOG) 2006, 25, 519–526. [Google Scholar] [CrossRef]
- Ibarra-Castanedo, C.; Gonzalez, D.; Klein, M.; Pilla, M.; Vallerand, S.; Maldague, X. Infrared image processing and data analysis. Infrared Phys. Technol. 2004, 46, 75–83. [Google Scholar] [CrossRef]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Balan, A.K.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 20–25 June 2017; pp. 3296–3297. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Falie, D.; Buzuloiu, V. Noise Characteristics of 3D Time-of-Flight Cameras. In Proceedings of the International Symposium on Signals, Circuits and Systems, Iasi, Romania, 13–14 July 2007; Volume 1, pp. 1–4. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems, Proceedings of the 29th Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Neural Information Processing Systems Foundation, Inc. (NIPS): La Jolla, CA, USA; pp. 91–99.
- McCormac, J.; Handa, A.; Leutenegger, S.; Davison, A.J. SceneNet RGB-D: Can 5M Synthetic Images Beat Generic ImageNet Pre-training on Indoor Segmentation? In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2697–2706. [Google Scholar]
- Eitel, A.; Springenberg, J.T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal deep learning for robust RGB-D object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 681–687. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
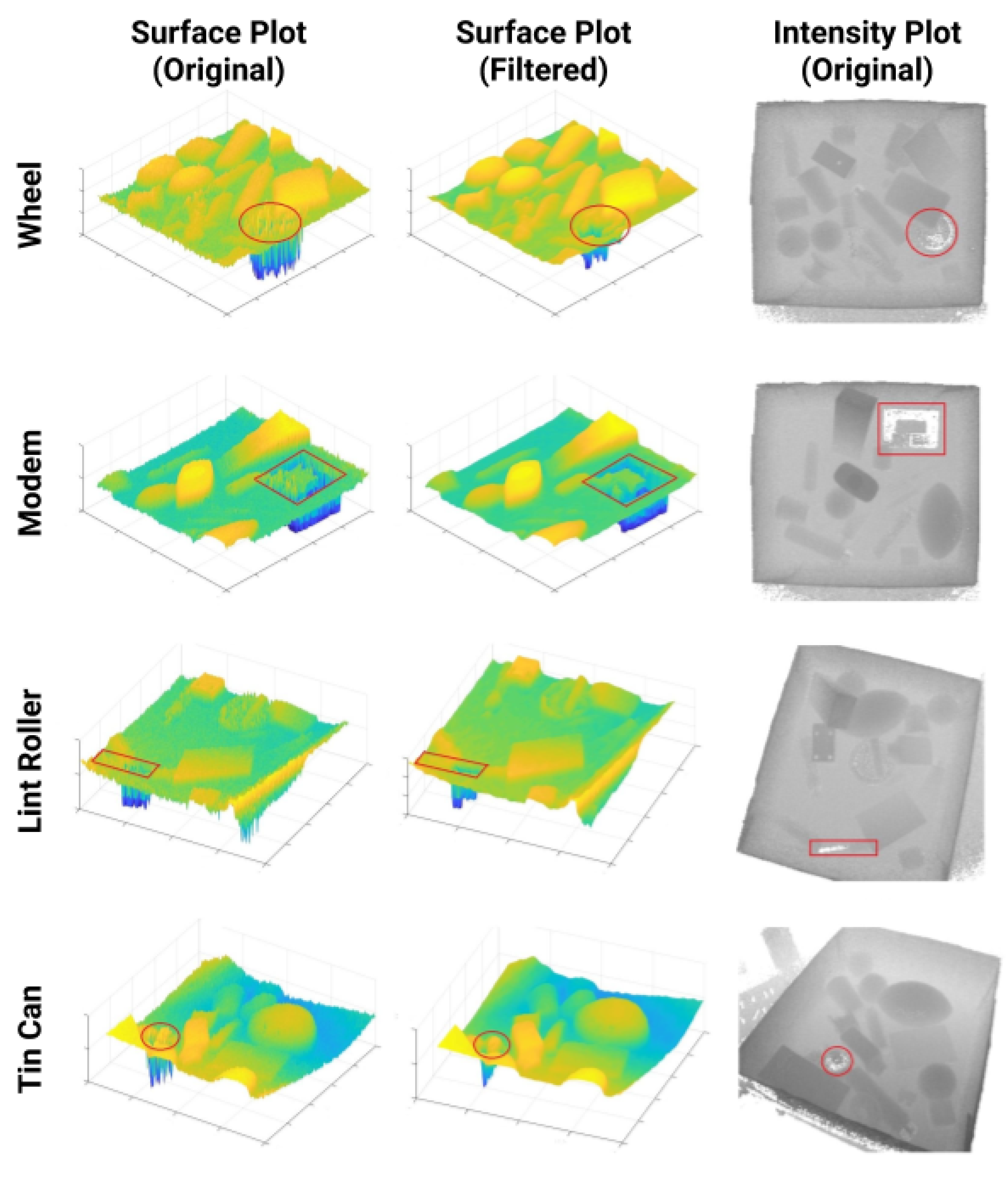{kind=link}
| Models | Testing Set | |
|---|---|---|
| Synthetic Clean Images | Real-World Images | |
| Model 1 (trained with synthetic clean images) | 93.5% | 40.96% |
| Model 2 (trained with synthetic noise-added images) | 96.1% | 46.3 |
| Model 1 | Model 2 | |||
|---|---|---|---|---|
| Objects | Testing Set: Synthetic Clean Images | Testing Set: Real-World Images | Testing Set: Synthetic Clean Images | Testing Set: Real-World Images |
| Football | 99.98 | 91.37 | 99.93 | 97.86 |
| Milk_Box | 96.36 | 90.06 | 97.44 | 93.52 |
| Printed_3D_Part | 98.54 | 76.85 | 98.58 | 88.89 |
| Thermos | 97.53 | 80.12 | 96.60 | 78.84 |
| Spherical_Ball | 99.67 | 77.87 | 99.58 | 77.67 |
| Container_Big | 97.83 | 65.12 | 98.24 | 75.48 |
| Modem | 96.96 | 71.58 | 97.68 | 67.77 |
| Container_Small | 96.73 | 63.35 | 97.83 | 61.10 |
| Cable_Reel | 98.69 | 54.63 | 98.29 | 56.63 |
| Ceramic_Mug | 96.33 | 51.23 | 96.89 | 55.75 |
| Paper_Cup | 98.33 | 41.88 | 98.62 | 54.86 |
| Cube | 95.60 | 43.84 | 95.78 | 54.20 |
| Tin_Can | 94.48 | 38.47 | 96.28 | 41.57 |
| Cream_Tube | 91.34 | 24.88 | 94.57 | 36.50 |
| Lego_Brick | 84.53 | 45.38 | 89.01 | 31.06 |
| Lint_Roller | 92.06 | 18.71 | 91.62 | 27.22 |
| Ointment_Tube | 85.26 | 28.48 | 84.06 | 24.09 |
| Torus_Toy | 96.67 | 21.82 | 96.74 | 20.10 |
| Deodorant_Bottle | 95.52 | 48.91 | 95.43 | 20.09 |
| Yogurt_Bottle | 95.72 | 11.30 | 96.79 | 19.94 |
| Glue_Stick | 88.90 | 12.52 | 88.09 | 19.73 |
| Wheel | 98.72 | 10.32 | 98.47 | 13.44 |
| Predicted Classes | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Football | Milk_Box | Printed_3D_Part | Thermos | Spherical_Ball | Container_Big | Modem | Container_Small | Cable_Reel | Ceramic_Mug | Paper_Cup | Cube | Tin_Can | Cream_Tube | Lego_Brick | Lint_Roller | Ointment_Tube | Torus_Toy | Deodorant_Bottle | Yogurt_Bottle | Glue_Stick | Wheel | ||
