Large-Scale Simultaneous Inference with Hypothesis Testing: Multiple Testing Procedures in Practice



Abstract
1. Introduction
2. Preliminaries
2.1. Formal Setting
2.2. Simulations in R
2.3. Focus on Pairwise Correlations
 |
| Listing 1: Generating multivariate normal data with the R package mvtnorm. An example is shown for a two-sample, two-sided t-test. Each population is defined by a mean vector of μ (called mu1 and mu2) and a covariance matrix of Σ (called Sigma1 and Sigma2). |
2.4. Focus on a Network Correlation Structure
 |
| Listing 2: Generating multivariate normal data with the R package mvgraphnorm. An example is shown for a two-sample, two-sided t-test. Each population is defined by a mean vector of μ (called mu1 and mu2) and a covariance matrix of Σ (called Sigma1 and Sigma2). Furthermore, g1 and g2 are two causal structures (networks). |
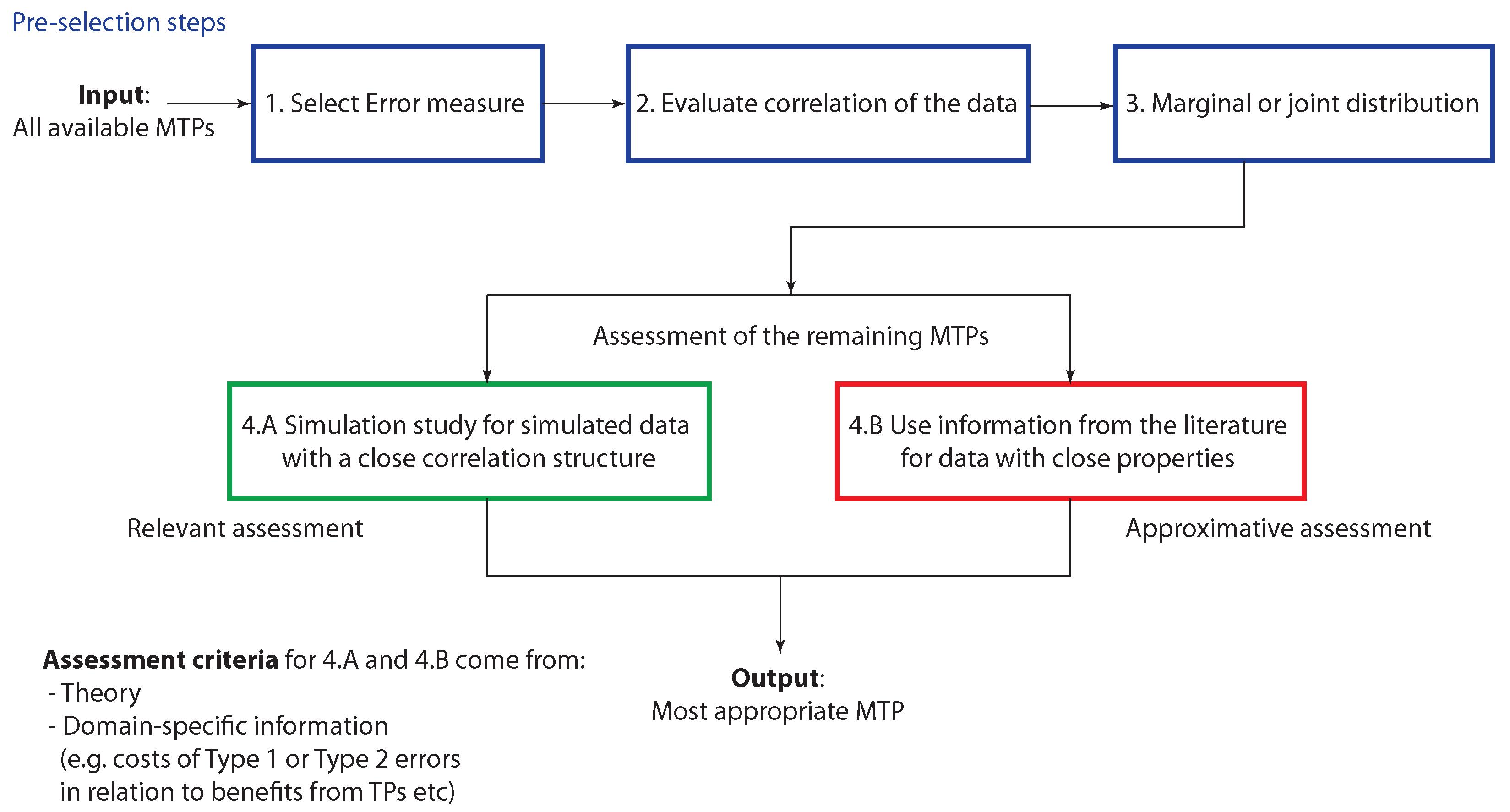
2.5. Application of Multiple Testing Procedures
 |
| Listing 3: Application of MTPs to raw p-values given by the variable p.values. |
3. Motivation of the Problem
3.1. Theoretical Considerations
3.2. Experimental Example
4. Types of Multiple Testing Procedures
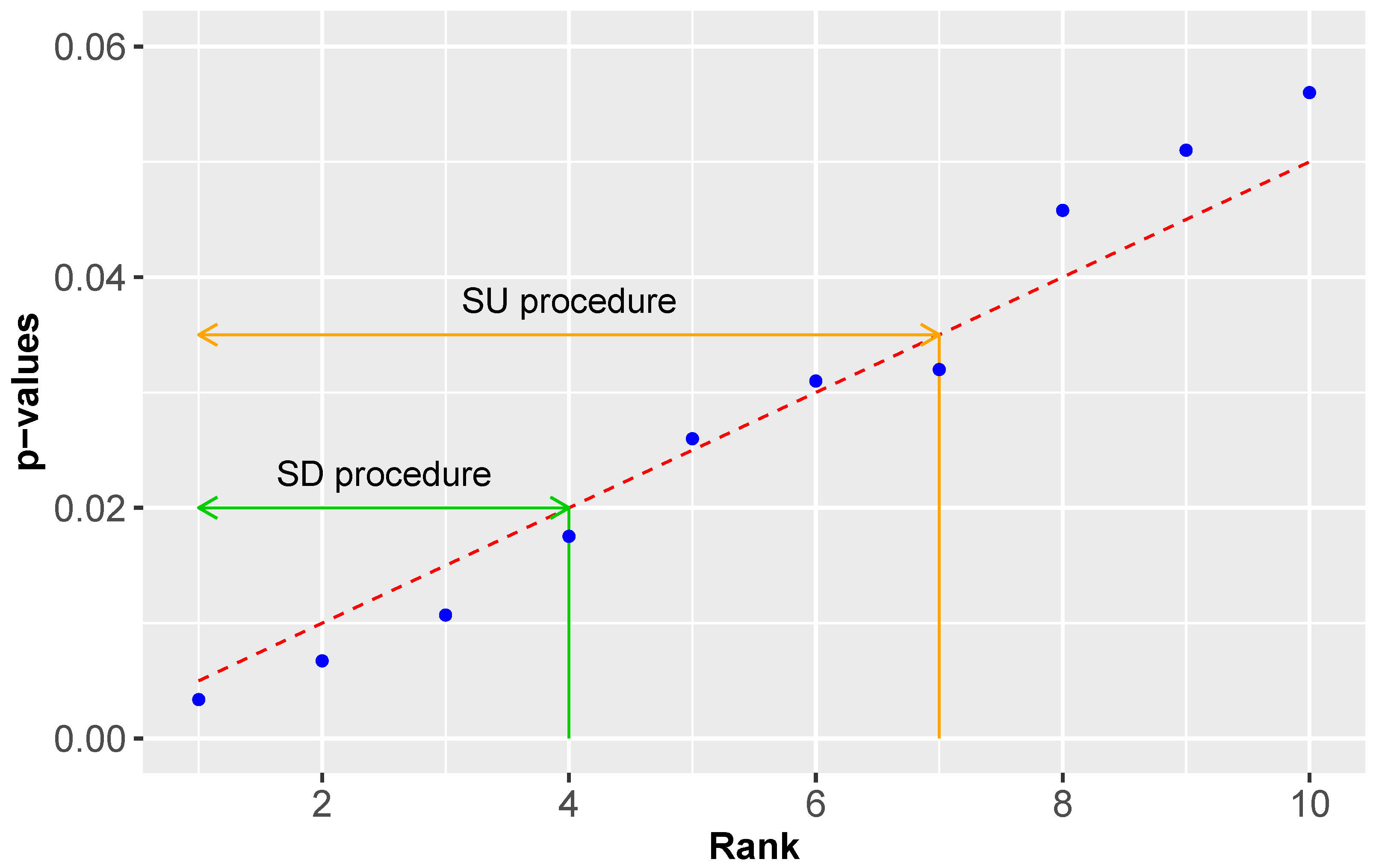
4.1. Single-Step vs. Stepwise Approaches
- Single-step (SS) procedure
- Step-up (SU) procedure
- Step-down (SD) procedure
