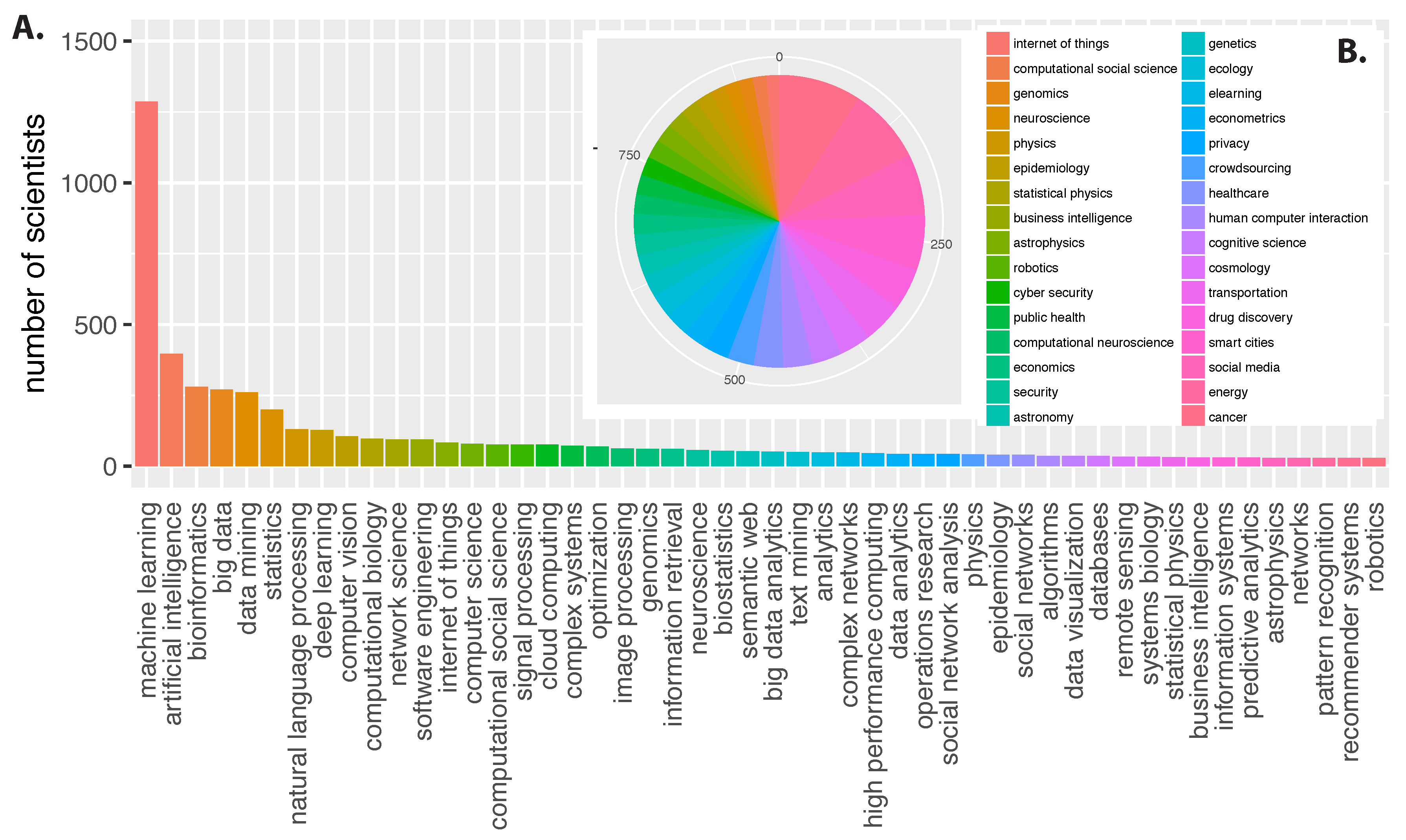
3.2. Global Community Landscape
In order to obtain a global overview among the connection between the different fields we infer a global network representation. Specifically, we are using the top 50 fields from
Figure 1A as variables and apply the BC3Net network inference method [
27]. Each field is represented by a binary vector of length
, corresponding to the number of scientists, where a ‘1’ indicates a research interest of a scientist in the field and a ‘0’ the lack of such an interest.