| Actual classes | Football | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Milk_Box | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Printed_3D_Part | 0 | 0 | 93 | 0 | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Thermos | 0 | 6 | 0 | 78 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Spherical_Ball | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Container_Big | 0 | 12 | 0 | 0 | 0 | 82 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Modem | 0 | 0 | 4 | 0 | 0 | 0 | 83 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Container_Small | 0 | 0 | 23 | 0 | 0 | 0 | 1 | 76 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Cable_Reel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 88 | 0 | 0 | 6 | 2 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Ceramic_Mug | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 83 | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Paper_Cup | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 90 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Cube | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 94 | 0 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Tin_Can | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 14 | 0 | 8 | 68 | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Cream_Tube | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 0 | 75 | 0 | 0 | 13 | 0 | 0 | 0 | 0 | 0 | |
| Lego_Brick | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Lint_Roller | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 32 | 6 | 0 | 0 | 0 | 62 | 0 | |
| Ointment_Tube | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 87 | 0 | 0 | 0 | 13 | 0 | |
| Torus_Toy | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | |
| Deodorant_Bottle | 0 | 0 | 0 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 13 | 7 | 6 | 5 | 0 | 41 | 12 | 0 | 0 | |
| Yogurt_Bottle | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 16 | 8 | 12 | 0 | 0 | 46 | 0 | 0 | |
| Glue_Stick | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 12 | 27 | 0 | 0 | 0 | 57 | 0 | |
| Wheel | 0 | 0 | 8 | 0 | 0 | 0 | 6 | 0 | 0 | 30 | 0 | 0 | 0 | 0 | 24 | 0 | 10 | 0 | 0 | 0 | 0 | 22 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baimukashev, D.; Zhilisbayev, A.; Kuzdeuov, A.; Oleinikov, A.; Fadeyev, D.; Makhataeva, Z.; Varol, H.A. Deep Learning Based Object Recognition Using Physically-Realistic Synthetic Depth Scenes. Mach. Learn. Knowl. Extr. 2019, 1, 883-903. https://doi.org/10.3390/make1030051
Baimukashev D, Zhilisbayev A, Kuzdeuov A, Oleinikov A, Fadeyev D, Makhataeva Z, Varol HA. Deep Learning Based Object Recognition Using Physically-Realistic Synthetic Depth Scenes. Machine Learning and Knowledge Extraction. 2019; 1(3):883-903. https://doi.org/10.3390/make1030051
Chicago/Turabian StyleBaimukashev, Daulet, Alikhan Zhilisbayev, Askat Kuzdeuov, Artemiy Oleinikov, Denis Fadeyev, Zhanat Makhataeva, and Huseyin Atakan Varol. 2019. "Deep Learning Based Object Recognition Using Physically-Realistic Synthetic Depth Scenes" Machine Learning and Knowledge Extraction 1, no. 3: 883-903. https://doi.org/10.3390/make1030051
APA StyleBaimukashev, D., Zhilisbayev, A., Kuzdeuov, A., Oleinikov, A., Fadeyev, D., Makhataeva, Z., & Varol, H. A. (2019). Deep Learning Based Object Recognition Using Physically-Realistic Synthetic Depth Scenes. Machine Learning and Knowledge Extraction, 1(3), 883-903. https://doi.org/10.3390/make1030051