4.2. Adaptive vs. Non-Adaptive Approaches
4.3. Marginal vs. Joint Multiple Testing Procedures
5. Controlling the FWER
5.1. Šidák Correction
5.2. Bonferroni Correction
5.3. Holm Correction
| Algorithm 1: SD Holm correction procedure. |
| Input: 1 2 while do 3 4 Reject |
5.4. Hochberg Correction
| Algorithm 2: SU Hochberg correction procedure |
| Input: 1 2 while do 3 4 Reject |
5.5. Hommel Correction
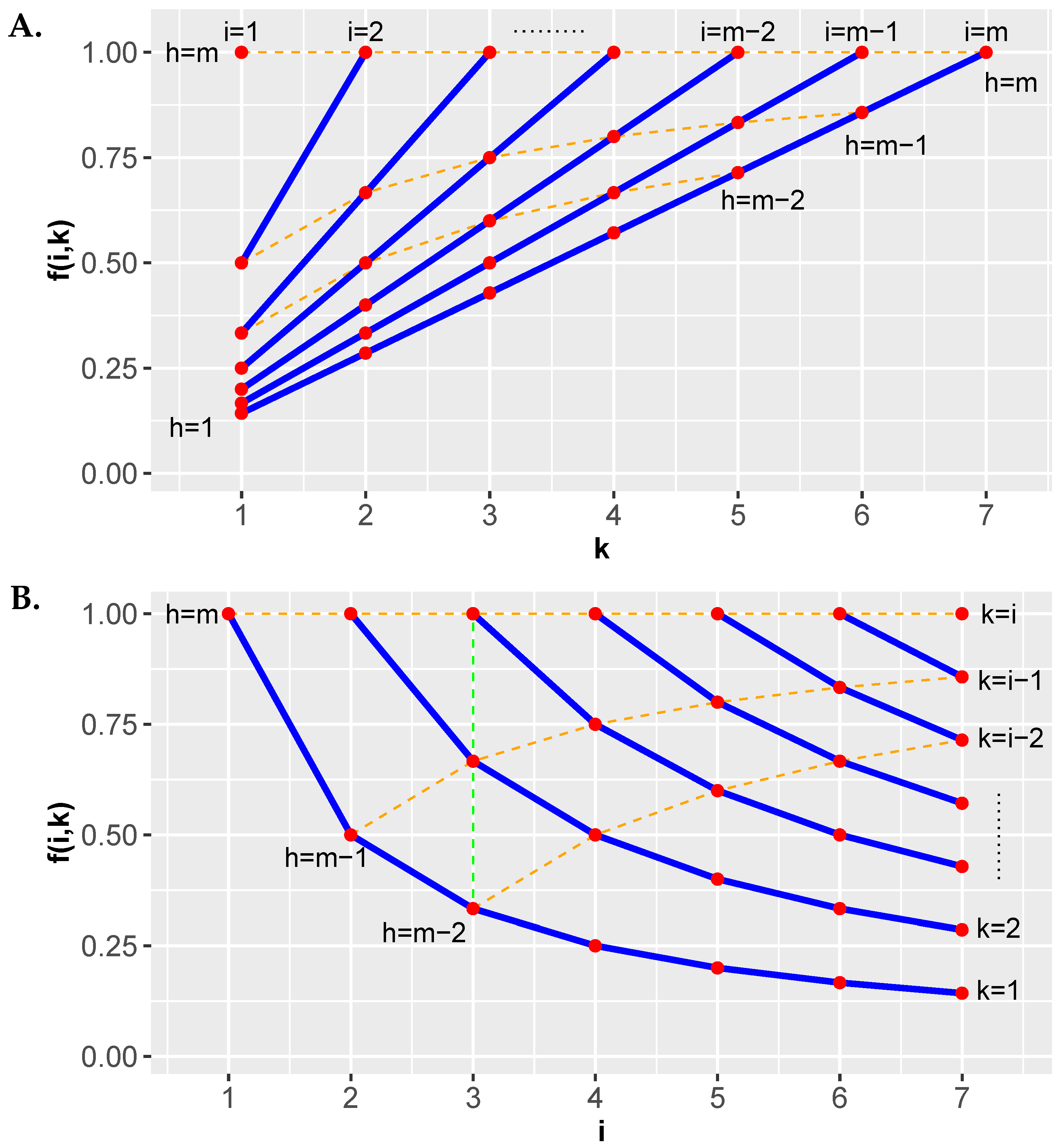
| Algorithm 3: Hommel correction procedure |
| Input: 1 2 while for at least one do 3 4 5 if then 6 Reject 7 else 8 Reject with |
5.5.1. Examples
- Example 1: . In this case, and . From this follows that no hypothesis can be rejected.