The basic idea of BC3Net is a bagging version of C3Net [
28] which gives conservative estimates of the relations between the variables using estimates of mutual information values. Previously, this method has been successfully used in genomics to infer causal gene regulatory networks from high-dimensional data [
29,
30] and in finance for inferring investor trading networks [
31].
To obtain a robust network we generate 1000 Bootstrapping data sets on which the BC3Net will be based. These Bootstrapping data sets are generated by sampling with replacement of the components of the profile vectors, corresponding to the scientists.
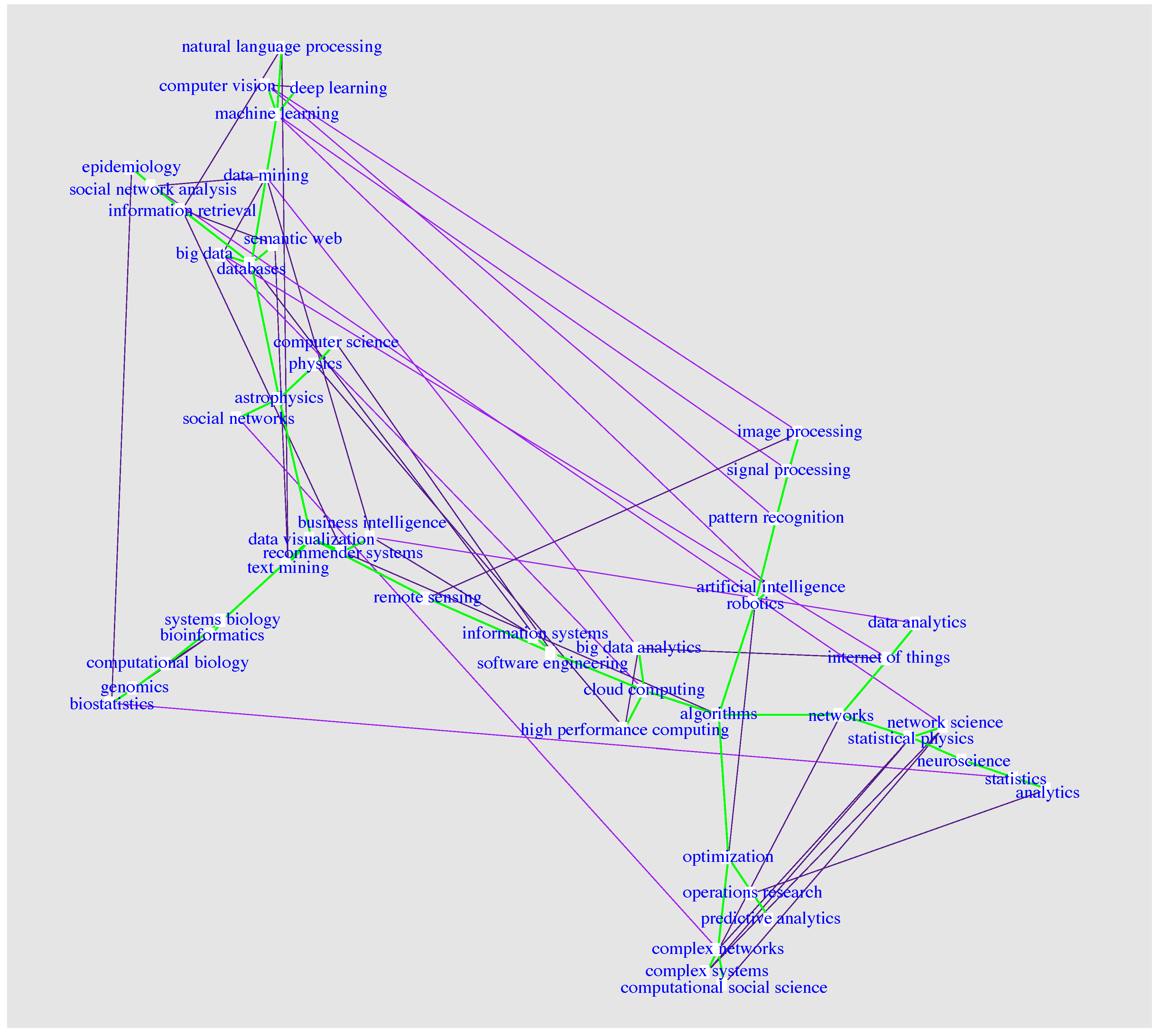
The resulting network is shown in
Figure 2. This network contains 88 edges between the 50 fields and, hence, is a sparse network with an edge density of 0.072. The network is connected and the minimum spanning tree (MST) [
32] of the network is shown by the green edges in
Figure 2. MST means that the edges in this tree are sufficient in order to obtain a connected network. Hence, these connections are not redundant. For this reason the MST can be seen as the backbone of the network that connects everything (every field) with each other.