- Example 2: . In this case, and . From this it follows that can be rejected.
- Example 3: . In this case, and . From this it follows that can be rejected.
5.6. Westfall-Young Procedure
| Algorithm 4: Westfall-Young step-down maxT procedure. |
 |
| Algorithm 5: Westfall-Young step-down minP procedure. |
 |
6. Controlling the FDR
6.1. Benjamini-Hochberg Procedure
| Algorithm 6: SU Benjamini-Hochberg procedure |
| Input: 1 2 while do 3 4 Reject |
6.1.1. Example
6.2. Adaptive Benjamini-Hochberg Procedure
6.3. Benjamini-Yekutieli Procedure
6.3.1. Example
6.4. Benjamini-Krieger-Yekutieli Procedure
- Step 1:
- Use a BH procedure with . Let r be the number of hypotheses rejected. If , no hypothesis is rejected. If reject all m hypotheses. In both cases, the procedure stops. Otherwise proceed.
- Step 2:
- Estimate the number of null hypotheses by .
- Step 3:
- Use a BH procedure with .
6.5. Blanchard-Roquain Procedure
6.5.1. BR-1S Procedure
6.5.2. BR-2S Procedure
- Stage 1:
- Estimate by BR-1S.
- Stage 2:
- Use within the SU procedure given by Equation (70). That means the estimate for the proportion of null hypotheses is used to find the larges index k for whichholds. If no such index exists then no hypothesis is rejected, otherwise reject the null hypotheses .
7. Computational Complexity
8. Summary
- Positive correlations (simulated data): BR is more powerful than BKY [67].
- General correlations (real data): BY has a higher PPV than BH [68].
- Positive correlations (simulated data): BKY is more powerful than BH [26].
- Positive correlations (simulated data): Hochberg, Holm and Hommel do not control the PFER for high correlations [69].
- General correlations (real data): SS MaxT and SD MaxT can be more powerful than Bonferroni, Holm and Hochberg [49].
- Random correlations (simulated data): SD minP is more powerful than SD maxT [71].
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fan, J.; Han, F.; Liu, H. Challenges of big data analysis. Natl. Sci. Rev. 2014, 1, 293–314. [Google Scholar] [CrossRef] [PubMed]
- Provost, F.; Fawcett, T. Data science and its relationship to big data and data-driven decision making. Big Data 2013, 1, 51–59. [Google Scholar] [CrossRef] [PubMed]
- Hayashi, C. What is data science? Fundamental concepts and a heuristic example. In Data Science, Classification, and Related Methods; Springer: Tokyo, Japan, 1998; pp. 40–51. [Google Scholar]
- Cleveland, W.S. Data science: An action plan for expanding the technical areas of the field of statistics. Int. Stat. Rev. 2001, 69, 21–26. [Google Scholar] [CrossRef]
- Hardin, J.; Hoerl, R.; Horton, N.J.; Nolan, D.; Baumer, B.; Hall-Holt, O.; Murrell, P.; Peng, R.; Roback, P.; Lang, D.T.; et al. Data Science in Statistics Curricula: Preparing Students to ‘Think with Data’. Am. Stat. 2015, 69, 343–353. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Moutari, S.; Dehmer, M. The process of analyzing data is the emergent feature of data science. Front. Genet. 2016, 7, 12. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Dehmer, M. Defining Data Science by a Data-Driven Quantification of the Community. Mach. Learn. Knowl. Extract. 2019, 1, 235–251. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Lehman, E. Testing Statistical Hypotheses; Springer: New York, NY, USA, 2005. [Google Scholar]
- Dudoit, S.; Van Der Laan, M.J. Multiple Testing Procedures With Applications to Genomics; Springer Science & Business Media: New York, NY, USA, 2007. [Google Scholar]
- Noble, W.S. How does multiple testing correction work? Nat. Biotechnol. 2009, 27, 1135. [Google Scholar] [CrossRef]
- Efron, B. Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Genovese, C.R.; Wasserman, L. Exceedance Control of the False Discovery Proportion. J. Am. Stat. Assoc. 2006, 101, 1408–1417. [Google Scholar] [CrossRef]
- Storey, J. A direct approach to false discovery rates. J. R. Stat. Soc. Ser. B 2002, 64, 479–498. [Google Scholar] [CrossRef]