There are several clusters visible in the network reflecting domain specific sub-communities. For instance, the fields biostatistics, genomics, computational biology, bioinformatics and systems biology are closely connected. Similarly, image processing, signal processing and pattern recognition or high performance computing, cloud computing, software engineering, big data analytics and informations systems. The intuitive similarity of these fields indicates that the shown network in
Figure 2 has a meaningful structure that summarizes the complex relationships between the fields.
3.4. Enrichment of Fields
The next analysis we perform is an enrichment analysis. In this analysis, we study whether the scientists with the highest number of citations in data science prefer to work in particular fields.
To perform such an enrichment analysis we need to assign to the scientists two attributes. The first attribute indicates if a scientist is highly cited or not, and the second attribute indicated if a scientist is interested in a particular field or not. We assign these attributes in the following way. First, we are rank ordering all scientists according to their number of citations. Second, we group this list of scientists into two subcategories by introducing a threshold. If the number of citations is above this threshold, we place this scientist in category ‘HC-Yes’, otherwise in category ‘HC-No’. That means we are distinguishing between scientists that have been highly cited (HC) or not. Third, we give each scientist a second attribute, ‘Field’. If a scientist has an interest in a specific ‘Field’ we give the scientist the label ‘Field-In’, otherwise ‘Field-Out’. That means we are distinguishing between scientists that have an interest in a particular field or not. As a result, each scientist has now two attributes on which we base our enrichment analysis (see Methods
Section 2 for details).
In our procedure, we have one parameter, namely the threshold to distinguish between highly cited scientists and the rest. This parameter is just the number of scientists we consider as highly cited. In
Table 2 we show the results of our enrichment analysis with Bonferroni correction for the 52 fields with the highest number of total citations. The number in the first row, correspond to this number of highly cited scientists (called top scientists). The largest threshold we are using is 2000 which corresponds to almost 50% of all scientists and, hence, is very anti-conservative. As we see, by increasing the number of scientists we consider highly cited (moving to the right hand-side of the table) the number of significant fields increases. On the other hand, for a threshold of 10, only the field ‘robotics’ tests significantly.
Overall, we are making the following observations. First, regardless of the chosen threshold, there are always some fields significant. This means there are indeed differences in research interests of scientists highly cited. Second, selecting one particular threshold to define highly cited scientists is subjective. However, it is clear that whatever value it should be this can only include a few percentage of all scientists. For this reason, 100 corresponding to 2.5% (=100/4060) of all scientists, is one sensible possible choice. For this threshold, we find ‘statistics’ and ‘robotics’ to be significant. Third, starting with 52 fields of our analysis, we find only a very few fields significant. Even for a threshold of 2000 there are only 8 fields enriched.
3.5. Joint Properties and Composition of the Community
Next, instead of studying individual properties of the community as in the last sections, we study now joint properties of the data science community. To do this, we analyze scientists and research fields together. In the following we call the research interests briefly ‘fields’.
First, put simply, we are interested in characterizing how many scientists are covered by how many fields. To do this we are rank ordering the fields according to number of scientists interested in and count the number of scientists that are interested in any of these fields. By successively removing fields and repeating the counting of the scientists we obtain the number of scientists in dependence on the rank ordering of the fields. This means every point on the resulting curve corresponds to (I) a group of fields and (II) a group of scientists. Both groups can be characterized. For instance, for each field in the group of fields one can determine the number of scientists interested in, allowing to identify the field with the minimal number of scientists. Hence, a group of fields can be characterized by the minimal number of scientists interested in any of these fields.
In the following, we consider
D the binary data matrix whereas the number of rows corresponds to the number of scientists
and the number of columns to the number of fields
. If
it means that scientist
i has a research interest in field
j. For instance, to identify how many fields are named by 10 or more scientists we are calculating
Here
is the theta function that gives one if its argument is true, and otherwise zero. From this, we find 157 fields with this property.