- Gordon, A.; Glazko, G.; Qiu, X.; Yakovlev, A. Control of the mean number of false discoveries, Bonferroni and stability of multiple testing. Ann. Appl. Stat. 2007, 1, 179–190. [Google Scholar] [CrossRef]
- Genovese, C.; Wasserman, L. Operating characteristics and extensions of the false discovery rate procedure. J. Royal Stat. Soc. Ser. B (Stat. Methodol.) 2002, 64, 499–517. [Google Scholar] [CrossRef]
- Bonferroni, E. Teoria statistica delle classi e calcolo delle probabilita. Pubblicazioni del R Istituto Superiore di Scienze Economiche e Commerciali di Firenze 1936, 8, 3–62. [Google Scholar]
- Schweder, T.; Spjøtvoll, E. Plots of p-values to evaluate many tests simultaneously. Biometrika 1982, 69, 493–502. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B (Methodol.) 1995, 57, 125–133. [Google Scholar] [CrossRef]
- Curran-Everett, D. Multiple comparisons: Philosophies and illustrations. Am. J. Physiol.-Regul. Integr. Comparat. Physiol. 2000, 279, R1–R8. [Google Scholar] [CrossRef] [PubMed]
- Šidák, Z. Rectangular confidence regions for the means of multivariate normal distributions. J. Am. Stat. Assoc. 1967, 62, 626–633. [Google Scholar] [CrossRef]
- Westfall, P.H.; Young, S.S. Resampling-Based Multiple Testing: Examples and Methods for p-Value Adjustment; John Wiley & Sons: New York, NY, USA, 1993; Volume 279. [Google Scholar]
- Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar]
- Hochberg, Y. A sharper Bonferroni procedure for multiple tests of significance. Biometrika 1988, 75, 800–802. [Google Scholar] [CrossRef]
- Benjamini, Y.; Yekutieli, D. The control of the false discovery rate in multiple testing under dependency. Ann. Stat. 2001, 29, 1165–1188. [Google Scholar]
- Benjamini, Y.; Krieger, A.M.; Yekutieli, D. Adaptive linear step-up procedures that control the false discovery rate. Biometrika 2006, 93, 491–507. [Google Scholar] [CrossRef]
- Romano, J.P.; Shaikh, A.M.; Wolf, M. Control of the false discovery rate under dependence using the bootstrap and subsampling. Test 2008, 17, 417. [Google Scholar] [CrossRef]
- Austin, S.R.; Dialsingh, I.; Altman, N. Multiple hypothesis testing: A review. J. Indian Soc. Agric. Stat. 2014, 68, 303-14. [Google Scholar]
- Dudoit, S.; van der Laan, M.; Pollard, K. Multiple Testing. Part I. Single-Step Procedures for Control of General Type I Error Rates. Stat. Appl. Genet. Mol. Biol. 2004, 3, 13. [Google Scholar] [CrossRef]
- Dudoit, S.; Gilbert, H.; van der Laan, M. Resampling-Based Empirical Bayes Multiple Testing Procedures for Controlling Generalized Tail Probability and Expected Value Error Rates: Focus on the False Discovery Rate and Simulation Study. Biometrical J. 2008, 50, 716–744. [Google Scholar] [CrossRef]
- Farcomeni, A. Multiple Testing Methods. In Medical Biostatistics for Complex Diseases; Emmert-Streib, F., Dehmer, M., Eds.; John Wiley & Sons, Ltd.: Weinheim, Germany, 2010; Chapter 3; pp. 45–72. Available online: https://onlinelibrary.wiley.com/doi/pdf/10.1002/9783527630332.ch3 (accessed on 25 May 2019). [CrossRef]
- Kim, K.I.; van de Wiel, M. Effects of dependence in high-dimensional multiple testing problems. BMC Bioinform. 2008, 9, 114. [Google Scholar] [CrossRef]
- Friguet, C.; Causeur, D. Estimation of the proportion of true null hypotheses in high-dimensional data under dependence. Comput. Stat. Data Anal. 2011, 55, 2665–2676. [Google Scholar] [CrossRef]
- Cai, T.T.; Liu, W. Large-scale multiple testing of correlations. J. Am. Stat. Assoc. 2016, 111, 229–240. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2008; ISBN 3-900051-07-0. [Google Scholar]
- Hochberg, J.; Tamhane, A. Multiple Comparison Procedures; John Wiley & Sons: New York, NY, USA, 1987. [Google Scholar]
- Simes, R.J. An improved Bonferroni procedure for multiple tests of significance. Biometrika 1986, 73, 751–754. [Google Scholar] [CrossRef]
- Genz, A.; Bretz, F.; Miwa, T.; Mi, X.; Leisch, F.; Scheipl, F.; Hothorn, T. mvtnorm: Multivariate Normal and t Distributions. R Package Version 1.0-9. 2019. Available online: https://cran.r-project.org/web/packages/mvtnorm/index.html (accessed on 23 August 2008).
- Genz, A.; Bretz, F. Computation of Multivariate Normal and t Probabilities; Lecture Notes in Statistics; Springer: Heidelberg, Germany, 2009. [Google Scholar]
- Emmert-Streib, F.; Tripathi, S.; Dehmer, M. Constrained covariance matrices with a biologically realistic structure: Comparison of methods for generating high-dimensional Gaussian graphical models. Front. Appl. Math. Stat. 2019, 5, 17. [Google Scholar] [CrossRef]
- Tripathi, S.; Emmert-Streib, F. Mvgraphnorm: Multivariate Gaussian Graphical Models. R Package Version 1.0.0. 2019. Available online: https://cran.r-project.org/web/packages/mvgraphnorm/index.html (accessed on 23 August 2008).
- Blanchard, G.; Dickhaus, T.; Hack, N.; Konietschke, F.; Rohmeyer, K.; Rosenblatt, J.; Scheer, M.; Werft, W. μTOSS-Multiple hypothesis testing in an open software system. In Proceedings of the First Workshop on Applications of Pattern Analysis, Windsor, UK, 1–3 September 2010; pp. 12–19. [Google Scholar]
- Pollard, K.; Dudoit, S.; van der Laan, M. Multiple Testing Procedures: R Multtest Package and Applications to Genomics. UC Berkeley Division of Biostatistics Working Paper Series. Technical Report, Working Paper 164. 2004. Available online: http://www.bepress.com/ucbbiostat/paper164 (accessed on 25 May 2019).
- Meijer, R.J.; Krebs, T.J.; Goeman, J.J. Hommel’s procedure in linear time. Biometrical J. 2019, 61, 73–82. [Google Scholar] [CrossRef] [PubMed]
- Bennett, C.M.; Baird, A.A.; Miller, M.B.; Wolford, G.L. Neural correlates of interspecies perspective taking in the post-mortem atlantic salmon: An argument for proper multiple comparisons correction. J. Serendipitous Unexpected Results 2011, 1, 1–5. [Google Scholar] [CrossRef]
- Bennett, C.M.; Wolford, G.L.; Miller, M.B. The principled control of false positives in neuroimaging. Soc. Cognit. Affect. Neurosci. 2009, 4, 417–422. [Google Scholar] [CrossRef]
- Nichols, T.; Hayasaka, S. Controlling the familywise error rate in functional neuroimaging: A comparative review. Stat. Methods Med. Res. 2003, 12, 419–446. [Google Scholar] [CrossRef]
- Diz, A.P.; Carvajal-Rodríguez, A.; Skibinski, D.O. Multiple hypothesis testing in proteomics: A strategy for experimental work. Mol. Cell. Proteomics 2011, 10, M110.004374. [Google Scholar] [CrossRef]
- Dudoit, S.; Shaffer, J.; Boldrick, J. Multiple hypothesis testing in microarray experiments. Stat. Sci. 2003, 18, 71–103. [Google Scholar] [CrossRef]
- Goeman, J.J.; Solari, A. Multiple hypothesis testing in genomics. Stat. Med. 2014, 33, 1946–1978. [Google Scholar] [CrossRef]
- Moskvina, V.; Schmidt, K.M. On multiple-testing correction in genome-wide association studies. Genet. Epidemiol. Off. Publ. Int. Genet. Epidemiol. Soc. 2008, 32, 567–573. [Google Scholar] [CrossRef]
- Harvey, C.R.; Liu, Y. Evaluating trading strategies. J. Portfolio Manag. 2014, 40, 108–118. [Google Scholar] [CrossRef]
- Miller, C.J.; Genovese, C.; Nichol, R.C.; Wasserman, L.; Connolly, A.; Reichart, D.; Hopkins, A.; Schneider, J.; Moore, A. Controlling the false-discovery rate in astrophysical data analysis. Astron. J. 2001, 122, 3492. [Google Scholar] [CrossRef]
- Cranmer, K. Statistical challenges for searches for new physics at the LHC. In Statistical Problems in Particle Physics, Astrophysics and Cosmology; World Scientific: London, UK, 2006; pp. 112–123. [Google Scholar]
- Döhler, S.; Durand, G.; Roquain, E. New FDR bounds for discrete and heterogeneous tests. Electronic J. Stat. 2018, 12, 1867–1900. [Google Scholar]
- Benjamini, Y.; Hochberg, Y. On the adaptive control of the false discovery rate in multiple testing with independent statistics. J. Educ. Behav. Stat. 2000, 25, 60–83. [Google Scholar] [CrossRef]
- Sarkar, S.K. On methods controlling the false discovery rate. Sankhyā Indian J. Stat. Ser. A (2008-) 2008, 70, 135–168. [Google Scholar]
- Shaffer, J.P. Multiple hypothesis testing. Annu. Rev. Psychol. 1995, 46, 561–584. [Google Scholar] [CrossRef]