From
D we obtain a vector
of length
where its component
corresponds to the number of scientists interested in field
j by
We use this vector to obtain a ranking of the fields in declining order according to their sizes
Here the components of the vector
correspond to the indices of the fields in a way that
give the size of the fields in declining order, i.e.,
.
We are using the ordering of the sizes of the fields by successively removing fields from
D to calculate how many scientists are covered by the remaining fields. Formally, this can be done by
Here we define
as the set
that includes all elements of
up to index
and
as the empty set. Furthermore, ‘
’ is the set difference operator that eliminates all elements in X from Y. That means
goes only over the fields that rank higher than
k. For instance, using Equation (
13) we obtain
for
and
for
.
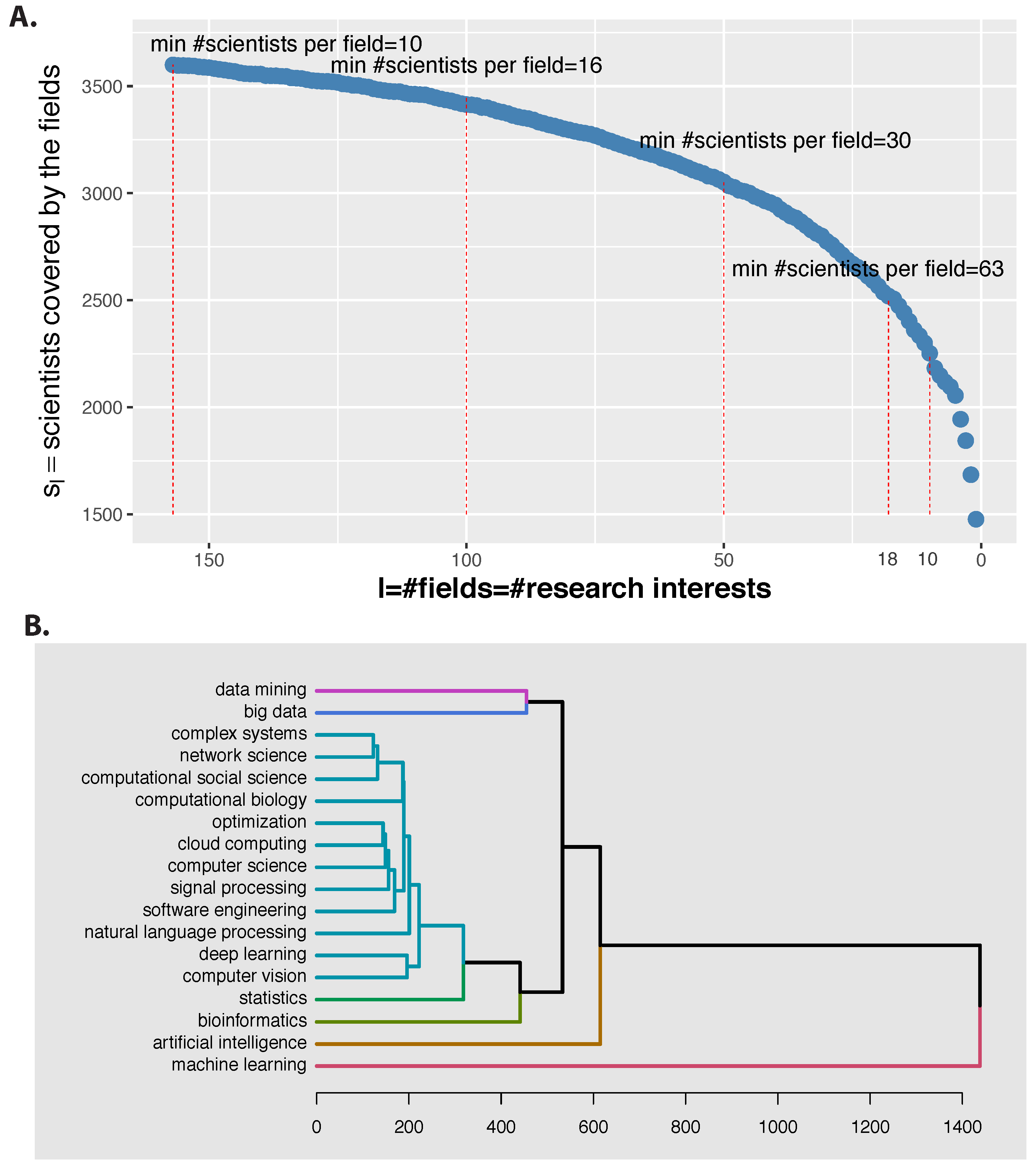
In
Figure 4A, we show the results. We limit in this figure our focus to
(or less fields), which corresponds to removing
fields. This leaves us with
scientists that have together only
l different research interests. From
Figure 4A one can see that the number of scientists covered by a certain number of fields (x-axis) is monotonously decreasing until the minimal number of
is reached for the last field (‘machine learning’). Interestingly, the values of
gives the minimal number of scientists for all of these
l fields, which is
for the leftmost point in
Figure 4A. For further selected values of
l we give the corresponding values in the figure.