- Dmitrienko, A.; Tamhane, A.C.; Bretz, F. Multiple Testing Problems in Pharmaceutical Statistics; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Hommel, G. A stagewise rejective multiple test procedure based on a modified Bonferroni test. Biometrika 1988, 75, 383–386. [Google Scholar] [CrossRef]
- Westfall, P.H.; Troendle, J.F. Multiple testing with minimal assumptions. Biometrical J. J. Math. Methods Biosci. 2008, 50, 745–755. [Google Scholar] [CrossRef]
- Goeman, J.J.; Solari, A. The sequential rejection principle of familywise error control. Ann. Stat. 2010, 38, 3782–3810. [Google Scholar] [CrossRef]
- Ge, Y.; Dudoit, S.; Speed, T. Resampling-based multiple testing for microarray data analysis. TEST 2003, 12, 1–77. [Google Scholar] [CrossRef]
- Rempala, G.A.; Yang, Y. On permutation procedures for strong control in multiple testing with gene expression data. Stat. Interface 2013, 6. [Google Scholar] [CrossRef]
- Ferreira, J.; Zwinderman, A. On the Benjamini–Hochberg method. Ann. Stat. 2006, 34, 1827–1849. [Google Scholar] [CrossRef]
- Liang, K.; Nettleton, D. Adaptive and dynamic adaptive procedures for false discovery rate control and estimation. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2012, 74, 163–182. [Google Scholar] [CrossRef]
- Blanchard, G.; Roquain, É. Adaptive false discovery rate control under independence and dependence. J. Mach. Learn. Res. 2009, 10, 2837–2871. [Google Scholar]
- Koo, I.; Yao, S.; Zhang, X.; Kim, S. Comparative analysis of false discovery rate methods in constructing metabolic association networks. J. Bioinform. Comput. Biol. 2014, 12, 1450018. [Google Scholar] [CrossRef]
- Frane, A.V. Are per-family type I error rates relevant in social and behavioral science? J. Mod. Appl. Stat. Methods 2015, 14, 5. [Google Scholar] [CrossRef]
- Westfall, P.H. On using the bootstrap for multiple comparisons. J. Biopharm. Stat. 2011, 21, 1187–1205. [Google Scholar] [CrossRef]
- Li, D.; Dye, T.D. Power and stability properties of resampling-based multiple testing procedures with applications to gene oncology studies. Comput. Math. Methods Med. 2013, 2013. [Google Scholar] [CrossRef]
- De Matos Simoes, R.; Dehmer, M.; Emmert-Streib, F. Interfacing cellular networks of S. cerevisiae and E. coli: Connecting dynamic and genetic information. BMC Genom. 2013, 14, 324. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Moutari, S.; Dehmer, M. A comprehensive survey of error measures for evaluating binary decision making in data science. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, e1303. [Google Scholar] [CrossRef]
- Storey, J.D.; Taylor, J.E.; Siegmund, D. Strong control, conservative point estimation and simultaneous conservative consistency of false discovery rates: A unified approach. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2004, 66, 187–205. [Google Scholar] [CrossRef]
- Gavrilov, Y.; Benjamini, Y.; Sarkar, S.K. An adaptive step-down procedure with proven FDR control under independence. Ann. Stat. 2009, 37, 619–629. [Google Scholar] [CrossRef]
- Genovese, C.R.; Roeder, K.; Wasserman, L. False discovery control with p-value weighting. Biometrika 2006, 93, 509–524. [Google Scholar] [CrossRef]
- Phillips, D.; Ghosh, D. Testing the disjunction hypothesis using Voronoi diagrams with applications to genetics. Ann. Appl. Stat. 2014, 8, 801–823. [Google Scholar] [CrossRef]
- Meinshausen, N.; Maathuis, M.H.; Bühlmann, P. Asymptotic optimality of the Westfall–Young permutation procedure for multiple testing under dependence. Ann. Stat. 2011, 39, 3369–3391. [Google Scholar] [CrossRef]
- Romano, J.P.; Wolf, M. Balanced control of generalized error rates. Ann. Stat. 2010, 38, 598–633. [Google Scholar] [CrossRef]
- Chen, H.; Chiang, R.H.; Storey, V.C. Business intelligence and analytics: from big data to big impact. MIS Q. 2012, 36, 1165–1188. [Google Scholar] [CrossRef]