From
Figure 4A, we can make two major observations that are important for the next section. First, despite the fact that in total we have 4040 research interests (fields), which is a very large number, only 157 fields attract 10 or more scientists. If one considers the fields as variables and the scientists as samples then it is clear that for any statistical model that builds on these variables and samples, a sufficient size of samples is required for obtaining robust results. Statistical models using variables with less than 10 samples are unlikely to result in robust estimates. For this reason,
Figure 4A is informative for assessing the potential quality and the number of fields as characterized by the minimal number of scientists (samples). In the next section, we will introduce a statistical model (Method-2) that will automatically perform a feature selection, but
Figure 4A allows to understand the size of the resulting feature set.
The second major observation from
Figure 4A is that the number of scientists covered by a few fields is still in the thousands. For instance, for
we have
scientists and for
we find even
scientists. That means even when we are reducing the number of fields considerably in a way as described above, we are still covering a large proportion of all scientists of the community.
Based on the above findings, we want to obtain a conservative overview about the connections among the largest fields in the community. For this reason, we select the 18 largest fields (having a minimal number of 63 scientists per field (see
Figure 4A)) and perform a hierarchical clustering for these fields. In
Figure 4B, we show the result using a Manhattan distance and a complete linkage clustering. Interestingly, the field ‘machine learning’ has the farthest distance to all other fields indicating that scientists with this interest work on many more fields beyond the 17 used in our analysis. This makes ‘machine learning’ the most diverse field of all. The second most diverse field is ‘artificial intelligence’. All other fields are more similar to each other with the mild exception of ‘data mining’ and ‘big data’.
3.6. Decomposition of the Community
After obtaining an overview of the community by studying its composition in the last sections, we present in the following two methods for decomposing the community. By ‘decomposing’ we mean the identification of major fields that span the data science community. The first method (Method-1) we introduce is semi-automatic with an intuitive interpretation whereas the second method (Method-2) is fully automatic and statistically well defined.
3.6.1. Method-1
Our first method for decomposing the community is based on the realization that we are having two different pieces of information available that make contributions to the community. The first one is about the number of citations and the second one is about the number of scientists interested in a particular field. Based on these two components we define a measure below, we are using for ranking the importance of the fields.
Specifically, for the quantification of ‘contribution to the community’ we are using the two variables, (I) the number of citations in a field
i,
, and (II) the number of scientists in a field
i,
. The number of scientists corresponds to the number of researcher using a particular label to express their research interest in a field, e.g., ‘statistics’ or ‘natural language processing’, whereas the number of citations corresponds to the total number of citations contributed by all scientists interested in a particular field. To make these numbers comparable, we normalize both by the maximal number of observed citations and scientists respectively. This results in the characterization of each field
i by the two-dimensional vector,
For these vectors we quantify the contribution of each field by the Euclidean norm of their corresponding vectors. Finally, we normalize these contributions to obtain the percentage of these contributions.
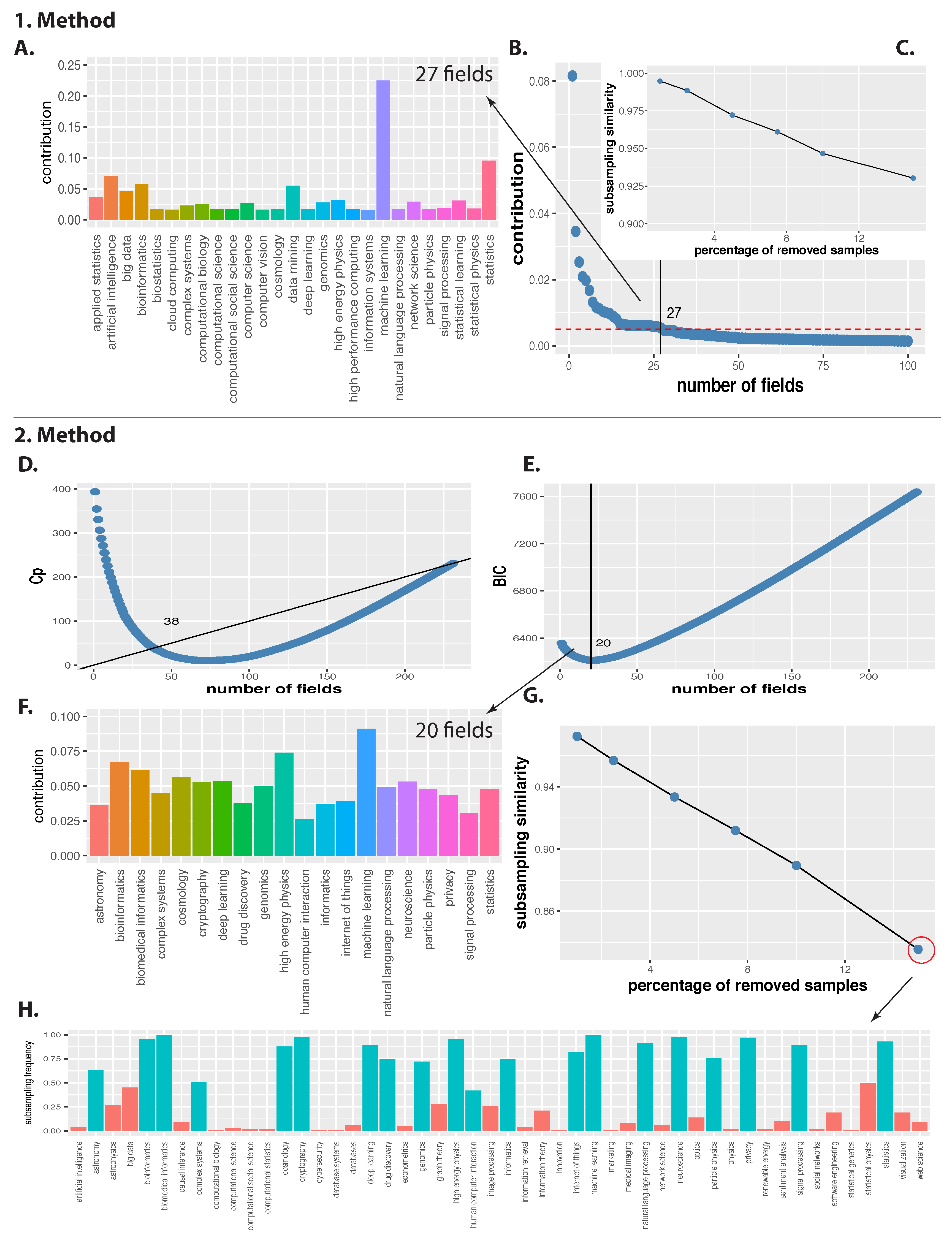
In
Figure 5B, we show the ranking of these contributions. We show only the first 100 fields because the contribution values are rapidly decreasing, as one can see. It is interesting to note that only very few fields have much larger contributions than all others. Specifically, the top 12 fields contribute together almost 25% (from a cumulative distribution, not shown).
In
Figure 5B, we added a dashed red line indicating a contribution of 0.005, which corresponds to 27 fields. The reason for choosing this threshold is motivated by the dip in the curve in
Figure 5B and our results shown in
Figure 4A. The detailed contributions of these 27 fields are shown in In
Figure 5A. Overall, ‘machine learning’ makes by far the largest contribution followed by ‘statistics’.