- Erevelles, S.; Fukawa, N.; Swayne, L. Big Data consumer analytics and the transformation of marketing. J. Bus. Res. 2016, 69, 897–904. [Google Scholar] [CrossRef]
- Jin, X.; Wah, B.W.; Cheng, X.; Wang, Y. Significance and challenges of big data research. Big Data Res. 2015, 2, 59–64. [Google Scholar] [CrossRef]
- Lynch, C. Big data: How do your data grow? Nature 2008, 455, 28–29. [Google Scholar] [CrossRef]
- Brunsdon, C.; Charlton, M. An assessment of the effectiveness of multiple hypothesis testing for geographical anomaly detection. Environ. Plan. B Plan. Des. 2011, 38, 216–230. [Google Scholar] [CrossRef]
- Döhler, S. Validation of credit default probabilities using multiple-testing procedures. J. Risk Model Validat. 2010, 4, 59. [Google Scholar] [CrossRef]
- Stevens, J.R.; Al Masud, A.; Suyundikov, A. A comparison of multiple testing adjustment methods with block-correlation positively-dependent tests. PLoS ONE 2017, 12, e0176124. [Google Scholar] [CrossRef]
- Pike, N. Using false discovery rates for multiple comparisons in ecology and evolution. Methods Ecol. Evol. 2011, 2, 278–282. [Google Scholar] [CrossRef]
- Benjamini, Y. Discovering the false discovery rate. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2010, 72, 405–416. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decision | ||||
|---|---|---|---|---|
| reject | accept | |||
| Truth | is true | |||
| is false | ||||
| R | m−R | m | ||
| Method | Error Control | ||||
|---|---|---|---|---|---|
| Bonferroni | FWER | s | 0.000389 s | 0.001163 s | 0.002932 s |
| Holm | FWER | s | 0.001569 s | 0.002897 s | 0.012100 s |
| Hochberg | FWER | s | 0.001430 s | 0.003673 s | 0.010471 s |
| Hommel | FWER | s | 4.556661 s | 23.389805 s | 2.6053 min |
| Hommel * | FWER | s | 0.001618 s | 0.003035 s | 0.008737 s |
| Benjamini-Hochberg | FDR | s | 0.001260 s | 0.003132 s | 0.011276 s |
| Benjamini-Yekutieli | FDR | s | 0.001168 s | 0.004412 s | 0.014482 s |
| Benjamini-Krieger-Yekutieli | FDR | s | 0.025884 s | 0.057175 s | 0.147631 s |
| Blanchard-Roquain | FDR | s | 0.024531 s | 0.048221 s | 0.126420 s |
| Method | Error Control | Procedure Type | Error Control Type | Correlation Assumed |
|---|---|---|---|---|
| Šidák | FWER | single-step | strong | non-negative |
| Šidák | FWER | step-down | strong | non-negative |
| Bonferroni | FWER | single-step | strong | any |
| Holm | FWER | step-down | strong | any |
| Hochberg | FWER | step-up | strong | PRDS |
| Hommel | FWER | step-down | strong | PRDS |
| maxT | FWER | single-step | strong | subset pivotality |
| minP | FWER | single-step | strong | subset pivotality |
| maxT | FWER | step-down | strong | subset pivotality |
| minP | FWER | step-down | strong | subset pivotality |
| Benjamini-Hochberg | FDR | step-up | strong | PRDS |
| Benjamini-Yekutieli | FDR | step-up | strong | any |
| Benjamini-Krieger-Yekutieli | FDR | step-up | strong | independence |
| BR-1S | FDR | step-up | strong | any |
| BR-2S | FDR | two-stage | strong | any |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Emmert-Streib, F.; Dehmer, M. Large-Scale Simultaneous Inference with Hypothesis Testing: Multiple Testing Procedures in Practice. Mach. Learn. Knowl. Extr. 2019, 1, 653-683. https://doi.org/10.3390/make1020039
Emmert-Streib F, Dehmer M. Large-Scale Simultaneous Inference with Hypothesis Testing: Multiple Testing Procedures in Practice. Machine Learning and Knowledge Extraction. 2019; 1(2):653-683. https://doi.org/10.3390/make1020039
Chicago/Turabian StyleEmmert-Streib, Frank, and Matthias Dehmer. 2019. "Large-Scale Simultaneous Inference with Hypothesis Testing: Multiple Testing Procedures in Practice" Machine Learning and Knowledge Extraction 1, no. 2: 653-683. https://doi.org/10.3390/make1020039
APA StyleEmmert-Streib, F., & Dehmer, M. (2019). Large-Scale Simultaneous Inference with Hypothesis Testing: Multiple Testing Procedures in Practice. Machine Learning and Knowledge Extraction, 1(2), 653-683. https://doi.org/10.3390/make1020039