To study the robustness of our results, we subsample the data. Specifically, we subsample the data by removing a certain percentage of samples and repeat the analysis. Here a sample corresponds to research interests of a scientist, hence, we repeat the analysis for randomly selecting a certain percentage of scientists which we exclude from our analysis. This mimics to some extend the randomness with which scientists register in Google Scholar. As a result we see if the top fields change or remain robust for the smaller data sets.
We measure the similarity of the randomized and nonrandomized analysis by quantifying the overlap of the fields in common as
Here
is the optimal number of fields we estimated from the whole data set,
corresponds to the number of subsampled data sets and ‘prs’ means ‘percentage of removed samples’.
The results from this analysis are shown in
Figure 5C. Overall, removing up to 15% of the samples (corresponding to the scientists) results in over 90% similarity in the fields. This indicates that our results are highly robust.
3.6.2. Method-2
The second decomposition we are defining, is based on the predictive abilities of the fields. For this, we are applying a two-step procedure. In the first step, we identify the key fields with respect to their predictive abilities. In the second step we quantify these by estimating their importance for the predictions.
For step one, we perform a forward-stepwise regression (FSR) [
33]. The FSR starts with the simplest model and enters successively one regressor (field) at a time. This builds a sequence of models. Specifically, at each stage of this stepwise procedure we enter the repressor that is most correlated with the residuals. This process is repeated until either all predictors have been entered, or the residuals are zero.
Our regression model is defined by
where the
s are the regression coefficients, the
are the predictors and
represents the unexplained part. For
the index
i corresponds to a scientist and
j to a field. The predictors can only assume two values because either scientist
i has an interest in research field
j, corresponding to
, or not, indicated by
. The value of
gives the natural logarithm of the total number of citations of scientist
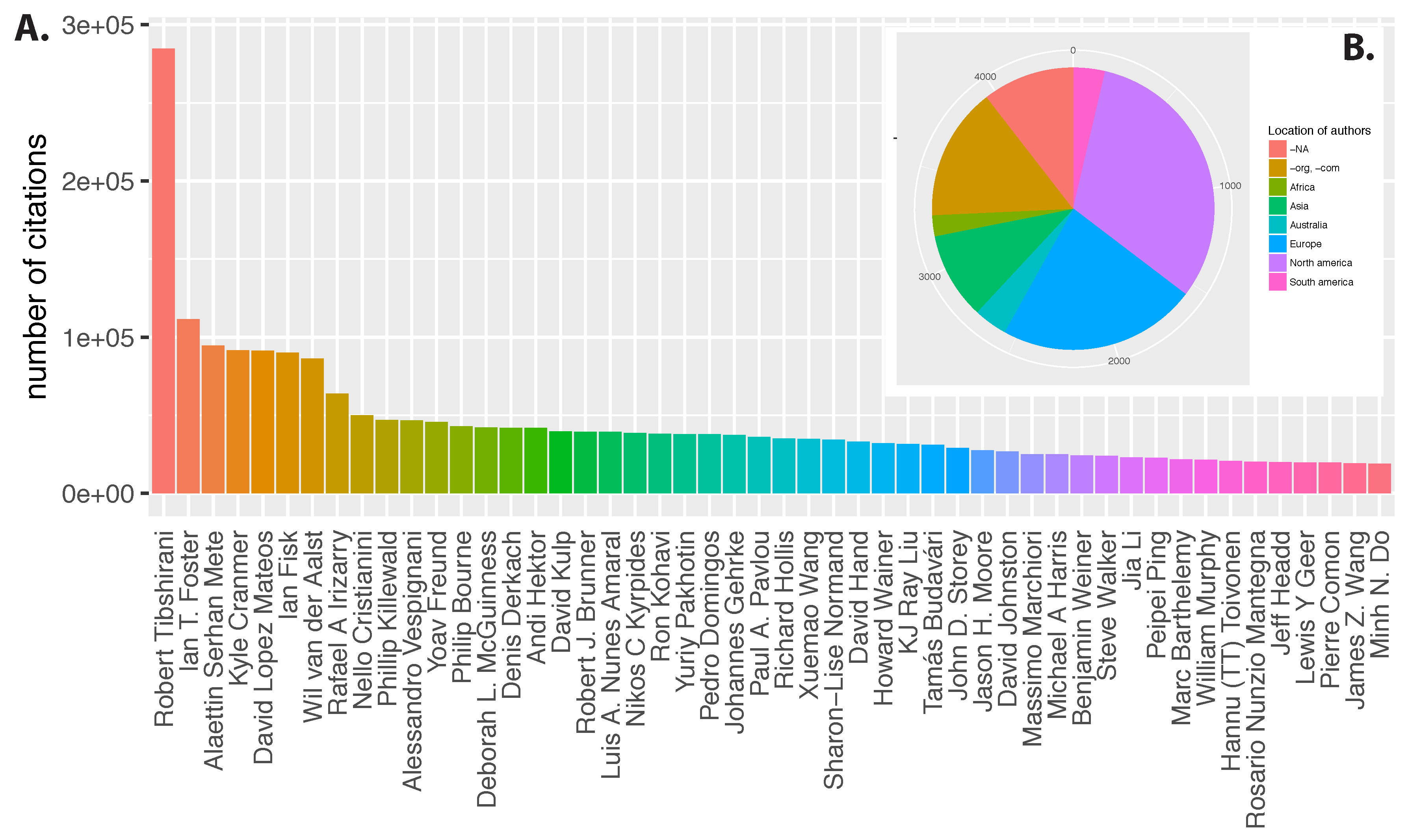
i. We used a logarithmic scaling because the number of citations of the scientists varies considerably (see
Figure 3) and the logarithmic scaling prevents that individual scientists with a very large number of citations dominate the model.
The result of this step are summarized in
Figure 5D,E. Specifically, we are showing two goodness-of-fit measures, Mallow’s Cp [
34,
35] and the BIC (Bayesian information criterion) [
18]. Regarding their interpretation, it is suggested to choose the Cp statistic approaching p (the number of repressors) from above. For the BIC, which is a variant of the AIC (Akaike information criterion)—with a stronger penalty for including additional variables to the model, the model with the lowest BIC should be selected. In
Figure 5D,E the optimal values of Cp and BIC are indicated by the intersections with the black lines.
As one can see from
Figure 5D,E, the statistical estimates for the number of fields that should be included in the model vary between 20 (for BIC) and 38 (for Cp). Beyond these numbers, the Cp- and BIC-curve clearly indicate that adding further fields (parameters) to the regression model leads only to marginal effects. It is known that Cp provides more relaxed estimates than BIC including all parameters of relevance to the model, whereas BIC is more conservative focusing on the major core of parameters. That means Mallow’s Cp is more likely to include false positives than BIC but less likely to have false negatives. Here we are interested in the major fields forming the core of data science community and for this reason we are using BIC as our selection criterion.
Based on the BIC results, we select the 20 fields with the highest contribution. For these fields we perform an additional regression, limited to those fields only. Then for the resulting model, we estimate the relative importance of the fields by using the method LMG [
19] for determining the contribution of a predictor to
for the regression model (see the Methods
Section 2.3 for details).
In
Figure 5F, we show the result of this importance analysis for the 20 fields. Overall, the top four fields are: machine learning, high energy physics, bioinformatics and biomedical informatics, whereas machine learning is clearly the most important field. Beyond these four fields, all others are similar in their importance except human-computer-interaction and signal processing, which are lowest.
To study the robustness of these results, we preform a subsampling analysis (see Method-1). We quantify the outcome with the subsampling similarity (subsim) as
Here
is the optimal number of fields we estimated from the whole data set using BIC,
corresponds to the number of subsampled data sets and ‘prs’ means ‘percentage of removed samples’.
In
Figure 5G we show results for prs
{1%, 2.5%, 5%, 7.5%, 10%, 15%}. For removing up to 5% of the samples, we observe a very high similarity of over 93% and even for removing 15% of all samples, we still have a similarity of almost 85%. This indicates a high robustness of the identified fields.
Finally, in
Figure 5H, we show the subsampling frequency of individual fields for 15% removed samples. In contrast to the subsampling similarity, we defined for estimating the similarity with the whole set of the 20 optimal fields, the subsampling frequency gives the appearance frequency of individual fields in the subsampled data. The green bars indicate the 20 major fields identified by BIC, whereas the red bars correspond to further fields beyond this set of fields that appeared during the subsampling. As one can clearly see, the subsampling frequency for the 20 major fields is always higher than for these additional fields except for ‘human computer interaction’.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}